Merge remote-tracking branch 'upstream/dygraph' into dy1
Showing
{kind=link}

351.6 KB
{kind=link}
121.3 KB
doc/imgs_words/arabic/ar_1.jpg
0 → 100644
{kind=link}

4.7 KB
doc/imgs_words/arabic/ar_2.jpg
0 → 100644
{kind=link}

3.6 KB
{kind=link}

6.4 KB
{kind=link}

4.5 KB
doc/imgs_words/bulgarian/bg_1.jpg
0 → 100644
{kind=link}
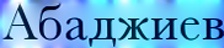
6.8 KB
doc/imgs_words/bulgarian/bg_2.jpg
0 → 100644
{kind=link}

12.2 KB
{kind=link}

65.3 KB
{kind=link}

72.7 KB
doc/imgs_words/hindi/hi_1.jpg
0 → 100644
{kind=link}

5.7 KB
doc/imgs_words/hindi/hi_2.jpg
0 → 100644
{kind=link}

6.5 KB
doc/imgs_words/italian/it_1.jpg
0 → 100644
{kind=link}

12.0 KB
doc/imgs_words/italian/it_2.jpg
0 → 100644
{kind=link}

9.4 KB
doc/imgs_words/kannada/ka_1.jpg
0 → 100644
{kind=link}

6.7 KB
doc/imgs_words/kannada/ka_2.jpg
0 → 100644
{kind=link}

7.8 KB
doc/imgs_words/marathi/mr_1.jpg
0 → 100644
{kind=link}

4.4 KB
doc/imgs_words/marathi/mr_2.jpg
0 → 100644
{kind=link}

2.8 KB
doc/imgs_words/nepali/ne_1.jpg
0 → 100644
{kind=link}

5.4 KB
doc/imgs_words/nepali/ne_2.jpg
0 → 100644
{kind=link}

4.1 KB
doc/imgs_words/occitan/oc_1.jpg
0 → 100644
{kind=link}

2.7 KB
doc/imgs_words/occitan/oc_2.jpg
0 → 100644
{kind=link}

6.5 KB
doc/imgs_words/persian/fa_1.jpg
0 → 100644
{kind=link}

3.9 KB
doc/imgs_words/persian/fa_2.jpg
0 → 100644
{kind=link}

5.3 KB
{kind=link}

15.0 KB
{kind=link}

11.4 KB
doc/imgs_words/russia/ru_1.jpg
0 → 100644
{kind=link}

12.5 KB
doc/imgs_words/russia/ru_2.jpg
0 → 100644
{kind=link}

6.0 KB
{kind=link}

4.5 KB
{kind=link}
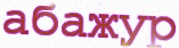
6.6 KB
{kind=link}

4.1 KB
{kind=link}

4.4 KB
doc/imgs_words/spanish/xi_1.jpg
0 → 100644
{kind=link}

8.5 KB
doc/imgs_words/spanish/xi_2.jpg
0 → 100644
{kind=link}

7.0 KB
doc/imgs_words/tamil/ta_1.jpg
0 → 100644
{kind=link}

6.1 KB
doc/imgs_words/tamil/ta_2.jpg
0 → 100644
{kind=link}

5.2 KB
doc/imgs_words/telugu/te_1.jpg
0 → 100644
{kind=link}

8.2 KB
doc/imgs_words/telugu/te_2.jpg
0 → 100644
{kind=link}

6.0 KB
doc/imgs_words/ukranian/uk_1.jpg
0 → 100644
{kind=link}

4.4 KB
doc/imgs_words/ukranian/uk_2.jpg
0 → 100644
{kind=link}

12.9 KB
doc/imgs_words/urdu/ur_1.jpg
0 → 100644
{kind=link}

5.0 KB
doc/imgs_words/urdu/ur_2.jpg
0 → 100644
{kind=link}

4.7 KB
doc/imgs_words/uyghur/ug_1.jpg
0 → 100644
{kind=link}

5.6 KB
doc/imgs_words/uyghur/ug_2.jpg
0 → 100644
{kind=link}

4.8 KB
ppocr/utils/dict/ar_dict.txt
0 → 100644
ppocr/utils/dict/be_dict.txt
0 → 100644
ppocr/utils/dict/bg_dict.txt
0 → 100644
此差异已折叠。
ppocr/utils/dict/fa_dict.txt
0 → 100644
ppocr/utils/dict/hi_dict.txt
0 → 100644
ppocr/utils/dict/it_dict.txt
0 → 100644
ppocr/utils/dict/ka_dict.txt
0 → 100644
ppocr/utils/dict/mr_dict.txt
0 → 100644
ppocr/utils/dict/ne_dict.txt
0 → 100644
ppocr/utils/dict/oc_dict.txt
0 → 100644
ppocr/utils/dict/pu_dict.txt
0 → 100644
ppocr/utils/dict/rs_dict.txt
0 → 100644
ppocr/utils/dict/rsc_dict.txt
0 → 100644
ppocr/utils/dict/ru_dict.txt
0 → 100644
ppocr/utils/dict/ta_dict.txt
0 → 100644
ppocr/utils/dict/te_dict.txt
0 → 100644
ppocr/utils/dict/ug_dict.txt
0 → 100644
ppocr/utils/dict/uk_dict.txt
0 → 100644
ppocr/utils/dict/ur_dict.txt
0 → 100644
ppocr/utils/dict/xi_dict.txt
0 → 100644