# Design Doc: Distributed Training Architecture
## Abstract
PaddlePaddle version 0.10.0 uses the "trainer-parameter server" architecture. We run multiple instances of trainers (where each trainer runs the same model) and parameter servers for distributed training. This architecture serves well, but has few limitations:
1. There is a need to write special code that handles tasks which should only be run on a single trainer. E.g., initializing the model, saving the model etc.
2. Model parallelism is hard: It would need all the if-else branches conditioned on the trainer ID to partition the model onto the trainers, and eventually manually writing out the inter-model-shard communication code to communicate between different trainers.
3. The user can not directly specify the parameter update rule: This would need to modify the parameter server code and compile a new binary. This makes things more complicated for researchers: A lot of extra effort is required to make this work. Besides, the training job submission program may not allow running arbitrary binaries.
This design doc discusses PaddlePaddle's new distributed training architecture that addresses the above mentioned limitations.
## Analysis
The assumption is that the user writes the trainer program in either Python or C++.
### Limitation 1
There are two basic functionalities in the trainer program:
1. The training logic such as loading / saving the model and printing out the logs.
2. The neural network definition such as the definition of the data layer, the fully connected layer, the cost function and the
optimizer.
When we train using PaddlePaddle v0.10.0 in a distributed fashion, multiple instances of the same Python code are run on different nodes, hence both: the
training logic as well as the neural network computation logic, is replicated.
The tasks that only need to be run once belong to the training logic. Hence if we only replicate the neural network computation part, and do **not**
replicate the training logic, the limitation mentioned above can be avoided.
### Limitation 2
Model parallelism means that a single model is partitioned into different components and each node runs one of the component separately. This comes at the extra cost of managing the
inter-model-shard communication between nodes.
PaddlePaddle should ideally be able to modify the neural network computation and figure out the support for model parallelism automatically. However, the
computation is only specified in Python code which sits outside of PaddlePaddle, hence PaddlePaddle can not support the feature in this setup.
Similar to how a compiler uses an intermediate representation (IR) so that the programmer does not need to manually optimize their code for most of the cases, we can have an intermediate representation in PaddlePaddle as well. The compiler optimizes the IR as follows:
 PaddlePaddle can support model parallelism by converting the IR so that the user no longer needs to manually perform the computation and operations in the Python component:
PaddlePaddle can support model parallelism by converting the IR so that the user no longer needs to manually perform the computation and operations in the Python component:
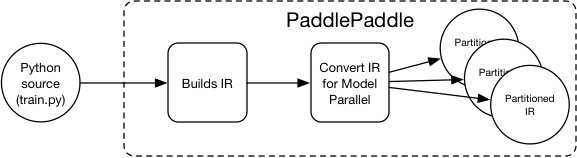 The IR for PaddlePaddle after refactoring is called a `Block`, it specifies the computation dependency graph and the variables used in the computation.
### Limitation 3
The user can not directly specify the parameter update rule for the parameter server in the Python module, since the parameter server does not use the same computation definition as the trainer. Instead, the update rule is baked inside the parameter server. The user can not specify the update rule explicitly.
This could be fixed by making the parameter server also run an IR, which can be different to the trainer side
For a detailed explanation, refer to this document -
[Design Doc: Parameter Server](./parameter_server.md)
## Distributed Training Architecture
The revamped distributed training architecture can address the above discussed limitations. Below is the illustration of how it does so:
The IR for PaddlePaddle after refactoring is called a `Block`, it specifies the computation dependency graph and the variables used in the computation.
### Limitation 3
The user can not directly specify the parameter update rule for the parameter server in the Python module, since the parameter server does not use the same computation definition as the trainer. Instead, the update rule is baked inside the parameter server. The user can not specify the update rule explicitly.
