diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
deleted file mode 100644
index dc7c62b06287ad333dd41082e566b0553d3a5341..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
+++ /dev/null
@@ -1,8 +0,0 @@
-*.pyc
-train.log
-output
-data/cifar-10-batches-py/
-data/cifar-10-python.tar.gz
-data/*.txt
-data/*.list
-data/mean.meta
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/index.md b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
similarity index 70%
rename from doc/fluid/new_docs/beginners_guide/basics/image_classification/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
index ce0d2bb1dc0cf73151ee9aceea7e4d7b24af1926..8d645718e12e4d976a8e71de105e11f495191fbf 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/image_classification/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
@@ -1,559 +1,576 @@
-
-# 图像分类
-
-本教程源代码目录在[book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-图像相比文字能够提供更加生动、容易理解及更具艺术感的信息,是人们转递与交换信息的重要来源。在本教程中,我们专注于图像识别领域的一个重要问题,即图像分类。
-
-图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。图像分类在很多领域有广泛应用,包括安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
-
-
-一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
-
-而基于深度学习的图像分类方法,可以通过有监督或无监督的方式**学习**层次化的特征描述,从而取代了手工设计或选择图像特征的工作。深度学习模型中的卷积神经网络(Convolution Neural Network, CNN)近年来在图像领域取得了惊人的成绩,CNN直接利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是图像识别的结果。这种基于"输入-输出"直接端到端的学习方法取得了非常好的效果,得到了广泛的应用。
-
-本教程主要介绍图像分类的深度学习模型,以及如何使用PaddlePaddle训练CNN模型。
-
-## 效果展示
-
-图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。
-
-
-
-图1. 通用图像分类展示
-
-
-
-图2展示了细粒度图像分类-花卉识别的效果,要求模型可以正确识别花的类别。
-
-
-
-图2. 细粒度图像分类展示
-
-
-
-一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。
-
-
-
-图3. 扰动图片展示[22]
-
-
-## 模型概览
-
-图像识别领域大量的研究成果都是建立在[PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/)、[ImageNet](http://image-net.org/)等公开的数据集上,很多图像识别算法通常在这些数据集上进行测试和比较。PASCAL VOC是2005年发起的一个视觉挑战赛,ImageNet是2010年发起的大规模视觉识别竞赛(ILSVRC)的数据集,在本章中我们基于这些竞赛的一些论文介绍图像分类模型。
-
-在2012年之前的传统图像分类方法可以用背景描述中提到的三步完成,但通常完整建立图像识别模型一般包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等几个阶段。
-1). **底层特征提取**: 通常从图像中按照固定步长、尺度提取大量局部特征描述。常用的局部特征包括SIFT(Scale-Invariant Feature Transform, 尺度不变特征转换) \[[1](#参考文献)\]、HOG(Histogram of Oriented Gradient, 方向梯度直方图) \[[2](#参考文献)\]、LBP(Local Bianray Pattern, 局部二值模式) \[[3](#参考文献)\] 等,一般也采用多种特征描述子,防止丢失过多的有用信息。
-2). **特征编码**: 底层特征中包含了大量冗余与噪声,为了提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,称作特征编码。常用的特征编码包括向量量化编码 \[[4](#参考文献)\]、稀疏编码 \[[5](#参考文献)\]、局部线性约束编码 \[[6](#参考文献)\]、Fisher向量编码 \[[7](#参考文献)\] 等。
-3). **空间特征约束**: 特征编码之后一般会经过空间特征约束,也称作**特征汇聚**。特征汇聚是指在一个空间范围内,对每一维特征取最大值或者平均值,可以获得一定特征不变形的特征表达。金字塔特征匹配是一种常用的特征聚会方法,这种方法提出将图像均匀分块,在分块内做特征汇聚。
-4). **通过分类器分类**: 经过前面步骤之后一张图像可以用一个固定维度的向量进行描述,接下来就是经过分类器对图像进行分类。通常使用的分类器包括SVM(Support Vector Machine, 支持向量机)、随机森林等。而使用核方法的SVM是最为广泛的分类器,在传统图像分类任务上性能很好。
-
-这种方法在PASCAL VOC竞赛中的图像分类算法中被广泛使用 \[[18](#参考文献)\]。[NEC实验室](http://www.nec-labs.com/)在ILSVRC2010中采用SIFT和LBP特征,两个非线性编码器以及SVM分类器获得图像分类的冠军 \[[8](#参考文献)\]。
-
-Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
-
-
-
-图4. ILSVRC图像分类Top-5错误率
-
-
-### CNN
-
-传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图5所示,我们先介绍用来构造CNN的常见组件。
-
-
-
-图5. CNN网络示例[20]
-
-
-- 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
-- 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
-- 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
-- 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
-- Dropout \[[10](#参考文献)\] : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
-
-另外,在训练过程中由于每层参数不断更新,会导致下一次输入分布发生变化,这样导致训练过程需要精心设计超参数。如2015年Sergey Ioffe和Christian Szegedy提出了Batch Normalization (BN)算法 \[[14](#参考文献)\] 中,每个batch对网络中的每一层特征都做归一化,使得每层分布相对稳定。BN算法不仅起到一定的正则作用,而且弱化了一些超参数的设计。经过实验证明,BN算法加速了模型收敛过程,在后来较深的模型中被广泛使用。
-
-接下来我们主要介绍VGG,GoogleNet和ResNet网络结构。
-
-### VGG
-
-牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 \[[11](#参考文献)\] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型\[[19](#参考文献)\]就是借鉴VGG模型的结构。
-
-
-
-图6. 基于ImageNet的VGG16模型
-
-
-### GoogleNet
-
-GoogleNet \[[12](#参考文献)\] 在2014年ILSVRC的获得了冠军,在介绍该模型之前我们先来了解NIN(Network in Network)模型 \[[13](#参考文献)\] 和Inception模块,因为GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想。
-
-NIN模型主要有两个特点:1) 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。2) 传统的CNN最后几层一般都是全连接层,参数较多。而NIN模型设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
-
-Inception模块如下图7所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
-
-
-
-图7. Inception模块
-
-
-GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没有采用传统的多层全连接层,而是像NIN网络一样采用了均值池化层;但与NIN不同的是,池化层后面接了一层到类别数映射的全连接层。除了这两个特点之外,由于网络中间层特征也很有判别性,GoogleNet在中间层添加了两个辅助分类器,在后向传播中增强梯度并且增强正则化,而整个网络的损失函数是这个三个分类器的损失加权求和。
-
-GoogleNet整体网络结构如图8所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
-
-
-
-图8. GoogleNet[12]
-
-
-
-上面介绍的是GoogleNet第一版模型(称作GoogleNet-v1)。GoogleNet-v2 \[[14](#参考文献)\] 引入BN层;GoogleNet-v3 \[[16](#参考文献)\] 对一些卷积层做了分解,进一步提高网络非线性能力和加深网络;GoogleNet-v4 \[[17](#参考文献)\] 引入下面要讲的ResNet设计思路。从v1到v4每一版的改进都会带来准确度的提升,介于篇幅,这里不再详细介绍v2到v4的结构。
-
-
-### ResNet
-
-ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题,ResNet提出了采用残差学习。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
-
-残差模块如图9所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
-
-
-
-图9. 残差模块
-
-
-图10展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
-
-
-
-图10. 基于ImageNet的ResNet模型
-
-
-
-## 数据准备
-
-通用图像分类公开的标准数据集常用的有[CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html)、[ImageNet](http://image-net.org/)、[COCO](http://mscoco.org/)等,常用的细粒度图像分类数据集包括[CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html)、[Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/)、[Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/)等。其中ImageNet数据集规模相对较大,如[模型概览](#模型概览)一章所讲,大量研究成果基于ImageNet。ImageNet数据从2010年来稍有变化,常用的是ImageNet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。
-
-由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用[CIFAR10]()数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。
-
-
-
-图11. CIFAR10数据集[21]
-
-
-Paddle API提供了自动加载cifar数据集模块 `paddle.dataset.cifar`。
-
-通过输入`python train.py`,就可以开始训练模型了,以下小节将详细介绍`train.py`的相关内容。
-
-### 模型结构
-
-#### Paddle 初始化
-
-让我们从导入 Paddle Fluid API 和辅助模块开始。
-
-```python
-import paddle
-import paddle.fluid as fluid
-import numpy
-import sys
-```
-
-本教程中我们提供了VGG和ResNet两个模型的配置。
-
-#### VGG
-
-首先介绍VGG模型结构,由于CIFAR10图片大小和数量相比ImageNet数据小很多,因此这里的模型针对CIFAR10数据做了一定的适配。卷积部分引入了BN和Dropout操作。
-VGG核心模块的输入是数据层,`vgg_bn_drop` 定义了16层VGG结构,每层卷积后面引入BN层和Dropout层,详细的定义如下:
-
-```python
-def vgg_bn_drop(input):
-def conv_block(ipt, num_filter, groups, dropouts):
-return fluid.nets.img_conv_group(
-input=ipt,
-pool_size=2,
-pool_stride=2,
-conv_num_filter=[num_filter] * groups,
-conv_filter_size=3,
-conv_act='relu',
-conv_with_batchnorm=True,
-conv_batchnorm_drop_rate=dropouts,
-pool_type='max')
-
-conv1 = conv_block(input, 64, 2, [0.3, 0])
-conv2 = conv_block(conv1, 128, 2, [0.4, 0])
-conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
-conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
-conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
-
-drop = fluid.layers.dropout(x=conv5, dropout_prob=0.5)
-fc1 = fluid.layers.fc(input=drop, size=512, act=None)
-bn = fluid.layers.batch_norm(input=fc1, act='relu')
-drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.5)
-fc2 = fluid.layers.fc(input=drop2, size=512, act=None)
-predict = fluid.layers.fc(input=fc2, size=10, act='softmax')
-return predict
-```
-
-1. 首先定义了一组卷积网络,即conv_block。卷积核大小为3x3,池化窗口大小为2x2,窗口滑动大小为2,groups决定每组VGG模块是几次连续的卷积操作,dropouts指定Dropout操作的概率。所使用的`img_conv_group`是在`paddle.networks`中预定义的模块,由若干组 Conv->BN->ReLu->Dropout 和 一组 Pooling 组成。
-
-2. 五组卷积操作,即 5个conv_block。 第一、二组采用两次连续的卷积操作。第三、四、五组采用三次连续的卷积操作。每组最后一个卷积后面Dropout概率为0,即不使用Dropout操作。
-
-3. 最后接两层512维的全连接。
-
-4. 通过上面VGG网络提取高层特征,然后经过全连接层映射到类别维度大小的向量,再通过Softmax归一化得到每个类别的概率,也可称作分类器。
-
-### ResNet
-
-ResNet模型的第1、3、4步和VGG模型相同,这里不再介绍。主要介绍第2步即CIFAR10数据集上ResNet核心模块。
-
-先介绍`resnet_cifar10`中的一些基本函数,再介绍网络连接过程。
-
-- `conv_bn_layer` : 带BN的卷积层。
-- `shortcut` : 残差模块的"直连"路径,"直连"实际分两种形式:残差模块输入和输出特征通道数不等时,采用1x1卷积的升维操作;残差模块输入和输出通道相等时,采用直连操作。
-- `basicblock` : 一个基础残差模块,即图9左边所示,由两组3x3卷积组成的路径和一条"直连"路径组成。
-- `bottleneck` : 一个瓶颈残差模块,即图9右边所示,由上下1x1卷积和中间3x3卷积组成的路径和一条"直连"路径组成。
-- `layer_warp` : 一组残差模块,由若干个残差模块堆积而成。每组中第一个残差模块滑动窗口大小与其他可以不同,以用来减少特征图在垂直和水平方向的大小。
-
-```python
-def conv_bn_layer(input,
-ch_out,
-filter_size,
-stride,
-padding,
-act='relu',
-bias_attr=False):
-tmp = fluid.layers.conv2d(
-input=input,
-filter_size=filter_size,
-num_filters=ch_out,
-stride=stride,
-padding=padding,
-act=None,
-bias_attr=bias_attr)
-return fluid.layers.batch_norm(input=tmp, act=act)
-
-
-def shortcut(input, ch_in, ch_out, stride):
-if ch_in != ch_out:
-return conv_bn_layer(input, ch_out, 1, stride, 0, None)
-else:
-return input
-
-
-def basicblock(input, ch_in, ch_out, stride):
-tmp = conv_bn_layer(input, ch_out, 3, stride, 1)
-tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, act=None, bias_attr=True)
-short = shortcut(input, ch_in, ch_out, stride)
-return fluid.layers.elementwise_add(x=tmp, y=short, act='relu')
-
-
-def layer_warp(block_func, input, ch_in, ch_out, count, stride):
-tmp = block_func(input, ch_in, ch_out, stride)
-for i in range(1, count):
-tmp = block_func(tmp, ch_out, ch_out, 1)
-return tmp
-```
-
-`resnet_cifar10` 的连接结构主要有以下几个过程。
-
-1. 底层输入连接一层 `conv_bn_layer`,即带BN的卷积层。
-2. 然后连接3组残差模块即下面配置3组 `layer_warp` ,每组采用图 10 左边残差模块组成。
-3. 最后对网络做均值池化并返回该层。
-
-注意:除过第一层卷积层和最后一层全连接层之外,要求三组 `layer_warp` 总的含参层数能够被6整除,即 `resnet_cifar10` 的 depth 要满足 `$(depth - 2) % 6 == 0$` 。
-
-```python
-def resnet_cifar10(ipt, depth=32):
-# depth should be one of 20, 32, 44, 56, 110, 1202
-assert (depth - 2) % 6 == 0
-n = (depth - 2) / 6
-nStages = {16, 64, 128}
-conv1 = conv_bn_layer(ipt, ch_out=16, filter_size=3, stride=1, padding=1)
-res1 = layer_warp(basicblock, conv1, 16, 16, n, 1)
-res2 = layer_warp(basicblock, res1, 16, 32, n, 2)
-res3 = layer_warp(basicblock, res2, 32, 64, n, 2)
-pool = fluid.layers.pool2d(
-input=res3, pool_size=8, pool_type='avg', pool_stride=1)
-predict = fluid.layers.fc(input=pool, size=10, act='softmax')
-return predict
-```
-
-## Infererence Program 配置
-
-网络输入定义为 `data_layer` (数据层),在图像分类中即为图像像素信息。CIFRAR10是RGB 3通道32x32大小的彩色图,因此输入数据大小为3072(3x32x32)。
-
-```python
-def inference_program():
-# The image is 32 * 32 with RGB representation.
-data_shape = [3, 32, 32]
-images = fluid.layers.data(name='pixel', shape=data_shape, dtype='float32')
-
-predict = resnet_cifar10(images, 32)
-# predict = vgg_bn_drop(images) # un-comment to use vgg net
-return predict
-```
-
-## Train Program 配置
-
-然后我们需要设置训练程序 `train_program`。它首先从推理程序中进行预测。
-在训练期间,它将从预测中计算 `avg_cost`。
-在有监督训练中需要输入图像对应的类别信息,同样通过`fluid.layers.data`来定义。训练中采用多类交叉熵作为损失函数,并作为网络的输出,预测阶段定义网络的输出为分类器得到的概率信息。
-
-**注意:** 训练程序应该返回一个数组,第一个返回参数必须是 `avg_cost`。训练器使用它来计算梯度。
-
-```python
-def train_program():
-predict = inference_program()
-
-label = fluid.layers.data(name='label', shape=[1], dtype='int64')
-cost = fluid.layers.cross_entropy(input=predict, label=label)
-avg_cost = fluid.layers.mean(cost)
-accuracy = fluid.layers.accuracy(input=predict, label=label)
-return [avg_cost, accuracy]
-```
-
-## Optimizer Function 配置
-
-在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
-
-```python
-def optimizer_program():
-return fluid.optimizer.Adam(learning_rate=0.001)
-```
-
-## 训练模型
-
-### Trainer 配置
-
-现在,我们需要配置 `Trainer`。`Trainer` 需要接受训练程序 `train_program`, `place` 和优化器 `optimizer_func`。
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-trainer = fluid.Trainer(
-train_func=train_program,
-optimizer_func=optimizer_program,
-place=place)
-```
-
-### Data Feeders 配置
-
-`cifar.train10()` 每次产生一条样本,在完成shuffle和batch之后,作为训练的输入。
-
-```python
-# Each batch will yield 128 images
-BATCH_SIZE = 128
-
-# Reader for training
-train_reader = paddle.batch(
-paddle.reader.shuffle(paddle.dataset.cifar.train10(), buf_size=50000),
-batch_size=BATCH_SIZE)
-
-# Reader for testing. A separated data set for testing.
-test_reader = paddle.batch(
-paddle.dataset.cifar.test10(), batch_size=BATCH_SIZE)
-```
-
-### Event Handler
-
-可以使用`event_handler`回调函数来观察训练过程,或进行测试等, 该回调函数是`trainer.train`函数里设定。
-
-`event_handler_plot`可以用来利用回调数据来打点画图:
-
-
-
-```python
-params_dirname = "image_classification_resnet.inference.model"
-
-from paddle.v2.plot import Ploter
-
-train_title = "Train cost"
-test_title = "Test cost"
-cost_ploter = Ploter(train_title, test_title)
-
-step = 0
-def event_handler_plot(event):
-global step
-if isinstance(event, fluid.EndStepEvent):
-if step % 1 == 0:
-cost_ploter.append(train_title, step, event.metrics[0])
-cost_ploter.plot()
-step += 1
-if isinstance(event, fluid.EndEpochEvent):
-avg_cost, accuracy = trainer.test(
-reader=test_reader,
-feed_order=['pixel', 'label'])
-cost_ploter.append(test_title, step, avg_cost)
-
-# save parameters
-if params_dirname is not None:
-trainer.save_params(params_dirname)
-```
-
-`event_handler` 用来在训练过程中输出文本日志
-
-```python
-params_dirname = "image_classification_resnet.inference.model"
-
-# event handler to track training and testing process
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-if event.step % 100 == 0:
-print("\nPass %d, Batch %d, Cost %f, Acc %f" %
-(event.step, event.epoch, event.metrics[0],
-event.metrics[1]))
-else:
-sys.stdout.write('.')
-sys.stdout.flush()
-
-if isinstance(event, fluid.EndEpochEvent):
-# Test against with the test dataset to get accuracy.
-avg_cost, accuracy = trainer.test(
-reader=test_reader, feed_order=['pixel', 'label'])
-
-print('\nTest with Pass {0}, Loss {1:2.2}, Acc {2:2.2}'.format(event.epoch, avg_cost, accuracy))
-
-# save parameters
-if params_dirname is not None:
-trainer.save_params(params_dirname)
-```
-
-### 训练
-
-通过`trainer.train`函数训练:
-
-**注意:** CPU,每个 Epoch 将花费大约15~20分钟。这部分可能需要一段时间。请随意修改代码,在GPU上运行测试,以提高培训速度。
-
-```python
-trainer.train(
-reader=train_reader,
-num_epochs=2,
-event_handler=event_handler,
-feed_order=['pixel', 'label'])
-```
-
-一轮训练log示例如下所示,经过1个pass, 训练集上平均 Accuracy 为0.59 ,测试集上平均 Accuracy 为0.6 。
-
-```text
-Pass 0, Batch 0, Cost 3.869598, Acc 0.164062
-...................................................................................................
-Pass 100, Batch 0, Cost 1.481038, Acc 0.460938
-...................................................................................................
-Pass 200, Batch 0, Cost 1.340323, Acc 0.523438
-...................................................................................................
-Pass 300, Batch 0, Cost 1.223424, Acc 0.593750
-..........................................................................................
-Test with Pass 0, Loss 1.1, Acc 0.6
-```
-
-图12是训练的分类错误率曲线图,运行到第200个pass后基本收敛,最终得到测试集上分类错误率为8.54%。
-
-
-
-图12. CIFAR10数据集上VGG模型的分类错误率
-
-
-## 应用模型
-
-可以使用训练好的模型对图片进行分类,下面程序展示了如何使用 `fluid.Inferencer` 接口进行推断,可以打开注释,更改加载的模型。
-
-### 生成预测输入数据
-
-`dog.png` is an example image of a dog. Turn it into an numpy array to match the data feeder format.
-
-```python
-# Prepare testing data.
-from PIL import Image
-import numpy as np
-import os
-
-def load_image(file):
-im = Image.open(file)
-im = im.resize((32, 32), Image.ANTIALIAS)
-
-im = np.array(im).astype(np.float32)
-# The storage order of the loaded image is W(width),
-# H(height), C(channel). PaddlePaddle requires
-# the CHW order, so transpose them.
-im = im.transpose((2, 0, 1)) # CHW
-im = im / 255.0
-
-# Add one dimension to mimic the list format.
-im = numpy.expand_dims(im, axis=0)
-return im
-
-cur_dir = os.getcwd()
-img = load_image(cur_dir + '/image/dog.png')
-```
-
-### Inferencer 配置和预测
-
-`Inferencer` 需要一个 `infer_func` 和 `param_path` 来设置网络和经过训练的参数。
-我们可以简单地插入前面定义的推理程序。
-现在我们准备做预测。
-
-```python
-inferencer = fluid.Inferencer(
-infer_func=inference_program, param_path=params_dirname, place=place)
-
-# inference
-results = inferencer.infer({'pixel': img})
-print("infer results: ", results)
-```
-
-## 总结
-
-传统图像分类方法由多个阶段构成,框架较为复杂,而端到端的CNN模型结构可一步到位,而且大幅度提升了分类准确率。本文我们首先介绍VGG、GoogleNet、ResNet三个经典的模型;然后基于CIFAR10数据集,介绍如何使用PaddlePaddle配置和训练CNN模型,尤其是VGG和ResNet模型;最后介绍如何使用PaddlePaddle的API接口对图片进行预测和特征提取。对于其他数据集比如ImageNet,配置和训练流程是同样的,大家可以自行进行实验。
-
-
-## 参考文献
-
-[1] D. G. Lowe, [Distinctive image features from scale-invariant keypoints](http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf). IJCV, 60(2):91-110, 2004.
-
-[2] N. Dalal, B. Triggs, [Histograms of Oriented Gradients for Human Detection](http://vision.stanford.edu/teaching/cs231b_spring1213/papers/CVPR05_DalalTriggs.pdf), Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2005.
-
-[3] Ahonen, T., Hadid, A., and Pietikinen, M. (2006). [Face description with local binary patterns: Application to face recognition](http://ieeexplore.ieee.org/document/1717463/). PAMI, 28.
-
-[4] J. Sivic, A. Zisserman, [Video Google: A Text Retrieval Approach to Object Matching in Videos](http://www.robots.ox.ac.uk/~vgg/publications/papers/sivic03.pdf), Proc. Ninth Int'l Conf. Computer Vision, pp. 1470-1478, 2003.
-
-[5] B. Olshausen, D. Field, [Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1?](http://redwood.psych.cornell.edu/papers/olshausen_field_1997.pdf), Vision Research, vol. 37, pp. 3311-3325, 1997.
-
-[6] Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., and Gong, Y. (2010). [Locality-constrained Linear Coding for image classification](http://ieeexplore.ieee.org/abstract/document/5540018/). In CVPR.
-
-[7] Perronnin, F., Sánchez, J., & Mensink, T. (2010). [Improving the fisher kernel for large-scale image classification](http://dl.acm.org/citation.cfm?id=1888101). In ECCV (4).
-
-[8] Lin, Y., Lv, F., Cao, L., Zhu, S., Yang, M., Cour, T., Yu, K., and Huang, T. (2011). [Large-scale image clas- sification: Fast feature extraction and SVM training](http://ieeexplore.ieee.org/document/5995477/). In CVPR.
-
-[9] Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). [ImageNet classification with deep convolutional neu- ral networks](http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf). In NIPS.
-
-[10] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. [Improving neural networks by preventing co-adaptation of feature detectors](https://arxiv.org/abs/1207.0580). arXiv preprint arXiv:1207.0580, 2012.
-
-[11] K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. [Return of the Devil in the Details: Delving Deep into Convolutional Nets](https://arxiv.org/abs/1405.3531). BMVC, 2014。
-
-[12] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A., [Going deeper with convolutions](https://arxiv.org/abs/1409.4842). In: CVPR. (2015)
-
-[13] Lin, M., Chen, Q., and Yan, S. [Network in network](https://arxiv.org/abs/1312.4400). In Proc. ICLR, 2014.
-
-[14] S. Ioffe and C. Szegedy. [Batch normalization: Accelerating deep network training by reducing internal covariate shift](https://arxiv.org/abs/1502.03167). In ICML, 2015.
-
-[15] K. He, X. Zhang, S. Ren, J. Sun. [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385). CVPR 2016.
-
-[16] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. [Rethinking the incep-tion architecture for computer vision](https://arxiv.org/abs/1512.00567). In: CVPR. (2016).
-
-[17] Szegedy, C., Ioffe, S., Vanhoucke, V. [Inception-v4, inception-resnet and the impact of residual connections on learning](https://arxiv.org/abs/1602.07261). arXiv:1602.07261 (2016).
-
-[18] Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A. [The Pascal Visual Object Classes Challenge: A Retrospective]((http://link.springer.com/article/10.1007/s11263-014-0733-5)). International Journal of Computer Vision, 111(1), 98-136, 2015.
-
-[19] He, K., Zhang, X., Ren, S., and Sun, J. [Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification](https://arxiv.org/abs/1502.01852). ArXiv e-prints, February 2015.
-
-[20] http://deeplearning.net/tutorial/lenet.html
-
-[21] https://www.cs.toronto.edu/~kriz/cifar.html
-
-[22] http://cs231n.github.io/classification/
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+
+# 图像分类
+
+本教程源代码目录在[book/image_classification](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/168.html)。
+
+## 背景介绍
+
+图像相比文字能够提供更加生动、容易理解及更具艺术感的信息,是人们转递与交换信息的重要来源。在本教程中,我们专注于图像识别领域的一个重要问题,即图像分类。
+
+图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。图像分类在很多领域有广泛应用,包括安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
+
+
+一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
+
+而基于深度学习的图像分类方法,可以通过有监督或无监督的方式**学习**层次化的特征描述,从而取代了手工设计或选择图像特征的工作。深度学习模型中的卷积神经网络(Convolution Neural Network, CNN)近年来在图像领域取得了惊人的成绩,CNN直接利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是图像识别的结果。这种基于"输入-输出"直接端到端的学习方法取得了非常好的效果,得到了广泛的应用。
+
+本教程主要介绍图像分类的深度学习模型,以及如何使用PaddlePaddle训练CNN模型。
+
+## 效果展示
+
+图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。
+
+
+
+图1. 通用图像分类展示
+
+
+
+图2展示了细粒度图像分类-花卉识别的效果,要求模型可以正确识别花的类别。
+
+
+
+
+图2. 细粒度图像分类展示
+
+
+
+一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。
+
+
+
+图3. 扰动图片展示[22]
+
+
+## 模型概览
+
+图像识别领域大量的研究成果都是建立在[PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/)、[ImageNet](http://image-net.org/)等公开的数据集上,很多图像识别算法通常在这些数据集上进行测试和比较。PASCAL VOC是2005年发起的一个视觉挑战赛,ImageNet是2010年发起的大规模视觉识别竞赛(ILSVRC)的数据集,在本章中我们基于这些竞赛的一些论文介绍图像分类模型。
+
+在2012年之前的传统图像分类方法可以用背景描述中提到的三步完成,但通常完整建立图像识别模型一般包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等几个阶段。
+
+ 1). **底层特征提取**: 通常从图像中按照固定步长、尺度提取大量局部特征描述。常用的局部特征包括SIFT(Scale-Invariant Feature Transform, 尺度不变特征转换) \[[1](#参考文献)\]、HOG(Histogram of Oriented Gradient, 方向梯度直方图) \[[2](#参考文献)\]、LBP(Local Bianray Pattern, 局部二值模式) \[[3](#参考文献)\] 等,一般也采用多种特征描述子,防止丢失过多的有用信息。
+
+ 2). **特征编码**: 底层特征中包含了大量冗余与噪声,为了提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,称作特征编码。常用的特征编码包括向量量化编码 \[[4](#参考文献)\]、稀疏编码 \[[5](#参考文献)\]、局部线性约束编码 \[[6](#参考文献)\]、Fisher向量编码 \[[7](#参考文献)\] 等。
+
+ 3). **空间特征约束**: 特征编码之后一般会经过空间特征约束,也称作**特征汇聚**。特征汇聚是指在一个空间范围内,对每一维特征取最大值或者平均值,可以获得一定特征不变形的特征表达。金字塔特征匹配是一种常用的特征聚会方法,这种方法提出将图像均匀分块,在分块内做特征汇聚。
+
+ 4). **通过分类器分类**: 经过前面步骤之后一张图像可以用一个固定维度的向量进行描述,接下来就是经过分类器对图像进行分类。通常使用的分类器包括SVM(Support Vector Machine, 支持向量机)、随机森林等。而使用核方法的SVM是最为广泛的分类器,在传统图像分类任务上性能很好。
+
+这种方法在PASCAL VOC竞赛中的图像分类算法中被广泛使用 \[[18](#参考文献)\]。[NEC实验室](http://www.nec-labs.com/)在ILSVRC2010中采用SIFT和LBP特征,两个非线性编码器以及SVM分类器获得图像分类的冠军 \[[8](#参考文献)\]。
+
+Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
+
+
+
+图4. ILSVRC图像分类Top-5错误率
+
+
+### CNN
+
+传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图5所示,我们先介绍用来构造CNN的常见组件。
+
+
+
+图5. CNN网络示例[20]
+
+
+- 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
+- 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
+- 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
+- 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
+- Dropout \[[10](#参考文献)\] : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
+
+另外,在训练过程中由于每层参数不断更新,会导致下一次输入分布发生变化,这样导致训练过程需要精心设计超参数。如2015年Sergey Ioffe和Christian Szegedy提出了Batch Normalization (BN)算法 \[[14](#参考文献)\] 中,每个batch对网络中的每一层特征都做归一化,使得每层分布相对稳定。BN算法不仅起到一定的正则作用,而且弱化了一些超参数的设计。经过实验证明,BN算法加速了模型收敛过程,在后来较深的模型中被广泛使用。
+
+接下来我们主要介绍VGG,GoogleNet和ResNet网络结构。
+
+### VGG
+
+牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 \[[11](#参考文献)\] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型\[[19](#参考文献)\]就是借鉴VGG模型的结构。
+
+
+
+图6. 基于ImageNet的VGG16模型
+
+
+### GoogleNet
+
+GoogleNet \[[12](#参考文献)\] 在2014年ILSVRC的获得了冠军,在介绍该模型之前我们先来了解NIN(Network in Network)模型 \[[13](#参考文献)\] 和Inception模块,因为GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想。
+
+NIN模型主要有两个特点:
+
+1) 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。
+
+2) 传统的CNN最后几层一般都是全连接层,参数较多。而NIN模型设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
+
+Inception模块如下图7所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
+
+
+
+图7. Inception模块
+
+
+GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没有采用传统的多层全连接层,而是像NIN网络一样采用了均值池化层;但与NIN不同的是,池化层后面接了一层到类别数映射的全连接层。除了这两个特点之外,由于网络中间层特征也很有判别性,GoogleNet在中间层添加了两个辅助分类器,在后向传播中增强梯度并且增强正则化,而整个网络的损失函数是这个三个分类器的损失加权求和。
+
+GoogleNet整体网络结构如图8所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
+
+
+
+图8. GoogleNet[12]
+
+
+
+上面介绍的是GoogleNet第一版模型(称作GoogleNet-v1)。GoogleNet-v2 \[[14](#参考文献)\] 引入BN层;GoogleNet-v3 \[[16](#参考文献)\] 对一些卷积层做了分解,进一步提高网络非线性能力和加深网络;GoogleNet-v4 \[[17](#参考文献)\] 引入下面要讲的ResNet设计思路。从v1到v4每一版的改进都会带来准确度的提升,介于篇幅,这里不再详细介绍v2到v4的结构。
+
+
+### ResNet
+
+ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题,ResNet提出了采用残差学习。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
+
+残差模块如图9所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
+
+
+
+图9. 残差模块
+
+
+图10展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
+
+
+
+图10. 基于ImageNet的ResNet模型
+
+
+
+## 数据准备
+
+通用图像分类公开的标准数据集常用的有[CIFAR](https://www.cs.toronto.edu/~kriz/cifar.html)、[ImageNet](http://image-net.org/)、[COCO](http://mscoco.org/)等,常用的细粒度图像分类数据集包括[CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html)、[Stanford Dog](http://vision.stanford.edu/aditya86/ImageNetDogs/)、[Oxford-flowers](http://www.robots.ox.ac.uk/~vgg/data/flowers/)等。其中ImageNet数据集规模相对较大,如[模型概览](#模型概览)一章所讲,大量研究成果基于ImageNet。ImageNet数据从2010年来稍有变化,常用的是ImageNet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。
+
+由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用[CIFAR10]()数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。
+
+
+
+图11. CIFAR10数据集[21]
+
+
+Paddle API提供了自动加载cifar数据集模块 `paddle.dataset.cifar`。
+
+通过输入`python train.py`,就可以开始训练模型了,以下小节将详细介绍`train.py`的相关内容。
+
+### 模型结构
+
+#### Paddle 初始化
+
+让我们从导入 Paddle Fluid API 和辅助模块开始。
+
+```python
+import paddle
+import paddle.fluid as fluid
+import numpy
+import sys
+from __future__ import print_function
+```
+
+本教程中我们提供了VGG和ResNet两个模型的配置。
+
+#### VGG
+
+首先介绍VGG模型结构,由于CIFAR10图片大小和数量相比ImageNet数据小很多,因此这里的模型针对CIFAR10数据做了一定的适配。卷积部分引入了BN和Dropout操作。
+VGG核心模块的输入是数据层,`vgg_bn_drop` 定义了16层VGG结构,每层卷积后面引入BN层和Dropout层,详细的定义如下:
+
+```python
+def vgg_bn_drop(input):
+ def conv_block(ipt, num_filter, groups, dropouts):
+ return fluid.nets.img_conv_group(
+ input=ipt,
+ pool_size=2,
+ pool_stride=2,
+ conv_num_filter=[num_filter] * groups,
+ conv_filter_size=3,
+ conv_act='relu',
+ conv_with_batchnorm=True,
+ conv_batchnorm_drop_rate=dropouts,
+ pool_type='max')
+
+ conv1 = conv_block(input, 64, 2, [0.3, 0])
+ conv2 = conv_block(conv1, 128, 2, [0.4, 0])
+ conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
+ conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
+ conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
+
+ drop = fluid.layers.dropout(x=conv5, dropout_prob=0.5)
+ fc1 = fluid.layers.fc(input=drop, size=512, act=None)
+ bn = fluid.layers.batch_norm(input=fc1, act='relu')
+ drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.5)
+ fc2 = fluid.layers.fc(input=drop2, size=512, act=None)
+ predict = fluid.layers.fc(input=fc2, size=10, act='softmax')
+ return predict
+```
+
+
+1. 首先定义了一组卷积网络,即conv_block。卷积核大小为3x3,池化窗口大小为2x2,窗口滑动大小为2,groups决定每组VGG模块是几次连续的卷积操作,dropouts指定Dropout操作的概率。所使用的`img_conv_group`是在`paddle.networks`中预定义的模块,由若干组 Conv->BN->ReLu->Dropout 和 一组 Pooling 组成。
+
+2. 五组卷积操作,即 5个conv_block。 第一、二组采用两次连续的卷积操作。第三、四、五组采用三次连续的卷积操作。每组最后一个卷积后面Dropout概率为0,即不使用Dropout操作。
+
+3. 最后接两层512维的全连接。
+
+4. 通过上面VGG网络提取高层特征,然后经过全连接层映射到类别维度大小的向量,再通过Softmax归一化得到每个类别的概率,也可称作分类器。
+
+### ResNet
+
+ResNet模型的第1、3、4步和VGG模型相同,这里不再介绍。主要介绍第2步即CIFAR10数据集上ResNet核心模块。
+
+先介绍`resnet_cifar10`中的一些基本函数,再介绍网络连接过程。
+
+ - `conv_bn_layer` : 带BN的卷积层。
+ - `shortcut` : 残差模块的"直连"路径,"直连"实际分两种形式:残差模块输入和输出特征通道数不等时,采用1x1卷积的升维操作;残差模块输入和输出通道相等时,采用直连操作。
+ - `basicblock` : 一个基础残差模块,即图9左边所示,由两组3x3卷积组成的路径和一条"直连"路径组成。
+ - `bottleneck` : 一个瓶颈残差模块,即图9右边所示,由上下1x1卷积和中间3x3卷积组成的路径和一条"直连"路径组成。
+ - `layer_warp` : 一组残差模块,由若干个残差模块堆积而成。每组中第一个残差模块滑动窗口大小与其他可以不同,以用来减少特征图在垂直和水平方向的大小。
+
+```python
+def conv_bn_layer(input,
+ ch_out,
+ filter_size,
+ stride,
+ padding,
+ act='relu',
+ bias_attr=False):
+ tmp = fluid.layers.conv2d(
+ input=input,
+ filter_size=filter_size,
+ num_filters=ch_out,
+ stride=stride,
+ padding=padding,
+ act=None,
+ bias_attr=bias_attr)
+ return fluid.layers.batch_norm(input=tmp, act=act)
+
+
+def shortcut(input, ch_in, ch_out, stride):
+ if ch_in != ch_out:
+ return conv_bn_layer(input, ch_out, 1, stride, 0, None)
+ else:
+ return input
+
+
+def basicblock(input, ch_in, ch_out, stride):
+ tmp = conv_bn_layer(input, ch_out, 3, stride, 1)
+ tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, act=None, bias_attr=True)
+ short = shortcut(input, ch_in, ch_out, stride)
+ return fluid.layers.elementwise_add(x=tmp, y=short, act='relu')
+
+
+def layer_warp(block_func, input, ch_in, ch_out, count, stride):
+ tmp = block_func(input, ch_in, ch_out, stride)
+ for i in range(1, count):
+ tmp = block_func(tmp, ch_out, ch_out, 1)
+ return tmp
+```
+
+`resnet_cifar10` 的连接结构主要有以下几个过程。
+
+1. 底层输入连接一层 `conv_bn_layer`,即带BN的卷积层。
+
+2. 然后连接3组残差模块即下面配置3组 `layer_warp` ,每组采用图 10 左边残差模块组成。
+
+3. 最后对网络做均值池化并返回该层。
+
+注意:除过第一层卷积层和最后一层全连接层之外,要求三组 `layer_warp` 总的含参层数能够被6整除,即 `resnet_cifar10` 的 depth 要满足 $(depth - 2) % 6 == 0$ 。
+
+```python
+def resnet_cifar10(ipt, depth=32):
+ # depth should be one of 20, 32, 44, 56, 110, 1202
+ assert (depth - 2) % 6 == 0
+ n = (depth - 2) / 6
+ nStages = {16, 64, 128}
+ conv1 = conv_bn_layer(ipt, ch_out=16, filter_size=3, stride=1, padding=1)
+ res1 = layer_warp(basicblock, conv1, 16, 16, n, 1)
+ res2 = layer_warp(basicblock, res1, 16, 32, n, 2)
+ res3 = layer_warp(basicblock, res2, 32, 64, n, 2)
+ pool = fluid.layers.pool2d(
+ input=res3, pool_size=8, pool_type='avg', pool_stride=1)
+ predict = fluid.layers.fc(input=pool, size=10, act='softmax')
+ return predict
+```
+
+## Infererence Program 配置
+
+网络输入定义为 `data_layer` (数据层),在图像分类中即为图像像素信息。CIFRAR10是RGB 3通道32x32大小的彩色图,因此输入数据大小为3072(3x32x32)。
+
+```python
+def inference_program():
+ # The image is 32 * 32 with RGB representation.
