diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/config.json"
similarity index 67%
rename from "data_source/exercises/\344\270\255\347\255\211/python/156.exercises/config.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/config.json"
index 0cb618f7a35e83d8aaf78d365a9f49730d217959..3cf5d365dfe570c2972432903ab1ad5bf79bd5cb 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/config.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/config.json"
@@ -1,5 +1,5 @@
{
- "node_id": "dailycode-eab0b681e8ab4258a3286cf1d7642d64",
+ "node_id": "dailycode-857b20ebfd244d708b1010bbecd88556",
"keywords": [],
"children": [],
"keywords_must": [],
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c38d07121739abfe413818b8f193f5ae083b286b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "596d96c92b4b46c39c8f9a5731941081",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b5eb75011acacd630783785a66d9121c04a2ef10
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/101.exercises/solution.md"
@@ -0,0 +1,82 @@
+# 对称二叉树
+
+给定一个二叉树,检查它是否是镜像对称的。
+
+
+
+例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
+
+ 1
+ / \
+ 2 2
+ / \ / \
+3 4 4 3
+
+
+
+
+但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
+
+ 1
+ / \
+ 2 2
+ \ \
+ 3 3
+
+
+
+
+进阶:
+
+你可以运用递归和迭代两种方法解决这个问题吗?
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+
+ def isSymmetric(self, root: TreeNode) -> bool:
+ def judge(left, right):
+ if not left and not right:
+ return True
+ elif not left or not right:
+ return False
+ else:
+ return left.val == right.val and judge(left.right, right.left) and judge(left.left, right.right)
+
+ return judge(root, root)
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/config.json"
similarity index 67%
rename from "data_source/exercises/\344\270\255\347\255\211/python/161.exercises/config.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/config.json"
index cbbc59d2b4f4c03e192406904f81d25937043eb3..0fcc32289fd508c087b01c448e992530b3cfb1be 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/config.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/config.json"
@@ -1,5 +1,5 @@
{
- "node_id": "dailycode-93691725213e43c3a260aeb9f012cd04",
+ "node_id": "dailycode-fffbbc837b574bf8b24cc5dbf815e374",
"keywords": [],
"children": [],
"keywords_must": [],
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c64b9b0c765ed455133be273f10e9dd6e18919ba
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "1a8b3997ea044b9aa0fc4b4c425c39a5",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..85f30f1655ac3cc6e29b3b5e934fde1f9d644fa6
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/104.exercises/solution.md"
@@ -0,0 +1,63 @@
+# 二叉树的最大深度
+
+给定一个二叉树,找出其最大深度。
+
+二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
+
+说明: 叶子节点是指没有子节点的节点。
+
+示例:
+给定二叉树 [3,9,20,null,null,15,7],
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+
+返回它的最大深度 3 。
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def maxDepth(self, root: TreeNode) -> int:
+ if root is None:
+ return 0
+ maxdepth = max(self.maxDepth(root.left),self.maxDepth(root.right)) + 1
+ return maxdepth
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/config.json"
similarity index 67%
rename from "data_source/exercises/\344\270\255\347\255\211/python/177.exercises/config.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/config.json"
index 1c94714292e9da45e2b3382f683044b315c25ea5..8923fb086364251d042cd29f1975f675c523b6e8 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/config.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/config.json"
@@ -1,5 +1,5 @@
{
- "node_id": "dailycode-11b18eef90c24b0dbb4e062de3ebfe75",
+ "node_id": "dailycode-d7b84e9a9afd4d659afb4a7f453180aa",
"keywords": [],
"children": [],
"keywords_must": [],
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1a75b906bc61af80dba0237be43e81a9667e5372
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "418607231ee44c04bf6bbb9e29f3ad69",
+ "author": "csdn.net",
+ "keywords": "树,二叉搜索树,数组,分治,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..ebc0d0fddcd8d2fdbb4b0d75a665b8a825af860f
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/108.exercises/solution.md"
@@ -0,0 +1,89 @@
+# 将有序数组转换为二叉搜索树
+
+给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
+
+高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
+
+
+
+示例 1:
+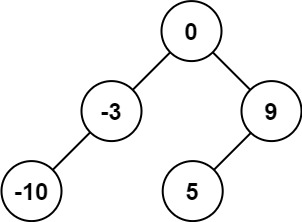 +
+
+输入:nums = [-10,-3,0,5,9]
+输出:[0,-3,9,-10,null,5]
+解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
+ +
+
+
+示例 2:
+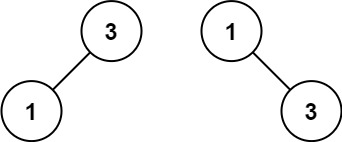 +
+
+输入:nums = [1,3]
+输出:[3,1]
+解释:[1,3] 和 [3,1] 都是高度平衡二叉搜索树。
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 104-104 <= nums[i] <= 104nums 按 严格递增 顺序排列
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def sortedArrayToBST(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: TreeNode
+ """
+ if not nums:
+ return None
+
+ mid = len(nums) // 2
+
+ root = TreeNode(nums[mid])
+
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/config.json"
similarity index 67%
rename from "data_source/exercises/\344\270\255\347\255\211/python/159.exercises/config.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/config.json"
index ce2775d150184e451bc3569ffc8648d1ed985b9a..3feac09941ba16b26408c778425f6987c70d3276 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/config.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/config.json"
@@ -1,5 +1,5 @@
{
- "node_id": "dailycode-b694a6666fd54ceabeec06b1cf481e76",
+ "node_id": "dailycode-2076f08b30ca41268d61320e997b2feb",
"keywords": [],
"children": [],
"keywords_must": [],
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.json"
similarity index 70%
rename from "data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.json"
index b199ca06ecea856f61b0e92bba69ea407b0e8417..c15d084d1b0d84931dec3c74eda2372182663c5c 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "b993e22fcd844d719b7028b0332dd289",
+ "exercise_id": "527b626cb0ac45e0bb5440fc57ba7aaf",
"author": "csdn.net",
"keywords": "树,深度优先搜索,二叉树"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..eb6a3c25b8d9c152edefd1e464879622062ea89c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/110.exercises/solution.md"
@@ -0,0 +1,99 @@
+# 平衡二叉树
+
+给定一个二叉树,判断它是否是高度平衡的二叉树。
+
+本题中,一棵高度平衡二叉树定义为:
+
+
+一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
+
+
+
+
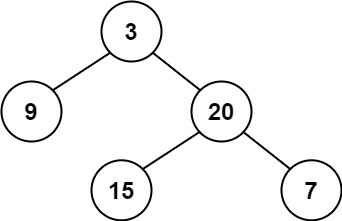
+示例 1:
+ +
+
+输入:root = [3,9,20,null,null,15,7]
+输出:true
+
+
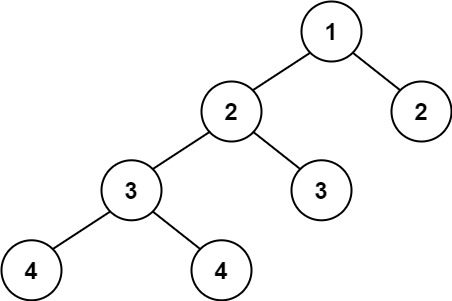
+示例 2:
+ +
+
+输入:root = [1,2,2,3,3,null,null,4,4]
+输出:false
+
+
+示例 3:
+
+
+输入:root = []
+输出:true
+
+
+
+
+提示:
+
+
+ - 树中的节点数在范围
[0, 5000] 内
+ -104 <= Node.val <= 104
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution(object):
+ def isBalanced(self, root):
+ if not root:
+ return True
+ left_depth = self.get_depth(root.left)
+ right_depth = self.get_depth(root.right)
+ if abs(left_depth - right_depth) > 1:
+ return False
+
+ else:
+ return self.isBalanced(root.left) and self.isBalanced(root.right)
+
+ def get_depth(self, root):
+
+ if root is None:
+ return 0
+ else:
+ return max(self.get_depth(root.left), self.get_depth(root.right)) + 1
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3ca6e0dd702aee67ecbef46ad52f56cfb3a635c1
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-a30e8dd902af4c63bccad92d15bf88a4",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2ad70cc690253a89939eee5b539218febb5d3af8
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "0d322201b5c84b42963c70f0d58a3b14",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..abe62efd905968e7bf4e5cd1fe186638be7eefab
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/111.exercises/solution.md"
@@ -0,0 +1,92 @@
+# 二叉树的最小深度
+
+给定一个二叉树,找出其最小深度。
+
+最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
+
+说明:叶子节点是指没有子节点的节点。
+
+
+
+示例 1:
+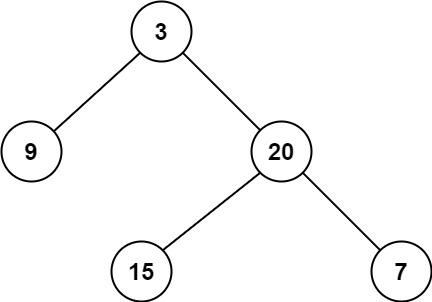 +
+
+输入:root = [3,9,20,null,null,15,7]
+输出:2
+
+
+示例 2:
+
+
+输入:root = [2,null,3,null,4,null,5,null,6]
+输出:5
+
+
+
+
+提示:
+
+
+ - 树中节点数的范围在
[0, 105] 内
+ -1000 <= Node.val <= 1000
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def minDepth(self, root: TreeNode) -> int:
+ if not root:
+ return 0
+ queue = [root]
+ count = 1
+ while queue:
+
+ next_queue = []
+ for node in queue:
+ if not node.left and not node.right:
+ return count
+ if node.left:
+ next_queue.append(node.left)
+ if node.right:
+ next_queue.append(node.right)
+ queue = next_queue
+ count += 1
+
+ return count
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d3d786431ecdfbb8b48276d3e00f9632949cb031
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-7d73aa3dd0cd4eb892fa44ddb37e4c2d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8f43038614959df57de5b4a4bce109483d11bba7
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "d31b89d8cc584f96b2d037e3bd0c270b",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..5c554b851767e7af97a94af4dfa9ce0f6281a782
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/112.exercises/solution.md"
@@ -0,0 +1,89 @@
+# 路径总和
+
+给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
+
+叶子节点 是指没有子节点的节点。
+
+
+
+示例 1:
+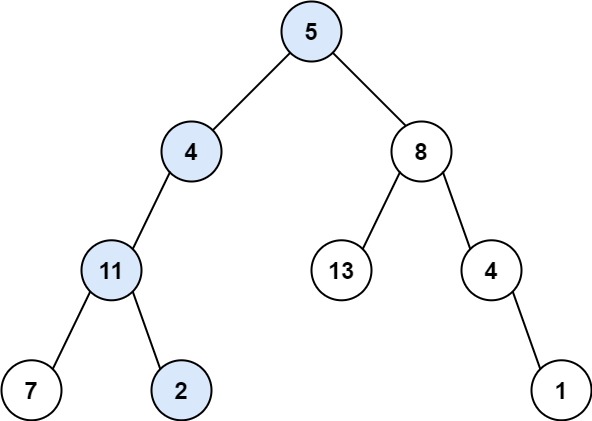 +
+
+输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
+输出:true
+
+
+示例 2:
+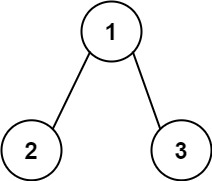 +
+
+输入:root = [1,2,3], targetSum = 5
+输出:false
+
+
+示例 3:
+
+
+输入:root = [1,2], targetSum = 0
+输出:false
+
+
+
+
+提示:
+
+
+ - 树中节点的数目在范围
[0, 5000] 内
+ -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def hasPathSum(self, root, sum):
+ """
+ :type root: TreeNode
+ :type sum: int
+ :rtype: bool
+ """
+ if root is None:
+ return False
+ if sum == root.val and root.left is None and root.right is None:
+ return True
+ return self.hasPathSum(root.left, sum-root.val) or self.hasPathSum(root.right, sum-root.val)
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..f726c248fb1b435a429ded92f51a7d2f9b9270bb
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ccae2c71a01242969ef74c6b66f3f9de",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/265.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.json"
similarity index 68%
rename from "data_source/exercises/\345\233\260\351\232\276/python/265.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.json"
index f35a8fe3adf7b6a0891e510ec935c51cb61c9411..75c051a99778586a4e15c9847fbebc1b1e3b234b 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/265.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "a1166dcdfb0249239e461a48463b66a9",
+ "exercise_id": "a31850a1e76b4f1e88bd85c9c24ec688",
"author": "csdn.net",
"keywords": "数组,动态规划"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..992b73bcd53eb8f071b0e7a6ef1f23ed50648f8b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/118.exercises/solution.md"
@@ -0,0 +1,80 @@
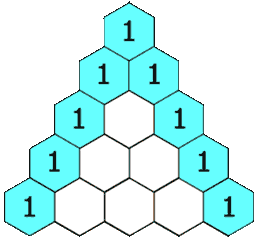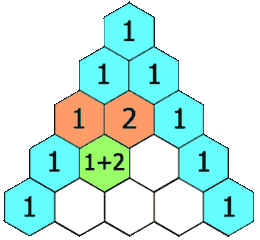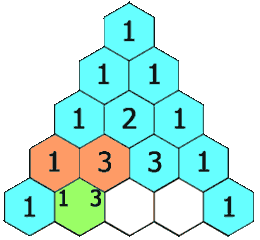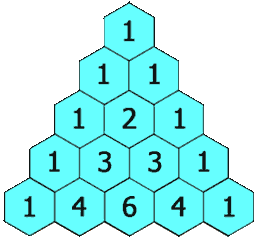
+# 杨辉三角
+
+给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
+
+在「杨辉三角」中,每个数是它左上方和右上方的数的和。
+
+
+
+
+
+示例 1:
+
+
+输入: numRows = 5
+输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
+
+
+示例 2:
+
+
+输入: numRows = 1
+输出: [[1]]
+
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+class Solution:
+ def generate(self, numRows: int) -> List[List[int]]:
+ if numRows == 0:
+ return []
+ if numRows == 1:
+ return [[1]]
+ if numRows == 2:
+ return [[1], [1, 1]]
+ result = [[1], [1, 1]] + [[] for i in range(numRows - 2)]
+ for i in range(2, numRows):
+ for j in range(i + 1):
+ if j == 0 or j == i:
+ result[i].append(1)
+ else:
+ result[i].append(result[i - 1][j - 1] + result[i - 1][j])
+ return result
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8a1cd3ee3caf0f10553f9c49cac875b1d2b38b55
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-84e718d951274716ac515bf786401eec",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..5ba48c6d330c45ef17ab1f60526c1aa62a509885
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "9d2fe777ecec45f8ba4729b64a610a63",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..40e04550d90fe53df1ad9b38062a8c75ce43867b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/119.exercises/solution.md"
@@ -0,0 +1,92 @@
+# 杨辉三角 II
+
+给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。
+
+在「杨辉三角」中,每个数是它左上方和右上方的数的和。
+
+
+
+
+
+示例 1:
+
+
+输入: rowIndex = 3
+输出: [1,3,3,1]
+
+
+示例 2:
+
+
+输入: rowIndex = 0
+输出: [1]
+
+
+示例 3:
+
+
+输入: rowIndex = 1
+输出: [1,1]
+
+
+
+
+提示:
+
+
+
+
+
+进阶:
+
+你可以优化你的算法到 O(rowIndex) 空间复杂度吗?
+
+
+## template
+
+```python
+
+class Solution(object):
+ def getRow(self, rowIndex):
+ """
+ :type rowIndex: int
+ :rtype: List[int]
+ """
+ if rowIndex == 0:
+ return [1]
+
+ pas = [1]
+ for i in range(rowIndex):
+
+ newLine = list(map(lambda x, y: x + y, [0] + pas, pas + [0]))
+ pas = newLine
+ return pas
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d988142e225deead5f7c4099e3b110226757655f
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-b731ace07be543f681b7f899761c0466",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b79c4e44873b1346c80901bc3e7256653fe06713
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c7e978e2413d43bf91613f4e6ff13213",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..78c8a12a60dc775366949b569235d9ec5286425b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/121.exercises/solution.md"
@@ -0,0 +1,83 @@
+# 买卖股票的最佳时机
+
+给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
+
+你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
+
+返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
+
+
+
+示例 1:
+
+
+输入:[7,1,5,3,6,4]
+输出:5
+解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
+ 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
+
+
+示例 2:
+
+
+输入:prices = [7,6,4,3,1]
+输出:0
+解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
+
+
+
+
+提示:
+
+
+ 1 <= prices.length <= 1050 <= prices[i] <= 104
+
+
+## template
+
+```python
+
+class Solution(object):
+ def maxProfit(self, prices):
+ """
+ :type prices: List[int]
+ :rtype: int
+ """
+ temp = []
+ if not prices or len(prices) == 1:
+ return 0
+ for i in range(len(prices) - 1):
+ temp.append(max(prices[i + 1 :]) - prices[i])
+ if max(temp) >= 0:
+ return max(temp)
+ else:
+ return 0
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..217d6ef4908f64e8bc7d1371407392bbc8d2bc01
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ecc091b493f749e8a3309f75b7170e78",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..38f52d889aaaa75f65f677ec3ec8aea80746e241
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "8603270bc7f24c5491c77be4ccb437ce",
+ "author": "csdn.net",
+ "keywords": "贪心,数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..afe4c557c3bc40c8e8ab563c4f284b352348c23a
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/122.exercises/solution.md"
@@ -0,0 +1,118 @@
+# 买卖股票的最佳时机 II
+
+给定一个数组 prices ,其中 prices[i] 是一支给定股票第 i 天的价格。
+
+设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
+
+注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+
+
+
+示例 1:
+
+
+输入: prices = [7,1,5,3,6,4]
+输出: 7
+解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
+ 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
+
+
+示例 2:
+
+
+输入: prices = [1,2,3,4,5]
+输出: 4
+解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
+ 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
+
+
+示例 3:
+
+
+输入: prices = [7,6,4,3,1]
+输出: 0
+解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
+
+
+
+提示:
+
+
+ 1 <= prices.length <= 3 * 1040 <= prices[i] <= 104
+
+
+## template
+
+```python
+class Solution(object):
+ def maxProfit(self, prices):
+ """
+ :type prices: List[int]
+ :rtype: int
+ """
+
+ hold = 0
+ pric = []
+ temp = []
+ flag = 0
+ msum = 0
+ if len(prices) <= 2:
+ if not prices:
+ return 0
+ if len(prices) == 1:
+ return 0
+ if prices[0] > prices[1]:
+ return 0
+ if prices[0] < prices[1]:
+ return prices[1] - prices[0]
+
+ for i in range(len(prices) - 1):
+ if prices[i + 1] > prices[i] and hold != 1:
+ hold = 1
+ flag = i
+ continue
+
+ if prices[i + 1] < prices[i] and hold == 1:
+ pric.append(prices[flag])
+ pric.append(prices[i])
+ hold = 0
+ else:
+ continue
+ for i in range(0, len(pric), 2):
+ temp.append(pric[i + 1] - pric[i])
+ msum = sum(temp)
+ if hold == 1:
+ msum = msum + prices[-1] - prices[flag]
+
+ return msum
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..300e8a73df643d1141386887351f52318bb64d79
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-38358c269a97421ab9ef0ddc4846a0a8",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.json"
similarity index 68%
rename from "data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.json"
index 5a6f54b170ed658fd54c71b29069bca4ddee1450..25cbaee44faba0c5fe2157d8ff6122805d18e73c 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "8211bd137d5249b28c413ef2fe4c8474",
+ "exercise_id": "14ba2edd5caa47d98a9d42a3dcbe1889",
"author": "csdn.net",
"keywords": "双指针,字符串"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b421624488bbfef8b288f76bfc0e7c1937c840ee
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/125.exercises/solution.md"
@@ -0,0 +1,85 @@
+# 验证回文串
+
+给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
+
+说明:本题中,我们将空字符串定义为有效的回文串。
+
+
+
+示例 1:
+
+
+输入: "A man, a plan, a canal: Panama"
+输出: true
+解释:"amanaplanacanalpanama" 是回文串
+
+
+示例 2:
+
+
+输入: "race a car"
+输出: false
+解释:"raceacar" 不是回文串
+
+
+
+
+提示:
+
+
+ 1 <= s.length <= 2 * 105- 字符串
s 由 ASCII 字符组成
+
+
+
+## template
+
+```python
+class Solution(object):
+ def isPalindrome(self, s):
+ """
+ :type s: str
+ :rtype: bool
+ """
+ i = 0
+ j = len(s) - 1
+ while i < j:
+ if s[i].isalnum() and s[j].isalnum():
+ if s[i].upper() == s[j].upper():
+ i += 1
+ j -= 1
+ else:
+ return False
+ else:
+ if not s[i].isalnum():
+ i += 1
+ if not s[j].isalnum():
+ j -= 1
+ return True
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e29592d775f2bf99a0caa1c6d17163b2790e619c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-b8b700c8be4a456889f3bdf2508bda92",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..32ec49e6fadd768c0576ab3566702f251da2380a
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ae412fd242cc4bb4a36d550479a9ab13",
+ "author": "csdn.net",
+ "keywords": "位运算,数组"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..85a675d2f17b2611ccf957f71999f86e657c92ae
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/136.exercises/solution.md"
@@ -0,0 +1,61 @@
+# 只出现一次的数字
+
+给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
+
+说明:
+
+你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
+
+示例 1:
+
+输入: [2,2,1]
+输出: 1
+
+
+示例 2:
+
+输入: [4,1,2,1,2]
+输出: 4
+
+
+## template
+
+```python
+class Solution:
+ def singleNumber(self, nums: List[int]) -> int:
+ nums = sorted(nums)
+ i = 0
+ while i < len(nums) - 1:
+ if nums[i] == nums[i + 1]:
+ i += 2
+ else:
+ return nums[i]
+ return nums[i]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..5ee306d0143076b8c11cfe05fdb8c9123722e421
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f38f728eb8ce496791f8904f6a664173",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b2805c649041899399fbcf2f718aad53d1355eb8
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c1ed8b0c386f4957a33dae2b72214ebc",
+ "author": "csdn.net",
+ "keywords": "哈希表,链表,双指针"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..1f1b4ca44ecaca22a87d1f4f77c4480704d56dcf
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/141.exercises/solution.md"
@@ -0,0 +1,103 @@
+# 环形链表
+
+给定一个链表,判断链表中是否有环。
+
+如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
+
+如果链表中存在环,则返回 true 。 否则,返回 false 。
+
+
+
+进阶:
+
+你能用 O(1)(即,常量)内存解决此问题吗?
+
+
+
+示例 1:
+
+
+
+输入:head = [3,2,0,-4], pos = 1
+输出:true
+解释:链表中有一个环,其尾部连接到第二个节点。
+
+
+示例 2:
+
+
+
+输入:head = [1,2], pos = 0
+输出:true
+解释:链表中有一个环,其尾部连接到第一个节点。
+
+
+示例 3:
+
+
+
+输入:head = [1], pos = -1
+输出:false
+解释:链表中没有环。
+
+
+
+
+提示:
+
+
+ - 链表中节点的数目范围是
[0, 104]
+ -105 <= Node.val <= 105pos 为 -1 或者链表中的一个 有效索引 。
+
+
+## template
+
+```python
+
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not (head and head.next):
+ return False
+ slow = head
+ fast = head.next
+ while fast.next and fast.next.next:
+ if slow == fast:
+ return True
+ slow = slow.next
+ fast = fast.next.next
+ return False
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d543b30a8e51ad951d66f19dce4180beb5032021
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-bc5c9dcfba284e84a8c6152a629882cd",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..adcd6d938bed778a03b56cdfa2c329c2594877ac
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "801926d6688b49c3aa255367ef29d997",
+ "author": "csdn.net",
+ "keywords": "栈,树,深度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..36065b16b0f1df74889097b9644af3ba1c91fd2b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/144.exercises/solution.md"
@@ -0,0 +1,104 @@
+# 二叉树的前序遍历
+
+给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
+
+
+
+示例 1:
+ +
+
+输入:root = [1,null,2,3]
+输出:[1,2,3]
+
+
+示例 2:
+
+
+输入:root = []
+输出:[]
+
+
+示例 3:
+
+
+输入:root = [1]
+输出:[1]
+
+
+示例 4:
+ +
+
+输入:root = [1,2]
+输出:[1,2]
+
+
+示例 5:
+ +
+
+输入:root = [1,null,2]
+输出:[1,2]
+
+
+
+
+提示:
+
+
+ - 树中节点数目在范围
[0, 100] 内
+ -100 <= Node.val <= 100
+
+
+
+进阶:递归算法很简单,你可以通过迭代算法完成吗?
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def __init__(self):
+ self.ans = []
+
+ def preorderTraversal(self, root: TreeNode) -> List[int]:
+ if not root:
+ return []
+ self.ans.append(root.val)
+ self.preorderTraversal(root.left)
+ self.preorderTraversal(root.right)
+ return self.ans
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ef40ff2f3549501719888fac0db8488f6a12788b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-d4fe0f464d814a09ba53b9dbfbf56e3a",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e63e57be3f4d4a0ca066f0280463829a13ecc562
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "54d6ae2161f2477997472d9efe8863c6",
+ "author": "csdn.net",
+ "keywords": "栈,树,深度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..fb0bfb4c721248aea147e47a9d2381389f662d1e
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/145.exercises/solution.md"
@@ -0,0 +1,72 @@
+# 二叉树的后序遍历
+
+给定一个二叉树,返回它的 后序 遍历。
+
+示例:
+
+输入: [1,null,2,3]
+ 1
+ \
+ 2
+ /
+ 3
+
+输出: [3,2,1]
+
+进阶: 递归算法很简单,你可以通过迭代算法完成吗?
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution(object):
+ def postorderTraversal(self, root: TreeNode):
+
+ if root is None:
+ return []
+
+ stack, output = [], []
+ stack.append(root)
+ while stack:
+ node = stack.pop()
+ output.append(node.val)
+
+ if node.left:
+ stack.append(node.left)
+ if node.right:
+ stack.append(node.right)
+
+ return output[::-1]
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3a34f2cf6181724de7a08b8ee22dfb328e5a339b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-66d52c7607294afba95f84755f347292",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b2a0fc9561d583c8d8f8a1cead53d06384bb103f
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "4bb5f28525fe48478a71b212cd28e59e",
+ "author": "csdn.net",
+ "keywords": "栈,设计"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..113654d6354d3f34968d317c15e83bcb47fc5f38
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/155.exercises/solution.md"
@@ -0,0 +1,97 @@
+# 最小栈
+
+设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
+
+
+ push(x) —— 将元素 x 推入栈中。pop() —— 删除栈顶的元素。top() —— 获取栈顶元素。getMin() —— 检索栈中的最小元素。
+
+
+
+示例:
+
+输入:
+["MinStack","push","push","push","getMin","pop","top","getMin"]
+[[],[-2],[0],[-3],[],[],[],[]]
+
+输出:
+[null,null,null,null,-3,null,0,-2]
+
+解释:
+MinStack minStack = new MinStack();
+minStack.push(-2);
+minStack.push(0);
+minStack.push(-3);
+minStack.getMin(); --> 返回 -3.
+minStack.pop();
+minStack.top(); --> 返回 0.
+minStack.getMin(); --> 返回 -2.
+
+
+
+
+提示:
+
+
+ pop、top 和 getMin 操作总是在 非空栈 上调用。
+
+
+## template
+
+```python
+class MinStack:
+ def __init__(self):
+ self.data = [(None, float("inf"))]
+
+ def push(self, x: "int") -> "None":
+ self.data.append((x, min(x, self.data[-1][1])))
+
+ def pop(self) -> "None":
+ if len(self.data) > 1:
+ self.data.pop()
+
+ def top(self) -> "int":
+ return self.data[-1][0]
+
+ def getMin(self) -> "int":
+ return self.data[-1][1]
+
+
+# Your MinStack object will be instantiated and called as such:
+# obj = MinStack()
+# obj.push(x)
+# obj.pop()
+# param_3 = obj.top()
+# param_4 = obj.getMin()
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8514c501df454e3592d3d22e4d9084c587e89a50
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-fd779c4b6023499ca4ca56d2a5622f53",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1a1584464ab533a549b1467194f2d97e542d92bb
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "d212ea52512549ee9e3064e2add0ba00",
+ "author": "csdn.net",
+ "keywords": "哈希表,链表,双指针"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..09478dd854ff44ad18c0a8cdfd358e67fe61a18b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/160.exercises/solution.md"
@@ -0,0 +1,138 @@
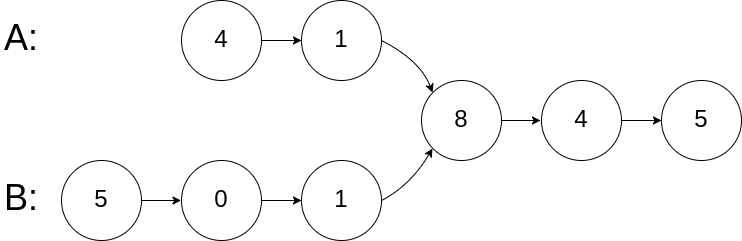
+# 相交链表
+
+给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
+
+图示两个链表在节点 c1 开始相交:
+
+
+
+题目数据 保证 整个链式结构中不存在环。
+
+注意,函数返回结果后,链表必须 保持其原始结构 。
+
+
+
+示例 1:
+
+
+
+
+输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
+输出:Intersected at '8'
+解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
+从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
+在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
+
+
+示例 2:
+
+
+
+
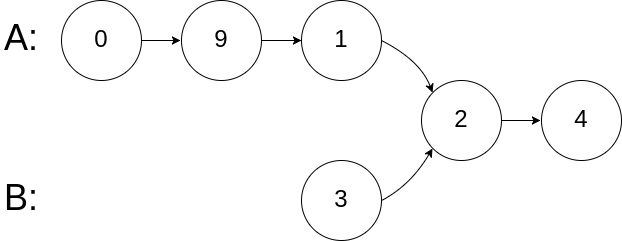
+输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
+输出:Intersected at '2'
+解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
+从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
+在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
+
+
+示例 3:
+
+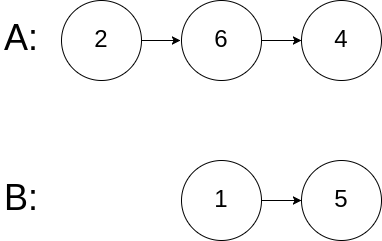
+
+
+输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
+输出:null
+解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
+由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
+这两个链表不相交,因此返回 null 。
+
+
+
+
+提示:
+
+
+ listA 中节点数目为 mlistB 中节点数目为 n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA 和 listB 没有交点,intersectVal 为 0
+ - 如果
listA 和 listB 有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
+
+
+
+
+进阶:你能否设计一个时间复杂度 O(n) 、仅用 O(1) 内存的解决方案?
+
+
+## template
+
+```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution:
+ def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
+ if not headA or not headB:
+ return None
+ wei_A = []
+ while headA:
+ wei_A.append(headA)
+ headA = headA.next
+ wei_A = wei_A[::-1]
+ wei_B = []
+ while headB:
+ wei_B.append(headB)
+ headB = headB.next
+ wei_B = wei_B[::-1]
+ count = -1
+ lA = len(wei_A)
+ lB = len(wei_B)
+ if lA < lB:
+ copy = wei_B
+ wei_B = wei_A
+ wei_A = copy
+ lA, lB = lB, lA
+ for i in range(lB):
+ if wei_A[i] == wei_B[i]:
+ count += 1
+ else:
+ break
+ if count != -1:
+ return wei_A[count]
+ else:
+ return None
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d71d484d594f655c18be6132e34d671cf40db064
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-9c0694e75d184730a04e2b16c008bcff",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..fab274927f1edb9118e49b6fb2d4508611f55e3a
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "35f3bc4609d04f7a84232885378e69c6",
+ "author": "csdn.net",
+ "keywords": "数组,双指针,二分查找"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..d564077199999efbc497d44c1e37ba0bff43ea4a
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/167.exercises/solution.md"
@@ -0,0 +1,92 @@
+# 两数之和 II
+
+给定一个已按照 非递减顺序排列 的整数数组 numbers ,请你从数组中找出两个数满足相加之和等于目标数 target 。
+
+函数应该以长度为 2 的整数数组的形式返回这两个数的下标值。numbers 的下标 从 1 开始计数 ,所以答案数组应当满足 1 <= answer[0] < answer[1] <= numbers.length 。
+
+你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
+
+
+示例 1:
+
+
+输入:numbers = [2,7,11,15], target = 9
+输出:[1,2]
+解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
+
+
+示例 2:
+
+
+输入:numbers = [2,3,4], target = 6
+输出:[1,3]
+
+
+示例 3:
+
+
+输入:numbers = [-1,0], target = -1
+输出:[1,2]
+
+
+
+
+提示:
+
+
+ 2 <= numbers.length <= 3 * 104-1000 <= numbers[i] <= 1000numbers 按 非递减顺序 排列-1000 <= target <= 1000- 仅存在一个有效答案
+
+
+
+## template
+
+```python
+
+class Solution(object):
+ def twoSum(self, numbers, target):
+ """
+ :type numbers: List[int]
+ :type target: int
+ :rtype: List[int]
+ """
+ d = {}
+ size = 0
+ while size < len(numbers):
+ if not numbers[size] in d:
+ d[numbers[size]] = size + 1
+ if target - numbers[size] in d:
+ if d[target - numbers[size]] < size + 1:
+ answer = [d[target - numbers[size]], size + 1]
+ return answer
+ size = size + 1
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..139709c59cd82893d2a972f3dffebb7770538560
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-2bc12d92020145e9ac2a3ffc6c585faa",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0ef4d59dfc00b111dd943bc229c04aaae89e0712
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "93d222e11bc247efb7e2e1bf99b1db48",
+ "author": "csdn.net",
+ "keywords": "数学,字符串"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..d8a01882abbecae367ef8f0090e5c42bd10fec6d
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/168.exercises/solution.md"
@@ -0,0 +1,111 @@
+# Excel表列名称
+
+给你一个整数 columnNumber ,返回它在 Excel 表中相对应的列名称。
+
+例如:
+
+
+A -> 1
+B -> 2
+C -> 3
+...
+Z -> 26
+AA -> 27
+AB -> 28
+...
+
+
+
+
+示例 1:
+
+
+输入:columnNumber = 1
+输出:"A"
+
+
+示例 2:
+
+
+输入:columnNumber = 28
+输出:"AB"
+
+
+示例 3:
+
+
+输入:columnNumber = 701
+输出:"ZY"
+
+
+示例 4:
+
+
+输入:columnNumber = 2147483647
+输出:"FXSHRXW"
+
+
+
+
+提示:
+
+
+ 1 <= columnNumber <= 231 - 1
+
+
+## template
+
+```python
+class Solution(object):
+ def convertToTitle(self, n):
+ """
+ :type n: int
+ :rtype: str
+ """
+ d = {}
+ r = []
+ a = ""
+ for i in range(1, 27):
+ d[i] = chr(64 + i)
+ if n <= 26:
+ return d[n]
+ if n % 26 == 0:
+ n = n / 26 - 1
+ a = "Z"
+ while n > 26:
+ s = n % 26
+ n = n // 26
+ r.append(s)
+ result = d[n]
+ for i in r[::-1]:
+ result += d[i]
+ return result + a
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..404efaaecaf757bc1e902b56179e9d93f45c0383
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-b39f0553588c467692394aaf6fac7c7e",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b1cf859be409a45088a6760daaa36d6ad52dc7c3
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "02def488570747418e9d712a1f26f324",
+ "author": "csdn.net",
+ "keywords": "数组,哈希表,分治,计数,排序"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..4508a17000f89ba6fbe2544da23619b84f131a7b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/169.exercises/solution.md"
@@ -0,0 +1,75 @@
+# 多数元素
+
+给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
+
+你可以假设数组是非空的,并且给定的数组总是存在多数元素。
+
+
+
+示例 1:
+
+
+输入:[3,2,3]
+输出:3
+
+示例 2:
+
+
+输入:[2,2,1,1,1,2,2]
+输出:2
+
+
+
+
+进阶:
+
+
+ - 尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
+
+
+
+## template
+
+```python
+class Solution:
+ def majorityElement(self, nums: List[int]) -> int:
+ count, candi = 0, 0
+ for i in nums:
+ if i == candi:
+ count += 1
+ else:
+ if count == 0:
+ candi = i
+ count = 1
+ else:
+ count -= 1
+ return candi
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0f09d4e1464a832662ec1985d166443a9a1c3c28
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-5305f23daf5b42dd98e7bbdc5293c844",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3792bae61c77ef2837be4ab5a22263e76e5ddfcc
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "aec8ebe4c8c34fc39cf954a403a34847",
+ "author": "csdn.net",
+ "keywords": "数学,字符串"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..d5e312a4a2ea6866dffec0a227f4455f3ad36058
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/171.exercises/solution.md"
@@ -0,0 +1,98 @@
+# Excel表列序号
+
+给你一个字符串 columnTitle ,表示 Excel 表格中的列名称。返回该列名称对应的列序号。
+
+
+
+例如,
+
+
+ A -> 1
+ B -> 2
+ C -> 3
+ ...
+ Z -> 26
+ AA -> 27
+ AB -> 28
+ ...
+
+
+
+
+示例 1:
+
+
+输入: columnTitle = "A"
+输出: 1
+
+
+示例 2:
+
+
+输入: columnTitle = "AB"
+输出: 28
+
+
+示例 3:
+
+
+输入: columnTitle = "ZY"
+输出: 701
+
+示例 4:
+
+
+输入: columnTitle = "FXSHRXW"
+输出: 2147483647
+
+
+
+
+提示:
+
+
+ 1 <= columnTitle.length <= 7columnTitle 仅由大写英文组成columnTitle 在范围 ["A", "FXSHRXW"] 内
+
+
+## template
+
+```python
+class Solution:
+ def titleToNumber(self, s: str) -> int:
+ ans = 0
+ for i in range(len(s)):
+ n = ord(s[i]) - ord("A") + 1
+ ans = ans * 26 + n
+ return ans
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d637f14a280c9c4c73f05861e08903ea69602900
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-a9a0b2f07bdd4d47aa980509ff681936",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.json"
similarity index 50%
rename from "data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.json"
index deb3f25f21a149af0bc7f8619bb6466bae3556c0..371f94365f947f48d90ddd0e6f04cb37427b49bd 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "a4d7fa87cede461a9ba8e62a01343421",
+ "exercise_id": "6b2211be24844846afddd9cec234f4e5",
"author": "csdn.net",
- "keywords": "shell"
+ "keywords": "数学"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e78341fe270fde1e937a9917f12740ddc912d8f7
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/172.exercises/solution.md"
@@ -0,0 +1,83 @@
+# 阶乘后的零
+
+给定一个整数 n ,返回 n! 结果中尾随零的数量。
+
+提示 n! = n * (n - 1) * (n - 2) * ... * 3 * 2 * 1
+
+
+
+示例 1:
+
+
+输入:n = 3
+输出:0
+解释:3! = 6 ,不含尾随 0
+
+
+示例 2:
+
+
+输入:n = 5
+输出:1
+解释:5! = 120 ,有一个尾随 0
+
+
+示例 3:
+
+
+输入:n = 0
+输出:0
+
+
+
+
+提示:
+
+
+
+
+
+进阶:你可以设计并实现对数时间复杂度的算法来解决此问题吗?
