diff --git a/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst b/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
index b782242a6632a5d42a512cf3b830d6e047c064ab..e4682ccb94e6fc60e184632dff9ee16a6bf16ec0 100644
--- a/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
+++ b/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
@@ -1,5 +1,5 @@
-服务器端部署 - Anakin
-#####################
+Anakin - 服务器端加速引擎
+#######################
使用文档
diff --git a/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst b/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst
deleted file mode 100644
index a5209e8560b31e9f0f776fba9a2b8c5bc150165c..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst
+++ /dev/null
@@ -1,8 +0,0 @@
-服务器端部署 - 原生引擎
-#######################
-
-.. toctree::
- :maxdepth: 2
-
- build_and_install_lib_cn.rst
- native_infer.rst
diff --git a/doc/fluid/new_docs/advanced_usage/index.rst b/doc/fluid/new_docs/advanced_usage/index.rst
index dea7c236619a0bdbf402f371571d947d1cdbba65..89166573eebca045e948046c69f3b7a3e0031d58 100644
--- a/doc/fluid/new_docs/advanced_usage/index.rst
+++ b/doc/fluid/new_docs/advanced_usage/index.rst
@@ -10,7 +10,6 @@
.. toctree::
:maxdepth: 2
- deploy/index_native.rst
deploy/index_anakin.rst
deploy/index_mobile.rst
development/contribute_to_paddle.md
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..dc7c62b06287ad333dd41082e566b0553d3a5341
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
@@ -0,0 +1,8 @@
+*.pyc
+train.log
+output
+data/cifar-10-batches-py/
+data/cifar-10-python.tar.gz
+data/*.txt
+data/*.list
+data/mean.meta
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
index 8d645718e12e4d976a8e71de105e11f495191fbf..4f20843596aa676962a36241f59560ec2a41257b 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
@@ -21,7 +21,7 @@
图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。
-
+
图1. 通用图像分类展示
@@ -30,7 +30,7 @@
-
+
图2. 细粒度图像分类展示
@@ -38,7 +38,7 @@
一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。
-
+
图3. 扰动图片展示[22]
@@ -61,7 +61,7 @@
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
-
+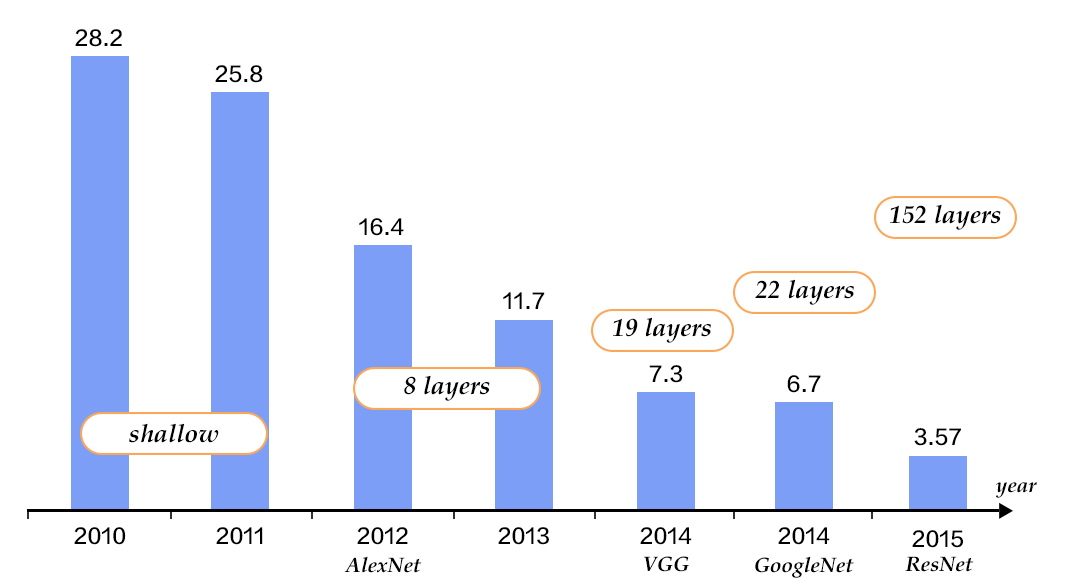
图4. ILSVRC图像分类Top-5错误率
@@ -70,7 +70,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图5所示,我们先介绍用来构造CNN的常见组件。
-
+
图5. CNN网络示例[20]
@@ -89,7 +89,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 \[[11](#参考文献)\] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型\[[19](#参考文献)\]就是借鉴VGG模型的结构。
-
+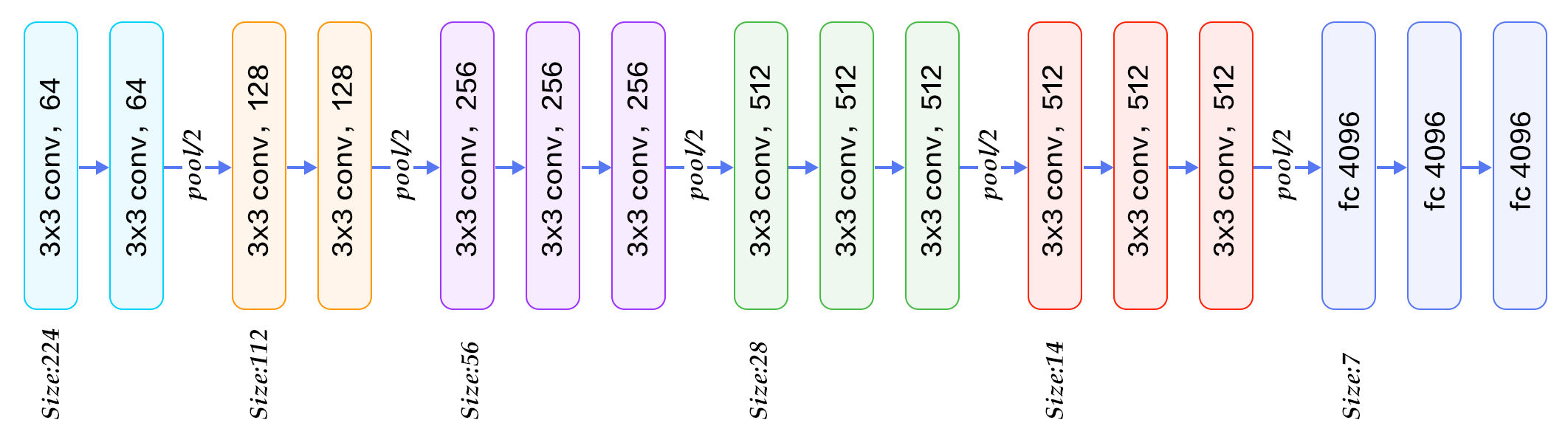
图6. 基于ImageNet的VGG16模型
@@ -106,7 +106,7 @@ NIN模型主要有两个特点:
Inception模块如下图7所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
-
+
图7. Inception模块
@@ -115,7 +115,7 @@ GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没
GoogleNet整体网络结构如图8所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
-
+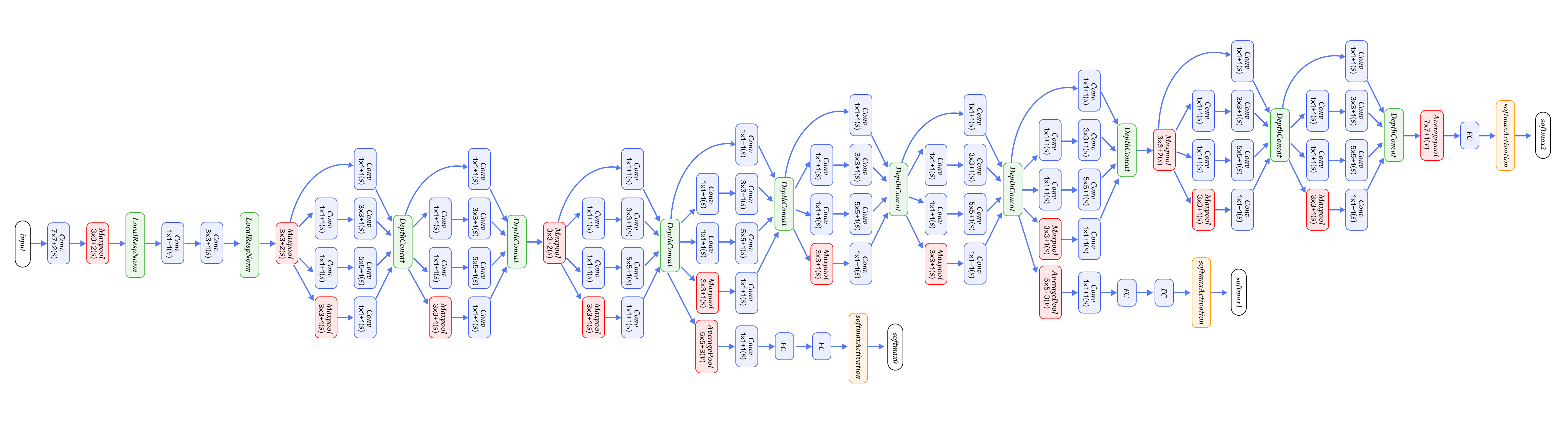
图8. GoogleNet[12]
@@ -130,14 +130,14 @@ ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类