+ data_shape = [3, 32, 32]
+ images = fluid.layers.data(name='pixel', shape=data_shape, dtype='float32')
+
+ predict = resnet_cifar10(images, 32)
+ # predict = vgg_bn_drop(images) # un-comment to use vgg net
+ return predict
+```
+
+## Train Program 配置
+
+然后我们需要设置训练程序 `train_program`。它首先从推理程序中进行预测。
+在训练期间,它将从预测中计算 `avg_cost`。
+在有监督训练中需要输入图像对应的类别信息,同样通过`fluid.layers.data`来定义。训练中采用多类交叉熵作为损失函数,并作为网络的输出,预测阶段定义网络的输出为分类器得到的概率信息。
+
+**注意:** 训练程序应该返回一个数组,第一个返回参数必须是 `avg_cost`。训练器使用它来计算梯度。
+
+```python
+def train_program():
+ predict = inference_program()
+
+ label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+ cost = fluid.layers.cross_entropy(input=predict, label=label)
+ avg_cost = fluid.layers.mean(cost)
+ accuracy = fluid.layers.accuracy(input=predict, label=label)
+ return [avg_cost, accuracy]
+```
+
+## Optimizer Function 配置
+
+在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
+
+```python
+def optimizer_program():
+ return fluid.optimizer.Adam(learning_rate=0.001)
+```
+
+## 训练模型
+
+### Trainer 配置
+
+现在,我们需要配置 `Trainer`。`Trainer` 需要接受训练程序 `train_program`, `place` 和优化器 `optimizer_func`。
+
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+trainer = fluid.Trainer(
+ train_func=train_program,
+ optimizer_func=optimizer_program,
+ place=place)
+```
+
+### Data Feeders 配置
+
+`cifar.train10()` 每次产生一条样本,在完成shuffle和batch之后,作为训练的输入。
+
+```python
+# Each batch will yield 128 images
+BATCH_SIZE = 128
+
+# Reader for training
+train_reader = paddle.batch(
+ paddle.reader.shuffle(paddle.dataset.cifar.train10(), buf_size=50000),
+ batch_size=BATCH_SIZE)
+
+# Reader for testing. A separated data set for testing.
+test_reader = paddle.batch(
+ paddle.dataset.cifar.test10(), batch_size=BATCH_SIZE)
+```
+
+### Event Handler
+
+可以使用`event_handler`回调函数来观察训练过程,或进行测试等, 该回调函数是`trainer.train`函数里设定。
+
+`event_handler_plot`可以用来利用回调数据来打点画图:
+
+
+
+图12. 训练结果
+
+
+
+```python
+params_dirname = "image_classification_resnet.inference.model"
+
+from paddle.v2.plot import Ploter
+
+train_title = "Train cost"
+test_title = "Test cost"
+cost_ploter = Ploter(train_title, test_title)
+
+step = 0
+def event_handler_plot(event):
+ global step
+ if isinstance(event, fluid.EndStepEvent):
+ if step % 1 == 0:
+ cost_ploter.append(train_title, step, event.metrics[0])
+ cost_ploter.plot()
+ step += 1
+ if isinstance(event, fluid.EndEpochEvent):
+ avg_cost, accuracy = trainer.test(
+ reader=test_reader,
+ feed_order=['pixel', 'label'])
+ cost_ploter.append(test_title, step, avg_cost)
+
+ # save parameters
+ if params_dirname is not None:
+ trainer.save_params(params_dirname)
+```
+
+`event_handler` 用来在训练过程中输出文本日志
+
+```python
+params_dirname = "image_classification_resnet.inference.model"
+
+# event handler to track training and testing process
+def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ if event.step % 100 == 0:
+ print("\nPass %d, Batch %d, Cost %f, Acc %f" %
+ (event.step, event.epoch, event.metrics[0],
+ event.metrics[1]))
+ else:
+ sys.stdout.write('.')
+ sys.stdout.flush()
+
+ if isinstance(event, fluid.EndEpochEvent):
+ # Test against with the test dataset to get accuracy.
+ avg_cost, accuracy = trainer.test(
+ reader=test_reader, feed_order=['pixel', 'label'])
+
+ print('\nTest with Pass {0}, Loss {1:2.2}, Acc {2:2.2}'.format(event.epoch, avg_cost, accuracy))
+
+ # save parameters
+ if params_dirname is not None:
+ trainer.save_params(params_dirname)
+```
+
+### 训练
+
+通过`trainer.train`函数训练:
+
+**注意:** CPU,每个 Epoch 将花费大约15~20分钟。这部分可能需要一段时间。请随意修改代码,在GPU上运行测试,以提高训练速度。
+
+```python
+trainer.train(
+ reader=train_reader,
+ num_epochs=2,
+ event_handler=event_handler,
+ feed_order=['pixel', 'label'])
+```
+
+一轮训练log示例如下所示,经过1个pass, 训练集上平均 Accuracy 为0.59 ,测试集上平均 Accuracy 为0.6 。
+
+```text
+Pass 0, Batch 0, Cost 3.869598, Acc 0.164062
+...................................................................................................
+Pass 100, Batch 0, Cost 1.481038, Acc 0.460938
+...................................................................................................
+Pass 200, Batch 0, Cost 1.340323, Acc 0.523438
+...................................................................................................
+Pass 300, Batch 0, Cost 1.223424, Acc 0.593750
+..........................................................................................
+Test with Pass 0, Loss 1.1, Acc 0.6
+```
+
+图13是训练的分类错误率曲线图,运行到第200个pass后基本收敛,最终得到测试集上分类错误率为8.54%。
+
+
+
+图13. CIFAR10数据集上VGG模型的分类错误率
+
+
+## 应用模型
+
+可以使用训练好的模型对图片进行分类,下面程序展示了如何使用 `fluid.Inferencer` 接口进行推断,可以打开注释,更改加载的模型。
+
+### 生成预测输入数据
+
+`dog.png` is an example image of a dog. Turn it into an numpy array to match the data feeder format.
+
+```python
+# Prepare testing data.
+from PIL import Image
+import numpy as np
+import os
+
+def load_image(file):
+ im = Image.open(file)
+ im = im.resize((32, 32), Image.ANTIALIAS)
+
+ im = np.array(im).astype(np.float32)
+ # The storage order of the loaded image is W(width),
+ # H(height), C(channel). PaddlePaddle requires
+ # the CHW order, so transpose them.
+ im = im.transpose((2, 0, 1)) # CHW
+ im = im / 255.0
+
+ # Add one dimension to mimic the list format.
+ im = numpy.expand_dims(im, axis=0)
+ return im
+
+cur_dir = os.getcwd()
+img = load_image(cur_dir + '/image/dog.png')
+```
+
+### Inferencer 配置和预测
+
+`Inferencer` 需要一个 `infer_func` 和 `param_path` 来设置网络和经过训练的参数。
+我们可以简单地插入前面定义的推理程序。
+现在我们准备做预测。
+
+```python
+inferencer = fluid.Inferencer(
+ infer_func=inference_program, param_path=params_dirname, place=place)
+label_list = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
+# inference
+results = inferencer.infer({'pixel': img})
+print("infer results: %s" % label_list[np.argmax(results[0])])
+```
+
+## 总结
+
+传统图像分类方法由多个阶段构成,框架较为复杂,而端到端的CNN模型结构可一步到位,而且大幅度提升了分类准确率。本文我们首先介绍VGG、GoogleNet、ResNet三个经典的模型;然后基于CIFAR10数据集,介绍如何使用PaddlePaddle配置和训练CNN模型,尤其是VGG和ResNet模型;最后介绍如何使用PaddlePaddle的API接口对图片进行预测和特征提取。对于其他数据集比如ImageNet,配置和训练流程是同样的,大家可以自行进行实验。
+
+
+## 参考文献
+
+[1] D. G. Lowe, [Distinctive image features from scale-invariant keypoints](http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf). IJCV, 60(2):91-110, 2004.
+
+[2] N. Dalal, B. Triggs, [Histograms of Oriented Gradients for Human Detection](http://vision.stanford.edu/teaching/cs231b_spring1213/papers/CVPR05_DalalTriggs.pdf), Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2005.
+
+[3] Ahonen, T., Hadid, A., and Pietikinen, M. (2006). [Face description with local binary patterns: Application to face recognition](http://ieeexplore.ieee.org/document/1717463/). PAMI, 28.
+
+[4] J. Sivic, A. Zisserman, [Video Google: A Text Retrieval Approach to Object Matching in Videos](http://www.robots.ox.ac.uk/~vgg/publications/papers/sivic03.pdf), Proc. Ninth Int'l Conf. Computer Vision, pp. 1470-1478, 2003.
+
+[5] B. Olshausen, D. Field, [Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1?](http://redwood.psych.cornell.edu/papers/olshausen_field_1997.pdf), Vision Research, vol. 37, pp. 3311-3325, 1997.
+
+[6] Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., and Gong, Y. (2010). [Locality-constrained Linear Coding for image classification](http://ieeexplore.ieee.org/abstract/document/5540018/). In CVPR.
+
+[7] Perronnin, F., Sánchez, J., & Mensink, T. (2010). [Improving the fisher kernel for large-scale image classification](http://dl.acm.org/citation.cfm?id=1888101). In ECCV (4).
+
+[8] Lin, Y., Lv, F., Cao, L., Zhu, S., Yang, M., Cour, T., Yu, K., and Huang, T. (2011). [Large-scale image clas- sification: Fast feature extraction and SVM training](http://ieeexplore.ieee.org/document/5995477/). In CVPR.
+
+[9] Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). [ImageNet classification with deep convolutional neu- ral networks](http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf). In NIPS.
+
+[10] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. [Improving neural networks by preventing co-adaptation of feature detectors](https://arxiv.org/abs/1207.0580). arXiv preprint arXiv:1207.0580, 2012.
+
+[11] K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. [Return of the Devil in the Details: Delving Deep into Convolutional Nets](https://arxiv.org/abs/1405.3531). BMVC, 2014。
+
+[12] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A., [Going deeper with convolutions](https://arxiv.org/abs/1409.4842). In: CVPR. (2015)
+
+[13] Lin, M., Chen, Q., and Yan, S. [Network in network](https://arxiv.org/abs/1312.4400). In Proc. ICLR, 2014.
+
+[14] S. Ioffe and C. Szegedy. [Batch normalization: Accelerating deep network training by reducing internal covariate shift](https://arxiv.org/abs/1502.03167). In ICML, 2015.
+
+[15] K. He, X. Zhang, S. Ren, J. Sun. [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385). CVPR 2016.
+
+[16] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. [Rethinking the incep-tion architecture for computer vision](https://arxiv.org/abs/1512.00567). In: CVPR. (2016).
+
+[17] Szegedy, C., Ioffe, S., Vanhoucke, V. [Inception-v4, inception-resnet and the impact of residual connections on learning](https://arxiv.org/abs/1602.07261). arXiv:1602.07261 (2016).
+
+[18] Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A. [The Pascal Visual Object Classes Challenge: A Retrospective]((http://link.springer.com/article/10.1007/s11263-014-0733-5)). International Journal of Computer Vision, 111(1), 98-136, 2015.
+
+[19] He, K., Zhang, X., Ren, S., and Sun, J. [Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification](https://arxiv.org/abs/1502.01852). ArXiv e-prints, February 2015.
+
+[20] http://deeplearning.net/tutorial/lenet.html
+
+[21] https://www.cs.toronto.edu/~kriz/cifar.html
+
+[22] http://cs231n.github.io/classification/
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png
new file mode 100644
index 0000000000000000000000000000000000000000..f3c5f2f7b0c84f83382b70124dcd439586ed4eb0
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..39580c20b583f2a15d17fd124a572c84e6e2db1d
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..97a1e3eee45c0db95e6a943ca3b8c0cf6c34d4b6
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..147e575bf49086811c43420d5a9c8f749e2da405
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png
new file mode 100644
index 0000000000000000000000000000000000000000..b4ebbbe6a50f5fd7cd0cccb52cdac5653e34654c
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..88c60fe87f802c5ce560bb15bbdbd229aeafc4e4
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/index.rst b/doc/fluid/new_docs/beginners_guide/basics/index.rst
index d16f8b947253a535567ddc8d7b227dd153d9b154..e1fd226116d88fbf137741242b304b367e598ba5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/index.rst
+++ b/doc/fluid/new_docs/beginners_guide/basics/index.rst
@@ -6,13 +6,13 @@
.. todo::
概述
-
+
.. toctree::
:maxdepth: 2
- image_classification/index.md
- word2vec/index.md
- recommender_system/index.md
- understand_sentiment/index.md
- label_semantic_roles/index.md
- machine_translation/index.md
+ image_classification/README.cn.md
+ word2vec/README.cn.md
+ recommender_system/README.cn.md
+ understand_sentiment/README.cn.md
+ label_semantic_roles/README.cn.md
+ machine_translation/README.cn.md
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
deleted file mode 100644
index 29b5622a53a1b0847e9f53febf1cc50dcf4f044a..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
+++ /dev/null
@@ -1,12 +0,0 @@
-data/train.list
-data/test.*
-data/conll05st-release.tar.gz
-data/conll05st-release
-data/predicate_dict
-data/label_dict
-data/word_dict
-data/emb
-data/feature
-output
-predict.res
-train.log
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/index.md b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
similarity index 54%
rename from doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
index 828ca738317992270487647e66b08b6d2f80e209..47e948bd1ffc0ca692dc9899193e94831ce4234b 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
@@ -1,568 +1,562 @@
-# 语义角色标注
-
-本教程源代码目录在[book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-自然语言分析技术大致分为三个层面:词法分析、句法分析和语义分析。语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。
-
-请看下面的例子,“遇到” 是谓词(Predicate,通常简写为“Pred”),“小明”是施事者(Agent),“小红”是受事者(Patient),“昨天” 是事件发生的时间(Time),“公园”是事情发生的地点(Location)。
-
-$$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_{\mbox{Time}}\mbox{在[公园]}_{\mbox{Location}}\mbox{[遇到]}_{\mbox{Predicate}}\mbox{了[小红]}_{\mbox{Patient}}\mbox{。}$$
-
-语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
-
-传统的SRL系统大多建立在句法分析基础之上,通常包括5个流程:
-
-1. 构建一棵句法分析树,例如,图1是对上面例子进行依存句法分析得到的一棵句法树。
-2. 从句法树上识别出给定谓词的候选论元。
-3. 候选论元剪除;一个句子中的候选论元可能很多,候选论元剪除就是从大量的候选项中剪除那些最不可能成为论元的候选项。
-4. 论元识别:这个过程是从上一步剪除之后的候选中判断哪些是真正的论元,通常当做一个二分类问题来解决。
-5. 对第4步的结果,通过多分类得到论元的语义角色标签。可以看到,句法分析是基础,并且后续步骤常常会构造的一些人工特征,这些特征往往也来自句法分析。
-
-
-
-图1. 依存句法分析句法树示例
-
-
-然而,完全句法分析需要确定句子所包含的全部句法信息,并确定句子各成分之间的关系,是一个非常困难的任务,目前技术下的句法分析准确率并不高,句法分析的细微错误都会导致SRL的错误。为了降低问题的复杂度,同时获得一定的句法结构信息,“浅层句法分析”的思想应运而生。浅层句法分析也称为部分句法分析(partial parsing)或语块划分(chunking)。和完全句法分析得到一颗完整的句法树不同,浅层句法分析只需要识别句子中某些结构相对简单的独立成分,例如:动词短语,这些被识别出来的结构称为语块。为了回避 “无法获得准确率较高的句法树” 所带来的困难,一些研究\[[1](#参考文献)\]也提出了基于语块(chunk)的SRL方法。基于语块的SRL方法将SRL作为一个序列标注问题来解决。序列标注任务一般都会采用BIO表示方式来定义序列标注的标签集,我们先来介绍这种表示方法。在BIO表示法中,B代表语块的开始,I代表语块的中间,O代表语块结束。通过B、I、O 三种标记将不同的语块赋予不同的标签,例如:对于一个角色为A的论元,将它所包含的第一个语块赋予标签B-A,将它所包含的其它语块赋予标签I-A,不属于任何论元的语块赋予标签O。
-
-我们继续以上面的这句话为例,图1展示了BIO表示方法。
-
-
-
-图2. BIO标注方法示例
-
-
-从上面的例子可以看到,根据序列标注结果可以直接得到论元的语义角色标注结果,是一个相对简单的过程。这种简单性体现在:(1)依赖浅层句法分析,降低了句法分析的要求和难度;(2)没有了候选论元剪除这一步骤;(3)论元的识别和论元标注是同时实现的。这种一体化处理论元识别和论元标注的方法,简化了流程,降低了错误累积的风险,往往能够取得更好的结果。
-
-与基于语块的SRL方法类似,在本教程中我们也将SRL看作一个序列标注问题,不同的是,我们只依赖输入文本序列,不依赖任何额外的语法解析结果或是复杂的人造特征,利用深度神经网络构建一个端到端学习的SRL系统。我们以[CoNLL-2004 and CoNLL-2005 Shared Tasks](http://www.cs.upc.edu/~srlconll/)任务中SRL任务的公开数据集为例,实践下面的任务:给定一句话和这句话里的一个谓词,通过序列标注的方式,从句子中找到谓词对应的论元,同时标注它们的语义角色。
-
-## 模型概览
-
-循环神经网络(Recurrent Neural Network)是一种对序列建模的重要模型,在自然语言处理任务中有着广泛地应用。不同于前馈神经网络(Feed-forward Neural Network),RNN能够处理输入之间前后关联的问题。LSTM是RNN的一种重要变种,常用来学习长序列中蕴含的长程依赖关系,我们在[情感分析](https://github.com/PaddlePaddle/book/tree/develop/05.understand_sentiment)一篇中已经介绍过,这一篇中我们依然利用LSTM来解决SRL问题。
-
-### 栈式循环神经网络(Stacked Recurrent Neural Network)
-
-深层网络有助于形成层次化特征,网络上层在下层已经学习到的初级特征基础上,形成更复杂的高级特征。尽管LSTM沿时间轴展开后等价于一个非常“深”的前馈网络,但由于LSTM各个时间步参数共享,`$t-1$`时刻状态到`$t$`时刻的映射,始终只经过了一次非线性映射,也就是说单层LSTM对状态转移的建模是 “浅” 的。堆叠多个LSTM单元,令前一个LSTM`$t$`时刻的输出,成为下一个LSTM单元`$t$`时刻的输入,帮助我们构建起一个深层网络,我们把它称为第一个版本的栈式循环神经网络。深层网络提高了模型拟合复杂模式的能力,能够更好地建模跨不同时间步的模式\[[2](#参考文献)\]。
-
-然而,训练一个深层LSTM网络并非易事。纵向堆叠多个LSTM单元可能遇到梯度在纵向深度上传播受阻的问题。通常,堆叠4层LSTM单元可以正常训练,当层数达到4~8层时,会出现性能衰减,这时必须考虑一些新的结构以保证梯度纵向顺畅传播,这是训练深层LSTM网络必须解决的问题。我们可以借鉴LSTM解决 “梯度消失梯度爆炸” 问题的智慧之一:在记忆单元(Memory Cell)这条信息传播的路线上没有非线性映射,当梯度反向传播时既不会衰减、也不会爆炸。因此,深层LSTM模型也可以在纵向上添加一条保证梯度顺畅传播的路径。
-
-一个LSTM单元完成的运算可以被分为三部分:(1)输入到隐层的映射(input-to-hidden) :每个时间步输入信息`$x$`会首先经过一个矩阵映射,再作为遗忘门,输入门,记忆单元,输出门的输入,注意,这一次映射没有引入非线性激活;(2)隐层到隐层的映射(hidden-to-hidden):这一步是LSTM计算的主体,包括遗忘门,输入门,记忆单元更新,输出门的计算;(3)隐层到输出的映射(hidden-to-output):通常是简单的对隐层向量进行激活。我们在第一个版本的栈式网络的基础上,加入一条新的路径:除上一层LSTM输出之外,将前层LSTM的输入到隐层的映射作为的一个新的输入,同时加入一个线性映射去学习一个新的变换。
-
-图3是最终得到的栈式循环神经网络结构示意图。
-
-
-
-图3. 基于LSTM的栈式循环神经网络结构示意图
-
-
-### 双向循环神经网络(Bidirectional Recurrent Neural Network)
-
-在LSTM中,`$t$`时刻的隐藏层向量编码了到`$t$`时刻为止所有输入的信息,但`$t$`时刻的LSTM可以看到历史,却无法看到未来。在绝大多数自然语言处理任务中,我们几乎总是能拿到整个句子。这种情况下,如果能够像获取历史信息一样,得到未来的信息,对序列学习任务会有很大的帮助。
-
-为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,`$t$`时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。
-
-
-
-图4. 基于LSTM的双向循环神经网络结构示意图
-
-
-需要说明的是,这种双向RNN结构和Bengio等人在机器翻译任务中使用的双向RNN结构\[[3](#参考文献), [4](#参考文献)\] 并不相同,我们会在后续[机器翻译](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.cn.md)任务中,介绍另一种双向循环神经网络。
-
-### 条件随机场 (Conditional Random Field)
-
-使用神经网络模型解决问题的思路通常是:前层网络学习输入的特征表示,网络的最后一层在特征基础上完成最终的任务。在SRL任务中,深层LSTM网络学习输入的特征表示,条件随机场(Conditional Random Filed, CRF)在特征的基础上完成序列标注,处于整个网络的末端。
-
-CRF是一种概率化结构模型,可以看作是一个概率无向图模型,结点表示随机变量,边表示随机变量之间的概率依赖关系。简单来讲,CRF学习条件概率`$P(X|Y)$`,其中 `$X = (x_1, x_2, ... , x_n)$` 是输入序列,`$Y = (y_1, y_2, ... , y_n)$` 是标记序列;解码过程是给定 `$X$`序列求解令`$P(Y|X)$`最大的`$Y$`序列,即`$Y^* = \mbox{arg max}_{Y} P(Y | X)$`。
-
-序列标注任务只需要考虑输入和输出都是一个线性序列,并且由于我们只是将输入序列作为条件,不做任何条件独立假设,因此输入序列的元素之间并不存在图结构。综上,在序列标注任务中使用的是如图5所示的定义在链式图上的CRF,称之为线性链条件随机场(Linear Chain Conditional Random Field)。
-
-
-
-图5. 序列标注任务中使用的线性链条件随机场
-
-
-根据线性链条件随机场上的因子分解定理\[[5](#参考文献)\],在给定观测序列`$X$`时,一个特定标记序列`$Y$`的概率可以定义为:
-
-$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
-
-其中`$Z(X)$`是归一化因子,`$t_j$` 是定义在边上的特征函数,依赖于当前和前一个位置,称为转移特征,表示对于输入序列`$X$`及其标注序列在 `$i$`及`$i - 1$`位置上标记的转移概率。`$s_k$`是定义在结点上的特征函数,称为状态特征,依赖于当前位置,表示对于观察序列`$X$`及其`$i$`位置的标记概率。`$\lambda_j$` 和 `$\mu_k$` 分别是转移特征函数和状态特征函数对应的权值。实际上,`$t$`和`$s$`可以用相同的数学形式表示,再对转移特征和状态特在各个位置`$i$`求和有:`$f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$`,把`$f$`统称为特征函数,于是`$P(Y|X)$`可表示为:
-
-$$p(Y|X, W) = \frac{1}{Z(X)}\text{exp}\sum_{k}\omega_{k}f_{k}(Y, X)$$
-
-`$\omega$`是特征函数对应的权值,是CRF模型要学习的参数。训练时,对于给定的输入序列和对应的标记序列集合`$D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$` ,通过正则化的极大似然估计,求解如下优化目标:
-
-$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W)\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
-
-这个优化目标可以通过反向传播算法和整个神经网络一起求解。解码时,对于给定的输入序列`$X$`,通过解码算法(通常有:维特比算法、Beam Search)求令出条件概率`$\bar{P}(Y|X)$`最大的输出序列 `$\bar{Y}$`。
-
-### 深度双向LSTM(DB-LSTM)SRL模型
-
-在SRL任务中,输入是 “谓词” 和 “一句话”,目标是从这句话中找到谓词的论元,并标注论元的语义角色。如果一个句子含有`$n$`个谓词,这个句子会被处理`$n$`次。一个最为直接的模型是下面这样:
-
-1. 构造输入;
-- 输入1是谓词,输入2是句子
-- 将输入1扩展成和输入2一样长的序列,用one-hot方式表示;
-2. one-hot方式的谓词序列和句子序列通过词表,转换为实向量表示的词向量序列;
-3. 将步骤2中的2个词向量序列作为双向LSTM的输入,学习输入序列的特征表示;
-4. CRF以步骤3中模型学习到的特征为输入,以标记序列为监督信号,实现序列标注;
-
-大家可以尝试上面这种方法。这里,我们提出一些改进,引入两个简单但对提高系统性能非常有效的特征:
-
-- 谓词上下文:上面的方法中,只用到了谓词的词向量表达谓词相关的所有信息,这种方法始终是非常弱的,特别是如果谓词在句子中出现多次,有可能引起一定的歧义。从经验出发,谓词前后若干个词的一个小片段,能够提供更丰富的信息,帮助消解歧义。于是,我们把这样的经验也添加到模型中,为每个谓词同时抽取一个“谓词上下文” 片段,也就是从这个谓词前后各取`$n$`个词构成的一个窗口片段;
-- 谓词上下文区域标记:为句子中的每一个词引入一个0-1二值变量,表示它们是否在“谓词上下文”片段中;
-
-修改后的模型如下(图6是一个深度为4的模型结构示意图):
-
-1. 构造输入
-- 输入1是句子序列,输入2是谓词序列,输入3是谓词上下文,从句子中抽取这个谓词前后各`$n$`个词,构成谓词上下文,用one-hot方式表示,输入4是谓词上下文区域标记,标记了句子中每一个词是否在谓词上下文中;
-- 将输入2~3均扩展为和输入1一样长的序列;
-2. 输入1~4均通过词表取词向量转换为实向量表示的词向量序列;其中输入1、3共享同一个词表,输入2和4各自独有词表;
-3. 第2步的4个词向量序列作为双向LSTM模型的输入;LSTM模型学习输入序列的特征表示,得到新的特性表示序列;
-4. CRF以第3步中LSTM学习到的特征为输入,以标记序列为监督信号,完成序列标注;
-
-
-
-图6. SRL任务上的深层双向LSTM模型
-
-
-
-## 数据介绍
-
-在此教程中,我们选用[CoNLL 2005](http://www.cs.upc.edu/~srlconll/)SRL任务开放出的数据集作为示例。需要特别说明的是,CoNLL 2005 SRL任务的训练数集和开发集在比赛之后并非免费进行公开,目前,能够获取到的只有测试集,包括Wall Street Journal的23节和Brown语料集中的3节。在本教程中,我们以测试集中的WSJ数据为训练集来讲解模型。但是,由于测试集中样本的数量远远不够,如果希望训练一个可用的神经网络SRL系统,请考虑付费获取全量数据。
-
-原始数据中同时包括了词性标注、命名实体识别、语法解析树等多种信息。本教程中,我们使用test.wsj文件夹中的数据进行训练和测试,并只会用到words文件夹(文本序列)和props文件夹(标注结果)下的数据。本教程使用的数据目录如下:
-
-```text
-conll05st-release/
-└── test.wsj
-├── props # 标注结果
-└── words # 输入文本序列
-```
-
-标注信息源自Penn TreeBank\[[7](#参考文献)\]和PropBank\[[8](#参考文献)\]的标注结果。PropBank标注结果的标签和我们在文章一开始示例中使用的标注结果标签不同,但原理是相同的,关于标注结果标签含义的说明,请参考论文\[[9](#参考文献)\]。
-
-原始数据需要进行数据预处理才能被PaddlePaddle处理,预处理包括下面几个步骤:
-
-1. 将文本序列和标记序列其合并到一条记录中;
-2. 一个句子如果含有`$n$`个谓词,这个句子会被处理`$n$`次,变成`$n$`条独立的训练样本,每个样本一个不同的谓词;
-3. 抽取谓词上下文和构造谓词上下文区域标记;
-4. 构造以BIO法表示的标记;
-5. 依据词典获取词对应的整数索引。
-
-
-```python
-# import paddle.v2.dataset.conll05 as conll05
-# conll05.corpus_reader函数完成上面第1步和第2步.
-# conll05.reader_creator函数完成上面第3步到第5步.
-# conll05.test函数可以获取处理之后的每条样本来供PaddlePaddle训练.
-```
-
-预处理完成之后一条训练样本包含9个特征,分别是:句子序列、谓词、谓词上下文(占 5 列)、谓词上下区域标志、标注序列。下表是一条训练样本的示例。
-
-| 句子序列 | 谓词 | 谓词上下文(窗口 = 5) | 谓词上下文区域标记 | 标注序列 |
-|---|---|---|---|---|
-| A | set | n't been set . × | 0 | B-A1 |
-| record | set | n't been set . × | 0 | I-A1 |
-| date | set | n't been set . × | 0 | I-A1 |
-| has | set | n't been set . × | 0 | O |
-| n't | set | n't been set . × | 1 | B-AM-NEG |
-| been | set | n't been set . × | 1 | O |
-| set | set | n't been set . × | 1 | B-V |
-| . | set | n't been set . × | 1 | O |
-
-
-除数据之外,我们同时提供了以下资源:
-
-| 文件名称 | 说明 |
-|---|---|
-| word_dict | 输入句子的词典,共计44068个词 |
-| label_dict | 标记的词典,共计106个标记 |
-| predicate_dict | 谓词的词典,共计3162个词 |
-| emb | 一个训练好的词表,32维 |
-
-我们在英文维基百科上训练语言模型得到了一份词向量用来初始化SRL模型。在SRL模型训练过程中,词向量不再被更新。关于语言模型和词向量可以参考[词向量](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec/README.cn.md) 这篇教程。我们训练语言模型的语料共有995,000,000个token,词典大小控制为4900,000词。CoNLL 2005训练语料中有5%的词不在这4900,000个词中,我们将它们全部看作未登录词,用``表示。
-
-获取词典,打印词典大小:
-
-```python
-import math, os
-import numpy as np
-import paddle
-import paddle.v2.dataset.conll05 as conll05
-import paddle.fluid as fluid
-import time
-
-with_gpu = os.getenv('WITH_GPU', '0') != '0'
-
-word_dict, verb_dict, label_dict = conll05.get_dict()
-word_dict_len = len(word_dict)
-label_dict_len = len(label_dict)
-pred_dict_len = len(verb_dict)
-
-print word_dict_len
-print label_dict_len
-print pred_dict_len
-```
-
-## 模型配置说明
-
-- 定义输入数据维度及模型超参数。
-
-```python
-mark_dict_len = 2 # 谓上下文区域标志的维度,是一个0-1 2值特征,因此维度为2
-word_dim = 32 # 词向量维度
-mark_dim = 5 # 谓词上下文区域通过词表被映射为一个实向量,这个是相邻的维度
-hidden_dim = 512 # LSTM隐层向量的维度 : 512 / 4
-depth = 8 # 栈式LSTM的深度
-mix_hidden_lr = 1e-3
-
-IS_SPARSE = True
-PASS_NUM = 10
-BATCH_SIZE = 10
-
-embedding_name = 'emb'
-```
-
-这里需要特别说明的是hidden_dim = 512指定了LSTM隐层向量的维度为128维,关于这一点请参考PaddlePaddle官方文档中[lstmemory](http://www.paddlepaddle.org/doc/ui/api/trainer_config_helpers/layers.html#lstmemory)的说明。
-
-- 如上文提到,我们用基于英文维基百科训练好的词向量来初始化序列输入、谓词上下文总共6个特征的embedding层参数,在训练中不更新。
-
-```python
-# 这里加载PaddlePaddle上版保存的二进制模型
-def load_parameter(file_name, h, w):
-with open(file_name, 'rb') as f:
-f.read(16) # skip header.
-return np.fromfile(f, dtype=np.float32).reshape(h, w)
-```
-
-- 8个LSTM单元以“正向/反向”的顺序对所有输入序列进行学习。
-
-```python
-def db_lstm(word, predicate, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, mark,
-**ignored):
-# 8 features
-predicate_embedding = fluid.layers.embedding(
-input=predicate,
-size=[pred_dict_len, word_dim],
-dtype='float32',
-is_sparse=IS_SPARSE,
-param_attr='vemb')
-
-mark_embedding = fluid.layers.embedding(
-input=mark,
-size=[mark_dict_len, mark_dim],
-dtype='float32',
-is_sparse=IS_SPARSE)
-
-word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2]
-# Since word vector lookup table is pre-trained, we won't update it this time.
-# trainable being False prevents updating the lookup table during training.
-emb_layers = [
-fluid.layers.embedding(
-size=[word_dict_len, word_dim],
-input=x,
-param_attr=fluid.ParamAttr(
-name=embedding_name, trainable=False)) for x in word_input
-]
-emb_layers.append(predicate_embedding)
-emb_layers.append(mark_embedding)
-
-# 8 LSTM units are trained through alternating left-to-right / right-to-left order
-# denoted by the variable `reverse`.
-hidden_0_layers = [
-fluid.layers.fc(input=emb, size=hidden_dim, act='tanh')
-for emb in emb_layers
-]
-
-hidden_0 = fluid.layers.sums(input=hidden_0_layers)
-
-lstm_0 = fluid.layers.dynamic_lstm(
-input=hidden_0,
-size=hidden_dim,
-candidate_activation='relu',
-gate_activation='sigmoid',
-cell_activation='sigmoid')
-
-# stack L-LSTM and R-LSTM with direct edges
-input_tmp = [hidden_0, lstm_0]
-
-# In PaddlePaddle, state features and transition features of a CRF are implemented
-# by a fully connected layer and a CRF layer seperately. The fully connected layer
-# with linear activation learns the state features, here we use fluid.layers.sums
-# (fluid.layers.fc can be uesed as well), and the CRF layer in PaddlePaddle:
-# fluid.layers.linear_chain_crf only
-# learns the transition features, which is a cost layer and is the last layer of the network.
-# fluid.layers.linear_chain_crf outputs the log probability of true tag sequence
-# as the cost by given the input sequence and it requires the true tag sequence
-# as target in the learning process.
-
-for i in range(1, depth):
-mix_hidden = fluid.layers.sums(input=[
-fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act='tanh'),
-fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act='tanh')
-])
-
-lstm = fluid.layers.dynamic_lstm(
-input=mix_hidden,
-size=hidden_dim,
-candidate_activation='relu',
-gate_activation='sigmoid',
-cell_activation='sigmoid',
-is_reverse=((i % 2) == 1))
-
-input_tmp = [mix_hidden, lstm]
-
-# 取最后一个栈式LSTM的输出和这个LSTM单元的输入到隐层映射,
-# 经过一个全连接层映射到标记字典的维度,来学习 CRF 的状态特征
-feature_out = fluid.layers.sums(input=[
-fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act='tanh'),
-fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act='tanh')
-])
-
-return feature_out
-```
-
-## 训练模型
-
-- 我们根据网络拓扑结构和模型参数来构造出trainer用来训练,在构造时还需指定优化方法,这里使用最基本的SGD方法(momentum设置为0),同时设定了学习率、正则等。
-
-- 数据介绍部分提到CoNLL 2005训练集付费,这里我们使用测试集训练供大家学习。conll05.test()每次产生一条样本,包含9个特征,shuffle和组完batch后作为训练的输入。
-
-- 通过feeding来指定每一个数据和data_layer的对应关系。 例如 下面feeding表示: conll05.test()产生数据的第0列对应word_data层的特征。
-
-- 可以使用event_handler回调函数来观察训练过程,或进行测试等。这里我们打印了训练过程的cost,该回调函数是trainer.train函数里设定。
-
-- 通过trainer.train函数训练
-
-```python
-def train(use_cuda, save_dirname=None, is_local=True):
-# define network topology
-
-# 句子序列
-word = fluid.layers.data(
-name='word_data', shape=[1], dtype='int64', lod_level=1)
-
-# 谓词
-predicate = fluid.layers.data(
-name='verb_data', shape=[1], dtype='int64', lod_level=1)
-
-# 谓词上下文5个特征
-ctx_n2 = fluid.layers.data(
-name='ctx_n2_data', shape=[1], dtype='int64', lod_level=1)
-ctx_n1 = fluid.layers.data(
-name='ctx_n1_data', shape=[1], dtype='int64', lod_level=1)
-ctx_0 = fluid.layers.data(
-name='ctx_0_data', shape=[1], dtype='int64', lod_level=1)
-ctx_p1 = fluid.layers.data(
-name='ctx_p1_data', shape=[1], dtype='int64', lod_level=1)
-ctx_p2 = fluid.layers.data(
-name='ctx_p2_data', shape=[1], dtype='int64', lod_level=1)
-
-# 谓词上下区域标志
-mark = fluid.layers.data(
-name='mark_data', shape=[1], dtype='int64', lod_level=1)
-
-# define network topology
-feature_out = db_lstm(**locals())
-
-# 标注序列
-target = fluid.layers.data(
-name='target', shape=[1], dtype='int64', lod_level=1)
-
-# 学习 CRF 的转移特征
-crf_cost = fluid.layers.linear_chain_crf(
-input=feature_out,
-label=target,
-param_attr=fluid.ParamAttr(
-name='crfw', learning_rate=mix_hidden_lr))
-
-avg_cost = fluid.layers.mean(crf_cost)
-
-sgd_optimizer = fluid.optimizer.SGD(
-learning_rate=fluid.layers.exponential_decay(
-learning_rate=0.01,
-decay_steps=100000,
-decay_rate=0.5,
-staircase=True))
-
-sgd_optimizer.minimize(avg_cost)
-
-# The CRF decoding layer is used for evaluation and inference.