+
+
+## template
+
+```python
+class Solution:
+ def trailingZeroes(self, n: int) -> int:
+ zero_count = 0
+ current_multiple = 5
+ while n >= current_multiple:
+ zero_count += n // current_multiple
+ current_multiple *= 5
+ return zero_count
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8a76d63126af1ce8039581f4fde1b0b7695dbe4c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ba1e4e9897d64eaf9ac066a03437b62f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..decb2ff5974530931eb002fb8439dd7da235f2eb
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "1ba368a03960439599d6d1b5e6867284",
+ "author": "csdn.net",
+ "keywords": "位运算,分治"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..bdda53441f0ed1a745799525e31fb06af6aa5f69
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/190.exercises/solution.md"
@@ -0,0 +1,82 @@
+# 颠倒二进制位
+
+颠倒给定的 32 位无符号整数的二进制位。
+
+提示:
+
+
+ - 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
+ - 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数 -1073741825。
+
+
+
+
+示例 1:
+
+
+输入:n = 00000010100101000001111010011100
+输出:964176192 (00111001011110000010100101000000)
+解释:输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596,
+ 因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
+
+示例 2:
+
+
+输入:n = 11111111111111111111111111111101
+输出:3221225471 (10111111111111111111111111111111)
+解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293,
+ 因此返回 3221225471 其二进制表示形式为 10111111111111111111111111111111 。
+
+
+
+提示:
+
+
+
+
+
+进阶: 如果多次调用这个函数,你将如何优化你的算法?
+
+
+## template
+
+```python
+class Solution:
+ def reverseBits(self, n: int) -> int:
+ j = 0
+ y = bin(n)[2::]
+ if len(y) != 32:
+ j = 32 - len(y)
+ m = y[::-1]
+ m = m + "0" * j
+ return int(m, 2)
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c66d46fc084ea46b856c3e2df22c006c96014560
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-e46a5de28b3b481ca0a2f72f087542bf",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.json"
similarity index 66%
rename from "data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.json"
index cf41a14625f7b3e08e457b2003f32cbf02283fa2..4548218872dcc5951fd8d179ebbee44488db850f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "9ac6dd56154b4494a3cf9d08fab84d02",
+ "exercise_id": "430b7b13abf747cc86a8ceb4b3db33d8",
"author": "csdn.net",
"keywords": "位运算"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..60507a63507287594633025a82614d325d04a99b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/191.exercises/solution.md"
@@ -0,0 +1,107 @@
+# 位1的个数
+
+编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量)。
+
+
+
+提示:
+
+
+ - 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
+ - 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
+
+
+
+
+示例 1:
+
+
+输入:00000000000000000000000000001011
+输出:3
+解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
+
+
+示例 2:
+
+
+输入:00000000000000000000000010000000
+输出:1
+解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
+
+
+示例 3:
+
+
+输入:11111111111111111111111111111101
+输出:31
+解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
+
+
+
+提示:
+
+
+
+
+
+
+
+进阶:
+
+
+ - 如果多次调用这个函数,你将如何优化你的算法?
+
+
+
+## template
+
+```python
+class Solution(object):
+ def majorityElement(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: int
+ """
+ n = len(nums)
+ if n == 1:
+ return nums[0]
+
+ dic = {}
+ for num in nums:
+ if num in dic.keys():
+ dic[num] += 1
+ if dic[num] > n / 2:
+ return num
+ else:
+ dic[num] = 1
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a555e5cc8b86cee0ad3de18200390ab278a30528
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-00d14814b994486488ba5843af2e195d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ff729f496083a50c62db6b1d100ae4648269b37e
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "2ae80a2197fc4ecf8a5cf1a7b5a944fe",
+ "author": "csdn.net",
+ "keywords": "哈希表,数学,双指针"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..60afca5f8c0c60c48da2b5dbc26f4c28f257708b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/202.exercises/solution.md"
@@ -0,0 +1,95 @@
+# 快乐数
+
+编写一个算法来判断一个数 n 是不是快乐数。
+
+「快乐数」定义为:
+
+
+ - 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
+ - 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
+ - 如果 可以变为 1,那么这个数就是快乐数。
+
+
+如果 n 是快乐数就返回 true ;不是,则返回 false 。
+
+
+
+示例 1:
+
+
+输入:19
+输出:true
+解释:
+12 + 92 = 82
+82 + 22 = 68
+62 + 82 = 100
+12 + 02 + 02 = 1
+
+
+示例 2:
+
+
+输入:n = 2
+输出:false
+
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+class Solution(object):
+ def isHappy(self, n):
+ """
+ :type n: int
+ :rtype: bool
+ """
+ d = {}
+ while True:
+ l = list(map(int, list(str(n))))
+ m = 0
+ for i in l:
+ m += i ** 2
+ if m in d:
+ print(d)
+ return False
+ if m == 1:
+ print(d)
+ return True
+ d[m] = m
+ n = m
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..29407cac85c8b6267a9ad5410811cd72c700cac6
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f9e03e7069b44ff183ff2c353b154b9d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ba2d33911652a960d8b644a5e38ec905c2366409
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ca6e65c26e5545acac0eb3d2f4da1baa",
+ "author": "csdn.net",
+ "keywords": "递归,链表"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c90595f14d96bfdfc9bbbdecff98a742a046f49b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/203.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 移除链表元素
+
+给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
+
+
+示例 1:
+ +
+
+输入:head = [1,2,6,3,4,5,6], val = 6
+输出:[1,2,3,4,5]
+
+
+示例 2:
+
+
+输入:head = [], val = 1
+输出:[]
+
+
+示例 3:
+
+
+输入:head = [7,7,7,7], val = 7
+输出:[]
+
+
+
+
+提示:
+
+
+ - 列表中的节点数目在范围
[0, 104] 内
+ 1 <= Node.val <= 500 <= val <= 50
+
+
+## template
+
+```python
+
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution(object):
+ def removeElements(self, head, val):
+ """
+ :type head: ListNode
+ :type val: int
+ :rtype: ListNode
+ """
+ p = ListNode(0)
+ p.next = head
+ while p.next:
+ if p.next.val == val:
+ if p.next == head:
+ head = head.next
+ p.next = head
+ else:
+ p.next = p.next.next
+ else:
+ p = p.next
+ return head
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..7a78ed0fc296891688299a5e542dedcf1033557b
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-dbd76c754b4040be93aa6f8f90e7b451",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..16bcd9ec86c490a6c95126a23ed0e23b57ee4e94
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c89c149170ef4f7f80640c0daaa90947",
+ "author": "csdn.net",
+ "keywords": "数组,数学,枚举,数论"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b916c5f37ab1eb9545be40826cc82c57adeb8865
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/204.exercises/solution.md"
@@ -0,0 +1,80 @@
+# 计数质数
+
+统计所有小于非负整数 n 的质数的数量。
+
+
+
+示例 1:
+
+输入:n = 10
+输出:4
+解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
+
+
+示例 2:
+
+输入:n = 0
+输出:0
+
+
+示例 3:
+
+输入:n = 1
+输出:0
+
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+
+class Solution:
+ def countPrimes(self, n: int) -> int:
+
+ is_prime = [1] * n
+
+ count = 0
+ for i in range(2, n):
+
+ if is_prime[i]:
+ count += 1
+
+ for j in range(i * i, n, i):
+ is_prime[j] = 0
+
+ return count
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d1255debbde53da9d4c360f095e1827d80e14600
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-0dea8f94ab7349a68257ce162478c6a7",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..fc261ca6196dbe89f89a8a358c1374b90dac16ad
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "59b9df4c8d5e478bbcc729f611519790",
+ "author": "csdn.net",
+ "keywords": "哈希表,字符串"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..34697e1b36558097bc4a911e67a0d02220d0b28c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/205.exercises/solution.md"
@@ -0,0 +1,94 @@
+# 同构字符串
+
+给定两个字符串 s 和 t,判断它们是否是同构的。
+
+如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
+
+每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
+
+
+
+示例 1:
+
+
+输入:s = "egg", t = "add"
+输出:true
+
+
+示例 2:
+
+
+输入:s = "foo", t = "bar"
+输出:false
+
+示例 3:
+
+
+输入:s = "paper", t = "title"
+输出:true
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+class Solution(object):
+ def isIsomorphic(self, s, t):
+ """
+ :type s: str
+ :type t: str
+ :rtype: bool
+ """
+
+ if len(s) != len(t):
+ return False
+ if len(s) == None or len(s) < 2:
+ return True
+
+ smap = {}
+ for i in range(len(s)):
+
+ if s[i] not in smap and t[i] in smap.values():
+ return False
+
+ if s[i] in smap and smap[s[i]] != t[i]:
+ return False
+
+ smap[s[i]] = t[i]
+
+ return True
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..61ac4edff083909852a846f2432e76788ccd5fd1
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-c0d398d68a614160a0d6e59063e79b3a",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2bcd56cb77faddaf859ff9e18e19eafdd5449017
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "2b89e3dc80484eda9e3ce71f840ca07e",
+ "author": "csdn.net",
+ "keywords": "递归,链表"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..632ad8989835f47774dcfc9beec91e77ca68dbc8
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/206.exercises/solution.md"
@@ -0,0 +1,104 @@
+# 反转链表
+
+给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
+
+
+
+
+
示例 1:
+

+
+输入:head = [1,2,3,4,5]
+输出:[5,4,3,2,1]
+
+
+
示例 2:
+

+
+输入:head = [1,2]
+输出:[2,1]
+
+
+
示例 3:
+
+
+输入:head = []
+输出:[]
+
+
+
+
+
提示:
+
+
+ - 链表中节点的数目范围是
[0, 5000]
+ -5000 <= Node.val <= 5000
+
+
+
+
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
+
+
给定一个整数数组,判断是否存在重复元素。
+
+如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
+
+
+
+示例 1:
+
+
+输入: [1,2,3,1]
+输出: true
+
+示例 2:
+
+
+输入: [1,2,3,4]
+输出: false
+
+示例 3:
+
+
+输入: [1,1,1,3,3,4,3,2,4,2]
+输出: true
+
+
+## template
+
+```python
+class Solution:
+ def containsDuplicate(self, nums: List[int]) -> bool:
+
+ nums.sort()
+ count = 0
+ while count < len(nums) - 1:
+ if nums[count] == nums[count + 1]:
+ return True
+ count += 1
+ return False
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8deade39f497dcaf3734116cb3b6b6950f29f593
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-c577cd4335a846a5bae08b419ecf7236",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..353c0f574e7ea0670c81d72f5da06d0d14b601ee
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ba81057039ca4027a1dec611797bbdc6",
+ "author": "csdn.net",
+ "keywords": "数组,哈希表,滑动窗口"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b106c22c92b072bfd88c90ea2967d0b084b1c9a3
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/219.exercises/solution.md"
@@ -0,0 +1,78 @@
+# 存在重复元素 II
+
+给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的 绝对值 至多为 k。
+
+
+
+示例 1:
+
+输入: nums = [1,2,3,1], k = 3
+输出: true
+
+示例 2:
+
+输入: nums = [1,0,1,1], k = 1
+输出: true
+
+示例 3:
+
+输入: nums = [1,2,3,1,2,3], k = 2
+输出: false
+
+
+## template
+
+```python
+class Solution:
+ def containsNearbyDuplicate(self, nums, k):
+ """
+ :type nums: List[int]
+ :type k: int
+ :rtype: bool
+ """
+
+ if len(list(set(nums))) == len(nums):
+ return False
+ left = 0
+ right = left + k
+ if k >= len(nums):
+ return len(list(set(nums))) < len(nums)
+ while right < len(nums):
+ while left < right:
+ if nums[left] == nums[right]:
+ return True
+ else:
+ right -= 1
+ left += 1
+ right = left + k
+ if len(list(set(nums[left:]))) < len(nums[left:]):
+ return True
+ return False
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..6ff28a621bc2111559189bf2f650b2c4d68e6c07
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-cffa52e97c224fdf8530778290a05c2d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..4e316c3fe460f8825d2329f2d8ab4126f470f4da
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ef25569152e840bba97c52891b63d50c",
+ "author": "csdn.net",
+ "keywords": "栈,设计,队列"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c127de84784614998b7bf0bce7dcf7a0ad49f34a
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/225.exercises/solution.md"
@@ -0,0 +1,133 @@
+# 用队列实现栈
+
+请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
+
+实现 MyStack 类:
+
+
+ void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() 返回栈顶元素。boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
+
+
+
+注意:
+
+
+ - 你只能使用队列的基本操作 —— 也就是
push to back、peek/pop from front、size 和 is empty 这些操作。
+ - 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
+
+
+
+
+示例:
+
+
+输入:
+["MyStack", "push", "push", "top", "pop", "empty"]
+[[], [1], [2], [], [], []]
+输出:
+[null, null, null, 2, 2, false]
+
+解释:
+MyStack myStack = new MyStack();
+myStack.push(1);
+myStack.push(2);
+myStack.top(); // 返回 2
+myStack.pop(); // 返回 2
+myStack.empty(); // 返回 False
+
+
+
+
+提示:
+
+
+ 1 <= x <= 9- 最多调用
100 次 push、pop、top 和 empty
+ - 每次调用
pop 和 top 都保证栈不为空
+
+
+
+
+进阶:你能否实现每种操作的均摊时间复杂度为 O(1) 的栈?换句话说,执行 n 个操作的总时间复杂度 O(n) ,尽管其中某个操作可能需要比其他操作更长的时间。你可以使用两个以上的队列。
+
+
+## template
+
+```python
+class MyStack:
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.queue = []
+ self.help = []
+
+ def push(self, x):
+ """
+ Push element x onto stack.
+ """
+
+ while len(self.queue) > 0:
+
+ self.help.append(self.queue.pop(0))
+
+ self.queue.append(x)
+
+ while len(self.help) > 0:
+
+ self.queue.append(self.help.pop(0))
+
+ def pop(self):
+ """
+ Removes the element on top of the stack and returns that element.
+ """
+
+ de = self.queue.pop(0)
+ return de
+
+ def top(self):
+ """
+ Get the top element.
+ """
+ de = self.queue[0]
+ return de
+
+ def empty(self) -> bool:
+ """
+ Returns whether the stack is empty.
+ """
+ if len(self.queue) == 0:
+ return True
+ return False
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..779d5290925d583d4dbb2c60082fd8e49b9797ac
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-86b0aaa37e4b44069fb95d809c4ef7de",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d35ba9efc1fb8b33e8ef4b453675635bedb77e7c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "da18811d80254852b6599c3d89672d3d",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..776734e7a1e338c66df41b889684ddc1a82fbefc
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/226.exercises/solution.md"
@@ -0,0 +1,80 @@
+# 翻转二叉树
+
+翻转一棵二叉树。
+
+示例:
+
+输入:
+
+ 4
+ / \
+ 2 7
+ / \ / \
+1 3 6 9
+
+输出:
+
+ 4
+ / \
+ 7 2
+ / \ / \
+9 6 3 1
+
+备注:
+这个问题是受到 Max Howell 的 原问题 启发的 :
+
+谷歌:我们90%的工程师使用您编写的软件(Homebrew),但是您却无法在面试时在白板上写出翻转二叉树这道题,这太糟糕了。
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution(object):
+ def invertTree(self, root):
+ """
+ :type root: TreeNode
+ :rtype: TreeNode
+ """
+
+ if not root:
+ return None
+ root.left, root.right = root.right, root.left
+
+ self.invertTree(root.left)
+ self.invertTree(root.right)
+
+ return root
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c44baa4072c52b1c2cf577e3d13789ae4319f86d
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-fddac17d19ec4980b2c56a61a6606757",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.json"
similarity index 65%
rename from "data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.json"
rename to "data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.json"
index 2f369bd62bf4b732ae42b61d765d88f10454eeec..14cfd30770dcc76287f0997b1bb1dd4f55becb3e 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.json"
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "9709c270ce6e4255b49fa2f3a89a8f1b",
+ "exercise_id": "1846ac34e8624af7b4080f3b6af1b5aa",
"author": "csdn.net",
"keywords": "数组"
}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..476f1717467b49a1d54e01264260d2635a9358de
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/228.exercises/solution.md"
@@ -0,0 +1,126 @@
+# 汇总区间
+
+给定一个无重复元素的有序整数数组 nums 。
+
+返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
+
+列表中的每个区间范围 [a,b] 应该按如下格式输出:
+
+
+ "a->b" ,如果 a != b"a" ,如果 a == b
+
+
+
+示例 1:
+
+
+输入:nums = [0,1,2,4,5,7]
+输出:["0->2","4->5","7"]
+解释:区间范围是:
+[0,2] --> "0->2"
+[4,5] --> "4->5"
+[7,7] --> "7"
+
+
+示例 2:
+
+
+输入:nums = [0,2,3,4,6,8,9]
+输出:["0","2->4","6","8->9"]
+解释:区间范围是:
+[0,0] --> "0"
+[2,4] --> "2->4"
+[6,6] --> "6"
+[8,9] --> "8->9"
+
+
+示例 3:
+
+
+输入:nums = []
+输出:[]
+
+
+示例 4:
+
+
+输入:nums = [-1]
+输出:["-1"]
+
+
+示例 5:
+
+
+输入:nums = [0]
+输出:["0"]
+
+
+
+
+提示:
+
+
+ 0 <= nums.length <= 20-231 <= nums[i] <= 231 - 1nums 中的所有值都 互不相同nums 按升序排列
+
+
+## template
+
+```python
+
+class Solution:
+ def summaryRanges(self, nums: List[int]) -> List[str]:
+ n = len(nums)
+
+ left = 0
+ right = 0
+
+ ans = []
+
+ while right < n:
+
+ while right < n - 1 and nums[right] + 1 == nums[right + 1]:
+ right += 1
+
+ tmp = [str(nums[left])]
+ if nums[left] != nums[right]:
+ tmp.append("->")
+ tmp.append(str(nums[right]))
+ ans.append("".join(tmp))
+
+ right += 1
+ left = right
+ return ans
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2df140be84d0be5ac703283f82fa8690025fa023
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-aed97c82a42c4d09a6833891aa2e6560",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..64a5d656d3b12584e304a6d44309834b8fc2ee08
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "0aa6b38595e340909e8d152c22a9ae16",
+ "author": "csdn.net",
+ "keywords": "位运算,递归,数学"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..171338145fda4b51d785bfeeeda2c4105fe1bc28
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/231.exercises/solution.md"
@@ -0,0 +1,98 @@
+# 2 的幂
+
+给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。
+
+如果存在一个整数 x 使得 n == 2x ,则认为 n 是 2 的幂次方。
+
+
+
+示例 1:
+
+
+输入:n = 1
+输出:true
+解释:20 = 1
+
+
+示例 2:
+
+
+输入:n = 16
+输出:true
+解释:24 = 16
+
+
+示例 3:
+
+
+输入:n = 3
+输出:false
+
+
+示例 4:
+
+
+输入:n = 4
+输出:true
+
+
+示例 5:
+
+
+输入:n = 5
+输出:false
+
+
+
+
+提示:
+
+
+
+
+
+进阶:你能够不使用循环/递归解决此问题吗?
+
+
+## template
+
+```python
+
+class Solution:
+ def isPowerOfTwo(self, n):
+ z = bin(n)[2:]
+ if z[0] != "1":
+ return False
+ for item in z[1:]:
+ if item != "0":
+ return False
+ return True
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..45575244fbbfe73a80381f4cdbb861c6bfabd01c
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-cb7541d2e206474e8310b24bbcaa603a",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..747cbedcbb10c2a01d8c6cea93c87d6cf8e7fd1d
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6ce261204e1f4348a5f2ad5e526bd238",
+ "author": "csdn.net",
+ "keywords": "栈,设计,队列"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..5f84610efb22ae798eca0049eb803ee495bb580e
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/232.exercises/solution.md"
@@ -0,0 +1,148 @@
+# 用栈实现队列
+
+请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
+
+实现 MyQueue 类:
+
+
+ void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并返回元素int peek() 返回队列开头的元素boolean empty() 如果队列为空,返回 true ;否则,返回 false
+
+
+
+说明:
+
+
+ - 你只能使用标准的栈操作 —— 也就是只有
push to top, peek/pop from top, size, 和 is empty 操作是合法的。
+ - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
+
+
+
+
+进阶:
+
+
+ - 你能否实现每个操作均摊时间复杂度为
O(1) 的队列?换句话说,执行 n 个操作的总时间复杂度为 O(n) ,即使其中一个操作可能花费较长时间。
+
+
+
+
+示例:
+
+
+输入:
+["MyQueue", "push", "push", "peek", "pop", "empty"]
+[[], [1], [2], [], [], []]
+输出:
+[null, null, null, 1, 1, false]
+
+解释:
+MyQueue myQueue = new MyQueue();
+myQueue.push(1); // queue is: [1]
+myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
+myQueue.peek(); // return 1
+myQueue.pop(); // return 1, queue is [2]
+myQueue.empty(); // return false
+
+
+
+
+
+
+提示:
+
+
+ 1 <= x <= 9- 最多调用
100 次 push、pop、peek 和 empty
+ - 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop 或者 peek 操作)
+
+
+
+## template
+
+```python
+class MyQueue:
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.stack_push = []
+ self.stack_pop = []
+
+ def push(self, x: int) -> None:
+ """
+ Push element x to the back of queue.
+ """
+ while self.stack_pop:
+ self.stack_push.append(self.stack_pop.pop())
+ self.stack_push.append(x)
+
+ def pop(self) -> int:
+ """
+ Removes the element from in front of queue and returns that element.
+ """
+ if self.empty():
+ return None
+ else:
+ while self.stack_push:
+ self.stack_pop.append(self.stack_push.pop())
+ return self.stack_pop.pop()
+
+ def peek(self) -> int:
+ """
+ Get the front element.
+ """
+ if self.empty():
+ return None
+ elif not self.stack_pop:
+ return self.stack_push[0]
+ else:
+ return self.stack_pop[-1]
+
+ def empty(self) -> bool:
+ """
+ Returns whether the queue is empty.
+ """
+ return not (self.stack_push or self.stack_pop)
+
+
+# Your MyQueue object will be instantiated and called as such:
+# obj = MyQueue()
+# obj.push(x)
+# param_2 = obj.pop()
+# param_3 = obj.peek()
+# param_4 = obj.empty()
+
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1846bdf4ccbc99520bc9825c508e0e71a585d303
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ac4b0ee0b49b4388acf7edb1b8a282a9",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a09374258c216f5d5e43db160d2ad4e93f72fd10
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "f2b560e10a604f1fa28ce4e46886c8dc",
+ "author": "csdn.net",
+ "keywords": "栈,递归,链表,双指针"
+}
\ No newline at end of file
diff --git "a/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..5f206779e814489bd299404fa9cfc3a9d449a58f
--- /dev/null
+++ "b/data/1.dailycode\345\210\235\351\230\266/3.python/234.exercises/solution.md"
@@ -0,0 +1,92 @@
+# 回文链表
+
+给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
+
+
+
+示例 1:
+ +
+
+输入:head = [1,2,2,1]
+输出:true
+
+
+示例 2:
+ +
+
+输入:head = [1,2]
+输出:false
+
+
+
+
+提示:
+
+
+ - 链表中节点数目在范围
[1, 105] 内
+ 0 <= Node.val <= 9
+
+
+
+进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
+
+
+## template
+
+```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution:
+ def isPalindrome(self, head: ListNode) -> bool:
+
+ lst = []
+
+ node = head
+
+ while node:
+ lst.append(node.val)
+ node = node.next
+
+ start = 0
+ end = len(lst) - 1
+
+ while start < end:
+ if lst[start] != lst[end]:
+ return False
+ start += 1
+ end -= 1
+
+ return True
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c2476deb89cf30f5ece974f56fdbaa90f9c7f74d
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-d39c19f3422842d4bd0ec6adf5a12e78",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b75dbb5b53f6463183b28ec6f6d77115376d58bb
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6e676186276f4879bfcd9fb546041c14",
+ "author": "csdn.net",
+ "keywords": "树,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..f3271d98718a21f6333ea84898f4d09b58f6dbc9
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/102.exercises/solution.md"
@@ -0,0 +1,87 @@
+# 二叉树的层序遍历
+
+给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+
+
+
+示例:
+二叉树:[3,9,20,null,null,15,7],
+
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+
+
+返回其层序遍历结果:
+
+
+[
+ [3],
+ [9,20],
+ [15,7]
+]
+
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution(object):
+ def levelOrder(self, root):
+ """
+ :type root: TreeNode
+ :rtype: List[List[int]]
+ """
+ if not root:
+ return []
+
+ queue, res = [root], []
+ while queue:
+ size = len(queue)
+ temp = []
+ for i in range(size):
+ data = queue.pop(0)
+ temp.append(data.val)
+ if data.left:
+ queue.append(data.left)
+ if data.right:
+ queue.append(data.right)
+ res.append(temp)
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..cd2a80b3f52c66eaa888d8237d9a357f9b8c98d8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-076557859b544f95a2873bfb35e2c94c",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e8d5e4228b8bce182943a3e999bfdd262c1add22
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "a556fe7a24864dd7ba234c963c36948f",
+ "author": "csdn.net",
+ "keywords": "树,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..77170350eb941d1caa2461d8b3859c5a60b10b19
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/103.exercises/solution.md"
@@ -0,0 +1,91 @@
+# 二叉树的锯齿形层序遍历
+
+给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
+
+例如:
+给定二叉树 [3,9,20,null,null,15,7],
+
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+
+
+返回锯齿形层序遍历如下:
+
+
+[
+ [3],
+ [20,9],
+ [15,7]
+]
+
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def zigzagLevelOrder(self, root: TreeNode) -> List[List[int]]:
+ import collections
+
+ if not root:
+ return []
+
+ res, q = [], collections.deque()
+ flag = False
+ q.append(root)
+
+ while q:
+ temp = []
+ flag = not flag
+ for _ in range(len(q)):
+ node = q.popleft()
+
+ if flag:
+ temp.append(node.val)
+
+ else:
+ temp.insert(0, node.val)
+ if node.left:
+ q.append(node.left)
+ if node.right:
+ q.append(node.right)
+ res.append(temp)
+
+ return res
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a178350118e1006d9f5762f89ddacbf8734c1cf8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ccd566240ba349dd8efd97bf8b840767",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..7b3364e5e415c4f16020920d96a8fe6cc672807f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6f8b176b8b2c40be9b35e4b7d7b02e5e",
+ "author": "csdn.net",
+ "keywords": "树,数组,哈希表,分治,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..202c59dba3059c3adef29a1ce4056a94d3212893
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/105.exercises/solution.md"
@@ -0,0 +1,80 @@
+# 从前序与中序遍历序列构造二叉树
+
+给定一棵树的前序遍历 preorder 与中序遍历 inorder。请构造二叉树并返回其根节点。
+
+
+
+示例 1:
+ +
+
+Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
+Output: [3,9,20,null,null,15,7]
+
+
+示例 2:
+
+
+Input: preorder = [-1], inorder = [-1]
+Output: [-1]
+
+
+
+
+提示:
+
+
+ 1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder 和 inorder 均无重复元素inorder 均出现在 preorderpreorder 保证为二叉树的前序遍历序列inorder 保证为二叉树的中序遍历序列
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def buildTree(self, preorder, inorder):
+ if not preorder:
+ return None
+ root = TreeNode(preorder[0])
+ i = inorder.index(root.val)
+ root.left = self.buildTree(preorder[1 : i + 1], inorder[:i])
+ root.right = self.buildTree(preorder[i + 1 :], inorder[i + 1 :])
+ return root
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e95c40174819fe9523828e9dab156fbefc62c33b
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-9e3a9fc2720b4bdeab6b1829ef403260",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1bbfbd6ddb46bca53da4918cc92881a48143d0ac
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "3b8c98553acc41259094988813abbfa1",
+ "author": "csdn.net",
+ "keywords": "树,数组,哈希表,分治,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c96ad10091432c8b9500d6b466b949021f03d5c2
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/106.exercises/solution.md"
@@ -0,0 +1,87 @@
+# 从中序与后序遍历序列构造二叉树
+
+根据一棵树的中序遍历与后序遍历构造二叉树。
+
+注意:
+你可以假设树中没有重复的元素。
+
+例如,给出
+
+中序遍历 inorder = [9,3,15,20,7]
+后序遍历 postorder = [9,15,7,20,3]
+
+返回如下的二叉树:
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+
+
+
+## template
+
+```python
+
+class Solution:
+ def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
+ def build_tree(in_left, in_right, post_left, post_right):
+ if in_left > in_right:
+ return
+
+ post_root = post_right
+
+ root = TreeNode(postorder[post_root])
+
+ in_root = inorder_map[root.val]
+
+ size_of_left = in_root - in_left
+
+ root.left = build_tree(
+ in_left, in_root - 1, post_left, post_left + size_of_left - 1
+ )
+
+ root.right = build_tree(
+ in_root + 1, in_right, post_left + size_of_left, post_root - 1
+ )
+
+ return root
+
+ size = len(inorder)
+
+ inorder_map = {}
+
+ for i in range(size):
+ inorder_map[inorder[i]] = i
+
+ return build_tree(0, size - 1, 0, size - 1)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..cd0dce8594ef5faaa65967714458da2f56971d24
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-23bb016c10994736ad14a29a819eba08",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3a53826b614172841a1e3908b9b6d09e246ac219
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6a4098c9e916419baa1969bad6b58b87",
+ "author": "csdn.net",
+ "keywords": "树,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e185a4da71e41fe6bb6825e9162a9352ed1b8973
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/107.exercises/solution.md"
@@ -0,0 +1,75 @@
+# 二叉树的层序遍历 II
+
+给定一个二叉树,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
+
+例如:
+给定二叉树 [3,9,20,null,null,15,7],
+
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+
+
+返回其自底向上的层序遍历为:
+
+
+[
+ [15,7],
+ [9,20],
+ [3]
+]
+
+
+
+## template
+
+```python
+
+class Solution(object):
+ res = dict()
+
+ def forwardSearch(self, root, depth):
+ if root != None:
+ if depth not in self.res.keys():
+ self.res[depth] = []
+ self.res[depth].append(root.val)
+ self.forwardSearch(root.left, depth + 1)
+ self.forwardSearch(root.right, depth + 1)
+
+ def levelOrderBottom(self, root):
+ self.forwardSearch(root, 1)
+ result = []
+ self.dic = dict()
+ for i in self.res.keys():
+ result.append(self.res[i])
+ return result[::-1]
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..edfd8a68ecb9c437dad213ca7497330d0d757b26
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-8b5ed7c1f80f476e91cb817707d93420",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3b0b8e8ca8aa0b35b554cfb5967760a496363c8f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "f5dd9b0f00a740e08275f50e60a4c7f6",
+ "author": "csdn.net",
+ "keywords": "树,二叉搜索树,链表,分治,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..29ee3ae3b629016e93a0041f132033b149607ded
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/109.exercises/solution.md"
@@ -0,0 +1,89 @@
+# 有序链表转换二叉搜索树
+
+给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定的有序链表: [-10, -3, 0, 5, 9],
+
+一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class TreeNode(object):
+ def __init__(self, val=0, left=None, right=None):
+ self.val = val
+ self.left = left
+ self.right = right
+
+
+class Solution:
+ def sortedListToBST(self, head: ListNode) -> TreeNode:
+
+ arr = []
+ cur = head
+ while cur:
+ arr.append(cur.val)
+ cur = cur.next
+ return self.dfs(arr)
+
+ def dfs(self, arr):
+ if not arr:
+ return
+ m = len(arr) // 2
+ root = TreeNode(arr[m])
+ root.left = self.dfs(arr[:m])
+ root.right = self.dfs(arr[m + 1 :])
+ return root
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b1bba92446d8637ff0d3f3e3a2c94d8c25e172f4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-bc6edef11e3a47a787ee47a8dd4bc00b",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a30ea7be0705d145dbec8e719d2fa74a822e4d8d
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "e8cbf541031d4cd09451b10cc48997ef",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,回溯,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..dc71d0157e816040d03c57905a4570334ac46f21
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/113.exercises/solution.md"
@@ -0,0 +1,96 @@
+# 路径总和 II
+
+给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
+
+叶子节点 是指没有子节点的节点。
+
+
+
+
+
+
示例 1:
+
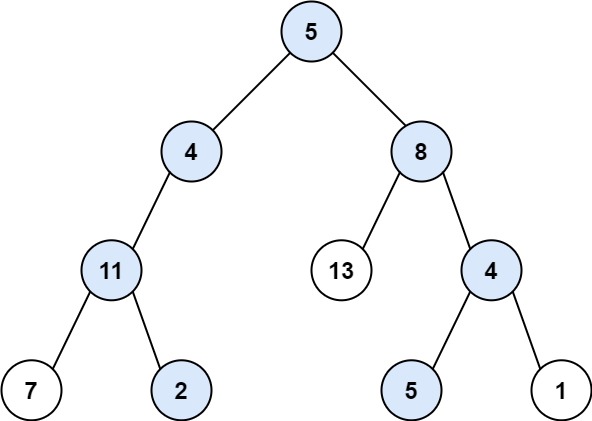
+
+输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
+输出:[[5,4,11,2],[5,8,4,5]]
+
+
+
示例 2:
+
+
+输入:root = [1,2,3], targetSum = 5
+输出:[]
+
+
+
示例 3:
+
+
+输入:root = [1,2], targetSum = 0
+输出:[]
+
+
+
+
+
提示:
+
+
+ - 树中节点总数在范围
[0, 5000] 内
+ -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
+
+
给你二叉树的根结点 root ,请你将它展开为一个单链表:
+
+
+ - 展开后的单链表应该同样使用
TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
+ - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
+
+
+
+
+示例 1:
+ +
+
+输入:root = [1,2,5,3,4,null,6]
+输出:[1,null,2,null,3,null,4,null,5,null,6]
+
+
+示例 2:
+
+
+输入:root = []
+输出:[]
+
+
+示例 3:
+
+
+输入:root = [0]
+输出:[0]
+
+
+
+
+提示:
+
+
+ - 树中结点数在范围
[0, 2000] 内
+ -100 <= Node.val <= 100
+
+
+
+进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
+
+
+## template
+
+```python
+
+class TreeNode(object):
+ def __init__(self, val=0, left=None, right=None):
+ self.val = val
+ self.left = left
+ self.right = right
+
+
+class Solution:
+ def flatten(self, root: TreeNode) -> None:
+ """
+ Do not return anything, modify root in-place instead.
+ """
+ while root != None:
+ if root.left == None:
+ root = root.right
+ else:
+ pre = root.left
+ while pre.right != None:
+ pre = pre.right
+ pre.right = root.right
+ root.right = root.left
+ root.left = None
+ root = root.right
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..5a2080a9b329d03248667e1da021be1d4d8d8cee
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-004a6053d6b5449a90ae38a2a5e6fed3",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..05cdd4bff8689e29cb8389ff0da7ddb6f6270c11
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "33c80fb572754e9fa104c8476e62e43a",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..3a4ad32c131cfb73b3d6db7f7bc1dd0b5c0af610
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/116.exercises/solution.md"
@@ -0,0 +1,106 @@
+# 填充每个节点的下一个右侧节点指针
+
+给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
+
+
+struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
+
+初始状态下,所有 next 指针都被设置为 NULL。
+
+
+
+进阶:
+
+
+ - 你只能使用常量级额外空间。
+ - 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
+
+
+
+
+示例:
+
+
+
+
+输入:root = [1,2,3,4,5,6,7]
+输出:[1,#,2,3,#,4,5,6,7,#]
+解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
+
+
+
+
+提示:
+
+
+ - 树中节点的数量少于
4096
+ -1000 <= node.val <= 1000
+
+
+## template
+
+```python
+class Node(object):
+ def __init__(self, val, left, right, next):
+ self.val = val
+ self.left = left
+ self.right = right
+ self.next = next
+
+
+class Solution(object):
+ def connect(self, root):
+ """
+ :type root: Node
+ :rtype: Node
+ """
+ if not root:
+ return
+ node = [root]
+ while node:
+ l = len(node)
+ for n in range(l):
+ cur = node.pop(0)
+ if n < (l - 1):
+ cur.next = node[0]
+ if cur.left:
+ node.append(cur.left)
+ if cur.right:
+ node.append(cur.right)
+ return root
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..76c7aa0e0867aeba58c25cb63167c095f97359b2
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-fbf28683ccb34ab49174db8f712078e5",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8d99d64932ebaf259e2c1d8b9d276a4197387a93
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "65d11c29b2f545db8f4d5005f46c800c",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..fb9c095a21bc875ac31ed9aabb86f270e6907ab5
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/117.exercises/solution.md"
@@ -0,0 +1,118 @@
+# 填充每个节点的下一个右侧节点指针 II
+
+给定一个二叉树
+
+
+struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
+
+初始状态下,所有 next 指针都被设置为 NULL。
+
+
+
+进阶:
+
+
+ - 你只能使用常量级额外空间。
+ - 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
+
+
+
+
+示例:
+
+
+
+
+输入:root = [1,2,3,4,5,null,7]
+输出:[1,#,2,3,#,4,5,7,#]
+解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。
+
+
+
+提示:
+
+
+ - 树中的节点数小于
6000
+ -100 <= node.val <= 100
+
+
+
+
+
+
+## template
+
+```python
+class Node(object):
+ def __init__(self, val, left, right, next):
+ self.val = val
+ self.left = left
+ self.right = right
+ self.next = next
+
+
+class Solution:
+ def connect(self, root: "Node") -> "Node":
+ if root == None:
+ return None
+ firstNode = root
+ while firstNode:
+ while firstNode and firstNode.left == None and firstNode.right == None:
+ firstNode = firstNode.next
+
+ if firstNode == None:
+ break
+ cur = firstNode
+ pre = None
+
+ while cur:
+ if cur.left:
+ if pre:
+ pre.next = cur.left
+ pre = cur.left
+ if cur.right:
+ if pre:
+ pre.next = cur.right
+ pre = cur.right
+ cur = cur.next
+ firstNode = firstNode.left if firstNode.left else firstNode.right
+ return root
+
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..7c430f49b21f88e34edee8e1b7620922d6c38352
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-818f6a9d056f41308b21223805362384",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..df8e6ef79a921a50ac050545f22859b8bcec8858
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "188e7cbca8ee4afeab14b55fba460080",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..f96d8eb467a9265f58cd4f837bda9578d0ffa03e
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/120.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 三角形最小路径和
+
+给定一个三角形 triangle ,找出自顶向下的最小路径和。
+
+每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
+
+
+
+示例 1:
+
+
+输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
+输出:11
+解释:如下面简图所示:
+ 2
+ 3 4
+ 6 5 7
+4 1 8 3
+自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
+
+
+示例 2:
+
+
+输入:triangle = [[-10]]
+输出:-10
+
+
+
+
+提示:
+
+
+ 1 <= triangle.length <= 200triangle[0].length == 1triangle[i].length == triangle[i - 1].length + 1-104 <= triangle[i][j] <= 104
+
+
+
+进阶:
+
+
+ - 你可以只使用
O(n) 的额外空间(n 为三角形的总行数)来解决这个问题吗?