残差模块如图9所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
-
+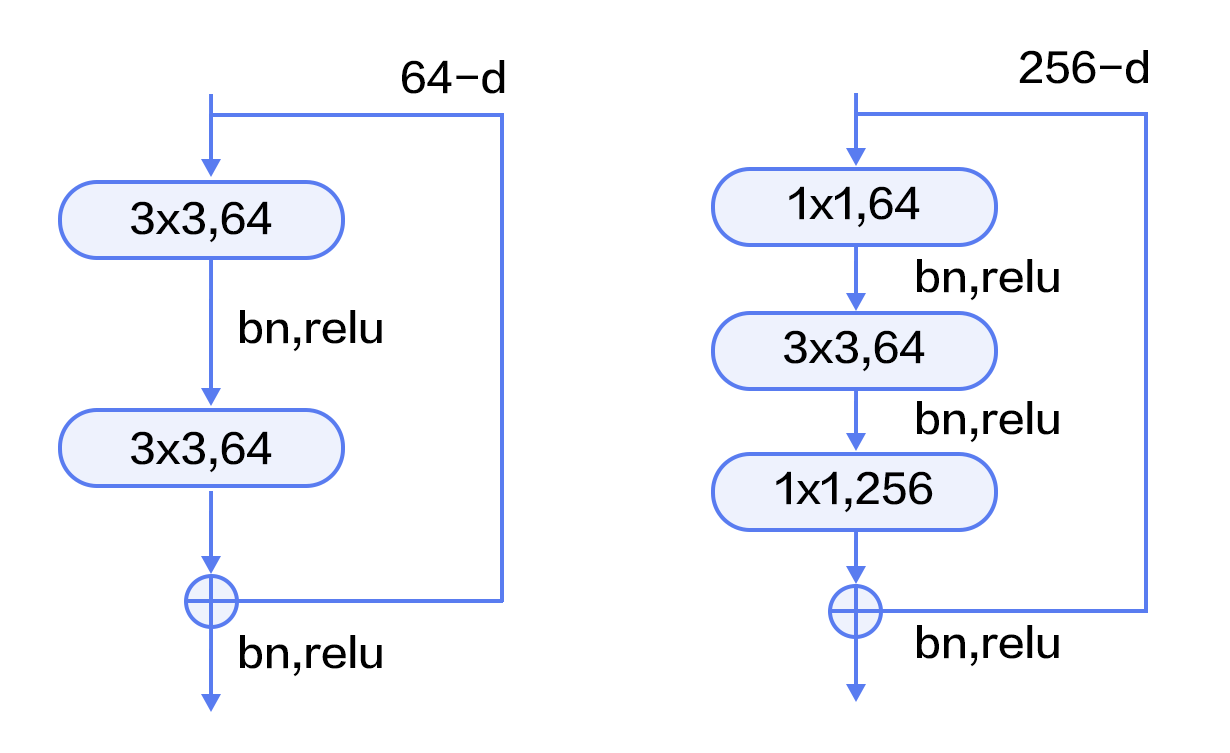
图9. 残差模块
图10展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
-
+
图10. 基于ImageNet的ResNet模型
@@ -149,7 +149,7 @@ ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类
由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用[CIFAR10]()数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。
-
+
图11. CIFAR10数据集[21]
@@ -377,7 +377,7 @@ test_reader = paddle.batch(
`event_handler_plot`可以用来利用回调数据来打点画图:
-
+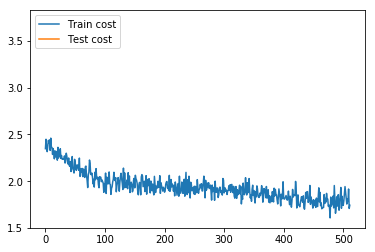
图12. 训练结果
@@ -469,7 +469,7 @@ Test with Pass 0, Loss 1.1, Acc 0.6
图13是训练的分类错误率曲线图,运行到第200个pass后基本收敛,最终得到测试集上分类错误率为8.54%。
-
+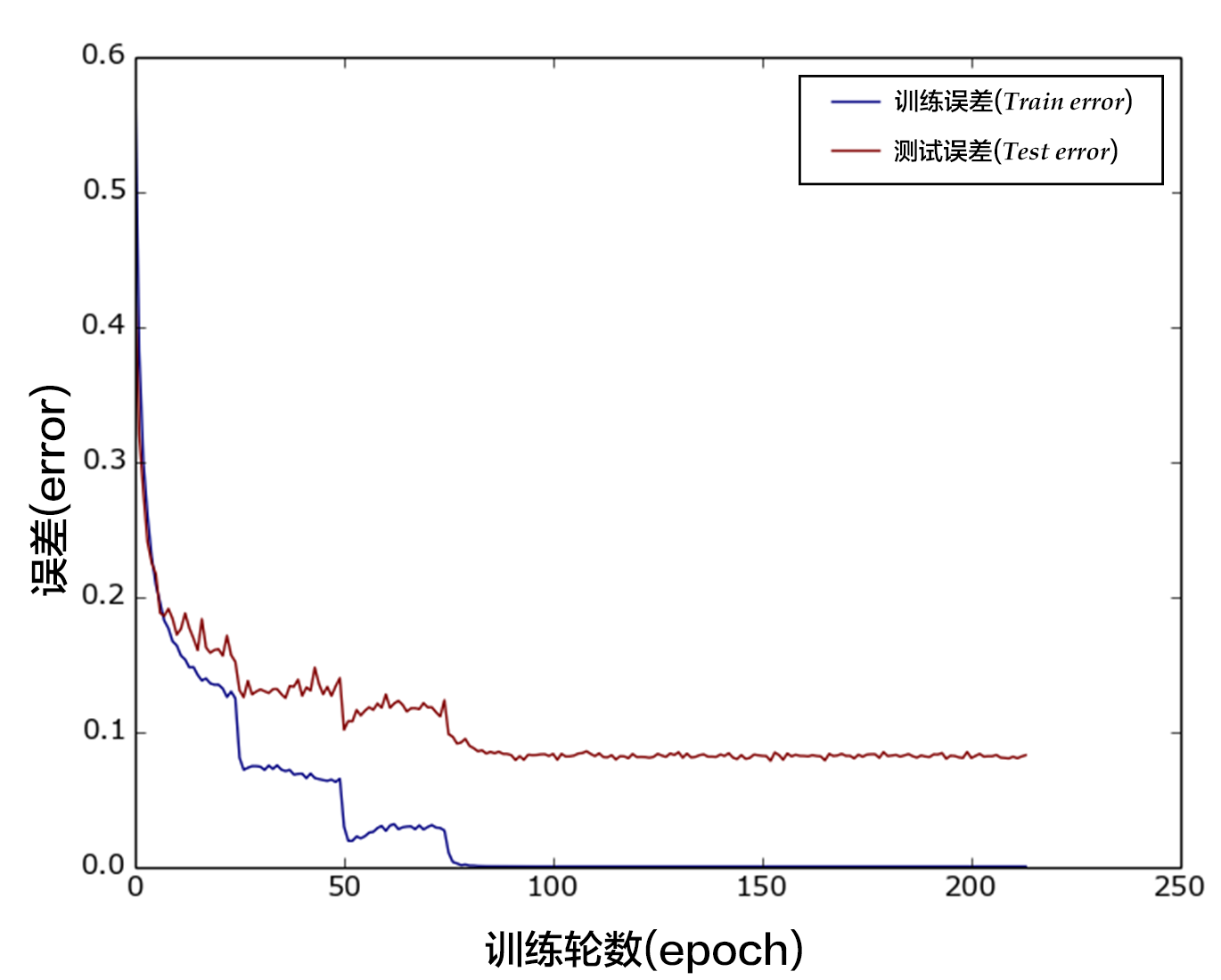
图13. CIFAR10数据集上VGG模型的分类错误率
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png
deleted file mode 100644
index f3c5f2f7b0c84f83382b70124dcd439586ed4eb0..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png
deleted file mode 100644
index ca8f858a902ea723d886d2b88c2c0a1005301c50..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png
deleted file mode 100644
index 38b21f21604b1bb84fc3f6aa96bd5fce45d15a55..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png
deleted file mode 100644
index 647c822e52cd55d50e5f207978f5e6ada86cf34c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png
deleted file mode 100644
index 04245cef60fe7126ae4c92ba8085273965078bee..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg
deleted file mode 100644
index 249dbf96df61c3352ea5bd80470f6c4a1e03ff10..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png
deleted file mode 100644
index 4660ac122e9d533023a21154d35eee29e3b08d27..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png
deleted file mode 100644
index 9591a0c1e8c0165c40ca560be35a7b9a91cd5027..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png
deleted file mode 100644
index 39580c20b583f2a15d17fd124a572c84e6e2db1d..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png
deleted file mode 100644
index 77f785e03bacd38c4c64a817874a58ff3298d2f3..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png
deleted file mode 100644
index 97a1e3eee45c0db95e6a943ca3b8c0cf6c34d4b6..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png
deleted file mode 100644
index 57e45cc0c27dd99b9918de2ff1228bc6b65f7424..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png
deleted file mode 100644
index 147e575bf49086811c43420d5a9c8f749e2da405..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png
deleted file mode 100644
index 0aeb4f254639fdbf18e916dc219ca61602596d85..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg
deleted file mode 100644
index c500eb01a90190ff66150871fe83ec275e2de8d7..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png
deleted file mode 100644
index c6336a9a69b95dc978719ce68896e3e752e67fed..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png
deleted file mode 100644