-# It shares weights with CRF layer. The sharing of parameters among multiple layers
-# is specified by using the same parameter name in these layers. If true tag sequence
-# is provided in training process, `fluid.layers.crf_decoding` calculates labelling error
-# for each input token and sums the error over the entire sequence.
-# Otherwise, `fluid.layers.crf_decoding` generates the labelling tags.
-crf_decode = fluid.layers.crf_decoding(
-input=feature_out, param_attr=fluid.ParamAttr(name='crfw'))
-
-train_data = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.conll05.test(), buf_size=8192),
-batch_size=BATCH_SIZE)
-
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
-
-feeder = fluid.DataFeeder(
-feed_list=[
-word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target
-],
-place=place)
-exe = fluid.Executor(place)
-
-def train_loop(main_program):
-exe.run(fluid.default_startup_program())
-embedding_param = fluid.global_scope().find_var(
-embedding_name).get_tensor()
-embedding_param.set(
-load_parameter(conll05.get_embedding(), word_dict_len, word_dim),
-place)
-
-start_time = time.time()
-batch_id = 0
-for pass_id in xrange(PASS_NUM):
-for data in train_data():
-cost = exe.run(main_program,
-feed=feeder.feed(data),
-fetch_list=[avg_cost])
-cost = cost[0]
-
-if batch_id % 10 == 0:
-print("avg_cost:" + str(cost))
-if batch_id != 0:
-print("second per batch: " + str((time.time(
-) - start_time) / batch_id))
-# Set the threshold low to speed up the CI test
-if float(cost) < 60.0:
-if save_dirname is not None:
-fluid.io.save_inference_model(save_dirname, [
-'word_data', 'verb_data', 'ctx_n2_data',
-'ctx_n1_data', 'ctx_0_data', 'ctx_p1_data',
-'ctx_p2_data', 'mark_data'
-], [feature_out], exe)
-return
-
-batch_id = batch_id + 1
-
-train_loop(fluid.default_main_program())
-```
-
-
-## 应用模型
-
-训练完成之后,需要依据某个我们关心的性能指标选择最优的模型进行预测,可以简单的选择测试集上标记错误最少的那个模型。以下我们给出一个使用训练后的模型进行预测的示例。
-
-```python
-def infer(use_cuda, save_dirname=None):
-if save_dirname is None:
-return
-
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-exe = fluid.Executor(place)
-
-inference_scope = fluid.core.Scope()
-with fluid.scope_guard(inference_scope):
-# Use fluid.io.load_inference_model to obtain the inference program desc,
-# the feed_target_names (the names of variables that will be fed
-# data using feed operators), and the fetch_targets (variables that
-# we want to obtain data from using fetch operators).
-[inference_program, feed_target_names,
-fetch_targets] = fluid.io.load_inference_model(save_dirname, exe)
-
-# Setup inputs by creating LoDTensors to represent sequences of words.
-# Here each word is the basic element of these LoDTensors and the shape of
-# each word (base_shape) should be [1] since it is simply an index to
-# look up for the corresponding word vector.
-# Suppose the length_based level of detail (lod) info is set to [[3, 4, 2]],
-# which has only one lod level. Then the created LoDTensors will have only
-# one higher level structure (sequence of words, or sentence) than the basic
-# element (word). Hence the LoDTensor will hold data for three sentences of
-# length 3, 4 and 2, respectively.
-# Note that lod info should be a list of lists.
-lod = [[3, 4, 2]]
-base_shape = [1]
-# The range of random integers is [low, high]
-word = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-pred = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=pred_dict_len - 1)
-ctx_n2 = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-ctx_n1 = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-ctx_0 = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-ctx_p1 = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-ctx_p2 = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=word_dict_len - 1)
-mark = fluid.create_random_int_lodtensor(
-lod, base_shape, place, low=0, high=mark_dict_len - 1)
-
-# Construct feed as a dictionary of {feed_target_name: feed_target_data}
-# and results will contain a list of data corresponding to fetch_targets.
-assert feed_target_names[0] == 'word_data'
-assert feed_target_names[1] == 'verb_data'
-assert feed_target_names[2] == 'ctx_n2_data'
-assert feed_target_names[3] == 'ctx_n1_data'
-assert feed_target_names[4] == 'ctx_0_data'
-assert feed_target_names[5] == 'ctx_p1_data'
-assert feed_target_names[6] == 'ctx_p2_data'
-assert feed_target_names[7] == 'mark_data'
-
-results = exe.run(inference_program,
-feed={
-feed_target_names[0]: word,
-feed_target_names[1]: pred,
-feed_target_names[2]: ctx_n2,
-feed_target_names[3]: ctx_n1,
-feed_target_names[4]: ctx_0,
-feed_target_names[5]: ctx_p1,
-feed_target_names[6]: ctx_p2,
-feed_target_names[7]: mark
-},
-fetch_list=fetch_targets,
-return_numpy=False)
-print(results[0].lod())
-np_data = np.array(results[0])
-print("Inference Shape: ", np_data.shape)
-```
-
-整个程序的入口如下:
-
-```python
-def main(use_cuda, is_local=True):
-if use_cuda and not fluid.core.is_compiled_with_cuda():
-return
-
-# Directory for saving the trained model
-save_dirname = "label_semantic_roles.inference.model"
-
-train(use_cuda, save_dirname, is_local)
-infer(use_cuda, save_dirname)
-
-
-main(use_cuda=False)
-```
-
-## 总结
-
-语义角色标注是许多自然语言理解任务的重要中间步骤。这篇教程中我们以语义角色标注任务为例,介绍如何利用PaddlePaddle进行序列标注任务。教程中所介绍的模型来自我们发表的论文\[[10](#参考文献)\]。由于 CoNLL 2005 SRL任务的训练数据目前并非完全开放,教程中只使用测试数据作为示例。在这个过程中,我们希望减少对其它自然语言处理工具的依赖,利用神经网络数据驱动、端到端学习的能力,得到一个和传统方法可比、甚至更好的模型。在论文中我们证实了这种可能性。关于模型更多的信息和讨论可以在论文中找到。
-
-## 参考文献
-1. Sun W, Sui Z, Wang M, et al. [Chinese semantic role labeling with shallow parsing](http://www.aclweb.org/anthology/D09-1#page=1513)[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1475-1483.
-2. Pascanu R, Gulcehre C, Cho K, et al. [How to construct deep recurrent neural networks](https://arxiv.org/abs/1312.6026)[J]. arXiv preprint arXiv:1312.6026, 2013.
-3. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](https://arxiv.org/abs/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
-4. Bahdanau D, Cho K, Bengio Y. [Neural machine translation by jointly learning to align and translate](https://arxiv.org/abs/1409.0473)[J]. arXiv preprint arXiv:1409.0473, 2014.
-5. Lafferty J, McCallum A, Pereira F. [Conditional random fields: Probabilistic models for segmenting and labeling sequence data](http://www.jmlr.org/papers/volume15/doppa14a/source/biblio.bib.old)[C]//Proceedings of the eighteenth international conference on machine learning, ICML. 2001, 1: 282-289.
-6. 李航. 统计学习方法[J]. 清华大学出版社, 北京, 2012.
-7. Marcus M P, Marcinkiewicz M A, Santorini B. [Building a large annotated corpus of English: The Penn Treebank](http://repository.upenn.edu/cgi/viewcontent.cgi?article=1246&context=cis_reports)[J]. Computational linguistics, 1993, 19(2): 313-330.
-8. Palmer M, Gildea D, Kingsbury P. [The proposition bank: An annotated corpus of semantic roles](http://www.mitpressjournals.org/doi/pdfplus/10.1162/0891201053630264)[J]. Computational linguistics, 2005, 31(1): 71-106.
-9. Carreras X, Màrquez L. [Introduction to the CoNLL-2005 shared task: Semantic role labeling](http://www.cs.upc.edu/~srlconll/st05/papers/intro.pdf)[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 152-164.
-10. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 语义角色标注
+
+本教程源代码目录在[book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/178.html)。
+
+## 背景介绍
+
+自然语言分析技术大致分为三个层面:词法分析、句法分析和语义分析。语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。
+
+请看下面的例子,“遇到” 是谓词(Predicate,通常简写为“Pred”),“小明”是施事者(Agent),“小红”是受事者(Patient),“昨天” 是事件发生的时间(Time),“公园”是事情发生的地点(Location)。
+
+$$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_\mbox{Time}\mbox{在[公园]}_{\mbox{Location}}\mbox{[遇到]}_{\mbox{Predicate}}\mbox{了[小红]}_{\mbox{Patient}}\mbox{。}$$
+
+语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
+
+传统的SRL系统大多建立在句法分析基础之上,通常包括5个流程:
+
+1. 构建一棵句法分析树,例如,图1是对上面例子进行依存句法分析得到的一棵句法树。
+2. 从句法树上识别出给定谓词的候选论元。
+3. 候选论元剪除;一个句子中的候选论元可能很多,候选论元剪除就是从大量的候选项中剪除那些最不可能成为论元的候选项。
+4. 论元识别:这个过程是从上一步剪除之后的候选中判断哪些是真正的论元,通常当做一个二分类问题来解决。
+5. 对第4步的结果,通过多分类得到论元的语义角色标签。可以看到,句法分析是基础,并且后续步骤常常会构造的一些人工特征,这些特征往往也来自句法分析。
+
+
+

+图1. 依存句法分析句法树示例
+
+

+图2. BIO标注方法示例
+
+
+图3. 基于LSTM的栈式循环神经网络结构示意图
+
+
+### 双向循环神经网络(Bidirectional Recurrent Neural Network)
+
+在LSTM中,$t$时刻的隐藏层向量编码了到$t$时刻为止所有输入的信息,但$t$时刻的LSTM可以看到历史,却无法看到未来。在绝大多数自然语言处理任务中,我们几乎总是能拿到整个句子。这种情况下,如果能够像获取历史信息一样,得到未来的信息,对序列学习任务会有很大的帮助。
+
+为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,$t$时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。
+
+
+
+图4. 基于LSTM的双向循环神经网络结构示意图
+
+
+需要说明的是,这种双向RNN结构和Bengio等人在机器翻译任务中使用的双向RNN结构\[[3](#参考文献), [4](#参考文献)\] 并不相同,我们会在后续[机器翻译](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/README.cn.md)任务中,介绍另一种双向循环神经网络。
+
+### 条件随机场 (Conditional Random Field)
+
+使用神经网络模型解决问题的思路通常是:前层网络学习输入的特征表示,网络的最后一层在特征基础上完成最终的任务。在SRL任务中,深层LSTM网络学习输入的特征表示,条件随机场(Conditional Random Filed, CRF)在特征的基础上完成序列标注,处于整个网络的末端。
+
+CRF是一种概率化结构模型,可以看作是一个概率无向图模型,结点表示随机变量,边表示随机变量之间的概率依赖关系。简单来讲,CRF学习条件概率$P(X|Y)$,其中 $X = (x_1, x_2, ... , x_n)$ 是输入序列,$Y = (y_1, y_2, ... , y_n)$ 是标记序列;解码过程是给定 $X$序列求解令$P(Y|X)$最大的$Y$序列,即$Y^* = \mbox{arg max}_{Y} P(Y | X)$。
+
+序列标注任务只需要考虑输入和输出都是一个线性序列,并且由于我们只是将输入序列作为条件,不做任何条件独立假设,因此输入序列的元素之间并不存在图结构。综上,在序列标注任务中使用的是如图5所示的定义在链式图上的CRF,称之为线性链条件随机场(Linear Chain Conditional Random Field)。
+
+
+
+图5. 序列标注任务中使用的线性链条件随机场
+
+
+根据线性链条件随机场上的因子分解定理\[[5](#参考文献)\],在给定观测序列$X$时,一个特定标记序列$Y$的概率可以定义为:
+
+$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
+
+其中$Z(X)$是归一化因子,$t_j$ 是定义在边上的特征函数,依赖于当前和前一个位置,称为转移特征,表示对于输入序列$X$及其标注序列在 $i$及$i - 1$位置上标记的转移概率。$s_k$是定义在结点上的特征函数,称为状态特征,依赖于当前位置,表示对于观察序列$X$及其$i$位置的标记概率。$\lambda_j$ 和 $\mu_k$ 分别是转移特征函数和状态特征函数对应的权值。实际上,$t$和$s$可以用相同的数学形式表示,再对转移特征和状态特在各个位置$i$求和有:$f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$,把$f$统称为特征函数,于是$P(Y|X)$可表示为:
+
+$$p(Y|X, W) = \frac{1}{Z(X)}\text{exp}\sum_{k}\omega_{k}f_{k}(Y, X)$$
+
+$\omega$是特征函数对应的权值,是CRF模型要学习的参数。训练时,对于给定的输入序列和对应的标记序列集合$D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$ ,通过正则化的极大似然估计,求解如下优化目标:
+
+$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W)\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
+
+这个优化目标可以通过反向传播算法和整个神经网络一起求解。解码时,对于给定的输入序列$X$,通过解码算法(通常有:维特比算法、Beam Search)求令出条件概率$\bar{P}(Y|X)$最大的输出序列 $\bar{Y}$。
+
+### 深度双向LSTM(DB-LSTM)SRL模型
+
+在SRL任务中,输入是 “谓词” 和 “一句话”,目标是从这句话中找到谓词的论元,并标注论元的语义角色。如果一个句子含有$n$个谓词,这个句子会被处理$n$次。一个最为直接的模型是下面这样:
+
+1. 构造输入;
+ - 输入1是谓词,输入2是句子
+ - 将输入1扩展成和输入2一样长的序列,用one-hot方式表示;
+2. one-hot方式的谓词序列和句子序列通过词表,转换为实向量表示的词向量序列;
+3. 将步骤2中的2个词向量序列作为双向LSTM的输入,学习输入序列的特征表示;
+4. CRF以步骤3中模型学习到的特征为输入,以标记序列为监督信号,实现序列标注;
+
+大家可以尝试上面这种方法。这里,我们提出一些改进,引入两个简单但对提高系统性能非常有效的特征:
+
+- 谓词上下文:上面的方法中,只用到了谓词的词向量表达谓词相关的所有信息,这种方法始终是非常弱的,特别是如果谓词在句子中出现多次,有可能引起一定的歧义。从经验出发,谓词前后若干个词的一个小片段,能够提供更丰富的信息,帮助消解歧义。于是,我们把这样的经验也添加到模型中,为每个谓词同时抽取一个“谓词上下文” 片段,也就是从这个谓词前后各取$n$个词构成的一个窗口片段;
+- 谓词上下文区域标记:为句子中的每一个词引入一个0-1二值变量,表示它们是否在“谓词上下文”片段中;
+
+修改后的模型如下(图6是一个深度为4的模型结构示意图):
+
+1. 构造输入
+ - 输入1是句子序列,输入2是谓词序列,输入3是谓词上下文,从句子中抽取这个谓词前后各$n$个词,构成谓词上下文,用one-hot方式表示,输入4是谓词上下文区域标记,标记了句子中每一个词是否在谓词上下文中;
+ - 将输入2~3均扩展为和输入1一样长的序列;
+2. 输入1~4均通过词表取词向量转换为实向量表示的词向量序列;其中输入1、3共享同一个词表,输入2和4各自独有词表;
+3. 第2步的4个词向量序列作为双向LSTM模型的输入;LSTM模型学习输入序列的特征表示,得到新的特性表示序列;
+4. CRF以第3步中LSTM学习到的特征为输入,以标记序列为监督信号,完成序列标注;
+
+
+

+图6. SRL任务上的深层双向LSTM模型
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bidirectional_stacked_lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bidirectional_stacked_lstm_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bio_example.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bio_example.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bio_example_en.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/bio_example_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/db_lstm_network_en.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/db_lstm_network_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/dependency_parsing.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/dependency_parsing.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/dependency_parsing_en.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/dependency_parsing_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/stacked_lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/image/stacked_lstm_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/.gitignore
deleted file mode 100644
index 6129b9e8645010fcb8372d9dc3dbb568dfa80907..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/.gitignore
+++ /dev/null
@@ -1,9 +0,0 @@
-data/wmt14
-data/pre-wmt14
-pretrained/wmt14_model
-gen.log
-gen_result
-train.log
-dataprovider_copy_1.py
-*.pyc
-multi-bleu.perl
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/index.md b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/README.cn.md
similarity index 71%
rename from doc/fluid/new_docs/beginners_guide/basics/machine_translation/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/machine_translation/README.cn.md
index fc161aaae9c37b0e1a596204e7138025a98adb1d..f37c559921483a3d7c619ed74903df56b0584bd5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/README.cn.md
@@ -1,448 +1,471 @@
-# 机器翻译
-
-本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
-
-早期机器翻译系统多为基于规则的翻译系统,需要由语言学家编写两种语言之间的转换规则,再将这些规则录入计算机。该方法对语言学家的要求非常高,而且我们几乎无法总结一门语言会用到的所有规则,更何况两种甚至更多的语言。因此,传统机器翻译方法面临的主要挑战是无法得到一个完备的规则集合\[[1](#参考文献)\]。
-
-为解决以上问题,统计机器翻译(Statistical Machine Translation, SMT)技术应运而生。在统计机器翻译技术中,转化规则是由机器自动从大规模的语料中学习得到的,而非我们人主动提供规则。因此,它克服了基于规则的翻译系统所面临的知识获取瓶颈的问题,但仍然存在许多挑战:1)人为设计许多特征(feature),但永远无法覆盖所有的语言现象;2)难以利用全局的特征;3)依赖于许多预处理环节,如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,而每个环节的错误会逐步累积,对翻译的影响也越来越大。
-
-近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:1)仍以统计机器翻译系统为框架,只是利用神经网络来改进其中的关键模块,如语言模型、调序模型等(见图1的左半部分);2)不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端的神经网络机器翻译(End-to-End Neural Machine Translation, End-to-End NMT)(见图1的右半部分),简称为NMT模型。
-
-
-图1. 基于神经网络的机器翻译系统
-
-
-本教程主要介绍NMT模型,以及如何用PaddlePaddle来训练一个NMT模型。
-
-## 效果展示
-
-以中英翻译(中文翻译到英文)的模型为例,当模型训练完毕时,如果输入如下已分词的中文句子:
-```text
-这些 是 希望 的 曙光 和 解脱 的 迹象 .
-```
-如果设定显示翻译结果的条数(即[柱搜索算法](#柱搜索算法)的宽度)为3,生成的英语句子如下:
-```text
-0 -5.36816 These are signs of hope and relief .
-1 -6.23177 These are the light of hope and relief .
-2 -7.7914 These are the light of hope and the relief of hope .
-```
-- 左起第一列是生成句子的序号;左起第二列是该条句子的得分(从大到小),分值越高越好;左起第三列是生成的英语句子。
-- 另外有两个特殊标志:``表示句子的结尾,``表示未登录词(unknown word),即未在训练字典中出现的词。
-
-## 模型概览
-
-本节依次介绍双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架以及柱搜索(beam search)算法。
-
-### 双向循环神经网络
-
-我们已经在[语义角色标注](https://github.com/PaddlePaddle/book/blob/develop/07.label_semantic_roles/README.cn.md)一章中介绍了一种双向循环神经网络,这里介绍Bengio团队在论文\[[2](#参考文献),[4](#参考文献)\]中提出的另一种结构。该结构的目的是输入一个序列,得到其在每个时刻的特征表示,即输出的每个时刻都用定长向量表示到该时刻的上下文语义信息。
-
-具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵(`$W_1, W_3$`),隐层到隐层自己的权重矩阵(`$W_2,W_5$`),前向隐层和后向隐层到输出层的权重矩阵(`$W_4, W_6$`)。注意,该网络的前向隐层和后向隐层之间没有连接。
-
-
-
-图3. 按时间步展开的双向循环神经网络
-
-
-### 编码器-解码器框架
-
-编码器-解码器(Encoder-Decoder)\[[2](#参考文献)\]框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
-
-
-图4. 编码器-解码器框架
-
-
-#### 编码器
-
-编码阶段分为三步:
-
-1. one-hot vector表示:将源语言句子`$x=\left \{ x_1,x_2,...,x_T \right \}$`的每个词`$x_i$`表示成一个列向量`$w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$`。这个向量`$w_i$`的维度与词汇表大小`$\left | V \right |$` 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
-
-2. 映射到低维语义空间的词向量:one-hot vector表示存在两个问题,1)生成的向量维度往往很大,容易造成维数灾难;2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为`$C\epsilon R^{K\times \left | V \right |}$`,用`$s_i=Cw_i$`表示第`$i$`个词的词向量,`$K$`为向量维度。
-
-3. 用RNN编码源语言词序列:这一过程的计算公式为`$h_i=\varnothing _\theta \left ( h_{i-1}, s_i \right )$`,其中`$h_0$`是一个全零的向量,`$\varnothing _\theta$`是一个非线性激活函数,最后得到的`$\mathbf{h}=\left \{ h_1,..., h_T \right \}$`就是RNN依次读入源语言`$T$`个词的状态编码序列。整句话的向量表示可以采用`$\mathbf{h}$`在最后一个时间步`$T$`的状态编码,或使用时间维上的池化(pooling)结果。
-
-第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列`$(x_1,x_2,...,x_T)$`的顺序依次编码源语言端词,并得到一系列隐层状态`$(\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_T})$`。类似的,后向GRU按照`$(x_T,x_{T-1},...,x_1)$`的顺序依次编码源语言端词,得到`$(\overleftarrow{h_1},\overleftarrow{h_2},...,\overleftarrow{h_T})$`。最后对于词`$x_i$`,通过拼接两个GRU的结果得到它的隐层状态,即`$h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T}$`。
-
-
-
-图5. 使用双向GRU的编码器
-
-
-#### 解码器
-
-机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
-
-1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)`$c$`、真实目标语言序列的第`$i$`个词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。计算公式如下:
-
-$$z_{i+1}=\phi _{\theta '}\left ( c,u_i,z_i \right )$$
-
-其中`$\phi _{\theta '}$`是一个非线性激活函数;`$c=q\mathbf{h}$`是源语言句子的上下文向量,在不使用[注意力机制](#注意力机制)时,如果[编码器](#编码器)的输出是源语言句子编码后的最后一个元素,则可以定义`$c=h_T$`;`$u_i$`是目标语言序列的第`$i$`个单词,`$u_0$`是目标语言序列的开始标记``,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
-
-2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。概率分布公式如下:
-
-$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
-
-其中`$W_sz_{i+1}+b_z$`是对每个可能的输出单词进行打分,再用softmax归一化就可以得到第`$i+1$`个词的概率`$p_{i+1}$`。
-
-3. 根据`$p_{i+1}$`和`$u_{i+1}$`计算代价。
-4. 重复步骤1~3,直到目标语言序列中的所有词处理完毕。
-
-机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见[柱搜索算法](#柱搜索算法)。
-
-### 柱搜索算法
-
-柱搜索([beam search](http://en.wikipedia.org/wiki/Beam_search))是一种启发式图搜索算法,用于在图或树中搜索有限集合中的最优扩展节点,通常用在解空间非常大的系统(如机器翻译、语音识别)中,原因是内存无法装下图或树中所有展开的解。如在机器翻译任务中希望翻译“`你好`”,就算目标语言字典中只有3个词(``, ``, `hello`),也可能生成无限句话(`hello`循环出现的次数不定),为了找到其中较好的翻译结果,我们可采用柱搜索算法。
-
-柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
-
-使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
-
-1. 每一个时刻,根据源语言句子的编码信息`$c$`、生成的第`$i$`个目标语言序列单词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。
-2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。
-3. 根据`$p_{i+1}$`采样出单词`$u_{i+1}$`。
-4. 重复步骤1~3,直到获得句子结束标记``或超过句子的最大生成长度为止。
-
-注意:`$z_{i+1}$`和`$p_{i+1}$`的计算公式同[解码器](#解码器)中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
-
-## 数据介绍
-
-本教程使用[WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/)数据集中的[bitexts(after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz)作为训练集,[dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz)作为测试集和生成集。
-
-### 数据预处理
-
-我们的预处理流程包括两步:
-- 将每个源语言到目标语言的平行语料库文件合并为一个文件:
-- 合并每个`XXX.src`和`XXX.trg`文件为`XXX`。
-- `XXX`中的第`$i$`行内容为`XXX.src`中的第`$i$`行和`XXX.trg`中的第`$i$`行连接,用'\t'分隔。
-- 创建训练数据的“源字典”和“目标字典”。每个字典都有**DICTSIZE**个单词,包括:语料中词频最高的(DICTSIZE - 3)个单词,和3个特殊符号``(序列的开始)、``(序列的结束)和``(未登录词)。
-
-### 示例数据
-
-因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的[较小规模的数据集](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz)。
-
-该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
-
-## 模型配置说明
-
-下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
-
-```python
-import contextlib
-
-import numpy as np
-import paddle
-import paddle.fluid as fluid
-import paddle.fluid.framework as framework
-import paddle.fluid.layers as pd
-from paddle.fluid.executor import Executor
-from functools import partial
-import os
-
-dict_size = 30000
-source_dict_dim = target_dict_dim = dict_size
-hidden_dim = 32
-word_dim = 16
-batch_size = 2
-max_length = 8
-topk_size = 50
-beam_size = 2
-
-decoder_size = hidden_dim
-```
-
-然后如下实现编码器框架:
-
-```python
-def encoder(is_sparse):
-src_word_id = pd.data(
-name="src_word_id", shape=[1], dtype='int64', lod_level=1)
-src_embedding = pd.embedding(
-input=src_word_id,
-size=[dict_size, word_dim],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr=fluid.ParamAttr(name='vemb'))
-
-fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
-lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
-encoder_out = pd.sequence_last_step(input=lstm_hidden0)
-return encoder_out
-```
-
-再实现训练模式下的解码器:
-
-```python
-def train_decoder(context, is_sparse):
-trg_language_word = pd.data(
-name="target_language_word", shape=[1], dtype='int64', lod_level=1)
-trg_embedding = pd.embedding(
-input=trg_language_word,
-size=[dict_size, word_dim],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr=fluid.ParamAttr(name='vemb'))
-
-rnn = pd.DynamicRNN()
-with rnn.block():
-current_word = rnn.step_input(trg_embedding)
-pre_state = rnn.memory(init=context)
-current_state = pd.fc(input=[current_word, pre_state],
-size=decoder_size,
-act='tanh')
-
-current_score = pd.fc(input=current_state,
-size=target_dict_dim,
-act='softmax')
-rnn.update_memory(pre_state, current_state)
-rnn.output(current_score)
-
-return rnn()
-```
-
-实现推测模式下的解码器:
-
-```python
-def decode(context, is_sparse):
-init_state = context
-array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
-counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
-
-# fill the first element with init_state
-state_array = pd.create_array('float32')
-pd.array_write(init_state, array=state_array, i=counter)
-
-# ids, scores as memory
-ids_array = pd.create_array('int64')
-scores_array = pd.create_array('float32')
-
-init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
-init_scores = pd.data(
-name="init_scores", shape=[1], dtype="float32", lod_level=2)
-
-pd.array_write(init_ids, array=ids_array, i=counter)
-pd.array_write(init_scores, array=scores_array, i=counter)
-
-cond = pd.less_than(x=counter, y=array_len)
-
-while_op = pd.While(cond=cond)
-with while_op.block():
-pre_ids = pd.array_read(array=ids_array, i=counter)
-pre_state = pd.array_read(array=state_array, i=counter)
-pre_score = pd.array_read(array=scores_array, i=counter)
-
-# expand the lod of pre_state to be the same with pre_score
-pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
-
-pre_ids_emb = pd.embedding(
-input=pre_ids,
-size=[dict_size, word_dim],
-dtype='float32',
-is_sparse=is_sparse)
-
-# use rnn unit to update rnn
-current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
-size=decoder_size,
-act='tanh')
-current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
-# use score to do beam search
-current_score = pd.fc(input=current_state_with_lod,
-size=target_dict_dim,
-act='softmax')
-topk_scores, topk_indices = pd.topk(current_score, k=topk_size)
-selected_ids, selected_scores = pd.beam_search(
-pre_ids, topk_indices, topk_scores, beam_size, end_id=10, level=0)
-
-pd.increment(x=counter, value=1, in_place=True)
-
-# update the memories
-pd.array_write(current_state, array=state_array, i=counter)
-pd.array_write(selected_ids, array=ids_array, i=counter)
-pd.array_write(selected_scores, array=scores_array, i=counter)
-
-pd.less_than(x=counter, y=array_len, cond=cond)
-
-translation_ids, translation_scores = pd.beam_search_decode(
-ids=ids_array, scores=scores_array)
-
-return translation_ids, translation_scores
-```
-
-进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
-
-```python
-def train_program(is_sparse):
-context = encoder(is_sparse)
-rnn_out = train_decoder(context, is_sparse)
-label = pd.data(
-name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
-cost = pd.cross_entropy(input=rnn_out, label=label)
-avg_cost = pd.mean(cost)
-return avg_cost
-
-
-def optimizer_func():
-return fluid.optimizer.Adagrad(
-learning_rate=1e-4,
-regularization=fluid.regularizer.L2DecayRegularizer(
-regularization_coeff=0.1))
-```
-
-## 训练模型
-
-### 定义训练环境
-定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
-
-### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.wmt.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
-
-```python
-train_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.wmt14.train(dict_size), buf_size=1000),
-batch_size=batch_size)
-```
-
-### 构造训练器(trainer)
-训练器需要一个训练程序和一个训练优化函数。
-
-```python
-is_sparse = False
-trainer = fluid.Trainer(
-train_func=partial(train_program, is_sparse),
-place=place,
-optimizer_func=optimizer_func)
-```
-
-### 提供数据
-
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`wmt14.train`产生的第一列的数据对应的是`src_word_id`这个特征。
-
-```python
-feed_order = [
-'src_word_id', 'target_language_word', 'target_language_next_word'
-]
-```
-
-### 事件处理器
-回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
-
-```python
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-if event.step % 10 == 0:
-print('pass_id=' + str(event.epoch) + ' batch=' + str(event.step))
-
-if event.step == 20:
-trainer.stop()
-```
-
-### 开始训练
-最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
-
-```python
-EPOCH_NUM = 1
-
-trainer.train(
-reader=train_reader,
-num_epochs=EPOCH_NUM,
-event_handler=event_handler,
-feed_order=feed_order)
-```
-
-## 应用模型
-
-### 定义解码部分
-
-使用上面定义的 `encoder` 和 `decoder` 函数来推测翻译后的对应id和分数.
-
-```python
-context = encoder(is_sparse)
-translation_ids, translation_scores = decode(context, is_sparse)
-```
-
-### 定义数据
-
-我们先初始化id和分数来生成tensors来作为输入数据。在这个预测例子中,我们用`wmt14.test`数据中的第一个记录来做推测,最后我们用"源字典"和"目标字典"来列印对应的句子结果。
-
-```python
-init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
-init_scores_data = np.array(
-[1. for _ in range(batch_size)], dtype='float32')
-init_ids_data = init_ids_data.reshape((batch_size, 1))
-init_scores_data = init_scores_data.reshape((batch_size, 1))
-init_lod = [1] * batch_size
-init_lod = [init_lod, init_lod]
-
-init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
-init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
-
-test_data = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.wmt14.test(dict_size), buf_size=1000),
-batch_size=batch_size)
-
-feed_order = ['src_word_id']
-feed_list = [
-framework.default_main_program().global_block().var(var_name)
-for var_name in feed_order
-]
-feeder = fluid.DataFeeder(feed_list, place)
-
-src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
-```
-
-### 测试
-现在我们可以进行预测了。我们要在`feed_order`提供对应参数,放在`executor`上运行以取得id和分数结果
-
-```python
-exe = Executor(place)
-exe.run(framework.default_startup_program())
-
-for data in test_data():
-feed_data = map(lambda x: [x[0]], data)
-feed_dict = feeder.feed(feed_data)
-feed_dict['init_ids'] = init_ids
-feed_dict['init_scores'] = init_scores
-
-results = exe.run(
-framework.default_main_program(),
-feed=feed_dict,
-fetch_list=[translation_ids, translation_scores],
-return_numpy=False)
-
-result_ids = np.array(results[0])
-result_scores = np.array(results[1])
-
-print("Original sentence:")
-print(" ".join([src_dict[w] for w in feed_data[0][0]]))
-print("Translated sentence:")
-print(" ".join([trg_dict[w] for w in result_ids]))
-print("Corresponding score: ", result_scores)
-
-break
-```
-
-## 总结
-
-端到端的神经网络机器翻译是近几年兴起的一种全新的机器翻译方法。本章中,我们介绍了NMT中典型的“编码器-解码器”框架。由于NMT是一个典型的Seq2Seq(Sequence to Sequence,序列到序列)学习问题,因此,Seq2Seq中的query改写(query rewriting)、摘要、单轮对话等问题都可以用本教程的模型来解决。
-
-## 参考文献
-
-1. Koehn P. [Statistical machine translation](https://books.google.com.hk/books?id=4v_Cx1wIMLkC&printsec=frontcover&hl=zh-CN&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false)[M]. Cambridge University Press, 2009.
-2. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](http://www.aclweb.org/anthology/D/D14/D14-1179.pdf)[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 1724-1734.
-3. Chung J, Gulcehre C, Cho K H, et al. [Empirical evaluation of gated recurrent neural networks on sequence modeling](https://arxiv.org/abs/1412.3555)[J]. arXiv preprint arXiv:1412.3555, 2014.
-4. Bahdanau D, Cho K, Bengio Y. [Neural machine translation by jointly learning to align and translate](https://arxiv.org/abs/1409.0473)[C]//Proceedings of ICLR 2015, 2015.
-5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 机器翻译
+
+本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
+
+## 背景介绍
+
+机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
+
+早期机器翻译系统多为基于规则的翻译系统,需要由语言学家编写两种语言之间的转换规则,再将这些规则录入计算机。该方法对语言学家的要求非常高,而且我们几乎无法总结一门语言会用到的所有规则,更何况两种甚至更多的语言。因此,传统机器翻译方法面临的主要挑战是无法得到一个完备的规则集合\[[1](#参考文献)\]。
+
+为解决以上问题,统计机器翻译(Statistical Machine Translation, SMT)技术应运而生。在统计机器翻译技术中,转化规则是由机器自动从大规模的语料中学习得到的,而非我们人主动提供规则。因此,它克服了基于规则的翻译系统所面临的知识获取瓶颈的问题,但仍然存在许多挑战:1)人为设计许多特征(feature),但永远无法覆盖所有的语言现象;2)难以利用全局的特征;3)依赖于许多预处理环节,如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,而每个环节的错误会逐步累积,对翻译的影响也越来越大。
+
+近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:1)仍以统计机器翻译系统为框架,只是利用神经网络来改进其中的关键模块,如语言模型、调序模型等(见图1的左半部分);2)不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端的神经网络机器翻译(End-to-End Neural Machine Translation, End-to-End NMT)(见图1的右半部分),简称为NMT模型。
+
+
+图1. 基于神经网络的机器翻译系统
+
+
+本教程主要介绍NMT模型,以及如何用PaddlePaddle来训练一个NMT模型。
+
+## 效果展示
+
+以中英翻译(中文翻译到英文)的模型为例,当模型训练完毕时,如果输入如下已分词的中文句子:
+```text
+这些 是 希望 的 曙光 和 解脱 的 迹象 .
+```
+如果设定显示翻译结果的条数(即[柱搜索算法](#柱搜索算法)的宽度)为3,生成的英语句子如下:
+```text
+0 -5.36816 These are signs of hope and relief .
+1 -6.23177 These are the light of hope and relief .
+2 -7.7914 These are the light of hope and the relief of hope .