This could be fixed by making the parameter server also run an IR, which can be different to the trainer side
For a detailed explanation, refer to this document -
[Design Doc: Parameter Server](./parameter_server.md)
## Distributed Training Architecture
The revamped distributed training architecture can address the above discussed limitations. Below is the illustration of how it does so:
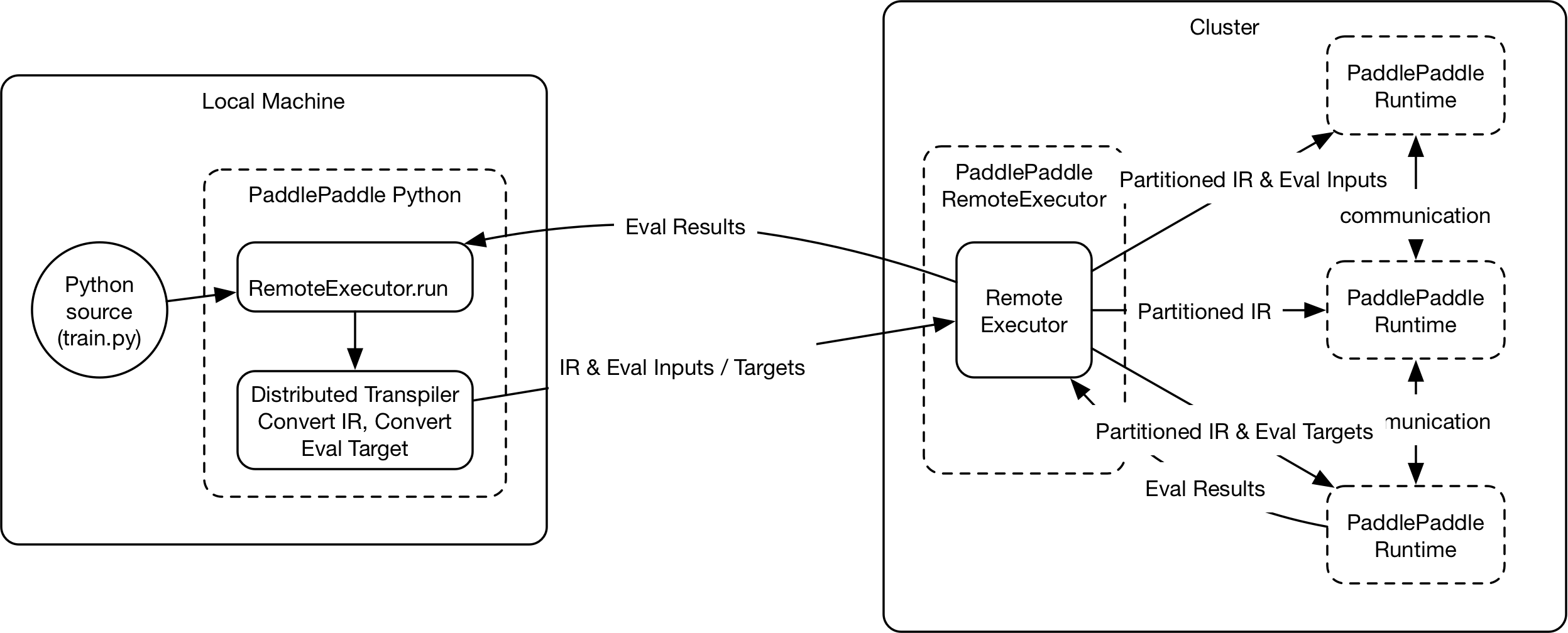 The major components are: *Python API*, *Distribute Transpiler* and *Remote Executor*.
### Python API
Python API is the Python library that user's Python code invokes, to read the data, build the neural network topology, and start training, etc.
```Python
images = fluid.layers.data(name='pixel', shape=[1, 28, 28], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
...
predict = fluid.layers.fc(input=conv_pool_2, size=10, act="softmax")
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(x=cost)
optimizer = fluid.optimizer.Adam(learning_rate=0.01)
optimizer.minimize(avg_cost)
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
batch_size=BATCH_SIZE)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
for pass_id in range(10):
for data in train_reader():
loss, acc = exe.run(trainer_prog,
feed=feeder.feed(data),
fetch_list=[avg_cost])
```
The code above is a typical local training program, the "Training Program" is built using helper functions such as
`fluid.layer.fc`. The training is done by calling `Executor.run`
iteratively.
For more details, the implementation of IR is [Program](../program.md), and `ProgramDesc` is the protobuf type.
[Executor](../executor.md) simply runs the `ProgramDesc`. For local training you generally use
`Executor` to run the program locally. For any kind of distributed training, you can use
`RemoteExecutor` to specify desired distributed training method with some optional arguments.
### Distributed Transpiler
The Distributed Transpiler automatically converts the IR (in protobuf format) to partitioned IRs. Then
the Remote Executor dispatches the new IRs to Remote Executors across the cluster.
Below are the steps that are followed :
1. User only need to change `Executor` to `RemoteExecutor` to change local program to distributed program.
1. `RemoteExecutor` calls `Distributed Transpiler` to "transpile" user's program to several IRs representing a
distributed training program:
1. Parse configurations from `RemoteExecutor`.
1. Determine the type of distributed program, can be DataParallelism, ModelParallelism or Streaming.
1. Partition the `ProgramDesc` according to type and add `send` / `recv` OP pair on the boundaries. Take
DataParallelism type for example, it removes the optimization operators and add a `send` OP to the
"trainer" role, then add the optimization operators to the parameter server role within the `recv` OP.