index b4ebbbe6a50f5fd7cd0cccb52cdac5653e34654c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png
deleted file mode 100644
index 88c60fe87f802c5ce560bb15bbdbd229aeafc4e4..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png
deleted file mode 100644
index 6270eefcfd7071bc1643ee06567e5b81aaf4c177..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/index.rst b/doc/fluid/new_docs/beginners_guide/basics/index.rst
index e1fd226116d88fbf137741242b304b367e598ba5..0fcb008e0a7773e81e5124da09fe07366130b924 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/index.rst
+++ b/doc/fluid/new_docs/beginners_guide/basics/index.rst
@@ -6,7 +6,7 @@
.. todo::
概述
-
+
.. toctree::
:maxdepth: 2
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..29b5622a53a1b0847e9f53febf1cc50dcf4f044a
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
@@ -0,0 +1,12 @@
+data/train.list
+data/test.*
+data/conll05st-release.tar.gz
+data/conll05st-release
+data/predicate_dict
+data/label_dict
+data/word_dict
+data/emb
+data/feature
+output
+predict.res
+train.log
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
index 47e948bd1ffc0ca692dc9899193e94831ce4234b..0891f5b6b16a1b715b44db6c47ba079adfcad4c5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
@@ -21,7 +21,7 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_\mb
5. 对第4步的结果,通过多分类得到论元的语义角色标签。可以看到,句法分析是基础,并且后续步骤常常会构造的一些人工特征,这些特征往往也来自句法分析。
-

+

图1. 依存句法分析句法树示例
-

+

图2. BIO标注方法示例
-
+
图3. 基于LSTM的栈式循环神经网络结构示意图
@@ -64,7 +64,7 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_\mb
为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,$t$时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。
-
+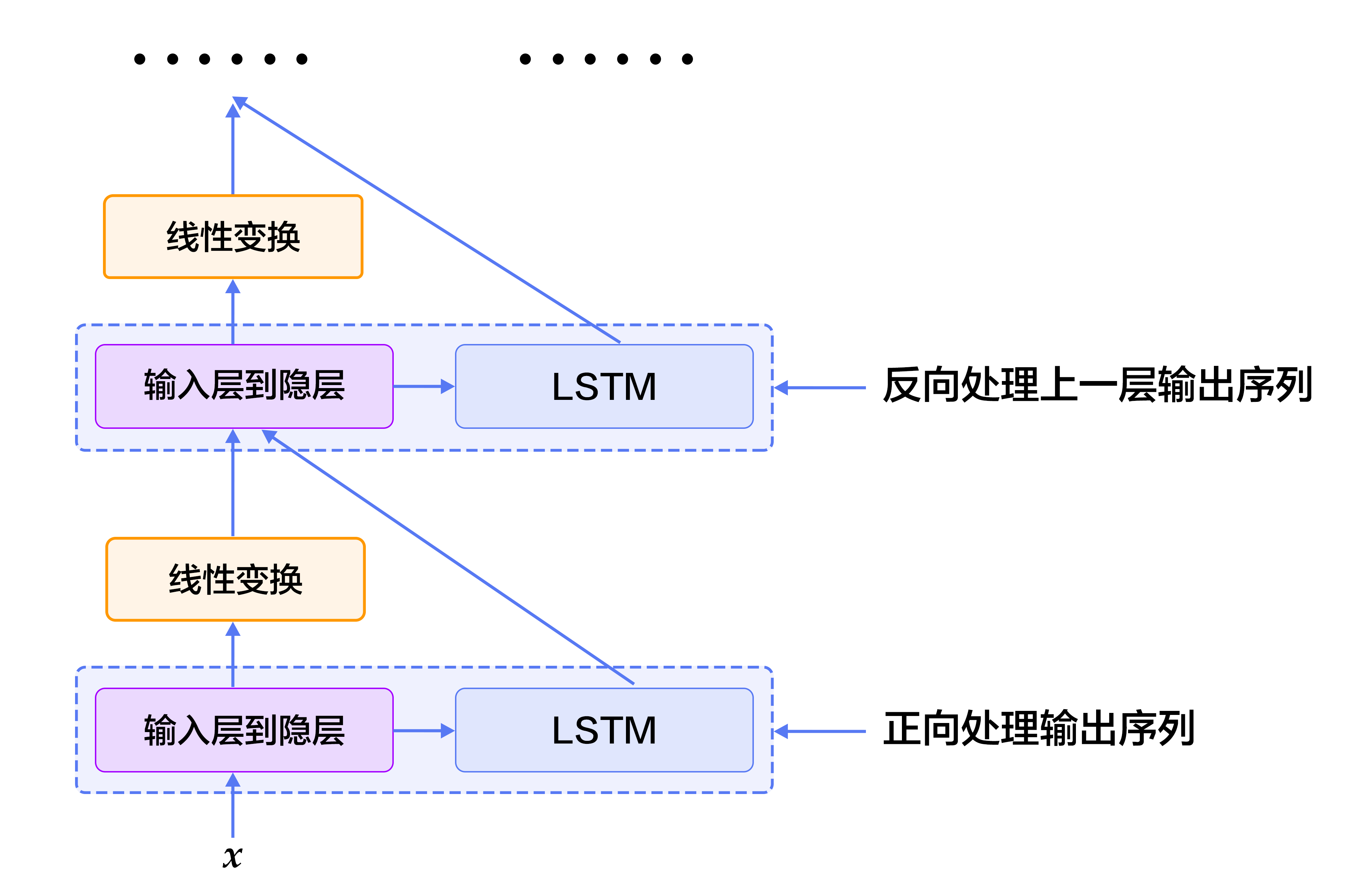
图4. 基于LSTM的双向循环神经网络结构示意图
@@ -79,7 +79,7 @@ CRF是一种概率化结构模型,可以看作是一个概率无向图模型
序列标注任务只需要考虑输入和输出都是一个线性序列,并且由于我们只是将输入序列作为条件,不做任何条件独立假设,因此输入序列的元素之间并不存在图结构。综上,在序列标注任务中使用的是如图5所示的定义在链式图上的CRF,称之为线性链条件随机场(Linear Chain Conditional Random Field)。
-
+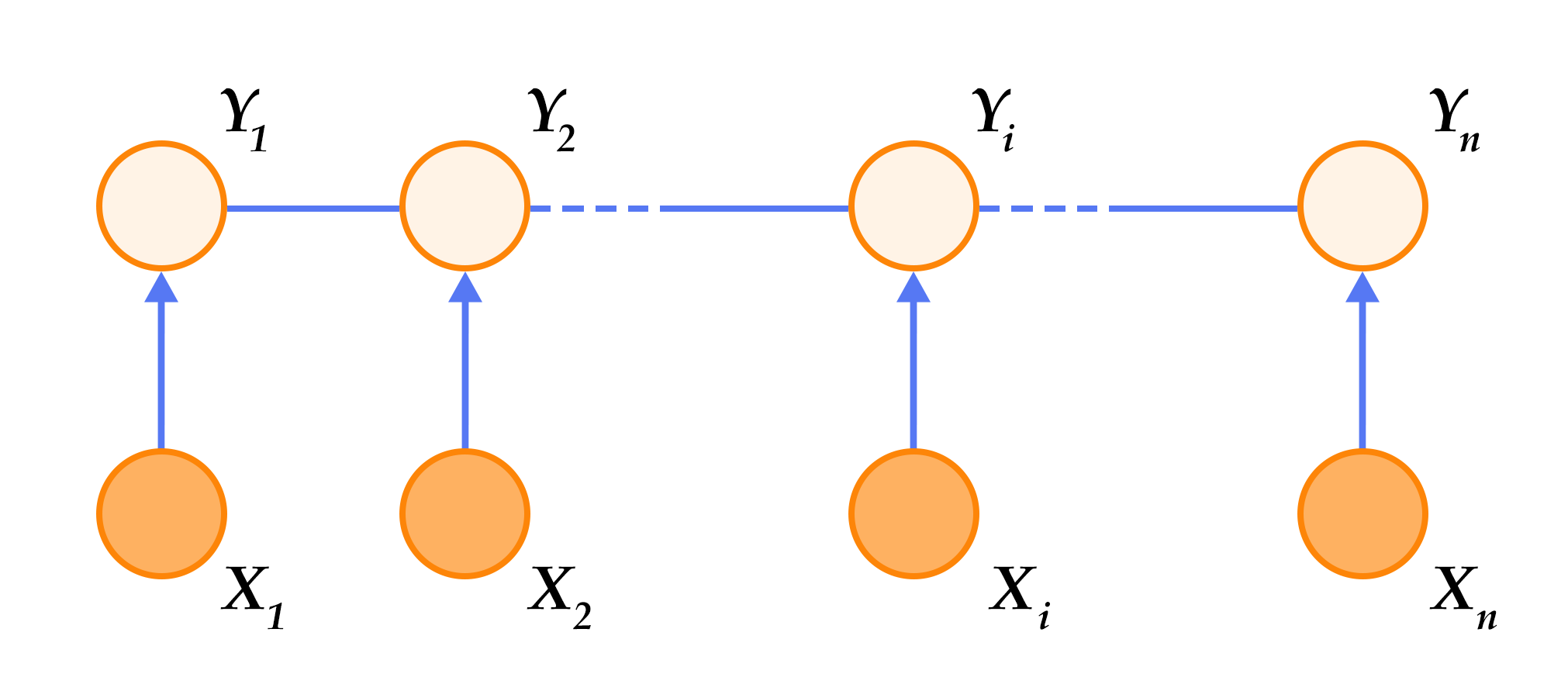
图5. 序列标注任务中使用的线性链条件随机场
@@ -123,7 +123,7 @@ $$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\pr
4. CRF以第3步中LSTM学习到的特征为输入,以标记序列为监督信号,完成序列标注;
-

+

图6. SRL任务上的深层双向LSTM模型
+
+

图1. 基于神经网络的机器翻译系统
-
+
-图3. 按时间步展开的双向循环神经网络
-
+
+
+
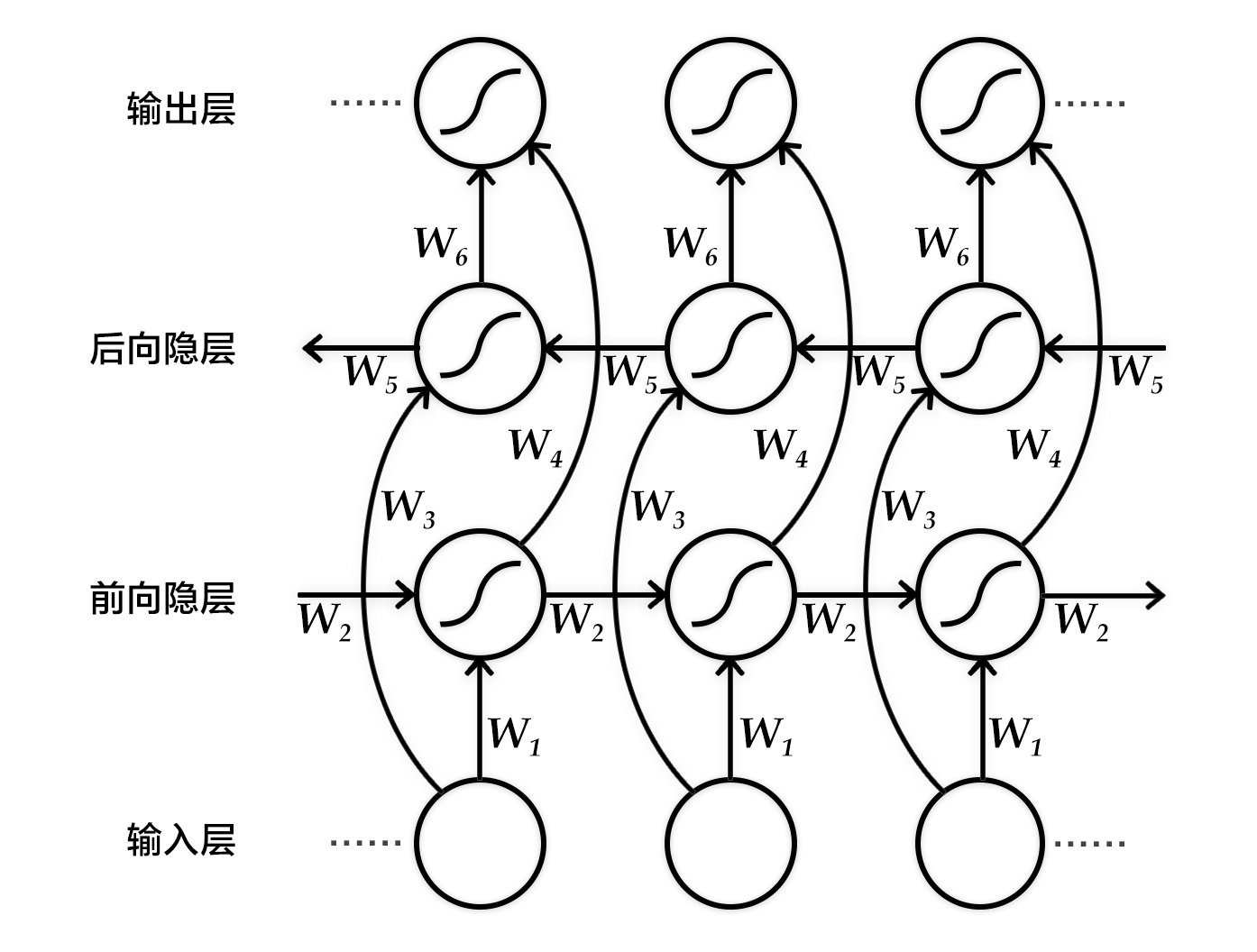
+图2. 按时间步展开的双向循环神经网络
+
-图4. 编码器-解码器框架
-
+
+

+图3. 编码器-解码器框架
+
-图5. 使用双向GRU的编码器
-
+
+
+图4. 使用双向GRU的编码器
+
`,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
@@ -100,7 +100,6 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
-
1. 每一个时刻,根据源语言句子的编码信息`$c$`、生成的第`$i$`个目标语言序列单词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。
2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png
deleted file mode 100644
index 9d8efd50a49d0305586f550344472ab94c93bed3..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png
deleted file mode 100644
index 4b35c88fc8ea2c503473c0c15711744e784d6af6..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png
deleted file mode 100644
