2020-09-12 13:36:44
Showing
docs/handson-cnn-tf/0.md
0 → 100644
docs/handson-cnn-tf/1.md
0 → 100644
docs/handson-cnn-tf/10.md
0 → 100644
docs/handson-cnn-tf/2.md
0 → 100644
docs/handson-cnn-tf/3.md
0 → 100644
docs/handson-cnn-tf/4.md
0 → 100644
docs/handson-cnn-tf/5.md
0 → 100644
docs/handson-cnn-tf/6.md
0 → 100644
docs/handson-cnn-tf/7.md
0 → 100644
docs/handson-cnn-tf/8.md
0 → 100644
docs/handson-cnn-tf/9.md
0 → 100644

67.0 KB

13.6 KB
39.2 KB
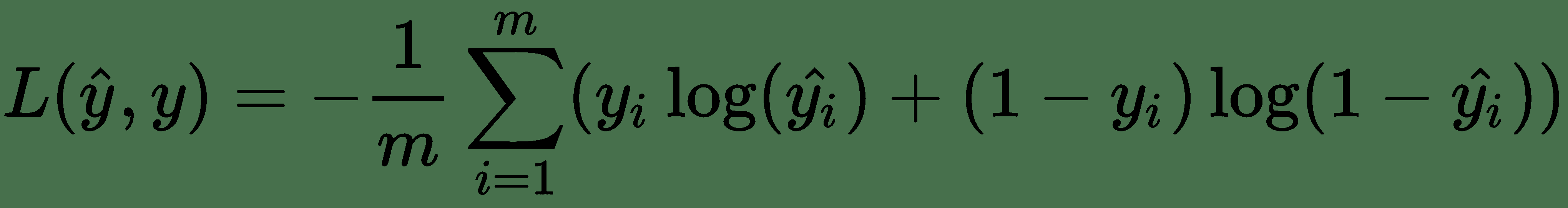
25.7 KB
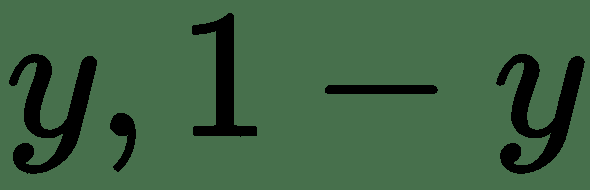

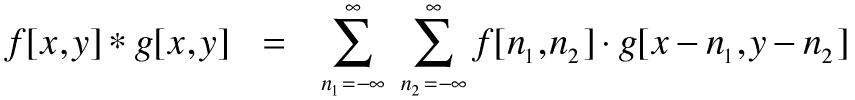
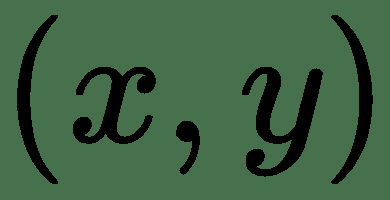

49.1 KB

17.3 KB
15.2 KB
12.8 KB
78.6 KB


35.7 KB

16.2 KB
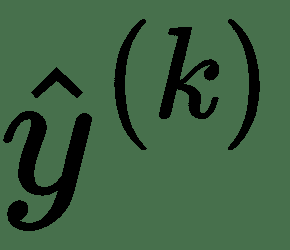
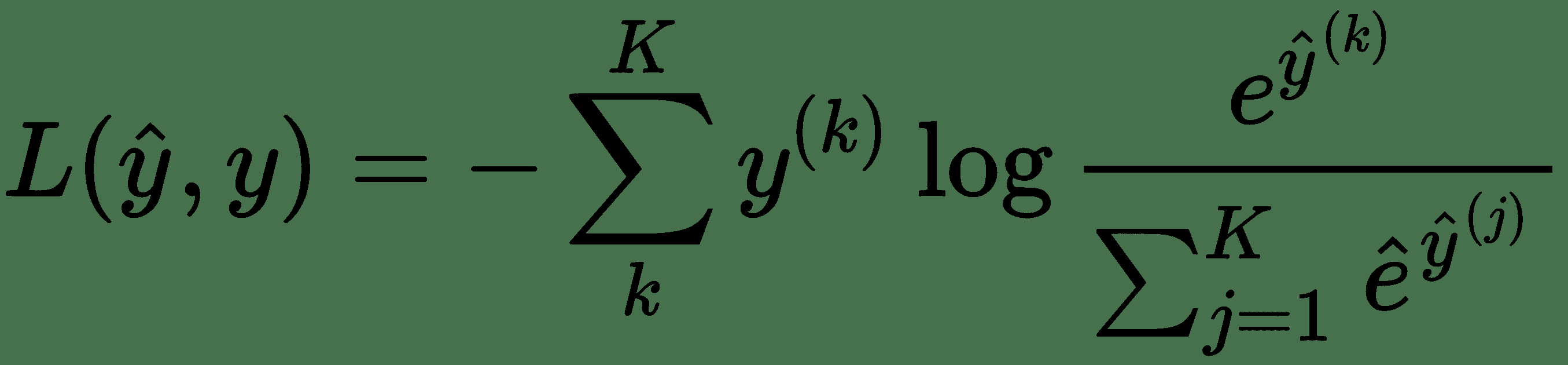
22.3 KB
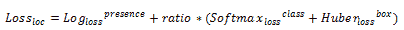
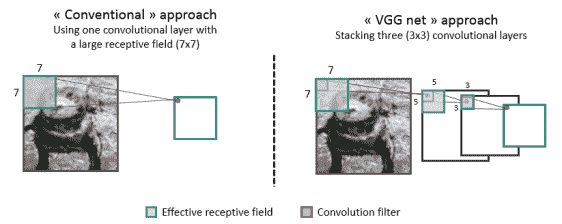

21.7 KB
12.8 KB
29.7 KB

19.4 KB
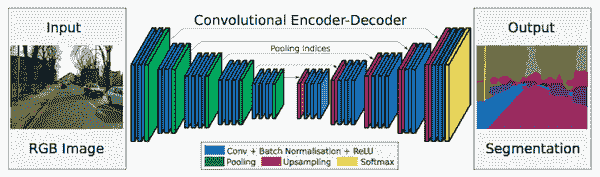
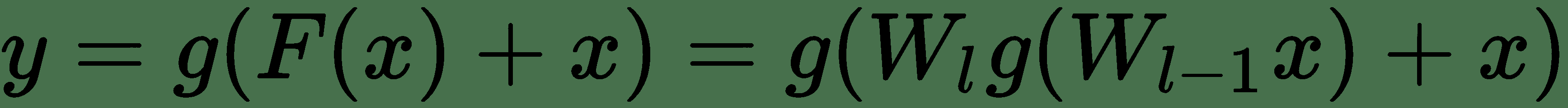
19.5 KB
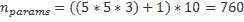
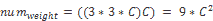
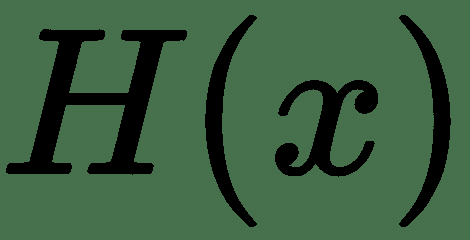
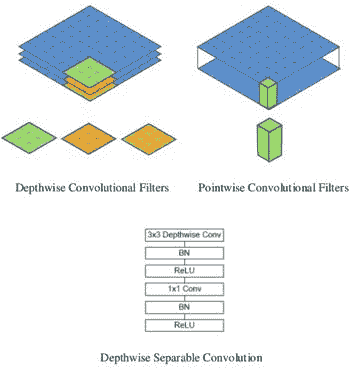