+
+
+
+## template
+
+```python
+
+class Solution(object):
+ def minimumTotal(self, triangle):
+ """
+ :type triangle: List[List[int]]
+ :rtype: int
+ """
+ n = len(triangle)
+ dp = triangle[-1]
+ for i in range(n - 2, -1, -1):
+ for j in range(i + 1):
+ dp[j] = triangle[i][j] + min(dp[j], dp[j + 1])
+ print dp
+ return dp[0]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..29576c86ad79470fd936106f4626eef3b1384570
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-3f2392278df946eb85cc12bcd4cf119e",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b87c1c63ad8cad28b2e28b2832aa33efd5fc9442
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ad9db217ae1d4514958e2e572769a342",
+ "author": "csdn.net",
+ "keywords": "并查集,数组,哈希表"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c2ec4ab66c230ba39d87f976806ede00b0637aa1
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/128.exercises/solution.md"
@@ -0,0 +1,87 @@
+# 最长连续序列
+
+给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
+
+请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
+
+
+
+示例 1:
+
+
+输入:nums = [100,4,200,1,3,2]
+输出:4
+解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
+
+示例 2:
+
+
+输入:nums = [0,3,7,2,5,8,4,6,0,1]
+输出:9
+
+
+
+
+提示:
+
+
+ 0 <= nums.length <= 105-109 <= nums[i] <= 109
+
+
+## template
+
+```python
+
+class Solution:
+ def longestConsecutive(self, nums: List[int]) -> int:
+ hash_dict = {}
+
+ max_length = 0
+
+ for num in nums:
+
+ if num not in hash_dict:
+
+ pre_length = hash_dict.get(num - 1, 0)
+ next_length = hash_dict.get(num + 1, 0)
+
+ cur_length = pre_length + 1 + next_length
+
+ if cur_length > max_length:
+ max_length = cur_length
+
+ hash_dict[num] = cur_length
+ hash_dict[num - pre_length] = cur_length
+ hash_dict[num + next_length] = cur_length
+
+ return max_length
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..4c150d9f3f9762bcd7dced7fddaa484dc178ddd7
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-bb2a47c7386d4ebb86e6ec104907029c",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..6ba591878b78d9ae8b3ddbcf1bb5b6acb3c558a9
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "76b4ac0db24f4b4a94c433efb15df60d",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..02536fe5ae8c0601da6f7058685c5e39dfbe1320
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/129.exercises/solution.md"
@@ -0,0 +1,101 @@
+# 求根节点到叶节点数字之和
+
+给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
+
+
+
每条从根节点到叶节点的路径都代表一个数字:
+
+
+ - 例如,从根节点到叶节点的路径
1 -> 2 -> 3 表示数字 123 。
+
+
+
计算从根节点到叶节点生成的 所有数字之和 。
+
+
叶节点 是指没有子节点的节点。
+
+
+
+
示例 1:
+
+
+输入:root = [1,2,3]
+输出:25
+解释:
+从根到叶子节点路径 1->2 代表数字 12
+从根到叶子节点路径 1->3 代表数字 13
+因此,数字总和 = 12 + 13 = 25
+
+
示例 2:
+
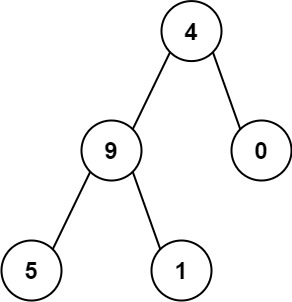
+
+输入:root = [4,9,0,5,1]
+输出:1026
+解释:
+从根到叶子节点路径 4->9->5 代表数字 495
+从根到叶子节点路径 4->9->1 代表数字 491
+从根到叶子节点路径 4->0 代表数字 40
+因此,数字总和 = 495 + 491 + 40 = 1026
+
+
+
+
+
提示:
+
+
+ - 树中节点的数目在范围
[1, 1000] 内
+ 0 <= Node.val <= 9- 树的深度不超过
10
+
+
+
m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
+
+
+
+
+
示例 1:
+

+
+输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]]
+输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]]
+解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
+
+
+
示例 2:
+
+
+输入:board = [["X"]]
+输出:[["X"]]
+
+
+
+
+
提示:
+
+
+ m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j] 为 'X' 或 'O'
+
+
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
+
+回文串 是正着读和反着读都一样的字符串。
+
+
+
+示例 1:
+
+
+输入:s = "aab"
+输出:[["a","a","b"],["aa","b"]]
+
+
+示例 2:
+
+
+输入:s = "a"
+输出:[["a"]]
+
+
+
+
+提示:
+
+
+ 1 <= s.length <= 16s 仅由小写英文字母组成
+
+
+## template
+
+```python
+class Solution(object):
+ def partition(self, s):
+ """
+ :type s: str
+ :rtype: List[List[str]]
+ """
+ if len(s) == 0:
+ return []
+ else:
+ res = []
+ self.dividedAndsel(s, [], res)
+ return res
+
+ def dividedAndsel(self, s, tmp, res):
+ if len(s) == 0:
+ res.append(tmp)
+ for i in range(1, len(s) + 1):
+ if s[:i] == s[:i][::-1]:
+ self.dividedAndsel(s[i:], tmp + [s[:i]], res)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..87a94f48b89a28b8463d5ba126ee2484d28a1147
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-7903ab0abaf248c582eb2080b6cab02a",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..536f9749772e003856068246b155a478897bd3d3
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "14ebb8bbca994ec4bc516ba42e910adf",
+ "author": "csdn.net",
+ "keywords": "深度优先搜索,广度优先搜索,图,哈希表"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..1b6cbf56310897406db32f33d787a8a806089d5f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/133.exercises/solution.md"
@@ -0,0 +1,131 @@
+# 克隆图
+
+给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
+
+图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
+
+class Node {
+ public int val;
+ public List<Node> neighbors;
+}
+
+
+
+测试用例格式:
+
+简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
+
+邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
+
+给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
+
+
+
+示例 1:
+
+
+
+输入:adjList = [[2,4],[1,3],[2,4],[1,3]]
+输出:[[2,4],[1,3],[2,4],[1,3]]
+解释:
+图中有 4 个节点。
+节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
+节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
+节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
+节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
+
+
+示例 2:
+
+
+
+输入:adjList = [[]]
+输出:[[]]
+解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
+
+
+示例 3:
+
+输入:adjList = []
+输出:[]
+解释:这个图是空的,它不含任何节点。
+
+
+示例 4:
+
+
+
+输入:adjList = [[2],[1]]
+输出:[[2],[1]]
+
+
+
+提示:
+
+
+ - 节点数不超过 100 。
+ - 每个节点值
Node.val 都是唯一的,1 <= Node.val <= 100。
+ - 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
+ - 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
+ - 图是连通图,你可以从给定节点访问到所有节点。
+
+
+
+## template
+
+```python
+class Node:
+ def __init__(self, val=0, neighbors=[]):
+ self.val = val
+ self.neighbors = neighbors
+
+
+class Solution:
+ def cloneGraph(self, node: "Node") -> "Node":
+ marked = {}
+
+ def dfs(node):
+ if not node:
+ return node
+
+ if node in marked:
+ return marked[node]
+
+ clone_node = Node(node.val, [])
+ marked[node] = clone_node
+
+ for neighbor in node.neighbors:
+ clone_node.neighbors.append(dfs(neighbor))
+
+ return clone_node
+
+ return dfs(node)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8f276634eb907152e162f94481833515a98bce8f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-120c2a3bf79846d98609c608ebe568ae",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8f34b412ae4331f89891e9e085f942e58568cd34
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "36185dedcad549708751361f56874bf5",
+ "author": "csdn.net",
+ "keywords": "贪心,数组"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..d75f03893e5152c1ec8d30de906ae580c31b741f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/134.exercises/solution.md"
@@ -0,0 +1,101 @@
+# 加油站
+
+在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
+
+你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
+
+如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
+
+说明:
+
+
+ - 如果题目有解,该答案即为唯一答案。
+ - 输入数组均为非空数组,且长度相同。
+ - 输入数组中的元素均为非负数。
+
+
+示例 1:
+
+输入:
+gas = [1,2,3,4,5]
+cost = [3,4,5,1,2]
+
+输出: 3
+
+解释:
+从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
+开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
+开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
+开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
+开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
+开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
+因此,3 可为起始索引。
+
+示例 2:
+
+输入:
+gas = [2,3,4]
+cost = [3,4,3]
+
+输出: -1
+
+解释:
+你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
+我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
+开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
+开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
+你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
+因此,无论怎样,你都不可能绕环路行驶一周。
+
+
+## template
+
+```python
+class Solution(object):
+ def canCompleteCircuit(self, gas, cost):
+ """
+ :type gas: List[int]
+ :type cost: List[int]
+ :rtype: int
+ """
+ n = len(gas)
+ if sum(gas) < sum(cost):
+ return -1
+ else:
+ start = 0
+ path = 0
+ for i in range(n):
+ path = path + (gas[i] - cost[i])
+ if path < 0:
+ start = i + 1
+ path = 0
+ return start
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..9b0125c38d1093966631d6aee246868523443532
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-e0c8fae20b664ff3a1d728dba5024174",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ed77755aa2cdea187967358491d6c4926f070c8a
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "29824658e1d54db1a7184adbd1e37516",
+ "author": "csdn.net",
+ "keywords": "位运算,数组"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..8bb220de0d42bde10fa9bae43d7c51cb729429ad
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/137.exercises/solution.md"
@@ -0,0 +1,79 @@
+# 只出现一次的数字 II
+
+给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
+
+
+
+示例 1:
+
+
+输入:nums = [2,2,3,2]
+输出:3
+
+
+示例 2:
+
+
+输入:nums = [0,1,0,1,0,1,99]
+输出:99
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 3 * 104-231 <= nums[i] <= 231 - 1nums 中,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次
+
+
+
+进阶:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
+
+
+## template
+
+```python
+
+class Solution(object):
+ def singleNumber(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: int
+ """
+ a = 0
+ b = 0
+ for num in nums:
+ a = (num ^ a) & ~b
+ b = (num ^ b) & ~a
+ return a
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..f4bf4fd2e6aaa4c68297250f14a6821defc1b9d5
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-80a3b8ff74db43638f416d2e1bf6b17f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..613ea7d64f60bee8122e9858daa0614faedfe8ef
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "56d73a6c6fc14885aca55e785ee7b1e6",
+ "author": "csdn.net",
+ "keywords": "哈希表,链表"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..258d3d65d36591f9e380d2eba5b78d5074725aaa
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/138.exercises/solution.md"
@@ -0,0 +1,127 @@
+# 复制带随机指针的链表
+
+给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
+
+构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
+
+例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
+
+返回复制链表的头节点。
+
+用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
+
+
+ val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
+
+你的代码 只 接受原链表的头节点 head 作为传入参数。
+
+
+
+示例 1:
+
+
+
+
+输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
+输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
+
+
+示例 2:
+
+
+
+
+输入:head = [[1,1],[2,1]]
+输出:[[1,1],[2,1]]
+
+
+示例 3:
+
+
+
+
+输入:head = [[3,null],[3,0],[3,null]]
+输出:[[3,null],[3,0],[3,null]]
+
+
+示例 4:
+
+
+输入:head = []
+输出:[]
+解释:给定的链表为空(空指针),因此返回 null。
+
+
+
+
+提示:
+
+
+ 0 <= n <= 1000-10000 <= Node.val <= 10000Node.random 为空(null)或指向链表中的节点。
+
+
+## template
+
+```python
+class Node(object):
+ def __init__(self, val, next, random):
+ self.val = val
+ self.next = next
+ self.random = random
+
+
+class Solution(object):
+ def copyRandomList(self, head):
+ """
+ :type head: Node
+ :rtype: Node
+ """
+ if head == None:
+ return None
+ memories = {}
+ node = head
+ while node != None:
+ cloneNode = Node(node.val, None, None)
+ memories[node] = cloneNode
+ node = node.next
+ node = head
+ while node:
+
+ memories.get(node).next = memories.get(node.next)
+ memories.get(node).random = memories.get(node.random)
+ node = node.next
+ return memories[head]
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3f19edebc8a988cf7c620dc9d6f683104d6afd40
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f614b895389b4cbdb4f0c816657b07d5",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..06a701912f45bcea33541382e4f2a11f0233f882
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "01894c4c2d7546b1bb57fd619362f1c6",
+ "author": "csdn.net",
+ "keywords": "字典树,记忆化搜索,哈希表,字符串,动态规划"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..29151277b2c27b00c353796a78c7c9d1c5619122
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/139.exercises/solution.md"
@@ -0,0 +1,83 @@
+# 单词拆分
+
+给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
+
+说明:
+
+
+ - 拆分时可以重复使用字典中的单词。
+ - 你可以假设字典中没有重复的单词。
+
+
+示例 1:
+
+输入: s = "leetcode", wordDict = ["leet", "code"]
+输出: true
+解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
+
+
+示例 2:
+
+输入: s = "applepenapple", wordDict = ["apple", "pen"]
+输出: true
+解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
+ 注意你可以重复使用字典中的单词。
+
+
+示例 3:
+
+输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
+输出: false
+
+
+
+## template
+
+```python
+
+class Solution(object):
+ def wordBreak(self, s, wordDict):
+ """
+ :type s: str
+ :type wordDict: List[str]
+ :rtype: bool
+ """
+ if not s:
+ return True
+ lenth = len(s)
+ dp = [False for i in range(lenth + 1)]
+ dp[0] = True
+ for i in range(1, lenth + 1):
+ for j in range(i):
+ if dp[j] and s[j:i] in wordDict:
+ dp[i] = True
+ break
+ return dp[-1]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..28ee3c7d5b10085ae36957bbf258da0e88c923df
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-acfd338816284b2a9706de1da46b2937",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..012fb072e8bed7225ad14a0d90e391a5b677b949
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "8a80ca04f6ef482a9ce79e7043387844",
+ "author": "csdn.net",
+ "keywords": "哈希表,链表,双指针"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..905827313b0228b6d96e34aed42ce4b3d66e0d52
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/142.exercises/solution.md"
@@ -0,0 +1,105 @@
+# 环形链表 II
+
+给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
+
+为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意,pos 仅仅是用于标识环的情况,并不会作为参数传递到函数中。
+
+说明:不允许修改给定的链表。
+
+进阶:
+
+
+
+
+
+示例 1:
+
+
+
+
+输入:head = [3,2,0,-4], pos = 1
+输出:返回索引为 1 的链表节点
+解释:链表中有一个环,其尾部连接到第二个节点。
+
+
+示例 2:
+
+
+
+
+输入:head = [1,2], pos = 0
+输出:返回索引为 0 的链表节点
+解释:链表中有一个环,其尾部连接到第一个节点。
+
+
+示例 3:
+
+
+
+
+输入:head = [1], pos = -1
+输出:返回 null
+解释:链表中没有环。
+
+
+
+
+提示:
+
+
+ - 链表中节点的数目范围在范围
[0, 104] 内
+ -105 <= Node.val <= 105pos 的值为 -1 或者链表中的一个有效索引
+
+
+## template
+
+```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution(object):
+ def detectCycle(self, head):
+ s = set()
+
+ node = head
+ while node is not None:
+ if node in s:
+ return node
+ else:
+ s.add(node)
+ node = node.next
+ return None
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2b4e6f76ab05e6a360330ae7089d6a0f5d0862b8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ff921d8bd1b24f35b0f8bfe0afd76f7d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..6fb069e0b3e75a58fd26191e07cc9bff238d9262
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "faaa889f3ee446238e3942ddccd5e050",
+ "author": "csdn.net",
+ "keywords": "栈,递归,链表,双指针"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..71d5062a7dba7981a83b91b392a80a055ff517e4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/143.exercises/solution.md"
@@ -0,0 +1,105 @@
+# 重排链表
+
+给定一个单链表 L 的头节点 head ,单链表 L 表示为:
+
+ L0 → L1 → … → Ln-1 → Ln
+请将其重新排列后变为:
+
+L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
+
+不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
+
+
+
+示例 1:
+
+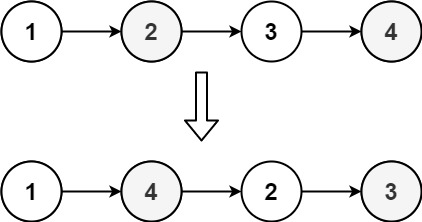
+
+
+输入: head = [1,2,3,4]
+输出: [1,4,2,3]
+
+示例 2:
+
+
+
+
+输入: head = [1,2,3,4,5]
+输出: [1,5,2,4,3]
+
+
+
+提示:
+
+
+ - 链表的长度范围为
[1, 5 * 104]
+ 1 <= node.val <= 1000
+
+
+## template
+
+```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution(object):
+ def reorderList(self, head):
+ """
+ :type head: ListNode
+ :rtype: None Do not return anything, modify head in-place instead.
+ """
+
+ if not head:
+ return
+
+ stack = []
+ s = head
+
+ while s.next:
+ stack.append(s.next)
+ s = s.next
+
+ s = head
+
+ n = 0
+ while stack:
+ if n % 2 == 0:
+ one = stack.pop()
+ else:
+ one = stack.pop(0)
+ one.next = None
+ s.next = one
+ s = s.next
+ n += 1
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..fdc538b8dcdd5637156f9ee3e80a2fbf12cee5b8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-2d29cb13e50e43beb197aa42f9e545ad",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2c27a199715bb58447a7c7bede04cfb8915bf327
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "b14bc572b48d4588bf4310aaf9927ebe",
+ "author": "csdn.net",
+ "keywords": "设计,哈希表,链表,双向链表"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c9752dc75c4e3a94b705ea1ff7f4eeddce37e460
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/146.exercises/solution.md"
@@ -0,0 +1,131 @@
+# LRU 缓存机制
+
+
+
+
+
+
实现 LRUCache 类:
+
+
+ LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
+
+
+
+
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
+
+
+
+示例:
+
+
+输入
+["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
+[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
+输出
+[null, null, null, 1, null, -1, null, -1, 3, 4]
+
+解释
+LRUCache lRUCache = new LRUCache(2);
+lRUCache.put(1, 1); // 缓存是 {1=1}
+lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
+lRUCache.get(1); // 返回 1
+lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
+lRUCache.get(2); // 返回 -1 (未找到)
+lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
+lRUCache.get(1); // 返回 -1 (未找到)
+lRUCache.get(3); // 返回 3
+lRUCache.get(4); // 返回 4
+
+
+
+
+提示:
+
+
+ 1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105 次 get 和 put
+
+
+
+## template
+
+```python
+
+class LRUCache:
+ def __init__(self, capacity):
+ """
+ :type capacity: int
+ """
+ self.maxlength = capacity
+ self.array = {}
+ self.array_list = []
+
+ def get(self, key):
+ """
+ :type key: int
+ :rtype: int
+ """
+ value = self.array.get(key)
+
+ if value is not None and self.array_list[0] is not key:
+ index = self.array_list.index(key)
+ self.array_list.pop(index)
+ self.array_list.insert(0, key)
+
+ value = value if value is not None else -1
+ return value
+
+ def put(self, key, value):
+ """
+ :type key: int
+ :type value: int
+ :rtype: void
+ """
+
+ if self.array.get(key) is not None:
+ index = self.array_list.index(key)
+ self.array.pop(key)
+ self.array_list.pop(index)
+
+ if len(self.array_list) >= self.maxlength:
+ key_t = self.array_list.pop(self.maxlength - 1)
+ self.array.pop(key_t)
+
+ self.array[key] = value
+ self.array_list.insert(0, key)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8437e6615b1198490f377c2975b77393239805fb
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-86d4efaa0b404960ae0ef6be7c9f3972",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..bd71e61aab8fb786d3297abaab76ff588585bc79
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "771f5289959844efb4f3e3dcf94228c4",
+ "author": "csdn.net",
+ "keywords": "链表,排序"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..44d25d53cdfae753e4bdce58d8744b33898303c8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/147.exercises/solution.md"
@@ -0,0 +1,108 @@
+# 对链表进行插入排序
+
+对链表进行插入排序。
+
+
+插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
+每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
+
+
+
+插入排序算法:
+
+
+ - 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
+ - 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
+ - 重复直到所有输入数据插入完为止。
+
+
+
+
+示例 1:
+
+输入: 4->2->1->3
+输出: 1->2->3->4
+
+
+示例 2:
+
+输入: -1->5->3->4->0
+输出: -1->0->3->4->5
+
+
+
+## template
+
+```python
+
+class LRUCache:
+ def __init__(self, capacity):
+ """
+ :type capacity: int
+ """
+ self.maxlength = capacity
+ self.array = {}
+ self.array_list = []
+
+ def get(self, key):
+ """
+ :type key: int
+ :rtype: int
+ """
+ value = self.array.get(key)
+
+ if value is not None and self.array_list[0] is not key:
+ index = self.array_list.index(key)
+ self.array_list.pop(index)
+ self.array_list.insert(0, key)
+
+ value = value if value is not None else -1
+ return value
+
+ def put(self, key, value):
+ """
+ :type key: int
+ :type value: int
+ :rtype: void
+ """
+
+ if self.array.get(key) is not None:
+ index = self.array_list.index(key)
+ self.array.pop(key)
+ self.array_list.pop(index)
+
+ if len(self.array_list) >= self.maxlength:
+ key_t = self.array_list.pop(self.maxlength - 1)
+ self.array.pop(key_t)
+
+ self.array[key] = value
+ self.array_list.insert(0, key)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..19a78d180fadf3f0415754881b558fe4546b46d4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-9a227370e4814fcf8f3dd19a2a34d72b",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..115cd5c013ad3e6a35029d718beb64fc36cef5e8
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "e2730b7376764544a6ea927fa978001f",
+ "author": "csdn.net",
+ "keywords": "链表,双指针,分治,排序,归并排序"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..20b37e585eabd449f9d9d1397981d7962becd82d
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/148.exercises/solution.md"
@@ -0,0 +1,121 @@
+# 排序链表
+
+给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
+
+进阶:
+
+
+ - 你可以在
O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
+
+
+
+
+示例 1:
+ +
+
+输入:head = [4,2,1,3]
+输出:[1,2,3,4]
+
+
+示例 2:
+ +
+
+输入:head = [-1,5,3,4,0]
+输出:[-1,0,3,4,5]
+
+
+示例 3:
+
+
+输入:head = []
+输出:[]
+
+
+
+
+提示:
+
+
+ - 链表中节点的数目在范围
[0, 5 * 104] 内
+ -105 <= Node.val <= 105
+
+
+## template
+
+```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution:
+ def sortList(self, head: ListNode) -> ListNode:
+ if head == None:
+ return None
+ else:
+ return self.mergeSort(head)
+
+ def mergeSort(self, head):
+ if head.next == None:
+ return head
+ fast = head
+ slow = head
+ pre = None
+
+ while fast != None and fast.next != None:
+ pre = slow
+ slow = slow.next
+ fast = fast.next.next
+ pre.next = None
+
+ left = self.mergeSort(head)
+ right = self.mergeSort(slow)
+
+ return self.merge(left, right)
+
+ def merge(self, left, right):
+ tempHead = ListNode(0)
+ cur = tempHead
+ while left != None and right != None:
+ if left.val <= right.val:
+ cur.next = left
+ cur = cur.next
+ left = left.next
+ else:
+ cur.next = right
+ cur = cur.next
+ right = right.next
+ if left != None:
+ cur.next = left
+ if right != None:
+ cur.next = right
+ return tempHead.next
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..657afbe6210d17ad2b52981564e51e99f8627401
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-742bb2336052427c9c5f5f822f3400da",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..86d7d3cb0f7dc0f3657755e3532fabdb21e165a4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "a12ba1c0b3a6463f96427d1ea2081fe8",
+ "author": "csdn.net",
+ "keywords": "栈,数组,数学"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..af5dbf333e1b1e284d5212a11c2fc2085a6eb045
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/150.exercises/solution.md"
@@ -0,0 +1,137 @@
+# 逆波兰表达式求值
+
+根据 逆波兰表示法,求表达式的值。
+
+有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
+
+
+
+说明:
+
+
+ - 整数除法只保留整数部分。
+ - 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
+
+
+
+
+示例 1:
+
+
+输入:tokens = ["2","1","+","3","*"]
+输出:9
+解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
+
+
+示例 2:
+
+
+输入:tokens = ["4","13","5","/","+"]
+输出:6
+解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
+
+
+示例 3:
+
+
+输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
+输出:22
+解释:
+该算式转化为常见的中缀算术表达式为:
+ ((10 * (6 / ((9 + 3) * -11))) + 17) + 5
+= ((10 * (6 / (12 * -11))) + 17) + 5
+= ((10 * (6 / -132)) + 17) + 5
+= ((10 * 0) + 17) + 5
+= (0 + 17) + 5
+= 17 + 5
+= 22
+
+
+
+提示:
+
+
+ 1 <= tokens.length <= 104tokens[i] 要么是一个算符("+"、"-"、"*" 或 "/"),要么是一个在范围 [-200, 200] 内的整数
+
+
+
+逆波兰表达式:
+
+逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
+
+
+ - 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 ) 。
+ - 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * ) 。
+
+
+逆波兰表达式主要有以下两个优点:
+
+
+ - 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + * 也可以依据次序计算出正确结果。
+ - 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
+
+
+
+## template
+
+```python
+class Solution(object):
+ def evalRPN(self, tokens):
+ """
+ :type tokens: List[str]
+ :rtype: int
+ """
+ stack = []
+ for token in tokens:
+
+ if token not in ["+", "-", "*", "/"]:
+ stack.append(int(token))
+ else:
+
+ num1 = stack.pop()
+ num2 = stack.pop()
+ if token == "+":
+ stack.append(num1 + num2)
+ elif token == "-":
+ stack.append(num2 - num1)
+ elif token == "*":
+ stack.append(num1 * num2)
+ elif token == "/":
+ if num1 * num2 < 0:
+ result = -((-num2) // num1)
+ stack.append(result)
+ else:
+ stack.append(num2 // num1)
+ print(stack)
+ return stack.pop()
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d3754512212c0135e3c22360eea3a67e94fa4ebd
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-00ad5576f2a243a785eda37dc0f4729f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.json"
similarity index 68%
rename from "data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.json"
rename to "data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.json"
index 1a548027cff6ea18ce1db075cc818d4921d91fa5..d63eb5121b07b4e177417beb4e3fee4d82321bdc 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.json"
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "d19daace667842859667355671df2976",
+ "exercise_id": "e9b73cb2875f492598d5b3043d9e3892",
"author": "csdn.net",
"keywords": "双指针,字符串"
}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c4eab5d23133442af050344842067c09dbaecfcf
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/151.exercises/solution.md"
@@ -0,0 +1,119 @@
+# 翻转字符串里的单词
+
+给你一个字符串 s ,逐个翻转字符串中的所有 单词 。
+
+单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
+
+请你返回一个翻转 s 中单词顺序并用单个空格相连的字符串。
+
+说明:
+
+
+ - 输入字符串
s 可以在前面、后面或者单词间包含多余的空格。
+ - 翻转后单词间应当仅用一个空格分隔。
+ - 翻转后的字符串中不应包含额外的空格。
+
+
+
+
+示例 1:
+
+
+输入:s = "the sky is blue"
+输出:"blue is sky the"
+
+
+示例 2:
+
+
+输入:s = " hello world "
+输出:"world hello"
+解释:输入字符串可以在前面或者后面包含多余的空格,但是翻转后的字符不能包括。
+
+
+示例 3:
+
+
+输入:s = "a good example"
+输出:"example good a"
+解释:如果两个单词间有多余的空格,将翻转后单词间的空格减少到只含一个。
+
+
+示例 4:
+
+
+输入:s = " Bob Loves Alice "
+输出:"Alice Loves Bob"
+
+
+示例 5:
+
+
+输入:s = "Alice does not even like bob"
+输出:"bob like even not does Alice"
+
+
+
+
+提示:
+
+
+ 1 <= s.length <= 104s 包含英文大小写字母、数字和空格 ' 's 中 至少存在一个 单词
+
+
+
+
+
+进阶:
+
+
+ - 请尝试使用
O(1) 额外空间复杂度的原地解法。
+
+
+
+## template
+
+```python
+class Solution:
+ def reverseWords(self, s: str) -> str:
+ str_list = s.split()
+ s1 = ""
+ for n, i in enumerate(str_list[::-1]):
+ if n == len(str_list) - 1:
+ s1 = s1 + i
+ else:
+ s1 = s1 + i + " "
+ return s1
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..11342a30f79a774672434cea5d952a43e0bba461
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-697c810c0cce485a9320ae102592cace",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..4e701c9ec95e5ea91a0a6d7148c8b8808e2f6c57
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "2e6ccd7b70744a749a8836b8927e3f7b",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a6e5521db1b4212d3b13921e60a4415b02568f6a
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/152.exercises/solution.md"
@@ -0,0 +1,77 @@
+# 乘积最大子数组
+
+给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
+
+
+
+示例 1:
+
+输入: [2,3,-2,4]
+输出: 6
+解释: 子数组 [2,3] 有最大乘积 6。
+
+
+示例 2:
+
+输入: [-2,0,-1]
+输出: 0
+解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
+
+
+## template
+
+```python
+
+class Solution:
+ def maxProduct(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+
+ length = len(nums)
+
+ dp = [[0] * 2 for _ in range(length)]
+
+ dp[0][0] = nums[0]
+ dp[0][1] = nums[0]
+
+ for i in range(1, length):
+
+ if nums[i] > 0:
+ dp[i][0] = min(nums[i], dp[i - 1][0] * nums[i])
+ dp[i][1] = max(nums[i], dp[i - 1][1] * nums[i])
+ else:
+ dp[i][0] = min(nums[i], dp[i - 1][1] * nums[i])
+ dp[i][1] = max(nums[i], dp[i - 1][0] * nums[i])
+
+ res = dp[0][1]
+ for i in range(1, length):
+ res = max(res, dp[i][1])
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..6e3e748fbdf2bba6a5189edc36b8f7b33af65ecb
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f78820577e5c4c2bbfe22cf3a0876ea9",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2ba9cb10ab84c47238315f5993754518f9a36b9d
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c4942f6c3e044ee8a72480829e7932ad",
+ "author": "csdn.net",
+ "keywords": "数组,二分查找"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..95cd2d4301ffecd9b8fccf4a7ee1d214d48246e1
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/153.exercises/solution.md"
@@ -0,0 +1,101 @@
+# 寻找旋转排序数组中的最小值
+
+已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
+
+ - 若旋转
4 次,则可以得到 [4,5,6,7,0,1,2]
+ - 若旋转
7 次,则可以得到 [0,1,2,4,5,6,7]
+
+
+注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
+
+给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
+
+
+
+示例 1:
+
+
+输入:nums = [3,4,5,1,2]
+输出:1
+解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。
+
+
+示例 2:
+
+
+输入:nums = [4,5,6,7,0,1,2]
+输出:0
+解释:原数组为 [0,1,2,4,5,6,7] ,旋转 4 次得到输入数组。
+
+
+示例 3:
+
+
+输入:nums = [11,13,15,17]
+输出:11
+解释:原数组为 [11,13,15,17] ,旋转 4 次得到输入数组。
+
+
+
+
+提示:
+
+
+ n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums 中的所有整数 互不相同nums 原来是一个升序排序的数组,并进行了 1 至 n 次旋转
+
+
+## template
+
+```python
+
+class Solution(object):
+ def findMin(self, nums):
+
+ flag = True
+ if nums[0] < nums[-1]:
+ flag = True
+ else:
+ flag = False
+
+ for i in range(1, len(nums)):
+ if flag:
+ if nums[i] < nums[i - 1]:
+ return nums[i]
+ else:
+ if nums[len(nums) - i] < nums[len(nums) - 1 - i]:
+ return nums[len(nums) - i]
+ return nums[0]
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8fb92225e357f3376c232f7559bcac4d0dbc220c
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-fc69696197c14928a786dfc59344a85f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..762dea32e326ce4126f8b1ad79055014a956af0f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "5e9817781af84a52b98f185b1a038379",
+ "author": "csdn.net",
+ "keywords": "数组,二分查找"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..6b37618fb711fc6dd25658785f396c4b50f5c697
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/162.exercises/solution.md"
@@ -0,0 +1,83 @@
+# 寻找峰值
+
+峰值元素是指其值严格大于左右相邻值的元素。
+
+给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
+
+你可以假设 nums[-1] = nums[n] = -∞ 。
+
+你必须实现时间复杂度为 O(log n) 的算法来解决此问题。
+
+
+
+示例 1:
+
+
+输入:nums = [1,2,3,1]
+输出:2
+解释:3 是峰值元素,你的函数应该返回其索引 2。
+
+示例 2:
+
+
+输入:nums = [1,2,1,3,5,6,4]
+输出:1 或 5
+解释:你的函数可以返回索引 1,其峰值元素为 2;
+ 或者返回索引 5, 其峰值元素为 6。
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 1000-231 <= nums[i] <= 231 - 1- 对于所有有效的
i 都有 nums[i] != nums[i + 1]
+
+
+
+## template
+
+```python
+class Solution:
+ def findPeakElement(self, nums: List[int]) -> int:
+
+ low = 0
+ high = len(nums) - 1
+
+ while low < high:
+ mid = int(low - (low - high) / 2)
+ if nums[mid] < nums[mid + 1]:
+ low = mid + 1
+ else:
+ high = mid
+
+ return low
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..80299768295e533370bfafe13eb7972bdeebb63b
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f11e99c6dc424c00809f701c5dad9ad1",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2467a480b97d4dc2d0185ea800deede0c4837753
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "bfe463f60cc14a43b09285f5c7e76ddf",
+ "author": "csdn.net",
+ "keywords": "双指针,字符串"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..620ed87d65d5cc4091baae6054580ee42463bb2c
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/165.exercises/solution.md"
@@ -0,0 +1,140 @@
+# 比较版本号
+
+给你两个版本号 version1 和 version2 ,请你比较它们。
+
+版本号由一个或多个修订号组成,各修订号由一个 '.' 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开始,最左边的修订号下标为 0 ,下一个修订号下标为 1 ,以此类推。例如,2.5.33 和 0.1 都是有效的版本号。
+
+比较版本号时,请按从左到右的顺序依次比较它们的修订号。比较修订号时,只需比较 忽略任何前导零后的整数值 。也就是说,修订号 1 和修订号 001 相等 。如果版本号没有指定某个下标处的修订号,则该修订号视为 0 。例如,版本 1.0 小于版本 1.1 ,因为它们下标为 0 的修订号相同,而下标为 1 的修订号分别为 0 和 1 ,0 < 1 。
+
+返回规则如下:
+
+
+ - 如果
version1 > version2 返回 1,
+ - 如果
version1 < version2 返回 -1,
+ - 除此之外返回
0。
+
+
+
+
+示例 1:
+
+
+输入:version1 = "1.01", version2 = "1.001"
+输出:0
+解释:忽略前导零,"01" 和 "001" 都表示相同的整数 "1"
+
+
+示例 2:
+
+
+输入:version1 = "1.0", version2 = "1.0.0"
+输出:0
+解释:version1 没有指定下标为 2 的修订号,即视为 "0"
+
+
+示例 3:
+
+
+输入:version1 = "0.1", version2 = "1.1"
+输出:-1
+解释:version1 中下标为 0 的修订号是 "0",version2 中下标为 0 的修订号是 "1" 。0 < 1,所以 version1 < version2
+
+
+示例 4:
+
+
+输入:version1 = "1.0.1", version2 = "1"
+输出:1
+
+
+示例 5:
+
+
+输入:version1 = "7.5.2.4", version2 = "7.5.3"
+输出:-1
+
+
+
+
+提示:
+
+
+ 1 <= version1.length, version2.length <= 500version1 和 version2 仅包含数字和 '.'version1 和 version2 都是 有效版本号version1 和 version2 的所有修订号都可以存储在 32 位整数 中
+
+
+## template
+
+```python
+class Solution(object):
+ def compareVersion(self, version1, version2):
+ """
+ 用split划分 转换为int 比较即可
+ :type version1: str
+ :type version2: str
+ :rtype: int
+ """
+ com1 = version1.split(".")
+ com2 = version2.split(".")
+
+ if len(com1) != len(com2):
+
+ if len(com1) > len(com2):
+ for i in range(len(com2)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ for i in range(len(com2), len(com1)):
+ if int(com1[i]) != 0:
+ return 1
+ return 0
+ else:
+ for i in range(len(com1)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ for i in range(len(com1), len(com2)):
+ if int(com2[i]) != 0:
+ return -1
+ return 0
+
+ for i in range(len(com1)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ else:
+ continue
+ return 0
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..707048129edcb15231009b80cab5bc22b02d1f6c
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ef2e6e13ff264b4cb8f2c845996d2ec3",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0e76820afdcbe896d811d26e1da01470fd29dcdf
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ac307c03f75a42829372ee123e3d01c7",
+ "author": "csdn.net",
+ "keywords": "哈希表,数学,字符串"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..955b20b7deababa4bacb980b3cb12b34505afd4f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/166.exercises/solution.md"
@@ -0,0 +1,128 @@
+# 分数到小数
+
+给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。
+
+如果小数部分为循环小数,则将循环的部分括在括号内。
+
+如果存在多个答案,只需返回 任意一个 。
+
+对于所有给定的输入,保证 答案字符串的长度小于 104 。
+
+
+
+示例 1:
+
+
+输入:numerator = 1, denominator = 2
+输出:"0.5"
+
+
+示例 2:
+
+
+输入:numerator = 2, denominator = 1
+输出:"2"
+
+
+示例 3:
+
+
+输入:numerator = 2, denominator = 3
+输出:"0.(6)"
+
+
+示例 4:
+
+
+输入:numerator = 4, denominator = 333
+输出:"0.(012)"
+
+
+示例 5:
+
+
+输入:numerator = 1, denominator = 5
+输出:"0.2"
+
+
+
+
+提示:
+
+
+ -231 <= numerator, denominator <= 231 - 1denominator != 0
+
+
+## template
+
+```python
+
+class Solution(object):
+ def fractionToDecimal(self, numerator, denominator):
+
+ if numerator < 0 and denominator < 0:
+ numerator, denominator = -numerator, -denominator
+
+ u = (numerator < 0) ^ (denominator < 0)
+
+ numerator = abs(numerator)
+ denominator = abs(denominator)
+ numerator = numerator % denominator
+
+ if numerator == 0:
+ return str(numerator // denominator)
+
+ s = str(abs(numerator) // denominator) + "."
