
fix:添加重写
Showing
2.7 KB
1.9 KB

2.3 KB

712 字节

486 字节
1.9 KB
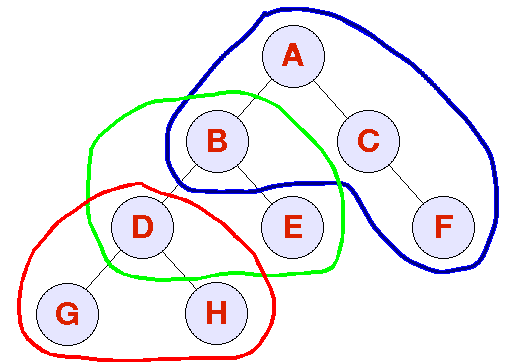
6.8 KB
290 字节
2.5 KB
2.5 KB

1.7 KB

1.7 KB
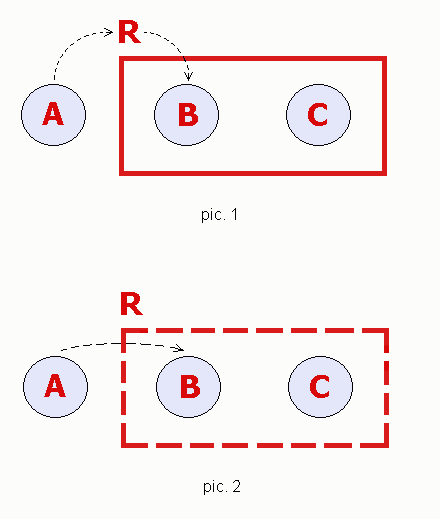

819 字节
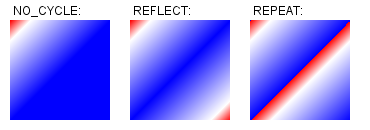
3.3 KB
4.1 KB
2.2 KB
3.1 KB
21.4 KB
24.9 KB
14.1 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

968 字节
{kind=link}

1.9 KB
{kind=link}

2.2 KB
{kind=link}
2.5 KB
{kind=link}
2.1 KB
{kind=link}
2.3 KB
{kind=link}
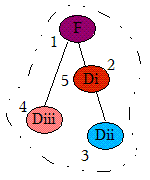
2.8 KB
{kind=link}
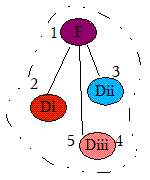
2.8 KB
{kind=link}
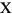
144 字节
{kind=link}
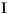
111 字节
{kind=link}
131 字节
{kind=link}
153 字节
{kind=link}
140 字节
{kind=link}
145 字节
{kind=link}
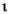
112 字节
{kind=link}
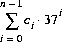
206 字节
{kind=link}
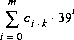
220 字节
{kind=link}
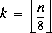
187 字节
{kind=link}
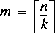
191 字节
{kind=link}
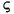
135 字节
{kind=link}
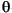
144 字节
{kind=link}
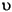
133 字节