11.4 KB
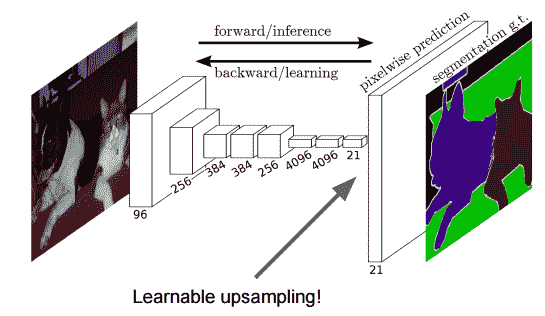
11.3 KB
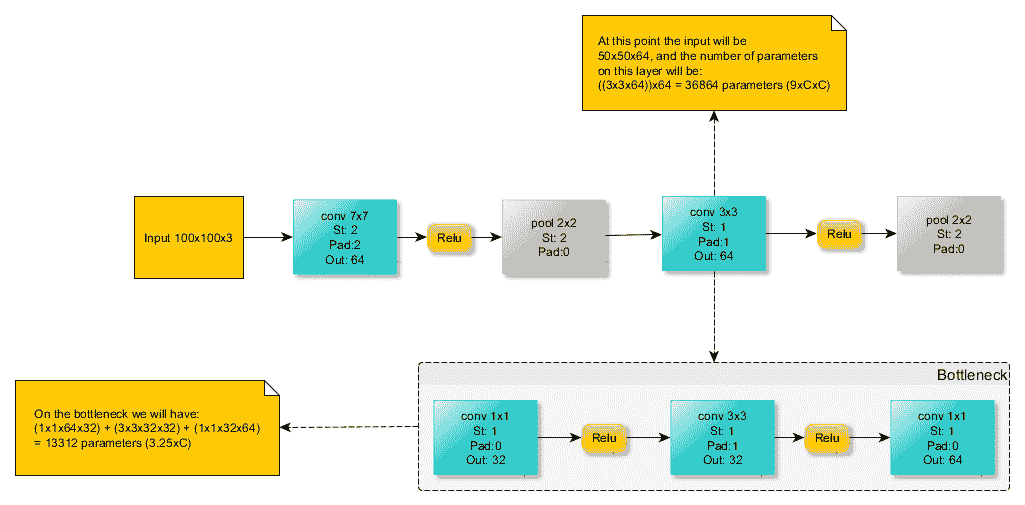
14.8 KB



99.7 KB

12.9 KB


16.5 KB
18.6 KB
13.3 KB






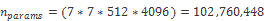
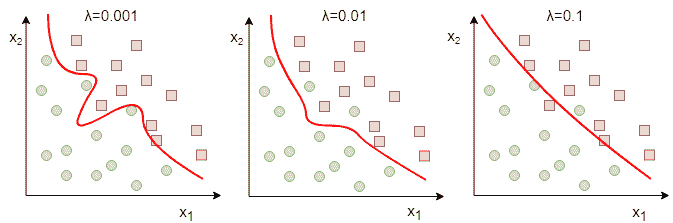
17.1 KB
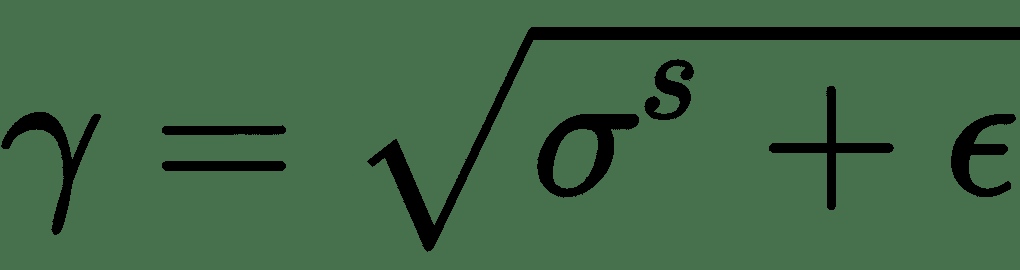
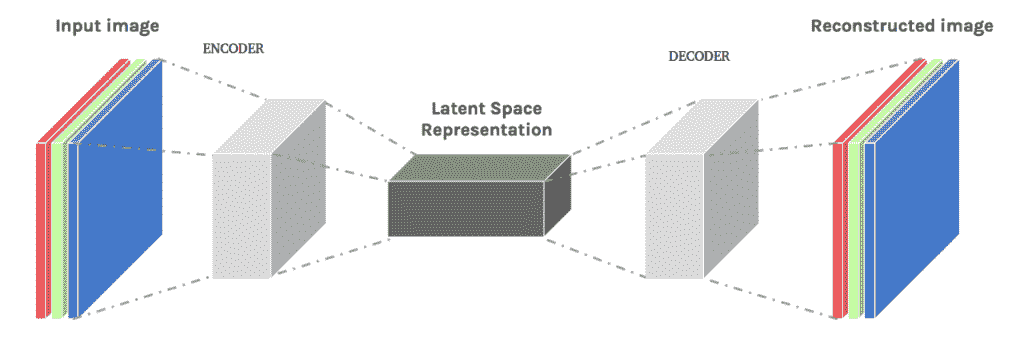
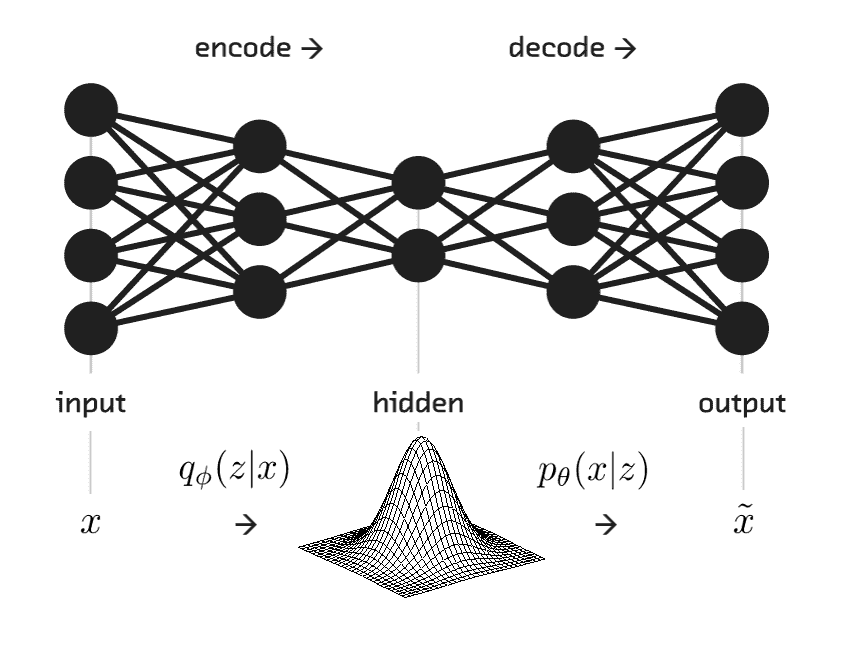
11.7 KB



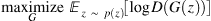
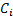