index 1b355e7786d25487a3f564af758c2c52c43b4690..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png
deleted file mode 100644
index 3728f782ee09d9308d02b42305027b2735467ead..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png
deleted file mode 100644
index 28d7a15a3bd65262bde22a3f41b5aa78b46b368a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png
deleted file mode 100644
index ea8585565da1ecaf241654c278c6f9b15e283286..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png
deleted file mode 100644
index 60aee0017de73f462e35708b1055aff8992c03e1..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png
deleted file mode 100644
index 6b73798fe632e0873b35c117b86f347c8cf3116a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png
deleted file mode 100644
index 0cde685b84106650a4df18ce335a23e6338d3d11..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png
deleted file mode 100644
index a6af429f23f0f7e82650139bbd8dcbef27a34abe..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png
deleted file mode 100644
index bf56d73ebf297fadf522389c7b6836dd379aa097..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png
deleted file mode 100644
index 557310e044b2b6687e5ea6895417ed946ac7bc11..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..f23901aeb3a9e7cd12611fc556742670d04a9bb5
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
@@ -0,0 +1,2 @@
+.idea
+.ipynb_checkpoints
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
index 0f7c97021f8ad463fc51ed169604b789ea068c3d..4b79e62f74e587fcd939d9f9e911af80992ea6a3 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
@@ -37,7 +37,7 @@ Prediction Score is 4.25
YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
-
+
图1. YouTube 推荐系统结构
@@ -48,7 +48,7 @@ YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐
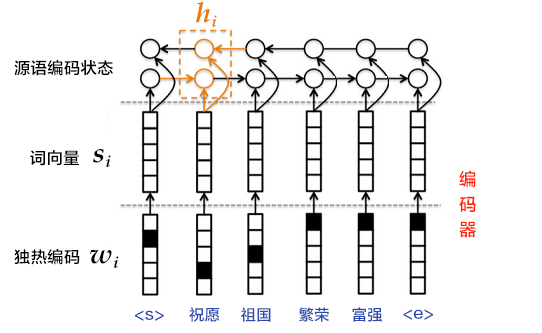
首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的$k$个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。
-
+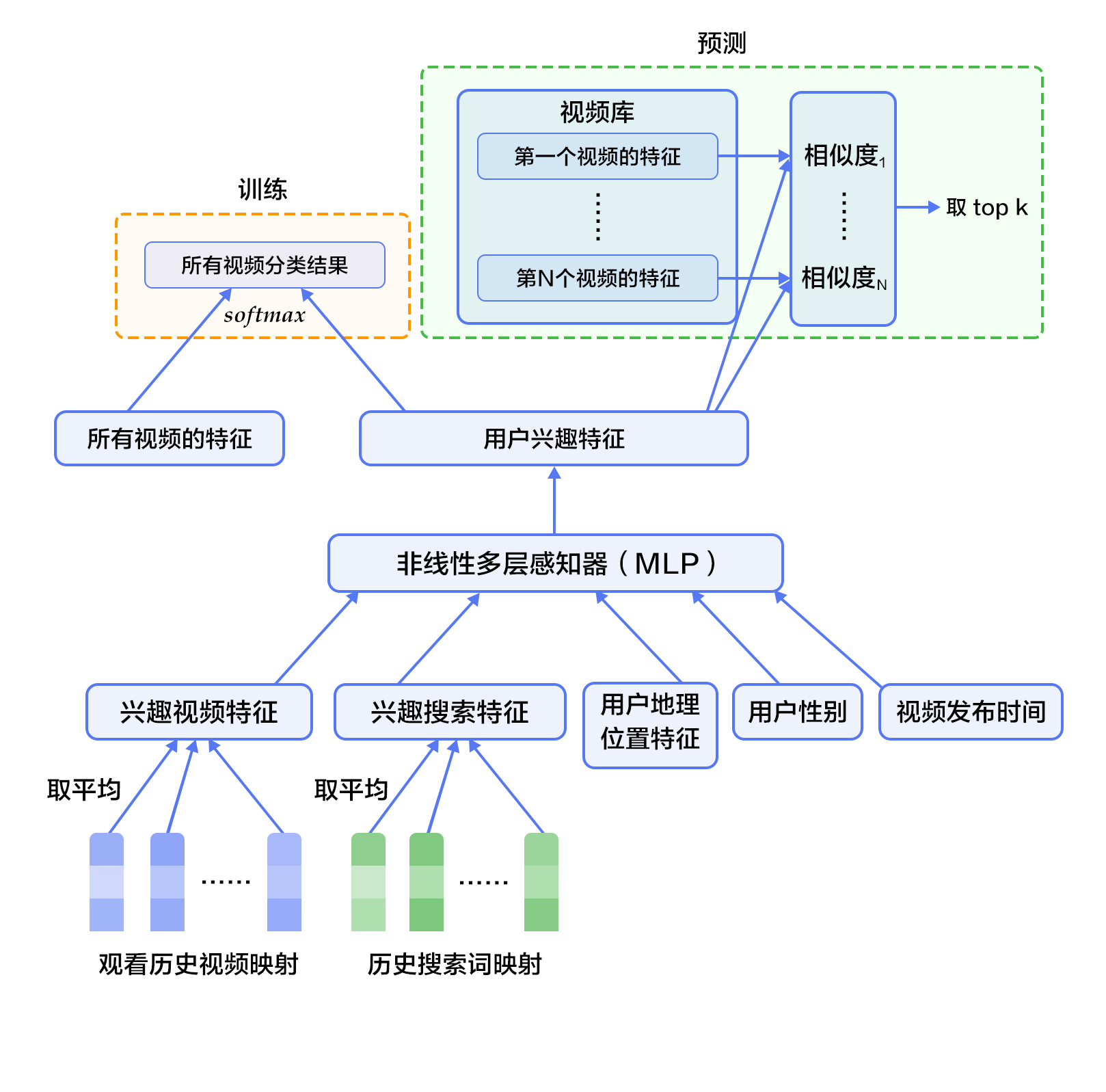
图2. 候选生成网络结构
@@ -73,7 +73,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
卷积神经网络主要由卷积(convolution)和池化(pooling)操作构成,其应用及组合方式灵活多变,种类繁多。本小结我们以如图3所示的网络进行讲解:
-
+
图3. 卷积神经网络文本分类模型
@@ -107,7 +107,7 @@ $$\hat c=max(c)$$
-
+
图4. 融合推荐模型
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png
deleted file mode 100644
index c213608e769f69fb2cfe8597f8e696ee53730e3d..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png
deleted file mode 100644
index 8aedb2204371e7691140ceffa5992f6080bbf097..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png
deleted file mode 100644
index 4298567ac5600173343299999965b20612e7affe..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png
deleted file mode 100644
index a98e7cc67606b31e4c945f7eb907563e46dcef56..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png
deleted file mode 100644
index 7fd97b9cc3a0b9105b41591af4e8f8e4646bd681..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png
deleted file mode 100644