+```
+
+- 左起第一列是生成句子的序号;左起第二列是该条句子的得分(从大到小),分值越高越好;左起第三列是生成的英语句子。
+
+- 另外有两个特殊标志:``表示句子的结尾,``表示未登录词(unknown word),即未在训练字典中出现的词。
+
+## 模型概览
+
+本节依次介绍双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架以及柱搜索(beam search)算法。
+
+### 双向循环神经网络
+
+我们已经在[语义角色标注](https://github.com/PaddlePaddle/book/blob/develop/07.label_semantic_roles/README.cn.md)一章中介绍了一种双向循环神经网络,这里介绍Bengio团队在论文\[[2](#参考文献),[4](#参考文献)\]中提出的另一种结构。该结构的目的是输入一个序列,得到其在每个时刻的特征表示,即输出的每个时刻都用定长向量表示到该时刻的上下文语义信息。
+
+具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵(`$W_1, W_3$`),隐层到隐层自己的权重矩阵(`$W_2,W_5$`),前向隐层和后向隐层到输出层的权重矩阵(`$W_4, W_6$`)。注意,该网络的前向隐层和后向隐层之间没有连接。
+
+
+
+图3. 按时间步展开的双向循环神经网络
+
+
+### 编码器-解码器框架
+
+编码器-解码器(Encoder-Decoder)\[[2](#参考文献)\]框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
+
+
+图4. 编码器-解码器框架
+
+
+#### 编码器
+
+编码阶段分为三步:
+
+1. one-hot vector表示:将源语言句子`$x=\left \{ x_1,x_2,...,x_T \right \}$`的每个词`$x_i$`表示成一个列向量`$w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$`。这个向量`$w_i$`的维度与词汇表大小`$\left | V \right |$` 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
+
+2. 映射到低维语义空间的词向量:one-hot vector表示存在两个问题,1)生成的向量维度往往很大,容易造成维数灾难;2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为`$C\epsilon R^{K\times \left | V \right |}$`,用`$s_i=Cw_i$`表示第`$i$`个词的词向量,`$K$`为向量维度。
+
+3. 用RNN编码源语言词序列:这一过程的计算公式为`$h_i=\varnothing _\theta \left ( h_{i-1}, s_i \right )$`,其中`$h_0$`是一个全零的向量,`$\varnothing _\theta$`是一个非线性激活函数,最后得到的`$\mathbf{h}=\left \{ h_1,..., h_T \right \}$`就是RNN依次读入源语言`$T$`个词的状态编码序列。整句话的向量表示可以采用`$\mathbf{h}$`在最后一个时间步`$T$`的状态编码,或使用时间维上的池化(pooling)结果。
+
+第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列`$(x_1,x_2,...,x_T)$`的顺序依次编码源语言端词,并得到一系列隐层状态`$(\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_T})$`。类似的,后向GRU按照`$(x_T,x_{T-1},...,x_1)$`的顺序依次编码源语言端词,得到`$(\overleftarrow{h_1},\overleftarrow{h_2},...,\overleftarrow{h_T})$`。最后对于词`$x_i$`,通过拼接两个GRU的结果得到它的隐层状态,即`$h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T}$`。
+
+
+
+图5. 使用双向GRU的编码器
+
+
+#### 解码器
+
+机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
+
+1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)`$c$`、真实目标语言序列的第`$i$`个词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。计算公式如下:
+$$z_{i+1}=\phi_{\theta '} \left ( c,u_i,z_i \right )$$
+其中`$\phi _{\theta '}$`是一个非线性激活函数;`$c=q\mathbf{h}$`是源语言句子的上下文向量,在不使用[注意力机制](#注意力机制)时,如果[编码器](#编码器)的输出是源语言句子编码后的最后一个元素,则可以定义`$c=h_T$`;`$u_i$`是目标语言序列的第`$i$`个单词,`$u_0$`是目标语言序列的开始标记``,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
+
+2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。概率分布公式如下:
+$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
+其中`$W_sz_{i+1}+b_z$`是对每个可能的输出单词进行打分,再用softmax归一化就可以得到第`$i+1$`个词的概率`$p_{i+1}$`。
+
+3. 根据`$p_{i+1}$`和`$u_{i+1}$`计算代价。
+
+4. 重复步骤1~3,直到目标语言序列中的所有词处理完毕。
+
+机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见[柱搜索算法](#柱搜索算法)。
+
+### 柱搜索算法
+
+柱搜索([beam search](http://en.wikipedia.org/wiki/Beam_search))是一种启发式图搜索算法,用于在图或树中搜索有限集合中的最优扩展节点,通常用在解空间非常大的系统(如机器翻译、语音识别)中,原因是内存无法装下图或树中所有展开的解。如在机器翻译任务中希望翻译“`你好`”,就算目标语言字典中只有3个词(``, ``, `hello`),也可能生成无限句话(`hello`循环出现的次数不定),为了找到其中较好的翻译结果,我们可采用柱搜索算法。
+
+柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
+
+使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
+
+1. 每一个时刻,根据源语言句子的编码信息`$c$`、生成的第`$i$`个目标语言序列单词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。
+
+2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。
+
+3. 根据`$p_{i+1}$`采样出单词`$u_{i+1}$`。
+
+4. 重复步骤1~3,直到获得句子结束标记``或超过句子的最大生成长度为止。
+
+注意:`$z_{i+1}$`和`$p_{i+1}$`的计算公式同[解码器](#解码器)中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
+
+## 数据介绍
+
+本教程使用[WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/)数据集中的[bitexts(after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz)作为训练集,[dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz)作为测试集和生成集。
+
+### 数据预处理
+
+我们的预处理流程包括两步:
+
+- 将每个源语言到目标语言的平行语料库文件合并为一个文件:
+
+- 合并每个`XXX.src`和`XXX.trg`文件为`XXX`。
+
+- `XXX`中的第`$i$`行内容为`XXX.src`中的第`$i$`行和`XXX.trg`中的第`$i$`行连接,用'\t'分隔。
+
+- 创建训练数据的“源字典”和“目标字典”。每个字典都有**DICTSIZE**个单词,包括:语料中词频最高的(DICTSIZE - 3)个单词,和3个特殊符号``(序列的开始)、``(序列的结束)和``(未登录词)。
+
+### 示例数据
+
+因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的[较小规模的数据集](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz)。
+
+该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
+
+## 模型配置说明
+
+下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+
+```python
+from __future__ import print_function
+import contextlib
+
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.framework as framework
+import paddle.fluid.layers as pd
+from paddle.fluid.executor import Executor
+from functools import partial
+import os
+
+dict_size = 30000
+source_dict_dim = target_dict_dim = dict_size
+hidden_dim = 32
+word_dim = 16
+batch_size = 2
+max_length = 8
+topk_size = 50
+beam_size = 2
+
+decoder_size = hidden_dim
+```
+
+然后如下实现编码器框架:
+
+ ```python
+ def encoder(is_sparse):
+ src_word_id = pd.data(
+ name="src_word_id", shape=[1], dtype='int64', lod_level=1)
+ src_embedding = pd.embedding(
+ input=src_word_id,
+ size=[dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr=fluid.ParamAttr(name='vemb'))
+
+ fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
+ lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
+ encoder_out = pd.sequence_last_step(input=lstm_hidden0)
+ return encoder_out
+ ```
+
+再实现训练模式下的解码器:
+
+```python
+ def train_decoder(context, is_sparse):
+ trg_language_word = pd.data(
+ name="target_language_word", shape=[1], dtype='int64', lod_level=1)
+ trg_embedding = pd.embedding(
+ input=trg_language_word,
+ size=[dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr=fluid.ParamAttr(name='vemb'))
+
+ rnn = pd.DynamicRNN()
+ with rnn.block():
+ current_word = rnn.step_input(trg_embedding)
+ pre_state = rnn.memory(init=context)
+ current_state = pd.fc(input=[current_word, pre_state],
+ size=decoder_size,
+ act='tanh')
+
+ current_score = pd.fc(input=current_state,
+ size=target_dict_dim,
+ act='softmax')
+ rnn.update_memory(pre_state, current_state)
+ rnn.output(current_score)
+
+ return rnn()
+```
+
+实现推测模式下的解码器:
+
+```python
+def decode(context, is_sparse):
+ init_state = context
+ array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
+ counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
+
+ # fill the first element with init_state
+ state_array = pd.create_array('float32')
+ pd.array_write(init_state, array=state_array, i=counter)
+
+ # ids, scores as memory
+ ids_array = pd.create_array('int64')
+ scores_array = pd.create_array('float32')
+
+ init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
+ init_scores = pd.data(
+ name="init_scores", shape=[1], dtype="float32", lod_level=2)
+
+ pd.array_write(init_ids, array=ids_array, i=counter)
+ pd.array_write(init_scores, array=scores_array, i=counter)
+
+ cond = pd.less_than(x=counter, y=array_len)
+
+ while_op = pd.While(cond=cond)
+ with while_op.block():
+ pre_ids = pd.array_read(array=ids_array, i=counter)
+ pre_state = pd.array_read(array=state_array, i=counter)
+ pre_score = pd.array_read(array=scores_array, i=counter)
+
+ # expand the lod of pre_state to be the same with pre_score
+ pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
+
+ pre_ids_emb = pd.embedding(
+ input=pre_ids,
+ size=[dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse)
+
+ # use rnn unit to update rnn
+ current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
+ size=decoder_size,
+ act='tanh')
+ current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
+ # use score to do beam search
+ current_score = pd.fc(input=current_state_with_lod,
+ size=target_dict_dim,
+ act='softmax')
+ topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
+ # calculate accumulated scores after topk to reduce computation cost
+ accu_scores = pd.elementwise_add(
+ x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
+ selected_ids, selected_scores = pd.beam_search(
+ pre_ids,
+ pre_score,
+ topk_indices,
+ accu_scores,
+ beam_size,
+ end_id=10,
+ level=0)
+
+ pd.increment(x=counter, value=1, in_place=True)
+
+ # update the memories
+ pd.array_write(current_state, array=state_array, i=counter)
+ pd.array_write(selected_ids, array=ids_array, i=counter)
+ pd.array_write(selected_scores, array=scores_array, i=counter)
+
+ # update the break condition: up to the max length or all candidates of
+ # source sentences have ended.
+ length_cond = pd.less_than(x=counter, y=array_len)
+ finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
+ pd.logical_and(x=length_cond, y=finish_cond, out=cond)
+
+ translation_ids, translation_scores = pd.beam_search_decode(
+ ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)
+
+ return translation_ids, translation_scores
+```
+
+进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
+
+```python
+def train_program(is_sparse):
+ context = encoder(is_sparse)
+ rnn_out = train_decoder(context, is_sparse)
+ label = pd.data(
+ name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
+ cost = pd.cross_entropy(input=rnn_out, label=label)
+ avg_cost = pd.mean(cost)
+ return avg_cost
+
+
+def optimizer_func():
+ return fluid.optimizer.Adagrad(
+ learning_rate=1e-4,
+ regularization=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=0.1))
+```
+
+## 训练模型
+
+### 定义训练环境
+定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
+
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+```
+
+### 定义数据提供器
+下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.wmt.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
+
+```python
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.wmt14.train(dict_size), buf_size=1000),
+ batch_size=batch_size)
+```
+
+### 构造训练器(trainer)
+训练器需要一个训练程序和一个训练优化函数。
+
+```python
+is_sparse = False
+trainer = fluid.Trainer(
+ train_func=partial(train_program, is_sparse),
+ place=place,
+ optimizer_func=optimizer_func)
+```
+
+### 提供数据
+
+`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`wmt14.train`产生的第一列的数据对应的是`src_word_id`这个特征。
+
+```python
+feed_order = [
+ 'src_word_id', 'target_language_word', 'target_language_next_word'
+ ]
+```
+
+### 事件处理器
+回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
+
+```python
+def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ if event.step % 10 == 0:
+ print('pass_id=' + str(event.epoch) + ' batch=' + str(event.step))
+
+ if event.step == 20:
+ trainer.stop()
+```
+
+### 开始训练
+最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
+
+```python
+EPOCH_NUM = 1
+
+trainer.train(
+ reader=train_reader,
+ num_epochs=EPOCH_NUM,
+ event_handler=event_handler,
+ feed_order=feed_order)
+```
+
+## 应用模型
+
+### 定义解码部分
+
+使用上面定义的 `encoder` 和 `decoder` 函数来推测翻译后的对应id和分数.
+
+```python
+context = encoder(is_sparse)
+translation_ids, translation_scores = decode(context, is_sparse)
+```
+
+### 定义数据
+
+我们先初始化id和分数来生成tensors来作为输入数据。在这个预测例子中,我们用`wmt14.test`数据中的第一个记录来做推测,最后我们用"源字典"和"目标字典"来列印对应的句子结果。
+
+```python
+init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
+init_scores_data = np.array(
+ [1. for _ in range(batch_size)], dtype='float32')
+init_ids_data = init_ids_data.reshape((batch_size, 1))
+init_scores_data = init_scores_data.reshape((batch_size, 1))
+init_lod = [1] * batch_size
+init_lod = [init_lod, init_lod]
+
+init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
+init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
+
+test_data = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.wmt14.test(dict_size), buf_size=1000),
+ batch_size=batch_size)
+
+feed_order = ['src_word_id']
+feed_list = [
+ framework.default_main_program().global_block().var(var_name)
+ for var_name in feed_order
+]
+feeder = fluid.DataFeeder(feed_list, place)
+
+src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
+```
+
+### 测试
+现在我们可以进行预测了。我们要在`feed_order`提供对应参数,放在`executor`上运行以取得id和分数结果
+
+```python
+exe = Executor(place)
+exe.run(framework.default_startup_program())
+
+for data in test_data():
+ feed_data = map(lambda x: [x[0]], data)
+ feed_dict = feeder.feed(feed_data)
+ feed_dict['init_ids'] = init_ids
+ feed_dict['init_scores'] = init_scores
+
+ results = exe.run(
+ framework.default_main_program(),
+ feed=feed_dict,
+ fetch_list=[translation_ids, translation_scores],
+ return_numpy=False)
+
+ result_ids = np.array(results[0])
+ result_scores = np.array(results[1])
+
+ print("Original sentence:")
+ print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))
+ print("Translated score and sentence:")
+ for i in xrange(beam_size):
+ start_pos = result_ids_lod[1][i] + 1
+ end_pos = result_ids_lod[1][i+1]
+ print("%d\t%.4f\t%s\n" % (i+1, result_scores[end_pos-1],
+ " ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))
+
+ break
+```
+
+## 总结
+
+端到端的神经网络机器翻译是近几年兴起的一种全新的机器翻译方法。本章中,我们介绍了NMT中典型的“编码器-解码器”框架。由于NMT是一个典型的Seq2Seq(Sequence to Sequence,序列到序列)学习问题,因此,Seq2Seq中的query改写(query rewriting)、摘要、单轮对话等问题都可以用本教程的模型来解决。
+
+## 参考文献
+
+1. Koehn P. [Statistical machine translation](https://books.google.com.hk/books?id=4v_Cx1wIMLkC&printsec=frontcover&hl=zh-CN&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false)[M]. Cambridge University Press, 2009.
+2. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](http://www.aclweb.org/anthology/D/D14/D14-1179.pdf)[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 1724-1734.
+3. Chung J, Gulcehre C, Cho K H, et al. [Empirical evaluation of gated recurrent neural networks on sequence modeling](https://arxiv.org/abs/1412.3555)[J]. arXiv preprint arXiv:1412.3555, 2014.
+4. Bahdanau D, Cho K, Bengio Y. [Neural machine translation by jointly learning to align and translate](https://arxiv.org/abs/1409.0473)[C]//Proceedings of ICLR 2015, 2015.
+5. Papineni K, Roukos S, Ward T, et al. [BLEU: a method for automatic evaluation of machine translation](http://dl.acm.org/citation.cfm?id=1073135)[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
deleted file mode 100644
index f23901aeb3a9e7cd12611fc556742670d04a9bb5..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
+++ /dev/null
@@ -1,2 +0,0 @@
-.idea
-.ipynb_checkpoints
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/index.md b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
similarity index 67%
rename from doc/fluid/new_docs/beginners_guide/basics/recommender_system/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
index 09a07f3dc30abc57ab3731af054dd83491acc9a6..0f7c97021f8ad463fc51ed169604b789ea068c3d 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
@@ -1,528 +1,537 @@
-# 个性化推荐
-
-本教程源代码目录在[book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-在网络技术不断发展和电子商务规模不断扩大的背景下,商品数量和种类快速增长,用户需要花费大量时间才能找到自己想买的商品,这就是信息超载问题。为了解决这个难题,推荐系统(Recommender System)应运而生。
-
-个性化推荐系统是信息过滤系统(Information Filtering System)的子集,它可以用在很多领域,如电影、音乐、电商和 Feed 流推荐等。推荐系统通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。与搜索引擎不同,推荐系统不需要用户准确地描述出自己的需求,而是根据分析历史行为建模,主动提供满足用户兴趣和需求的信息。
-
-传统的推荐系统方法主要有:
-
-- 协同过滤推荐(Collaborative Filtering Recommendation):该方法收集分析用户历史行为、活动、偏好,计算一个用户与其他用户的相似度,利用目标用户的相似用户对商品评价的加权评价值,来预测目标用户对特定商品的喜好程度。优点是可以给用户推荐未浏览过的新产品;缺点是对于没有任何行为的新用户存在冷启动的问题,同时也存在用户与商品之间的交互数据不够多造成的稀疏问题,会导致模型难以找到相近用户。
-- 基于内容过滤推荐[[1](#参考文献)](Content-based Filtering Recommendation):该方法利用商品的内容描述,抽象出有意义的特征,通过计算用户的兴趣和商品描述之间的相似度,来给用户做推荐。优点是简单直接,不需要依据其他用户对商品的评价,而是通过商品属性进行商品相似度度量,从而推荐给用户所感兴趣商品的相似商品;缺点是对于没有任何行为的新用户同样存在冷启动的问题。
-- 组合推荐[[2](#参考文献)](Hybrid Recommendation):运用不同的输入和技术共同进行推荐,以弥补各自推荐技术的缺点。
-
-其中协同过滤是应用最广泛的技术之一,它又可以分为多个子类:基于用户 (User-Based)的推荐[[3](#参考文献)] 、基于物品(Item-Based)的推荐[[4](#参考文献)]、基于社交网络关系(Social-Based)的推荐[[5](#参考文献)]、基于模型(Model-based)的推荐等。1994年明尼苏达大学推出的GroupLens系统[[3](#参考文献)]一般被认为是推荐系统成为一个相对独立的研究方向的标志。该系统首次提出了基于协同过滤来完成推荐任务的思想,此后,基于该模型的协同过滤推荐引领了推荐系统十几年的发展方向。
-
-深度学习具有优秀的自动提取特征的能力,能够学习多层次的抽象特征表示,并对异质或跨域的内容信息进行学习,可以一定程度上处理推荐系统冷启动问题[[6](#参考文献)]。本教程主要介绍个性化推荐的深度学习模型,以及如何使用PaddlePaddle实现模型。
-
-## 效果展示
-
-我们使用包含用户信息、电影信息与电影评分的数据集作为个性化推荐的应用场景。当我们训练好模型后,只需要输入对应的用户ID和电影ID,就可以得出一个匹配的分数(范围[0,5],分数越高视为兴趣越大),然后根据所有电影的推荐得分排序,推荐给用户可能感兴趣的电影。
-
-```
-Input movie_id: 1962
-Input user_id: 1
-Prediction Score is 4.25
-```
-
-## 模型概览
-
-本章中,我们首先介绍YouTube的视频推荐系统[[7](#参考文献)],然后介绍我们实现的融合推荐模型。
-
-### YouTube的深度神经网络推荐系统
-
-YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
-
-
-
-图1. YouTube 推荐系统结构
-
-
-#### 候选生成网络(Candidate Generation Network)
-
-候选生成网络将推荐问题建模为一个类别数极大的多类分类问题:对于一个Youtube用户,使用其观看历史(视频ID)、搜索词记录(search tokens)、人口学信息(如地理位置、用户登录设备)、二值特征(如性别,是否登录)和连续特征(如用户年龄)等,对视频库中所有视频进行多分类,得到每一类别的分类结果(即每一个视频的推荐概率),最终输出概率较高的几百个视频。
-
-首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的`$k$`个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。
-
-
-
-图2. 候选生成网络结构
-
-
-对于一个用户`$U$`,预测此刻用户要观看的视频`$\omega$`为视频`$i$`的概率公式为:
-
-$$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
-
-其中`$u$`为用户`$U$`的特征表示,`$V$`为视频库集合,`$v_i$`为视频库中第`$i$`个视频的特征表示。`$u$`和`$v_i$`为长度相等的向量,两者点积可以通过全连接层实现。
-
-考虑到softmax分类的类别数非常多,为了保证一定的计算效率:1)训练阶段,使用负样本类别采样将实际计算的类别数缩小至数千;2)推荐(预测)阶段,忽略softmax的归一化计算(不影响结果),将类别打分问题简化为点积(dot product)空间中的最近邻(nearest neighbor)搜索问题,取与`$u$`最近的`$k$`个视频作为生成的候选。
-
-#### 排序网络(Ranking Network)
-排序网络的结构类似于候选生成网络,但是它的目标是对候选进行更细致的打分排序。和传统广告排序中的特征抽取方法类似,这里也构造了大量的用于视频排序的相关特征(如视频 ID、上次观看时间等)。这些特征的处理方式和候选生成网络类似,不同之处是排序网络的顶部是一个加权逻辑回归(weighted logistic regression),它对所有候选视频进行打分,从高到底排序后将分数较高的一些视频返回给用户。
-
-### 融合推荐模型
-本节会使卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
-
-#### 文本卷积神经网络(CNN)
-
-卷积神经网络经常用来处理具有类似网格拓扑结构(grid-like topology)的数据。例如,图像可以视为二维网格的像素点,自然语言可以视为一维的词序列。卷积神经网络可以提取多种局部特征,并对其进行组合抽象得到更高级的特征表示。实验表明,卷积神经网络能高效地对图像及文本问题进行建模处理。
-
-卷积神经网络主要由卷积(convolution)和池化(pooling)操作构成,其应用及组合方式灵活多变,种类繁多。本小结我们以如图3所示的网络进行讲解:
-
-
-
-图3. 卷积神经网络文本分类模型
-
-
-假设待处理句子的长度为`$n$`,其中第`$i$`个词的词向量(word embedding)为`$x_i\in\mathbb{R}^k$`,`$k$`为维度大小。
-
-首先,进行词向量的拼接操作:将每`$h$`个词拼接起来形成一个大小为`$h$`的词窗口,记为`$x_{i:i+h-1}$`,它表示词序列`$x_{i},x_{i+1},\ldots,x_{i+h-1}$`的拼接,其中,`$i$`表示词窗口中第一个词在整个句子中的位置,取值范围从`$1$`到`$n-h+1$`,`$x_{i:i+h-1}\in\mathbb{R}^{hk}$`。
-
-其次,进行卷积操作:把卷积核(kernel)`$w\in\mathbb{R}^{hk}$`应用于包含`$h$`个词的窗口`$x_{i:i+h-1}$`,得到特征`$c_i=f(w\cdot x_{i:i+h-1}+b)$`,其中`$b\in\mathbb{R}$`为偏置项(bias),`$f$`为非线性激活函数,如`$sigmoid$`。将卷积核应用于句子中所有的词窗口`${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$`,产生一个特征图(feature map):
-
-$$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
-
-接下来,对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征`$\hat c$`,它是特征图中所有元素的最大值:
-
-$$\hat c=max(c)$$
-
-#### 模型概览
-
-在融合推荐模型的电影推荐系统中:
-
-1. 首先,使用用户特征和电影特征作为神经网络的输入,其中:
-
-- 用户特征融合了四个属性信息,分别是用户ID、性别、职业和年龄。
-
-- 电影特征融合了三个属性信息,分别是电影ID、电影类型ID和电影名称。
-
-2. 对用户特征,将用户ID映射为维度大小为256的向量表示,输入全连接层,并对其他三个属性也做类似的处理。然后将四个属性的特征表示分别全连接并相加。
-
-3. 对电影特征,将电影ID以类似用户ID的方式进行处理,电影类型ID以向量的形式直接输入全连接层,电影名称用文本卷积神经网络得到其定长向量表示。然后将三个属性的特征表示分别全连接并相加。
-
-4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
-
-
-
-图4. 融合推荐模型
-
-
-## 数据准备
-
-### 数据介绍与下载
-
-我们以 [MovieLens 百万数据集(ml-1m)](http://files.grouplens.org/datasets/movielens/ml-1m.zip)为例进行介绍。ml-1m 数据集包含了 6,000 位用户对 4,000 部电影的 1,000,000 条评价(评分范围 1~5 分,均为整数),由 GroupLens Research 实验室搜集整理。
-
-Paddle在API中提供了自动加载数据的模块。数据模块为 `paddle.dataset.movielens`
-
-
-```python
-import paddle
-movie_info = paddle.dataset.movielens.movie_info()
-print movie_info.values()[0]
-```
-
-
-```python
-# Run this block to show dataset's documentation
-# help(paddle.dataset.movielens)
-```
-
-在原始数据中包含电影的特征数据,用户的特征数据,和用户对电影的评分。
-
-例如,其中某一个电影特征为:
-
-
-```python
-movie_info = paddle.dataset.movielens.movie_info()
-print movie_info.values()[0]
-```
-
-
-
-
-这表示,电影的id是1,标题是《Toy Story》,该电影被分为到三个类别中。这三个类别是动画,儿童,喜剧。
-
-
-```python
-user_info = paddle.dataset.movielens.user_info()
-print user_info.values()[0]
-```
-
-
-
-
-这表示,该用户ID是1,女性,年龄比18岁还年轻。职业ID是10。
-
-
-其中,年龄使用下列分布
-* 1: "Under 18"
-* 18: "18-24"
-* 25: "25-34"
-* 35: "35-44"
-* 45: "45-49"
-* 50: "50-55"
-* 56: "56+"
-
-职业是从下面几种选项里面选则得出:
-* 0: "other" or not specified
-* 1: "academic/educator"
-* 2: "artist"
-* 3: "clerical/admin"
-* 4: "college/grad student"
-* 5: "customer service"
-* 6: "doctor/health care"
-* 7: "executive/managerial"
-* 8: "farmer"
-* 9: "homemaker"
-* 10: "K-12 student"
-* 11: "lawyer"
-* 12: "programmer"
-* 13: "retired"
-* 14: "sales/marketing"
-* 15: "scientist"
-* 16: "self-employed"
-* 17: "technician/engineer"
-* 18: "tradesman/craftsman"
-* 19: "unemployed"
-* 20: "writer"
-
-而对于每一条训练/测试数据,均为 <用户特征> + <电影特征> + 评分。
-
-例如,我们获得第一条训练数据:
-
-
-```python
-train_set_creator = paddle.dataset.movielens.train()
-train_sample = next(train_set_creator())
-uid = train_sample[0]
-mov_id = train_sample[len(user_info[uid].value())]
-print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id], train_sample[-1])
-```
-
-User rates Movie with Score [5.0]
-
-
-即用户1对电影1193的评价为5分。
-
-## 模型配置说明
-
-下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
-
-
-```python
-import math
-import sys
-import numpy as np
-import paddle
-import paddle.fluid as fluid
-import paddle.fluid.layers as layers
-import paddle.fluid.nets as nets
-
-IS_SPARSE = True
-USE_GPU = False
-BATCH_SIZE = 256
-```
-
-然后为我们的用户特征综合模型定义模型配置
-
-```python
-def get_usr_combined_features():
-
-USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
-
-uid = layers.data(name='user_id', shape=[1], dtype='int64')
-
-usr_emb = layers.embedding(
-input=uid,
-dtype='float32',
-size=[USR_DICT_SIZE, 32],
-param_attr='user_table',
-is_sparse=IS_SPARSE)
-
-usr_fc = layers.fc(input=usr_emb, size=32)
-
-USR_GENDER_DICT_SIZE = 2
-
-usr_gender_id = layers.data(name='gender_id', shape=[1], dtype='int64')
-
-usr_gender_emb = layers.embedding(
-input=usr_gender_id,
-size=[USR_GENDER_DICT_SIZE, 16],
-param_attr='gender_table',
-is_sparse=IS_SPARSE)
-
-usr_gender_fc = layers.fc(input=usr_gender_emb, size=16)
-
-USR_AGE_DICT_SIZE = len(paddle.dataset.movielens.age_table)
-usr_age_id = layers.data(name='age_id', shape=[1], dtype="int64")
-
-usr_age_emb = layers.embedding(
-input=usr_age_id,
-size=[USR_AGE_DICT_SIZE, 16],
-is_sparse=IS_SPARSE,
-param_attr='age_table')
-
-usr_age_fc = layers.fc(input=usr_age_emb, size=16)
-
-USR_JOB_DICT_SIZE = paddle.dataset.movielens.max_job_id() + 1
-usr_job_id = layers.data(name='job_id', shape=[1], dtype="int64")
-
-usr_job_emb = layers.embedding(
-input=usr_job_id,
-size=[USR_JOB_DICT_SIZE, 16],
-param_attr='job_table',
-is_sparse=IS_SPARSE)
-
-usr_job_fc = layers.fc(input=usr_job_emb, size=16)
-
-concat_embed = layers.concat(
-input=[usr_fc, usr_gender_fc, usr_age_fc, usr_job_fc], axis=1)
-
-usr_combined_features = layers.fc(input=concat_embed, size=200, act="tanh")
-
-return usr_combined_features
-```
-
-如上述代码所示,对于每个用户,我们输入4维特征。其中包括user_id,gender_id,age_id,job_id。这几维特征均是简单的整数值。为了后续神经网络处理这些特征方便,我们借鉴NLP中的语言模型,将这几维离散的整数值,变换成embedding取出。分别形成usr_emb, usr_gender_emb, usr_age_emb, usr_job_emb。
-
-然后,我们对于所有的用户特征,均输入到一个全连接层(fc)中。将所有特征融合为一个200维度的特征。
-
-进而,我们对每一个电影特征做类似的变换,网络配置为:
-
-
-```python
-def get_mov_combined_features():
-
-MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
-
-mov_id = layers.data(name='movie_id', shape=[1], dtype='int64')
-
-mov_emb = layers.embedding(
-input=mov_id,
-dtype='float32',
-size=[MOV_DICT_SIZE, 32],
-param_attr='movie_table',
-is_sparse=IS_SPARSE)
-
-mov_fc = layers.fc(input=mov_emb, size=32)
-
-CATEGORY_DICT_SIZE = len(paddle.dataset.movielens.movie_categories())
-
-category_id = layers.data(
-name='category_id', shape=[1], dtype='int64', lod_level=1)
-
-mov_categories_emb = layers.embedding(
-input=category_id, size=[CATEGORY_DICT_SIZE, 32], is_sparse=IS_SPARSE)
-
-mov_categories_hidden = layers.sequence_pool(
-input=mov_categories_emb, pool_type="sum")
-
-MOV_TITLE_DICT_SIZE = len(paddle.dataset.movielens.get_movie_title_dict())
-
-mov_title_id = layers.data(
-name='movie_title', shape=[1], dtype='int64', lod_level=1)
-
-mov_title_emb = layers.embedding(
-input=mov_title_id, size=[MOV_TITLE_DICT_SIZE, 32], is_sparse=IS_SPARSE)
-
-mov_title_conv = nets.sequence_conv_pool(
-input=mov_title_emb,
-num_filters=32,
-filter_size=3,
-act="tanh",
-pool_type="sum")
-
-concat_embed = layers.concat(
-input=[mov_fc, mov_categories_hidden, mov_title_conv], axis=1)
-
-mov_combined_features = layers.fc(input=concat_embed, size=200, act="tanh")
-
-return mov_combined_features
-```
-
-电影标题名称(title)是一个序列的整数,整数代表的是这个词在索引序列中的下标。这个序列会被送入 `sequence_conv_pool` 层,这个层会在时间维度上使用卷积和池化。因为如此,所以输出会是固定长度,尽管输入的序列长度各不相同。
-
-最后,我们定义一个`inference_program`来使用余弦相似度计算用户特征与电影特征的相似性。
-
-```python
-def inference_program():
-usr_combined_features = get_usr_combined_features()
-mov_combined_features = get_mov_combined_features()
-
-inference = layers.cos_sim(X=usr_combined_features, Y=mov_combined_features)
-scale_infer = layers.scale(x=inference, scale=5.0)
-
-return scale_infer
-```
-
-进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
-
-```python
-def train_program():
-
-scale_infer = inference_program()
-
-label = layers.data(name='score', shape=[1], dtype='float32')
-square_cost = layers.square_error_cost(input=scale_infer, label=label)
-avg_cost = layers.mean(square_cost)
-
-return [avg_cost, scale_infer]
-
-
-def optimizer_func():
-return fluid.optimizer.SGD(learning_rate=0.2)
-```
-
-
-## 训练模型
-
-### 定义训练环境
-定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
-
-### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.movielens.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
-
-```python
-train_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.movielens.train(), buf_size=8192),
-batch_size=BATCH_SIZE)
-
-test_reader = paddle.batch(
-paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
-```
-
-### 构造训练器(trainer)
-训练器需要一个训练程序和一个训练优化函数。
-
-```python
-trainer = fluid.Trainer(
-train_func=train_program, place=place, optimizer_func=optimizer_func)
-```
-
-### 提供数据
-
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`movielens.train`产生的第一列的数据对应的是`user_id`这个特征。
-
-```python
-feed_order = [
-'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
-'movie_title', 'score'
-]
-```
-
-### 事件处理器
-回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
-
-```python
-# Specify the directory path to save the parameters
-params_dirname = "recommender_system.inference.model"
-
-from paddle.v2.plot import Ploter
-test_title = "Test cost"
-plot_cost = Ploter(test_title)
-
-
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-avg_cost_set = trainer.test(
-reader=test_reader, feed_order=feed_order)
-
-# get avg cost
-avg_cost = np.array(avg_cost_set).mean()
-
-plot_cost.append(test_title, event.step, avg_cost_set[0])
-plot_cost.plot()
-
-print("avg_cost: %s" % avg_cost)
-print('BatchID {0}, Test Loss {1:0.2}'.format(event.epoch + 1,
-float(avg_cost)))
-
-if event.step == 20: # Adjust this number for accuracy
-trainer.save_params(params_dirname)
-trainer.stop()
-```
-
-### 开始训练
-最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
-
-```python
-trainer.train(
-num_epochs=1,
-event_handler=event_handler,
-reader=train_reader,
-feed_order=feed_order)
-```
-
-## 应用模型
-
-### 构建预测器
-传入`inference_program`和`params_dirname`来初始化一个预测器, `params_dirname`用来存放训练过程中的各个参数。
-
-```python
-inferencer = fluid.Inferencer(
-inference_program, param_path=params_dirname, place=place)
-```
-
-### 生成测试用输入数据
-使用 create_lod_tensor(data, lod, place) 的API来生成细节层次的张量。`data`是一个序列,每个元素是一个索引号的序列。`lod`是细节层次的信息,对应于`data`。比如,data = [[10, 2, 3], [2, 3]] 意味着它包含两个序列,长度分别是3和2。于是相应地 lod = [[3, 2]],它表明其包含一层细节信息,意味着 `data` 有两个序列,长度分别是3和2。
-
-在这个预测例子中,我们试着预测用户ID为1的用户对于电影'Hunchback of Notre Dame'的评分
-
-```python
-infer_movie_id = 783
-infer_movie_name = paddle.dataset.movielens.movie_info()[infer_movie_id].title