+ q = {}
+ l = []
+ while numerator < denominator:
+ numerator = numerator * 10
+ l.append(numerator)
+ q[numerator] = numerator // denominator
+ numerator = numerator % denominator * 10
+
+ while numerator not in q and numerator != 0:
+ l.append(numerator)
+ q[numerator] = numerator // denominator
+ numerator = numerator % denominator
+ numerator = numerator * 10
+
+ for i in range(0, len(l)):
+ if numerator == l[i]:
+ s = s + "("
+ s = s + str(q[l[i]])
+ if "(" in s:
+ s = s + ")"
+ if u:
+ s = "-" + s
+ return s
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e27590c8c821cfbe5712de8d2684da6e1b797c21
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-273b0db29807463f91e540fb86784a75",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d2d13a2d7e6463ee18016755cb97065838d14acb
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "f9056b7e01224bcfa51a3ced5cc76440",
+ "author": "csdn.net",
+ "keywords": "栈,树,设计,二叉搜索树,二叉树,迭代器"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..7aa84111bde8804bf9f327ddc12415d9aa4899dc
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/173.exercises/solution.md"
@@ -0,0 +1,128 @@
+# 二叉搜索树迭代器
+
+实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
+
+
+
+ BSTIterator(TreeNode root) 初始化 BSTIterator 类的一个对象。BST 的根节点 root 会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。boolean hasNext() 如果向指针右侧遍历存在数字,则返回 true ;否则返回 false 。int next()将指针向右移动,然后返回指针处的数字。
+
+
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
+
+
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
+
+
+
+示例:
+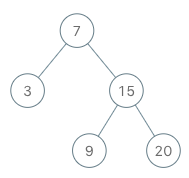 +
+
+输入
+["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"]
+[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []]
+输出
+[null, 3, 7, true, 9, true, 15, true, 20, false]
+
+解释
+BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]);
+bSTIterator.next(); // 返回 3
+bSTIterator.next(); // 返回 7
+bSTIterator.hasNext(); // 返回 True
+bSTIterator.next(); // 返回 9
+bSTIterator.hasNext(); // 返回 True
+bSTIterator.next(); // 返回 15
+bSTIterator.hasNext(); // 返回 True
+bSTIterator.next(); // 返回 20
+bSTIterator.hasNext(); // 返回 False
+
+
+
+
+提示:
+
+
+ - 树中节点的数目在范围
[1, 105] 内
+ 0 <= Node.val <= 106- 最多调用
105 次 hasNext 和 next 操作
+
+
+
+
+进阶:
+
+
+ - 你可以设计一个满足下述条件的解决方案吗?
next() 和 hasNext() 操作均摊时间复杂度为 O(1) ,并使用 O(h) 内存。其中 h 是树的高度。
+
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class BSTIterator:
+ def __init__(self, root: TreeNode):
+ self.index = -1
+ self.node_list = []
+ self._iterator(root)
+
+ def _iterator(self, root):
+ if not root:
+ return
+ self._iterator(root.left)
+ self.node_list.append(root.val)
+ self._iterator(root.right)
+
+ def next(self) -> int:
+ """
+ @return the next smallest number
+ """
+ self.index += 1
+ return self.node_list[self.index]
+
+ def hasNext(self) -> bool:
+ """
+ @return whether we have a next smallest number
+ """
+ return self.index + 1 < len(self.node_list)
+
+
+# Your BSTIterator object will be instantiated and called as such:
+# obj = BSTIterator(root)
+# param_1 = obj.next()
+# param_2 = obj.hasNext()
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2e1e484e1ae29ea4f3a208f7dce23bcfd857f997
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-40cda282f742431882315432586cf67e",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..05552589b9eceee06aa6ea1c4eceb091a28549be
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "48239df283334fd39c5d0c2744369c2a",
+ "author": "csdn.net",
+ "keywords": "贪心,字符串,排序"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..fe8bd064229042a956632e96b3f542ab16d42db2
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/179.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 最大数
+
+给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
+
+注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
+
+
+
+示例 1:
+
+
+输入:nums = [10,2]
+输出:"210"
+
+示例 2:
+
+
+输入:nums = [3,30,34,5,9]
+输出:"9534330"
+
+
+示例 3:
+
+
+输入:nums = [1]
+输出:"1"
+
+
+示例 4:
+
+
+输入:nums = [10]
+输出:"10"
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 1000 <= nums[i] <= 109
+
+
+## template
+
+```python
+
+class Solution(object):
+ def largestNumber(self, nums):
+ n = len(nums)
+
+ for i in range(n):
+ for j in range(n - i - 1):
+ temp_1 = str(nums[j])
+ temp_2 = str(nums[j + 1])
+ if int(temp_1 + temp_2) < int(temp_2 + temp_1):
+ temp = nums[j]
+ nums[j] = nums[j + 1]
+ nums[j + 1] = temp
+ output = ""
+ for num in nums:
+ output = output + str(num)
+ return str(int(output))
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..35fe080306eb120c201a18f19fb6513d2bb95d0f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-f1f828a586b84bba88262a7eb4992e1f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..57b669eaa6cd7a63de0606450c50044ad04e0e12
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "3d5dffe04e954a04a3a23df3f19fd0f5",
+ "author": "csdn.net",
+ "keywords": "位运算,哈希表,字符串,滑动窗口,哈希函数,滚动哈希"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e8e6bb6c506c391ced19608502449d3ff3986cbb
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/187.exercises/solution.md"
@@ -0,0 +1,77 @@
+# 重复的DNA序列
+
+所有 DNA 都由一系列缩写为 'A','C','G' 和 'T' 的核苷酸组成,例如:"ACGAATTCCG"。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
+
+编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
+
+
+
+示例 1:
+
+
+输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
+输出:["AAAAACCCCC","CCCCCAAAAA"]
+
+
+示例 2:
+
+
+输入:s = "AAAAAAAAAAAAA"
+输出:["AAAAAAAAAA"]
+
+
+
+
+提示:
+
+
+ 0 <= s.length <= 105s[i] 为 'A'、'C'、'G' 或 'T'
+
+
+## template
+
+```python
+class Solution:
+ def findRepeatedDnaSequences(self, s: str) -> List[str]:
+ n = len(s)
+ res = []
+ dic = {}
+ for i in range(n - 9):
+ if s[i : i + 10] not in dic:
+ dic[s[i : i + 10]] = 1
+ else:
+ dic[s[i : i + 10]] += 1
+ if dic[s[i : i + 10]] == 2:
+ res.append(s[i : i + 10])
+ return res
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b0236ccd893ba967944912dc6db17ebab0332d39
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-75dfa69388d6448690bd8c4a80654295",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..627b2374a7999ffe8c5a879531b2eabe99366894
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "f8d4c9c5e53a4e308af15766723fd868",
+ "author": "csdn.net",
+ "keywords": "数组,数学,双指针"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b24fb07e4b59ee489142b8920446beaea8986945
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/189.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 旋转数组
+
+给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
+
+
+
+进阶:
+
+
+ - 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
+ - 你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
+
+
+
+
+示例 1:
+
+
+输入: nums = [1,2,3,4,5,6,7], k = 3
+输出: [5,6,7,1,2,3,4]
+解释:
+向右旋转 1 步: [7,1,2,3,4,5,6]
+向右旋转 2 步: [6,7,1,2,3,4,5]
+向右旋转 3 步: [5,6,7,1,2,3,4]
+
+
+示例 2:
+
+
+输入:nums = [-1,-100,3,99], k = 2
+输出:[3,99,-1,-100]
+解释:
+向右旋转 1 步: [99,-1,-100,3]
+向右旋转 2 步: [3,99,-1,-100]
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 10 <= k <= 105
+
+
+
+
+## template
+
+```python
+class Solution:
+ def rotate(self, nums: List[int], k: int) -> None:
+ """
+ Do not return anything, modify nums in-place instead.
+ """
+ n = 0
+ while n < k:
+ c = nums.pop()
+ nums.insert(0, c)
+
+ n += 1
+ return nums
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..f34085dfc4d8f992080671152cdb2bf605c23f47
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-eddb5bec90fd4e17aec581f1a7f2ac5c",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..969a3ca982e5da98a4e7484c6a0d1b5e54e33423
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ea8fa229d3c243a4a6f6ebfdccdd5bfd",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..506b70e3a1a82b37d8691364ab1acaea7c3a2ec4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/198.exercises/solution.md"
@@ -0,0 +1,77 @@
+# 打家劫舍
+
+你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
+
+给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
+
+
+
+示例 1:
+
+
+输入:[1,2,3,1]
+输出:4
+解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
+ 偷窃到的最高金额 = 1 + 3 = 4 。
+
+示例 2:
+
+
+输入:[2,7,9,3,1]
+输出:12
+解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
+ 偷窃到的最高金额 = 2 + 9 + 1 = 12 。
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 1000 <= nums[i] <= 400
+
+
+## template
+
+```python
+
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ if not nums:
+ return 0
+ if len(nums) == 1:
+ return nums[0]
+ dp = [nums[0], max(nums[0], nums[1])]
+ for i in range(2, len(nums)):
+ dp.append(max(nums[i] + dp[i - 2], dp[i - 1]))
+ return dp[-1]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3d646d11f6e208c5837d68e31be21150f2743736
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-33094a35b79a41a397e0a906ec2e318f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a0d76cf436a4ac5dfc152f3a2e1c6e78dca5525d
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "b1ba5727356c443b859bfb64fc002898",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,二叉树"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..2e344d40d4b44991103af49ead19d0aa32111a5f
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/199.exercises/solution.md"
@@ -0,0 +1,96 @@
+# 二叉树的右视图
+
+给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
+
+
+
+示例 1:
+
+
+
+
+输入: [1,2,3,null,5,null,4]
+输出: [1,3,4]
+
+
+示例 2:
+
+
+输入: [1,null,3]
+输出: [1,3]
+
+
+示例 3:
+
+
+输入: []
+输出: []
+
+
+
+
+提示:
+
+
+ - 二叉树的节点个数的范围是
[0,100]
+ -100 <= Node.val <= 100
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def rightSideView(self, root: TreeNode) -> List[int]:
+ if not root:
+ return []
+ res = []
+ curnode = [root]
+ nexnode = []
+ res.append(curnode[0].val)
+
+ while curnode:
+ for s in curnode:
+ if s.right:
+ nexnode.append(s.right)
+ if s.left:
+ nexnode.append(s.left)
+ if nexnode:
+ res.append(nexnode[0].val)
+ curnode = nexnode
+ nexnode = []
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a24453f06d2f5c19b00d965bb2c93a1fc1fe5d09
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-72651cf7970c4a9c837aee8016c169d1",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..85647b8ec785d0a45bf5b7abdfaa086d706d98fa
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "22a947b155ff40e9825fdf1bb533aa04",
+ "author": "csdn.net",
+ "keywords": "深度优先搜索,广度优先搜索,并查集,数组,矩阵"
+}
\ No newline at end of file
diff --git "a/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..aba42f3184ca13e7110526932703c250228ccef4
--- /dev/null
+++ "b/data/2.dailycode\344\270\255\351\230\266/3.python/200.exercises/solution.md"
@@ -0,0 +1,101 @@
+# 岛屿数量
+
+给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
+
+岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
+
+此外,你可以假设该网格的四条边均被水包围。
+
+
+
+示例 1:
+
+
+输入:grid = [
+ ["1","1","1","1","0"],
+ ["1","1","0","1","0"],
+ ["1","1","0","0","0"],
+ ["0","0","0","0","0"]
+]
+输出:1
+
+
+示例 2:
+
+
+输入:grid = [
+ ["1","1","0","0","0"],
+ ["1","1","0","0","0"],
+ ["0","0","1","0","0"],
+ ["0","0","0","1","1"]
+]
+输出:3
+
+
+
+
+提示:
+
+
+ m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j] 的值为 '0' 或 '1'
+
+
+## template
+
+```python
+
+class Solution:
+ def depthSearch(self, grid, i, j):
+ if i < 0 or j < 0 or i >= len(grid) or j >= len(grid[0]):
+ return
+ if grid[i][j] == "0":
+ return
+ grid[i][j] = "0"
+ self.depthSearch(grid, i - 1, j)
+ self.depthSearch(grid, i + 1, j)
+ self.depthSearch(grid, i, j - 1)
+ self.depthSearch(grid, i, j + 1)
+
+ def numIslands(self, grid: List[List[str]]) -> int:
+ if not grid:
+ return 0
+ w, h = len(grid[0]), len(grid)
+ cnt = 0
+ for i in range(h):
+ for j in range(w):
+ if grid[i][j] == "1":
+ self.depthSearch(grid, i, j)
+ cnt += 1
+ return cnt
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..55a5bc262a0ad0f1fa45add2ce15258faeeb353d
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-a98b07d061a346e7836267fbb5796e65",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..092173f30c90226557e03285d43017c744e2cbbf
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "957672d2d8c748ccb07ee1c232af6b41",
+ "author": "csdn.net",
+ "keywords": "字符串,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..4e47cd10078c31aaad3b55bc1f44256f83d35e85
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/115.exercises/solution.md"
@@ -0,0 +1,91 @@
+# 不同的子序列
+
+给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
+
+字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
+
+题目数据保证答案符合 32 位带符号整数范围。
+
+
+
+示例 1:
+
+
+输入:s = "rabbbit", t = "rabbit"
+输出:3
+解释:
+如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
+rabbbit
+rabbbit
+rabbbit
+
+示例 2:
+
+
+输入:s = "babgbag", t = "bag"
+输出:5
+解释:
+如下图所示, 有 5 种可以从 s 中得到 "bag" 的方案。
+babgbag
+babgbag
+babgbag
+babgbag
+babgbag
+
+
+
+
+提示:
+
+
+ 0 <= s.length, t.length <= 1000s 和 t 由英文字母组成
+
+
+## template
+
+```python
+
+class Solution:
+ def numDistinct(self, s: str, t: str) -> int:
+ if t == "" and s == "":
+ return 0
+ if t == "":
+ return 1
+ dp = [[0 for i in range(len(s) + 1)] for j in range(len(t) + 1)]
+ for j in range(0, len(s) + 1):
+ dp[0][j] = 1
+ for i in range(1, len(t) + 1):
+ for j in range(1, len(s) + 1):
+ dp[i][j] = dp[i][j - 1]
+ if s[j - 1] == t[i - 1]:
+ dp[i][j] += dp[i - 1][j - 1]
+ return dp[-1][-1]
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..72adfcd9d5159c2ca3f447a217d0393f038f589e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-90790bba74e54755a2dee597322d6e6d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2b6f82f71fc945161bc6a1630518933693040bd6
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "9f8db2724d104eef9b86d4b3b4a5a44f",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..7c3ef4547d226152dd45700f508c084b34adc512
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/123.exercises/solution.md"
@@ -0,0 +1,99 @@
+# 买卖股票的最佳时机 III
+
+给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
+
+设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
+
+注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+
+
+
+示例 1:
+
+
+输入:prices = [3,3,5,0,0,3,1,4]
+输出:6
+解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
+ 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
+
+示例 2:
+
+
+输入:prices = [1,2,3,4,5]
+输出:4
+解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
+ 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
+ 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
+
+
+示例 3:
+
+
+输入:prices = [7,6,4,3,1]
+输出:0
+解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
+
+示例 4:
+
+
+输入:prices = [1]
+输出:0
+
+
+
+
+提示:
+
+
+ 1 <= prices.length <= 1050 <= prices[i] <= 105
+
+
+## template
+
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ k = 2
+ n = len(prices)
+ dp_i_1_0 = 0
+ dp_i_1_1 = -prices[0]
+ dp_i_2_0 = 0
+ dp_i_2_1 = -prices[0]
+ for i in range(1, n):
+ dp_i_1_0 = max(dp_i_1_0, dp_i_1_1 + prices[i])
+ dp_i_1_1 = max(dp_i_1_1, -prices[i])
+ dp_i_2_0 = max(dp_i_2_0, dp_i_2_1 + prices[i])
+ dp_i_2_1 = max(dp_i_2_1, dp_i_1_0 - prices[i])
+ return dp_i_2_0
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..75545595b002b96227caac03b1e9b212cf38830f
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-4edb8def83124472ac03b745fad35664",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b53c4f4655463c1e33891ba04cca1654e9e2887b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "cddc0e94a1984dd4a980198707e090cc",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,动态规划,二叉树"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..bb3342d1efb1056f09446a8c48283b83c0d2f34b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/124.exercises/solution.md"
@@ -0,0 +1,86 @@
+# 二叉树中的最大路径和
+
+路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
+
+路径和 是路径中各节点值的总和。
+
+给你一个二叉树的根节点 root ,返回其 最大路径和 。
+
+
+
+示例 1:
+ +
+
+输入:root = [1,2,3]
+输出:6
+解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
+
+示例 2:
+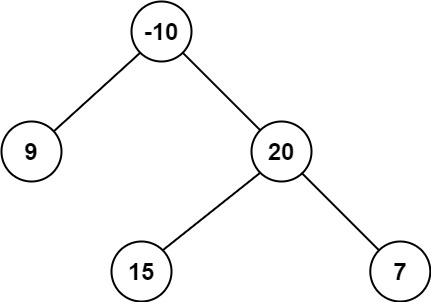 +
+
+输入:root = [-10,9,20,null,null,15,7]
+输出:42
+解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
+
+
+
+
+提示:
+
+
+ - 树中节点数目范围是
[1, 3 * 104]
+ -1000 <= Node.val <= 1000
+
+
+## template
+
+```python
+
+class Solution:
+ def __init__(self):
+ self.result = float("-inf")
+
+ def maxPathSum(self, root: TreeNode) -> int:
+ if root == None:
+ return 0
+ self.getMax(root)
+ return self.result
+
+ def getMax(self, root):
+ if root == None:
+ return 0
+
+ left = max(0, self.getMax(root.left))
+ right = max(0, self.getMax(root.right))
+
+ self.result = max(self.result, left + right + root.val)
+ return max(left, right) + root.val
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..abb682e8861baa724d1caf9c8d8103d21752d9ff
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-7fc8d0105e73409ba569a7a0ce94f291",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0201c81fe1b6b7ec09e8284846ea7d837d66eeb4
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "1c00b22e362a444995d6bd2eff9d01be",
+ "author": "csdn.net",
+ "keywords": "广度优先搜索,哈希表,字符串,回溯"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a0fb31b7294c1bd5d8012631dabf61d77451f0b7
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/126.exercises/solution.md"
@@ -0,0 +1,112 @@
+# 单词接龙 II
+
+按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
+
+
+
+
+ - 每对相邻的单词之间仅有单个字母不同。
+ - 转换过程中的每个单词
si(1 <= i <= k)必须是字典 wordList 中的单词。注意,beginWord 不必是字典 wordList 中的单词。
+ sk == endWord
+
+
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
+
+
+
+
示例 1:
+
+
+输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
+输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]]
+解释:存在 2 种最短的转换序列:
+"hit" -> "hot" -> "dot" -> "dog" -> "cog"
+"hit" -> "hot" -> "lot" -> "log" -> "cog"
+
+
+
示例 2:
+
+
+输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
+输出:[]
+解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。
+
+
+
+
+
提示:
+
+
+ 1 <= beginWord.length <= 7endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord 和 wordList[i] 由小写英文字母组成beginWord != endWordwordList 中的所有单词 互不相同
+
+
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
+
+
+ - 序列中第一个单词是
beginWord 。
+ - 序列中最后一个单词是
endWord 。
+ - 每次转换只能改变一个字母。
+ - 转换过程中的中间单词必须是字典
wordList 中的单词。
+
+
+给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
+
+
+示例 1:
+
+
+输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
+输出:5
+解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
+
+
+示例 2:
+
+
+输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
+输出:0
+解释:endWord "cog" 不在字典中,所以无法进行转换。
+
+
+
+提示:
+
+
+ 1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord 和 wordList[i] 由小写英文字母组成beginWord != endWordwordList 中的所有字符串 互不相同
+
+
+## template
+
+```python
+class Solution:
+ def ladderLength(self, beginWord, endWord, wordList):
+ """
+ :type beginWord: str
+ :type endWord: str
+ :type wordList: List[str]
+ :rtype: int
+ """
+
+ if endWord not in wordList:
+ return 0
+
+ if beginWord in wordList:
+ wordList.remove(beginWord)
+ wordDict = dict()
+
+ for word in wordList:
+ for i in range(len(word)):
+ tmp = word[:i] + "_" + word[i + 1 :]
+ wordDict[tmp] = wordDict.get(tmp, []) + [word]
+
+ stack, visited = [(beginWord, 1)], set()
+
+ while stack:
+ word, step = stack.pop(0)
+ if word not in visited:
+ visited.add(word)
+
+ if word == endWord:
+ return step
+
+ for i in range(len(word)):
+ tmp = word[:i] + "_" + word[i + 1 :]
+ neigh_words = wordDict.get(tmp, [])
+
+ for neigh in neigh_words:
+ if neigh not in visited:
+ stack.append((neigh, step + 1))
+
+ return 0
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0f09d39e6d441142dab291679b1844af9eed825e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-6f96939e6b4c489fa6c311e084e6cad6",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c03b65b582d266ac3caef9bed787c497bab9eb9c
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c1730674847b45749f2e3d6dd06f43b8",
+ "author": "csdn.net",
+ "keywords": "字符串,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..661fae5ce9f2ee85b990b8508e6d04ca49020b50
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/132.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 分割回文串 II
+
+给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
+
+返回符合要求的 最少分割次数 。
+
+
+
+
+
+
示例 1:
+
+
+输入:s = "aab"
+输出:1
+解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。
+
+
+
示例 2:
+
+
+输入:s = "a"
+输出:0
+
+
+
示例 3:
+
+
+输入:s = "ab"
+输出:1
+
+
+
+
+
提示:
+
+
+ 1 <= s.length <= 2000s 仅由小写英文字母组成
+
+
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
+
+你需要按照以下要求,帮助老师给这些孩子分发糖果:
+
+
+ - 每个孩子至少分配到 1 个糖果。
+ - 评分更高的孩子必须比他两侧的邻位孩子获得更多的糖果。
+
+
+那么这样下来,老师至少需要准备多少颗糖果呢?
+
+
+
+示例 1:
+
+
+输入:[1,0,2]
+输出:5
+解释:你可以分别给这三个孩子分发 2、1、2 颗糖果。
+
+
+示例 2:
+
+
+输入:[1,2,2]
+输出:4
+解释:你可以分别给这三个孩子分发 1、2、1 颗糖果。
+ 第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
+
+
+## template
+
+```python
+class Solution(object):
+ def candy(self, ratings):
+ """
+ :type ratings: List[int]
+ :rtype: int
+ """
+ if ratings == None:
+ return 0
+ lenth = len(ratings)
+ dp = [1 for i in range(lenth)]
+ sum = 0
+ for i in range(1, len(ratings)):
+ if ratings[i] > ratings[i - 1]:
+ dp[i] = dp[i - 1] + 1
+ for i in range(len(ratings) - 2, -1, -1):
+ if ratings[i] > ratings[i + 1] and dp[i] <= dp[i + 1]:
+ dp[i] = dp[i + 1] + 1
+ for i in range(lenth):
+ sum += dp[i]
+ return sum
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e5f71fc2833b103b32a2dd2e054d949d589c7802
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-c12fefc5309b4cb7842e7587a1d366a9",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..bf9f406ea6abb571128421610ffff0bfd637d93e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "d28fda4f9c8149e18b8044fb166e824f",
+ "author": "csdn.net",
+ "keywords": "字典树,记忆化搜索,哈希表,字符串,动态规划,回溯"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..45780ba68cee1e8745ed5fdcd5e37299ebc70163
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/140.exercises/solution.md"
@@ -0,0 +1,109 @@
+# 单词拆分 II
+
+给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
+
+说明:
+
+
+ - 分隔时可以重复使用字典中的单词。
+ - 你可以假设字典中没有重复的单词。
+
+
+示例 1:
+
+输入:
+s = "catsanddog"
+wordDict = ["cat", "cats", "and", "sand", "dog"]
+输出:
+[
+ "cats and dog",
+ "cat sand dog"
+]
+
+
+示例 2:
+
+输入:
+s = "pineapplepenapple"
+wordDict = ["apple", "pen", "applepen", "pine", "pineapple"]
+输出:
+[
+ "pine apple pen apple",
+ "pineapple pen apple",
+ "pine applepen apple"
+]
+解释: 注意你可以重复使用字典中的单词。
+
+
+示例 3:
+
+输入:
+s = "catsandog"
+wordDict = ["cats", "dog", "sand", "and", "cat"]
+输出:
+[]
+
+
+
+## template
+
+```python
+class Solution(object):
+ def dfs(self, low, length, s, res, vaild, path=[]):
+ if low == length:
+ res.append(" ".join(path))
+ return
+ for i in range(low, length):
+ if vaild[low][i]:
+ self.dfs(i + 1, length, s, res, vaild, path + [s[low : i + 1]])
+
+ def wordBreak(self, s, wordDict):
+ """
+ :type s: str
+ :type wordDict: List[str]
+ :rtype: List[str]
+ """
+ length = len(s)
+ vaild = [[False] * length for _ in range(length)]
+ dp = [False for _ in range(length + 1)]
+ dp[0] = True
+ wordDict = set(wordDict)
+ for i in range(1, length + 1):
+ for j in range(i + 1):
+ word = s[j:i]
+ if dp[j] and word in wordDict:
+ dp[i] = True
+ vaild[j][i - 1] = True
+ res = []
+ if dp[-1]:
+ self.dfs(0, length, s, res, vaild)
+ return res
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..8537b0bf5dbeb90397c27e239431e43a92d2d526
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-4654129f5c054b9db02fbdb1d7ad643b",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..41b0974a62dcd006cf487953e147de1a462129d2
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "c46851f1de3a4abfba2e35193034607a",
+ "author": "csdn.net",
+ "keywords": "几何,哈希表,数学"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b9692a5aa1dee71bc9d812fefd5b1142b0cc4fe3
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/149.exercises/solution.md"
@@ -0,0 +1,91 @@
+# 直线上最多的点数
+
+给你一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
+
+
+
+示例 1:
+ +
+
+输入:points = [[1,1],[2,2],[3,3]]
+输出:3
+
+
+示例 2:
+ +
+
+输入:points = [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]]
+输出:4
+
+
+
+
+提示:
+
+
+ 1 <= points.length <= 300points[i].length == 2-104 <= xi, yi <= 104points 中的所有点 互不相同
+
+
+## template
+
+```python
+class Solution:
+ def maxPoints(self, points: List[List[int]]) -> int:
+ if len(points) <= 2:
+ return len(points)
+ maxNum = 0
+ for i in range(len(points)):
+ maxNum = max(maxNum, self.find(points[i], points[:i] + points[i + 1 :]))
+ return maxNum + 1
+
+ def find(self, point, pointList):
+ memories = {}
+ count = 0
+ inf = float("inf")
+ for curPoint in pointList:
+ if curPoint[1] == point[1] and curPoint[0] != point[0]:
+ memories[inf] = memories.get(inf, 0) + 1
+ elif curPoint[1] == point[1] and curPoint[0] == point[0]:
+
+ count += 1
+ else:
+ slope = (curPoint[0] - point[0]) / (curPoint[1] - point[1])
+ memories[slope] = memories.get(slope, 0) + 1
+ if memories:
+ return count + max(memories.values())
+
+ else:
+
+ return count
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..3d40c68372727735bb3328268ecaa07a5db26018
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-0fba717312d245eba1aa75cd675a098a",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0d4143ed2a9ab91e3d552940962af77a93530fcc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "b5a91013625e4596b6d6c16eb2bd79a4",
+ "author": "csdn.net",
+ "keywords": "数组,二分查找"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a69963573b90ba72a4b6ade6b876ae30c753bf9e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/154.exercises/solution.md"
@@ -0,0 +1,93 @@
+# 寻找旋转排序数组中的最小值 II
+
+已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,4,4,5,6,7] 在变化后可能得到:
+
+ - 若旋转
4 次,则可以得到 [4,5,6,7,0,1,4]
+ - 若旋转
7 次,则可以得到 [0,1,4,4,5,6,7]
+
+
+注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
+
+给你一个可能存在 重复 元素值的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
+
+
+
+示例 1:
+
+
+输入:nums = [1,3,5]
+输出:1
+
+
+示例 2:
+
+
+输入:nums = [2,2,2,0,1]
+输出:0
+
+
+
+
+提示:
+
+
+ n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums 原来是一个升序排序的数组,并进行了 1 至 n 次旋转
+
+
+
+进阶:
+
+
+
+
+## template
+
+```python
+
+class Solution:
+ def findMin(self, nums: List[int]) -> int:
+ left = 0
+ right = len(nums) - 1
+ while left < right:
+ mid = left + (right - left) // 2
+ if nums[mid] > nums[right]:
+ left = mid + 1
+ elif nums[mid] == nums[right]:
+ right -= 1
+ else:
+ right = mid
+ return nums[left]
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..66e9db4fcd3bc5151a5597360c505198d6466508
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-21b2806a36f44cd0a9b208a42d402849",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1d3c10b12e20194417cb6e1ef10548a1d623941c
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "937ab77a60ca4b3b9af54b3dab2a3764",
+ "author": "csdn.net",
+ "keywords": "数组,桶排序,基数排序,排序"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..7f97f2cc1c96aa3bbb367475c49dc29c73d079ce
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/164.exercises/solution.md"
@@ -0,0 +1,87 @@
+# 最大间距
+
+给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。
+
+如果数组元素个数小于 2,则返回 0。
+
+示例 1:
+
+输入: [3,6,9,1]
+输出: 3
+解释: 排序后的数组是 [1,3,6,9], 其中相邻元素 (3,6) 和 (6,9) 之间都存在最大差值 3。
+
+示例 2:
+
+输入: [10]
+输出: 0
+解释: 数组元素个数小于 2,因此返回 0。
+
+说明:
+
+
+ - 你可以假设数组中所有元素都是非负整数,且数值在 32 位有符号整数范围内。
+ - 请尝试在线性时间复杂度和空间复杂度的条件下解决此问题。
+
+
+
+## template
+
+```python
+class Solution(object):
+ def maximumGap(self, nums):
+ if len(nums) < 2:
+ return 0
+ min_val, max_val = min(nums), max(nums)
+ if min_val == max_val:
+ return 0
+
+ n = len(nums) + 1
+ step = (max_val - min_val) // n
+
+ exist = [0 for _ in range(n + 1)]
+ max_num = [0 for _ in range(n + 1)]
+ min_num = [0 for _ in range(n + 1)]
+
+ for num in nums:
+ idx = self.findBucketIndex(num, min_val, max_val, n)
+ max_num[idx] = num if not exist[idx] else max(num, max_num[idx])
+ min_num[idx] = num if not exist[idx] else min(num, min_num[idx])
+ exist[idx] = 1
+ res = 0
+ pre = max_num[0]
+ for i in range(1, n + 1):
+ if exist[i]:
+ res = max(res, min_num[i] - pre)
+ pre = max_num[i]
+ return res
+
+ def findBucketIndex(self, num, min_val, max_val, n):
+ return int((num - min_val) * n / (max_val - min_val))
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ce0618a06edc825d78e4837990407b227d529e8a
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-34dc808512454a07852f82a9a5cd6b33",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ed0bf22db2972c386e29523a07cf9ac6e52db4a5
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6c2501b9ae9e4a66b190108ea289548b",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划,矩阵"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..98bc1941ffbb9a8230f25de2e0672f8bc7aae0e3
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/174.exercises/solution.md"
@@ -0,0 +1,106 @@
+# 地下城游戏
+
+
+
+一些恶魔抓住了公主(P)并将她关在了地下城的右下角。地下城是由 M x N 个房间组成的二维网格。我们英勇的骑士(K)最初被安置在左上角的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。
+
+骑士的初始健康点数为一个正整数。如果他的健康点数在某一时刻降至 0 或以下,他会立即死亡。
+
+有些房间由恶魔守卫,因此骑士在进入这些房间时会失去健康点数(若房间里的值为负整数,则表示骑士将损失健康点数);其他房间要么是空的(房间里的值为 0),要么包含增加骑士健康点数的魔法球(若房间里的值为正整数,则表示骑士将增加健康点数)。
+
+为了尽快到达公主,骑士决定每次只向右或向下移动一步。
+
+
+
+编写一个函数来计算确保骑士能够拯救到公主所需的最低初始健康点数。
+
+例如,考虑到如下布局的地下城,如果骑士遵循最佳路径 右 -> 右 -> 下 -> 下,则骑士的初始健康点数至少为 7。
+
+
+
+| -2 (K) |
+-3 |
+3 |
+
+
+| -5 |
+-10 |
+1 |
+
+
+| 10 |
+30 |
+-5 (P) |
+
+
+
+
+
+
+说明:
+
+
+ -
+
骑士的健康点数没有上限。
+
+ - 任何房间都可能对骑士的健康点数造成威胁,也可能增加骑士的健康点数,包括骑士进入的左上角房间以及公主被监禁的右下角房间。
+
+
+## template
+
+```python
+class Solution:
+ def calculateMinimumHP(self, dungeon: List[List[int]]) -> int:
+ m = len(dungeon)
+ n = len(dungeon[0])
+
+ dp = [[float("inf")] * (n + 1) for _ in range(m + 1)]
+
+ dp[m - 1][n] = 1
+ dp[m][n - 1] = 1
+
+ for i in range(m - 1, -1, -1):
+ for j in range(n - 1, -1, -1):
+ dp[i][j] = max(min(dp[i][j + 1], dp[i + 1][j]) - dungeon[i][j], 1)
+
+ return dp[0][0]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..bf72d5007b4ea1fbd1f60ae47ebcbe1c8faeed73
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ffb46162d04b486e8ee501c7741058e3",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..7572f9017f896c4490a5b53baf4c09046e62ab02
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "6c5d72467a724708986ec06cd91422fa",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..8da01a9aaf6dc56f427852c5af130c95b14efabd
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/188.exercises/solution.md"
@@ -0,0 +1,89 @@
+# 买卖股票的最佳时机 IV
+
+给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
+
+设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
+
+注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+
+
+
+示例 1:
+
+
+输入:k = 2, prices = [2,4,1]
+输出:2
+解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
+
+示例 2:
+
+
+输入:k = 2, prices = [3,2,6,5,0,3]
+输出:7
+解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
+ 随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
+
+
+
+提示:
+
+
+ 0 <= k <= 1000 <= prices.length <= 10000 <= prices[i] <= 1000
+
+
+## template
+
+```python
+class Solution:
+ def maxProfit(self, k, prices):
+ if not prices:
+ return 0
+ n = len(prices)
+ max_k = n // 2
+ if k >= max_k:
+ res = 0
+ for i in range(n - 1):
+ res += max(0, prices[i + 1] - prices[i])
+ return res
+ else:
+ max_k = k
+
+ dp = [[[0] * 2 for _ in range(k + 1)] for _ in range(n)]
+ for i in range(max_k + 1):
+ dp[0][i][1] = -prices[0]
+ for i in range(1, n):
+ for k in range(1, max_k + 1):
+ dp[i][k][0] = max(dp[i - 1][k][0], dp[i - 1][k][1] + prices[i])
+ dp[i][k][1] = max(dp[i - 1][k][1], dp[i - 1][k - 1][0] - prices[i])
+ return dp[n - 1][max_k][0]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..de1bdfdf2d983b6f1edbd759f6aac3ef2fb9b166
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-d8e499125a8944dc842e2af890faa2f8",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c17382fd2836d83acf9d323b948e0c7423640d16
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "7cc81fe3e8b549f09d8892808a9d1bd8",
+ "author": "csdn.net",
+ "keywords": "字典树,数组,字符串,回溯,矩阵"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..0cf0d174d6f4b1833a191f02d67411ca58864569
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/212.exercises/solution.md"
@@ -0,0 +1,107 @@
+# 单词搜索 II
+
+给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
+
+单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
+
+
+
+示例 1:
+ +
+
+输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
+输出:["eat","oath"]
+
+
+示例 2:
+ +
+
+输入:board = [["a","b"],["c","d"]], words = ["abcb"]
+输出:[]
+
+
+
+
+提示:
+
+
+ m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j] 是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i] 由小写英文字母组成words 中的所有字符串互不相同
+
+
+## template
+
+```python
+class Solution:
+ def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
+ if not board or not board[0] or not words:
+ return []
+ self.root = {}
+ for word in words:
+ node = self.root
+ for char in word:
+ if char not in node:
+ node[char] = {}
+ node = node[char]
+ node["#"] = word
+ res = []
+ for i in range(len(board)):
+ for j in range(len(board[0])):
+ tmp_state = []
+ self.dfs(i, j, board, tmp_state, self.root, res)
+ return res
+
+ def dfs(self, i, j, board, tmp_state, node, res):
+ if "#" in node and node["#"] not in res:
+ res.append(node["#"])
+ if [i, j] not in tmp_state and board[i][j] in node:
+ tmp = tmp_state + [[i, j]]
+ candidate = []
+ if i - 1 >= 0:
+ candidate.append([i - 1, j])
+ if i + 1 < len(board):
+ candidate.append([i + 1, j])
+ if j - 1 >= 0:
+ candidate.append([i, j - 1])
+ if j + 1 < len(board[0]):
+ candidate.append([i, j + 1])
+ node = node[board[i][j]]
+ if "#" in node and node["#"] not in res:
+ res.append(node["#"])
+ for item in candidate:
+ self.dfs(item[0], item[1], board, tmp, node, res)
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0d1732b2cf7337abbd508076199de9d6f30eb7f4
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ba5392791829449db47076b4ead47a10",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..81b53f4b4434e930e7b9e5abf43d30e3f12591f5
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "e59ab886eb074d5885206b6030b67fab",
+ "author": "csdn.net",
+ "keywords": "字符串,字符串匹配,哈希函数,滚动哈希"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..75be6dbb62ed1f8f8a7728b9a19d610e4d1eb0a5
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/214.exercises/solution.md"
@@ -0,0 +1,71 @@
+# 最短回文串
+
+给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
+
+
+
+示例 1:
+
+
+输入:s = "aacecaaa"
+输出:"aaacecaaa"
+
+
+示例 2:
+
+
+输入:s = "abcd"
+输出:"dcbabcd"
+
+
+
+
+提示:
+
+
+ 0 <= s.length <= 5 * 104s 仅由小写英文字母组成
+
+
+## template
+
+```python
+class Solution:
+ def shortestPalindrome(self, s: str) -> str:
+ N = len(s)
+ idx1 = 0
+ for idx2 in range(N - 1, -1, -1):
+ if s[idx1] == s[idx2]:
+ idx1 += 1
+ if idx1 == N:
+ return s
+ return s[idx1:][::-1] + self.shortestPalindrome(s[:idx1]) + s[idx1:]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..61a5fe3b5c3bf16844238f40836e3c10a2b44c51
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-bfeba7c90b4a46118f2abe3060b3d314",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..f45e44981bb43cd9e106028027f0a33e93b6194d
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "b6fe69f685d545d1a8497595765278fd",
+ "author": "csdn.net",
+ "keywords": "树状数组,线段树,数组,分治,有序集合,扫描线,堆(优先队列)"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..074f84bb12b4c871c2df4967292a9e3aa29e44a8
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/218.exercises/solution.md"
@@ -0,0 +1,130 @@
+# 天际线问题
+
+城市的天际线是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。给你所有建筑物的位置和高度,请返回由这些建筑物形成的 天际线 。
+
+每个建筑物的几何信息由数组 buildings 表示,其中三元组 buildings[i] = [lefti, righti, heighti] 表示:
+
+
+ lefti 是第 i 座建筑物左边缘的 x 坐标。righti 是第 i 座建筑物右边缘的 x 坐标。heighti 是第 i 座建筑物的高度。
+
+天际线 应该表示为由 “关键点” 组成的列表,格式 [[x1,y1],[x2,y2],...] ,并按 x 坐标 进行 排序 。关键点是水平线段的左端点。列表中最后一个点是最右侧建筑物的终点,y 坐标始终为 0 ,仅用于标记天际线的终点。此外,任何两个相邻建筑物之间的地面都应被视为天际线轮廓的一部分。
+
+注意:输出天际线中不得有连续的相同高度的水平线。例如 [...[2 3], [4 5], [7 5], [11 5], [12 7]...] 是不正确的答案;三条高度为 5 的线应该在最终输出中合并为一个:[...[2 3], [4 5], [12 7], ...]