index 90c9b09fb78db98391ee199934f2d16efd6d6652..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png
deleted file mode 100644
index 6fc8e11967000ec48c1c0a6fa3c2eaecb80cbb84..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png
deleted file mode 100644
index 61e63d9147cbc2901706ef80776d706e5368c3c5..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png
deleted file mode 100644
index fbcae2be81141be955076e877b94b0ea5d7e4d4a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..667762d327cb160376a4119fa9df9db41b6443b2
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
@@ -0,0 +1,10 @@
+data/aclImdb
+data/imdb
+data/pre-imdb
+data/mosesdecoder-master
+*.log
+model_output
+dataprovider_copy_1.py
+model.list
+*.pyc
+.DS_Store
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
index 5844b6fe137c2401a04e47b5b489434ee9b363f1..9900dfb9a67dc6f8940bd7dd3abfa15ac8a3488f 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
@@ -37,7 +37,7 @@
循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的\[[4](#参考文献)\]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
-
+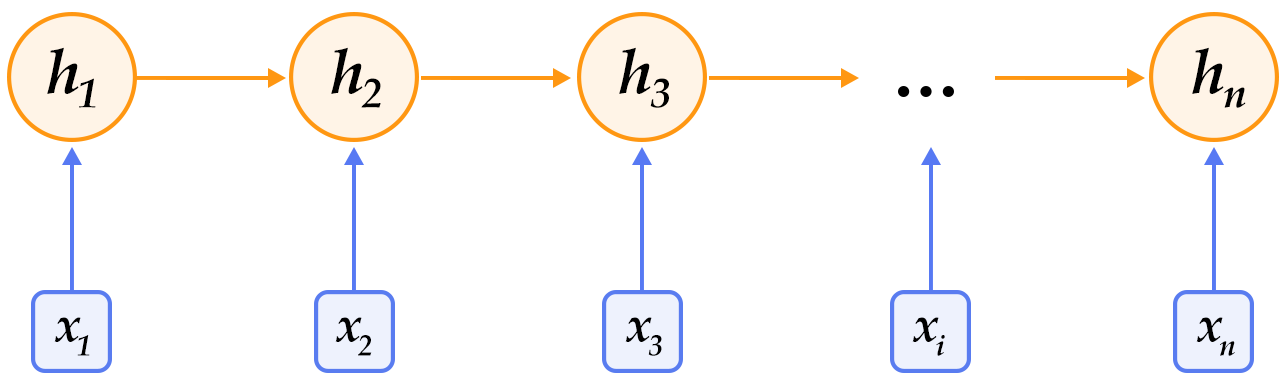
图1. 循环神经网络按时间展开的示意图
@@ -66,7 +66,7 @@ $$ h_t = o_t\odot tanh(c_t) $$
其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:
-
+
图2. 时刻$t$的LSTM [7]
@@ -83,7 +83,7 @@ $$ h_t=Recrurent(x_t,h_{t-1})$$
如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
-
+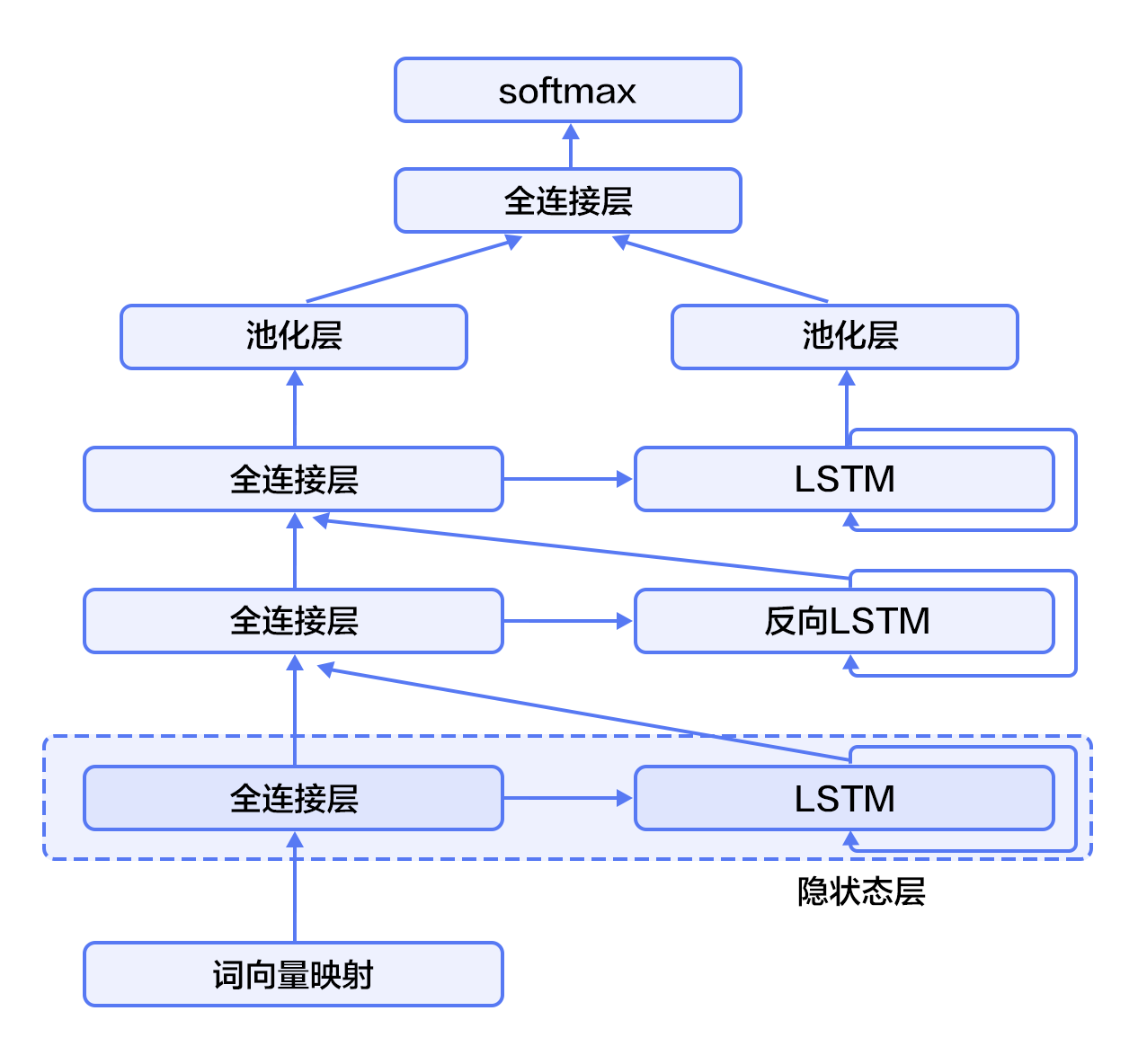
图3. 栈式双向LSTM用于文本分类
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png
deleted file mode 100644
index 98fbea413a98a619004ca669c67f5f867fe974c9..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png
deleted file mode 100644
index d73a00bf2c1fca2f9b8c26bccf5ea844fa1db50b..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png
deleted file mode 100644
index 26c904102a6e6c4e30f0048b81373ae8c148b355..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg
deleted file mode 100644
index 6b2adf70f2b5112a2e82505da5cff9f5fd0c6298..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png
deleted file mode 100644
index 8b5dbd726178b5555c513294e7b10a81acc96ff5..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..a620e0279c310d213d4e6d8e99e666962c11e352
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
@@ -0,0 +1,3 @@
+data/train.list
+data/test.list
+data/simple-examples*
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
index d21c7ddcc501f863b5ce672123dbbc6c26528f15..2c68cdac4f10319359b74bc92569dfd3f65380b5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
@@ -34,7 +34,7 @@ $$X = USV^T$$
本章中,当词向量训练好后,我们可以用数据可视化算法t-SNE\[[4](#参考文献)\]画出词语特征在二维上的投影(如下图所示)。从图中可以看出,语义相关的词语(如a, the, these; big, huge)在投影上距离很近,语意无关的词(如say, business; decision, japan)在投影上的距离很远。
- 
+ 
图1. 词向量的二维投影
@@ -90,7 +90,7 @@ $$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
其中$f(w_t, w_{t-1}, ..., w_{t-n+1})$表示根据历史n-1个词得到当前词$w_t$的条件概率,$R(\theta)$表示参数正则项。
- 
+ 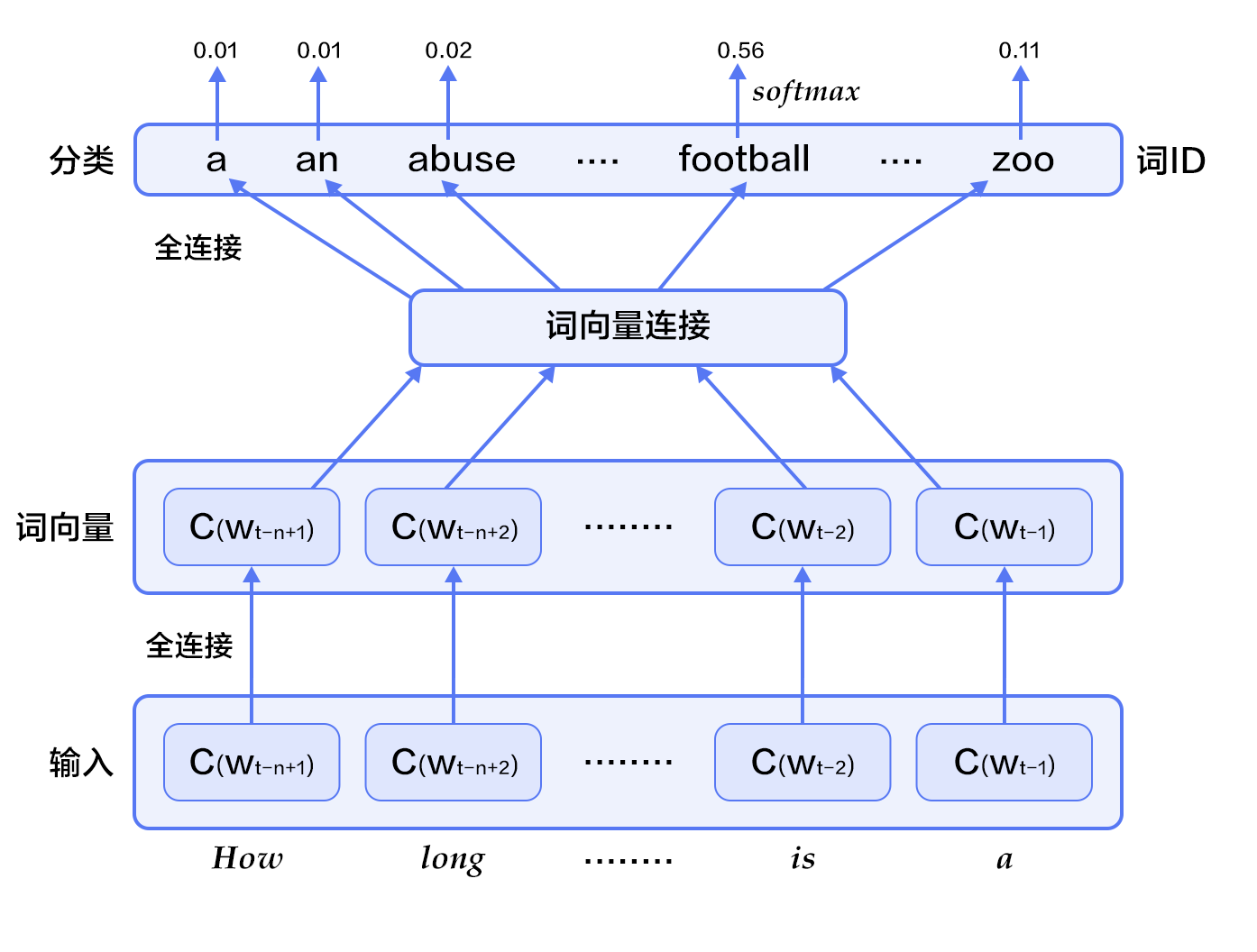