-user_id = fluid.create_lod_tensor([[1]], [[1]], place)
-gender_id = fluid.create_lod_tensor([[1]], [[1]], place)
-age_id = fluid.create_lod_tensor([[0]], [[1]], place)
-job_id = fluid.create_lod_tensor([[10]], [[1]], place)
-movie_id = fluid.create_lod_tensor([[783]], [[1]], place) # Hunchback of Notre Dame
-category_id = fluid.create_lod_tensor([[10, 8, 9]], [[3]], place) # Animation, Children's, Musical
-movie_title = fluid.create_lod_tensor([[1069, 4140, 2923, 710, 988]], [[5]],
-place) # 'hunchback','of','notre','dame','the'
-```
-
-### 测试
-现在我们可以进行预测了。我们要提供的`feed_order`应该和训练过程一致。
-
-
-```python
-results = inferencer.infer(
-{
-'user_id': user_id,
-'gender_id': gender_id,
-'age_id': age_id,
-'job_id': job_id,
-'movie_id': movie_id,
-'category_id': category_id,
-'movie_title': movie_title
-},
-return_numpy=False)
-```
-
-## 总结
-
-本章介绍了传统的推荐系统方法和YouTube的深度神经网络推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在推荐系统领域大放异彩。
-
-## 参考文献
-
-1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
-2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
-3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
-4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
-5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
-6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
-7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
-
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 个性化推荐
+
+本教程源代码目录在[book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/176.html)。
+
+## 背景介绍
+
+在网络技术不断发展和电子商务规模不断扩大的背景下,商品数量和种类快速增长,用户需要花费大量时间才能找到自己想买的商品,这就是信息超载问题。为了解决这个难题,推荐系统(Recommender System)应运而生。
+
+个性化推荐系统是信息过滤系统(Information Filtering System)的子集,它可以用在很多领域,如电影、音乐、电商和 Feed 流推荐等。推荐系统通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。与搜索引擎不同,推荐系统不需要用户准确地描述出自己的需求,而是根据分析历史行为建模,主动提供满足用户兴趣和需求的信息。
+
+传统的推荐系统方法主要有:
+
+- 协同过滤推荐(Collaborative Filtering Recommendation):该方法收集分析用户历史行为、活动、偏好,计算一个用户与其他用户的相似度,利用目标用户的相似用户对商品评价的加权评价值,来预测目标用户对特定商品的喜好程度。优点是可以给用户推荐未浏览过的新产品;缺点是对于没有任何行为的新用户存在冷启动的问题,同时也存在用户与商品之间的交互数据不够多造成的稀疏问题,会导致模型难以找到相近用户。
+- 基于内容过滤推荐[[1](#参考文献)](Content-based Filtering Recommendation):该方法利用商品的内容描述,抽象出有意义的特征,通过计算用户的兴趣和商品描述之间的相似度,来给用户做推荐。优点是简单直接,不需要依据其他用户对商品的评价,而是通过商品属性进行商品相似度度量,从而推荐给用户所感兴趣商品的相似商品;缺点是对于没有任何行为的新用户同样存在冷启动的问题。
+- 组合推荐[[2](#参考文献)](Hybrid Recommendation):运用不同的输入和技术共同进行推荐,以弥补各自推荐技术的缺点。
+
+其中协同过滤是应用最广泛的技术之一,它又可以分为多个子类:基于用户 (User-Based)的推荐[[3](#参考文献)] 、基于物品(Item-Based)的推荐[[4](#参考文献)]、基于社交网络关系(Social-Based)的推荐[[5](#参考文献)]、基于模型(Model-based)的推荐等。1994年明尼苏达大学推出的GroupLens系统[[3](#参考文献)]一般被认为是推荐系统成为一个相对独立的研究方向的标志。该系统首次提出了基于协同过滤来完成推荐任务的思想,此后,基于该模型的协同过滤推荐引领了推荐系统十几年的发展方向。
+
+深度学习具有优秀的自动提取特征的能力,能够学习多层次的抽象特征表示,并对异质或跨域的内容信息进行学习,可以一定程度上处理推荐系统冷启动问题[[6](#参考文献)]。本教程主要介绍个性化推荐的深度学习模型,以及如何使用PaddlePaddle实现模型。
+
+## 效果展示
+
+我们使用包含用户信息、电影信息与电影评分的数据集作为个性化推荐的应用场景。当我们训练好模型后,只需要输入对应的用户ID和电影ID,就可以得出一个匹配的分数(范围[0,5],分数越高视为兴趣越大),然后根据所有电影的推荐得分排序,推荐给用户可能感兴趣的电影。
+
+```
+Input movie_id: 1962
+Input user_id: 1
+Prediction Score is 4.25
+```
+
+## 模型概览
+
+本章中,我们首先介绍YouTube的视频推荐系统[[7](#参考文献)],然后介绍我们实现的融合推荐模型。
+
+### YouTube的深度神经网络推荐系统
+
+YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
+
+
+
+图1. YouTube 推荐系统结构
+
+
+#### 候选生成网络(Candidate Generation Network)
+
+候选生成网络将推荐问题建模为一个类别数极大的多类分类问题:对于一个Youtube用户,使用其观看历史(视频ID)、搜索词记录(search tokens)、人口学信息(如地理位置、用户登录设备)、二值特征(如性别,是否登录)和连续特征(如用户年龄)等,对视频库中所有视频进行多分类,得到每一类别的分类结果(即每一个视频的推荐概率),最终输出概率较高的几百个视频。
+
+首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的$k$个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。
+
+
+
+图2. 候选生成网络结构
+
+
+对于一个用户$U$,预测此刻用户要观看的视频$\omega$为视频$i$的概率公式为:
+
+$$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
+
+其中$u$为用户$U$的特征表示,$V$为视频库集合,$v_i$为视频库中第$i$个视频的特征表示。$u$和$v_i$为长度相等的向量,两者点积可以通过全连接层实现。
+
+考虑到softmax分类的类别数非常多,为了保证一定的计算效率:1)训练阶段,使用负样本类别采样将实际计算的类别数缩小至数千;2)推荐(预测)阶段,忽略softmax的归一化计算(不影响结果),将类别打分问题简化为点积(dot product)空间中的最近邻(nearest neighbor)搜索问题,取与$u$最近的$k$个视频作为生成的候选。
+
+#### 排序网络(Ranking Network)
+排序网络的结构类似于候选生成网络,但是它的目标是对候选进行更细致的打分排序。和传统广告排序中的特征抽取方法类似,这里也构造了大量的用于视频排序的相关特征(如视频 ID、上次观看时间等)。这些特征的处理方式和候选生成网络类似,不同之处是排序网络的顶部是一个加权逻辑回归(weighted logistic regression),它对所有候选视频进行打分,从高到底排序后将分数较高的一些视频返回给用户。
+
+### 融合推荐模型
+本节会使卷积神经网络(Convolutional Neural Networks)来学习电影名称的表示。下面会依次介绍文本卷积神经网络以及融合推荐模型。
+
+#### 文本卷积神经网络(CNN)
+
+卷积神经网络经常用来处理具有类似网格拓扑结构(grid-like topology)的数据。例如,图像可以视为二维网格的像素点,自然语言可以视为一维的词序列。卷积神经网络可以提取多种局部特征,并对其进行组合抽象得到更高级的特征表示。实验表明,卷积神经网络能高效地对图像及文本问题进行建模处理。
+
+卷积神经网络主要由卷积(convolution)和池化(pooling)操作构成,其应用及组合方式灵活多变,种类繁多。本小结我们以如图3所示的网络进行讲解:
+
+
+
+图3. 卷积神经网络文本分类模型
+
+
+假设待处理句子的长度为$n$,其中第$i$个词的词向量(word embedding)为$x_i\in\mathbb{R}^k$,$k$为维度大小。
+
+首先,进行词向量的拼接操作:将每$h$个词拼接起来形成一个大小为$h$的词窗口,记为$x_{i:i+h-1}$,它表示词序列$x_{i},x_{i+1},\ldots,x_{i+h-1}$的拼接,其中,$i$表示词窗口中第一个词在整个句子中的位置,取值范围从$1$到$n-h+1$,$x_{i:i+h-1}\in\mathbb{R}^{hk}$。
+
+其次,进行卷积操作:把卷积核(kernel)$w\in\mathbb{R}^{hk}$应用于包含$h$个词的窗口$x_{i:i+h-1}$,得到特征$c_i=f(w\cdot x_{i:i+h-1}+b)$,其中$b\in\mathbb{R}$为偏置项(bias),$f$为非线性激活函数,如$sigmoid$。将卷积核应用于句子中所有的词窗口${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$,产生一个特征图(feature map):
+
+$$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
+
+接下来,对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征$\hat c$,它是特征图中所有元素的最大值:
+
+$$\hat c=max(c)$$
+
+#### 模型概览
+
+在融合推荐模型的电影推荐系统中:
+
+1. 首先,使用用户特征和电影特征作为神经网络的输入,其中:
+
+ - 用户特征融合了四个属性信息,分别是用户ID、性别、职业和年龄。
+
+ - 电影特征融合了三个属性信息,分别是电影ID、电影类型ID和电影名称。
+
+2. 对用户特征,将用户ID映射为维度大小为256的向量表示,输入全连接层,并对其他三个属性也做类似的处理。然后将四个属性的特征表示分别全连接并相加。
+
+3. 对电影特征,将电影ID以类似用户ID的方式进行处理,电影类型ID以向量的形式直接输入全连接层,电影名称用文本卷积神经网络得到其定长向量表示。然后将三个属性的特征表示分别全连接并相加。
+
+4. 得到用户和电影的向量表示后,计算二者的余弦相似度作为推荐系统的打分。最后,用该相似度打分和用户真实打分的差异的平方作为该回归模型的损失函数。
+
+
+
+
+图4. 融合推荐模型
+
+
+## 数据准备
+
+### 数据介绍与下载
+
+我们以 [MovieLens 百万数据集(ml-1m)](http://files.grouplens.org/datasets/movielens/ml-1m.zip)为例进行介绍。ml-1m 数据集包含了 6,000 位用户对 4,000 部电影的 1,000,000 条评价(评分范围 1~5 分,均为整数),由 GroupLens Research 实验室搜集整理。
+
+Paddle在API中提供了自动加载数据的模块。数据模块为 `paddle.dataset.movielens`
+
+
+```python
+import paddle
+movie_info = paddle.dataset.movielens.movie_info()
+print movie_info.values()[0]
+```
+
+
+```python
+# Run this block to show dataset's documentation
+# help(paddle.dataset.movielens)
+```
+
+在原始数据中包含电影的特征数据,用户的特征数据,和用户对电影的评分。
+
+例如,其中某一个电影特征为:
+
+
+```python
+movie_info = paddle.dataset.movielens.movie_info()
+print movie_info.values()[0]
+```
+
+
+
+
+这表示,电影的id是1,标题是《Toy Story》,该电影被分为到三个类别中。这三个类别是动画,儿童,喜剧。
+
+
+```python
+user_info = paddle.dataset.movielens.user_info()
+print user_info.values()[0]
+```
+
+
+
+
+这表示,该用户ID是1,女性,年龄比18岁还年轻。职业ID是10。
+
+
+其中,年龄使用下列分布
+
+* 1: "Under 18"
+* 18: "18-24"
+* 25: "25-34"
+* 35: "35-44"
+* 45: "45-49"
+* 50: "50-55"
+* 56: "56+"
+
+职业是从下面几种选项里面选则得出:
+
+* 0: "other" or not specified
+* 1: "academic/educator"
+* 2: "artist"
+* 3: "clerical/admin"
+* 4: "college/grad student"
+* 5: "customer service"
+* 6: "doctor/health care"
+* 7: "executive/managerial"
+* 8: "farmer"
+* 9: "homemaker"
+* 10: "K-12 student"
+* 11: "lawyer"
+* 12: "programmer"
+* 13: "retired"
+* 14: "sales/marketing"
+* 15: "scientist"
+* 16: "self-employed"
+* 17: "technician/engineer"
+* 18: "tradesman/craftsman"
+* 19: "unemployed"
+* 20: "writer"
+
+而对于每一条训练/测试数据,均为 <用户特征> + <电影特征> + 评分。
+
+例如,我们获得第一条训练数据:
+
+
+```python
+train_set_creator = paddle.dataset.movielens.train()
+train_sample = next(train_set_creator())
+uid = train_sample[0]
+mov_id = train_sample[len(user_info[uid].value())]
+print "User %s rates Movie %s with Score %s"%(user_info[uid], movie_info[mov_id], train_sample[-1])
+```
+
+ User rates Movie with Score [5.0]
+
+
+即用户1对电影1193的评价为5分。
+
+## 模型配置说明
+
+下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+
+
+```python
+from __future__ import print_function
+import math
+import sys
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as layers
+import paddle.fluid.nets as nets
+
+IS_SPARSE = True
+USE_GPU = False
+BATCH_SIZE = 256
+```
+
+然后为我们的用户特征综合模型定义模型配置
+
+```python
+def get_usr_combined_features():
+
+ USR_DICT_SIZE = paddle.dataset.movielens.max_user_id() + 1
+
+ uid = layers.data(name='user_id', shape=[1], dtype='int64')
+
+ usr_emb = layers.embedding(
+ input=uid,
+ dtype='float32',
+ size=[USR_DICT_SIZE, 32],
+ param_attr='user_table',
+ is_sparse=IS_SPARSE)
+
+ usr_fc = layers.fc(input=usr_emb, size=32)
+
+ USR_GENDER_DICT_SIZE = 2
+
+ usr_gender_id = layers.data(name='gender_id', shape=[1], dtype='int64')
+
+ usr_gender_emb = layers.embedding(
+ input=usr_gender_id,
+ size=[USR_GENDER_DICT_SIZE, 16],
+ param_attr='gender_table',
+ is_sparse=IS_SPARSE)
+
+ usr_gender_fc = layers.fc(input=usr_gender_emb, size=16)
+
+ USR_AGE_DICT_SIZE = len(paddle.dataset.movielens.age_table)
+ usr_age_id = layers.data(name='age_id', shape=[1], dtype="int64")
+
+ usr_age_emb = layers.embedding(
+ input=usr_age_id,
+ size=[USR_AGE_DICT_SIZE, 16],
+ is_sparse=IS_SPARSE,
+ param_attr='age_table')
+
+ usr_age_fc = layers.fc(input=usr_age_emb, size=16)
+
+ USR_JOB_DICT_SIZE = paddle.dataset.movielens.max_job_id() + 1
+ usr_job_id = layers.data(name='job_id', shape=[1], dtype="int64")
+
+ usr_job_emb = layers.embedding(
+ input=usr_job_id,
+ size=[USR_JOB_DICT_SIZE, 16],
+ param_attr='job_table',
+ is_sparse=IS_SPARSE)
+
+ usr_job_fc = layers.fc(input=usr_job_emb, size=16)
+
+ concat_embed = layers.concat(
+ input=[usr_fc, usr_gender_fc, usr_age_fc, usr_job_fc], axis=1)
+
+ usr_combined_features = layers.fc(input=concat_embed, size=200, act="tanh")
+
+ return usr_combined_features
+```
+
+如上述代码所示,对于每个用户,我们输入4维特征。其中包括user_id,gender_id,age_id,job_id。这几维特征均是简单的整数值。为了后续神经网络处理这些特征方便,我们借鉴NLP中的语言模型,将这几维离散的整数值,变换成embedding取出。分别形成usr_emb, usr_gender_emb, usr_age_emb, usr_job_emb。
+
+然后,我们对于所有的用户特征,均输入到一个全连接层(fc)中。将所有特征融合为一个200维度的特征。
+
+进而,我们对每一个电影特征做类似的变换,网络配置为:
+
+
+```python
+def get_mov_combined_features():
+
+ MOV_DICT_SIZE = paddle.dataset.movielens.max_movie_id() + 1
+
+ mov_id = layers.data(name='movie_id', shape=[1], dtype='int64')
+
+ mov_emb = layers.embedding(
+ input=mov_id,
+ dtype='float32',
+ size=[MOV_DICT_SIZE, 32],
+ param_attr='movie_table',
+ is_sparse=IS_SPARSE)
+
+ mov_fc = layers.fc(input=mov_emb, size=32)
+
+ CATEGORY_DICT_SIZE = len(paddle.dataset.movielens.movie_categories())
+
+ category_id = layers.data(
+ name='category_id', shape=[1], dtype='int64', lod_level=1)
+
+ mov_categories_emb = layers.embedding(
+ input=category_id, size=[CATEGORY_DICT_SIZE, 32], is_sparse=IS_SPARSE)
+
+ mov_categories_hidden = layers.sequence_pool(
+ input=mov_categories_emb, pool_type="sum")
+
+ MOV_TITLE_DICT_SIZE = len(paddle.dataset.movielens.get_movie_title_dict())
+
+ mov_title_id = layers.data(
+ name='movie_title', shape=[1], dtype='int64', lod_level=1)
+
+ mov_title_emb = layers.embedding(
+ input=mov_title_id, size=[MOV_TITLE_DICT_SIZE, 32], is_sparse=IS_SPARSE)
+
+ mov_title_conv = nets.sequence_conv_pool(
+ input=mov_title_emb,
+ num_filters=32,
+ filter_size=3,
+ act="tanh",
+ pool_type="sum")
+
+ concat_embed = layers.concat(
+ input=[mov_fc, mov_categories_hidden, mov_title_conv], axis=1)
+
+ mov_combined_features = layers.fc(input=concat_embed, size=200, act="tanh")
+
+ return mov_combined_features
+```
+
+电影标题名称(title)是一个序列的整数,整数代表的是这个词在索引序列中的下标。这个序列会被送入 `sequence_conv_pool` 层,这个层会在时间维度上使用卷积和池化。因为如此,所以输出会是固定长度,尽管输入的序列长度各不相同。
+
+最后,我们定义一个`inference_program`来使用余弦相似度计算用户特征与电影特征的相似性。
+
+```python
+def inference_program():
+ usr_combined_features = get_usr_combined_features()
+ mov_combined_features = get_mov_combined_features()
+
+ inference = layers.cos_sim(X=usr_combined_features, Y=mov_combined_features)
+ scale_infer = layers.scale(x=inference, scale=5.0)
+
+ return scale_infer
+```
+
+进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
+
+```python
+def train_program():
+
+ scale_infer = inference_program()
+
+ label = layers.data(name='score', shape=[1], dtype='float32')
+ square_cost = layers.square_error_cost(input=scale_infer, label=label)
+ avg_cost = layers.mean(square_cost)
+
+ return [avg_cost, scale_infer]
+
+
+def optimizer_func():
+ return fluid.optimizer.SGD(learning_rate=0.2)
+```
+
+
+## 训练模型
+
+### 定义训练环境
+定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
+
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+```
+
+### 定义数据提供器
+下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.movielens.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
+
+```python
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.movielens.train(), buf_size=8192),
+ batch_size=BATCH_SIZE)
+
+test_reader = paddle.batch(
+ paddle.dataset.movielens.test(), batch_size=BATCH_SIZE)
+```
+
+### 构造训练器(trainer)
+训练器需要一个训练程序和一个训练优化函数。
+
+```python
+trainer = fluid.Trainer(
+ train_func=train_program, place=place, optimizer_func=optimizer_func)
+```
+
+### 提供数据
+
+`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`movielens.train`产生的第一列的数据对应的是`user_id`这个特征。
+
+```python
+feed_order = [
+ 'user_id', 'gender_id', 'age_id', 'job_id', 'movie_id', 'category_id',
+ 'movie_title', 'score'
+]
+```
+
+### 事件处理器
+回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
+
+```python
+# Specify the directory path to save the parameters
+params_dirname = "recommender_system.inference.model"
+
+from paddle.v2.plot import Ploter
+test_title = "Test cost"
+plot_cost = Ploter(test_title)
+
+
+def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ avg_cost_set = trainer.test(
+ reader=test_reader, feed_order=feed_order)
+
+ # get avg cost
+ avg_cost = np.array(avg_cost_set).mean()
+
+ plot_cost.append(test_title, event.step, avg_cost_set[0])
+ plot_cost.plot()
+
+ print("avg_cost: %s" % avg_cost)
+ print('BatchID {0}, Test Loss {1:0.2}'.format(event.epoch + 1,
+ float(avg_cost)))
+
+ if event.step == 20: # Adjust this number for accuracy
+ trainer.save_params(params_dirname)
+ trainer.stop()
+```
+
+### 开始训练
+最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
+
+```python
+trainer.train(
+ num_epochs=1,
+ event_handler=event_handler,
+ reader=train_reader,
+ feed_order=feed_order)
+```
+
+## 应用模型
+
+### 构建预测器
+传入`inference_program`和`params_dirname`来初始化一个预测器, `params_dirname`用来存放训练过程中的各个参数。
+
+```python
+inferencer = fluid.Inferencer(
+ inference_program, param_path=params_dirname, place=place)
+```
+
+### 生成测试用输入数据
+使用 create_lod_tensor(data, lod, place) 的API来生成细节层次的张量。`data`是一个序列,每个元素是一个索引号的序列。`lod`是细节层次的信息,对应于`data`。比如,data = [[10, 2, 3], [2, 3]] 意味着它包含两个序列,长度分别是3和2。于是相应地 lod = [[3, 2]],它表明其包含一层细节信息,意味着 `data` 有两个序列,长度分别是3和2。
+
+在这个预测例子中,我们试着预测用户ID为1的用户对于电影'Hunchback of Notre Dame'的评分
+
+```python
+infer_movie_id = 783
+infer_movie_name = paddle.dataset.movielens.movie_info()[infer_movie_id].title
+user_id = fluid.create_lod_tensor([[1]], [[1]], place)
+gender_id = fluid.create_lod_tensor([[1]], [[1]], place)
+age_id = fluid.create_lod_tensor([[0]], [[1]], place)
+job_id = fluid.create_lod_tensor([[10]], [[1]], place)
+movie_id = fluid.create_lod_tensor([[783]], [[1]], place) # Hunchback of Notre Dame
+category_id = fluid.create_lod_tensor([[10, 8, 9]], [[3]], place) # Animation, Children's, Musical
+movie_title = fluid.create_lod_tensor([[1069, 4140, 2923, 710, 988]], [[5]],
+ place) # 'hunchback','of','notre','dame','the'
+```
+
+### 测试
+现在我们可以进行预测了。我们要提供的`feed_order`应该和训练过程一致。
+
+
+```python
+results = inferencer.infer(
+ {
+ 'user_id': user_id,
+ 'gender_id': gender_id,
+ 'age_id': age_id,
+ 'job_id': job_id,
+ 'movie_id': movie_id,
+ 'category_id': category_id,
+ 'movie_title': movie_title
+ },
+ return_numpy=False)
+
+predict_rating = np.array(results[0])
+print("Predict Rating of user id 1 on movie \"" + infer_movie_name + "\" is " + str(predict_rating[0][0]))
+print("Actual Rating of user id 1 on movie \"" + infer_movie_name + "\" is 4.")
+
+```
+
+## 总结
+
+本章介绍了传统的推荐系统方法和YouTube的深度神经网络推荐系统,并以电影推荐为例,使用PaddlePaddle训练了一个个性化推荐神经网络模型。推荐系统几乎涵盖了电商系统、社交网络、广告推荐、搜索引擎等领域的方方面面,而在图像处理、自然语言处理等领域已经发挥重要作用的深度学习技术,也将会在推荐系统领域大放异彩。
+
+## 参考文献
+
+1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
+2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
+3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
+4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
+5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
+6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
+7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
+
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
deleted file mode 100644
index 667762d327cb160376a4119fa9df9db41b6443b2..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
+++ /dev/null
@@ -1,10 +0,0 @@
-data/aclImdb
-data/imdb
-data/pre-imdb
-data/mosesdecoder-master
-*.log
-model_output
-dataprovider_copy_1.py
-model.list
-*.pyc
-.DS_Store
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/index.md b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
similarity index 70%
rename from doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
index 624de7e4d439953c7255481fb0c9d62ce94f3900..5844b6fe137c2401a04e47b5b489434ee9b363f1 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
@@ -1,354 +1,356 @@
-# 情感分析
-
-本教程源代码目录在[book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-在自然语言处理中,情感分析一般是指判断一段文本所表达的情绪状态。其中,一段文本可以是一个句子,一个段落或一个文档。情绪状态可以是两类,如(正面,负面),(高兴,悲伤);也可以是三类,如(积极,消极,中性)等等。情感分析的应用场景十分广泛,如把用户在购物网站(亚马逊、天猫、淘宝等)、旅游网站、电影评论网站上发表的评论分成正面评论和负面评论;或为了分析用户对于某一产品的整体使用感受,抓取产品的用户评论并进行情感分析等等。表格1展示了对电影评论进行情感分析的例子:
-
-| 电影评论 | 类别 |
-| -------- | ----- |
-| 在冯小刚这几年的电影里,算最好的一部的了| 正面 |
-| 很不好看,好像一个地方台的电视剧 | 负面 |
-| 圆方镜头全程炫技,色调背景美则美矣,但剧情拖沓,口音不伦不类,一直努力却始终无法入戏| 负面|
-|剧情四星。但是圆镜视角加上婺源的风景整个非常有中国写意山水画的感觉,看得实在太舒服了。。|正面|
-
-表格 1 电影评论情感分析
-
-在自然语言处理中,情感分析属于典型的**文本分类**问题,即把需要进行情感分析的文本划分为其所属类别。文本分类涉及文本表示和分类方法两个问题。在深度学习的方法出现之前,主流的文本表示方法为词袋模型BOW(bag of words),话题模型等等;分类方法有SVM(support vector machine), LR(logistic regression)等等。
-
-对于一段文本,BOW表示会忽略其词顺序、语法和句法,将这段文本仅仅看做是一个词集合,因此BOW方法并不能充分表示文本的语义信息。例如,句子“这部电影糟糕透了”和“一个乏味,空洞,没有内涵的作品”在情感分析中具有很高的语义相似度,但是它们的BOW表示的相似度为0。又如,句子“一个空洞,没有内涵的作品”和“一个不空洞而且有内涵的作品”的BOW相似度很高,但实际上它们的意思很不一样。
-
-本章我们所要介绍的深度学习模型克服了BOW表示的上述缺陷,它在考虑词顺序的基础上把文本映射到低维度的语义空间,并且以端对端(end to end)的方式进行文本表示及分类,其性能相对于传统方法有显著的提升\[[1](#参考文献)\]。
-
-## 模型概览
-本章所使用的文本表示模型为卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)及其扩展。下面依次介绍这几个模型。
-
-### 文本卷积神经网络简介(CNN)
-
-我们在[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过应用于文本数据的卷积神经网络模型的计算过程,这里进行一个简单的回顾。
-
-对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
-
-对于一般的短文本分类问题,上文所述的简单的文本卷积网络即可达到很高的正确率\[[1](#参考文献)\]。若想得到更抽象更高级的文本特征表示,可以构建深层文本卷积神经网络\[[2](#参考文献),[3](#参考文献)\]。
-
-### 循环神经网络(RNN)
-
-循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的\[[4](#参考文献)\]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
-
-
-
-图1. 循环神经网络按时间展开的示意图
-
-
-循环神经网络按时间展开后如图1所示:在第`$t$`时刻,网络读入第`$t$`个输入`$x_t$`(向量表示)及前一时刻隐层的状态值`$h_{t-1}$`(向量表示,`$h_0$`一般初始化为`$0$`向量),计算得出本时刻隐层的状态值`$h_t$`,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为`$f$`,则其公式可表示为:
-
-$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
-
-其中`$W_{xh}$`是输入到隐层的矩阵参数,`$W_{hh}$`是隐层到隐层的矩阵参数,`$b_h$`为隐层的偏置向量(bias)参数,`$\sigma$`为`$sigmoid$`函数。
-
-在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入`$x_t$`。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
-
-### 长短期记忆网络(LSTM)
-
-对于较长的序列数据,循环神经网络的训练过程中容易出现梯度消失或爆炸现象\[[6](#参考文献)\]。为了解决这一问题,Hochreiter S, Schmidhuber J. (1997)提出了LSTM(long short term memory\[[5](#参考文献)\])。
-
-相比于简单的循环神经网络,LSTM增加了记忆单元`$c$`、输入门`$i$`、遗忘门`$f$`及输出门`$o$`。这些门及记忆单元组合起来大大提升了循环神经网络处理长序列数据的能力。若将基于LSTM的循环神经网络表示的函数记为`$F$`,则其公式为:
-
-$$ h_t=F(x_t,h_{t-1})$$
-
-`$F$`由下列公式组合而成\[[7](#参考文献)\]:
-$$ i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} $$
-$$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
-$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
-$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
-$$ h_t = o_t\odot tanh(c_t) $$
-其中,`$i_t, f_t, c_t, o_t$`分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的`$W$`及`$b$`为模型参数,`$tanh$`为双曲正切函数,`$\odot$`表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元`$c$`的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元`$c$`,如图2所示:
-
-
-
-图2. 时刻`$t$`的LSTM [7]
-
-
-LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
-
-$$ h_t=Recrurent(x_t,h_{t-1})$$
-
-其中,`$Recrurent$`可以表示简单的循环神经网络、GRU或LSTM。
-
-### 栈式双向LSTM(Stacked Bidirectional LSTM)
-
-对于正常顺序的循环神经网络,`$h_t$`包含了`$t$`时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
-
-如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
-
-
-
-图3. 栈式双向LSTM用于文本分类
-
-
-
-## 数据集介绍
-
-我们以[IMDB情感分析数据集](http://ai.stanford.edu/%7Eamaas/data/sentiment/)为例进行介绍。IMDB数据集的训练集和测试集分别包含25000个已标注过的电影评论。其中,负面评论的得分小于等于4,正面评论的得分大于等于7,满分10分。
-```text
-aclImdb
-|- test
-|-- neg
-|-- pos
-|- train
-|-- neg
-|-- pos
-```
-Paddle在`dataset/imdb.py`中提实现了imdb数据集的自动下载和读取,并提供了读取字典、训练数据、测试数据等API。
-
-## 配置模型
-
-在该示例中,我们实现了两种文本分类算法,分别基于[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过的文本卷积神经网络,以及[栈式双向LSTM](#栈式双向LSTM(Stacked Bidirectional LSTM))。我们首先引入要用到的库和定义全局变量:
-
-```python
-import paddle
-import paddle.fluid as fluid
-from functools import partial
-import numpy as np
-
-CLASS_DIM = 2
-EMB_DIM = 128
-HID_DIM = 512
-BATCH_SIZE = 128
-USE_GPU = False
-```
-
-
-### 文本卷积神经网络
-我们构建神经网络`convolution_net`,示例代码如下。
-需要注意的是:`fluid.nets.sequence_conv_pool` 包含卷积和池化层两个操作。
-
-```python
-def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
-emb = fluid.layers.embedding(
-input=data, size=[input_dim, emb_dim], is_sparse=True)
-conv_3 = fluid.nets.sequence_conv_pool(
-input=emb,
-num_filters=hid_dim,
-filter_size=3,
-act="tanh",
-pool_type="sqrt")
-conv_4 = fluid.nets.sequence_conv_pool(
-input=emb,
-num_filters=hid_dim,
-filter_size=4,
-act="tanh",
-pool_type="sqrt")
-prediction = fluid.layers.fc(
-input=[conv_3, conv_4], size=class_dim, act="softmax")
-return prediction
-```
-
-网络的输入`input_dim`表示的是词典的大小,`class_dim`表示类别数。这里,我们使用[`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) API实现了卷积和池化操作。
-
-### 栈式双向LSTM
-
-栈式双向神经网络`stacked_lstm_net`的代码片段如下:
-
-```python
-def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
-
-emb = fluid.layers.embedding(
-input=data, size=[input_dim, emb_dim], is_sparse=True)
-
-fc1 = fluid.layers.fc(input=emb, size=hid_dim)
-lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
-
-inputs = [fc1, lstm1]
-
-for i in range(2, stacked_num + 1):
-fc = fluid.layers.fc(input=inputs, size=hid_dim)
-lstm, cell = fluid.layers.dynamic_lstm(
-input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
-inputs = [fc, lstm]
-
-fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
-lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
-
-prediction = fluid.layers.fc(input=[fc_last, lstm_last],
-size=class_dim,
-act='softmax')
-return prediction
-```
-以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。`paddle.activation.Softmax`函数用来计算分类属于某个类别的概率。
-
-重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个。我们以`convolution_net`为例。
-
-接下来我们定义预测程序(`inference_program`)。预测程序使用`convolution_net`来对`fluid.layer.data`的输入进行预测。
-
-```python
-def inference_program(word_dict):
-data = fluid.layers.data(
-name="words", shape=[1], dtype="int64", lod_level=1)
-
-dict_dim = len(word_dict)
-net = convolution_net(data, dict_dim, CLASS_DIM, EMB_DIM, HID_DIM)
-return net
-```
-
-我们这里定义了`training_program`。它使用了从`inference_program`返回的结果来计算误差。我们同时定义了优化函数`optimizer_func`。
-
-因为是有监督的学习,训练集的标签也在`paddle.layer.data`中定义了。在训练过程中,交叉熵用来在`paddle.layer.classification_cost`中作为损失函数。
-
-在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为 损耗(cost)。
-
-```python
-def train_program(word_dict):
-prediction = inference_program(word_dict)
-label = fluid.layers.data(name="label", shape=[1], dtype="int64")
-cost = fluid.layers.cross_entropy(input=prediction, label=label)
-avg_cost = fluid.layers.mean(cost)
-accuracy = fluid.layers.accuracy(input=prediction, label=label)
-return [avg_cost, accuracy]
-
-
-def optimizer_func():
-return fluid.optimizer.Adagrad(learning_rate=0.002)
-```
-
-## 训练模型
-
-### 定义训练环境
-
-定义您的训练是在CPU上还是在GPU上:
-
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
-
-### 定义数据提供器
-
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.train 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
-
-注意:读取IMDB的数据可能会花费几分钟的时间,请耐心等待。
-
-```python
-print("Loading IMDB word dict....")
-word_dict = paddle.dataset.imdb.word_dict()
-
-print ("Reading training data....")
-train_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.imdb.train(word_dict), buf_size=25000),
-batch_size=BATCH_SIZE)
-```
-
-### 构造训练器(trainer)
-训练器需要一个训练程序和一个训练优化函数。
-
-```python
-trainer = fluid.Trainer(
-train_func=partial(train_program, word_dict),
-place=place,
-optimizer_func=optimizer_func)
-```
-
-### 提供数据
-
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
-
-```python
-feed_order = ['words', 'label']
-```
-
-### 事件处理器
-
-回调函数event_handler在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
-
-```python
-# Specify the directory path to save the parameters
-params_dirname = "understand_sentiment_conv.inference.model"
-
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-print("Step {0}, Epoch {1} Metrics {2}".format(
-event.step, event.epoch, map(np.array, event.metrics)))
-
-if event.step == 10:
-trainer.save_params(params_dirname)
-trainer.stop()
-```
-
-### 开始训练
-
-最后,我们传入训练循环数(num_epoch)和一些别的参数,调用 trainer.train 来开始训练。
-
-```python
-trainer.train(
-num_epochs=1,
-event_handler=event_handler,
-reader=train_reader,
-feed_order=feed_order)
-```
-
-## 应用模型
-
-### 构建预测器
-
-传入`inference_program`和`params_dirname`来初始化一个预测器, `params_dirname`用来存放训练过程中的各个参数。
-
-```python
-inferencer = fluid.Inferencer(
-inference_program, param_path=params_dirname, place=place)
-```
-
-### 生成测试用输入数据
-
-为了进行预测,我们任意选取3个评论。请随意选取您看好的3个。我们把评论中的每个词对应到`word_dict`中的id。如果词典中没有这个词,则设为`unknown`。
-然后我们用`create_lod_tensor`来创建细节层次的张量。
-
-```python
-reviews_str = [
-'read the book forget the movie', 'this is a great movie', 'this is very bad'
-]
-reviews = [c.split() for c in reviews_str]
-
-UNK = word_dict['']
-lod = []
-for c in reviews:
-lod.append([word_dict.get(words, UNK) for words in c])
-
-base_shape = [[len(c) for c in lod]]
-
-tensor_words = fluid.create_lod_tensor(lod, base_shape, place)
-```
-
-## 应用模型
-
-现在我们可以对每一条评论进行正面或者负面的预测啦。
-
-```python
-results = inferencer.infer({'words': tensor_words})
-
-for i, r in enumerate(results[0]):
-print("Predict probability of ", r[0], " to be positive and ", r[1], " to be negative for review \'", reviews_str[i], "\'")
-
-```
-
-
-## 总结
-
-本章我们以情感分析为例,介绍了使用深度学习的方法进行端对端的短文本分类,并且使用PaddlePaddle完成了全部相关实验。同时,我们简要介绍了两种文本处理模型:卷积神经网络和循环神经网络。在后续的章节中我们会看到这两种基本的深度学习模型在其它任务上的应用。
-
-
-## 参考文献
-1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
-2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
-3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
-4. Siegelmann H T, Sontag E D. [On the computational power of neural nets](http://research.cs.queensu.ca/home/akl/cisc879/papers/SELECTED_PAPERS_FROM_VARIOUS_SOURCES/05070215382317071.pdf)[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
-5. Hochreiter S, Schmidhuber J. [Long short-term memory](http://web.eecs.utk.edu/~itamar/courses/ECE-692/Bobby_paper1.pdf)[J]. Neural computation, 1997, 9(8): 1735-1780.
-6. Bengio Y, Simard P, Frasconi P. [Learning long-term dependencies with gradient descent is difficult](http://www-dsi.ing.unifi.it/~paolo/ps/tnn-94-gradient.pdf)[J]. IEEE transactions on neural networks, 1994, 5(2): 157-166.
-7. Graves A. [Generating sequences with recurrent neural networks](http://arxiv.org/pdf/1308.0850)[J]. arXiv preprint arXiv:1308.0850, 2013.