40.5 KB
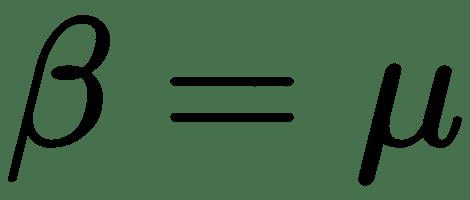
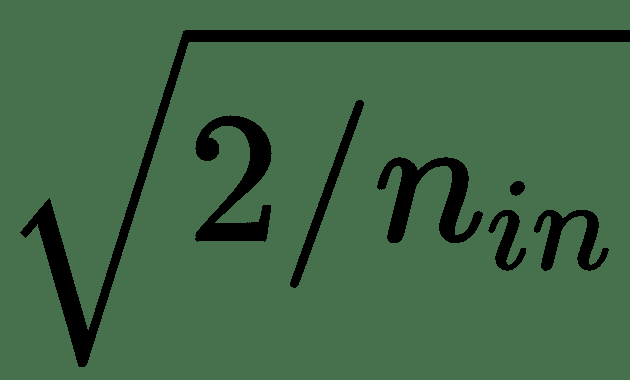






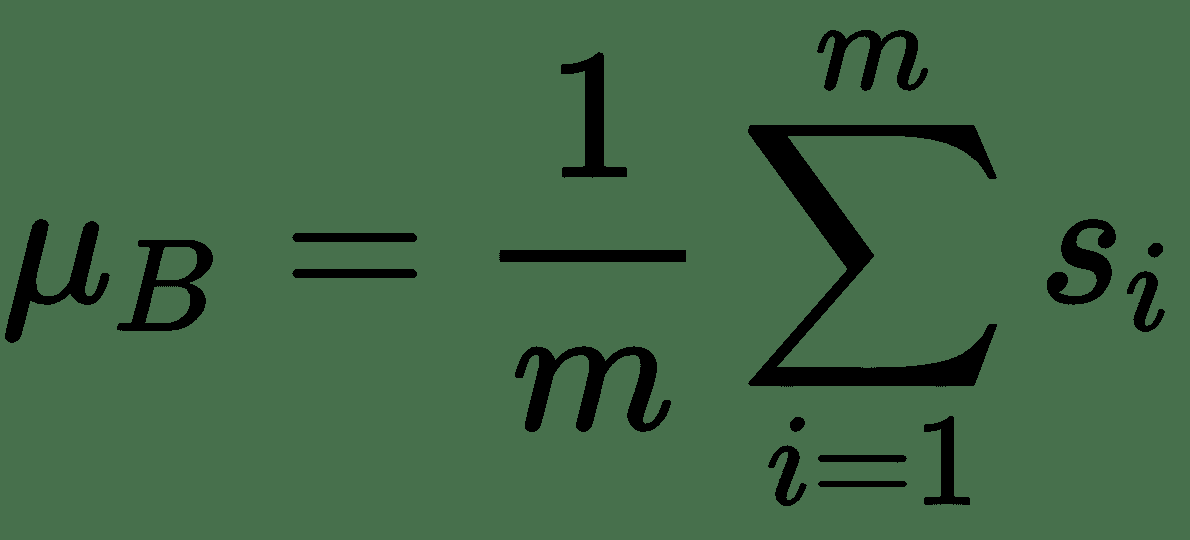


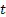
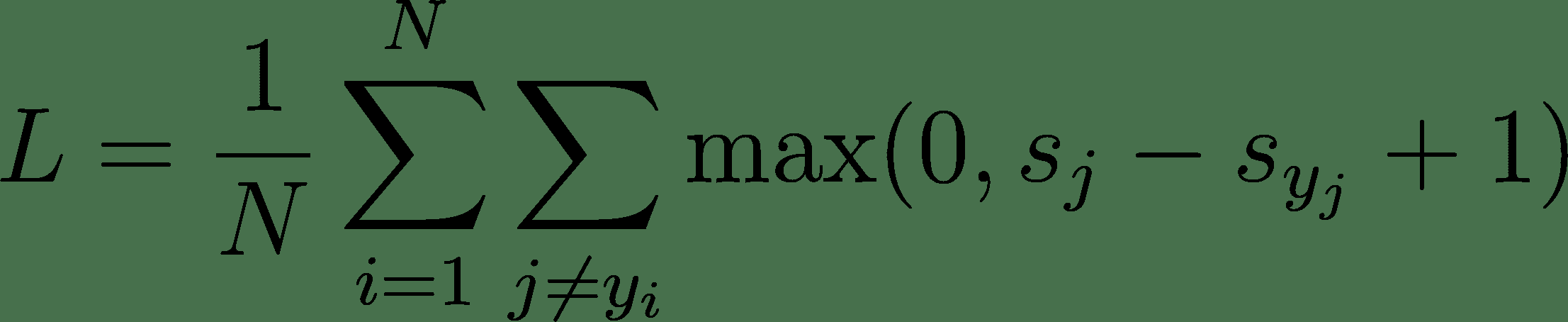
12.7 KB
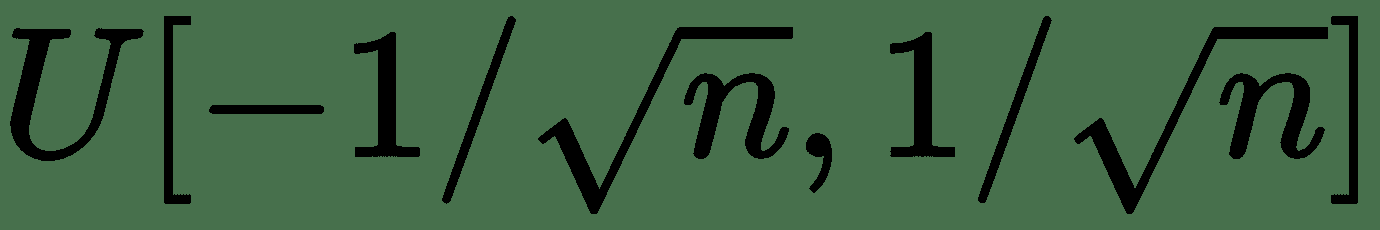
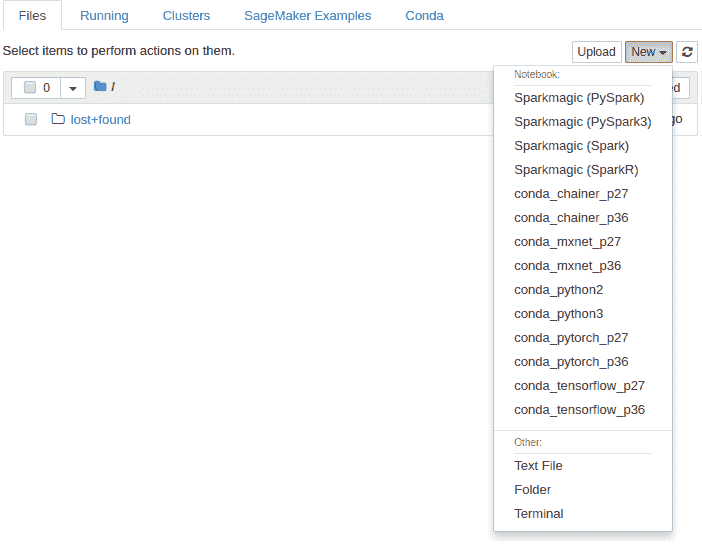
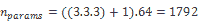