图2. N-gram神经网络模型
@@ -122,7 +122,7 @@ $$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
- 
+ 
图3. CBOW模型
@@ -137,7 +137,7 @@ $$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
- 
+ 
图4. Skip-gram模型
@@ -194,7 +194,7 @@ dream that one day
本配置的模型结构如下图所示:
- 
+ 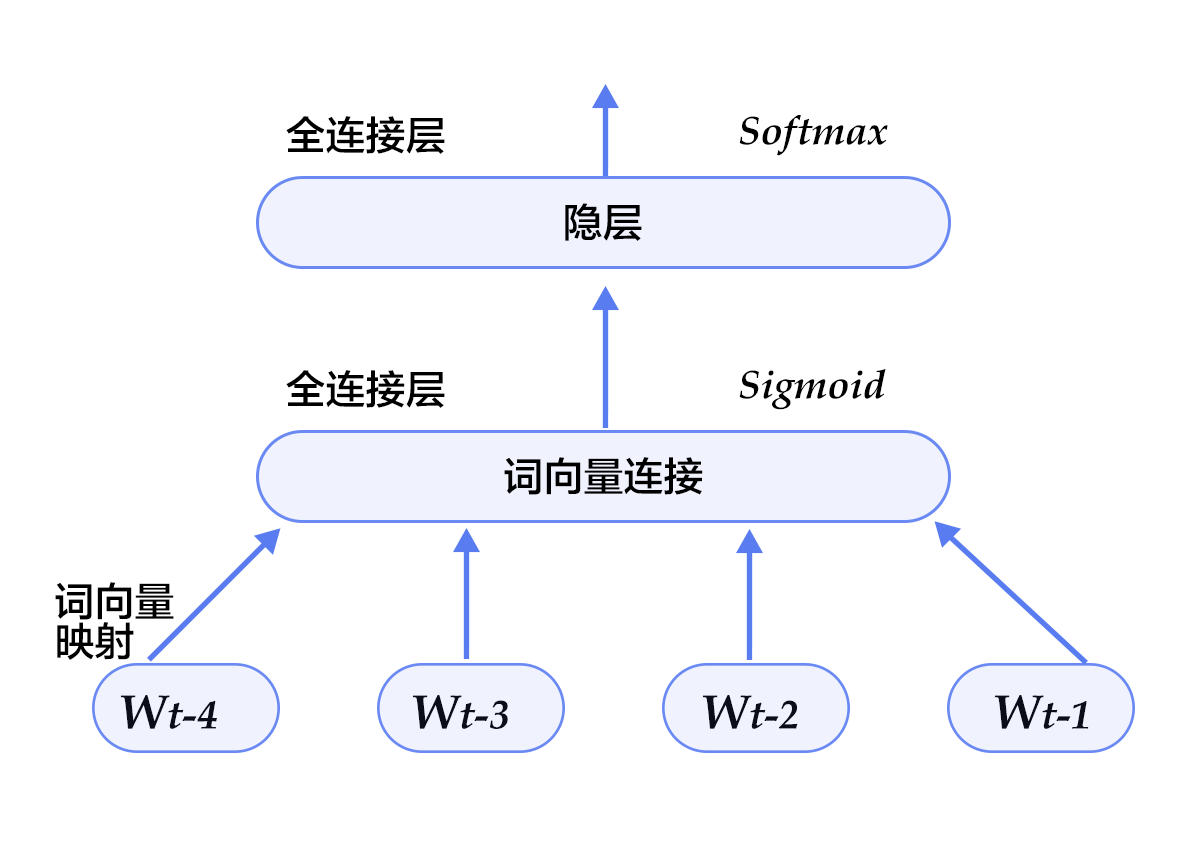
图5. 模型配置中的N-gram神经网络模型
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png
deleted file mode 100644
index 384f59919a2c8dedb198e97d51434616648932e1..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png
deleted file mode 100644
index 76b7d4bc0f99372465bd9aa34721513d39ad0776..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png
deleted file mode 100644
index d985c393e618e9b79df05e4ff0ae57ccc93744d0..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png
deleted file mode 100644
index 2e16ab2f443732b8ef5404a8e7cd2457bc5eee23..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png
deleted file mode 100644
index 2449dce6a86b43b1b997ff418ed0dba56848463f..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png
deleted file mode 100644
index 1e0b40a8f7aefdf46d42761305511f281c08e595..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png
deleted file mode 100644
index 158bd64b8f8729dea67834a8d591d21bce8b8564..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png
deleted file mode 100644
index ce4a8bf4769183cbaff91793753d2350a3ce936c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png
deleted file mode 100644
index a3ab385845d3dc8b5c670bae91225bc8dd47a8bb..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png
deleted file mode 100644
index 3c36c6d1f66eb98ea78c0673965d02a4ee3aa288..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
index 27d25b43961ce74d73e391b735369501fb80a231..9574dbea2f9a39bb196b61bb4fd12ba7c378f75a 100644
--- a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
@@ -15,7 +15,7 @@ $$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldo
## 效果展示
我们使用从[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。
- 
+ 
图1. 预测值 V.S. 真实值
@@ -40,13 +40,9 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
-
1. 初始化参数,其中包括权重$\omega_i$和偏置$b$,对其进行初始化(如0均值,1方差)。
-
2. 网络正向传播计算网络输出和损失函数。
-
3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
-
4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
## 数据集
@@ -84,7 +80,7 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。
- 
+ 
图2. 各维属性的取值范围
@@ -199,10 +195,12 @@ step = 0
def event_handler_plot(event):
global step
if isinstance(event, fluid.EndStepEvent):
- if event.step % 10 == 0: # record the test cost every 10 seconds
+ if step % 10 == 0: # record a train cost every 10 batches
+ plot_cost.append(train_title, step, event.metrics[0])
+
+ if step % 100 == 0: # record a test cost every 100 batches
test_metrics = trainer.test(
reader=test_reader, feed_order=feed_order)
-
plot_cost.append(test_title, step, test_metrics[0])
plot_cost.plot()
@@ -210,12 +208,13 @@ def event_handler_plot(event):