-8. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](http://arxiv.org/pdf/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
-9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 情感分析
+
+本教程源代码目录在[book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/177.html)。
+
+## 背景介绍
+
+在自然语言处理中,情感分析一般是指判断一段文本所表达的情绪状态。其中,一段文本可以是一个句子,一个段落或一个文档。情绪状态可以是两类,如(正面,负面),(高兴,悲伤);也可以是三类,如(积极,消极,中性)等等。情感分析的应用场景十分广泛,如把用户在购物网站(亚马逊、天猫、淘宝等)、旅游网站、电影评论网站上发表的评论分成正面评论和负面评论;或为了分析用户对于某一产品的整体使用感受,抓取产品的用户评论并进行情感分析等等。表格1展示了对电影评论进行情感分析的例子:
+
+| 电影评论 | 类别 |
+| -------- | ----- |
+| 在冯小刚这几年的电影里,算最好的一部的了| 正面 |
+| 很不好看,好像一个地方台的电视剧 | 负面 |
+| 圆方镜头全程炫技,色调背景美则美矣,但剧情拖沓,口音不伦不类,一直努力却始终无法入戏| 负面|
+|剧情四星。但是圆镜视角加上婺源的风景整个非常有中国写意山水画的感觉,看得实在太舒服了。。|正面|
+
+表格 1 电影评论情感分析
+
+在自然语言处理中,情感分析属于典型的**文本分类**问题,即把需要进行情感分析的文本划分为其所属类别。文本分类涉及文本表示和分类方法两个问题。在深度学习的方法出现之前,主流的文本表示方法为词袋模型BOW(bag of words),话题模型等等;分类方法有SVM(support vector machine), LR(logistic regression)等等。
+
+对于一段文本,BOW表示会忽略其词顺序、语法和句法,将这段文本仅仅看做是一个词集合,因此BOW方法并不能充分表示文本的语义信息。例如,句子“这部电影糟糕透了”和“一个乏味,空洞,没有内涵的作品”在情感分析中具有很高的语义相似度,但是它们的BOW表示的相似度为0。又如,句子“一个空洞,没有内涵的作品”和“一个不空洞而且有内涵的作品”的BOW相似度很高,但实际上它们的意思很不一样。
+
+本章我们所要介绍的深度学习模型克服了BOW表示的上述缺陷,它在考虑词顺序的基础上把文本映射到低维度的语义空间,并且以端对端(end to end)的方式进行文本表示及分类,其性能相对于传统方法有显著的提升\[[1](#参考文献)\]。
+
+## 模型概览
+本章所使用的文本表示模型为卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)及其扩展。下面依次介绍这几个模型。
+
+### 文本卷积神经网络简介(CNN)
+
+我们在[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过应用于文本数据的卷积神经网络模型的计算过程,这里进行一个简单的回顾。
+
+对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
+
+对于一般的短文本分类问题,上文所述的简单的文本卷积网络即可达到很高的正确率\[[1](#参考文献)\]。若想得到更抽象更高级的文本特征表示,可以构建深层文本卷积神经网络\[[2](#参考文献),[3](#参考文献)\]。
+
+### 循环神经网络(RNN)
+
+循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的\[[4](#参考文献)\]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
+
+
+
+图1. 循环神经网络按时间展开的示意图
+
+
+循环神经网络按时间展开后如图1所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
+
+$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
+
+其中$W_{xh}$是输入到隐层的矩阵参数,$W_{hh}$是隐层到隐层的矩阵参数,$b_h$为隐层的偏置向量(bias)参数,$\sigma$为$sigmoid$函数。
+
+在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
+
+### 长短期记忆网络(LSTM)
+
+对于较长的序列数据,循环神经网络的训练过程中容易出现梯度消失或爆炸现象\[[6](#参考文献)\]。为了解决这一问题,Hochreiter S, Schmidhuber J. (1997)提出了LSTM(long short term memory\[[5](#参考文献)\])。
+
+相比于简单的循环神经网络,LSTM增加了记忆单元$c$、输入门$i$、遗忘门$f$及输出门$o$。这些门及记忆单元组合起来大大提升了循环神经网络处理长序列数据的能力。若将基于LSTM的循环神经网络表示的函数记为$F$,则其公式为:
+
+$$ h_t=F(x_t,h_{t-1})$$
+
+$F$由下列公式组合而成\[[7](#参考文献)\]:
+$$ i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} $$
+$$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
+$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
+$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
+$$ h_t = o_t\odot tanh(c_t) $$
+其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:
+
+
+
+图2. 时刻$t$的LSTM [7]
+
+
+LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
+
+$$ h_t=Recrurent(x_t,h_{t-1})$$
+
+其中,$Recrurent$可以表示简单的循环神经网络、GRU或LSTM。
+
+### 栈式双向LSTM(Stacked Bidirectional LSTM)
+
+对于正常顺序的循环神经网络,$h_t$包含了$t$时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
+
+如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
+
+
+
+图3. 栈式双向LSTM用于文本分类
+
+
+
+## 数据集介绍
+
+我们以[IMDB情感分析数据集](http://ai.stanford.edu/%7Eamaas/data/sentiment/)为例进行介绍。IMDB数据集的训练集和测试集分别包含25000个已标注过的电影评论。其中,负面评论的得分小于等于4,正面评论的得分大于等于7,满分10分。
+```text
+aclImdb
+|- test
+ |-- neg
+ |-- pos
+|- train
+ |-- neg
+ |-- pos
+```
+Paddle在`dataset/imdb.py`中提实现了imdb数据集的自动下载和读取,并提供了读取字典、训练数据、测试数据等API。
+
+## 配置模型
+
+在该示例中,我们实现了两种文本分类算法,分别基于[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节介绍过的文本卷积神经网络,以及[栈式双向LSTM](#栈式双向LSTM(Stacked Bidirectional LSTM))。我们首先引入要用到的库和定义全局变量:
+
+```python
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+from functools import partial
+import numpy as np
+
+CLASS_DIM = 2
+EMB_DIM = 128
+HID_DIM = 512
+STACKED_NUM = 3
+BATCH_SIZE = 128
+USE_GPU = False
+```
+
+
+### 文本卷积神经网络
+我们构建神经网络`convolution_net`,示例代码如下。
+需要注意的是:`fluid.nets.sequence_conv_pool` 包含卷积和池化层两个操作。
+
+```python
+def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
+ emb = fluid.layers.embedding(
+ input=data, size=[input_dim, emb_dim], is_sparse=True)
+ conv_3 = fluid.nets.sequence_conv_pool(
+ input=emb,
+ num_filters=hid_dim,
+ filter_size=3,
+ act="tanh",
+ pool_type="sqrt")
+ conv_4 = fluid.nets.sequence_conv_pool(
+ input=emb,
+ num_filters=hid_dim,
+ filter_size=4,
+ act="tanh",
+ pool_type="sqrt")
+ prediction = fluid.layers.fc(
+ input=[conv_3, conv_4], size=class_dim, act="softmax")
+ return prediction
+```
+
+网络的输入`input_dim`表示的是词典的大小,`class_dim`表示类别数。这里,我们使用[`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) API实现了卷积和池化操作。
+
+### 栈式双向LSTM
+
+栈式双向神经网络`stacked_lstm_net`的代码片段如下:
+
+```python
+def stacked_lstm_net(data, input_dim, class_dim, emb_dim, hid_dim, stacked_num):
+
+ emb = fluid.layers.embedding(
+ input=data, size=[input_dim, emb_dim], is_sparse=True)
+
+ fc1 = fluid.layers.fc(input=emb, size=hid_dim)
+ lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=hid_dim)
+
+ inputs = [fc1, lstm1]
+
+ for i in range(2, stacked_num + 1):
+ fc = fluid.layers.fc(input=inputs, size=hid_dim)
+ lstm, cell = fluid.layers.dynamic_lstm(
+ input=fc, size=hid_dim, is_reverse=(i % 2) == 0)
+ inputs = [fc, lstm]
+
+ fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max')
+ lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max')
+
+ prediction = fluid.layers.fc(
+ input=[fc_last, lstm_last], size=class_dim, act='softmax')
+ return prediction
+```
+以上的栈式双向LSTM抽象出了高级特征并把其映射到和分类类别数同样大小的向量上。`paddle.activation.Softmax`函数用来计算分类属于某个类别的概率。
+
+重申一下,此处我们可以调用`convolution_net`或`stacked_lstm_net`的任何一个。我们以`convolution_net`为例。
+
+接下来我们定义预测程序(`inference_program`)。预测程序使用`convolution_net`来对`fluid.layer.data`的输入进行预测。
+
+```python
+def inference_program(word_dict):
+ data = fluid.layers.data(
+ name="words", shape=[1], dtype="int64", lod_level=1)
+
+ dict_dim = len(word_dict)
+ net = convolution_net(data, dict_dim, CLASS_DIM, EMB_DIM, HID_DIM)
+ # net = stacked_lstm_net(data, dict_dim, CLASS_DIM, EMB_DIM, HID_DIM, STACKED_NUM)
+ return net
+```
+
+我们这里定义了`training_program`。它使用了从`inference_program`返回的结果来计算误差。我们同时定义了优化函数`optimizer_func`。
+
+因为是有监督的学习,训练集的标签也在`paddle.layer.data`中定义了。在训练过程中,交叉熵用来在`paddle.layer.classification_cost`中作为损失函数。
+
+在测试过程中,分类器会计算各个输出的概率。第一个返回的数值规定为 损耗(cost)。
+
+```python
+def train_program(word_dict):
+ prediction = inference_program(word_dict)
+ label = fluid.layers.data(name="label", shape=[1], dtype="int64")
+ cost = fluid.layers.cross_entropy(input=prediction, label=label)
+ avg_cost = fluid.layers.mean(cost)
+ accuracy = fluid.layers.accuracy(input=prediction, label=label)
+ return [avg_cost, accuracy]
+
+
+def optimizer_func():
+ return fluid.optimizer.Adagrad(learning_rate=0.002)
+```
+
+## 训练模型
+
+### 定义训练环境
+
+定义您的训练是在CPU上还是在GPU上:
+
+
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+```
+
+### 定义数据提供器
+
+下一步是为训练和测试定义数据提供器。提供器读入一个大小为 BATCH_SIZE的数据。paddle.dataset.imdb.train 每次会在乱序化后提供一个大小为BATCH_SIZE的数据,乱序化的大小为缓存大小buf_size。
+
+注意:读取IMDB的数据可能会花费几分钟的时间,请耐心等待。
+
+```python
+print("Loading IMDB word dict....")
+word_dict = paddle.dataset.imdb.word_dict()
+
+print ("Reading training data....")
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.imdb.train(word_dict), buf_size=25000),
+ batch_size=BATCH_SIZE)
+```
+
+### 构造训练器(trainer)
+训练器需要一个训练程序和一个训练优化函数。
+
+```python
+trainer = fluid.Trainer(
+ train_func=partial(train_program, word_dict),
+ place=place,
+ optimizer_func=optimizer_func)
+```
+
+### 提供数据
+
+`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`imdb.train`产生的第一列的数据对应的是`words`这个特征。
+
+```python
+feed_order = ['words', 'label']
+```
+
+### 事件处理器
+
+回调函数event_handler在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
+
+```python
+# Specify the directory path to save the parameters
+params_dirname = "understand_sentiment_conv.inference.model"
+
+def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ print("Step {0}, Epoch {1} Metrics {2}".format(
+ event.step, event.epoch, map(np.array, event.metrics)))
+
+ if event.step == 10:
+ trainer.save_params(params_dirname)
+ trainer.stop()
+```
+
+### 开始训练
+
+最后,我们传入训练循环数(num_epoch)和一些别的参数,调用 trainer.train 来开始训练。
+
+```python
+trainer.train(
+ num_epochs=1,
+ event_handler=event_handler,
+ reader=train_reader,
+ feed_order=feed_order)
+```
+
+## 应用模型
+
+### 构建预测器
+
+传入`inference_program`和`params_dirname`来初始化一个预测器, `params_dirname`用来存放训练过程中的各个参数。
+
+```python
+inferencer = fluid.Inferencer(
+ infer_func=partial(inference_program, word_dict), param_path=params_dirname, place=place)
+```
+
+### 生成测试用输入数据
+
+为了进行预测,我们任意选取3个评论。请随意选取您看好的3个。我们把评论中的每个词对应到`word_dict`中的id。如果词典中没有这个词,则设为`unknown`。
+然后我们用`create_lod_tensor`来创建细节层次的张量。
+
+```python
+reviews_str = [
+ 'read the book forget the movie', 'this is a great movie', 'this is very bad'
+]
+reviews = [c.split() for c in reviews_str]
+
+UNK = word_dict['']
+lod = []
+for c in reviews:
+ lod.append([word_dict.get(words, UNK) for words in c])
+
+base_shape = [[len(c) for c in lod]]
+
+tensor_words = fluid.create_lod_tensor(lod, base_shape, place)
+```
+
+## 应用模型
+
+现在我们可以对每一条评论进行正面或者负面的预测啦。
+
+```python
+results = inferencer.infer({'words': tensor_words})
+
+for i, r in enumerate(results[0]):
+ print("Predict probability of ", r[0], " to be positive and ", r[1], " to be negative for review \'", reviews_str[i], "\'")
+
+```
+
+
+## 总结
+
+本章我们以情感分析为例,介绍了使用深度学习的方法进行端对端的短文本分类,并且使用PaddlePaddle完成了全部相关实验。同时,我们简要介绍了两种文本处理模型:卷积神经网络和循环神经网络。在后续的章节中我们会看到这两种基本的深度学习模型在其它任务上的应用。
+
+
+## 参考文献
+1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
+2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
+3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
+4. Siegelmann H T, Sontag E D. [On the computational power of neural nets](http://research.cs.queensu.ca/home/akl/cisc879/papers/SELECTED_PAPERS_FROM_VARIOUS_SOURCES/05070215382317071.pdf)[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
+5. Hochreiter S, Schmidhuber J. [Long short-term memory](http://web.eecs.utk.edu/~itamar/courses/ECE-692/Bobby_paper1.pdf)[J]. Neural computation, 1997, 9(8): 1735-1780.
+6. Bengio Y, Simard P, Frasconi P. [Learning long-term dependencies with gradient descent is difficult](http://www-dsi.ing.unifi.it/~paolo/ps/tnn-94-gradient.pdf)[J]. IEEE transactions on neural networks, 1994, 5(2): 157-166.
+7. Graves A. [Generating sequences with recurrent neural networks](http://arxiv.org/pdf/1308.0850)[J]. arXiv preprint arXiv:1308.0850, 2013.
+8. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](http://arxiv.org/pdf/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
+9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
deleted file mode 100644
index a620e0279c310d213d4e6d8e99e666962c11e352..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
+++ /dev/null
@@ -1,3 +0,0 @@
-data/train.list
-data/test.list
-data/simple-examples*
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/index.md b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
similarity index 56%
rename from doc/fluid/new_docs/beginners_guide/basics/word2vec/index.md
rename to doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
index e73a6334ca1acd49379604f24d3d4e463192a902..d21c7ddcc501f863b5ce672123dbbc6c26528f15 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/word2vec/index.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
@@ -1,440 +1,444 @@
-
-# 词向量
-
-本教程源代码目录在[book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-
-本章我们介绍词的向量表征,也称为word embedding。词向量是自然语言处理中常见的一个操作,是搜索引擎、广告系统、推荐系统等互联网服务背后常见的基础技术。
-
-在这些互联网服务里,我们经常要比较两个词或者两段文本之间的相关性。为了做这样的比较,我们往往先要把词表示成计算机适合处理的方式。最自然的方式恐怕莫过于向量空间模型(vector space model)。
-在这种方式里,每个词被表示成一个实数向量(one-hot vector),其长度为字典大小,每个维度对应一个字典里的每个词,除了这个词对应维度上的值是1,其他元素都是0。
-
-One-hot vector虽然自然,但是用处有限。比如,在互联网广告系统里,如果用户输入的query是“母亲节”,而有一个广告的关键词是“康乃馨”。虽然按照常理,我们知道这两个词之间是有联系的——母亲节通常应该送给母亲一束康乃馨;但是这两个词对应的one-hot vectors之间的距离度量,无论是欧氏距离还是余弦相似度(cosine similarity),由于其向量正交,都认为这两个词毫无相关性。 得出这种与我们相悖的结论的根本原因是:每个词本身的信息量都太小。所以,仅仅给定两个词,不足以让我们准确判别它们是否相关。要想精确计算相关性,我们还需要更多的信息——从大量数据里通过机器学习方法归纳出来的知识。
-
-在机器学习领域里,各种“知识”被各种模型表示,词向量模型(word embedding model)就是其中的一类。通过词向量模型可将一个 one-hot vector映射到一个维度更低的实数向量(embedding vector),如`$embedding(Mother's\ Day) = [0.3, 4.2, -1.5, ...], embedding(Carnation) = [0.2, 5.6, -2.3, ...]$`。在这个映射到的实数向量表示中,希望两个语义(或用法)上相似的词对应的词向量“更像”,这样如“母亲节”和“康乃馨”的对应词向量的余弦相似度就不再为零了。
-
-词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵`$X$`。`$X$`是一个`$|V| \times |V|$` 大小的矩阵,`$X_{ij}$`表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,`$|V|$`为词汇表的大小。对`$X$`做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的`$U$`即视为所有词的词向量:
-
-$$X = USV^T$$
-
-但这样的传统做法有很多问题:
-1) 由于很多词没有出现,导致矩阵极其稀疏,因此需要对词频做额外处理来达到好的矩阵分解效果;
-2) 矩阵非常大,维度太高(通常达到`$10^6*10^6$`的数量级);
-3) 需要手动去掉停用词(如although, a,...),不然这些频繁出现的词也会影响矩阵分解的效果。
-
-
-基于神经网络的模型不需要计算存储一个在全语料上统计的大表,而是通过学习语义信息得到词向量,因此能很好地解决以上问题。在本章里,我们将展示基于神经网络训练词向量的细节,以及如何用PaddlePaddle训练一个词向量模型。
-
-
-## 效果展示
-
-本章中,当词向量训练好后,我们可以用数据可视化算法t-SNE\[[4](#参考文献)\]画出词语特征在二维上的投影(如下图所示)。从图中可以看出,语义相关的词语(如a, the, these; big, huge)在投影上距离很近,语意无关的词(如say, business; decision, japan)在投影上的距离很远。
-
-
-
-图1. 词向量的二维投影
-
-
-另一方面,我们知道两个向量的余弦值在`$[-1,1]$`的区间内:两个完全相同的向量余弦值为1, 两个相互垂直的向量之间余弦值为0,两个方向完全相反的向量余弦值为-1,即相关性和余弦值大小成正比。因此我们还可以计算两个词向量的余弦相似度:
-
-```
-similarity: 0.899180685161
-please input two words: big huge
-
-please input two words: from company
-similarity: -0.0997506977351
-```
-
-以上结果可以通过运行`calculate_dis.py`, 加载字典里的单词和对应训练特征结果得到,我们将在[应用模型](#应用模型)中详细描述用法。
-
-
-## 模型概览
-
-在这里我们介绍三个训练词向量的模型:N-gram模型,CBOW模型和Skip-gram模型,它们的中心思想都是通过上下文得到一个词出现的概率。对于N-gram模型,我们会先介绍语言模型的概念,并在之后的[训练模型](#训练模型)中,带大家用PaddlePaddle实现它。而后两个模型,是近年来最有名的神经元词向量模型,由 Tomas Mikolov 在Google 研发\[[3](#参考文献)\],虽然它们很浅很简单,但训练效果很好。
-
-### 语言模型
-
-在介绍词向量模型之前,我们先来引入一个概念:语言模型。
-语言模型旨在为语句的联合概率函数`$P(w_1, ..., w_T)$`建模, 其中`$w_i$`表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。
-这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。 以信息检索为例,当你在搜索“how long is a football bame”时(bame是一个医学名词),搜索引擎会提示你是否希望搜索"how long is a football game", 这是因为根据语言模型计算出“how long is a football bame”的概率很低,而与bame近似的,可能引起错误的词中,game会使该句生成的概率最大。
-
-对语言模型的目标概率`$P(w_1, ..., w_T)$`,如果假设文本中每个词都是相互独立的,则整句话的联合概率可以表示为其中所有词语条件概率的乘积,即:
-
-$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t)$$
-
-然而我们知道语句中的每个词出现的概率都与其前面的词紧密相关, 所以实际上通常用条件概率表示语言模型:
-
-$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})$$
-
-
-
-### N-gram neural model
-
-在计算语言学中,n-gram是一种重要的文本表示方法,表示一个文本中连续的n个项。基于具体的应用场景,每一项可以是一个字母、单词或者音节。 n-gram模型也是统计语言模型中的一种重要方法,用n-gram训练语言模型时,一般用每个n-gram的历史n-1个词语组成的内容来预测第n个词。
-
-Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
-
-我们在上文中已经讲到用条件概率建模语言模型,即一句话中第`$t$`个词的概率和该句话的前`$t-1$`个词相关。可实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面`n-1`个词的影响,则有:
-
-$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
-
-给定一些真实语料,这些语料中都是有意义的句子,N-gram模型的优化目标则是最大化目标函数:
-
-$$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
-
-其中`$f(w_t, w_{t-1}, ..., w_{t-n+1})$`表示根据历史n-1个词得到当前词`$w_t$`的条件概率,`$R(\theta)$`表示参数正则项。
-
-
-
-图2. N-gram神经网络模型
-
-
-图2展示了N-gram神经网络模型,从下往上看,该模型分为以下几个部分:
-- 对于每个样本,模型输入`$w_{t-n+1},...w_{t-1}$`, 输出句子第t个词为字典中`|V|`个词的概率。
-
-每个输入词`$w_{t-n+1},...w_{t-1}$`首先通过映射矩阵映射到词向量`$C(w_{t-n+1}),...C(w_{t-1})$`。
-
-- 然后所有词语的词向量连接成一个大向量,并经过一个非线性映射得到历史词语的隐层表示:
-
-$$g=Utanh(\theta^Tx + b_1) + Wx + b_2$$
-
-其中,`$x$`为所有词语的词向量连接成的大向量,表示文本历史特征;`$\theta$`、`$U$`、`$b_1$`、`$b_2$`和`$W$`分别为词向量层到隐层连接的参数。`$g$`表示未经归一化的所有输出单词概率,`$g_i$`表示未经归一化的字典中第`$i$`个单词的输出概率。
-
-- 根据softmax的定义,通过归一化`$g_i$`, 生成目标词`$w_t$`的概率为:
-
-$$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
-
-- 整个网络的损失值(cost)为多类分类交叉熵,用公式表示为
-
-$$J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
-
-其中`$y_k^i$`表示第`$i$`个样本第`$k$`类的真实标签(0或1),`$softmax(g_k^i)$`表示第i个样本第k类softmax输出的概率。
-
-
-
-### Continuous Bag-of-Words model(CBOW)
-
-CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
-
-
-
-图3. CBOW模型
-
-
-具体来说,不考虑上下文的词语输入顺序,CBOW是用上下文词语的词向量的均值来预测当前词。即:
-
-$$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
-
-其中`$x_t$`为第`$t$`个词的词向量,分类分数(score)向量 `$z=U*context$`,最终的分类`$y$`采用softmax,损失函数采用多类分类交叉熵。
-
-### Skip-gram model
-
-CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
-
-
-
-图4. Skip-gram模型
-
-
-如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到`$2n$`个词的词向量(`$2n$`表示当前输入词的前后各`$n$`个词),然后分别通过softmax得到这`$2n$`个词的分类损失值之和。
-
-
-## 数据准备
-
-### 数据介绍
-
-本教程使用Penn Treebank (PTB)(经Tomas Mikolov预处理过的版本)数据集。PTB数据集较小,训练速度快,应用于Mikolov的公开语言模型训练工具\[[2](#参考文献)\]中。其统计情况如下:
-
-
-
-
-| 训练数据 |
-验证数据 |
-测试数据 |
-
-
-| ptb.train.txt |
-ptb.valid.txt |
-ptb.test.txt |
-
-
-| 42068句 |
-3370句 |
-3761句 |
-
-
-
-
-
-### 数据预处理
-
-本章训练的是5-gram模型,表示在PaddlePaddle训练时,每条数据的前4个词用来预测第5个词。PaddlePaddle提供了对应PTB数据集的python包`paddle.dataset.imikolov`,自动做数据的下载与预处理,方便大家使用。
-
-预处理会把数据集中的每一句话前后加上开始符号``以及结束符号``。然后依据窗口大小(本教程中为5),从头到尾每次向右滑动窗口并生成一条数据。
-
-如"I have a dream that one day" 一句提供了5条数据:
-
-```text
- I have a dream
-I have a dream that
-have a dream that one
-a dream that one day
-dream that one day
-```
-
-最后,每个输入会按其单词次在字典里的位置,转化成整数的索引序列,作为PaddlePaddle的输入。
-
-## 编程实现
-
-本配置的模型结构如下图所示:
-
-
-
-图5. 模型配置中的N-gram神经网络模型
-
-
-首先,加载所需要的包:
-
-```python
-import paddle
-import paddle.fluid as fluid
-import numpy
-from functools import partial
-import math
-import os
-import sys
-```
-
-然后,定义参数:
-```python
-EMBED_SIZE = 32 # word vector dimension
-HIDDEN_SIZE = 256 # hidden layer dimension
-N = 5 # train 5-gram
-BATCH_SIZE = 32 # batch size
-
-# can use CPU or GPU
-use_cuda = os.getenv('WITH_GPU', '0') != '0'
-
-word_dict = paddle.dataset.imikolov.build_dict()
-dict_size = len(word_dict)
-```
-
-不同于之前的PaddlePaddle v2版本,在新的Fluid版本里,我们不必再手动计算词向量。PaddlePaddle提供了一个内置的方法`fluid.layers.embedding`,我们就可以直接用它来构造 N-gram 神经网络。
-
-- 我们来定义我们的 N-gram 神经网络结构。这个结构在训练和预测中都会使用到。因为词向量比较稀疏,我们传入参数 `is_sparse == True`, 可以加速稀疏矩阵的更新。
-
-```python
-def inference_program(is_sparse):
-first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
-second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
-third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
-fourth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
-
-embed_first = fluid.layers.embedding(
-input=first_word,
-size=[dict_size, EMBED_SIZE],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr='shared_w')
-embed_second = fluid.layers.embedding(
-input=second_word,
-size=[dict_size, EMBED_SIZE],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr='shared_w')
-embed_third = fluid.layers.embedding(
-input=third_word,
-size=[dict_size, EMBED_SIZE],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr='shared_w')
-embed_fourth = fluid.layers.embedding(
-input=fourth_word,
-size=[dict_size, EMBED_SIZE],
-dtype='float32',
-is_sparse=is_sparse,
-param_attr='shared_w')
-
-concat_embed = fluid.layers.concat(
-input=[embed_first, embed_second, embed_third, embed_fourth], axis=1)
-hidden1 = fluid.layers.fc(input=concat_embed,
-size=HIDDEN_SIZE,
-act='sigmoid')
-predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax')
-return predict_word
-```
-
-- 基于以上的神经网络结构,我们可以如下定义我们的`训练`方法
-
-```python
-def train_program(is_sparse):
-# The declaration of 'next_word' must be after the invoking of inference_program,
-# or the data input order of train program would be [next_word, firstw, secondw,
-# thirdw, fourthw], which is not correct.
-predict_word = inference_program(is_sparse)
-next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
-cost = fluid.layers.cross_entropy(input=predict_word, label=next_word)
-avg_cost = fluid.layers.mean(cost)
-return avg_cost
-```
-
-- 现在我们可以开始训练啦。如今的版本较之以前就简单了许多。我们有现成的训练和测试集:`paddle.dataset.imikolov.train()`和`paddle.dataset.imikolov.test()`。两者都会返回一个读取器。在PaddlePaddle中,读取器是一个Python的函数,每次调用,会读取下一条数据。它是一个Python的generator。
-
-`paddle.batch` 会读入一个读取器,然后输出一个批次化了的读取器。`event_handler`亦可以一并传入`trainer.train`来时不时的输出每个步骤,批次的训练情况。
-
-```python
-def optimizer_func():
-# Note here we need to choose more sophisticated optimizers
-# such as AdaGrad with a decay rate. The normal SGD converges
-# very slowly.
-# optimizer=fluid.optimizer.SGD(learning_rate=0.001),
-return fluid.optimizer.AdagradOptimizer(
-learning_rate=3e-3,
-regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
-
-
-def train(use_cuda, train_program, params_dirname):
-train_reader = paddle.batch(
-paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE)
-test_reader = paddle.batch(
-paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE)
-
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-# We output cost every 10 steps.
-if event.step % 10 == 0:
-outs = trainer.test(
-reader=test_reader,
-feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
-avg_cost = outs[0]
-
-print "Step %d: Average Cost %f" % (event.step, avg_cost)
-
-# If average cost is lower than 5.8, we consider the model good enough to stop.
-# Note 5.8 is a relatively high value. In order to get a better model, one should
-# aim for avg_cost lower than 3.5. But the training could take longer time.
-if avg_cost < 5.8:
-trainer.save_params(params_dirname)
-trainer.stop()
-
-if math.isnan(avg_cost):
-sys.exit("got NaN loss, training failed.")
-
-trainer = fluid.Trainer(
-train_func=train_program,
-optimizer_func=optimizer_func,
-place=place)
-
-trainer.train(
-reader=train_reader,
-num_epochs=1,
-event_handler=event_handler,
-feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
-```
-
-- `trainer.train`将会开始训练。从`event_handler`返回的监控情况如下:
-
-```python
-Step 0: Average Cost 7.337213
-Step 10: Average Cost 6.136128
-Step 20: Average Cost 5.766995
-...
-```
-
-## 模型应用
-在模型训练后,我们可以用它做一些预测。
-
-### 预测下一个词
-我们可以用我们训练过的模型,在得知之前的 N-gram 后,预测下一个词。
-
-```python
-def infer(use_cuda, inference_program, params_dirname=None):
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-inferencer = fluid.Inferencer(
-infer_func=inference_program, param_path=params_dirname, place=place)
-
-# Setup inputs by creating 4 LoDTensors representing 4 words. Here each word
-# is simply an index to look up for the corresponding word vector and hence
-# the shape of word (base_shape) should be [1]. The length-based level of
-# detail (lod) info of each LoDtensor should be [[1]] meaning there is only
-# one lod_level and there is only one sequence of one word on this level.
-# Note that lod info should be a list of lists.
-
-data1 = [[211]] # 'among'
-data2 = [[6]] # 'a'
-data3 = [[96]] # 'group'
-data4 = [[4]] # 'of'
-lod = [[1]]
-
-first_word = fluid.create_lod_tensor(data1, lod, place)
-second_word = fluid.create_lod_tensor(data2, lod, place)
-third_word = fluid.create_lod_tensor(data3, lod, place)
-fourth_word = fluid.create_lod_tensor(data4, lod, place)
-
-result = inferencer.infer(
-{
-'firstw': first_word,
-'secondw': second_word,
-'thirdw': third_word,
-'fourthw': fourth_word
-},
-return_numpy=False)
-
-print(numpy.array(result[0]))
-most_possible_word_index = numpy.argmax(result[0])
-print(most_possible_word_index)
-print([
-key for key, value in word_dict.iteritems()
-if value == most_possible_word_index
-][0])
-```
-
-在经历3分钟的短暂训练后,我们得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`a`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。
-
-
-```python
-[[0.00106646 0.0007907 0.00072041 ... 0.00049024 0.00041355 0.00084464]]
-6
-a
-```
-
-整个程序的入口很简单:
-
-```python
-def main(use_cuda, is_sparse):
-if use_cuda and not fluid.core.is_compiled_with_cuda():
-return
-
-params_dirname = "word2vec.inference.model"
-
-train(
-use_cuda=use_cuda,
-train_program=partial(train_program, is_sparse),
-params_dirname=params_dirname)
-
-infer(
-use_cuda=use_cuda,
-inference_program=partial(inference_program, is_sparse),
-params_dirname=params_dirname)
-
-
-main(use_cuda=use_cuda, is_sparse=True)
-```
-
-
-## 总结
-本章中,我们介绍了词向量、语言模型和词向量的关系、以及如何通过训练神经网络模型获得词向量。在信息检索中,我们可以根据向量间的余弦夹角,来判断query和文档关键词这二者间的相关性。在句法分析和语义分析中,训练好的词向量可以用来初始化模型,以得到更好的效果。在文档分类中,有了词向量之后,可以用聚类的方法将文档中同义词进行分组,也可以用 N-gram 来预测下一个词。希望大家在本章后能够自行运用词向量进行相关领域的研究。
-
-
-## 参考文献
-1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning research, 2003, 3(Feb): 1137-1155.
-2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
-3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013.
-4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov): 2579-2605.
-5. https://en.wikipedia.org/wiki/Singular_value_decomposition
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+
+# 词向量
+
+本教程源代码目录在[book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/175.html)。
+
+## 背景介绍
+
+本章我们介绍词的向量表征,也称为word embedding。词向量是自然语言处理中常见的一个操作,是搜索引擎、广告系统、推荐系统等互联网服务背后常见的基础技术。
+
+在这些互联网服务里,我们经常要比较两个词或者两段文本之间的相关性。为了做这样的比较,我们往往先要把词表示成计算机适合处理的方式。最自然的方式恐怕莫过于向量空间模型(vector space model)。
+在这种方式里,每个词被表示成一个实数向量(one-hot vector),其长度为字典大小,每个维度对应一个字典里的每个词,除了这个词对应维度上的值是1,其他元素都是0。
+
+One-hot vector虽然自然,但是用处有限。比如,在互联网广告系统里,如果用户输入的query是“母亲节”,而有一个广告的关键词是“康乃馨”。虽然按照常理,我们知道这两个词之间是有联系的——母亲节通常应该送给母亲一束康乃馨;但是这两个词对应的one-hot vectors之间的距离度量,无论是欧氏距离还是余弦相似度(cosine similarity),由于其向量正交,都认为这两个词毫无相关性。 得出这种与我们相悖的结论的根本原因是:每个词本身的信息量都太小。所以,仅仅给定两个词,不足以让我们准确判别它们是否相关。要想精确计算相关性,我们还需要更多的信息——从大量数据里通过机器学习方法归纳出来的知识。
+
+在机器学习领域里,各种“知识”被各种模型表示,词向量模型(word embedding model)就是其中的一类。通过词向量模型可将一个 one-hot vector映射到一个维度更低的实数向量(embedding vector),如$embedding(母亲节) = [0.3, 4.2, -1.5, ...], embedding(康乃馨) = [0.2, 5.6, -2.3, ...]$。在这个映射到的实数向量表示中,希望两个语义(或用法)上相似的词对应的词向量“更像”,这样如“母亲节”和“康乃馨”的对应词向量的余弦相似度就不再为零了。
+
+词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵$X$。$X$是一个$|V| \times |V|$ 大小的矩阵,$X_{ij}$表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,$|V|$为词汇表的大小。对$X$做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的$U$即视为所有词的词向量:
+
+$$X = USV^T$$
+
+但这样的传统做法有很多问题:
+
+1) 由于很多词没有出现,导致矩阵极其稀疏,因此需要对词频做额外处理来达到好的矩阵分解效果;
+
+2) 矩阵非常大,维度太高(通常达到$10^6 \times 10^6$的数量级);
+
+3) 需要手动去掉停用词(如although, a,...),不然这些频繁出现的词也会影响矩阵分解的效果。
+
+基于神经网络的模型不需要计算存储一个在全语料上统计的大表,而是通过学习语义信息得到词向量,因此能很好地解决以上问题。在本章里,我们将展示基于神经网络训练词向量的细节,以及如何用PaddlePaddle训练一个词向量模型。
+
+
+## 效果展示
+
+本章中,当词向量训练好后,我们可以用数据可视化算法t-SNE\[[4](#参考文献)\]画出词语特征在二维上的投影(如下图所示)。从图中可以看出,语义相关的词语(如a, the, these; big, huge)在投影上距离很近,语意无关的词(如say, business; decision, japan)在投影上的距离很远。
+
+
+ 
+ 图1. 词向量的二维投影
+
+
+另一方面,我们知道两个向量的余弦值在$[-1,1]$的区间内:两个完全相同的向量余弦值为1, 两个相互垂直的向量之间余弦值为0,两个方向完全相反的向量余弦值为-1,即相关性和余弦值大小成正比。因此我们还可以计算两个词向量的余弦相似度:
+
+```
+
+please input two words: big huge
+similarity: 0.899180685161
+
+please input two words: from company
+similarity: -0.0997506977351
+
+```
+
+以上结果可以通过运行`calculate_dis.py`, 加载字典里的单词和对应训练特征结果得到,我们将在[应用模型](#应用模型)中详细描述用法。
+
+
+## 模型概览
+
+在这里我们介绍三个训练词向量的模型:N-gram模型,CBOW模型和Skip-gram模型,它们的中心思想都是通过上下文得到一个词出现的概率。对于N-gram模型,我们会先介绍语言模型的概念,并在之后的[训练模型](#训练模型)中,带大家用PaddlePaddle实现它。而后两个模型,是近年来最有名的神经元词向量模型,由 Tomas Mikolov 在Google 研发\[[3](#参考文献)\],虽然它们很浅很简单,但训练效果很好。
+
+### 语言模型
+
+在介绍词向量模型之前,我们先来引入一个概念:语言模型。
+语言模型旨在为语句的联合概率函数$P(w_1, ..., w_T)$建模, 其中$w_i$表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。
+这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。 以信息检索为例,当你在搜索“how long is a football bame”时(bame是一个医学名词),搜索引擎会提示你是否希望搜索"how long is a football game", 这是因为根据语言模型计算出“how long is a football bame”的概率很低,而与bame近似的,可能引起错误的词中,game会使该句生成的概率最大。
+
+对语言模型的目标概率$P(w_1, ..., w_T)$,如果假设文本中每个词都是相互独立的,则整句话的联合概率可以表示为其中所有词语条件概率的乘积,即:
+
+$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t)$$
+
+然而我们知道语句中的每个词出现的概率都与其前面的词紧密相关, 所以实际上通常用条件概率表示语言模型:
+
+$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})$$
+
+
+
+### N-gram neural model
+
+在计算语言学中,n-gram是一种重要的文本表示方法,表示一个文本中连续的n个项。基于具体的应用场景,每一项可以是一个字母、单词或者音节。 n-gram模型也是统计语言模型中的一种重要方法,用n-gram训练语言模型时,一般用每个n-gram的历史n-1个词语组成的内容来预测第n个词。
+
+Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
+
+我们在上文中已经讲到用条件概率建模语言模型,即一句话中第$t$个词的概率和该句话的前$t-1$个词相关。可实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面`n-1`个词的影响,则有:
+
+$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
+
+给定一些真实语料,这些语料中都是有意义的句子,N-gram模型的优化目标则是最大化目标函数:
+
+$$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
+
+其中$f(w_t, w_{t-1}, ..., w_{t-n+1})$表示根据历史n-1个词得到当前词$w_t$的条件概率,$R(\theta)$表示参数正则项。
+
+
+ 
+ 图2. N-gram神经网络模型
+
+
+图2展示了N-gram神经网络模型,从下往上看,该模型分为以下几个部分:
+ - 对于每个样本,模型输入$w_{t-n+1},...w_{t-1}$, 输出句子第t个词为字典中`|V|`个词的概率。
+
+ 每个输入词$w_{t-n+1},...w_{t-1}$首先通过映射矩阵映射到词向量$C(w_{t-n+1}),...C(w_{t-1})$。
+
+ - 然后所有词语的词向量连接成一个大向量,并经过一个非线性映射得到历史词语的隐层表示:
+
+ $$g=Utanh(\theta^Tx + b_1) + Wx + b_2$$
+
+ 其中,$x$为所有词语的词向量连接成的大向量,表示文本历史特征;$\theta$、$U$、$b_1$、$b_2$和$W$分别为词向量层到隐层连接的参数。$g$表示未经归一化的所有输出单词概率,$g_i$表示未经归一化的字典中第$i$个单词的输出概率。
+
+ - 根据softmax的定义,通过归一化$g_i$, 生成目标词$w_t$的概率为:
+
+ $$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
+
+ - 整个网络的损失值(cost)为多类分类交叉熵,用公式表示为
+
+ $$J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
+
+ 其中$y_k^i$表示第$i$个样本第$k$类的真实标签(0或1),$softmax(g_k^i)$表示第i个样本第k类softmax输出的概率。
+
+
+
+### Continuous Bag-of-Words model(CBOW)
+
+CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
+
+
+ 
+ 图3. CBOW模型
+
+
+具体来说,不考虑上下文的词语输入顺序,CBOW是用上下文词语的词向量的均值来预测当前词。即:
+
+$$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
+
+其中$x_t$为第$t$个词的词向量,分类分数(score)向量 $z=U*context$,最终的分类$y$采用softmax,损失函数采用多类分类交叉熵。
+
+### Skip-gram model
+
+CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
+
+
+ 
+ 图4. Skip-gram模型
+
+
+如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到$2n$个词的词向量($2n$表示当前输入词的前后各$n$个词),然后分别通过softmax得到这$2n$个词的分类损失值之和。
+
+
+## 数据准备
+
+### 数据介绍
+
+本教程使用Penn Treebank (PTB)(经Tomas Mikolov预处理过的版本)数据集。PTB数据集较小,训练速度快,应用于Mikolov的公开语言模型训练工具\[[2](#参考文献)\]中。其统计情况如下:
+
+
+
+
+ | 训练数据 |
+ 验证数据 |
+ 测试数据 |
+
+
+ | ptb.train.txt |
+ ptb.valid.txt |
+ ptb.test.txt |
+
+
+ | 42068句 |
+ 3370句 |
+ 3761句 |
+
+
+
+
+
+### 数据预处理
+
+本章训练的是5-gram模型,表示在PaddlePaddle训练时,每条数据的前4个词用来预测第5个词。PaddlePaddle提供了对应PTB数据集的python包`paddle.dataset.imikolov`,自动做数据的下载与预处理,方便大家使用。
+
+预处理会把数据集中的每一句话前后加上开始符号``以及结束符号``。然后依据窗口大小(本教程中为5),从头到尾每次向右滑动窗口并生成一条数据。
+
+如"I have a dream that one day" 一句提供了5条数据:
+
+```text
+ I have a dream
+I have a dream that
+have a dream that one
+a dream that one day
+dream that one day
+```
+
+最后,每个输入会按其单词次在字典里的位置,转化成整数的索引序列,作为PaddlePaddle的输入。
+
+## 编程实现
+
+本配置的模型结构如下图所示:
+
+
+ 
+ 图5. 模型配置中的N-gram神经网络模型
+
+
+首先,加载所需要的包:
+
+```python
+import paddle
+import paddle.fluid as fluid
+import numpy
+from functools import partial
+import math
+import os
+import sys
+from __future__ import print_function
+```
+
+然后,定义参数:
+```python
+EMBED_SIZE = 32 # word vector dimension
+HIDDEN_SIZE = 256 # hidden layer dimension
+N = 5 # train 5-gram
+BATCH_SIZE = 32 # batch size
+
+# can use CPU or GPU
+use_cuda = os.getenv('WITH_GPU', '0') != '0'
+
+word_dict = paddle.dataset.imikolov.build_dict()
+dict_size = len(word_dict)
+```
+
+不同于之前的PaddlePaddle v2版本,在新的Fluid版本里,我们不必再手动计算词向量。PaddlePaddle提供了一个内置的方法`fluid.layers.embedding`,我们就可以直接用它来构造 N-gram 神经网络。
+
+- 我们来定义我们的 N-gram 神经网络结构。这个结构在训练和预测中都会使用到。因为词向量比较稀疏,我们传入参数 `is_sparse == True`, 可以加速稀疏矩阵的更新。
+
+```python
+def inference_program(is_sparse):
+ first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
+ second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
+ third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
+ fourth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
+
+ embed_first = fluid.layers.embedding(
+ input=first_word,
+ size=[dict_size, EMBED_SIZE],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr='shared_w')
+ embed_second = fluid.layers.embedding(
+ input=second_word,
+ size=[dict_size, EMBED_SIZE],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr='shared_w')
+ embed_third = fluid.layers.embedding(
+ input=third_word,
+ size=[dict_size, EMBED_SIZE],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr='shared_w')
+ embed_fourth = fluid.layers.embedding(
+ input=fourth_word,
+ size=[dict_size, EMBED_SIZE],
+ dtype='float32',
+ is_sparse=is_sparse,
+ param_attr='shared_w')
+
+ concat_embed = fluid.layers.concat(
+ input=[embed_first, embed_second, embed_third, embed_fourth], axis=1)
+ hidden1 = fluid.layers.fc(input=concat_embed,
+ size=HIDDEN_SIZE,
+ act='sigmoid')
+ predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax')
+ return predict_word
+```
+
+- 基于以上的神经网络结构,我们可以如下定义我们的`训练`方法
+
+```python
+def train_program(is_sparse):
+ # The declaration of 'next_word' must be after the invoking of inference_program,
+ # or the data input order of train program would be [next_word, firstw, secondw,
+ # thirdw, fourthw], which is not correct.