+
+
+
+示例 1:
+ +
+
+输入:buildings = [[2,9,10],[3,7,15],[5,12,12],[15,20,10],[19,24,8]]
+输出:[[2,10],[3,15],[7,12],[12,0],[15,10],[20,8],[24,0]]
+解释:
+图 A 显示输入的所有建筑物的位置和高度,
+图 B 显示由这些建筑物形成的天际线。图 B 中的红点表示输出列表中的关键点。
+
+示例 2:
+
+
+输入:buildings = [[0,2,3],[2,5,3]]
+输出:[[0,3],[5,0]]
+
+
+
+
+提示:
+
+
+ 1 <= buildings.length <= 1040 <= lefti < righti <= 231 - 11 <= heighti <= 231 - 1buildings 按 lefti 非递减排序
+
+
+## template
+
+```python
+import heapq
+class Solution:
+ def getSkyline(self, buildings: List[List[int]]) -> List[List[int]]:
+ right_heap = []
+ height_lst = []
+
+ ans = []
+
+ for building in buildings:
+ left, right, height = building
+
+ while right_heap and right_heap[0][0] < left:
+
+ old_highest = height_lst[-1]
+
+ last_right, last_height = heapq.heappop(right_heap)
+ height_lst.pop(bisect.bisect_left(height_lst, last_height))
+
+ new_highest = height_lst[-1] if height_lst else 0
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == last_right:
+ ans.pop()
+ ans.append([last_right, new_highest])
+
+ old_highest = height_lst[-1] if height_lst else 0
+
+ bisect.insort_left(height_lst, height)
+ heapq.heappush(right_heap, (right, height))
+
+ new_highest = height_lst[-1]
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == left:
+ ans.pop()
+ ans.append([left, new_highest])
+
+ while right_heap:
+
+ old_highest = height_lst[-1]
+
+ last_right, last_height = heapq.heappop(right_heap)
+ height_lst.pop(bisect.bisect_left(height_lst, last_height))
+
+ new_highest = height_lst[-1] if height_lst else 0
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == last_right:
+ ans.pop()
+ ans.append([last_right, new_highest])
+
+ return ans
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..d78880f5182d5b434be50862ce574d619f549f75
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-7a500c3cb76f4abf8917ba35a95d8291",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a41b6f852426fcbff6a3cf0e14fdcaa42aae9eb1
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "d5be14108c2e4812ad3bc0c26e761af3",
+ "author": "csdn.net",
+ "keywords": "栈,递归,数学,字符串"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..5ae4901d5206b18390bacc173f9ee5c76f005ccd
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/224.exercises/solution.md"
@@ -0,0 +1,96 @@
+# 基本计算器
+
+给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
+
+
+
+示例 1:
+
+
+输入:s = "1 + 1"
+输出:2
+
+
+示例 2:
+
+
+输入:s = " 2-1 + 2 "
+输出:3
+
+
+示例 3:
+
+
+输入:s = "(1+(4+5+2)-3)+(6+8)"
+输出:23
+
+
+
+
+提示:
+
+
+ 1 <= s.length <= 3 * 105s 由数字、'+'、'-'、'('、')'、和 ' ' 组成s 表示一个有效的表达式
+
+
+## template
+
+```python
+class Solution:
+ def calculate(self, s: str) -> int:
+ s = s.replace(" ", "")
+ n = len(s)
+ sign = 1
+ stack = [sign]
+ i = sumS = 0
+ while i < n:
+ if s[i] == "(":
+ stack.append(sign)
+ i += 1
+ elif s[i] == ")":
+ stack.pop()
+ i += 1
+ elif s[i] == "+":
+ sign = stack[-1]
+ i += 1
+ elif s[i] == "-":
+ sign = -stack[-1]
+ i += 1
+ else:
+ num = 0
+ while i < n and s[i].isdigit():
+ num = num * 10 + int(s[i])
+ i += 1
+ sumS += sign * num
+ return sumS
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0268bb6b9594af397cdad432128127336ca6ff5c
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-932df926102648ed8cb8c27ba69ea2d6",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..5ef82e3bcd802b5d8d1a52ddee4dabd157387adb
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "9c03389fe307492986e80afea41f8a85",
+ "author": "csdn.net",
+ "keywords": "递归,数学,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..026481410015b593c68c2b91c3eee6b2daedeaa9
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/233.exercises/solution.md"
@@ -0,0 +1,69 @@
+# 数字 1 的个数
+
+给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
+
+
+
+示例 1:
+
+
+输入:n = 13
+输出:6
+
+
+示例 2:
+
+
+输入:n = 0
+输出:0
+
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+class Solution:
+ def countDigitOne(self, n: int) -> int:
+ res, i = 0, 1
+ while i <= n:
+ res += n // (i * 10) * i
+ x = (n // i) % 10
+ res += i if x > 1 else (n % i + 1) * x
+ i *= 10
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..4b7482bdc1857683041a12e9d9eb11d178a28d02
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-7eae6bacc38c4a249d3c69fd1de4942c",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..05ed0e1f5b950adb0eeee3843ab7ff51b1943463
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "b9547e11047740c6a0299b7761da9aff",
+ "author": "csdn.net",
+ "keywords": "队列,数组,滑动窗口,单调队列,堆(优先队列)"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a2c1489aa5ef33867a5afe91c164e3dc62131d1b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/239.exercises/solution.md"
@@ -0,0 +1,111 @@
+# 滑动窗口最大值
+
+给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
+
+返回滑动窗口中的最大值。
+
+
+
+示例 1:
+
+
+输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
+输出:[3,3,5,5,6,7]
+解释:
+滑动窗口的位置 最大值
+--------------- -----
+[1 3 -1] -3 5 3 6 7 3
+ 1 [3 -1 -3] 5 3 6 7 3
+ 1 3 [-1 -3 5] 3 6 7 5
+ 1 3 -1 [-3 5 3] 6 7 5
+ 1 3 -1 -3 [5 3 6] 7 6
+ 1 3 -1 -3 5 [3 6 7] 7
+
+
+示例 2:
+
+
+输入:nums = [1], k = 1
+输出:[1]
+
+
+示例 3:
+
+
+输入:nums = [1,-1], k = 1
+输出:[1,-1]
+
+
+示例 4:
+
+
+输入:nums = [9,11], k = 2
+输出:[11]
+
+
+示例 5:
+
+
+输入:nums = [4,-2], k = 2
+输出:[4]
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 105-104 <= nums[i] <= 1041 <= k <= nums.length
+
+
+## template
+
+```python
+class Solution(object):
+ def maxSlidingWindow(self, nums, k):
+ """
+ :type nums: List[int]
+ :type k: int
+ :rtype: List[int]
+ """
+ if len(nums) == 0:
+ return []
+ if k == 1:
+ return nums
+
+ res = []
+ res.append(max(nums[:k]))
+ for i in range(1, len(nums) - k + 1):
+ m = max(nums[i : i + k])
+ res.append(m)
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..35be00d6b51ff65c55d0a4ba2c06b987b484bc68
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-5e8c68a89e0c4a45a251df4b9fa2cde5",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..20ec37e0825a8ff88c7993ec20c16ba93003812b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "333acbbfa64b462cb648201c2005798d",
+ "author": "csdn.net",
+ "keywords": "递归,数学,字符串"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..55901b455f36b0d6bb4447453eaf93f413219acf
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/273.exercises/solution.md"
@@ -0,0 +1,123 @@
+# 整数转换英文表示
+
+将非负整数 num 转换为其对应的英文表示。
+
+
+
+示例 1:
+
+
+输入:num = 123
+输出:"One Hundred Twenty Three"
+
+
+示例 2:
+
+
+输入:num = 12345
+输出:"Twelve Thousand Three Hundred Forty Five"
+
+
+示例 3:
+
+
+输入:num = 1234567
+输出:"One Million Two Hundred Thirty Four Thousand Five Hundred Sixty Seven"
+
+
+示例 4:
+
+
+输入:num = 1234567891
+输出:"One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One"
+
+
+
+
+提示:
+
+
+
+
+## template
+
+```python
+class Solution(object):
+ def numberToWords(self, num):
+ """
+ :type num: int
+ :rtype: str
+ """
+ def helper(num):
+ n = int(num)
+ num = str(n)
+ if n < 100:
+ return subhelper(num)
+ else:
+ return ["One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine"][int(num[0]) - 1] + " Hundred " + subhelper(num[1:]) if num[1:] != "00" else ["One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine"][int(num[0]) - 1] + " Hundred"
+
+ def subhelper(num):
+ n = int(num)
+ l1 = ["Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine"]
+ l2 = ["Ten", "Eleven", "Twelve", "Thirteen", "Fourteen", "Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
+ l3 = ["Twenty", "Thirty", "Forty", "Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
+ if n < 10:
+ return l1[int(num)]
+ if 10 <= n < 20:
+ return l2[n - 10]
+ if 20 <= n < 100:
+ return l3[int(num[0]) - 2] + " " + l1[int(num[1])] if num[1] != "0" else l3[int(num[0]) - 2]
+
+ res = ""
+ if num >= 1000000000:
+ res = helper(str(num)[0]) + " Billion"
+ if str(num)[1:4] != "000":
+ res += " " + helper(str(num)[1:4]) + " Million"
+ if str(num)[4:7] != "000":
+ res += " " + helper(str(num)[4:7]) + " Thousand"
+ if str(num)[7:] != "000":
+ res += " " + helper(str(num)[7:])
+ elif num >= 1000000:
+ res = helper(str(num)[:-6]) + " Million"
+ if str(num)[-6:-3] != "000":
+ res += " " + helper(str(num)[-6:-3]) + " Thousand"
+ if str(num)[-3:] != "000":
+ res += " " + helper(str(num)[-3:])
+ elif num >= 1000:
+ res = helper(str(num)[:-3]) + " Thousand"
+ if str(num)[-3:] != "000":
+ res += " " + helper(str(num)[-3:])
+ else:
+ return helper(str(num))
+
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..f2cf9dbf1249cfc6c77c1fdf60321568cb3c0fe5
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-c663c474906f418b83e0673b32f1ead9",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..79c655250a3bac72729efe6d8c0c9a67b910b0ab
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "901c10273a6a44c4979080819e4b4db6",
+ "author": "csdn.net",
+ "keywords": "数学,字符串,回溯"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..40ac47ec1ab2283755e7067a9c689c37c9977196
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/282.exercises/solution.md"
@@ -0,0 +1,127 @@
+# 给表达式添加运算符
+
+给定一个仅包含数字 0-9 的字符串 num 和一个目标值整数 target ,在 num 的数字之间添加 二元 运算符(不是一元)+、- 或 * ,返回所有能够得到目标值的表达式。
+
+
+
+示例 1:
+
+
+输入: num = "123", target = 6
+输出: ["1+2+3", "1*2*3"]
+
+
+示例 2:
+
+
+输入: num = "232", target = 8
+输出: ["2*3+2", "2+3*2"]
+
+示例 3:
+
+
+输入: num = "105", target = 5
+输出: ["1*0+5","10-5"]
+
+示例 4:
+
+
+输入: num = "00", target = 0
+输出: ["0+0", "0-0", "0*0"]
+
+
+示例 5:
+
+
+输入: num = "3456237490", target = 9191
+输出: []
+
+
+
+提示:
+
+
+ 1 <= num.length <= 10num 仅含数字-231 <= target <= 231 - 1
+
+
+## template
+
+```python
+
+class Solution:
+ def __init__(self):
+ self.size = 0
+ self.num = []
+ self.now = []
+ self.sign = []
+
+ def addOperators(self, num: str, target: int) -> List[str]:
+ if not num:
+ return []
+
+ self.size = len(num)
+ self.num = num
+ self.now.append(num[0])
+ self.dfs(0, num[0] == "0")
+
+ ans = []
+ for ss in self.sign:
+ if eval(ss) == target:
+ ans.append(ss)
+ return ans
+
+ def dfs(self, i, zero_start):
+ if i == self.size - 1:
+ self.sign.append("".join(self.now))
+ else:
+
+ self.now.extend(["+", self.num[i + 1]])
+ self.dfs(i + 1, self.num[i + 1] == "0")
+ self.now.pop()
+ self.now.pop()
+
+ self.now.extend(["-", self.num[i + 1]])
+ self.dfs(i + 1, self.num[i + 1] == "0")
+ self.now.pop()
+ self.now.pop()
+
+ self.now.extend(["*", self.num[i + 1]])
+ self.dfs(i + 1, self.num[i + 1] == "0")
+ self.now.pop()
+ self.now.pop()
+
+ if not zero_start:
+ self.now.extend([self.num[i + 1]])
+ self.dfs(i + 1, False)
+ self.now.pop()
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..120c5f0768ab1adf88b1d34b7f57b2eccec74776
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-33b3f9fd6c13481c8d2590bdd572882f",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..18e593e85d46cb5f554eae45d37a15a21928e3f1
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "3bea4795f7f5492fbad68f8451c96dae",
+ "author": "csdn.net",
+ "keywords": "设计,双指针,数据流,排序,堆(优先队列)"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..9d9e0c5b69695978ab592b5a523fb8575d846ccc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/295.exercises/solution.md"
@@ -0,0 +1,94 @@
+# 数据流的中位数
+
+中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
+
+例如,
+
+[2,3,4] 的中位数是 3
+
+[2,3] 的中位数是 (2 + 3) / 2 = 2.5
+
+设计一个支持以下两种操作的数据结构:
+
+
+ - void addNum(int num) - 从数据流中添加一个整数到数据结构中。
+ - double findMedian() - 返回目前所有元素的中位数。
+
+
+示例:
+
+addNum(1)
+addNum(2)
+findMedian() -> 1.5
+addNum(3)
+findMedian() -> 2
+
+进阶:
+
+
+ - 如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法?
+ - 如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法?
+
+
+
+## template
+
+```python
+class MedianFinder(object):
+ def __init__(self):
+ """
+ initialize your data structure here.
+ """
+ self.array = []
+
+ def addNum(self, num):
+ """
+ :type num: int
+ :rtype: None
+ """
+ self.array.append(num)
+
+ def findMedian(self):
+ """
+ :rtype: float
+ """
+ self.array.sort()
+ n = len(self.array)
+ if n % 2 == 1:
+ return self.array[n // 2]
+ else:
+ return (self.array[n // 2] + self.array[n // 2 - 1]) / 2.0
+
+ # Your MedianFinder object will be instantiated and called as such:
+ # obj = MedianFinder()
+ # obj.addNum(num)
+ # param_2 = obj.findMedian()
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..61b14e92bec2ead515519d144b9d22cea6e6f4cc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-8a4aee3c45ea46339bf58ca9ea4f5cc8",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..7416a86a905b893374811fe3f885bcac5b494480
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "9df6749433804794b84867682483afae",
+ "author": "csdn.net",
+ "keywords": "树,深度优先搜索,广度优先搜索,设计,字符串,二叉树"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..63b322445fb85d7ab3b28face331bac530274bcc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/297.exercises/solution.md"
@@ -0,0 +1,124 @@
+# 二叉树的序列化与反序列化
+
+序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
+
+请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
+
+提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
+
+
+
+示例 1:
+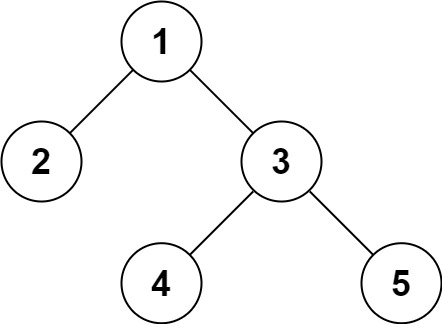 +
+
+输入:root = [1,2,3,null,null,4,5]
+输出:[1,2,3,null,null,4,5]
+
+
+示例 2:
+
+
+输入:root = []
+输出:[]
+
+
+示例 3:
+
+
+输入:root = [1]
+输出:[1]
+
+
+示例 4:
+
+
+输入:root = [1,2]
+输出:[1,2]
+
+
+
+
+提示:
+
+
+ - 树中结点数在范围
[0, 104] 内
+ -1000 <= Node.val <= 1000
+
+
+## template
+
+```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Codec:
+ def serialize(self, root):
+ """Encodes a tree to a single string.
+
+ :type root: TreeNode
+ :rtype: str
+ """
+ if root == None:
+ return "null,"
+ left_serialize = self.serialize(root.left)
+ right_serialize = self.serialize(root.right)
+ return str(root.val) + "," + left_serialize + right_serialize
+
+ def deserialize(self, data):
+ """Decodes your encoded data to tree.
+
+ :type data: str
+ :rtype: TreeNode
+ """
+
+ def dfs(queue):
+ val = queue.popleft()
+ if val == "null":
+ return None
+ node = TreeNode(val)
+ node.left = dfs(queue)
+ node.right = dfs(queue)
+ return node
+
+ from collections import deque
+
+ queue = deque(data.split(","))
+
+ return dfs(queue)
+
+
+# Your Codec object will be instantiated and called as such:
+# codec = Codec()
+# codec.deserialize(codec.serialize(root))
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..51a67907434751fcd004ff3dfc9173809c7178d8
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-e880312110fb46ceadc544b6ed115906",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..976d0336c2f269460481d0054a3b84ad036968fe
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "267f71e554aa4cb9bf32e530bb2636a7",
+ "author": "csdn.net",
+ "keywords": "广度优先搜索,字符串,回溯"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..bd0775f6e0c8baaeb2f5ff5af7e2bfdca641b3fc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/301.exercises/solution.md"
@@ -0,0 +1,129 @@
+# 删除无效的括号
+
+给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。
+
+返回所有可能的结果。答案可以按 任意顺序 返回。
+
+
+
+示例 1:
+
+
+输入:s = "()())()"
+输出:["(())()","()()()"]
+
+
+示例 2:
+
+
+输入:s = "(a)())()"
+输出:["(a())()","(a)()()"]
+
+
+示例 3:
+
+
+输入:s = ")("
+输出:[""]
+
+
+
+
+提示:
+
+
+ 1 <= s.length <= 25s 由小写英文字母以及括号 '(' 和 ')' 组成s 中至多含 20 个括号
+
+
+## template
+
+```python
+
+class Solution:
+ def removeInvalidParentheses(self, s: str) -> List[str]:
+ left, right = 0, 0
+ for c in s:
+ if c == "(":
+ left += 1
+ elif c == ")":
+ if left == 0:
+ right += 1
+ else:
+ left -= 1
+ else:
+ pass
+
+ def is_valid(s):
+ level = 0
+ for c in s:
+ if c == "(":
+ level += 1
+ elif c == ")":
+ if level == 0:
+ return False
+ else:
+ level -= 1
+ else:
+ pass
+
+ return level == 0
+
+ def dfs(s, index, left, right, res):
+ """
+ from index to find ( or ),
+ left and right means how many ( and ) to remove
+ """
+
+ if (left == 0) and (right == 0) and is_valid(s):
+ res.append(s)
+ return
+
+ for i in range(index, len(s)):
+ c = s[i]
+ if c in ["(", ")"]:
+
+ if (i > 0) and (c == s[i - 1]):
+ continue
+
+ if (c == ")") and (right > 0):
+ dfs(s[:i] + s[i + 1 :], i, left, right - 1, res)
+ elif (c == "(") and (left > 0):
+ dfs(s[:i] + s[i + 1 :], i, left - 1, right, res)
+ else:
+ pass
+
+ res = []
+ dfs(s, 0, left, right, res)
+
+ return list(set(res))
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..496dd2cd4f6aac6b206c2a5411d658a97a3496ce
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-99e2ce5d579b418691a01b9b43063348",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..9e5d1276d236949e29e2be997763e7cae4f8ad6c
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "5c38bd35f77545fc928bec3fdae5a92d",
+ "author": "csdn.net",
+ "keywords": "数组,动态规划"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e52d5f340ff80d8e1fd299bc740b1c3a29152197
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/312.exercises/solution.md"
@@ -0,0 +1,78 @@
+# 戳气球
+
+有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
+
+现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i + 1] 枚硬币。 这里的 i - 1 和 i + 1 代表和 i 相邻的两个气球的序号。如果 i - 1或 i + 1 超出了数组的边界,那么就当它是一个数字为 1 的气球。
+
+求所能获得硬币的最大数量。
+
+
+示例 1:
+
+
+输入:nums = [3,1,5,8]
+输出:167
+解释:
+nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> []
+coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167
+
+示例 2:
+
+
+输入:nums = [1,5]
+输出:10
+
+
+
+
+提示:
+
+
+ n == nums.length1 <= n <= 5000 <= nums[i] <= 100
+
+
+## template
+
+```python
+class Solution:
+ def maxCoins(self, nums: List[int]) -> int:
+ n=len(nums)+2
+ nums=[1]+nums+[1]
+ dp=[[0]*n for _ in range(n)]
+ for i in range(n-1,-1,-1):
+ for j in range(i,n):
+ if j-i>1:
+ for k in range(i+1,j):
+ dp[i][j]=max(dp[i][j],dp[i][k]+dp[k][j]+nums[i]*nums[k]*nums[j])
+ return dp[0][n-1]
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..b924dcf9376c50ca4728e541cefeabf63fe3b602
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-95d43f8a946e4dc997e79aba562388e8",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..555d0c8fcad737812b53c0581c75841fc45c0327
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "65672ae7af0b4e6782fad8f7053964c0",
+ "author": "csdn.net",
+ "keywords": "树状数组,线段树,数组,二分查找,分治,有序集合,归并排序"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e5e5d68115161e74a7f1ebf3778e05e727c1a543
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/315.exercises/solution.md"
@@ -0,0 +1,123 @@
+# 计算右侧小于当前元素的个数
+
+给你`一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
+
+
+
+示例 1:
+
+
+输入:nums = [5,2,6,1]
+输出:[2,1,1,0]
+解释:
+5 的右侧有 2 个更小的元素 (2 和 1)
+2 的右侧仅有 1 个更小的元素 (1)
+6 的右侧有 1 个更小的元素 (1)
+1 的右侧有 0 个更小的元素
+
+
+示例 2:
+
+
+输入:nums = [-1]
+输出:[0]
+
+
+示例 3:
+
+
+输入:nums = [-1,-1]
+输出:[0,0]
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 105-104 <= nums[i] <= 104
+
+
+## template
+
+```python
+class Solution:
+ def countSmaller(self, nums: List[int]) -> List[int]:
+ n = len(nums)
+ if n == 0:
+ return []
+
+ numsarr = [[nums[i], i] for i in range(n)]
+
+ res = [0 for _ in range(n)]
+
+ def merge(left, right):
+
+ if left == right:
+ pass
+ else:
+
+ mid = left + (right - left) // 2
+
+ merge(left, mid)
+ merge(mid + 1, right)
+
+ temp = []
+
+ i = left
+ j = mid + 1
+
+ while i <= mid and j <= right:
+
+ if numsarr[i][0] <= numsarr[j][0]:
+ temp.append(numsarr[j])
+ j += 1
+
+ else:
+ temp.append(numsarr[i])
+ res[numsarr[i][1]] += right - j + 1
+ i += 1
+
+ while i <= mid:
+ temp.append(numsarr[i])
+ i += 1
+ while j <= right:
+ temp.append(numsarr[j])
+ j += 1
+
+ numsarr[left : right + 1] = temp[:]
+
+ merge(0, n - 1)
+ return res
+
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..aed2188f65a54d88fd42e1450d642ba3e7faad7e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-3920724258d64d77a9b4fef2aef8d95d",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..aee13cc899dbb58fd7d94e440ffc4f34df81717e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "1a5dc11810b04e0d8a83fdd16ba87e1c",
+ "author": "csdn.net",
+ "keywords": "栈,贪心,单调栈"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..f10a88bd2683033680d28ee1676f9007803a3021
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/321.exercises/solution.md"
@@ -0,0 +1,92 @@
+# 拼接最大数
+
+给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
+
+求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
+
+说明: 请尽可能地优化你算法的时间和空间复杂度。
+
+示例 1:
+
+输入:
+nums1 = [3, 4, 6, 5]
+nums2 = [9, 1, 2, 5, 8, 3]
+k = 5
+输出:
+[9, 8, 6, 5, 3]
+
+示例 2:
+
+输入:
+nums1 = [6, 7]
+nums2 = [6, 0, 4]
+k = 5
+输出:
+[6, 7, 6, 0, 4]
+
+示例 3:
+
+输入:
+nums1 = [3, 9]
+nums2 = [8, 9]
+k = 3
+输出:
+[9, 8, 9]
+
+
+## template
+
+```python
+
+class Solution:
+ def maxNumber(self, nums1: List[int], nums2: List[int], k: int) -> List[int]:
+ def pick_max(nums, k):
+ stack = []
+ drop = len(nums) - k
+ for num in nums:
+ while drop and stack and stack[-1] < num:
+ stack.pop()
+ drop -= 1
+ stack.append(num)
+ return stack[:k]
+
+ def merge(A, B):
+ lst = []
+ while A or B:
+ bigger = A if A > B else B
+ lst.append(bigger[0])
+ bigger.pop(0)
+ return lst
+
+ return max(
+ merge(pick_max(nums1, i), pick_max(nums2, k - i))
+ for i in range(k + 1)
+ if i <= len(nums1) and k - i <= len(nums2)
+ )
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..959ecb324a0dff4238dc3e37d8ff7234e8fb35fe
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-cb69b420425f4a989878a984d31703eb",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..0153ce591a568ea983ea79abdee8d8ab5e2f8c58
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "a9f7e57050c1400588485673f78712b3",
+ "author": "csdn.net",
+ "keywords": "树状数组,线段树,数组,二分查找,分治,有序集合,归并排序"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..bc77c49adee9c33a6a4199b5f93c6147af9d7e7e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/327.exercises/solution.md"
@@ -0,0 +1,118 @@
+# 区间和的个数
+
+给你一个整数数组 nums 以及两个整数 lower 和 upper 。求数组中,值位于范围 [lower, upper] (包含 lower 和 upper)之内的 区间和的个数 。
+
+区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
+
+
+示例 1:
+
+
+输入:nums = [-2,5,-1], lower = -2, upper = 2
+输出:3
+解释:存在三个区间:[0,0]、[2,2] 和 [0,2] ,对应的区间和分别是:-2 、-1 、2 。
+
+
+示例 2:
+
+
+输入:nums = [0], lower = 0, upper = 0
+输出:1
+
+
+
+
+提示:
+
+
+ 1 <= nums.length <= 105-231 <= nums[i] <= 231 - 1-105 <= lower <= upper <= 105- 题目数据保证答案是一个 32 位 的整数
+
+
+
+## template
+
+```python
+
+class Solution:
+ def countRangeSum(self, nums: List[int], lower: int, upper: int) -> int:
+
+ prefix = [0]
+ last = 0
+ for num in nums:
+ last += num
+ prefix.append(last)
+
+ print(prefix)
+
+ def count(pp, left, right):
+
+ if left == right:
+ return 0
+ else:
+ mid = (left + right) // 2
+
+ ans = count(pp, left, mid) + count(pp, mid + 1, right)
+
+ i1, i2, i3 = left, mid + 1, mid + 1
+ while i1 <= mid:
+ while i2 <= right and pp[i2] - pp[i1] < lower:
+ i2 += 1
+ while i3 <= right and pp[i3] - pp[i1] <= upper:
+ i3 += 1
+ ans += i3 - i2
+ i1 += 1
+
+ result = []
+ i1, i2 = left, mid + 1
+ while i1 <= mid and i2 <= right:
+ if pp[i1] <= pp[i2]:
+ result.append(pp[i1])
+ i1 += 1
+ else:
+ result.append(pp[i2])
+ i2 += 1
+ while i1 <= mid:
+ result.append(pp[i1])
+ i1 += 1
+ while i2 <= right:
+ result.append(pp[i2])
+ i2 += 1
+
+ for i in range(len(result)):
+ pp[i + left] = result[i]
+
+ return ans
+
+ return count(prefix, 0, len(prefix) - 1)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..c0cda76c84c8b4230096096939dba76a5d14103e
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-a55b46bb6ab24197ba17538b33b9133c",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/269.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.json"
similarity index 61%
rename from "data_source/exercises/\345\233\260\351\232\276/python/269.exercises/solution.json"
rename to "data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.json"
index 04ea76d48389201026f24e58e1873b9aaf144ba7..22e91f0a081f1a45215b13f6c59875740eff689c 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/269.exercises/solution.json"
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.json"
@@ -1,7 +1,7 @@
{
"type": "code_options",
"source": "solution.md",
- "exercise_id": "e98b991e0d434dc6b47c4575b9d978d8",
+ "exercise_id": "fd4e98b762304cfe85d93cfab28abd02",
"author": "csdn.net",
- "keywords": "深度优先搜索,广度优先搜索,图,拓扑排序,数组,字符串"
+ "keywords": "深度优先搜索,广度优先搜索,图,拓扑排序,记忆化搜索,动态规划"
}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..253823f3ddc22b2774456e67dec7cce6cc77b4e7
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/329.exercises/solution.md"
@@ -0,0 +1,106 @@
+# 矩阵中的最长递增路径
+
+给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。
+
+对于每个单元格,你可以往上,下,左,右四个方向移动。 你 不能 在 对角线 方向上移动或移动到 边界外(即不允许环绕)。
+
+
+
+示例 1:
+ +
+
+输入:matrix = [[9,9,4],[6,6,8],[2,1,1]]
+输出:4
+解释:最长递增路径为 [1, 2, 6, 9]。
+
+示例 2:
+ +
+
+输入:matrix = [[3,4,5],[3,2,6],[2,2,1]]
+输出:4
+解释:最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
+
+
+示例 3:
+
+
+输入:matrix = [[1]]
+输出:1
+
+
+
+
+提示:
+
+
+ m == matrix.lengthn == matrix[i].length1 <= m, n <= 2000 <= matrix[i][j] <= 231 - 1
+
+
+## template
+
+```python
+
+class Solution:
+ def longestIncreasingPath(self, matrix):
+ """
+ :type matrix: List[List[int]]
+ :rtype: int
+ """
+ a = len(matrix)
+ dic = {}
+ nums_max = 1
+ if a == 0:
+ nums_max = 0
+ else:
+ b = len(matrix[0])
+ for i in range(a):
+ for j in range(b):
+ dic[(i,j)] = matrix[i][j]
+ v = dic.keys()
+ nums1 = [[1 for i in range(b)] for j in range(a)]
+ dic = sorted(dic.items(),key = lambda x:x[1])
+ for k in dic:
+ i = k[0][0]
+ j = k[0][1]
+ if (i+1,j) in v and matrix[i+1][j]给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
+
+示例 1:
+
+输入: nums = [1,3], n = 6
+输出: 1
+解释:
+根据 nums 里现有的组合 [1], [3], [1,3],可以得出 1, 3, 4。
+现在如果我们将 2 添加到 nums 中, 组合变为: [1], [2], [3], [1,3], [2,3], [1,2,3]。
+其和可以表示数字 1, 2, 3, 4, 5, 6,能够覆盖 [1, 6] 区间里所有的数。
+所以我们最少需要添加一个数字。
+
+示例 2:
+
+输入: nums = [1,5,10], n = 20
+输出: 2
+解释: 我们需要添加 [2, 4]。
+
+
+示例 3:
+
+输入: nums = [1,2,2], n = 5
+输出: 0
+
+
+
+## template
+
+```python
+
+class Solution:
+ def minPatches(self, nums: List[int], n: int) -> int:
+ count = 0
+ miss = 1
+ idx = 0
+ while miss <= n:
+ if idx < len(nums) and nums[idx] <= miss:
+ miss += nums[idx]
+ idx += 1
+ else:
+ count += 1
+ miss += miss
+ return count
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..81b1708f6322dbf5d76a57d286873a26bf199d0b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ec344b2a5bb142379e0e19b8a34a7831",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..1ae5da2c6002159780603236f972a1cbedec59de
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "ad9aad91b74c4ce889128bfdc4493b9f",
+ "author": "csdn.net",
+ "keywords": "几何,数组,数学"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..5aa71cb52679a5253d15658bed1f193048e98b13
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/335.exercises/solution.md"
@@ -0,0 +1,83 @@
+# 路径交叉
+
+给你一个整数数组 distance 。
+
+从 X-Y 平面上的点 (0,0) 开始,先向北移动 distance[0] 米,然后向西移动 distance[1] 米,向南移动 distance[2] 米,向东移动 distance[3] 米,持续移动。也就是说,每次移动后你的方位会发生逆时针变化。
+
+判断你所经过的路径是否相交。如果相交,返回 true ;否则,返回 false 。
+
+
+
+示例 1:
+ +
+
+输入:distance = [2,1,1,2]
+输出:true
+
+
+示例 2:
+ +
+
+输入:distance = [1,2,3,4]
+输出:false
+
+
+示例 3:
+ +
+
+输入:distance = [1,1,1,1]
+输出:true
+
+
+
+提示:
+
+
+ 1 <= distance.length <= 1051 <= distance[i] <= 105
+
+
+## template
+
+```python
+
+class Solution:
+ def isSelfCrossing(self, x: List[int]) -> bool:
+ n = len(x)
+ if n < 3: return False
+ for i in range(3, n):
+ if x[i] >= x[i - 2] and x[i - 3] >= x[i - 1]:
+ return True
+ if i >= 4 and x[i - 3] == x[i - 1] and x[i] + x[i - 4] >= x[i - 2]:
+ return True
+ if i >= 5 and x[i - 3] >= x[i - 1] and x[i - 2] >= x[i - 4] and x[i - 1] + x[i - 5] >= x[i - 3] and x[i] + x[i - 4] >= x[i - 2]:
+ return True
+ return False
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..2624bd25ec22acd37d105d8fef3809e0ddb32724
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-c5a4b49c8b714ad69aab4451d4319706",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..be462dc0dda1ab0db66069557abfd029ebc4b65b
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "032b0d56c73f41eea42a882da7c19de7",
+ "author": "csdn.net",
+ "keywords": "字典树,数组,哈希表,字符串"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..6ccc05b73c69d8ea7b28a60aede910a9d7b88368
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/336.exercises/solution.md"
@@ -0,0 +1,116 @@
+# 回文对
+
+给定一组 互不相同 的单词, 找出所有 不同 的索引对 (i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
+
+
+
+示例 1:
+
+
+输入:words = ["abcd","dcba","lls","s","sssll"]
+输出:[[0,1],[1,0],[3,2],[2,4]]
+解释:可拼接成的回文串为 ["dcbaabcd","abcddcba","slls","llssssll"]
+
+
+示例 2:
+
+
+输入:words = ["bat","tab","cat"]
+输出:[[0,1],[1,0]]
+解释:可拼接成的回文串为 ["battab","tabbat"]
+
+示例 3:
+
+
+输入:words = ["a",""]
+输出:[[0,1],[1,0]]
+
+
+
+提示:
+
+
+ 1 <= words.length <= 50000 <= words[i].length <= 300words[i] 由小写英文字母组成
+
+
+## template
+
+```python
+class Solution:
+ def palindromePairs(self, words: List[str]) -> List[List[int]]:
+ def is_palindrome(str, start, end):
+ """检查子串是否是回文串
+ """
+ part_word = str[start : end + 1]
+ return part_word == part_word[::-1]
+
+ def find_reversed_word(str, start, end):
+ """查找子串是否在哈希表中
+ Return:
+ 不在哈希表中,返回 -1
+ 否则返回对应的索引
+ """
+ part_word = str[start : end + 1]
+ ret = hash_map.get(part_word, -1)
+ return ret
+
+ hash_map = {}
+ for i in range(len(words)):
+ word = words[i][::-1]
+ hash_map[word] = i
+
+ res = []
+
+ for i in range(len(words)):
+ word = words[i]
+ word_len = len(word)
+
+ if is_palindrome(word, 0, word_len - 1) and "" in hash_map and word != "":
+ res.append([hash_map.get(""), i])
+ for j in range(word_len):
+
+ if is_palindrome(word, j, word_len - 1):
+
+ left_part_index = find_reversed_word(word, 0, j - 1)
+
+ if left_part_index != -1 and left_part_index != i:
+ res.append([i, left_part_index])
+
+ if is_palindrome(word, 0, j - 1):
+
+ right_part_index = find_reversed_word(word, j, word_len - 1)
+ if right_part_index != -1 and right_part_index != i:
+ res.append([right_part_index, i])
+
+ return res
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..bcbc9a05580fc4684c5bb7fc0115de3327618bd4
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-ecf5b64aa97b47db8a64f5030772b33e",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..514cda370c4c3e754b8b92f6dc023951a3796de8
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "a10b9a0d46e441d3aecccdfcbedbf83b",
+ "author": "csdn.net",
+ "keywords": "设计,二分查找,有序集合"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b837742367182b83bf802027151ea5b80b1839dc
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/352.exercises/solution.md"
@@ -0,0 +1,143 @@
+# 将数据流变为多个不相交区间
+
+ 给你一个由非负整数 a1, a2, ..., an 组成的数据流输入,请你将到目前为止看到的数字总结为不相交的区间列表。
+
+实现 SummaryRanges 类:
+
+
+
+
+ SummaryRanges() 使用一个空数据流初始化对象。void addNum(int val) 向数据流中加入整数 val 。int[][] getIntervals() 以不相交区间 [starti, endi] 的列表形式返回对数据流中整数的总结。
+
+
+
+
示例:
+
+
+输入:
+["SummaryRanges", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals"]
+[[], [1], [], [3], [], [7], [], [2], [], [6], []]
+输出:
+[null, null, [[1, 1]], null, [[1, 1], [3, 3]], null, [[1, 1], [3, 3], [7, 7]], null, [[1, 3], [7, 7]], null, [[1, 3], [6, 7]]]
+
+解释:
+SummaryRanges summaryRanges = new SummaryRanges();
+summaryRanges.addNum(1); // arr = [1]
+summaryRanges.getIntervals(); // 返回 [[1, 1]]
+summaryRanges.addNum(3); // arr = [1, 3]
+summaryRanges.getIntervals(); // 返回 [[1, 1], [3, 3]]
+summaryRanges.addNum(7); // arr = [1, 3, 7]
+summaryRanges.getIntervals(); // 返回 [[1, 1], [3, 3], [7, 7]]
+summaryRanges.addNum(2); // arr = [1, 2, 3, 7]
+summaryRanges.getIntervals(); // 返回 [[1, 3], [7, 7]]
+summaryRanges.addNum(6); // arr = [1, 2, 3, 6, 7]
+summaryRanges.getIntervals(); // 返回 [[1, 3], [6, 7]]
+
+
+
+
+
提示:
+
+
+ 0 <= val <= 104- 最多调用
addNum 和 getIntervals 方法 3 * 104 次
+
+
+
+
+进阶:如果存在大量合并,并且与数据流的大小相比,不相交区间的数量很小,该怎么办?
