Merge pull request #160 from breezedeus/dev
v2.1: better models
Showing
此差异已折叠。
cnocr/data_utils/block_shuffle.py
0 → 100644
cnocr/lr_scheduler.py
0 → 100644
cnocr/models/mobilenet.py
0 → 100644
docs/cnocr/cn_ocr.md
0 → 100644
docs/cnstd_cnocr.md
0 → 100644
docs/command.md
0 → 100644
docs/contact.md
0 → 100644
docs/demo.md
0 → 100644
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
docs/examples/taobao4.jpg
0 → 100644
{kind=link}

139.8 KB
docs/faq.md
0 → 100644
docs/figs/demo.jpg
0 → 100644
{kind=link}
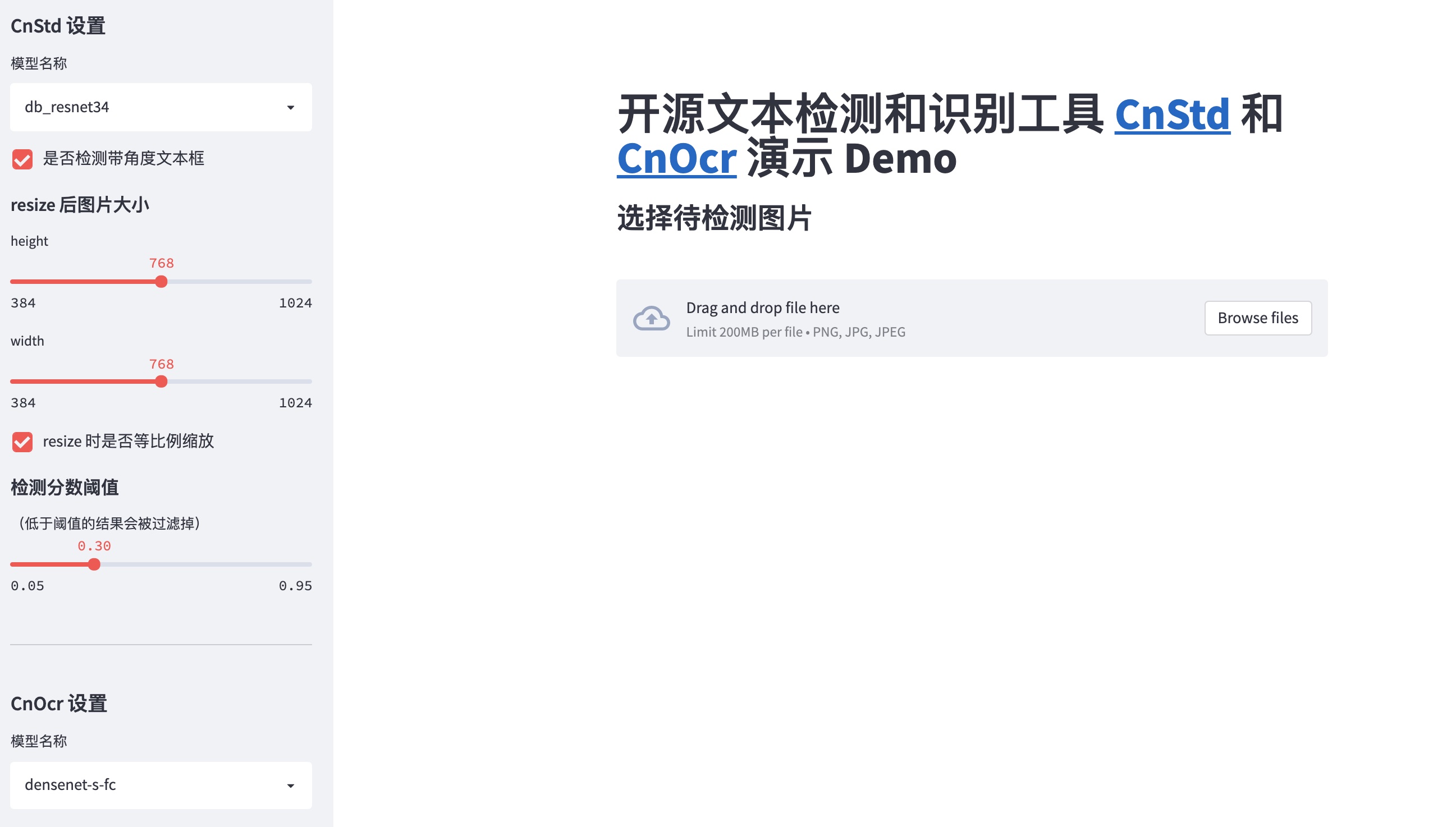
241.8 KB
docs/figs/jinlong.ico
0 → 100755
1.1 KB
docs/figs/jinlong.png
0 → 100644
{kind=link}