107.6 KB
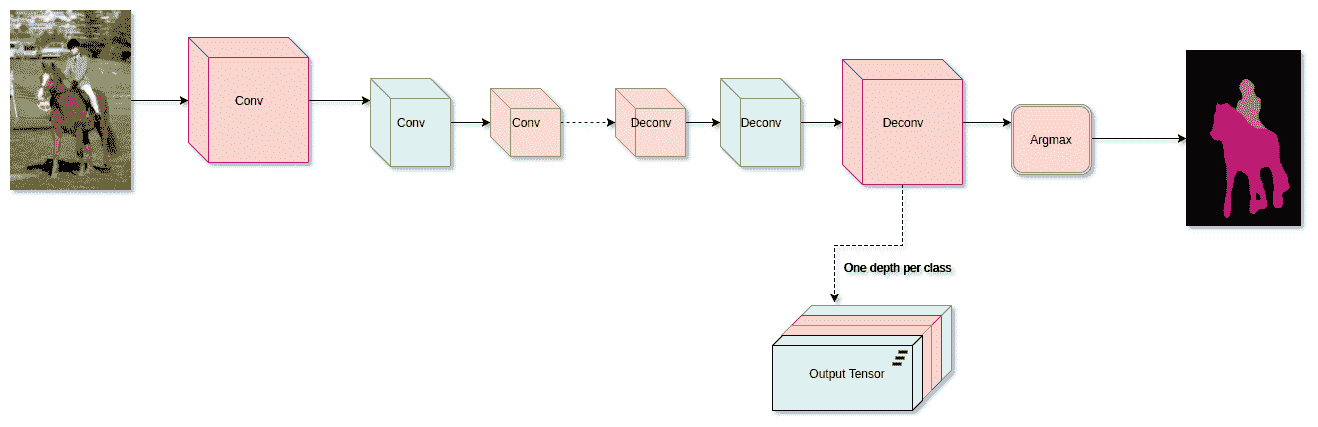
15.1 KB


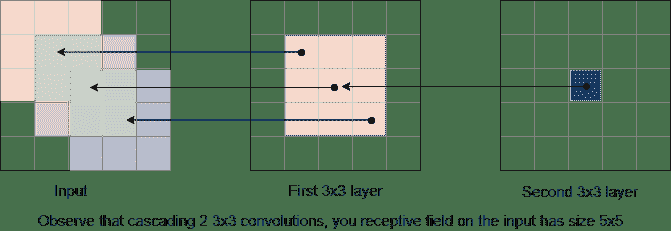
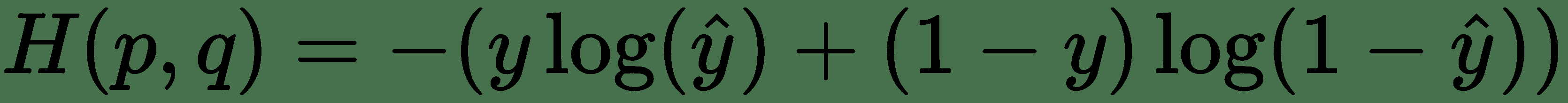
17.5 KB
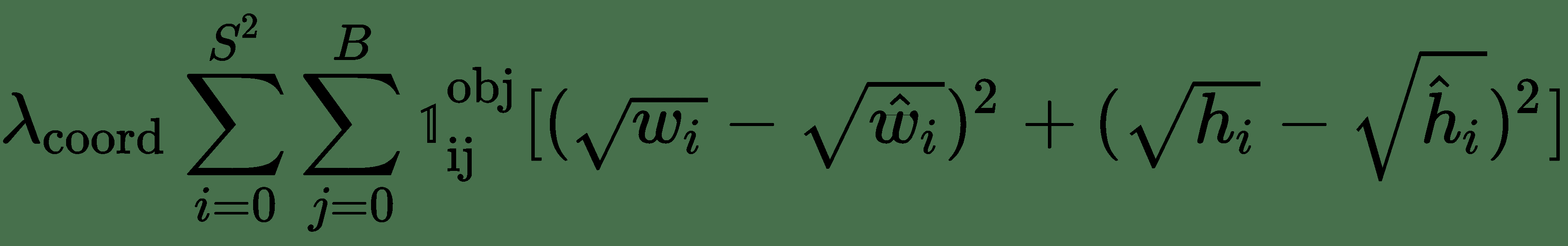
26.1 KB


21.2 KB

32.8 KB

12.0 KB


53.9 KB


47.4 KB

12.5 KB

134.4 KB
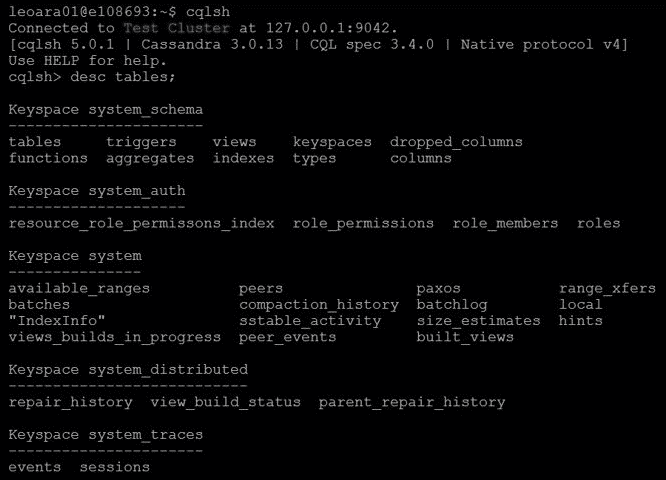
23.8 KB

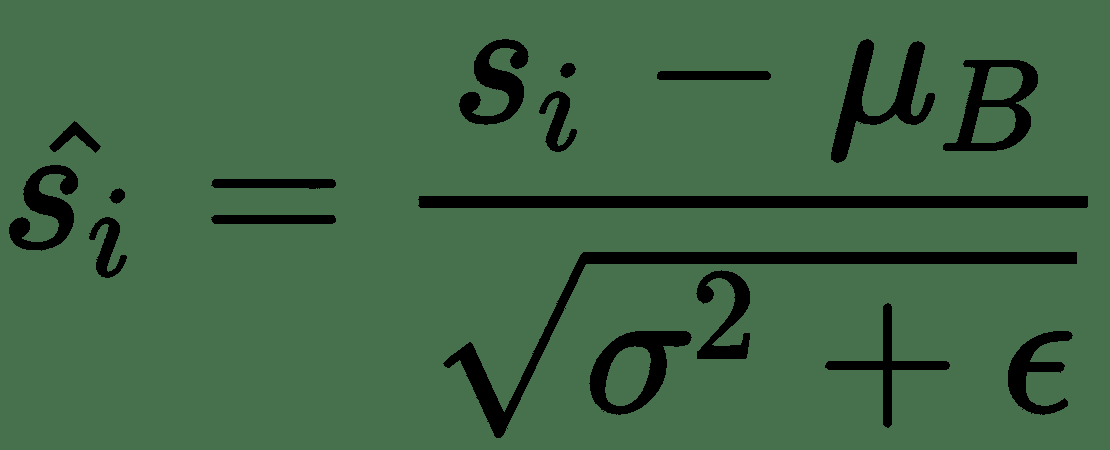

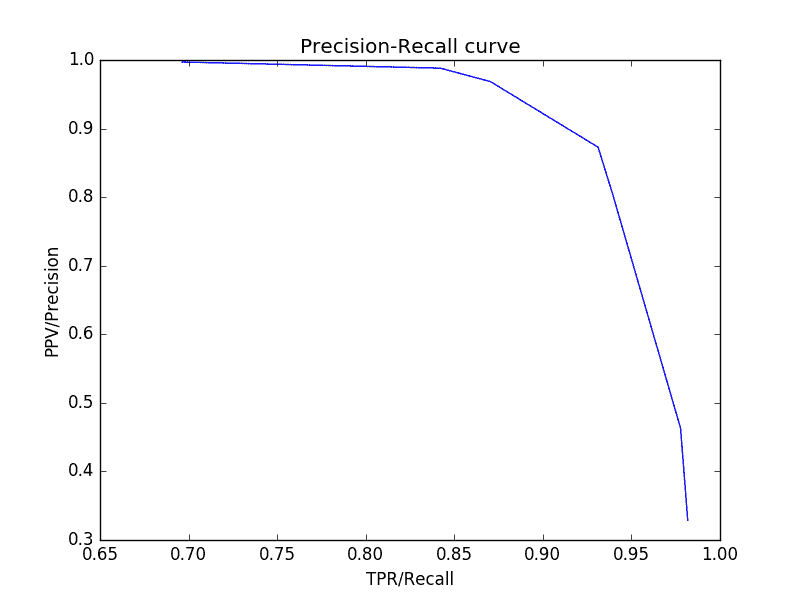
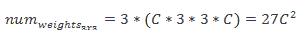

55.4 KB


168.6 KB



31.0 KB



141.9 KB




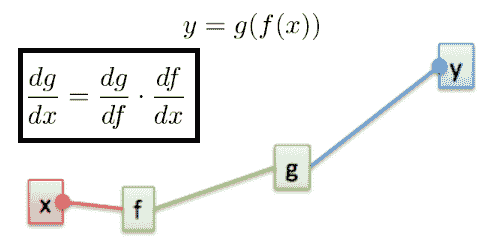


13.8 KB

16.3 KB
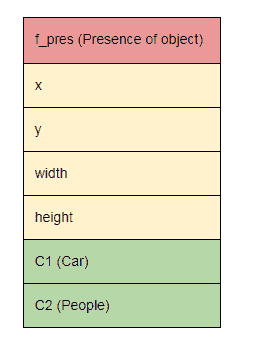
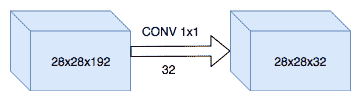
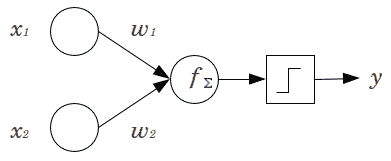
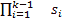