+
+
+## template
+
+```python
+
+class SummaryRanges:
+ def __init__(self):
+ self.rec = set()
+
+ self.s = list()
+
+ def binarySearch_l(self, x: int):
+ s = self.s
+ l, r = 0, len(s) - 1
+ while l < r:
+ mid = l + r >> 1
+ if s[mid][0] >= x:
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+ def binarySearch(self, x: int):
+ s = self.s
+ l, r = 0, len(s) - 1
+ while l < r:
+ mid = l + r >> 1
+ if s[mid][1] >= x:
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+ def addNum(self, val: int) -> None:
+ rec, s = self.rec, self.s
+ if val in rec:
+ return
+ else:
+
+ if val - 1 not in rec and val + 1 not in rec:
+
+ s.append([val, val])
+ s.sort()
+ elif val - 1 in rec and val + 1 not in rec:
+
+ p = self.binarySearch(val - 1)
+ s[p][1] = val
+ elif val - 1 not in rec and val + 1 in rec:
+
+ p = self.binarySearch_l(val + 1)
+ s[p][0] = val
+ else:
+
+ p = self.binarySearch(val)
+ s[p - 1][1] = s[p][1]
+
+ s.pop(p)
+ rec.add(val)
+
+ def getIntervals(self) -> List[List[int]]:
+ return self.s
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..82fccd5f43ddb1f8b45beb7f298d32e42d62619c
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-4f5090940591403ca172ef548aca00e6",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..87444c4fe56c58070e68044b5fb9be71bcb3e55d
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "15a847964c244a82ad1fb736d864210a",
+ "author": "csdn.net",
+ "keywords": "数组,二分查找,动态规划,排序"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..ecef139efd390d8cdae036f2ebbb1b3130850a44
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/354.exercises/solution.md"
@@ -0,0 +1,85 @@
+# 俄罗斯套娃信封问题
+
+给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
+
+当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
+
+请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
+
+注意:不允许旋转信封。
+
+
+示例 1:
+
+
+输入:envelopes = [[5,4],[6,4],[6,7],[2,3]]
+输出:3
+解释:最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
+
+示例 2:
+
+
+输入:envelopes = [[1,1],[1,1],[1,1]]
+输出:1
+
+
+
+
+提示:
+
+
+ 1 <= envelopes.length <= 5000envelopes[i].length == 21 <= wi, hi <= 104
+
+
+## template
+
+```python
+class Solution:
+ def maxEnvelopes(self, envelopes) -> int:
+ """
+ :param envelopes: List[List[int]]
+ :return: int
+ """
+ n = len(envelopes)
+ if not n:
+ return 0
+ envelopes.sort(key=lambda x: (x[0], -x[1]))
+
+ dp = [1] * n
+ for i in range(n):
+ for j in range(i):
+ if envelopes[j][1] < envelopes[i][1]:
+ dp[i] = max(dp[i], dp[j] + 1)
+ return max(dp)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..a0a0d1e58c025f34f6034e8a89ab7752236d3803
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-1d84779041b143bcae3cdfa77949add4",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..ef37c9b4086fd0cb3d8c723a07cec2d196da2842
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "0ea29761a91f4dc5a8469011d23778d4",
+ "author": "csdn.net",
+ "keywords": "数组,二分查找,动态规划,矩阵,有序集合"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b774ec014c1bc68c2c724e50de416a7703e5e0e4
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/363.exercises/solution.md"
@@ -0,0 +1,97 @@
+# 矩形区域不超过 K 的最大数值和
+
+给你一个 m x n 的矩阵 matrix 和一个整数 k ,找出并返回矩阵内部矩形区域的不超过 k 的最大数值和。
+
+题目数据保证总会存在一个数值和不超过 k 的矩形区域。
+
+
+
+示例 1:
+ +
+
+输入:matrix = [[1,0,1],[0,-2,3]], k = 2
+输出:2
+解释:蓝色边框圈出来的矩形区域 [[0, 1], [-2, 3]] 的数值和是 2,且 2 是不超过 k 的最大数字(k = 2)。
+
+
+示例 2:
+
+
+输入:matrix = [[2,2,-1]], k = 3
+输出:3
+
+
+
+
+提示:
+
+
+ m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-100 <= matrix[i][j] <= 100-105 <= k <= 105
+
+
+
+进阶:如果行数远大于列数,该如何设计解决方案?
+
+
+## template
+
+```python
+import bisect
+
+class Solution:
+ def maxSumSubmatrix(self, matrix: List[List[int]], k: int) -> int:
+ m = len(matrix)
+ Row, Col = len(matrix), len(matrix[0])
+ res = float("-inf")
+ for ru in range(Row):
+ col_sum = [0 for _ in range(Col)]
+ for rd in range(ru, Row):
+ for c in range(Col):
+ if matrix[rd][c] == k:
+ return k
+ col_sum[c] += matrix[rd][c]
+
+ presum = [0]
+ cur_sum = 0
+ for colsum in col_sum:
+ cur_sum += colsum
+ idx = bisect.bisect_left(presum, cur_sum - k)
+ if idx < len(presum):
+ res = max(res, cur_sum - presum[idx])
+ if res == k:
+ return k
+ bisect.insort(presum, cur_sum)
+
+ return res
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/config.json"
new file mode 100644
index 0000000000000000000000000000000000000000..e9d8c6d3872e97fe0b18a1bfe2ef7025186c2034
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/config.json"
@@ -0,0 +1,10 @@
+{
+ "node_id": "dailycode-2bc30335c35f434fba906bd79c9d6052",
+ "keywords": [],
+ "children": [],
+ "keywords_must": [],
+ "keywords_forbid": [],
+ "export": [
+ "solution.json"
+ ]
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.json"
new file mode 100644
index 0000000000000000000000000000000000000000..483d16e8e1debf674d062728372b7e8269c2431f
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.json"
@@ -0,0 +1,7 @@
+{
+ "type": "code_options",
+ "source": "solution.md",
+ "exercise_id": "e9e727954d394c91b956823f1d3af22d",
+ "author": "csdn.net",
+ "keywords": "设计,数组,哈希表,数学,随机化"
+}
\ No newline at end of file
diff --git "a/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.md"
new file mode 100644
index 0000000000000000000000000000000000000000..4cdc74603f870ac88075b296afb9fe8ad2cde107
--- /dev/null
+++ "b/data/3.dailycode\351\253\230\351\230\266/3.python/381.exercises/solution.md"
@@ -0,0 +1,106 @@
+# O(1) 时间插入、删除和获取随机元素
+
+设计一个支持在平均 时间复杂度 O(1) 下, 执行以下操作的数据结构。
+
+注意: 允许出现重复元素。
+
+
+ insert(val):向集合中插入元素 val。remove(val):当 val 存在时,从集合中移除一个 val。getRandom:从现有集合中随机获取一个元素。每个元素被返回的概率应该与其在集合中的数量呈线性相关。
+
+示例:
+
+// 初始化一个空的集合。
+RandomizedCollection collection = new RandomizedCollection();
+
+// 向集合中插入 1 。返回 true 表示集合不包含 1 。
+collection.insert(1);
+
+// 向集合中插入另一个 1 。返回 false 表示集合包含 1 。集合现在包含 [1,1] 。
+collection.insert(1);
+
+// 向集合中插入 2 ,返回 true 。集合现在包含 [1,1,2] 。
+collection.insert(2);
+
+// getRandom 应当有 2/3 的概率返回 1 ,1/3 的概率返回 2 。
+collection.getRandom();
+
+// 从集合中删除 1 ,返回 true 。集合现在包含 [1,2] 。
+collection.remove(1);
+
+// getRandom 应有相同概率返回 1 和 2 。
+collection.getRandom();
+
+
+
+## template
+
+```python
+class RandomizedSet:
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.dict = {}
+ self.list = []
+
+ def insert(self, val: int) -> bool:
+ """
+ Inserts a value to the set. Returns true if the set did not already contain the specified element.
+ """
+ if val in self.dict:
+ return False
+ self.dict[val] = len(self.list)
+ self.list.append(val)
+ return True
+
+ def remove(self, val: int) -> bool:
+ """
+ Removes a value from the set. Returns true if the set contained the specified element.
+ """
+ if val in self.dict:
+
+ last_element, idx = self.list[-1], self.dict[val]
+ self.list[idx], self.dict[last_element] = last_element, idx
+
+ self.list.pop()
+ del self.dict[val]
+ return True
+ return False
+
+ def getRandom(self) -> int:
+ """
+ Get a random element from the set.
+ """
+ return choice(self.list)
+
+
+```
+
+## 答案
+
+```python
+
+```
+
+## 选项
+
+### A
+
+```python
+
+```
+
+### B
+
+```python
+
+```
+
+### C
+
+```python
+
+```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/102.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/102.exercises/solution.md"
index 6bd85c7c59d956698075f330c0b2b0529a58acc6..f3271d98718a21f6333ea84898f4d09b58f6dbc9 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/102.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/102.exercises/solution.md"
@@ -29,7 +29,34 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution(object):
+ def levelOrder(self, root):
+ """
+ :type root: TreeNode
+ :rtype: List[List[int]]
+ """
+ if not root:
+ return []
+
+ queue, res = [root], []
+ while queue:
+ size = len(queue)
+ temp = []
+ for i in range(size):
+ data = queue.pop(0)
+ temp.append(data.val)
+ if data.left:
+ queue.append(data.left)
+ if data.right:
+ queue.append(data.right)
+ res.append(temp)
+ return res
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/103.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/103.exercises/solution.md"
index dba7400de8fc2d4f4923616a4ea27d92027eadb6..77170350eb941d1caa2461d8b3859c5a60b10b19 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/103.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/103.exercises/solution.md"
@@ -27,8 +27,41 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def zigzagLevelOrder(self, root: TreeNode) -> List[List[int]]:
+ import collections
+
+ if not root:
+ return []
+
+ res, q = [], collections.deque()
+ flag = False
+ q.append(root)
+
+ while q:
+ temp = []
+ flag = not flag
+ for _ in range(len(q)):
+ node = q.popleft()
+
+ if flag:
+ temp.append(node.val)
+
+ else:
+ temp.insert(0, node.val)
+ if node.left:
+ q.append(node.left)
+ if node.right:
+ q.append(node.right)
+ res.append(temp)
+
+ return res
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/105.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/105.exercises/solution.md"
index 5520477fecad135c9062af1f58fe6960f59ff273..202c59dba3059c3adef29a1ce4056a94d3212893 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/105.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/105.exercises/solution.md"
@@ -36,8 +36,21 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def buildTree(self, preorder, inorder):
+ if not preorder:
+ return None
+ root = TreeNode(preorder[0])
+ i = inorder.index(root.val)
+ root.left = self.buildTree(preorder[1 : i + 1], inorder[:i])
+ root.right = self.buildTree(preorder[i + 1 :], inorder[i + 1 :])
+ return root
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/106.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/106.exercises/solution.md"
index d2e83ed8ce233bf90fc83f8120d6804b39bf2f7c..c96ad10091432c8b9500d6b466b949021f03d5c2 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/106.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/106.exercises/solution.md"
@@ -24,6 +24,39 @@
```python
+class Solution:
+ def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
+ def build_tree(in_left, in_right, post_left, post_right):
+ if in_left > in_right:
+ return
+
+ post_root = post_right
+
+ root = TreeNode(postorder[post_root])
+
+ in_root = inorder_map[root.val]
+
+ size_of_left = in_root - in_left
+
+ root.left = build_tree(
+ in_left, in_root - 1, post_left, post_left + size_of_left - 1
+ )
+
+ root.right = build_tree(
+ in_root + 1, in_right, post_left + size_of_left, post_root - 1
+ )
+
+ return root
+
+ size = len(inorder)
+
+ inorder_map = {}
+
+ for i in range(size):
+ inorder_map[inorder[i]] = i
+
+ return build_tree(0, size - 1, 0, size - 1)
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/107.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/107.exercises/solution.md"
index 9fa8535b8d061b60518bdf35a45bc2c9d397aff8..e185a4da71e41fe6bb6825e9162a9352ed1b8973 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/107.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/107.exercises/solution.md"
@@ -28,7 +28,24 @@
```python
-
+class Solution(object):
+ res = dict()
+
+ def forwardSearch(self, root, depth):
+ if root != None:
+ if depth not in self.res.keys():
+ self.res[depth] = []
+ self.res[depth].append(root.val)
+ self.forwardSearch(root.left, depth + 1)
+ self.forwardSearch(root.right, depth + 1)
+
+ def levelOrderBottom(self, root):
+ self.forwardSearch(root, 1)
+ result = []
+ self.dic = dict()
+ for i in self.res.keys():
+ result.append(self.res[i])
+ return result[::-1]
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/109.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/109.exercises/solution.md"
index 22343e03e7802088b54ceb041a36dac8cdeb0d82..29ee3ae3b629016e93a0041f132033b149607ded 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/109.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/109.exercises/solution.md"
@@ -21,7 +21,44 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class TreeNode(object):
+ def __init__(self, val=0, left=None, right=None):
+ self.val = val
+ self.left = left
+ self.right = right
+
+
+class Solution:
+ def sortedListToBST(self, head: ListNode) -> TreeNode:
+
+ arr = []
+ cur = head
+ while cur:
+ arr.append(cur.val)
+ cur = cur.next
+ return self.dfs(arr)
+
+ def dfs(self, arr):
+ if not arr:
+ return
+ m = len(arr) // 2
+ root = TreeNode(arr[m])
+ root.left = self.dfs(arr[:m])
+ root.right = self.dfs(arr[m + 1 :])
+ return root
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/113.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/113.exercises/solution.md"
index c1429145292913230cfc43b17c0de5cfe17a5949..dc71d0157e816040d03c57905a4570334ac46f21 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/113.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/113.exercises/solution.md"
@@ -46,6 +46,26 @@
```python
+class Solution:
+ def pathSum(self, root: TreeNode, sum: int) -> List[List[int]]:
+ pathvalue = 0
+ path = []
+ result = []
+
+ def preorder(node, pathvalue, sum, path, result):
+ if node == None:
+ return
+ pathvalue += node.val
+ path.append(node.val)
+ if pathvalue == sum and node.left == None and node.right == None:
+ result.append(list(path)) # 注意加list
+ preorder(node.left, pathvalue, sum, path, result)
+ preorder(node.right, pathvalue, sum, path, result)
+ pathvalue -= node.val
+ path.pop()
+
+ preorder(root, pathvalue, sum, path, result)
+ return result
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/114.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/114.exercises/solution.md"
index 109ce00adee9420390d4e0f11636929925fb01f3..ba2c8f3ea70ffd89f70a8acd858ebef55828450f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/114.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/114.exercises/solution.md"
@@ -48,6 +48,29 @@
```python
+class TreeNode(object):
+ def __init__(self, val=0, left=None, right=None):
+ self.val = val
+ self.left = left
+ self.right = right
+
+
+class Solution:
+ def flatten(self, root: TreeNode) -> None:
+ """
+ Do not return anything, modify root in-place instead.
+ """
+ while root != None:
+ if root.left == None:
+ root = root.right
+ else:
+ pre = root.left
+ while pre.right != None:
+ pre = pre.right
+ pre.right = root.right
+ root.right = root.left
+ root.left = None
+ root = root.right
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/116.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/116.exercises/solution.md"
index 0f4598057823624d4ed93428df14322ff8d8f75a..3a4ad32c131cfb73b3d6db7f7bc1dd0b5c0af610 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/116.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/116.exercises/solution.md"
@@ -48,7 +48,34 @@ struct Node {
## template
```python
-
+class Node(object):
+ def __init__(self, val, left, right, next):
+ self.val = val
+ self.left = left
+ self.right = right
+ self.next = next
+
+
+class Solution(object):
+ def connect(self, root):
+ """
+ :type root: Node
+ :rtype: Node
+ """
+ if not root:
+ return
+ node = [root]
+ while node:
+ l = len(node)
+ for n in range(l):
+ cur = node.pop(0)
+ if n < (l - 1):
+ cur.next = node[0]
+ if cur.left:
+ node.append(cur.left)
+ if cur.right:
+ node.append(cur.right)
+ return root
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/117.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/117.exercises/solution.md"
index 3f514608519ec2bfae2774ce463aa0fe51cee1d3..fb9c095a21bc875ac31ed9aabb86f270e6907ab5 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/117.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/117.exercises/solution.md"
@@ -52,6 +52,41 @@ struct Node {
## template
```python
+class Node(object):
+ def __init__(self, val, left, right, next):
+ self.val = val
+ self.left = left
+ self.right = right
+ self.next = next
+
+
+class Solution:
+ def connect(self, root: "Node") -> "Node":
+ if root == None:
+ return None
+ firstNode = root
+ while firstNode:
+ while firstNode and firstNode.left == None and firstNode.right == None:
+ firstNode = firstNode.next
+
+ if firstNode == None:
+ break
+ cur = firstNode
+ pre = None
+
+ while cur:
+ if cur.left:
+ if pre:
+ pre.next = cur.left
+ pre = cur.left
+ if cur.right:
+ if pre:
+ pre.next = cur.right
+ pre = cur.right
+ cur = cur.next
+ firstNode = firstNode.left if firstNode.left else firstNode.right
+ return root
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/120.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/120.exercises/solution.md"
index 8a08afe2513a491cf4989dc99a8cf6599b3365d1..f96d8eb467a9265f58cd4f837bda9578d0ffa03e 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/120.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/120.exercises/solution.md"
@@ -50,6 +50,19 @@
```python
+class Solution(object):
+ def minimumTotal(self, triangle):
+ """
+ :type triangle: List[List[int]]
+ :rtype: int
+ """
+ n = len(triangle)
+ dp = triangle[-1]
+ for i in range(n - 2, -1, -1):
+ for j in range(i + 1):
+ dp[j] = triangle[i][j] + min(dp[j], dp[j + 1])
+ print dp
+ return dp[0]
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/128.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/128.exercises/solution.md"
index 9bb347e091f6e7e23b123ce99dea6759dc6e3a72..c2ec4ab66c230ba39d87f976806ede00b0637aa1 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/128.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/128.exercises/solution.md"
@@ -34,6 +34,29 @@
```python
+class Solution:
+ def longestConsecutive(self, nums: List[int]) -> int:
+ hash_dict = {}
+
+ max_length = 0
+
+ for num in nums:
+
+ if num not in hash_dict:
+
+ pre_length = hash_dict.get(num - 1, 0)
+ next_length = hash_dict.get(num + 1, 0)
+
+ cur_length = pre_length + 1 + next_length
+
+ if cur_length > max_length:
+ max_length = cur_length
+
+ hash_dict[num] = cur_length
+ hash_dict[num - pre_length] = cur_length
+ hash_dict[num + next_length] = cur_length
+
+ return max_length
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/129.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/129.exercises/solution.md"
index b42a42b6b271a27e9987204a7b4bb637d0e432b7..02536fe5ae8c0601da6f7058685c5e39dfbe1320 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/129.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/129.exercises/solution.md"
@@ -53,8 +53,25 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def sumNumbers(self, root: TreeNode) -> int:
+ def dfs(root: TreeNode, sumNumber: int) -> int:
+ if not root:
+ return 0
+ tmpsum = sumNumber * 10 + root.val
+
+ if not root.left and not root.right:
+ return tmpsum
+ else:
+ return dfs(root.left, tmpsum) + dfs(root.right, tmpsum)
+
+ return dfs(root, 0)
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/130.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/130.exercises/solution.md"
index 6898f422f268b3757ae08111c746c00adf22c4ba..7b4cf36c941dca644d1efbba0d00ec2cbd829565 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/130.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/130.exercises/solution.md"
@@ -37,6 +37,50 @@
## template
```python
+class Solution:
+ def solve(self, board: List[List[str]]) -> None:
+ """
+ Do not return anything, modify board in-place instead.
+ """
+ if not board or len(board) == 0:
+ return
+
+ m = len(board)
+ n = len(board[0])
+
+ from collections import deque
+
+ queue = deque()
+
+ for i in range(m):
+
+ if board[i][0] == "O":
+ queue.append((i, 0))
+ if board[i][n - 1] == "O":
+ queue.append((i, n - 1))
+
+ for j in range(n):
+
+ if board[0][j] == "O":
+ queue.append((0, j))
+ if board[m - 1][j] == "O":
+ queue.append((m - 1, j))
+
+ while queue:
+ x, y = queue.popleft()
+ board[x][y] = "M"
+
+ for nx, ny in [(x - 1, y), (x + 1, y), (x, y - 1), (x, y + 1)]:
+ if 0 <= nx < m and 0 <= ny < n and board[nx][ny] == "O":
+ queue.append((nx, ny))
+
+ for i in range(m):
+ for j in range(n):
+ if board[i][j] == "O":
+ board[i][j] = "X"
+ if board[i][j] == "M":
+ board[i][j] = "O"
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/131.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/131.exercises/solution.md"
index d55b476f04733ab2858d90d4f704d038bd578925..d7994fb6402313a24ba5ce0d5cf2181075e31579 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/131.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/131.exercises/solution.md"
@@ -33,6 +33,25 @@
## template
```python
+class Solution(object):
+ def partition(self, s):
+ """
+ :type s: str
+ :rtype: List[List[str]]
+ """
+ if len(s) == 0:
+ return []
+ else:
+ res = []
+ self.dividedAndsel(s, [], res)
+ return res
+
+ def dividedAndsel(self, s, tmp, res):
+ if len(s) == 0:
+ res.append(tmp)
+ for i in range(1, len(s) + 1):
+ if s[:i] == s[:i][::-1]:
+ self.dividedAndsel(s[i:], tmp + [s[:i]], res)
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/133.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/133.exercises/solution.md"
index fbc9e348801d7d1a8154d2d1bea0179cad711807..1b6cbf56310897406db32f33d787a8a806089d5f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/133.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/133.exercises/solution.md"
@@ -74,6 +74,32 @@
## template
```python
+class Node:
+ def __init__(self, val=0, neighbors=[]):
+ self.val = val
+ self.neighbors = neighbors
+
+
+class Solution:
+ def cloneGraph(self, node: "Node") -> "Node":
+ marked = {}
+
+ def dfs(node):
+ if not node:
+ return node
+
+ if node in marked:
+ return marked[node]
+
+ clone_node = Node(node.val, [])
+ marked[node] = clone_node
+
+ for neighbor in node.neighbors:
+ clone_node.neighbors.append(dfs(neighbor))
+
+ return clone_node
+
+ return dfs(node)
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/134.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/134.exercises/solution.md"
index f004720e23b4de324414302be047f7a7c6972db4..d75f03893e5152c1ec8d30de906ae580c31b741f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/134.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/134.exercises/solution.md"
@@ -51,6 +51,25 @@ cost = [3,4,3]
## template
```python
+class Solution(object):
+ def canCompleteCircuit(self, gas, cost):
+ """
+ :type gas: List[int]
+ :type cost: List[int]
+ :rtype: int
+ """
+ n = len(gas)
+ if sum(gas) < sum(cost):
+ return -1
+ else:
+ start = 0
+ path = 0
+ for i in range(n):
+ path = path + (gas[i] - cost[i])
+ if path < 0:
+ start = i + 1
+ path = 0
+ return start
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/137.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/137.exercises/solution.md"
index da24fefd9deb37cd9a3097b792281ddb24764cef..8bb220de0d42bde10fa9bae43d7c51cb729429ad 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/137.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/137.exercises/solution.md"
@@ -37,6 +37,18 @@
```python
+class Solution(object):
+ def singleNumber(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: int
+ """
+ a = 0
+ b = 0
+ for num in nums:
+ a = (num ^ a) & ~b
+ b = (num ^ b) & ~a
+ return a
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/138.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/138.exercises/solution.md"
index f7ad177b14829541917ce8349bf52b0b1c066a25..258d3d65d36591f9e380d2eba5b78d5074725aaa 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/138.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/138.exercises/solution.md"
@@ -68,6 +68,34 @@
## template
```python
+class Node(object):
+ def __init__(self, val, next, random):
+ self.val = val
+ self.next = next
+ self.random = random
+
+
+class Solution(object):
+ def copyRandomList(self, head):
+ """
+ :type head: Node
+ :rtype: Node
+ """
+ if head == None:
+ return None
+ memories = {}
+ node = head
+ while node != None:
+ cloneNode = Node(node.val, None, None)
+ memories[node] = cloneNode
+ node = node.next
+ node = head
+ while node:
+
+ memories.get(node).next = memories.get(node.next)
+ memories.get(node).random = memories.get(node.random)
+ node = node.next
+ return memories[head]
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/139.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/139.exercises/solution.md"
index cbb6f1e521a67b905e832836329a87500e84cf4c..29151277b2c27b00c353796a78c7c9d1c5619122 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/139.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/139.exercises/solution.md"
@@ -35,6 +35,24 @@
```python
+class Solution(object):
+ def wordBreak(self, s, wordDict):
+ """
+ :type s: str
+ :type wordDict: List[str]
+ :rtype: bool
+ """
+ if not s:
+ return True
+ lenth = len(s)
+ dp = [False for i in range(lenth + 1)]
+ dp[0] = True
+ for i in range(1, lenth + 1):
+ for j in range(i):
+ if dp[j] and s[j:i] in wordDict:
+ dp[i] = True
+ break
+ return dp[-1]
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/142.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/142.exercises/solution.md"
index 200c25a22384ab2c835670637e38e4d3244d7a62..905827313b0228b6d96e34aed42ce4b3d66e0d52 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/142.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/142.exercises/solution.md"
@@ -58,7 +58,23 @@
## template
```python
-
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution(object):
+ def detectCycle(self, head):
+ s = set()
+
+ node = head
+ while node is not None:
+ if node in s:
+ return node
+ else:
+ s.add(node)
+ node = node.next
+ return None
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/143.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/143.exercises/solution.md"
index bbeb773d71efeca818cdf4e1e379486d57658453..71d5062a7dba7981a83b91b392a80a055ff517e4 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/143.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/143.exercises/solution.md"
@@ -40,6 +40,40 @@
## template
```python
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution(object):
+ def reorderList(self, head):
+ """
+ :type head: ListNode
+ :rtype: None Do not return anything, modify head in-place instead.
+ """
+
+ if not head:
+ return
+
+ stack = []
+ s = head
+
+ while s.next:
+ stack.append(s.next)
+ s = s.next
+
+ s = head
+
+ n = 0
+ while stack:
+ if n % 2 == 0:
+ one = stack.pop()
+ else:
+ one = stack.pop(0)
+ one.next = None
+ s.next = one
+ s = s.next
+ n += 1
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/146.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/146.exercises/solution.md"
index 55476871a6869fd5054d3d3a0d42196aa8a1f50d..c9752dc75c4e3a94b705ea1ff7f4eeddce37e460 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/146.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/146.exercises/solution.md"
@@ -58,6 +58,49 @@ lRUCache.get(4); // 返回 4
```python
+class LRUCache:
+ def __init__(self, capacity):
+ """
+ :type capacity: int
+ """
+ self.maxlength = capacity
+ self.array = {}
+ self.array_list = []
+
+ def get(self, key):
+ """
+ :type key: int
+ :rtype: int
+ """
+ value = self.array.get(key)
+
+ if value is not None and self.array_list[0] is not key:
+ index = self.array_list.index(key)
+ self.array_list.pop(index)
+ self.array_list.insert(0, key)
+
+ value = value if value is not None else -1
+ return value
+
+ def put(self, key, value):
+ """
+ :type key: int
+ :type value: int
+ :rtype: void
+ """
+
+ if self.array.get(key) is not None:
+ index = self.array_list.index(key)
+ self.array.pop(key)
+ self.array_list.pop(index)
+
+ if len(self.array_list) >= self.maxlength:
+ key_t = self.array_list.pop(self.maxlength - 1)
+ self.array.pop(key_t)
+
+ self.array[key] = value
+ self.array_list.insert(0, key)
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/147.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/147.exercises/solution.md"
index 9a00c06117b1d9f896d9df44b600fe850f896339..44d25d53cdfae753e4bdce58d8744b33898303c8 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/147.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/147.exercises/solution.md"
@@ -35,6 +35,49 @@
```python
+class LRUCache:
+ def __init__(self, capacity):
+ """
+ :type capacity: int
+ """
+ self.maxlength = capacity
+ self.array = {}
+ self.array_list = []
+
+ def get(self, key):
+ """
+ :type key: int
+ :rtype: int
+ """
+ value = self.array.get(key)
+
+ if value is not None and self.array_list[0] is not key:
+ index = self.array_list.index(key)
+ self.array_list.pop(index)
+ self.array_list.insert(0, key)
+
+ value = value if value is not None else -1
+ return value
+
+ def put(self, key, value):
+ """
+ :type key: int
+ :type value: int
+ :rtype: void
+ """
+
+ if self.array.get(key) is not None:
+ index = self.array_list.index(key)
+ self.array.pop(key)
+ self.array_list.pop(index)
+
+ if len(self.array_list) >= self.maxlength:
+ key_t = self.array_list.pop(self.maxlength - 1)
+ self.array.pop(key_t)
+
+ self.array[key] = value
+ self.array_list.insert(0, key)
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/148.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/148.exercises/solution.md"
index c55d8eafe1a78ce2635fc4dc48250931a02fdb63..20b37e585eabd449f9d9d1397981d7962becd82d 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/148.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/148.exercises/solution.md"
@@ -44,7 +44,53 @@
## template
```python
-
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+class Solution:
+ def sortList(self, head: ListNode) -> ListNode:
+ if head == None:
+ return None
+ else:
+ return self.mergeSort(head)
+
+ def mergeSort(self, head):
+ if head.next == None:
+ return head
+ fast = head
+ slow = head
+ pre = None
+
+ while fast != None and fast.next != None:
+ pre = slow
+ slow = slow.next
+ fast = fast.next.next
+ pre.next = None
+
+ left = self.mergeSort(head)
+ right = self.mergeSort(slow)
+
+ return self.merge(left, right)
+
+ def merge(self, left, right):
+ tempHead = ListNode(0)
+ cur = tempHead
+ while left != None and right != None:
+ if left.val <= right.val:
+ cur.next = left
+ cur = cur.next
+ left = left.next
+ else:
+ cur.next = right
+ cur = cur.next
+ right = right.next
+ if left != None:
+ cur.next = left
+ if right != None:
+ cur.next = right
+ return tempHead.next
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/150.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/150.exercises/solution.md"
index 31c509b71f4908e7e38bc38a1e0fad49b539965e..af5dbf333e1b1e284d5212a11c2fc2085a6eb045 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/150.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/150.exercises/solution.md"
@@ -77,6 +77,35 @@
## template
```python
+class Solution(object):
+ def evalRPN(self, tokens):
+ """
+ :type tokens: List[str]
+ :rtype: int
+ """
+ stack = []
+ for token in tokens:
+
+ if token not in ["+", "-", "*", "/"]:
+ stack.append(int(token))
+ else:
+
+ num1 = stack.pop()
+ num2 = stack.pop()
+ if token == "+":
+ stack.append(num1 + num2)
+ elif token == "-":
+ stack.append(num2 - num1)
+ elif token == "*":
+ stack.append(num1 * num2)
+ elif token == "/":
+ if num1 * num2 < 0:
+ result = -((-num2) // num1)
+ stack.append(result)
+ else:
+ stack.append(num2 // num1)
+ print(stack)
+ return stack.pop()
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/151.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/151.exercises/solution.md"
index 0e953108f2379f3faeb41ead41265b5ecddfd138..c4eab5d23133442af050344842067c09dbaecfcf 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/151.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/151.exercises/solution.md"
@@ -78,6 +78,16 @@
## template
```python
+class Solution:
+ def reverseWords(self, s: str) -> str:
+ str_list = s.split()
+ s1 = ""
+ for n, i in enumerate(str_list[::-1]):
+ if n == len(str_list) - 1:
+ s1 = s1 + i
+ else:
+ s1 = s1 + i + " "
+ return s1
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/152.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/152.exercises/solution.md"
index 3fb50e562e4c2044bed10c674dea53b1456b0812..a6e5521db1b4212d3b13921e60a4415b02568f6a 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/152.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/152.exercises/solution.md"
@@ -22,6 +22,31 @@
```python
+class Solution:
+ def maxProduct(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+
+ length = len(nums)
+
+ dp = [[0] * 2 for _ in range(length)]
+
+ dp[0][0] = nums[0]
+ dp[0][1] = nums[0]
+
+ for i in range(1, length):
+
+ if nums[i] > 0:
+ dp[i][0] = min(nums[i], dp[i - 1][0] * nums[i])
+ dp[i][1] = max(nums[i], dp[i - 1][1] * nums[i])
+ else:
+ dp[i][0] = min(nums[i], dp[i - 1][1] * nums[i])
+ dp[i][1] = max(nums[i], dp[i - 1][0] * nums[i])
+
+ res = dp[0][1]
+ for i in range(1, length):
+ res = max(res, dp[i][1])
+ return res
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/153.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/153.exercises/solution.md"
index a3c217cd7998861748c355b5491df4580e003f56..95cd2d4301ffecd9b8fccf4a7ee1d214d48246e1 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/153.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/153.exercises/solution.md"
@@ -53,6 +53,24 @@
```python
+class Solution(object):
+ def findMin(self, nums):
+
+ flag = True
+ if nums[0] < nums[-1]:
+ flag = True
+ else:
+ flag = False
+
+ for i in range(1, len(nums)):
+ if flag:
+ if nums[i] < nums[i - 1]:
+ return nums[i]
+ else:
+ if nums[len(nums) - i] < nums[len(nums) - 1 - i]:
+ return nums[len(nums) - i]
+ return nums[0]
+
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.md"
deleted file mode 100644
index b7d60fcad51dea90f7916703ed651083c348daeb..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/156.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 上下翻转二叉树
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.json"
deleted file mode 100644
index 562e2e07e72a868d914afb8dfb66b141b32bdad2..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "9f961ad0206648198ba16c674bd376f7",
- "author": "csdn.net",
- "keywords": "哈希表,字符串,滑动窗口"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.md"
deleted file mode 100644
index f4d564fa7c535ae22397044831c0305cc3e6ff05..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/159.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 至多包含两个不同字符的最长子串
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.md"
deleted file mode 100644
index b71f1c113d749cfe7ceb6ccdeca0556e6b58eba2..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/161.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 相隔为 1 的编辑距离
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/162.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/162.exercises/solution.md"
index 15a260a6e5c25111a2f1c07d17bd79615e43551d..6b37618fb711fc6dd25658785f396c4b50f5c697 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/162.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/162.exercises/solution.md"
@@ -40,8 +40,20 @@
## template
```python
+class Solution:
+ def findPeakElement(self, nums: List[int]) -> int:
+ low = 0
+ high = len(nums) - 1
+ while low < high:
+ mid = int(low - (low - high) / 2)
+ if nums[mid] < nums[mid + 1]:
+ low = mid + 1
+ else:
+ high = mid
+
+ return low
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/165.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/165.exercises/solution.md"
index 760cd97e51a72ab5935fe0435d45d79f8c57730d..620ed87d65d5cc4091baae6054580ee42463bb2c 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/165.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/165.exercises/solution.md"
@@ -69,8 +69,48 @@
## template
```python
-
-
+class Solution(object):
+ def compareVersion(self, version1, version2):
+ """
+ 用split划分 转换为int 比较即可
+ :type version1: str
+ :type version2: str
+ :rtype: int
+ """
+ com1 = version1.split(".")
+ com2 = version2.split(".")
+
+ if len(com1) != len(com2):
+
+ if len(com1) > len(com2):
+ for i in range(len(com2)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ for i in range(len(com2), len(com1)):
+ if int(com1[i]) != 0:
+ return 1
+ return 0
+ else:
+ for i in range(len(com1)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ for i in range(len(com1), len(com2)):
+ if int(com2[i]) != 0:
+ return -1
+ return 0
+
+ for i in range(len(com1)):
+ if int(com1[i]) > int(com2[i]):
+ return 1
+ elif int(com1[i]) < int(com2[i]):
+ return -1
+ else:
+ continue
+ return 0
```
## 答案
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/166.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/166.exercises/solution.md"
index 0184dbc8f4193925d97d9f45e444f3cf26c688a8..955b20b7deababa4bacb980b3cb12b34505afd4f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/166.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/166.exercises/solution.md"
@@ -59,6 +59,45 @@
```python
+class Solution(object):
+ def fractionToDecimal(self, numerator, denominator):
+
+ if numerator < 0 and denominator < 0:
+ numerator, denominator = -numerator, -denominator
+
+ u = (numerator < 0) ^ (denominator < 0)
+
+ numerator = abs(numerator)
+ denominator = abs(denominator)
+ numerator = numerator % denominator
+
+ if numerator == 0:
+ return str(numerator // denominator)
+
+ s = str(abs(numerator) // denominator) + "."