492.2 KB
docs/figs/std-ocr.jpg
0 → 100644
{kind=link}
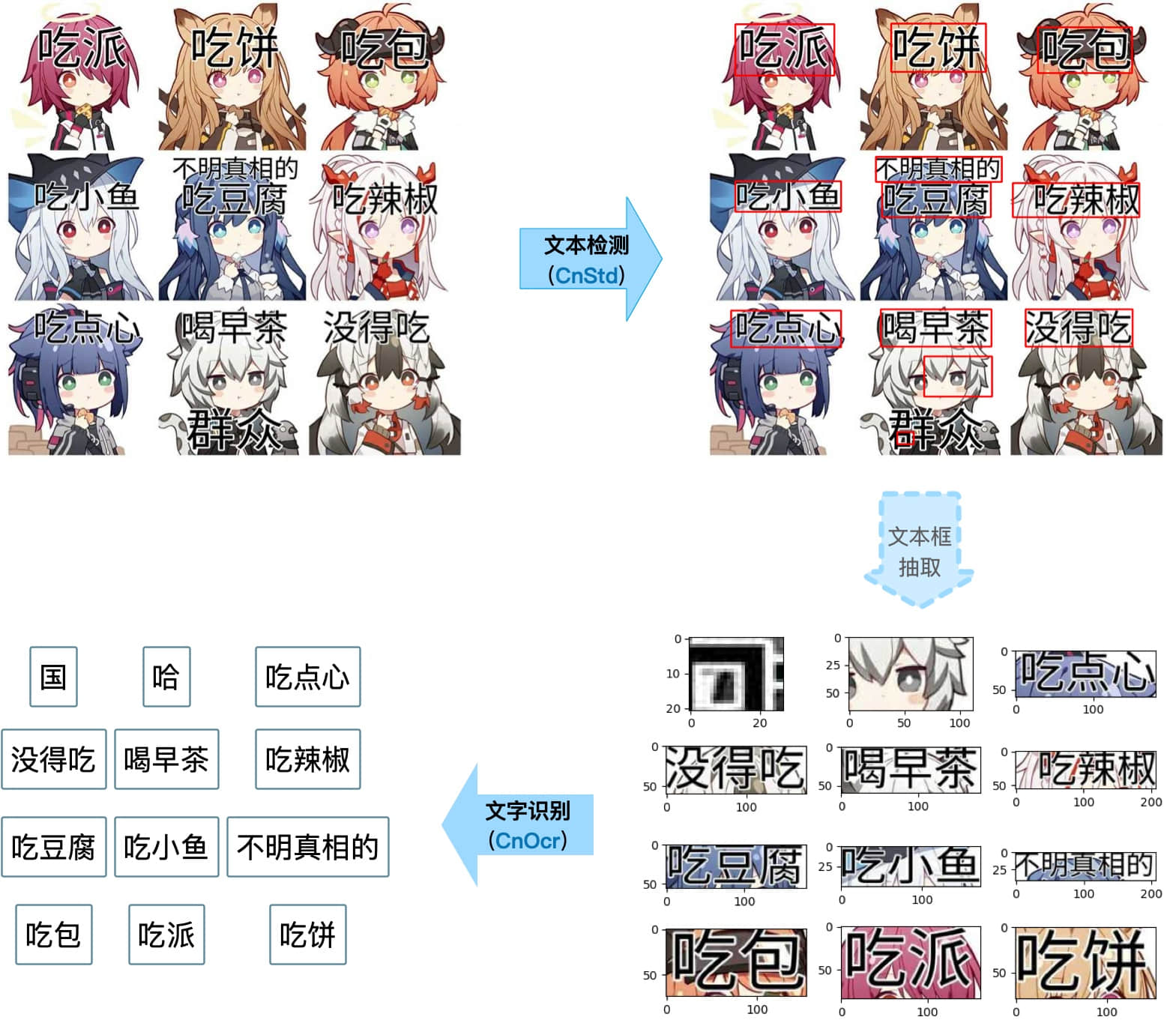
237.0 KB
docs/index.md
0 → 100644
docs/install.md
0 → 100644
docs/intro-cnstd-cnocr.pdf
0 → 100644
文件已添加
docs/models.md
0 → 100644
docs/requirements.txt
0 → 100644
docs/static/css/custom.css
0 → 100644
docs/std_ocr.md
0 → 100644
docs/train.md
0 → 100644
docs/usage.md
0 → 100644
examples/taobao4.jpg
已删除
100644 → 0
{kind=link}

359.2 KB
mkdocs.yml
0 → 100644
| ... | ... | @@ -31,6 +31,7 @@ pyasn1-modules==0.2.8 # via google-auth |
| pyasn1==0.4.8 # via pyasn1-modules, rsa | ||
| pydeprecate==0.3.1 # via pytorch-lightning | ||
| pyparsing==2.4.7 # via packaging | ||
| python-levenshtein==0.12.0 # via -r requirements.in | ||
| pytorch-lightning==1.4.4 # via -r requirements.in | ||
| pyyaml==5.4.1 # via pytorch-lightning | ||
| requests-oauthlib==1.3.0 # via google-auth-oauthlib | ||
| ... | ... |