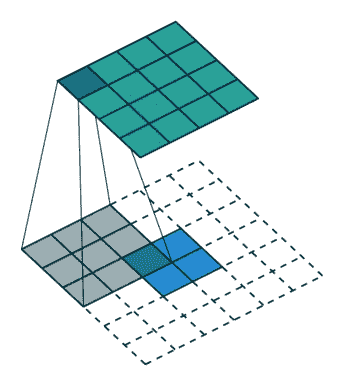



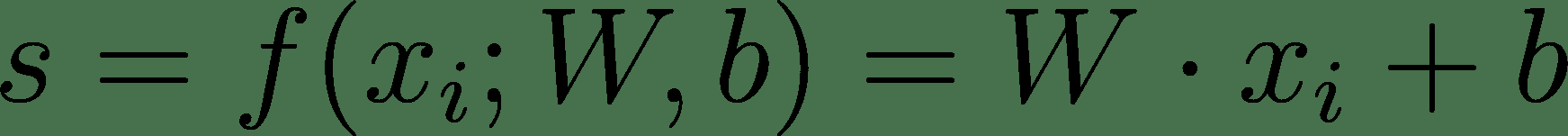
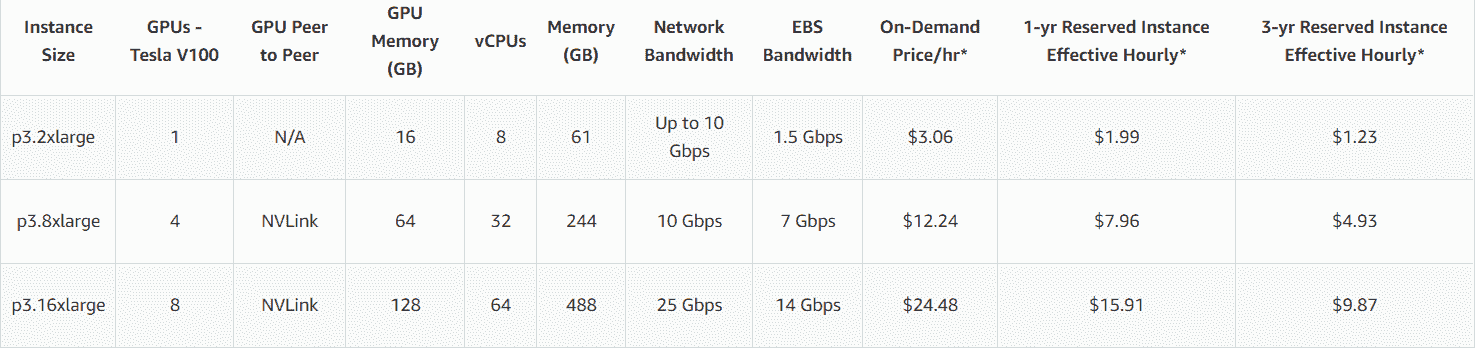
24.7 KB
20.0 KB
40.4 KB



21.0 KB

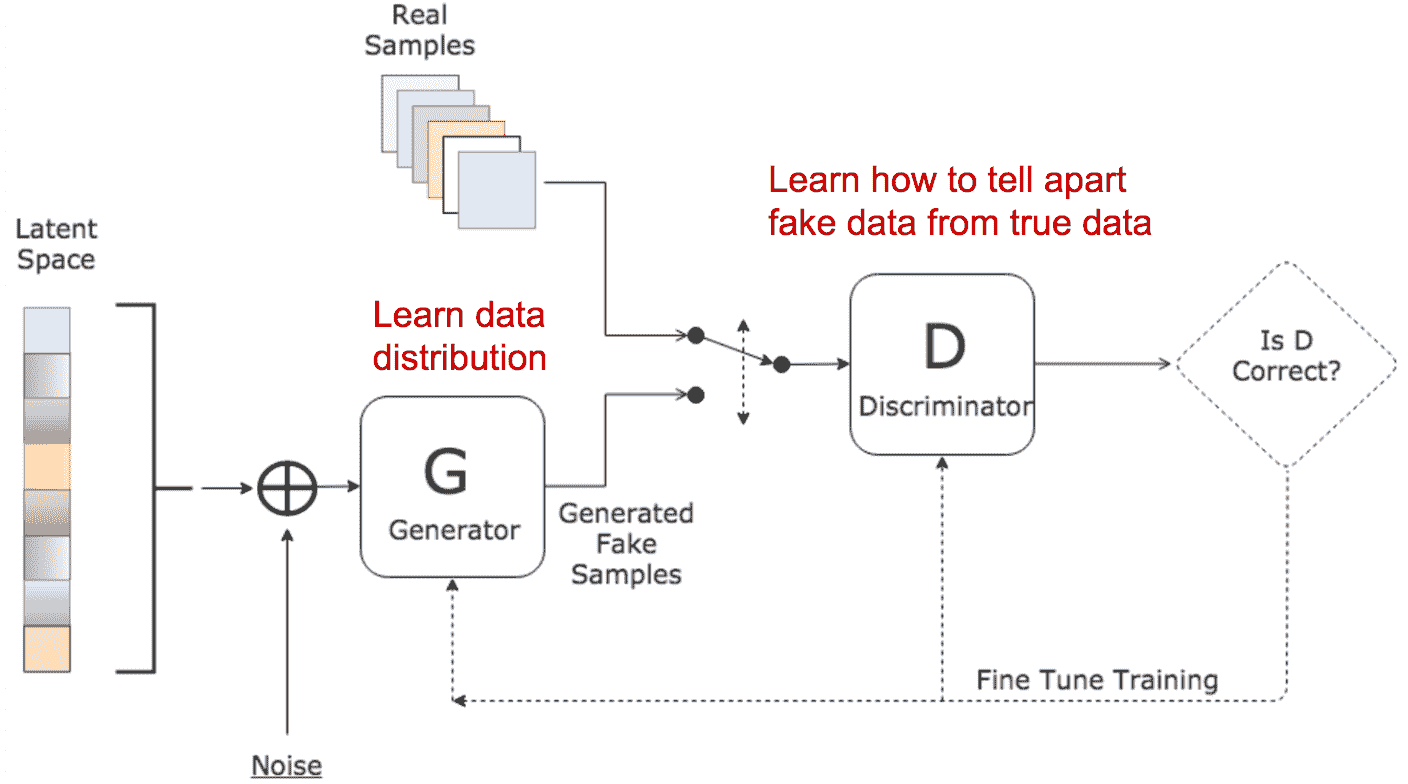
25.1 KB
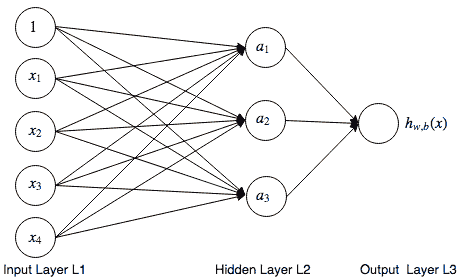
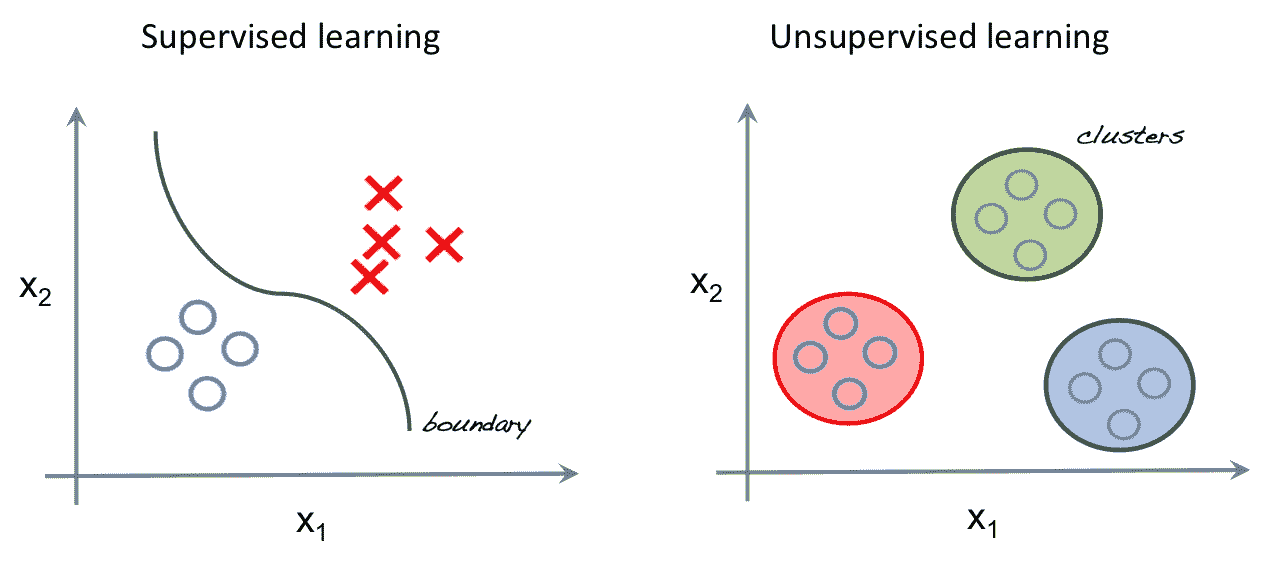
13.6 KB
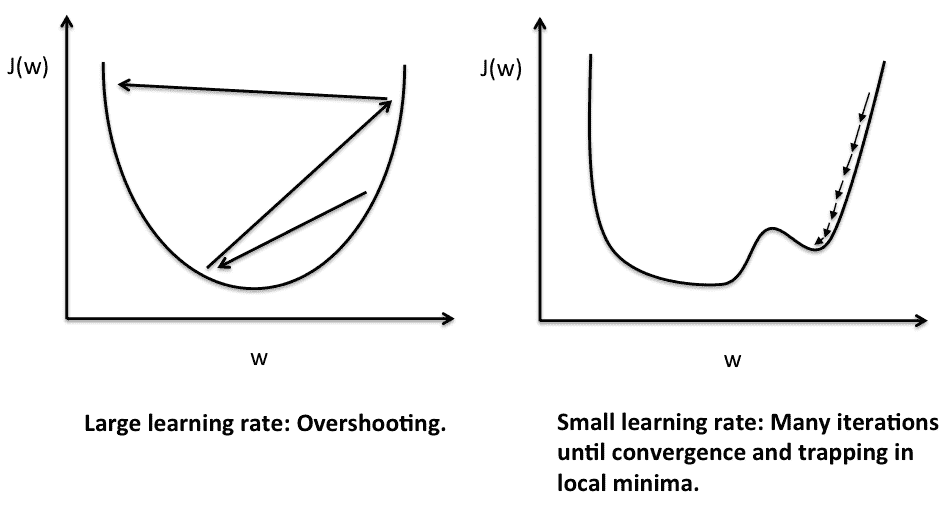
12.7 KB


10.2 KB


28.6 KB

28.6 KB




27.2 KB

45.9 KB
29.6 KB


226.2 KB





79.9 KB




24.1 KB
15.9 KB
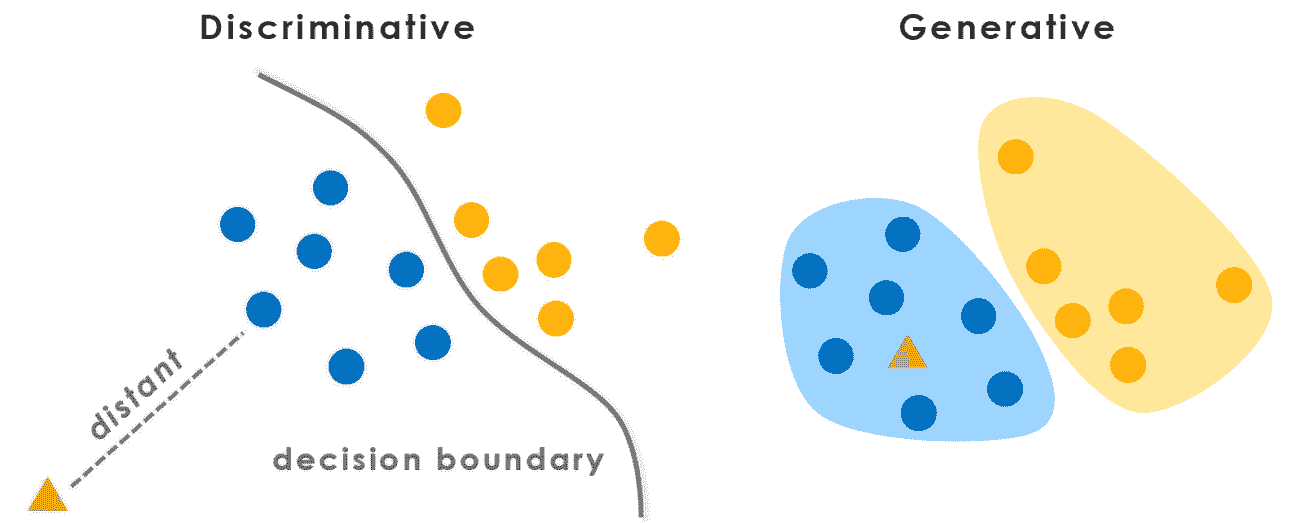
11.7 KB


39.9 KB
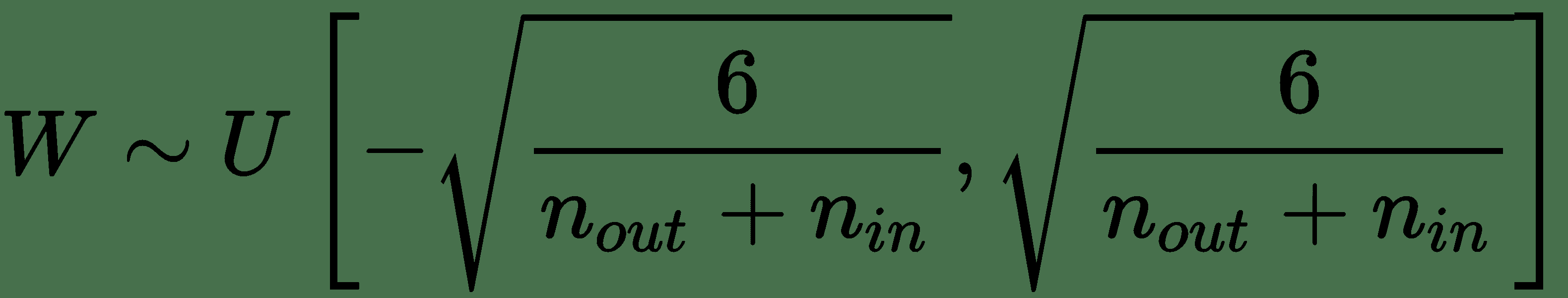
23.0 KB

25.7 KB


29.5 KB



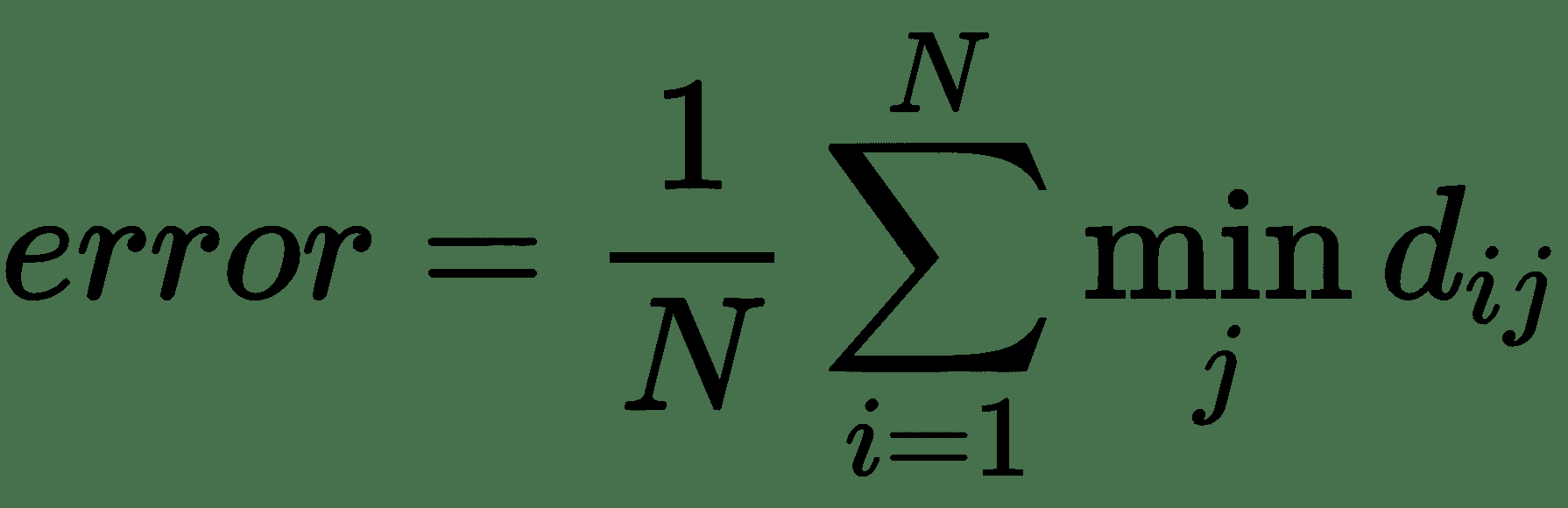
12.6 KB


21.9 KB
44.4 KB


20.3 KB


33.2 KB





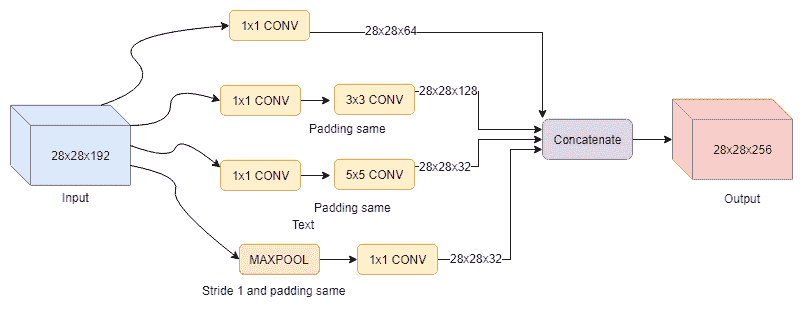
11.5 KB

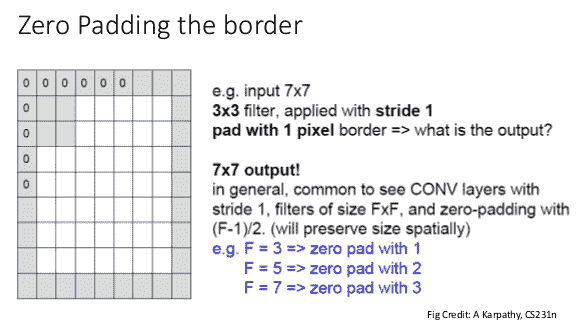
55.5 KB


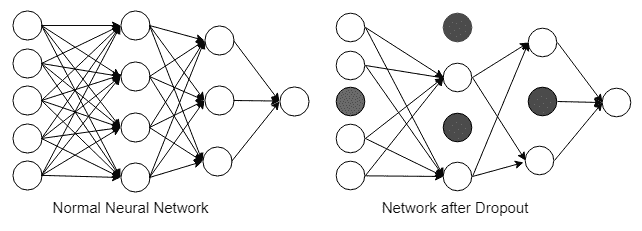
18.7 KB
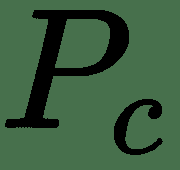