+ predict_word = inference_program(is_sparse)
+ next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
+ cost = fluid.layers.cross_entropy(input=predict_word, label=next_word)
+ avg_cost = fluid.layers.mean(cost)
+ return avg_cost
+```
+
+- 现在我们可以开始训练啦。如今的版本较之以前就简单了许多。我们有现成的训练和测试集:`paddle.dataset.imikolov.train()`和`paddle.dataset.imikolov.test()`。两者都会返回一个读取器。在PaddlePaddle中,读取器是一个Python的函数,每次调用,会读取下一条数据。它是一个Python的generator。
+
+`paddle.batch` 会读入一个读取器,然后输出一个批次化了的读取器。`event_handler`亦可以一并传入`trainer.train`来时不时的输出每个步骤,批次的训练情况。
+
+```python
+def optimizer_func():
+ # Note here we need to choose more sophisticated optimizers
+ # such as AdaGrad with a decay rate. The normal SGD converges
+ # very slowly.
+ # optimizer=fluid.optimizer.SGD(learning_rate=0.001),
+ return fluid.optimizer.AdagradOptimizer(
+ learning_rate=3e-3,
+ regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
+
+
+def train(use_cuda, train_program, params_dirname):
+ train_reader = paddle.batch(
+ paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE)
+ test_reader = paddle.batch(
+ paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE)
+
+ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+
+ def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ # We output cost every 10 steps.
+ if event.step % 10 == 0:
+ outs = trainer.test(
+ reader=test_reader,
+ feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
+ avg_cost = outs[0]
+
+ print("Step %d: Average Cost %f" % (event.step, avg_cost))
+
+ # If average cost is lower than 5.8, we consider the model good enough to stop.
+ # Note 5.8 is a relatively high value. In order to get a better model, one should
+ # aim for avg_cost lower than 3.5. But the training could take longer time.
+ if avg_cost < 5.8:
+ trainer.save_params(params_dirname)
+ trainer.stop()
+
+ if math.isnan(avg_cost):
+ sys.exit("got NaN loss, training failed.")
+
+ trainer = fluid.Trainer(
+ train_func=train_program,
+ optimizer_func=optimizer_func,
+ place=place)
+
+ trainer.train(
+ reader=train_reader,
+ num_epochs=1,
+ event_handler=event_handler,
+ feed_order=['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'])
+```
+
+- `trainer.train`将会开始训练。从`event_handler`返回的监控情况如下:
+
+```text
+Step 0: Average Cost 7.337213
+Step 10: Average Cost 6.136128
+Step 20: Average Cost 5.766995
+...
+```
+
+## 模型应用
+在模型训练后,我们可以用它做一些预测。
+
+### 预测下一个词
+我们可以用我们训练过的模型,在得知之前的 N-gram 后,预测下一个词。
+
+```python
+def infer(use_cuda, inference_program, params_dirname=None):
+ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+ inferencer = fluid.Inferencer(
+ infer_func=inference_program, param_path=params_dirname, place=place)
+
+ # Setup inputs by creating 4 LoDTensors representing 4 words. Here each word
+ # is simply an index to look up for the corresponding word vector and hence
+ # the shape of word (base_shape) should be [1]. The length-based level of
+ # detail (lod) info of each LoDtensor should be [[1]] meaning there is only
+ # one lod_level and there is only one sequence of one word on this level.
+ # Note that lod info should be a list of lists.
+
+ data1 = [[211]] # 'among'
+ data2 = [[6]] # 'a'
+ data3 = [[96]] # 'group'
+ data4 = [[4]] # 'of'
+ lod = [[1]]
+
+ first_word = fluid.create_lod_tensor(data1, lod, place)
+ second_word = fluid.create_lod_tensor(data2, lod, place)
+ third_word = fluid.create_lod_tensor(data3, lod, place)
+ fourth_word = fluid.create_lod_tensor(data4, lod, place)
+
+ result = inferencer.infer(
+ {
+ 'firstw': first_word,
+ 'secondw': second_word,
+ 'thirdw': third_word,
+ 'fourthw': fourth_word
+ },
+ return_numpy=False)
+
+ print(numpy.array(result[0]))
+ most_possible_word_index = numpy.argmax(result[0])
+ print(most_possible_word_index)
+ print([
+ key for key, value in word_dict.iteritems()
+ if value == most_possible_word_index
+ ][0])
+```
+
+在经历3分钟的短暂训练后,我们得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`a`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。
+
+```text
+[[0.00106646 0.0007907 0.00072041 ... 0.00049024 0.00041355 0.00084464]]
+6
+a
+```
+
+整个程序的入口很简单:
+
+```python
+def main(use_cuda, is_sparse):
+ if use_cuda and not fluid.core.is_compiled_with_cuda():
+ return
+
+ params_dirname = "word2vec.inference.model"
+
+ train(
+ use_cuda=use_cuda,
+ train_program=partial(train_program, is_sparse),
+ params_dirname=params_dirname)
+
+ infer(
+ use_cuda=use_cuda,
+ inference_program=partial(inference_program, is_sparse),
+ params_dirname=params_dirname)
+
+
+main(use_cuda=use_cuda, is_sparse=True)
+```
+
+
+## 总结
+本章中,我们介绍了词向量、语言模型和词向量的关系、以及如何通过训练神经网络模型获得词向量。在信息检索中,我们可以根据向量间的余弦夹角,来判断query和文档关键词这二者间的相关性。在句法分析和语义分析中,训练好的词向量可以用来初始化模型,以得到更好的效果。在文档分类中,有了词向量之后,可以用聚类的方法将文档中同义词进行分组,也可以用 N-gram 来预测下一个词。希望大家在本章后能够自行运用词向量进行相关领域的研究。
+
+
+## 参考文献
+1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning research, 2003, 3(Feb): 1137-1155.
+2. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
+3. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space](https://arxiv.org/pdf/1301.3781.pdf)[J]. arXiv preprint arXiv:1301.3781, 2013.
+4. Maaten L, Hinton G. [Visualizing data using t-SNE](https://lvdmaaten.github.io/publications/papers/JMLR_2008.pdf)[J]. Journal of Machine Learning Research, 2008, 9(Nov): 2579-2605.
+5. https://en.wikipedia.org/wiki/Singular_value_decomposition
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png
old mode 100755
new mode 100644
diff --git a/doc/fluid/new_docs/beginners_guide/install/install_doc.rst b/doc/fluid/new_docs/beginners_guide/install/install_doc.rst
index 8a66a95f45ea18dbfdc2450694517d5df8c47efd..18788d2eae048ac5120b0b7afd63cd784a235798 100644
--- a/doc/fluid/new_docs/beginners_guide/install/install_doc.rst
+++ b/doc/fluid/new_docs/beginners_guide/install/install_doc.rst
@@ -57,7 +57,28 @@ paddlepaddle-gpu==0.11.0 使用CUDA 7.5和cuDNN 5编译的0.11.0版
您可以在 `Release History `_
中找到paddlepaddle-gpu的各个发行版本。
-如果需要获取并安装最新的PaddlePaddle开发分支,可以从我们的 `CI系统 `_ 中下载最新的whl安装包和c-api开发包并安装。如需登录,请点击“Log in as guest”。
+如果需要获取并安装最新的(开发分支)PaddlePaddle,可以从我们的CI系统中下载最新的whl
+安装包和c-api开发包并安装,您可以从下面的表格中找到需要的版本:
+
+如果在点击下面链接时出现如下登陆界面,点击“Log in as guest”即可开始下载:
+
+.. image:: paddleci.png
+ :scale: 50 %
+ :align: center
+
+.. csv-table:: 各个版本最新的whl包
+ :header: "版本说明", "cp27-cp27mu", "cp27-cp27m"
+ :widths: 1, 3, 3
+
+ "stable_cuda9.0_cudnn7", "`paddlepaddle_gpu-0.14.0-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "stable_cuda8.0_cudnn7", "`paddlepaddle_gpu-0.14.0.post87-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0.post87-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "stable_cuda8.0_cudnn5", "`paddlepaddle_gpu-0.14.0.post85-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0.post85-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "cpu_avx_mkl", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cpu_avx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cpu_noavx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `_"
+ "cuda8.0_cudnn5_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cuda8.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cuda9.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
.. _FAQ:
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
index ba43ada5100ed1db7192de9c795b4b8a6596d705..27d25b43961ce74d73e391b735369501fb80a231 100644
--- a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
@@ -1,329 +1,290 @@
-```eval_rst
-.. _quick_start_fit_a_line:
-```
-# 线性回归
-让我们从经典的线性回归(Linear Regression \[[1](#参考文献)\])模型开始这份教程。在这一章里,你将使用真实的数据集建立起一个房价预测模型,并且了解到机器学习中的若干重要概念。
-
-本教程源代码目录在[book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-给定一个大小为`$n$`的数据集 `${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$`,其中`$x_{i1}, \ldots, x_{id}$`是第`$i$`个样本`$d$`个属性上的取值,`$y_i$`是该样本待预测的目标。线性回归模型假设目标`$y_i$`可以被属性间的线性组合描述,即
-
-$$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldots,n$$
-
-例如,在我们将要建模的房价预测问题里,`$x_{ij}$`是描述房子`$i$`的各种属性(比如房间的个数、周围学校和医院的个数、交通状况等),而 `$y_i$`是房屋的价格。
-
-初看起来,这个假设实在过于简单了,变量间的真实关系很难是线性的。但由于线性回归模型有形式简单和易于建模分析的优点,它在实际问题中得到了大量的应用。很多经典的统计学习、机器学习书籍\[[2,3,4](#参考文献)\]也选择对线性模型独立成章重点讲解。
-
-## 效果展示
-我们使用从[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。
-
-
-图1. 预测值 V.S. 真实值
-
-## 模型概览
-
-### 模型定义
-
-在波士顿房价数据集中,和房屋相关的值共有14个:前13个用来描述房屋相关的各种信息,即模型中的 `$x_i$`;最后一个值为我们要预测的该类房屋价格的中位数,即模型中的 `$y_i$`。因此,我们的模型就可以表示成:
-
-$$\hat{Y} = \omega_1X_{1} + \omega_2X_{2} + \ldots + \omega_{13}X_{13} + b$$
-
-`$\hat{Y}$` 表示模型的预测结果,用来和真实值`$Y$`区分。模型要学习的参数即:`$\omega_1, \ldots, \omega_{13}, b$`。
-
-建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值`$\hat{Y}$`尽可能地接近真实值`$Y$`。这里我们引入损失函数([Loss Function](https://en.wikipedia.org/wiki/Loss_function),或Cost Function)这个概念。 输入任意一个数据样本的目标值`$y_{i}$`和模型给出的预测值`$\hat{y_{i}}$`,损失函数输出一个非负的实值。这个实值通常用来反映模型误差的大小。
-
-对于线性回归模型来讲,最常见的损失函数就是均方误差(Mean Squared Error, [MSE](https://en.wikipedia.org/wiki/Mean_squared_error))了,它的形式是:
-
-$$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
-
-即对于一个大小为`$n$`的测试集,`$MSE$`是`$n$`个数据预测结果误差平方的均值。
-
-### 训练过程
-
-定义好模型结构之后,我们要通过以下几个步骤进行模型训练
-1. 初始化参数,其中包括权重`$\omega_i$`和偏置`$b$`,对其进行初始化(如0均值,1方差)。
-2. 网络正向传播计算网络输出和损失函数。
-3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
-4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
-
-## 数据集
-
-### 数据集介绍
-这份数据集共506行,每行包含了波士顿郊区的一类房屋的相关信息及该类房屋价格的中位数。其各维属性的意义如下:
-
-
-
-
-
- | 属性名 |
- 解释 |
- 类型 |
-
-
-
-
- | CRIM |
- 该镇的人均犯罪率 |
- 连续值 |
-
-
- | ZN |
- 占地面积超过25,000平方呎的住宅用地比例 |
- 连续值 |
-
-
- | INDUS |
- 非零售商业用地比例 |
- 连续值 |
-
-
- | CHAS |
- 是否邻近 Charles River |
- 离散值,1=邻近;0=不邻近 |
-
-
- | NOX |
- 一氧化氮浓度 |
- 连续值 |
-
-
- | RM |
- 每栋房屋的平均客房数 |
- 连续值 |
-
-
- | AGE |
- 1940年之前建成的自用单位比例 |
- 连续值 |
-
-
- | DIS |
- 到波士顿5个就业中心的加权距离 |
- 连续值 |
-
-
- | RAD |
- 到径向公路的可达性指数 |
- 连续值 |
-
-
- | TAX |
- 全值财产税率 |
- 连续值 |
-
-
- | PTRATIO |
- 学生与教师的比例 |
- 连续值 |
-
-
- | B |
- 1000(BK - 0.63)^2,其中BK为黑人占比 |
- 连续值 |
-
-
- | LSTAT |
- 低收入人群占比 |
- 连续值 |
-
-
- | MEDV |
- 同类房屋价格的中位数 |
- 连续值 |
-
-
-
-
-
-### 数据预处理
-#### 连续值与离散值
-观察一下数据,我们的第一个发现是:所有的13维属性中,有12维的连续值和1维的离散值(CHAS)。离散值虽然也常使用类似0、1、2这样的数字表示,但是其含义与连续值是不同的,因为这里的差值没有实际意义。例如,我们用0、1、2来分别表示红色、绿色和蓝色的话,我们并不能因此说“蓝色和红色”比“绿色和红色”的距离更远。所以通常对一个有`$d$`个可能取值的离散属性,我们会将它们转为`$d$`个取值为0或1的二值属性或者将每个可能取值映射为一个多维向量。不过就这里而言,因为CHAS本身就是一个二值属性,就省去了这个麻烦。
-
-#### 属性的归一化
-另外一个稍加观察即可发现的事实是,各维属性的取值范围差别很大(如图2所示)。例如,属性B的取值范围是[0.32, 396.90],而属性NOX的取值范围是[0.3850, 0.8170]。这里就要用到一个常见的操作-归一化(normalization)了。归一化的目标是把各位属性的取值范围放缩到差不多的区间,例如[-0.5,0.5]。这里我们使用一种很常见的操作方法:减掉均值,然后除以原取值范围。
-
-做归一化(或 [Feature scaling](https://en.wikipedia.org/wiki/Feature_scaling))至少有以下3个理由:
-- 过大或过小的数值范围会导致计算时的浮点上溢或下溢。
-- 不同的数值范围会导致不同属性对模型的重要性不同(至少在训练的初始阶段如此),而这个隐含的假设常常是不合理的。这会对优化的过程造成困难,使训练时间大大的加长。
-- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。
-
-
-图2. 各维属性的取值范围
-
-#### 整理训练集与测试集
-我们将数据集分割为两份:一份用于调整模型的参数,即进行模型的训练,模型在这份数据集上的误差被称为**训练误差**;另外一份被用来测试,模型在这份数据集上的误差被称为**测试误差**。我们训练模型的目的是为了通过从训练数据中找到规律来预测未知的新数据,所以测试误差是更能反映模型表现的指标。分割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为`$8:2$`
-
-
-在更复杂的模型训练过程中,我们往往还会多使用一种数据集:验证集。因为复杂的模型中常常还有一些超参数([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization))需要调节,所以我们会尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现选择相对最好的一组超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。由于本章训练的模型比较简单,我们暂且忽略掉这个过程。
-
-## 训练
-
-`fit_a_line/trainer.py`演示了训练的整体过程。
-
-### 配置数据提供器(Datafeeder)
-首先我们引入必要的库:
-```python
-import paddle
-import paddle.fluid as fluid
-import numpy
-```
-
-我们通过uci_housing模块引入了数据集合[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)
-
-其中,在uci_housing模块中封装了:
-
-1. 数据下载的过程。下载数据保存在~/.cache/paddle/dataset/uci_housing/housing.data。
-2. [数据预处理](#数据预处理)的过程。
-
-接下来我们定义了用于训练和测试的数据提供器。提供器每次读入一个大小为`BATCH_SIZE`的数据批次。如果用户希望加一些随机性,她可以同时定义一个批次大小和一个缓存大小。这样的话,每次数据提供器会从缓存中随机读取批次大小那么多的数据。
-
-```python
-BATCH_SIZE = 20
-
-train_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.uci_housing.train(), buf_size=500),
-batch_size=BATCH_SIZE)
-
-test_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.uci_housing.test(), buf_size=500),
-batch_size=BATCH_SIZE)
-```
-
-### 配置训练程序
-训练程序的目的是定义一个训练模型的网络结构。对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。更加复杂的结果,比如卷积神经网络,递归神经网络等会在随后的章节中介绍。训练程序必须返回`平均损失`作为第一个返回值,因为它会被后面反向传播算法所用到。
-
-```python
-def train_program():
-y = fluid.layers.data(name='y', shape=[1], dtype='float32')
-
-# feature vector of length 13
-x = fluid.layers.data(name='x', shape=[13], dtype='float32')
-y_predict = fluid.layers.fc(input=x, size=1, act=None)
-
-loss = fluid.layers.square_error_cost(input=y_predict, label=y)
-avg_loss = fluid.layers.mean(loss)
-
-return avg_loss
-```
-
-### 定义运算场所
-我们可以定义运算是发生在CPU还是GPU
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
-
-### 创建训练器
-训练器会读入一个训练程序和一些必要的其他参数:
-
-```python
-trainer = fluid.Trainer(
-train_func=train_program,
-place=place,
-optimizer_func=fluid.optimizer.SGD(learning_rate=0.001))
-```
-
-### 开始提供数据
-PaddlePaddle提供了读取数据者发生器机制来读取训练数据。读取数据者会一次提供多列数据,因此我们需要一个Python的list来定义读取顺序。
-
-```python
-feed_order=['x', 'y']
-```
-
-除此之外,可以定义一个事件相应器来处理类似`打印训练进程`的事件:
-
-```python
-# Specify the directory path to save the parameters
-params_dirname = "fit_a_line.inference.model"
-
-# Plot data
-from paddle.v2.plot import Ploter
-train_title = "Train cost"
-test_title = "Test cost"
-plot_cost = Ploter(train_title, test_title)
-
-step = 0
-
-# event_handler to print training and testing info
-def event_handler_plot(event):
-global step
-if isinstance(event, fluid.EndStepEvent):
-if event.step % 10 == 0: # every 10 batches, record a test cost
-test_metrics = trainer.test(
-reader=test_reader, feed_order=feed_order)
-
-plot_cost.append(test_title, step, test_metrics[0])
-plot_cost.plot()
-
-if test_metrics[0] < 10.0:
-# If the accuracy is good enough, we can stop the training.
-print('loss is less than 10.0, stop')
-trainer.stop()
-
-# We can save the trained parameters for the inferences later
-if params_dirname is not None:
-trainer.save_params(params_dirname)
-
-step += 1
-```
-
-### 开始训练
-我们现在可以通过调用`trainer.train()`来开始训练
-
-```python
-%matplotlib inline
-
-# The training could take up to a few minutes.
-trainer.train(
-reader=train_reader,
-num_epochs=100,
-event_handler=event_handler_plot,
-feed_order=feed_order)
-```
-
-
-
-## 预测
-提供一个`inference_program`和一个`params_dirname`来初始化预测器。`params_dirname`用来存储我们的参数。
-
-### 设定预测程序
-类似于`trainer.train`,预测器需要一个预测程序来做预测。我们可以稍加修改我们的训练程序来把预测值包含进来。
-
-
-```python
-def inference_program():
-x = fluid.layers.data(name='x', shape=[13], dtype='float32')
-y_predict = fluid.layers.fc(input=x, size=1, act=None)
-return y_predict
-```
-
-### 预测
-预测器会从`params_dirname`中读取已经训练好的模型,来对从未遇见过的数据进行预测。
-
-```python
-inferencer = fluid.Inferencer(
-infer_func=inference_program, param_path=params_dirname, place=place)
-
-batch_size = 10
-tensor_x = numpy.random.uniform(0, 10, [batch_size, 13]).astype("float32")
-
-results = inferencer.infer({'x': tensor_x})
-print("infer results: ", results[0])
-```
-
-## 总结
-在这章里,我们借助波士顿房价这一数据集,介绍了线性回归模型的基本概念,以及如何使用PaddlePaddle实现训练和测试的过程。很多的模型和技巧都是从简单的线性回归模型演化而来,因此弄清楚线性模型的原理和局限非常重要。
-
-
-## 参考文献
-1. https://en.wikipedia.org/wiki/Linear_regression
-2. Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
-3. Murphy K P. Machine learning: a probabilistic perspective[M]. MIT press, 2012.
-4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 线性回归
+让我们从经典的线性回归(Linear Regression \[[1](#参考文献)\])模型开始这份教程。在这一章里,你将使用真实的数据集建立起一个房价预测模型,并且了解到机器学习中的若干重要概念。
+
+本教程源代码目录在[book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/137.html)。
+
+## 背景介绍
+给定一个大小为$n$的数据集 ${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$,其中$x_{i1}, \ldots, x_{id}$是第$i$个样本$d$个属性上的取值,$y_i$是该样本待预测的目标。线性回归模型假设目标$y_i$可以被属性间的线性组合描述,即
+
+$$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldots,n$$
+
+例如,在我们将要建模的房价预测问题里,$x_{ij}$是描述房子$i$的各种属性(比如房间的个数、周围学校和医院的个数、交通状况等),而 $y_i$是房屋的价格。
+
+初看起来,这个假设实在过于简单了,变量间的真实关系很难是线性的。但由于线性回归模型有形式简单和易于建模分析的优点,它在实际问题中得到了大量的应用。很多经典的统计学习、机器学习书籍\[[2,3,4](#参考文献)\]也选择对线性模型独立成章重点讲解。
+
+## 效果展示
+我们使用从[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。
+
+ 
+ 图1. 预测值 V.S. 真实值
+
+
+## 模型概览
+
+### 模型定义
+
+在波士顿房价数据集中,和房屋相关的值共有14个:前13个用来描述房屋相关的各种信息,即模型中的 $x_i$;最后一个值为我们要预测的该类房屋价格的中位数,即模型中的 $y_i$。因此,我们的模型就可以表示成:
+
+$$\hat{Y} = \omega_1X_{1} + \omega_2X_{2} + \ldots + \omega_{13}X_{13} + b$$
+
+$\hat{Y}$ 表示模型的预测结果,用来和真实值$Y$区分。模型要学习的参数即:$\omega_1, \ldots, \omega_{13}, b$。
+
+建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值$\hat{Y}$尽可能地接近真实值$Y$。这里我们引入损失函数([Loss Function](https://en.wikipedia.org/wiki/Loss_function),或Cost Function)这个概念。 输入任意一个数据样本的目标值$y_{i}$和模型给出的预测值$\hat{y_{i}}$,损失函数输出一个非负的实值。这个实值通常用来反映模型误差的大小。
+
+对于线性回归模型来讲,最常见的损失函数就是均方误差(Mean Squared Error, [MSE](https://en.wikipedia.org/wiki/Mean_squared_error))了,它的形式是:
+
+$$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
+
+即对于一个大小为$n$的测试集,$MSE$是$n$个数据预测结果误差平方的均值。
+
+### 训练过程
+
+定义好模型结构之后,我们要通过以下几个步骤进行模型训练
+
+ 1. 初始化参数,其中包括权重$\omega_i$和偏置$b$,对其进行初始化(如0均值,1方差)。
+
+ 2. 网络正向传播计算网络输出和损失函数。
+
+ 3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
+
+ 4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
+
+## 数据集
+
+### 数据集介绍
+这份数据集共506行,每行包含了波士顿郊区的一类房屋的相关信息及该类房屋价格的中位数。其各维属性的意义如下:
+
+| 属性名 | 解释 | 类型 |
+| ------| ------ | ------ |
+| CRIM | 该镇的人均犯罪率 | 连续值 |
+| ZN | 占地面积超过25,000平方呎的住宅用地比例 | 连续值 |
+| INDUS | 非零售商业用地比例 | 连续值 |
+| CHAS | 是否邻近 Charles River | 离散值,1=邻近;0=不邻近 |
+| NOX | 一氧化氮浓度 | 连续值 |
+| RM | 每栋房屋的平均客房数 | 连续值 |
+| AGE | 1940年之前建成的自用单位比例 | 连续值 |
+| DIS | 到波士顿5个就业中心的加权距离 | 连续值 |
+| RAD | 到径向公路的可达性指数 | 连续值 |
+| TAX | 全值财产税率 | 连续值 |
+| PTRATIO | 学生与教师的比例 | 连续值 |
+| B | 1000(BK - 0.63)^2,其中BK为黑人占比 | 连续值 |
+| LSTAT | 低收入人群占比 | 连续值 |
+| MEDV | 同类房屋价格的中位数 | 连续值 |
+
+### 数据预处理
+#### 连续值与离散值
+观察一下数据,我们的第一个发现是:所有的13维属性中,有12维的连续值和1维的离散值(CHAS)。离散值虽然也常使用类似0、1、2这样的数字表示,但是其含义与连续值是不同的,因为这里的差值没有实际意义。例如,我们用0、1、2来分别表示红色、绿色和蓝色的话,我们并不能因此说“蓝色和红色”比“绿色和红色”的距离更远。所以通常对一个有$d$个可能取值的离散属性,我们会将它们转为$d$个取值为0或1的二值属性或者将每个可能取值映射为一个多维向量。不过就这里而言,因为CHAS本身就是一个二值属性,就省去了这个麻烦。
+
+#### 属性的归一化
+另外一个稍加观察即可发现的事实是,各维属性的取值范围差别很大(如图2所示)。例如,属性B的取值范围是[0.32, 396.90],而属性NOX的取值范围是[0.3850, 0.8170]。这里就要用到一个常见的操作-归一化(normalization)了。归一化的目标是把各位属性的取值范围放缩到差不多的区间,例如[-0.5,0.5]。这里我们使用一种很常见的操作方法:减掉均值,然后除以原取值范围。
+
+做归一化(或 [Feature scaling](https://en.wikipedia.org/wiki/Feature_scaling))至少有以下3个理由:
+- 过大或过小的数值范围会导致计算时的浮点上溢或下溢。
+- 不同的数值范围会导致不同属性对模型的重要性不同(至少在训练的初始阶段如此),而这个隐含的假设常常是不合理的。这会对优化的过程造成困难,使训练时间大大的加长。
+- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。
+
+
+ 
+ 图2. 各维属性的取值范围
+
+
+#### 整理训练集与测试集
+我们将数据集分割为两份:一份用于调整模型的参数,即进行模型的训练,模型在这份数据集上的误差被称为**训练误差**;另外一份被用来测试,模型在这份数据集上的误差被称为**测试误差**。我们训练模型的目的是为了通过从训练数据中找到规律来预测未知的新数据,所以测试误差是更能反映模型表现的指标。分割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为$8:2$
+
+
+在更复杂的模型训练过程中,我们往往还会多使用一种数据集:验证集。因为复杂的模型中常常还有一些超参数([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization))需要调节,所以我们会尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现选择相对最好的一组超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。由于本章训练的模型比较简单,我们暂且忽略掉这个过程。
+
+## 训练
+
+`fit_a_line/trainer.py`演示了训练的整体过程。
+
+### 配置数据提供器(Datafeeder)
+首先我们引入必要的库:
+```python
+import paddle
+import paddle.fluid as fluid
+import numpy
+from __future__ import print_function
+```
+
+我们通过uci_housing模块引入了数据集合[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)
+
+其中,在uci_housing模块中封装了:
+
+1. 数据下载的过程。下载数据保存在~/.cache/paddle/dataset/uci_housing/housing.data。
+2. [数据预处理](#数据预处理)的过程。
+
+接下来我们定义了用于训练和测试的数据提供器。提供器每次读入一个大小为`BATCH_SIZE`的数据批次。如果用户希望加一些随机性,她可以同时定义一个批次大小和一个缓存大小。这样的话,每次数据提供器会从缓存中随机读取批次大小那么多的数据。
+
+```python
+BATCH_SIZE = 20
+
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.uci_housing.train(), buf_size=500),
+ batch_size=BATCH_SIZE)
+
+test_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.uci_housing.test(), buf_size=500),
+ batch_size=BATCH_SIZE)
+```
+
+### 配置训练程序
+训练程序的目的是定义一个训练模型的网络结构。对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。更加复杂的结果,比如卷积神经网络,递归神经网络等会在随后的章节中介绍。训练程序必须返回`平均损失`作为第一个返回值,因为它会被后面反向传播算法所用到。
+
+```python
+def train_program():
+ y = fluid.layers.data(name='y', shape=[1], dtype='float32')
+
+ # feature vector of length 13
+ x = fluid.layers.data(name='x', shape=[13], dtype='float32')
+ y_predict = fluid.layers.fc(input=x, size=1, act=None)
+
+ loss = fluid.layers.square_error_cost(input=y_predict, label=y)
+ avg_loss = fluid.layers.mean(loss)
+
+ return avg_loss
+```
+
+### Optimizer Function 配置
+
+在下面的 `SGD optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
+
+```python
+def optimizer_program():
+ return fluid.optimizer.SGD(learning_rate=0.001)
+```
+
+### 定义运算场所
+我们可以定义运算是发生在CPU还是GPU
+
+```python
+use_cuda = False
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+```
+
+### 创建训练器
+训练器会读入一个训练程序和一些必要的其他参数:
+
+```python
+trainer = fluid.Trainer(
+ train_func=train_program,
+ place=place,
+ optimizer_func=optimizer_program)
+```
+
+### 开始提供数据
+PaddlePaddle提供了读取数据者发生器机制来读取训练数据。读取数据者会一次提供多列数据,因此我们需要一个Python的list来定义读取顺序。
+
+```python
+feed_order=['x', 'y']
+```
+
+除此之外,可以定义一个事件相应器来处理类似`打印训练进程`的事件:
+
+```python
+# Specify the directory to save the parameters
+params_dirname = "fit_a_line.inference.model"
+
+# Plot data
+from paddle.v2.plot import Ploter
+train_title = "Train cost"
+test_title = "Test cost"
+plot_cost = Ploter(train_title, test_title)
+
+step = 0
+
+# event_handler prints training and testing info
+def event_handler_plot(event):
+ global step
+ if isinstance(event, fluid.EndStepEvent):
+ if event.step % 10 == 0: # record the test cost every 10 seconds
+ test_metrics = trainer.test(
+ reader=test_reader, feed_order=feed_order)
+
+ plot_cost.append(test_title, step, test_metrics[0])
+ plot_cost.plot()
+
+ if test_metrics[0] < 10.0:
+ # If the accuracy is good enough, we can stop the training.
+ print('loss is less than 10.0, stop')
+ trainer.stop()
+
+ # We can save the trained parameters for the inferences later
+ if params_dirname is not None:
+ trainer.save_params(params_dirname)
+
+ step += 1
+```
+
+### 开始训练
+我们现在可以通过调用`trainer.train()`来开始训练
+
+```python
+%matplotlib inline
+
+# The training could take up to a few minutes.
+trainer.train(
+ reader=train_reader,
+ num_epochs=100,
+ event_handler=event_handler_plot,
+ feed_order=feed_order)
+```
+
+
+ 
+ 图3. 训练结果
+
+
+
+## 预测
+提供一个`inference_program`和一个`params_dirname`来初始化预测器。`params_dirname`用来存储我们的参数。
+
+### 设定预测程序
+类似于`trainer.train`,预测器需要一个预测程序来做预测。我们可以稍加修改我们的训练程序来把预测值包含进来。
+
+
+```python
+def inference_program():
+ x = fluid.layers.data(name='x', shape=[13], dtype='float32')
+ y_predict = fluid.layers.fc(input=x, size=1, act=None)
+ return y_predict
+```
+
+### 预测
+预测器会从`params_dirname`中读取已经训练好的模型,来对从未遇见过的数据进行预测。
+
+```python
+inferencer = fluid.Inferencer(
+ infer_func=inference_program, param_path=params_dirname, place=place)
+
+batch_size = 10
+test_reader = paddle.batch(paddle.dataset.uci_housing.test(),batch_size=batch_size)
+test_data = test_reader().next()
+test_feat = numpy.array([data[0] for data in test_data]).astype("float32")
+test_label = numpy.array([data[1] for data in test_data]).astype("float32")
+
+results = inferencer.infer({'x': test_feat})
+
+print("infer results: (House Price)")
+for k in range(0, batch_size-1):
+ print("%d. %f" % (k, results[0][k]))
+
+print("\nground truth:")
+for k in range(0, batch_size-1):
+ print("%d. %f" % (k, test_label[k]))
+```
+
+## 总结
+在这章里,我们借助波士顿房价这一数据集,介绍了线性回归模型的基本概念,以及如何使用PaddlePaddle实现训练和测试的过程。很多的模型和技巧都是从简单的线性回归模型演化而来,因此弄清楚线性模型的原理和局限非常重要。
+
+
+## 参考文献
+1. https://en.wikipedia.org/wiki/Linear_regression
+2. Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
+3. Murphy K P. Machine learning: a probabilistic perspective[M]. MIT press, 2012.