# If the accuracy is good enough, we can stop the training.
print('loss is less than 10.0, stop')
trainer.stop()
-
- # We can save the trained parameters for the inferences later
- if params_dirname is not None:
- trainer.save_params(params_dirname)
-
step += 1
+
+ if isinstance(event, fluid.EndEpochEvent):
+ if event.epoch % 10 == 0:
+ # We can save the trained parameters for the inferences later
+ if params_dirname is not None:
+ trainer.save_params(params_dirname)
```
### 开始训练
@@ -231,11 +230,10 @@ trainer.train(
event_handler=event_handler_plot,
feed_order=feed_order)
```
-
-
- 
- 图3. 训练结果
-
+
+

+图3 训练结果
+
- 
- 图1. MNIST图片示例
+
+图1. MNIST图片示例
MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
@@ -40,12 +40,12 @@ $$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
-$$ L_{cross-entropy} (label, y) = -\sum_i label_ilog(y_i) $$
+$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
+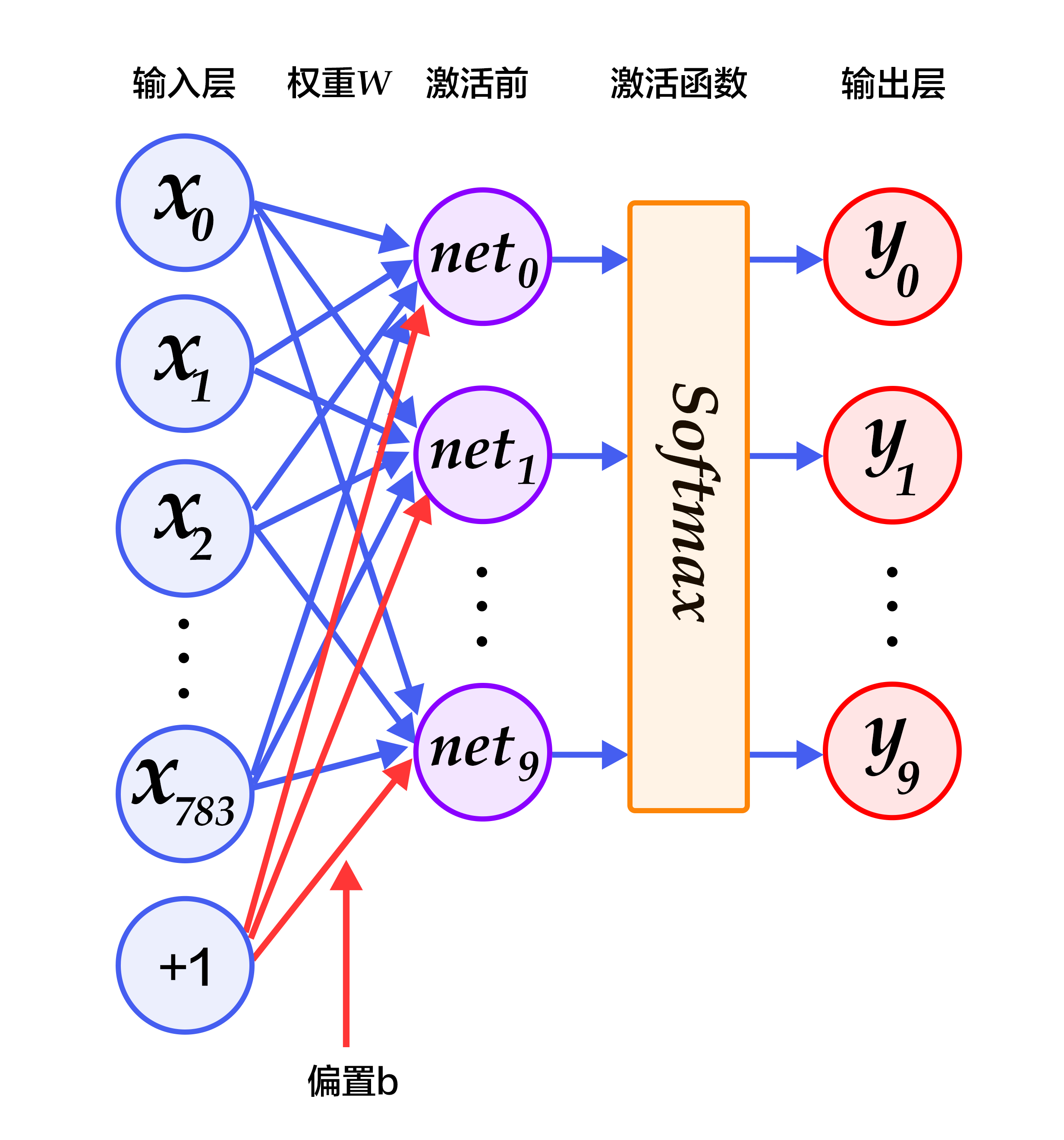
图2. softmax回归网络结构图
@@ -54,16 +54,14 @@ $$ L_{cross-entropy} (label, y) = -\sum_i label_ilog(y_i) $$
Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
-
2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
-
3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
图3为多层感知器的网络结构图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
+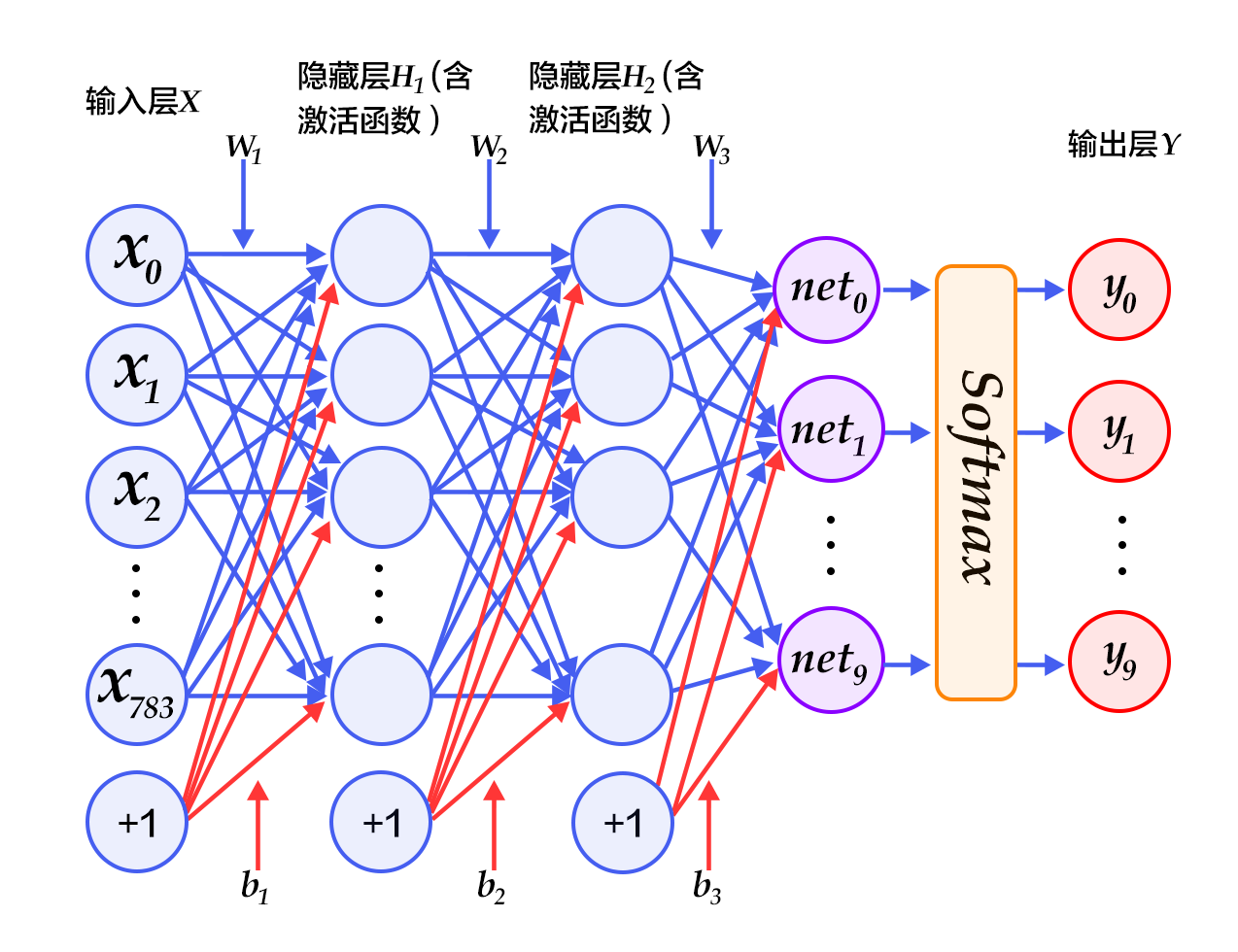
图3. 多层感知器网络结构图
@@ -72,7 +70,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
-
+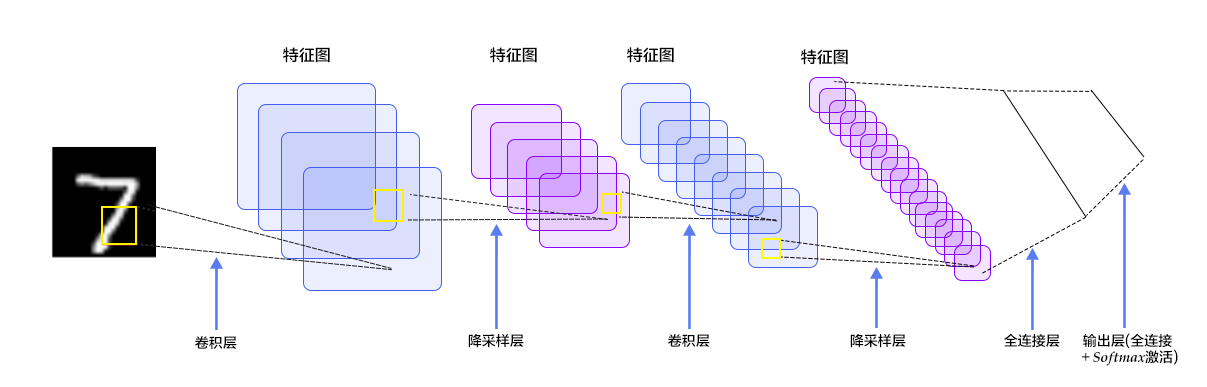
图4. LeNet-5卷积神经网络结构
@@ -81,7 +79,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
-
+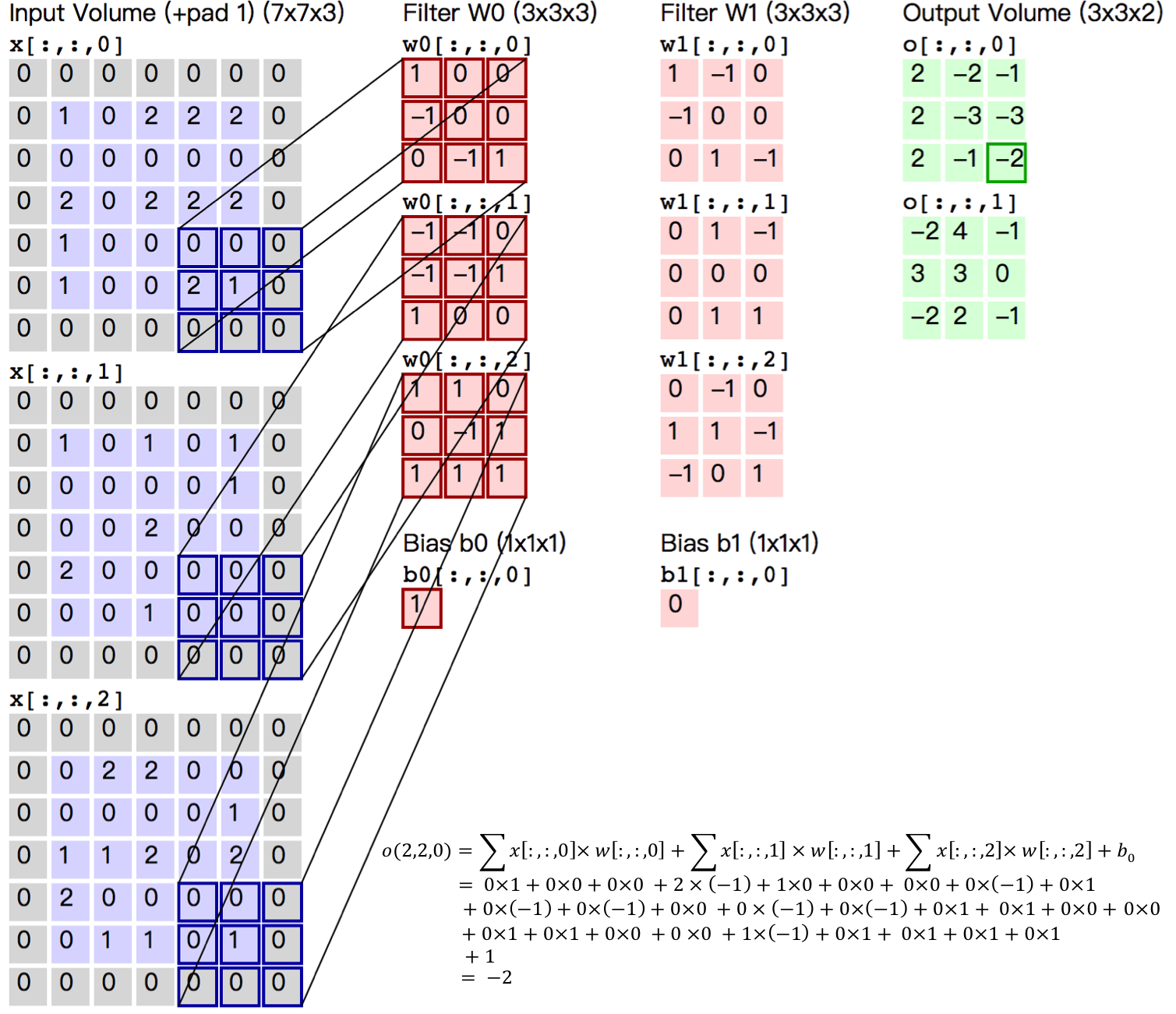
图5. 卷积层图片
@@ -98,7 +96,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
#### 池化层
-
+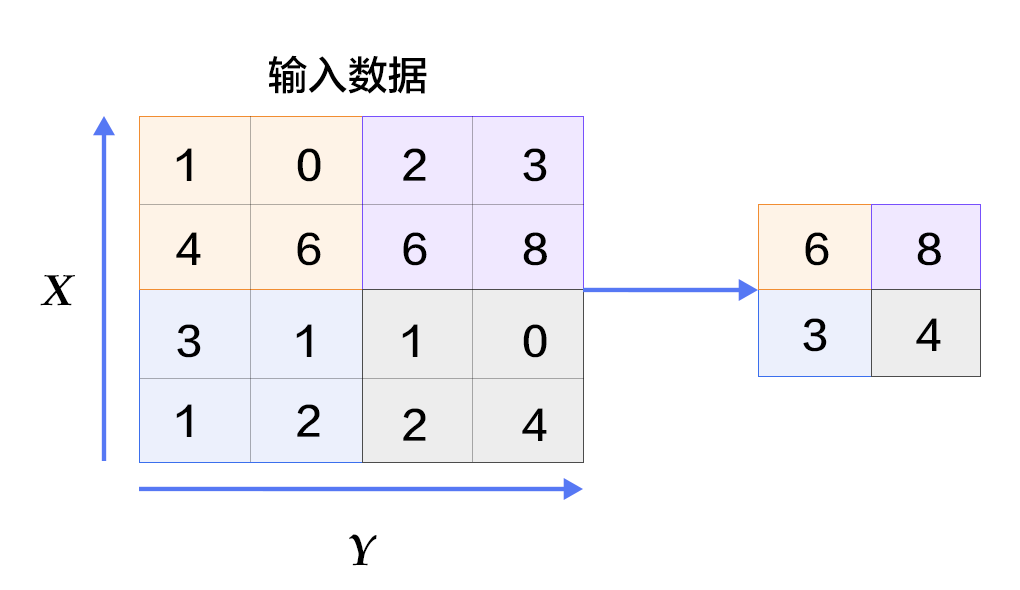
图6. 池化层图片
@@ -106,8 +104,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
-### 常见激活函数介绍
-
+### 常见激活函数介绍
- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
