Uploaded markdown docs for testing syncing with web docs
Showing
{kind=link}
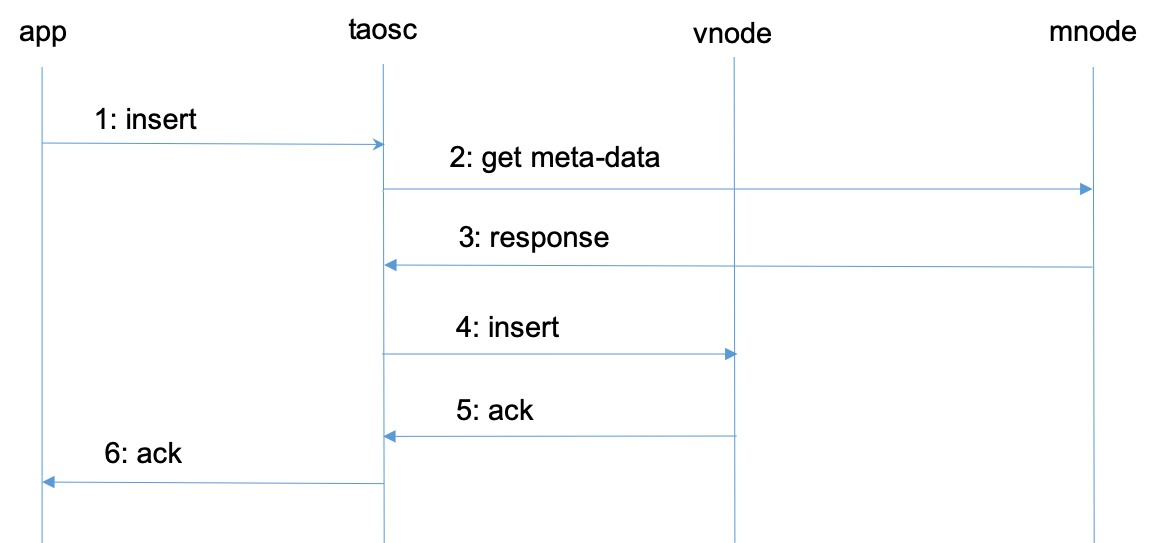
43.2 KB
{kind=link}
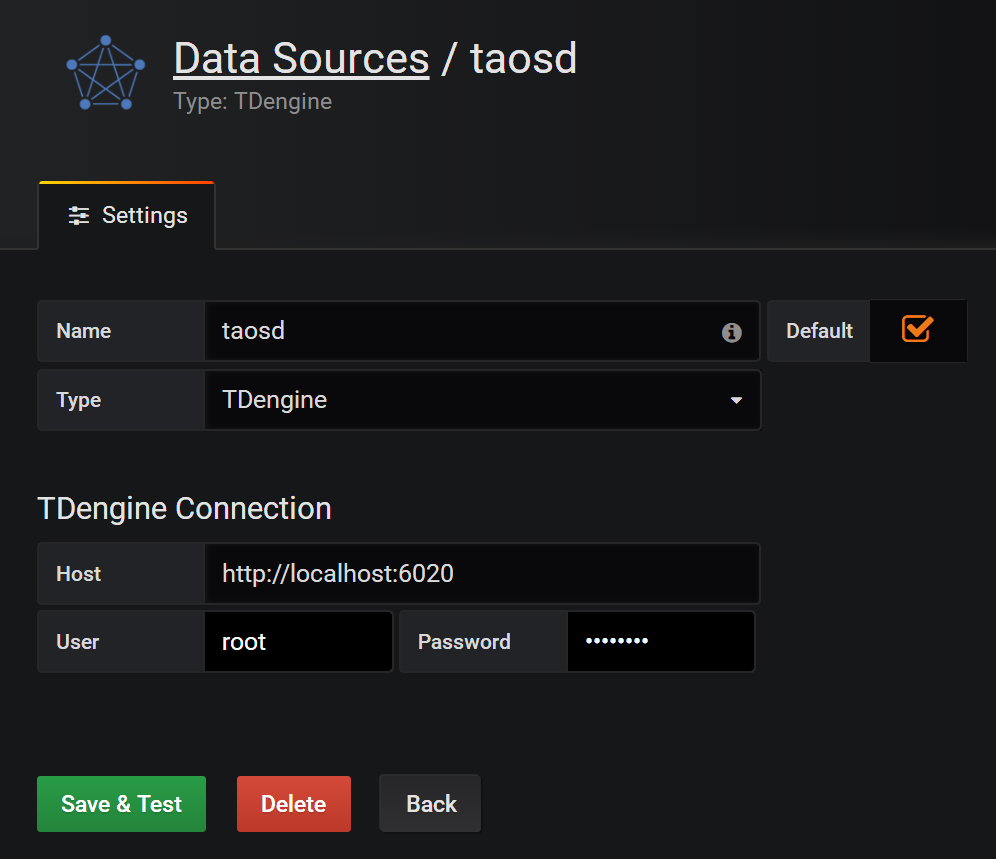
120.2 KB
{kind=link}
74.6 KB
{kind=link}
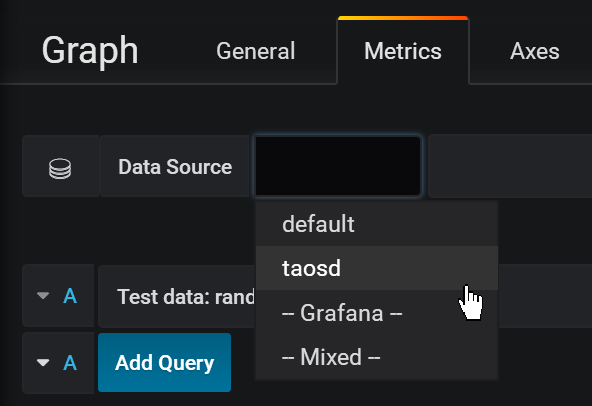
26.0 KB
