
Write New Layers¶
This tutorial will guide you to write customized layers in PaddlePaddle. We will utilize fully connected layer as an example to guide you through the following steps for writing a new layer.
- Derive equations for the forward and backward part of the layer.
- Implement C++ class for the layer.
- Write gradient check unit test to make sure the gradients are correctly computed.
- Implement Python wrapper for the layer.
Derive Equations¶
First we need to derive equations of the forward and backward part of the layer. The forward part computes the output given an input. The backward part computes the gradients of the input and the parameters given the the gradients of the output.
The illustration of a fully connected layer is shown in the following figure. In a fully connected layer, all output nodes are connected to all the input nodes.
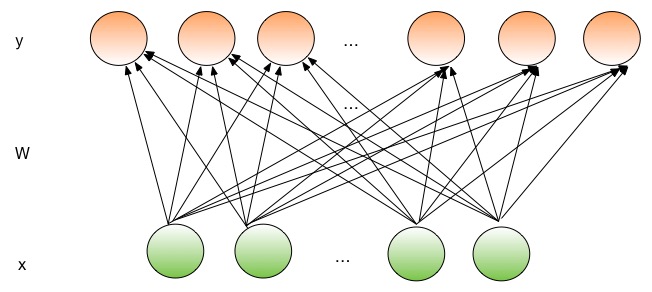
The forward part of a layer transforms an input into the corresponding output. Fully connected layer takes a dense input vector with dimension \(D_i\). It uses a transformation matrix \(W\) with size \(D_i \times D_o\) to project \(x\) into a \(D_o\) dimensional vector, and add a bias vector \(b\) with dimension \(D_o\) to the vector.
where \(f(.)\) is an nonlinear activation function, such as sigmoid, tanh, and Relu.
The transformation matrix \(W\) and bias vector \(b\) are the parameters of the layer. The parameters of a layer are learned during training in the backward pass. The backward pass computes the gradients of the output function with respect to all parameters and inputs. The optimizer can use chain rule to compute the gradients of the loss function with respect to each parameter.
Suppose our loss function is \(c(y)\), then
Suppose \(z = W^T x + b\), then
This derivative can be automatically computed by our base layer class.
Then, for fully connected layer, we need to compute:
where \(\mathbf 1\) is an all one vector, \(W_{ij}\) is the number at the i-th row and j-th column of the matrix \(W\), \(z_j\) is the j-th component of the vector \(z\), and \(x_i\) is the i-th component of the vector \(x\).
Finally we can use chain rule to calculate \(\frac{\partial z}{\partial x}\), and \(\frac{\partial z}{\partial W}\). The details of the computation will be given in the next section.
Implement C++ Class¶
The C++ class of the layer implements the initialization, forward, and backward part of the layer. The fully connected layer is at paddle/gserver/layers/FullyConnectedLayer.h and paddle/gserver/layers/FullyConnectedLayer.cpp. We list simplified version of the code below.
It needs to derive the base class paddle::Layer, and it needs to override the following functions:
- constructor and destructor.
initfunction. It is used to initialize the parameters and settings.forward. It implements the forward part of the layer.backward. It implements the backward part of the layer.prefetch. It is utilized to determine the rows corresponding parameter matrix to prefetch from parameter server. You do not need to override this function if your layer does not need remote sparse update. (most layers do not need to support remote sparse update)
The header file is listed below:
namespace paddle {
/**
* A layer has full connections to all neurons in the previous layer.
* It computes an inner product with a set of learned weights, and
* (optionally) adds biases.
*
* The config file api is fc_layer.
*/
class FullyConnectedLayer : public Layer {
protected:
WeightList weights_;
std::unique_ptr<Weight> biases_;
public:
explicit FullyConnectedLayer(const LayerConfig& config)
: Layer(config) {}
~FullyConnectedLayer() {}
bool init(const LayerMap& layerMap, const ParameterMap& parameterMap);
Weight& getWeight(int idx) { return *weights_[idx]; }
void prefetch();
void forward(PassType passType);
void backward(const UpdateCallback& callback = nullptr);
};
} // namespace paddle
It defines the parameters as class variables. We use Weight class as abstraction of parameters. It supports multi-thread update. The details of this class will be described in details in the implementations.
weights_is a list of weights for the transformation matrices. The current implementation can have more than one inputs. Thus, it has a list of weights. One weight corresponds to an input.biases_is a weight for the bias vector.
The fully connected layer does not have layer configuration hyper-parameters. If there are some layer hyper-parameters, a common practice is to store it in LayerConfig& config, and put it into a class variable in the constructor.
The following code snippet implements the init function.
- First, every
initfunction must call theinitfunction of the base classLayer::init(layerMap, parameterMap);. This statement will initialize the required variables and connections for each layer. - The it initializes all the weights matrices \(W\). The current implementation can have more than one inputs. Thus, it has a list of weights.
- Finally, it initializes the bias.
bool FullyConnectedLayer::init(const LayerMap& layerMap,
const ParameterMap& parameterMap) {
/* Initialize the basic parent class */
Layer::init(layerMap, parameterMap);
/* initialize the weightList */
CHECK(inputLayers_.size() == parameters_.size());
for (size_t i = 0; i < inputLayers_.size(); i++) {
// Option the parameters
size_t height = inputLayers_[i]->getSize();
size_t width = getSize();
// create a new weight
if (parameters_[i]->isSparse()) {
CHECK_LE(parameters_[i]->getSize(), width * height);
} else {
CHECK_EQ(parameters_[i]->getSize(), width * height);
}
Weight* w = new Weight(height, width, parameters_[i]);
// append the new weight to the list
weights_.emplace_back(w);
}
/* initialize biases_ */
if (biasParameter_.get() != NULL) {
biases_ = std::unique_ptr<Weight>(new Weight(1, getSize(), biasParameter_));
}
return true;
}
The implementation of the forward part has the following steps.
- Every layer must call
Layer::forward(passType);at the beginning of itsforwardfunction. - Then it allocates memory for the output using
reserveOutput(batchSize, size);. This step is necessary because we support the batches to have different batch sizes.reserveOutputwill change the size of the output accordingly. For the sake of efficiency, we will allocate new memory if we want to expand the matrix, but we will reuse the existing memory block if we want to shrink the matrix. - Then it computes \(\sum_i W_i x + b\) using Matrix operations.
getInput(i).valueretrieve the matrix of the i-th input. Each input is a \(batchSize \times dim\) matrix, where each row represents an single input in a batch. For a complete lists of supported matrix operations, please refer topaddle/math/Matrix.handpaddle/math/BaseMatrix.h. - Finally it applies the activation function using
forwardActivation();. It will automatically applies the corresponding activation function specifies in the network configuration.
void FullyConnectedLayer::forward(PassType passType) {
Layer::forward(passType);
/* malloc memory for the output_ if necessary */
int batchSize = getInput(0).getBatchSize();
int size = getSize();
{
// Settup the size of the output.
reserveOutput(batchSize, size);
}
MatrixPtr outV = getOutputValue();
// Apply the the transformation matrix to each input.
for (size_t i = 0; i != inputLayers_.size(); ++i) {
auto input = getInput(i);
CHECK(input.value) << "The input of 'fc' layer must be matrix";
i == 0 ? outV->mul(input.value, weights_[i]->getW(), 1, 0)
: outV->mul(input.value, weights_[i]->getW(), 1, 1);
}
/* add the bias-vector */
if (biases_.get() != NULL) {
outV->addBias(*(biases_->getW()), 1);
}
/* activation */ {
forwardActivation();
}
}
The implementation of the backward part has the following steps.
backwardActivation()computes the gradients of the activation. The gradients will be multiplies in place to the gradients of the output, which can be retrieved usinggetOutputGrad().- Compute the gradients of bias. Notice that we an use
biases_->getWGrad()to get the gradient matrix of the corresponding parameter. After the gradient of one parameter is updated, it MUST callgetParameterPtr()->incUpdate(callback);. This is utilize for parameter update over multiple threads or multiple machines. - Then it computes the gradients of the transformation matrices and inputs, and it calls
incUpdatefor the corresponding parameter. This gives the framework the chance to know whether it has gathered all the gradient to one parameter so that it can do some overlapping work (e.g., network communication)
void FullyConnectedLayer::backward(const UpdateCallback& callback) {
/* Do derivation for activations.*/ {
backwardActivation();
}
if (biases_ && biases_->getWGrad()) {
biases_->getWGrad()->collectBias(*getOutputGrad(), 1);
biases_->getParameterPtr()->incUpdate(callback);
}
bool syncFlag = hl_get_sync_flag();
for (size_t i = 0; i != inputLayers_.size(); ++i) {
/* Calculate the W-gradient for the current layer */
if (weights_[i]->getWGrad()) {
MatrixPtr input_T = getInputValue(i)->getTranspose();
MatrixPtr oGrad = getOutputGrad();
{
weights_[i]->getWGrad()->mul(input_T, oGrad, 1, 1);
}
}
/* Calculate the input layers error */
MatrixPtr preGrad = getInputGrad(i);
if (NULL != preGrad) {
MatrixPtr weights_T = weights_[i]->getW()->getTranspose();
preGrad->mul(getOutputGrad(), weights_T, 1, 1);
}
{
weights_[i]->getParameterPtr()->incUpdate(callback);
}
}
}
The prefetch function specifies the rows that need to be fetched from parameter server during training. It is only useful for remote sparse training. In remote sparse training, the full parameter matrix is stored distributedly at the parameter server. When the layer uses a batch for training, only a subset of locations of the input is non-zero in this batch. Thus, this layer only needs the rows of the transformation matrix corresponding to the locations of these non-zero entries. The prefetch function specifies the ids of these rows.
Most of the layers do not need remote sparse training function. You do not need to override this function in this case.
void FullyConnectedLayer::prefetch() {
for (size_t i = 0; i != inputLayers_.size(); ++i) {
auto* sparseParam =
dynamic_cast<SparsePrefetchRowCpuMatrix*>(weights_[i]->getW().get());
if (sparseParam) {
MatrixPtr input = getInputValue(i);
sparseParam->addRows(input);
}
}
}
Finally, you can use REGISTER_LAYER(fc, FullyConnectedLayer); to register the layer. fc is the identifier of the layer, and FullyConnectedLayer is the class name of the layer.
namespace paddle {
REGISTER_LAYER(fc, FullyConnectedLayer);
}
If the cpp file is put into paddle/gserver/layers, it will be automatically added to the compilation list.
Write Gradient Check Unit Test¶
An easy way to verify the correctness of new layer’s implementation is to write a gradient check unit test. Gradient check unit test utilizes finite difference method to verify the gradient of a layer. It modifies the input with a small perturbation \(\Delta x\) and observes the changes of output \(\Delta y\), the gradient can be computed as \(\frac{\Delta y}{\Delta x }\). This gradient can be compared with the gradient computed by the backward function of the layer to ensure the correctness of the gradient computation. Notice that the gradient check only tests the correctness of the gradient computation, it does not necessarily guarantee the correctness of the implementation of the forward and backward function. You need to write more sophisticated unit tests to make sure your layer is implemented correctly.
All the gradient check unit tests are located in paddle/gserver/tests/test_LayerGrad.cpp. You are recommended to put your test into a new test file if you are planning to write a new layer. The gradient test of the gradient check unit test of the fully connected layer is listed below. It has the following steps.
- Create layer configuration. A layer configuration can include the following attributes:
- size of the bias parameter. (4096 in our example)
- type of the layer. (fc in our example)
- size of the layer. (4096 in our example)
- activation type. (softmax in our example)
- dropout rate. (0.1 in our example)
- configure the input of the layer. In our example, we have only one input.
- type of the input (
INPUT_DATA) in our example. It can be one of the following types INPUT_DATA: dense vector.INPUT_LABEL: integer.INPUT_DATA_TARGET: dense vector, but it does not used to compute gradient.INPUT_SEQUENCE_DATA: dense vector with sequence information.INPUT_HASSUB_SEQUENCE_DATA: dense vector with both sequence and sub-sequence information.INPUT_SEQUENCE_LABEL: integer with sequence information.INPUT_SPARSE_NON_VALUE_DATA: 0-1 sparse data.INPUT_SPARSE_FLOAT_VALUE_DATA: float sparse data.
- type of the input (
- name of the input. (
layer_0in our example) - size of the input. (8192 in our example)
- number of non-zeros, only useful for sparse inputs.
- format of sparse data, only useful for sparse inputs.
- each inputs needs to call
config.layerConfig.add_inputs();once. - call
testLayerGradto perform gradient checks. It has the following arguments. - layer and input configurations. (
configin our example) - type of the layer. (
fcin our example) - batch size of the gradient check. (100 in our example)
- whether the input is transpose. Most layers need to set it to
false. (falsein our example) - whether to use weights. Some layers or activations perform normalization so that the sum of their output is a constant. For example, the sum of output of a softmax activation is one. In this case, we cannot correctly compute the gradients using regular gradient check techniques. A weighted sum of the output, which is not a constant, is utilized to compute the gradients. (
truein our example, because the activation of a fully connected layer can be softmax)
- layer and input configurations. (
- call
void testFcLayer(string format, size_t nnz) {
// Create layer configuration.
TestConfig config;
config.biasSize = 4096;
config.layerConfig.set_type("fc");
config.layerConfig.set_size(4096);
config.layerConfig.set_active_type("softmax");
config.layerConfig.set_drop_rate(0.1);
// Setup inputs.
config.inputDefs.push_back(
{INPUT_DATA, "layer_0", 8192, nnz, ParaSparse(format)});
config.layerConfig.add_inputs();
LOG(INFO) << config.inputDefs[0].sparse.sparse << " "
<< config.inputDefs[0].sparse.format;
for (auto useGpu : {false, true}) {
testLayerGrad(config, "fc", 100, /* trans */ false, useGpu,
/* weight */ true);
}
}
If you are creating a new file for the test, such as paddle/gserver/tests/testFCGrad.cpp, you need to add the file to paddle/gserver/tests/CMakeLists.txt. An example is given below. All the unit tests will run when you execute the command make tests. Notice that some layers might need high accuracy for the gradient check unit tests to work well. You need to configure WITH_DOUBLE to ON when configuring cmake.
add_unittest_without_exec(test_FCGrad
test_FCGrad.cpp
LayerGradUtil.cpp
TestUtil.cpp)
add_test(NAME test_FCGrad
COMMAND test_FCGrad)
Implement Python Wrapper¶
Implementing Python wrapper allows us to use the added layer in configuration files. All the Python wrappers are in file python/paddle/trainer/config_parser.py. An example of the Python wrapper for fully connected layer is listed below. It has the following steps:
- Use
@config_layer('fc')at the decorator for all the Python wrapper class.fcis the identifier of the layer. - Implements
__init__constructor function. - It first call
super(FCLayer, self).__init__(name, 'fc', size, inputs=inputs, **xargs)base constructor function.FCLayeris the Python wrapper class name, andfcis the layer identifier name. They must be correct in order for the wrapper to work. - Then it computes the size and format (whether sparse) of each transformation matrix as well as the size.
- It first call
- Implements
@config_layer('fc')
class FCLayer(LayerBase):
def __init__(
self,
name,
size,
inputs,
bias=True,
**xargs):
super(FCLayer, self).__init__(name, 'fc', size, inputs=inputs, **xargs)
for input_index in xrange(len(self.inputs)):
input_layer = self.get_input_layer(input_index)
psize = self.config.size * input_layer.size
dims = [input_layer.size, self.config.size]
format = self.inputs[input_index].format
sparse = format == "csr" or format == "csc"
if sparse:
psize = self.inputs[input_index].nnz
self.create_input_parameter(input_index, psize, dims, sparse, format)
self.create_bias_parameter(bias, self.config.size)
In network configuration, the layer can be specifies using the following code snippets. The arguments of this class are:
nameis the name identifier of the layer instance.typeis the type of the layer, specified using layer identifier.sizeis the output size of the layer.biasspecifies whether this layer instance has bias.inputsspecifies a list of layer instance names as inputs.
Layer(
name = "fc1",
type = "fc",
size = 64,
bias = True,
inputs = [Input("pool3")]
)
You are also recommended to implement a helper for the Python wrapper, which makes it easier to write models. You can refer to python/paddle/trainer_config_helpers/layers.py for examples.