1. Dispatch the partitioned graph to different `RemoteExecutor` in the cluster.
1. `RemoteExecutor` on each node run the received `ProgramDesc` utill the end.
### RemoteExecutor
As shown in the graph, `RemoteExecutor.run` sends the IR to the cluster for Execution.
You can also use parameter `fetch_list` to interactively fetch variable back to local for
log printing.
The Python `RemoteExecutor` is derived from `Executor` class.
```python
exe = RemoteExecutor(
feed=feeder.feed(data),
fetch_list=[avg_cost],
job_desc=JobDesc(
jobname,
num_trainer,
num_pserver,
cpu_per_trainer,
gpu_per_trainer,
mem_per_trainer,
cpu_per_pserver,
mem_per_pserver
))
for data in train_reader():
loss, acc = exe.run(trainer_prog,
feed=feeder.feed(data),
fetch_list=[avg_cost])
```
`JobDesc` object describe the distributed job resource specification to run on
Cluster environment.
The major components are: *Python API*, *Distribute Transpiler* and *Remote Executor*.
### Python API
Python API is the Python library that user's Python code invokes, to read the data, build the neural network topology, and start training, etc.
```Python
images = fluid.layers.data(name='pixel', shape=[1, 28, 28], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
...
predict = fluid.layers.fc(input=conv_pool_2, size=10, act="softmax")
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(x=cost)
optimizer = fluid.optimizer.Adam(learning_rate=0.01)
optimizer.minimize(avg_cost)
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
batch_size=BATCH_SIZE)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
for pass_id in range(10):
for data in train_reader():
loss, acc = exe.run(trainer_prog,
feed=feeder.feed(data),
fetch_list=[avg_cost])
```
The code above is a typical local training program, the "Training Program" is built using helper functions such as
`fluid.layer.fc`. The training is done by calling `Executor.run`
iteratively.
For more details, the implementation of IR is [Program](../program.md), and `ProgramDesc` is the protobuf type.
[Executor](../executor.md) simply runs the `ProgramDesc`. For local training you generally use
`Executor` to run the program locally. For any kind of distributed training, you can use
`RemoteExecutor` to specify desired distributed training method with some optional arguments.
### Distributed Transpiler
The Distributed Transpiler automatically converts the IR (in protobuf format) to partitioned IRs. Then
the Remote Executor dispatches the new IRs to Remote Executors across the cluster.
Below are the steps that are followed :
1. User only need to change `Executor` to `RemoteExecutor` to change local program to distributed program.
1. `RemoteExecutor` calls `Distributed Transpiler` to "transpile" user's program to several IRs representing a
distributed training program:
1. Parse configurations from `RemoteExecutor`.
1. Determine the type of distributed program, can be DataParallelism, ModelParallelism or Streaming.
1. Partition the `ProgramDesc` according to type and add `send` / `recv` OP pair on the boundaries. Take
DataParallelism type for example, it removes the optimization operators and add a `send` OP to the
"trainer" role, then add the optimization operators to the parameter server role within the `recv` OP.
1. Dispatch the partitioned graph to different `RemoteExecutor` in the cluster.
1. `RemoteExecutor` on each node run the received `ProgramDesc` utill the end.
### RemoteExecutor
As shown in the graph, `RemoteExecutor.run` sends the IR to the cluster for Execution.
You can also use parameter `fetch_list` to interactively fetch variable back to local for
log printing.
The Python `RemoteExecutor` is derived from `Executor` class.
```python
exe = RemoteExecutor(
feed=feeder.feed(data),
fetch_list=[avg_cost],
job_desc=JobDesc(
jobname,
num_trainer,
num_pserver,
cpu_per_trainer,
gpu_per_trainer,
mem_per_trainer,
cpu_per_pserver,
mem_per_pserver
))
for data in train_reader():
loss, acc = exe.run(trainer_prog,
feed=feeder.feed(data),
fetch_list=[avg_cost])
```
`JobDesc` object describe the distributed job resource specification to run on
Cluster environment.