51.1 KB

16.9 KB
12.5 KB

16.8 KB


12.7 KB

57.9 KB

12.7 KB

15.3 KB

118.5 KB

10.9 KB

17.8 KB
12.2 KB
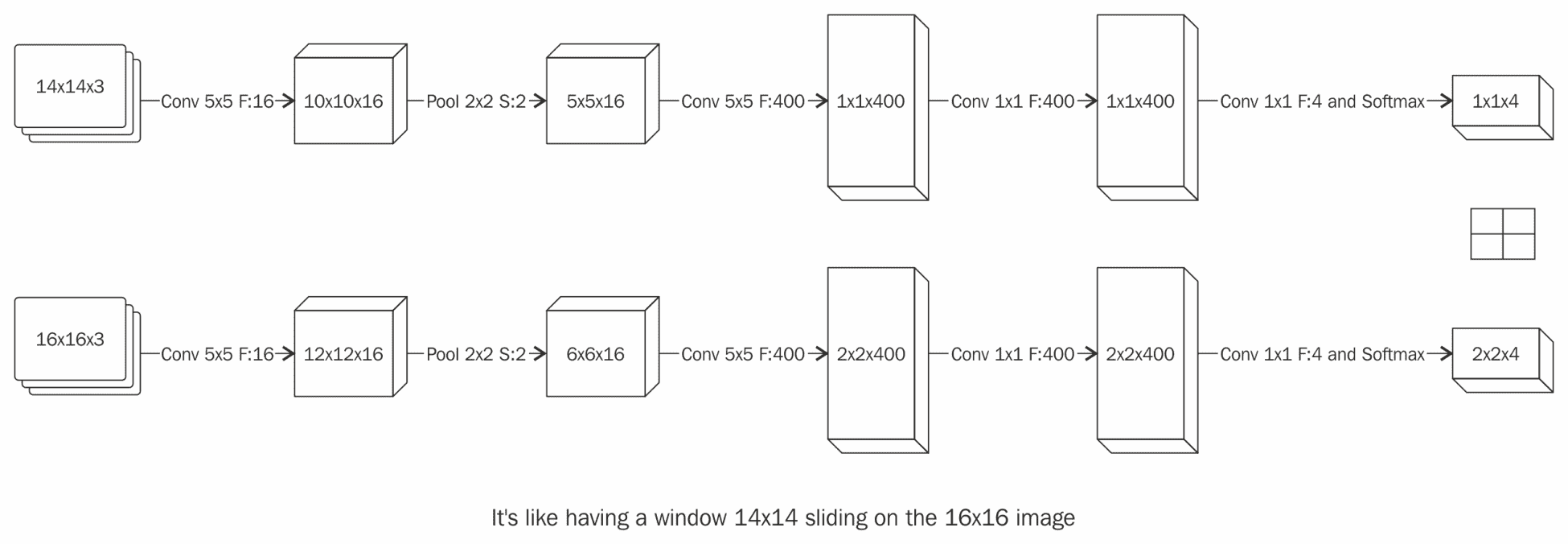
21.9 KB

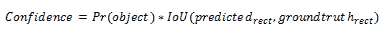



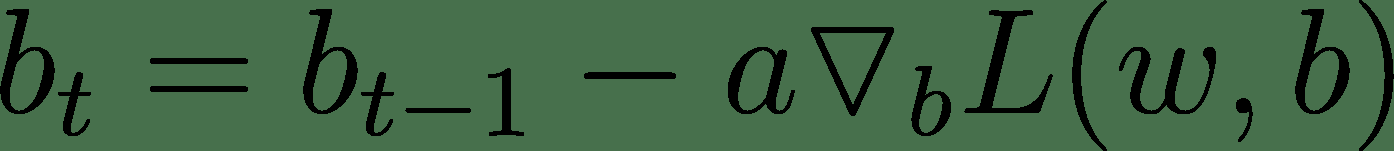

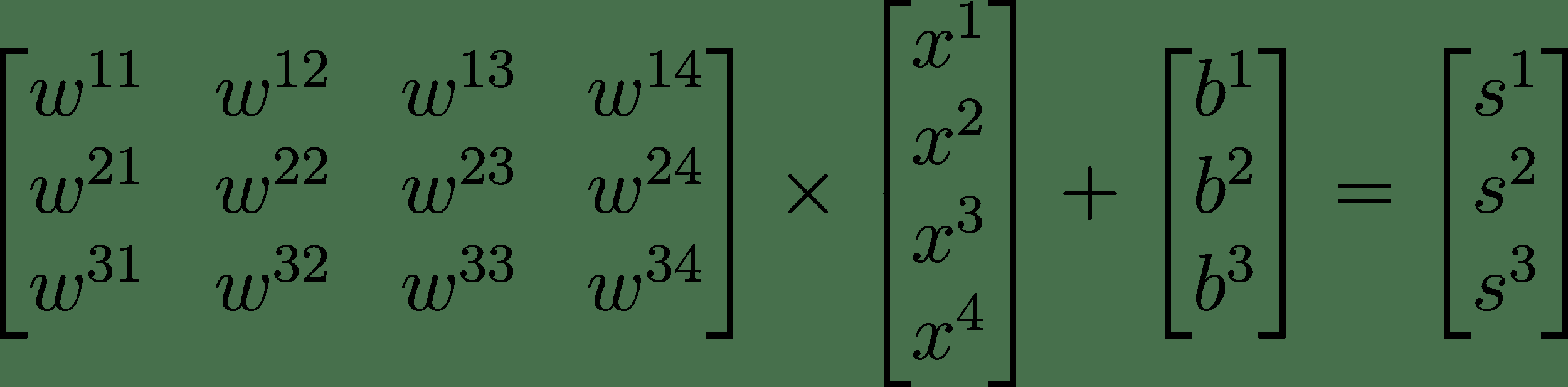
27.5 KB
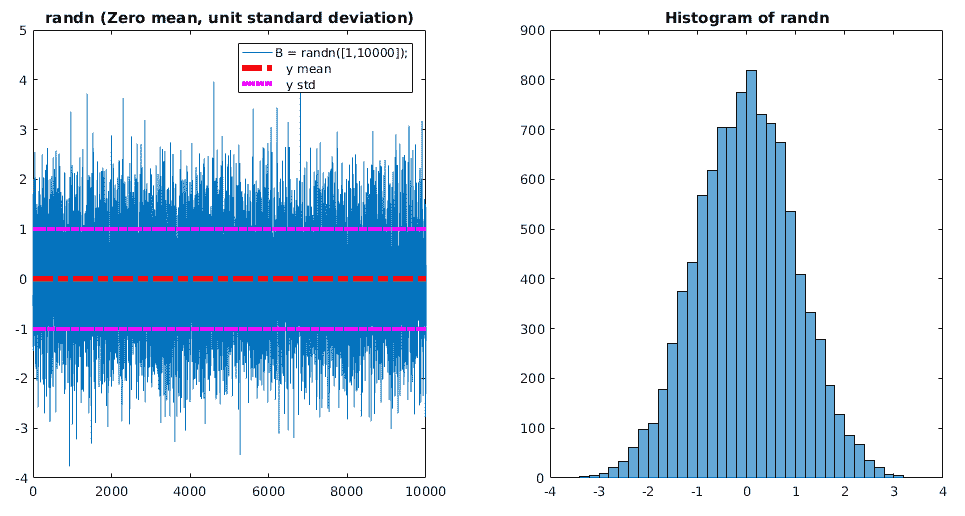
10.5 KB

35.2 KB