{kind=link}

43.8 KB
{kind=link}
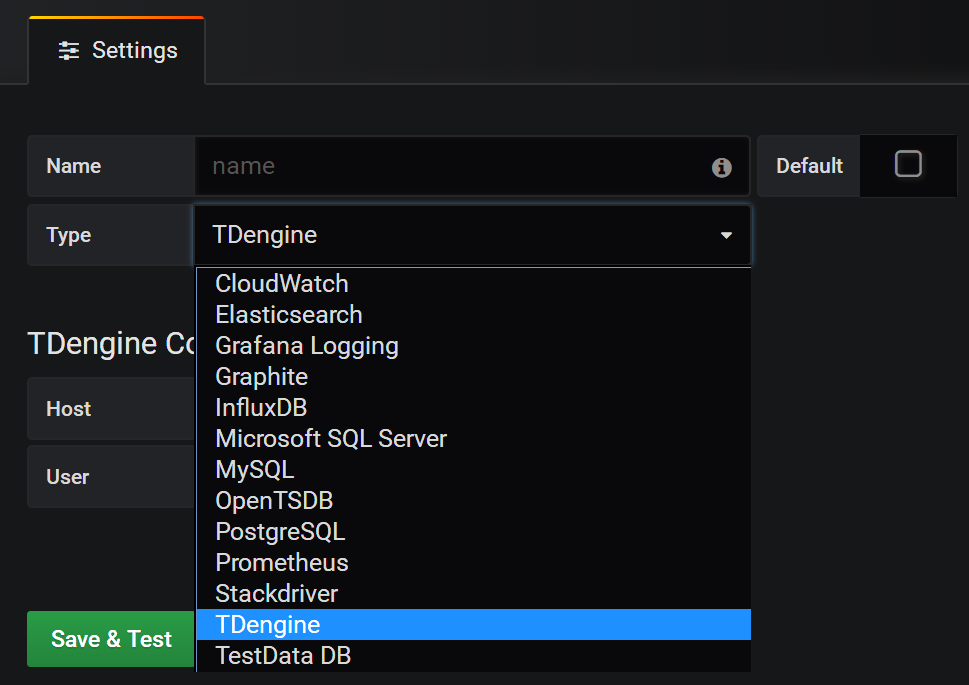
67.4 KB
{kind=link}
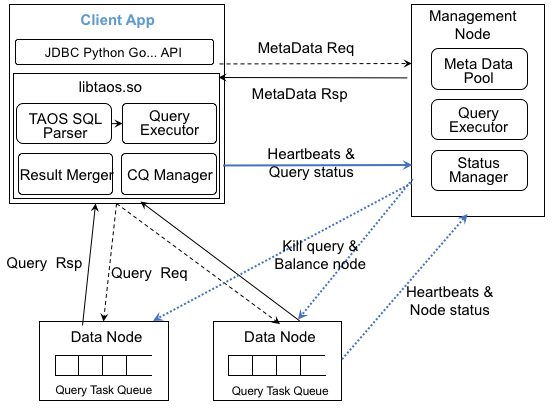
60.3 KB
{kind=link}
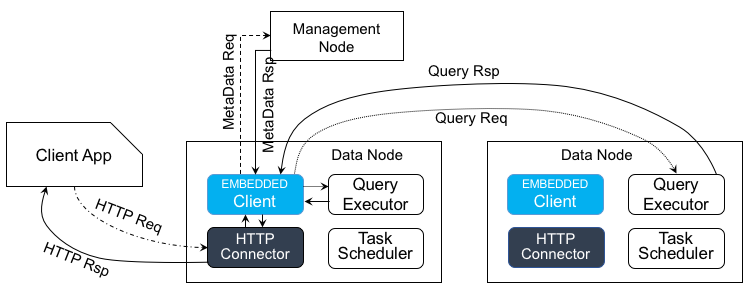
48.8 KB
{kind=link}
21.1 KB
{kind=link}
22.0 KB
{kind=link}