- tanh激活函数: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
@@ -136,20 +133,18 @@ PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mni
我们建议使用 Fluid API,因为它更容易学起来。
下面是快速的 Fluid API 概述。
-
1. `inference_program`:指定如何从数据输入中获得预测的函数。
这是指定网络流的地方。
-2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
+1. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
这是指定损失计算的地方。
-3. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
+1. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
-4. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
+1. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
通过 `event_handler` 回调函数,用户可以监控培训的进展。
-5. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
-
+1. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
然后,它可以推断数据和返回预测。
在这个演示中,我们将深入了解它们。
@@ -240,6 +235,7 @@ def train_program():
acc = fluid.layers.accuracy(input=predict, label=label)
return [avg_cost, acc]
+
```
#### Optimizer Function 配置
@@ -255,9 +251,9 @@ def optimizer_program():
下一步,我们开始训练过程。`paddle.dataset.movielens.train()`和`paddle.dataset.movielens.test()`分别做训练和测试数据集。这两个函数各自返回一个reader——PaddlePaddle中的reader是一个Python函数,每次调用的时候返回一个Python yield generator。
-下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B 。reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
+下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B。reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
-`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader 。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
+`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
```python
train_reader = paddle.batch(
@@ -280,7 +276,6 @@ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
trainer = fluid.Trainer(
train_func=train_program, place=place, optimizer_func=optimizer_program)
-
```
#### Event Handler 配置
@@ -315,11 +310,10 @@ def event_handler(event):
`event_handler_plot` 可以用来在训练过程中画图如下:
-
-
-
-图7. 训练结果
-
+
+

+图7 训练结果
+