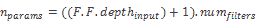
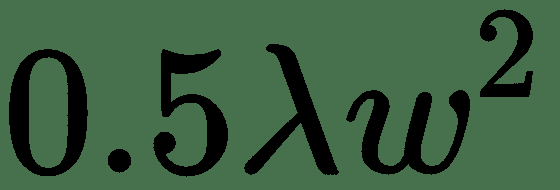

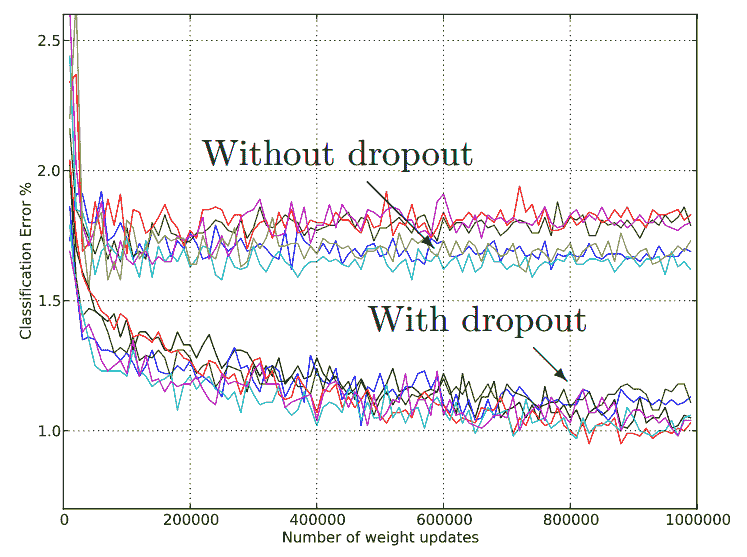
23.9 KB
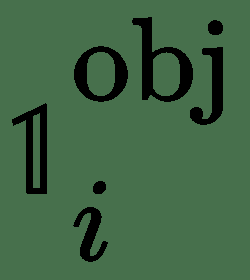

23.7 KB



11.8 KB
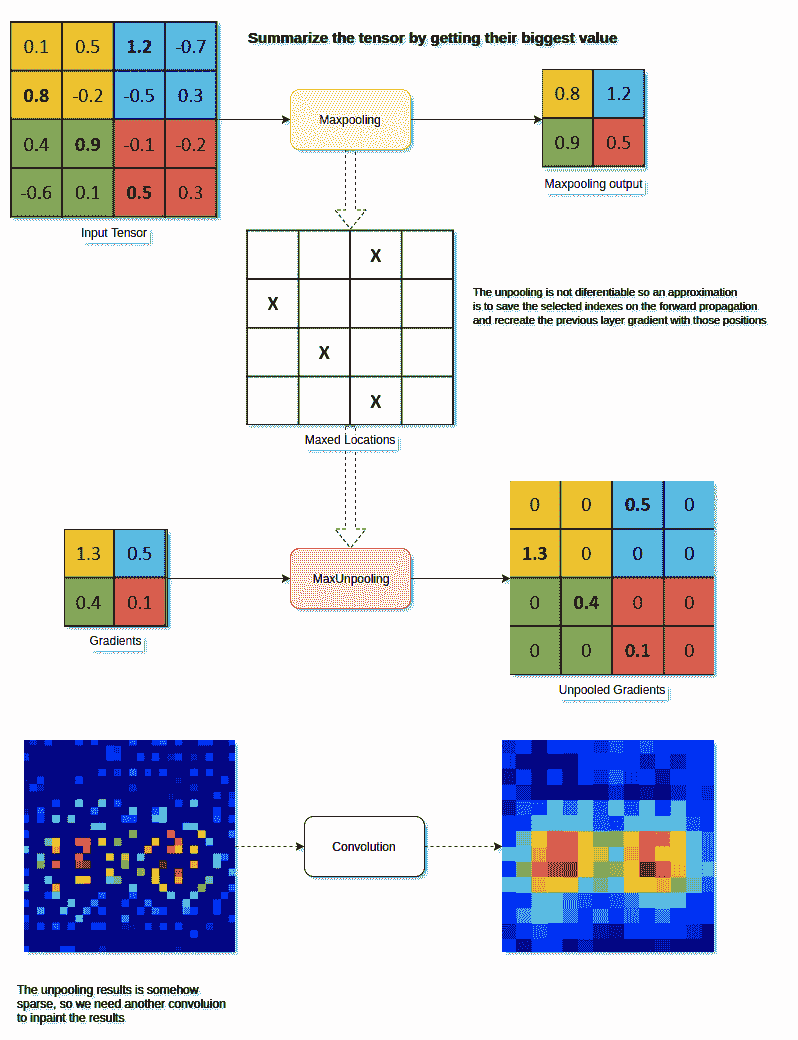
19.2 KB



12.9 KB

10.1 KB
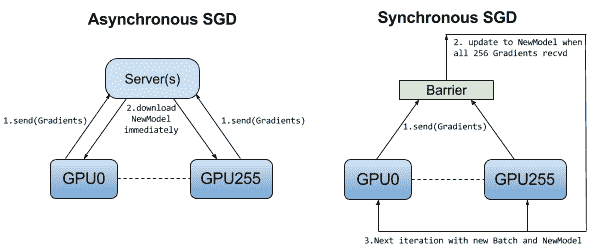


12.8 KB
11.2 KB


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}