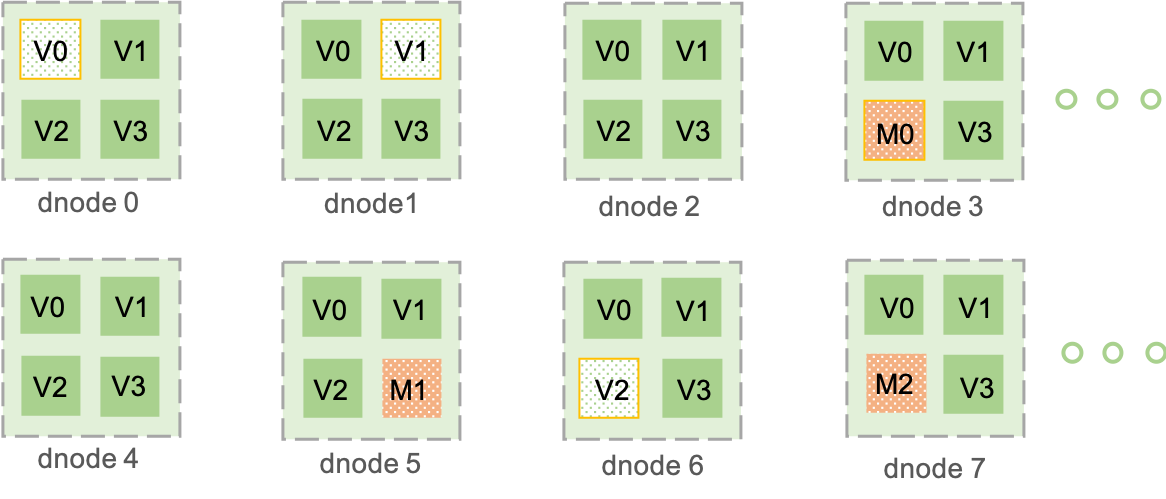
65.8 KB
{kind=link}
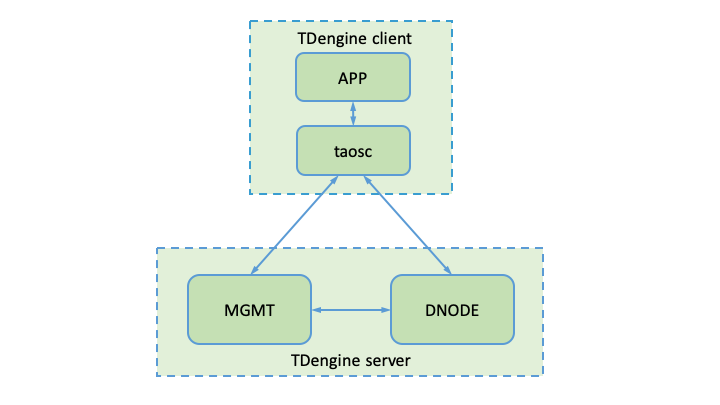
25.0 KB
{kind=link}
6.8 KB
{kind=link}
24.3 KB
Fork自 taosdata / TDengine
43.2 KB
120.2 KB
74.6 KB
26.0 KB
43.8 KB
67.4 KB
60.3 KB
48.8 KB
21.1 KB
22.0 KB
65.8 KB
25.0 KB
6.8 KB
24.3 KB