+4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/predictions_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/predictions_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..f111c7cd766b7e9981513cc8c65be87dbbf3a79e
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/predictions_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges.png b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges.png
index 5d86b12715f46afbafb7d50e2938e184219b5b95..5325df4800985983e17476f007658d1cdb170b1c 100644
Binary files a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges.png and b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..6d6a079bfdcc33617f6cf36612b271b48be6304f
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/ranges_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/train_and_test.png b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/train_and_test1.png
similarity index 100%
rename from doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/train_and_test.png
rename to doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/image/train_and_test1.png
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/README.cn.md b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/README.cn.md
index c04a949a3f6550048f2a3447070829aeb640b995..3289116991cb8ebaa4a6fb78e100ce16f633d69c 100644
--- a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/README.cn.md
@@ -1,453 +1,453 @@
-# 识别数字
-
-本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
-
-## 背景介绍
-当我们学习编程的时候,编写的第一个程序一般是实现打印"Hello World"。而机器学习(或深度学习)的入门教程,一般都是 [MNIST](http://yann.lecun.com/exdb/mnist/) 数据库上的手写识别问题。原因是手写识别属于典型的图像分类问题,比较简单,同时MNIST数据集也很完备。MNIST数据集作为一个简单的计算机视觉数据集,包含一系列如图1所示的手写数字图片和对应的标签。图片是28x28的像素矩阵,标签则对应着0~9的10个数字。每张图片都经过了大小归一化和居中处理。
-
-
-图1. MNIST图片示例
-
-MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
-
-Yann LeCun早先在手写字符识别上做了很多研究,并在研究过程中提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
-
-有很多算法在MNIST上进行实验。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
-
-本教程中,我们从简单的模型Softmax回归开始,带大家入门手写字符识别,并逐步进行模型优化。
-
-
-## 模型概览
-
-基于MNIST数据训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
-- `$X$`是输入:MNIST图片是`$28\times28$` 的二维图像,为了进行计算,我们将其转化为`$784$`维向量,即`$X=\left ( x_0, x_1, \dots, x_{783} \right )$`。
-- `$Y$`是输出:分类器的输出是10类数字(0-9),即`$Y=\left ( y_0, y_1, \dots, y_9 \right )$`,每一维`$y_i$`代表图片分类为第`$i$`类数字的概率。
-- `$L$`是图片的真实标签:`$L=\left ( l_0, l_1, \dots, l_9 \right )$`也是10维,但只有一维为1,其他都为0。
-
-### Softmax回归(Softmax Regression)
-
-最简单的Softmax回归模型是先将输入层经过一个全连接层得到的特征,然后直接通过softmax 函数进行多分类\[[9](#参考文献)\]。
-
-输入层的数据`$X$`传到输出层,在激活操作之前,会乘以相应的权重 `$W$` ,并加上偏置变量 `$b$` ,具体如下:
-
-$$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
-
-其中 `$ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $`
-
-对于有 `$N$` 个类别的多分类问题,指定 `$N$` 个输出节点,`$N$` 维结果向量经过softmax将归一化为 `$N$` 个[0,1]范围内的实数值,分别表示该样本属于这 `$N$` 个类别的概率。此处的 `$y_i$` 即对应该图片为数字 `$i$` 的预测概率。
-
-在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy),公式如下:
-
-$$ \text{crossentropy}(label, y) = -\sum_i label_ilog(y_i) $$
-
-图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
-
-图2. softmax回归网络结构图
-
-### 多层感知器(Multilayer Perceptron, MLP)
-
-Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
-
-1. 经过第一个隐藏层,可以得到 `$ H_1 = \phi(W_1X + b_1) $`,其中`$\phi$`代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
-2. 经过第二个隐藏层,可以得到 `$ H_2 = \phi(W_2H_1 + b_2) $`。
-3. 最后,再经过输出层,得到的`$Y=\text{softmax}(W_3H_2 + b_3)$`,即为最后的分类结果向量。
-
-
-图3为多层感知器的网络结构图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
-
-图3. 多层感知器网络结构图
-
-### 卷积神经网络(Convolutional Neural Network, CNN)
-
-在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
-
-
-图4. LeNet-5卷积神经网络结构
-
-#### 卷积层
-
-卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
-
-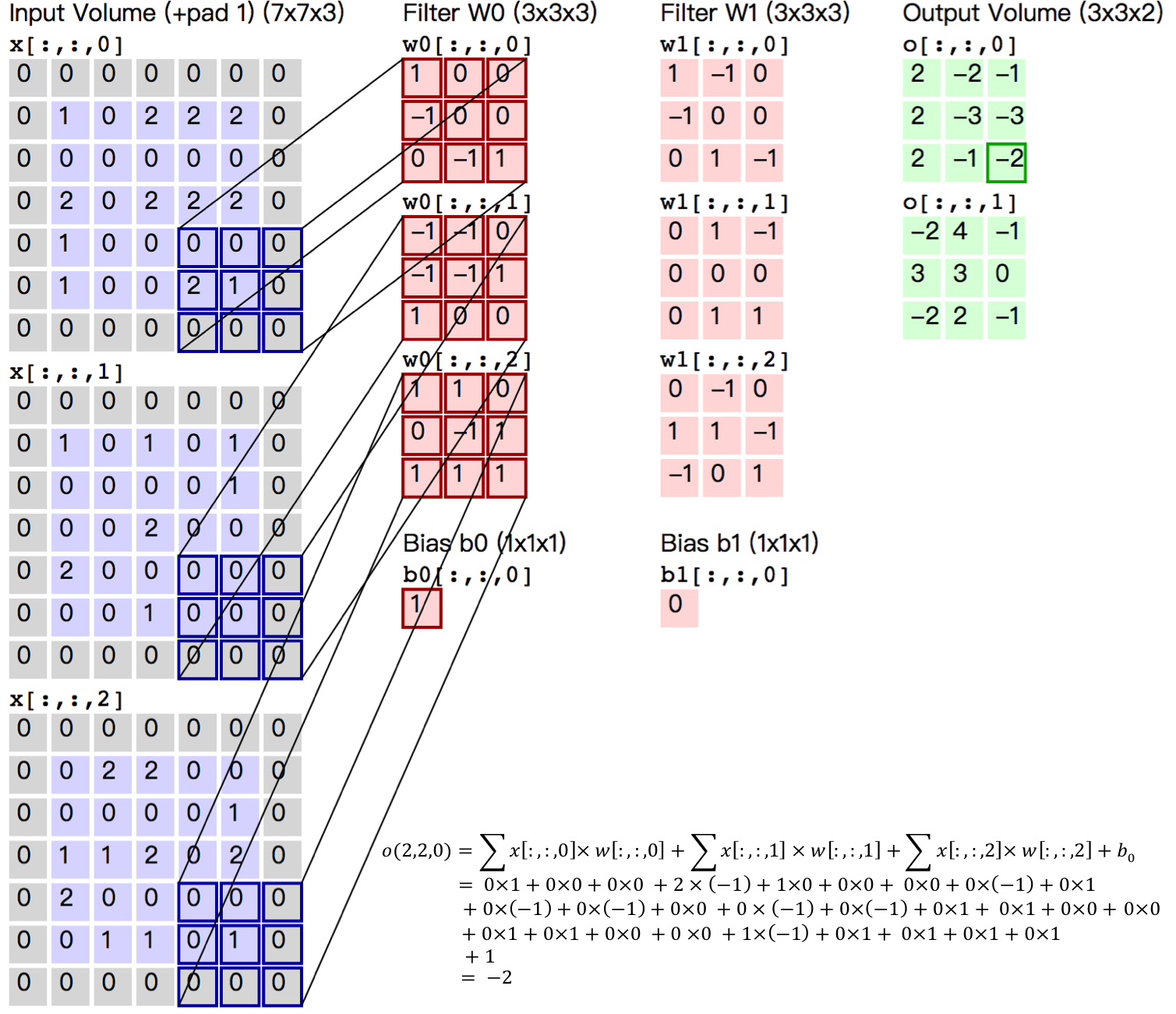
-图5. 卷积层图片
-
-图5给出一个卷积计算过程的示例图,输入图像大小为`$H=5,W=5,D=3$`,即`$5 \times 5$`大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用`$K$`表示)组卷积核,即图中滤波器`$W_0$`和`$W_1$`。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含(`$D=3$`)个`$3 \times 3$`(用`$F \times F$`表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向(`$W$`方向)和垂直方向(`$H$`方向)的滑动步长为2(用`$S$`表示);对输入图像周围各填充1(用`$P$`表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为`$3 \times 3 \times 2$`(用`$H_{o} \times W_{o} \times K$`表示)大小的特征图,即`$3 \times 3$`大小的2通道特征图,其中`$H_o$`计算公式为:`$H_o = (H - F + 2 \times P)/S + 1$`,`$W_o$`同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置`$b_o$`,偏置通常对于每个输出特征图是共享的。输出特征图`$o[:,:,0]$`中的最后一个`$-2$`计算如图5右下角公式所示。
-
-在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为`$D \times F \times F \times K$`。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
-
-- 局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野(receptive field)。在图像卷积操作中,即神经元在空间维度(spatial dimension,即上图示例H和W所在的平面)是局部连接,但在深度上是全部连接。对于二维图像本身而言,也是局部像素关联较强。这种局部连接保证了学习后的过滤器能够对于局部的输入特征有最强的响应。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的。
-
-- 权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例如图4中计算`$o[:,:,0]$`的每个每个神经元的滤波器均相同,都为`$W_0$`,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 (参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/))。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
-
-通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
-
-#### 池化层
-
-
-图6. 池化层图片
-
-池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图6所示。
-
-更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
-
-### 常见激活函数介绍
-- sigmoid激活函数: `$ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $`
-
-- tanh激活函数: `$ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $`
-
-实际上,tanh函数只是规模变化的sigmoid函数,将sigmoid函数值放大2倍之后再向下平移1个单位:tanh(x) = 2sigmoid(2x) - 1 。
-
-- ReLU激活函数: `$ f(x) = max(0, x) $`
-
-更详细的介绍请参考[维基百科激活函数](https://en.wikipedia.org/wiki/Activation_function)。
-
-## 数据介绍
-
-PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mnist/)数据的模块`paddle.dataset.mnist`。加载后的数据位于`/home/username/.cache/paddle/dataset/mnist`下:
-
-
-
-
-
- | 文件名称 |
- 说明 |
-
-
-
-
-
- | train-images-idx3-ubyte |
- 训练数据图片,60,000条数据 |
-
-
- | train-labels-idx1-ubyte |
- 训练数据标签,60,000条数据 |
-
-
- | t10k-images-idx3-ubyte |
- 测试数据图片,10,000条数据 |
-
-
- | t10k-labels-idx1-ubyte |
- 测试数据标签,10,000条数据 |
-
-
-
-
-
-## Fluid API 概述
-
-演示将使用最新的 `Fluid API`。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
-我们建议使用 Fluid API,因为它更容易学起来。
-
-下面是快速的 Fluid API 概述。
-1. `inference_program`:指定如何从数据输入中获得预测的函数。
-这是指定网络流的地方。
-
-1. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
-这是指定损失计算的地方。
-
-1. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
-
-1. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
-通过 `event_handler` 回调函数,用户可以监控培训的进展。
-
-1. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
-然后,它可以推断数据和返回预测。
-
-在这个演示中,我们将深入了解它们。
-
-## 配置说明
-加载 PaddlePaddle 的 Fluid API 包。
-
-```python
-import paddle
-import paddle.fluid as fluid
-```
-
-### Program Functions 配置
-
-我们需要设置“推理程序”函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
-我们需要将图像数据馈送到分类器。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
-让我们创建一个数据层来读取图像并将其连接到分类网络。
-
-- Softmax回归:只通过一层简单的以softmax为激活函数的全连接层,就可以得到分类的结果。
-
-```python
-def softmax_regression():
-img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
-predict = fluid.layers.fc(
-input=img, size=10, act='softmax')
-return predict
-```
-
-- 多层感知器:下面代码实现了一个含有两个隐藏层(即全连接层)的多层感知器。其中两个隐藏层的激活函数均采用ReLU,输出层的激活函数用Softmax。
-
-```python
-def multilayer_perceptron():
-img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
-# 第一个全连接层,激活函数为ReLU
-hidden = fluid.layers.fc(input=img, size=200, act='relu')
-# 第二个全连接层,激活函数为ReLU
-hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
-# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
-prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
-return prediction
-```
-
-- 卷积神经网络LeNet-5: 输入的二维图像,首先经过两次卷积层到池化层,再经过全连接层,最后使用以softmax为激活函数的全连接层作为输出层。
-
-```python
-def convolutional_neural_network():
-img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
-# 第一个卷积-池化层
-conv_pool_1 = fluid.nets.simple_img_conv_pool(
-input=img,
-filter_size=5,
-num_filters=20,
-pool_size=2,
-pool_stride=2,
-act="relu")
-conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
-# 第二个卷积-池化层
-conv_pool_2 = fluid.nets.simple_img_conv_pool(
-input=conv_pool_1,
-filter_size=5,
-num_filters=50,
-pool_size=2,
-pool_stride=2,
-act="relu")
-# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
-prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
-return prediction
-```
-
-#### Train Program 配置
-然后我们需要设置训练程序 `train_program`。它首先从分类器中进行预测。
-在训练期间,它将从预测中计算 `avg_cost`。
-
-**注意:** 训练程序应该返回一个数组,第一个返回参数必须是 `avg_cost`。训练器使用它来计算梯度。
-
-请随意修改代码,测试 Softmax 回归 `softmax_regression`, `MLP` 和 卷积神经网络 `convolutional neural network` 分类器之间的不同结果。
-
-```python
-def train_program():
-label = fluid.layers.data(name='label', shape=[1], dtype='int64')
-
-# predict = softmax_regression() # uncomment for Softmax回归
-# predict = multilayer_perceptron() # uncomment for 多层感知器
-predict = convolutional_neural_network() # uncomment for LeNet5卷积神经网络
-cost = fluid.layers.cross_entropy(input=predict, label=label)
-avg_cost = fluid.layers.mean(cost)
-acc = fluid.layers.accuracy(input=predict, label=label)
-return [avg_cost, acc]
-
-
-# 该模型运行在单个CPU上
-```
-
-#### Optimizer Function 配置
-
-在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
-
-```python
-def optimizer_program():
-return fluid.optimizer.Adam(learning_rate=0.001)
-```
-
-### 数据集 Feeders 配置
-
-下一步,我们开始训练过程。`paddle.dataset.movielens.train()`和`paddle.dataset.movielens.test()`分别做训练和测试数据集。这两个函数各自返回一个reader——PaddlePaddle中的reader是一个Python函数,每次调用的时候返回一个Python yield generator。
-
-下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B —— reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
-
-`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader —— 在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
-
-```python
-train_reader = paddle.batch(
-paddle.reader.shuffle(
-paddle.dataset.mnist.train(), buf_size=500),
-batch_size=64)
-
-test_reader = paddle.batch(
-paddle.dataset.mnist.test(), batch_size=64)
-```
-
-### Trainer 配置
-
-现在,我们需要配置 `Trainer`。`Trainer` 需要接受训练程序 `train_program`, `place` 和优化器 `optimizer`。
-
-```python
-# 该模型运行在单个CPU上
-use_cuda = False # set to True if training with GPU
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
-trainer = fluid.Trainer(
-train_func=train_program, place=place, optimizer_func=optimizer_program)
-```
-
-#### Event Handler 配置
-
-Fluid API 在训练期间为回调函数提供了一个钩子。用户能够通过机制监控培训进度。
-我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter 笔记本 ,看看有什么不同。
-
-`event_handler` 用来在训练过程中输出训练结果
-
-```python
-# Save the parameter into a directory. The Inferencer can load the parameters from it to do infer
-params_dirname = "recognize_digits_network.inference.model"
-lists = []
-def event_handler(event):
-if isinstance(event, fluid.EndStepEvent):
-if event.step % 100 == 0:
-# event.metrics maps with train program return arguments.
-# event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
-print "Pass %d, Batch %d, Cost %f" % (
-event.step, event.epoch, event.metrics[0])
-
-if isinstance(event, fluid.EndEpochEvent):
-avg_cost, acc = trainer.test(
-reader=test_reader, feed_order=['img', 'label'])
-
-print("Test with Epoch %d, avg_cost: %s, acc: %s" % (event.epoch, avg_cost, acc))
-
-# save parameters
-trainer.save_params(params_dirname)
-lists.append((event.epoch, avg_cost, acc))
-```
-
-`event_handler_plot` 可以用来在训练过程中画图如下:
-
-
-
-```python
-from paddle.v2.plot import Ploter
-
-train_title = "Train cost"
-test_title = "Test cost"
-cost_ploter = Ploter(train_title, test_title)
-step = 0
-lists = []
-
-# event_handler to plot a figure
-def event_handler_plot(event):
-global step
-if isinstance(event, fluid.EndStepEvent):
-if step % 100 == 0:
-# event.metrics maps with train program return arguments.
-# event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
-cost_ploter.append(train_title, step, event.metrics[0])
-cost_ploter.plot()
-step += 1
-if isinstance(event, fluid.EndEpochEvent):
-# save parameters
-trainer.save_params(params_dirname)
-
-avg_cost, acc = trainer.test(
-reader=test_reader, feed_order=['img', 'label'])
-cost_ploter.append(test_title, step, avg_cost)
-lists.append((event.epoch, avg_cost, acc))
-```
-
-#### 开始训练
-
-既然我们设置了 `event_handler` 和 `data reader`,我们就可以开始训练模型了。
-
-`feed_order` 用于将数据目录映射到 `train_program`
-
-```python
-trainer.train(
-num_epochs=5,
-event_handler=event_handler,
-reader=train_reader,
-feed_order=['img', 'label'])
-```
-
-训练过程是完全自动的,event_handler里打印的日志类似如下所示:
-
-```
-Pass 0, Batch 0, Cost 0.125650
-Pass 100, Batch 0, Cost 0.161387
-Pass 200, Batch 0, Cost 0.040036
-Pass 300, Batch 0, Cost 0.023391
-Pass 400, Batch 0, Cost 0.005856
-Pass 500, Batch 0, Cost 0.003315
-Pass 600, Batch 0, Cost 0.009977
-Pass 700, Batch 0, Cost 0.020959
-Pass 800, Batch 0, Cost 0.105560
-Pass 900, Batch 0, Cost 0.239809
-Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
-```
-
-训练之后,检查模型的预测准确度。用 MNIST 训练的时候,一般 softmax回归模型的分类准确率为约为 92.34%,多层感知器为97.66%,卷积神经网络可以达到 99.20%。
-
-
-## 应用模型
-
-可以使用训练好的模型对手写体数字图片进行分类,下面程序展示了如何使用 `fluid.Inferencer` 接口进行推断。
-
-### Inference 配置
-
-`Inference` 需要一个 `infer_func` 和 `param_path` 来设置网络和经过训练的参数。
-我们可以简单地插入在此之前定义的分类器。
-
-```python
-inferencer = fluid.Inferencer(
-# infer_func=softmax_regression, # uncomment for softmax regression
-# infer_func=multilayer_perceptron, # uncomment for MLP
-infer_func=convolutional_neural_network, # uncomment for LeNet5
-param_path=params_dirname,
-place=place)
-```
-
-### 生成预测输入数据
-
-`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据馈送格式。
-
-```python
-# Prepare the test image
-import os
-import numpy as np
-from PIL import Image
-def load_image(file):
-im = Image.open(file).convert('L')
-im = im.resize((28, 28), Image.ANTIALIAS)
-im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
-im = im / 255.0 * 2.0 - 1.0
-return im
-
-cur_dir = cur_dir = os.getcwd()
-img = load_image(cur_dir + '/image/infer_3.png')
-```
-
-### 预测
-
-现在我们准备做预测。
-
-```python
-results = inferencer.infer({'img': img})
-lab = np.argsort(results) # probs and lab are the results of one batch data
-print "Label of image/infer_3.png is: %d" % lab[0][0][-1]
-```
-
-## 总结
-
-本教程的softmax回归、多层感知器和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
-
-## 参考文献
-
-1. LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. ["Gradient-based learning applied to document recognition."](http://ieeexplore.ieee.org/abstract/document/726791/) Proceedings of the IEEE 86, no. 11 (1998): 2278-2324.
-2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A753279&dswid=-434) (2014).
-3. Decoste, Dennis, and Bernhard Schölkopf. ["Training invariant support vector machines."](http://link.springer.com/article/10.1023/A:1012454411458) Machine learning 46, no. 1-3 (2002): 161-190.
-4. Simard, Patrice Y., David Steinkraus, and John C. Platt. ["Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.8494&rep=rep1&type=pdf) In ICDAR, vol. 3, pp. 958-962. 2003.
-5. Salakhutdinov, Ruslan, and Geoffrey E. Hinton. ["Learning a Nonlinear Embedding by Preserving Class Neighbourhood Structure."](http://www.jmlr.org/proceedings/papers/v2/salakhutdinov07a/salakhutdinov07a.pdf) In AISTATS, vol. 11. 2007.
-6. Cireşan, Dan Claudiu, Ueli Meier, Luca Maria Gambardella, and Jürgen Schmidhuber. ["Deep, big, simple neural nets for handwritten digit recognition."](http://www.mitpressjournals.org/doi/abs/10.1162/NECO_a_00052) Neural computation 22, no. 12 (2010): 3207-3220.
-7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
-8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
-9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
-10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
-
-
-
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
+# 识别数字
+
+本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/167.html)。
+
+## 背景介绍
+当我们学习编程的时候,编写的第一个程序一般是实现打印"Hello World"。而机器学习(或深度学习)的入门教程,一般都是 [MNIST](http://yann.lecun.com/exdb/mnist/) 数据库上的手写识别问题。原因是手写识别属于典型的图像分类问题,比较简单,同时MNIST数据集也很完备。MNIST数据集作为一个简单的计算机视觉数据集,包含一系列如图1所示的手写数字图片和对应的标签。图片是28x28的像素矩阵,标签则对应着0~9的10个数字。每张图片都经过了大小归一化和居中处理。
+
+
+ 
+ 图1. MNIST图片示例
+
+
+MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
+
+Yann LeCun早先在手写字符识别上做了很多研究,并在研究过程中提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等(请参见[图像分类](https://github.com/PaddlePaddle/book/tree/develop/03.image_classification) 教程),人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
+
+有很多算法在MNIST上进行实验。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)\[[1](#参考文献)\]。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法\[[2](#参考文献)\]、支持向量机(SVM)\[[3](#参考文献)\]、神经网络\[[4-7](#参考文献)\]和Boosting方法\[[8](#参考文献)\]等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
+
+本教程中,我们从简单的模型Softmax回归开始,带大家入门手写字符识别,并逐步进行模型优化。
+
+
+## 模型概览
+
+基于MNIST数据训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
+- $X$是输入:MNIST图片是$28\times28$ 的二维图像,为了进行计算,我们将其转化为$784$维向量,即$X=\left ( x_0, x_1, \dots, x_{783} \right )$。
+- $Y$是输出:分类器的输出是10类数字(0-9),即$Y=\left ( y_0, y_1, \dots, y_9 \right )$,每一维$y_i$代表图片分类为第$i$类数字的概率。
+- $L$是图片的真实标签:$L=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。
+
+### Softmax回归(Softmax Regression)
+
+最简单的Softmax回归模型是先将输入层经过一个全连接层得到的特征,然后直接通过softmax 函数进行多分类\[[9](#参考文献)\]。
+
+输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
+
+$$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
+
+其中 $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
+
+对于有 $N$ 个类别的多分类问题,指定 $N$ 个输出节点,$N$ 维结果向量经过softmax将归一化为 $N$ 个[0,1]范围内的实数值,分别表示该样本属于这 $N$ 个类别的概率。此处的 $y_i$ 即对应该图片为数字 $i$ 的预测概率。
+
+在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
+
+$$ L_{cross-entropy} (label, y) = -\sum_i label_ilog(y_i) $$
+
+图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
+
+
+
+图2. softmax回归网络结构图
+
+
+### 多层感知器(Multilayer Perceptron, MLP)
+
+Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
+
+1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
+
+2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
+
+3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
+
+
+图3为多层感知器的网络结构图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
+
+
+
+图3. 多层感知器网络结构图
+
+
+### 卷积神经网络(Convolutional Neural Network, CNN)
+
+在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
+
+
+
+图4. LeNet-5卷积神经网络结构
+
+
+#### 卷积层
+
+卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
+
+
+
+图5. 卷积层图片
+
+
+图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3)$个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
+
+在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D \times F \times F \times K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
+
+- 局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野(receptive field)。在图像卷积操作中,即神经元在空间维度(spatial dimension,即上图示例H和W所在的平面)是局部连接,但在深度上是全部连接。对于二维图像本身而言,也是局部像素关联较强。这种局部连接保证了学习后的过滤器能够对于局部的输入特征有最强的响应。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的。
+
+- 权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例如图4中计算$o[:,:,0]$的每个每个神经元的滤波器均相同,都为$W_0$,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 (参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/))。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
+
+通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
+
+#### 池化层
+
+
+
+图6. 池化层图片
+
+
+池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图6所示。
+
+更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
+
+### 常见激活函数介绍
+
+- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
+
+- tanh激活函数: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
+
+ 实际上,tanh函数只是规模变化的sigmoid函数,将sigmoid函数值放大2倍之后再向下平移1个单位:tanh(x) = 2sigmoid(2x) - 1 。
+
+- ReLU激活函数: $ f(x) = max(0, x) $
+
+更详细的介绍请参考[维基百科激活函数](https://en.wikipedia.org/wiki/Activation_function)。
+
+## 数据介绍
+
+PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mnist/)数据的模块`paddle.dataset.mnist`。加载后的数据位于`/home/username/.cache/paddle/dataset/mnist`下:
+
+
+| 文件名称 | 说明 |
+|----------------------|-------------------------|
+|train-images-idx3-ubyte| 训练数据图片,60,000条数据 |
+|train-labels-idx1-ubyte| 训练数据标签,60,000条数据 |
+|t10k-images-idx3-ubyte | 测试数据图片,10,000条数据 |
+|t10k-labels-idx1-ubyte | 测试数据标签,10,000条数据 |
+
+## Fluid API 概述
+
+演示将使用最新的 `Fluid API`。Fluid API是最新的 PaddlePaddle API。它在不牺牲性能的情况下简化了模型配置。
+我们建议使用 Fluid API,因为它更容易学起来。
+
+下面是快速的 Fluid API 概述。
+
+1. `inference_program`:指定如何从数据输入中获得预测的函数。
+这是指定网络流的地方。
+
+2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
+这是指定损失计算的地方。
+
+3. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
+
+4. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
+通过 `event_handler` 回调函数,用户可以监控培训的进展。
+
+5. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
+
+然后,它可以推断数据和返回预测。
+
+在这个演示中,我们将深入了解它们。
+
+## 配置说明
+加载 PaddlePaddle 的 Fluid API 包。
+
+```python
+import paddle
+import paddle.fluid as fluid
+from __future__ import print_function
+```
+
+### Program Functions 配置
+
+我们需要设置“推理程序”函数。我们想用这个程序来演示三个不同的分类器,每个分类器都定义为 Python 函数。
+我们需要将图像数据馈送到分类器。Paddle 为读取数据提供了一个特殊的层 `layer.data` 层。
+让我们创建一个数据层来读取图像并将其连接到分类网络。
+
+- Softmax回归:只通过一层简单的以softmax为激活函数的全连接层,就可以得到分类的结果。
+
+```python
+def softmax_regression():
+ img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ predict = fluid.layers.fc(
+ input=img, size=10, act='softmax')
+ return predict
+```
+
+- 多层感知器:下面代码实现了一个含有两个隐藏层(即全连接层)的多层感知器。其中两个隐藏层的激活函数均采用ReLU,输出层的激活函数用Softmax。
+
+```python
+def multilayer_perceptron():
+ img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # 第一个全连接层,激活函数为ReLU
+ hidden = fluid.layers.fc(input=img, size=200, act='relu')
+ # 第二个全连接层,激活函数为ReLU
+ hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
+ # 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
+ prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
+ return prediction
+```
+
+- 卷积神经网络LeNet-5: 输入的二维图像,首先经过两次卷积层到池化层,再经过全连接层,最后使用以softmax为激活函数的全连接层作为输出层。
+
+```python
+def convolutional_neural_network():
+ img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
+ # 第一个卷积-池化层
+ conv_pool_1 = fluid.nets.simple_img_conv_pool(
+ input=img,
+ filter_size=5,
+ num_filters=20,
+ pool_size=2,
+ pool_stride=2,
+ act="relu")
+ conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
+ # 第二个卷积-池化层
+ conv_pool_2 = fluid.nets.simple_img_conv_pool(
+ input=conv_pool_1,
+ filter_size=5,
+ num_filters=50,
+ pool_size=2,
+ pool_stride=2,
+ act="relu")
+ # 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
+ prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
+ return prediction
+```
+
+#### Train Program 配置
+然后我们需要设置训练程序 `train_program`。它首先从分类器中进行预测。
+在训练期间,它将从预测中计算 `avg_cost`。
+
+**注意:** 训练程序应该返回一个数组,第一个返回参数必须是 `avg_cost`。训练器使用它来计算梯度。
+
+请随意修改代码,测试 Softmax 回归 `softmax_regression`, `MLP` 和 卷积神经网络 `convolutional neural network` 分类器之间的不同结果。
+
+```python
+def train_program():
+ label = fluid.layers.data(name='label', shape=[1], dtype='int64')
+
+ # predict = softmax_regression() # uncomment for Softmax回归
+ # predict = multilayer_perceptron() # uncomment for 多层感知器
+ predict = convolutional_neural_network() # uncomment for LeNet5卷积神经网络
+ cost = fluid.layers.cross_entropy(input=predict, label=label)
+ avg_cost = fluid.layers.mean(cost)
+ acc = fluid.layers.accuracy(input=predict, label=label)
+ return [avg_cost, acc]
+
+```
+
+#### Optimizer Function 配置
+
+在下面的 `Adam optimizer`,`learning_rate` 是训练的速度,与网络的训练收敛速度有关系。
+
+```python
+def optimizer_program():
+ return fluid.optimizer.Adam(learning_rate=0.001)
+```
+
+### 数据集 Feeders 配置
+
+下一步,我们开始训练过程。`paddle.dataset.movielens.train()`和`paddle.dataset.movielens.test()`分别做训练和测试数据集。这两个函数各自返回一个reader——PaddlePaddle中的reader是一个Python函数,每次调用的时候返回一个Python yield generator。
+
+下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B 。reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
+
+`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader 。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
+
+```python
+train_reader = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.mnist.train(), buf_size=500),
+ batch_size=64)
+
+test_reader = paddle.batch(
+ paddle.dataset.mnist.test(), batch_size=64)
+```
+
+### Trainer 配置
+
+现在,我们需要配置 `Trainer`。`Trainer` 需要接受训练程序 `train_program`, `place` 和优化器 `optimizer`。
+
+```python
+# 该模型运行在单个CPU上
+use_cuda = False # set to True if training with GPU
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+
+trainer = fluid.Trainer(
+ train_func=train_program, place=place, optimizer_func=optimizer_program)
+
+```
+
+#### Event Handler 配置
+
+Fluid API 在训练期间为回调函数提供了一个钩子。用户能够通过机制监控培训进度。
+我们将在这里演示两个 `event_handler` 程序。请随意修改 Jupyter 笔记本 ,看看有什么不同。
+
+`event_handler` 用来在训练过程中输出训练结果
+
+```python
+# Save the parameter into a directory. The Inferencer can load the parameters from it to do infer
+params_dirname = "recognize_digits_network.inference.model"
+lists = []
+def event_handler(event):
+ if isinstance(event, fluid.EndStepEvent):
+ if event.step % 100 == 0:
+ # event.metrics maps with train program return arguments.
+ # event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
+ print("Pass %d, Batch %d, Cost %f" % (
+ event.step, event.epoch, event.metrics[0]))
+
+ if isinstance(event, fluid.EndEpochEvent):
+ avg_cost, acc = trainer.test(
+ reader=test_reader, feed_order=['img', 'label'])
+
+ print("Test with Epoch %d, avg_cost: %s, acc: %s" % (event.epoch, avg_cost, acc))
+
+ # save parameters
+ trainer.save_params(params_dirname)
+ lists.append((event.epoch, avg_cost, acc))
+```
+
+`event_handler_plot` 可以用来在训练过程中画图如下:
+
+
+
+
+图7. 训练结果
+
+
+
+```python
+from paddle.v2.plot import Ploter
+
+train_title = "Train cost"
+test_title = "Test cost"
+cost_ploter = Ploter(train_title, test_title)
+step = 0
+lists = []
+
+# event_handler to plot a figure
+def event_handler_plot(event):
+ global step
+ if isinstance(event, fluid.EndStepEvent):
+ if step % 100 == 0:
+ # event.metrics maps with train program return arguments.
+ # event.metrics[0] will yeild avg_cost and event.metrics[1] will yeild acc in this example.
+ cost_ploter.append(train_title, step, event.metrics[0])
+ cost_ploter.plot()
+ step += 1
+ if isinstance(event, fluid.EndEpochEvent):
+ # save parameters
+ trainer.save_params(params_dirname)
+
+ avg_cost, acc = trainer.test(
+ reader=test_reader, feed_order=['img', 'label'])
+ cost_ploter.append(test_title, step, avg_cost)
+ lists.append((event.epoch, avg_cost, acc))
+```
+
+#### 开始训练
+
+既然我们设置了 `event_handler` 和 `data reader`,我们就可以开始训练模型了。
+
+`feed_order` 用于将数据目录映射到 `train_program`
+
+```python
+trainer.train(
+ num_epochs=5,
+ event_handler=event_handler,
+ reader=train_reader,
+ feed_order=['img', 'label'])
+```
+
+训练过程是完全自动的,event_handler里打印的日志类似如下所示:
+
+```
+Pass 0, Batch 0, Cost 0.125650
+Pass 100, Batch 0, Cost 0.161387
+Pass 200, Batch 0, Cost 0.040036
+Pass 300, Batch 0, Cost 0.023391
+Pass 400, Batch 0, Cost 0.005856
+Pass 500, Batch 0, Cost 0.003315
+Pass 600, Batch 0, Cost 0.009977
+Pass 700, Batch 0, Cost 0.020959
+Pass 800, Batch 0, Cost 0.105560
+Pass 900, Batch 0, Cost 0.239809
+Test with Epoch 0, avg_cost: 0.053097883707459624, acc: 0.9822850318471338
+```
+
+训练之后,检查模型的预测准确度。用 MNIST 训练的时候,一般 softmax回归模型的分类准确率为约为 92.34%,多层感知器为97.66%,卷积神经网络可以达到 99.20%。
+
+
+## 应用模型
+
+可以使用训练好的模型对手写体数字图片进行分类,下面程序展示了如何使用 `fluid.Inferencer` 接口进行推断。
+
+### Inference 配置
+
+`Inference` 需要一个 `infer_func` 和 `param_path` 来设置网络和经过训练的参数。
+我们可以简单地插入在此之前定义的分类器。
+
+```python
+inferencer = fluid.Inferencer(
+ # infer_func=softmax_regression, # uncomment for softmax regression
+ # infer_func=multilayer_perceptron, # uncomment for MLP
+ infer_func=convolutional_neural_network, # uncomment for LeNet5
+ param_path=params_dirname,
+ place=place)
+```
+
+### 生成预测输入数据
+
+`infer_3.png` 是数字 3 的一个示例图像。把它变成一个 numpy 数组以匹配数据馈送格式。
+
+```python
+# Prepare the test image
+import os
+import numpy as np
+from PIL import Image
+def load_image(file):
+ im = Image.open(file).convert('L')
+ im = im.resize((28, 28), Image.ANTIALIAS)
+ im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
+ im = im / 255.0 * 2.0 - 1.0
+ return im
+
+cur_dir = cur_dir = os.getcwd()
+img = load_image(cur_dir + '/image/infer_3.png')
+```
+
+### 预测
+
+现在我们准备做预测。
+
+```python
+results = inferencer.infer({'img': img})
+lab = np.argsort(results) # probs and lab are the results of one batch data
+print ("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
+```
+
+## 总结
+
+本教程的softmax回归、多层感知器和卷积神经网络是最基础的深度学习模型,后续章节中复杂的神经网络都是从它们衍生出来的,因此这几个模型对之后的学习大有裨益。同时,我们也观察到从最简单的softmax回归变换到稍复杂的卷积神经网络的时候,MNIST数据集上的识别准确率有了大幅度的提升,原因是卷积层具有局部连接和共享权重的特性。在之后学习新模型的时候,希望大家也要深入到新模型相比原模型带来效果提升的关键之处。此外,本教程还介绍了PaddlePaddle模型搭建的基本流程,从dataprovider的编写、网络层的构建,到最后的训练和预测。对这个流程熟悉以后,大家就可以用自己的数据,定义自己的网络模型,并完成自己的训练和预测任务了。
+
+## 参考文献
+
+1. LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. ["Gradient-based learning applied to document recognition."](http://ieeexplore.ieee.org/abstract/document/726791/) Proceedings of the IEEE 86, no. 11 (1998): 2278-2324.
+2. Wejéus, Samuel. ["A Neural Network Approach to Arbitrary SymbolRecognition on Modern Smartphones."](http://www.diva-portal.org/smash/record.jsf?pid=diva2%3A753279&dswid=-434) (2014).
+3. Decoste, Dennis, and Bernhard Schölkopf. ["Training invariant support vector machines."](http://link.springer.com/article/10.1023/A:1012454411458) Machine learning 46, no. 1-3 (2002): 161-190.
+4. Simard, Patrice Y., David Steinkraus, and John C. Platt. ["Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.8494&rep=rep1&type=pdf) In ICDAR, vol. 3, pp. 958-962. 2003.
+5. Salakhutdinov, Ruslan, and Geoffrey E. Hinton. ["Learning a Nonlinear Embedding by Preserving Class Neighbourhood Structure."](http://www.jmlr.org/proceedings/papers/v2/salakhutdinov07a/salakhutdinov07a.pdf) In AISTATS, vol. 11. 2007.
+6. Cireşan, Dan Claudiu, Ueli Meier, Luca Maria Gambardella, and Jürgen Schmidhuber. ["Deep, big, simple neural nets for handwritten digit recognition."](http://www.mitpressjournals.org/doi/abs/10.1162/NECO_a_00052) Neural computation 22, no. 12 (2010): 3207-3220.
+7. Deng, Li, Michael L. Seltzer, Dong Yu, Alex Acero, Abdel-rahman Mohamed, and Geoffrey E. Hinton. ["Binary coding of speech spectrograms using a deep auto-encoder."](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.185.1908&rep=rep1&type=pdf) In Interspeech, pp. 1692-1695. 2010.
+8. Kégl, Balázs, and Róbert Busa-Fekete. ["Boosting products of base classifiers."](http://dl.acm.org/citation.cfm?id=1553439) In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 497-504. ACM, 2009.
+9. Rosenblatt, Frank. ["The perceptron: A probabilistic model for information storage and organization in the brain."](http://psycnet.apa.org/journals/rev/65/6/386/) Psychological review 65, no. 6 (1958): 386.
+10. Bishop, Christopher M. ["Pattern recognition."](http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf) Machine Learning 128 (2006): 1-58.
+
+
+
本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..bc1a9a4ccf81972dc0d69cf4c808a52218e14d61
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_train_log_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_train_log_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..77524754df906ab096e120bd657449f4565c3418
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/cnn_train_log_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/conv_layer.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/conv_layer.png
new file mode 100644
index 0000000000000000000000000000000000000000..c751892ba0be3ae803b5933c3f33487ecfb6fe7f
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/conv_layer.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/max_pooling_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/max_pooling_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..c626723512b6ee02abd55e5bab65e7629d130522
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/max_pooling_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..1fedea6a75abbf132cbbcf8ab10ce045997d697a
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_train_log_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_train_log_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..7d5508a1eccfcea1925f438043ee93b57769bebf
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/mlp_train_log_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_regression_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_regression_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..833d3c663c94dd2d57fd19686949ded37a91f541
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_regression_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_train_log_en.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_train_log_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..6fa0a951d5262effb707e3e15af8cb900e5560b8
Binary files /dev/null and b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/softmax_train_log_en.png differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/train_and_test.png b/doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/train_and_test2.png
similarity index 100%
rename from doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/train_and_test.png
rename to doc/fluid/new_docs/beginners_guide/quick_start/recognize_digits/image/train_and_test2.png