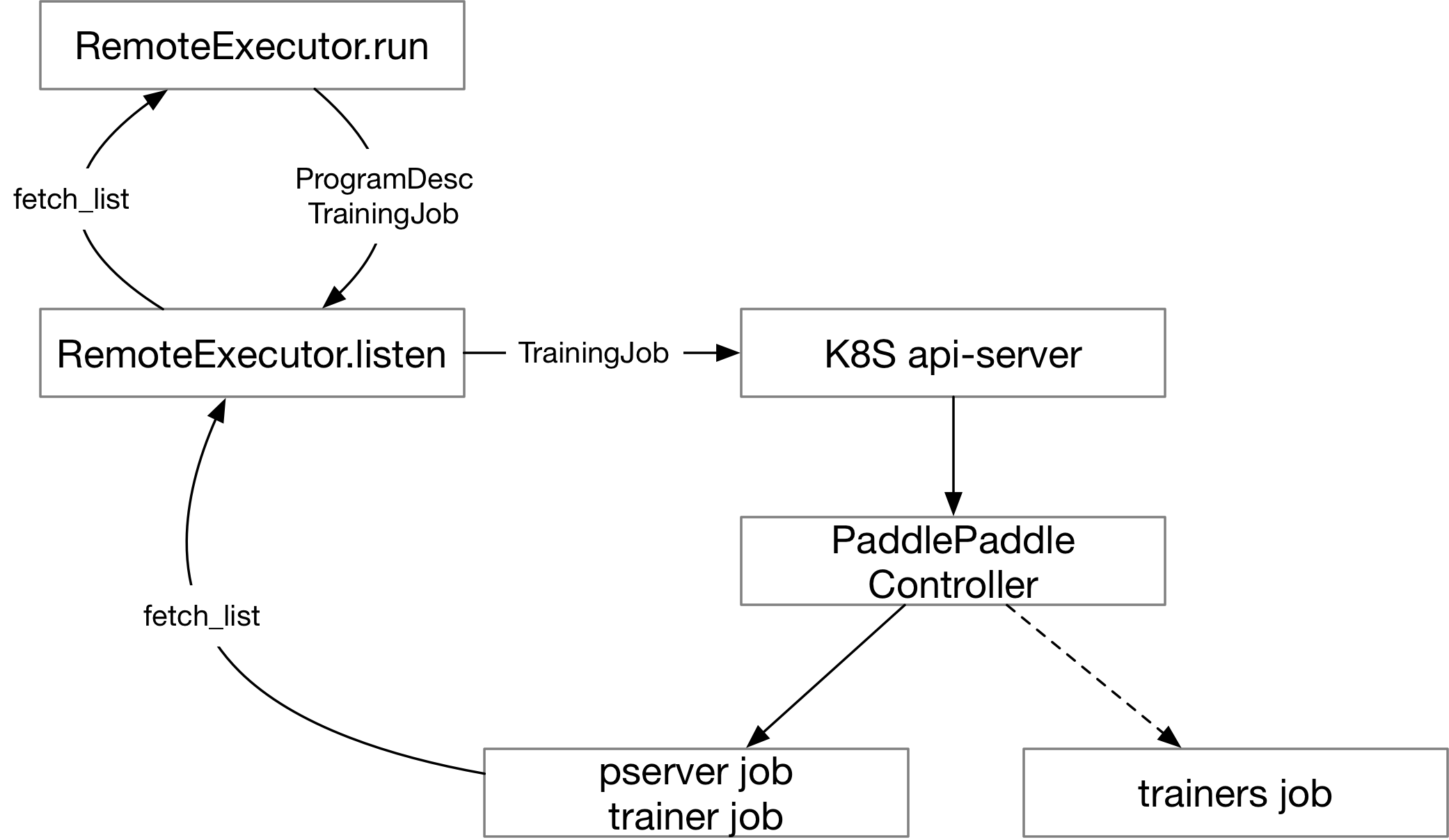 `RemoteExecutor.run` sends the `ProgramDesc` and
[TrainingJob](https://github.com/PaddlePaddle/cloud/blob/develop/doc/autoscale/README.md#training-job-resource)
to a server in the cluster which executes `RemoteExecutor.listen`. This server is responsible
to start the final Kubernetes Jobs to run the different role of `ProgramDesc`.
### Placement Algorithm
Our first implementation will only support "trainer-parameter server" placement: the parameters, initializers, and optimizers are all placed on the PaddlePaddle runtimes with the parameter server role. Everything else will be placed on the PaddlePaddle runtimes with the trainer role. This has the same functionality as the "trainer-parameter server" architecture of PaddlePaddle v0.10.0, but is more generic and flexible.
In the future, a more general placement algorithm should be implemented, which makes placements according to the input IR, and a model of device computation time and device communication time. Model parallelism requires the generic placement algorithm.