+ q = {}
+ l = []
+ while numerator < denominator:
+ numerator = numerator * 10
+ l.append(numerator)
+ q[numerator] = numerator // denominator
+ numerator = numerator % denominator * 10
+
+ while numerator not in q and numerator != 0:
+ l.append(numerator)
+ q[numerator] = numerator // denominator
+ numerator = numerator % denominator
+ numerator = numerator * 10
+
+ for i in range(0, len(l)):
+ if numerator == l[i]:
+ s = s + "("
+ s = s + str(q[l[i]])
+ if "(" in s:
+ s = s + ")"
+ if u:
+ s = "-" + s
+ return s
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/173.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/173.exercises/solution.md"
index 6805a02b84ca9d530088001a5892efed66cf4457..7aa84111bde8804bf9f327ddc12415d9aa4899dc 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/173.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/173.exercises/solution.md"
@@ -61,7 +61,43 @@ bSTIterator.hasNext(); // 返回 False
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class BSTIterator:
+ def __init__(self, root: TreeNode):
+ self.index = -1
+ self.node_list = []
+ self._iterator(root)
+
+ def _iterator(self, root):
+ if not root:
+ return
+ self._iterator(root.left)
+ self.node_list.append(root.val)
+ self._iterator(root.right)
+
+ def next(self) -> int:
+ """
+ @return the next smallest number
+ """
+ self.index += 1
+ return self.node_list[self.index]
+
+ def hasNext(self) -> bool:
+ """
+ @return whether we have a next smallest number
+ """
+ return self.index + 1 < len(self.node_list)
+
+
+# Your BSTIterator object will be instantiated and called as such:
+# obj = BSTIterator(root)
+# param_1 = obj.next()
+# param_2 = obj.hasNext()
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.json"
deleted file mode 100644
index 90e12cbc0ead91faf44f54f07ed767d806b48b9d..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "75cb32f560dc4a41850c41b8a52f3e09",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.md"
deleted file mode 100644
index 18ae30c3a4860a933dbbcc9c74adece793d6b4b7..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/177.exercises/solution.md"
+++ /dev/null
@@ -1,55 +0,0 @@
-# 第N高的薪水
-
-编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
-
-+----+--------+
-| Id | Salary |
-+----+--------+
-| 1 | 100 |
-| 2 | 200 |
-| 3 | 300 |
-+----+--------+
-
-
-例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
-
-+------------------------+
-| getNthHighestSalary(2) |
-+------------------------+
-| 200 |
-+------------------------+
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/config.json"
deleted file mode 100644
index 3a90650cdd865e42e346719eb7fd88e3589346a5..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-1c04e099a7fe4c5a8807cb714cccb545",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.json"
deleted file mode 100644
index 35f798b104d8e38265836781e8f2c493ad409ad7..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "270e7864b56d4254955b30b93c85451b",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.md"
deleted file mode 100644
index d297fbb19034a375b4cca40a5685d62fd6295667..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/178.exercises/solution.md"
+++ /dev/null
@@ -1,67 +0,0 @@
-# 分数排名
-
-编写一个 SQL 查询来实现分数排名。
-
-如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
-
-+----+-------+
-| Id | Score |
-+----+-------+
-| 1 | 3.50 |
-| 2 | 3.65 |
-| 3 | 4.00 |
-| 4 | 3.85 |
-| 5 | 4.00 |
-| 6 | 3.65 |
-+----+-------+
-
-
-例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
-
-+-------+------+
-| Score | Rank |
-+-------+------+
-| 4.00 | 1 |
-| 4.00 | 1 |
-| 3.85 | 2 |
-| 3.65 | 3 |
-| 3.65 | 3 |
-| 3.50 | 4 |
-+-------+------+
-
-
-重要提示:对于 MySQL 解决方案,如果要转义用作列名的保留字,可以在关键字之前和之后使用撇号。例如 `Rank`
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/179.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/179.exercises/solution.md"
index a046ca956184e31f8480afdc3ad4b11fd274d7c8..fe8bd064229042a956632e96b3f542ab16d42db2 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/179.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/179.exercises/solution.md"
@@ -47,6 +47,22 @@
```python
+class Solution(object):
+ def largestNumber(self, nums):
+ n = len(nums)
+
+ for i in range(n):
+ for j in range(n - i - 1):
+ temp_1 = str(nums[j])
+ temp_2 = str(nums[j + 1])
+ if int(temp_1 + temp_2) < int(temp_2 + temp_1):
+ temp = nums[j]
+ nums[j] = nums[j + 1]
+ nums[j + 1] = temp
+ output = ""
+ for num in nums:
+ output = output + str(num)
+ return str(int(output))
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/config.json"
deleted file mode 100644
index 6c72a8376214e55f8fb7841909e0b3af904def4f..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-ddc469a905d540c0947b071e3a1f2104",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.json"
deleted file mode 100644
index 42810c3909fe67e0ce34babf1957ac1f553aa7bb..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "d914beb248f541e7b429b27bc0e74fc7",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.md"
deleted file mode 100644
index 86f81f27b8bb787e245d8f0e7e5ab180105be865..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/180.exercises/solution.md"
+++ /dev/null
@@ -1,81 +0,0 @@
-# 连续出现的数字
-
-表:Logs
-
-
-+-------------+---------+
-| Column Name | Type |
-+-------------+---------+
-| id | int |
-| num | varchar |
-+-------------+---------+
-id 是这个表的主键。
-
-
-
-编写一个 SQL 查询,查找所有至少连续出现三次的数字。
-
-返回的结果表中的数据可以按 任意顺序 排列。
-
-
-
-查询结果格式如下面的例子所示:
-
-
-
-
-Logs 表:
-+----+-----+
-| Id | Num |
-+----+-----+
-| 1 | 1 |
-| 2 | 1 |
-| 3 | 1 |
-| 4 | 2 |
-| 5 | 1 |
-| 6 | 2 |
-| 7 | 2 |
-+----+-----+
-
-Result 表:
-+-----------------+
-| ConsecutiveNums |
-+-----------------+
-| 1 |
-+-----------------+
-1 是唯一连续出现至少三次的数字。
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/config.json"
deleted file mode 100644
index 7fa623912bc580c62677ba9aac07d9354500e8c3..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-ef833ac6c03843cfb0b6942582202b85",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.json"
deleted file mode 100644
index 58f7ac347b5d2b5d9c893a84e7ad298a03c84997..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "23a7c3aaad084cc9898bb5b78c0a8f1a",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.md"
deleted file mode 100644
index 334ebefa99c99d0a627ae0f3a851a37a33bce3e3..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/184.exercises/solution.md"
+++ /dev/null
@@ -1,70 +0,0 @@
-# 部门工资最高的员工
-
-Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
-
-+----+-------+--------+--------------+
-| Id | Name | Salary | DepartmentId |
-+----+-------+--------+--------------+
-| 1 | Joe | 70000 | 1 |
-| 2 | Jim | 90000 | 1 |
-| 3 | Henry | 80000 | 2 |
-| 4 | Sam | 60000 | 2 |
-| 5 | Max | 90000 | 1 |
-+----+-------+--------+--------------+
-
-Department 表包含公司所有部门的信息。
-
-+----+----------+
-| Id | Name |
-+----+----------+
-| 1 | IT |
-| 2 | Sales |
-+----+----------+
-
-编写一个 SQL 查询,找出每个部门工资最高的员工。对于上述表,您的 SQL 查询应返回以下行(行的顺序无关紧要)。
-
-+------------+----------+--------+
-| Department | Employee | Salary |
-+------------+----------+--------+
-| IT | Max | 90000 |
-| IT | Jim | 90000 |
-| Sales | Henry | 80000 |
-+------------+----------+--------+
-
-解释:
-
-Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高。
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/config.json"
deleted file mode 100644
index 5946329d3f1b811ac7dbd3a6135a6e9724f45d32..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-0237ef7add04423ba14101b215134c1d",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.md"
deleted file mode 100644
index 65ea7140fb11f11ff6c4726ebcda5b051e1c3162..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/186.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 翻转字符串里的单词 II
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/187.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/187.exercises/solution.md"
index 557e19082b1a59dc80b0b7037b5194aa5372e79b..e8e6bb6c506c391ced19608502449d3ff3986cbb 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/187.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/187.exercises/solution.md"
@@ -33,6 +33,19 @@
## template
```python
+class Solution:
+ def findRepeatedDnaSequences(self, s: str) -> List[str]:
+ n = len(s)
+ res = []
+ dic = {}
+ for i in range(n - 9):
+ if s[i : i + 10] not in dic:
+ dic[s[i : i + 10]] = 1
+ else:
+ dic[s[i : i + 10]] += 1
+ if dic[s[i : i + 10]] == 2:
+ res.append(s[i : i + 10])
+ return res
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/189.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/189.exercises/solution.md"
index 327f5686ef11e5c219fbcaad77d1b8a61b3dc1fd..b24fb07e4b59ee489142b8920446beaea8986945 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/189.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/189.exercises/solution.md"
@@ -50,6 +50,18 @@
## template
```python
+class Solution:
+ def rotate(self, nums: List[int], k: int) -> None:
+ """
+ Do not return anything, modify nums in-place instead.
+ """
+ n = 0
+ while n < k:
+ c = nums.pop()
+ nums.insert(0, c)
+
+ n += 1
+ return nums
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/config.json"
deleted file mode 100644
index 8eec8096964e660b9f16afd85d4c77432e6e1cd7..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-e6479018b631496fa241dbade3d24226",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.md"
deleted file mode 100644
index 0cdfdc8fee9dacfd8171baba5874884cfe47a74a..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/192.exercises/solution.md"
+++ /dev/null
@@ -1,68 +0,0 @@
-# 统计词频
-
-写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
-
-为了简单起见,你可以假设:
-
-
- words.txt只包括小写字母和 ' ' 。- 每个单词只由小写字母组成。
- - 单词间由一个或多个空格字符分隔。
-
-
-示例:
-
-假设 words.txt 内容如下:
-
-the day is sunny the the
-the sunny is is
-
-
-你的脚本应当输出(以词频降序排列):
-
-the 4
-is 3
-sunny 2
-day 1
-
-
-说明:
-
-
- - 不要担心词频相同的单词的排序问题,每个单词出现的频率都是唯一的。
- - 你可以使用一行 Unix pipes 实现吗?
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/config.json"
deleted file mode 100644
index 31300b198506e008e9d48d54527de0a6b3ff5b0a..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-92df827a4bf6490aa56bbe894ebaa290",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.md"
deleted file mode 100644
index c070ed8ad384efd0afc1c10e09f21ad0e8f5e2b1..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\344\270\255\347\255\211/python/194.exercises/solution.md"
+++ /dev/null
@@ -1,58 +0,0 @@
-# 转置文件
-
-给定一个文件 file.txt,转置它的内容。
-
-你可以假设每行列数相同,并且每个字段由 ' ' 分隔。
-
-
-
-示例:
-
-假设 file.txt 文件内容如下:
-
-
-name age
-alice 21
-ryan 30
-
-
-应当输出:
-
-
-name alice ryan
-age 21 30
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/198.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/198.exercises/solution.md"
index 2e6f8dfb03114e0455bcea4d04a14dcc39932b63..506b70e3a1a82b37d8691364ab1acaea7c3a2ec4 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/198.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/198.exercises/solution.md"
@@ -37,6 +37,16 @@
```python
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ if not nums:
+ return 0
+ if len(nums) == 1:
+ return nums[0]
+ dp = [nums[0], max(nums[0], nums[1])]
+ for i in range(2, len(nums)):
+ dp.append(max(nums[i] + dp[i - 2], dp[i - 1]))
+ return dp[-1]
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/199.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/199.exercises/solution.md"
index c1d766a9fc38e9a7baafc58d95f1803c665bea39..2e344d40d4b44991103af49ead19d0aa32111a5f 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/199.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/199.exercises/solution.md"
@@ -40,7 +40,32 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def rightSideView(self, root: TreeNode) -> List[int]:
+ if not root:
+ return []
+ res = []
+ curnode = [root]
+ nexnode = []
+ res.append(curnode[0].val)
+
+ while curnode:
+ for s in curnode:
+ if s.right:
+ nexnode.append(s.right)
+ if s.left:
+ nexnode.append(s.left)
+ if nexnode:
+ res.append(nexnode[0].val)
+ curnode = nexnode
+ nexnode = []
+ return res
```
diff --git "a/data_source/exercises/\344\270\255\347\255\211/python/200.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/python/200.exercises/solution.md"
index 731bf2659af4801b0ab6abbc2acdadd734474a21..aba42f3184ca13e7110526932703c250228ccef4 100644
--- "a/data_source/exercises/\344\270\255\347\255\211/python/200.exercises/solution.md"
+++ "b/data_source/exercises/\344\270\255\347\255\211/python/200.exercises/solution.md"
@@ -48,6 +48,29 @@
```python
+class Solution:
+ def depthSearch(self, grid, i, j):
+ if i < 0 or j < 0 or i >= len(grid) or j >= len(grid[0]):
+ return
+ if grid[i][j] == "0":
+ return
+ grid[i][j] = "0"
+ self.depthSearch(grid, i - 1, j)
+ self.depthSearch(grid, i + 1, j)
+ self.depthSearch(grid, i, j - 1)
+ self.depthSearch(grid, i, j + 1)
+
+ def numIslands(self, grid: List[List[str]]) -> int:
+ if not grid:
+ return 0
+ w, h = len(grid[0]), len(grid)
+ cnt = 0
+ for i in range(h):
+ for j in range(w):
+ if grid[i][j] == "1":
+ self.depthSearch(grid, i, j)
+ cnt += 1
+ return cnt
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/115.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/115.exercises/solution.md"
index 736b4f49e8b099be8390ce8e98d4f553c26e1668..4e47cd10078c31aaad3b55bc1f44256f83d35e85 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/115.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/115.exercises/solution.md"
@@ -47,7 +47,21 @@
```python
-
+class Solution:
+ def numDistinct(self, s: str, t: str) -> int:
+ if t == "" and s == "":
+ return 0
+ if t == "":
+ return 1
+ dp = [[0 for i in range(len(s) + 1)] for j in range(len(t) + 1)]
+ for j in range(0, len(s) + 1):
+ dp[0][j] = 1
+ for i in range(1, len(t) + 1):
+ for j in range(1, len(s) + 1):
+ dp[i][j] = dp[i][j - 1]
+ if s[j - 1] == t[i - 1]:
+ dp[i][j] += dp[i - 1][j - 1]
+ return dp[-1][-1]
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/123.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/123.exercises/solution.md"
index 6b8fdafdc22204492473e2249b67066f22a4bfc9..7c3ef4547d226152dd45700f508c084b34adc512 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/123.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/123.exercises/solution.md"
@@ -53,7 +53,22 @@
## template
```python
-
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ k = 2
+ n = len(prices)
+ dp_i_1_0 = 0
+ dp_i_1_1 = -prices[0]
+ dp_i_2_0 = 0
+ dp_i_2_1 = -prices[0]
+ for i in range(1, n):
+ dp_i_1_0 = max(dp_i_1_0, dp_i_1_1 + prices[i])
+ dp_i_1_1 = max(dp_i_1_1, -prices[i])
+ dp_i_2_0 = max(dp_i_2_0, dp_i_2_1 + prices[i])
+ dp_i_2_1 = max(dp_i_2_1, dp_i_1_0 - prices[i])
+ return dp_i_2_0
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/124.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/124.exercises/solution.md"
index d0c3ab07b6f3a623af009ee9d6b5009c0d22c611..bb3342d1efb1056f09446a8c48283b83c0d2f34b 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/124.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/124.exercises/solution.md"
@@ -37,6 +37,25 @@
```python
+class Solution:
+ def __init__(self):
+ self.result = float("-inf")
+
+ def maxPathSum(self, root: TreeNode) -> int:
+ if root == None:
+ return 0
+ self.getMax(root)
+ return self.result
+
+ def getMax(self, root):
+ if root == None:
+ return 0
+
+ left = max(0, self.getMax(root.left))
+ right = max(0, self.getMax(root.right))
+
+ self.result = max(self.result, left + right + root.val)
+ return max(left, right) + root.val
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/126.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/126.exercises/solution.md"
index cb60e6556717b3a095125f7e701280e76137966b..a0fb31b7294c1bd5d8012631dabf61d77451f0b7 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/126.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/126.exercises/solution.md"
@@ -52,7 +52,36 @@
## template
```python
-
+class Solution:
+ def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
+ import collections
+ ans = []
+ steps = float("inf")
+ if not beginWord or not endWord or not wordList or endWord not in wordList:
+ return []
+ word_dict = collections.defaultdict(list)
+ L = len(beginWord)
+ for word in wordList:
+ for i in range(L):
+ word_dict[word[:i] + "*" + word[i+1:]].append(word)
+ queue = [[beginWord]]
+ cost = {beginWord : 0}
+ while queue:
+ words_list= queue.pop(0)
+ cur_word = words_list[-1]
+ if cur_word == endWord:
+ ans.append(words_list[:])
+ else:
+ for i in range(L):
+ intermediate_word = cur_word[:i] + "*" + cur_word[i+1:]
+ for word in word_dict[intermediate_word]:
+ w_l_temp = words_list[:]
+ if word not in cost or cost[word] >= cost[cur_word] + 1:
+ cost[word] = cost[cur_word] + 1
+ w_l_temp.append(word)
+ queue.append(w_l_temp[:])
+
+ return ans
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/127.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/127.exercises/solution.md"
index 45c20576ddaf833f536a462396e4ec4abafd7623..d8310499b4a7c2abe22d55b4dbd0b9f77161544e 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/127.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/127.exercises/solution.md"
@@ -45,7 +45,46 @@
## template
```python
-
+class Solution:
+ def ladderLength(self, beginWord, endWord, wordList):
+ """
+ :type beginWord: str
+ :type endWord: str
+ :type wordList: List[str]
+ :rtype: int
+ """
+
+ if endWord not in wordList:
+ return 0
+
+ if beginWord in wordList:
+ wordList.remove(beginWord)
+ wordDict = dict()
+
+ for word in wordList:
+ for i in range(len(word)):
+ tmp = word[:i] + "_" + word[i + 1 :]
+ wordDict[tmp] = wordDict.get(tmp, []) + [word]
+
+ stack, visited = [(beginWord, 1)], set()
+
+ while stack:
+ word, step = stack.pop(0)
+ if word not in visited:
+ visited.add(word)
+
+ if word == endWord:
+ return step
+
+ for i in range(len(word)):
+ tmp = word[:i] + "_" + word[i + 1 :]
+ neigh_words = wordDict.get(tmp, [])
+
+ for neigh in neigh_words:
+ if neigh not in visited:
+ stack.append((neigh, step + 1))
+
+ return 0
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/132.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/132.exercises/solution.md"
index 4cd3b22290f55fbec646c8ae7d07480da27d091f..661fae5ce9f2ee85b990b8508e6d04ca49020b50 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/132.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/132.exercises/solution.md"
@@ -46,7 +46,24 @@
```python
-
+class Solution:
+ def minCut(self, s):
+ size = len(s)
+
+ is_palindrome = [[False] * size for _ in range(size)]
+ for r in range(size):
+ for l in range(r, -1, -1):
+ if s[l] == s[r] and (r - l <= 2 or is_palindrome[l + 1][r - 1]):
+ is_palindrome[l][r] = True
+
+ dp = [i for i in range(size)]
+ for i in range(1, size):
+ if is_palindrome[0][i]:
+ dp[i] = 0
+ else:
+ dp[i] = min(dp[j] + 1 for j in range(i) if is_palindrome[j + 1][i])
+
+ return dp[-1]
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/135.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/135.exercises/solution.md"
index 56f234e553f7a4214d67e1441eeae6e5951b2cb9..dd11add211555c3c81bb4d0d6c71397d88c4fb33 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/135.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/135.exercises/solution.md"
@@ -33,7 +33,26 @@
## template
```python
-
+class Solution(object):
+ def candy(self, ratings):
+ """
+ :type ratings: List[int]
+ :rtype: int
+ """
+ if ratings == None:
+ return 0
+ lenth = len(ratings)
+ dp = [1 for i in range(lenth)]
+ sum = 0
+ for i in range(1, len(ratings)):
+ if ratings[i] > ratings[i - 1]:
+ dp[i] = dp[i - 1] + 1
+ for i in range(len(ratings) - 2, -1, -1):
+ if ratings[i] > ratings[i + 1] and dp[i] <= dp[i + 1]:
+ dp[i] = dp[i + 1] + 1
+ for i in range(lenth):
+ sum += dp[i]
+ return sum
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/140.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/140.exercises/solution.md"
index d2377ae44f1fe1681c9cc5f4b0003018ba91bfe1..45780ba68cee1e8745ed5fdcd5e37299ebc70163 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/140.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/140.exercises/solution.md"
@@ -48,6 +48,36 @@ wordDict = ["cats", "dog", "sand", "and"
## template
```python
+class Solution(object):
+ def dfs(self, low, length, s, res, vaild, path=[]):
+ if low == length:
+ res.append(" ".join(path))
+ return
+ for i in range(low, length):
+ if vaild[low][i]:
+ self.dfs(i + 1, length, s, res, vaild, path + [s[low : i + 1]])
+
+ def wordBreak(self, s, wordDict):
+ """
+ :type s: str
+ :type wordDict: List[str]
+ :rtype: List[str]
+ """
+ length = len(s)
+ vaild = [[False] * length for _ in range(length)]
+ dp = [False for _ in range(length + 1)]
+ dp[0] = True
+ wordDict = set(wordDict)
+ for i in range(1, length + 1):
+ for j in range(i + 1):
+ word = s[j:i]
+ if dp[j] and word in wordDict:
+ dp[i] = True
+ vaild[j][i - 1] = True
+ res = []
+ if dp[-1]:
+ self.dfs(0, length, s, res, vaild)
+ return res
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/149.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/149.exercises/solution.md"
index 924a3994a70de4eccbbb71cdf8881380d099d673..b9692a5aa1dee71bc9d812fefd5b1142b0cc4fe3 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/149.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/149.exercises/solution.md"
@@ -33,7 +33,34 @@
## template
```python
-
+class Solution:
+ def maxPoints(self, points: List[List[int]]) -> int:
+ if len(points) <= 2:
+ return len(points)
+ maxNum = 0
+ for i in range(len(points)):
+ maxNum = max(maxNum, self.find(points[i], points[:i] + points[i + 1 :]))
+ return maxNum + 1
+
+ def find(self, point, pointList):
+ memories = {}
+ count = 0
+ inf = float("inf")
+ for curPoint in pointList:
+ if curPoint[1] == point[1] and curPoint[0] != point[0]:
+ memories[inf] = memories.get(inf, 0) + 1
+ elif curPoint[1] == point[1] and curPoint[0] == point[0]:
+
+ count += 1
+ else:
+ slope = (curPoint[0] - point[0]) / (curPoint[1] - point[1])
+ memories[slope] = memories.get(slope, 0) + 1
+ if memories:
+ return count + max(memories.values())
+
+ else:
+
+ return count
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/154.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/154.exercises/solution.md"
index 6620155cd879e8bfcd09b890f719698b95022e9a..a69963573b90ba72a4b6ade6b876ae30c753bf9e 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/154.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/154.exercises/solution.md"
@@ -51,7 +51,19 @@
```python
-
+class Solution:
+ def findMin(self, nums: List[int]) -> int:
+ left = 0
+ right = len(nums) - 1
+ while left < right:
+ mid = left + (right - left) // 2
+ if nums[mid] > nums[right]:
+ left = mid + 1
+ elif nums[mid] == nums[right]:
+ right -= 1
+ else:
+ right = mid
+ return nums[left]
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/config.json" "b/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/config.json"
deleted file mode 100644
index ab049c67e9896ccc8a7586cc0d9fd70a855a1a64..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-84631fc0702a4a999bce155aaab1d17e",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.json" "b/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.json"
deleted file mode 100644
index d6a0cebed217527d483f25d32ce730357b85f916..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "d93105a1777c4ea29f6ee12016e57bdc",
- "author": "csdn.net",
- "keywords": "字符串,交互,模拟"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.md"
deleted file mode 100644
index d799dd6e90bc06cecc3b609f0cbfea764518a276..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/158.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 用 Read4 读取 N 个字符 II
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/164.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/164.exercises/solution.md"
index 3215d31002c5dc5a6bb3cd4731faba9cdab3261b..7f97f2cc1c96aa3bbb367475c49dc29c73d079ce 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/164.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/164.exercises/solution.md"
@@ -27,7 +27,36 @@
## template
```python
-
+class Solution(object):
+ def maximumGap(self, nums):
+ if len(nums) < 2:
+ return 0
+ min_val, max_val = min(nums), max(nums)
+ if min_val == max_val:
+ return 0
+
+ n = len(nums) + 1
+ step = (max_val - min_val) // n
+
+ exist = [0 for _ in range(n + 1)]
+ max_num = [0 for _ in range(n + 1)]
+ min_num = [0 for _ in range(n + 1)]
+
+ for num in nums:
+ idx = self.findBucketIndex(num, min_val, max_val, n)
+ max_num[idx] = num if not exist[idx] else max(num, max_num[idx])
+ min_num[idx] = num if not exist[idx] else min(num, min_num[idx])
+ exist[idx] = 1
+ res = 0
+ pre = max_num[0]
+ for i in range(1, n + 1):
+ if exist[i]:
+ res = max(res, min_num[i] - pre)
+ pre = max_num[i]
+ return res
+
+ def findBucketIndex(self, num, min_val, max_val, n):
+ return int((num - min_val) * n / (max_val - min_val))
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/174.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/174.exercises/solution.md"
index fc635decfc0f50b1560adf5bafdbec98c5f563fc..98bc1941ffbb9a8230f25de2e0672f8bc7aae0e3 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/174.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/174.exercises/solution.md"
@@ -61,7 +61,21 @@ table.dungeon, .dungeon th, .dungeon td {
## template
```python
+class Solution:
+ def calculateMinimumHP(self, dungeon: List[List[int]]) -> int:
+ m = len(dungeon)
+ n = len(dungeon[0])
+ dp = [[float("inf")] * (n + 1) for _ in range(m + 1)]
+
+ dp[m - 1][n] = 1
+ dp[m][n - 1] = 1
+
+ for i in range(m - 1, -1, -1):
+ for j in range(n - 1, -1, -1):
+ dp[i][j] = max(min(dp[i][j + 1], dp[i + 1][j]) - dungeon[i][j], 1)
+
+ return dp[0][0]
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/config.json" "b/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/config.json"
deleted file mode 100644
index 093b870aebcd7dc698fb353bb19b4063666eee2e..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-276f914f5c864bc9bcd3f3663cce1600",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.json" "b/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.json"
deleted file mode 100644
index baeab96ad85ff5b6c91f222a4de6ebd4736d625b..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "899bf9e5b2c247db98f3adae4adf87dc",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.md"
deleted file mode 100644
index e85639c6eb8b0c90ddfcda58cf1535ff38e2ebd7..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/185.exercises/solution.md"
+++ /dev/null
@@ -1,75 +0,0 @@
-# 部门工资前三高的所有员工
-
-Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
-
-+----+-------+--------+--------------+
-| Id | Name | Salary | DepartmentId |
-+----+-------+--------+--------------+
-| 1 | Joe | 85000 | 1 |
-| 2 | Henry | 80000 | 2 |
-| 3 | Sam | 60000 | 2 |
-| 4 | Max | 90000 | 1 |
-| 5 | Janet | 69000 | 1 |
-| 6 | Randy | 85000 | 1 |
-| 7 | Will | 70000 | 1 |
-+----+-------+--------+--------------+
-
-Department 表包含公司所有部门的信息。
-
-+----+----------+
-| Id | Name |
-+----+----------+
-| 1 | IT |
-| 2 | Sales |
-+----+----------+
-
-编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
-
-+------------+----------+--------+
-| Department | Employee | Salary |
-+------------+----------+--------+
-| IT | Max | 90000 |
-| IT | Randy | 85000 |
-| IT | Joe | 85000 |
-| IT | Will | 70000 |
-| Sales | Henry | 80000 |
-| Sales | Sam | 60000 |
-+------------+----------+--------+
-
-解释:
-
-IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/188.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/188.exercises/solution.md"
index 4fa430bdaf89e89a44ba1446b0bc85339b4c7cbe..8da01a9aaf6dc56f427852c5af130c95b14efabd 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/188.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/188.exercises/solution.md"
@@ -37,7 +37,28 @@
## template
```python
-
+class Solution:
+ def maxProfit(self, k, prices):
+ if not prices:
+ return 0
+ n = len(prices)
+ max_k = n // 2
+ if k >= max_k:
+ res = 0
+ for i in range(n - 1):
+ res += max(0, prices[i + 1] - prices[i])
+ return res
+ else:
+ max_k = k
+
+ dp = [[[0] * 2 for _ in range(k + 1)] for _ in range(n)]
+ for i in range(max_k + 1):
+ dp[0][i][1] = -prices[0]
+ for i in range(1, n):
+ for k in range(1, max_k + 1):
+ dp[i][k][0] = max(dp[i - 1][k][0], dp[i - 1][k][1] + prices[i])
+ dp[i][k][1] = max(dp[i - 1][k][1], dp[i - 1][k - 1][0] - prices[i])
+ return dp[n - 1][max_k][0]
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/212.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/212.exercises/solution.md"
index 4601f6b041f13f0d17423fc6e534ea7830068cde..0cf0d174d6f4b1833a191f02d67411ca58864569 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/212.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/212.exercises/solution.md"
@@ -39,7 +39,44 @@
## template
```python
-
+class Solution:
+ def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
+ if not board or not board[0] or not words:
+ return []
+ self.root = {}
+ for word in words:
+ node = self.root
+ for char in word:
+ if char not in node:
+ node[char] = {}
+ node = node[char]
+ node["#"] = word
+ res = []
+ for i in range(len(board)):
+ for j in range(len(board[0])):
+ tmp_state = []
+ self.dfs(i, j, board, tmp_state, self.root, res)
+ return res
+
+ def dfs(self, i, j, board, tmp_state, node, res):
+ if "#" in node and node["#"] not in res:
+ res.append(node["#"])
+ if [i, j] not in tmp_state and board[i][j] in node:
+ tmp = tmp_state + [[i, j]]
+ candidate = []
+ if i - 1 >= 0:
+ candidate.append([i - 1, j])
+ if i + 1 < len(board):
+ candidate.append([i + 1, j])
+ if j - 1 >= 0:
+ candidate.append([i, j - 1])
+ if j + 1 < len(board[0]):
+ candidate.append([i, j + 1])
+ node = node[board[i][j]]
+ if "#" in node and node["#"] not in res:
+ res.append(node["#"])
+ for item in candidate:
+ self.dfs(item[0], item[1], board, tmp, node, res)
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/214.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/214.exercises/solution.md"
index fef69756665713d0043c98b09213b75b10998169..75be6dbb62ed1f8f8a7728b9a19d610e4d1eb0a5 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/214.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/214.exercises/solution.md"
@@ -31,7 +31,16 @@
## template
```python
-
+class Solution:
+ def shortestPalindrome(self, s: str) -> str:
+ N = len(s)
+ idx1 = 0
+ for idx2 in range(N - 1, -1, -1):
+ if s[idx1] == s[idx2]:
+ idx1 += 1
+ if idx1 == N:
+ return s
+ return s[idx1:][::-1] + self.shortestPalindrome(s[:idx1]) + s[idx1:]
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/218.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/218.exercises/solution.md"
index 5deb694b8d7995009f8c520734742204e2b6f346..074f84bb12b4c871c2df4967292a9e3aa29e44a8 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/218.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/218.exercises/solution.md"
@@ -47,6 +47,58 @@
## template
```python
+import heapq
+class Solution:
+ def getSkyline(self, buildings: List[List[int]]) -> List[List[int]]:
+ right_heap = []
+ height_lst = []
+
+ ans = []
+
+ for building in buildings:
+ left, right, height = building
+
+ while right_heap and right_heap[0][0] < left:
+
+ old_highest = height_lst[-1]
+
+ last_right, last_height = heapq.heappop(right_heap)
+ height_lst.pop(bisect.bisect_left(height_lst, last_height))
+
+ new_highest = height_lst[-1] if height_lst else 0
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == last_right:
+ ans.pop()
+ ans.append([last_right, new_highest])
+
+ old_highest = height_lst[-1] if height_lst else 0
+
+ bisect.insort_left(height_lst, height)
+ heapq.heappush(right_heap, (right, height))
+
+ new_highest = height_lst[-1]
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == left:
+ ans.pop()
+ ans.append([left, new_highest])
+
+ while right_heap:
+
+ old_highest = height_lst[-1]
+
+ last_right, last_height = heapq.heappop(right_heap)
+ height_lst.pop(bisect.bisect_left(height_lst, last_height))
+
+ new_highest = height_lst[-1] if height_lst else 0
+
+ if new_highest != old_highest:
+ if ans and ans[-1][0] == last_right:
+ ans.pop()
+ ans.append([last_right, new_highest])
+
+ return ans
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/224.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/224.exercises/solution.md"
index c6d9e02579a3341404870902cbde0a52de1e2772..5ae4901d5206b18390bacc173f9ee5c76f005ccd 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/224.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/224.exercises/solution.md"
@@ -39,7 +39,33 @@
## template
```python
-
+class Solution:
+ def calculate(self, s: str) -> int:
+ s = s.replace(" ", "")
+ n = len(s)
+ sign = 1
+ stack = [sign]
+ i = sumS = 0
+ while i < n:
+ if s[i] == "(":
+ stack.append(sign)
+ i += 1
+ elif s[i] == ")":
+ stack.pop()
+ i += 1
+ elif s[i] == "+":
+ sign = stack[-1]
+ i += 1
+ elif s[i] == "-":
+ sign = -stack[-1]
+ i += 1
+ else:
+ num = 0
+ while i < n and s[i].isdigit():
+ num = num * 10 + int(s[i])
+ i += 1
+ sumS += sign * num
+ return sumS
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/233.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/233.exercises/solution.md"
index 12ace47572bdff278279d83501d64e6e47969b6b..026481410015b593c68c2b91c3eee6b2daedeaa9 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/233.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/233.exercises/solution.md"
@@ -30,7 +30,15 @@
## template
```python
-
+class Solution:
+ def countDigitOne(self, n: int) -> int:
+ res, i = 0, 1
+ while i <= n:
+ res += n // (i * 10) * i
+ x = (n // i) % 10
+ res += i if x > 1 else (n % i + 1) * x
+ i *= 10
+ return res
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/239.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/239.exercises/solution.md"
index 4b5a61ebe8753c3d1d27c5c0decb090a4ee3cac7..a2c1489aa5ef33867a5afe91c164e3dc62131d1b 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/239.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/239.exercises/solution.md"
@@ -63,7 +63,24 @@
## template
```python
-
+class Solution(object):
+ def maxSlidingWindow(self, nums, k):
+ """
+ :type nums: List[int]
+ :type k: int
+ :rtype: List[int]
+ """
+ if len(nums) == 0:
+ return []
+ if k == 1:
+ return nums
+
+ res = []
+ res.append(max(nums[:k]))
+ for i in range(1, len(nums) - k + 1):
+ m = max(nums[i : i + k])
+ res.append(m)
+ return res
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/config.json" "b/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/config.json"
deleted file mode 100644
index 0fdcbcb23e7f6dad07a2b7823adb178ba1bdcf6c..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-f22ef4a76d274cf3a86b0a39ca633ad3",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.json" "b/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.json"
deleted file mode 100644
index 7e0f96f6844a371f249823dabf9e3cf00ad26987..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "c9904f069c824f5faaffaf2fed29eb56",
- "author": "csdn.net",
- "keywords": "递归,数组,字符串"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.md"
deleted file mode 100644
index 6037f7be0064d78ab6fdd437e5577fc156c53840..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/248.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 中心对称数 III
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/config.json" "b/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/config.json"
deleted file mode 100644
index 4acebd14e594a95a0c91271747a613405e4aad11..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-c301e89460c74758ad4e74620f28f32d",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.json" "b/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.json"
deleted file mode 100644
index 0e10fa685b98f2d41964f73d5929661c1c50c6c5..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "629ae5169ce149db9bb2c40d4f8a293a",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.md"
deleted file mode 100644
index d479bdc9bafc14dd8272ab2379100bbcb4e99675..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/262.exercises/solution.md"
+++ /dev/null
@@ -1,146 +0,0 @@
-# 行程和用户
-
-表:Trips
-
-
-
-+-------------+----------+
-| Column Name | Type |
-+-------------+----------+
-| Id | int |
-| Client_Id | int |
-| Driver_Id | int |
-| City_Id | int |
-| Status | enum |
-| Request_at | date |
-+-------------+----------+
-Id 是这张表的主键。
-这张表中存所有出租车的行程信息。每段行程有唯一 Id ,其中 Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。
-Status 是一个表示行程状态的枚举类型,枚举成员为(‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’) 。
-
-
-
-
-
-
-
-+-------------+----------+
-| Column Name | Type |
-+-------------+----------+
-| Users_Id | int |
-| Banned | enum |
-| Role | enum |
-+-------------+----------+
-Users_Id 是这张表的主键。
-这张表中存所有用户,每个用户都有一个唯一的 Users_Id ,Role 是一个表示用户身份的枚举类型,枚举成员为 (‘client’, ‘driver’, ‘partner’) 。
-Banned 是一个表示用户是否被禁止的枚举类型,枚举成员为 (‘Yes’, ‘No’) 。
-
-
-
-
-
写一段 SQL 语句查出 "2013-10-01" 至 "2013-10-03" 期间非禁止用户(乘客和司机都必须未被禁止)的取消率。非禁止用户即 Banned 为 No 的用户,禁止用户即 Banned 为 Yes 的用户。
-
-
取消率 的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。
-
-
返回结果表中的数据可以按任意顺序组织。其中取消率 Cancellation Rate 需要四舍五入保留 两位小数 。
-
-
-
-
查询结果格式如下例所示:
-
-
-Trips 表:
-+----+-----------+-----------+---------+---------------------+------------+
-| Id | Client_Id | Driver_Id | City_Id | Status | Request_at |
-+----+-----------+-----------+---------+---------------------+------------+
-| 1 | 1 | 10 | 1 | completed | 2013-10-01 |
-| 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-01 |
-| 3 | 3 | 12 | 6 | completed | 2013-10-01 |
-| 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-01 |
-| 5 | 1 | 10 | 1 | completed | 2013-10-02 |
-| 6 | 2 | 11 | 6 | completed | 2013-10-02 |
-| 7 | 3 | 12 | 6 | completed | 2013-10-02 |
-| 8 | 2 | 12 | 12 | completed | 2013-10-03 |
-| 9 | 3 | 10 | 12 | completed | 2013-10-03 |
-| 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-03 |
-+----+-----------+-----------+---------+---------------------+------------+
-
-Users 表:
-+----------+--------+--------+
-| Users_Id | Banned | Role |
-+----------+--------+--------+
-| 1 | No | client |
-| 2 | Yes | client |
-| 3 | No | client |
-| 4 | No | client |
-| 10 | No | driver |
-| 11 | No | driver |
-| 12 | No | driver |
-| 13 | No | driver |
-+----------+--------+--------+
-
-Result 表:
-+------------+-------------------+
-| Day | Cancellation Rate |
-+------------+-------------------+
-| 2013-10-01 | 0.33 |
-| 2013-10-02 | 0.00 |
-| 2013-10-03 | 0.50 |
-+------------+-------------------+
-
-2013-10-01:
- - 共有 4 条请求,其中 2 条取消。
- - 然而,Id=2 的请求是由禁止用户(User_Id=2)发出的,所以计算时应当忽略它。
- - 因此,总共有 3 条非禁止请求参与计算,其中 1 条取消。
- - 取消率为 (1 / 3) = 0.33
-2013-10-02:
- - 共有 3 条请求,其中 0 条取消。
- - 然而,Id=6 的请求是由禁止用户发出的,所以计算时应当忽略它。
- - 因此,总共有 2 条非禁止请求参与计算,其中 0 条取消。
- - 取消率为 (0 / 2) = 0.00
-2013-10-03:
- - 共有 3 条请求,其中 1 条取消。
- - 然而,Id=8 的请求是由禁止用户发出的,所以计算时应当忽略它。
- - 因此,总共有 2 条非禁止请求参与计算,其中 1 条取消。
- - 取消率为 (1 / 2) = 0.50
-
-
-
3
```python
-
+class Solution:
+ def maxNumber(self, nums1: List[int], nums2: List[int], k: int) -> List[int]:
+ def pick_max(nums, k):
+ stack = []
+ drop = len(nums) - k
+ for num in nums:
+ while drop and stack and stack[-1] < num:
+ stack.pop()
+ drop -= 1
+ stack.append(num)
+ return stack[:k]
+
+ def merge(A, B):
+ lst = []
+ while A or B:
+ bigger = A if A > B else B
+ lst.append(bigger[0])
+ bigger.pop(0)
+ return lst
+
+ return max(
+ merge(pick_max(nums1, i), pick_max(nums2, k - i))
+ for i in range(k + 1)
+ if i <= len(nums1) and k - i <= len(nums2)
+ )
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/327.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/327.exercises/solution.md"
index 67e6efe1e7a0ddd3a1a5dfe89e0db01766d3f16e..bc77c49adee9c33a6a4199b5f93c6147af9d7e7e 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/327.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/327.exercises/solution.md"
@@ -36,6 +36,58 @@
```python
+class Solution:
+ def countRangeSum(self, nums: List[int], lower: int, upper: int) -> int:
+
+ prefix = [0]
+ last = 0
+ for num in nums:
+ last += num
+ prefix.append(last)
+
+ print(prefix)
+
+ def count(pp, left, right):
+
+ if left == right:
+ return 0
+ else:
+ mid = (left + right) // 2
+
+ ans = count(pp, left, mid) + count(pp, mid + 1, right)
+
+ i1, i2, i3 = left, mid + 1, mid + 1
+ while i1 <= mid:
+ while i2 <= right and pp[i2] - pp[i1] < lower:
+ i2 += 1
+ while i3 <= right and pp[i3] - pp[i1] <= upper:
+ i3 += 1
+ ans += i3 - i2
+ i1 += 1
+
+ result = []
+ i1, i2 = left, mid + 1
+ while i1 <= mid and i2 <= right:
+ if pp[i1] <= pp[i2]:
+ result.append(pp[i1])
+ i1 += 1
+ else:
+ result.append(pp[i2])
+ i2 += 1
+ while i1 <= mid:
+ result.append(pp[i1])
+ i1 += 1
+ while i2 <= right:
+ result.append(pp[i2])
+ i2 += 1
+
+ for i in range(len(result)):
+ pp[i + left] = result[i]
+
+ return ans
+
+ return count(prefix, 0, len(prefix) - 1)
+
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/329.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/329.exercises/solution.md"
index 3e5401a826c2803872cbec951d48affe7f33efd9..253823f3ddc22b2774456e67dec7cce6cc77b4e7 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/329.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/329.exercises/solution.md"
@@ -44,6 +44,38 @@
```python
+class Solution:
+ def longestIncreasingPath(self, matrix):
+ """
+ :type matrix: List[List[int]]
+ :rtype: int
+ """
+ a = len(matrix)
+ dic = {}
+ nums_max = 1
+ if a == 0:
+ nums_max = 0
+ else:
+ b = len(matrix[0])
+ for i in range(a):
+ for j in range(b):
+ dic[(i,j)] = matrix[i][j]
+ v = dic.keys()
+ nums1 = [[1 for i in range(b)] for j in range(a)]
+ dic = sorted(dic.items(),key = lambda x:x[1])
+ for k in dic:
+ i = k[0][0]
+ j = k[0][1]
+ if (i+1,j) in v and matrix[i+1][j] int:
+ count = 0
+ miss = 1
+ idx = 0
+ while miss <= n:
+ if idx < len(nums) and nums[idx] <= miss:
+ miss += nums[idx]
+ idx += 1
+ else:
+ count += 1
+ miss += miss
+ return count
+
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/335.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/335.exercises/solution.md"
index 0427224f5c0502d9127457a1eabd8d436f070c61..5aa71cb52679a5253d15658bed1f193048e98b13 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/335.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/335.exercises/solution.md"
@@ -42,7 +42,18 @@
```python
-
+class Solution:
+ def isSelfCrossing(self, x: List[int]) -> bool:
+ n = len(x)
+ if n < 3: return False
+ for i in range(3, n):
+ if x[i] >= x[i - 2] and x[i - 3] >= x[i - 1]:
+ return True
+ if i >= 4 and x[i - 3] == x[i - 1] and x[i] + x[i - 4] >= x[i - 2]:
+ return True
+ if i >= 5 and x[i - 3] >= x[i - 1] and x[i - 2] >= x[i - 4] and x[i - 1] + x[i - 5] >= x[i - 3] and x[i] + x[i - 4] >= x[i - 2]:
+ return True
+ return False
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/336.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/336.exercises/solution.md"
index 826ff178c407c2f3dfa4c92011a11163736ac93a..6ccc05b73c69d8ea7b28a60aede910a9d7b88368 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/336.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/336.exercises/solution.md"
@@ -39,7 +39,53 @@
## template
```python
+class Solution:
+ def palindromePairs(self, words: List[str]) -> List[List[int]]:
+ def is_palindrome(str, start, end):
+ """检查子串是否是回文串
+ """
+ part_word = str[start : end + 1]
+ return part_word == part_word[::-1]
+ def find_reversed_word(str, start, end):
+ """查找子串是否在哈希表中
+ Return:
+ 不在哈希表中,返回 -1
+ 否则返回对应的索引
+ """
+ part_word = str[start : end + 1]
+ ret = hash_map.get(part_word, -1)
+ return ret
+
+ hash_map = {}
+ for i in range(len(words)):
+ word = words[i][::-1]
+ hash_map[word] = i
+
+ res = []
+
+ for i in range(len(words)):
+ word = words[i]
+ word_len = len(word)
+
+ if is_palindrome(word, 0, word_len - 1) and "" in hash_map and word != "":
+ res.append([hash_map.get(""), i])
+ for j in range(word_len):
+
+ if is_palindrome(word, j, word_len - 1):
+
+ left_part_index = find_reversed_word(word, 0, j - 1)
+
+ if left_part_index != -1 and left_part_index != i:
+ res.append([i, left_part_index])
+
+ if is_palindrome(word, 0, j - 1):
+
+ right_part_index = find_reversed_word(word, j, word_len - 1)
+ if right_part_index != -1 and right_part_index != i:
+ res.append([right_part_index, i])
+
+ return res
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/352.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/352.exercises/solution.md"
index 3b0596441d3850537a5615366591b6c3804c4bd1..b837742367182b83bf802027151ea5b80b1839dc 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/352.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/352.exercises/solution.md"
@@ -57,6 +57,62 @@ summaryRanges.getIntervals(); // 返回 [[1, 3], [6, 7]]
```python
+class SummaryRanges:
+ def __init__(self):
+ self.rec = set()
+
+ self.s = list()
+
+ def binarySearch_l(self, x: int):
+ s = self.s
+ l, r = 0, len(s) - 1
+ while l < r:
+ mid = l + r >> 1
+ if s[mid][0] >= x:
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+ def binarySearch(self, x: int):
+ s = self.s
+ l, r = 0, len(s) - 1
+ while l < r:
+ mid = l + r >> 1
+ if s[mid][1] >= x:
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+ def addNum(self, val: int) -> None:
+ rec, s = self.rec, self.s
+ if val in rec:
+ return
+ else:
+
+ if val - 1 not in rec and val + 1 not in rec:
+
+ s.append([val, val])
+ s.sort()
+ elif val - 1 in rec and val + 1 not in rec:
+
+ p = self.binarySearch(val - 1)
+ s[p][1] = val
+ elif val - 1 not in rec and val + 1 in rec:
+
+ p = self.binarySearch_l(val + 1)
+ s[p][0] = val
+ else:
+
+ p = self.binarySearch(val)
+ s[p - 1][1] = s[p][1]
+
+ s.pop(p)
+ rec.add(val)
+
+ def getIntervals(self) -> List[List[int]]:
+ return self.s
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/354.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/354.exercises/solution.md"
index 528b85311cd3ee6640fd5b5dff236cea99a38ebd..ecef139efd390d8cdae036f2ebbb1b3130850a44 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/354.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/354.exercises/solution.md"
@@ -37,6 +37,23 @@
## template
```python
+class Solution:
+ def maxEnvelopes(self, envelopes) -> int:
+ """
+ :param envelopes: List[List[int]]
+ :return: int
+ """
+ n = len(envelopes)
+ if not n:
+ return 0
+ envelopes.sort(key=lambda x: (x[0], -x[1]))
+
+ dp = [1] * n
+ for i in range(n):
+ for j in range(i):
+ if envelopes[j][1] < envelopes[i][1]:
+ dp[i] = max(dp[i], dp[j] + 1)
+ return max(dp)
```
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/config.json" "b/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/config.json"
deleted file mode 100644
index 336a544ed551cd5ab1adbe93eb8b7888a147974f..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-2f8fb484114145efbad81e79d007df7a",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.json" "b/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.json"
deleted file mode 100644
index f6b9d599aafe54bce92d02706277e3b0040af410..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "654f10c386dc4009afdc26dd35f18258",
- "author": "csdn.net",
- "keywords": "贪心,哈希表,字符串,计数,排序,堆(优先队列)"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.md"
deleted file mode 100644
index 7509c3dbcce08356173688d29f785ea82a82ef09..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\345\233\260\351\232\276/python/358.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# K 距离间隔重排字符串
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/363.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/363.exercises/solution.md"
index 9fc6eb37b90c7780b935f2e12956138edc53ff6f..b774ec014c1bc68c2c724e50de416a7703e5e0e4 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/363.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/363.exercises/solution.md"
@@ -41,8 +41,33 @@
## template
```python
-
-
+import bisect
+
+class Solution:
+ def maxSumSubmatrix(self, matrix: List[List[int]], k: int) -> int:
+ m = len(matrix)
+ Row, Col = len(matrix), len(matrix[0])
+ res = float("-inf")
+ for ru in range(Row):
+ col_sum = [0 for _ in range(Col)]
+ for rd in range(ru, Row):
+ for c in range(Col):
+ if matrix[rd][c] == k:
+ return k
+ col_sum[c] += matrix[rd][c]
+
+ presum = [0]
+ cur_sum = 0
+ for colsum in col_sum:
+ cur_sum += colsum
+ idx = bisect.bisect_left(presum, cur_sum - k)
+ if idx < len(presum):
+ res = max(res, cur_sum - presum[idx])
+ if res == k:
+ return k
+ bisect.insort(presum, cur_sum)
+
+ return res
```
## 答案
diff --git "a/data_source/exercises/\345\233\260\351\232\276/python/381.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/python/381.exercises/solution.md"
index d9b417d23ae1e6158ee393d569ab3e0e86a9e608..4cdc74603f870ac88075b296afb9fe8ad2cde107 100644
--- "a/data_source/exercises/\345\233\260\351\232\276/python/381.exercises/solution.md"
+++ "b/data_source/exercises/\345\233\260\351\232\276/python/381.exercises/solution.md"
@@ -38,6 +38,43 @@ collection.getRandom();
## template
```python
+class RandomizedSet:
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.dict = {}
+ self.list = []
+
+ def insert(self, val: int) -> bool:
+ """
+ Inserts a value to the set. Returns true if the set did not already contain the specified element.
+ """
+ if val in self.dict:
+ return False
+ self.dict[val] = len(self.list)
+ self.list.append(val)
+ return True
+
+ def remove(self, val: int) -> bool:
+ """
+ Removes a value from the set. Returns true if the set contained the specified element.
+ """
+ if val in self.dict:
+
+ last_element, idx = self.list[-1], self.dict[val]
+ self.list[idx], self.dict[last_element] = last_element, idx
+
+ self.list.pop()
+ del self.dict[val]
+ return True
+ return False
+
+ def getRandom(self) -> int:
+ """
+ Get a random element from the set.
+ """
+ return choice(self.list)
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/101.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/101.exercises/solution.md"
index f173fc9ec898a9463b0a2795045df20d0c1fcd0c..b5eb75011acacd630783785a66d9121c04a2ef10 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/101.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/101.exercises/solution.md"
@@ -34,8 +34,25 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+
+ def isSymmetric(self, root: TreeNode) -> bool:
+ def judge(left, right):
+ if not left and not right:
+ return True
+ elif not left or not right:
+ return False
+ else:
+ return left.val == right.val and judge(left.right, right.left) and judge(left.left, right.right)
+
+ return judge(root, root)
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/104.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/104.exercises/solution.md"
index 8f509fdeabbf45fcb1eb52f89b4948bef7755b32..85f30f1655ac3cc6e29b3b5e934fde1f9d644fa6 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/104.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/104.exercises/solution.md"
@@ -21,7 +21,18 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution:
+ def maxDepth(self, root: TreeNode) -> int:
+ if root is None:
+ return 0
+ maxdepth = max(self.maxDepth(root.left),self.maxDepth(root.right)) + 1
+ return maxdepth
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/108.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/108.exercises/solution.md"
index 99f66846e0db17e95e21adbd5e4dac505fa93ff6..ebc0d0fddcd8d2fdbb4b0d75a665b8a825af860f 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/108.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/108.exercises/solution.md"
@@ -37,8 +37,29 @@
## template
```python
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+class Solution:
+ def sortedArrayToBST(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: TreeNode
+ """
+ if not nums:
+ return None
+
+ mid = len(nums) // 2
+
+ root = TreeNode(nums[mid])
+
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/110.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/110.exercises/solution.md"
index 5319fda0c4a7233c37604fbc855e01dcc74236f2..eb6a3c25b8d9c152edefd1e464879622062ea89c 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/110.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/110.exercises/solution.md"
@@ -44,7 +44,31 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution(object):
+ def isBalanced(self, root):
+ if not root:
+ return True
+ left_depth = self.get_depth(root.left)
+ right_depth = self.get_depth(root.right)
+ if abs(left_depth - right_depth) > 1:
+ return False
+
+ else:
+ return self.isBalanced(root.left) and self.isBalanced(root.right)
+
+ def get_depth(self, root):
+
+ if root is None:
+ return 0
+ else:
+ return max(self.get_depth(root.left), self.get_depth(root.right)) + 1
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/111.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/111.exercises/solution.md"
index 6ec2e5eeb79ade15c48dbaccd967137e58dc0264..abe62efd905968e7bf4e5cd1fe186638be7eefab 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/111.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/111.exercises/solution.md"
@@ -35,7 +35,33 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def minDepth(self, root: TreeNode) -> int:
+ if not root:
+ return 0
+ queue = [root]
+ count = 1
+ while queue:
+
+ next_queue = []
+ for node in queue:
+ if not node.left and not node.right:
+ return count
+ if node.left:
+ next_queue.append(node.left)
+ if node.right:
+ next_queue.append(node.right)
+ queue = next_queue
+ count += 1
+
+ return count
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/112.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/112.exercises/solution.md"
index 0e0f1b2002ba0515f180db86833324279abdcd6e..5c554b851767e7af97a94af4dfa9ce0f6281a782 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/112.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/112.exercises/solution.md"
@@ -41,8 +41,25 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def hasPathSum(self, root, sum):
+ """
+ :type root: TreeNode
+ :type sum: int
+ :rtype: bool
+ """
+ if root is None:
+ return False
+ if sum == root.val and root.left is None and root.right is None:
+ return True
+ return self.hasPathSum(root.left, sum-root.val) or self.hasPathSum(root.right, sum-root.val)
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/118.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/118.exercises/solution.md"
index 58e27d00e66e101caab899c824a1b689ebf6dc6d..992b73bcd53eb8f071b0e7a6ef1f23ed50648f8b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/118.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/118.exercises/solution.md"
@@ -34,7 +34,22 @@
## template
```python
-
+class Solution:
+ def generate(self, numRows: int) -> List[List[int]]:
+ if numRows == 0:
+ return []
+ if numRows == 1:
+ return [[1]]
+ if numRows == 2:
+ return [[1], [1, 1]]
+ result = [[1], [1, 1]] + [[] for i in range(numRows - 2)]
+ for i in range(2, numRows):
+ for j in range(i + 1):
+ if j == 0 or j == i:
+ result[i].append(1)
+ else:
+ result[i].append(result[i - 1][j - 1] + result[i - 1][j])
+ return result
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/119.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/119.exercises/solution.md"
index 49dcfc1f1d8f5957d07d983abc0bef15d910452b..40e04550d90fe53df1ad9b38062a8c75ce43867b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/119.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/119.exercises/solution.md"
@@ -48,7 +48,21 @@
```python
-
+class Solution(object):
+ def getRow(self, rowIndex):
+ """
+ :type rowIndex: int
+ :rtype: List[int]
+ """
+ if rowIndex == 0:
+ return [1]
+
+ pas = [1]
+ for i in range(rowIndex):
+
+ newLine = list(map(lambda x, y: x + y, [0] + pas, pas + [0]))
+ pas = newLine
+ return pas
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/121.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/121.exercises/solution.md"
index 0f513b1cd3a27193036336bf06995e8f9201718f..78c8a12a60dc775366949b569235d9ec5286425b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/121.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/121.exercises/solution.md"
@@ -39,7 +39,21 @@
```python
-
+class Solution(object):
+ def maxProfit(self, prices):
+ """
+ :type prices: List[int]
+ :rtype: int
+ """
+ temp = []
+ if not prices or len(prices) == 1:
+ return 0
+ for i in range(len(prices) - 1):
+ temp.append(max(prices[i + 1 :]) - prices[i])
+ if max(temp) >= 0:
+ return max(temp)
+ else:
+ return 0
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/122.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/122.exercises/solution.md"
index 0081fdd71db00a3f70dc02a32522360bd2a35069..afe4c557c3bc40c8e8ab563c4f284b352348c23a 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/122.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/122.exercises/solution.md"
@@ -46,6 +46,47 @@
## template
```python
+class Solution(object):
+ def maxProfit(self, prices):
+ """
+ :type prices: List[int]
+ :rtype: int
+ """
+
+ hold = 0
+ pric = []
+ temp = []
+ flag = 0
+ msum = 0
+ if len(prices) <= 2:
+ if not prices:
+ return 0
+ if len(prices) == 1:
+ return 0
+ if prices[0] > prices[1]:
+ return 0
+ if prices[0] < prices[1]:
+ return prices[1] - prices[0]
+
+ for i in range(len(prices) - 1):
+ if prices[i + 1] > prices[i] and hold != 1:
+ hold = 1
+ flag = i
+ continue
+
+ if prices[i + 1] < prices[i] and hold == 1:
+ pric.append(prices[flag])
+ pric.append(prices[i])
+ hold = 0
+ else:
+ continue
+ for i in range(0, len(pric), 2):
+ temp.append(pric[i + 1] - pric[i])
+ msum = sum(temp)
+ if hold == 1:
+ msum = msum + prices[-1] - prices[flag]
+
+ return msum
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/125.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/125.exercises/solution.md"
index 5ee8ae7c262e9ca72e1d19678415efbb40798036..b421624488bbfef8b288f76bfc0e7c1937c840ee 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/125.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/125.exercises/solution.md"
@@ -35,8 +35,27 @@
## template
```python
-
-
+class Solution(object):
+ def isPalindrome(self, s):
+ """
+ :type s: str
+ :rtype: bool
+ """
+ i = 0
+ j = len(s) - 1
+ while i < j:
+ if s[i].isalnum() and s[j].isalnum():
+ if s[i].upper() == s[j].upper():
+ i += 1
+ j -= 1
+ else:
+ return False
+ else:
+ if not s[i].isalnum():
+ i += 1
+ if not s[j].isalnum():
+ j -= 1
+ return True
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/136.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/136.exercises/solution.md"
index fcde33e3f34a58673c5fdf5acc70e1bdfb514fc4..85a675d2f17b2611ccf957f71999f86e657c92ae 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/136.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/136.exercises/solution.md"
@@ -21,7 +21,16 @@
## template
```python
-
+class Solution:
+ def singleNumber(self, nums: List[int]) -> int:
+ nums = sorted(nums)
+ i = 0
+ while i < len(nums) - 1:
+ if nums[i] == nums[i + 1]:
+ i += 2
+ else:
+ return nums[i]
+ return nums[i]
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/141.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/141.exercises/solution.md"
index d3174d42fe04d19ff12ac90c5c729aab4ec419bd..1f1b4ca44ecaca22a87d1f4f77c4480704d56dcf 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/141.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/141.exercises/solution.md"
@@ -56,7 +56,24 @@
```python
-
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not (head and head.next):
+ return False
+ slow = head
+ fast = head.next
+ while fast.next and fast.next.next:
+ if slow == fast:
+ return True
+ slow = slow.next
+ fast = fast.next.next
+ return False
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/144.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/144.exercises/solution.md"
index c21587f0cf6d51b9dae3e441e5a368292fb6c6bd..36065b16b0f1df74889097b9644af3ba1c91fd2b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/144.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/144.exercises/solution.md"
@@ -56,7 +56,24 @@
## template
```python
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+
+class Solution:
+ def __init__(self):
+ self.ans = []
+
+ def preorderTraversal(self, root: TreeNode) -> List[int]:
+ if not root:
+ return []
+ self.ans.append(root.val)
+ self.preorderTraversal(root.left)
+ self.preorderTraversal(root.right)
+ return self.ans
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/145.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/145.exercises/solution.md"
index 1e8eaec4ff7ceffb63d91240abacd38ec45bb22c..fb0bfb4c721248aea147e47a9d2381389f662d1e 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/145.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/145.exercises/solution.md"
@@ -19,8 +19,30 @@
## template
```python
-
-
+class TreeNode:
+ def __init__(self, x):
+ self.val = x
+ self.left = None
+ self.right = None
+
+class Solution(object):
+ def postorderTraversal(self, root: TreeNode):
+
+ if root is None:
+ return []
+
+ stack, output = [], []
+ stack.append(root)
+ while stack:
+ node = stack.pop()
+ output.append(node.val)
+
+ if node.left:
+ stack.append(node.left)
+ if node.right:
+ stack.append(node.right)
+
+ return output[::-1]
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/155.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/155.exercises/solution.md"
index 983a1e08eb9f65c8a3d22bf2408ad6ab151cdb66..113654d6354d3f34968d317c15e83bcb47fc5f38 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/155.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/155.exercises/solution.md"
@@ -43,7 +43,30 @@ minStack.getMin(); --> 返回 -2.
## template
```python
+class MinStack:
+ def __init__(self):
+ self.data = [(None, float("inf"))]
+ def push(self, x: "int") -> "None":
+ self.data.append((x, min(x, self.data[-1][1])))
+
+ def pop(self) -> "None":
+ if len(self.data) > 1:
+ self.data.pop()
+
+ def top(self) -> "int":
+ return self.data[-1][0]
+
+ def getMin(self) -> "int":
+ return self.data[-1][1]
+
+
+# Your MinStack object will be instantiated and called as such:
+# obj = MinStack()
+# obj.push(x)
+# obj.pop()
+# param_3 = obj.top()
+# param_4 = obj.getMin()
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/config.json"
deleted file mode 100644
index eba729c4478368c7fa6a68dcae0435975421666a..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-6aa93f8d83754e9b9d523b1e54677f65",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.json"
deleted file mode 100644
index dfb568d636220da2a94b877dd59eb359d4ae2c29..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "071ef10ee9f3444d94761ed4b557406b",
- "author": "csdn.net",
- "keywords": "字符串,交互,模拟"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.md"
deleted file mode 100644
index 629f584f0be0fe7c6f1c24a9ccb0ea8cedfd986c..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/157.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 用 Read4 读取 N 个字符
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/160.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/160.exercises/solution.md"
index be26ba5600aabb37b39abe3bcca561f1193d3393..09478dd854ff44ad18c0a8cdfd358e67fe61a18b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/160.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/160.exercises/solution.md"
@@ -71,7 +71,43 @@
## template
```python
-
+class ListNode:
+ def __init__(self, x):
+ self.val = x
+ self.next = None
+
+
+class Solution:
+ def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
+ if not headA or not headB:
+ return None
+ wei_A = []
+ while headA:
+ wei_A.append(headA)
+ headA = headA.next
+ wei_A = wei_A[::-1]
+ wei_B = []
+ while headB:
+ wei_B.append(headB)
+ headB = headB.next
+ wei_B = wei_B[::-1]
+ count = -1
+ lA = len(wei_A)
+ lB = len(wei_B)
+ if lA < lB:
+ copy = wei_B
+ wei_B = wei_A
+ wei_A = copy
+ lA, lB = lB, lA
+ for i in range(lB):
+ if wei_A[i] == wei_B[i]:
+ count += 1
+ else:
+ break
+ if count != -1:
+ return wei_A[count]
+ else:
+ return None
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/config.json"
deleted file mode 100644
index f3cbbfe04027ea69de66e6b2d2d824531819264b..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-63abe2ccbafd4d149f19a94cc2aed708",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.md"
deleted file mode 100644
index d322e60c237518d2cedeec8ca8c2a94740364c23..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/163.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 缺失的区间
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/167.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/167.exercises/solution.md"
index 9dd5fb1eae3b338e6a149aefff606f7996fa9770..d564077199999efbc497d44c1e37ba0bff43ea4a 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/167.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/167.exercises/solution.md"
@@ -46,7 +46,23 @@
```python
-
+class Solution(object):
+ def twoSum(self, numbers, target):
+ """
+ :type numbers: List[int]
+ :type target: int
+ :rtype: List[int]
+ """
+ d = {}
+ size = 0
+ while size < len(numbers):
+ if not numbers[size] in d:
+ d[numbers[size]] = size + 1
+ if target - numbers[size] in d:
+ if d[target - numbers[size]] < size + 1:
+ answer = [d[target - numbers[size]], size + 1]
+ return answer
+ size = size + 1
```
## 答案
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/168.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/168.exercises/solution.md"
index 381ea71b6c252f6652231e340b8ea39edd8ea11e..d8a01882abbecae367ef8f0090e5c42bd10fec6d 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/168.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/168.exercises/solution.md"
@@ -57,7 +57,30 @@ AB -> 28
## template
```python
-
+class Solution(object):
+ def convertToTitle(self, n):
+ """
+ :type n: int
+ :rtype: str
+ """
+ d = {}
+ r = []
+ a = ""
+ for i in range(1, 27):
+ d[i] = chr(64 + i)
+ if n <= 26:
+ return d[n]
+ if n % 26 == 0:
+ n = n / 26 - 1
+ a = "Z"
+ while n > 26:
+ s = n % 26
+ n = n // 26
+ r.append(s)
+ result = d[n]
+ for i in r[::-1]:
+ result += d[i]
+ return result + a
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/169.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/169.exercises/solution.md"
index 6dae713f64d380e32000a313127b6c9fe32175c9..4508a17000f89ba6fbe2544da23619b84f131a7b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/169.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/169.exercises/solution.md"
@@ -31,6 +31,19 @@
## template
```python
+class Solution:
+ def majorityElement(self, nums: List[int]) -> int:
+ count, candi = 0, 0
+ for i in nums:
+ if i == candi:
+ count += 1
+ else:
+ if count == 0:
+ candi = i
+ count = 1
+ else:
+ count -= 1
+ return candi
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/config.json"
deleted file mode 100644
index 5dcfb85d339a5aa5f66cf488239a2d0a203b6e52..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-df441d9a8d174eefa9b4f7376aa2f108",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.json"
deleted file mode 100644
index b3f9884cc584befa72ad3e547f97462bae4146f8..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "a4e155e73cdd431a9c951807db7b0b66",
- "author": "csdn.net",
- "keywords": "设计,数组,哈希表,双指针,数据流"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.md"
deleted file mode 100644
index 9220aaeba95fa9e4f8fcdde10ee342fbeb164b6a..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/170.exercises/solution.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# 两数之和 III
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/171.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/171.exercises/solution.md"
index f0fd20dfce3b9c724cc2ee4d02d1d96b0cee37eb..d5e312a4a2ea6866dffec0a227f4455f3ad36058 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/171.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/171.exercises/solution.md"
@@ -60,6 +60,13 @@
## template
```python
+class Solution:
+ def titleToNumber(self, s: str) -> int:
+ ans = 0
+ for i in range(len(s)):
+ n = ord(s[i]) - ord("A") + 1
+ ans = ans * 26 + n
+ return ans
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/172.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/172.exercises/solution.md"
index ffc9158a999257d963c80c2eb3d474f4116605b8..e78341fe270fde1e937a9917f12740ddc912d8f7 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/172.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/172.exercises/solution.md"
@@ -45,7 +45,14 @@
## template
```python
-
+class Solution:
+ def trailingZeroes(self, n: int) -> int:
+ zero_count = 0
+ current_multiple = 5
+ while n >= current_multiple:
+ zero_count += n // current_multiple
+ current_multiple *= 5
+ return zero_count
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/config.json"
deleted file mode 100644
index ff24da90a396ca0f60ef7c321c6521e91f491f28..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-eadc2a1070764217a2ad25adb1035a46",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.json"
deleted file mode 100644
index c5ccd728d211c1fb47a195d1107a6e7dfa5f14c0..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "7b89342d3c2a42d18340f4ce72f50744",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.md"
deleted file mode 100644
index 0ac4c21b4a69295a2d11e24a855a922754286063..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/175.exercises/solution.md"
+++ /dev/null
@@ -1,69 +0,0 @@
-# 组合两个表
-
-表1: Person
-
-+-------------+---------+
-| 列名 | 类型 |
-+-------------+---------+
-| PersonId | int |
-| FirstName | varchar |
-| LastName | varchar |
-+-------------+---------+
-PersonId 是上表主键
-
-
-表2: Address
-
-+-------------+---------+
-| 列名 | 类型 |
-+-------------+---------+
-| AddressId | int |
-| PersonId | int |
-| City | varchar |
-| State | varchar |
-+-------------+---------+
-AddressId 是上表主键
-
-
-
-
-编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
-
-
-
-FirstName, LastName, City, State
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/config.json"
deleted file mode 100644
index af2dbb0d167fded81db6953acc523baea99ce24a..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-d3c479c2622c447687e3fb7e15de1ea4",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.json"
deleted file mode 100644
index f34f2fdb51604e54c46d5a5f584123c55e112e51..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "57eda2ec9e414abe985bfab8206388ff",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.md"
deleted file mode 100644
index 75d2f2ef073181318b2a8fae9a7256788a239b55..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/176.exercises/solution.md"
+++ /dev/null
@@ -1,55 +0,0 @@
-# 第二高的薪水
-
-编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
-
-+----+--------+
-| Id | Salary |
-+----+--------+
-| 1 | 100 |
-| 2 | 200 |
-| 3 | 300 |
-+----+--------+
-
-
-例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
-
-+---------------------+
-| SecondHighestSalary |
-+---------------------+
-| 200 |
-+---------------------+
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/config.json"
deleted file mode 100644
index 2963041b473fcd29ce4d4fbdc9424d7d1180bb9e..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-8df5d16990f1484597a1e6052c2eb5c1",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.json"
deleted file mode 100644
index 7c9aaedfbcaa56e705791558ef373290e68646ee..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "1a6eaa6d11b14d6890597700888efd43",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.md"
deleted file mode 100644
index 3357daf4d660072a67065feac59749bcce04c66f..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/181.exercises/solution.md"
+++ /dev/null
@@ -1,56 +0,0 @@
-# 超过经理收入的员工
-
-Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
-
-+----+-------+--------+-----------+
-| Id | Name | Salary | ManagerId |
-+----+-------+--------+-----------+
-| 1 | Joe | 70000 | 3 |
-| 2 | Henry | 80000 | 4 |
-| 3 | Sam | 60000 | NULL |
-| 4 | Max | 90000 | NULL |
-+----+-------+--------+-----------+
-
-
-给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
-
-+----------+
-| Employee |
-+----------+
-| Joe |
-+----------+
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/config.json"
deleted file mode 100644
index 4858e6c4538b8cd764dc96f40560be3132252383..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-d13ab8edfde04e129b31e4efb3052cd2",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.json"
deleted file mode 100644
index b55f1e7bc50e723d83e8d94944a1f81aeaa377ec..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "0535dc76a70c49b78cfaebd47b24d8c5",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.md"
deleted file mode 100644
index aed765db64ad1664134cec4adc3b5d1718d30c47..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/182.exercises/solution.md"
+++ /dev/null
@@ -1,59 +0,0 @@
-# 查找重复的电子邮箱
-
-编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
-
-示例:
-
-+----+---------+
-| Id | Email |
-+----+---------+
-| 1 | a@b.com |
-| 2 | c@d.com |
-| 3 | a@b.com |
-+----+---------+
-
-
-根据以上输入,你的查询应返回以下结果:
-
-+---------+
-| Email |
-+---------+
-| a@b.com |
-+---------+
-
-
-说明:所有电子邮箱都是小写字母。
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/config.json"
deleted file mode 100644
index 54e05f5195d522f136704771c7533424cc1c479e..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-cc84e6279dfd4f20b078317c168abf4f",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.json"
deleted file mode 100644
index 96e9b586c64ef8600b0c760a59844fd8dc4d5641..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "247cd415345b4389829d3232cedd7f59",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.md"
deleted file mode 100644
index 21833fab8f4a69a7d16252af8930860da5f441bd..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/183.exercises/solution.md"
+++ /dev/null
@@ -1,69 +0,0 @@
-# 从不订购的客户
-
-某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
-
-Customers 表:
-
-+----+-------+
-| Id | Name |
-+----+-------+
-| 1 | Joe |
-| 2 | Henry |
-| 3 | Sam |
-| 4 | Max |
-+----+-------+
-
-
-Orders 表:
-
-+----+------------+
-| Id | CustomerId |
-+----+------------+
-| 1 | 3 |
-| 2 | 1 |
-+----+------------+
-
-
-例如给定上述表格,你的查询应返回:
-
-+-----------+
-| Customers |
-+-----------+
-| Henry |
-| Max |
-+-----------+
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/190.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/190.exercises/solution.md"
index d2bdb2f9aa7f2db3e3341e5bb31620839303d791..bdda53441f0ed1a745799525e31fb06af6aa5f69 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/190.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/190.exercises/solution.md"
@@ -43,7 +43,15 @@
## template
```python
-
+class Solution:
+ def reverseBits(self, n: int) -> int:
+ j = 0
+ y = bin(n)[2::]
+ if len(y) != 32:
+ j = 32 - len(y)
+ m = y[::-1]
+ m = m + "0" * j
+ return int(m, 2)
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/191.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/191.exercises/solution.md"
index d035d863b17b1e847f027737c3253c80efccfd59..60507a63507287594633025a82614d325d04a99b 100644
--- "a/data_source/exercises/\347\256\200\345\215\225/python/191.exercises/solution.md"
+++ "b/data_source/exercises/\347\256\200\345\215\225/python/191.exercises/solution.md"
@@ -59,7 +59,24 @@
## template
```python
-
+class Solution(object):
+ def majorityElement(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: int
+ """
+ n = len(nums)
+ if n == 1:
+ return nums[0]
+
+ dic = {}
+ for num in nums:
+ if num in dic.keys():
+ dic[num] += 1
+ if dic[num] > n / 2:
+ return num
+ else:
+ dic[num] = 1
```
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/config.json"
deleted file mode 100644
index 9b6790c33f7ecf1d9367b9d1cd28a33c667ce73c..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-c9d7f91ab5a145a7baeceffb4427d69b",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.json"
deleted file mode 100644
index d399e692472a775c0f0574e2d8c7828240d68e3f..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "c9c96094632643beb815c338f65b9420",
- "author": "csdn.net",
- "keywords": "shell"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.md"
deleted file mode 100644
index 52bcc630058ea8adc91057ec05d32a603bb9d615..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/193.exercises/solution.md"
+++ /dev/null
@@ -1,60 +0,0 @@
-# 有效电话号码
-
-给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个单行 bash 脚本输出所有有效的电话号码。
-
-你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
-
-你也可以假设每行前后没有多余的空格字符。
-
-
-
-示例:
-
-假设 file.txt 内容如下:
-
-
-987-123-4567
-123 456 7890
-(123) 456-7890
-
-
-你的脚本应当输出下列有效的电话号码:
-
-
-987-123-4567
-(123) 456-7890
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/config.json"
deleted file mode 100644
index 81d5f6f232f3fcb7b83b2a226be3c4ce7b63365e..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-397b53d653ae4c209d619135604a0678",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.json"
deleted file mode 100644
index 591444b98708844a79d598efb8ef1ea16b8c20d4..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "f9cdb75bc4ad406cb8a4570ced428651",
- "author": "csdn.net",
- "keywords": "shell"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.md"
deleted file mode 100644
index 7a879473084cf53290ef898d85616a5c1a00feba..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/195.exercises/solution.md"
+++ /dev/null
@@ -1,62 +0,0 @@
-# 第十行
-
-给定一个文本文件 file.txt,请只打印这个文件中的第十行。
-
-示例:
-
-假设 file.txt 有如下内容:
-
-Line 1
-Line 2
-Line 3
-Line 4
-Line 5
-Line 6
-Line 7
-Line 8
-Line 9
-Line 10
-
-
-你的脚本应当显示第十行:
-
-Line 10
-
-
-说明:
-1. 如果文件少于十行,你应当输出什么?
-2. 至少有三种不同的解法,请尝试尽可能多的方法来解题。
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/config.json"
deleted file mode 100644
index d11d261f7e286f96b6488ec8512aa351de2020ce..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-0f9800f6e82849758bc24e394fc25810",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.json"
deleted file mode 100644
index f4637f74a5b5715ccbed27d129ce50484541ae37..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "8df35c71b43d4fa296464edbfdcb47ed",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.md"
deleted file mode 100644
index 1749b851a80823c76c2852e64dcee65dd2f9dfb4..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/196.exercises/solution.md"
+++ /dev/null
@@ -1,66 +0,0 @@
-# 删除重复的电子邮箱
-
-编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
-
-+----+------------------+
-| Id | Email |
-+----+------------------+
-| 1 | john@example.com |
-| 2 | bob@example.com |
-| 3 | john@example.com |
-+----+------------------+
-Id 是这个表的主键。
-
-
-例如,在运行你的查询语句之后,上面的 Person 表应返回以下几行:
-
-+----+------------------+
-| Id | Email |
-+----+------------------+
-| 1 | john@example.com |
-| 2 | bob@example.com |
-+----+------------------+
-
-
-
-
-提示:
-
-
- - 执行 SQL 之后,输出是整个
Person 表。
- - 使用
delete 语句。
-
-
-
-## template
-
-```python
-
-
-```
-
-## 答案
-
-```python
-
-```
-
-## 选项
-
-### A
-
-```python
-
-```
-
-### B
-
-```python
-
-```
-
-### C
-
-```python
-
-```
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/config.json" "b/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/config.json"
deleted file mode 100644
index d995a201360152e60d9abd6efc906304fb986e92..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/config.json"
+++ /dev/null
@@ -1,10 +0,0 @@
-{
- "node_id": "dailycode-0229acddf7c347489af3e22ed1792c26",
- "keywords": [],
- "children": [],
- "keywords_must": [],
- "keywords_forbid": [],
- "export": [
- "solution.json"
- ]
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.json" "b/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.json"
deleted file mode 100644
index 524a43952a9822a29d237a5e2dafc4f9eb09307e..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.json"
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "type": "code_options",
- "source": "solution.md",
- "exercise_id": "bff0c0adad734cfa82ca1b207df54264",
- "author": "csdn.net",
- "keywords": "数据库"
-}
\ No newline at end of file
diff --git "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.md" "b/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.md"
deleted file mode 100644
index 0bc30c4a880dcc05ef0b6615ac9b87132ded3020..0000000000000000000000000000000000000000
--- "a/data_source/exercises/\347\256\200\345\215\225/python/197.exercises/solution.md"
+++ /dev/null
@@ -1,82 +0,0 @@
-# 上升的温度
-
-
-
-
表 Weather
-
-
-+---------------+---------+
-| Column Name | Type |
-+---------------+---------+
-| id | int |
-| recordDate | date |
-| temperature | int |
-+---------------+---------+
-id 是这个表的主键
-该表包含特定日期的温度信息
-
-
-
-
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
-
-
返回结果 不要求顺序 。
-
-
查询结果格式如下例:
-
-
-Weather
-+----+------------+-------------+
-| id | recordDate | Temperature |
-+----+------------+-------------+
-| 1 | 2015-01-01 | 10 |
-| 2 | 2015-01-02 | 25 |
-| 3 | 2015-01-03 | 20 |
-| 4 | 2015-01-04 | 30 |
-+----+------------+-------------+
-
-Result table:
-+----+
-| id |
-+----+
-| 2 |
-| 4 |
-+----+
-2015-01-02 的温度比前一天高(10 -> 25)
-2015-01-04 的温度比前一天高(20 -> 30)
-
-
-