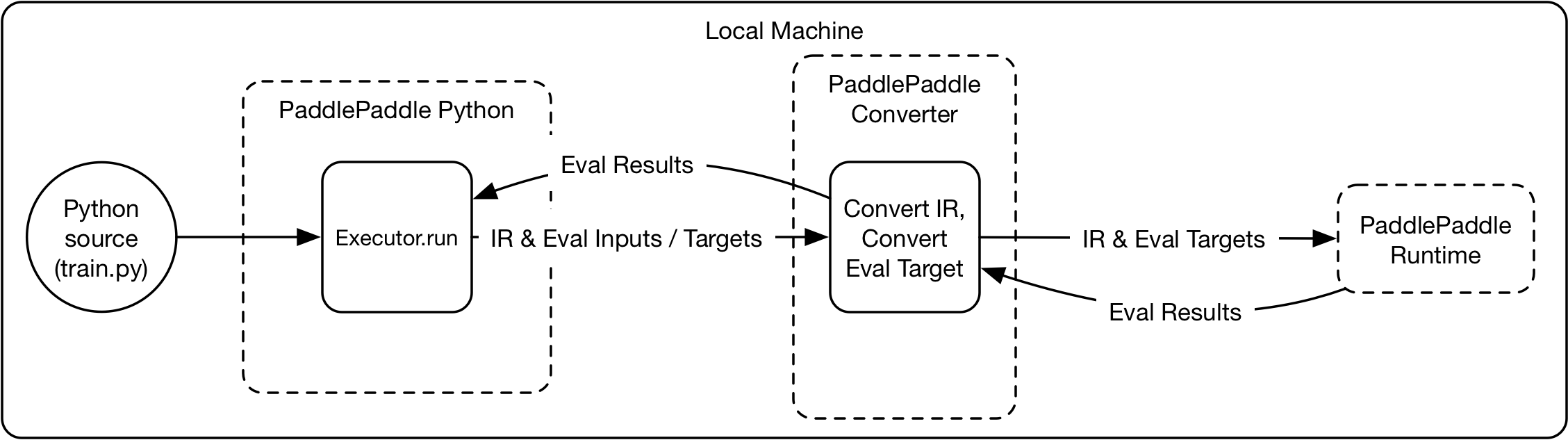
### Local Training Architecture
The local training architecture will be the same as the distributed training architecture, the difference is that everything runs locally, and there is just one PaddlePaddle runtime:
`RemoteExecutor.run` sends the `ProgramDesc` and
[TrainingJob](https://github.com/PaddlePaddle/cloud/blob/develop/doc/autoscale/README.md#training-job-resource)
to a server in the cluster which executes `RemoteExecutor.listen`. This server is responsible
to start the final Kubernetes Jobs to run the different role of `ProgramDesc`.
### Placement Algorithm
Our first implementation will only support "trainer-parameter server" placement: the parameters, initializers, and optimizers are all placed on the PaddlePaddle runtimes with the parameter server role. Everything else will be placed on the PaddlePaddle runtimes with the trainer role. This has the same functionality as the "trainer-parameter server" architecture of PaddlePaddle v0.10.0, but is more generic and flexible.
In the future, a more general placement algorithm should be implemented, which makes placements according to the input IR, and a model of device computation time and device communication time. Model parallelism requires the generic placement algorithm.
### Local Training Architecture
The local training architecture will be the same as the distributed training architecture, the difference is that everything runs locally, and there is just one PaddlePaddle runtime:
 ### Training Data
In PaddlePaddle v0.10.0, training data is typically read
with [data reader](../reader/README.md) from Python. This approach is
no longer efficient when training distributedly since the Python
process no longer runs on the same node with the trainer processes,
the Python reader will need to read from the distributed filesystem
(assuming it has the access) and send to the trainers, doubling the
network traffic.
When doing distributed training, the user can still use Python data
reader: the training data are sent with `Executor.run`. However, should
be used for debugging purpose only. The users are encouraged to use
the read data OPs.
## References:
[1] [TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf)
[2] [TensorFlow: A System for Large-Scale Machine Learning](https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf)
### Training Data
In PaddlePaddle v0.10.0, training data is typically read
with [data reader](../reader/README.md) from Python. This approach is
no longer efficient when training distributedly since the Python
process no longer runs on the same node with the trainer processes,
the Python reader will need to read from the distributed filesystem
(assuming it has the access) and send to the trainers, doubling the
network traffic.
When doing distributed training, the user can still use Python data
reader: the training data are sent with `Executor.run`. However, should
be used for debugging purpose only. The users are encouraged to use
the read data OPs.
## References:
[1] [TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf)
[2] [TensorFlow: A System for Large-Scale Machine Learning](https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf)