diff --git "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257.pdf" "b/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257.pdf"
deleted file mode 100644
index 75e5959b1a87c2e6d0141b522d25774952cc9248..0000000000000000000000000000000000000000
Binary files "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257.pdf" and /dev/null differ
diff --git "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\344\272\256\347\231\275\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf" "b/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\344\272\256\347\231\275\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf"
deleted file mode 100644
index 589dcea8b735887f79a386a63cd72b37b215bf20..0000000000000000000000000000000000000000
Binary files "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\344\272\256\347\231\275\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf" and /dev/null differ
diff --git "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\345\270\246\347\233\256\345\275\225.pdf" "b/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\345\270\246\347\233\256\345\275\225.pdf"
deleted file mode 100644
index daeac80b44025bf2289ffbc5e4fa1c6f6525c5fc..0000000000000000000000000000000000000000
Binary files "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\345\270\246\347\233\256\345\275\225.pdf" and /dev/null differ
diff --git "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf" "b/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf"
deleted file mode 100644
index 9228da6b50c5d417e60e5a235b50ef609cbd2c94..0000000000000000000000000000000000000000
Binary files "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\346\232\227\351\273\221\347\211\210\357\274\210\344\277\235\347\234\237\357\274\211.pdf" and /dev/null differ
diff --git "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\357\274\210\347\262\276\347\256\200\347\211\210\357\274\211.md" "b/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\357\274\210\347\262\276\347\256\200\347\211\210\357\274\211.md"
deleted file mode 100644
index a477bf82e1f481fb49e37dff988d7222569423e2..0000000000000000000000000000000000000000
--- "a/\344\272\214\345\223\245\347\232\204Java\350\277\233\351\230\266\344\271\213\350\267\257 PDF \347\246\273\347\272\277\347\211\210/\344\272\214\345\223\245\347\232\204 Java \350\277\233\351\230\266\344\271\213\350\267\257\357\274\210\347\262\276\347\256\200\347\211\210\357\274\211.md"
+++ /dev/null
@@ -1,26327 +0,0 @@
-
-
-# 第一章:小册简介
-
-以上就是小册的封面了,自我感觉还不错哈,简洁大方,但包含的信息又足够的丰富:
-
-- 小册名字:二哥的 Java 进阶之路
-- 小册作者:沉默王二
-- 小册品质:能在 GitHub 取得 7600+ star 自认为品质是有目共睹的,尤其是国内还有不少小伙伴在访问 GitHub 的时候很不顺利。
-- 小册风格:通俗易懂、风趣幽默、深度解析,新手可以拿来入门,老手可以拿来进阶,重要的知识,比如说面试高频的内容会从应用到源码挖个底朝天,还会穿插介绍一些计算机底层知识,力求讲个明白)
-- 小册简介:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java面试等核心知识点。学Java,就认准二哥的Java进阶之路😄
-- 小册品位:底部用了梵高 1889 年的《星空》(the starry night),绝美的漩涡星空,耀眼的月亮,宁静的村庄,还有一颗燃烧着火焰的巨大柏树,我想小册的艺术品位也是恰到好处的。
-- 小册角色:为了增加小册的趣味性,我特意为此追加了两个虚拟角色,一个二哥,一个三妹,二哥负责教,三妹负责学。这样大家在学习 Java 的时候代入感也会更强烈一些,希望这样的设定能博得大家的欢心。
-
-## 小册包含哪些内容?
-
-三妹出场:“二哥,帮读者朋友们问一下哈,为什么会有《二哥的Java进阶之路》这份小册呢?”
-
-*二哥巴拉巴拉 ing...*
-
-小册的内容主要来源于我的开源知识库《[Java程序员进阶之路](https://github.com/itwanger/toBeBetterJavaer)》,目前在 GitHub 上收获 7600+ star,深受读者喜爱。小册之所以叫《二哥的Java进阶之路》,是因为这样更方便小册的读者知道这份小册的作者是谁,IP 感更强烈一些。
-
-如果有读者是第一次阅读这份小册,肯定又会问,“二哥是哪个鸟人?”
-
-噢噢噢噢,正是鄙人了,一个英俊潇洒的男人(见下图),你可以通过我的微信公众号“**沉默王二**”了解更多关于我的信息,总之,就是一个非常喜欢王小波的程序员了,写得一手风趣幽默的技术文章,所以被读者“尊称”为二哥就对了。现实中,三妹也是真实存在的哦。
-
-
-
-《**二哥的 Java 进阶之路**》是我自学 Java 以来所有原创文章和学习资料的大聚合。[在线网站](https://tobebetterjavaer.com/)和 [GitHub 仓库](https://github.com/itwanger/toBeBetterJavaer)里的内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发(包括开发/构建/测试、JavaWeb、SSM、Spring Boot、Linux、Nginx、Docker、k8s、微服务&分布式、消息队列等)、Java 面试等核心内容。这也是小册最终版会覆盖的内容。
-
-小册旨在为学习 Java 的小伙伴提供一系列:
-
- - **优质的原创 Java 教程**
- - **全面清晰的 Java 学习路线**
- - **免费但靠谱的 Java 学习资料**
- - **精选的 Java 岗求职面试指南**
- - **Java 企业级开发所需的必备技术**
-
-接下来,送你 4 个“掏心掏肺”的阅读建议:
-
-- 如果你是零基础的小白,可以按照小册的顺序一路读下去,小册的内容安排都是经过我精心安排的;
-- 否则,请按照目录按需阅读,该跳过的跳过,该放慢节奏的放慢节奏。
-- 小册中会有一个虚拟人物,三妹,当然她的原型也是真实存在的,目的就是通过我们之间的对话,来增强文章的趣味性,以便你能更轻松地获取知识。
-- 最重要的一点,“光看不练假把戏”,请在阅读的过程中把该敲的代码敲了,把该记的笔记记了,语雀、思维导图、GitHub 仓库都可以,养成好的学习习惯。
-
-如果你喜欢在线阅读,请戳下面这个网址:
-
-> [https://tobebetterjavaer.com](https://tobebetterjavaer.com)
-
-首页见下图,同样简洁、清新、方便沉浸式阅读:
-
-
-
-你也可以到技术派的[教程栏(戳这里)](https://paicoding.com/column)里阅读,目前正在连载更新中。
-
-
-
->技术派是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,采用主流的互联网技术架构、全新的UI设计、支持一键源码部署,拥有完整的文章&教程发布/搜索/评论/统计流程等,[代码完全开源(可戳)](https://github.com/itwanger/paicoding),没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目👍 。
-
-如果你在阅读过程中感觉这份小册写的还不错,甚至有亿点点收获,**请肆无忌惮地把这份小册分享给你的同事、同学、舍友、朋友,让他们也进步亿点点,赠人玫瑰手有余香嘛**。
-
-如果这份小册有幸被更多人看得到,我的虚荣心也会得到恰当的满足,嘿嘿😜
-
-## 如何获取最新版?
-
-小册会持续保持**更新**,如果想获得最新版,请在我的微信公众号 **沉默王二** 后台回复 **222** 获取(你懂我的意思吧,我肯定是足够二才有这样的勇气定义这样一个关键字)!
-
-
-
-## 面试指南(配套教程)
-
-《Java 面试指南》是[二哥编程星球的](https://tobebetterjavaer.com/zhishixingqiu/)的一个内部小册,和《Java 进阶之路》内容互补。相比开源的版本来说,《Java 面试指南》添加了下面这些板块和内容:
-
-- 面试准备篇(20+篇),手把手教你如何准备面试。
-- 职场修炼篇(10+篇),手摸手教你如何在职场中如鱼得水。
-- 技术提升篇(30+篇),手拉手教你如何成为团队不可或缺的技术攻坚小能手。
-- 面经分享篇(20+篇),手牵手教你如何在面试中知彼知己,百战不殆。
-- 场景设计篇(20+篇),手握手教你如何在面试中脱颖而出。
-
-### 内容概览
-
-#### 面试准备篇
-
-所谓临阵磨枪,不快也光。更何况提前做好充足的准备呢?这 20+篇文章会系统地引导你该如何做准备。
-
-
-
-#### 职场修炼篇
-
-如何平滑度过试用期?如何平滑度过 35 岁程序员危机?如何在繁重的工作中持续成长?如何做副业?等等,都是大家迫切关心的问题,这 10+篇文章会一一为你揭晓答案。
-
-
-
-#### 技术提升篇
-
-编程能力、技术功底,是我们程序员安身立命之本,是我们求职/工作的最核心的武器。
-
-
-
-#### 面经分享篇
-
-知彼知己,方能百战不殆,我们必须得站在学长学姐的肩膀上,才能走得更远更快。
-
-
-
-#### 场景设计题篇
-
-这里收录的都是精华,让天底下没有难背的八股文;场景设计题篇页都是面试中经常考察的大项,可以让你和面试官对线半小时(😁)
-
-
-
-### 星球其他资源
-
-除了《Java 面试指南》外,星球还提供了《编程喵实战项目笔记》、《二哥的 LeetCode 刷题笔记》,以及技术派实战项目配套的 120+篇硬核教程。
-
-
-
-这里重点介绍一下技术派吧,这个项目上线后,一直广受好评,读者朋友们的认可度非常高,项目配套的教程也足够的硬核。
-
-
-
-这是部分目录(共计 120 篇,大厂篇、基础篇、进阶篇、工程篇,全部落地)。
-
-开篇:
-
-- 技术答疑(⭐️)
-- 技术派问题反馈及解决方案(⭐️)
-- 踩坑实录之本地缓存Caffeine采坑实录(⭐️)
-- 技术派系统架构、功能模块一览(⭐️⭐️⭐️⭐️⭐️)
-
-大厂篇:
-
-- 技术派产品调研,让你了解产品诞生背后的故事(⭐️⭐️)
-- 技术派产品设计(⭐️)
-- 技术派交互视觉设计(⭐️)
-- 技术派整体架构方案设计全过程(⭐️⭐️⭐️)
-- 技术方案详细设计(⭐️⭐️⭐️⭐️)
-- 技术派项目管理流程(⭐️⭐️)
-- 技术派项目管理研发阶段(⭐️⭐️⭐️)
-
-基础篇:
-
-- 技术派中实体对象 DO、DTO、VO 到底代表了什么(⭐️)
-- 通过技术派项目讲解 MVC 分层架构的应用(⭐️⭐️)
-- 技术派整合本地缓存之Guava(⭐️⭐️⭐️)
-- 技术派整合本地缓存之Caffeine(⭐️⭐️⭐️⭐️)
-- 技术派整合 Redis(⭐️)
-- 技术派中基于 Redis 的缓存示例(⭐️⭐️⭐️)
-- 技术派中基于Cacheable注解实现缓存示例(⭐️⭐️)
-- 技术派中的事务使用实例(⭐️⭐️⭐️)
-- 事务使用的 7 条注意事项(⭐️⭐️⭐️)
-- 技术派中的多配置文件说明(⭐️)
-- 技术派整合 Logback/lombok 配置日志输出(⭐️)
-- 技术派整合邮件服务实现邮件发送(⭐️)
-- Web 三大组件之 Filter 在技术派中的应用(⭐️)
-- Web 三大组件之 Servlet 在技术派中的应用(⭐️)
-- Web 三大组件之 listenter 在技术派中的应用(⭐️)
-- 技术派实时在线人数统计-单机版(⭐️)
-
-进阶篇:
-
-- 技术派之扫码登录实现原理(⭐️)
-- 技术派身份验证之session与 cookie(⭐️)
-- 技术派中基于异常日志的报警通知(⭐️)
-
-扩展篇:
-
-- 技术派的数据库表自动初始化实现方案(⭐️⭐️⭐️⭐️⭐️)
-- 技术派中基于 filter 实现请求日志记录(⭐️)
-
-工程篇:
-
-- 技术派项目工程搭建手册(⭐️⭐️⭐️⭐️)
-- 技术派本地多机器部署开发教程(⭐️⭐️)
-- 技术派服务器部署指导手册(⭐️⭐️)
-- 技术派的 MVC 分层架构(⭐️⭐️)
-- 技术派 Docker 本机部署开发手册(⭐️⭐️⭐️)
-- 技术派多环境配置管理(⭐️)
-
-欣赏一下技术派实战项目的首页吧,绝壁清新、高级、上档次!
-
-
-
-### 星球限时优惠
-
-一年前,星球的定价是 99 元一年,第一批优惠券的额度是 30 元,等于说 69 元的低价就可以加入,再扣除掉星球手续费,几乎就是纯粹做公益。
-
-随着时间的推移,星球积累的干货/资源越来越多,我花在星球上的时间也越来越多,[星球的知识图谱](https://tobebetterjavaer.com/zhishixingqiu/map.html)里沉淀的问题,你可以戳这个[链接](https://tobebetterjavaer.com/zhishixingqiu/map.html)去感受一下。有学习计划啊、有学生党秋招&春招&offer选择&考研&实习&专升本&培训班的问题啊、有工作党方向选择&转行&求职&职业规划的问题啊,还有大大小小的技术细节,我都竭尽全力去帮助球友,并且得到了球友的认可和尊重。
-
-目前星球已经 2100+ 人了,所以星球也涨价到了 119 元,后续会讲星球的价格调整为 139 元/年,所以想加入的小伙伴一定要趁早。
-
-
-
-你可以添加我的微信(没有⼿机号再申请微信,故使⽤企业微信。不过,请放⼼,这个号的消息也是
-我本⼈处理,平时最常看这个微信)领取星球专属优惠券(推荐),限时 80/年 加⼊(续费半价)!
-
- -
-
-或者你也可以微信扫码或者长按自动识别领取 30 元优惠券,**89/年** 加入!
-
-
-
-
-或者你也可以微信扫码或者长按自动识别领取 30 元优惠券,**89/年** 加入!
-
- -
-对了,**加入星球后记得花 10 分钟时间看一下星球的两个置顶贴,你会发现物超所值**!
-
-成功没有一蹴而就,没有一飞冲天,但只要你能够一步一个脚印,就能取得你心满意足的好结果,请给自己一个机会!
-
-最后,把二哥的座右铭送给你:**没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟**。
-
-共勉 ⛽️。
-
-## 如何贡献?
-
-对了,如果你在阅读的过程中遇到一些错误,欢迎到我的开源仓库提交 issue、PR(审核通过后可成为 Contributor),我会第一时间修正,感谢你为后来者做出的贡献。
-
->- GitHub:[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)
->- 码云:[https://gitee.com/itwanger/toBeBetterJavaer](https://gitee.com/itwanger/toBeBetterJavaer)
-
-## 更新记录
-
-### V1.0-2023年04月11日
-
-第一版《二哥的 Java 进阶之路》正式完结发布!
-
-# 第二章:Java概述及环境配置
-
-## 2.1 Java简介
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.1 Java简介](https://tobebetterjavaer.com/overview/what-is-java.html)
-
-## 2.2 安装JDK
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.2 安装 JDK](https://tobebetterjavaer.com/overview/jdk-install-config.html)
-
-
-
-## 2.3 安装IDEA
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.3 安装Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html)
-
-
-
-## 2.4 第一个Java程序
-
-“三妹,今天,我们来编写第一个 Java 程序,Hello World 期待吗?”
-
-三妹点了点头,表示认同(😂)。
-
-“好的,那我们直接开始。”
-
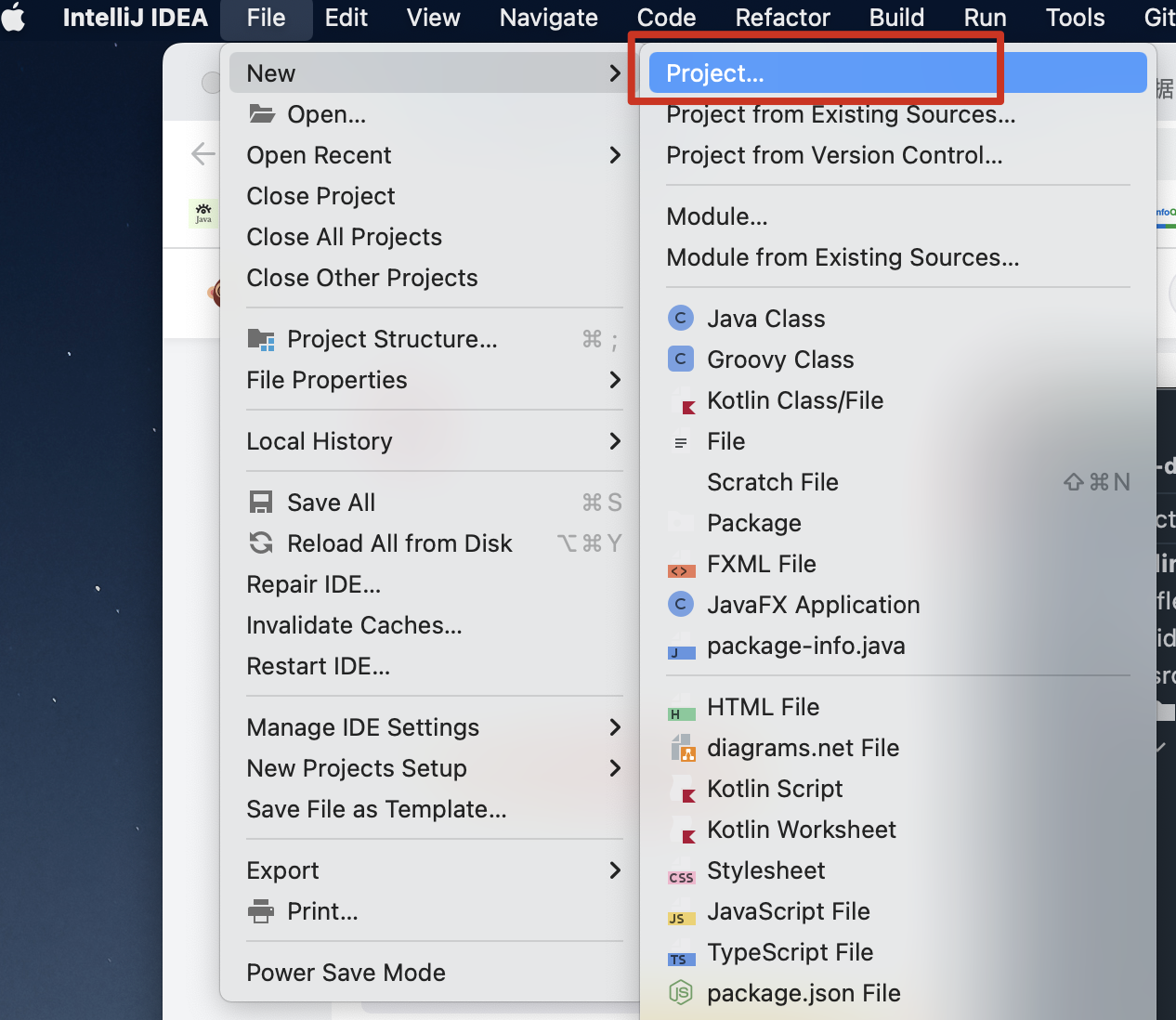
-打开 [Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html),新建一个学习 Java 的项目,点击 File → New → Project。
-
-
-
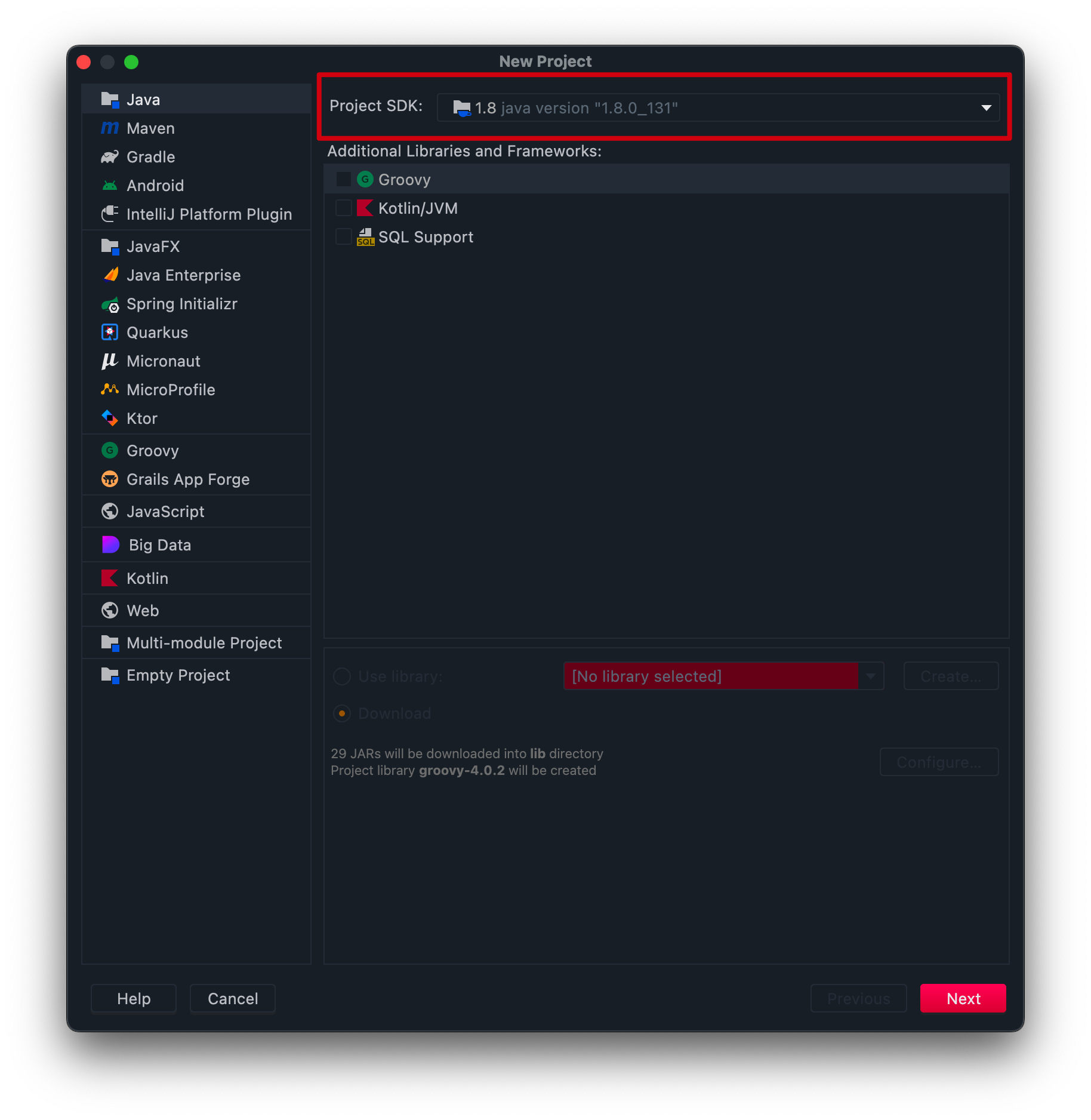
-选择 JDK 版本,比如之前我们[安装的 JDK 8](https://tobebetterjavaer.com/overview/jdk-install-config.html)。
-
-
-
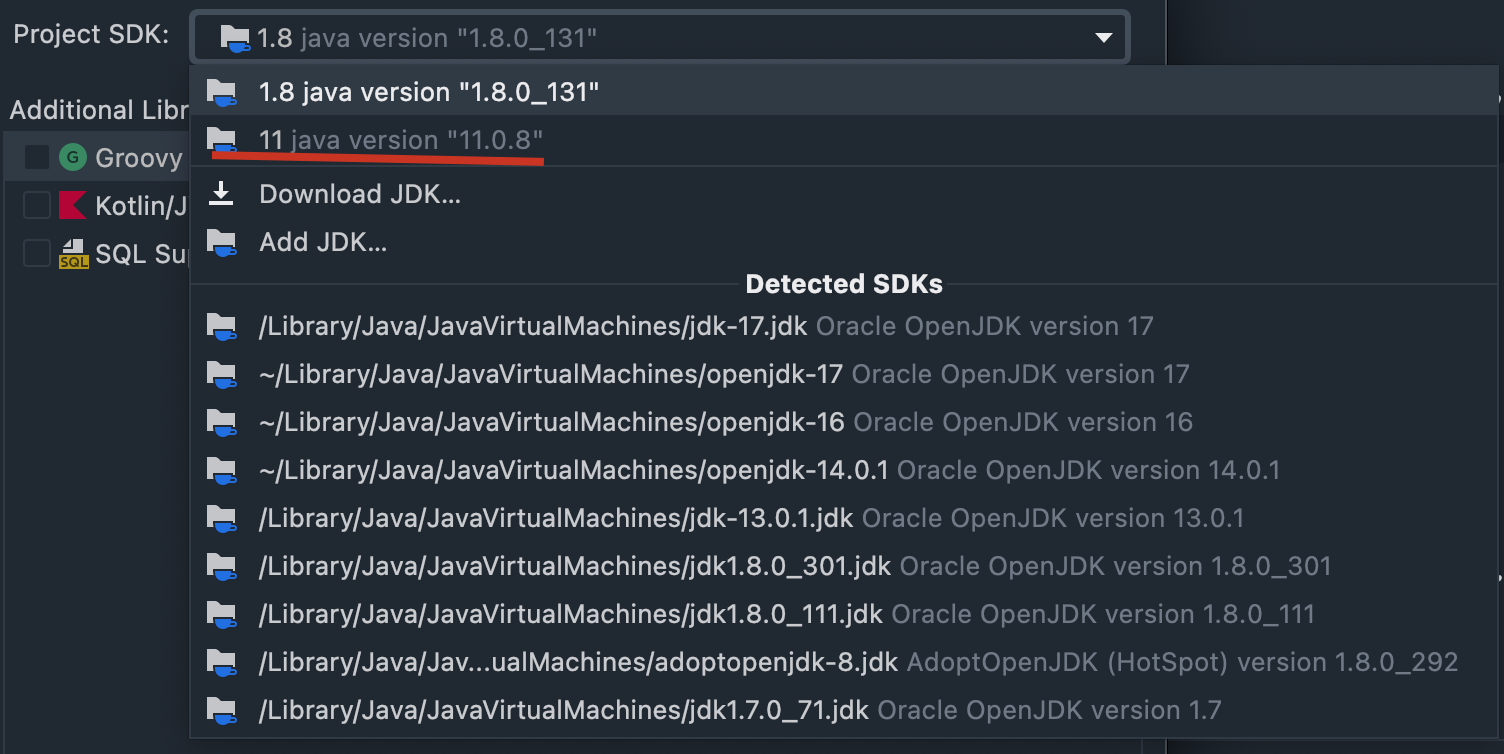
-你也可以选择 JDK 11 或者最新的 JDK 17 或者添加新的 JDK 版本,但(不建议)。
-
-
-
-然后点击「next」,直到填写项目名字,比如说 tobebetterjavaerdemo。
-
-
-
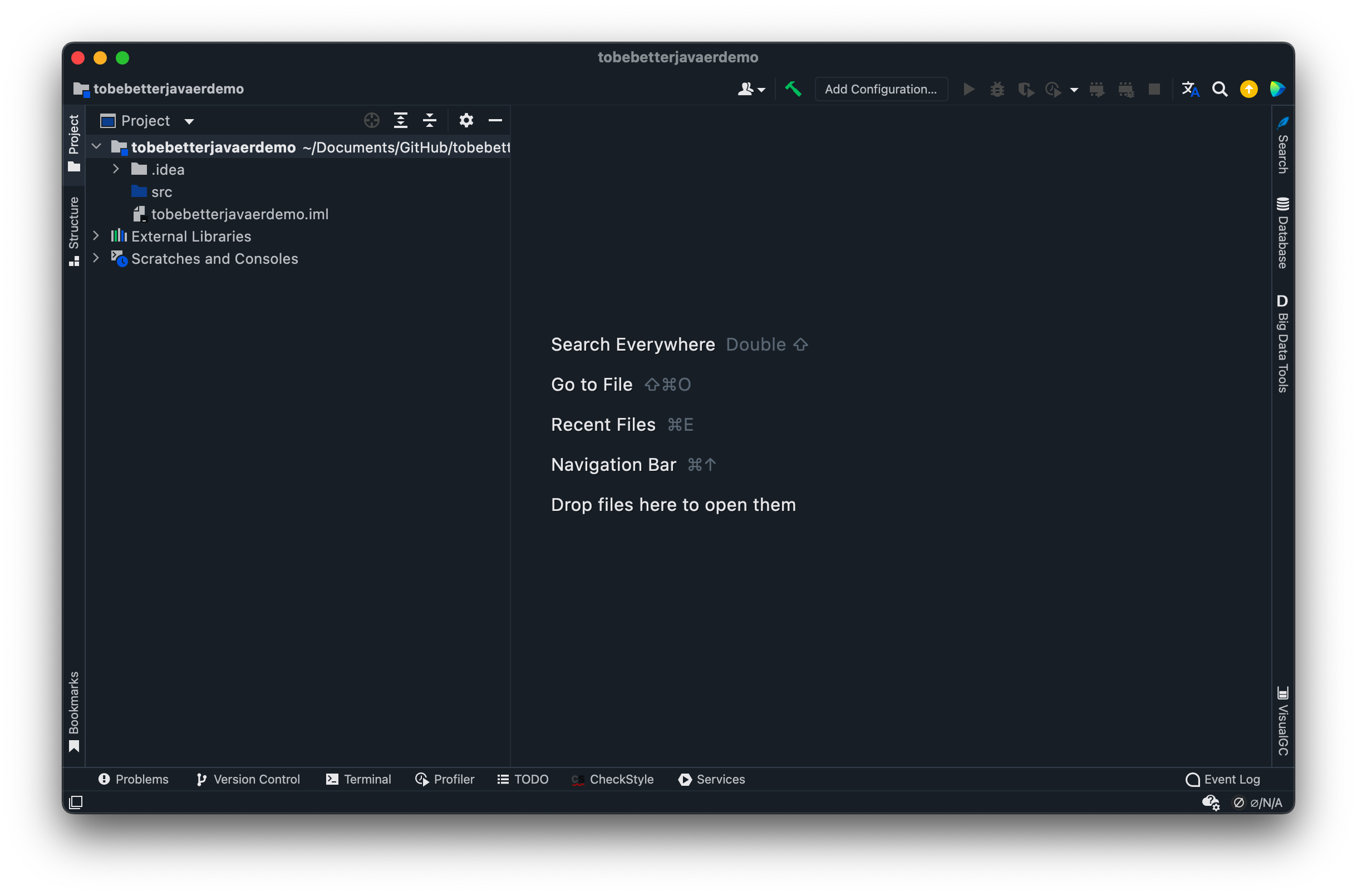
-然后点击 finish,之后就可以看到我们新建的项目界面了。
-
-
-
-如果你的 Intellij IDEA 主题和二哥不一样,没关系,当然了,如果你也是个有颜值追求的家伙,可以安装 Vuesion Theme 插件,安装方法[戳这里](https://tobebetterjavaer.com/ide/shenji-chajian-10.html)。
-
-“OK,到这里,我们已经把学习 Java 的环境准备好了,接下来就可以写第一个 Hello World 程序了。”我自信地对三妹说。
-
-一般我们会把源代码放在 src 目录下(source 的前缀,所以学编程,英语中常用的单词必须得会,不会就去学)。
-
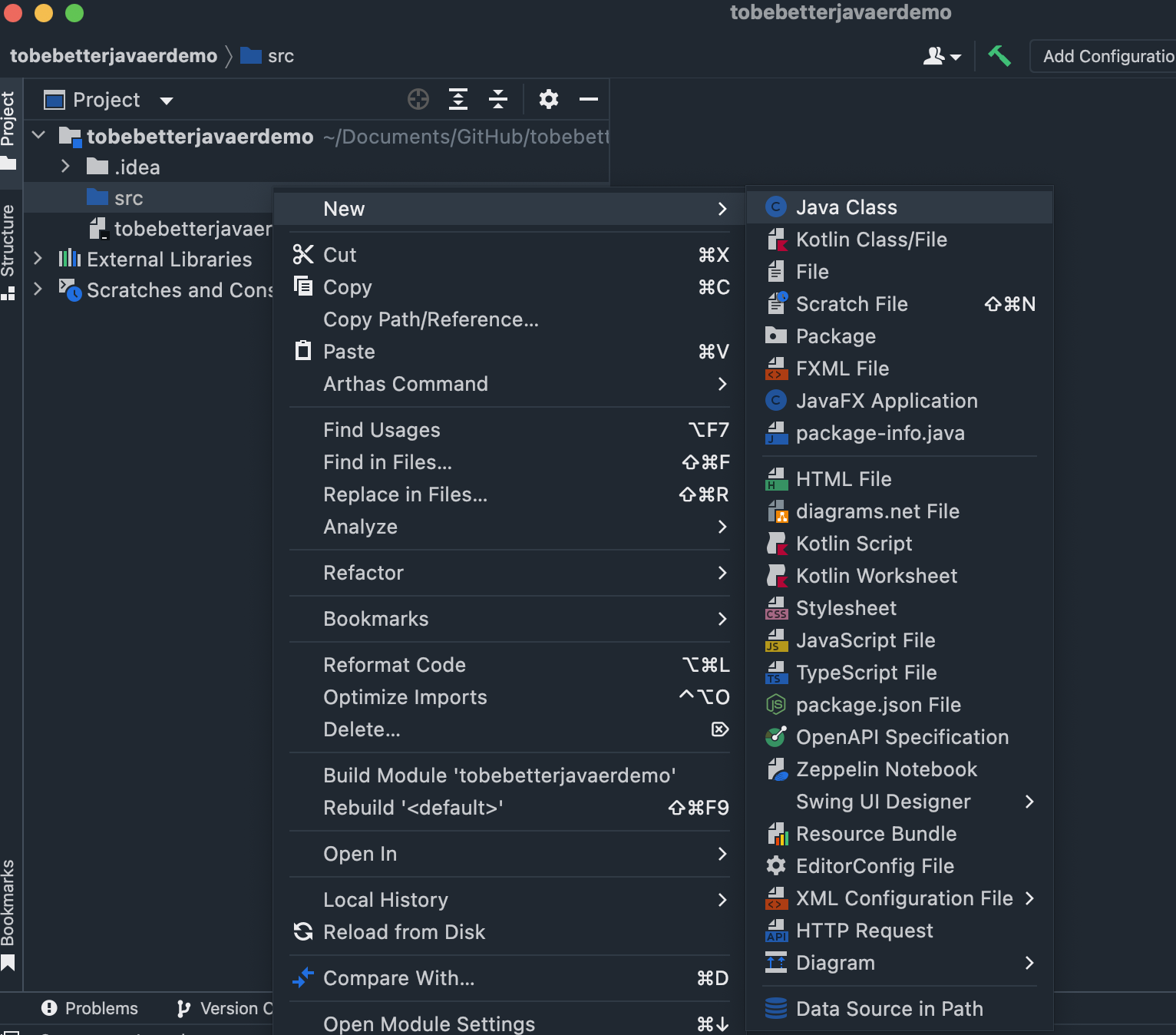
-右键 src 目录,在菜单中依次选择 New → Java Class。
-
-
-
-填写 Class 名,也就是类名(不知道类名是啥,后面会讲),注意大小写敏感,然后按下 enter 键。
-
-
-
-就会出现这样的代码。
-
-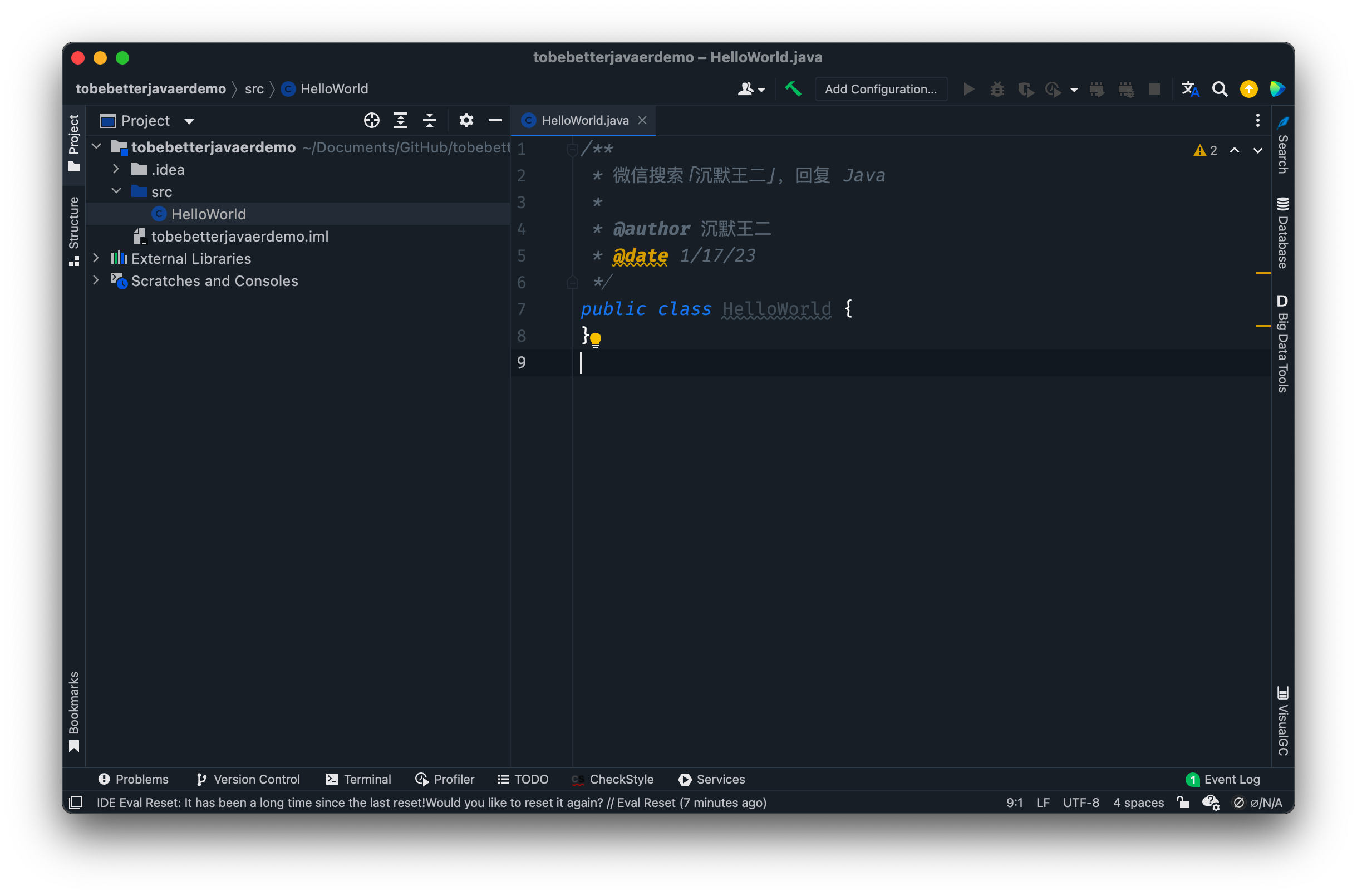
-
-注释是二哥配置好的,你如果没配置可能没有,`public class HelloWorld {}` 是 Intellij IDEA 帮我们自动生成的。
-
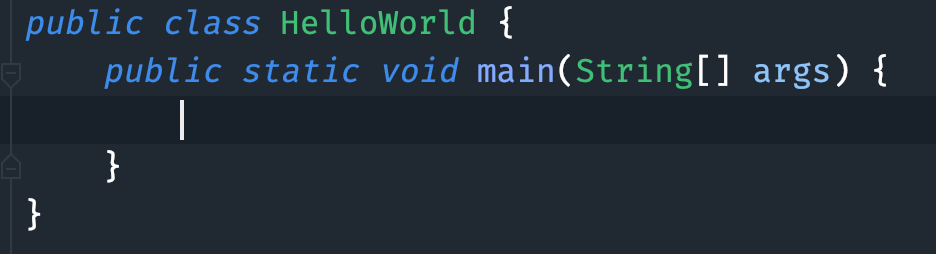
-之后在大括号里面键入 `main` 等 Intellij IDEA 给出提示后键入 enter 键。
-
-Intellij IDEA 就会帮我们自动生成 main 方法,也就是这段代码。
-
-
-
-然后在 main 方法中键入 `so` 等出现提示后键入 enter 键。
-
-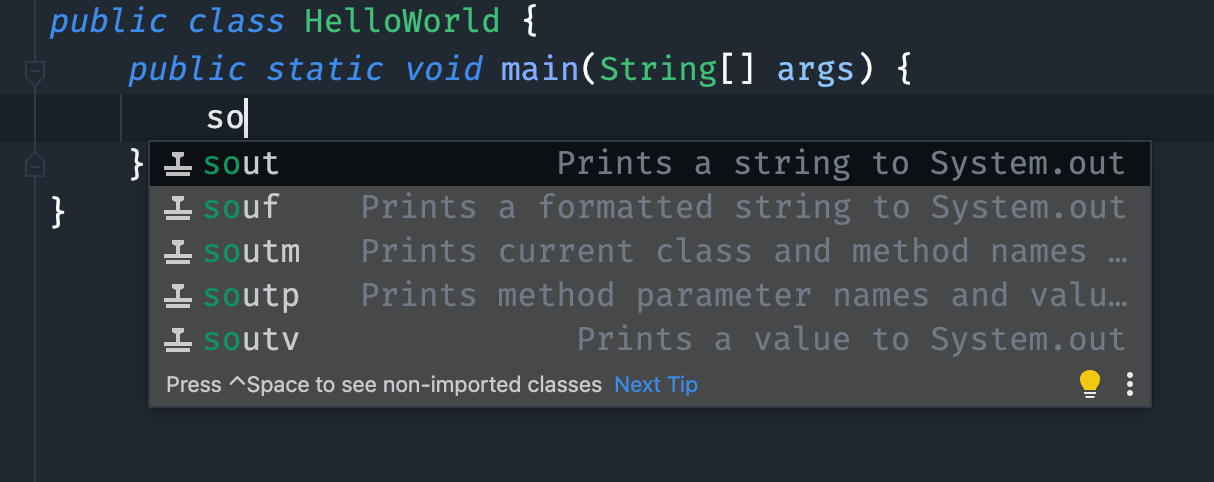
-
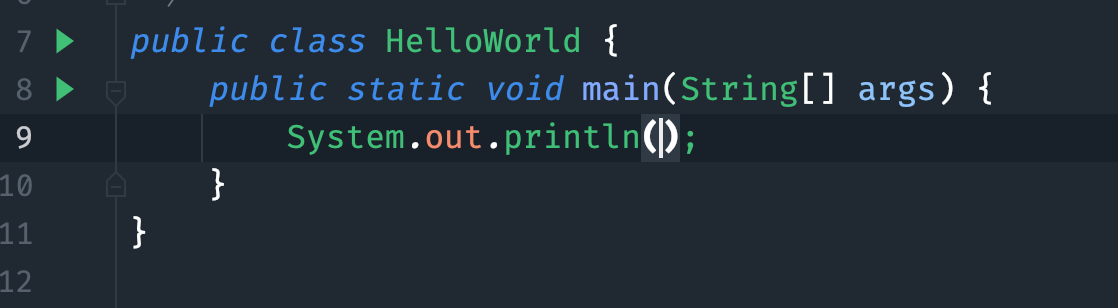
-Intellij IDEA 就会帮我们自动添加 `System.out.println()`,这是一个向控制台输出的方法(小白先不管它是什么意思,后面会讲)。
-
-
-
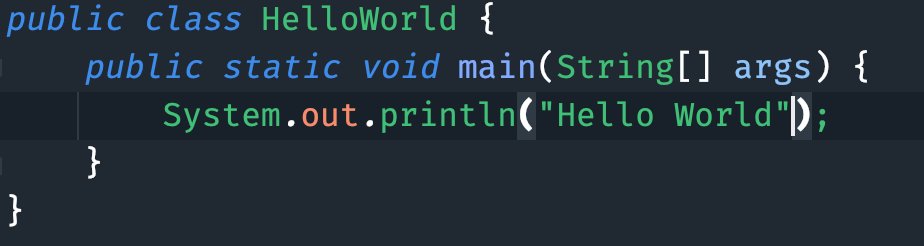
-接着在 `println()` 的小括号中键入 `"Hello World"`,注意是英文的双引号,中文的会报错哦,三妹。
-
-
-
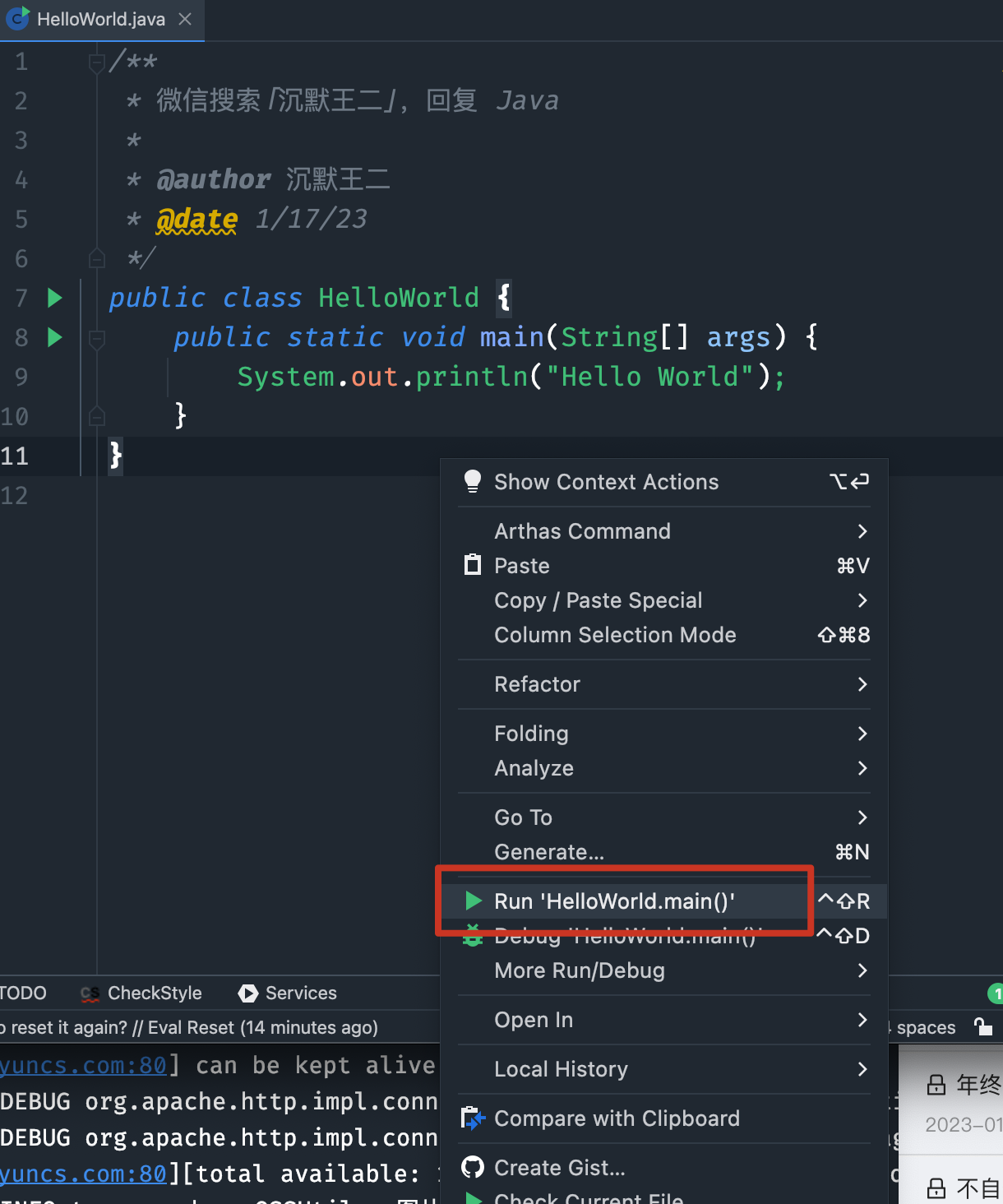
-然后在 HelloWorld.java 的代码编辑器,也就是光标所在的位置右键,选择「Run 'HelloWorld.main()'」。
-
-
-
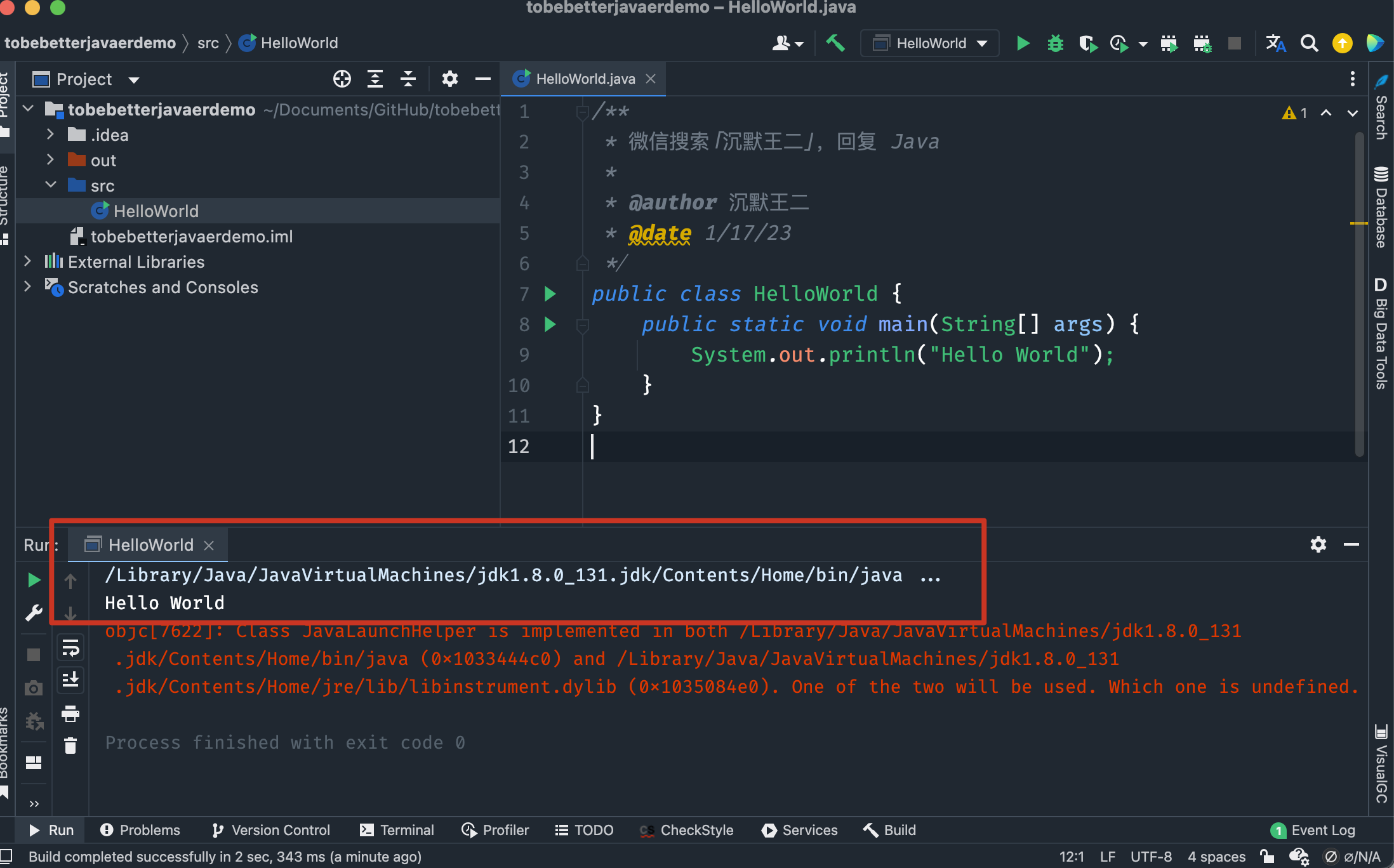
-等 Intellij IDEA 编译&运行后就可以在控制台看到这样的输出内容。
-
-
-
-这就表明我们的第一个 Java 代码完成了,恭喜自己一下吧,三妹!
-
-“二哥,你太棒了,好激动哦!!!!!!!”
-
-下面,我们来简单解释一下这段代码。
-
-第一个 Java 程序非常简单,我们来改一下输出内容,把 Hello World 替换掉:
-
-```java
-public class HelloWorld {
- public static void main(String[] args) {
- System.out.println("三妹,少看手机少打游戏,好好学,美美哒。");
- }
-}
-```
-
-- class 关键字:用于在 Java 中声明一个[类](https://tobebetterjavaer.com/oo/object-class.html)。
-- public 关键字:一个表示可见性的[访问修饰符](https://tobebetterjavaer.com/oo/access-control.html)。
-- [static 关键字](https://tobebetterjavaer.com/oo/static.html):我们可以用它来声明任何一个方法,被 static 修饰后的方法称之为静态方法。静态方法不需要为其创建对象就能调用。
-- void 关键字:表示该方法不返回任何值。
-- main 关键字:表示该方法为主方法,也就是程序运行的入口。`main()` 方法由 Java 虚拟机执行,配合上 static 关键字后,可以不用创建对象就可以调用,可以节省不少内存空间。
-- `String [] args`:`main()` 方法的参数,类型为 [String](https://tobebetterjavaer.com/string/immutable.html) [数组](https://tobebetterjavaer.com/array/array.html),参数名为 args。
-- `System.out.println()`:一个 Java 语句,一般情况下是将传递的参数打印到控制台。System 是 java.lang 包中的一个 final 类,该类提供的设施包括标准输入,标准输出和错误输出流等等。out 是 System 类的静态成员字段,类型为 [PrintStream](https://tobebetterjavaer.com/io/print.html),它与主机的标准输出控制台进行映射。println 是 PrintStream 类的一个方法,通过调用 print 方法并添加一个换行符实现的。
-
-“实在记不住也没关系,我们后面还会讲哦(可以跳转的地方都会展开细讲)。”我的话令三妹感到非常开心。
-
-好,接下来再告诉你一点额外的知识点(如果觉得比较难可跳过),三妹。
-
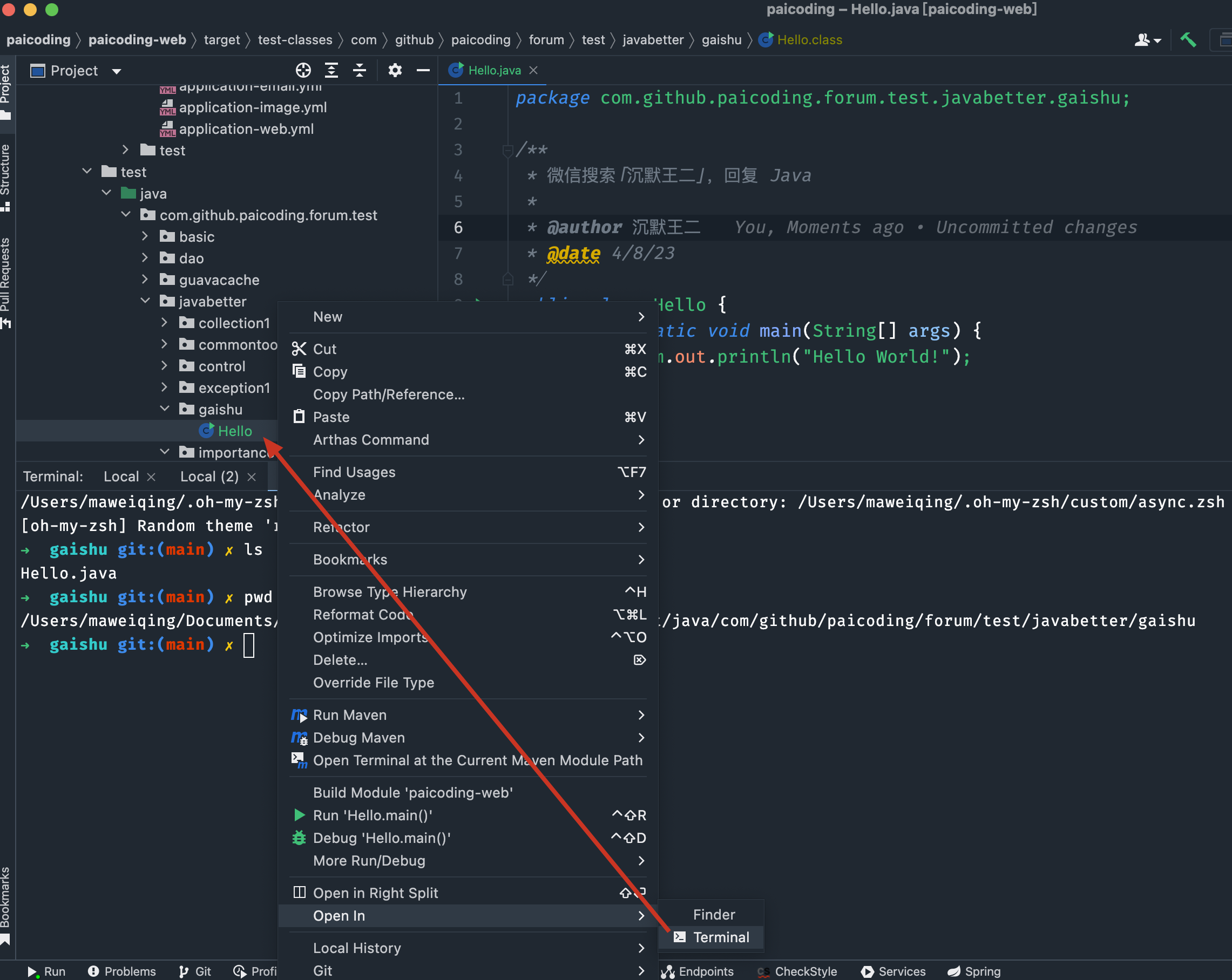
-在 Intellij IDEA 的 terminal 面板中,可以看到对应的 java 源代码文件和编译后的 .class 文件。
-
-可以在对应的文件上右键选择 open in terminal 打开。
-
-
-
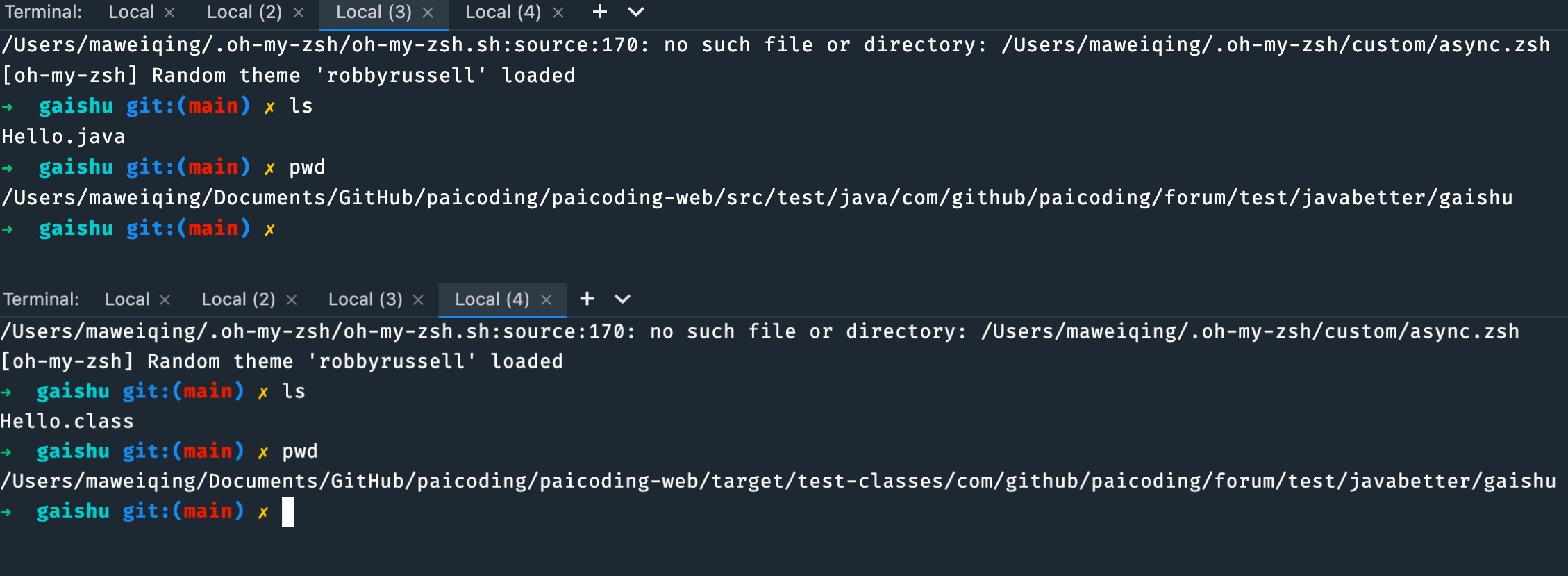
-可以通过 pwd 命令查看当前包路径,通过 ls 命令查看包路径下面有哪些文件。
-
-
-
-class 文件在 target 目录下,classes 为 src/main 目录下的 class 文件;test-classes 为 src/test 目录下的 class 文件。
-
-
-
-“二哥,.class 文件和 .java 源代码,它们之间的关系是什么样的呢?”三妹还是挺喜欢学习的嘛,发现的问题都很关键。
-
-“不错不错,都能挖掘到这个点了。”
-
-.java 是源代码,也就是我们开发人员可以看懂的,可以编写的;.class 是字节码文件,是经过 javac 编译后的文件,是交给 [JVM](https://tobebetterjavaer.com/jvm/what-is-jvm.html) 执行的文件。
-
-“三妹,这里再顺带给你讲一下,Java 是编译型语言还是解释型语言。”
-
-“好啊,我正要问这个‘编译’到底是怎么回事呢?”
-
-Java 的第一道工序是通过 javac 命令把 Java 源码编译成字节码。
-
-比如说我们可以主动执行 `javac Hello.java` 命令将源代码文件编译为 Hello.class 文件(用 Intellij IDEA 的话,并不需要我们主动去编译「javac」,直接运行就可以自动生成 .class 文件)。
-
-
-
-之后,我们可以通过 java 命令运行字节码(比如说 `java Hello`),此时就有 2 种处理方式了。
-
-- 1、字节码由 JVM 逐条解释执行。
-- 2、部分字节码可能由 [JIT(即时编译,戳链接了解](https://tobebetterjavaer.com/jvm/jit.html))编译为机器指令直接执行。
-
-①、逐条解释执行:
-
-逐条解释执行是 Java 虚拟机的基本执行模式。在这种模式下,Java 虚拟机会逐条读取字节码文件中的指令,并将其解释为对应的底层操作。解释执行的优点是实现简单,启动速度较快,但由于每次执行都需要对字节码进行解释,因此执行效率相对较低。
-
-总结一下逐条解释执行的特点:
-
-- 实现简单
-- 启动速度较快
-- 执行效率较低
-
-②、JIT 即时编译:
-
-为了提高 Java 程序的执行效率,Java 虚拟机引入了即时编译([JIT,Just-In-Time Compilation](https://tobebetterjavaer.com/jvm/jit.html))技术。在 JIT 模式下,Java 虚拟机会在运行时将频繁执行的字节码编译为本地机器码,这样就可以直接在硬件上运行,而不需要再次解释。这样做的结果是显著提高了程序的执行速度。需要注意的是,JIT 编译器并不会编译所有的字节码,而是根据一定的策略,仅编译被频繁调用的代码段(热点代码)。
-
-总结一下 JIT 即时编译的特点:
-
-- 提高执行效率
-- 编译热点代码
-- 动态优化
-
-实际上,现代 Java 虚拟机(如 HotSpot)通常会结合这两种执行方式,即解释执行和 JIT 即时编译。在程序运行初期,Java 虚拟机会采用解释执行,以减少启动时间。随着程序的运行,Java 虚拟机会识别出热点代码并使用 JIT 编译器将其编译为本地机器码,从而提高程序的执行效率。这种结合策略称为混合模式。
-
-
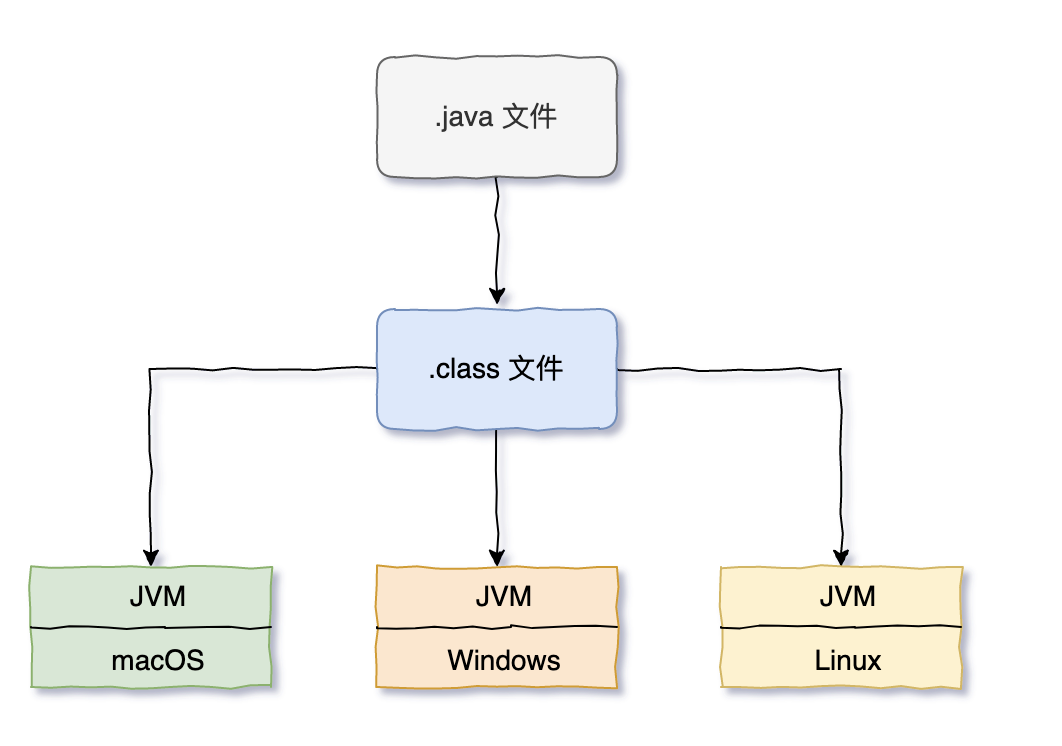
-也就是说,为了跨平台,Java 源代码首先会编译成字节码,字节码不是机器语言,需要 JVM 来解释。
-
-
-
-有了 JVM 这个中间层,Java 的运行效率就没有直接把源代码编译为机器码来得效率更高,这个应该能理解吗,多了中间商嘛。所以为了提高效率,JVM 引入了 JIT 编译器,把一些经常执行的字节码直接搞成机器码。
-
-所以,Java 是解释和编译并存。但通常来说,我们会说“Java 是编译型语言”,尽管这样并不准确,主要是 JIT 是后面才出现的,“先入为主嘛”。
-
-“好的,二哥,我了解了。”
-
-# 第三章:Java语法基础
-
-## 3.1 Java关键字和保留字
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.1 Java关键字和保留字](https://tobebetterjavaer.com/basic-extra-meal/48-keywords.html)
-
-
-
-## 3.2 Java注释
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.2 Java注释](https://tobebetterjavaer.com/basic-grammar/javadoc.html)
-
-
-
-## 3.3 Java数据类型
-
-“Java 是一种静态类型的编程语言,这意味着所有变量必须在使用之前声明好,也就是必须得先指定变量的类型和名称。”我吸了一口麦香可可奶茶后对三妹说。
-
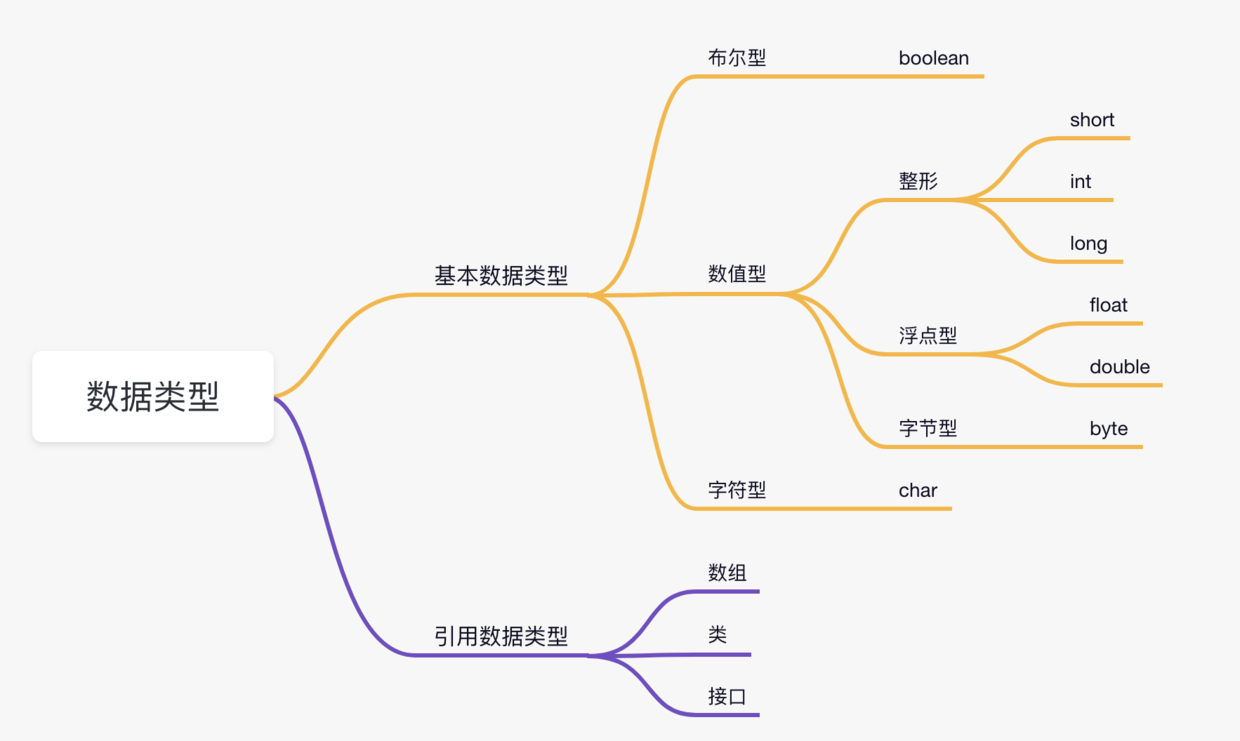
-Java 中的数据类型可分为 2 种:
-
-1)**基本数据类型**。
-
-基本数据类型是 Java 语言操作数据的基础,包括 boolean、char、byte、short、int、long、float 和 double,共 8 种。
-
-2)**引用数据类型**。
-
-除了基本数据类型以外的类型,都是所谓的引用类型。常见的有[数组](https://tobebetterjavaer.com/array/array.html)(对,没错,数组是引用类型,后面我们会讲)、class(也就是[类](https://tobebetterjavaer.com/oo/object-class.html)),以及[接口](https://tobebetterjavaer.com/oo/interface.html)(指向的是实现接口的类的对象)。
-
-来个思维导图,感受下。
-
-
-
-[变量](https://tobebetterjavaer.com/oo/var.html)可以分为局部变量、成员变量、静态变量。
-
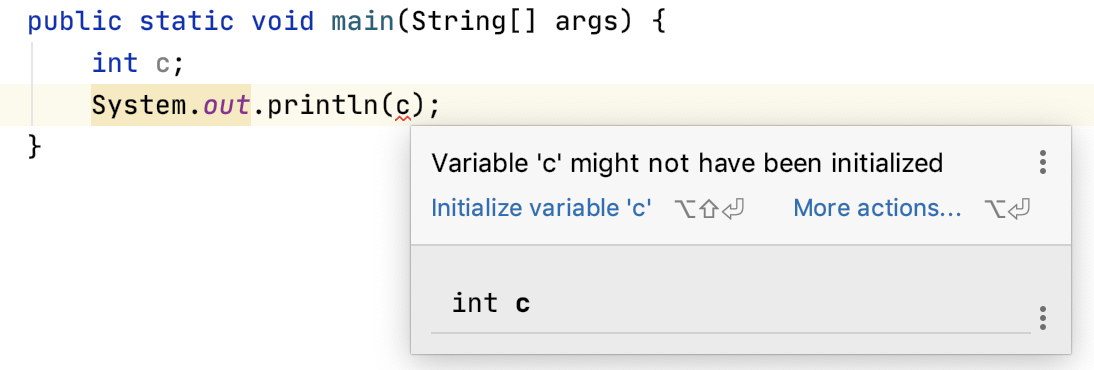
-当变量是局部变量的时候,必须得先初始化,否则编译器不允许你使用它。拿 int 来举例吧,看下图。
-
-
-
-当变量是成员变量或者静态变量时,可以不进行初始化,它们会有一个默认值,仍然以 int 为例,来看代码:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalVar {
- private int a;
- static int b;
-
- public static void main(String[] args) {
- LocalVar lv = new LocalVar();
- System.out.println(lv.a);
- System.out.println(b);
- }
-}
-```
-
-来看输出结果:
-
-```
-0
-0
-```
-
-瞧见没,int 作为成员变量时或者静态变量时的默认值是 0。那不同的基本数据类型,是有不同的默认值和大小的,来个表格感受下。
-
-| 数据类型 | 默认值 | 大小 |
-| -------- | -------- | ------ |
-| boolean | false | 1 比特 |
-| char | '\u0000' | 2 字节 |
-| byte | 0 | 1 字节 |
-| short | 0 | 2 字节 |
-| int | 0 | 4 字节 |
-| long | 0L | 8 字节 |
-| float | 0.0f | 4 字节 |
-| double | 0.0 | 8 字节 |
-
-### 01、比特和字节
-
-那三妹可能要问,“比特和字节是什么鬼?”
-
-比特币(Bitcoin)听说过吧?字节跳动(Byte Dance)听说过吧?这些名字当然不是乱起的,确实和比特、字节有关系。
-
-#### **1)bit(比特)**
-
-比特作为信息技术的最基本存储单位,非常小,但大名鼎鼎的比特币就是以此命名的,它的简写为小写字母“b”。
-
-大家都知道,计算机是以二进制存储数据的,二进制的一位,就是 1 比特,也就是说,比特要么为 0 要么为 1。
-
-#### **2)Byte(字节)**
-
-通常来说,一个英文字符是一个字节,一个中文字符是两个字节。字节与比特的换算关系是:1 字节 = 8 比特。
-
-在往上的单位就是 KB,并不是 1000 字节,因为计算机只认识二进制,因此是 2 的 10 次方,也就是 1024 个字节。
-
-(终于知道 1024 和程序员的关系了吧?狗头保命)
-
-
-
-### 02、基本数据类型
-
-接下来,我们再来详细地了解一下 8 种基本数据类型。
-
-#### 1)布尔
-
-布尔(boolean)仅用于存储两个值:true 和 false,也就是真和假,通常用于条件的判断。代码示例:
-
-```java
-boolean hasMoney = true;
-boolean hasGirlFriend = false;
-```
-
-#### 2)byte
-
-一个字节可以表示 2^8 = 256 个不同的值。由于 byte 是有符号的,它的值可以是负数或正数,其取值范围是 -128 到 127(包括 -128 和 127)。
-
-在网络传输、大文件读写时,为了节省空间,常用字节来作为数据的传输方式。代码示例:
-
-```java
-byte b; // 声明一个 byte 类型变量
-b = 10; // 将值 10 赋给变量 b
-byte c = -100; // 声明并初始化一个 byte 类型变量 c,赋值为 -100
-```
-
-#### 3)short
-
-short 的取值范围在 -32,768 和 32,767 之间,包含 32,767。代码示例:
-
-```java
-short s; // 声明一个 short 类型变量
-s = 1000; // 将值 1000 赋给变量 s
-short t = -2000; // 声明并初始化一个 short 类型变量 t,赋值为 -2000
-```
-
-实际开发中,short 比较少用,整型用 int 就 OK。
-
-#### 3)int
-
-int 的取值范围在 -2,147,483,648(-2 ^ 31)和 2,147,483,647(2 ^ 31 -1)(含)之间。如果没有特殊需求,整型数据就用 int。代码示例:
-
-```java
-int i; // 声明一个 int 类型变量
-i = 1000000; // 将值 1000000 赋给变量 i
-int j = -2000000; // 声明并初始化一个 int 类型变量 j,赋值为 -2000000
-```
-
-#### 5)long
-
-long 的取值范围在 -9,223,372,036,854,775,808(-2^63) 和 9,223,372,036,854,775,807(2^63 -1)(含)之间。如果 int 存储不下,就用 long。代码示例:
-
-```java
-long l; // 声明一个 long 类型变量
-l = 100000000000L; // 将值 100000000000L 赋给变量 l(注意要加上 L 后缀)
-long m = -20000000000L; // 声明并初始化一个 long 类型变量 m,赋值为 -20000000000L
-```
-
-为了和 int 作区分,long 型变量在声明的时候,末尾要带上大写的“L”。不用小写的“l”,是因为小写的“l”容易和数字“1”混淆。
-
-#### 6)float
-
-float 是单精度的浮点数(单精度浮点数的有效数字大约为 6 到 7 位),32 位(4 字节),遵循 IEEE 754(二进制浮点数算术标准),取值范围为 1.4E-45 到 3.4E+38。float 不适合用于精确的数值,比如说金额。代码示例:
-
-```java
-float f; // 声明一个 float 类型变量
-f = 3.14159f; // 将值 3.14159f 赋给变量 f(注意要加上 f 后缀)
-float g = -2.71828f; // 声明并初始化一个 float 类型变量 g,赋值为 -2.71828f
-```
-
-为了和 double 作区分,float 型变量在声明的时候,末尾要带上小写的“f”。不需要使用大写的“F”,是因为小写的“f”很容易辨别。
-
-#### 7)double
-
-double 是双精度浮点数(双精度浮点数的有效数字大约为 15 到 17 位),占 64 位(8 字节),也遵循 IEEE 754 标准,取值范围大约 ±4.9E-324 到 ±1.7976931348623157E308。double 同样不适合用于精确的数值,比如说金额。
-
-代码示例:
-
-```java
-double myDouble = 3.141592653589793;
-```
-
-在进行金融计算或需要精确小数计算的场景中,可以使用 [BigDecimal 类](https://tobebetterjavaer.com/basic-grammar/bigdecimal-biginteger.html)来避免浮点数舍入误差。BigDecimal 可以表示一个任意大小且精度完全准确的浮点数。
-
-> 在实际开发中,如果不是特别大的金额(精确到 0.01 元,也就是一分钱),一般建议乘以 100 转成整型进行处理。
-
-#### 8)char
-
-char 用于表示 Unicode 字符,占 16 位(2 字节)的存储空间,取值范围为 0 到 65,535。
-
-代码示例:
-
-```java
-char letterA = 'A'; // 用英文的单引号包裹住。
-```
-
-注意,字符字面量应该用单引号('')包围,而不是双引号(""),因为[双引号表示字符串字面量](https://tobebetterjavaer.com/string/constant-pool.html)。
-
-### 03、单精度和双精度
-
-单精度(single-precision)和双精度(double-precision)是指两种不同精度的浮点数表示方法。
-
-单精度是这样的格式,1 位符号,8 位指数,23 位小数。
-
-
-
-单精度浮点数通常占用 32 位(4 字节)存储空间。数值范围大约是 ±1.4E-45 到 ±3.4028235E38,精度大约为 6 到 9 位有效数字。
-
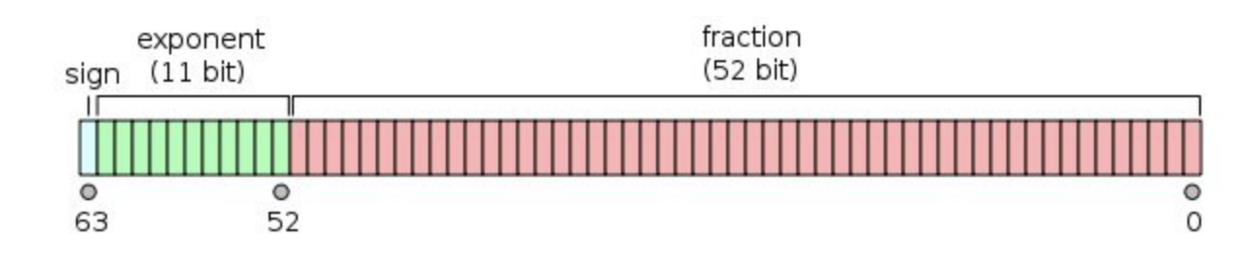
-双精度是这样的格式,1 位符号,11 位指数,52 为小数。
-
-
-
-双精度浮点数通常占用 64 位(8 字节)存储空间,数值范围大约是 ±4.9E-324 到 ±1.7976931348623157E308,精度大约为 15 到 17 位有效数字。
-
-计算精度取决于小数位(尾数)。小数位越多,则能表示的数越大,那么计算精度则越高。
-
-一个数由若干位数字组成,其中影响测量精度的数字称作有效数字,也称有效数位。有效数字指科学计算中用以表示一个浮点数精度的那些数字。一般地,指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字。如 1.24 和 0.00124 的有效数字都有 3 位。
-
-以下是确定有效数字的一些基本规则:
-
-- 非零数字总是有效的。
-- 位于两个非零数字之间的零是有效的。
-- 对于小数,从左侧开始的第一个非零数字之前的零是无效的。
-- 对于整数,从右侧开始的第一个非零数字之后的零是无效的。
-
-下面是一些示例,说明如何确定有效数字:
-
-- 1234:4 个有效数字(所有数字都是非零数字)
-- 1002:4 个有效数字(零位于两个非零数字之间)
-- 0.00234:3 个有效数字(从左侧开始的前两个零是无效的)
-- 1200:2 个有效数字(从右侧开始的两个零是无效的)
-
-### 04、int 和 char 类型互转
-
-int 和 char 之间比较特殊,可以互转,也会在以后的学习当中经常遇到。
-
-1)可以通过[强制类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html)将整型 int 转换为字符 char。
-
-```java
-int value_int = 65;
-char value_char = (char) value_int;
-System.out.println(value_char);
-```
-
-输出 `A`(其 [ASCII 值](https://tobebetterjavaer.com/basic-extra-meal/java-unicode.html)可以通过整数 65 来表示)。
-
-2)可以使用 `Character.forDigit()` 方法将整型 int 转换为字符 char,参数 radix 为基数,十进制为 10,十六进制为 16。。
-
-```java
-int radix = 10;
-int value_int = 6;
-char value_char = Character.forDigit(value_int , radix);
-System.out.println(value_char );
-```
-
-Character 为 char 的包装器类型。我们随后会讲。
-
-3)可以使用 int 的包装器类型 Integer 的 `toString()` 方法+String 的 `charAt()` 方法转成 char。
-
-```java
-int value_int = 1;
-char value_char = Integer.toString(value_int).charAt(0);
-System.out.println(value_char );
-```
-
-4)char 转 int
-
-当然了,如果只是简单的 char 转 int,直接赋值就可以了。
-
-```java
-int a = 'a';
-```
-
-因为发生了[自动类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html),后面会细讲。
-
-### 05、包装器类型
-
-包装器类型(Wrapper Types)是 Java 中的一种特殊类型,用于将基本数据类型(如 int、float、char 等)转换为对应的[对象类型](https://tobebetterjavaer.com/oo/object-class.html)。
-
-Java 提供了以下包装器类型,与基本数据类型一一对应:
-
-- Byte(对应 byte)
-- Short(对应 short)
-- Integer(对应 int)
-- Long(对应 long)
-- Float(对应 float)
-- Double(对应 double)
-- Character(对应 char)
-- Boolean(对应 boolean)
-
-包装器类型允许我们使用基本数据类型提供的各种实用方法,并兼容需要对象类型的场景。例如,我们可以使用 Integer 类的 parseInt 方法将字符串转换为整数,或使用 Character 类的 isDigit 方法检查字符是否为数字,还有前面提到的 `Character.forDigit()` 方法。
-
-下面是一个简单的示例,演示了如何使用包装器类型:
-
-```java
-// 使用 Integer 包装器类型
-Integer integerValue = new Integer(42);
-System.out.println("整数值: " + integerValue);
-
-// 将字符串转换为整数
-String numberString = "123";
-int parsedNumber = Integer.parseInt(numberString);
-System.out.println("整数值: " + parsedNumber);
-
-// 使用 Character 包装器类型
-Character charValue = new Character('A');
-System.out.println("字符: " + charValue);
-
-// 检查字符是否为数字
-char testChar = '9';
-if (Character.isDigit(testChar)) {
-System.out.println("字符是个数字.");
-}
-```
-
-上面的示例中,我们创建了一个 [Integer 类型](https://tobebetterjavaer.com/basic-extra-meal/int-cache.html)的对象 integerValue 并为其赋值 42。然后,我们将其值打印到控制台。
-
-我们有一个包含数字的[字符串](https://tobebetterjavaer.com/string/immutable.html) numberString。我们使用 `Integer.parseInt()` 方法将其转换为整数 parsedNumber。然后,我们将转换后的值打印到控制台。
-
-我们有一个字符变量 testChar,并为其赋值字符 '9'。我们使用 `Character.isDigit()` 方法检查 testChar 是否为数字字符。如果是数字字符,我们将输出一条消息到控制台。
-
-从 Java 5 开始,[自动装箱(Autoboxing)和自动拆箱(Unboxing)机制](https://tobebetterjavaer.com/basic-extra-meal/box.html)允许我们在基本数据类型和包装器类型之间自动转换,无需显式地调用构造方法或转换方法(链接里会细讲)。
-
-```java
-Integer integerValue = 42; // 自动装箱,等同于 new Integer(42)
-int primitiveValue = integerValue; // 自动拆箱,等同于 integerValue.intValue()
-```
-
-### 06、引用数据类型
-
-基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有的(学完数组&字符串,以及面向对象编程后会更加清楚,这里先简单过一下)。
-
-[String](https://tobebetterjavaer.com/string/immutable.html) 是最典型的引用数据类型,所以我们就拿 String 类举例,看下面这段代码:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalRef {
- private String a;
- static String b;
-
- public static void main(String[] args) {
- LocalRef lv = new LocalRef();
- System.out.println(lv.a);
- System.out.println(b);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-null
-null
-```
-
-null 在 Java 中是一个很神奇的存在,在你以后的程序生涯中,见它的次数不会少,尤其是伴随着令人烦恼的“[空指针异常](https://tobebetterjavaer.com/exception/npe.html)”,也就是所谓的 `NullPointerException`。
-
-也就是说,引用数据类型的默认值为 null,包括数组和接口。
-
-那你是不是很好奇,为什么[数组](https://tobebetterjavaer.com/array/array.html)和[接口](https://tobebetterjavaer.com/oo/interface.html)也是引用数据类型啊?
-
-先来看数组:
-
-```java
-int [] arrays = {1,2,3};
-System.out.println(arrays);
-```
-
-arrays 是一个 int 类型的数组,对吧?打印结果如下所示:
-
-```
-[I@2d209079
-```
-
-`[I` 表示数组是 int 类型的,@ 后面是十六进制的 hashCode——这样的打印结果太“人性化”了,一般人表示看不懂!为什么会这样显示呢?查看一下 `java.lang.Object` 类的 `toString()` 方法就明白了。
-
-
-
-数组虽然没有显式定义成一个类,但它的确是一个对象,继承了祖先类 Object 的所有方法。那为什么数组不单独定义一个类来表示呢?就像字符串 String 类那样呢?
-
-一个合理的解释是 Java 将其隐藏了。假如真的存在一个 Array.java,我们也可以假想它真实的样子,它必须要定义一个容器来存放数组的元素,就像 String 类那样。
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- /** The value is used for character storage. */
- private final char value[];
-}
-```
-
-数组内部定义数组?没必要的!
-
-再来看接口:
-
-```java
-List list = new ArrayList<>();
-System.out.println(list);
-```
-
-[List](https://tobebetterjavaer.com/collection/gailan.html) 是一个非常典型的接口:
-
-```java
-public interface List extends Collection {}
-```
-
-而 [ArrayList](https://tobebetterjavaer.com/collection/arraylist.html) 是 List 接口的一个实现:
-
-```java
-public class ArrayList extends AbstractList
- implements List, RandomAccess, Cloneable, java.io.Serializable
-{}
-```
-
-对于接口类型的引用变量来说,你没法直接 new 一个:
-
-
-
-只能 new 一个实现它的类的对象——那自然接口也是引用数据类型了。
-
-来看一下基本数据类型和引用数据类型之间最大的差别。
-
-基本数据类型:
-
-- 1、变量名指向具体的数值。
-- 2、基本数据类型存储在栈上。
-
-引用数据类型:
-
-- 1、变量名指向的是存储对象的内存地址,在栈上。
-- 2、内存地址指向的对象存储在堆上。
-
-### 07、堆和栈
-
-看到这,三妹是不是又要问,“堆是什么,栈又是什么?”
-
-堆是堆(heap),栈是栈(stack),如果看到“堆栈”的话,请不要怀疑自己,那是翻译的错,堆栈也是栈,反正我很不喜欢“堆栈”这种叫法,容易让新人掉坑里。
-
-堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java 中的对象就放在这里,这样做的好处就是:
-
-> 当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
-
-栈,能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快。既然访问速度快,要好好利用啊!Java 就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
-
-不是的,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
-
-这么说就理解了吧?
-
-如果还不理解的话,可以看一下这个视频,讲的非常不错:[什么是堆?什么是栈?他们之间有什么区别和联系?](https://www.zhihu.com/question/19729973/answer/2238950166)
-
-用图来表示一下,左侧是栈,右侧是堆。
-
-
-
-这里再补充一些额外的知识点,能看懂就继续吸收,看不懂可以先去学下一节,以后再来补,没关系的。学习就是这样,可以跳过,可以温故。
-
-举个例子。
-
-```java
-String a = new String("沉默王二")
-```
-
-这段代码会先在堆里创建一个 沉默王二的字符串对象,然后再把对象的引用 a 放到栈里面。这里面还会涉及到[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html),后面会讲。
-
-那么对于这样一段代码,有基本数据类型的变量,有引用类型的变量,堆和栈都是如何存储他们的呢?
-
-```java
-public void test()
-{
- int i = 4;
- int y = 2;
- Object o1 = new Object();
-}
-```
-
-我来画个图表示下。
-
-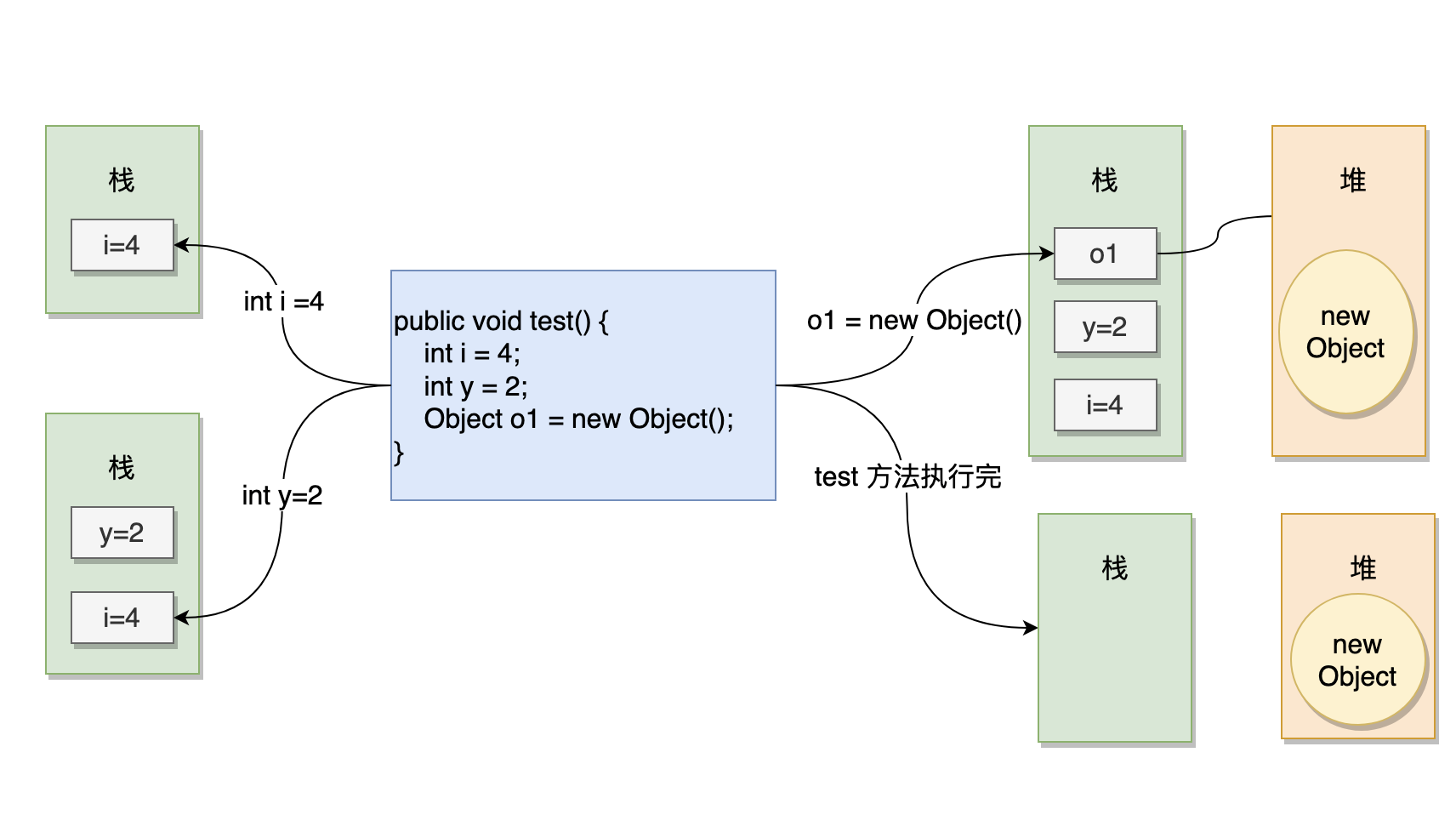
-
-应该一目了然了吧?
-
-“好了,三妹,关于 Java 中的数据类型就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
-
-### 08、小结
-
-本文详细探讨了 Java 数据类型,包括比特与字节、基本数据类型、单精度与双精度、int 与 char 互转、包装器类型、引用数据类型以及堆与栈的内存模型。通过阅读本文,你将全面了解 Java 数据类型的概念与使用方法,为 Java 编程打下坚实基础。
-
-
-
-## 3.4 Java数据类型转换
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.4 Java数据类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html)
-
-
-
-## 3.5 Java基本数据类型缓存池
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.5 Java基本数据类型缓存池](https://tobebetterjavaer.com/basic-extra-meal/int-cache.html)
-
-## 3.6 Java运算符
-
-“二哥,让我盲猜一下哈,运算符是不是指的就是加减乘除啊?”三妹的脸上泛着甜甜的笑容,我想她一定对提出的问题很有自信。
-
-“是的,三妹。运算符在 Java 中占据着重要的位置,对程序的执行有着很大的帮助。除了常见的加减乘除,还有许多其他类型的运算符,来看下面这张思维导图。”
-
-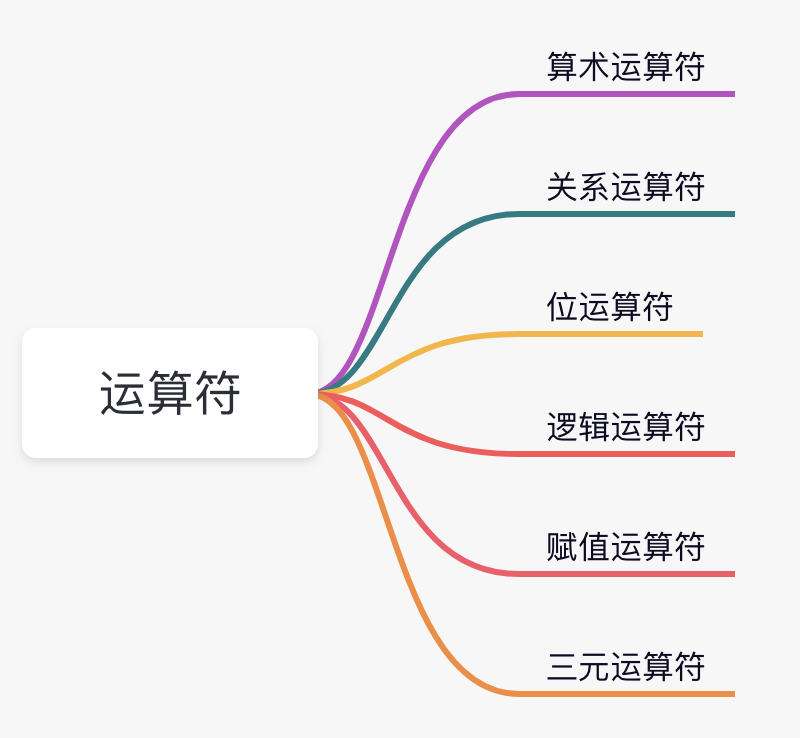
-
-
-### 01、算术运算符
-
-算术运算符除了最常见的加减乘除,还有一个取余的运算符,用于得到除法运算后的余数,来串代码感受下。
-
-```java
-int a = 10;
-int b = 5;
-
-System.out.println(a + b);//15
-System.out.println(a - b);//5
-System.out.println(a * b);//50
-System.out.println(a / b);//2
-System.out.println(a % b);//0
-
-b = 3;
-System.out.println(a + b);//13
-System.out.println(a - b);//7
-System.out.println(a * b);//30
-System.out.println(a / b);//3
-System.out.println(a % b);//1
-```
-
-对于初学者来说,加法(+)、减法(-)、乘法(*)很好理解,但除法(/)和取余(%)会有一点点疑惑。在以往的认知里,10/3 是除不尽的,结果应该是 3.333333...,而不应该是 3。相应的,余数也不应该是 1。这是为什么呢?
-
-因为数字在程序中可以分为两种,一种是整型,一种是浮点型(不清楚的同学可以回头看看[数据类型那篇](https://tobebetterjavaer.com/basic-grammar/basic-data-type.html)),整型和整型的运算结果就是整型,不会出现浮点型。否则,就会出现浮点型。
-
-```java
-int a = 10;
-float c = 3.0f;
-double d = 3.0;
-System.out.println(a / c); // 3.3333333
-System.out.println(a / d); // 3.3333333333333335
-System.out.println(a % c); // 1.0
-System.out.println(a % d); // 1.0
-```
-
-需要注意的是,当浮点数除以 0 的时候,结果为 Infinity 或者 NaN。
-
-```java
-System.out.println(10.0 / 0.0); // Infinity
-System.out.println(0.0 / 0.0); // NaN
-```
-
-Infinity 的中文意思是无穷大,NaN 的中文意思是这不是一个数字(Not a Number)。
-
-当整数除以 0 的时候(`10 / 0`),会抛出[异常](https://tobebetterjavaer.com/exception/gailan.html):
-
-```
-Exception in thread "main" java.lang.ArithmeticException: / by zero
- at com.itwanger.eleven.ArithmeticOperator.main(ArithmeticOperator.java:32)
-```
-
-所以整数在进行除法运算时,需要先判断除数是否为 0,以免程序抛出异常。
-
-算术运算符中还有两种特殊的运算符,自增运算符(++)和自减运算符(--),它们也叫做一元运算符,只有一个操作数。
-
-```java
-int x = 10;
-System.out.println(x++);//10 (11)
-System.out.println(++x);//12
-System.out.println(x--);//12 (11)
-System.out.println(--x);//10
-```
-
-一元运算符可以放在数字的前面或者后面,放在前面叫前自增(前自减),放在后面叫后自增(后自减)。
-
-前自增和后自增是有区别的,拿 `int y = ++x` 这个表达式来说(x = 10),它可以拆分为 `x = x+1 = 11; y = x = 11`,所以表达式的结果为 `x = 11, y = 11`。拿 `int y = x++` 这个表达式来说(x = 10),它可以拆分为 `y = x = 10; x = x+1 = 11`,所以表达式的结果为 `x = 11, y = 10`。
-
-```java
-int x = 10;
-int y = ++x;
-System.out.println(y + " " + x);// 11 11
-
-x = 10;
-y = x++;
-System.out.println(y + " " + x);// 10 11
-```
-
-对于前自减和后自减来说,你可以自己试一把。
-
-### 02、关系运算符
-
-关系运算符用来比较两个操作数,返回结果为 true 或者 false。
-
-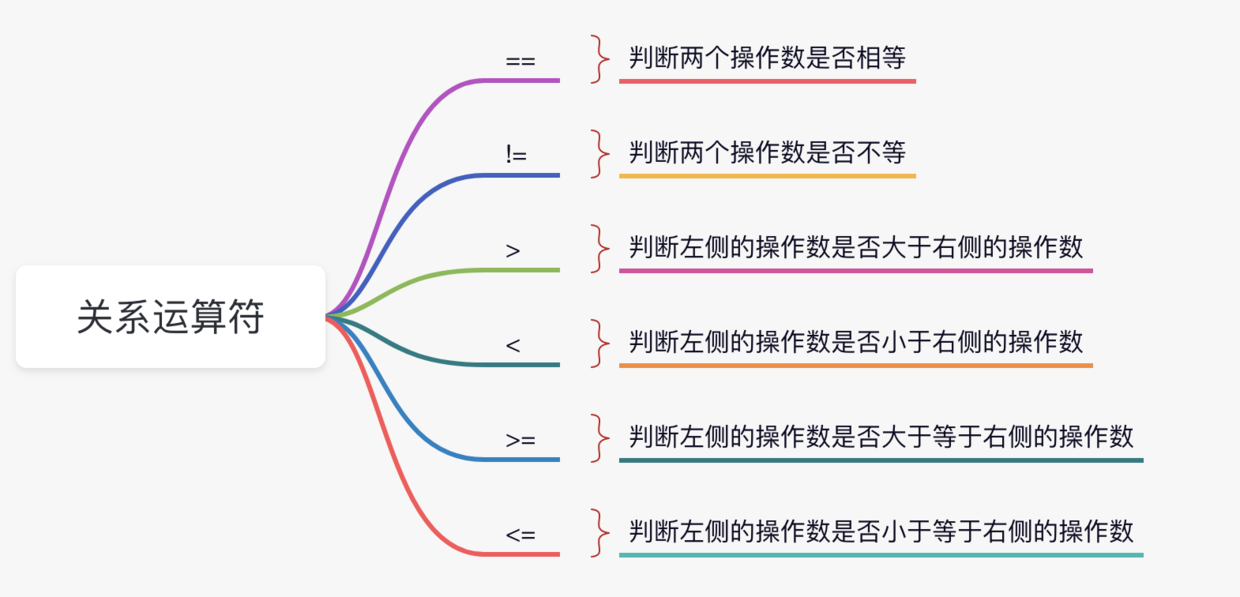
-
-来看示例:
-
-```java
-int a = 10, b = 20;
-System.out.println(a == b); // false
-System.out.println(a != b); // true
-System.out.println(a > b); // false
-System.out.println(a < b); // true
-System.out.println(a >= b); // false
-System.out.println(a <= b); // true
-```
-
-### 03、位运算符
-
-在学习位运算符之前,需要先学习一下二进制,因为位运算符操作的不是整型数值(int、long、short、char、byte)本身,而是整型数值对应的二进制。
-
-```java
-System.out.println(Integer.toBinaryString(60)); // 111100
-System.out.println(Integer.toBinaryString(13)); // 1101
-```
-
- 从程序的输出结果可以看得出来,60 的二进制是 0011 1100(用 0 补到 8 位),13 的二进制是 0000 1101。
-
-PS:现代的二进制记数系统由戈特弗里德·威廉·莱布尼茨于 1679 年设计。莱布尼茨是德意志哲学家、数学家,历史上少见的通才。
-
-
-
-来看示例:
-
-```java
-int a = 60, b = 13;
-System.out.println("a 的二进制:" + Integer.toBinaryString(a)); // 111100
-System.out.println("b 的二进制:" + Integer.toBinaryString(b)); // 1101
-
-int c = a & b;
-System.out.println("a & b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a | b;
-System.out.println("a | b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a ^ b;
-System.out.println("a ^ b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = ~a;
-System.out.println("~a:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a << 2;
-System.out.println("a << 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a >> 2;
-System.out.println("a >> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a >>> 2;
-System.out.println("a >>> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-```
-
-对于初学者来说,位运算符无法从直观上去计算出结果,不像加减乘除那样。因为我们日常接触的都是十进制,位运算的时候需要先转成二进制,然后再计算出结果。
-
-鉴于此,初学者在写代码的时候其实很少会用到位运算。对于编程高手来说,为了提高程序的性能,会在一些地方使用位运算。比如说,HashMap 在计算哈希值的时候:
-
-```java
-static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
-}
-```
-
-如果对位运算一点都不懂的话,遇到这样的源码就很吃力。所以说,虽然位运算用的少,但还是要懂。
-
-1)按位左移运算符:
-
-```java
-System.out.println(10<<2);//10*2^2=10*4=40
-System.out.println(10<<3);//10*2^3=10*8=80
-System.out.println(20<<2);//20*2^2=20*4=80
-System.out.println(15<<4);//15*2^4=15*16=240
-```
-
-`10<<2` 等于 10 乘以 2 的 2 次方;`10<<3` 等于 10 乘以 2 的 3 次方。
-
-2)按位右移运算符:
-
-```java
-System.out.println(10>>2);//10/2^2=10/4=2
-System.out.println(20>>2);//20/2^2=20/4=5
-System.out.println(20>>3);//20/2^3=20/8=2
-```
-
-`10>>2` 等于 10 除以 2 的 2 次方;`20>>2` 等于 20 除以 2 的 2 次方。
-
-### 04、逻辑运算符
-
-逻辑与运算符(&&):多个条件中只要有一个为 false 结果就为 false。
-
-逻辑或运算符(||):多个条件只要有一个为 true 结果就为 true。
-
-```java
-int a=10;
-int b=5;
-int c=20;
-System.out.println(ab||ab|a aList = new ArrayList<>();
-for (int element : anArray) {
- aList.add(element);
-}
-```
-
-更优雅的方式是通过 Arrays 类的 `asList()` 方法:
-
-```java
-List aList = Arrays.asList(anArray);
-```
-
-不过需要注意的是,Arrays.asList 的参数需要是 Integer 数组,而 anArray 目前是 int 类型,我们需要换另外一种方式。
-
-```java
-List aList = Arrays.stream(anArray).boxed().collect(Collectors.toList());
-```
-
-这又涉及到了 Java [流](https://tobebetterjavaer.com/java8/stream.html)的知识,后面会讲到。
-
-还有一个需要注意的是,Arrays.asList 方法返回的 ArrayList 并不是 `java.util.ArrayList`,它其实是 Arrays 类的一个内部类:
-
-```java
-private static class ArrayList extends AbstractList
- implements RandomAccess, java.io.Serializable{}
-```
-
-如果需要添加元素或者删除元素的话,需要把它转成 `java.util.ArrayList`。
-
-```java
-new ArrayList<>(Arrays.asList(anArray));
-```
-
-Java 8 新增了 Stream 流的概念,这就意味着我们也可以将数组转成 Stream 进行操作。
-
-```java
-String[] anArray = new String[] {"沉默王二", "一枚有趣的程序员", "好好珍重他"};
-Stream aStream = Arrays.stream(anArray);
-```
-
-如果想对数组进行排序的话,可以使用 Arrays 类提供的 `sort()` 方法。
-
-- 基本数据类型按照升序排列
-- 实现了 Comparable 接口的对象按照 `compareTo()` 的排序
-
-来看第一个例子:
-
-```java
-int[] anArray = new int[] {5, 2, 1, 4, 8};
-Arrays.sort(anArray);
-```
-
-排序后的结果如下所示:
-
-```java
-[1, 2, 4, 5, 8]
-```
-
-来看第二个例子:
-
-```java
-String[] yetAnotherArray = new String[] {"A", "E", "Z", "B", "C"};
-Arrays.sort(yetAnotherArray, 1, 3,
- Comparator.comparing(String::toString).reversed());
-```
-
-只对 1-3 位置上的元素进行反序,所以结果如下所示:
-
-```
-[A, Z, E, B, C]
-```
-
-有时候,我们需要从数组中查找某个具体的元素,最直接的方式就是通过遍历的方式:
-
-```java
-int[] anArray = new int[] {5, 2, 1, 4, 8};
-for (int i = 0; i < anArray.length; i++) {
- if (anArray[i] == 4) {
- System.out.println("找到了 " + i);
- break;
- }
-}
-```
-
-上例中从数组中查询元素 4,找到后通过 break 关键字退出循环。
-
-如果数组提前进行了排序,就可以使用二分查找法,这样效率就会更高一些。`Arrays.binarySearch()` 方法可供我们使用,它需要传递一个数组,和要查找的元素。
-
-```java
-int[] anArray = new int[] {1, 2, 3, 4, 5};
-int index = Arrays.binarySearch(anArray, 4);
-```
-
-“除了一维数组,还有二维数组,三妹你可以去研究下,比如说用二维数组打印一下杨辉三角。”说完,我就去阳台上休息了,留三妹在那里学习,不能打扰她。
-
-
-
-## 4.2 掌握Java二维数组
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.2 掌握Java二维数组](https://tobebetterjavaer.com/array/double-array.html)
-
-
-
-## 4.3 打印Java数组
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.3 打印Java数组](https://tobebetterjavaer.com/array/print.html)
-
-## 4.4 解读String类源码
-
-我正坐在沙发上津津有味地读刘欣大佬的《码农翻身》——Java 帝国这一章,门铃响了。起身打开门一看,是三妹,她从学校回来了。
-
-“三妹,你回来的真及时,今天我们打算讲 Java 中的字符串呢。”等三妹换鞋的时候我说。
-
-“哦,可以呀,哥。听说字符串的细节特别多,什么[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)了、字符串不可变性了、[字符串拼接](https://tobebetterjavaer.com/string/join.html)了、字符串长度限制了等等,你最好慢慢讲,否则我可能一时半会消化不了。”三妹的态度显得很诚恳。
-
-“嗯,我已经想好了,今天就只带你大概认识一下字符串,主要读一读它的源码,其他的细节咱们后面再慢慢讲,保证你能及时消化。”
-
-“好,那就开始吧。”三妹已经准备好坐在了电脑桌的边上。
-
-我应了一声后走到电脑桌前坐下来,顺手打开 [Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html),并找到了 String 的源码(Java 8)。
-
-### String 类的声明
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
-}
-```
-
-“第一,String 类是 [final](https://tobebetterjavaer.com/oo/final.html) 的,意味着它不能被子类继承。”
-
-“第二,String 类实现了 [Serializable 接口](https://tobebetterjavaer.com/io/Serializbale.html),意味着它可以[序列化](https://tobebetterjavaer.com/io/serialize.html)。”
-
-“第三,String 类实现了 [Comparable 接口](https://tobebetterjavaer.com/basic-extra-meal/comparable-omparator.html),意味着最好不要用‘==’来[比较两个字符串是否相等](https://tobebetterjavaer.com/string/equals.html),而应该用 `compareTo()` 方法去比较。”
-
-因为 == 是用来比较两个对象的地址,这个在讲字符串比较的时候会详细讲。如果只是说比较字符串内容的话,可以使用 String 类的 equals 方法:
-
-```java
-public boolean equals(Object anObject) {
- if (this == anObject) {
- return true;
- }
- if (anObject instanceof String) {
- String anotherString = (String) anObject;
- int n = value.length;
- if (n == anotherString.value.length) {
- char v1[] = value;
- char v2[] = anotherString.value;
- int i = 0;
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- }
- return false;
-}
-```
-
-“第四,[StringBuffer、StringBuilder 和 String](https://tobebetterjavaer.com/string/builder-buffer.html) 一样,都实现了 CharSequence 接口,所以它们仨属于近亲。由于 String 是不可变的,所以遇到字符串拼接的时候就可以考虑一下 String 的另外两个好兄弟,StringBuffer 和 StringBuilder,它俩是可变的。”
-
-### String 类的底层实现
-
-```java
-private final char value[];
-```
-
-“第五,Java 9 以前,String 是用 char 型[数组](https://tobebetterjavaer.com/array/array.html)实现的,之后改成了 byte 型数组实现,并增加了 coder 来表示编码。这样做的好处是在 Latin1 字符为主的程序里,可以把 String 占用的内存减少一半。当然,天下没有免费的午餐,这个改进在节省内存的同时引入了编码检测的开销。”
-
->Latin1(Latin-1)是一种单字节字符集(即每个字符只使用一个字节的编码方式),也称为ISO-8859-1(国际标准化组织8859-1),它包含了西欧语言中使用的所有字符,包括英语、法语、德语、西班牙语、葡萄牙语、意大利语等等。在Latin1编码中,每个字符使用一个8位(即一个字节)的编码,可以表示256种不同的字符,其中包括ASCII字符集中的所有字符,即0x00到0x7F,以及其他西欧语言中的特殊字符,例如é、ü、ñ等等。由于Latin1只使用一个字节表示一个字符,因此在存储和传输文本时具有较小的存储空间和较快的速度
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- @Stable
- private final byte[] value;
- private final byte coder;
- private int hash;
-}
-```
-
-接下来,我们来详细地说一下。
-
-从 `char[]` 到 `byte[]`,最主要的目的是**节省字符串占用的内存空间**。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
-
-我们使用 `jmap -histo:live pid | head -n 10` 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
-
-以我正在运行着的[编程喵](https://github.com/itwanger/coding-more)项目实例(基于 Java 8)来说,结果是这样的。
-
-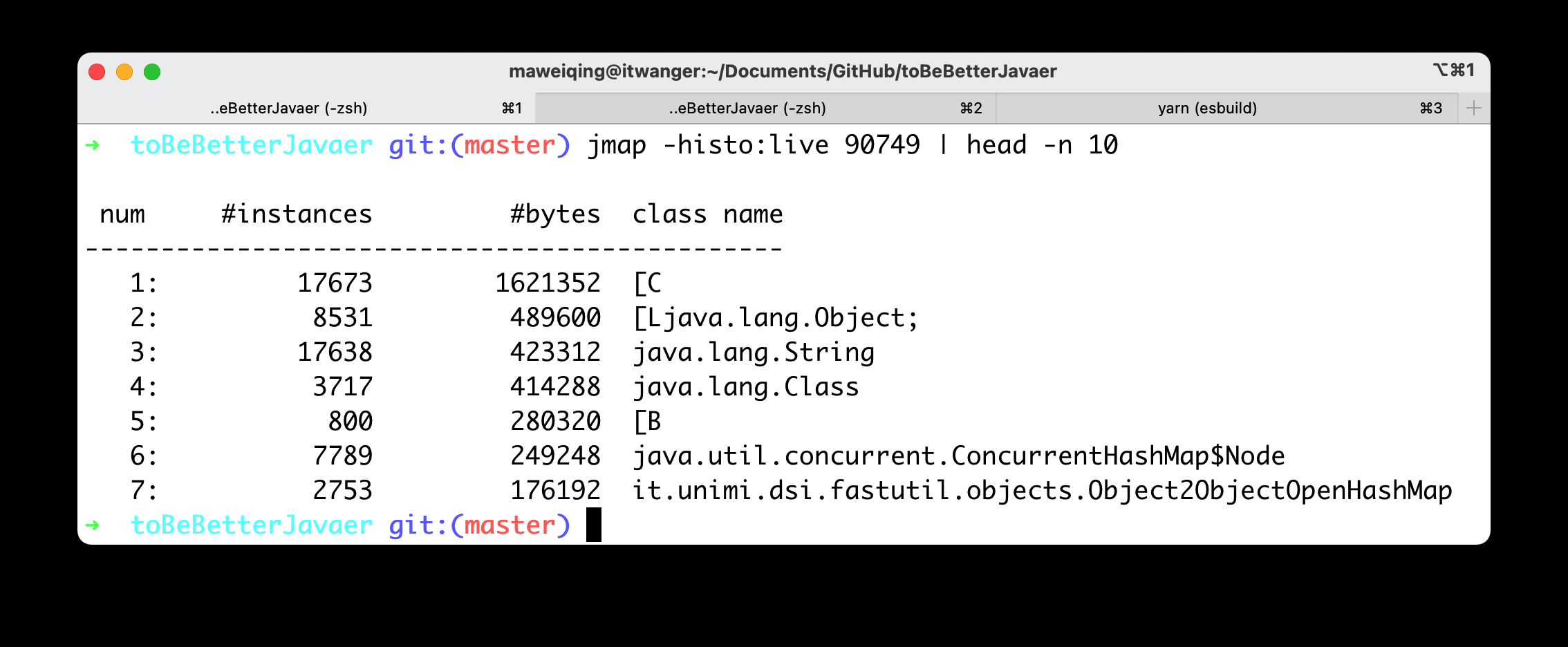
-
-其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
-
-由于 Java 8 的 String 内部实现仍然是 `char[]`,所以我们可以看到内存占用排在第 1 位的就是 char 数组。
-
-`char[]` 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
-
-那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类,就没什么必要,对吧?
-
-众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 [编码](https://tobebetterjavaer.com/basic-extra-meal/java-unicode.html),其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
-
-也就是说,使用 `char[]` 来表示 String 就会导致,即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
-
->PS:在计算机中,单字节字符通常指的是一个字节(8位)可以表示的字符,而双字节字符则指需要两个字节(16位)才能表示的字符。单字节字符和双字节字符的定义是相对的,不同的编码方式对应的单字节和双字节字符集也不同。常见的单字节字符集有ASCII(美国信息交换标准代码)、ISO-8859(国际标准化组织标准编号8859)、GBK(汉字内码扩展规范)、GB2312(中国国家标准,现在已经被GBK取代),像拉丁字母、数字、标点符号、控制字符都是单字节字符。双字节字符集包括 Unicode、UTF-8、GB18030(中国国家标准),中文、日文、韩文、拉丁文扩展字符属于双字节字符。
-
-当然了,仅仅将 `char[]` 优化为 `byte[]` 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
-
-换句话说,对于:
-
-```java
-String name = "jack";
-```
-
-这样的,使用 Latin-1 编码,占用 4 个字节就够了。
-
-但对于:
-
-```java
-String name = "小二";
-```
-
-这种,木的办法,只能使用 UTF16 来编码。
-
-针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
-
-```java
-/**
- * The identifier of the encoding used to encode the bytes in
- * {@code value}. The supported values in this implementation are
- *
- * LATIN1
- * UTF16
- *
- * @implNote This field is trusted by the VM, and is a subject to
- * constant folding if String instance is constant. Overwriting this
- * field after construction will cause problems.
- */
-private final byte coder;
-```
-
-Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
-
-也就是说,从 `char[]` 到 `byte[]`,**中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节**。
-
-在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
-
-- 如果只有一个字节,那么最高的比特位为 0;
-- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
-
-具体的表现形式为:
-
-- 0xxxxxxx:一个字节;
-- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
-- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
-- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
-
-也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
-
-那你可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
-
-的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
-
-- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
-- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
-
-但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
-
-所以UTF-16在Java的世界里,就可以视为一个定长的编码。
-
->参考链接:[https://www.zhihu.com/question/447224628](https://www.zhihu.com/question/447224628)
-
-### String 类的 hashCode 方法
-
-“第六,每一个字符串都会有一个 hash 值,这个哈希值在很大概率是不会重复的,因此 String 很适合来作为 [HashMap](https://tobebetterjavaer.com/collection/hashmap.html) 的键值。”
-
-来看 String 类的 hashCode 方法。
-
-```java
-private int hash; // Cache the hash code for the string
-
-public int hashCode() {
- int h = hash;
- if (h == 0 && value.length > 0) {
- char val[] = value;
-
- for (int i = 0; i < value.length; i++) {
- h = 31 * h + val[i];
- }
- hash = h;
- }
- return h;
-}
-```
-
-hashCode 方法首先检查是否已经计算过哈希码,如果已经计算过,则直接返回缓存的哈希码。否则,方法将使用一个循环遍历字符串的所有字符,并使用一个乘法和加法的组合计算哈希码。这种计算方法被称为“31 倍哈希法”。计算完成后,将得到的哈希值存储在 hash 成员变量中,以便下次调用 hashCode 方法时直接返回该值,而不需要重新计算。这是一种缓存优化,称为“惰性计算”。
-
-31倍哈希法(31-Hash)是一种简单有效的字符串哈希算法,常用于对字符串进行哈希处理。该算法的基本思想是将字符串中的每个字符乘以一个固定的质数31的幂次方,并将它们相加得到哈希值。具体地,假设字符串为s,长度为n,则31倍哈希值计算公式如下:
-
-```
-H(s) = (s[0] * 31^(n-1)) + (s[1] * 31^(n-2)) + ... + (s[n-1] * 31^0)
-```
-
-其中,s[i]表示字符串s中第i个字符的ASCII码值,`^`表示幂运算。
-
-31倍哈希法的优点在于简单易实现,计算速度快,同时也比较均匀地分布在哈希表中。
-
-[hashCode 方法](https://tobebetterjavaer.com/basic-extra-meal/hashcode.html),我们会在另外一个章节里详细讲,戳前面的链接了解。
-
-我们可以通过以下方法模拟 String 的 hashCode 方法:
-
-```java
-public class HashCodeExample {
- public static void main(String[] args) {
- String text = "沉默王二";
- int hashCode = computeHashCode(text);
- System.out.println("字符串 \"" + text + "\" 的哈希码是: " + hashCode);
-
- System.out.println("String 的 hashCode " + text.hashCode());
- }
-
- public static int computeHashCode(String text) {
- int h = 0;
- for (int i = 0; i < text.length(); i++) {
- h = 31 * h + text.charAt(i);
- }
- return h;
- }
-}
-```
-
-看一下结果:
-
-```
-字符串 "沉默王二" 的哈希码是: 867758096
-String 的 hashCode 867758096
-```
-
-结果是一样的,又学到了吧?
-
-### String 类的 substring 方法
-
-String 类中还有一个方法比较常用 substring,用来截取字符串的,来看源码。
-
-```java
-public String substring(int beginIndex) {
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- int subLen = value.length - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
-}
-```
-
-substring 方法首先检查参数的有效性,如果参数无效,则抛出 StringIndexOutOfBoundsException [异常](https://tobebetterjavaer.com/exception/gailan.html)。接下来,方法根据参数计算子字符串的长度。如果子字符串长度小于零,抛出StringIndexOutOfBoundsException异常。
-
-如果 beginIndex 为 0,且 endIndex 等于字符串的长度,说明子串与原字符串相同,因此直接返回原字符串。否则,使用 value 数组(原字符串的字符数组)的一部分创建一个新的 String 对象并返回。
-
-下面是几个使用 substring 方法的示例:
-
-①、提取字符串中的一段子串:
-
-```java
-String str = "Hello, world!";
-String subStr = str.substring(7, 12); // 从第7个字符(包括)提取到第12个字符(不包括)
-System.out.println(subStr); // 输出 "world"
-```
-
-②、提取字符串中的前缀或后缀:
-
-```java
-String str = "Hello, world!";
-String prefix = str.substring(0, 5); // 提取前5个字符,即 "Hello,"
-String suffix = str.substring(7); // 提取从第7个字符开始的所有字符,即 "world!"
-```
-
-③、处理字符串中的空格和分隔符:
-
-```java
-String str = " Hello, world! ";
-String trimmed = str.trim(); // 去除字符串开头和结尾的空格
-String[] words = trimmed.split("\\s+"); // 将字符串按照空格分隔成单词数组
-String firstWord = words[0].substring(0, 1); // 提取第一个单词的首字母
-System.out.println(firstWord); // 输出 "H"
-```
-
-④、处理字符串中的数字和符号:
-
-```java
-String str = "1234-5678-9012-3456";
-String[] parts = str.split("-"); // 将字符串按照连字符分隔成四个部分
-String last4Digits = parts[3].substring(1); // 提取最后一个部分的后三位数字
-System.out.println(last4Digits); // 输出 "456"
-```
-
-总之,substring 方法可以根据需求灵活地提取字符串中的子串,为字符串处理提供了便利。
-
-### String 类的 indexOf 方法
-
-indexOf 方法用于查找一个子字符串在原字符串中第一次出现的位置,并返回该位置的索引。来看该方法的源码:
-
-```java
-/*
- * 查找字符数组 target 在字符数组 source 中第一次出现的位置。
- * sourceOffset 和 sourceCount 参数指定 source 数组中要搜索的范围,
- * targetOffset 和 targetCount 参数指定 target 数组中要搜索的范围,
- * fromIndex 参数指定开始搜索的位置。
- * 如果找到了 target 数组,则返回它在 source 数组中的位置索引(从0开始),
- * 否则返回-1。
- */
-static int indexOf(char[] source, int sourceOffset, int sourceCount,
- char[] target, int targetOffset, int targetCount,
- int fromIndex) {
- // 如果开始搜索的位置已经超出 source 数组的范围,则直接返回-1(如果 target 数组为空,则返回 sourceCount)
- if (fromIndex >= sourceCount) {
- return (targetCount == 0 ? sourceCount : -1);
- }
- // 如果开始搜索的位置小于0,则从0开始搜索
- if (fromIndex < 0) {
- fromIndex = 0;
- }
- // 如果 target 数组为空,则直接返回开始搜索的位置
- if (targetCount == 0) {
- return fromIndex;
- }
-
- // 查找 target 数组的第一个字符在 source 数组中的位置
- char first = target[targetOffset];
- int max = sourceOffset + (sourceCount - targetCount);
-
- // 循环查找 target 数组在 source 数组中的位置
- for (int i = sourceOffset + fromIndex; i <= max; i++) {
- /* Look for first character. */
- // 如果 source 数组中当前位置的字符不是 target 数组的第一个字符,则在 source 数组中继续查找 target 数组的第一个字符
- if (source[i] != first) {
- while (++i <= max && source[i] != first);
- }
-
- /* Found first character, now look at the rest of v2 */
- // 如果在 source 数组中找到了 target 数组的第一个字符,则继续查找 target 数组的剩余部分是否匹配
- if (i <= max) {
- int j = i + 1;
- int end = j + targetCount - 1;
- for (int k = targetOffset + 1; j < end && source[j]
- == target[k]; j++, k++);
-
- // 如果 target 数组全部匹配,则返回在 source 数组中的位置索引
- if (j == end) {
- /* Found whole string. */
- return i - sourceOffset;
- }
- }
- }
- // 没有找到 target 数组,则返回-1
- return -1;
-}
-```
-
-来看示例。
-
-①、示例1:查找子字符串的位置
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf("world"); // 查找 "world" 子字符串在 str 中第一次出现的位置
-System.out.println(index); // 输出 7
-```
-
-②、示例2:查找字符串中某个字符的位置
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf(","); // 查找逗号在 str 中第一次出现的位置
-System.out.println(index); // 输出 5
-```
-
-③、示例3:查找子字符串的位置(从指定位置开始查找)
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf("l", 3); // 从索引为3的位置开始查找 "l" 子字符串在 str 中第一次出现的位置
-System.out.println(index); // 输出 3
-```
-
-④、示例4:查找多个子字符串
-
-```java
-String str = "Hello, world!";
-int index1 = str.indexOf("o"); // 查找 "o" 子字符串在 str 中第一次出现的位置
-int index2 = str.indexOf("o", 5); // 从索引为5的位置开始查找 "o" 子字符串在 str 中第一次出现的位置
-System.out.println(index1); // 输出 4
-System.out.println(index2); // 输出 8
-```
-
-### String 类的其他方法
-
-比如说 `length()` 用于返回字符串长度。
-
-比如说 `isEmpty()` 用于判断字符串是否为空。
-
-比如说 `charAt()` 用于返回指定索引处的字符。
-
-比如说 `getBytes()` 用于返回字符串的字节数组,可以指定编码方式,比如说:
-
-```java
-String text = "沉默王二";
-System.out.println(Arrays.toString(text.getBytes(StandardCharsets.UTF_8)));
-```
-
-比如说 `trim()` 用于去除字符串两侧的空白字符,来看源码:
-
-```java
-public String trim() {
- int len = value.length;
- int st = 0;
- char[] val = value; /* avoid getfield opcode */
-
- while ((st < len) && (val[st] <= ' ')) {
- st++;
- }
- while ((st < len) && (val[len - 1] <= ' ')) {
- len--;
- }
- return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
-}
-```
-
-举例:`" 沉默王二 ".trim()` 会返回"沉默王二"
-
-除此之外,还有 [split](https://tobebetterjavaer.com/string/split.html)、[equals](https://tobebetterjavaer.com/string/equals.html)、[join](https://tobebetterjavaer.com/string/join.html) 等这些方法,我们后面会一一来细讲。
-
-
-
-## 4.5 String为什么不可变
-
-String 可能是 Java 中使用频率最高的引用类型了,因此 String 类的设计者可以说是用心良苦。
-
-比如说 String 的不可变性。
-
-- String 类被 [final 关键字](https://tobebetterjavaer.com/oo/final.html)修饰,所以它不会有子类,这就意味着没有子类可以[重写](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)它的方法,改变它的行为。
-- String 类的数据存储在 `char[]` 数组中,而这个数组也被 final 关键字修饰了,这就表示 String 对象是没法被修改的,只要初始化一次,值就确定了。
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- /** The value is used for character storage. */
- private final char value[];
-}
-```
-
-“哥,为什么要这样设计呢?”三妹有些不解。
-
-“我先简单来说下,三妹,能懂最好,不能懂后面再细说。”
-
-第一,可以保证 String 对象的安全性,避免被篡改,毕竟像密码这种隐私信息一般就是用字符串存储的。
-
-以下是一个简单的 Java 示例,演示了字符串的不可变性如何有助于保证 String 对象的安全性。在本例中,我们创建了一个简单的 User 类,该类使用 String 类型的字段存储用户名和密码。同时,我们使用一个静态方法 getUserCredentials 从外部获取用户凭据。
-
-```java
-class User {
- private String username;
- private String password;
-
- public User(String username, String password) {
- this.username = username;
- this.password = password;
- }
-
- public String getUsername() {
- return username;
- }
-
- public String getPassword() {
- return password;
- }
-}
-
-public class StringSecurityExample {
- public static void main(String[] args) {
- String username = "沉默王二";
- String password = "123456";
- User user = new User(username, password);
-
- // 获取用户凭据
- String[] credentials = getUserCredentials(user);
-
- // 尝试修改从 getUserCredentials 返回的用户名和密码字符串
- credentials[0] = "陈清扬";
- credentials[1] = "612311";
-
- // 输出原始 User 对象中的用户名和密码
- System.out.println("原始用户名: " + user.getUsername()); // 输出 "JohnDoe"
- System.out.println("原始密码: " + user.getPassword()); // 输出 "mySecurePassword"
- }
-
- public static String[] getUserCredentials(User user) {
- String[] credentials = new String[2];
- credentials[0] = user.getUsername();
- credentials[1] = user.getPassword();
- return credentials;
- }
-}
-```
-
-在这个示例中,尽管我们尝试修改 getUserCredentials 返回的字符串数组(即用户名和密码),但原始 User 对象中的用户名和密码保持不变。这证明了字符串的不可变性有助于保护 String 对象的安全性。
-
-第二,保证哈希值不会频繁变更。毕竟要经常作为[哈希表](https://tobebetterjavaer.com/collection/hashmap.html)的键值,经常变更的话,哈希表的性能就会很差劲。
-
-在 String 类中,哈希值是在第一次计算时缓存的,后续对该哈希值的请求将直接使用缓存值。这有助于提高哈希表等数据结构的性能。以下是一个简单的示例,演示了字符串的哈希值缓存机制:
-
-```java
-String text1 = "沉默王二";
-String text2 = "沉默王二";
-
-// 计算字符串 text1 的哈希值,此时会进行计算并缓存哈希值
-int hashCode1 = text1.hashCode();
-System.out.println("第一次计算 text1 的哈希值: " + hashCode1);
-
-// 再次计算字符串 text1 的哈希值,此时直接返回缓存的哈希值
-int hashCode1Cached = text1.hashCode();
-System.out.println("第二次计算: " + hashCode1Cached);
-
-// 计算字符串 text2 的哈希值,由于字符串常量池的存在,实际上 text1 和 text2 指向同一个字符串对象
-// 所以这里直接返回缓存的哈希值
-int hashCode2 = text2.hashCode();
-System.out.println("text2 直接使用缓存: " + hashCode2);
-```
-
-在这个示例中,我们创建了两个具有相同内容的字符串 text1 和 text2。首次计算 text1 的哈希值时,会进行实际计算并缓存该值。当我们再次计算 text1 的哈希值或计算具有相同内容的 text2 的哈希值时,将直接返回缓存的哈希值,而不进行重新计算。
-
-由于 String 对象是不可变的,其哈希值在创建后不会发生变化。这使得 String 类可以缓存哈希值,提高哈希表等数据结构的性能。如果 String 是可变的,那么在每次修改时都需要重新计算哈希值,这会降低性能。
-
-第三,可以实现[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html),Java 会将相同内容的字符串存储在字符串常量池中。这样,具有相同内容的字符串变量可以指向同一个 String 对象,节省内存空间。
-
-“由于字符串的不可变性,String 类的一些方法实现最终都返回了新的字符串对象。”等三妹稍微缓了一会后,我继续说到。
-
-“就拿 `substring()` 方法来说。”
-
-```java
-public String substring(int beginIndex) {
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- int subLen = value.length - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
-}
-```
-
-`substring()` 方法用于截取字符串,最终返回的都是 new 出来的新字符串对象。
-
-“还有 `concat()` 方法。”
-
-```java
-public String concat(String str) {
- int olen = str.length();
- if (olen == 0) {
- return this;
- }
- if (coder() == str.coder()) {
- byte[] val = this.value;
- byte[] oval = str.value;
- int len = val.length + oval.length;
- byte[] buf = Arrays.copyOf(val, len);
- System.arraycopy(oval, 0, buf, val.length, oval.length);
- return new String(buf, coder);
- }
- int len = length();
- byte[] buf = StringUTF16.newBytesFor(len + olen);
- getBytes(buf, 0, UTF16);
- str.getBytes(buf, len, UTF16);
- return new String(buf, UTF16);
-}
-```
-
-`concat()` 方法用于拼接字符串,不管编码是否一致,最终也返回的是新的字符串对象。
-
-“`replace()` 替换方法其实也一样,三妹,你可以自己一会看一下源码,也是返回新的字符串对象。”
-
-“这就意味着,不管是截取、拼接,还是替换,都不是在原有的字符串上进行的,而是重新生成了新的字符串对象。也就是说,这些操作执行过后,**原来的字符串对象并没有发生改变**。”
-
-“三妹,你记住,String 对象一旦被创建后就固定不变了,对 String 对象的任何修改都不会影响到原来的字符串对象,都会生成新的字符串对象。”
-
-“嗯嗯,记住了,哥。”三妹很乖。
-
-“那今天就先讲到这吧,后面我们再对每一个细分领域深入地展开一下。你可以找一些资料先预习下,我出去散会心。。。。。”
-
-
-
-
-## 4.6 深入理解Java字符串常量池
-
-“三妹,今天我们来学习一下字符串常量池,这是字符串中非常关键的一个知识点。”我话音未落,青岛路小学那边传来了嘹亮的歌声就钻进了我的耳朵,“唱 ~ 山 ~ 歌 ~”,我都有点情不自禁地哼唱起来了。
-
-三妹赶紧拦住我说,“好了,开始吧,哥。”
-
-### new String("二哥")创建了几个对象
-
-“先从这道面试题开始吧!”
-
-```java
-String s = new String("二哥");
-```
-
-“这行代码创建了几个[对象](https://tobebetterjavaer.com/oo/object-class.html)?”
-
-“不就一个吗?”三妹不假思索地回答。
-
-“不,两个!”我直接否定了三妹的答案,“使用 new 关键字创建一个字符串对象时,Java 虚拟机会先在字符串常量池中查找有没有‘二哥’这个字符串对象,如果有,就不会在字符串常量池中创建‘二哥’这个对象了,直接在堆中创建一个‘二哥’的字符串对象,然后将堆中这个‘二哥’的对象地址返回赋值给变量 s。”
-
-“如果没有,先在字符串常量池中创建一个‘二哥’的字符串对象,然后再在堆中创建一个‘二哥’的字符串对象,然后将堆中这个‘二哥’的字符串对象地址返回赋值给变量 s。”
-
-我画图表示一下,会更加清楚。
-
-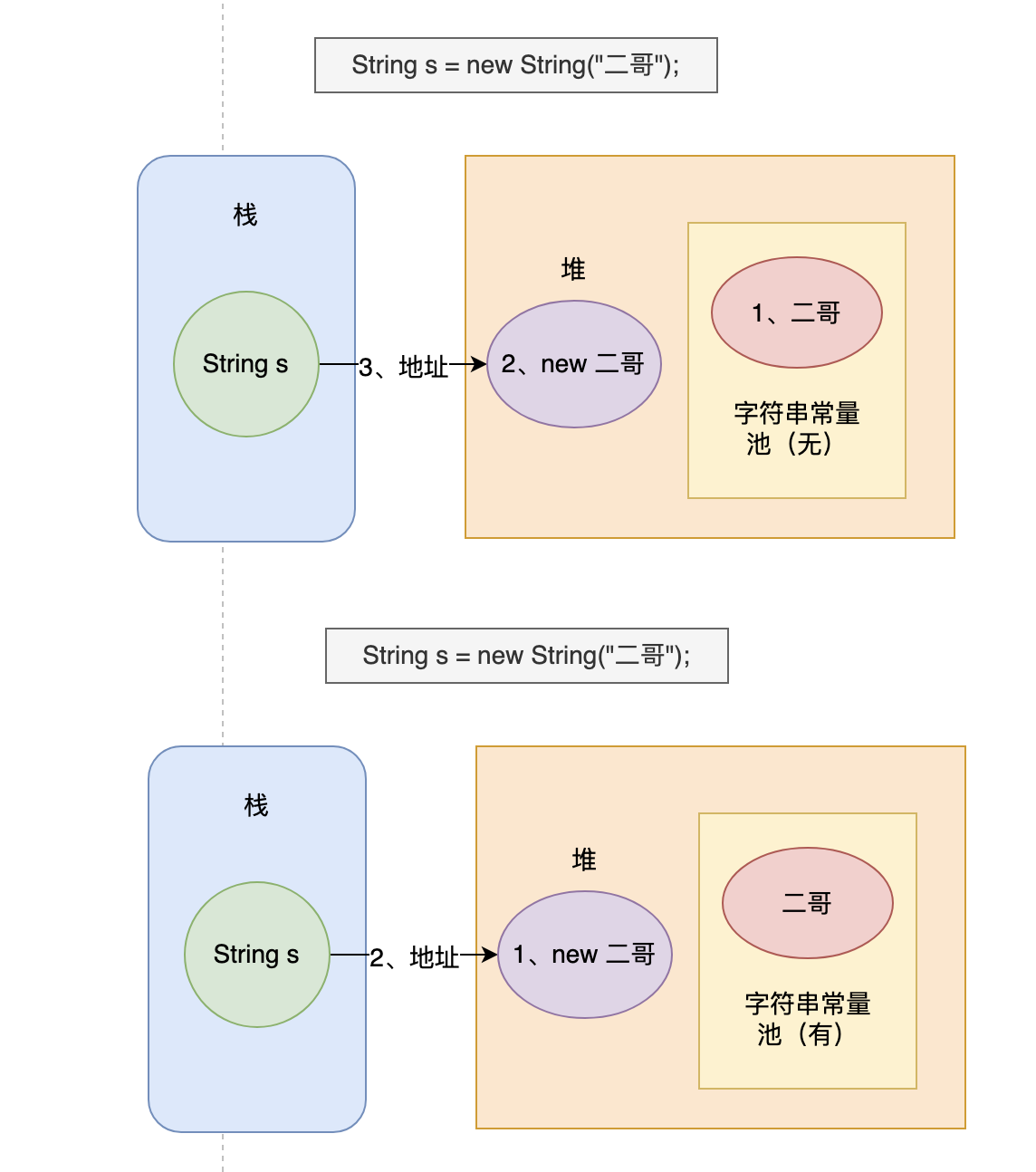
-
-在Java中,栈上存储的是基本数据类型的变量和对象的引用,而对象本身则存储在堆上。
-
-对于这行代码 `String s = new String("二哥");`,它创建了两个对象:一个是字符串对象 "二哥",它被添加到了字符串常量池中,另一个是通过 new String() 构造函数创建的字符串对象 "二哥",它被分配在堆内存中,同时引用变量 s 存储在栈上,它指向堆内存中的字符串对象 "二哥"。
-
-“**为什么要先在字符串常量池中创建对象,然后再在堆上创建呢**?这样不就多此一举了?”三妹敏锐地发现了问题。
-
-我回答,“是的。由于字符串的使用频率实在是太高了,所以 Java 虚拟机为了提高性能和减少内存开销,在创建字符串对象的时候进行了一些优化,特意为字符串开辟了一块空间——也就是字符串常量池。”
-
-### 字符串常量池的作用
-
-通常情况下,我们会采用双引号的方式来创建字符串对象,而不是通过 new 关键字的方式,就像下面👇🏻这样,这样就不会多此一举:
-
-```java
-String s = "三妹";
-```
-
-当执行 `String s = "三妹"` 时,Java 虚拟机会先在字符串常量池中查找有没有“三妹”这个字符串对象,如果有,则不创建任何对象,直接将字符串常量池中这个“三妹”的对象地址返回,赋给变量 s;如果没有,在字符串常量池中创建“三妹”这个对象,然后将其地址返回,赋给变量 s。
-
-
-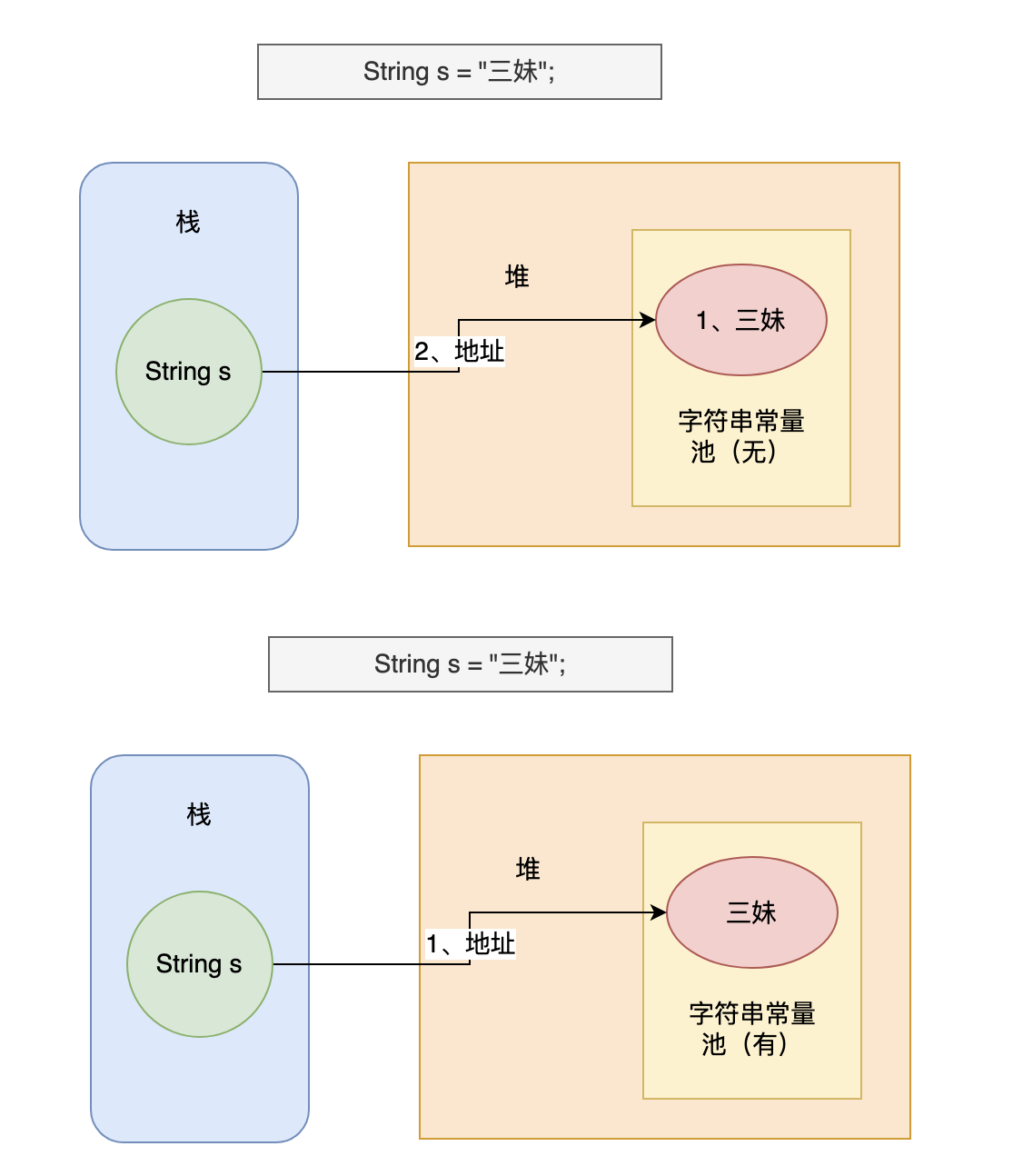
-
-Java 虚拟机创建了一个字符串对象 "三妹",它被添加到了字符串常量池中,同时引用变量 s 存储在栈上,它指向字符串常量池中的字符串对象 "三妹"。你看,是不是省了一步,比之前高效了。
-
-
-“哦,我明白了,哥。”三妹突然插话到,“有了字符串常量池,就可以通过双引号的方式直接创建字符串对象,不用再通过 new 的方式在堆中创建对象了,对吧?”
-
-“是滴。new 的方式始终会创建一个对象,不管字符串的内容是否已经存在,而双引号的方式会重复利用字符串常量池中已经存在的对象。”我说。
-
-来看下面这个例子:
-
-```java
-String s = new String("二哥");
-String s1 = new String("二哥");
-```
-
-按照我们之前的分析,这两行代码会创建三个对象,字符串常量池中一个,堆上两个。
-
-再来看下面这个例子:
-
-```java
-String s = "三妹";
-String s1 = "三妹";
-```
-
-这两行代码只会创建一个对象,就是字符串常量池中的那个。这样的话,性能肯定就提高了!
-
-### 字符串常量池在内存中的什么位置呢?
-
-“那哥,字符串常量池在内存中的什么位置呢?”三妹问。
-
-我说,“三妹,你这个问题问得好呀!”
-
-分为三个阶段。
-
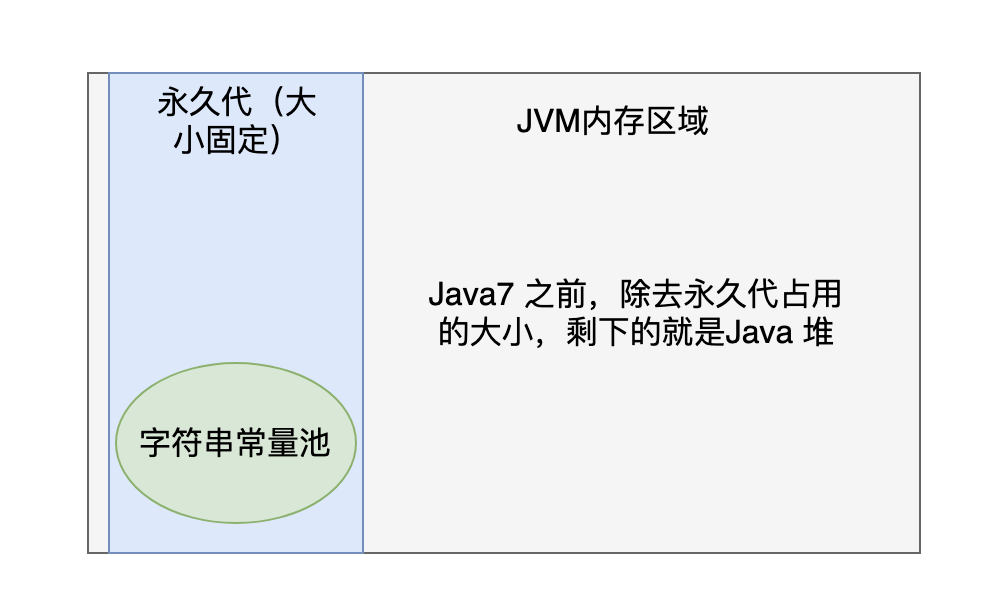
-#### Java 7 之前
-
-在 Java 7 之前,字符串常量池位于永久代(Permanent Generation)的内存区域中,主要用来存储一些字符串常量(静态数据的一种)。永久代是 Java 堆(Java Heap)的一部分,用于存储类信息、方法信息、常量池信息等静态数据。
-
-而 Java 堆是 JVM 中存储对象实例和数组的内存区域,也就是说,永久代是 Java 堆的一个子区域。
-
-换句话说,永久代中存储的静态数据与堆中存储的对象实例和数组是分开的,它们有不同的生命周期和分配方式。
-
-但是,永久代和堆的大小是相互影响的,因为它们都使用了 JVM 堆内存,因此它们的大小都受到 JVM 堆大小的限制。
-
-于是,当我们创建一个字符串常量时,它会被储存在永久代的字符串常量池中。如果我们创建一个普通字符串对象,则它将被储存在堆中。如果字符串对象的内容是一个已经存在于字符串常量池中的字符串常量,那么这个对象会指向已经存在的字符串常量,而不是重新创建一个新的字符串对象。
-
-画幅图,大概就是这个样子。
-
-
-
-
-
-#### Java 7
-
-需要注意的是,永久代的大小是有限的,并且很难准确地确定一个应用程序需要多少永久代空间。如果我们在应用程序中使用了大量的类、方法、常量等静态数据,就有可能导致永久代空间不足。这种情况下,JVM 就会抛出 OutOfMemoryError 错误。
-
-因此,从 Java 7 开始,为了解决永久代空间不足的问题,将字符串常量池从永久代中移动到堆中。这个改变也是为了更好地支持动态语言的运行时特性。
-
-再画幅图,大概就是这样子。
-
-
-
-#### Java 8
-
-到了 Java 8,永久代(PermGen)被取消,并由元空间(Metaspace)取代。元空间是一块本机内存区域,和 JVM 内存区域是分开的。不过,元空间的作用依然和之前的永久代一样,用于存储类信息、方法信息、常量池信息等静态数据。
-
-与永久代不同,元空间具有一些优点,例如:
-
-- 它不会导致 OutOfMemoryError 错误,因为元空间的大小可以动态调整。
-- 元空间使用本机内存,而不是 JVM 堆内存,这可以避免堆内存的碎片化问题。
-- 元空间中的垃圾收集与堆中的垃圾收集是分离的,这可以避免应用程序在运行过程中因为进行类加载和卸载而频繁地触发 Full GC。
-
-再画幅图,对比来看一下,就会一目了然。
-
-
-
-
-### 永久代、方法区、元空间
-
-
-“哥,能再简单给我解释一下方法区,永久代和元空间的概念吗?有点模糊。”三妹说。
-
-“可以呀。”
-
-- 方法区是 Java 虚拟机规范中的一个概念,就像是一个[接口](https://tobebetterjavaer.com/oo/interface.html)吧;
-- 永久代是 HotSpot 虚拟机中对方法区的一个实现,就像是接口的实现类;
-- Java 8 的时候,移除了永久代,取而代之的是元空间,是方法区的另外一种实现,更灵活了。
-
-永久代是放在运行时数据区中的,所以它的大小受到 Java 虚拟机本身大小的限制,所以 Java 8 之前,会经常遇到 `java.lang.OutOfMemoryError: PremGen Space` 的异常,PremGen Space 就是方法区的意思;而元空间是直接放在内存中的,所以只受本机可用内存的限制。
-
-“明白了吧,三妹?”我问。
-
-“嗯嗯。”三妹回答。
-
-“那关于字符串常量池,就先说这么多吧,是不是还挺有意思的。”我说。
-
-“是的,我现在是彻底搞懂了字符串常量池,哥,你真棒!”三妹说。
-
-
-
-## 4.7 详解 String.intern() 方法
-
-“哥,你发给我的那篇文章我看了,结果直接把我给看得不想学 Java 了!”三妹气冲冲地说。
-
-“哪一篇啊?”看着三妹面色沉重,我关心地问到。
-
-“就是[美团技术团队深入解析 `String.intern()` 那篇](https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html)啊!”三妹回答。
-
-“哦,我想起来了,不挺好一篇文章嘛,深入浅出,精品中的精品,看完后你应该对 String 的 intern 方法彻底理解了才对呀。”
-
-“好是好,但我就是看不懂!”三妹委屈地说,“哥,还是你亲自给我讲讲吧?”
-
-“好吧,上次学的[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)你都搞清楚了吧?”
-
-“嗯。”三妹微微的点了点头。
-
-要理解美团技术团队的这篇文章,你只需要记住这几点内容:
-
-第一,使用双引号声明的字符串对象会保存在字符串常量池中。
-
-第二,使用 new 关键字创建的字符串对象会先从字符串常量池中找,如果没找到就创建一个,然后再在堆中创建字符串对象;如果找到了,就直接在堆中创建字符串对象。
-
-第三,针对没有使用双引号声明的字符串对象来说,就像下面代码中的 s1 那样:
-
-```java
-String s1 = new String("二哥") + new String("三妹");
-```
-
-如果想把 s1 的内容也放入字符串常量池的话,可以调用 `intern()` 方法来完成。
-
-不过,需要注意的是,Java 7 的时候,字符串常量池从永久代中移动到了堆中,虽然此时永久代还没有完全被移除。Java 8 的时候,永久代被彻底移除。
-
-这个变化也直接影响了 `String.intern()` 方法在执行时的策略,Java 7 之前,执行 `String.intern()` 方法的时候,不管对象在堆中是否已经创建,字符串常量池中仍然会创建一个内容完全相同的新对象; Java 7 之后呢,由于字符串常量池放在了堆中,执行 `String.intern()` 方法的时候,如果对象在堆中已经创建了,字符串常量池中就不需要再创建新的对象了,而是直接保存堆中对象的引用,也就节省了一部分的内存空间。
-
-“还没有理解清楚,二哥”,三妹很苦恼。
-
-“嗯。。。别怕,三妹,先来猜猜这段代码输出的结果吧。”我说。
-
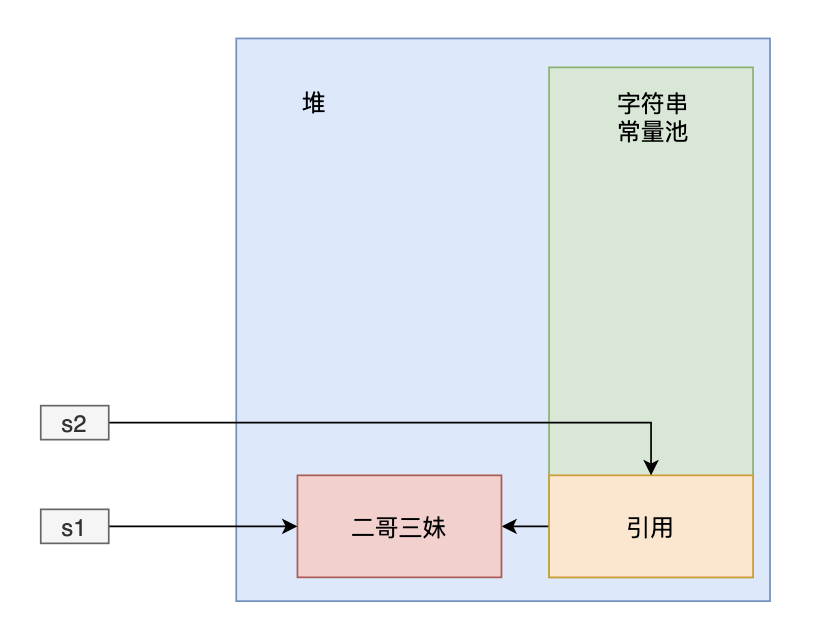
-```java
-String s1 = new String("二哥三妹");
-String s2 = s1.intern();
-System.out.println(s1 == s2);
-```
-
-“哥,这我完全猜不出啊,还是你直接解释吧。”三妹说。
-
-“好吧。”
-
-第一行代码,字符串常量池中会先创建一个“二哥三妹”的对象,然后堆中会再创建一个“二哥三妹”的对象,s1 引用的是堆中的对象。
-
-第二行代码,对 s1 执行 `intern()` 方法,该方法会从字符串常量池中查找“二哥三妹”这个字符串是否存在,此时是存在的,所以 s2 引用的是字符串常量池中的对象。
-
-也就意味着 s1 和 s2 的引用地址是不同的,一个来自堆,一个来自字符串常量池,所以输出的结果为 false。
-
-“来看一下运行结果。”我说。
-
-```
-false
-```
-
-“我来画幅图,帮助你理解下。”看到三妹惊讶的表情,我耐心地说。
-
-
-
-“这下理解了吧?”我问三妹。
-
-“嗯嗯,一下子就豁然开朗了!”三妹说。
-
-“好,我们再来看下面这段代码。”
-
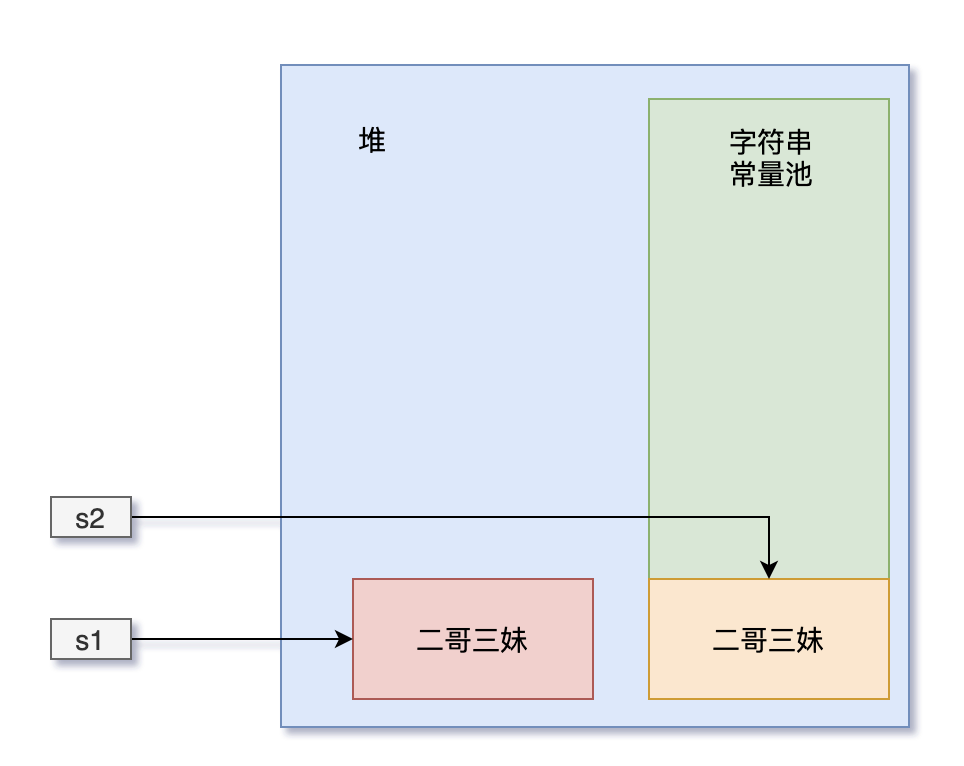
-```java
-String s1 = new String("二哥") + new String("三妹");
-String s2 = s1.intern();
-System.out.println(s1 == s2);
-```
-
-“难道也输出 false ?”三妹有点不确定。
-
-“不,这段代码会输出 true。”我否定了三妹的猜测。
-
-“为啥呀?”三妹迫切地想要知道答案。
-
-第一行代码,会在字符串常量池中创建两个对象,一个是“二哥”,一个是“三妹”,然后在堆中会创建两个匿名对象“二哥”和“三妹”,最后还有一个“二哥三妹”的对象(稍后会解释),s1 引用的是堆中“二哥三妹”这个对象。
-
-第二行代码,对 s1 执行 `intern()` 方法,该方法会从字符串常量池中查找“二哥三妹”这个对象是否存在,此时不存在的,但堆中已经存在了,所以字符串常量池中保存的是堆中这个“二哥三妹”对象的引用,也就是说,s2 和 s1 的引用地址是相同的,所以输出的结果为 true。
-
-“来看一下运行结果。”我胸有成竹地说。
-
-```
-true
-```
-
-“我再来画幅图,帮助你理解下。”
-
-
-
-“哇,我明白了!”三妹长舒一口气,大有感慨 intern 也没什么难理解的意味,“不过,我有一个疑惑,“二哥三妹”这个对象是什么时候创建的呢?”
-
-“三妹,不错嘛,能抓住问题的关键。再来解释一下 `String s1 = new String("二哥") + new String("三妹")` 这行代码。”我对三妹的表现非常开心。
-
-1. 创建 "二哥" 字符串对象,存储在字符串常量池中。
-2. 创建 "三妹" 字符串对象,存储在字符串常量池中。
-3. 执行 `new String("二哥")`,在堆上创建一个字符串对象,内容为 "二哥"。
-4. 执行 `new String("三妹")`,在堆上创建一个字符串对象,内容为 "三妹"。
-5. 执行 `new String("二哥") + new String("三妹")`,会创建一个 StringBuilder 对象,并将 "二哥" 和 "三妹" 追加到其中,然后调用 StringBuilder 对象的 toString() 方法,将其转换为一个新的字符串对象,内容为 "二哥三妹"。这个新的字符串对象存储在堆上。
-
-也就是说,当编译器遇到 `+` 号这个操作符的时候,会将 `new String("二哥") + new String("三妹")` 这行代码编译为以下代码:
-
-```
-new StringBuilder().append("二哥").append("三妹").toString();
-```
-
-实际执行过程如下:
-
-- 创建一个 StringBuilder 对象。
-- 在 StringBuilder 对象上调用 append("二哥"),将 "二哥" 追加到 StringBuilder 中。
-- 在 StringBuilder 对象上调用 append("三妹"),将 "三妹" 追加到 StringBuilder 中。
-- 在 StringBuilder 对象上调用 toString() 方法,将 StringBuilder 转换为一个新的字符串对象,内容为 "二哥三妹"。
-
-关于 [StringBuilder](https://tobebetterjavaer.com/string/builder-buffer.html),我们随后会详细地讲到。今天先了解到这。
-
-不过需要注意的是,尽管 intern 可以确保所有具有相同内容的字符串共享相同的内存空间,但也不要烂用 intern,因为任何的缓存池都是有大小限制的,不能无缘无故就占用了相对稀缺的缓存空间,导致其他字符串没有坑位可占。
-
-另外,字符串常量池本质上是一个固定大小的 StringTable,如果放进去的字符串过多,就会造成严重的哈希冲突,从而导致链表变长,链表变长也就意味着字符串常量池的性能会大幅下降,因为要一个一个找是需要花费时间的。
-
-“好了,三妹,关于 String 的 intern 就讲到这吧,这次理解了吧?”我问。
-
-“哥,你真棒!”
-
-看到三妹一点一滴的进步,我也感到由衷的开心。
-
-
-
-## 4.8 String、StringBuilder、StringBuffer
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.8 StringBuilder和StringBuffer](https://tobebetterjavaer.com/string/builder-buffer.html)
-
-## 4.9 String相等判断
-
-“二哥,如何比较两个字符串相等啊?”三妹问。
-
-“这个问题看似简单,却在 Stack Overflow 上有超过 370 万+的访问量。”我说,“这个问题也可以引申为 `.equals()` 和 ‘==’ 操作符有什么区别。”
-
-- “==”操作符用于比较两个对象的地址是否相等。
-- `.equals()` 方法用于比较两个对象的内容是否相等。
-
-“不是很理解。”三妹感到很困惑。
-
-“我来举个不恰当又很恰当的例子,一看你就明白了,三妹。”
-
-有一对双胞胎,姐姐叫阿丽塔,妹妹叫洛丽塔。我们普通人可能完全无法分辨谁是姐姐谁是妹妹,可她们的妈妈却可以轻而易举地辨认出。
-
-
-
-
-`.equals()` 就好像我们普通人,看见阿丽塔以为是洛丽塔,看见洛丽塔以为是阿丽塔,看起来一样就觉得她们是同一个人;“==”操作符就好像她们的妈妈,要求更严格,观察更细致,一眼就能分辨出谁是姐姐谁是妹妹。
-
-```java
-String alita = new String("小萝莉");
-String luolita = new String("小萝莉");
-
-System.out.println(alita.equals(luolita)); // true
-System.out.println(alita == luolita); // false
-```
-
-就上面这段代码来说,`.equals()` 输出的结果为 true,而“==”操作符输出的结果为 false——前者要求内容相等就可以,后者要求必须是同一个对象。
-
-“三妹,之前已经学过了,Java 的所有类都默认地继承 Object 这个超类,该类有一个名为 `.equals()` 的方法。”一边说,我一边打开了 Object 类的源码。
-
-```java
-public boolean equals(Object obj) {
- return (this == obj);
-}
-```
-
-你看,Object 类的 `.equals()` 方法默认采用的是“==”操作符进行比较。假如子类没有重写该方法的话,那么“==”操作符和 `.equals()` 方法的功效就完全一样——比较两个对象的内存地址是否相等。
-
-但实际情况中,有不少类重写了 `.equals()` 方法,因为比较内存地址的要求比较严格,不太符合现实中所有的场景需求。拿 String 类来说,我们在比较字符串的时候,的确只想判断它们俩的内容是相等的就可以了,并不想比较它们俩是不是同一个对象。
-
-况且,字符串有[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)的概念,本身就推荐使用 `String s = "字符串"` 这种形式来创建字符串对象,而不是通过 new 关键字的方式,因为可以把字符串缓存在字符串常量池中,方便下次使用,不用遇到 new 就在堆上开辟一块新的空间。
-
-“哦,我明白了。”三妹说。
-
-“那就来看一下 String 类的 `.equals()` 方法的源码吧。”我说。
-
-```java
-public boolean equals(Object anObject) {
- if (this == anObject) {
- return true;
- }
- if (anObject instanceof String) {
- String aString = (String)anObject;
- if (coder() == aString.coder()) {
- return isLatin1() ? StringLatin1.equals(value, aString.value)
- : StringUTF16.equals(value, aString.value);
- }
- }
- return false;
-}
-```
-
-首先,如果两个字符串对象的可以“==”,那就直接返回 true 了,因为这种情况下,字符串内容是必然相等的。否则就按照字符编码进行比较,分为 UTF16 和 Latin1,差别不是很大,就拿 Latin1 的来说吧。
-
-```java
-@HotSpotIntrinsicCandidate
-public static boolean equals(byte[] value, byte[] other) {
- if (value.length == other.length) {
- for (int i = 0; i < value.length; i++) {
- if (value[i] != other[i]) {
- return false;
- }
- }
- return true;
- }
- return false;
-}
-```
-
-这个 JDK 版本是 Java 17,也就是最新的 LTS(长期支持)版本。该版本中,String 类使用字节数组实现的,所以比较两个字符串的内容是否相等时,可以先比较字节数组的长度是否相等,不相等就直接返回 false;否则就遍历两个字符串的字节数组,只有有一个字节不相等,就返回 false。
-
-这是 Java 8 中的 equals 方法源码:
-
-```java
-public boolean equals(Object anObject) {
- // 判断是否为同一对象
- if (this == anObject) {
- return true;
- }
- // 判断对象是否为 String 类型
- if (anObject instanceof String) {
- String anotherString = (String)anObject;
- int n = value.length;
- // 判断字符串长度是否相等
- if (n == anotherString.value.length) {
- char v1[] = value;
- char v2[] = anotherString.value;
- int i = 0;
- // 判断每个字符是否相等
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- }
- return false;
-}
-```
-
-JDK 8 比 JDK 17 更容易懂一些:首先判断两个对象是否为同一个对象,如果是,则返回 true。接着,判断对象是否为 String 类型,如果不是,则返回 false。如果对象为 String 类型,则比较两个字符串的长度是否相等,如果长度不相等,则返回 false。如果长度相等,则逐个比较每个字符是否相等,如果都相等,则返回 true,否则返回 false。
-
-“嗯,二哥,这段源码不难理解。”三妹自信地说。
-
-“那出几道题考考你吧!”我说。
-
-第一题:
-
-```java
-new String("小萝莉").equals("小萝莉")
-```
-
-“输出什么呢?”我问。
-
-“`.equals()` 比较的是两个字符串对象的内容是否相等,所以结果为 true。”三妹不假思索地答到。
-
-
-第二题:
-
-```java
-new String("小萝莉") == "小萝莉"
-```
-
-“==操作符左侧的是在堆中创建的对象,右侧是在字符串常量池中的对象,尽管内容相同,但内存地址不同,所以返回 false。”三妹答。
-
-第三题:
-
-```java
-new String("小萝莉") == new String("小萝莉")
-```
-
-“new 出来的对象肯定是完全不同的内存地址,所以返回 false。”三妹答。
-
-第四题:
-
-```java
-"小萝莉" == "小萝莉"
-```
-
-“字符串常量池中只会有一个相同内容的对象,所以返回 true。”三妹答。
-
-第五题:
-
-```java
-"小萝莉" == "小" + "萝莉"
-```
-
-“由于‘小’和‘萝莉’都在字符串常量池,所以编译器在遇到‘+’操作符的时候将其自动优化为“小萝莉”,所以返回 true。”
-
-PS:至于为什么,查看这篇[String、StringBuilder、StringBuffer](https://tobebetterjavaer.com/string/builder-buffer.html)
-
-第六题:
-
-```java
-new String("小萝莉").intern() == "小萝莉"
-```
-
-“`new String("小萝莉")` 在执行的时候,会先在字符串常量池中创建对象,然后再在堆中创建对象;执行 `intern()` 方法的时候发现字符串常量池中已经有了‘小萝莉’这个对象,所以就直接返回字符串常量池中的对象引用了,那再与字符串常量池中的‘小萝莉’比较,当然会返回 true 了。”三妹说。
-
-PS:[intern](https://tobebetterjavaer.com/string/intern.html) 方法我们之前已经深究过了。
-
-哇,不得不说,三妹前几节的字符串相关内容都完全学会了呀!
-
-“三妹,哥再给你补充一点。”我说。
-
-“如果要进行两个字符串对象的内容比较,除了 `.equals()` 方法,还有其他两个可选的方案。”
-
-1)`Objects.equals()`
-
-`Objects.equals()` 这个静态方法的优势在于不需要在调用之前判空。
-
-```java
-public static boolean equals(Object a, Object b) {
- return (a == b) || (a != null && a.equals(b));
-}
-```
-
-如果直接使用 `a.equals(b)`,则需要在调用之前对 a 进行判空,否则可能会抛出空指针 `java.lang.NullPointerException`。`Objects.equals()` 用起来就完全没有这个担心。
-
-```java
-Objects.equals("小萝莉", new String("小" + "萝莉")) // --> true
-Objects.equals(null, new String("小" + "萝莉")); // --> false
-Objects.equals(null, null) // --> true
-
-String a = null;
-a.equals(new String("小" + "萝莉")); // throw exception
-```
-
-2)String 类的 `.contentEquals()`
-
-`.contentEquals()` 的优势在于可以将字符串与任何的字符序列(StringBuffer、StringBuilder、String、CharSequence)进行比较。
-
-```java
-public boolean contentEquals(CharSequence cs) {
- // Argument is a StringBuffer, StringBuilder
- if (cs instanceof AbstractStringBuilder) {
- if (cs instanceof StringBuffer) {
- synchronized(cs) {
- return nonSyncContentEquals((AbstractStringBuilder)cs);
- }
- } else {
- return nonSyncContentEquals((AbstractStringBuilder)cs);
- }
- }
- // Argument is a String
- if (cs instanceof String) {
- return equals(cs);
- }
- // Argument is a generic CharSequence
- int n = cs.length();
- if (n != length()) {
- return false;
- }
- byte[] val = this.value;
- if (isLatin1()) {
- for (int i = 0; i < n; i++) {
- if ((val[i] & 0xff) != cs.charAt(i)) {
- return false;
- }
- }
- } else {
- if (!StringUTF16.contentEquals(val, cs, n)) {
- return false;
- }
- }
- return true;
-}
-```
-
-从源码上可以看得出,如果 cs 是 StringBuffer,该方法还会进行同步,非常的智能化;如果是 String 的话,其实调用的还是 `equals()` 方法。当然了,这也就意味着使用该方法进行比较的时候,多出来了很多步骤,性能上有些损失。
-
-同样来看一下 JDK 8 的源码:
-
-```java
-public boolean contentEquals(CharSequence cs) {
- // argument can be any CharSequence implementation
- if (cs.length() != value.length) {
- return false;
- }
- // Argument is a StringBuffer, StringBuilder or String
- if (cs instanceof AbstractStringBuilder) {
- char v1[] = value;
- char v2[] = ((AbstractStringBuilder)cs).getValue();
- int i = 0;
- int n = value.length;
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- // Argument is a String
- if (cs.equals(this))
- return true;
- // Argument is a non-String, non-AbstractStringBuilder CharSequence
- char v1[] = value;
- int i = 0;
- int n = value.length;
- while (n-- != 0) {
- if (v1[i] != cs.charAt(i))
- return false;
- i++;
- }
- return true;
-}
-```
-
-同样更容易理解一些:首先判断参数长度是否相等,不相等则返回 false。如果参数是 AbstractStringBuilder 的实例,则取出其 char 数组,遍历比较两个 char 数组的每个元素是否相等。如果参数是 String 的实例,则直接调用 equals 方法比较两个字符串是否相等。如果参数是其他实现了 CharSequence 接口的对象,则遍历比较两个对象的每个字符是否相等。
-
-“是的,总体上感觉还是 `Objects.equals()` 比较舒服。”三妹的眼睛是雪亮的,发现了这个方法的优点。
-
-
-
-## 4.10 String拼接
-
-“哥,你让我看的《[Java 开发手册](https://tobebetterjavaer.com/pdf/ali-java-shouce.html)》上有这么一段内容:循环体内,拼接字符串最好使用 StringBuilder 的 `append()` 方法,而不是 + 号操作符。这是为什么呀?”三妹疑惑地问。
-
-“其实这个问题,我们之前已经[聊过](https://tobebetterjavaer.com/string/builder-buffer.html)。”我慢吞吞地回答道,“不过,三妹,哥今天来给你深入地讲讲。”
-
-PS:三妹能在学习的过程中不断地发现问题,让我感到非常的开心。其实很多时候,我们不应该只是把知识点记在心里,还应该问一问自己,到底是为什么,只有迈出去这一步,才能真正的成长起来。
-
-### javap 探究+号操作符拼接字符串的本质
-
-“+ 号操作符其实被 Java 在编译的时候重新解释了,换一种说法就是,+ 号操作符是一种语法糖,让字符串的拼接变得更简便了。”一边给三妹解释,我一边在 Intellij IDEA 中敲出了下面这段代码。
-
-```java
-class Demo {
- public static void main(String[] args) {
- String chenmo = "沉默";
- String wanger = "王二";
- System.out.println(chenmo + wanger);
- }
-}
-```
-
-在 Java 8 的环境下,使用 `javap -c Demo.class` 反编译字节码后,可以看到以下内容:
-
-```
-Compiled from "Demo.java"
-class Demo {
- Demo();
- Code:
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."":()V
- 4: return
-
- public static void main(java.lang.String[]);
- Code:
- 0: ldc #2 // String 沉默
- 2: astore_1
- 3: ldc #3 // String 王二
- 5: astore_2
- 6: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
- 9: new #5 // class java/lang/StringBuilder
- 12: dup
- 13: invokespecial #6 // Method java/lang/StringBuilder."":()V
- 16: aload_1
- 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 20: aload_2
- 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
- 27: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
- 30: return
-}
-```
-
-“你看,三妹,这里有一个 new 关键字,并且 class 类型为 `java/lang/StringBuilder`。”我指着标号为 9 的那行对三妹说,“这意味着新建了一个 StringBuilder 的对象。”
-
-“然后看标号为 17 的这行,是一个 invokevirtual 指令,用于调用对象的方法,也就是 StringBuilder 对象的 `append()` 方法。”
-
-“也就意味着把 chenmo("沉默")这个字符串添加到 StringBuilder 对象中了。”
-
-“再往下看,标号为 21 的这行,又调用了一次 `append()` 方法,意味着把 wanger("王二")这个字符串添加到 StringBuilder 对象中了。”
-
-换成 Java 代码来表示的话,大概是这个样子:
-
-```java
-class Demo {
- public static void main(String[] args) {
- String chenmo = "沉默";
- String wanger = "王二";
- System.out.println((new StringBuilder(chenmo)).append(wanger).toString());
- }
-}
-```
-
-“哦,原来编译的时候把“+”号操作符替换成了 StringBuilder 的 `append()` 方法啊。”三妹恍然大悟。
-
-“是的,不过到了 Java 9(不是长期支持版本,所以我会拿 Java 11 来演示),情况发生了一些改变,同样的代码,字节码指令完全不同了。”我说。
-
-同样的代码,在 Java 11 的环境下,字节码指令是这样的:
-
-```
-Compiled from "Demo.java"
-public class com.itwanger.thirtyseven.Demo {
- public com.itwanger.thirtyseven.Demo();
- Code:
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."":()V
- 4: return
-
- public static void main(java.lang.String[]);
- Code:
- 0: ldc #2 // String
- 2: astore_1
- 3: iconst_0
- 4: istore_2
- 5: iload_2
- 6: bipush 10
- 8: if_icmpge 41
- 11: new #3 // class java/lang/String
- 14: dup
- 15: ldc #4 // String 沉默
- 17: invokespecial #5 // Method java/lang/String."":(Ljava/lang/String;)V
- 20: astore_3
- 21: ldc #6 // String 王二
- 23: astore 4
- 25: aload_1
- 26: aload_3
- 27: aload 4
- 29: invokedynamic #7, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
- 34: astore_1
- 35: iinc 2, 1
- 38: goto 5
- 41: return
-}
-```
-
-看标号为 29 的这行,字节码指令为 `invokedynamic`,该指令允许由应用级的代码来决定方法解析,所谓的应用级的代码其实是一个方法——被称为引导方法(Bootstrap Method),简称 BSM,BSM 会返回一个 CallSite(调用点) 对象,这个对象就和 `invokedynamic` 指令链接在一起。以后再执行这条 `invokedynamic` 指令时就不会创建新的 CallSite 对象。CallSite 其实就是一个 MethodHandle(方法句柄)的 holder,指向一个调用点真正执行的方法——此时就是 `StringConcatFactory.makeConcatWithConstants()` 方法。
-
-“哥,你别再说了,再说我就听不懂了。”三妹打断了我的话。
-
-“好吧,总之就是 Java 9 以后,JDK 用了另外一种方法来动态解释 + 号操作符,具体的实现方式在字节码指令层面已经看不到了,所以我就以 Java 8 来继续讲解吧。”
-
-### 为什么要编译为 StringBuilder.append
-
-“再回到《Java 开发手册》上的那段内容:循环体内,拼接字符串最好使用 StringBuilder 的 `append()` 方法,而不是 + 号操作符。原因就在于循环体内如果用 + 号操作符的话,就会产生大量的 StringBuilder 对象,不仅占用了更多的内存空间,还会让 Java 虚拟机不停的进行垃圾回收,从而降低了程序的性能。”
-
-更好的写法就是在循环的外部新建一个 StringBuilder 对象,然后使用 `append()` 方法将循环体内的字符串添加进来:
-
-```java
-class Demo {
- public static void main(String[] args) {
- StringBuilder sb = new StringBuilder();
- for (int i = 1; i < 10; i++) {
- String chenmo = "沉默";
- String wanger = "王二";
- sb.append(chenmo);
- sb.append(wanger);
- }
- System.out.println(sb);
- }
-}
-```
-
-来做个小测试。
-
-第一个,for 循环中使用”+”号操作符。
-
-```java
-String result = "";
-for (int i = 0; i < 100000; i++) {
- result += "六六六";
-}
-```
-
-第二个,for 循环外部新建 StringBuilder,循环体内使用 `append()` 方法。
-
-```java
-StringBuilder sb = new StringBuilder();
-for (int i = 0; i < 100000; i++) {
- sb.append("六六六");
-}
-```
-
-“这两个小测试分别会耗时多长时间呢?三妹你来运行下。”
-
-“哇,第一个小测试的执行时间是 6212 毫秒,第二个只用了不到 1 毫秒,差距也太大了吧!”三妹说。
-
-“是的,这下明白了原因吧?”我说。
-
-“是的,哥,原来如此。”
-
-### append方法源码解析
-
-“好了,三妹,来看一下 StringBuilder 类的 `append()` 方法的源码吧!”
-
-```java
-public StringBuilder append(String str) {
- super.append(str);
- return this;
-}
-```
-
-这 3 行代码其实没啥看的。我们来看父类 AbstractStringBuilder 的 `append()` 方法:
-
-```java
-public AbstractStringBuilder append(String str) {
- if (str == null)
- return appendNull();
- int len = str.length();
- ensureCapacityInternal(count + len);
- str.getChars(0, len, value, count);
- count += len;
- return this;
-}
-```
-
-1)判断拼接的字符串是不是 null,如果是,当做字符串“null”来处理。`appendNull()` 方法的源码如下:
-
-```java
-private AbstractStringBuilder appendNull() {
- int c = count;
- ensureCapacityInternal(c + 4);
- final char[] value = this.value;
- value[c++] = 'n';
- value[c++] = 'u';
- value[c++] = 'l';
- value[c++] = 'l';
- count = c;
- return this;
-}
-```
-
-2)获取字符串的长度。
-
-3)`ensureCapacityInternal()` 方法的源码如下:
-
-```java
-private void ensureCapacityInternal(int minimumCapacity) {
- // overflow-conscious code
- if (minimumCapacity - value.length > 0) {
- value = Arrays.copyOf(value,
- newCapacity(minimumCapacity));
- }
-}
-```
-
-由于字符串内部是用数组实现的,所以需要先判断拼接后的字符数组长度是否超过当前数组的长度,如果超过,先对数组进行扩容,然后把原有的值复制到新的数组中。
-
- 4)将拼接的字符串 str 复制到目标数组 value 中。
-
-```java
-str.getChars(0, len, value, count)
-```
-
-5)更新数组的长度 count。
-
-### String.concat 拼接字符串
-
-“除了可以使用 + 号操作符,StringBuilder 的 `append()` 方法,还有其他的字符串拼接方法吗?”三妹问。
-
-“有啊,比如说 String 类的 `concat()` 方法,有点像 StringBuilder 类的 `append()` 方法。”
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-System.out.println(chenmo.concat(wanger));
-```
-
-可以来看一下 `concat()` 方法的源码。
-
-```java
-public String concat(String str) {
- int otherLen = str.length();
- if (otherLen == 0) {
- return this;
- }
- int len = value.length;
- char buf[] = Arrays.copyOf(value, len + otherLen);
- str.getChars(buf, len);
- return new String(buf, true);
-}
-```
-
-1)如果拼接的字符串的长度为 0,那么返回拼接前的字符串。
-
-2)将原字符串的字符数组 value 复制到变量 buf 数组中。
-
-3)把拼接的字符串 str 复制到字符数组 buf 中,并返回新的字符串对象。
-
-我一行一行地给三妹解释着。
-
-“和 `+` 号操作符相比,`concat()` 方法在遇到字符串为 null 的时候,会抛出 NullPointerException,而“+”号操作符会把 null 当做是“null”字符串来处理。”
-
-如果拼接的字符串是一个空字符串(""),那么 concat 的效率要更高一点,毕竟不需要 `new StringBuilder` 对象。
-
-如果拼接的字符串非常多,`concat()` 的效率就会下降,因为创建的字符串对象越来越多。
-
-“还有吗?”三妹似乎对字符串拼接很感兴趣。
-
-“有,当然有。”
-
-### String.join 拼接字符串
-
-String 类有一个静态方法 `join()`,可以这样来使用。
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-String cmower = String.join("", chenmo, wanger);
-System.out.println(cmower);
-```
-
-第一个参数为字符串连接符,比如说:
-
-```java
-String message = String.join("-", "王二", "太特么", "有趣了");
-```
-
-输出结果为:`王二-太特么-有趣了`。
-
-来看一下 join 方法的源码:
-
-```java
-public static String join(CharSequence delimiter, CharSequence... elements) {
- Objects.requireNonNull(delimiter);
- Objects.requireNonNull(elements);
- // Number of elements not likely worth Arrays.stream overhead.
- StringJoiner joiner = new StringJoiner(delimiter);
- for (CharSequence cs: elements) {
- joiner.add(cs);
- }
- return joiner.toString();
-}
-```
-
-里面新建了一个叫 StringJoiner 的对象,然后通过 for-each 循环把可变参数添加了进来,最后调用 `toString()` 方法返回 String。
-
-### StringUtils.join 拼接字符串
-
-“实际的工作中,`org.apache.commons.lang3.StringUtils` 的 `join()` 方法也经常用来进行字符串拼接。”
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-StringUtils.join(chenmo, wanger);
-```
-
-该方法不用担心 NullPointerException。
-
-```java
-StringUtils.join(null) = null
-StringUtils.join([]) = ""
-StringUtils.join([null]) = ""
-StringUtils.join(["a", "b", "c"]) = "abc"
-StringUtils.join([null, "", "a"]) = "a"
-```
-
-来看一下源码:
-
-```java
-public static String join(final Object[] array, String separator, final int startIndex, final int endIndex) {
- if (array == null) {
- return null;
- }
- if (separator == null) {
- separator = EMPTY;
- }
-
- final StringBuilder buf = new StringBuilder(noOfItems * 16);
-
- for (int i = startIndex; i < endIndex; i++) {
- if (i > startIndex) {
- buf.append(separator);
- }
- if (array[i] != null) {
- buf.append(array[i]);
- }
- }
- return buf.toString();
-}
-```
-
-内部使用的仍然是 StringBuilder。
-
-“好了,三妹,关于字符串拼接的知识点我们就讲到这吧。注意 Java 9 以后,对 + 号操作符的解释和之前发生了变化,字节码指令已经不同了,等后面你学了[字节码指令](https://tobebetterjavaer.com/jvm/zijiema-zhiling.html)后我们再详细地讲一次。”我说。
-
-“嗯,哥,你休息吧,我把这些例子再重新跑一遍。”三妹说。
-
-
-
-## 4.11 String拆分
-
-“哥,我感觉字符串拆分没什么可讲的呀,直接上 String 类的 `split()` 方法不就可以了!”三妹毫不客气地说。
-
-“假如你真的这么觉得,那可要注意了,事情远没这么简单。”我微笑着说。
-
-假如现在有这样一串字符序列“沉默王二,一枚有趣的程序员”,需要按照中文逗号“,”进行拆分,这意味着第一串字符序列为逗号前面的“沉默王二”,第二串字符序列为逗号后面的“一枚有趣的程序员”。
-
-“这不等于没说吗?哥!”还没等我说,三妹就打断了我。
-
-“别着急嘛,等哥说完。”我依然保持着微笑继续说,“在拆分之前,要先进行检查,判断一下这串字符是否包含逗号,否则应该抛出异常。”
-
-```java
-public class Test {
- public static void main(String[] args) {
- String cmower = "沉默王二,一枚有趣的程序员";
- if (cmower.contains(",")) {
- String [] parts = cmower.split(",");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
- } else {
- throw new IllegalArgumentException("当前字符串没有包含逗号");
- }
- }
-}
-```
-
-“三妹你看,这段代码挺严谨的吧?”我说,“来看一下程序的输出结果。”
-
-```
-第一部分:沉默王二 第二部分:一枚有趣的程序员
-```
-
-“的确和预期完全一致。”三妹说。
-
-“这是建立在字符串是确定的情况下,最重要的是分隔符是确定的。否则,麻烦就来了。”我说,“大约有 12 种英文特殊符号,如果直接拿这些特殊符号替换上面代码中的分隔符(中文逗号),这段程序在运行的时候就会出现以下提到的错误。”
-
-
-- 反斜杠 `\`(ArrayIndexOutOfBoundsException)
-- 插入符号 `^`(同上)
-- 美元符号 `$`(同上)
-- 逗点 `.`(同上)
-- 竖线 `|`(正常,没有出错)
-- 问号 `?`(PatternSyntaxException)
-- 星号 `*`(同上)
-- 加号 `+`(同上)
-- 左小括号或者右小括号 `()`(同上)
-- 左方括号或者右方括号 `[]`(同上)
-- 左大括号或者右大括号 `{}`(同上)
-
-“那遇到这些特殊符号该怎么办呢?”三妹问。
-
-“用正则表达式。”我说,“正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。”
-
-我在 GitHub 上找打了一个开源的正则表达式学习文档,非常详细。一开始写正则表达式的时候难免会感觉到非常生疏,你可以查看一下这份文档。记不住没关系,遇到就查。
-
->[https://github.com/cdoco/learn-regex-zh](https://github.com/cdoco/learn-regex-zh)
-
-除了这份文档,还有一份:
-
->[https://github.com/cdoco/common-regex](https://github.com/cdoco/common-regex)
-
-作者收集了一些在平时项目开发中经常用到的正则表达式,可以直接拿来用。
-
-“哥,你真周到。”三妹笑着说。
-
-“好了,来用英文逗点 `.` 替换一下分隔符。”我说。
-
-```java
-String cmower = "沉默王二.一枚有趣的程序员";
-if (cmower.contains(".")) {
- String [] parts = cmower.split("\\.");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-由于英文逗点属于特殊符号,所以在使用 `split()` 方法的时候,就需要使用正则表达式 `\\.` 而不能直接使用 `.`。
-
-“为什么用两个反斜杠呢?”三妹问。
-
-“因为反斜杠本身就是一个特殊字符,需要用反斜杠来转义。”我说。
-
-当然了,你也可以使用 `[]` 来包裹住英文逗点“.”,`[]` 也是一个正则表达式,用来匹配方括号中包含的任意字符。
-
-```java
-cmower.split("[.]");
-```
-
-除此之外, 还可以使用 Pattern 类的 `quote()` 方法来包裹英文逗点“.”,该方法会返回一个使用 `\Q\E` 包裹的字符串。
-
-
-
-来看示例:
-
-```java
-String [] parts = cmower.split(Pattern.quote("."));
-```
-
-当 `split()` 方法的参数是正则表达式的时候,方法最终会执行下面这行代码:
-
-```java
-return Pattern.compile(regex).split(this, limit);
-```
-
-也就意味着,拆分字符串有了新的选择,可以不使用 String 类的 `split()` 方法,直接用下面的方式。
-
-```java
-public class TestPatternSplit {
- private static Pattern twopart = Pattern.compile("\\.");
-
- public static void main(String[] args) {
- String [] parts = twopart.split("沉默王二.一枚有趣的程序员");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
- }
-}
-```
-
-“为什么要把 Pattern 表达式声明称 static 的呢?”三妹问。
-
-“由于模式是确定的,通过 static 的预编译功能可以提高程序的效率。”我说,“除此之外,还可以使用 Pattern 配合 Matcher 类进行字符串拆分,这样做的好处是可以对要拆分的字符串进行一些严格的限制,来看这段示例代码。”
-
-```java
-public class TestPatternMatch {
- /**
- * 使用预编译功能,提高效率
- */
- private static Pattern twopart = Pattern.compile("(.+)\\.(.+)");
-
- public static void main(String[] args) {
- checkString("沉默王二.一枚有趣的程序员");
- checkString("沉默王二.");
- checkString(".一枚有趣的程序员");
- }
-
- private static void checkString(String str) {
- Matcher m = twopart.matcher(str);
- if (m.matches()) {
- System.out.println("第一部分:" + m.group(1) + " 第二部分:" + m.group(2));
- } else {
- System.out.println("不匹配");
- }
- }
-}
-```
-
-正则表达式 `(.+)\\.(.+)` 的意思是,不仅要把字符串按照英文标点的方式拆成两部分,并且英文逗点的前后要有内容。
-
-来看一下程序的输出结果:
-
-```java
-第一部分:沉默王二 第二部分:一枚有趣的程序员
-不匹配
-不匹配
-```
-
-不过,使用 Matcher 来匹配一些简单的字符串时相对比较沉重一些,使用 String 类的 `split()` 仍然是首选,因为该方法还有其他一些牛逼的功能。比如说,如果你想把分隔符包裹在拆分后的字符串的第一部分,可以这样做:
-
-```java
-String cmower = "沉默王二,一枚有趣的程序员";
-if (cmower.contains(",")) {
- String [] parts = cmower.split("(?<=,)");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-程序输出的结果如下所示:
-
-```
-第一部分:沉默王二, 第二部分:一枚有趣的程序员
-```
-
-可以看到分隔符“,”包裹在了第一部分,如果希望包裹在第二部分,可以这样做:
-
-```java
-String [] parts = cmower.split("(?=,)");
-```
-
-“`?<=` 和 `?=` 是什么东东啊?”三妹好奇地问。
-
-“它其实是正则表达式中的断言模式。”我说,“你有时间的话,可以看看前面我推荐的两份开源文档。”
-
-
-
-“`split()` 方法可以传递 2 个参数,第一个为分隔符,第二个为拆分的字符串个数。”我说。
-
-```java
-String cmower = "沉默王二,一枚有趣的程序员,宠爱他";
-if (cmower.contains(",")) {
- String [] parts = cmower.split(",", 2);
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-进入 debug 模式的话,可以看到以下内容:
-
-
-
-也就是说,传递 2 个参数的时候,会直接调用 `substring()` 进行截取,第二个分隔符后的就不再拆分了。
-
-来看一下程序输出的结果:
-
-```
-第一部分:沉默王二 第二部分:一枚有趣的程序员,宠爱他
-```
-
-“没想到啊,这个字符串拆分还挺讲究的呀!”三妹感慨地说。
-
-“是的,其实字符串拆分在实际的工作当中还是挺经常用的。前端经常会按照规则传递一长串字符序列到后端,后端就需要按照规则把字符串拆分再做处理。”我说。
-
-“嗯,我把今天的内容温习下,二哥,你休息会。”三妹说。
-
----
-
-GitHub 上标星 7600+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 7600+ 的 Java 教程](https://tobebetterjavaer.com/overview/)
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
-
-# 第五章:面向对象编程
-
-# 5.1 Java中的类和对象
-
-#“二哥,那天我在图书馆复习《Java进阶之路》的时候,刚好碰见一个学长,他问我有没有‘对象’,我说还没有啊。结果你猜他说什么,‘要不要我给你 new 一个啊?’我当时就懵了,new 是啥意思啊,二哥?”三妹满是疑惑的问我。
-
-“哈哈,三妹,你学长还挺幽默啊。new 是 Java 中的一个关键字,用来把类变成对象。”我笑着对三妹说,“对象和类是 Java 中最基本的两个概念,可以说撑起了面向对象编程(OOP)的一片天。”
-
-### 01、面向过程和面向对象
-
-三妹是不是要问,什么是 OOP?
-
-OOP 的英文全称是 Object Oriented Programming,要理解它的话,就要先理解面向对象,要想理解面向对象的话,就要先理解面向过程,因为一开始没有面向对象的编程语言,都是面向过程。
-
-举个简单点的例子来区分一下面向过程和面向对象。
-
-有一天,你想吃小碗汤了,怎么办呢?有两个选择:
-
-1)自己买食材,豆腐皮啊、肉啊、蒜苔啊等等,自己动手做。
-
-2)到饭店去,只需要对老板喊一声,“来份小碗汤。”
-
-第一种就是面向过程,第二种就是面向对象。
-
-面向过程有什么劣势呢?假如你买了小碗汤的食材,临了又想吃宫保鸡丁了,你是不是还得重新买食材?
-
-面向对象有什么优势呢?假如你不想吃小碗汤了,你只需要对老板说,“我那个小碗汤如果没做的话,换成宫保鸡丁吧!”
-
-面向过程是流程化的,一步一步,上一步做完了,再做下一步。
-
-面向对象是模块化的,我做我的,你做你的,我需要你做的话,我就告诉你一声。我不需要知道你到底怎么做,只看功劳不看苦劳。
-
-不过,如果追到底的话,面向对象的底层其实还是面向过程,只不过把面向过程进行了抽象化,封装成了类,方便我们的调用。
-
-### 02、类
-
-对象可以是现实中看得见的任何物体,比如说,一只特立独行的猪;也可以是想象中的任何虚拟物体,比如说能七十二变的孙悟空。
-
-Java 通过类(class)来定义这些物体,这些物体有什么状态,通过字段来定义,比如说比如说猪的颜色是纯色还是花色;这些物体有什么行为,通过方法来定义,比如说猪会吃,会睡觉。
-
-来,定义一个简单的类给你看看。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 2020/11/19
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {
- }
-
- private void sleep() {
- }
-
- private void dadoudou() {
- }
-}
-```
-
-一个类可以包含:
-
-- 字段(Filed)
-- 方法(Method)
-- 构造方法(Constructor)
-
-在 Person 类中,字段有 3 个,分别是 name、age 和 sex,它们也称为成员[变量](https://tobebetterjavaer.com/oo/var.html)——在类内部但在方法外部,方法内部的叫临时变量。
-
-成员变量有时候也叫做实例变量,在编译时不占用内存空间,在运行时获取内存,也就是说,只有在对象实例化(`new Person()`)后,字段才会获取到内存,这也正是它被称作“实例”变量的原因。
-
-[方法](https://tobebetterjavaer.com/oo/method.html)有 3 个,分别是 `eat()`、`sleep()` 和 `dadoudou()`,表示 Person 这个对象可以做什么,也就是吃饭睡觉打豆豆。
-
-那三妹是不是要问,“怎么没有[构造方法](https://tobebetterjavaer.com/oo/construct.html)呢?”
-
-的确在 Person 类的源码文件(.java)中没看到,但在反编译后的字节码文件(.class)中是可以看得到的。
-
-```java
-//
-// Source code recreated from a .class file by IntelliJ IDEA
-// (powered by Fernflower decompiler)
-//
-
-package com.itwanger.twentythree;
-
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public Person() {
- }
-
- private void eat() {
- }
-
- private void sleep() {
- }
-
- private void dadoudou() {
- }
-}
-```
-
-`public Person(){}` 就是默认的构造方法,因为是空的构造方法(方法体中没有内容),所以可以缺省。Java 聪明就聪明在这,有些很死板的代码不需要开发人员添加,它会偷偷地做了。
-
-### 03、new 一个对象
-
-创建 Java 对象时,需要用到 `new` 关键字。
-
-```java
-Person person = new Person();
-```
-
-这行代码就通过 Person 类创建了一个 Person 对象。所有**对象**在创建的时候都会在**堆内存中分配空间**。
-
-创建对象的时候,需要一个 `main()` 方法作为入口, `main()` 方法可以在当前类中,也可以在另外一个类中。
-
-第一种:`main()` 方法直接放在 Person 类中。
-
-```java
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {}
- private void sleep() {}
- private void dadoudou() {}
-
- public static void main(String[] args) {
- Person person = new Person();
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-null
-0
-0
-```
-
-第二种:`main()` 方法不在 Person 类中,而在另外一个类中。
-
-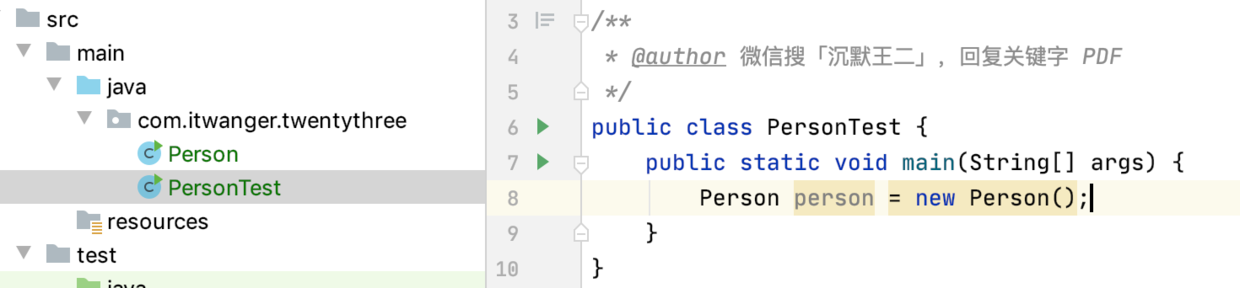
-
-实际开发中,我们通常不在当前类中直接创建对象并使用它,而是放在使用对象的类中,比如说上图中的 PersonTest 类。
-
-可以把 PersonTest 类和 Person 类放在两个文件中,也可以放在一个文件(命名为 PersonTest.java)中,就像下面这样。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class PersonTest {
- public static void main(String[] args) {
- Person person = new Person();
- }
-}
-
-class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {}
- private void sleep() {}
- private void dadoudou() {}
-}
-```
-
-### 04、初始化对象
-
-在之前的例子中,程序输出结果为:
-
-```
-null
-0
-0
-```
-
-为什么会有这样的输出结果呢?因为 Person 对象没有初始化,因此输出了 String 的默认值 null,int 的默认值 0。
-
-那怎么初始化 Person 对象(对字段赋值)呢?
-
-#### 第一种:通过对象的引用变量。
-
-```java
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public static void main(String[] args) {
- Person person = new Person();
- person.name = "沉默王二";
- person.age = 18;
- person.sex = 1;
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-person 被称为对象 Person 的引用变量,见下图:
-
-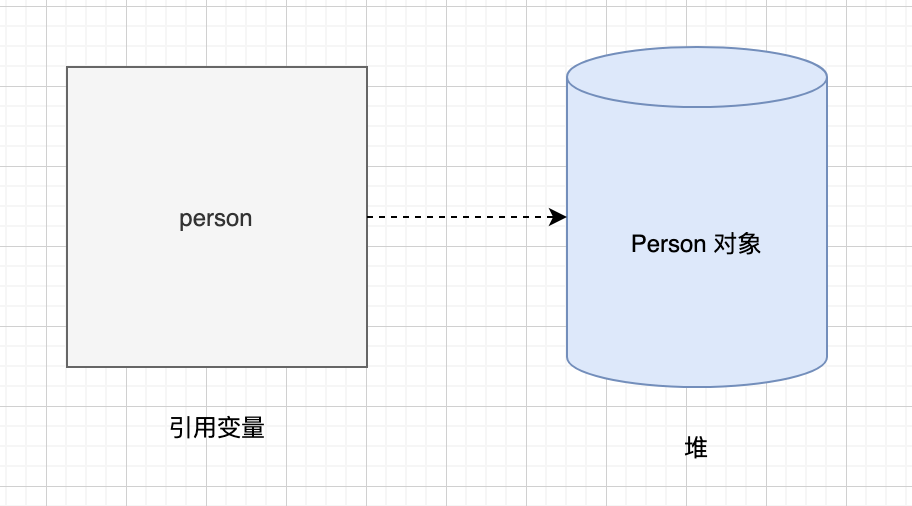
-
-通过对象的引用变量,可以直接对字段进行初始化(`person.name = "沉默王二"`),所以以上代码输出结果如下所示:
-
-```
-沉默王二
-18
-1
-```
-
-#### 第二种:通过方法初始化。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public void initialize(String n, int a, int s) {
- name = n;
- age = a;
- sex = s;
- }
-
- public static void main(String[] args) {
- Person person = new Person();
- person.initialize("沉默王二",18,1);
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-在 Person 类中新增方法 `initialize()`,然后在新建对象后传参进行初始化(`person.initialize("沉默王二", 18, 1)`)。
-
-#### 第三种:通过构造方法初始化。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public Person(String name, int age, int sex) {
- this.name = name;
- this.age = age;
- this.sex = sex;
- }
-
- public static void main(String[] args) {
- Person person = new Person("沉默王二", 18, 1);
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-这也是最标准的一种做法,直接在 new 的时候把参数传递过去。
-
-补充一点知识,匿名对象。匿名对象意味着没有引用变量,它只能在创建的时候被使用一次。
-
-```java
-new Person();
-```
-
-可以直接通过匿名对象调用方法:
-
-```java
-new Person().initialize("沉默王二", 18, 1);
-```
-
-### 05、关于对象
-
-#### **1)抽象的历程**
-
-所有编程语言都是一种抽象,甚至可以说,我们能够解决的问题的复杂程度取决于抽象的类型和质量。
-
-Smalltalk 是历史上第一门获得成功的面向对象语言,也为 Java 提供了灵感。它有 5 个基本特征:
-
-- 万物皆对象。
-- 一段程序实际上就是多个对象通过发送消息的方式来告诉彼此该做什么。
-- 通过组合的方式,可以将多个对象封装成其他更为基础的对象。
-- 对象是通过类实例化的。
-- 同一类型的对象可以接收相同的消息。
-
-总结一句话就是:
-
->状态+行为+标识=对象,每个对象在内存中都会有一个唯一的地址。
-
-#### **2)对象具有接口**
-
-所有的对象,都可以被归为一类,并且同一类对象拥有一些共同的行为和特征。在 Java 中,class 关键字用来定义一个类型。
-
-创建抽象数据类型是面向对象编程的一个基本概念。你可以创建某种类型的变量,Java 中称之为对象或者实例,然后你就可以操作这些变量,Java 中称之为发送消息或者发送请求,最后对象决定自己该怎么做。
-
-类描述了一系列具有相同特征和行为的对象,从宽泛的概念上来说,类其实就是一种自定义的数据类型。
-
-一旦创建了一个类,就可以用它创建任意多个对象。面向对象编程语言遇到的最大一个挑战就是,如何把现实/虚拟的元素抽象为 Java 中的对象。
-
-对象能够接收什么样的请求是由它的[接口](https://tobebetterjavaer.com/oo/interface.html)定义的。具体是怎么做到的,就由它的实现方法来实现。
-
-#### **3)访问权限修饰符**
-
-类的创建者有时候也被称为 API 提供者,对应的,类的使用者就被称为 API 调用者。
-
-JDK 就给我们提供了 Java 的基础实现,JDK 的作者也就是基础 API 的提供者(Java 多线程部分的作者 Doug Lea 是被 Java 程序员敬佩的一个大佬),我们这些 Java 语言的使用者,说白了就是 JDK 的调用者。
-
-
-
-当然了,假如我们也提供了新的类给其他调用者,我们也就成为了新的创建者。
-
-API 创建者在创建新的类的时候,只暴露必要的接口,而隐藏其他所有不必要的信息,之所以要这么做,是因为如果这些信息对调用者是不可见的,那么创建者就可以随意修改隐藏的信息,而不用担心对调用者的影响。
-
-这里就必须要讲到 [Java 的权限修饰符](https://tobebetterjavaer.com/oo/access-control.html)。
-
-访问权限修饰符的第一个作用是,防止类的调用者接触到他们不该接触的内部实现;第二个作用是,让类的创建者可以轻松修改内部机制而不用担心影响到调用者的使用。
-
-- public
-- private
-- protected
-
-还有一种“默认”的权限修饰符,是缺省的,它修饰的类可以访问同一个包下面的其他类。
-
-#### **4)组合**
-
-我们可以把一个创建好的类作为另外一个类的成员变量来使用,利用已有的类组成成一个新的类,被称为“复用”,组合代表的关系是 has-a 的关系。
-
-#### **5)继承**
-
-[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html)是 Java 中非常重要的一个概念,子类继承父类,也就拥有了父类中 protected 和 public 修饰的方法和字段,同时,子类还可以扩展一些自己的方法和字段,也可以重写继承过来方法。
-
-常见的例子,就是形状可以有子类圆形、方形、三角形,它们的基础接口是相同的,比如说都有一个 `draw()` 的方法,子类可以继承这个方法实现自己的绘制方法。
-
-如果子类只是重写了父类的方法,那么它们之间的关系就是 is-a 的关系,但如果子类增加了新的方法,那么它们之间的关系就变成了 is-like-a 的关系。
-
-#### **6)多态**
-
-比如说有一个父类Shape
-
-```java
-public class Shape {
- public void draw() {
- System.out.println("形状");
- }
-}
-```
-
-子类Circle
-
-```java
-public class Circle extends Shape{
- @Override
- public void draw() {
- System.out.println("圆形");
- }
-}
-```
-
-子类Line
-
-```java
-public class Line extends Shape {
- @Override
- public void draw() {
- System.out.println("线");
- }
-}
-```
-
-测试类
-
-```java
-public class Test {
- public static void main(String[] args) {
- Shape shape1 = new Line();
- shape1.draw();
- Shape shape2 = new Circle();
- shape2.draw();
- }
-}
-```
-
-运行结果:
-
-```
-线
-圆形
-```
-
-在测试类中,shape1 的类型为 Shape,shape2 的类型也为 Shape,但调用 `draw()` 方法后,却能自动调用子类 Line 和 Circle 的 `draw()` 方法,这是为什么呢?
-
-其实就是 Java 中的[多态](https://tobebetterjavaer.com/oo/polymorphism.html)。
-
-### 06、小结
-
-“怎么样,三妹,是不是对 Java 有了更深入更清晰的理解?”终于讲完了,我深呼了一口气,好舒畅啊!
-
-“是的,哥,感觉 Java 也就那么回事嘛。”哎呀,三妹有点狂了起来,“万物皆对象,除了基本数据类型。”
-
-“哇,三妹,你可以啊,都会自己梳理总结了。”我倍感欣慰,觉得果然是劳有所获,你讲的认真,听众就能理解和 get,满足了。
-
-## 5.2 Java中的包
-
-“三妹,这一节,我们简单过一下 Java 中的包,也就是 package,这个一点就透,很好掌握。”我放下手中的雪碧,翻开笔记本,登上 GitHub,点开《二哥的 Java 进阶之路》,找到这篇「Java 中的包」,开始滔滔不绝起来。
-
-“二哥,你等一下。”让我打开思维导图做一下笔记📒。
-
-### 关于包
-
-在前面的代码中,我们把类和接口命名为`Person`、`Student`、`Hello`等简单的名字。
-
-在团队开发中,如果小明写了一个`Person`类,小红也写了一个`Person`类,现在,小白既想用小明的`Person`,也想用小红的`Person`,怎么办?
-
-如果小军写了一个`Arrays`类,恰好 JDK 也自带了一个`Arrays`类,如何解决类名冲突?
-
-在 Java 中,我们使用`package`来解决名字冲突。
-
-Java 定义了一种名字空间,称之为包:`package`。一个类总是属于某个包,类名(比如`Person`)只是一个简写,真正的完整类名是`包名.类名`。
-
-例如:
-
-小明的`Person`类存放在包`ming`下面,因此,完整类名是`ming.Person`;
-
-小红的`Person`类存放在包`hong`下面,因此,完整类名是`hong.Person`;
-
-小军的`Arrays`类存放在包`mr.jun`下面,因此,完整类名是`mr.jun.Arrays`;
-
-JDK 的`Arrays`类存放在包`java.util`下面,因此,完整类名是`java.util.Arrays`。
-
-在定义`class`的时候,我们需要在第一行声明这个`class`属于哪个包。
-
-小明的`Person.java`文件:
-
-```java
-package ming; // 申明包名ming
-
-public class Person {
-}
-```
-
-小军的`Arrays.java`文件:
-
-```java
-package mr.jun; // 申明包名mr.jun
-
-public class Arrays {
-}
-```
-
-在 Java 虚拟机执行的时候,JVM 只看完整类名,因此,只要包名不同,类就不同。
-
-包可以是多层结构,用`.`隔开。例如:`java.util`。
-
-
->要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系。
-
-
-没有定义包名的`class`,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
-
-我们还需要按照包结构把上面的 Java 文件组织起来。假设以`package_sample`作为根目录,`src`作为源码目录,那么所有文件结构就是:
-
-```ascii
-package_sample
-└─ src
- ├─ hong
- │ └─ Person.java
- │ ming
- │ └─ Person.java
- └─ mr
- └─ jun
- └─ Arrays.java
-```
-
-即所有 Java 文件对应的目录层次要和包的层次一致。
-
-编译后的`.class`文件也需要按照包结构存放。如果使用 IDE,把编译后的`.class`文件放到`bin`目录下,那么,编译的文件结构就是:
-
-```ascii
-package_sample
-└─ bin
- ├─ hong
- │ └─ Person.class
- │ ming
- │ └─ Person.class
- └─ mr
- └─ jun
- └─ Arrays.class
-```
-
-编译的命令相对比较复杂,我们需要在`src`目录下执行`javac`命令:
-
-```
-javac -d ../bin ming/Person.java hong/Person.java mr/jun/Arrays.java
-```
-
-在 IDE 中,会自动根据包结构编译所有 Java 源码,所以不必担心使用命令行编译的复杂命令。
-
-### 包的作用域
-
-位于同一个包的类,可以访问包作用域的字段和方法。
-
-不用`public`、`protected`、`private`修饰的字段和方法就是包作用域。例如,`Person`类定义在`hello`包下面:
-
-```java
-package hello;
-
-public class Person {
- // 包作用域:
- void hello() {
- System.out.println("Hello!");
- }
-}
-```
-
-`Main`类也定义在`hello`包下面,就可以直接访问 Person 类:
-
-```java
-package hello;
-
-public class Main {
- public static void main(String[] args) {
- Person p = new Person();
- p.hello(); // 可以调用,因为Main和Person在同一个包
- }
-}
-```
-
-### 导入包
-
-在一个`class`中,我们总会引用其他的`class`。例如,小明的`ming.Person`类,如果要引用小军的`mr.jun.Arrays`类,他有三种写法:
-
-第一种,直接写出完整类名,例如:
-
-```java
-// Person.java
-package ming;
-
-public class Person {
- public void run() {
- mr.jun.Arrays arrays = new mr.jun.Arrays();
- }
-}
-```
-
-很显然,每次都要写完整的类名比较痛苦。
-
-因此,第二种写法是用`import`语句,导入小军的`Arrays`,然后写简单类名:
-
-```java
-// Person.java
-package ming;
-
-// 导入完整类名:
-import mr.jun.Arrays;
-
-public class Person {
- public void run() {
- Arrays arrays = new Arrays();
- }
-}
-```
-
-在写`import`的时候,可以使用`*`,表示把这个包下面的所有`class`都导入进来(但不包括子包的`class`):
-
-```java
-// Person.java
-package ming;
-
-// 导入mr.jun包的所有class:
-import mr.jun.*;
-
-public class Person {
- public void run() {
- Arrays arrays = new Arrays();
- }
-}
-```
-
-我们一般不推荐这种写法,因为在导入了多个包后,很难看出`Arrays`类属于哪个包。
-
-还有一种`import static`的语法,它可以导入一个类的静态字段和静态方法:
-
-```java
-package main;
-
-// 导入System类的所有静态字段和静态方法:
-import static java.lang.System.*;
-
-public class Main {
- public static void main(String[] args) {
- // 相当于调用System.out.println(…)
- out.println("Hello, world!");
- }
-}
-```
-
-`import static`很少使用。
-
-Java 编译器最终编译出的`.class`文件只使用 *完整类名*,因此,在代码中,当编译器遇到一个`class`名称时:
-
-- 如果是完整类名,就直接根据完整类名查找这个`class`;
-- 如果是简单类名,按下面的顺序依次查找:
- - 查找当前`package`是否存在这个`class`;
- - 查找`import`的包是否包含这个`class`;
- - 查找`java.lang`包是否包含这个`class`。
-
-如果按照上面的规则还无法确定类名,则编译报错。
-
-我们来看一个例子:
-
-```java
-// Main.java
-package test;
-
-import java.text.Format;
-
-public class Main {
- public static void main(String[] args) {
- java.util.List list; // ok,使用完整类名 -> java.util.List
- Format format = null; // ok,使用import的类 -> java.text.Format
- String s = "hi"; // ok,使用java.lang包的String -> java.lang.String
- System.out.println(s); // ok,使用java.lang包的System -> java.lang.System
- MessageFormat mf = null; // 编译错误:无法找到MessageFormat: MessageFormat cannot be resolved to a type
- }
-}
-```
-
-因此,编写 class 的时候,编译器会自动帮我们做两个 import 动作:
-
-- 默认自动`import`当前`package`的其他`class`;
-- 默认自动`import java.lang.*`。
-
-
->注意:自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入。
-
-
-如果有两个`class`名称相同,例如,`mr.jun.Arrays`和`java.util.Arrays`,那么只能`import`其中一个,另一个必须写完整类名。
-
-### 包的最佳实践
-
-为了避免名字冲突,我们需要确定唯一的包名。推荐的做法是使用倒置的域名来确保唯一性。例如:
-
-- org.apache
-- org.apache.commons.log
-- com.tobebetterjavaer.sample
-
-子包就可以根据功能自行命名。
-
-要注意不要和`java.lang`包的类重名,即自己的类不要使用这些名字:
-
-- String
-- System
-- Runtime
-- ...
-
-要注意也不要和 JDK 常用类重名:
-
-- java.util.List
-- java.text.Format
-- java.math.BigInteger
-- ...
-
-
-### 小结
-
-Java 内建的`package`机制是为了避免`class`命名冲突;
-
-JDK 的核心类使用`java.lang`包,编译器会自动导入;
-
-JDK 的其它常用类定义在`java.util.*`,`java.math.*`,`java.text.*`,……;
-
-包名推荐使用倒置的域名,例如`org.apache`。
-
----
-
-> 参考链接:[https://www.liaoxuefeng.com/wiki/1252599548343744/1260467032946976](https://www.liaoxuefeng.com/wiki/1252599548343744/1260467032946976),整理:沉默王二
-
-
-
-
-
-
-
-## 5.3 Java中的变量
-
-“二哥,听说 Java 变量在以后的日子里经常用,能不能提前给我透露透露?”三妹咪了一口麦香可可奶茶后对我说。
-
-“三妹啊,搬个凳子坐我旁边,听二哥来给你慢慢说啊。”
-
-Java 变量就好像一个容器,可以保存程序在运行过程中的值,它在声明的时候会定义对应的[数据类型](https://tobebetterjavaer.com/basic-grammar/basic-data-type.html)(Java 分为两种数据类型:基本数据类型和引用数据类型)。变量按照作用域的范围又可分为三种类型:局部变量,成员变量和静态变量。
-
-比如说,`int data = 88;`,其中 data 就是一个变量,它的值为 88,类型为整型(int)。
-
-
-### 01、局部变量
-
-在方法体内声明的变量被称为局部变量,该变量只能在该方法内使用,类中的其他方法并不知道该变量。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalVariable {
- public static void main(String[] args) {
- int a = 10;
- int b = 10;
- int c = a + b;
- System.out.println(c);
- }
-}
-```
-
-其中 a、b、c 就是局部变量,它们只能在当前这个 main 方法中使用。
-
-声明局部变量时的注意事项:
-
-- 局部变量声明在方法、构造方法或者语句块中。
-- 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,将会被销毁。
-- 访问修饰符不能用于局部变量。
-- 局部变量只在声明它的方法、构造方法或者语句块中可见。
-- 局部变量是在栈上分配的。
-- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
-
-### 02、成员变量
-
-在类内部但在方法体外声明的变量称为成员变量,或者实例变量,或者字段。之所以称为实例变量,是因为该变量只能通过类的实例(对象)来访问。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class InstanceVariable {
- int data = 88;
- public static void main(String[] args) {
- InstanceVariable iv = new InstanceVariable();
- System.out.println(iv.data); // 88
- }
-}
-```
-
-其中 iv 是一个变量,它是一个引用类型的变量。`new` 关键字可以创建一个类的实例(也称为对象),通过“=”操作符赋值给 iv 这个变量,iv 就成了这个对象的引用,通过 `iv.data` 就可以访问成员变量了。
-
-声明成员变量时的注意事项:
-
-- 成员变量声明在一个类中,但在方法、构造方法和语句块之外。
-- 当一个对象被实例化之后,每个成员变量的值就跟着确定。
-- 成员变量在对象创建的时候创建,在对象被销毁的时候销毁。
-- 成员变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息。
-- 成员变量可以声明在使用前或者使用后。
-- 访问修饰符可以修饰成员变量。
-- 成员变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把成员变量设为私有。通过使用访问修饰符可以使成员变量对子类可见;成员变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。
-
-### 03、静态变量
-
-通过 [static 关键字](https://tobebetterjavaer.com/oo/static.html)声明的变量被称为静态变量(类变量),它可以直接被类访问,来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class StaticVariable {
- static int data = 99;
- public static void main(String[] args) {
- System.out.println(StaticVariable.data); // 99
- }
-}
-```
-
-其中 data 就是静态变量,通过`类名.静态变量`就可以访问了,不需要创建类的实例。
-
-声明静态变量时的注意事项:
-
-- 静态变量在类中以 static 关键字声明,但必须在方法构造方法和语句块之外。
-- 无论一个类创建了多少个对象,类只拥有静态变量的一份拷贝。
-- 静态变量除了被声明为常量外很少使用。
-- 静态变量储存在静态存储区。
-- 静态变量在程序开始时创建,在程序结束时销毁。
-- 与成员变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为 public 类型。
-- 静态变量的默认值和实例变量相似。
-- 静态变量还可以在静态语句块中初始化。
-
-### 04、常量
-
-在 Java 中,有些数据的值是不会发生改变的,这些数据被叫做常量——使用 [final 关键字](https://tobebetterjavaer.com/oo/final.html)修饰的成员变量。常量的值一旦给定就无法改变!
-
-常量在程序运行过程中主要有 2 个作用:
-
-- 代表常数,便于修改(例如:圆周率的值,`final double PI = 3.14`)
-- 增强程序的可读性(例如:常量 UP、DOWN 用来代表上和下,`final int UP = 0`)
-
-Java 要求常量名必须大写。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class FinalVariable {
- final String CHEN = "沉";
- static final String MO = "默";
- public static void main(String[] args) {
- FinalVariable fv = new FinalVariable();
- System.out.println(fv.CHEN);
- System.out.println(MO);
- }
-}
-```
-
-“好了,三妹,关于 Java 变量就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
-
-“是啊,二哥,我想以后还会再见到它们吧?”
-
-“那见的次数可就多了,就好像你每天眨眼的次数一样多。”
-
-
-## 5.4 Java中的方法
-
-“二哥,这一节我们学什么呢?”三妹满是期待的问我。
-
-“这一节我们来了解一下 Java 中的方法——什么是方法?如何声明方法?方法有哪几种?什么是实例方法?什么是静态方法?什么是抽象方法?什么是本地方法?”我笑着对三妹说,“我开始了啊,你要注意力集中啊。”
-
-### 01、Java中的方法是什么?
-
-方法用来实现代码的可重用性,我们编写一次方法,并多次使用它。通过增加或者删除方法中的一部分代码,就可以提高整体代码的可读性。
-
-只有方法被调用时,它才会执行。Java 中最有名的方法当属 `main()` 方法,这是程序的入口。
-
-### 02、如何声明方法?
-
-方法的声明反映了方法的一些信息,比如说可见性、返回类型、方法名和参数。如下图所示。
-
-
-
-**访问权限**:它指定了方法的可见性。Java 提供了四种[访问权限修饰符](https://tobebetterjavaer.com/oo/access-control.html):
-
-- public:该方法可以被所有类访问。
-- private:该方法只能在定义它的类中访问。
-- protected:该方法可以被同一个包中的类,或者不同包中的子类访问。
-- default:如果一个方法没有使用任何访问权限修饰符,那么它是 package-private 的,意味着该方法只能被同一个包中的类可见。
-
-**返回类型**:方法返回的数据类型,可以是基本数据类型、对象和集合,如果不需要返回数据,则使用 void 关键字。
-
-**方法名**:方法名最好反应出方法的功能,比如,我们要创建一个将两个数字相减的方法,那么方法名最好是 subtract。
-
-方法名最好是一个动词,并且以小写字母开头。如果方法名包含两个以上单词,那么第一个单词最好是动词,然后是形容词或者名词,并且要以驼峰式的命名方式命名。比如:
-
-- 一个单词的方法名:`sum()`
-- 多个单词的方法名:`stringComparision()`
-
-一个方法可能与同一个类中的另外一个方法同名,这被称为方法重载。
-
-**参数**:参数被放在一个圆括号内,如果有多个参数,可以使用逗号隔开。参数包含两个部分,参数类型和参数名。如果方法没有参数,圆括号是空的。
-
-**方法签名**:每一个方法都有一个签名,包括方法名和参数。
-
-**方法体**:方法体放在一对花括号内,把一些代码放在一起,用来执行特定的任务。
-
-### 03、方法有哪几种?
-
-方法可以分为两种,一种叫标准类库方法,一种叫用户自定义方法。
-
-#### **1)预先定义方法**
-
-Java 提供了大量预先定义好的方法供我们调用,也称为标准类库方法,或者内置方法。比如说 String 类的 `length()`、`equals()`、`compare()` 方法,以及我们在初学 Java 阶段最常用的 `println()` 方法,用来在控制台打印信息。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class PredefinedMethodDemo {
- public static void main(String[] args) {
- System.out.println("沉默王二,一枚有趣的程序员");
- }
-}
-```
-
-在上面的代码中,我们使用了两个预先定义的方法,`main()` 方法是程序运行的入口,`println()` 方法是 `PrintStream` 类的一个方法。这些方法已经提前定义好了,所以我们可以直接使用它们。
-
-我们可以通过集成开发工具查看预先定义方法的方法签名,当我们把鼠标停留在 `println()` 方法上面时,就会显示下图中的内容:
-
-
-
-`println()` 方法的访问权限修饰符是 public,返回类型为 void,方法名为 println,参数为 `String x`,以及 Javadoc(方法是干嘛的)。
-
-预先定义方法让编程变得简单了起来,我们只需要在实现某些功能的时候直接调用这些方法即可,不需要重新编写。
-
-Java 的一个非常大的优势,就是,JDK 的设计者(开发者)为我们提供了大量的标准类库方法,这对于初学编程的新手来说极其友好;不仅如此,GitHub/码云上也有大量可以直接拿到生产环境下使用的第三方类库,比如说 hutool 啊、Apache 包啊、一线大厂或者顶级开发大佬贡献的类库,比如说 Druid、Gson 等等。
-
-但如果你想从一个初级开发者(俗称调包侠)晋升为一名优秀的 Java 工程师,那就需要深入研究这些源码,并掌握,最好是能自己写出来这些源码,最起码能自定义一些源码,以便为我们所用。
-
-#### **2)用户自定义方法**
-
-当预先定义方法无法满足我们的要求时,就需要自定义一些方法,比如说,我们来定义这样一个方法,用来检查数字是偶数还是奇数。
-
-```java
-public static void findEvenOdd(int num) {
- if (num % 2 == 0) {
- System.out.println(num + " 是偶数");
- } else {
- System.out.println(num + " 是奇数");
- }
-}
-```
-
-方法名叫做 `findEvenOdd`,访问权限修饰符是 public,并且是静态的(static),返回类型是 void,参数有一个整型(int)的 num。方法体中有一个 if else 语句,如果 num 可以被 2 整除,那么就打印这个数字是偶数,否则就打印这个数字是奇数。
-
-方法被定义好后,如何被调用呢?
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class EvenOddDemo {
- public static void main(String[] args) {
- findEvenOdd(10);
- findEvenOdd(11);
- }
-
- public static void findEvenOdd(int num) {
- if (num % 2 == 0) {
- System.out.println(num + " 是偶数");
- } else {
- System.out.println(num + " 是奇数");
- }
- }
-}
-```
-
-`main()` 方法是程序的入口,并且是静态的,那么就可以直接调用同样是静态方法的 `findEvenOdd()`。
-
-当一个方法被 static 关键字修饰时,它就是一个静态方法。换句话说,静态方法是属于类的,不属于类实例的(不需要通过 new 关键字创建对象来调用,直接通过类名就可以调用)。
-
-### 04、什么是实例方法?
-
-没有使用 [static 关键字](https://tobebetterjavaer.com/oo/static.html)修饰,但在类中声明的方法被称为实例方法,在调用实例方法之前,必须创建类的对象。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class InstanceMethodExample {
- public static void main(String[] args) {
- InstanceMethodExample instanceMethodExample = new InstanceMethodExample();
- System.out.println(instanceMethodExample.add(1, 2));
- }
-
- public int add(int a, int b) {
- return a + b;
- }
-}
-```
-
-`add()` 方法是一个实例方法,需要创建 InstanceMethodExample 对象来访问。
-
-实例方法有两种特殊类型:
-
-- getter 方法
-- setter 方法
-
-getter 方法用来获取私有变量(private 修饰的字段)的值,setter 方法用来设置私有变量的值。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public int getSex() {
- return sex;
- }
-
- public void setSex(int sex) {
- this.sex = sex;
- }
-}
-```
-
-getter 方法以 get 开头,setter 方法以 set 开头。
-
-### 05、什么是静态方法?
-
-相应的,有 [static 关键字](https://tobebetterjavaer.com/oo/static.html)修饰的方法就叫做静态方法。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 8/9/22
- */
-public class StaticMethodExample {
- public static void main(String[] args) {
- System.out.println(add(1,2));
- }
-
- public static int add(int a, int b) {
- return a + b;
- }
-}
-```
-
-StaticMethodExample 类中,mian 和 add 方法都是静态方法,不同的是,main 方法是程序的入口。当我们调用静态方法的时候,就不需要 new 出来类的对象,就可以直接调用静态方法了,一些工具类的方法都是静态方法,比如说 hutool 工具类库,里面有大量的静态方法可以直接调用。
-
-> Hutool 的目标是使用一个工具方法代替一段复杂代码,从而最大限度的避免“复制粘贴”代码的问题,彻底改变我们写代码的方式。
-
-以计算 MD5 为例:
-
-- 👴【以前】打开搜索引擎 -> 搜“Java MD5 加密” -> 打开某篇博客-> 复制粘贴 -> 改改好用
-- 👦【现在】引入 Hutool -> SecureUtil.md5()
-
-Hutool 的存在就是为了减少代码搜索成本,避免网络上参差不齐的代码出现导致的 bug。
-
-### 06、什么是抽象方法?
-
-没有方法体的方法被称为抽象方法,它总是在[抽象类](https://tobebetterjavaer.com/oo/abstract.html)中声明。这意味着如果类有抽象方法的话,这个类就必须是抽象的。可以使用 atstract 关键字创建抽象方法和抽象类。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-abstract class AbstractDemo {
- abstract void display();
-}
-```
-
-当一个类继承了抽象类后,就必须重写抽象方法:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class MyAbstractDemo extends AbstractDemo {
- @Override
- void display() {
- System.out.println("重写了抽象方法");
- }
-
- public static void main(String[] args) {
- MyAbstractDemo myAbstractDemo = new MyAbstractDemo();
- myAbstractDemo.display();
- }
-}
-```
-
-输出结果如下所示:
-
-```
-重写了抽象方法
-```
-
-“关于方法,我们就讲到这里吧,学会了类/变量/方法,基本上就可以做一个入门级的 Java 程序员了。”我面露微笑,继续对三妹说,“继续加油吧!”
-
-“好的,谢谢二哥你的细心帮助。”
-
-
-## 5.5 Java可变参数
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.5 Java可变参数](https://tobebetterjavaer.com/basic-extra-meal/varables.html)
-
-
-
-## 5.6 Java native方法
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.6 Java native方法](https://tobebetterjavaer.com/oo/native-method.html)
-
-
-## 5.7 Java构造方法
-
-“三妹,[上一节](https://tobebetterjavaer.com/oo/method.html)学了 Java 中的方法,接着学构造方法的话,难度就小很多了。”刚吃完中午饭,虽然有些困意,但趁机学个 10 分钟也是不错的,睡眠会更心满意足一些,于是我面露微笑地对三妹说。
-
-“在 Java 中,构造方法是一种特殊的方法,当一个类被实例化的时候,就会调用构造方法。只有在构造方法被调用的时候,对象才会被分配内存空间。每次使用 `new` 关键字创建对象的时候,构造方法至少会被调用一次。”
-
-“如果你在一个类中没有看见构造方法,并不是因为构造方法不存在,而是被缺省了,编译器会给这个类提供一个默认的构造方法。就是说,Java 有两种类型的构造方法:**无参构造方法和有参构造方法**。”
-
-“注意,之所以叫它构造方法,是因为对象在创建的时候,需要通过构造方法初始化值——描写对象有哪些初始化状态。”
-
-“哥,你缓缓,一口气说这么多,也真有你的。”三妹听得聚精会神,但也知道关心她这个既当哥又当老师的二哥了。
-
-### 01、创建构造方法的规则
-
-构造方法必须符合以下规则:
-
-- 构造方法的名字必须和类名一样;
-- 构造方法没有返回类型,包括 void;
-- 构造方法不能是抽象的(abstract)、静态的(static)、最终的(final)、同步的(synchronized)。
-
-简单解析一下最后一条规则。
-
-- 由于构造方法不能被子类继承,所以用 final 和 abstract 关键字修饰没有意义;
-- 构造方法用于初始化一个对象,所以用 static 关键字修饰没有意义;
-- 多个线程不会同时创建内存地址相同的同一个对象,所以用 synchronized 关键字修饰没有必要。
-
-构造方法的语法格式如下:
-
-```java
-class class_name {
- public class_name(){} // 默认无参构造方法
- public ciass_name([paramList]){} // 定义有参数列表的构造方法
- …
- // 类主体
-}
-```
-
-值得注意的是,如果用 void 声明构造方法的话,编译时不会报错,但 Java 会把这个所谓的“构造方法”当成普通方法来处理。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 2020/11/26
- */
-public class Demo {
- void Demo(){ }
-}
-```
-
-`void Demo(){}` 看起来很符合构造方法的写法(与类名相同),但其实只是一个不符合规范的普通方法,方法名的首字母使用了大写,方法体为空,它并不是默认的无参构造方法,可以通过反编译后的字节码验证。
-
-```java
-public class Demo {
- public Demo() {
- }
-
- void Demo() {
- }
-}
-```
-
-`public Demo() {}` 才是真正的无参构造方法。
-
-不过,可以使用[访问权限修饰符](https://tobebetterjavaer.com/oo/access-control.html)(private、protected、public、default)来修饰构造方法,访问权限修饰符决定了构造方法的创建方式。
-
-
-### 02、默认构造方法
-
-如果一个构造方法中没有任何参数,那么它就是一个默认构造方法,也称为无参构造方法。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class Bike {
- Bike(){
- System.out.println("一辆自行车被创建");
- }
-
- public static void main(String[] args) {
- Bike bike = new Bike();
- }
-}
-```
-
-在上面这个例子中,我们为 Bike 类中创建了一个无参的构造方法,它在我们创建对象的时候被调用。
-
-程序输出结果如下所示:
-
-```
-一辆自行车被创建
-```
-
-通常情况下,无参构造方法是可以缺省的,我们开发者并不需要显式的声明无参构造方法,把这项工作交给编译器就可以了。
-
-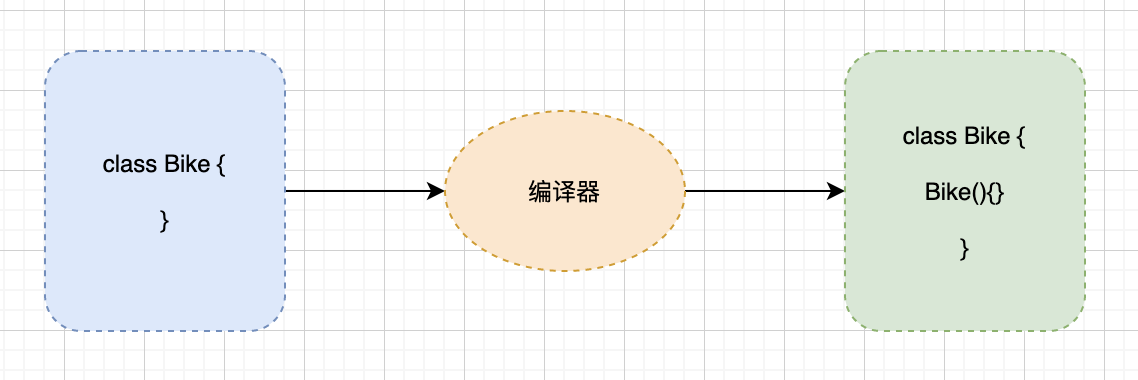
-
-“二哥,默认构造方法的目的是什么?它为什么是一个空的啊?”三妹疑惑地看着我,提出了这个尖锐的问题。
-
-“三妹啊,默认构造方法的目的主要是为对象的字段提供默认值,看下面这个例子你就明白了。”我胸有成竹地回答道。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
-
- public static void main(String[] args) {
- Person p = new Person();
- System.out.println("姓名 " + p.name + " 年龄 " + p.age);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-姓名 null 年龄 0
-```
-
-在上面的例子中,默认构造方法初始化了 name 和 age 的值,name 是 String 类型,所以默认值为 null,age 是 int 类型,所以默认值为 0。如果没有默认构造方法的话,这项工作就无法完成了。
-
-
-### 03、有参构造方法
-
-有参数的构造方法被称为有参构造方法,参数可以有一个或多个。有参构造方法可以为不同的对象提供不同的值。当然,也可以提供相同的值。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class ParamConstructorPerson {
- private String name;
- private int age;
-
- public ParamConstructorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- ParamConstructorPerson p1 = new ParamConstructorPerson("沉默王二",18);
- p1.out();
-
- ParamConstructorPerson p2 = new ParamConstructorPerson("沉默王三",16);
- p2.out();
- }
-}
-```
-
-在上面的例子中,构造方法有两个参数(name 和 age),这样的话,我们在创建对象的时候就可以直接为 name 和 age 赋值了。
-
-```java
-new ParamConstructorPerson("沉默王二",18);
-new ParamConstructorPerson("沉默王三",16);
-```
-
-如果没有有参构造方法的话,就需要通过 setter 方法给字段赋值了。
-
-
-### 04、重载构造方法
-
-在 Java 中,构造方法和方法类似,只不过没有返回类型。它也可以像方法一样被[重载](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)。构造方法的重载也很简单,只需要提供不同的参数列表即可。编译器会通过参数的数量来决定应该调用哪一个构造方法。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class OverloadingConstrutorPerson {
- private String name;
- private int age;
- private int sex;
-
- public OverloadingConstrutorPerson(String name, int age, int sex) {
- this.name = name;
- this.age = age;
- this.sex = sex;
- }
-
- public OverloadingConstrutorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age + " 性别 " + sex);
- }
-
- public static void main(String[] args) {
- OverloadingConstrutorPerson p1 = new OverloadingConstrutorPerson("沉默王二",18, 1);
- p1.out();
-
- OverloadingConstrutorPerson p2 = new OverloadingConstrutorPerson("沉默王三",16);
- p2.out();
- }
-}
-```
-
-创建对象的时候,如果传递的是三个参数,那么就会调用 `OverloadingConstrutorPerson(String name, int age, int sex)` 这个构造方法;如果传递的是两个参数,那么就会调用 `OverloadingConstrutorPerson(String name, int age)` 这个构造方法。
-
-
-### 05、构造方法和方法的区别
-
-构造方法和方法之间的区别还是蛮多的,比如说下面这些:
-
-
-
-
-
-### 06、复制对象
-
-复制一个对象可以通过下面三种方式完成:
-
-- 通过构造方法
-- 通过对象的值
-- 通过 Object 类的 `clone()` 方法
-
-#### 1)通过构造方法
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class CopyConstrutorPerson {
- private String name;
- private int age;
-
- public CopyConstrutorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public CopyConstrutorPerson(CopyConstrutorPerson person) {
- this.name = person.name;
- this.age = person.age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- CopyConstrutorPerson p1 = new CopyConstrutorPerson("沉默王二",18);
- p1.out();
-
- CopyConstrutorPerson p2 = new CopyConstrutorPerson(p1);
- p2.out();
- }
-}
-```
-
-在上面的例子中,有一个参数为 CopyConstrutorPerson 的构造方法,可以把该参数的字段直接复制到新的对象中,这样的话,就可以在 new 关键字创建新对象的时候把之前的 p1 对象传递过去。
-
-#### 2)通过对象的值
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class CopyValuePerson {
- private String name;
- private int age;
-
- public CopyValuePerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public CopyValuePerson() {
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- CopyValuePerson p1 = new CopyValuePerson("沉默王二",18);
- p1.out();
-
- CopyValuePerson p2 = new CopyValuePerson();
- p2.name = p1.name;
- p2.age = p1.age;
-
- p2.out();
- }
-}
-```
-
-这种方式比较粗暴,直接拿 p1 的字段值复制给 p2 对象(`p2.name = p1.name`)。
-
-#### 3)通过 Object 类的 `clone()` 方法
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class ClonePerson implements Cloneable {
- private String name;
- private int age;
-
- public ClonePerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- ClonePerson p1 = new ClonePerson("沉默王二",18);
- p1.out();
-
- ClonePerson p2 = (ClonePerson) p1.clone();
- p2.out();
- }
-}
-```
-
-通过 `clone()` 方法复制对象的时候,ClonePerson 必须先实现 Cloneable 接口的 `clone()` 方法,然后再调用 `clone()` 方法(`ClonePerson p2 = (ClonePerson) p1.clone()`)。
-
->拓展阅读:[浅拷贝与深拷贝](https://tobebetterjavaer.com/basic-extra-meal/deep-copy.html)
-
-### 07、ending
-
-“二哥,我能问一些问题吗?”三妹精神焕发,没有丝毫的疲惫。
-
-“当然可以啊,你问。”我很欣赏三妹孜孜不倦的态度。
-
-“构造方法真的不返回任何值吗?”
-
-“构造方法虽然没有返回值,但返回的是类的对象。”
-
-“构造方法只能完成字段初始化的工作吗?”
-
-“初始化字段只是构造方法的一种工作,它还可以做更多,比如启动线程,调用其他方法等。”
-
-“好的,二哥,我的问题问完了,今天的学习可以结束了!”三妹一脸得意的样子。
-
-“那你记得复习下一节的内容哦。”感受到三妹已经学到了知识,我也很欣慰。
-
-## 5.8 Java访问权限修饰符
-
-“我们先来讨论一下为什么需要访问权限控制。其实之前我们在讲[类和对象](https://tobebetterjavaer.com/oo/object-class.html)的时候有提到,今天我们来详细地聊一聊,三妹。”我开门见山地说,“三妹,你打开思维导图,记得做笔记哦。”
-
-“好的。”三妹应声回答。
-
-考虑两个场景:
-
-场景 1:工程师 A 编写了一个类 ClassA,但是工程师 A 并不希望 ClassA 被其他类都访问到,该如何处理呢?
-
-场景 2:工程师 A 编写了一个类 ClassA,其中有两个方法 fun1、fun2,工程师只想让 fun1 对外可见,也就是说,如果别的工程师来调用 ClassA,只可以调用方法 fun1,该怎么处理呢?
-
-此时,访问权限控制便可以起到作用了。
-
-在 Java 中,提供了四种访问权限控制:
-
-- 默认访问权限(包访问权限)
-- public
-- private
-- protected
-
-类只可以用默认访问权限和 public 修饰。比如说:
-
-```java
-public class Wanger{}
-```
-
-或者
-
-```java
-class Wanger{}
-```
-
-但变量和方法则都可以修饰。
-
-### 1. 修饰类
-
-- 默认访问权限(包访问权限):用来修饰类的话,表示该类只对同一个包中的其他类可见。
-- public:用来修饰类的话,表示该类对其他所有的类都可见。
-
-
-例 1:
-
-Main.java:
-
-```java
-package com.tobetterjavaer.test1;
-
-public class Main {
- public static void main(String\[\] args) {
-
- People people = new People("Tom");
- System.out.println(people.getName());
- }
-
-}
-```
-
-People.java
-
-```java
-package com.tobetterjavaer.test1;
-
-class People {//默认访问权限(包访问权限)
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-从代码可以看出,修饰 People 类采用的是默认访问权限,而由于 People 类和 Main 类在同一个包中,因此 People 类对于 Main 类是可见的。
-
-例子 2:
-
-People.java
-
-```java
-package com.tobetterjavaer.test2;
-
-class People {//默认访问权限(包访问权限)
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-此时 People 类和 Main 类不在同一个包中,会发生什么情况呢?
-
-下面是 Main 类中的提示的错误:
-
-
-
-
-
-提示 Peolple 类在 Main 类中不可见。从这里就可以看出,如果用默认访问权限去修饰一个类,该类只对同一个包中的其他类可见,对于不同包中的类是不可见的。
-
-正如上图的快速修正提示所示,将 People 类的默认访问权限更改为 public 的话,People 类对于 Main 类便可见了。
-
-### 2. 修饰方法和变量
-
-- 默认访问权限(包访问权限):如果一个类的方法或变量被包访问权限修饰,也就意味着只能在同一个包中的其他类中显示地调用该类的方法或者变量,在不同包中的类中不能显式地调用该类的方法或变量。
-- private:如果一个类的方法或者变量被 private 修饰,那么这个类的方法或者变量只能在该类本身中被访问,在类外以及其他类中都不能显式的进行访问。
-- protected:如果一个类的方法或者变量被 protected 修饰,对于同一个包的类,这个类的方法或变量是可以被访问的。对于不同包的类,只有继承于该类的类才可以访问到该类的方法或者变量。
-- public:被 public 修饰的方法或者变量,在任何地方都是可见的。
-
-
-例 3:
-
-Main.java 没有变化
-
-People.java
-
-```java
-package com.tobebetterjavaer.test1;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- String getName() { //默认访问权限(包访问权限)
- return name;
- }
-
- void setName(String name) { //默认访问权限(包访问权限)
- this.name = name;
- }
-}
-```
-
-此时在 Main 类是可以显示调用方法 getName 和 setName 的。
-
-但是如果 People 类和 Main 类不在同一个包中:
-
-```java
-package com.tobebetterjavaer.test2; //与Main类处于不同包中
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- String getName() { //默认访问权限(包访问权限)
- return name;
- }
-
- void setName(String name) { //默认访问权限(包访问权限)
- this.name = name;
- }
-}
-```
-
-此时在 Main 类中会提示错误:
-
-
-
-
-
-由此可以看出,如果用默认访问权限来修饰类的方法或者变量,则只能在同一个包的其他类中进行访问。
-
-例 4:
-
-People.java
-
-```java
-package com.tobebetterjavaer.test1;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- protected String getName() {
- return name;
- }
-
- protected void setName(String name) {
- this.name = name;
- }
-}
-```
-
-此时是可以在 Main 中显示调用方法 getName 和 setName 的。
-
-如果 People 类和 Main 类处于不同包中:
-
-```java
-package com.tobebetterjavaer.test2;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- protected String getName() {
- return name;
- }
-
- protected void setName(String name) {
- this.name = name;
- }
-}
-```
-
-则会在 Main 中报错:
-
-
-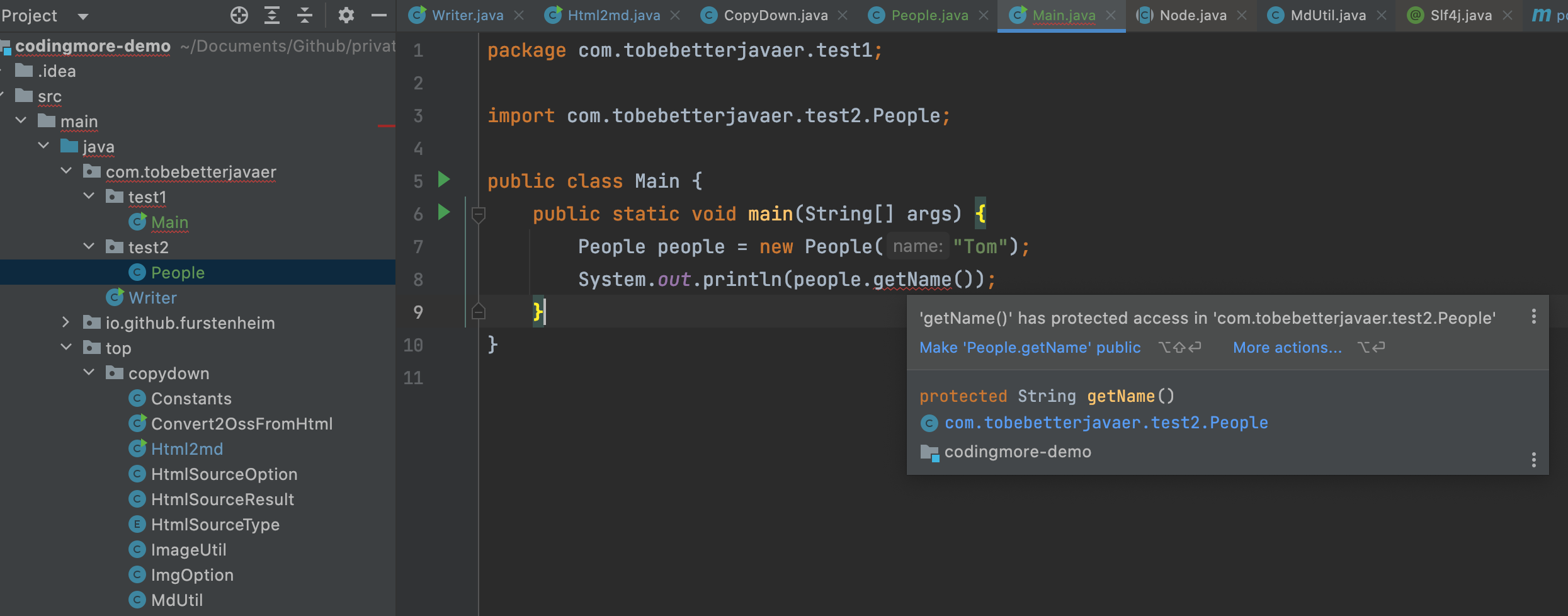
-
-
-如果在 com.cxh.test1 中定一个类 Man 继承 People,则可以在类 Man 中显示调用方法 getName 和 setName:
-
-```java
-package com.tobebetterjavaer.test1;
-
-import com.tobebetterjavaer.test2.People;
-
-public class Man extends People {
-
- public Man(String name){
- super(name);
- }
-
- public String toString() {
- return getName();
- }
-}
-```
-
-补充一些关于 Java 包和类文件的知识:
-
-1)Java 中的包主要是为了防止类文件命名冲突以及方便进行代码组织和管理;
-
-2)对于一个 Java 源代码文件,如果存在 public 类的话,只能有一个 public 类,且此时源代码文件的名称必须和 public 类的名称完全相同。
-
-另外,如果还存在其他类,这些类在包外是不可见的。如果源代码文件没有 public 类,则源代码文件的名称可以随意命名。
-
-“三妹,理解了吧?”我问三妹。
-
-“是的,很简单,换句话说,不想让别人看的就 private,想让人看的就 public,想同一个班级/部门看的就默认,想让下一级看的就 protected,对吧?哥”三妹很自信地回答。
-
-“不错不错,总结得有那味了。”
-
->原文链接:[https://www.cnblogs.com/dolphin0520/p/3734915.html](https://www.cnblogs.com/dolphin0520/p/3734915.html) 作者: Matrix海子,编辑:沉默王二
-
-
-
-## 5.9 Java代码初始化块
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.9 Java代码初始化块](https://tobebetterjavaer.com/oo/code-init.html)
-
-
-
-## 5.10 Java抽象类
-
-“二哥,你这明显加快了更新的频率呀!”三妹对于我最近的肝劲由衷的佩服了起来。
-
-“哈哈,是呀,我要给广大的学弟学妹们一个完整的 Java 学习体系,记住我们的口号,**学 Java 就上二哥的 Java 进阶之路**。”我对未来充满了信心。
-
-“那就开始吧。”三妹说。
-
-### 01、定义抽象类
-
-定义抽象类的时候需要用到关键字 `abstract`,放在 `class` 关键字前,就像下面这样。
-
-```java
-abstract class AbstractPlayer {
-}
-```
-
-关于抽象类的命名,《[阿里的 Java 开发手册](https://tobebetterjavaer.com/pdf/ali-java-shouce.html)》上有强调,“抽象类命名要使用 Abstract 或 Base 开头”,这条规约还是值得遵守的,真正做到名如其意。
-
-### 02、抽象类的特征
-
-抽象类是不能实例化的,尝试通过 `new` 关键字实例化的话,编译器会报错,提示“类是抽象的,不能实例化”。
-
-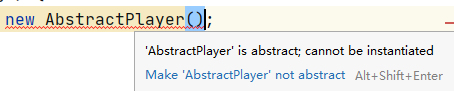
-
-虽然抽象类不能实例化,但可以有子类。子类通过 `extends` 关键字来继承抽象类。就像下面这样。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
-}
-```
-
-如果一个类定义了一个或多个抽象方法,那么这个类必须是抽象类。
-
-当我们尝试在一个普通类中定义抽象方法的时候,编译器会有两处错误提示。第一处在类级别上,提示“这个类必须通过 `abstract` 关键字定义”,见下图。
-
-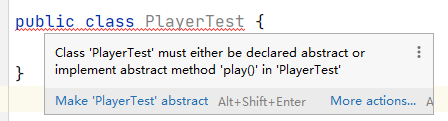
-
-第二处在尝试定义 abstract 的方法上,提示“抽象方法所在的类不是抽象的”,见下图。
-
-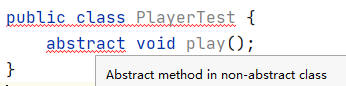
-
-抽象类中既可以定义抽象方法,也可以定义普通方法,就像下面这样:
-
-```java
-public abstract class AbstractPlayer {
- abstract void play();
-
- public void sleep() {
- System.out.println("运动员也要休息而不是挑战极限");
- }
-}
-```
-
-抽象类派生的子类必须实现父类中定义的抽象方法。比如说,抽象类 AbstractPlayer 中定义了 `play()` 方法,子类 BasketballPlayer 中就必须实现。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是张伯伦,篮球场上得过 100 分");
- }
-}
-```
-
-如果没有实现的话,编译器会提示“子类必须实现抽象方法”,见下图。
-
-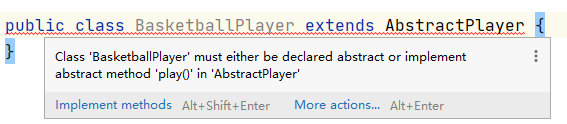
-
-### 03、抽象类的应用场景
-
-“二哥,抽象方法我明白了,那什么时候使用抽象方法呢?能给我讲讲它的应用场景吗?”三妹及时的插话道。
-
-“这问题问的恰到好处呀!”我扶了扶眼镜继续说。
-
-#### **01)第一种场景**
-
-当我们希望一些通用的功能被多个子类复用的时候,就可以使用抽象类。比如说,AbstractPlayer 抽象类中有一个普通的方法 `sleep()`,表明所有运动员都需要休息,那么这个方法就可以被子类复用。
-
-```java
-abstract class AbstractPlayer {
- public void sleep() {
- System.out.println("运动员也要休息而不是挑战极限");
- }
-}
-```
-
-子类 BasketballPlayer 继承了 AbstractPlayer 类:
-
-```java
-class BasketballPlayer extends AbstractPlayer {
-}
-```
-
-也就拥有了 `sleep()` 方法。BasketballPlayer 的对象可以直接调用父类的 `sleep()` 方法:
-
-```java
-BasketballPlayer basketballPlayer = new BasketballPlayer();
-basketballPlayer.sleep();
-```
-
-子类 FootballPlayer 继承了 AbstractPlayer 类:
-
-```java
-class FootballPlayer extends AbstractPlayer {
-}
-```
-
-也拥有了 `sleep()` 方法,FootballPlayer 的对象也可以直接调用父类的 `sleep()` 方法:
-
-```java
-FootballPlayer footballPlayer = new FootballPlayer();
-footballPlayer.sleep();
-```
-
-这样是不是就实现了代码的复用呢?
-
-#### **02)第二种场景**
-
-当我们需要在抽象类中定义好 API,然后在子类中扩展实现的时候就可以使用抽象类。比如说,AbstractPlayer 抽象类中定义了一个抽象方法 `play()`,表明所有运动员都可以从事某项运动,但需要对应子类去扩展实现,表明篮球运动员打篮球,足球运动员踢足球。
-
-```java
-abstract class AbstractPlayer {
- abstract void play();
-}
-```
-
-BasketballPlayer 继承了 AbstractPlayer 类,扩展实现了自己的 `play()` 方法。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是张伯伦,我篮球场上得过 100 分,");
- }
-}
-```
-
-FootballPlayer 继承了 AbstractPlayer 类,扩展实现了自己的 `play()` 方法。
-
-```java
-public class FootballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是C罗,我能接住任意高度的头球");
- }
-}
-```
-
-为了进一步展示抽象类的特性,我们再来看一个具体的示例。
-
->PS:[网站](https://tobebetterjavaer.com/oo/abstract.html)评论区说涉及到了文件的读写以及 Java 8 的新特性,不适合新人,如果觉得自己实在是看不懂,跳过,等学了 IO 流再来看也行。如果说是为了复习 Java 基础知识,就不存在这个问题了。
-
-假设现在有一个文件,里面的内容非常简单,只有一个“Hello World”,现在需要有一个读取器将内容从文件中读取出来,最好能按照大写的方式,或者小写的方式来读。
-
-这时候,最好定义一个抽象类 BaseFileReader:
-
-```java
-/**
- * 抽象类,定义了一个读取文件的基础框架,其中 mapFileLine 是一个抽象方法,具体实现需要由子类来完成
- */
-abstract class BaseFileReader {
- protected Path filePath; // 定义一个 protected 的 Path 对象,表示读取的文件路径
-
- /**
- * 构造方法,传入读取的文件路径
- * @param filePath 读取的文件路径
- */
- protected BaseFileReader(Path filePath) {
- this.filePath = filePath;
- }
-
- /**
- * 读取文件的方法,返回一个字符串列表
- * @return 字符串列表,表示文件的内容
- * @throws IOException 如果文件读取出错,抛出该异常
- */
- public List readFile() throws IOException {
- return Files.lines(filePath) // 使用 Files 类的 lines 方法,读取文件的每一行
- .map(this::mapFileLine) // 对每一行应用 mapFileLine 方法,将其转化为指定的格式
- .collect(Collectors.toList()); // 将处理后的每一行收集到一个字符串列表中,返回
- }
-
- /**
- * 抽象方法,子类需要实现该方法,将文件中的每一行转化为指定的格式
- * @param line 文件中的每一行
- * @return 转化后的字符串
- */
- protected abstract String mapFileLine(String line);
-}
-```
-
-- filePath 为文件路径,使用 protected 修饰,表明该成员变量可以在需要时被子类访问到。
-
-- `readFile()` 方法用来读取文件,方法体里面调用了抽象方法 `mapFileLine()`——需要子类来扩展实现大小写的不同读取方式。
-
-在我看来,BaseFileReader 类设计的就非常合理,并且易于扩展,子类只需要专注于具体的大小写实现方式就可以了。
-
-小写的方式:
-
-```java
-class LowercaseFileReader extends BaseFileReader {
- protected LowercaseFileReader(Path filePath) {
- super(filePath);
- }
-
- @Override
- protected String mapFileLine(String line) {
- return line.toLowerCase();
- }
-}
-```
-
-大写的方式:
-
-```java
-class UppercaseFileReader extends BaseFileReader {
- protected UppercaseFileReader(Path filePath) {
- super(filePath);
- }
-
- @Override
- protected String mapFileLine(String line) {
- return line.toUpperCase();
- }
-}
-```
-
-从文件里面一行一行读取内容的代码被子类复用了。与此同时,子类只需要专注于自己该做的工作,LowercaseFileReader 以小写的方式读取文件内容,UppercaseFileReader 以大写的方式读取文件内容。
-
-来看一下测试类 FileReaderTest:
-
-```java
-public class FileReaderTest {
- public static void main(String[] args) throws URISyntaxException, IOException {
- URL location = FileReaderTest.class.getClassLoader().getResource("helloworld.txt");
- Path path = Paths.get(location.toURI());
- BaseFileReader lowercaseFileReader = new LowercaseFileReader(path);
- BaseFileReader uppercaseFileReader = new UppercaseFileReader(path);
- System.out.println(lowercaseFileReader.readFile());
- System.out.println(uppercaseFileReader.readFile());
- }
-}
-```
-
-在项目的 resource 目录下建一个文本文件,名字叫 helloworld.txt,里面的内容就是“Hello World”。文件的具体位置如下图所示,我用的集成开发环境是 Intellij IDEA。
-
-
-
-
-在 resource 目录下的文件可以通过 `ClassLoader.getResource()` 的方式获取到 URI 路径,然后就可以取到文本内容了。
-
-输出结果如下所示:
-
-```
-[hello world]
-[HELLO WORLD]
-```
-
-### 04、抽象类总结
-
-好了,对于抽象类我们简单总结一下:
-
-- 1、抽象类不能被实例化。
-- 2、抽象类应该至少有一个抽象方法,否则它没有任何意义。
-- 3、抽象类中的抽象方法没有方法体。
-- 4、抽象类的子类必须给出父类中的抽象方法的具体实现,除非该子类也是抽象类。
-
-“完了吗?二哥”三妹似乎还沉浸在聆听教诲的快乐中。
-
-“是滴,这次我们系统化的学习了抽象类,可以说面面俱到了。三妹你可以把代码敲一遍,加强了一些印象,电脑交给你了。”说完,我就跑到阳台去抽烟了。
-
-“呼。。。。。”一个大大的眼圈飘散开来,又是愉快的一天~
-
-
-## 5.11 Java接口
-
-“今天开始讲 Java 的接口。”我对三妹说,“对于面向对象编程来说,抽象是一个极具魅力的特征。如果一个程序员的抽象思维很差,那他在编程中就会遇到很多困难,无法把业务变成具体的代码。在 Java 中,可以通过两种形式来达到抽象的目的,一种上一篇的主角——[抽象类](https://tobebetterjavaer.com/oo/abstract.html),另外一种就是今天的主角——[接口](https://tobebetterjavaer.com/oo/interface.html)。”
-
-“二哥,开讲之前,先恭喜你呀。我看你朋友圈说《[Java进阶之路](https://github.com/itwanger/toBeBetterJavaer)》开源知识库在 GitHub 上收到了第一笔赞赏呀,虽然只有一块钱,但我也替你感到开心。”三妹的脸上洋溢着自信的微笑,仿佛这钱是打给她的一样。
-
-
-
->PS:2021-04-29到2023-02-11期间,《二哥的 Java 进阶之路》收到了 58 笔赞赏,真的非常感谢大家的认可和支持😍,我会继续肝下去的。
-
-“是啊,早上起来的时候看到这条信息,还真的是挺开心的,虽然只有一块钱,但是开源的第一笔,也是我人生当中的第一笔,真的非常感谢这个读者,值得纪念的一天。”我自己也掩饰不住内心的激动。
-
-“有了这份鼓励,我相信你更新下去的动力更足了!”三妹今天说的话真的是特别令人喜欢。
-
-
-
-“是呀是呀,让我们开始吧!”
-
-### 01、定义接口
-
-“接口是什么呀?”三妹顺着我的话题及时的插话到。
-
-接口通过 interface 关键字来定义,它可以包含一些常量和方法,来看下面这个示例。
-
-```java
-public interface Electronic {
- // 常量
- String LED = "LED";
-
- // 抽象方法
- int getElectricityUse();
-
- // 静态方法
- static boolean isEnergyEfficient(String electtronicType) {
- return electtronicType.equals(LED);
- }
-
- // 默认方法
- default void printDescription() {
- System.out.println("电子");
- }
-}
-```
-
-来看一下这段代码反编译后的字节码。
-
-```java
-public interface Electronic
-{
-
- public abstract int getElectricityUse();
-
- public static boolean isEnergyEfficient(String electtronicType)
- {
- return electtronicType.equals("LED");
- }
-
- public void printDescription()
- {
- System.out.println("\u7535\u5B50");
- }
-
- public static final String LED = "LED";
-}
-```
-
-发现没?接口中定义的所有变量或者方法,都会自动添加上 `public` 关键字。
-
-接下来,我来一一解释下 Electronic 接口中的核心知识点。
-
-**1)接口中定义的变量会在编译的时候自动加上 `public static final` 修饰符**(注意看一下反编译后的字节码),也就是说上例中的 LED 变量其实就是一个常量。
-
-Java 官方文档上有这样的声明:
-
->Every field declaration in the body of an interface is implicitly public, static, and final.
-
-换句话说,接口可以用来作为常量类使用,还能省略掉 `public static final`,看似不错的一种选择,对吧?
-
-不过,这种选择并不可取。因为接口的本意是对方法进行抽象,而常量接口会对子类中的变量造成命名空间上的“污染”。
-
-**2)没有使用 `private`、`default` 或者 `static` 关键字修饰的方法是隐式抽象的**,在编译的时候会自动加上 `public abstract` 修饰符。也就是说上例中的 `getElectricityUse()` 其实是一个抽象方法,没有方法体——这是定义接口的本意。
-
-**3)从 Java 8 开始,接口中允许有静态方法**,比如说上例中的 `isEnergyEfficient()` 方法。
-
-静态方法无法由(实现了该接口的)类的对象调用,它只能通过接口名来调用,比如说 `Electronic.isEnergyEfficient("LED")`。
-
-接口中定义静态方法的目的是为了提供一种简单的机制,使我们不必创建对象就能调用方法,从而提高接口的竞争力。
-
-**4)接口中允许定义 `default` 方法**也是从 Java 8 开始的,比如说上例中的 `printDescription()` 方法,它始终由一个代码块组成,为实现该接口而不覆盖该方法的类提供默认实现。既然要提供默认实现,就要有方法体,换句话说,默认方法后面不能直接使用“;”号来结束——编译器会报错。
-
-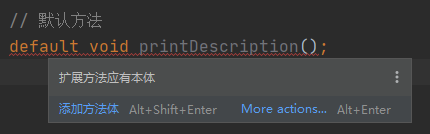
-
-“为什么要在接口中定义默认方法呢?”三妹好奇地问到。
-
-允许在接口中定义默认方法的理由很充分,因为一个接口可能有多个实现类,这些类就必须实现接口中定义的抽象类,否则编译器就会报错。假如我们需要在所有的实现类中追加某个具体的方法,在没有 `default` 方法的帮助下,我们就必须挨个对实现类进行修改。
-
-由之前的例子我们就可以得出下面这些结论:
-
-- 接口中允许定义变量
-- 接口中允许定义抽象方法
-- 接口中允许定义静态方法(Java 8 之后)
-- 接口中允许定义默认方法(Java 8 之后)
-
-除此之外,我们还应该知道:
-
-**1)接口不允许直接实例化**,否则编译器会报错。
-
-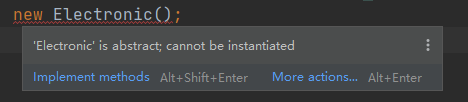
-
-需要定义一个类去实现接口,见下例。
-
-```java
-public class Computer implements Electronic {
-
- public static void main(String[] args) {
- new Computer();
- }
-
- @Override
- public int getElectricityUse() {
- return 0;
- }
-}
-```
-
-然后再实例化。
-
-```
-Electronic e = new Computer();
-```
-
-**2)接口可以是空的**,既可以不定义变量,也可以不定义方法。最典型的例子就是 Serializable 接口,在 `java.io` 包下。
-
-```java
-public interface Serializable {
-}
-```
-
-Serializable 接口用来为序列化的具体实现提供一个标记,也就是说,只要某个类实现了 Serializable 接口,那么它就可以用来序列化了。
-
-**3)不要在定义接口的时候使用 final 关键字**,否则会报编译错误,因为接口就是为了让子类实现的,而 final 阻止了这种行为。
-
-
-
-**4)接口的抽象方法不能是 private、protected 或者 final**,否则编译器都会报错。
-
-
-
-**5)接口的变量是隐式 `public static final`(常量)**,所以其值无法改变。
-
-### 02、接口的作用
-
-“接口可以做什么呢?”三妹见缝插针,问的很及时。
-
-**第一,使某些实现类具有我们想要的功能**,比如说,实现了 Cloneable 接口的类具有拷贝的功能,实现了 Comparable 或者 Comparator 的类具有比较功能。
-
-Cloneable 和 Serializable 一样,都属于标记型接口,它们内部都是空的。实现了 Cloneable 接口的类可以使用 `Object.clone()` 方法,否则会抛出 CloneNotSupportedException。
-
-```java
-public class CloneableTest implements Cloneable {
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- CloneableTest c1 = new CloneableTest();
- CloneableTest c2 = (CloneableTest) c1.clone();
- }
-}
-```
-
-运行后没有报错。现在把 `implements Cloneable` 去掉。
-
-```java
-public class CloneableTest {
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- CloneableTest c1 = new CloneableTest();
- CloneableTest c2 = (CloneableTest) c1.clone();
-
- }
-}
-```
-
-运行后抛出 CloneNotSupportedException:
-
-```
-Exception in thread "main" java.lang.CloneNotSupportedException: com.cmower.baeldung.interface1.CloneableTest
- at java.base/java.lang.Object.clone(Native Method)
- at com.cmower.baeldung.interface1.CloneableTest.clone(CloneableTest.java:6)
- at com.cmower.baeldung.interface1.CloneableTest.main(CloneableTest.java:11)
-```
-
-
-**第二,Java 原则上只支持单一继承,但通过接口可以实现多重继承的目的**。
-
-如果有两个类共同继承(extends)一个父类,那么父类的方法就会被两个子类重写。然后,如果有一个新类同时继承了这两个子类,那么在调用重写方法的时候,编译器就不能识别要调用哪个类的方法了。这也正是著名的菱形问题,见下图。
-
-
-
-
-简单解释下,ClassC 同时继承了 ClassA 和 ClassB,ClassC 的对象在调用 ClassA 和 ClassB 中重写的方法时,就不知道该调用 ClassA 的方法,还是 ClassB 的方法。
-
-接口没有这方面的困扰。来定义两个接口,Fly 接口会飞,Run 接口会跑。
-
-```java
-public interface Fly {
- void fly();
-}
-public interface Run {
- void run();
-}
-```
-
-然后让 Pig 类同时实现这两个接口。
-
-```java
-public class Pig implements Fly,Run{
- @Override
- public void fly() {
- System.out.println("会飞的猪");
- }
-
- @Override
- public void run() {
- System.out.println("会跑的猪");
- }
-}
-```
-
-在某种形式上,接口实现了多重继承的目的:现实世界里,猪的确只会跑,但在雷军的眼里,站在风口的猪就会飞,这就需要赋予这只猪更多的能力,通过抽象类是无法实现的,只能通过接口。
-
-**第三,实现多态**。
-
-什么是多态呢?通俗的理解,就是同一个事件发生在不同的对象上会产生不同的结果,鼠标左键点击窗口上的 X 号可以关闭窗口,点击超链接却可以打开新的网页。
-
-多态可以通过继承(`extends`)的关系实现,也可以通过接口的形式实现。
-
-Shape 接口表示一个形状。
-
-```java
-public interface Shape {
- String name();
-}
-```
-
-Circle 类实现了 Shape 接口,并重写了 `name()` 方法。
-
-```java
-public class Circle implements Shape {
- @Override
- public String name() {
- return "圆";
- }
-}
-```
-
-Square 类也实现了 Shape 接口,并重写了 `name()` 方法。
-
-```java
-public class Square implements Shape {
- @Override
- public String name() {
- return "正方形";
- }
-}
-```
-
-然后来看测试类。
-
-```java
-List shapes = new ArrayList<>();
-Shape circleShape = new Circle();
-Shape squareShape = new Square();
-
-shapes.add(circleShape);
-shapes.add(squareShape);
-
-for (Shape shape : shapes) {
- System.out.println(shape.name());
-}
-```
-
-这就实现了多态,变量 circleShape、squareShape 的引用类型都是 Shape,但执行 `shape.name()` 方法的时候,Java 虚拟机知道该去调用 Circle 的 `name()` 方法还是 Square 的 `name()` 方法。
-
-说一下多态存在的 3 个前提:
-
-- 1、要有继承关系,比如说 Circle 和 Square 都实现了 Shape 接口。
-- 2、子类要重写父类的方法,Circle 和 Square 都重写了 `name()` 方法。
-- 3、父类引用指向子类对象,circleShape 和 squareShape 的类型都为 Shape,但前者指向的是 Circle 对象,后者指向的是 Square 对象。
-
-然后,我们来看一下测试结果:
-
-```
-圆
-正方形
-```
-
-也就意味着,尽管在 for 循环中,shape 的类型都为 Shape,但在调用 `name()` 方法的时候,它知道 Circle 对象应该调用 Circle 类的 `name()` 方法,Square 对象应该调用 Square 类的 `name()` 方法。
-
-### 03、接口的三种模式
-
-**在编程领域,好的设计模式能够让我们的代码事半功倍**。在使用接口的时候,经常会用到三种模式,分别是策略模式、适配器模式和工厂模式。
-
-#### 1)策略模式
-
-策略模式的思想是,针对一组算法,将每一种算法封装到具有共同接口的实现类中,接口的设计者可以在不影响调用者的情况下对算法做出改变。示例如下:
-
-```java
-// 接口:教练
-interface Coach {
- // 方法:防守
- void defend();
-}
-
-// 何塞·穆里尼奥
-class Hesai implements Coach {
-
- @Override
- public void defend() {
- System.out.println("防守赢得冠军");
- }
-}
-
-// 德普·瓜迪奥拉
-class Guatu implements Coach {
-
- @Override
- public void defend() {
- System.out.println("进攻就是最好的防守");
- }
-}
-
-public class Demo {
- // 参数为接口
- public static void defend(Coach coach) {
- coach.defend();
- }
-
- public static void main(String[] args) {
- // 为同一个方法传递不同的对象
- defend(new Hesai());
- defend(new Guatu());
- }
-}
-```
-
-`Demo.defend()` 方法可以接受不同风格的 Coach,并根据所传递的参数对象的不同而产生不同的行为,这被称为“策略模式”。
-
-#### 2)适配器模式
-
-适配器模式的思想是,针对调用者的需求对原有的接口进行转接。生活当中最常见的适配器就是HDMI(英语:`High Definition Multimedia Interface`,中文:高清多媒体接口)线,可以同时发送音频和视频信号。适配器模式的示例如下:
-
-```java
-interface Coach {
- void defend();
- void attack();
-}
-
-// 抽象类实现接口,并置空方法
-abstract class AdapterCoach implements Coach {
- public void defend() {};
- public void attack() {};
-}
-
-// 新类继承适配器
-class Hesai extends AdapterCoach {
- public void defend() {
- System.out.println("防守赢得冠军");
- }
-}
-
-public class Demo {
- public static void main(String[] args) {
- Coach coach = new Hesai();
- coach.defend();
- }
-}
-```
-Coach 接口中定义了两个方法(`defend()` 和 `attack()`),如果类直接实现该接口的话,就需要对两个方法进行实现。
-
-如果我们只需要对其中一个方法进行实现的话,就可以使用一个抽象类作为中间件,即适配器(AdapterCoach),用这个抽象类实现接口,并对抽象类中的方法置空(方法体只有一对花括号),这时候,新类就可以绕过接口,继承抽象类,我们就可以只对需要的方法进行覆盖,而不是接口中的所有方法。
-
-#### 3)工厂模式
-
-所谓的工厂模式理解起来也不难,就是什么工厂生产什么,比如说宝马工厂生产宝马,奔驰工厂生产奔驰,A 级学院毕业 A 级教练,C 级学院毕业 C 级教练。示例如下:
-
-```java
-// 教练
-interface Coach {
- void command();
-}
-
-// 教练学院
-interface CoachFactory {
- Coach createCoach();
-}
-
-// A级教练
-class ACoach implements Coach {
-
- @Override
- public void command() {
- System.out.println("我是A级证书教练");
- }
-
-}
-
-// A级教练学院
-class ACoachFactory implements CoachFactory {
-
- @Override
- public Coach createCoach() {
- return new ACoach();
- }
-
-}
-
-// C级教练
-class CCoach implements Coach {
-
- @Override
- public void command() {
- System.out.println("我是C级证书教练");
- }
-
-}
-
-// C级教练学院
-class CCoachFactory implements CoachFactory {
-
- @Override
- public Coach createCoach() {
- return new CCoach();
- }
-
-}
-
-public class Demo {
- public static void create(CoachFactory factory) {
- factory.createCoach().command();
- }
-
- public static void main(String[] args) {
- // 对于一支球队来说,需要什么样的教练就去找什么样的学院
- // 学院会介绍球队对应水平的教练。
- create(new ACoachFactory());
- create(new CCoachFactory());
- }
-}
-```
-
-有两个接口,一个是 Coach(教练),可以 `command()`(指挥球队);另外一个是 CoachFactory(教练学院),能 `createCoach()`(教出一名优秀的教练)。然后 ACoach 类实现 Coach 接口,ACoachFactory 类实现 CoachFactory 接口;CCoach 类实现 Coach 接口,CCoachFactory 类实现 CoachFactory 接口。当需要 A 级教练时,就去找 A 级教练学院;当需要 C 级教练时,就去找 C 级教练学院。
-
-依次类推,我们还可以用 BCoach 类实现 Coach 接口,BCoachFactory 类实现 CoachFactory 接口,从而不断地丰富教练的梯队。
-
-“怎么样三妹,一下子接收这么多知识点不容易吧?”
-
-“其实还好啊,二哥你讲的这么细致,我都做好笔记📒了,学习嘛,认真一点,效果就会好很多了。”
-
-三妹这种积极乐观的态度真的让我感觉到“付出就会有收获”,💪🏻。
-
-### 04、抽象类和接口的区别
-
-简单总结一下抽象类和接口的区别。
-
-在 Java 中,通过关键字 `abstract` 定义的类叫做抽象类。Java 是一门面向对象的语言,因此所有的对象都是通过类来描述的;但反过来,并不是所有的类都是用来描述对象的,抽象类就是其中的一种。
-
-以下示例展示了一个简单的抽象类:
-
-```java
-// 个人认为,一名教练必须攻守兼备
-abstract class Coach {
- public abstract void defend();
-
- public abstract void attack();
-}
-```
-
-我们知道,有抽象方法的类被称为抽象类,也就意味着抽象类中还能有不是抽象方法的方法。这样的类就不能算作纯粹的接口,尽管它也可以提供接口的功能——只能说抽象类是普通类与接口之间的一种中庸之道。
-
-**接口(英文:Interface),在 Java 中是一个抽象类型,是抽象方法的集合**;接口通过关键字 `interface` 来定义。接口与抽象类的不同之处在于:
-
-- 1、抽象类可以有方法体的方法,但接口没有(Java 8 以前)。
-- 2、接口中的成员变量隐式为 `static final`,但抽象类不是的。
-- 3、一个类可以实现多个接口,但只能继承一个抽象类。
-
-以下示例展示了一个简单的接口:
-
-```java
-// 隐式的abstract
-interface Coach {
- // 隐式的public
- void defend();
- void attack();
-}
-```
-
-- 接口是隐式抽象的,所以声明时没有必要使用 `abstract` 关键字;
-- 接口的每个方法都是隐式抽象的,所以同样不需要使用 `abstract` 关键字;
-- 接口中的方法都是隐式 `public` 的。
-
-“哦,我理解了哥。那我再问一下,抽象类和接口有什么差别呢?”
-
-“哇,三妹呀,你这个问题恰到好处,问到了点子上。”我不由得为三妹竖起了大拇指。
-
-#### 1)语法层面上
-
-- 抽象类可以提供成员方法的实现细节,而接口中只能存在 public abstract 方法;
-- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的;
-- 接口中不能含有静态代码块,而抽象类可以有静态代码块;
-- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
-
-#### 2)设计层面上
-
-抽象类是对一种事物的抽象,即对类抽象,继承抽象类的子类和抽象类本身是一种 `is-a` 的关系。而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
-
-举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类 Airplane,将鸟设计为一个类 Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。
-
-此时可以将 飞行 设计为一个接口 Fly,包含方法 fly(),然后 Airplane 和 Bird 分别根据自己的需要实现 Fly 这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承 Airplane 即可,对于鸟也是类似的,不同种类的鸟直接继承 Bird 类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
-
-接口是对类的某种行为的一种抽象,接口和类之间并没有很强的关联关系,举个例子来说,所有的类都可以实现 [`Serializable` 接口](https://tobebetterjavaer.com/io/Serializbale.html),从而具有序列化的功能,但不能说所有的类和 Serializable 之间是 `is-a` 的关系。
-
-抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过 ppt 里面的模板,如果用模板 A 设计了 ppt B 和 ppt C,ppt B 和 ppt C 公共的部分就是模板 A 了,如果它们的公共部分需要改动,则只需要改动模板 A 就可以了,不需要重新对 ppt B 和 ppt C 进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
-
-## 5.12 Java内部类
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.12 Java内部类](https://tobebetterjavaer.com/oo/inner-class.html)
-
-
-## 5.13 Java封装继承多态
-
-在谈 Java 面向对象的时候,不得不提到面向对象的三大特征:[封装](https://tobebetterjavaer.com/oo/encapsulation.html)、[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html)、[多态](https://tobebetterjavaer.com/oo/polymorphism.html)。三大特征紧密联系而又有区别,合理使用继承能大大减少重复代码,**提高代码复用性。**
-
-### 1)封装
-
-“三妹,准备好了没,我们来讲 Java 封装,算是 Java 的三大特征之一,理清楚了,对以后的编程有较大的帮助。”我对三妹说。
-
-“好的,哥,准备好了。”三妹一边听我说,一边迅速地打开了 XMind,看来一边学习一边总结思维导图这个高效的学习方式三妹已经牢记在心了。
-
-封装从字面上来理解就是包装的意思,专业点就是信息隐藏,**是指利用抽象将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体**。
-
-数据被保护在类的内部,尽可能地隐藏内部的实现细节,只保留一些对外接口使之与外部发生联系。
-
-其他对象只能通过已经授权的操作来与这个封装的对象进行交互。也就是说用户是无需知道对象内部的细节(当然也无从知道),但可以通过该对象对外的提供的接口来访问该对象。
-
-使用封装有 4 大好处:
-
-- 1、良好的封装能够减少耦合。
-- 2、类内部的结构可以自由修改。
-- 3、可以对成员进行更精确的控制。
-- 4、隐藏信息,实现细节。
-
-首先我们先来看两个类。
-
-Husband.java
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private int age ;
- private Wife wife;
-
- /*
- * setter()、getter()是该对象对外开发的接口
- */
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public String getSex() {
- return sex;
- }
-
- public void setSex(String sex) {
- this.sex = sex;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public void setWife(Wife wife) {
- this.wife = wife;
- }
-}
-```
-
-Wife.java
-
-```java
-public class Wife {
- private String name;
- private int age;
- private String sex;
- private Husband husband;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public String getSex() {
- return sex;
- }
-
- public void setSex(String sex) {
- this.sex = sex;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public void setHusband(Husband husband) {
- this.husband = husband;
- }
-
- public Husband getHusband() {
- return husband;
- }
-
-}
-```
-
-可以看得出, Husband 类里面的 wife 属性是没有 `getter()`的,同时 Wife 类的 age 属性也是没有 `getter()`方法的。至于理由我想三妹你是懂的。
-
-没有哪个女人愿意别人知道她的年龄。
-
-所以封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果不想被外界方法,我们大可不必提供方法给外界访问。
-
-但是如果一个类没有提供给外界任何可以访问的方法,那么这个类也没有什么意义了。
-
-比如我们将一个房子看做是一个对象,里面有漂亮的装饰,如沙发、电视剧、空调、茶桌等等都是该房子的私有属性,但是如果我们没有那些墙遮挡,是不是别人就会一览无余呢?没有一点儿隐私!
-
-因为存在那个遮挡的墙,我们既能够有自己的隐私而且我们可以随意的更改里面的摆设而不会影响到外面的人。
-
-但是如果没有门窗,一个包裹的严严实实的黑盒子,又有什么存在的意义呢?所以通过门窗别人也能够看到里面的风景。所以说门窗就是房子对象留给外界访问的接口。
-
-通过这个我们还不能真正体会封装的好处。现在我们从程序的角度来分析封装带来的好处。如果我们不使用封装,那么该对象就没有 `setter()`和 `getter()`,那么 Husband 类应该这样写:
-
-```java
-public class Husband {
- public String name ;
- public String sex ;
- public int age ;
- public Wife wife;
-}
-```
-
-我们应该这样来使用它:
-
-```java
-Husband husband = new Husband();
-husband.age = 30;
-husband.name = "张三";
-husband.sex = "男"; //貌似有点儿多余
-```
-
-但是哪天如果我们需要修改 Husband,例如将 age 修改为 String 类型的呢?你只有一处使用了这个类还好,如果你有几十个甚至上百个这样地方,你是不是要改到崩溃。如果使用了封装,我们完全可以不需要做任何修改,只需要稍微改变下 Husband 类的 `setAge()`方法即可。
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private String age ; /* 改成 String类型的*/
- private Wife wife;
-
- public String getAge() {
- return age;
- }
-
- public void setAge(int age) {
- //转换即可
- this.age = String.valueOf(age);
- }
-
- /** 省略其他属性的setter、getter **/
-
-}
-```
-
-其他的地方依然这样引用( `husband.setAge(22)` )保持不变。
-
-到了这里我们确实可以看出,**封装确实可以使我们更容易地修改类的内部实现,而无需修改使用了该类的代码**。
-
-我们再看这个好处:**封装可以对成员变量进行更精确的控制**。
-
-还是那个 Husband,一般来说我们在引用这个对象的时候是不容易出错的,但是有时你迷糊了,写成了这样:
-
-```java
-Husband husband = new Husband();
-husband.age = 300;
-```
-
-也许你是因为粗心写成了这样,你发现了还好,如果没有发现那就麻烦大了,谁见过 300 岁的老妖怪啊!
-
-但是使用封装我们就可以避免这个问题,我们对 age 的访问入口做一些控制(setter)如:
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private int age ; /* 改成 String类型的*/
- private Wife wife;
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- if(age > 120){
- System.out.println("ERROR:error age input...."); //提示錯誤信息
- }else{
- this.age = age;
- }
-
- }
-
- /** 省略其他属性的setter、getter **/
-
-}
-```
-
-上面都是对 setter 方法的控制,其实通过封装我们也能够对对象的出口做出很好的控制。例如性别在数据库中一般都是以 1、0 的方式来存储的,但是在前台我们又不能展示 1、0,这里我们只需要在 `getter()`方法里面做一些转换即可。
-
-```java
-public String getSexName() {
- if("0".equals(sex)){
- sexName = "女";
- }
- else if("1".equals(sex)){
- sexName = "男";
- }
- return sexName;
-}
-```
-
-在使用的时候我们只需要使用 sexName 即可实现正确的性别显示。同理也可以用于针对不同的状态做出不同的操作。
-
-```java
-public String getCzHTML(){
- if("1".equals(zt)){
- czHTML = "启用";
- }
- else{
- czHTML = "禁用";
- }
- return czHTML;
-}
-```
-
-“好了,关于封装我们就暂时就聊这么多吧。”我喝了一口普洱茶后,对三妹说。
-
-“好的,哥,我懂了。”
-
-> 参考链接:[https://www.cnblogs.com/chenssy/p/3351835.html](https://www.cnblogs.com/chenssy/p/3351835.html),整理:沉默王二
-
-### 2)继承
-
-#### 01、什么是继承
-
-**继承**(英语:inheritance)是面向对象软件技术中的一个概念。它使得**复用以前的代码非常容易。**
-
-Java 语言是非常典型的面向对象的语言,在 Java 语言中**继承就是子类继承父类的属性和方法,使得子类对象(实例)具有父类的属性和方法,或子类从父类继承方法,使得子类具有父类相同的方法**。
-
-我们来举个例子:动物有很多种,是一个比较大的概念。在动物的种类中,我们熟悉的有猫(Cat)、狗(Dog)等动物,它们都有动物的一般特征(比如能够吃东西,能够发出声音),不过又在细节上有区别(不同动物的吃的不同,叫声不一样)。
-
-在 Java 语言中实现 Cat 和 Dog 等类的时候,就需要继承 Animal 这个类。继承之后 Cat、Dog 等具体动物类就是子类,Animal 类就是父类。
-
-
-
-#### 02、为什么需要继承
-
-三妹,你可能会问**为什么需要继承**?
-
-如果仅仅只有两三个类,每个类的属性和方法很有限的情况下确实没必要实现继承,但事情并非如此,事实上一个系统中往往有很多个类并且有着很多相似之处,比如猫和狗同属动物,或者学生和老师同属人。各个类可能又有很多个相同的属性和方法,这样的话如果每个类都重新写不仅代码显得很乱,代码工作量也很大。
-
-这时继承的优势就出来了:可以直接使用父类的属性和方法,自己也可以有自己新的属性和方法满足拓展,父类的方法如果自己有需求更改也可以重写。这样**使用继承不仅大大的减少了代码量,也使得代码结构更加清晰可见**。
-
-
-
-所以这样从代码的层面上来看我们设计这个完整的 Animal 类是这样的:
-
-```java
-class Animal
-{
- public int id;
- public String name;
- public int age;
- public int weight;
-
- public Animal(int id, String name, int age, int weight) {
- this.id = id;
- this.name = name;
- this.age = age;
- this.weight = weight;
- }
- //这里省略get set方法
- public void sayHello()
- {
- System.out.println("hello");
- }
- public void eat()
- {
- System.out.println("I'm eating");
- }
- public void sing()
- {
- System.out.println("sing");
- }
-}
-```
-
-而 Dog,Cat,Chicken 类可以这样设计:
-
-```java
-class Dog extends Animal//继承animal
-{
- public Dog(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
-}
-class Cat extends Animal{
-
- public Cat(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
-}
-class Chicken extends Animal{
-
- public Chicken(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
- //鸡下蛋
- public void layEggs()
- {
- System.out.println("我是老母鸡下蛋啦,咯哒咯!咯哒咯!");
- }
-}
-```
-
-各自的类继承 Animal 后可以直接使用 Animal 类的属性和方法而不需要重复编写,各个类如果有自己的方法也可很容易地拓展。
-
-#### 03、继承的分类
-
-继承分为单继承和多继承,Java 语言只支持类的单继承,但可以通过实现接口的方式达到多继承的目的。**这个我们之前在讲接口的时候就提到过,这里我们再聊一下。**
-
-继承 | 定义 | 优缺点 |
----| ---- | ------ |
-单继承|一个子类只拥有一个父类|优点:在类层次结构上比较清晰
-
-对了,**加入星球后记得花 10 分钟时间看一下星球的两个置顶贴,你会发现物超所值**!
-
-成功没有一蹴而就,没有一飞冲天,但只要你能够一步一个脚印,就能取得你心满意足的好结果,请给自己一个机会!
-
-最后,把二哥的座右铭送给你:**没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟**。
-
-共勉 ⛽️。
-
-## 如何贡献?
-
-对了,如果你在阅读的过程中遇到一些错误,欢迎到我的开源仓库提交 issue、PR(审核通过后可成为 Contributor),我会第一时间修正,感谢你为后来者做出的贡献。
-
->- GitHub:[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)
->- 码云:[https://gitee.com/itwanger/toBeBetterJavaer](https://gitee.com/itwanger/toBeBetterJavaer)
-
-## 更新记录
-
-### V1.0-2023年04月11日
-
-第一版《二哥的 Java 进阶之路》正式完结发布!
-
-# 第二章:Java概述及环境配置
-
-## 2.1 Java简介
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.1 Java简介](https://tobebetterjavaer.com/overview/what-is-java.html)
-
-## 2.2 安装JDK
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.2 安装 JDK](https://tobebetterjavaer.com/overview/jdk-install-config.html)
-
-
-
-## 2.3 安装IDEA
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[2.3 安装Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html)
-
-
-
-## 2.4 第一个Java程序
-
-“三妹,今天,我们来编写第一个 Java 程序,Hello World 期待吗?”
-
-三妹点了点头,表示认同(😂)。
-
-“好的,那我们直接开始。”
-
-打开 [Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html),新建一个学习 Java 的项目,点击 File → New → Project。
-
-
-
-选择 JDK 版本,比如之前我们[安装的 JDK 8](https://tobebetterjavaer.com/overview/jdk-install-config.html)。
-
-
-
-你也可以选择 JDK 11 或者最新的 JDK 17 或者添加新的 JDK 版本,但(不建议)。
-
-
-
-然后点击「next」,直到填写项目名字,比如说 tobebetterjavaerdemo。
-
-
-
-然后点击 finish,之后就可以看到我们新建的项目界面了。
-
-
-
-如果你的 Intellij IDEA 主题和二哥不一样,没关系,当然了,如果你也是个有颜值追求的家伙,可以安装 Vuesion Theme 插件,安装方法[戳这里](https://tobebetterjavaer.com/ide/shenji-chajian-10.html)。
-
-“OK,到这里,我们已经把学习 Java 的环境准备好了,接下来就可以写第一个 Hello World 程序了。”我自信地对三妹说。
-
-一般我们会把源代码放在 src 目录下(source 的前缀,所以学编程,英语中常用的单词必须得会,不会就去学)。
-
-右键 src 目录,在菜单中依次选择 New → Java Class。
-
-
-
-填写 Class 名,也就是类名(不知道类名是啥,后面会讲),注意大小写敏感,然后按下 enter 键。
-
-
-
-就会出现这样的代码。
-
-
-
-注释是二哥配置好的,你如果没配置可能没有,`public class HelloWorld {}` 是 Intellij IDEA 帮我们自动生成的。
-
-之后在大括号里面键入 `main` 等 Intellij IDEA 给出提示后键入 enter 键。
-
-Intellij IDEA 就会帮我们自动生成 main 方法,也就是这段代码。
-
-
-
-然后在 main 方法中键入 `so` 等出现提示后键入 enter 键。
-
-
-
-Intellij IDEA 就会帮我们自动添加 `System.out.println()`,这是一个向控制台输出的方法(小白先不管它是什么意思,后面会讲)。
-
-
-
-接着在 `println()` 的小括号中键入 `"Hello World"`,注意是英文的双引号,中文的会报错哦,三妹。
-
-
-
-然后在 HelloWorld.java 的代码编辑器,也就是光标所在的位置右键,选择「Run 'HelloWorld.main()'」。
-
-
-
-等 Intellij IDEA 编译&运行后就可以在控制台看到这样的输出内容。
-
-
-
-这就表明我们的第一个 Java 代码完成了,恭喜自己一下吧,三妹!
-
-“二哥,你太棒了,好激动哦!!!!!!!”
-
-下面,我们来简单解释一下这段代码。
-
-第一个 Java 程序非常简单,我们来改一下输出内容,把 Hello World 替换掉:
-
-```java
-public class HelloWorld {
- public static void main(String[] args) {
- System.out.println("三妹,少看手机少打游戏,好好学,美美哒。");
- }
-}
-```
-
-- class 关键字:用于在 Java 中声明一个[类](https://tobebetterjavaer.com/oo/object-class.html)。
-- public 关键字:一个表示可见性的[访问修饰符](https://tobebetterjavaer.com/oo/access-control.html)。
-- [static 关键字](https://tobebetterjavaer.com/oo/static.html):我们可以用它来声明任何一个方法,被 static 修饰后的方法称之为静态方法。静态方法不需要为其创建对象就能调用。
-- void 关键字:表示该方法不返回任何值。
-- main 关键字:表示该方法为主方法,也就是程序运行的入口。`main()` 方法由 Java 虚拟机执行,配合上 static 关键字后,可以不用创建对象就可以调用,可以节省不少内存空间。
-- `String [] args`:`main()` 方法的参数,类型为 [String](https://tobebetterjavaer.com/string/immutable.html) [数组](https://tobebetterjavaer.com/array/array.html),参数名为 args。
-- `System.out.println()`:一个 Java 语句,一般情况下是将传递的参数打印到控制台。System 是 java.lang 包中的一个 final 类,该类提供的设施包括标准输入,标准输出和错误输出流等等。out 是 System 类的静态成员字段,类型为 [PrintStream](https://tobebetterjavaer.com/io/print.html),它与主机的标准输出控制台进行映射。println 是 PrintStream 类的一个方法,通过调用 print 方法并添加一个换行符实现的。
-
-“实在记不住也没关系,我们后面还会讲哦(可以跳转的地方都会展开细讲)。”我的话令三妹感到非常开心。
-
-好,接下来再告诉你一点额外的知识点(如果觉得比较难可跳过),三妹。
-
-在 Intellij IDEA 的 terminal 面板中,可以看到对应的 java 源代码文件和编译后的 .class 文件。
-
-可以在对应的文件上右键选择 open in terminal 打开。
-
-
-
-可以通过 pwd 命令查看当前包路径,通过 ls 命令查看包路径下面有哪些文件。
-
-
-
-class 文件在 target 目录下,classes 为 src/main 目录下的 class 文件;test-classes 为 src/test 目录下的 class 文件。
-
-
-
-“二哥,.class 文件和 .java 源代码,它们之间的关系是什么样的呢?”三妹还是挺喜欢学习的嘛,发现的问题都很关键。
-
-“不错不错,都能挖掘到这个点了。”
-
-.java 是源代码,也就是我们开发人员可以看懂的,可以编写的;.class 是字节码文件,是经过 javac 编译后的文件,是交给 [JVM](https://tobebetterjavaer.com/jvm/what-is-jvm.html) 执行的文件。
-
-“三妹,这里再顺带给你讲一下,Java 是编译型语言还是解释型语言。”
-
-“好啊,我正要问这个‘编译’到底是怎么回事呢?”
-
-Java 的第一道工序是通过 javac 命令把 Java 源码编译成字节码。
-
-比如说我们可以主动执行 `javac Hello.java` 命令将源代码文件编译为 Hello.class 文件(用 Intellij IDEA 的话,并不需要我们主动去编译「javac」,直接运行就可以自动生成 .class 文件)。
-
-
-
-之后,我们可以通过 java 命令运行字节码(比如说 `java Hello`),此时就有 2 种处理方式了。
-
-- 1、字节码由 JVM 逐条解释执行。
-- 2、部分字节码可能由 [JIT(即时编译,戳链接了解](https://tobebetterjavaer.com/jvm/jit.html))编译为机器指令直接执行。
-
-①、逐条解释执行:
-
-逐条解释执行是 Java 虚拟机的基本执行模式。在这种模式下,Java 虚拟机会逐条读取字节码文件中的指令,并将其解释为对应的底层操作。解释执行的优点是实现简单,启动速度较快,但由于每次执行都需要对字节码进行解释,因此执行效率相对较低。
-
-总结一下逐条解释执行的特点:
-
-- 实现简单
-- 启动速度较快
-- 执行效率较低
-
-②、JIT 即时编译:
-
-为了提高 Java 程序的执行效率,Java 虚拟机引入了即时编译([JIT,Just-In-Time Compilation](https://tobebetterjavaer.com/jvm/jit.html))技术。在 JIT 模式下,Java 虚拟机会在运行时将频繁执行的字节码编译为本地机器码,这样就可以直接在硬件上运行,而不需要再次解释。这样做的结果是显著提高了程序的执行速度。需要注意的是,JIT 编译器并不会编译所有的字节码,而是根据一定的策略,仅编译被频繁调用的代码段(热点代码)。
-
-总结一下 JIT 即时编译的特点:
-
-- 提高执行效率
-- 编译热点代码
-- 动态优化
-
-实际上,现代 Java 虚拟机(如 HotSpot)通常会结合这两种执行方式,即解释执行和 JIT 即时编译。在程序运行初期,Java 虚拟机会采用解释执行,以减少启动时间。随着程序的运行,Java 虚拟机会识别出热点代码并使用 JIT 编译器将其编译为本地机器码,从而提高程序的执行效率。这种结合策略称为混合模式。
-
-
-也就是说,为了跨平台,Java 源代码首先会编译成字节码,字节码不是机器语言,需要 JVM 来解释。
-
-
-
-有了 JVM 这个中间层,Java 的运行效率就没有直接把源代码编译为机器码来得效率更高,这个应该能理解吗,多了中间商嘛。所以为了提高效率,JVM 引入了 JIT 编译器,把一些经常执行的字节码直接搞成机器码。
-
-所以,Java 是解释和编译并存。但通常来说,我们会说“Java 是编译型语言”,尽管这样并不准确,主要是 JIT 是后面才出现的,“先入为主嘛”。
-
-“好的,二哥,我了解了。”
-
-# 第三章:Java语法基础
-
-## 3.1 Java关键字和保留字
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.1 Java关键字和保留字](https://tobebetterjavaer.com/basic-extra-meal/48-keywords.html)
-
-
-
-## 3.2 Java注释
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.2 Java注释](https://tobebetterjavaer.com/basic-grammar/javadoc.html)
-
-
-
-## 3.3 Java数据类型
-
-“Java 是一种静态类型的编程语言,这意味着所有变量必须在使用之前声明好,也就是必须得先指定变量的类型和名称。”我吸了一口麦香可可奶茶后对三妹说。
-
-Java 中的数据类型可分为 2 种:
-
-1)**基本数据类型**。
-
-基本数据类型是 Java 语言操作数据的基础,包括 boolean、char、byte、short、int、long、float 和 double,共 8 种。
-
-2)**引用数据类型**。
-
-除了基本数据类型以外的类型,都是所谓的引用类型。常见的有[数组](https://tobebetterjavaer.com/array/array.html)(对,没错,数组是引用类型,后面我们会讲)、class(也就是[类](https://tobebetterjavaer.com/oo/object-class.html)),以及[接口](https://tobebetterjavaer.com/oo/interface.html)(指向的是实现接口的类的对象)。
-
-来个思维导图,感受下。
-
-
-
-[变量](https://tobebetterjavaer.com/oo/var.html)可以分为局部变量、成员变量、静态变量。
-
-当变量是局部变量的时候,必须得先初始化,否则编译器不允许你使用它。拿 int 来举例吧,看下图。
-
-
-
-当变量是成员变量或者静态变量时,可以不进行初始化,它们会有一个默认值,仍然以 int 为例,来看代码:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalVar {
- private int a;
- static int b;
-
- public static void main(String[] args) {
- LocalVar lv = new LocalVar();
- System.out.println(lv.a);
- System.out.println(b);
- }
-}
-```
-
-来看输出结果:
-
-```
-0
-0
-```
-
-瞧见没,int 作为成员变量时或者静态变量时的默认值是 0。那不同的基本数据类型,是有不同的默认值和大小的,来个表格感受下。
-
-| 数据类型 | 默认值 | 大小 |
-| -------- | -------- | ------ |
-| boolean | false | 1 比特 |
-| char | '\u0000' | 2 字节 |
-| byte | 0 | 1 字节 |
-| short | 0 | 2 字节 |
-| int | 0 | 4 字节 |
-| long | 0L | 8 字节 |
-| float | 0.0f | 4 字节 |
-| double | 0.0 | 8 字节 |
-
-### 01、比特和字节
-
-那三妹可能要问,“比特和字节是什么鬼?”
-
-比特币(Bitcoin)听说过吧?字节跳动(Byte Dance)听说过吧?这些名字当然不是乱起的,确实和比特、字节有关系。
-
-#### **1)bit(比特)**
-
-比特作为信息技术的最基本存储单位,非常小,但大名鼎鼎的比特币就是以此命名的,它的简写为小写字母“b”。
-
-大家都知道,计算机是以二进制存储数据的,二进制的一位,就是 1 比特,也就是说,比特要么为 0 要么为 1。
-
-#### **2)Byte(字节)**
-
-通常来说,一个英文字符是一个字节,一个中文字符是两个字节。字节与比特的换算关系是:1 字节 = 8 比特。
-
-在往上的单位就是 KB,并不是 1000 字节,因为计算机只认识二进制,因此是 2 的 10 次方,也就是 1024 个字节。
-
-(终于知道 1024 和程序员的关系了吧?狗头保命)
-
-
-
-### 02、基本数据类型
-
-接下来,我们再来详细地了解一下 8 种基本数据类型。
-
-#### 1)布尔
-
-布尔(boolean)仅用于存储两个值:true 和 false,也就是真和假,通常用于条件的判断。代码示例:
-
-```java
-boolean hasMoney = true;
-boolean hasGirlFriend = false;
-```
-
-#### 2)byte
-
-一个字节可以表示 2^8 = 256 个不同的值。由于 byte 是有符号的,它的值可以是负数或正数,其取值范围是 -128 到 127(包括 -128 和 127)。
-
-在网络传输、大文件读写时,为了节省空间,常用字节来作为数据的传输方式。代码示例:
-
-```java
-byte b; // 声明一个 byte 类型变量
-b = 10; // 将值 10 赋给变量 b
-byte c = -100; // 声明并初始化一个 byte 类型变量 c,赋值为 -100
-```
-
-#### 3)short
-
-short 的取值范围在 -32,768 和 32,767 之间,包含 32,767。代码示例:
-
-```java
-short s; // 声明一个 short 类型变量
-s = 1000; // 将值 1000 赋给变量 s
-short t = -2000; // 声明并初始化一个 short 类型变量 t,赋值为 -2000
-```
-
-实际开发中,short 比较少用,整型用 int 就 OK。
-
-#### 3)int
-
-int 的取值范围在 -2,147,483,648(-2 ^ 31)和 2,147,483,647(2 ^ 31 -1)(含)之间。如果没有特殊需求,整型数据就用 int。代码示例:
-
-```java
-int i; // 声明一个 int 类型变量
-i = 1000000; // 将值 1000000 赋给变量 i
-int j = -2000000; // 声明并初始化一个 int 类型变量 j,赋值为 -2000000
-```
-
-#### 5)long
-
-long 的取值范围在 -9,223,372,036,854,775,808(-2^63) 和 9,223,372,036,854,775,807(2^63 -1)(含)之间。如果 int 存储不下,就用 long。代码示例:
-
-```java
-long l; // 声明一个 long 类型变量
-l = 100000000000L; // 将值 100000000000L 赋给变量 l(注意要加上 L 后缀)
-long m = -20000000000L; // 声明并初始化一个 long 类型变量 m,赋值为 -20000000000L
-```
-
-为了和 int 作区分,long 型变量在声明的时候,末尾要带上大写的“L”。不用小写的“l”,是因为小写的“l”容易和数字“1”混淆。
-
-#### 6)float
-
-float 是单精度的浮点数(单精度浮点数的有效数字大约为 6 到 7 位),32 位(4 字节),遵循 IEEE 754(二进制浮点数算术标准),取值范围为 1.4E-45 到 3.4E+38。float 不适合用于精确的数值,比如说金额。代码示例:
-
-```java
-float f; // 声明一个 float 类型变量
-f = 3.14159f; // 将值 3.14159f 赋给变量 f(注意要加上 f 后缀)
-float g = -2.71828f; // 声明并初始化一个 float 类型变量 g,赋值为 -2.71828f
-```
-
-为了和 double 作区分,float 型变量在声明的时候,末尾要带上小写的“f”。不需要使用大写的“F”,是因为小写的“f”很容易辨别。
-
-#### 7)double
-
-double 是双精度浮点数(双精度浮点数的有效数字大约为 15 到 17 位),占 64 位(8 字节),也遵循 IEEE 754 标准,取值范围大约 ±4.9E-324 到 ±1.7976931348623157E308。double 同样不适合用于精确的数值,比如说金额。
-
-代码示例:
-
-```java
-double myDouble = 3.141592653589793;
-```
-
-在进行金融计算或需要精确小数计算的场景中,可以使用 [BigDecimal 类](https://tobebetterjavaer.com/basic-grammar/bigdecimal-biginteger.html)来避免浮点数舍入误差。BigDecimal 可以表示一个任意大小且精度完全准确的浮点数。
-
-> 在实际开发中,如果不是特别大的金额(精确到 0.01 元,也就是一分钱),一般建议乘以 100 转成整型进行处理。
-
-#### 8)char
-
-char 用于表示 Unicode 字符,占 16 位(2 字节)的存储空间,取值范围为 0 到 65,535。
-
-代码示例:
-
-```java
-char letterA = 'A'; // 用英文的单引号包裹住。
-```
-
-注意,字符字面量应该用单引号('')包围,而不是双引号(""),因为[双引号表示字符串字面量](https://tobebetterjavaer.com/string/constant-pool.html)。
-
-### 03、单精度和双精度
-
-单精度(single-precision)和双精度(double-precision)是指两种不同精度的浮点数表示方法。
-
-单精度是这样的格式,1 位符号,8 位指数,23 位小数。
-
-
-
-单精度浮点数通常占用 32 位(4 字节)存储空间。数值范围大约是 ±1.4E-45 到 ±3.4028235E38,精度大约为 6 到 9 位有效数字。
-
-双精度是这样的格式,1 位符号,11 位指数,52 为小数。
-
-
-
-双精度浮点数通常占用 64 位(8 字节)存储空间,数值范围大约是 ±4.9E-324 到 ±1.7976931348623157E308,精度大约为 15 到 17 位有效数字。
-
-计算精度取决于小数位(尾数)。小数位越多,则能表示的数越大,那么计算精度则越高。
-
-一个数由若干位数字组成,其中影响测量精度的数字称作有效数字,也称有效数位。有效数字指科学计算中用以表示一个浮点数精度的那些数字。一般地,指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字。如 1.24 和 0.00124 的有效数字都有 3 位。
-
-以下是确定有效数字的一些基本规则:
-
-- 非零数字总是有效的。
-- 位于两个非零数字之间的零是有效的。
-- 对于小数,从左侧开始的第一个非零数字之前的零是无效的。
-- 对于整数,从右侧开始的第一个非零数字之后的零是无效的。
-
-下面是一些示例,说明如何确定有效数字:
-
-- 1234:4 个有效数字(所有数字都是非零数字)
-- 1002:4 个有效数字(零位于两个非零数字之间)
-- 0.00234:3 个有效数字(从左侧开始的前两个零是无效的)
-- 1200:2 个有效数字(从右侧开始的两个零是无效的)
-
-### 04、int 和 char 类型互转
-
-int 和 char 之间比较特殊,可以互转,也会在以后的学习当中经常遇到。
-
-1)可以通过[强制类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html)将整型 int 转换为字符 char。
-
-```java
-int value_int = 65;
-char value_char = (char) value_int;
-System.out.println(value_char);
-```
-
-输出 `A`(其 [ASCII 值](https://tobebetterjavaer.com/basic-extra-meal/java-unicode.html)可以通过整数 65 来表示)。
-
-2)可以使用 `Character.forDigit()` 方法将整型 int 转换为字符 char,参数 radix 为基数,十进制为 10,十六进制为 16。。
-
-```java
-int radix = 10;
-int value_int = 6;
-char value_char = Character.forDigit(value_int , radix);
-System.out.println(value_char );
-```
-
-Character 为 char 的包装器类型。我们随后会讲。
-
-3)可以使用 int 的包装器类型 Integer 的 `toString()` 方法+String 的 `charAt()` 方法转成 char。
-
-```java
-int value_int = 1;
-char value_char = Integer.toString(value_int).charAt(0);
-System.out.println(value_char );
-```
-
-4)char 转 int
-
-当然了,如果只是简单的 char 转 int,直接赋值就可以了。
-
-```java
-int a = 'a';
-```
-
-因为发生了[自动类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html),后面会细讲。
-
-### 05、包装器类型
-
-包装器类型(Wrapper Types)是 Java 中的一种特殊类型,用于将基本数据类型(如 int、float、char 等)转换为对应的[对象类型](https://tobebetterjavaer.com/oo/object-class.html)。
-
-Java 提供了以下包装器类型,与基本数据类型一一对应:
-
-- Byte(对应 byte)
-- Short(对应 short)
-- Integer(对应 int)
-- Long(对应 long)
-- Float(对应 float)
-- Double(对应 double)
-- Character(对应 char)
-- Boolean(对应 boolean)
-
-包装器类型允许我们使用基本数据类型提供的各种实用方法,并兼容需要对象类型的场景。例如,我们可以使用 Integer 类的 parseInt 方法将字符串转换为整数,或使用 Character 类的 isDigit 方法检查字符是否为数字,还有前面提到的 `Character.forDigit()` 方法。
-
-下面是一个简单的示例,演示了如何使用包装器类型:
-
-```java
-// 使用 Integer 包装器类型
-Integer integerValue = new Integer(42);
-System.out.println("整数值: " + integerValue);
-
-// 将字符串转换为整数
-String numberString = "123";
-int parsedNumber = Integer.parseInt(numberString);
-System.out.println("整数值: " + parsedNumber);
-
-// 使用 Character 包装器类型
-Character charValue = new Character('A');
-System.out.println("字符: " + charValue);
-
-// 检查字符是否为数字
-char testChar = '9';
-if (Character.isDigit(testChar)) {
-System.out.println("字符是个数字.");
-}
-```
-
-上面的示例中,我们创建了一个 [Integer 类型](https://tobebetterjavaer.com/basic-extra-meal/int-cache.html)的对象 integerValue 并为其赋值 42。然后,我们将其值打印到控制台。
-
-我们有一个包含数字的[字符串](https://tobebetterjavaer.com/string/immutable.html) numberString。我们使用 `Integer.parseInt()` 方法将其转换为整数 parsedNumber。然后,我们将转换后的值打印到控制台。
-
-我们有一个字符变量 testChar,并为其赋值字符 '9'。我们使用 `Character.isDigit()` 方法检查 testChar 是否为数字字符。如果是数字字符,我们将输出一条消息到控制台。
-
-从 Java 5 开始,[自动装箱(Autoboxing)和自动拆箱(Unboxing)机制](https://tobebetterjavaer.com/basic-extra-meal/box.html)允许我们在基本数据类型和包装器类型之间自动转换,无需显式地调用构造方法或转换方法(链接里会细讲)。
-
-```java
-Integer integerValue = 42; // 自动装箱,等同于 new Integer(42)
-int primitiveValue = integerValue; // 自动拆箱,等同于 integerValue.intValue()
-```
-
-### 06、引用数据类型
-
-基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有的(学完数组&字符串,以及面向对象编程后会更加清楚,这里先简单过一下)。
-
-[String](https://tobebetterjavaer.com/string/immutable.html) 是最典型的引用数据类型,所以我们就拿 String 类举例,看下面这段代码:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalRef {
- private String a;
- static String b;
-
- public static void main(String[] args) {
- LocalRef lv = new LocalRef();
- System.out.println(lv.a);
- System.out.println(b);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-null
-null
-```
-
-null 在 Java 中是一个很神奇的存在,在你以后的程序生涯中,见它的次数不会少,尤其是伴随着令人烦恼的“[空指针异常](https://tobebetterjavaer.com/exception/npe.html)”,也就是所谓的 `NullPointerException`。
-
-也就是说,引用数据类型的默认值为 null,包括数组和接口。
-
-那你是不是很好奇,为什么[数组](https://tobebetterjavaer.com/array/array.html)和[接口](https://tobebetterjavaer.com/oo/interface.html)也是引用数据类型啊?
-
-先来看数组:
-
-```java
-int [] arrays = {1,2,3};
-System.out.println(arrays);
-```
-
-arrays 是一个 int 类型的数组,对吧?打印结果如下所示:
-
-```
-[I@2d209079
-```
-
-`[I` 表示数组是 int 类型的,@ 后面是十六进制的 hashCode——这样的打印结果太“人性化”了,一般人表示看不懂!为什么会这样显示呢?查看一下 `java.lang.Object` 类的 `toString()` 方法就明白了。
-
-
-
-数组虽然没有显式定义成一个类,但它的确是一个对象,继承了祖先类 Object 的所有方法。那为什么数组不单独定义一个类来表示呢?就像字符串 String 类那样呢?
-
-一个合理的解释是 Java 将其隐藏了。假如真的存在一个 Array.java,我们也可以假想它真实的样子,它必须要定义一个容器来存放数组的元素,就像 String 类那样。
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- /** The value is used for character storage. */
- private final char value[];
-}
-```
-
-数组内部定义数组?没必要的!
-
-再来看接口:
-
-```java
-List list = new ArrayList<>();
-System.out.println(list);
-```
-
-[List](https://tobebetterjavaer.com/collection/gailan.html) 是一个非常典型的接口:
-
-```java
-public interface List extends Collection {}
-```
-
-而 [ArrayList](https://tobebetterjavaer.com/collection/arraylist.html) 是 List 接口的一个实现:
-
-```java
-public class ArrayList extends AbstractList
- implements List, RandomAccess, Cloneable, java.io.Serializable
-{}
-```
-
-对于接口类型的引用变量来说,你没法直接 new 一个:
-
-
-
-只能 new 一个实现它的类的对象——那自然接口也是引用数据类型了。
-
-来看一下基本数据类型和引用数据类型之间最大的差别。
-
-基本数据类型:
-
-- 1、变量名指向具体的数值。
-- 2、基本数据类型存储在栈上。
-
-引用数据类型:
-
-- 1、变量名指向的是存储对象的内存地址,在栈上。
-- 2、内存地址指向的对象存储在堆上。
-
-### 07、堆和栈
-
-看到这,三妹是不是又要问,“堆是什么,栈又是什么?”
-
-堆是堆(heap),栈是栈(stack),如果看到“堆栈”的话,请不要怀疑自己,那是翻译的错,堆栈也是栈,反正我很不喜欢“堆栈”这种叫法,容易让新人掉坑里。
-
-堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java 中的对象就放在这里,这样做的好处就是:
-
-> 当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
-
-栈,能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快。既然访问速度快,要好好利用啊!Java 就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
-
-不是的,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
-
-这么说就理解了吧?
-
-如果还不理解的话,可以看一下这个视频,讲的非常不错:[什么是堆?什么是栈?他们之间有什么区别和联系?](https://www.zhihu.com/question/19729973/answer/2238950166)
-
-用图来表示一下,左侧是栈,右侧是堆。
-
-
-
-这里再补充一些额外的知识点,能看懂就继续吸收,看不懂可以先去学下一节,以后再来补,没关系的。学习就是这样,可以跳过,可以温故。
-
-举个例子。
-
-```java
-String a = new String("沉默王二")
-```
-
-这段代码会先在堆里创建一个 沉默王二的字符串对象,然后再把对象的引用 a 放到栈里面。这里面还会涉及到[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html),后面会讲。
-
-那么对于这样一段代码,有基本数据类型的变量,有引用类型的变量,堆和栈都是如何存储他们的呢?
-
-```java
-public void test()
-{
- int i = 4;
- int y = 2;
- Object o1 = new Object();
-}
-```
-
-我来画个图表示下。
-
-
-
-应该一目了然了吧?
-
-“好了,三妹,关于 Java 中的数据类型就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
-
-### 08、小结
-
-本文详细探讨了 Java 数据类型,包括比特与字节、基本数据类型、单精度与双精度、int 与 char 互转、包装器类型、引用数据类型以及堆与栈的内存模型。通过阅读本文,你将全面了解 Java 数据类型的概念与使用方法,为 Java 编程打下坚实基础。
-
-
-
-## 3.4 Java数据类型转换
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.4 Java数据类型转换](https://tobebetterjavaer.com/basic-grammar/type-cast.html)
-
-
-
-## 3.5 Java基本数据类型缓存池
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[3.5 Java基本数据类型缓存池](https://tobebetterjavaer.com/basic-extra-meal/int-cache.html)
-
-## 3.6 Java运算符
-
-“二哥,让我盲猜一下哈,运算符是不是指的就是加减乘除啊?”三妹的脸上泛着甜甜的笑容,我想她一定对提出的问题很有自信。
-
-“是的,三妹。运算符在 Java 中占据着重要的位置,对程序的执行有着很大的帮助。除了常见的加减乘除,还有许多其他类型的运算符,来看下面这张思维导图。”
-
-
-
-
-### 01、算术运算符
-
-算术运算符除了最常见的加减乘除,还有一个取余的运算符,用于得到除法运算后的余数,来串代码感受下。
-
-```java
-int a = 10;
-int b = 5;
-
-System.out.println(a + b);//15
-System.out.println(a - b);//5
-System.out.println(a * b);//50
-System.out.println(a / b);//2
-System.out.println(a % b);//0
-
-b = 3;
-System.out.println(a + b);//13
-System.out.println(a - b);//7
-System.out.println(a * b);//30
-System.out.println(a / b);//3
-System.out.println(a % b);//1
-```
-
-对于初学者来说,加法(+)、减法(-)、乘法(*)很好理解,但除法(/)和取余(%)会有一点点疑惑。在以往的认知里,10/3 是除不尽的,结果应该是 3.333333...,而不应该是 3。相应的,余数也不应该是 1。这是为什么呢?
-
-因为数字在程序中可以分为两种,一种是整型,一种是浮点型(不清楚的同学可以回头看看[数据类型那篇](https://tobebetterjavaer.com/basic-grammar/basic-data-type.html)),整型和整型的运算结果就是整型,不会出现浮点型。否则,就会出现浮点型。
-
-```java
-int a = 10;
-float c = 3.0f;
-double d = 3.0;
-System.out.println(a / c); // 3.3333333
-System.out.println(a / d); // 3.3333333333333335
-System.out.println(a % c); // 1.0
-System.out.println(a % d); // 1.0
-```
-
-需要注意的是,当浮点数除以 0 的时候,结果为 Infinity 或者 NaN。
-
-```java
-System.out.println(10.0 / 0.0); // Infinity
-System.out.println(0.0 / 0.0); // NaN
-```
-
-Infinity 的中文意思是无穷大,NaN 的中文意思是这不是一个数字(Not a Number)。
-
-当整数除以 0 的时候(`10 / 0`),会抛出[异常](https://tobebetterjavaer.com/exception/gailan.html):
-
-```
-Exception in thread "main" java.lang.ArithmeticException: / by zero
- at com.itwanger.eleven.ArithmeticOperator.main(ArithmeticOperator.java:32)
-```
-
-所以整数在进行除法运算时,需要先判断除数是否为 0,以免程序抛出异常。
-
-算术运算符中还有两种特殊的运算符,自增运算符(++)和自减运算符(--),它们也叫做一元运算符,只有一个操作数。
-
-```java
-int x = 10;
-System.out.println(x++);//10 (11)
-System.out.println(++x);//12
-System.out.println(x--);//12 (11)
-System.out.println(--x);//10
-```
-
-一元运算符可以放在数字的前面或者后面,放在前面叫前自增(前自减),放在后面叫后自增(后自减)。
-
-前自增和后自增是有区别的,拿 `int y = ++x` 这个表达式来说(x = 10),它可以拆分为 `x = x+1 = 11; y = x = 11`,所以表达式的结果为 `x = 11, y = 11`。拿 `int y = x++` 这个表达式来说(x = 10),它可以拆分为 `y = x = 10; x = x+1 = 11`,所以表达式的结果为 `x = 11, y = 10`。
-
-```java
-int x = 10;
-int y = ++x;
-System.out.println(y + " " + x);// 11 11
-
-x = 10;
-y = x++;
-System.out.println(y + " " + x);// 10 11
-```
-
-对于前自减和后自减来说,你可以自己试一把。
-
-### 02、关系运算符
-
-关系运算符用来比较两个操作数,返回结果为 true 或者 false。
-
-
-
-来看示例:
-
-```java
-int a = 10, b = 20;
-System.out.println(a == b); // false
-System.out.println(a != b); // true
-System.out.println(a > b); // false
-System.out.println(a < b); // true
-System.out.println(a >= b); // false
-System.out.println(a <= b); // true
-```
-
-### 03、位运算符
-
-在学习位运算符之前,需要先学习一下二进制,因为位运算符操作的不是整型数值(int、long、short、char、byte)本身,而是整型数值对应的二进制。
-
-```java
-System.out.println(Integer.toBinaryString(60)); // 111100
-System.out.println(Integer.toBinaryString(13)); // 1101
-```
-
- 从程序的输出结果可以看得出来,60 的二进制是 0011 1100(用 0 补到 8 位),13 的二进制是 0000 1101。
-
-PS:现代的二进制记数系统由戈特弗里德·威廉·莱布尼茨于 1679 年设计。莱布尼茨是德意志哲学家、数学家,历史上少见的通才。
-
-
-
-来看示例:
-
-```java
-int a = 60, b = 13;
-System.out.println("a 的二进制:" + Integer.toBinaryString(a)); // 111100
-System.out.println("b 的二进制:" + Integer.toBinaryString(b)); // 1101
-
-int c = a & b;
-System.out.println("a & b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a | b;
-System.out.println("a | b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a ^ b;
-System.out.println("a ^ b:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = ~a;
-System.out.println("~a:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a << 2;
-System.out.println("a << 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a >> 2;
-System.out.println("a >> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-
-c = a >>> 2;
-System.out.println("a >>> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
-```
-
-对于初学者来说,位运算符无法从直观上去计算出结果,不像加减乘除那样。因为我们日常接触的都是十进制,位运算的时候需要先转成二进制,然后再计算出结果。
-
-鉴于此,初学者在写代码的时候其实很少会用到位运算。对于编程高手来说,为了提高程序的性能,会在一些地方使用位运算。比如说,HashMap 在计算哈希值的时候:
-
-```java
-static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
-}
-```
-
-如果对位运算一点都不懂的话,遇到这样的源码就很吃力。所以说,虽然位运算用的少,但还是要懂。
-
-1)按位左移运算符:
-
-```java
-System.out.println(10<<2);//10*2^2=10*4=40
-System.out.println(10<<3);//10*2^3=10*8=80
-System.out.println(20<<2);//20*2^2=20*4=80
-System.out.println(15<<4);//15*2^4=15*16=240
-```
-
-`10<<2` 等于 10 乘以 2 的 2 次方;`10<<3` 等于 10 乘以 2 的 3 次方。
-
-2)按位右移运算符:
-
-```java
-System.out.println(10>>2);//10/2^2=10/4=2
-System.out.println(20>>2);//20/2^2=20/4=5
-System.out.println(20>>3);//20/2^3=20/8=2
-```
-
-`10>>2` 等于 10 除以 2 的 2 次方;`20>>2` 等于 20 除以 2 的 2 次方。
-
-### 04、逻辑运算符
-
-逻辑与运算符(&&):多个条件中只要有一个为 false 结果就为 false。
-
-逻辑或运算符(||):多个条件只要有一个为 true 结果就为 true。
-
-```java
-int a=10;
-int b=5;
-int c=20;
-System.out.println(ab||ab|a aList = new ArrayList<>();
-for (int element : anArray) {
- aList.add(element);
-}
-```
-
-更优雅的方式是通过 Arrays 类的 `asList()` 方法:
-
-```java
-List aList = Arrays.asList(anArray);
-```
-
-不过需要注意的是,Arrays.asList 的参数需要是 Integer 数组,而 anArray 目前是 int 类型,我们需要换另外一种方式。
-
-```java
-List aList = Arrays.stream(anArray).boxed().collect(Collectors.toList());
-```
-
-这又涉及到了 Java [流](https://tobebetterjavaer.com/java8/stream.html)的知识,后面会讲到。
-
-还有一个需要注意的是,Arrays.asList 方法返回的 ArrayList 并不是 `java.util.ArrayList`,它其实是 Arrays 类的一个内部类:
-
-```java
-private static class ArrayList extends AbstractList
- implements RandomAccess, java.io.Serializable{}
-```
-
-如果需要添加元素或者删除元素的话,需要把它转成 `java.util.ArrayList`。
-
-```java
-new ArrayList<>(Arrays.asList(anArray));
-```
-
-Java 8 新增了 Stream 流的概念,这就意味着我们也可以将数组转成 Stream 进行操作。
-
-```java
-String[] anArray = new String[] {"沉默王二", "一枚有趣的程序员", "好好珍重他"};
-Stream aStream = Arrays.stream(anArray);
-```
-
-如果想对数组进行排序的话,可以使用 Arrays 类提供的 `sort()` 方法。
-
-- 基本数据类型按照升序排列
-- 实现了 Comparable 接口的对象按照 `compareTo()` 的排序
-
-来看第一个例子:
-
-```java
-int[] anArray = new int[] {5, 2, 1, 4, 8};
-Arrays.sort(anArray);
-```
-
-排序后的结果如下所示:
-
-```java
-[1, 2, 4, 5, 8]
-```
-
-来看第二个例子:
-
-```java
-String[] yetAnotherArray = new String[] {"A", "E", "Z", "B", "C"};
-Arrays.sort(yetAnotherArray, 1, 3,
- Comparator.comparing(String::toString).reversed());
-```
-
-只对 1-3 位置上的元素进行反序,所以结果如下所示:
-
-```
-[A, Z, E, B, C]
-```
-
-有时候,我们需要从数组中查找某个具体的元素,最直接的方式就是通过遍历的方式:
-
-```java
-int[] anArray = new int[] {5, 2, 1, 4, 8};
-for (int i = 0; i < anArray.length; i++) {
- if (anArray[i] == 4) {
- System.out.println("找到了 " + i);
- break;
- }
-}
-```
-
-上例中从数组中查询元素 4,找到后通过 break 关键字退出循环。
-
-如果数组提前进行了排序,就可以使用二分查找法,这样效率就会更高一些。`Arrays.binarySearch()` 方法可供我们使用,它需要传递一个数组,和要查找的元素。
-
-```java
-int[] anArray = new int[] {1, 2, 3, 4, 5};
-int index = Arrays.binarySearch(anArray, 4);
-```
-
-“除了一维数组,还有二维数组,三妹你可以去研究下,比如说用二维数组打印一下杨辉三角。”说完,我就去阳台上休息了,留三妹在那里学习,不能打扰她。
-
-
-
-## 4.2 掌握Java二维数组
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.2 掌握Java二维数组](https://tobebetterjavaer.com/array/double-array.html)
-
-
-
-## 4.3 打印Java数组
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.3 打印Java数组](https://tobebetterjavaer.com/array/print.html)
-
-## 4.4 解读String类源码
-
-我正坐在沙发上津津有味地读刘欣大佬的《码农翻身》——Java 帝国这一章,门铃响了。起身打开门一看,是三妹,她从学校回来了。
-
-“三妹,你回来的真及时,今天我们打算讲 Java 中的字符串呢。”等三妹换鞋的时候我说。
-
-“哦,可以呀,哥。听说字符串的细节特别多,什么[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)了、字符串不可变性了、[字符串拼接](https://tobebetterjavaer.com/string/join.html)了、字符串长度限制了等等,你最好慢慢讲,否则我可能一时半会消化不了。”三妹的态度显得很诚恳。
-
-“嗯,我已经想好了,今天就只带你大概认识一下字符串,主要读一读它的源码,其他的细节咱们后面再慢慢讲,保证你能及时消化。”
-
-“好,那就开始吧。”三妹已经准备好坐在了电脑桌的边上。
-
-我应了一声后走到电脑桌前坐下来,顺手打开 [Intellij IDEA](https://tobebetterjavaer.com/overview/IDEA-install-config.html),并找到了 String 的源码(Java 8)。
-
-### String 类的声明
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
-}
-```
-
-“第一,String 类是 [final](https://tobebetterjavaer.com/oo/final.html) 的,意味着它不能被子类继承。”
-
-“第二,String 类实现了 [Serializable 接口](https://tobebetterjavaer.com/io/Serializbale.html),意味着它可以[序列化](https://tobebetterjavaer.com/io/serialize.html)。”
-
-“第三,String 类实现了 [Comparable 接口](https://tobebetterjavaer.com/basic-extra-meal/comparable-omparator.html),意味着最好不要用‘==’来[比较两个字符串是否相等](https://tobebetterjavaer.com/string/equals.html),而应该用 `compareTo()` 方法去比较。”
-
-因为 == 是用来比较两个对象的地址,这个在讲字符串比较的时候会详细讲。如果只是说比较字符串内容的话,可以使用 String 类的 equals 方法:
-
-```java
-public boolean equals(Object anObject) {
- if (this == anObject) {
- return true;
- }
- if (anObject instanceof String) {
- String anotherString = (String) anObject;
- int n = value.length;
- if (n == anotherString.value.length) {
- char v1[] = value;
- char v2[] = anotherString.value;
- int i = 0;
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- }
- return false;
-}
-```
-
-“第四,[StringBuffer、StringBuilder 和 String](https://tobebetterjavaer.com/string/builder-buffer.html) 一样,都实现了 CharSequence 接口,所以它们仨属于近亲。由于 String 是不可变的,所以遇到字符串拼接的时候就可以考虑一下 String 的另外两个好兄弟,StringBuffer 和 StringBuilder,它俩是可变的。”
-
-### String 类的底层实现
-
-```java
-private final char value[];
-```
-
-“第五,Java 9 以前,String 是用 char 型[数组](https://tobebetterjavaer.com/array/array.html)实现的,之后改成了 byte 型数组实现,并增加了 coder 来表示编码。这样做的好处是在 Latin1 字符为主的程序里,可以把 String 占用的内存减少一半。当然,天下没有免费的午餐,这个改进在节省内存的同时引入了编码检测的开销。”
-
->Latin1(Latin-1)是一种单字节字符集(即每个字符只使用一个字节的编码方式),也称为ISO-8859-1(国际标准化组织8859-1),它包含了西欧语言中使用的所有字符,包括英语、法语、德语、西班牙语、葡萄牙语、意大利语等等。在Latin1编码中,每个字符使用一个8位(即一个字节)的编码,可以表示256种不同的字符,其中包括ASCII字符集中的所有字符,即0x00到0x7F,以及其他西欧语言中的特殊字符,例如é、ü、ñ等等。由于Latin1只使用一个字节表示一个字符,因此在存储和传输文本时具有较小的存储空间和较快的速度
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- @Stable
- private final byte[] value;
- private final byte coder;
- private int hash;
-}
-```
-
-接下来,我们来详细地说一下。
-
-从 `char[]` 到 `byte[]`,最主要的目的是**节省字符串占用的内存空间**。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
-
-我们使用 `jmap -histo:live pid | head -n 10` 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
-
-以我正在运行着的[编程喵](https://github.com/itwanger/coding-more)项目实例(基于 Java 8)来说,结果是这样的。
-
-
-
-其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
-
-由于 Java 8 的 String 内部实现仍然是 `char[]`,所以我们可以看到内存占用排在第 1 位的就是 char 数组。
-
-`char[]` 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
-
-那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类,就没什么必要,对吧?
-
-众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 [编码](https://tobebetterjavaer.com/basic-extra-meal/java-unicode.html),其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
-
-也就是说,使用 `char[]` 来表示 String 就会导致,即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
-
->PS:在计算机中,单字节字符通常指的是一个字节(8位)可以表示的字符,而双字节字符则指需要两个字节(16位)才能表示的字符。单字节字符和双字节字符的定义是相对的,不同的编码方式对应的单字节和双字节字符集也不同。常见的单字节字符集有ASCII(美国信息交换标准代码)、ISO-8859(国际标准化组织标准编号8859)、GBK(汉字内码扩展规范)、GB2312(中国国家标准,现在已经被GBK取代),像拉丁字母、数字、标点符号、控制字符都是单字节字符。双字节字符集包括 Unicode、UTF-8、GB18030(中国国家标准),中文、日文、韩文、拉丁文扩展字符属于双字节字符。
-
-当然了,仅仅将 `char[]` 优化为 `byte[]` 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
-
-换句话说,对于:
-
-```java
-String name = "jack";
-```
-
-这样的,使用 Latin-1 编码,占用 4 个字节就够了。
-
-但对于:
-
-```java
-String name = "小二";
-```
-
-这种,木的办法,只能使用 UTF16 来编码。
-
-针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
-
-```java
-/**
- * The identifier of the encoding used to encode the bytes in
- * {@code value}. The supported values in this implementation are
- *
- * LATIN1
- * UTF16
- *
- * @implNote This field is trusted by the VM, and is a subject to
- * constant folding if String instance is constant. Overwriting this
- * field after construction will cause problems.
- */
-private final byte coder;
-```
-
-Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
-
-也就是说,从 `char[]` 到 `byte[]`,**中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节**。
-
-在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
-
-- 如果只有一个字节,那么最高的比特位为 0;
-- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
-
-具体的表现形式为:
-
-- 0xxxxxxx:一个字节;
-- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
-- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
-- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
-
-也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
-
-那你可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
-
-的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
-
-- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
-- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
-
-但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
-
-所以UTF-16在Java的世界里,就可以视为一个定长的编码。
-
->参考链接:[https://www.zhihu.com/question/447224628](https://www.zhihu.com/question/447224628)
-
-### String 类的 hashCode 方法
-
-“第六,每一个字符串都会有一个 hash 值,这个哈希值在很大概率是不会重复的,因此 String 很适合来作为 [HashMap](https://tobebetterjavaer.com/collection/hashmap.html) 的键值。”
-
-来看 String 类的 hashCode 方法。
-
-```java
-private int hash; // Cache the hash code for the string
-
-public int hashCode() {
- int h = hash;
- if (h == 0 && value.length > 0) {
- char val[] = value;
-
- for (int i = 0; i < value.length; i++) {
- h = 31 * h + val[i];
- }
- hash = h;
- }
- return h;
-}
-```
-
-hashCode 方法首先检查是否已经计算过哈希码,如果已经计算过,则直接返回缓存的哈希码。否则,方法将使用一个循环遍历字符串的所有字符,并使用一个乘法和加法的组合计算哈希码。这种计算方法被称为“31 倍哈希法”。计算完成后,将得到的哈希值存储在 hash 成员变量中,以便下次调用 hashCode 方法时直接返回该值,而不需要重新计算。这是一种缓存优化,称为“惰性计算”。
-
-31倍哈希法(31-Hash)是一种简单有效的字符串哈希算法,常用于对字符串进行哈希处理。该算法的基本思想是将字符串中的每个字符乘以一个固定的质数31的幂次方,并将它们相加得到哈希值。具体地,假设字符串为s,长度为n,则31倍哈希值计算公式如下:
-
-```
-H(s) = (s[0] * 31^(n-1)) + (s[1] * 31^(n-2)) + ... + (s[n-1] * 31^0)
-```
-
-其中,s[i]表示字符串s中第i个字符的ASCII码值,`^`表示幂运算。
-
-31倍哈希法的优点在于简单易实现,计算速度快,同时也比较均匀地分布在哈希表中。
-
-[hashCode 方法](https://tobebetterjavaer.com/basic-extra-meal/hashcode.html),我们会在另外一个章节里详细讲,戳前面的链接了解。
-
-我们可以通过以下方法模拟 String 的 hashCode 方法:
-
-```java
-public class HashCodeExample {
- public static void main(String[] args) {
- String text = "沉默王二";
- int hashCode = computeHashCode(text);
- System.out.println("字符串 \"" + text + "\" 的哈希码是: " + hashCode);
-
- System.out.println("String 的 hashCode " + text.hashCode());
- }
-
- public static int computeHashCode(String text) {
- int h = 0;
- for (int i = 0; i < text.length(); i++) {
- h = 31 * h + text.charAt(i);
- }
- return h;
- }
-}
-```
-
-看一下结果:
-
-```
-字符串 "沉默王二" 的哈希码是: 867758096
-String 的 hashCode 867758096
-```
-
-结果是一样的,又学到了吧?
-
-### String 类的 substring 方法
-
-String 类中还有一个方法比较常用 substring,用来截取字符串的,来看源码。
-
-```java
-public String substring(int beginIndex) {
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- int subLen = value.length - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
-}
-```
-
-substring 方法首先检查参数的有效性,如果参数无效,则抛出 StringIndexOutOfBoundsException [异常](https://tobebetterjavaer.com/exception/gailan.html)。接下来,方法根据参数计算子字符串的长度。如果子字符串长度小于零,抛出StringIndexOutOfBoundsException异常。
-
-如果 beginIndex 为 0,且 endIndex 等于字符串的长度,说明子串与原字符串相同,因此直接返回原字符串。否则,使用 value 数组(原字符串的字符数组)的一部分创建一个新的 String 对象并返回。
-
-下面是几个使用 substring 方法的示例:
-
-①、提取字符串中的一段子串:
-
-```java
-String str = "Hello, world!";
-String subStr = str.substring(7, 12); // 从第7个字符(包括)提取到第12个字符(不包括)
-System.out.println(subStr); // 输出 "world"
-```
-
-②、提取字符串中的前缀或后缀:
-
-```java
-String str = "Hello, world!";
-String prefix = str.substring(0, 5); // 提取前5个字符,即 "Hello,"
-String suffix = str.substring(7); // 提取从第7个字符开始的所有字符,即 "world!"
-```
-
-③、处理字符串中的空格和分隔符:
-
-```java
-String str = " Hello, world! ";
-String trimmed = str.trim(); // 去除字符串开头和结尾的空格
-String[] words = trimmed.split("\\s+"); // 将字符串按照空格分隔成单词数组
-String firstWord = words[0].substring(0, 1); // 提取第一个单词的首字母
-System.out.println(firstWord); // 输出 "H"
-```
-
-④、处理字符串中的数字和符号:
-
-```java
-String str = "1234-5678-9012-3456";
-String[] parts = str.split("-"); // 将字符串按照连字符分隔成四个部分
-String last4Digits = parts[3].substring(1); // 提取最后一个部分的后三位数字
-System.out.println(last4Digits); // 输出 "456"
-```
-
-总之,substring 方法可以根据需求灵活地提取字符串中的子串,为字符串处理提供了便利。
-
-### String 类的 indexOf 方法
-
-indexOf 方法用于查找一个子字符串在原字符串中第一次出现的位置,并返回该位置的索引。来看该方法的源码:
-
-```java
-/*
- * 查找字符数组 target 在字符数组 source 中第一次出现的位置。
- * sourceOffset 和 sourceCount 参数指定 source 数组中要搜索的范围,
- * targetOffset 和 targetCount 参数指定 target 数组中要搜索的范围,
- * fromIndex 参数指定开始搜索的位置。
- * 如果找到了 target 数组,则返回它在 source 数组中的位置索引(从0开始),
- * 否则返回-1。
- */
-static int indexOf(char[] source, int sourceOffset, int sourceCount,
- char[] target, int targetOffset, int targetCount,
- int fromIndex) {
- // 如果开始搜索的位置已经超出 source 数组的范围,则直接返回-1(如果 target 数组为空,则返回 sourceCount)
- if (fromIndex >= sourceCount) {
- return (targetCount == 0 ? sourceCount : -1);
- }
- // 如果开始搜索的位置小于0,则从0开始搜索
- if (fromIndex < 0) {
- fromIndex = 0;
- }
- // 如果 target 数组为空,则直接返回开始搜索的位置
- if (targetCount == 0) {
- return fromIndex;
- }
-
- // 查找 target 数组的第一个字符在 source 数组中的位置
- char first = target[targetOffset];
- int max = sourceOffset + (sourceCount - targetCount);
-
- // 循环查找 target 数组在 source 数组中的位置
- for (int i = sourceOffset + fromIndex; i <= max; i++) {
- /* Look for first character. */
- // 如果 source 数组中当前位置的字符不是 target 数组的第一个字符,则在 source 数组中继续查找 target 数组的第一个字符
- if (source[i] != first) {
- while (++i <= max && source[i] != first);
- }
-
- /* Found first character, now look at the rest of v2 */
- // 如果在 source 数组中找到了 target 数组的第一个字符,则继续查找 target 数组的剩余部分是否匹配
- if (i <= max) {
- int j = i + 1;
- int end = j + targetCount - 1;
- for (int k = targetOffset + 1; j < end && source[j]
- == target[k]; j++, k++);
-
- // 如果 target 数组全部匹配,则返回在 source 数组中的位置索引
- if (j == end) {
- /* Found whole string. */
- return i - sourceOffset;
- }
- }
- }
- // 没有找到 target 数组,则返回-1
- return -1;
-}
-```
-
-来看示例。
-
-①、示例1:查找子字符串的位置
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf("world"); // 查找 "world" 子字符串在 str 中第一次出现的位置
-System.out.println(index); // 输出 7
-```
-
-②、示例2:查找字符串中某个字符的位置
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf(","); // 查找逗号在 str 中第一次出现的位置
-System.out.println(index); // 输出 5
-```
-
-③、示例3:查找子字符串的位置(从指定位置开始查找)
-
-```java
-String str = "Hello, world!";
-int index = str.indexOf("l", 3); // 从索引为3的位置开始查找 "l" 子字符串在 str 中第一次出现的位置
-System.out.println(index); // 输出 3
-```
-
-④、示例4:查找多个子字符串
-
-```java
-String str = "Hello, world!";
-int index1 = str.indexOf("o"); // 查找 "o" 子字符串在 str 中第一次出现的位置
-int index2 = str.indexOf("o", 5); // 从索引为5的位置开始查找 "o" 子字符串在 str 中第一次出现的位置
-System.out.println(index1); // 输出 4
-System.out.println(index2); // 输出 8
-```
-
-### String 类的其他方法
-
-比如说 `length()` 用于返回字符串长度。
-
-比如说 `isEmpty()` 用于判断字符串是否为空。
-
-比如说 `charAt()` 用于返回指定索引处的字符。
-
-比如说 `getBytes()` 用于返回字符串的字节数组,可以指定编码方式,比如说:
-
-```java
-String text = "沉默王二";
-System.out.println(Arrays.toString(text.getBytes(StandardCharsets.UTF_8)));
-```
-
-比如说 `trim()` 用于去除字符串两侧的空白字符,来看源码:
-
-```java
-public String trim() {
- int len = value.length;
- int st = 0;
- char[] val = value; /* avoid getfield opcode */
-
- while ((st < len) && (val[st] <= ' ')) {
- st++;
- }
- while ((st < len) && (val[len - 1] <= ' ')) {
- len--;
- }
- return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
-}
-```
-
-举例:`" 沉默王二 ".trim()` 会返回"沉默王二"
-
-除此之外,还有 [split](https://tobebetterjavaer.com/string/split.html)、[equals](https://tobebetterjavaer.com/string/equals.html)、[join](https://tobebetterjavaer.com/string/join.html) 等这些方法,我们后面会一一来细讲。
-
-
-
-## 4.5 String为什么不可变
-
-String 可能是 Java 中使用频率最高的引用类型了,因此 String 类的设计者可以说是用心良苦。
-
-比如说 String 的不可变性。
-
-- String 类被 [final 关键字](https://tobebetterjavaer.com/oo/final.html)修饰,所以它不会有子类,这就意味着没有子类可以[重写](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)它的方法,改变它的行为。
-- String 类的数据存储在 `char[]` 数组中,而这个数组也被 final 关键字修饰了,这就表示 String 对象是没法被修改的,只要初始化一次,值就确定了。
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence {
- /** The value is used for character storage. */
- private final char value[];
-}
-```
-
-“哥,为什么要这样设计呢?”三妹有些不解。
-
-“我先简单来说下,三妹,能懂最好,不能懂后面再细说。”
-
-第一,可以保证 String 对象的安全性,避免被篡改,毕竟像密码这种隐私信息一般就是用字符串存储的。
-
-以下是一个简单的 Java 示例,演示了字符串的不可变性如何有助于保证 String 对象的安全性。在本例中,我们创建了一个简单的 User 类,该类使用 String 类型的字段存储用户名和密码。同时,我们使用一个静态方法 getUserCredentials 从外部获取用户凭据。
-
-```java
-class User {
- private String username;
- private String password;
-
- public User(String username, String password) {
- this.username = username;
- this.password = password;
- }
-
- public String getUsername() {
- return username;
- }
-
- public String getPassword() {
- return password;
- }
-}
-
-public class StringSecurityExample {
- public static void main(String[] args) {
- String username = "沉默王二";
- String password = "123456";
- User user = new User(username, password);
-
- // 获取用户凭据
- String[] credentials = getUserCredentials(user);
-
- // 尝试修改从 getUserCredentials 返回的用户名和密码字符串
- credentials[0] = "陈清扬";
- credentials[1] = "612311";
-
- // 输出原始 User 对象中的用户名和密码
- System.out.println("原始用户名: " + user.getUsername()); // 输出 "JohnDoe"
- System.out.println("原始密码: " + user.getPassword()); // 输出 "mySecurePassword"
- }
-
- public static String[] getUserCredentials(User user) {
- String[] credentials = new String[2];
- credentials[0] = user.getUsername();
- credentials[1] = user.getPassword();
- return credentials;
- }
-}
-```
-
-在这个示例中,尽管我们尝试修改 getUserCredentials 返回的字符串数组(即用户名和密码),但原始 User 对象中的用户名和密码保持不变。这证明了字符串的不可变性有助于保护 String 对象的安全性。
-
-第二,保证哈希值不会频繁变更。毕竟要经常作为[哈希表](https://tobebetterjavaer.com/collection/hashmap.html)的键值,经常变更的话,哈希表的性能就会很差劲。
-
-在 String 类中,哈希值是在第一次计算时缓存的,后续对该哈希值的请求将直接使用缓存值。这有助于提高哈希表等数据结构的性能。以下是一个简单的示例,演示了字符串的哈希值缓存机制:
-
-```java
-String text1 = "沉默王二";
-String text2 = "沉默王二";
-
-// 计算字符串 text1 的哈希值,此时会进行计算并缓存哈希值
-int hashCode1 = text1.hashCode();
-System.out.println("第一次计算 text1 的哈希值: " + hashCode1);
-
-// 再次计算字符串 text1 的哈希值,此时直接返回缓存的哈希值
-int hashCode1Cached = text1.hashCode();
-System.out.println("第二次计算: " + hashCode1Cached);
-
-// 计算字符串 text2 的哈希值,由于字符串常量池的存在,实际上 text1 和 text2 指向同一个字符串对象
-// 所以这里直接返回缓存的哈希值
-int hashCode2 = text2.hashCode();
-System.out.println("text2 直接使用缓存: " + hashCode2);
-```
-
-在这个示例中,我们创建了两个具有相同内容的字符串 text1 和 text2。首次计算 text1 的哈希值时,会进行实际计算并缓存该值。当我们再次计算 text1 的哈希值或计算具有相同内容的 text2 的哈希值时,将直接返回缓存的哈希值,而不进行重新计算。
-
-由于 String 对象是不可变的,其哈希值在创建后不会发生变化。这使得 String 类可以缓存哈希值,提高哈希表等数据结构的性能。如果 String 是可变的,那么在每次修改时都需要重新计算哈希值,这会降低性能。
-
-第三,可以实现[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html),Java 会将相同内容的字符串存储在字符串常量池中。这样,具有相同内容的字符串变量可以指向同一个 String 对象,节省内存空间。
-
-“由于字符串的不可变性,String 类的一些方法实现最终都返回了新的字符串对象。”等三妹稍微缓了一会后,我继续说到。
-
-“就拿 `substring()` 方法来说。”
-
-```java
-public String substring(int beginIndex) {
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- int subLen = value.length - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
-}
-```
-
-`substring()` 方法用于截取字符串,最终返回的都是 new 出来的新字符串对象。
-
-“还有 `concat()` 方法。”
-
-```java
-public String concat(String str) {
- int olen = str.length();
- if (olen == 0) {
- return this;
- }
- if (coder() == str.coder()) {
- byte[] val = this.value;
- byte[] oval = str.value;
- int len = val.length + oval.length;
- byte[] buf = Arrays.copyOf(val, len);
- System.arraycopy(oval, 0, buf, val.length, oval.length);
- return new String(buf, coder);
- }
- int len = length();
- byte[] buf = StringUTF16.newBytesFor(len + olen);
- getBytes(buf, 0, UTF16);
- str.getBytes(buf, len, UTF16);
- return new String(buf, UTF16);
-}
-```
-
-`concat()` 方法用于拼接字符串,不管编码是否一致,最终也返回的是新的字符串对象。
-
-“`replace()` 替换方法其实也一样,三妹,你可以自己一会看一下源码,也是返回新的字符串对象。”
-
-“这就意味着,不管是截取、拼接,还是替换,都不是在原有的字符串上进行的,而是重新生成了新的字符串对象。也就是说,这些操作执行过后,**原来的字符串对象并没有发生改变**。”
-
-“三妹,你记住,String 对象一旦被创建后就固定不变了,对 String 对象的任何修改都不会影响到原来的字符串对象,都会生成新的字符串对象。”
-
-“嗯嗯,记住了,哥。”三妹很乖。
-
-“那今天就先讲到这吧,后面我们再对每一个细分领域深入地展开一下。你可以找一些资料先预习下,我出去散会心。。。。。”
-
-
-
-
-## 4.6 深入理解Java字符串常量池
-
-“三妹,今天我们来学习一下字符串常量池,这是字符串中非常关键的一个知识点。”我话音未落,青岛路小学那边传来了嘹亮的歌声就钻进了我的耳朵,“唱 ~ 山 ~ 歌 ~”,我都有点情不自禁地哼唱起来了。
-
-三妹赶紧拦住我说,“好了,开始吧,哥。”
-
-### new String("二哥")创建了几个对象
-
-“先从这道面试题开始吧!”
-
-```java
-String s = new String("二哥");
-```
-
-“这行代码创建了几个[对象](https://tobebetterjavaer.com/oo/object-class.html)?”
-
-“不就一个吗?”三妹不假思索地回答。
-
-“不,两个!”我直接否定了三妹的答案,“使用 new 关键字创建一个字符串对象时,Java 虚拟机会先在字符串常量池中查找有没有‘二哥’这个字符串对象,如果有,就不会在字符串常量池中创建‘二哥’这个对象了,直接在堆中创建一个‘二哥’的字符串对象,然后将堆中这个‘二哥’的对象地址返回赋值给变量 s。”
-
-“如果没有,先在字符串常量池中创建一个‘二哥’的字符串对象,然后再在堆中创建一个‘二哥’的字符串对象,然后将堆中这个‘二哥’的字符串对象地址返回赋值给变量 s。”
-
-我画图表示一下,会更加清楚。
-
-
-
-在Java中,栈上存储的是基本数据类型的变量和对象的引用,而对象本身则存储在堆上。
-
-对于这行代码 `String s = new String("二哥");`,它创建了两个对象:一个是字符串对象 "二哥",它被添加到了字符串常量池中,另一个是通过 new String() 构造函数创建的字符串对象 "二哥",它被分配在堆内存中,同时引用变量 s 存储在栈上,它指向堆内存中的字符串对象 "二哥"。
-
-“**为什么要先在字符串常量池中创建对象,然后再在堆上创建呢**?这样不就多此一举了?”三妹敏锐地发现了问题。
-
-我回答,“是的。由于字符串的使用频率实在是太高了,所以 Java 虚拟机为了提高性能和减少内存开销,在创建字符串对象的时候进行了一些优化,特意为字符串开辟了一块空间——也就是字符串常量池。”
-
-### 字符串常量池的作用
-
-通常情况下,我们会采用双引号的方式来创建字符串对象,而不是通过 new 关键字的方式,就像下面👇🏻这样,这样就不会多此一举:
-
-```java
-String s = "三妹";
-```
-
-当执行 `String s = "三妹"` 时,Java 虚拟机会先在字符串常量池中查找有没有“三妹”这个字符串对象,如果有,则不创建任何对象,直接将字符串常量池中这个“三妹”的对象地址返回,赋给变量 s;如果没有,在字符串常量池中创建“三妹”这个对象,然后将其地址返回,赋给变量 s。
-
-
-
-
-Java 虚拟机创建了一个字符串对象 "三妹",它被添加到了字符串常量池中,同时引用变量 s 存储在栈上,它指向字符串常量池中的字符串对象 "三妹"。你看,是不是省了一步,比之前高效了。
-
-
-“哦,我明白了,哥。”三妹突然插话到,“有了字符串常量池,就可以通过双引号的方式直接创建字符串对象,不用再通过 new 的方式在堆中创建对象了,对吧?”
-
-“是滴。new 的方式始终会创建一个对象,不管字符串的内容是否已经存在,而双引号的方式会重复利用字符串常量池中已经存在的对象。”我说。
-
-来看下面这个例子:
-
-```java
-String s = new String("二哥");
-String s1 = new String("二哥");
-```
-
-按照我们之前的分析,这两行代码会创建三个对象,字符串常量池中一个,堆上两个。
-
-再来看下面这个例子:
-
-```java
-String s = "三妹";
-String s1 = "三妹";
-```
-
-这两行代码只会创建一个对象,就是字符串常量池中的那个。这样的话,性能肯定就提高了!
-
-### 字符串常量池在内存中的什么位置呢?
-
-“那哥,字符串常量池在内存中的什么位置呢?”三妹问。
-
-我说,“三妹,你这个问题问得好呀!”
-
-分为三个阶段。
-
-#### Java 7 之前
-
-在 Java 7 之前,字符串常量池位于永久代(Permanent Generation)的内存区域中,主要用来存储一些字符串常量(静态数据的一种)。永久代是 Java 堆(Java Heap)的一部分,用于存储类信息、方法信息、常量池信息等静态数据。
-
-而 Java 堆是 JVM 中存储对象实例和数组的内存区域,也就是说,永久代是 Java 堆的一个子区域。
-
-换句话说,永久代中存储的静态数据与堆中存储的对象实例和数组是分开的,它们有不同的生命周期和分配方式。
-
-但是,永久代和堆的大小是相互影响的,因为它们都使用了 JVM 堆内存,因此它们的大小都受到 JVM 堆大小的限制。
-
-于是,当我们创建一个字符串常量时,它会被储存在永久代的字符串常量池中。如果我们创建一个普通字符串对象,则它将被储存在堆中。如果字符串对象的内容是一个已经存在于字符串常量池中的字符串常量,那么这个对象会指向已经存在的字符串常量,而不是重新创建一个新的字符串对象。
-
-画幅图,大概就是这个样子。
-
-
-
-
-
-#### Java 7
-
-需要注意的是,永久代的大小是有限的,并且很难准确地确定一个应用程序需要多少永久代空间。如果我们在应用程序中使用了大量的类、方法、常量等静态数据,就有可能导致永久代空间不足。这种情况下,JVM 就会抛出 OutOfMemoryError 错误。
-
-因此,从 Java 7 开始,为了解决永久代空间不足的问题,将字符串常量池从永久代中移动到堆中。这个改变也是为了更好地支持动态语言的运行时特性。
-
-再画幅图,大概就是这样子。
-
-
-
-#### Java 8
-
-到了 Java 8,永久代(PermGen)被取消,并由元空间(Metaspace)取代。元空间是一块本机内存区域,和 JVM 内存区域是分开的。不过,元空间的作用依然和之前的永久代一样,用于存储类信息、方法信息、常量池信息等静态数据。
-
-与永久代不同,元空间具有一些优点,例如:
-
-- 它不会导致 OutOfMemoryError 错误,因为元空间的大小可以动态调整。
-- 元空间使用本机内存,而不是 JVM 堆内存,这可以避免堆内存的碎片化问题。
-- 元空间中的垃圾收集与堆中的垃圾收集是分离的,这可以避免应用程序在运行过程中因为进行类加载和卸载而频繁地触发 Full GC。
-
-再画幅图,对比来看一下,就会一目了然。
-
-
-
-
-### 永久代、方法区、元空间
-
-
-“哥,能再简单给我解释一下方法区,永久代和元空间的概念吗?有点模糊。”三妹说。
-
-“可以呀。”
-
-- 方法区是 Java 虚拟机规范中的一个概念,就像是一个[接口](https://tobebetterjavaer.com/oo/interface.html)吧;
-- 永久代是 HotSpot 虚拟机中对方法区的一个实现,就像是接口的实现类;
-- Java 8 的时候,移除了永久代,取而代之的是元空间,是方法区的另外一种实现,更灵活了。
-
-永久代是放在运行时数据区中的,所以它的大小受到 Java 虚拟机本身大小的限制,所以 Java 8 之前,会经常遇到 `java.lang.OutOfMemoryError: PremGen Space` 的异常,PremGen Space 就是方法区的意思;而元空间是直接放在内存中的,所以只受本机可用内存的限制。
-
-“明白了吧,三妹?”我问。
-
-“嗯嗯。”三妹回答。
-
-“那关于字符串常量池,就先说这么多吧,是不是还挺有意思的。”我说。
-
-“是的,我现在是彻底搞懂了字符串常量池,哥,你真棒!”三妹说。
-
-
-
-## 4.7 详解 String.intern() 方法
-
-“哥,你发给我的那篇文章我看了,结果直接把我给看得不想学 Java 了!”三妹气冲冲地说。
-
-“哪一篇啊?”看着三妹面色沉重,我关心地问到。
-
-“就是[美团技术团队深入解析 `String.intern()` 那篇](https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html)啊!”三妹回答。
-
-“哦,我想起来了,不挺好一篇文章嘛,深入浅出,精品中的精品,看完后你应该对 String 的 intern 方法彻底理解了才对呀。”
-
-“好是好,但我就是看不懂!”三妹委屈地说,“哥,还是你亲自给我讲讲吧?”
-
-“好吧,上次学的[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)你都搞清楚了吧?”
-
-“嗯。”三妹微微的点了点头。
-
-要理解美团技术团队的这篇文章,你只需要记住这几点内容:
-
-第一,使用双引号声明的字符串对象会保存在字符串常量池中。
-
-第二,使用 new 关键字创建的字符串对象会先从字符串常量池中找,如果没找到就创建一个,然后再在堆中创建字符串对象;如果找到了,就直接在堆中创建字符串对象。
-
-第三,针对没有使用双引号声明的字符串对象来说,就像下面代码中的 s1 那样:
-
-```java
-String s1 = new String("二哥") + new String("三妹");
-```
-
-如果想把 s1 的内容也放入字符串常量池的话,可以调用 `intern()` 方法来完成。
-
-不过,需要注意的是,Java 7 的时候,字符串常量池从永久代中移动到了堆中,虽然此时永久代还没有完全被移除。Java 8 的时候,永久代被彻底移除。
-
-这个变化也直接影响了 `String.intern()` 方法在执行时的策略,Java 7 之前,执行 `String.intern()` 方法的时候,不管对象在堆中是否已经创建,字符串常量池中仍然会创建一个内容完全相同的新对象; Java 7 之后呢,由于字符串常量池放在了堆中,执行 `String.intern()` 方法的时候,如果对象在堆中已经创建了,字符串常量池中就不需要再创建新的对象了,而是直接保存堆中对象的引用,也就节省了一部分的内存空间。
-
-“还没有理解清楚,二哥”,三妹很苦恼。
-
-“嗯。。。别怕,三妹,先来猜猜这段代码输出的结果吧。”我说。
-
-```java
-String s1 = new String("二哥三妹");
-String s2 = s1.intern();
-System.out.println(s1 == s2);
-```
-
-“哥,这我完全猜不出啊,还是你直接解释吧。”三妹说。
-
-“好吧。”
-
-第一行代码,字符串常量池中会先创建一个“二哥三妹”的对象,然后堆中会再创建一个“二哥三妹”的对象,s1 引用的是堆中的对象。
-
-第二行代码,对 s1 执行 `intern()` 方法,该方法会从字符串常量池中查找“二哥三妹”这个字符串是否存在,此时是存在的,所以 s2 引用的是字符串常量池中的对象。
-
-也就意味着 s1 和 s2 的引用地址是不同的,一个来自堆,一个来自字符串常量池,所以输出的结果为 false。
-
-“来看一下运行结果。”我说。
-
-```
-false
-```
-
-“我来画幅图,帮助你理解下。”看到三妹惊讶的表情,我耐心地说。
-
-
-
-“这下理解了吧?”我问三妹。
-
-“嗯嗯,一下子就豁然开朗了!”三妹说。
-
-“好,我们再来看下面这段代码。”
-
-```java
-String s1 = new String("二哥") + new String("三妹");
-String s2 = s1.intern();
-System.out.println(s1 == s2);
-```
-
-“难道也输出 false ?”三妹有点不确定。
-
-“不,这段代码会输出 true。”我否定了三妹的猜测。
-
-“为啥呀?”三妹迫切地想要知道答案。
-
-第一行代码,会在字符串常量池中创建两个对象,一个是“二哥”,一个是“三妹”,然后在堆中会创建两个匿名对象“二哥”和“三妹”,最后还有一个“二哥三妹”的对象(稍后会解释),s1 引用的是堆中“二哥三妹”这个对象。
-
-第二行代码,对 s1 执行 `intern()` 方法,该方法会从字符串常量池中查找“二哥三妹”这个对象是否存在,此时不存在的,但堆中已经存在了,所以字符串常量池中保存的是堆中这个“二哥三妹”对象的引用,也就是说,s2 和 s1 的引用地址是相同的,所以输出的结果为 true。
-
-“来看一下运行结果。”我胸有成竹地说。
-
-```
-true
-```
-
-“我再来画幅图,帮助你理解下。”
-
-
-
-“哇,我明白了!”三妹长舒一口气,大有感慨 intern 也没什么难理解的意味,“不过,我有一个疑惑,“二哥三妹”这个对象是什么时候创建的呢?”
-
-“三妹,不错嘛,能抓住问题的关键。再来解释一下 `String s1 = new String("二哥") + new String("三妹")` 这行代码。”我对三妹的表现非常开心。
-
-1. 创建 "二哥" 字符串对象,存储在字符串常量池中。
-2. 创建 "三妹" 字符串对象,存储在字符串常量池中。
-3. 执行 `new String("二哥")`,在堆上创建一个字符串对象,内容为 "二哥"。
-4. 执行 `new String("三妹")`,在堆上创建一个字符串对象,内容为 "三妹"。
-5. 执行 `new String("二哥") + new String("三妹")`,会创建一个 StringBuilder 对象,并将 "二哥" 和 "三妹" 追加到其中,然后调用 StringBuilder 对象的 toString() 方法,将其转换为一个新的字符串对象,内容为 "二哥三妹"。这个新的字符串对象存储在堆上。
-
-也就是说,当编译器遇到 `+` 号这个操作符的时候,会将 `new String("二哥") + new String("三妹")` 这行代码编译为以下代码:
-
-```
-new StringBuilder().append("二哥").append("三妹").toString();
-```
-
-实际执行过程如下:
-
-- 创建一个 StringBuilder 对象。
-- 在 StringBuilder 对象上调用 append("二哥"),将 "二哥" 追加到 StringBuilder 中。
-- 在 StringBuilder 对象上调用 append("三妹"),将 "三妹" 追加到 StringBuilder 中。
-- 在 StringBuilder 对象上调用 toString() 方法,将 StringBuilder 转换为一个新的字符串对象,内容为 "二哥三妹"。
-
-关于 [StringBuilder](https://tobebetterjavaer.com/string/builder-buffer.html),我们随后会详细地讲到。今天先了解到这。
-
-不过需要注意的是,尽管 intern 可以确保所有具有相同内容的字符串共享相同的内存空间,但也不要烂用 intern,因为任何的缓存池都是有大小限制的,不能无缘无故就占用了相对稀缺的缓存空间,导致其他字符串没有坑位可占。
-
-另外,字符串常量池本质上是一个固定大小的 StringTable,如果放进去的字符串过多,就会造成严重的哈希冲突,从而导致链表变长,链表变长也就意味着字符串常量池的性能会大幅下降,因为要一个一个找是需要花费时间的。
-
-“好了,三妹,关于 String 的 intern 就讲到这吧,这次理解了吧?”我问。
-
-“哥,你真棒!”
-
-看到三妹一点一滴的进步,我也感到由衷的开心。
-
-
-
-## 4.8 String、StringBuilder、StringBuffer
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[4.8 StringBuilder和StringBuffer](https://tobebetterjavaer.com/string/builder-buffer.html)
-
-## 4.9 String相等判断
-
-“二哥,如何比较两个字符串相等啊?”三妹问。
-
-“这个问题看似简单,却在 Stack Overflow 上有超过 370 万+的访问量。”我说,“这个问题也可以引申为 `.equals()` 和 ‘==’ 操作符有什么区别。”
-
-- “==”操作符用于比较两个对象的地址是否相等。
-- `.equals()` 方法用于比较两个对象的内容是否相等。
-
-“不是很理解。”三妹感到很困惑。
-
-“我来举个不恰当又很恰当的例子,一看你就明白了,三妹。”
-
-有一对双胞胎,姐姐叫阿丽塔,妹妹叫洛丽塔。我们普通人可能完全无法分辨谁是姐姐谁是妹妹,可她们的妈妈却可以轻而易举地辨认出。
-
-
-
-
-`.equals()` 就好像我们普通人,看见阿丽塔以为是洛丽塔,看见洛丽塔以为是阿丽塔,看起来一样就觉得她们是同一个人;“==”操作符就好像她们的妈妈,要求更严格,观察更细致,一眼就能分辨出谁是姐姐谁是妹妹。
-
-```java
-String alita = new String("小萝莉");
-String luolita = new String("小萝莉");
-
-System.out.println(alita.equals(luolita)); // true
-System.out.println(alita == luolita); // false
-```
-
-就上面这段代码来说,`.equals()` 输出的结果为 true,而“==”操作符输出的结果为 false——前者要求内容相等就可以,后者要求必须是同一个对象。
-
-“三妹,之前已经学过了,Java 的所有类都默认地继承 Object 这个超类,该类有一个名为 `.equals()` 的方法。”一边说,我一边打开了 Object 类的源码。
-
-```java
-public boolean equals(Object obj) {
- return (this == obj);
-}
-```
-
-你看,Object 类的 `.equals()` 方法默认采用的是“==”操作符进行比较。假如子类没有重写该方法的话,那么“==”操作符和 `.equals()` 方法的功效就完全一样——比较两个对象的内存地址是否相等。
-
-但实际情况中,有不少类重写了 `.equals()` 方法,因为比较内存地址的要求比较严格,不太符合现实中所有的场景需求。拿 String 类来说,我们在比较字符串的时候,的确只想判断它们俩的内容是相等的就可以了,并不想比较它们俩是不是同一个对象。
-
-况且,字符串有[字符串常量池](https://tobebetterjavaer.com/string/constant-pool.html)的概念,本身就推荐使用 `String s = "字符串"` 这种形式来创建字符串对象,而不是通过 new 关键字的方式,因为可以把字符串缓存在字符串常量池中,方便下次使用,不用遇到 new 就在堆上开辟一块新的空间。
-
-“哦,我明白了。”三妹说。
-
-“那就来看一下 String 类的 `.equals()` 方法的源码吧。”我说。
-
-```java
-public boolean equals(Object anObject) {
- if (this == anObject) {
- return true;
- }
- if (anObject instanceof String) {
- String aString = (String)anObject;
- if (coder() == aString.coder()) {
- return isLatin1() ? StringLatin1.equals(value, aString.value)
- : StringUTF16.equals(value, aString.value);
- }
- }
- return false;
-}
-```
-
-首先,如果两个字符串对象的可以“==”,那就直接返回 true 了,因为这种情况下,字符串内容是必然相等的。否则就按照字符编码进行比较,分为 UTF16 和 Latin1,差别不是很大,就拿 Latin1 的来说吧。
-
-```java
-@HotSpotIntrinsicCandidate
-public static boolean equals(byte[] value, byte[] other) {
- if (value.length == other.length) {
- for (int i = 0; i < value.length; i++) {
- if (value[i] != other[i]) {
- return false;
- }
- }
- return true;
- }
- return false;
-}
-```
-
-这个 JDK 版本是 Java 17,也就是最新的 LTS(长期支持)版本。该版本中,String 类使用字节数组实现的,所以比较两个字符串的内容是否相等时,可以先比较字节数组的长度是否相等,不相等就直接返回 false;否则就遍历两个字符串的字节数组,只有有一个字节不相等,就返回 false。
-
-这是 Java 8 中的 equals 方法源码:
-
-```java
-public boolean equals(Object anObject) {
- // 判断是否为同一对象
- if (this == anObject) {
- return true;
- }
- // 判断对象是否为 String 类型
- if (anObject instanceof String) {
- String anotherString = (String)anObject;
- int n = value.length;
- // 判断字符串长度是否相等
- if (n == anotherString.value.length) {
- char v1[] = value;
- char v2[] = anotherString.value;
- int i = 0;
- // 判断每个字符是否相等
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- }
- return false;
-}
-```
-
-JDK 8 比 JDK 17 更容易懂一些:首先判断两个对象是否为同一个对象,如果是,则返回 true。接着,判断对象是否为 String 类型,如果不是,则返回 false。如果对象为 String 类型,则比较两个字符串的长度是否相等,如果长度不相等,则返回 false。如果长度相等,则逐个比较每个字符是否相等,如果都相等,则返回 true,否则返回 false。
-
-“嗯,二哥,这段源码不难理解。”三妹自信地说。
-
-“那出几道题考考你吧!”我说。
-
-第一题:
-
-```java
-new String("小萝莉").equals("小萝莉")
-```
-
-“输出什么呢?”我问。
-
-“`.equals()` 比较的是两个字符串对象的内容是否相等,所以结果为 true。”三妹不假思索地答到。
-
-
-第二题:
-
-```java
-new String("小萝莉") == "小萝莉"
-```
-
-“==操作符左侧的是在堆中创建的对象,右侧是在字符串常量池中的对象,尽管内容相同,但内存地址不同,所以返回 false。”三妹答。
-
-第三题:
-
-```java
-new String("小萝莉") == new String("小萝莉")
-```
-
-“new 出来的对象肯定是完全不同的内存地址,所以返回 false。”三妹答。
-
-第四题:
-
-```java
-"小萝莉" == "小萝莉"
-```
-
-“字符串常量池中只会有一个相同内容的对象,所以返回 true。”三妹答。
-
-第五题:
-
-```java
-"小萝莉" == "小" + "萝莉"
-```
-
-“由于‘小’和‘萝莉’都在字符串常量池,所以编译器在遇到‘+’操作符的时候将其自动优化为“小萝莉”,所以返回 true。”
-
-PS:至于为什么,查看这篇[String、StringBuilder、StringBuffer](https://tobebetterjavaer.com/string/builder-buffer.html)
-
-第六题:
-
-```java
-new String("小萝莉").intern() == "小萝莉"
-```
-
-“`new String("小萝莉")` 在执行的时候,会先在字符串常量池中创建对象,然后再在堆中创建对象;执行 `intern()` 方法的时候发现字符串常量池中已经有了‘小萝莉’这个对象,所以就直接返回字符串常量池中的对象引用了,那再与字符串常量池中的‘小萝莉’比较,当然会返回 true 了。”三妹说。
-
-PS:[intern](https://tobebetterjavaer.com/string/intern.html) 方法我们之前已经深究过了。
-
-哇,不得不说,三妹前几节的字符串相关内容都完全学会了呀!
-
-“三妹,哥再给你补充一点。”我说。
-
-“如果要进行两个字符串对象的内容比较,除了 `.equals()` 方法,还有其他两个可选的方案。”
-
-1)`Objects.equals()`
-
-`Objects.equals()` 这个静态方法的优势在于不需要在调用之前判空。
-
-```java
-public static boolean equals(Object a, Object b) {
- return (a == b) || (a != null && a.equals(b));
-}
-```
-
-如果直接使用 `a.equals(b)`,则需要在调用之前对 a 进行判空,否则可能会抛出空指针 `java.lang.NullPointerException`。`Objects.equals()` 用起来就完全没有这个担心。
-
-```java
-Objects.equals("小萝莉", new String("小" + "萝莉")) // --> true
-Objects.equals(null, new String("小" + "萝莉")); // --> false
-Objects.equals(null, null) // --> true
-
-String a = null;
-a.equals(new String("小" + "萝莉")); // throw exception
-```
-
-2)String 类的 `.contentEquals()`
-
-`.contentEquals()` 的优势在于可以将字符串与任何的字符序列(StringBuffer、StringBuilder、String、CharSequence)进行比较。
-
-```java
-public boolean contentEquals(CharSequence cs) {
- // Argument is a StringBuffer, StringBuilder
- if (cs instanceof AbstractStringBuilder) {
- if (cs instanceof StringBuffer) {
- synchronized(cs) {
- return nonSyncContentEquals((AbstractStringBuilder)cs);
- }
- } else {
- return nonSyncContentEquals((AbstractStringBuilder)cs);
- }
- }
- // Argument is a String
- if (cs instanceof String) {
- return equals(cs);
- }
- // Argument is a generic CharSequence
- int n = cs.length();
- if (n != length()) {
- return false;
- }
- byte[] val = this.value;
- if (isLatin1()) {
- for (int i = 0; i < n; i++) {
- if ((val[i] & 0xff) != cs.charAt(i)) {
- return false;
- }
- }
- } else {
- if (!StringUTF16.contentEquals(val, cs, n)) {
- return false;
- }
- }
- return true;
-}
-```
-
-从源码上可以看得出,如果 cs 是 StringBuffer,该方法还会进行同步,非常的智能化;如果是 String 的话,其实调用的还是 `equals()` 方法。当然了,这也就意味着使用该方法进行比较的时候,多出来了很多步骤,性能上有些损失。
-
-同样来看一下 JDK 8 的源码:
-
-```java
-public boolean contentEquals(CharSequence cs) {
- // argument can be any CharSequence implementation
- if (cs.length() != value.length) {
- return false;
- }
- // Argument is a StringBuffer, StringBuilder or String
- if (cs instanceof AbstractStringBuilder) {
- char v1[] = value;
- char v2[] = ((AbstractStringBuilder)cs).getValue();
- int i = 0;
- int n = value.length;
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- // Argument is a String
- if (cs.equals(this))
- return true;
- // Argument is a non-String, non-AbstractStringBuilder CharSequence
- char v1[] = value;
- int i = 0;
- int n = value.length;
- while (n-- != 0) {
- if (v1[i] != cs.charAt(i))
- return false;
- i++;
- }
- return true;
-}
-```
-
-同样更容易理解一些:首先判断参数长度是否相等,不相等则返回 false。如果参数是 AbstractStringBuilder 的实例,则取出其 char 数组,遍历比较两个 char 数组的每个元素是否相等。如果参数是 String 的实例,则直接调用 equals 方法比较两个字符串是否相等。如果参数是其他实现了 CharSequence 接口的对象,则遍历比较两个对象的每个字符是否相等。
-
-“是的,总体上感觉还是 `Objects.equals()` 比较舒服。”三妹的眼睛是雪亮的,发现了这个方法的优点。
-
-
-
-## 4.10 String拼接
-
-“哥,你让我看的《[Java 开发手册](https://tobebetterjavaer.com/pdf/ali-java-shouce.html)》上有这么一段内容:循环体内,拼接字符串最好使用 StringBuilder 的 `append()` 方法,而不是 + 号操作符。这是为什么呀?”三妹疑惑地问。
-
-“其实这个问题,我们之前已经[聊过](https://tobebetterjavaer.com/string/builder-buffer.html)。”我慢吞吞地回答道,“不过,三妹,哥今天来给你深入地讲讲。”
-
-PS:三妹能在学习的过程中不断地发现问题,让我感到非常的开心。其实很多时候,我们不应该只是把知识点记在心里,还应该问一问自己,到底是为什么,只有迈出去这一步,才能真正的成长起来。
-
-### javap 探究+号操作符拼接字符串的本质
-
-“+ 号操作符其实被 Java 在编译的时候重新解释了,换一种说法就是,+ 号操作符是一种语法糖,让字符串的拼接变得更简便了。”一边给三妹解释,我一边在 Intellij IDEA 中敲出了下面这段代码。
-
-```java
-class Demo {
- public static void main(String[] args) {
- String chenmo = "沉默";
- String wanger = "王二";
- System.out.println(chenmo + wanger);
- }
-}
-```
-
-在 Java 8 的环境下,使用 `javap -c Demo.class` 反编译字节码后,可以看到以下内容:
-
-```
-Compiled from "Demo.java"
-class Demo {
- Demo();
- Code:
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."":()V
- 4: return
-
- public static void main(java.lang.String[]);
- Code:
- 0: ldc #2 // String 沉默
- 2: astore_1
- 3: ldc #3 // String 王二
- 5: astore_2
- 6: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
- 9: new #5 // class java/lang/StringBuilder
- 12: dup
- 13: invokespecial #6 // Method java/lang/StringBuilder."":()V
- 16: aload_1
- 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 20: aload_2
- 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
- 27: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
- 30: return
-}
-```
-
-“你看,三妹,这里有一个 new 关键字,并且 class 类型为 `java/lang/StringBuilder`。”我指着标号为 9 的那行对三妹说,“这意味着新建了一个 StringBuilder 的对象。”
-
-“然后看标号为 17 的这行,是一个 invokevirtual 指令,用于调用对象的方法,也就是 StringBuilder 对象的 `append()` 方法。”
-
-“也就意味着把 chenmo("沉默")这个字符串添加到 StringBuilder 对象中了。”
-
-“再往下看,标号为 21 的这行,又调用了一次 `append()` 方法,意味着把 wanger("王二")这个字符串添加到 StringBuilder 对象中了。”
-
-换成 Java 代码来表示的话,大概是这个样子:
-
-```java
-class Demo {
- public static void main(String[] args) {
- String chenmo = "沉默";
- String wanger = "王二";
- System.out.println((new StringBuilder(chenmo)).append(wanger).toString());
- }
-}
-```
-
-“哦,原来编译的时候把“+”号操作符替换成了 StringBuilder 的 `append()` 方法啊。”三妹恍然大悟。
-
-“是的,不过到了 Java 9(不是长期支持版本,所以我会拿 Java 11 来演示),情况发生了一些改变,同样的代码,字节码指令完全不同了。”我说。
-
-同样的代码,在 Java 11 的环境下,字节码指令是这样的:
-
-```
-Compiled from "Demo.java"
-public class com.itwanger.thirtyseven.Demo {
- public com.itwanger.thirtyseven.Demo();
- Code:
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."":()V
- 4: return
-
- public static void main(java.lang.String[]);
- Code:
- 0: ldc #2 // String
- 2: astore_1
- 3: iconst_0
- 4: istore_2
- 5: iload_2
- 6: bipush 10
- 8: if_icmpge 41
- 11: new #3 // class java/lang/String
- 14: dup
- 15: ldc #4 // String 沉默
- 17: invokespecial #5 // Method java/lang/String."":(Ljava/lang/String;)V
- 20: astore_3
- 21: ldc #6 // String 王二
- 23: astore 4
- 25: aload_1
- 26: aload_3
- 27: aload 4
- 29: invokedynamic #7, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
- 34: astore_1
- 35: iinc 2, 1
- 38: goto 5
- 41: return
-}
-```
-
-看标号为 29 的这行,字节码指令为 `invokedynamic`,该指令允许由应用级的代码来决定方法解析,所谓的应用级的代码其实是一个方法——被称为引导方法(Bootstrap Method),简称 BSM,BSM 会返回一个 CallSite(调用点) 对象,这个对象就和 `invokedynamic` 指令链接在一起。以后再执行这条 `invokedynamic` 指令时就不会创建新的 CallSite 对象。CallSite 其实就是一个 MethodHandle(方法句柄)的 holder,指向一个调用点真正执行的方法——此时就是 `StringConcatFactory.makeConcatWithConstants()` 方法。
-
-“哥,你别再说了,再说我就听不懂了。”三妹打断了我的话。
-
-“好吧,总之就是 Java 9 以后,JDK 用了另外一种方法来动态解释 + 号操作符,具体的实现方式在字节码指令层面已经看不到了,所以我就以 Java 8 来继续讲解吧。”
-
-### 为什么要编译为 StringBuilder.append
-
-“再回到《Java 开发手册》上的那段内容:循环体内,拼接字符串最好使用 StringBuilder 的 `append()` 方法,而不是 + 号操作符。原因就在于循环体内如果用 + 号操作符的话,就会产生大量的 StringBuilder 对象,不仅占用了更多的内存空间,还会让 Java 虚拟机不停的进行垃圾回收,从而降低了程序的性能。”
-
-更好的写法就是在循环的外部新建一个 StringBuilder 对象,然后使用 `append()` 方法将循环体内的字符串添加进来:
-
-```java
-class Demo {
- public static void main(String[] args) {
- StringBuilder sb = new StringBuilder();
- for (int i = 1; i < 10; i++) {
- String chenmo = "沉默";
- String wanger = "王二";
- sb.append(chenmo);
- sb.append(wanger);
- }
- System.out.println(sb);
- }
-}
-```
-
-来做个小测试。
-
-第一个,for 循环中使用”+”号操作符。
-
-```java
-String result = "";
-for (int i = 0; i < 100000; i++) {
- result += "六六六";
-}
-```
-
-第二个,for 循环外部新建 StringBuilder,循环体内使用 `append()` 方法。
-
-```java
-StringBuilder sb = new StringBuilder();
-for (int i = 0; i < 100000; i++) {
- sb.append("六六六");
-}
-```
-
-“这两个小测试分别会耗时多长时间呢?三妹你来运行下。”
-
-“哇,第一个小测试的执行时间是 6212 毫秒,第二个只用了不到 1 毫秒,差距也太大了吧!”三妹说。
-
-“是的,这下明白了原因吧?”我说。
-
-“是的,哥,原来如此。”
-
-### append方法源码解析
-
-“好了,三妹,来看一下 StringBuilder 类的 `append()` 方法的源码吧!”
-
-```java
-public StringBuilder append(String str) {
- super.append(str);
- return this;
-}
-```
-
-这 3 行代码其实没啥看的。我们来看父类 AbstractStringBuilder 的 `append()` 方法:
-
-```java
-public AbstractStringBuilder append(String str) {
- if (str == null)
- return appendNull();
- int len = str.length();
- ensureCapacityInternal(count + len);
- str.getChars(0, len, value, count);
- count += len;
- return this;
-}
-```
-
-1)判断拼接的字符串是不是 null,如果是,当做字符串“null”来处理。`appendNull()` 方法的源码如下:
-
-```java
-private AbstractStringBuilder appendNull() {
- int c = count;
- ensureCapacityInternal(c + 4);
- final char[] value = this.value;
- value[c++] = 'n';
- value[c++] = 'u';
- value[c++] = 'l';
- value[c++] = 'l';
- count = c;
- return this;
-}
-```
-
-2)获取字符串的长度。
-
-3)`ensureCapacityInternal()` 方法的源码如下:
-
-```java
-private void ensureCapacityInternal(int minimumCapacity) {
- // overflow-conscious code
- if (minimumCapacity - value.length > 0) {
- value = Arrays.copyOf(value,
- newCapacity(minimumCapacity));
- }
-}
-```
-
-由于字符串内部是用数组实现的,所以需要先判断拼接后的字符数组长度是否超过当前数组的长度,如果超过,先对数组进行扩容,然后把原有的值复制到新的数组中。
-
- 4)将拼接的字符串 str 复制到目标数组 value 中。
-
-```java
-str.getChars(0, len, value, count)
-```
-
-5)更新数组的长度 count。
-
-### String.concat 拼接字符串
-
-“除了可以使用 + 号操作符,StringBuilder 的 `append()` 方法,还有其他的字符串拼接方法吗?”三妹问。
-
-“有啊,比如说 String 类的 `concat()` 方法,有点像 StringBuilder 类的 `append()` 方法。”
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-System.out.println(chenmo.concat(wanger));
-```
-
-可以来看一下 `concat()` 方法的源码。
-
-```java
-public String concat(String str) {
- int otherLen = str.length();
- if (otherLen == 0) {
- return this;
- }
- int len = value.length;
- char buf[] = Arrays.copyOf(value, len + otherLen);
- str.getChars(buf, len);
- return new String(buf, true);
-}
-```
-
-1)如果拼接的字符串的长度为 0,那么返回拼接前的字符串。
-
-2)将原字符串的字符数组 value 复制到变量 buf 数组中。
-
-3)把拼接的字符串 str 复制到字符数组 buf 中,并返回新的字符串对象。
-
-我一行一行地给三妹解释着。
-
-“和 `+` 号操作符相比,`concat()` 方法在遇到字符串为 null 的时候,会抛出 NullPointerException,而“+”号操作符会把 null 当做是“null”字符串来处理。”
-
-如果拼接的字符串是一个空字符串(""),那么 concat 的效率要更高一点,毕竟不需要 `new StringBuilder` 对象。
-
-如果拼接的字符串非常多,`concat()` 的效率就会下降,因为创建的字符串对象越来越多。
-
-“还有吗?”三妹似乎对字符串拼接很感兴趣。
-
-“有,当然有。”
-
-### String.join 拼接字符串
-
-String 类有一个静态方法 `join()`,可以这样来使用。
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-String cmower = String.join("", chenmo, wanger);
-System.out.println(cmower);
-```
-
-第一个参数为字符串连接符,比如说:
-
-```java
-String message = String.join("-", "王二", "太特么", "有趣了");
-```
-
-输出结果为:`王二-太特么-有趣了`。
-
-来看一下 join 方法的源码:
-
-```java
-public static String join(CharSequence delimiter, CharSequence... elements) {
- Objects.requireNonNull(delimiter);
- Objects.requireNonNull(elements);
- // Number of elements not likely worth Arrays.stream overhead.
- StringJoiner joiner = new StringJoiner(delimiter);
- for (CharSequence cs: elements) {
- joiner.add(cs);
- }
- return joiner.toString();
-}
-```
-
-里面新建了一个叫 StringJoiner 的对象,然后通过 for-each 循环把可变参数添加了进来,最后调用 `toString()` 方法返回 String。
-
-### StringUtils.join 拼接字符串
-
-“实际的工作中,`org.apache.commons.lang3.StringUtils` 的 `join()` 方法也经常用来进行字符串拼接。”
-
-```java
-String chenmo = "沉默";
-String wanger = "王二";
-StringUtils.join(chenmo, wanger);
-```
-
-该方法不用担心 NullPointerException。
-
-```java
-StringUtils.join(null) = null
-StringUtils.join([]) = ""
-StringUtils.join([null]) = ""
-StringUtils.join(["a", "b", "c"]) = "abc"
-StringUtils.join([null, "", "a"]) = "a"
-```
-
-来看一下源码:
-
-```java
-public static String join(final Object[] array, String separator, final int startIndex, final int endIndex) {
- if (array == null) {
- return null;
- }
- if (separator == null) {
- separator = EMPTY;
- }
-
- final StringBuilder buf = new StringBuilder(noOfItems * 16);
-
- for (int i = startIndex; i < endIndex; i++) {
- if (i > startIndex) {
- buf.append(separator);
- }
- if (array[i] != null) {
- buf.append(array[i]);
- }
- }
- return buf.toString();
-}
-```
-
-内部使用的仍然是 StringBuilder。
-
-“好了,三妹,关于字符串拼接的知识点我们就讲到这吧。注意 Java 9 以后,对 + 号操作符的解释和之前发生了变化,字节码指令已经不同了,等后面你学了[字节码指令](https://tobebetterjavaer.com/jvm/zijiema-zhiling.html)后我们再详细地讲一次。”我说。
-
-“嗯,哥,你休息吧,我把这些例子再重新跑一遍。”三妹说。
-
-
-
-## 4.11 String拆分
-
-“哥,我感觉字符串拆分没什么可讲的呀,直接上 String 类的 `split()` 方法不就可以了!”三妹毫不客气地说。
-
-“假如你真的这么觉得,那可要注意了,事情远没这么简单。”我微笑着说。
-
-假如现在有这样一串字符序列“沉默王二,一枚有趣的程序员”,需要按照中文逗号“,”进行拆分,这意味着第一串字符序列为逗号前面的“沉默王二”,第二串字符序列为逗号后面的“一枚有趣的程序员”。
-
-“这不等于没说吗?哥!”还没等我说,三妹就打断了我。
-
-“别着急嘛,等哥说完。”我依然保持着微笑继续说,“在拆分之前,要先进行检查,判断一下这串字符是否包含逗号,否则应该抛出异常。”
-
-```java
-public class Test {
- public static void main(String[] args) {
- String cmower = "沉默王二,一枚有趣的程序员";
- if (cmower.contains(",")) {
- String [] parts = cmower.split(",");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
- } else {
- throw new IllegalArgumentException("当前字符串没有包含逗号");
- }
- }
-}
-```
-
-“三妹你看,这段代码挺严谨的吧?”我说,“来看一下程序的输出结果。”
-
-```
-第一部分:沉默王二 第二部分:一枚有趣的程序员
-```
-
-“的确和预期完全一致。”三妹说。
-
-“这是建立在字符串是确定的情况下,最重要的是分隔符是确定的。否则,麻烦就来了。”我说,“大约有 12 种英文特殊符号,如果直接拿这些特殊符号替换上面代码中的分隔符(中文逗号),这段程序在运行的时候就会出现以下提到的错误。”
-
-
-- 反斜杠 `\`(ArrayIndexOutOfBoundsException)
-- 插入符号 `^`(同上)
-- 美元符号 `$`(同上)
-- 逗点 `.`(同上)
-- 竖线 `|`(正常,没有出错)
-- 问号 `?`(PatternSyntaxException)
-- 星号 `*`(同上)
-- 加号 `+`(同上)
-- 左小括号或者右小括号 `()`(同上)
-- 左方括号或者右方括号 `[]`(同上)
-- 左大括号或者右大括号 `{}`(同上)
-
-“那遇到这些特殊符号该怎么办呢?”三妹问。
-
-“用正则表达式。”我说,“正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。”
-
-我在 GitHub 上找打了一个开源的正则表达式学习文档,非常详细。一开始写正则表达式的时候难免会感觉到非常生疏,你可以查看一下这份文档。记不住没关系,遇到就查。
-
->[https://github.com/cdoco/learn-regex-zh](https://github.com/cdoco/learn-regex-zh)
-
-除了这份文档,还有一份:
-
->[https://github.com/cdoco/common-regex](https://github.com/cdoco/common-regex)
-
-作者收集了一些在平时项目开发中经常用到的正则表达式,可以直接拿来用。
-
-“哥,你真周到。”三妹笑着说。
-
-“好了,来用英文逗点 `.` 替换一下分隔符。”我说。
-
-```java
-String cmower = "沉默王二.一枚有趣的程序员";
-if (cmower.contains(".")) {
- String [] parts = cmower.split("\\.");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-由于英文逗点属于特殊符号,所以在使用 `split()` 方法的时候,就需要使用正则表达式 `\\.` 而不能直接使用 `.`。
-
-“为什么用两个反斜杠呢?”三妹问。
-
-“因为反斜杠本身就是一个特殊字符,需要用反斜杠来转义。”我说。
-
-当然了,你也可以使用 `[]` 来包裹住英文逗点“.”,`[]` 也是一个正则表达式,用来匹配方括号中包含的任意字符。
-
-```java
-cmower.split("[.]");
-```
-
-除此之外, 还可以使用 Pattern 类的 `quote()` 方法来包裹英文逗点“.”,该方法会返回一个使用 `\Q\E` 包裹的字符串。
-
-
-
-来看示例:
-
-```java
-String [] parts = cmower.split(Pattern.quote("."));
-```
-
-当 `split()` 方法的参数是正则表达式的时候,方法最终会执行下面这行代码:
-
-```java
-return Pattern.compile(regex).split(this, limit);
-```
-
-也就意味着,拆分字符串有了新的选择,可以不使用 String 类的 `split()` 方法,直接用下面的方式。
-
-```java
-public class TestPatternSplit {
- private static Pattern twopart = Pattern.compile("\\.");
-
- public static void main(String[] args) {
- String [] parts = twopart.split("沉默王二.一枚有趣的程序员");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
- }
-}
-```
-
-“为什么要把 Pattern 表达式声明称 static 的呢?”三妹问。
-
-“由于模式是确定的,通过 static 的预编译功能可以提高程序的效率。”我说,“除此之外,还可以使用 Pattern 配合 Matcher 类进行字符串拆分,这样做的好处是可以对要拆分的字符串进行一些严格的限制,来看这段示例代码。”
-
-```java
-public class TestPatternMatch {
- /**
- * 使用预编译功能,提高效率
- */
- private static Pattern twopart = Pattern.compile("(.+)\\.(.+)");
-
- public static void main(String[] args) {
- checkString("沉默王二.一枚有趣的程序员");
- checkString("沉默王二.");
- checkString(".一枚有趣的程序员");
- }
-
- private static void checkString(String str) {
- Matcher m = twopart.matcher(str);
- if (m.matches()) {
- System.out.println("第一部分:" + m.group(1) + " 第二部分:" + m.group(2));
- } else {
- System.out.println("不匹配");
- }
- }
-}
-```
-
-正则表达式 `(.+)\\.(.+)` 的意思是,不仅要把字符串按照英文标点的方式拆成两部分,并且英文逗点的前后要有内容。
-
-来看一下程序的输出结果:
-
-```java
-第一部分:沉默王二 第二部分:一枚有趣的程序员
-不匹配
-不匹配
-```
-
-不过,使用 Matcher 来匹配一些简单的字符串时相对比较沉重一些,使用 String 类的 `split()` 仍然是首选,因为该方法还有其他一些牛逼的功能。比如说,如果你想把分隔符包裹在拆分后的字符串的第一部分,可以这样做:
-
-```java
-String cmower = "沉默王二,一枚有趣的程序员";
-if (cmower.contains(",")) {
- String [] parts = cmower.split("(?<=,)");
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-程序输出的结果如下所示:
-
-```
-第一部分:沉默王二, 第二部分:一枚有趣的程序员
-```
-
-可以看到分隔符“,”包裹在了第一部分,如果希望包裹在第二部分,可以这样做:
-
-```java
-String [] parts = cmower.split("(?=,)");
-```
-
-“`?<=` 和 `?=` 是什么东东啊?”三妹好奇地问。
-
-“它其实是正则表达式中的断言模式。”我说,“你有时间的话,可以看看前面我推荐的两份开源文档。”
-
-
-
-“`split()` 方法可以传递 2 个参数,第一个为分隔符,第二个为拆分的字符串个数。”我说。
-
-```java
-String cmower = "沉默王二,一枚有趣的程序员,宠爱他";
-if (cmower.contains(",")) {
- String [] parts = cmower.split(",", 2);
- System.out.println("第一部分:" + parts[0] +" 第二部分:" + parts[1]);
-}
-```
-
-进入 debug 模式的话,可以看到以下内容:
-
-
-
-也就是说,传递 2 个参数的时候,会直接调用 `substring()` 进行截取,第二个分隔符后的就不再拆分了。
-
-来看一下程序输出的结果:
-
-```
-第一部分:沉默王二 第二部分:一枚有趣的程序员,宠爱他
-```
-
-“没想到啊,这个字符串拆分还挺讲究的呀!”三妹感慨地说。
-
-“是的,其实字符串拆分在实际的工作当中还是挺经常用的。前端经常会按照规则传递一长串字符序列到后端,后端就需要按照规则把字符串拆分再做处理。”我说。
-
-“嗯,我把今天的内容温习下,二哥,你休息会。”三妹说。
-
----
-
-GitHub 上标星 7600+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 7600+ 的 Java 教程](https://tobebetterjavaer.com/overview/)
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
-
-# 第五章:面向对象编程
-
-# 5.1 Java中的类和对象
-
-#“二哥,那天我在图书馆复习《Java进阶之路》的时候,刚好碰见一个学长,他问我有没有‘对象’,我说还没有啊。结果你猜他说什么,‘要不要我给你 new 一个啊?’我当时就懵了,new 是啥意思啊,二哥?”三妹满是疑惑的问我。
-
-“哈哈,三妹,你学长还挺幽默啊。new 是 Java 中的一个关键字,用来把类变成对象。”我笑着对三妹说,“对象和类是 Java 中最基本的两个概念,可以说撑起了面向对象编程(OOP)的一片天。”
-
-### 01、面向过程和面向对象
-
-三妹是不是要问,什么是 OOP?
-
-OOP 的英文全称是 Object Oriented Programming,要理解它的话,就要先理解面向对象,要想理解面向对象的话,就要先理解面向过程,因为一开始没有面向对象的编程语言,都是面向过程。
-
-举个简单点的例子来区分一下面向过程和面向对象。
-
-有一天,你想吃小碗汤了,怎么办呢?有两个选择:
-
-1)自己买食材,豆腐皮啊、肉啊、蒜苔啊等等,自己动手做。
-
-2)到饭店去,只需要对老板喊一声,“来份小碗汤。”
-
-第一种就是面向过程,第二种就是面向对象。
-
-面向过程有什么劣势呢?假如你买了小碗汤的食材,临了又想吃宫保鸡丁了,你是不是还得重新买食材?
-
-面向对象有什么优势呢?假如你不想吃小碗汤了,你只需要对老板说,“我那个小碗汤如果没做的话,换成宫保鸡丁吧!”
-
-面向过程是流程化的,一步一步,上一步做完了,再做下一步。
-
-面向对象是模块化的,我做我的,你做你的,我需要你做的话,我就告诉你一声。我不需要知道你到底怎么做,只看功劳不看苦劳。
-
-不过,如果追到底的话,面向对象的底层其实还是面向过程,只不过把面向过程进行了抽象化,封装成了类,方便我们的调用。
-
-### 02、类
-
-对象可以是现实中看得见的任何物体,比如说,一只特立独行的猪;也可以是想象中的任何虚拟物体,比如说能七十二变的孙悟空。
-
-Java 通过类(class)来定义这些物体,这些物体有什么状态,通过字段来定义,比如说比如说猪的颜色是纯色还是花色;这些物体有什么行为,通过方法来定义,比如说猪会吃,会睡觉。
-
-来,定义一个简单的类给你看看。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 2020/11/19
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {
- }
-
- private void sleep() {
- }
-
- private void dadoudou() {
- }
-}
-```
-
-一个类可以包含:
-
-- 字段(Filed)
-- 方法(Method)
-- 构造方法(Constructor)
-
-在 Person 类中,字段有 3 个,分别是 name、age 和 sex,它们也称为成员[变量](https://tobebetterjavaer.com/oo/var.html)——在类内部但在方法外部,方法内部的叫临时变量。
-
-成员变量有时候也叫做实例变量,在编译时不占用内存空间,在运行时获取内存,也就是说,只有在对象实例化(`new Person()`)后,字段才会获取到内存,这也正是它被称作“实例”变量的原因。
-
-[方法](https://tobebetterjavaer.com/oo/method.html)有 3 个,分别是 `eat()`、`sleep()` 和 `dadoudou()`,表示 Person 这个对象可以做什么,也就是吃饭睡觉打豆豆。
-
-那三妹是不是要问,“怎么没有[构造方法](https://tobebetterjavaer.com/oo/construct.html)呢?”
-
-的确在 Person 类的源码文件(.java)中没看到,但在反编译后的字节码文件(.class)中是可以看得到的。
-
-```java
-//
-// Source code recreated from a .class file by IntelliJ IDEA
-// (powered by Fernflower decompiler)
-//
-
-package com.itwanger.twentythree;
-
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public Person() {
- }
-
- private void eat() {
- }
-
- private void sleep() {
- }
-
- private void dadoudou() {
- }
-}
-```
-
-`public Person(){}` 就是默认的构造方法,因为是空的构造方法(方法体中没有内容),所以可以缺省。Java 聪明就聪明在这,有些很死板的代码不需要开发人员添加,它会偷偷地做了。
-
-### 03、new 一个对象
-
-创建 Java 对象时,需要用到 `new` 关键字。
-
-```java
-Person person = new Person();
-```
-
-这行代码就通过 Person 类创建了一个 Person 对象。所有**对象**在创建的时候都会在**堆内存中分配空间**。
-
-创建对象的时候,需要一个 `main()` 方法作为入口, `main()` 方法可以在当前类中,也可以在另外一个类中。
-
-第一种:`main()` 方法直接放在 Person 类中。
-
-```java
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {}
- private void sleep() {}
- private void dadoudou() {}
-
- public static void main(String[] args) {
- Person person = new Person();
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-null
-0
-0
-```
-
-第二种:`main()` 方法不在 Person 类中,而在另外一个类中。
-
-
-
-实际开发中,我们通常不在当前类中直接创建对象并使用它,而是放在使用对象的类中,比如说上图中的 PersonTest 类。
-
-可以把 PersonTest 类和 Person 类放在两个文件中,也可以放在一个文件(命名为 PersonTest.java)中,就像下面这样。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class PersonTest {
- public static void main(String[] args) {
- Person person = new Person();
- }
-}
-
-class Person {
- private String name;
- private int age;
- private int sex;
-
- private void eat() {}
- private void sleep() {}
- private void dadoudou() {}
-}
-```
-
-### 04、初始化对象
-
-在之前的例子中,程序输出结果为:
-
-```
-null
-0
-0
-```
-
-为什么会有这样的输出结果呢?因为 Person 对象没有初始化,因此输出了 String 的默认值 null,int 的默认值 0。
-
-那怎么初始化 Person 对象(对字段赋值)呢?
-
-#### 第一种:通过对象的引用变量。
-
-```java
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public static void main(String[] args) {
- Person person = new Person();
- person.name = "沉默王二";
- person.age = 18;
- person.sex = 1;
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-person 被称为对象 Person 的引用变量,见下图:
-
-
-
-通过对象的引用变量,可以直接对字段进行初始化(`person.name = "沉默王二"`),所以以上代码输出结果如下所示:
-
-```
-沉默王二
-18
-1
-```
-
-#### 第二种:通过方法初始化。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public void initialize(String n, int a, int s) {
- name = n;
- age = a;
- sex = s;
- }
-
- public static void main(String[] args) {
- Person person = new Person();
- person.initialize("沉默王二",18,1);
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-在 Person 类中新增方法 `initialize()`,然后在新建对象后传参进行初始化(`person.initialize("沉默王二", 18, 1)`)。
-
-#### 第三种:通过构造方法初始化。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public Person(String name, int age, int sex) {
- this.name = name;
- this.age = age;
- this.sex = sex;
- }
-
- public static void main(String[] args) {
- Person person = new Person("沉默王二", 18, 1);
-
- System.out.println(person.name);
- System.out.println(person.age);
- System.out.println(person.sex);
- }
-}
-```
-
-这也是最标准的一种做法,直接在 new 的时候把参数传递过去。
-
-补充一点知识,匿名对象。匿名对象意味着没有引用变量,它只能在创建的时候被使用一次。
-
-```java
-new Person();
-```
-
-可以直接通过匿名对象调用方法:
-
-```java
-new Person().initialize("沉默王二", 18, 1);
-```
-
-### 05、关于对象
-
-#### **1)抽象的历程**
-
-所有编程语言都是一种抽象,甚至可以说,我们能够解决的问题的复杂程度取决于抽象的类型和质量。
-
-Smalltalk 是历史上第一门获得成功的面向对象语言,也为 Java 提供了灵感。它有 5 个基本特征:
-
-- 万物皆对象。
-- 一段程序实际上就是多个对象通过发送消息的方式来告诉彼此该做什么。
-- 通过组合的方式,可以将多个对象封装成其他更为基础的对象。
-- 对象是通过类实例化的。
-- 同一类型的对象可以接收相同的消息。
-
-总结一句话就是:
-
->状态+行为+标识=对象,每个对象在内存中都会有一个唯一的地址。
-
-#### **2)对象具有接口**
-
-所有的对象,都可以被归为一类,并且同一类对象拥有一些共同的行为和特征。在 Java 中,class 关键字用来定义一个类型。
-
-创建抽象数据类型是面向对象编程的一个基本概念。你可以创建某种类型的变量,Java 中称之为对象或者实例,然后你就可以操作这些变量,Java 中称之为发送消息或者发送请求,最后对象决定自己该怎么做。
-
-类描述了一系列具有相同特征和行为的对象,从宽泛的概念上来说,类其实就是一种自定义的数据类型。
-
-一旦创建了一个类,就可以用它创建任意多个对象。面向对象编程语言遇到的最大一个挑战就是,如何把现实/虚拟的元素抽象为 Java 中的对象。
-
-对象能够接收什么样的请求是由它的[接口](https://tobebetterjavaer.com/oo/interface.html)定义的。具体是怎么做到的,就由它的实现方法来实现。
-
-#### **3)访问权限修饰符**
-
-类的创建者有时候也被称为 API 提供者,对应的,类的使用者就被称为 API 调用者。
-
-JDK 就给我们提供了 Java 的基础实现,JDK 的作者也就是基础 API 的提供者(Java 多线程部分的作者 Doug Lea 是被 Java 程序员敬佩的一个大佬),我们这些 Java 语言的使用者,说白了就是 JDK 的调用者。
-
-
-
-当然了,假如我们也提供了新的类给其他调用者,我们也就成为了新的创建者。
-
-API 创建者在创建新的类的时候,只暴露必要的接口,而隐藏其他所有不必要的信息,之所以要这么做,是因为如果这些信息对调用者是不可见的,那么创建者就可以随意修改隐藏的信息,而不用担心对调用者的影响。
-
-这里就必须要讲到 [Java 的权限修饰符](https://tobebetterjavaer.com/oo/access-control.html)。
-
-访问权限修饰符的第一个作用是,防止类的调用者接触到他们不该接触的内部实现;第二个作用是,让类的创建者可以轻松修改内部机制而不用担心影响到调用者的使用。
-
-- public
-- private
-- protected
-
-还有一种“默认”的权限修饰符,是缺省的,它修饰的类可以访问同一个包下面的其他类。
-
-#### **4)组合**
-
-我们可以把一个创建好的类作为另外一个类的成员变量来使用,利用已有的类组成成一个新的类,被称为“复用”,组合代表的关系是 has-a 的关系。
-
-#### **5)继承**
-
-[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html)是 Java 中非常重要的一个概念,子类继承父类,也就拥有了父类中 protected 和 public 修饰的方法和字段,同时,子类还可以扩展一些自己的方法和字段,也可以重写继承过来方法。
-
-常见的例子,就是形状可以有子类圆形、方形、三角形,它们的基础接口是相同的,比如说都有一个 `draw()` 的方法,子类可以继承这个方法实现自己的绘制方法。
-
-如果子类只是重写了父类的方法,那么它们之间的关系就是 is-a 的关系,但如果子类增加了新的方法,那么它们之间的关系就变成了 is-like-a 的关系。
-
-#### **6)多态**
-
-比如说有一个父类Shape
-
-```java
-public class Shape {
- public void draw() {
- System.out.println("形状");
- }
-}
-```
-
-子类Circle
-
-```java
-public class Circle extends Shape{
- @Override
- public void draw() {
- System.out.println("圆形");
- }
-}
-```
-
-子类Line
-
-```java
-public class Line extends Shape {
- @Override
- public void draw() {
- System.out.println("线");
- }
-}
-```
-
-测试类
-
-```java
-public class Test {
- public static void main(String[] args) {
- Shape shape1 = new Line();
- shape1.draw();
- Shape shape2 = new Circle();
- shape2.draw();
- }
-}
-```
-
-运行结果:
-
-```
-线
-圆形
-```
-
-在测试类中,shape1 的类型为 Shape,shape2 的类型也为 Shape,但调用 `draw()` 方法后,却能自动调用子类 Line 和 Circle 的 `draw()` 方法,这是为什么呢?
-
-其实就是 Java 中的[多态](https://tobebetterjavaer.com/oo/polymorphism.html)。
-
-### 06、小结
-
-“怎么样,三妹,是不是对 Java 有了更深入更清晰的理解?”终于讲完了,我深呼了一口气,好舒畅啊!
-
-“是的,哥,感觉 Java 也就那么回事嘛。”哎呀,三妹有点狂了起来,“万物皆对象,除了基本数据类型。”
-
-“哇,三妹,你可以啊,都会自己梳理总结了。”我倍感欣慰,觉得果然是劳有所获,你讲的认真,听众就能理解和 get,满足了。
-
-## 5.2 Java中的包
-
-“三妹,这一节,我们简单过一下 Java 中的包,也就是 package,这个一点就透,很好掌握。”我放下手中的雪碧,翻开笔记本,登上 GitHub,点开《二哥的 Java 进阶之路》,找到这篇「Java 中的包」,开始滔滔不绝起来。
-
-“二哥,你等一下。”让我打开思维导图做一下笔记📒。
-
-### 关于包
-
-在前面的代码中,我们把类和接口命名为`Person`、`Student`、`Hello`等简单的名字。
-
-在团队开发中,如果小明写了一个`Person`类,小红也写了一个`Person`类,现在,小白既想用小明的`Person`,也想用小红的`Person`,怎么办?
-
-如果小军写了一个`Arrays`类,恰好 JDK 也自带了一个`Arrays`类,如何解决类名冲突?
-
-在 Java 中,我们使用`package`来解决名字冲突。
-
-Java 定义了一种名字空间,称之为包:`package`。一个类总是属于某个包,类名(比如`Person`)只是一个简写,真正的完整类名是`包名.类名`。
-
-例如:
-
-小明的`Person`类存放在包`ming`下面,因此,完整类名是`ming.Person`;
-
-小红的`Person`类存放在包`hong`下面,因此,完整类名是`hong.Person`;
-
-小军的`Arrays`类存放在包`mr.jun`下面,因此,完整类名是`mr.jun.Arrays`;
-
-JDK 的`Arrays`类存放在包`java.util`下面,因此,完整类名是`java.util.Arrays`。
-
-在定义`class`的时候,我们需要在第一行声明这个`class`属于哪个包。
-
-小明的`Person.java`文件:
-
-```java
-package ming; // 申明包名ming
-
-public class Person {
-}
-```
-
-小军的`Arrays.java`文件:
-
-```java
-package mr.jun; // 申明包名mr.jun
-
-public class Arrays {
-}
-```
-
-在 Java 虚拟机执行的时候,JVM 只看完整类名,因此,只要包名不同,类就不同。
-
-包可以是多层结构,用`.`隔开。例如:`java.util`。
-
-
->要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系。
-
-
-没有定义包名的`class`,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
-
-我们还需要按照包结构把上面的 Java 文件组织起来。假设以`package_sample`作为根目录,`src`作为源码目录,那么所有文件结构就是:
-
-```ascii
-package_sample
-└─ src
- ├─ hong
- │ └─ Person.java
- │ ming
- │ └─ Person.java
- └─ mr
- └─ jun
- └─ Arrays.java
-```
-
-即所有 Java 文件对应的目录层次要和包的层次一致。
-
-编译后的`.class`文件也需要按照包结构存放。如果使用 IDE,把编译后的`.class`文件放到`bin`目录下,那么,编译的文件结构就是:
-
-```ascii
-package_sample
-└─ bin
- ├─ hong
- │ └─ Person.class
- │ ming
- │ └─ Person.class
- └─ mr
- └─ jun
- └─ Arrays.class
-```
-
-编译的命令相对比较复杂,我们需要在`src`目录下执行`javac`命令:
-
-```
-javac -d ../bin ming/Person.java hong/Person.java mr/jun/Arrays.java
-```
-
-在 IDE 中,会自动根据包结构编译所有 Java 源码,所以不必担心使用命令行编译的复杂命令。
-
-### 包的作用域
-
-位于同一个包的类,可以访问包作用域的字段和方法。
-
-不用`public`、`protected`、`private`修饰的字段和方法就是包作用域。例如,`Person`类定义在`hello`包下面:
-
-```java
-package hello;
-
-public class Person {
- // 包作用域:
- void hello() {
- System.out.println("Hello!");
- }
-}
-```
-
-`Main`类也定义在`hello`包下面,就可以直接访问 Person 类:
-
-```java
-package hello;
-
-public class Main {
- public static void main(String[] args) {
- Person p = new Person();
- p.hello(); // 可以调用,因为Main和Person在同一个包
- }
-}
-```
-
-### 导入包
-
-在一个`class`中,我们总会引用其他的`class`。例如,小明的`ming.Person`类,如果要引用小军的`mr.jun.Arrays`类,他有三种写法:
-
-第一种,直接写出完整类名,例如:
-
-```java
-// Person.java
-package ming;
-
-public class Person {
- public void run() {
- mr.jun.Arrays arrays = new mr.jun.Arrays();
- }
-}
-```
-
-很显然,每次都要写完整的类名比较痛苦。
-
-因此,第二种写法是用`import`语句,导入小军的`Arrays`,然后写简单类名:
-
-```java
-// Person.java
-package ming;
-
-// 导入完整类名:
-import mr.jun.Arrays;
-
-public class Person {
- public void run() {
- Arrays arrays = new Arrays();
- }
-}
-```
-
-在写`import`的时候,可以使用`*`,表示把这个包下面的所有`class`都导入进来(但不包括子包的`class`):
-
-```java
-// Person.java
-package ming;
-
-// 导入mr.jun包的所有class:
-import mr.jun.*;
-
-public class Person {
- public void run() {
- Arrays arrays = new Arrays();
- }
-}
-```
-
-我们一般不推荐这种写法,因为在导入了多个包后,很难看出`Arrays`类属于哪个包。
-
-还有一种`import static`的语法,它可以导入一个类的静态字段和静态方法:
-
-```java
-package main;
-
-// 导入System类的所有静态字段和静态方法:
-import static java.lang.System.*;
-
-public class Main {
- public static void main(String[] args) {
- // 相当于调用System.out.println(…)
- out.println("Hello, world!");
- }
-}
-```
-
-`import static`很少使用。
-
-Java 编译器最终编译出的`.class`文件只使用 *完整类名*,因此,在代码中,当编译器遇到一个`class`名称时:
-
-- 如果是完整类名,就直接根据完整类名查找这个`class`;
-- 如果是简单类名,按下面的顺序依次查找:
- - 查找当前`package`是否存在这个`class`;
- - 查找`import`的包是否包含这个`class`;
- - 查找`java.lang`包是否包含这个`class`。
-
-如果按照上面的规则还无法确定类名,则编译报错。
-
-我们来看一个例子:
-
-```java
-// Main.java
-package test;
-
-import java.text.Format;
-
-public class Main {
- public static void main(String[] args) {
- java.util.List list; // ok,使用完整类名 -> java.util.List
- Format format = null; // ok,使用import的类 -> java.text.Format
- String s = "hi"; // ok,使用java.lang包的String -> java.lang.String
- System.out.println(s); // ok,使用java.lang包的System -> java.lang.System
- MessageFormat mf = null; // 编译错误:无法找到MessageFormat: MessageFormat cannot be resolved to a type
- }
-}
-```
-
-因此,编写 class 的时候,编译器会自动帮我们做两个 import 动作:
-
-- 默认自动`import`当前`package`的其他`class`;
-- 默认自动`import java.lang.*`。
-
-
->注意:自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入。
-
-
-如果有两个`class`名称相同,例如,`mr.jun.Arrays`和`java.util.Arrays`,那么只能`import`其中一个,另一个必须写完整类名。
-
-### 包的最佳实践
-
-为了避免名字冲突,我们需要确定唯一的包名。推荐的做法是使用倒置的域名来确保唯一性。例如:
-
-- org.apache
-- org.apache.commons.log
-- com.tobebetterjavaer.sample
-
-子包就可以根据功能自行命名。
-
-要注意不要和`java.lang`包的类重名,即自己的类不要使用这些名字:
-
-- String
-- System
-- Runtime
-- ...
-
-要注意也不要和 JDK 常用类重名:
-
-- java.util.List
-- java.text.Format
-- java.math.BigInteger
-- ...
-
-
-### 小结
-
-Java 内建的`package`机制是为了避免`class`命名冲突;
-
-JDK 的核心类使用`java.lang`包,编译器会自动导入;
-
-JDK 的其它常用类定义在`java.util.*`,`java.math.*`,`java.text.*`,……;
-
-包名推荐使用倒置的域名,例如`org.apache`。
-
----
-
-> 参考链接:[https://www.liaoxuefeng.com/wiki/1252599548343744/1260467032946976](https://www.liaoxuefeng.com/wiki/1252599548343744/1260467032946976),整理:沉默王二
-
-
-
-
-
-
-
-## 5.3 Java中的变量
-
-“二哥,听说 Java 变量在以后的日子里经常用,能不能提前给我透露透露?”三妹咪了一口麦香可可奶茶后对我说。
-
-“三妹啊,搬个凳子坐我旁边,听二哥来给你慢慢说啊。”
-
-Java 变量就好像一个容器,可以保存程序在运行过程中的值,它在声明的时候会定义对应的[数据类型](https://tobebetterjavaer.com/basic-grammar/basic-data-type.html)(Java 分为两种数据类型:基本数据类型和引用数据类型)。变量按照作用域的范围又可分为三种类型:局部变量,成员变量和静态变量。
-
-比如说,`int data = 88;`,其中 data 就是一个变量,它的值为 88,类型为整型(int)。
-
-
-### 01、局部变量
-
-在方法体内声明的变量被称为局部变量,该变量只能在该方法内使用,类中的其他方法并不知道该变量。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class LocalVariable {
- public static void main(String[] args) {
- int a = 10;
- int b = 10;
- int c = a + b;
- System.out.println(c);
- }
-}
-```
-
-其中 a、b、c 就是局部变量,它们只能在当前这个 main 方法中使用。
-
-声明局部变量时的注意事项:
-
-- 局部变量声明在方法、构造方法或者语句块中。
-- 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,将会被销毁。
-- 访问修饰符不能用于局部变量。
-- 局部变量只在声明它的方法、构造方法或者语句块中可见。
-- 局部变量是在栈上分配的。
-- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
-
-### 02、成员变量
-
-在类内部但在方法体外声明的变量称为成员变量,或者实例变量,或者字段。之所以称为实例变量,是因为该变量只能通过类的实例(对象)来访问。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class InstanceVariable {
- int data = 88;
- public static void main(String[] args) {
- InstanceVariable iv = new InstanceVariable();
- System.out.println(iv.data); // 88
- }
-}
-```
-
-其中 iv 是一个变量,它是一个引用类型的变量。`new` 关键字可以创建一个类的实例(也称为对象),通过“=”操作符赋值给 iv 这个变量,iv 就成了这个对象的引用,通过 `iv.data` 就可以访问成员变量了。
-
-声明成员变量时的注意事项:
-
-- 成员变量声明在一个类中,但在方法、构造方法和语句块之外。
-- 当一个对象被实例化之后,每个成员变量的值就跟着确定。
-- 成员变量在对象创建的时候创建,在对象被销毁的时候销毁。
-- 成员变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息。
-- 成员变量可以声明在使用前或者使用后。
-- 访问修饰符可以修饰成员变量。
-- 成员变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把成员变量设为私有。通过使用访问修饰符可以使成员变量对子类可见;成员变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。
-
-### 03、静态变量
-
-通过 [static 关键字](https://tobebetterjavaer.com/oo/static.html)声明的变量被称为静态变量(类变量),它可以直接被类访问,来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class StaticVariable {
- static int data = 99;
- public static void main(String[] args) {
- System.out.println(StaticVariable.data); // 99
- }
-}
-```
-
-其中 data 就是静态变量,通过`类名.静态变量`就可以访问了,不需要创建类的实例。
-
-声明静态变量时的注意事项:
-
-- 静态变量在类中以 static 关键字声明,但必须在方法构造方法和语句块之外。
-- 无论一个类创建了多少个对象,类只拥有静态变量的一份拷贝。
-- 静态变量除了被声明为常量外很少使用。
-- 静态变量储存在静态存储区。
-- 静态变量在程序开始时创建,在程序结束时销毁。
-- 与成员变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为 public 类型。
-- 静态变量的默认值和实例变量相似。
-- 静态变量还可以在静态语句块中初始化。
-
-### 04、常量
-
-在 Java 中,有些数据的值是不会发生改变的,这些数据被叫做常量——使用 [final 关键字](https://tobebetterjavaer.com/oo/final.html)修饰的成员变量。常量的值一旦给定就无法改变!
-
-常量在程序运行过程中主要有 2 个作用:
-
-- 代表常数,便于修改(例如:圆周率的值,`final double PI = 3.14`)
-- 增强程序的可读性(例如:常量 UP、DOWN 用来代表上和下,`final int UP = 0`)
-
-Java 要求常量名必须大写。来看下面这个示例:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class FinalVariable {
- final String CHEN = "沉";
- static final String MO = "默";
- public static void main(String[] args) {
- FinalVariable fv = new FinalVariable();
- System.out.println(fv.CHEN);
- System.out.println(MO);
- }
-}
-```
-
-“好了,三妹,关于 Java 变量就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
-
-“是啊,二哥,我想以后还会再见到它们吧?”
-
-“那见的次数可就多了,就好像你每天眨眼的次数一样多。”
-
-
-## 5.4 Java中的方法
-
-“二哥,这一节我们学什么呢?”三妹满是期待的问我。
-
-“这一节我们来了解一下 Java 中的方法——什么是方法?如何声明方法?方法有哪几种?什么是实例方法?什么是静态方法?什么是抽象方法?什么是本地方法?”我笑着对三妹说,“我开始了啊,你要注意力集中啊。”
-
-### 01、Java中的方法是什么?
-
-方法用来实现代码的可重用性,我们编写一次方法,并多次使用它。通过增加或者删除方法中的一部分代码,就可以提高整体代码的可读性。
-
-只有方法被调用时,它才会执行。Java 中最有名的方法当属 `main()` 方法,这是程序的入口。
-
-### 02、如何声明方法?
-
-方法的声明反映了方法的一些信息,比如说可见性、返回类型、方法名和参数。如下图所示。
-
-
-
-**访问权限**:它指定了方法的可见性。Java 提供了四种[访问权限修饰符](https://tobebetterjavaer.com/oo/access-control.html):
-
-- public:该方法可以被所有类访问。
-- private:该方法只能在定义它的类中访问。
-- protected:该方法可以被同一个包中的类,或者不同包中的子类访问。
-- default:如果一个方法没有使用任何访问权限修饰符,那么它是 package-private 的,意味着该方法只能被同一个包中的类可见。
-
-**返回类型**:方法返回的数据类型,可以是基本数据类型、对象和集合,如果不需要返回数据,则使用 void 关键字。
-
-**方法名**:方法名最好反应出方法的功能,比如,我们要创建一个将两个数字相减的方法,那么方法名最好是 subtract。
-
-方法名最好是一个动词,并且以小写字母开头。如果方法名包含两个以上单词,那么第一个单词最好是动词,然后是形容词或者名词,并且要以驼峰式的命名方式命名。比如:
-
-- 一个单词的方法名:`sum()`
-- 多个单词的方法名:`stringComparision()`
-
-一个方法可能与同一个类中的另外一个方法同名,这被称为方法重载。
-
-**参数**:参数被放在一个圆括号内,如果有多个参数,可以使用逗号隔开。参数包含两个部分,参数类型和参数名。如果方法没有参数,圆括号是空的。
-
-**方法签名**:每一个方法都有一个签名,包括方法名和参数。
-
-**方法体**:方法体放在一对花括号内,把一些代码放在一起,用来执行特定的任务。
-
-### 03、方法有哪几种?
-
-方法可以分为两种,一种叫标准类库方法,一种叫用户自定义方法。
-
-#### **1)预先定义方法**
-
-Java 提供了大量预先定义好的方法供我们调用,也称为标准类库方法,或者内置方法。比如说 String 类的 `length()`、`equals()`、`compare()` 方法,以及我们在初学 Java 阶段最常用的 `println()` 方法,用来在控制台打印信息。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class PredefinedMethodDemo {
- public static void main(String[] args) {
- System.out.println("沉默王二,一枚有趣的程序员");
- }
-}
-```
-
-在上面的代码中,我们使用了两个预先定义的方法,`main()` 方法是程序运行的入口,`println()` 方法是 `PrintStream` 类的一个方法。这些方法已经提前定义好了,所以我们可以直接使用它们。
-
-我们可以通过集成开发工具查看预先定义方法的方法签名,当我们把鼠标停留在 `println()` 方法上面时,就会显示下图中的内容:
-
-
-
-`println()` 方法的访问权限修饰符是 public,返回类型为 void,方法名为 println,参数为 `String x`,以及 Javadoc(方法是干嘛的)。
-
-预先定义方法让编程变得简单了起来,我们只需要在实现某些功能的时候直接调用这些方法即可,不需要重新编写。
-
-Java 的一个非常大的优势,就是,JDK 的设计者(开发者)为我们提供了大量的标准类库方法,这对于初学编程的新手来说极其友好;不仅如此,GitHub/码云上也有大量可以直接拿到生产环境下使用的第三方类库,比如说 hutool 啊、Apache 包啊、一线大厂或者顶级开发大佬贡献的类库,比如说 Druid、Gson 等等。
-
-但如果你想从一个初级开发者(俗称调包侠)晋升为一名优秀的 Java 工程师,那就需要深入研究这些源码,并掌握,最好是能自己写出来这些源码,最起码能自定义一些源码,以便为我们所用。
-
-#### **2)用户自定义方法**
-
-当预先定义方法无法满足我们的要求时,就需要自定义一些方法,比如说,我们来定义这样一个方法,用来检查数字是偶数还是奇数。
-
-```java
-public static void findEvenOdd(int num) {
- if (num % 2 == 0) {
- System.out.println(num + " 是偶数");
- } else {
- System.out.println(num + " 是奇数");
- }
-}
-```
-
-方法名叫做 `findEvenOdd`,访问权限修饰符是 public,并且是静态的(static),返回类型是 void,参数有一个整型(int)的 num。方法体中有一个 if else 语句,如果 num 可以被 2 整除,那么就打印这个数字是偶数,否则就打印这个数字是奇数。
-
-方法被定义好后,如何被调用呢?
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class EvenOddDemo {
- public static void main(String[] args) {
- findEvenOdd(10);
- findEvenOdd(11);
- }
-
- public static void findEvenOdd(int num) {
- if (num % 2 == 0) {
- System.out.println(num + " 是偶数");
- } else {
- System.out.println(num + " 是奇数");
- }
- }
-}
-```
-
-`main()` 方法是程序的入口,并且是静态的,那么就可以直接调用同样是静态方法的 `findEvenOdd()`。
-
-当一个方法被 static 关键字修饰时,它就是一个静态方法。换句话说,静态方法是属于类的,不属于类实例的(不需要通过 new 关键字创建对象来调用,直接通过类名就可以调用)。
-
-### 04、什么是实例方法?
-
-没有使用 [static 关键字](https://tobebetterjavaer.com/oo/static.html)修饰,但在类中声明的方法被称为实例方法,在调用实例方法之前,必须创建类的对象。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class InstanceMethodExample {
- public static void main(String[] args) {
- InstanceMethodExample instanceMethodExample = new InstanceMethodExample();
- System.out.println(instanceMethodExample.add(1, 2));
- }
-
- public int add(int a, int b) {
- return a + b;
- }
-}
-```
-
-`add()` 方法是一个实例方法,需要创建 InstanceMethodExample 对象来访问。
-
-实例方法有两种特殊类型:
-
-- getter 方法
-- setter 方法
-
-getter 方法用来获取私有变量(private 修饰的字段)的值,setter 方法用来设置私有变量的值。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
- private int sex;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public int getSex() {
- return sex;
- }
-
- public void setSex(int sex) {
- this.sex = sex;
- }
-}
-```
-
-getter 方法以 get 开头,setter 方法以 set 开头。
-
-### 05、什么是静态方法?
-
-相应的,有 [static 关键字](https://tobebetterjavaer.com/oo/static.html)修饰的方法就叫做静态方法。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 8/9/22
- */
-public class StaticMethodExample {
- public static void main(String[] args) {
- System.out.println(add(1,2));
- }
-
- public static int add(int a, int b) {
- return a + b;
- }
-}
-```
-
-StaticMethodExample 类中,mian 和 add 方法都是静态方法,不同的是,main 方法是程序的入口。当我们调用静态方法的时候,就不需要 new 出来类的对象,就可以直接调用静态方法了,一些工具类的方法都是静态方法,比如说 hutool 工具类库,里面有大量的静态方法可以直接调用。
-
-> Hutool 的目标是使用一个工具方法代替一段复杂代码,从而最大限度的避免“复制粘贴”代码的问题,彻底改变我们写代码的方式。
-
-以计算 MD5 为例:
-
-- 👴【以前】打开搜索引擎 -> 搜“Java MD5 加密” -> 打开某篇博客-> 复制粘贴 -> 改改好用
-- 👦【现在】引入 Hutool -> SecureUtil.md5()
-
-Hutool 的存在就是为了减少代码搜索成本,避免网络上参差不齐的代码出现导致的 bug。
-
-### 06、什么是抽象方法?
-
-没有方法体的方法被称为抽象方法,它总是在[抽象类](https://tobebetterjavaer.com/oo/abstract.html)中声明。这意味着如果类有抽象方法的话,这个类就必须是抽象的。可以使用 atstract 关键字创建抽象方法和抽象类。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-abstract class AbstractDemo {
- abstract void display();
-}
-```
-
-当一个类继承了抽象类后,就必须重写抽象方法:
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class MyAbstractDemo extends AbstractDemo {
- @Override
- void display() {
- System.out.println("重写了抽象方法");
- }
-
- public static void main(String[] args) {
- MyAbstractDemo myAbstractDemo = new MyAbstractDemo();
- myAbstractDemo.display();
- }
-}
-```
-
-输出结果如下所示:
-
-```
-重写了抽象方法
-```
-
-“关于方法,我们就讲到这里吧,学会了类/变量/方法,基本上就可以做一个入门级的 Java 程序员了。”我面露微笑,继续对三妹说,“继续加油吧!”
-
-“好的,谢谢二哥你的细心帮助。”
-
-
-## 5.5 Java可变参数
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.5 Java可变参数](https://tobebetterjavaer.com/basic-extra-meal/varables.html)
-
-
-
-## 5.6 Java native方法
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.6 Java native方法](https://tobebetterjavaer.com/oo/native-method.html)
-
-
-## 5.7 Java构造方法
-
-“三妹,[上一节](https://tobebetterjavaer.com/oo/method.html)学了 Java 中的方法,接着学构造方法的话,难度就小很多了。”刚吃完中午饭,虽然有些困意,但趁机学个 10 分钟也是不错的,睡眠会更心满意足一些,于是我面露微笑地对三妹说。
-
-“在 Java 中,构造方法是一种特殊的方法,当一个类被实例化的时候,就会调用构造方法。只有在构造方法被调用的时候,对象才会被分配内存空间。每次使用 `new` 关键字创建对象的时候,构造方法至少会被调用一次。”
-
-“如果你在一个类中没有看见构造方法,并不是因为构造方法不存在,而是被缺省了,编译器会给这个类提供一个默认的构造方法。就是说,Java 有两种类型的构造方法:**无参构造方法和有参构造方法**。”
-
-“注意,之所以叫它构造方法,是因为对象在创建的时候,需要通过构造方法初始化值——描写对象有哪些初始化状态。”
-
-“哥,你缓缓,一口气说这么多,也真有你的。”三妹听得聚精会神,但也知道关心她这个既当哥又当老师的二哥了。
-
-### 01、创建构造方法的规则
-
-构造方法必须符合以下规则:
-
-- 构造方法的名字必须和类名一样;
-- 构造方法没有返回类型,包括 void;
-- 构造方法不能是抽象的(abstract)、静态的(static)、最终的(final)、同步的(synchronized)。
-
-简单解析一下最后一条规则。
-
-- 由于构造方法不能被子类继承,所以用 final 和 abstract 关键字修饰没有意义;
-- 构造方法用于初始化一个对象,所以用 static 关键字修饰没有意义;
-- 多个线程不会同时创建内存地址相同的同一个对象,所以用 synchronized 关键字修饰没有必要。
-
-构造方法的语法格式如下:
-
-```java
-class class_name {
- public class_name(){} // 默认无参构造方法
- public ciass_name([paramList]){} // 定义有参数列表的构造方法
- …
- // 类主体
-}
-```
-
-值得注意的是,如果用 void 声明构造方法的话,编译时不会报错,但 Java 会把这个所谓的“构造方法”当成普通方法来处理。
-
-```java
-/**
- * 微信搜索「沉默王二」,回复 Java
- *
- * @author 沉默王二
- * @date 2020/11/26
- */
-public class Demo {
- void Demo(){ }
-}
-```
-
-`void Demo(){}` 看起来很符合构造方法的写法(与类名相同),但其实只是一个不符合规范的普通方法,方法名的首字母使用了大写,方法体为空,它并不是默认的无参构造方法,可以通过反编译后的字节码验证。
-
-```java
-public class Demo {
- public Demo() {
- }
-
- void Demo() {
- }
-}
-```
-
-`public Demo() {}` 才是真正的无参构造方法。
-
-不过,可以使用[访问权限修饰符](https://tobebetterjavaer.com/oo/access-control.html)(private、protected、public、default)来修饰构造方法,访问权限修饰符决定了构造方法的创建方式。
-
-
-### 02、默认构造方法
-
-如果一个构造方法中没有任何参数,那么它就是一个默认构造方法,也称为无参构造方法。
-
-```java
-/**
- * @author 微信搜「沉默王二」,回复关键字 PDF
- */
-public class Bike {
- Bike(){
- System.out.println("一辆自行车被创建");
- }
-
- public static void main(String[] args) {
- Bike bike = new Bike();
- }
-}
-```
-
-在上面这个例子中,我们为 Bike 类中创建了一个无参的构造方法,它在我们创建对象的时候被调用。
-
-程序输出结果如下所示:
-
-```
-一辆自行车被创建
-```
-
-通常情况下,无参构造方法是可以缺省的,我们开发者并不需要显式的声明无参构造方法,把这项工作交给编译器就可以了。
-
-
-
-“二哥,默认构造方法的目的是什么?它为什么是一个空的啊?”三妹疑惑地看着我,提出了这个尖锐的问题。
-
-“三妹啊,默认构造方法的目的主要是为对象的字段提供默认值,看下面这个例子你就明白了。”我胸有成竹地回答道。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class Person {
- private String name;
- private int age;
-
- public static void main(String[] args) {
- Person p = new Person();
- System.out.println("姓名 " + p.name + " 年龄 " + p.age);
- }
-}
-```
-
-输出结果如下所示:
-
-```
-姓名 null 年龄 0
-```
-
-在上面的例子中,默认构造方法初始化了 name 和 age 的值,name 是 String 类型,所以默认值为 null,age 是 int 类型,所以默认值为 0。如果没有默认构造方法的话,这项工作就无法完成了。
-
-
-### 03、有参构造方法
-
-有参数的构造方法被称为有参构造方法,参数可以有一个或多个。有参构造方法可以为不同的对象提供不同的值。当然,也可以提供相同的值。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class ParamConstructorPerson {
- private String name;
- private int age;
-
- public ParamConstructorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- ParamConstructorPerson p1 = new ParamConstructorPerson("沉默王二",18);
- p1.out();
-
- ParamConstructorPerson p2 = new ParamConstructorPerson("沉默王三",16);
- p2.out();
- }
-}
-```
-
-在上面的例子中,构造方法有两个参数(name 和 age),这样的话,我们在创建对象的时候就可以直接为 name 和 age 赋值了。
-
-```java
-new ParamConstructorPerson("沉默王二",18);
-new ParamConstructorPerson("沉默王三",16);
-```
-
-如果没有有参构造方法的话,就需要通过 setter 方法给字段赋值了。
-
-
-### 04、重载构造方法
-
-在 Java 中,构造方法和方法类似,只不过没有返回类型。它也可以像方法一样被[重载](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)。构造方法的重载也很简单,只需要提供不同的参数列表即可。编译器会通过参数的数量来决定应该调用哪一个构造方法。
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class OverloadingConstrutorPerson {
- private String name;
- private int age;
- private int sex;
-
- public OverloadingConstrutorPerson(String name, int age, int sex) {
- this.name = name;
- this.age = age;
- this.sex = sex;
- }
-
- public OverloadingConstrutorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age + " 性别 " + sex);
- }
-
- public static void main(String[] args) {
- OverloadingConstrutorPerson p1 = new OverloadingConstrutorPerson("沉默王二",18, 1);
- p1.out();
-
- OverloadingConstrutorPerson p2 = new OverloadingConstrutorPerson("沉默王三",16);
- p2.out();
- }
-}
-```
-
-创建对象的时候,如果传递的是三个参数,那么就会调用 `OverloadingConstrutorPerson(String name, int age, int sex)` 这个构造方法;如果传递的是两个参数,那么就会调用 `OverloadingConstrutorPerson(String name, int age)` 这个构造方法。
-
-
-### 05、构造方法和方法的区别
-
-构造方法和方法之间的区别还是蛮多的,比如说下面这些:
-
-
-
-
-
-### 06、复制对象
-
-复制一个对象可以通过下面三种方式完成:
-
-- 通过构造方法
-- 通过对象的值
-- 通过 Object 类的 `clone()` 方法
-
-#### 1)通过构造方法
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class CopyConstrutorPerson {
- private String name;
- private int age;
-
- public CopyConstrutorPerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public CopyConstrutorPerson(CopyConstrutorPerson person) {
- this.name = person.name;
- this.age = person.age;
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- CopyConstrutorPerson p1 = new CopyConstrutorPerson("沉默王二",18);
- p1.out();
-
- CopyConstrutorPerson p2 = new CopyConstrutorPerson(p1);
- p2.out();
- }
-}
-```
-
-在上面的例子中,有一个参数为 CopyConstrutorPerson 的构造方法,可以把该参数的字段直接复制到新的对象中,这样的话,就可以在 new 关键字创建新对象的时候把之前的 p1 对象传递过去。
-
-#### 2)通过对象的值
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class CopyValuePerson {
- private String name;
- private int age;
-
- public CopyValuePerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public CopyValuePerson() {
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) {
- CopyValuePerson p1 = new CopyValuePerson("沉默王二",18);
- p1.out();
-
- CopyValuePerson p2 = new CopyValuePerson();
- p2.name = p1.name;
- p2.age = p1.age;
-
- p2.out();
- }
-}
-```
-
-这种方式比较粗暴,直接拿 p1 的字段值复制给 p2 对象(`p2.name = p1.name`)。
-
-#### 3)通过 Object 类的 `clone()` 方法
-
-```java
-/**
- * @author 沉默王二,一枚有趣的程序员
- */
-public class ClonePerson implements Cloneable {
- private String name;
- private int age;
-
- public ClonePerson(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public void out() {
- System.out.println("姓名 " + name + " 年龄 " + age);
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- ClonePerson p1 = new ClonePerson("沉默王二",18);
- p1.out();
-
- ClonePerson p2 = (ClonePerson) p1.clone();
- p2.out();
- }
-}
-```
-
-通过 `clone()` 方法复制对象的时候,ClonePerson 必须先实现 Cloneable 接口的 `clone()` 方法,然后再调用 `clone()` 方法(`ClonePerson p2 = (ClonePerson) p1.clone()`)。
-
->拓展阅读:[浅拷贝与深拷贝](https://tobebetterjavaer.com/basic-extra-meal/deep-copy.html)
-
-### 07、ending
-
-“二哥,我能问一些问题吗?”三妹精神焕发,没有丝毫的疲惫。
-
-“当然可以啊,你问。”我很欣赏三妹孜孜不倦的态度。
-
-“构造方法真的不返回任何值吗?”
-
-“构造方法虽然没有返回值,但返回的是类的对象。”
-
-“构造方法只能完成字段初始化的工作吗?”
-
-“初始化字段只是构造方法的一种工作,它还可以做更多,比如启动线程,调用其他方法等。”
-
-“好的,二哥,我的问题问完了,今天的学习可以结束了!”三妹一脸得意的样子。
-
-“那你记得复习下一节的内容哦。”感受到三妹已经学到了知识,我也很欣慰。
-
-## 5.8 Java访问权限修饰符
-
-“我们先来讨论一下为什么需要访问权限控制。其实之前我们在讲[类和对象](https://tobebetterjavaer.com/oo/object-class.html)的时候有提到,今天我们来详细地聊一聊,三妹。”我开门见山地说,“三妹,你打开思维导图,记得做笔记哦。”
-
-“好的。”三妹应声回答。
-
-考虑两个场景:
-
-场景 1:工程师 A 编写了一个类 ClassA,但是工程师 A 并不希望 ClassA 被其他类都访问到,该如何处理呢?
-
-场景 2:工程师 A 编写了一个类 ClassA,其中有两个方法 fun1、fun2,工程师只想让 fun1 对外可见,也就是说,如果别的工程师来调用 ClassA,只可以调用方法 fun1,该怎么处理呢?
-
-此时,访问权限控制便可以起到作用了。
-
-在 Java 中,提供了四种访问权限控制:
-
-- 默认访问权限(包访问权限)
-- public
-- private
-- protected
-
-类只可以用默认访问权限和 public 修饰。比如说:
-
-```java
-public class Wanger{}
-```
-
-或者
-
-```java
-class Wanger{}
-```
-
-但变量和方法则都可以修饰。
-
-### 1. 修饰类
-
-- 默认访问权限(包访问权限):用来修饰类的话,表示该类只对同一个包中的其他类可见。
-- public:用来修饰类的话,表示该类对其他所有的类都可见。
-
-
-例 1:
-
-Main.java:
-
-```java
-package com.tobetterjavaer.test1;
-
-public class Main {
- public static void main(String\[\] args) {
-
- People people = new People("Tom");
- System.out.println(people.getName());
- }
-
-}
-```
-
-People.java
-
-```java
-package com.tobetterjavaer.test1;
-
-class People {//默认访问权限(包访问权限)
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-从代码可以看出,修饰 People 类采用的是默认访问权限,而由于 People 类和 Main 类在同一个包中,因此 People 类对于 Main 类是可见的。
-
-例子 2:
-
-People.java
-
-```java
-package com.tobetterjavaer.test2;
-
-class People {//默认访问权限(包访问权限)
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-此时 People 类和 Main 类不在同一个包中,会发生什么情况呢?
-
-下面是 Main 类中的提示的错误:
-
-
-
-
-
-提示 Peolple 类在 Main 类中不可见。从这里就可以看出,如果用默认访问权限去修饰一个类,该类只对同一个包中的其他类可见,对于不同包中的类是不可见的。
-
-正如上图的快速修正提示所示,将 People 类的默认访问权限更改为 public 的话,People 类对于 Main 类便可见了。
-
-### 2. 修饰方法和变量
-
-- 默认访问权限(包访问权限):如果一个类的方法或变量被包访问权限修饰,也就意味着只能在同一个包中的其他类中显示地调用该类的方法或者变量,在不同包中的类中不能显式地调用该类的方法或变量。
-- private:如果一个类的方法或者变量被 private 修饰,那么这个类的方法或者变量只能在该类本身中被访问,在类外以及其他类中都不能显式的进行访问。
-- protected:如果一个类的方法或者变量被 protected 修饰,对于同一个包的类,这个类的方法或变量是可以被访问的。对于不同包的类,只有继承于该类的类才可以访问到该类的方法或者变量。
-- public:被 public 修饰的方法或者变量,在任何地方都是可见的。
-
-
-例 3:
-
-Main.java 没有变化
-
-People.java
-
-```java
-package com.tobebetterjavaer.test1;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- String getName() { //默认访问权限(包访问权限)
- return name;
- }
-
- void setName(String name) { //默认访问权限(包访问权限)
- this.name = name;
- }
-}
-```
-
-此时在 Main 类是可以显示调用方法 getName 和 setName 的。
-
-但是如果 People 类和 Main 类不在同一个包中:
-
-```java
-package com.tobebetterjavaer.test2; //与Main类处于不同包中
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- String getName() { //默认访问权限(包访问权限)
- return name;
- }
-
- void setName(String name) { //默认访问权限(包访问权限)
- this.name = name;
- }
-}
-```
-
-此时在 Main 类中会提示错误:
-
-
-
-
-
-由此可以看出,如果用默认访问权限来修饰类的方法或者变量,则只能在同一个包的其他类中进行访问。
-
-例 4:
-
-People.java
-
-```java
-package com.tobebetterjavaer.test1;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- protected String getName() {
- return name;
- }
-
- protected void setName(String name) {
- this.name = name;
- }
-}
-```
-
-此时是可以在 Main 中显示调用方法 getName 和 setName 的。
-
-如果 People 类和 Main 类处于不同包中:
-
-```java
-package com.tobebetterjavaer.test2;
-
-public class People {
-
- private String name = null;
-
- public People(String name) {
- this.name = name;
- }
-
- protected String getName() {
- return name;
- }
-
- protected void setName(String name) {
- this.name = name;
- }
-}
-```
-
-则会在 Main 中报错:
-
-
-
-
-
-如果在 com.cxh.test1 中定一个类 Man 继承 People,则可以在类 Man 中显示调用方法 getName 和 setName:
-
-```java
-package com.tobebetterjavaer.test1;
-
-import com.tobebetterjavaer.test2.People;
-
-public class Man extends People {
-
- public Man(String name){
- super(name);
- }
-
- public String toString() {
- return getName();
- }
-}
-```
-
-补充一些关于 Java 包和类文件的知识:
-
-1)Java 中的包主要是为了防止类文件命名冲突以及方便进行代码组织和管理;
-
-2)对于一个 Java 源代码文件,如果存在 public 类的话,只能有一个 public 类,且此时源代码文件的名称必须和 public 类的名称完全相同。
-
-另外,如果还存在其他类,这些类在包外是不可见的。如果源代码文件没有 public 类,则源代码文件的名称可以随意命名。
-
-“三妹,理解了吧?”我问三妹。
-
-“是的,很简单,换句话说,不想让别人看的就 private,想让人看的就 public,想同一个班级/部门看的就默认,想让下一级看的就 protected,对吧?哥”三妹很自信地回答。
-
-“不错不错,总结得有那味了。”
-
->原文链接:[https://www.cnblogs.com/dolphin0520/p/3734915.html](https://www.cnblogs.com/dolphin0520/p/3734915.html) 作者: Matrix海子,编辑:沉默王二
-
-
-
-## 5.9 Java代码初始化块
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.9 Java代码初始化块](https://tobebetterjavaer.com/oo/code-init.html)
-
-
-
-## 5.10 Java抽象类
-
-“二哥,你这明显加快了更新的频率呀!”三妹对于我最近的肝劲由衷的佩服了起来。
-
-“哈哈,是呀,我要给广大的学弟学妹们一个完整的 Java 学习体系,记住我们的口号,**学 Java 就上二哥的 Java 进阶之路**。”我对未来充满了信心。
-
-“那就开始吧。”三妹说。
-
-### 01、定义抽象类
-
-定义抽象类的时候需要用到关键字 `abstract`,放在 `class` 关键字前,就像下面这样。
-
-```java
-abstract class AbstractPlayer {
-}
-```
-
-关于抽象类的命名,《[阿里的 Java 开发手册](https://tobebetterjavaer.com/pdf/ali-java-shouce.html)》上有强调,“抽象类命名要使用 Abstract 或 Base 开头”,这条规约还是值得遵守的,真正做到名如其意。
-
-### 02、抽象类的特征
-
-抽象类是不能实例化的,尝试通过 `new` 关键字实例化的话,编译器会报错,提示“类是抽象的,不能实例化”。
-
-
-
-虽然抽象类不能实例化,但可以有子类。子类通过 `extends` 关键字来继承抽象类。就像下面这样。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
-}
-```
-
-如果一个类定义了一个或多个抽象方法,那么这个类必须是抽象类。
-
-当我们尝试在一个普通类中定义抽象方法的时候,编译器会有两处错误提示。第一处在类级别上,提示“这个类必须通过 `abstract` 关键字定义”,见下图。
-
-
-
-第二处在尝试定义 abstract 的方法上,提示“抽象方法所在的类不是抽象的”,见下图。
-
-
-
-抽象类中既可以定义抽象方法,也可以定义普通方法,就像下面这样:
-
-```java
-public abstract class AbstractPlayer {
- abstract void play();
-
- public void sleep() {
- System.out.println("运动员也要休息而不是挑战极限");
- }
-}
-```
-
-抽象类派生的子类必须实现父类中定义的抽象方法。比如说,抽象类 AbstractPlayer 中定义了 `play()` 方法,子类 BasketballPlayer 中就必须实现。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是张伯伦,篮球场上得过 100 分");
- }
-}
-```
-
-如果没有实现的话,编译器会提示“子类必须实现抽象方法”,见下图。
-
-
-
-### 03、抽象类的应用场景
-
-“二哥,抽象方法我明白了,那什么时候使用抽象方法呢?能给我讲讲它的应用场景吗?”三妹及时的插话道。
-
-“这问题问的恰到好处呀!”我扶了扶眼镜继续说。
-
-#### **01)第一种场景**
-
-当我们希望一些通用的功能被多个子类复用的时候,就可以使用抽象类。比如说,AbstractPlayer 抽象类中有一个普通的方法 `sleep()`,表明所有运动员都需要休息,那么这个方法就可以被子类复用。
-
-```java
-abstract class AbstractPlayer {
- public void sleep() {
- System.out.println("运动员也要休息而不是挑战极限");
- }
-}
-```
-
-子类 BasketballPlayer 继承了 AbstractPlayer 类:
-
-```java
-class BasketballPlayer extends AbstractPlayer {
-}
-```
-
-也就拥有了 `sleep()` 方法。BasketballPlayer 的对象可以直接调用父类的 `sleep()` 方法:
-
-```java
-BasketballPlayer basketballPlayer = new BasketballPlayer();
-basketballPlayer.sleep();
-```
-
-子类 FootballPlayer 继承了 AbstractPlayer 类:
-
-```java
-class FootballPlayer extends AbstractPlayer {
-}
-```
-
-也拥有了 `sleep()` 方法,FootballPlayer 的对象也可以直接调用父类的 `sleep()` 方法:
-
-```java
-FootballPlayer footballPlayer = new FootballPlayer();
-footballPlayer.sleep();
-```
-
-这样是不是就实现了代码的复用呢?
-
-#### **02)第二种场景**
-
-当我们需要在抽象类中定义好 API,然后在子类中扩展实现的时候就可以使用抽象类。比如说,AbstractPlayer 抽象类中定义了一个抽象方法 `play()`,表明所有运动员都可以从事某项运动,但需要对应子类去扩展实现,表明篮球运动员打篮球,足球运动员踢足球。
-
-```java
-abstract class AbstractPlayer {
- abstract void play();
-}
-```
-
-BasketballPlayer 继承了 AbstractPlayer 类,扩展实现了自己的 `play()` 方法。
-
-```java
-public class BasketballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是张伯伦,我篮球场上得过 100 分,");
- }
-}
-```
-
-FootballPlayer 继承了 AbstractPlayer 类,扩展实现了自己的 `play()` 方法。
-
-```java
-public class FootballPlayer extends AbstractPlayer {
- @Override
- void play() {
- System.out.println("我是C罗,我能接住任意高度的头球");
- }
-}
-```
-
-为了进一步展示抽象类的特性,我们再来看一个具体的示例。
-
->PS:[网站](https://tobebetterjavaer.com/oo/abstract.html)评论区说涉及到了文件的读写以及 Java 8 的新特性,不适合新人,如果觉得自己实在是看不懂,跳过,等学了 IO 流再来看也行。如果说是为了复习 Java 基础知识,就不存在这个问题了。
-
-假设现在有一个文件,里面的内容非常简单,只有一个“Hello World”,现在需要有一个读取器将内容从文件中读取出来,最好能按照大写的方式,或者小写的方式来读。
-
-这时候,最好定义一个抽象类 BaseFileReader:
-
-```java
-/**
- * 抽象类,定义了一个读取文件的基础框架,其中 mapFileLine 是一个抽象方法,具体实现需要由子类来完成
- */
-abstract class BaseFileReader {
- protected Path filePath; // 定义一个 protected 的 Path 对象,表示读取的文件路径
-
- /**
- * 构造方法,传入读取的文件路径
- * @param filePath 读取的文件路径
- */
- protected BaseFileReader(Path filePath) {
- this.filePath = filePath;
- }
-
- /**
- * 读取文件的方法,返回一个字符串列表
- * @return 字符串列表,表示文件的内容
- * @throws IOException 如果文件读取出错,抛出该异常
- */
- public List readFile() throws IOException {
- return Files.lines(filePath) // 使用 Files 类的 lines 方法,读取文件的每一行
- .map(this::mapFileLine) // 对每一行应用 mapFileLine 方法,将其转化为指定的格式
- .collect(Collectors.toList()); // 将处理后的每一行收集到一个字符串列表中,返回
- }
-
- /**
- * 抽象方法,子类需要实现该方法,将文件中的每一行转化为指定的格式
- * @param line 文件中的每一行
- * @return 转化后的字符串
- */
- protected abstract String mapFileLine(String line);
-}
-```
-
-- filePath 为文件路径,使用 protected 修饰,表明该成员变量可以在需要时被子类访问到。
-
-- `readFile()` 方法用来读取文件,方法体里面调用了抽象方法 `mapFileLine()`——需要子类来扩展实现大小写的不同读取方式。
-
-在我看来,BaseFileReader 类设计的就非常合理,并且易于扩展,子类只需要专注于具体的大小写实现方式就可以了。
-
-小写的方式:
-
-```java
-class LowercaseFileReader extends BaseFileReader {
- protected LowercaseFileReader(Path filePath) {
- super(filePath);
- }
-
- @Override
- protected String mapFileLine(String line) {
- return line.toLowerCase();
- }
-}
-```
-
-大写的方式:
-
-```java
-class UppercaseFileReader extends BaseFileReader {
- protected UppercaseFileReader(Path filePath) {
- super(filePath);
- }
-
- @Override
- protected String mapFileLine(String line) {
- return line.toUpperCase();
- }
-}
-```
-
-从文件里面一行一行读取内容的代码被子类复用了。与此同时,子类只需要专注于自己该做的工作,LowercaseFileReader 以小写的方式读取文件内容,UppercaseFileReader 以大写的方式读取文件内容。
-
-来看一下测试类 FileReaderTest:
-
-```java
-public class FileReaderTest {
- public static void main(String[] args) throws URISyntaxException, IOException {
- URL location = FileReaderTest.class.getClassLoader().getResource("helloworld.txt");
- Path path = Paths.get(location.toURI());
- BaseFileReader lowercaseFileReader = new LowercaseFileReader(path);
- BaseFileReader uppercaseFileReader = new UppercaseFileReader(path);
- System.out.println(lowercaseFileReader.readFile());
- System.out.println(uppercaseFileReader.readFile());
- }
-}
-```
-
-在项目的 resource 目录下建一个文本文件,名字叫 helloworld.txt,里面的内容就是“Hello World”。文件的具体位置如下图所示,我用的集成开发环境是 Intellij IDEA。
-
-
-
-
-在 resource 目录下的文件可以通过 `ClassLoader.getResource()` 的方式获取到 URI 路径,然后就可以取到文本内容了。
-
-输出结果如下所示:
-
-```
-[hello world]
-[HELLO WORLD]
-```
-
-### 04、抽象类总结
-
-好了,对于抽象类我们简单总结一下:
-
-- 1、抽象类不能被实例化。
-- 2、抽象类应该至少有一个抽象方法,否则它没有任何意义。
-- 3、抽象类中的抽象方法没有方法体。
-- 4、抽象类的子类必须给出父类中的抽象方法的具体实现,除非该子类也是抽象类。
-
-“完了吗?二哥”三妹似乎还沉浸在聆听教诲的快乐中。
-
-“是滴,这次我们系统化的学习了抽象类,可以说面面俱到了。三妹你可以把代码敲一遍,加强了一些印象,电脑交给你了。”说完,我就跑到阳台去抽烟了。
-
-“呼。。。。。”一个大大的眼圈飘散开来,又是愉快的一天~
-
-
-## 5.11 Java接口
-
-“今天开始讲 Java 的接口。”我对三妹说,“对于面向对象编程来说,抽象是一个极具魅力的特征。如果一个程序员的抽象思维很差,那他在编程中就会遇到很多困难,无法把业务变成具体的代码。在 Java 中,可以通过两种形式来达到抽象的目的,一种上一篇的主角——[抽象类](https://tobebetterjavaer.com/oo/abstract.html),另外一种就是今天的主角——[接口](https://tobebetterjavaer.com/oo/interface.html)。”
-
-“二哥,开讲之前,先恭喜你呀。我看你朋友圈说《[Java进阶之路](https://github.com/itwanger/toBeBetterJavaer)》开源知识库在 GitHub 上收到了第一笔赞赏呀,虽然只有一块钱,但我也替你感到开心。”三妹的脸上洋溢着自信的微笑,仿佛这钱是打给她的一样。
-
-
-
->PS:2021-04-29到2023-02-11期间,《二哥的 Java 进阶之路》收到了 58 笔赞赏,真的非常感谢大家的认可和支持😍,我会继续肝下去的。
-
-“是啊,早上起来的时候看到这条信息,还真的是挺开心的,虽然只有一块钱,但是开源的第一笔,也是我人生当中的第一笔,真的非常感谢这个读者,值得纪念的一天。”我自己也掩饰不住内心的激动。
-
-“有了这份鼓励,我相信你更新下去的动力更足了!”三妹今天说的话真的是特别令人喜欢。
-
-
-
-“是呀是呀,让我们开始吧!”
-
-### 01、定义接口
-
-“接口是什么呀?”三妹顺着我的话题及时的插话到。
-
-接口通过 interface 关键字来定义,它可以包含一些常量和方法,来看下面这个示例。
-
-```java
-public interface Electronic {
- // 常量
- String LED = "LED";
-
- // 抽象方法
- int getElectricityUse();
-
- // 静态方法
- static boolean isEnergyEfficient(String electtronicType) {
- return electtronicType.equals(LED);
- }
-
- // 默认方法
- default void printDescription() {
- System.out.println("电子");
- }
-}
-```
-
-来看一下这段代码反编译后的字节码。
-
-```java
-public interface Electronic
-{
-
- public abstract int getElectricityUse();
-
- public static boolean isEnergyEfficient(String electtronicType)
- {
- return electtronicType.equals("LED");
- }
-
- public void printDescription()
- {
- System.out.println("\u7535\u5B50");
- }
-
- public static final String LED = "LED";
-}
-```
-
-发现没?接口中定义的所有变量或者方法,都会自动添加上 `public` 关键字。
-
-接下来,我来一一解释下 Electronic 接口中的核心知识点。
-
-**1)接口中定义的变量会在编译的时候自动加上 `public static final` 修饰符**(注意看一下反编译后的字节码),也就是说上例中的 LED 变量其实就是一个常量。
-
-Java 官方文档上有这样的声明:
-
->Every field declaration in the body of an interface is implicitly public, static, and final.
-
-换句话说,接口可以用来作为常量类使用,还能省略掉 `public static final`,看似不错的一种选择,对吧?
-
-不过,这种选择并不可取。因为接口的本意是对方法进行抽象,而常量接口会对子类中的变量造成命名空间上的“污染”。
-
-**2)没有使用 `private`、`default` 或者 `static` 关键字修饰的方法是隐式抽象的**,在编译的时候会自动加上 `public abstract` 修饰符。也就是说上例中的 `getElectricityUse()` 其实是一个抽象方法,没有方法体——这是定义接口的本意。
-
-**3)从 Java 8 开始,接口中允许有静态方法**,比如说上例中的 `isEnergyEfficient()` 方法。
-
-静态方法无法由(实现了该接口的)类的对象调用,它只能通过接口名来调用,比如说 `Electronic.isEnergyEfficient("LED")`。
-
-接口中定义静态方法的目的是为了提供一种简单的机制,使我们不必创建对象就能调用方法,从而提高接口的竞争力。
-
-**4)接口中允许定义 `default` 方法**也是从 Java 8 开始的,比如说上例中的 `printDescription()` 方法,它始终由一个代码块组成,为实现该接口而不覆盖该方法的类提供默认实现。既然要提供默认实现,就要有方法体,换句话说,默认方法后面不能直接使用“;”号来结束——编译器会报错。
-
-
-
-“为什么要在接口中定义默认方法呢?”三妹好奇地问到。
-
-允许在接口中定义默认方法的理由很充分,因为一个接口可能有多个实现类,这些类就必须实现接口中定义的抽象类,否则编译器就会报错。假如我们需要在所有的实现类中追加某个具体的方法,在没有 `default` 方法的帮助下,我们就必须挨个对实现类进行修改。
-
-由之前的例子我们就可以得出下面这些结论:
-
-- 接口中允许定义变量
-- 接口中允许定义抽象方法
-- 接口中允许定义静态方法(Java 8 之后)
-- 接口中允许定义默认方法(Java 8 之后)
-
-除此之外,我们还应该知道:
-
-**1)接口不允许直接实例化**,否则编译器会报错。
-
-
-
-需要定义一个类去实现接口,见下例。
-
-```java
-public class Computer implements Electronic {
-
- public static void main(String[] args) {
- new Computer();
- }
-
- @Override
- public int getElectricityUse() {
- return 0;
- }
-}
-```
-
-然后再实例化。
-
-```
-Electronic e = new Computer();
-```
-
-**2)接口可以是空的**,既可以不定义变量,也可以不定义方法。最典型的例子就是 Serializable 接口,在 `java.io` 包下。
-
-```java
-public interface Serializable {
-}
-```
-
-Serializable 接口用来为序列化的具体实现提供一个标记,也就是说,只要某个类实现了 Serializable 接口,那么它就可以用来序列化了。
-
-**3)不要在定义接口的时候使用 final 关键字**,否则会报编译错误,因为接口就是为了让子类实现的,而 final 阻止了这种行为。
-
-
-
-**4)接口的抽象方法不能是 private、protected 或者 final**,否则编译器都会报错。
-
-
-
-**5)接口的变量是隐式 `public static final`(常量)**,所以其值无法改变。
-
-### 02、接口的作用
-
-“接口可以做什么呢?”三妹见缝插针,问的很及时。
-
-**第一,使某些实现类具有我们想要的功能**,比如说,实现了 Cloneable 接口的类具有拷贝的功能,实现了 Comparable 或者 Comparator 的类具有比较功能。
-
-Cloneable 和 Serializable 一样,都属于标记型接口,它们内部都是空的。实现了 Cloneable 接口的类可以使用 `Object.clone()` 方法,否则会抛出 CloneNotSupportedException。
-
-```java
-public class CloneableTest implements Cloneable {
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- CloneableTest c1 = new CloneableTest();
- CloneableTest c2 = (CloneableTest) c1.clone();
- }
-}
-```
-
-运行后没有报错。现在把 `implements Cloneable` 去掉。
-
-```java
-public class CloneableTest {
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-
- public static void main(String[] args) throws CloneNotSupportedException {
- CloneableTest c1 = new CloneableTest();
- CloneableTest c2 = (CloneableTest) c1.clone();
-
- }
-}
-```
-
-运行后抛出 CloneNotSupportedException:
-
-```
-Exception in thread "main" java.lang.CloneNotSupportedException: com.cmower.baeldung.interface1.CloneableTest
- at java.base/java.lang.Object.clone(Native Method)
- at com.cmower.baeldung.interface1.CloneableTest.clone(CloneableTest.java:6)
- at com.cmower.baeldung.interface1.CloneableTest.main(CloneableTest.java:11)
-```
-
-
-**第二,Java 原则上只支持单一继承,但通过接口可以实现多重继承的目的**。
-
-如果有两个类共同继承(extends)一个父类,那么父类的方法就会被两个子类重写。然后,如果有一个新类同时继承了这两个子类,那么在调用重写方法的时候,编译器就不能识别要调用哪个类的方法了。这也正是著名的菱形问题,见下图。
-
-
-
-
-简单解释下,ClassC 同时继承了 ClassA 和 ClassB,ClassC 的对象在调用 ClassA 和 ClassB 中重写的方法时,就不知道该调用 ClassA 的方法,还是 ClassB 的方法。
-
-接口没有这方面的困扰。来定义两个接口,Fly 接口会飞,Run 接口会跑。
-
-```java
-public interface Fly {
- void fly();
-}
-public interface Run {
- void run();
-}
-```
-
-然后让 Pig 类同时实现这两个接口。
-
-```java
-public class Pig implements Fly,Run{
- @Override
- public void fly() {
- System.out.println("会飞的猪");
- }
-
- @Override
- public void run() {
- System.out.println("会跑的猪");
- }
-}
-```
-
-在某种形式上,接口实现了多重继承的目的:现实世界里,猪的确只会跑,但在雷军的眼里,站在风口的猪就会飞,这就需要赋予这只猪更多的能力,通过抽象类是无法实现的,只能通过接口。
-
-**第三,实现多态**。
-
-什么是多态呢?通俗的理解,就是同一个事件发生在不同的对象上会产生不同的结果,鼠标左键点击窗口上的 X 号可以关闭窗口,点击超链接却可以打开新的网页。
-
-多态可以通过继承(`extends`)的关系实现,也可以通过接口的形式实现。
-
-Shape 接口表示一个形状。
-
-```java
-public interface Shape {
- String name();
-}
-```
-
-Circle 类实现了 Shape 接口,并重写了 `name()` 方法。
-
-```java
-public class Circle implements Shape {
- @Override
- public String name() {
- return "圆";
- }
-}
-```
-
-Square 类也实现了 Shape 接口,并重写了 `name()` 方法。
-
-```java
-public class Square implements Shape {
- @Override
- public String name() {
- return "正方形";
- }
-}
-```
-
-然后来看测试类。
-
-```java
-List shapes = new ArrayList<>();
-Shape circleShape = new Circle();
-Shape squareShape = new Square();
-
-shapes.add(circleShape);
-shapes.add(squareShape);
-
-for (Shape shape : shapes) {
- System.out.println(shape.name());
-}
-```
-
-这就实现了多态,变量 circleShape、squareShape 的引用类型都是 Shape,但执行 `shape.name()` 方法的时候,Java 虚拟机知道该去调用 Circle 的 `name()` 方法还是 Square 的 `name()` 方法。
-
-说一下多态存在的 3 个前提:
-
-- 1、要有继承关系,比如说 Circle 和 Square 都实现了 Shape 接口。
-- 2、子类要重写父类的方法,Circle 和 Square 都重写了 `name()` 方法。
-- 3、父类引用指向子类对象,circleShape 和 squareShape 的类型都为 Shape,但前者指向的是 Circle 对象,后者指向的是 Square 对象。
-
-然后,我们来看一下测试结果:
-
-```
-圆
-正方形
-```
-
-也就意味着,尽管在 for 循环中,shape 的类型都为 Shape,但在调用 `name()` 方法的时候,它知道 Circle 对象应该调用 Circle 类的 `name()` 方法,Square 对象应该调用 Square 类的 `name()` 方法。
-
-### 03、接口的三种模式
-
-**在编程领域,好的设计模式能够让我们的代码事半功倍**。在使用接口的时候,经常会用到三种模式,分别是策略模式、适配器模式和工厂模式。
-
-#### 1)策略模式
-
-策略模式的思想是,针对一组算法,将每一种算法封装到具有共同接口的实现类中,接口的设计者可以在不影响调用者的情况下对算法做出改变。示例如下:
-
-```java
-// 接口:教练
-interface Coach {
- // 方法:防守
- void defend();
-}
-
-// 何塞·穆里尼奥
-class Hesai implements Coach {
-
- @Override
- public void defend() {
- System.out.println("防守赢得冠军");
- }
-}
-
-// 德普·瓜迪奥拉
-class Guatu implements Coach {
-
- @Override
- public void defend() {
- System.out.println("进攻就是最好的防守");
- }
-}
-
-public class Demo {
- // 参数为接口
- public static void defend(Coach coach) {
- coach.defend();
- }
-
- public static void main(String[] args) {
- // 为同一个方法传递不同的对象
- defend(new Hesai());
- defend(new Guatu());
- }
-}
-```
-
-`Demo.defend()` 方法可以接受不同风格的 Coach,并根据所传递的参数对象的不同而产生不同的行为,这被称为“策略模式”。
-
-#### 2)适配器模式
-
-适配器模式的思想是,针对调用者的需求对原有的接口进行转接。生活当中最常见的适配器就是HDMI(英语:`High Definition Multimedia Interface`,中文:高清多媒体接口)线,可以同时发送音频和视频信号。适配器模式的示例如下:
-
-```java
-interface Coach {
- void defend();
- void attack();
-}
-
-// 抽象类实现接口,并置空方法
-abstract class AdapterCoach implements Coach {
- public void defend() {};
- public void attack() {};
-}
-
-// 新类继承适配器
-class Hesai extends AdapterCoach {
- public void defend() {
- System.out.println("防守赢得冠军");
- }
-}
-
-public class Demo {
- public static void main(String[] args) {
- Coach coach = new Hesai();
- coach.defend();
- }
-}
-```
-Coach 接口中定义了两个方法(`defend()` 和 `attack()`),如果类直接实现该接口的话,就需要对两个方法进行实现。
-
-如果我们只需要对其中一个方法进行实现的话,就可以使用一个抽象类作为中间件,即适配器(AdapterCoach),用这个抽象类实现接口,并对抽象类中的方法置空(方法体只有一对花括号),这时候,新类就可以绕过接口,继承抽象类,我们就可以只对需要的方法进行覆盖,而不是接口中的所有方法。
-
-#### 3)工厂模式
-
-所谓的工厂模式理解起来也不难,就是什么工厂生产什么,比如说宝马工厂生产宝马,奔驰工厂生产奔驰,A 级学院毕业 A 级教练,C 级学院毕业 C 级教练。示例如下:
-
-```java
-// 教练
-interface Coach {
- void command();
-}
-
-// 教练学院
-interface CoachFactory {
- Coach createCoach();
-}
-
-// A级教练
-class ACoach implements Coach {
-
- @Override
- public void command() {
- System.out.println("我是A级证书教练");
- }
-
-}
-
-// A级教练学院
-class ACoachFactory implements CoachFactory {
-
- @Override
- public Coach createCoach() {
- return new ACoach();
- }
-
-}
-
-// C级教练
-class CCoach implements Coach {
-
- @Override
- public void command() {
- System.out.println("我是C级证书教练");
- }
-
-}
-
-// C级教练学院
-class CCoachFactory implements CoachFactory {
-
- @Override
- public Coach createCoach() {
- return new CCoach();
- }
-
-}
-
-public class Demo {
- public static void create(CoachFactory factory) {
- factory.createCoach().command();
- }
-
- public static void main(String[] args) {
- // 对于一支球队来说,需要什么样的教练就去找什么样的学院
- // 学院会介绍球队对应水平的教练。
- create(new ACoachFactory());
- create(new CCoachFactory());
- }
-}
-```
-
-有两个接口,一个是 Coach(教练),可以 `command()`(指挥球队);另外一个是 CoachFactory(教练学院),能 `createCoach()`(教出一名优秀的教练)。然后 ACoach 类实现 Coach 接口,ACoachFactory 类实现 CoachFactory 接口;CCoach 类实现 Coach 接口,CCoachFactory 类实现 CoachFactory 接口。当需要 A 级教练时,就去找 A 级教练学院;当需要 C 级教练时,就去找 C 级教练学院。
-
-依次类推,我们还可以用 BCoach 类实现 Coach 接口,BCoachFactory 类实现 CoachFactory 接口,从而不断地丰富教练的梯队。
-
-“怎么样三妹,一下子接收这么多知识点不容易吧?”
-
-“其实还好啊,二哥你讲的这么细致,我都做好笔记📒了,学习嘛,认真一点,效果就会好很多了。”
-
-三妹这种积极乐观的态度真的让我感觉到“付出就会有收获”,💪🏻。
-
-### 04、抽象类和接口的区别
-
-简单总结一下抽象类和接口的区别。
-
-在 Java 中,通过关键字 `abstract` 定义的类叫做抽象类。Java 是一门面向对象的语言,因此所有的对象都是通过类来描述的;但反过来,并不是所有的类都是用来描述对象的,抽象类就是其中的一种。
-
-以下示例展示了一个简单的抽象类:
-
-```java
-// 个人认为,一名教练必须攻守兼备
-abstract class Coach {
- public abstract void defend();
-
- public abstract void attack();
-}
-```
-
-我们知道,有抽象方法的类被称为抽象类,也就意味着抽象类中还能有不是抽象方法的方法。这样的类就不能算作纯粹的接口,尽管它也可以提供接口的功能——只能说抽象类是普通类与接口之间的一种中庸之道。
-
-**接口(英文:Interface),在 Java 中是一个抽象类型,是抽象方法的集合**;接口通过关键字 `interface` 来定义。接口与抽象类的不同之处在于:
-
-- 1、抽象类可以有方法体的方法,但接口没有(Java 8 以前)。
-- 2、接口中的成员变量隐式为 `static final`,但抽象类不是的。
-- 3、一个类可以实现多个接口,但只能继承一个抽象类。
-
-以下示例展示了一个简单的接口:
-
-```java
-// 隐式的abstract
-interface Coach {
- // 隐式的public
- void defend();
- void attack();
-}
-```
-
-- 接口是隐式抽象的,所以声明时没有必要使用 `abstract` 关键字;
-- 接口的每个方法都是隐式抽象的,所以同样不需要使用 `abstract` 关键字;
-- 接口中的方法都是隐式 `public` 的。
-
-“哦,我理解了哥。那我再问一下,抽象类和接口有什么差别呢?”
-
-“哇,三妹呀,你这个问题恰到好处,问到了点子上。”我不由得为三妹竖起了大拇指。
-
-#### 1)语法层面上
-
-- 抽象类可以提供成员方法的实现细节,而接口中只能存在 public abstract 方法;
-- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的;
-- 接口中不能含有静态代码块,而抽象类可以有静态代码块;
-- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
-
-#### 2)设计层面上
-
-抽象类是对一种事物的抽象,即对类抽象,继承抽象类的子类和抽象类本身是一种 `is-a` 的关系。而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
-
-举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类 Airplane,将鸟设计为一个类 Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。
-
-此时可以将 飞行 设计为一个接口 Fly,包含方法 fly(),然后 Airplane 和 Bird 分别根据自己的需要实现 Fly 这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承 Airplane 即可,对于鸟也是类似的,不同种类的鸟直接继承 Bird 类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
-
-接口是对类的某种行为的一种抽象,接口和类之间并没有很强的关联关系,举个例子来说,所有的类都可以实现 [`Serializable` 接口](https://tobebetterjavaer.com/io/Serializbale.html),从而具有序列化的功能,但不能说所有的类和 Serializable 之间是 `is-a` 的关系。
-
-抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过 ppt 里面的模板,如果用模板 A 设计了 ppt B 和 ppt C,ppt B 和 ppt C 公共的部分就是模板 A 了,如果它们的公共部分需要改动,则只需要改动模板 A 就可以了,不需要重新对 ppt B 和 ppt C 进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
-
-## 5.12 Java内部类
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.12 Java内部类](https://tobebetterjavaer.com/oo/inner-class.html)
-
-
-## 5.13 Java封装继承多态
-
-在谈 Java 面向对象的时候,不得不提到面向对象的三大特征:[封装](https://tobebetterjavaer.com/oo/encapsulation.html)、[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html)、[多态](https://tobebetterjavaer.com/oo/polymorphism.html)。三大特征紧密联系而又有区别,合理使用继承能大大减少重复代码,**提高代码复用性。**
-
-### 1)封装
-
-“三妹,准备好了没,我们来讲 Java 封装,算是 Java 的三大特征之一,理清楚了,对以后的编程有较大的帮助。”我对三妹说。
-
-“好的,哥,准备好了。”三妹一边听我说,一边迅速地打开了 XMind,看来一边学习一边总结思维导图这个高效的学习方式三妹已经牢记在心了。
-
-封装从字面上来理解就是包装的意思,专业点就是信息隐藏,**是指利用抽象将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体**。
-
-数据被保护在类的内部,尽可能地隐藏内部的实现细节,只保留一些对外接口使之与外部发生联系。
-
-其他对象只能通过已经授权的操作来与这个封装的对象进行交互。也就是说用户是无需知道对象内部的细节(当然也无从知道),但可以通过该对象对外的提供的接口来访问该对象。
-
-使用封装有 4 大好处:
-
-- 1、良好的封装能够减少耦合。
-- 2、类内部的结构可以自由修改。
-- 3、可以对成员进行更精确的控制。
-- 4、隐藏信息,实现细节。
-
-首先我们先来看两个类。
-
-Husband.java
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private int age ;
- private Wife wife;
-
- /*
- * setter()、getter()是该对象对外开发的接口
- */
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public String getSex() {
- return sex;
- }
-
- public void setSex(String sex) {
- this.sex = sex;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public void setWife(Wife wife) {
- this.wife = wife;
- }
-}
-```
-
-Wife.java
-
-```java
-public class Wife {
- private String name;
- private int age;
- private String sex;
- private Husband husband;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public String getSex() {
- return sex;
- }
-
- public void setSex(String sex) {
- this.sex = sex;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- public void setHusband(Husband husband) {
- this.husband = husband;
- }
-
- public Husband getHusband() {
- return husband;
- }
-
-}
-```
-
-可以看得出, Husband 类里面的 wife 属性是没有 `getter()`的,同时 Wife 类的 age 属性也是没有 `getter()`方法的。至于理由我想三妹你是懂的。
-
-没有哪个女人愿意别人知道她的年龄。
-
-所以封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果不想被外界方法,我们大可不必提供方法给外界访问。
-
-但是如果一个类没有提供给外界任何可以访问的方法,那么这个类也没有什么意义了。
-
-比如我们将一个房子看做是一个对象,里面有漂亮的装饰,如沙发、电视剧、空调、茶桌等等都是该房子的私有属性,但是如果我们没有那些墙遮挡,是不是别人就会一览无余呢?没有一点儿隐私!
-
-因为存在那个遮挡的墙,我们既能够有自己的隐私而且我们可以随意的更改里面的摆设而不会影响到外面的人。
-
-但是如果没有门窗,一个包裹的严严实实的黑盒子,又有什么存在的意义呢?所以通过门窗别人也能够看到里面的风景。所以说门窗就是房子对象留给外界访问的接口。
-
-通过这个我们还不能真正体会封装的好处。现在我们从程序的角度来分析封装带来的好处。如果我们不使用封装,那么该对象就没有 `setter()`和 `getter()`,那么 Husband 类应该这样写:
-
-```java
-public class Husband {
- public String name ;
- public String sex ;
- public int age ;
- public Wife wife;
-}
-```
-
-我们应该这样来使用它:
-
-```java
-Husband husband = new Husband();
-husband.age = 30;
-husband.name = "张三";
-husband.sex = "男"; //貌似有点儿多余
-```
-
-但是哪天如果我们需要修改 Husband,例如将 age 修改为 String 类型的呢?你只有一处使用了这个类还好,如果你有几十个甚至上百个这样地方,你是不是要改到崩溃。如果使用了封装,我们完全可以不需要做任何修改,只需要稍微改变下 Husband 类的 `setAge()`方法即可。
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private String age ; /* 改成 String类型的*/
- private Wife wife;
-
- public String getAge() {
- return age;
- }
-
- public void setAge(int age) {
- //转换即可
- this.age = String.valueOf(age);
- }
-
- /** 省略其他属性的setter、getter **/
-
-}
-```
-
-其他的地方依然这样引用( `husband.setAge(22)` )保持不变。
-
-到了这里我们确实可以看出,**封装确实可以使我们更容易地修改类的内部实现,而无需修改使用了该类的代码**。
-
-我们再看这个好处:**封装可以对成员变量进行更精确的控制**。
-
-还是那个 Husband,一般来说我们在引用这个对象的时候是不容易出错的,但是有时你迷糊了,写成了这样:
-
-```java
-Husband husband = new Husband();
-husband.age = 300;
-```
-
-也许你是因为粗心写成了这样,你发现了还好,如果没有发现那就麻烦大了,谁见过 300 岁的老妖怪啊!
-
-但是使用封装我们就可以避免这个问题,我们对 age 的访问入口做一些控制(setter)如:
-
-```java
-public class Husband {
-
- /*
- * 对属性的封装
- * 一个人的姓名、性别、年龄、妻子都是这个人的私有属性
- */
- private String name ;
- private String sex ;
- private int age ; /* 改成 String类型的*/
- private Wife wife;
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- if(age > 120){
- System.out.println("ERROR:error age input...."); //提示錯誤信息
- }else{
- this.age = age;
- }
-
- }
-
- /** 省略其他属性的setter、getter **/
-
-}
-```
-
-上面都是对 setter 方法的控制,其实通过封装我们也能够对对象的出口做出很好的控制。例如性别在数据库中一般都是以 1、0 的方式来存储的,但是在前台我们又不能展示 1、0,这里我们只需要在 `getter()`方法里面做一些转换即可。
-
-```java
-public String getSexName() {
- if("0".equals(sex)){
- sexName = "女";
- }
- else if("1".equals(sex)){
- sexName = "男";
- }
- return sexName;
-}
-```
-
-在使用的时候我们只需要使用 sexName 即可实现正确的性别显示。同理也可以用于针对不同的状态做出不同的操作。
-
-```java
-public String getCzHTML(){
- if("1".equals(zt)){
- czHTML = "启用";
- }
- else{
- czHTML = "禁用";
- }
- return czHTML;
-}
-```
-
-“好了,关于封装我们就暂时就聊这么多吧。”我喝了一口普洱茶后,对三妹说。
-
-“好的,哥,我懂了。”
-
-> 参考链接:[https://www.cnblogs.com/chenssy/p/3351835.html](https://www.cnblogs.com/chenssy/p/3351835.html),整理:沉默王二
-
-### 2)继承
-
-#### 01、什么是继承
-
-**继承**(英语:inheritance)是面向对象软件技术中的一个概念。它使得**复用以前的代码非常容易。**
-
-Java 语言是非常典型的面向对象的语言,在 Java 语言中**继承就是子类继承父类的属性和方法,使得子类对象(实例)具有父类的属性和方法,或子类从父类继承方法,使得子类具有父类相同的方法**。
-
-我们来举个例子:动物有很多种,是一个比较大的概念。在动物的种类中,我们熟悉的有猫(Cat)、狗(Dog)等动物,它们都有动物的一般特征(比如能够吃东西,能够发出声音),不过又在细节上有区别(不同动物的吃的不同,叫声不一样)。
-
-在 Java 语言中实现 Cat 和 Dog 等类的时候,就需要继承 Animal 这个类。继承之后 Cat、Dog 等具体动物类就是子类,Animal 类就是父类。
-
-
-
-#### 02、为什么需要继承
-
-三妹,你可能会问**为什么需要继承**?
-
-如果仅仅只有两三个类,每个类的属性和方法很有限的情况下确实没必要实现继承,但事情并非如此,事实上一个系统中往往有很多个类并且有着很多相似之处,比如猫和狗同属动物,或者学生和老师同属人。各个类可能又有很多个相同的属性和方法,这样的话如果每个类都重新写不仅代码显得很乱,代码工作量也很大。
-
-这时继承的优势就出来了:可以直接使用父类的属性和方法,自己也可以有自己新的属性和方法满足拓展,父类的方法如果自己有需求更改也可以重写。这样**使用继承不仅大大的减少了代码量,也使得代码结构更加清晰可见**。
-
-
-
-所以这样从代码的层面上来看我们设计这个完整的 Animal 类是这样的:
-
-```java
-class Animal
-{
- public int id;
- public String name;
- public int age;
- public int weight;
-
- public Animal(int id, String name, int age, int weight) {
- this.id = id;
- this.name = name;
- this.age = age;
- this.weight = weight;
- }
- //这里省略get set方法
- public void sayHello()
- {
- System.out.println("hello");
- }
- public void eat()
- {
- System.out.println("I'm eating");
- }
- public void sing()
- {
- System.out.println("sing");
- }
-}
-```
-
-而 Dog,Cat,Chicken 类可以这样设计:
-
-```java
-class Dog extends Animal//继承animal
-{
- public Dog(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
-}
-class Cat extends Animal{
-
- public Cat(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
-}
-class Chicken extends Animal{
-
- public Chicken(int id, String name, int age, int weight) {
- super(id, name, age, weight);//调用父类构造方法
- }
- //鸡下蛋
- public void layEggs()
- {
- System.out.println("我是老母鸡下蛋啦,咯哒咯!咯哒咯!");
- }
-}
-```
-
-各自的类继承 Animal 后可以直接使用 Animal 类的属性和方法而不需要重复编写,各个类如果有自己的方法也可很容易地拓展。
-
-#### 03、继承的分类
-
-继承分为单继承和多继承,Java 语言只支持类的单继承,但可以通过实现接口的方式达到多继承的目的。**这个我们之前在讲接口的时候就提到过,这里我们再聊一下。**
-
-继承 | 定义 | 优缺点 |
----| ---- | ------ |
-单继承|一个子类只拥有一个父类|优点:在类层次结构上比较清晰
缺点:结构的丰富度有时不能满足使用需求|
-多继承(Java 不支持,但可以用其它方式满足多继承使用需求)|一个子类拥有多个直接的父类|优点:子类的丰富度很高
缺点:容易造成混乱|
-
-##### **单继承**
-
-单继承,一个子类只有一个父类,如我们上面讲过的 Animal 类和它的子类。**单继承在类层次结构上比较清晰,但缺点是结构的丰富度有时不能满足使用需求**。
-
-##### **多继承**
-
-多继承,一个子类有多个直接的父类。这样做的好处是子类拥有所有父类的特征,**子类的丰富度很高,但是缺点就是容易造成混乱**。下图为一个混乱的例子。
-
-
-
-Java 虽然不支持多继承,但是 Java 有三种实现多继承效果的方式,**分别是**内部类、多层继承和实现接口。
-
-[内部类](https://tobebetterjavaer.com/oo/inner-class.html)可以继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,可以达到多继承的效果。
-
-**多层继承:**子类继承父类,父类如果还继承其他的类,那么这就叫**多层继承**。这样子类就会拥有所有被继承类的属性和方法。
-
-
-
-[实现接口](https://tobebetterjavaer.com/oo/interface.html)无疑是满足多继承使用需求的最好方式,一个类可以实现多个接口满足自己在丰富性和复杂环境的使用需求。
-
-类和接口相比,**类就是一个实体,有属性和方法,而接口更倾向于一组方法**。举个例子,就拿斗罗大陆的唐三来看,他存在的继承关系可能是这样的:
-
-
-
-#### 04、如何实现继承
-
-##### **extends 关键字**
-
-在 Java 中,类的继承是单一继承,也就是说一个子类只能拥有一个父类,所以**extends**只能继承一个类。其使用语法为:
-
-```java
-class 子类名 extends 父类名{}
-```
-
-例如 Dog 类继承 Animal 类,它是这样的:
-
-```java
-class Animal{} //定义Animal类
-class Dog extends Animal{} //Dog类继承Animal类
-```
-
-子类继承父类后,就拥有父类的非私有的**属性和方法**。如果不明白,请看这个案例,在 IDEA 下创建一个项目,创建一个 test 类做测试,分别创建 Animal 类和 Dog 类,Animal 作为父类写一个 sayHello()方法,Dog 类继承 Animal 类之后就可以调用 sayHello()方法。具体代码为:
-
-```java
-class Animal {
- public void sayHello()//父类的方法
- {
- System.out.println("hello,everybody");
- }
-}
-class Dog extends Animal//继承animal
-{ }
-public class test {
- public static void main(String[] args) {
- Dog dog=new Dog();
- dog.sayHello();
- }
-}
-```
-
-点击运行的时候 Dog 子类可以直接使用 Animal 父类的方法。
-
-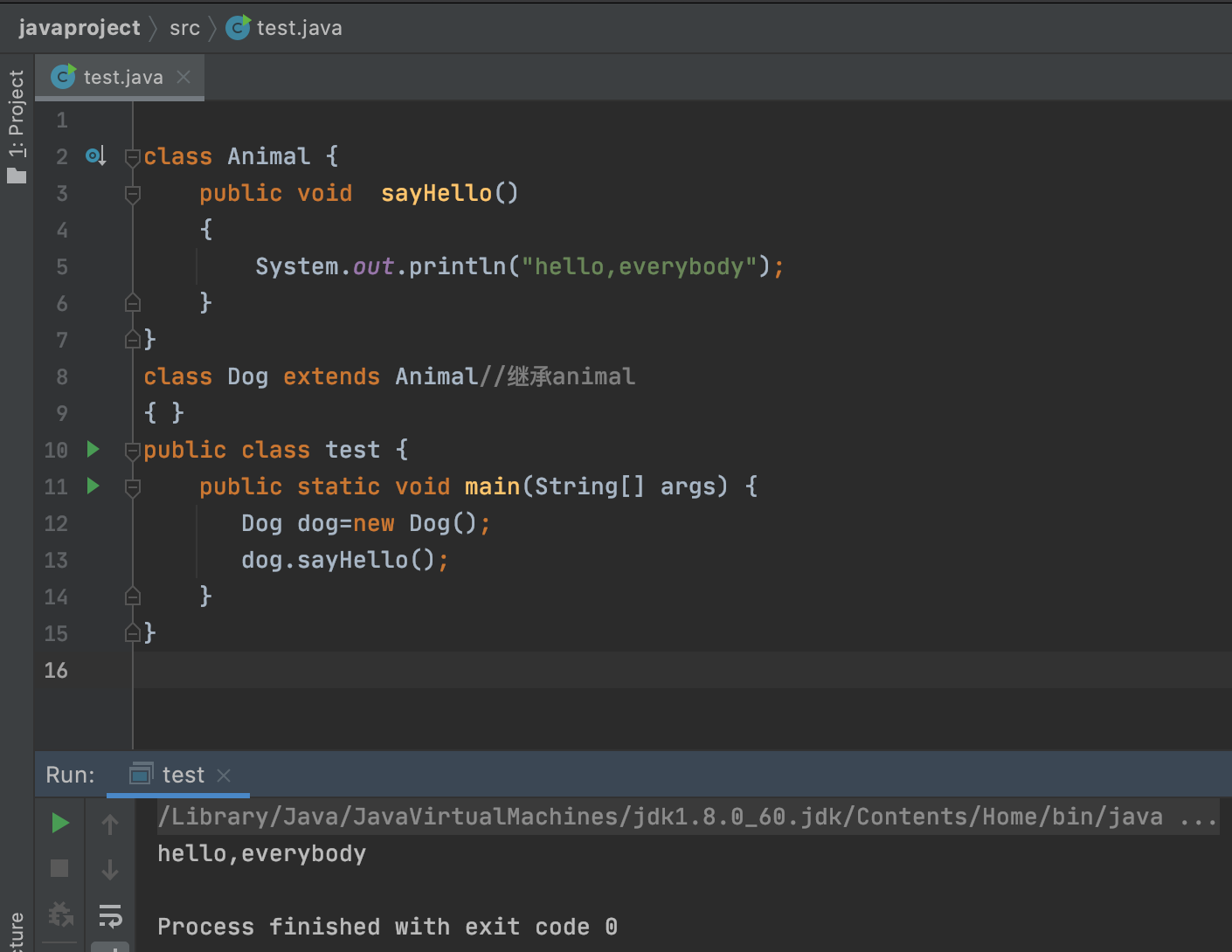
-
-##### **implements 关键字**
-
-使用 implements 关键字可以变相使 Java 拥有多继承的特性,使用范围为类实现接口的情况,一个类可以实现多个接口(接口与接口之间用逗号分开)。
-
-我们来看一个案例,创建一个 test2 类做测试,分别创建 doA 接口和 doB 接口,doA 接口声明 sayHello()方法,doB 接口声明 eat()方法,创建 Cat2 类实现 doA 和 doB 接口,并且在类中需要重写 sayHello()方法和 eat()方法。具体代码为:
-
-```java
-interface doA{
- void sayHello();
-}
-interface doB{
- void eat();
- //以下会报错 接口中的方法不能具体定义只能声明
- //public void eat(){System.out.println("eating");}
-}
-class Cat2 implements doA,doB{
- @Override//必须重写接口内的方法
- public void sayHello() {
- System.out.println("hello!");
- }
- @Override
- public void eat() {
- System.out.println("I'm eating");
- }
-}
-public class test2 {
- public static void main(String[] args) {
- Cat2 cat=new Cat2();
- cat.sayHello();
- cat.eat();
- }
-}
-```
-
-Cat 类实现 doA 和 doB 接口的时候,需要实现其声明的方法,点击运行结果如下,这就是一个类实现接口的简单案例:
-
-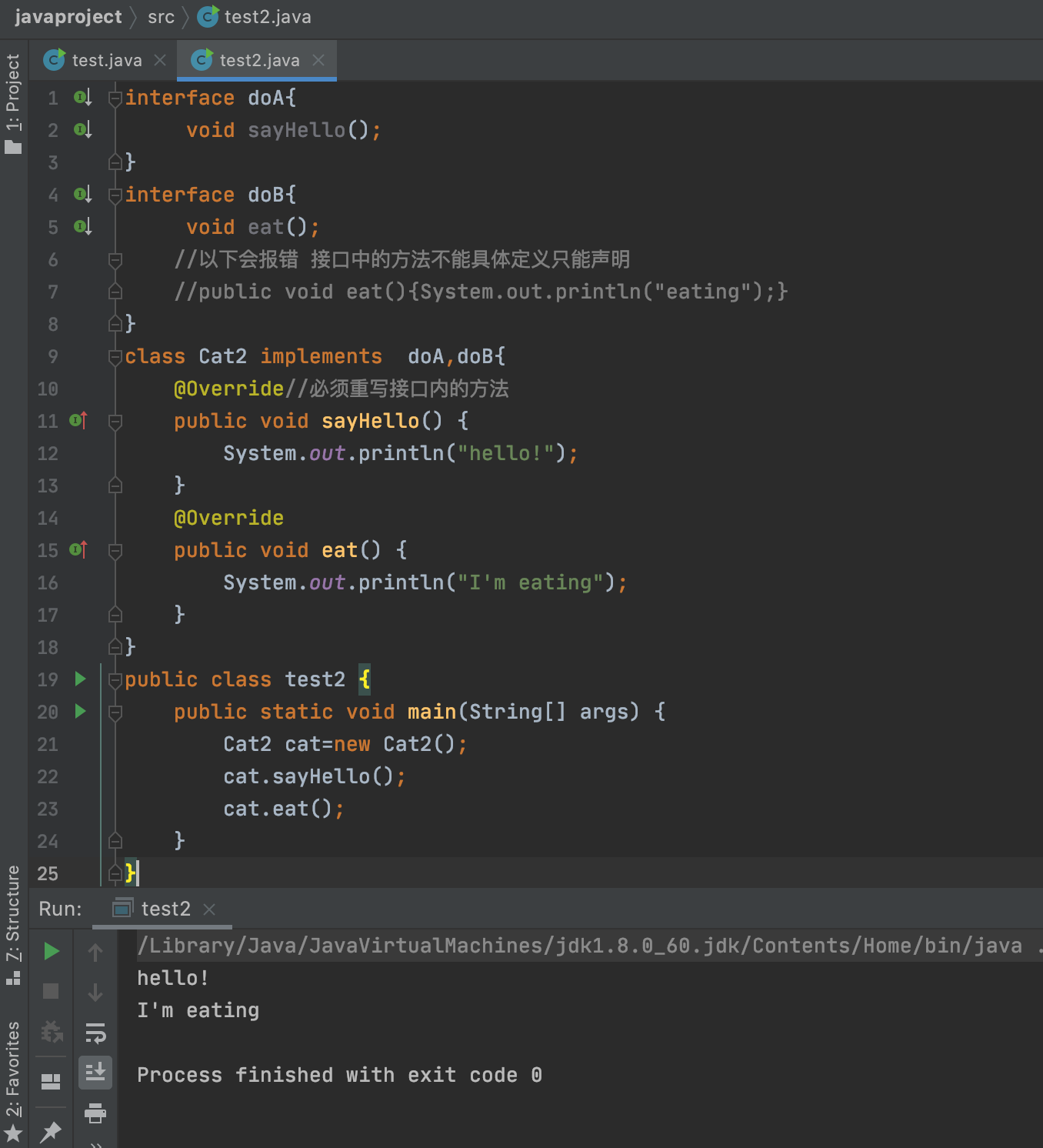
-
-#### 05、继承的特点
-
-继承的主要内容就是子类继承父类,并重写父类的方法。使用子类的属性或方法时候,首先要创建一个对象,而对象通过[构造方法](https://tobebetterjavaer.com/oo/construct.html)去创建,在构造方法中我们可能会调用子父类的一些属性和方法,所以就需要提前掌握 [this 和 super关键字](https://tobebetterjavaer.com/oo/this-super.html)。
-
-创建完这个对象之后,再调用**重写**父类后的方法,注意[重写和重载的区别](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)。
-
-##### this 和 super 关键字
-
->[后面](https://tobebetterjavaer.com/oo/this-super.html)会详细讲,这里先来简单了解一下。
-
-this 和 super 关键字是继承中**非常重要的知识点**,分别表示当前对象的引用和父类对象的引用,两者有很大相似又有一些区别。
-
-**this 表示当前对象,是指向自己的引用。**
-
-```java
-this.属性 // 调用成员变量,要区别成员变量和局部变量
-this.() // 调用本类的某个方法
-this() // 表示调用本类构造方法
-```
-
-**super 表示父类对象,是指向父类的引用。**
-
-```java
-super.属性 // 表示父类对象中的成员变量
-super.方法() // 表示父类对象中定义的方法
-super() // 表示调用父类构造方法
-```
-
-##### 构造方法
-
-[构造方法](https://tobebetterjavaer.com/oo/construct.html)是一种特殊的方法,**它是一个与类同名的方法**。在继承中**构造方法是一种比较特殊的方法**(比如不能继承),所以要了解和学习在继承中构造方法的规则和要求。
-
-继承中的构造方法有以下几点需要注意:
-
-**父类的构造方法不能被继承:**
-
-因为构造方法语法是**与类同名**,而继承则不更改方法名,如果子类继承父类的构造方法,那明显与构造方法的语法冲突了。比如 Father 类的构造方法名为 Father(),Son 类如果继承 Father 类的构造方法 Father(),那就和构造方法定义:**构造方法与类同名**冲突了,所以在子类中不能继承父类的构造方法,但子类会调用父类的构造方法。
-
-**子类的构造过程必须调用其父类的构造方法:**
-
-Java 虚拟机**构造子类对象前会先构造父类对象,父类对象构造完成之后再来构造子类特有的属性,**这被称为**内存叠加**。而 Java 虚拟机构造父类对象会执行父类的构造方法,所以子类构造方法必须调用 super()即父类的构造方法。就比如一个简单的继承案例应该这么写:
-
-```java
-class A{
- public String name;
- public A() {//无参构造
- }
- public A (String name){//有参构造
- }
-}
-class B extends A{
- public B() {//无参构造
- super();
- }
- public B(String name) {//有参构造
- //super();
- super(name);
- }
-}
-```
-
-**如果子类的构造方法中没有显示地调用父类构造方法,则系统默认调用父类无参数的构造方法。**
-
-你可能有时候在写继承的时候子类并没有使用 super()调用,程序依然没问题,其实这样是为了节省代码,系统执行时会自动添加父类的无参构造方式,如果不信的话我们对上面的类稍作修改执行:
-
-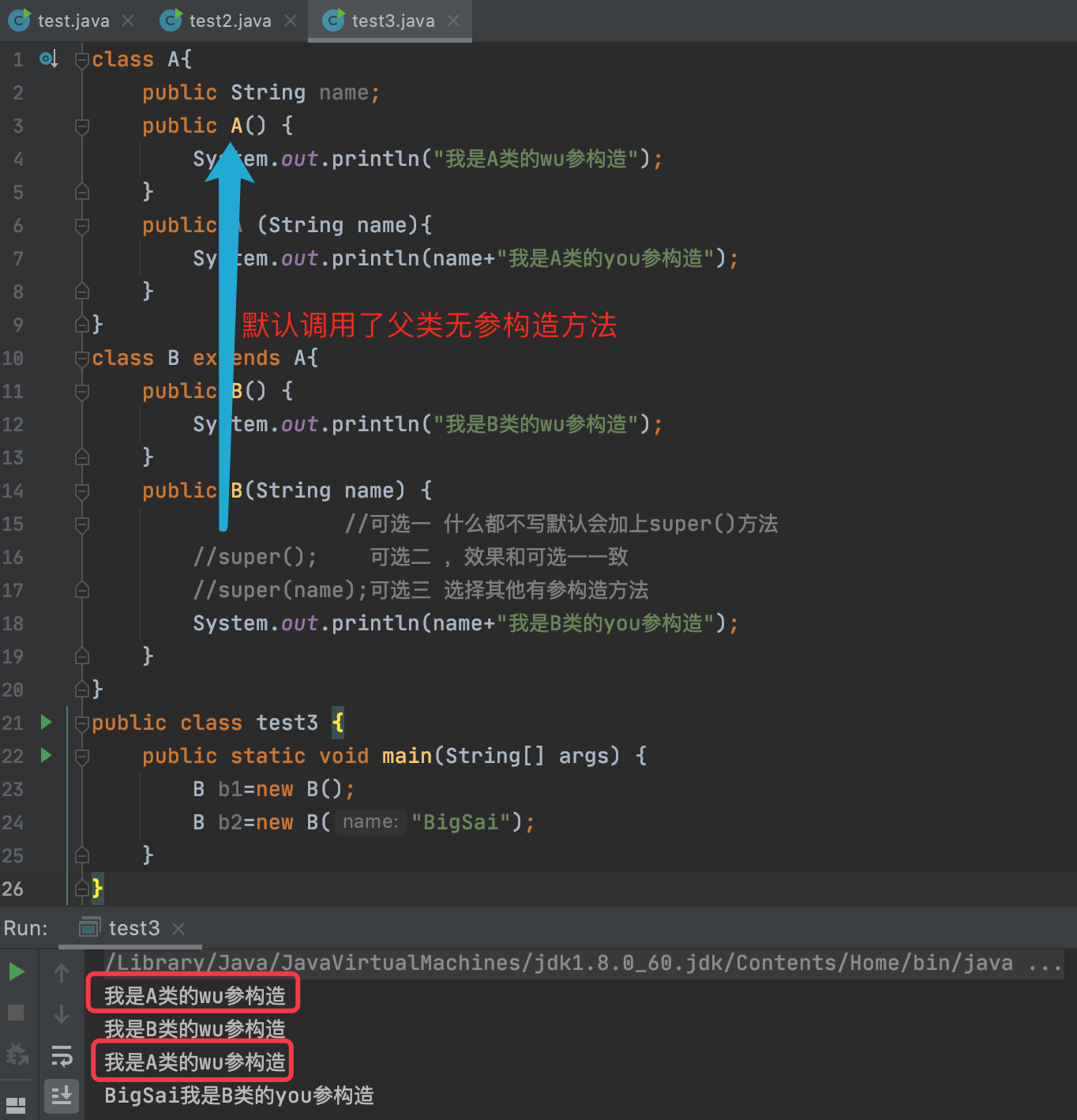
-
-##### 方法重写(Override)
-
-[方法重写](https://tobebetterjavaer.com/basic-extra-meal/Overriding.html)也就是子类中出现和父类中一模一样的方法(包括返回值类型,方法名,参数列表),它建立在继承的基础上。你可以理解为方法的**外壳不变,但是核心内容重写**。
-
-在这里提供一个简单易懂的方法重写案例:
-
-```java
-class E1{
- public void doA(int a){
- System.out.println("这是父类的方法");
- }
-}
-class E2 extends E1{
- @Override
- public void doA(int a) {
- System.out.println("我重写父类方法,这是子类的方法");
- }
-}
-```
-
-其中`@Override` 注解显示声明该方法为注解方法,可以帮你检查重写方法的语法正确性,当然如果不加也是可以的,但建议加上。
-
-##### 方法重载(Overload)
-
-如果有两个方法的**方法名相同**,但参数不一致,那么可以说一个方法是另一个方法的[重载](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)。
-
-重载可以通常理解为完成同一个事情的方法名相同,但是参数列表不同其他条件也可能不同。一个简单的方法重载的例子,类 E3 中的 add()方法就是一个重载方法。
-
-```java
-class E3{
- public int add(int a,int b){
- return a+b;
- }
- public double add(double a,double b) {
- return a+b;
- }
- public int add(int a,int b,int c) {
- return a+b+c;
- }
-}
-```
-
-#### 06、继承与修饰符
-
-Java 修饰符的作用就是对类或类成员进行修饰或限制,每个修饰符都有自己的作用,而在继承中可能有些特殊修饰符使得被修饰的属性或方法不能被继承,或者继承需要一些其他的条件。
-
-Java 语言提供了很多修饰符,修饰符用来定义类、方法或者变量,通常放在语句的最前端。主要分为以下两类:
-
-- [访问权限修饰符](https://tobebetterjavaer.com/oo/access-control.html),也就是 public、private、protected 等
-- 非访问修饰符,也就是 static、final、abstract 等
-
-##### 访问修饰符
-
-Java 子类重写继承的方法时,**不可以降低方法的访问权限**,**子类继承父类的访问修饰符作用域不能比父类小**,也就是更加开放,假如父类是 protected 修饰的,其子类只能是 protected 或者 public,绝对不能是 default(默认的访问范围)或者 private。所以在继承中需要重写的方法不能使用 private 修饰词修饰。
-
-如果还是不太清楚可以看几个小案例就很容易搞懂,写一个 A1 类中用四种修饰词实现四个方法,用子类 A2 继承 A1,重写 A1 方法时候你就会发现父类私有方法不能重写,非私有方法重写使用的修饰符作用域不能变小(大于等于)。
-
-
-
-正确的案例应该为:
-
-```java
-class A1 {
- private void doA(){ }
- void doB(){}//default
- protected void doC(){}
- public void doD(){}
-}
-class A2 extends A1{
-
- @Override
- public void doB() { }//继承子类重写的方法访问修饰符权限可扩大
-
- @Override
- protected void doC() { }//继承子类重写的方法访问修饰符权限可和父类一致
-
- @Override
- public void doD() { }//不可用protected或者default修饰
-}
-```
-
-还要注意的是,**继承当中子类抛出的异常必须是父类抛出的异常或父类抛出异常的子异常**。下面的一个案例四种方法测试可以发现子类方法的异常不可大于父类对应方法抛出异常的范围。
-
-
-
-正确的案例应该为:
-
-```java
-class B1{
- public void doA() throws Exception{}
- public void doB() throws Exception{}
- public void doC() throws IOException{}
- public void doD() throws IOException{}
-}
-class B2 extends B1{
- //异常范围和父类可以一致
- @Override
- public void doA() throws Exception { }
- //异常范围可以比父类更小
- @Override
- public void doB() throws IOException { }
- //异常范围 不可以比父类范围更大
- @Override
- public void doC() throws IOException { }//不可抛出Exception等比IOException更大的异常
- @Override
- public void doD() throws IOException { }
-}
-```
-
-##### 非访问修饰符
-
-访问修饰符用来控制访问权限,而非访问修饰符每个都有各自的作用,下面针对 static、final、abstract 修饰符进行介绍。
-
-[static 修饰符](https://tobebetterjavaer.com/oo/static.html)
-
-static 翻译为“静态的”,能够与变量,方法和类一起使用,**称为静态变量,静态方法(也称为类变量、类方法)**。如果在一个类中使用 static 修饰变量或者方法的话,它们**可以直接通过类访问,不需要创建一个类的对象来访问成员。**
-
-我们在设计类的时候可能会使用静态方法,有很多工具类比如`Math`,`Arrays`等类里面就写了很多静态方法。
-
-可以看以下的案例证明上述规则:
-
-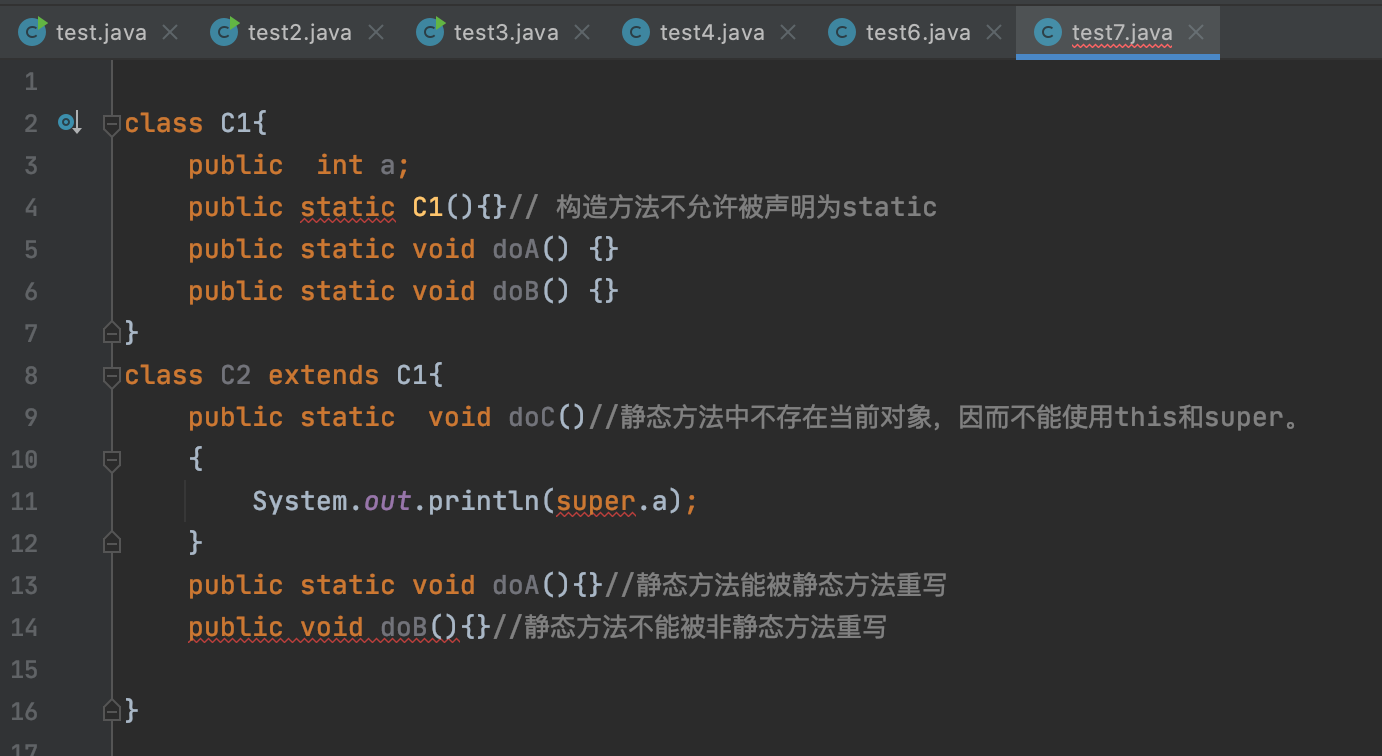
-
-源代码为:
-
-```java
-class C1{
- public int a;
- public C1(){}
- // public static C1(){}// 构造方法不允许被声明为static
- public static void doA() {}
- public static void doB() {}
-}
-class C2 extends C1{
- public static void doC()//静态方法中不存在当前对象,因而不能使用this和super。
- {
- //System.out.println(super.a);
- }
- public static void doA(){}//静态方法能被静态方法重写
- // public void doB(){}//静态方法不能被非静态方法重写
-}
-```
-
-[final 修饰符](https://tobebetterjavaer.com/oo/final.html)
-
-final 变量:
-
-- final 表示"最后的、最终的"含义,**变量一旦赋值后,不能被重新赋值**。被 final 修饰的实例变量必须显式指定初始值(即不能只声明)。final 修饰符通常和 static 修饰符一起使用来创建类常量。
-
-final 方法:
-
-- **父类中的 final 方法可以被子类继承,但是不能被子类重写**。声明 final 方法的主要目的是防止该方法的内容被修改。
-
-final 类:
-
-- **final 类不能被继承**,没有类能够继承 final 类的任何特性。
-
-所以无论是变量、方法还是类被 final 修饰之后,都有代表最终、最后的意思。内容无法被修改。
-
-[abstract 修饰符](https://tobebetterjavaer.com/oo/abstract.html)
-
-abstract 英文名为“抽象的”,主要用来修饰类和方法,称为抽象类和抽象方法。
-
-**抽象方法**:有很多不同类的方法是相似的,但是具体内容又不太一样,所以我们只能抽取他的声明,没有具体的方法体,即抽象方法可以表达概念但无法具体实现。
-
-**抽象类**:**有抽象方法的类必须是抽象类**,抽象类可以表达概念但是无法构造实体的类。
-
-
-
-比如我们可以这样设计一个 People 抽象类以及一个抽象方法,在子类中具体完成:
-
-```java
-abstract class People{
- public abstract void sayHello();//抽象方法
-}
-class Chinese extends People{
- @Override
- public void sayHello() {//实现抽象方法
- System.out.println("你好");
- }
-}
-class Japanese extends People{
- @Override
- public void sayHello() {//实现抽象方法
- System.out.println("口你七哇");
- }
-}
-class American extends People{
- @Override
- public void sayHello() {//实现抽象方法
- System.out.println("hello");
- }
-}
-```
-
-#### 07、Object 类和转型
-
-提到 Java 继承,不得不提及所有类的根类:Object(java.lang.Object)类,如果一个类没有显式声明它的父类(即没有写 extends xx),那么默认这个类的父类就是 Object 类,任何类都可以使用 Object 类的方法,创建的类也可和 Object 进行向上、向下转型,所以 Object 类是掌握和理解继承所必须的知识点。
-
-Java 向上和向下转型在 Java 中运用很多,也是建立在继承的基础上,所以 Java 转型也是掌握和理解继承所必须的知识点。
-
-##### Object 类概述
-
-1. Object 是类层次结构的**根类**,所有的类都隐式的继承自 Object 类。
-2. Java 中,所有的对象都拥有 Object 的默认方法。
-3. Object 类有一个[构造方法](https://tobebetterjavaer.com/oo/construct.html),并且是**无参构造方法**。
-
-Object 是 Java 所有类的父类,是整个类继承结构的顶端,也是最抽象的一个类。
-
-像 toString()、equals()、hashCode()、wait()、notify()、getClass()等都是 Object 的方法。你以后可能会经常碰到,但其中遇到更多的就是 toString()方法和 equals()方法,我们经常需要重写这两种方法满足我们的使用需求。
-
-toString()方法表示返回该对象的字符串,由于各个对象构造不同所以需要重写,如果不重写的话默认返回`类名@hashCode`格式。
-
-**如果重写 toString()方法后**直接调用 toString()方法就可以返回我们自定义的该类转成字符串类型的内容输出,而不需要每次都手动的拼凑成字符串内容输出,大大简化输出操作。
-
-equals()方法主要比较两个对象是否相等,因为对象的相等不一定非要严格要求两个对象地址上的相同,有时内容上的相同我们就会认为它相等,比如 String 类就重写了euqals()方法,通过[字符串的内容比较是否相等](https://tobebetterjavaer.com/string/equals.html)。
-
-
-
-##### 向上转型
-
-**向上转型** : 通过子类对象(小范围)实例化父类对象(大范围),这种属于自动转换。用一张图就能很好地表示向上转型的逻辑:
-
-
-
-父类引用变量指向子类对象后,只能使用父类已声明的方法,但方法如果被重写会执行子类的方法,如果方法未被重写那么将执行父类的方法。
-
-##### 向下转型
-
-**向下转型** : 通过父类对象(大范围)实例化子类对象(小范围),在书写上父类对象需要加括号`()`强制转换为子类类型。但父类引用变量实际引用必须是子类对象才能成功转型,这里也用一张图就能很好表示向下转型的逻辑:
-
-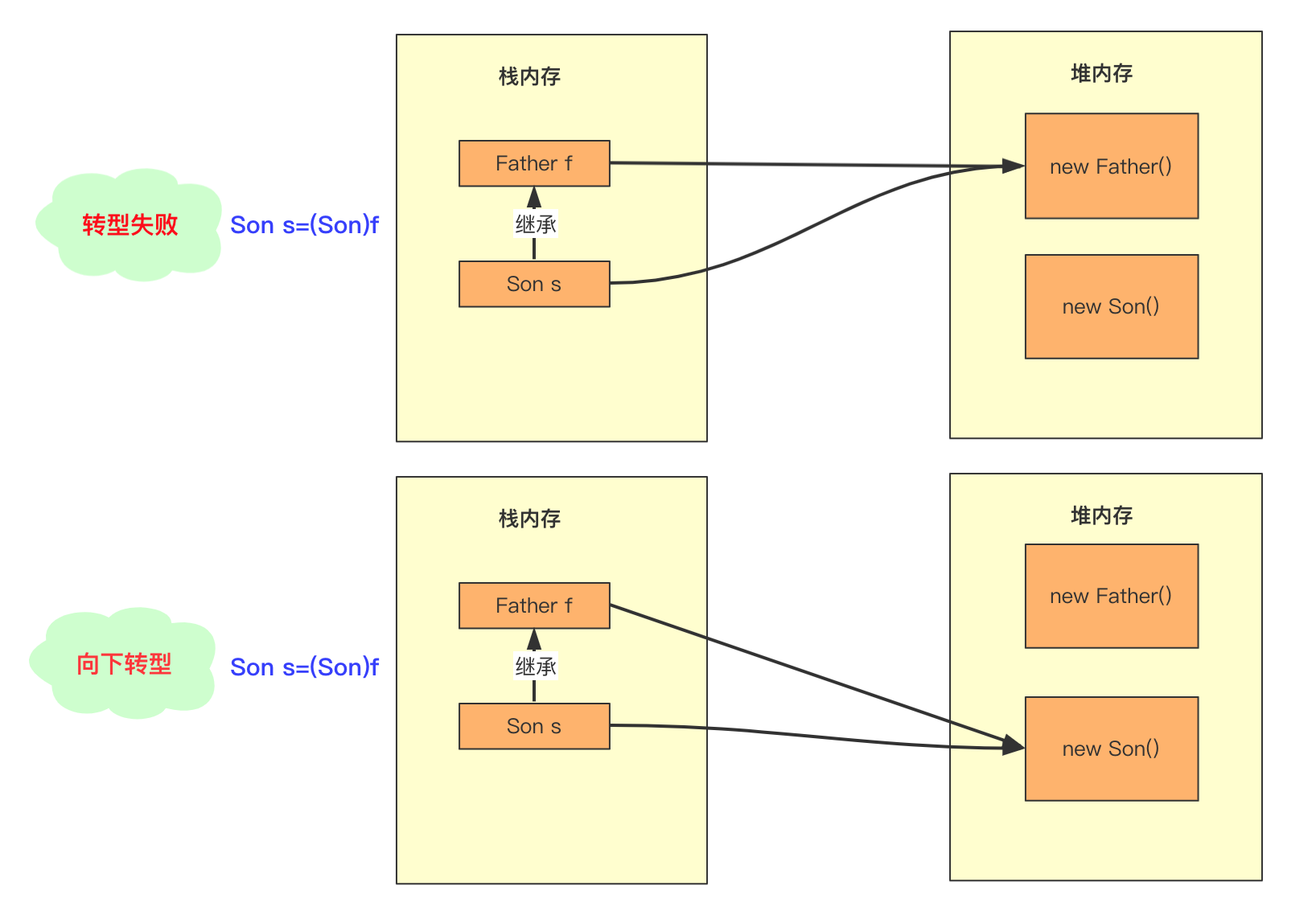
-
-子类引用变量指向父类引用变量指向的对象后(一个 Son()对象),就完成向下转型,就可以调用一些子类特有而父类没有的方法 。
-
-在这里写一个向上转型和向下转型的案例:
-
-```java
-Object object=new Integer(666);//向上转型
-
-Integer i=(Integer)object;//向下转型Object->Integer,object的实质还是指向Integer
-
-String str=(String)object;//错误的向下转型,虽然编译器不会报错但是运行会报错
-```
-
-#### 08、子父类初始化顺序
-
-在 Java 继承中,父子类初始化先后顺序为:
-
-1. 父类中静态成员变量和静态代码块
-2. 子类中静态成员变量和静态代码块
-3. 父类中普通成员变量和代码块,父类的构造方法
-4. 子类中普通成员变量和代码块,子类的构造方法
-
-总的来说,就是**静态>非静态,父类>子类,非构造方法>构造方法**。同一类别(例如普通变量和普通代码块)成员变量和代码块执行从前到后,需要注意逻辑。
-
-这个也不难理解,静态变量也称类变量,可以看成一个全局变量,静态成员变量和静态代码块在类加载的时候就初始化,而非静态变量和代码块在对象创建的时候初始化。所以静态快于非静态初始化。
-
-而在创建子类对象的时候需要先创建父类对象,所以父类优先于子类。
-
-而在调用构造方法的时候,是对成员变量进行一些初始化操作,所以普通成员变量和代码块优于构造方法执行。
-
-至于更深层次为什么这个顺序,就要更深入了解 JVM 执行流程啦。下面一个测试代码为:
-
-```java
-class Father{
- public Father() {
- System.out.println(++b1+"父类构造方法");
- }//父类构造方法 第四
- static int a1=0;//父类static 第一 注意顺序
- static {
- System.out.println(++a1+"父类static");
- }
- int b1=a1;//父类成员变量和代码块 第三
- {
- System.out.println(++b1+"父类代码块");
- }
-}
-class Son extends Father{
- public Son() {
- System.out.println(++b2+"子类构造方法");
- }//子类构造方法 第六
- static {//子类static第二步
- System.out.println(++a1+"子类static");
- }
- int b2=b1;//子类成员变量和代码块 第五
- {
- System.out.println(++b2 + "子类代码块");
- }
-}
-public class test9 {
- public static void main(String[] args) {
- Son son=new Son();
- }
-}
-```
-
-执行结果:
-
-
-
-
-### 3)多态
-
-Java 多态是指在面向对象编程中,同一个类的对象在不同情况下表现出不同的行为和状态。
-
-- 子类可以继承父类的属性和方法,子类对象可以直接使用父类中的方法和变量。
-- 子类可以对从父类继承的方法进行重新实现,使得子类对象调用这个方法时表现出不同的行为。
-- 可以将子类对象赋给父类类型的变量,这样就可以通过父类类型的变量调用子类中重写的方法,实现多态。
-
-“很枯燥,有没有?再具体的分析一下。”
-
-#### 01、多态是什么
-
-在我刻板的印象里,西游记里的那段孙悟空和二郎神的精彩对战就能很好的解释“多态”这个词:一个孙悟空,能七十二变;一个二郎神,也能七十二变;他们都可以变成不同的形态,但只需要悄悄地喊一声“变”。
-
-Java的多态是什么呢?其实就是一种能力——同一个行为具有不同的表现形式;换句话说就是,执行一段代码,Java 在运行时能根据对象的不同产生不同的结果。和孙悟空和二郎神都只需要喊一声“变”,然后就变了,并且每次变得还不一样;一个道理。
-
-多态的前提条件有三个:
-
-* 子类继承父类
-* 子类覆盖父类的方法
-* 父类引用指向子类对象
-
-多态的一个简单应用,来看程序清单1-1:
-
-```java
-//子类继承父类
-public class Wangxiaoer extends Wanger {
- public void write() { // 子类覆盖父类方法
- System.out.println("记住仇恨,表明我们要奋发图强的心智");
- }
-
- public static void main(String[] args) {
- // 父类引用指向子类对象
- Wanger[] wangers = { new Wanger(), new Wangxiaoer() };
-
- for (Wanger wanger : wangers) {
- // 对象是王二的时候输出:勿忘国耻
- // 对象是王小二的时候输出:记住仇恨,表明我们要奋发图强的心智
- wanger.write();
- }
- }
-}
-
-class Wanger {
- public void write() {
- System.out.println("勿忘国耻");
- }
-}
-```
-
-#### 02、多态与后期绑定
-
-现在,我们来思考一个问题:程序清单1-1在执行 `wanger.write()` 时,由于编译器只有一个 Wanger 引用,它怎么知道究竟该调用父类 Wanger 的 `write()` 方法,还是子类 Wangxiaoer 的 `write()` 方法呢?
-
-答案是在运行时根据对象的类型进行后期绑定,编译器在编译阶段并不知道对象的类型,但是Java的方法调用机制能找到正确的方法体,然后执行出正确的结果。
-
-多态机制提供的一个重要的好处程序具有良好的扩展性。来看程序清单2-1:
-
-```java
-//子类继承父类
-public class Wangxiaoer extends Wanger {
- public void write() { // 子类覆盖父类方法
- System.out.println("记住仇恨,表明我们要奋发图强的心智");
- }
-
- public void eat() {
- System.out.println("我不喜欢读书,我就喜欢吃");
- }
-
- public static void main(String[] args) {
- // 父类引用指向子类对象
- Wanger[] wangers = { new Wanger(), new Wangxiaoer() };
-
- for (Wanger wanger : wangers) {
- // 对象是王二的时候输出:勿忘国耻
- // 对象是王小二的时候输出:记住仇恨,表明我们要奋发图强的心智
- wanger.write();
- }
- }
-}
-
-class Wanger {
- public void write() {
- System.out.println("勿忘国耻");
- }
-
- public void read() {
- System.out.println("每周读一本好书");
- }
-}
-```
-
-在程序清单 2-1 中,我们在 Wanger 类中增加了 read() 方法,在 Wangxiaoer 类中增加了eat()方法,但这丝毫不会影响到 write() 方法的调用。write() 方法忽略了周围代码发生的变化,依然正常运行。这让我想起了金庸《倚天屠龙记》里九阳真经的口诀:“他强由他强,清风拂山岗;他横由他横,明月照大江。”
-
-多态的这个优秀的特性,让我们在修改代码的时候不必过于紧张,因为多态是一项让程序员“将改变的与未改变的分离开来”的重要特性。
-
-#### 03、多态与构造方法
-
-在构造方法中调用多态方法,会产生一个奇妙的结果,我们来看程序清单3-1:
-
-```java
-public class Wangxiaosan extends Wangsan {
- private int age = 3;
- public Wangxiaosan(int age) {
- this.age = age;
- System.out.println("王小三的年龄:" + this.age);
- }
-
- public void write() { // 子类覆盖父类方法
- System.out.println("我小三上幼儿园的年龄是:" + this.age);
- }
-
- public static void main(String[] args) {
- new Wangxiaosan(4);
-// 上幼儿园之前
-// 我小三上幼儿园的年龄是:0
-// 上幼儿园之后
-// 王小三的年龄:4
- }
-}
-
-class Wangsan {
- Wangsan () {
- System.out.println("上幼儿园之前");
- write();
- System.out.println("上幼儿园之后");
- }
- public void write() {
- System.out.println("老子上幼儿园的年龄是3岁半");
- }
-}
-```
-
-从输出结果上看,是不是有点诧异?明明在创建 Wangxiaosan 对象的时候,年龄传递的是 4,但输出结果既不是“老子上幼儿园的年龄是 3 岁半”,也不是“我小三上幼儿园的年龄是:4”。
-
-为什么?
-
-因为在创建子类对象时,会先去调用父类的构造方法,而父类构造方法中又调用了被子类覆盖的多态方法,由于父类并不清楚子类对象中的属性值是什么,于是把int类型的属性暂时初始化为 0,然后再调用子类的构造方法(子类构造方法知道王小二的年龄是 4)。
-
-#### 04、多态与向下转型
-
-向下转型是指将父类引用强转为子类类型;这是不安全的,因为有的时候,父类引用指向的是父类对象,向下转型就会抛出 ClassCastException,表示类型转换失败;但如果父类引用指向的是子类对象,那么向下转型就是成功的。
-
-来看程序清单4-1:
-
-```java
-public class Wangxiaosi extends Wangsi {
- public void write() {
- System.out.println("记住仇恨,表明我们要奋发图强的心智");
- }
-
- public void eat() {
- System.out.println("我不喜欢读书,我就喜欢吃");
- }
-
- public static void main(String[] args) {
- Wangsi[] wangsis = { new Wangsi(), new Wangxiaosi() };
-
- // wangsis[1]能够向下转型
- ((Wangxiaosi) wangsis[1]).write();
- // wangsis[0]不能向下转型
- ((Wangxiaosi)wangsis[0]).write();
- }
-}
-
-class Wangsi {
- public void write() {
- System.out.println("勿忘国耻");
- }
-
- public void read() {
- System.out.println("每周读一本好书");
- }
-}
-```
-
-“好了,三妹,到此为止,我们就将 Java 的三大特性,封装继承多态全部讲完了,希望你能重新把他们梳理一下。”
-
-“好的,二哥,遵命。”三妹顽皮地笑了。
-
-### 4)小结
-
-好啦,三妹,本次继承就介绍到这里啦,Java 面向对象三大特征之一继承——优秀的你已经掌握。
-
-封装:是对类的封装,封装是对类的属性和方法进行封装,只对外暴露方法而不暴露具体使用细节,所以我们一般设计类成员变量时候大多设为私有而通过一些 get、set 方法去读写。
-
-继承:子类继承父类,即“子承父业”,子类拥有父类除私有的所有属性和方法,自己还能在此基础上拓展自己新的属性和方法。主要目的是**复用代码**。
-
-**多态**:多态是同一个行为具有多个不同表现形式或形态的能力。即一个父类可能有若干子类,各子类实现父类方法有多种多样,调用父类方法时,父类引用变量指向不同子类实例而执行不同方法,这就是所谓父类方法是多态的。
-
-最后送你一张图捋一捋其中的关系吧。
-
-
-
-“好的,二哥,我来消化一下,今天内容真不少。你先去休息一下。”三妹回应到。
-
-> 参考链接:[https://bbs.huaweicloud.com/blogs/271358](https://bbs.huaweicloud.com/blogs/271358),作者:bigsai,整理:沉默王二
-
-
-
-
-## 5.14 Java this和super关键字
-
-“哥,被喊大舅子的感觉怎么样啊?”三妹不怀好意地对我说,她眼睛里充满着不屑。
-
-“说实话,这种感觉还不错。”我有点难为情的回答她,“不过,有一点令我感到些许失落。大家的焦点似乎都是你的颜值,完全忽略了我的盛世美颜啊!”
-
-“哥,你想啥呢,那是因为你文章写得好,不然谁认识我是谁啊!有你这样的哥哥,我还是挺自豪的。”三妹郑重其事地说,“话说今天咱学啥呢?”
-
-“三妹啊,你这句话说得我喜欢。今天来学习一下 Java 中的 this 关键字吧。”喝了一口农夫山泉后,我对三妹说。
-
-“this 关键字有很多种用法,其中最常用的一个是,它可以作为引用变量,指向当前对象。”我面带着朴实无华的微笑继续说,“除此之外, this 关键字还可以完成以下工作。”
-
-- 调用当前类的方法;
-- `this()` 可以调用当前类的构造方法;
-- this 可以作为参数在方法中传递;
-- this 可以作为参数在构造方法中传递;
-- this 可以作为方法的返回值,返回当前类的对象。
-
-### 01、 指向当前对象
-
-“三妹,来看下面这段代码。”话音刚落,我就在键盘上噼里啪啦一阵敲。
-
-```java
-public class WithoutThisStudent {
- String name;
- int age;
-
- WithoutThisStudent(String name, int age) {
- name = name;
- age = age;
- }
-
- void out() {
- System.out.println(name+" " + age);
- }
-
- public static void main(String[] args) {
- WithoutThisStudent s1 = new WithoutThisStudent("沉默王二", 18);
- WithoutThisStudent s2 = new WithoutThisStudent("沉默王三", 16);
-
- s1.out();
- s2.out();
- }
-}
-```
-
-“在上面的例子中,构造方法的参数名和实例变量名相同,由于没有使用 this 关键字,所以无法为实例变量赋值。”我抬起右手的食指,指着屏幕上的 name 和 age 对着三妹说。
-
-“来看一下程序的输出结果。”
-
-```
-null 0
-null 0
-```
-
-“从结果中可以看得出来,尽管创建对象的时候传递了参数,但实例变量并没有赋值。这是因为如果构造方法中没有使用 this 关键字的话,name 和 age 指向的并不是实例变量而是参数本身。”我把脖子扭向右侧,看着三妹说。
-
-“那怎么解决这个问题呢?哥。”三妹着急地问。
-
-“如果参数名和实例变量名产生了冲突.....”我正准备给出答案,三妹打断了我。
-
-“难道用 this 吗?”三妹脱口而出。
-
-“哇,越来越棒了呀,你。”我感觉三妹在学习 Java 这条道路上逐渐有了自己主动思考的意愿。
-
-“是的,来看加上 this 关键字后的代码。”
-
-安静的屋子里又响起了一阵噼里啪啦的键盘声。
-
-```java
-public class WithThisStudent {
- String name;
- int age;
-
- WithThisStudent(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- void out() {
- System.out.println(name+" " + age);
- }
-
- public static void main(String[] args) {
- WithThisStudent s1 = new WithThisStudent("沉默王二", 18);
- WithThisStudent s2 = new WithThisStudent("沉默王三", 16);
-
- s1.out();
- s2.out();
- }
-}
-```
-
-“再来看一下程序的输出结果。”
-
-```
-沉默王二 18
-沉默王三 16
-```
-
-“这次,实例变量有值了,在构造方法中,`this.xxx` 指向的就是实例变量,而不再是参数本身了。”我慢吞吞地说着,“当然了,如果参数名和实例变量名不同的话,就不必使用 this 关键字,但我建议使用 this 关键字,这样的代码更有意义。”
-
-### 02、调用当前类的方法
-
-“仔细听,三妹,看我敲键盘的速度是不是够快。”
-
-```java
-public class InvokeCurrentClassMethod {
- void method1() {}
- void method2() {
- method1();
- }
-
- public static void main(String[] args) {
- new InvokeCurrentClassMethod().method1();
- }
-}
-```
-
-“仔细瞧,三妹,上面这段代码中没有见到 this 关键字吧?”我面带着神秘的微笑,准备给三妹变个魔术。
-
-“确实没有,哥,我确认过了。”
-
-“那接下来,神奇的事情就要发生了。”我突然感觉刘谦附身了。
-
-我快速的在 classes 目录下找到 InvokeCurrentClassMethod.class 文件,然后双击打开(IDEA 默认会使用 FernFlower 打开字节码文件)。
-
-```java
-public class InvokeCurrentClassMethod {
- public InvokeCurrentClassMethod() {
- }
-
- void method1() {
- }
-
- void method2() {
- this.method1();
- }
-
- public static void main(String[] args) {
- (new InvokeCurrentClassMethod()).method1();
- }
-}
-```
-
-“瞪大眼睛仔细瞧,三妹,`this` 关键字是不是出现了?”
-
-“哇,真的呢,好神奇啊!”三妹为了配合我的演出,也是十二分的卖力。
-
-“我们可以在一个类中使用 this 关键字来调用另外一个方法,如果没有使用的话,编译器会自动帮我们加上。”我对自己深厚的编程功底充满自信,“在源代码中,`method2()` 在调用 `method1()` 的时候并没有使用 this 关键字,但通过反编译后的字节码可以看得到。”
-
-### 03、调用当前类的构造方法
-
-“再来看下面这段代码。”
-
-```java
-public class InvokeConstrutor {
- InvokeConstrutor() {
- System.out.println("hello");
- }
-
- InvokeConstrutor(int count) {
- this();
- System.out.println(count);
- }
-
- public static void main(String[] args) {
- InvokeConstrutor invokeConstrutor = new InvokeConstrutor(10);
- }
-}
-```
-
-“在有参构造方法 `InvokeConstrutor(int count)` 中,使用了 `this()` 来调用无参构造方法 `InvokeConstrutor()`。”这次,我换成了左手的食指,指着屏幕对三妹说,“`this()` 可用于调用当前类的构造方法——构造方法可以重用了。”
-
-“来看一下输出结果。”
-
-```
-hello
-10
-```
-
-“真的啊,无参构造方法也被调用了,所以程序输出了 hello。”三妹看到输出结果后不假思索地说。
-
-“也可以在无参构造方法中使用 `this()` 并传递参数来调用有参构造方法。”话音没落,我就在键盘上敲了起来,“来看下面这段代码。”
-
-```java
-public class InvokeParamConstrutor {
- InvokeParamConstrutor() {
- this(10);
- System.out.println("hello");
- }
-
- InvokeParamConstrutor(int count) {
- System.out.println(count);
- }
-
- public static void main(String[] args) {
- InvokeParamConstrutor invokeConstrutor = new InvokeParamConstrutor();
- }
-}
-```
-
-“再来看一下程序的输出结果。”
-
-```
-10
-hello
-```
-
-“不过,需要注意的是,`this()` 必须放在构造方法的第一行,否则就报错了。”
-
-
-
-### 04、作为参数在方法中传递
-
-“来看下面这段代码。”
-
-```java
-public class ThisAsParam {
- void method1(ThisAsParam p) {
- System.out.println(p);
- }
-
- void method2() {
- method1(this);
- }
-
- public static void main(String[] args) {
- ThisAsParam thisAsParam = new ThisAsParam();
- System.out.println(thisAsParam);
- thisAsParam.method2();
- }
-}
-```
-
-“`this` 关键字可以作为参数在方法中传递,此时,它指向的是当前类的对象。”一不小心,半个小时过去了,我感到嗓子冒烟,于是赶紧又喝了一口水,润润嗓子后继续说道。
-
-“来看一下输出结果,你就明白了,三妹。”
-
-```
-com.itwanger.twentyseven.ThisAsParam@77459877
-com.itwanger.twentyseven.ThisAsParam@77459877
-```
-
-“`method2()` 调用了 `method1()`,并传递了参数 this,`method1()` 中打印了当前对象的字符串。 `main()` 方法中打印了 thisAsParam 对象的字符串。从输出结果中可以看得出来,两者是同一个对象。”
-
-### 05、作为参数在构造方法中传递
-
-“继续来看代码。”
-
-```java
-public class ThisAsConstrutorParam {
- int count = 10;
-
- ThisAsConstrutorParam() {
- Data data = new Data(this);
- data.out();
- }
-
- public static void main(String[] args) {
- new ThisAsConstrutorParam();
- }
-}
-
-class Data {
- ThisAsConstrutorParam param;
- Data(ThisAsConstrutorParam param) {
- this.param = param;
- }
-
- void out() {
- System.out.println(param.count);
- }
-}
-```
-
-“在构造方法 `ThisAsConstrutorParam()` 中,我们使用 this 关键字作为参数传递给了 Data 对象,它其实指向的就是 `new ThisAsConstrutorParam()` 这个对象。”
-
-“`this` 关键字也可以作为参数在构造方法中传递,它指向的是当前类的对象。当我们需要在多个类中使用一个对象的时候,这非常有用。”
-
-“来看一下输出结果。”
-
-```
-10
-```
-
-### 06、作为方法的返回值
-
-“需要休息会吗?三妹”
-
-“没事的,哥,我的注意力还是很集中的,你继续讲吧。”
-
-“好的,那来继续看代码。”
-
-```java
-public class ThisAsMethodResult {
- ThisAsMethodResult getThisAsMethodResult() {
- return this;
- }
-
- void out() {
- System.out.println("hello");
- }
-
- public static void main(String[] args) {
- new ThisAsMethodResult().getThisAsMethodResult().out();
- }
-}
-```
-
-“`getThisAsMethodResult()` 方法返回了 this 关键字,指向的就是 `new ThisAsMethodResult()` 这个对象,所以可以紧接着调用 `out()` 方法——达到了链式调用的目的,这也是 this 关键字非常经典的一种用法。”
-
-“链式调用的形式在 JavaScript 代码更加常见。”为了向三妹证实这一点,我打开了 jQuery 的源码。
-
-“原来这么多链式调用啊!”三妹感叹到。
-
-“是的。”我点点头,然后指着 `getThisAsMethodResult()` 方法的返回值对三妹说,“需要注意的是,`this` 关键字作为方法的返回值的时候,方法的返回类型为类的类型。”
-
-“来看一下输出结果。”
-
-```
-hello
-```
-
-“那么,关于 this 关键字的介绍,就到此为止了。”我活动了一下僵硬的脖子后,对三妹说,“如果你学习劲头还可以的话,我们顺带把 super 关键字捎带着过一下,怎么样?”
-
-“不用了吧,听说 super 关键字更简单,我自己看看就行了,不用你讲了!”
-
-“不不不,三妹啊,你得假装听一下,不然我怎么向读者们交差。”
-
-“噢噢噢噢。”三妹意味深长地笑了。
-
-### 07、super 关键字
-
-“super 关键字的用法主要有三种。”
-
-- 指向父类对象;
-- 调用父类的方法;
-- `super()` 可以调用父类的构造方法。
-
-“其实和 this 有些相似,只不过用意不大相同。”我端起水瓶,咕咚咕咚又喝了几大口,好渴。“每当创建一个子类对象的时候,也会隐式的创建父类对象,由 super 关键字引用。”
-
-“如果父类和子类拥有同样名称的字段,super 关键字可以用来访问父类的同名字段。”
-
-“来看下面这段代码。”
-
-```java
-public class ReferParentField {
- public static void main(String[] args) {
- new Dog().printColor();
- }
-}
-
-class Animal {
- String color = "白色";
-}
-
-class Dog extends Animal {
- String color = "黑色";
-
- void printColor() {
- System.out.println(color);
- System.out.println(super.color);
- }
-}
-```
-
-“父类 Animal 中有一个名为 color 的字段,子类 Dog 中也有一个名为 color 的字段,子类的 `printColor()` 方法中,通过 super 关键字可以访问父类的 color。”
-
-“来看一下输出结果。”
-
-```
-黑色
-白色
-```
-
-“当子类和父类的方法名相同时,可以使用 super 关键字来调用父类的方法。换句话说,super 关键字可以用于方法重写时访问到父类的方法。”
-
-
-```java
-public class ReferParentMethod {
- public static void main(String[] args) {
- new Dog().work();
- }
-}
-
-class Animal {
- void eat() {
- System.out.println("吃...");
- }
-}
-
-class Dog extends Animal {
- @Override
- void eat() {
- System.out.println("吃...");
- }
-
- void bark() {
- System.out.println("汪汪汪...");
- }
-
- void work() {
- super.eat();
- bark();
- }
-}
-```
-
-“瞧,三妹。父类 Animal 和子类 Dog 中都有一个名为 `eat()` 的方法,通过 `super.eat()` 可以访问到父类的 `eat()` 方法。”
-
-等三妹在自我消化的时候,我在键盘上又敲完了一串代码。
-
-```java
-public class ReferParentConstructor {
- public static void main(String[] args) {
- new Dog();
- }
-}
-
-class Animal {
- Animal(){
- System.out.println("动物来了");
- }
-}
-
-class Dog extends Animal {
- Dog() {
- super();
- System.out.println("狗狗来了");
- }
-}
-```
-
-“子类 Dog 的构造方法中,第一行代码为 `super()`,它就是用来调用父类的构造方法的。”
-
-“来看一下输出结果。”
-
-```
-动物来了
-狗狗来了
-```
-
-“当然了,在默认情况下,`super()` 是可以省略的,编译器会主动去调用父类的构造方法。也就是说,子类即使不使用 `super()` 主动调用父类的构造方法,父类的构造方法仍然会先执行。”
-
-```java
-public class ReferParentConstructor {
- public static void main(String[] args) {
- new Dog();
- }
-}
-
-class Animal {
- Animal(){
- System.out.println("动物来了");
- }
-}
-
-class Dog extends Animal {
- Dog() {
- System.out.println("狗狗来了");
- }
-}
-```
-
-“输出结果和之前一样。”
-
-```
-动物来了
-狗狗来了
-```
-
-“`super()` 也可以用来调用父类的有参构造方法,这样可以提高代码的可重用性。”
-
-```java
-class Person {
- int id;
- String name;
-
- Person(int id, String name) {
- this.id = id;
- this.name = name;
- }
-}
-
-class Emp extends Person {
- float salary;
-
- Emp(int id, String name, float salary) {
- super(id, name);
- this.salary = salary;
- }
-
- void display() {
- System.out.println(id + " " + name + " " + salary);
- }
-}
-
-public class CallParentParamConstrutor {
- public static void main(String[] args) {
- new Emp(1, "沉默王二", 20000f).display();
- }
-}
-```
-
-“Emp 类继承了 Person 类,也就继承了 id 和 name 字段,当在 Emp 中新增了 salary 字段后,构造方法中就可以使用 `super(id, name)` 来调用父类的有参构造方法。”
-
-“来看一下输出结果。”
-
-```
-1 沉默王二 20000.0
-```
-
-三妹点了点头,所有所思。
-
-
-## 5.15 Java static关键字
-
-“哥,你牙龈肿痛轻点没?周一的《教妹学 Java》(二哥的Java进阶之路前身)你都没有更新,偷懒了呀!”三妹关心地问我。
-
-“今天周四了,吃了三天的药,疼痛已经减轻不少,咱妈还给我打了电话,让我买点牛黄解毒片下下火。”我面带着微笑对三妹说,“学习可不能落下,今天我们来学 Java 中 `static` 关键字吧。”
-
-“static 是 Java 中比较难以理解的一个关键字,也是各大公司的面试官最喜欢问到的一个知识点之一。”我喝了一口咖啡继续说道。
-
-“既然是面试重点,那我可得好好学习下。”三妹连忙说。
-
-“static 关键字的作用可以用一句话来描述:‘**方便在没有创建对象的情况下进行调用**,包括变量和方法’。也就是说,只要类被加载了,就可以通过类名进行访问。”我扶了扶沉重眼镜,继续说到,“static 可以用来修饰类的成员变量,以及成员方法。我们一个个来看。”
-
-### 01、静态变量
-
-“如果在声明变量的时候使用了 static 关键字,那么这个变量就被称为静态变量。静态变量只在类加载的时候获取一次内存空间,这使得静态变量很节省内存空间。”家里的暖气有点足,我跑去开了一点窗户后继续说道。
-
-“来考虑这样一个 Student 类。”话音刚落,我就在键盘上噼里啪啦一阵敲。
-
-```java
-public class Student {
- String name;
- int age;
- String school = "郑州大学";
-}
-```
-
-这段代码敲完后,我对三妹说:“假设郑州大学录取了一万名新生,那么在创建一万个 Student 对象的时候,所有的字段(name、age 和 school)都会获取到一块内存。学生的姓名和年纪不尽相同,但都属于郑州大学,如果每创建一个对象,school 这个字段都要占用一块内存的话,就很浪费,对吧?三妹。”
-
-“因此,最好将 school 这个字段设置为 static,这样就只会占用一块内存,而不是一万块。”
-
-安静的房子里又响起了一阵噼里啪啦的键盘声。
-
-```java
-public class Student {
- String name;
- int age;
- static String school = "郑州大学";
-
- public Student(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- public static void main(String[] args) {
- Student s1 = new Student("沉默王二", 18);
- Student s2 = new Student("沉默王三", 16);
- }
-}
-```
-
-“瞧,三妹。s1 和 s2 这两个引用变量存放在栈区(stack),沉默王二+18 这个对象和沉默王三+16 这个对象存放在堆区(heap),school 这个静态变量存放在静态区。”
-
-“等等,哥,栈、堆、静态区?”三妹的脸上塞满了疑惑。
-
-“哦哦,别担心,三妹,画幅图你就全明白了。”说完我就打开 draw.io 这个网址,认真地画起了图。
-
-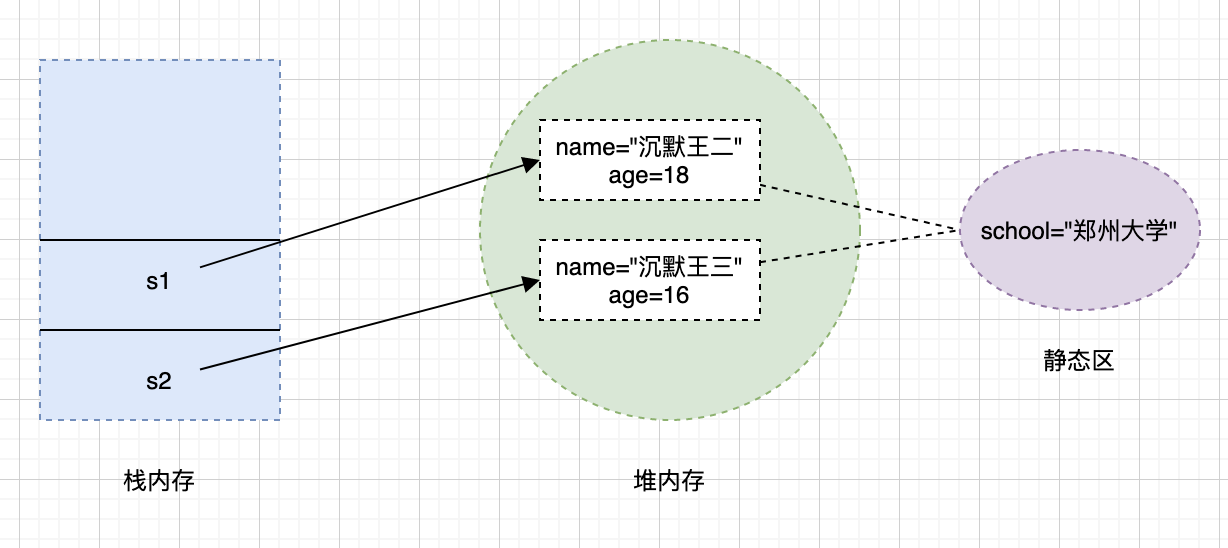
-
-“现在,是不是一下子就明白了?”看着这幅漂亮的手绘图,我心里有点小开心。
-
-“哇,哥,惊艳了呀!”三妹也不忘拍马屁,给我了一个大大的赞。
-
-“好了,三妹,我们来看下面这串代码。”
-
-```java
-public class Counter {
- int count = 0;
-
- Counter() {
- count++;
- System.out.println(count);
- }
-
- public static void main(String args[]) {
- Counter c1 = new Counter();
- Counter c2 = new Counter();
- Counter c3 = new Counter();
- }
-}
-```
-
-“我们创建一个成员变量 count,并且在构造函数中让它自增。因为成员变量会在创建对象的时候获取内存,因此每一个对象都会有一个 count 的副本, count 的值并不会随着对象的增多而递增。”
-
-我在侃侃而谈,而三妹似乎有些不太明白。
-
-
-
-
-“没关系,三妹,你先盲猜一下,这段代码输出的结果是什么?”
-
-“按照你的逻辑,应该输出三个 1?是这样吗?”三妹眨眨眼,有点不太自信地回答。
-
-“哎呀,不错哟。”
-
-我在 IDEA 中点了一下运行按钮,程序跑了起来。
-
-```
-1
-1
-1
-```
-
-“每创建一个 Counter 对象,count 的值就从 0 自增到 1。三妹,想一下,如果 count 是静态的呢?”
-
-“我不知道啊。”
-
-“嗯,来看下面这段代码。”
-
-```java
-public class StaticCounter {
- static int count = 0;
-
- StaticCounter() {
- count++;
- System.out.println(count);
- }
-
- public static void main(String args[]) {
- StaticCounter c1 = new StaticCounter();
- StaticCounter c2 = new StaticCounter();
- StaticCounter c3 = new StaticCounter();
- }
-}
-```
-
-“来看一下输出结果。”
-
-```
-1
-2
-3
-```
-
-“简单解释一下哈,由于静态变量只会获取一次内存空间,所以任何对象对它的修改都会得到保留,所以每创建一个对象,count 的值就会加 1,所以最终的结果是 3,明白了吧?三妹。这就是静态变量和成员变量之间的差别。”
-
-“另外,需要注意的是,由于静态变量属于一个类,所以不要通过对象引用来访问,而应该直接通过类名来访问,否则编译器会发出警告。”
-
-
-
-
-### 02、静态方法
-
-“说完静态变量,我们来说静态方法。”说完,我准备点一支华子来抽,三妹阻止了我,她指一指烟盒上的「吸烟有害身体健康」,我笑了。
-
-“好吧。”我只好喝了一口咖啡继续说,“如果方法上加了 static 关键字,那么它就是一个静态方法。”
-
-“静态方法有以下这些特征。”
-
-- 静态方法属于这个类而不是这个类的对象;
-- 调用静态方法的时候不需要创建这个类的对象;
-- 静态方法可以访问静态变量。
-
-“来,继续上代码”
-
-```java
-public class StaticMethodStudent {
- String name;
- int age;
- static String school = "郑州大学";
-
- public StaticMethodStudent(String name, int age) {
- this.name = name;
- this.age = age;
- }
-
- static void change() {
- school = "河南大学";
- }
-
- void out() {
- System.out.println(name + " " + age + " " + school);
- }
-
- public static void main(String[] args) {
- StaticMethodStudent.change();
-
- StaticMethodStudent s1 = new StaticMethodStudent("沉默王二", 18);
- StaticMethodStudent s2 = new StaticMethodStudent("沉默王三", 16);
-
- s1.out();
- s2.out();
- }
-}
-```
-
-“仔细听,三妹。`change()` 方法就是一个静态方法,所以它可以直接访问静态变量 school,把它的值更改为河南大学;并且,可以通过类名直接调用 `change()` 方法,就像 ` StaticMethodStudent.change()` 这样。”
-
-“来看一下程序的输出结果吧。”
-
-```
-沉默王二 18 河南大学
-沉默王三 16 河南大学
-```
-
-“需要注意的是,静态方法不能访问非静态变量和调用非静态方法。你看,三妹,我稍微改动一下代码,编译器就会报错。”
-
-“先是在静态方法中访问非静态变量,编译器不允许。”
-
-
-
-“然后在静态方法中访问非静态方法,编译器同样不允许。”
-
-
-
-“关于静态方法的使用,这下清楚了吧,三妹?”
-
-看着三妹点点头,我欣慰地笑了。
-
-“哥,我想到了一个问题,为什么 main 方法是静态的啊?”没想到,三妹串联知识点的功力还是不错的。
-
-“如果 main 方法不是静态的,就意味着 Java 虚拟机在执行的时候需要先创建一个对象才能调用 main 方法,而 main 方法作为程序的入口,创建一个额外的对象显得非常多余。”我不假思索的回答令三妹感到非常的钦佩。
-
-“java.lang.Math 类的几乎所有方法都是静态的,可以直接通过类名来调用,不需要创建类的对象。”
-
-
-
-### 03、静态代码块
-
-“三妹,站起来活动一下,我的脖子都有点僵硬了。”
-
-我们一起走到窗户边,映入眼帘的是从天而降的雪花。三妹和我都高兴坏了,迫不及待地打开窗口,伸出手去触摸雪花的温度,那种稍纵即逝的冰凉,真的舒服极了。
-
-“北国风光,千里冰封,万里雪飘。望长城内外,惟余莽莽;大河上下,顿失滔滔。山舞银蛇,原驰蜡象,欲与天公试比高。须晴日,看红装素裹,分外妖娆。。。。。。”三妹竟然情不自禁地朗诵起了《沁园春·雪》。
-
-确实令人欣喜,这是 2020 年洛阳的第一场雪,的确令人感到开心。
-
-片刻之后。
-
-“除了静态变量和静态方法,static 关键字还有一个重要的作用。”我心情愉悦地对三妹说,“用一个 static 关键字,外加一个大括号括起来的代码被称为静态代码块。”
-
-“就像下面这串代码。”
-
-```java
-public class StaticBlock {
- static {
- System.out.println("静态代码块");
- }
-
- public static void main(String[] args) {
- System.out.println("main 方法");
- }
-}
-```
-
-“静态代码块通常用来初始化一些静态变量,它会优先于 `main()` 方法执行。”
-
-
-“来看一下程序的输出结果吧。”
-
-```
-静态代码块
-main 方法
-```
-
-“二哥,既然静态代码块先于 `main()` 方法执行,那没有 `main()` 方法的 Java 类能执行成功吗?”三妹的脑回路越来越令我敬佩了。
-
-“Java 1.6 是可以的,但 Java 7 开始就无法执行了。”我胸有成竹地回答到。
-
-```java
-public class StaticBlockNoMain {
- static {
- System.out.println("静态代码块,没有 main");
- }
-}
-```
-
-“在命令行中执行 `java StaticBlockNoMain` 的时候,会抛出 NoClassDefFoundError 的错误。”
-
-
-
-“三妹,来看下面这个例子。”
-
-```java
-public class StaticBlockDemo {
- public static List writes = new ArrayList<>();
-
- static {
- writes.add("沉默王二");
- writes.add("沉默王三");
- writes.add("沉默王四");
-
- System.out.println("第一块");
- }
-
- static {
- writes.add("沉默王五");
- writes.add("沉默王六");
-
- System.out.println("第二块");
- }
-}
-```
-
-“writes 是一个静态的 ArrayList,所以不太可能在声明的时候完成初始化,因此需要在静态代码块中完成初始化。”
-
-“静态代码块在初始集合的时候,真的非常有用。在实际的项目开发中,通常使用静态代码块来加载配置文件到内存当中。”
-
-### 04、静态内部类
-
-“三妹啊,除了以上只写,static 还有一个不太常用的功能——静态内部类。”
-
-“Java 允许我们在一个类中声明一个内部类,它提供了一种令人信服的方式,允许我们只在一个地方使用一些变量,使代码更具有条理性和可读性。”
-
-“常见的内部类有四种,成员内部类、局部内部类、匿名内部类和静态内部类,限于篇幅原因,前三种不在我们本次的讨论范围之内,以后有机会再细说。”
-
-“来看下面这个例子。”三妹有点走神,我敲了敲她的脑袋后继续说。
-
-```java
-public class Singleton {
- private Singleton() {}
-
- private static class SingletonHolder {
- public static final Singleton instance = new Singleton();
- }
-
- public static Singleton getInstance() {
- return SingletonHolder.instance;
- }
-}
-```
-
-“三妹,打起精神,马上就结束了。”
-
-“哦哦,这段代码看起来很别致啊,哥。”
-
-“是的,三妹,这段代码在以后创建单例的时候还会见到。”
-
-“第一次加载 Singleton 类时并不会初始化 instance,只有第一次调用 `getInstance()` 方法时 Java 虚拟机才开始加载 SingletonHolder 并初始化 instance,这样不仅能确保线程安全,也能保证 Singleton 类的唯一性。不过,创建单例更优雅的一种方式是使用枚举,以后再讲给你听。”
-
-“需要注意的是。第一,静态内部类不能访问外部类的所有成员变量;第二,静态内部类可以访问外部类的所有静态变量,包括私有静态变量。第三,外部类不能声明为 static。”
-
-“三妹,你看,在 Singleton 类上加 static 后,编译器就提示错误了。”
-
-
-
-三妹点了点头,所有所思。
-
-
-
-## 5.16 Java final关键字
-
-“哥,今天学什么呢?”
-
-“今天学一个重要的关键字——final。 ”我面带着朴实无华的微笑回答着她,“对了,三妹,你打算考研吗?”
-
-“还没想过,我今年才大一呢,到时候再说吧,你决定。”
-
-“好吧。”我摊摊手,表示很无辜,真的是所有的决定都交给我这个哥哥了,如果决定错了,锅得背上。
-
-### 01、final 变量
-
-“好了,我们先来看 final 修饰的变量吧!”
-
-“被 final 修饰的变量无法重新赋值。换句话说,final 变量一旦初始化,就无法更改。”
-
-“来看这行代码。”
-
-```java
-final int age = 18;
-```
-
-“当尝试将 age 的值修改为 30 的时候,编译器就生气了。”
-
-
-
-“再来看这段代码。”
-
-```java
-public class Pig {
- private String name;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-“这是一个很普通的 Java 类,它有一个字段 name。”
-
-“然后,我们创建一个测试类,并声明一个 final 修饰的 Pig 对象。”
-
-```java
-final Pig pig = new Pig();
-```
-
-“如果尝试将 pig 重新赋值的话,编译器同样会生气。”
-
-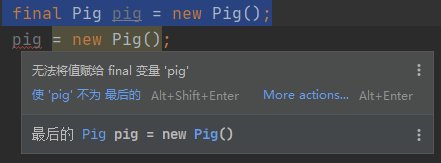
-
-“但我们仍然可以去修改 pig 对象的 name。”
-
-```java
-final Pig pig = new Pig();
-pig.setName("特立独行");
-System.out.println(pig.getName()); // 特立独行
-```
-
-“另外,final 修饰的成员变量必须有一个默认值,否则编译器将会提醒没有初始化。”
-
-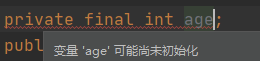
-
-“final 和 static 一起修饰的成员变量叫做常量,常量名必须全部大写。”
-
-```java
-public class Pig {
- private final int age = 1;
- public static final double PRICE = 36.5;
-}
-```
-
-“有时候,我们还会用 final 关键字来修饰参数,它意味着参数在方法体内不能被再修改。”
-
-“来看下面这段代码。”
-
-```java
-public class ArgFinalTest {
- public void arg(final int age) {
- }
-
- public void arg1(final String name) {
- }
-}
-```
-
-“如果尝试去修改它的话,编译器会提示以下错误。”
-
-
-
-### 02、final 方法
-
-“被 final 修饰的方法不能被重写。如果我们在设计一个类的时候,认为某些方法不应该被重写,就应该把它设计成 final 的。”
-
-“Thread 类就是一个例子,它本身不是 final 的,这意味着我们可以扩展它,但它的 `isAlive()` 方法是 final 的。”
-
-```java
-public class Thread implements Runnable {
- public final native boolean isAlive();
-}
-```
-“需要注意的是,该方法是一个本地(native)方法,用于确认线程是否处于活跃状态。而本地方法是由操作系统决定的,因此重写该方法并不容易实现。”
-
-“来看这段代码。”
-
-```java
-public class Actor {
- public final void show() {
-
- }
-}
-```
-
-“当我们想要重写该方法的话,就会出现编译错误。”
-
-
-
-
-“三妹,来问你一个问题吧。”正想趁三妹回答问题的时候喝口水。
-
-“你说吧,哥。”
-
-“一个类是 final 的,和一个类不是 final,但它所有的方法都是 final 的,考虑一下,它们之间有什么区别?”
-
-“我能想到的一点,就是前者不能被[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html),也就是说方法无法被重写;后者呢,可以被继承,然后追加一些非 final 的方法。”还没等我把水咽下去,三妹就回答好了,着实惊呆了我。
-
-“嗯嗯嗯,没毛病没毛病,进步很大啊!”
-
-“那必须啊,谁叫我是你妹呢。”
-
-### 03、final 类
-
-“如果一个类使用了 final 关键字修饰,那么它就无法被继承.....”
-
-“等等,哥,我知道,String 类就是一个 final 类。”还没等我说完,三妹就抢着说到。
-
-“说得没毛病。”
-
-```java
-public final class String
- implements java.io.Serializable, Comparable, CharSequence,
- Constable, ConstantDesc {}
-```
-
-“那三妹你知道为什么 String 类要设计成 final 吗?”
-
-“这个还真不知道。”三妹的表情透露出这种无奈。
-
-“原因大致有 3 个。”
-
-- 为了实现字符串常量池
-- 为了线程安全
-- 为了 HashCode 的不可变性
-
-“想了解更详细的原因,可以一会看看我之前写的这篇文章。”
-
-[为什么 Java 字符串是不可变的?](https://tobebetterjavaer.com/string/immutable.html)
-
-“任何尝试从 final 类继承的行为将会引发编译错误。来看这段代码。”
-
-```java
-public final class Writer {
- private String name;
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-}
-```
-
-“尝试去继承它,编译器会提示以下错误,Writer 类是 final 的,无法继承。”
-
-
-
-“不过,类是 final 的,并不意味着该类的对象是不可变的。”
-
-“来看这段代码。”
-
-```java
-Writer writer = new Writer();
-writer.setName("沉默王二");
-System.out.println(writer.getName()); // 沉默王二
-```
-
-“Writer 的 name 字段的默认值是 null,但可以通过 settter 方法将其更改为沉默王二。也就是说,如果一个类只是 final 的,那么它并不是不可变的全部条件。”
-
-“关于不可变类,我们留到后面来细讲。”
-
-[不可变类](https://tobebetterjavaer.com/basic-extra-meal/immutable.html)
-
-“把一个类设计成 final 的,有其安全方面的考虑,但不应该故意为之,因为把一个类定义成 final 的,意味着它没办法继承,假如这个类的一些方法存在一些问题的话,我们就无法通过重写的方式去修复它。”
-
-“三妹,final 关键字我们就学到这里吧,你一会再学习一下 Java 字符串为什么是不可变的和不可变类。”我揉一揉犯困的双眼,疲惫地给三妹说,“学完这两个知识点,你会对 final 的认知更清晰一些。”
-
-“好的,二哥,我这就去学习去。你去休息会。”
-
-我起身站到阳台上,看着窗外的车水马龙,不一会儿,就发起来呆。
-
-“好想去再看一场周杰伦的演唱会,不知道 2021 有没有这个机会。”
-
-我心里这样想着,天渐渐地暗了下来。
-
-
-
-## 5.17 Java instanceof关键字
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.17 Java instanceof关键字](https://tobebetterjavaer.com/basic-extra-meal/instanceof.html)
-
-## 5.18 Java不可变对象
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[5.18 Java不可变对象](https://tobebetterjavaer.com/basic-extra-meal/immutable.html)
-
-
-
-## 5.19 Java方法重写和方法重载
-
-入冬的夜,总是来得特别的早。我静静地站在阳台,目光所及之处,不过是若隐若现的钢筋混凝土,还有那毫无情调的灯光。
-
-“哥,别站在那发呆了。今天学啥啊,七点半我就要回学校了,留给你的时间不多了,你要抓紧哦。”三妹傲娇的声音一下子把我从游离的状态拉回到了现实。
-
-“今天要学习 Java 中的方法重载与方法重写。”我迅速地走到电脑前面,打开一份 Excel 文档,看了一下《教妹学 Java(二哥的 Java 进阶之路前身)》的进度,然后对三妹说。
-
-“如果一个类有多个名字相同但参数个数不同的方法,我们通常称这些方法为方法重载。 ”我面带着朴实无华的微笑继续说,“如果方法的功能是一样的,但参数不同,使用相同的名字可以提高程序的可读性。”
-
-“如果子类具有和父类一样的方法(参数相同、返回类型相同、方法名相同,但方法体可能不同),我们称之为方法重写。 方法重写用于提供父类已经声明的方法的特殊实现,是实现多态的基础条件。”
-
-“只不过,方法重载与方法重写在名字上很相似,就像是兄弟俩,导致初学者经常把它们俩搞混。”
-
-“方法重载的英文名叫 Overloading,方法重写的英文名叫 Overriding,因此,不仅中文名很相近,英文名之间也很相近,这就更容易让初学者搞混了。”
-
-“但两者其实是完全不同的!通过下面这张图,你就能看得一清二楚。”
-
-话音刚落,我就在 IDEA 中噼里啪啦地敲了起来。两段代码,分别是方法重写和方法重载。然后,把这两段代码截图到 draw.io(一个很漂亮的在线画图网站)上,加了一些文字说明。最后,打开 Photoscape X,把两张图片合并到了一起。
-
-
-
-### 01、方法重载
-
-“三妹,你仔细听哦。”我缓了一口气后继续说道。
-
-“在 Java 中,有两种方式可以达到方法重载的目的。”
-
-“第一,改变参数的数目。来看下面这段代码。”
-
-```java
-public class OverloadingByParamNum {
- public static void main(String[] args) {
- System.out.println(Adder.add(10, 19));
- System.out.println(Adder.add(10, 19, 20));
- }
-}
-
-class Adder {
- static int add(int a, int b) {
- return a + b;
- }
-
- static int add(int a, int b, int c) {
- return a + b + c;
- }
-}
-```
-
-“Adder 类有两个方法,第一个 `add()` 方法有两个参数,在调用的时候可以传递两个参数;第二个 `add()` 方法有三个参数,在调用的时候可以传递三个参数。”
-
-“二哥,这样的代码不会显得啰嗦吗?如果有四个参数的时候就再追加一个方法?”三妹突然提了一个很尖锐的问题。
-
-“那倒是,这个例子只是为了说明方法重载的一种类型。如果参数类型相同的话,Java 提供了可变参数的方式,就像下面这样。”
-
-```java
-static int add(int ... args) {
- int sum = 0;
- for ( int a: args) {
- sum += a;
- }
- return sum;
-}
-```
-
-“第二,通过改变参数类型,也可以达到方法重载的目的。来看下面这段代码。”
-
-```java
-public class OverloadingByParamType {
- public static void main(String[] args) {
- System.out.println(Adder.add(10, 19));
- System.out.println(Adder.add(10.1, 19.2));
- }
-}
-
-class Adder {
- static int add(int a, int b) {
- return a + b;
- }
-
- static double add(double a, double b) {
- return a + b;
- }
-}
-```
-
-“Adder 类有两个方法,第一个 `add()` 方法的参数类型为 int,第二个 `add()` 方法的参数类型为 double。”
-
-“二哥,改变参数的数目和类型都可以实现方法重载,为什么改变方法的返回值类型就不可以呢?”三妹很能抓住问题的重点嘛。
-
-“因为仅仅改变返回值类型的话,会把编译器搞懵逼的。”我略带调皮的口吻回答她。
-
-“编译时报错优于运行时报错,所以当两个方法的名字相同,参数个数和类型也相同的时候,虽然返回值类型不同,但依然会提示方法已经被定义的错误。”
-
-
-
-“你想啊,三妹。我们在调用一个方法的时候,可以指定返回值类型,也可以不指定。当不指定的时候,直接指定 `add(1, 2)` 的时候,编译器就不知道该调用返回 int 的 `add()` 方法还是返回 double 的 `add()` 方法,产生了歧义。”
-
-“方法的返回值只是作为方法运行后的一个状态,它是保持方法的调用者和被调用者进行通信的一个纽带,但并不能作为某个方法的‘标识’。”
-
-“二哥,我想到了一个点,`main()` 方法可以重载吗?”
-
-“三妹,这是个好问题啊!答案是肯定的,毕竟 `main()` 方法也是个方法,只不过,Java 虚拟机在运行的时候只会调用带有 String 数组的那个 `main()` 方法。”
-
-```java
-public class OverloadingMain {
- public static void main(String[] args) {
- System.out.println("String[] args");
- }
-
- public static void main(String args) {
- System.out.println("String args");
- }
-
- public static void main() {
- System.out.println("无参");
- }
-}
-```
-
-“第一个 `main()` 方法的参数形式为 `String[] args`,是最标准的写法;第二个 `main()` 方法的参数形式为 `String args`,少了中括号;第三个 `main()` 方法没有参数。”
-
-“来看一下程序的输出结果。”
-
-```
-String[] args
-```
-
-“从结果中,我们可以看得出,尽管 `main()` 方法可以重载,但程序只认标准写法。”
-
-“由于可以通过改变参数类型的方式实现方法重载,那么当传递的参数没有找到匹配的方法时,就会发生隐式的类型转换。”
-
-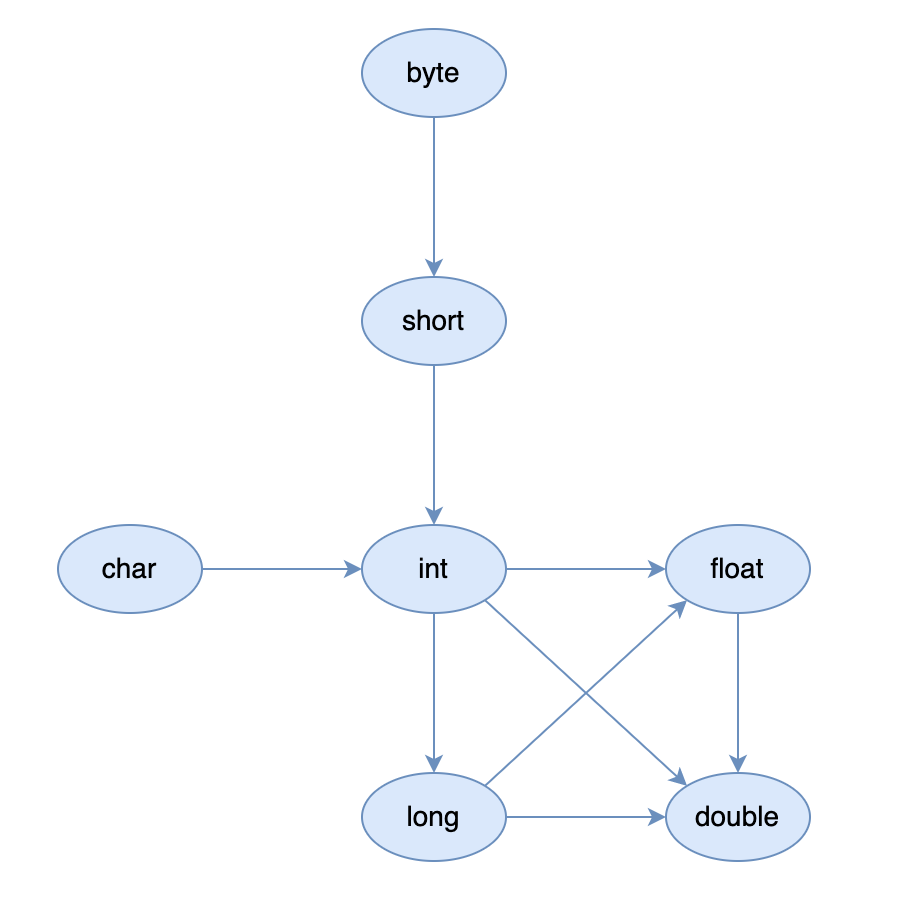
-
-“如上图所示,byte 可以向上转换为 short、int、long、float 和 double,short 可以向上转换为 int、long、float 和 double,char 可以向上转换为 int、long、float 和 double,依次类推。”
-
-“三妹,来看下面这个示例。”
-
-```java
-public class OverloadingTypePromotion {
- void sum(int a, long b) {
- System.out.println(a + b);
- }
-
- void sum(int a, int b, int c) {
- System.out.println(a + b + c);
- }
-
- public static void main(String args[]) {
- OverloadingTypePromotion obj = new OverloadingTypePromotion();
- obj.sum(20, 20);
- obj.sum(20, 20, 20);
- }
-}
-```
-
-“执行 `obj.sum(20, 20)` 的时候,发现没有 `sum(int a, int b)` 的方法,所以此时第二个 20 向上转型为 long,所以调用的是 `sum(int a, long b)` 的方法。”
-
-“再来看一个示例。”
-
-```java
-public class OverloadingTypePromotion1 {
- void sum(int a, int b) {
- System.out.println("int");
- }
-
- void sum(long a, long b) {
- System.out.println("long");
- }
-
- public static void main(String args[]) {
- OverloadingTypePromotion1 obj = new OverloadingTypePromotion1();
- obj.sum(20, 20);
- }
-}
-```
-
-“执行 `obj.sum(20, 20)` 的时候,发现有 `sum(int a, int b)` 的方法,所以就不会向上转型为 long,调用 `sum(long a, long b)`。”
-
-“来看一下程序的输出结果。”
-
-```
-int
-```
-
-“继续来看示例。”
-
-```java
-public class OverloadingTypePromotion2 {
- void sum(long a, int b) {
- System.out.println("long int");
- }
-
- void sum(int a, long b) {
- System.out.println("int long");
- }
-
- public static void main(String args[]) {
- OverloadingTypePromotion2 obj = new OverloadingTypePromotion2();
- obj.sum(20, 20);
- }
-}
-```
-
-“二哥,我又想到一个问题。当有两个方法 `sum(long a, int b)` 和 `sum(int a, long b)`,参数个数相同,参数类型相同,只不过位置不同的时候,会发生什么呢?”
-
-“当通过 `obj.sum(20, 20)` 来调用 sum 方法的时候,编译器会提示错误。”
-
-
-“不明确,编译器会很为难,究竟是把第一个 20 从 int 转成 long 呢,还是把第二个 20 从 int 转成 long,智障了!所以,不能写这样让编译器左右为难的代码。”
-
-### 02、方法重写
-
-“三妹,累吗?我们稍微休息一下吧。”我把眼镜摘下来,放到桌子上,闭上了眼睛,开始胡思乱想起来。
-
-2000 年,周杰伦横空出世,让青黄不接的唱片行业为之一振,由此开启了新一代天王争霸的黄金时代。2020 年,杰伦胖了,也贪玩了,一年出一张单曲都变得可遇不可求。
-
-20 年前,程序员很稀有;20 年后,程序员内卷了。时间永远不会停下脚步,明年会不会好起来呢?
-
-“哥,醒醒,你就说休息一会,没说睡着啊。赶紧,我还有半个小时就要走了。”
-
-我戴上眼镜,对三妹继续说道:“在 Java 中,方法重写需要满足以下三个规则。”
-
-- 重写的方法必须和父类中的方法有着相同的名字;
-- 重写的方法必须和父类中的方法有着相同的参数;
-- 必须是 is-a 的关系(继承关系)。
-
-“来看下面这段代码。”
-
-```java
-public class Bike extends Vehicle {
- public static void main(String[] args) {
- Bike bike = new Bike();
- bike.run();
- }
-}
-
-class Vehicle {
- void run() {
- System.out.println("车辆在跑");
- }
-}
-```
-
-“来看一下程序的输出结果。”
-
-```
-车辆在跑
-```
-
-“Bike is-a Vehicle,自行车是一种车,没错。Vehicle 类有一个 `run()` 的方法,也就是说车辆可以跑,Bike 继承了 Vehicle,也可以跑。但如果 Bike 没有重写 `run()` 方法的话,自行车就只能是‘车辆在跑’,而不是‘自行车在跑’,对吧?”
-
-“如果有了方法重写,一切就好办了。”
-
-```java
-public class Bike extends Vehicle {
- @Override
- void run() {
- System.out.println("自行车在跑");
- }
-
- public static void main(String[] args) {
- Bike bike = new Bike();
- bike.run();
- }
-}
-
-class Vehicle {
- void run() {
- System.out.println("车辆在跑");
- }
-}
-```
-
-我把鼠标移动到 Bike 类的 `run()` 方法,对三妹说:“你看,在方法重写的时候,IDEA 会建议使用 `@Override` 注解,显式的表示这是一个重写后的方法,尽管可以缺省。”
-
-“来看一下程序的输出结果。”
-
-```
-自行车在跑
-```
-
-“Bike 重写了 `run()` 方法,也就意味着,Bike 可以跑出自己的风格。”
-
-好,接下来说一下重写时应当遵守的 12 条规则,应当谨记哦。
-
-#### **规则一:只能重写继承过来的方法**。
-
-因为重写是在子类重新实现从父类[继承](https://tobebetterjavaer.com/oo/extends-bigsai.html)过来的方法时发生的,所以只能重写继承过来的方法,这很好理解。这就意味着,只能重写那些被 public、protected 或者 default 修饰的方法,private 修饰的方法无法被重写。
-
-Animal 类有 `move()`、`eat()` 和 `sleep()` 三个方法:
-
-```java
-public class Animal {
- public void move() { }
-
- protected void eat() { }
-
- void sleep(){ }
-}
-```
-
-Dog 类来重写这三个方法:
-
-```java
-public class Dog extends Animal {
- public void move() { }
-
- protected void eat() { }
-
- void sleep(){ }
-}
-```
-
-OK,完全没有问题。但如果父类中的方法是 private 的,就行不通了。
-
-```java
-public class Animal {
- private void move() { }
-}
-```
-
-此时,Dog 类中的 `move()` 方法就不再是一个重写方法了,因为父类的 `move()` 方法是 private 的,对子类并不可见。
-
-```java
-public class Dog extends Animal {
- public void move() { }
-}
-```
-
-#### **规则二:final、static 的方法不能被重写**。
-
-一个方法是 [final](https://tobebetterjavaer.com/oo/final.html) 的就意味着它无法被子类继承到,所以就没办法重写。
-
-```java
-public class Animal {
- final void move() { }
-}
-```
-
-由于父类 Animal 中的 `move()` 是 final 的,所以子类在尝试重写该方法的时候就出现编译错误了!
-
-
-
-同样的,如果一个方法是 [static](https://tobebetterjavaer.com/oo/static.html) 的,也不允许重写,因为静态方法可用于父类以及子类的所有实例。
-
-```java
-public class Animal {
- final void move() { }
-}
-```
-
-重写的目的在于根据对象的类型不同而表现出多态,而静态方法不需要创建对象就可以使用。没有了对象,重写所需要的“对象的类型”也就没有存在的意义了。
-
-
-
-#### **规则三:重写的方法必须有相同的参数列表**。
-
-```java
-public class Animal {
- void eat(String food) { }
-}
-```
-
-Dog 类中的 `eat()` 方法保持了父类方法 `eat()` 的同一个调调,都有一个参数——String 类型的 food。
-
-```java
-public class Dog extends Animal {
- public void eat(String food) { }
-}
-```
-
-一旦子类没有按照这个规则来,比如说增加了一个参数:
-
-```java
-public class Dog extends Animal {
- public void eat(String food, int amount) { }
-}
-```
-
-这就不再是重写的范畴了,当然也不是重载的范畴,因为重载考虑的是同一个类。
-
-**规则四:重写的方法必须返回相同的类型**。
-
-父类没有返回类型:
-
-```java
-public class Animal {
- void eat(String food) { }
-}
-```
-
-子类尝试返回 String:
-
-```java
-public class Dog extends Animal {
- public String eat(String food) {
- return null;
- }
-}
-```
-
-于是就编译出错了(返回类型不兼容)。
-
-
-
-#### **规则五:重写的方法不能使用限制等级更严格的权限修饰符**。
-
-可以这样来理解:
-
-- 如果被重写的方法是 default,那么重写的方法可以是 default、protected 或者 public。
-- 如果被重写的方法是 protected,那么重写的方法只能是 protected 或者 public。
-- 如果被重写的方法是 public, 那么重写的方法就只能是 public。
-
-举个例子,父类中的方法是 protected:
-
-```java
-public class Animal {
- protected void eat() { }
-}
-```
-
-子类中的方法可以是 public:
-
-```java
-public class Dog extends Animal {
- public void eat() { }
-}
-```
-
-如果子类中的方法用了更严格的权限修饰符,编译器就报错了。
-
-
-
-#### **规则六:重写后的方法不能抛出比父类中更高级别的异常**。
-
-举例来说,如果父类中的方法抛出的是 IOException,那么子类中重写的方法不能抛出 Exception,可以是 IOException 的子类或者不抛出任何[异常](https://tobebetterjavaer.com/exception/gailan.html)。这条规则只适用于可检查的异常。
-
-可检查(checked)异常必须在源代码中显式地进行捕获处理,不检查(unchecked)异常就是所谓的运行时异常,比如说 NullPointerException、ArrayIndexOutOfBoundsException 之类的,不会在编译器强制要求。
-
-父类抛出 IOException:
-
-```java
-public class Animal {
- protected void eat() throws IOException { }
-}
-```
-
-子类抛出 FileNotFoundException 是可以满足重写的规则的,因为 FileNotFoundException 是 IOException 的子类。
-
-```java
-public class Dog extends Animal {
- public void eat() throws FileNotFoundException { }
-}
-```
-
-如果子类抛出了一个新的异常,并且是一个 checked 异常:
-
-```java
-public class Dog extends Animal {
- public void eat() throws FileNotFoundException, InterruptedException { }
-}
-```
-
-那编译器就会提示错误:
-
-```
-Error:(9, 16) java: com.itwanger.overriding.Dog中的eat()无法覆盖com.itwanger.overriding.Animal中的eat()
- 被覆盖的方法未抛出java.lang.InterruptedException
-```
-
-但如果子类抛出的是一个 unchecked 异常,那就没有冲突:
-
-```java
-public class Dog extends Animal {
- public void eat() throws FileNotFoundException, IllegalArgumentException { }
-}
-```
-
-如果子类抛出的是一个更高级别的异常:
-
-```java
-public class Dog extends Animal {
- public void eat() throws Exception { }
-}
-```
-
-编译器同样会提示错误,因为 Exception 是 IOException 的父类。
-
-```
-Error:(9, 16) java: com.itwanger.overriding.Dog中的eat()无法覆盖com.itwanger.overriding.Animal中的eat()
- 被覆盖的方法未抛出java.lang.Exception
-```
-
-#### **规则七:可以在子类中通过 super 关键字来调用父类中被重写的方法**。
-
-子类继承父类的方法而不是重新实现是很常见的一种做法,在这种情况下,可以按照下面的形式调用父类的方法:
-
-```java
-super.overriddenMethodName();
-```
-
-来看例子。
-
-```java
-public class Animal {
- protected void eat() { }
-}
-```
-
-子类重写了 `eat()` 方法,然后在子类的 `eat()` 方法中,可以在方法体的第一行通过 `super.eat()` 调用父类的方法,然后再增加属于自己的代码。
-
-```java
-public class Dog extends Animal {
- public void eat() {
- super.eat();
- // Dog-eat
- }
-}
-```
-
-#### **规则八:构造方法不能被重写**。
-
-因为[构造方法](https://tobebetterjavaer.com/oo/construct.html)很特殊,而且子类的构造方法不能和父类的构造方法同名(类名不同),所以构造方法和重写之间没有任何关系。
-
-#### **规则九:如果一个类继承了抽象类,抽象类中的抽象方法必须在子类中被重写**。
-
-先来看这样一个接口:
-
-```java
-public interface Animal {
- void move();
-}
-```
-
-接口中的方法默认都是抽象方法,通过反编译是可以看得到的:
-
-```java
-public interface Animal
-{
- public abstract void move();
-}
-```
-
-如果一个抽象类实现了 Animal 接口,`move()` 方法不是必须被重写的:
-
-```java
-public abstract class AbstractDog implements Animal {
- protected abstract void bark();
-}
-```
-
-但如果一个类继承了抽象类 AbstractDog,那么 Animal 接口中的 `move()` 方法和抽象类 AbstractDog 中的抽象方法 `bark()` 都必须被重写:
-
-```java
-public class BullDog extends AbstractDog {
-
- public void move() {}
-
- protected void bark() {}
-}
-```
-
-#### **规则十:synchronized 关键字对重写规则没有任何影响**。
-
-[synchronized 关键字](https://tobebetterjavaer.com/thread/synchronized-1.html)用于在多线程环境中获取和释放监听对象,因此它对重写规则没有任何影响,这就意味着 synchronized 方法可以去重写一个非同步方法。
-
-#### **规则十一:strictfp 关键字对重写规则没有任何影响**。
-
-如果你想让浮点运算更加精确,而且不会因为硬件平台的不同导致执行的结果不一致的话,可以在方法上添加 [strictfp 关键字,之前讲过](https://tobebetterjavaer.com/basic-extra-meal/48-keywords.html)。因此 strictfp 关键字和重写规则无关。
-
-### 03、总结
-
-“好了,三妹,我来简单做个总结。”我瞥了一眼电脑右上角的时钟,离三妹离开的时间不到 10 分钟了。
-
-“首先来说一下方法重载时的注意事项,‘两同一不同’。”
-
-“‘两同’:在同一个类,方法名相同。”
-
-“‘一不同’:参数不同。”
-
-“再来说一下方法重写时的注意事项,‘两同一小一大’。”
-
-“‘两同’:方法名相同,参数相同。”
-
-“‘一小’:子类方法声明的异常类型要比父类小一些或者相等。”
-
-“‘一大’:子类方法的访问权限应该比父类的更大或者相等。”
-
-“记住了吧?三妹。带上口罩,拿好手机,咱准备出门吧。”今天限号,没法开车送三妹去学校了。
-
-
-
-
-## 5.20 Java注解
-
-“二哥,这节讲注解吗?”三妹问。
-
-“是的。”我说,“注解是 Java 中非常重要的一部分,但经常被忽视也是真的。之所以这么说是因为我们更倾向成为一名注解的使用者而不是创建者。`@Override` 注解用过吧?[方法重写](https://tobebetterjavaer.com/basic-extra-meal/override-overload.html)的时候用到过。但你知道怎么自定义一个注解吗?”
-
-三妹毫不犹豫地摇摇头,摆摆手,不好意思地承认自己的确没有自定义过。
-
-
-
-“好吧,哥来告诉你吧。”
-
-注解(Annotation)是在 Java 1.5 时引入的概念,同 class 和 interface 一样,也属于一种类型。注解提供了一系列数据用来装饰程序代码(类、方法、字段等),但是注解并不是所装饰代码的一部分,它对代码的运行效果没有直接影响,由编译器决定该执行哪些操作。
-
-来看一段代码。
-
-```java
-public class AutowiredTest {
- @Autowired
- private String name;
-
- public static void main(String[] args) {
- System.out.println("沉默王二,一枚有趣的程序员");
- }
-}
-```
-
-注意到 `@Autowired` 这个注解了吧?它本来是为 Spring(后面会讲)容器注入 Bean 的,现在被我无情地扔在了字段 name 的身上,但这段代码所在的项目中并没有启用 Spring,意味着 `@Autowired` 注解此时只是一个摆设。
-
-“既然只是个摆设,那你这个地方为什么还要用 `@Autowired` 呢?”三妹好奇地问。
-
-“傻呀你,就是给你举个例子,证明:注解对代码的运行效果没有直接影响,明白我的用意了吧?”我毫不客气地说。
-
-“哦。”三妹若有所思地说。
-
-“认真听哈,接下来给你讲讲注解的生命周期。”我瞅了瞅三妹,看她是否在专注的听,然后继续说,“注解的生命周期有 3 种策略,定义在 RetentionPolicy 枚举中。”
-
-1)SOURCE:在源文件中有效,被编译器丢弃。
-
-2)CLASS:在编译器生成的字节码文件中有效,但在运行时会被处理类文件的 JVM 丢弃。
-
-3)RUNTIME:在运行时有效。这也是注解生命周期中最常用的一种策略,它允许程序通过反射的方式访问注解,并根据注解的定义执行相应的代码。
-
-“然后我们来讲注解装饰的目标。”我看三妹还在线,就继续说。
-
-注解的目标定义了注解将适用于哪一种级别的 Java 代码上,有些注解只适用于方法,有些只适用于成员变量,有些只适用于类,有些则都适用。截止到 Java 9,注解的类型一共有 11 种,定义在 ElementType 枚举中。
-
-1)TYPE:用于类、接口、注解、枚举
-
-2)FIELD:用于字段(类的成员变量),或者枚举常量
-
-3)METHOD:用于方法
-
-4)PARAMETER:用于普通方法或者构造方法的参数
-
-5)CONSTRUCTOR:用于构造方法
-
-6)LOCAL_VARIABLE:用于变量
-
-7)ANNOTATION_TYPE:用于注解
-
-8)PACKAGE:用于包
-
-9)TYPE_PARAMETER:用于泛型参数
-
-10)TYPE_USE:用于声明语句、泛型或者强制转换语句中的类型
-
-11)MODULE:用于模块
-
-“哥,你将这些我都记不住,能不能直接开撸注解呀!!!!!”三妹不耐烦了。
-
-“确实哈,说再多,都不如撸个注解来得让人心动。撸个什么样的注解呢?一个字段注解吧,它用来标记对象在序列化成 JSON 的时候要不要包含这个字段。”我笑着对三妹说,“怎么样?”
-
-“好呀!”
-
-“来看下面这段代码。”
-
-```java
-@Retention(RetentionPolicy.RUNTIME)
-@Target(ElementType.FIELD)
-public @interface JsonField {
- public String value() default "";
-}
-```
-
-1)JsonField 注解的生命周期是 RUNTIME,也就是运行时有效。
-
-2)JsonField 注解装饰的目标是 FIELD,也就是针对字段的。
-
-3)创建注解需要用到 `@interface` 关键字。
-
-4)JsonField 注解有一个参数,名字为 value,类型为 String,默认值为一个空字符串。
-
-“为什么参数名要为 value 呢?有什么特殊的含义吗?”三妹问。
-
-“当然是有的,value 允许注解的使用者提供一个无需指定名字的参数。举个例子,我们可以在一个字段上使用 `@JsonField(value = "沉默王二")`,也可以把 `value =` 省略,变成 `@JsonField("沉默王二")`。”我说。
-
-
-
-
-
-“那 `default ""` 有什么特殊含义吗?”三妹继续问。
-
-“当然也是有的,它允许我们在一个字段上直接使用 `@JsonField`,而无需指定参数的名和值。”我回答说。
-
-
-“明白了,那 `@JsonField` 注解已经撸好了,是不是可以使用它了呀?”三妹激动地说。
-
-“嗯,假设有一个 Writer 类,他有 3 个字段,分别是 age、name 和 bookName,后 2 个是必须序列化的字段。就可以这样来用 `@JsonField` 注解。”我说。
-
-```java
-public class Writer {
- private int age;
-
- @JsonField("writerName")
- private String name;
-
- @JsonField
- private String bookName;
-
- public Writer(int age, String name, String bookName) {
- this.age = age;
- this.name = name;
- this.bookName = bookName;
- }
-
- // getter / setter
-
- @Override
- public String toString() {
- return "Writer{" +
- "age=" + age +
- ", name='" + name + '\'' +
- ", bookName='" + bookName + '\'' +
- '}';
- }
-}
-```
-
-1)name 上的 `@JsonField` 注解提供了显式的字符串值。
-
-2)bookName 上的 `@JsonField` 注解使用了缺省项。
-
-接下来,我们来编写序列化类 JsonSerializer,内容如下:
-
-```java
-public class JsonSerializer {
- public static String serialize(Object object) throws IllegalAccessException {
- Class objectClass = object.getClass();
- Map jsonElements = new HashMap<>();
- for (Field field : objectClass.getDeclaredFields()) {
- field.setAccessible(true);
- if (field.isAnnotationPresent(JsonField.class)) {
- jsonElements.put(getSerializedKey(field), (String) field.get(object));
- }
- }
- return toJsonString(jsonElements);
- }
-
- private static String getSerializedKey(Field field) {
- String annotationValue = field.getAnnotation(JsonField.class).value();
- if (annotationValue.isEmpty()) {
- return field.getName();
- } else {
- return annotationValue;
- }
- }
-
- private static String toJsonString(Map jsonMap) {
- String elementsString = jsonMap.entrySet()
- .stream()
- .map(entry -> "\"" + entry.getKey() + "\":\"" + entry.getValue() + "\"")
- .collect(Collectors.joining(","));
- return "{" + elementsString + "}";
- }
-}
-```
-
-“JsonSerializer 类的内容看起来似乎有点多啊,二哥,我有点看不懂。”三妹说。
-
-“不要怕,我一点点来解释,直到你搞明白为止。”
-
-1)`serialize()` 方法是用来序列化对象的,它接收一个 Object 类型的参数。`objectClass.getDeclaredFields()` 通过反射的方式获取对象声明的所有字段,然后进行 for 循环遍历。在 for 循环中,先通过 `field.setAccessible(true)` 将反射对象的可访问性设置为 true,供序列化使用(如果没有这个步骤的话,private 字段是无法获取的,会抛出 IllegalAccessException 异常);再通过 `isAnnotationPresent()` 判断字段是否装饰了 `JsonField` 注解,如果是的话,调用 `getSerializedKey()` 方法,以及获取该对象上由此字段表示的值,并放入 jsonElements 中。
-
-2)`getSerializedKey()` 方法用来获取字段上注解的值,如果注解的值是空的,则返回字段名。
-
-3)`toJsonString()` 方法借助 Stream 流的方式返回格式化后的 JSON 字符串。Stream 流你还没有接触过,不过没关系,后面我再给你讲。
-
-“现在是不是豁然开朗了?”我问三妹,看到三妹点了点头,我继续说,“接下来,我们来写一个测试类 JsonFieldTest。”
-
-```java
-public class JsonFieldTest {
- public static void main(String[] args) throws IllegalAccessException {
- Writer cmower = new Writer(18,"沉默王二","Web全栈开发进阶之路");
- System.out.println(JsonSerializer.serialize(cmower));
- }
-}
-```
-
-程序输出结果如下:
-
-```
-{"bookName":"Web全栈开发进阶之路","writerName":"沉默王二"}
-```
-
-从结果上来看:
-
-1)Writer 类的 age 字段没有装饰 `@JsonField` 注解,所以没有序列化。
-
-2)Writer 类的 name 字段装饰了 `@JsonField` 注解,并且显示指定了字符串“writerName”,所以序列化后变成了 writerName。
-
-3)Writer 类的 bookName 字段装饰了 `@JsonField` 注解,但没有显式指定值,所以序列化后仍然是 bookName。
-
-“怎么样,三妹,是不是也不是特别难?”我对三妹说。
-
-“撸个注解好像真没什么难度,但你接下来的那个 JsonSerializer 我还需要再消化一下。”三妹很认真地说。
-
-“嗯,你好好复习下,我看会《编译原理》。”说完我拿起桌子边上的一本书就走了。
-
-
-
-
-## 5.21 Java枚举(enum)
-
-“今天我们来学习枚举吧,三妹!”我说,“同学让你去她家玩了两天,感觉怎么样呀?”
-
-“心情放松了不少。”三妹说,“可以开始学 Java 了,二哥。”
-
-“OK。”
-
-“枚举(enum),是 Java 1.5 时引入的关键字,它表示一种特殊类型的类,继承自 java.lang.Enum。”
-
-“我们来新建一个枚举 PlayerType。”
-
-```java
-public enum PlayerType {
- TENNIS,
- FOOTBALL,
- BASKETBALL
-}
-```
-
-“二哥,我没看到有继承关系呀!”
-
-“别着急,看一下反编译后的字节码,你就明白了。”
-
-```java
-public final class PlayerType extends Enum
-{
-
- public static PlayerType[] values()
- {
- return (PlayerType[])$VALUES.clone();
- }
-
- public static PlayerType valueOf(String name)
- {
- return (PlayerType)Enum.valueOf(com/cmower/baeldung/enum1/PlayerType, name);
- }
-
- private PlayerType(String s, int i)
- {
- super(s, i);
- }
-
- public static final PlayerType TENNIS;
- public static final PlayerType FOOTBALL;
- public static final PlayerType BASKETBALL;
- private static final PlayerType $VALUES[];
-
- static
- {
- TENNIS = new PlayerType("TENNIS", 0);
- FOOTBALL = new PlayerType("FOOTBALL", 1);
- BASKETBALL = new PlayerType("BASKETBALL", 2);
- $VALUES = (new PlayerType[] {
- TENNIS, FOOTBALL, BASKETBALL
- });
- }
-}
-```
-
-“看到没?Java 编译器帮我们做了很多隐式的工作,不然手写一个枚举就没那么省心省事了。”
-
-- 要继承 Enum 类;
-- 要写构造方法;
-- 要声明静态变量和数组;
-- 要用 static 块来初始化静态变量和数组;
-- 要提供静态方法,比如说 `values()` 和 `valueOf(String name)`。
-
-“确实,作为开发者,我们的代码量减少了,枚举看起来简洁明了。”三妹说。
-
-“既然枚举是一种特殊的类,那它其实是可以定义在一个类的内部的,这样它的作用域就可以限定于这个外部类中使用。”我说。
-
-```java
-public class Player {
- private PlayerType type;
- public enum PlayerType {
- TENNIS,
- FOOTBALL,
- BASKETBALL
- }
-
- public boolean isBasketballPlayer() {
- return getType() == PlayerType.BASKETBALL;
- }
-
- public PlayerType getType() {
- return type;
- }
-
- public void setType(PlayerType type) {
- this.type = type;
- }
-}
-```
-
-PlayerType 就相当于 Player 的内部类。
-
-由于枚举是 final 的,所以可以确保在 Java 虚拟机中仅有一个常量对象,基于这个原因,我们可以使用“==”运算符来比较两个枚举是否相等,参照 `isBasketballPlayer()` 方法。
-
-“那为什么不使用 `equals()` 方法判断呢?”三妹问。
-
-```java
-if(player.getType().equals(Player.PlayerType.BASKETBALL)){};
-```
-
-“我来给你解释下。”
-
-“==”运算符比较的时候,如果两个对象都为 null,并不会发生 `NullPointerException`,而 `equals()` 方法则会。
-
-另外, “==”运算符会在编译时进行检查,如果两侧的类型不匹配,会提示错误,而 `equals()` 方法则不会。
-
-
-
-“枚举还可用于 switch 语句,和基本数据类型的用法一致。”我说。
-
-```java
-switch (playerType) {
- case TENNIS:
- return "网球运动员费德勒";
- case FOOTBALL:
- return "足球运动员C罗";
- case BASKETBALL:
- return "篮球运动员詹姆斯";
- case UNKNOWN:
- throw new IllegalArgumentException("未知");
- default:
- throw new IllegalArgumentException(
- "运动员类型: " + playerType);
-
-}
-```
-
-“如果枚举中需要包含更多信息的话,可以为其添加一些字段,比如下面示例中的 name,此时需要为枚举添加一个带参的构造方法,这样就可以在定义枚举时添加对应的名称了。”我继续说。
-
-```java
-public enum PlayerType {
- TENNIS("网球"),
- FOOTBALL("足球"),
- BASKETBALL("篮球");
-
- private String name;
-
- PlayerType(String name) {
- this.name = name;
- }
-}
-```
-
-“get 了吧,三妹?”
-
-“嗯,比较好理解。”
-
-“那接下来,我就来说点不一样的。”
-
-“来吧,我准备好了。”
-
-“EnumSet 是一个专门针对枚举类型的 [Set 接口](https://tobebetterjavaer.com/collection/gailan.html)(后面会讲)的实现类,它是处理枚举类型数据的一把利器,非常高效。”我说,“从名字上就可以看得出,EnumSet 不仅和 Set 有关系,和枚举也有关系。”
-
-“因为 EnumSet 是一个抽象类,所以创建 EnumSet 时不能使用 new 关键字。不过,EnumSet 提供了很多有用的静态工厂方法。”
-
-
-
-“来看下面这个例子,我们使用 `noneOf()` 静态工厂方法创建了一个空的 PlayerType 类型的 EnumSet;使用 `allOf()` 静态工厂方法创建了一个包含所有 PlayerType 类型的 EnumSet。”
-
-```java
-public class EnumSetTest {
- public enum PlayerType {
- TENNIS,
- FOOTBALL,
- BASKETBALL
- }
-
- public static void main(String[] args) {
- EnumSet enumSetNone = EnumSet.noneOf(PlayerType.class);
- System.out.println(enumSetNone);
-
- EnumSet enumSetAll = EnumSet.allOf(PlayerType.class);
- System.out.println(enumSetAll);
- }
-}
-```
-
-“来看一下输出结果。”
-
-```java
-[]
-[TENNIS, FOOTBALL, BASKETBALL]
-```
-
-有了 EnumSet 后,就可以使用 Set 的一些方法了,见下图。
-
-
-
-“除了 EnumSet,还有 EnumMap,是一个专门针对枚举类型的 Map 接口的实现类,它可以将枚举常量作为键来使用。EnumMap 的效率比 HashMap 还要高,可以直接通过数组下标(枚举的 ordinal 值)访问到元素。”
-
-“和 EnumSet 不同,EnumMap 不是一个抽象类,所以创建 EnumMap 时可以使用 new 关键字。”
-
-```java
-EnumMap enumMap = new EnumMap<>(PlayerType.class);
-```
-
-有了 EnumMap 对象后就可以使用 Map 的一些方法了,见下图。
-
-
-
-和 [HashMap](https://tobebetterjavaer.com/collection/hashmap.html)(后面会讲)的使用方法大致相同,来看下面的例子。
-
-```java
-EnumMap enumMap = new EnumMap<>(PlayerType.class);
-enumMap.put(PlayerType.BASKETBALL,"篮球运动员");
-enumMap.put(PlayerType.FOOTBALL,"足球运动员");
-enumMap.put(PlayerType.TENNIS,"网球运动员");
-System.out.println(enumMap);
-
-System.out.println(enumMap.get(PlayerType.BASKETBALL));
-System.out.println(enumMap.containsKey(PlayerType.BASKETBALL));
-System.out.println(enumMap.remove(PlayerType.BASKETBALL));
-```
-
-“来看一下输出结果。”
-
-```
-{TENNIS=网球运动员, FOOTBALL=足球运动员, BASKETBALL=篮球运动员}
-篮球运动员
-true
-篮球运动员
-```
-
-“除了以上这些,《Effective Java》这本书里还提到了一点,如果要实现单例的话,最好使用枚举的方式。”我说。
-
-“等等二哥,单例是什么?”三妹没等我往下说,就连忙问道。
-
-“单例(Singleton)用来保证一个类仅有一个对象,并提供一个访问它的全局访问点,在一个进程中。因为这个类只有一个对象,所以就不能再使用 `new` 关键字来创建新的对象了。”
-
-“Java 标准库有一些类就是单例,比如说 Runtime 这个类。”
-
-```java
-Runtime runtime = Runtime.getRuntime();
-```
-
-“Runtime 类可以用来获取 Java 程序运行时的环境。”
-
-“关于单例,懂了些吧?”我问三妹。
-
-“噢噢噢噢。”三妹点了点头。
-
-“通常情况下,实现单例并非易事,来看下面这种写法。”
-
-```java
-public class Singleton {
- private volatile static Singleton singleton;
- private Singleton (){}
- public static Singleton getSingleton() {
- if (singleton == null) {
- synchronized (Singleton.class) {
- if (singleton == null) {
- singleton = new Singleton();
- }
- }
- }
- return singleton;
- }
-}
-```
-
-“要用到 [volatile](https://tobebetterjavaer.com/thread/volatile.html)、[synchronized](https://tobebetterjavaer.com/thread/synchronized-1.html) 关键字等等,但枚举的出现,让代码量减少到极致。”
-
-```java
-public enum EasySingleton{
- INSTANCE;
-}
-```
-
-“就这?”三妹睁大了眼睛。
-
-“对啊,枚举默认实现了 [Serializable 接口](https://tobebetterjavaer.com/io/Serializbale.html),因此 Java 虚拟机可以保证该类为单例,这与传统的实现方式不大相同。传统方式中,我们必须确保单例在反序列化期间不能创建任何新实例。”我说。
-
-“好了,关于枚举就讲这么多吧,三妹,你把这些代码都手敲一遍吧!”
-
-“好勒,这就安排。二哥,你去休息吧。”
-
-“嗯嗯。”讲了这么多,必须跑去抽烟机那里安排一根华子了。
-
----
-
-GitHub 上标星 7600+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 7600+ 的 Java 教程](https://tobebetterjavaer.com/overview/)
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
-
-# 第六章:Java 集合框架
-
-
-
-## 6.1 List、Set、Map、队列,全面解析
-
-眼瞅着三妹的王者荣耀杀得正嗨,我趁机喊到:“别打了,三妹,我们来一起学习 Java 的集合框架吧。”
-
-“才不要呢,等我打完这一局啊。”三妹倔强地说。
-
-“好吧。”我只好摊摊手地说,“那我先画张集合框架的结构图等着你。”
-
-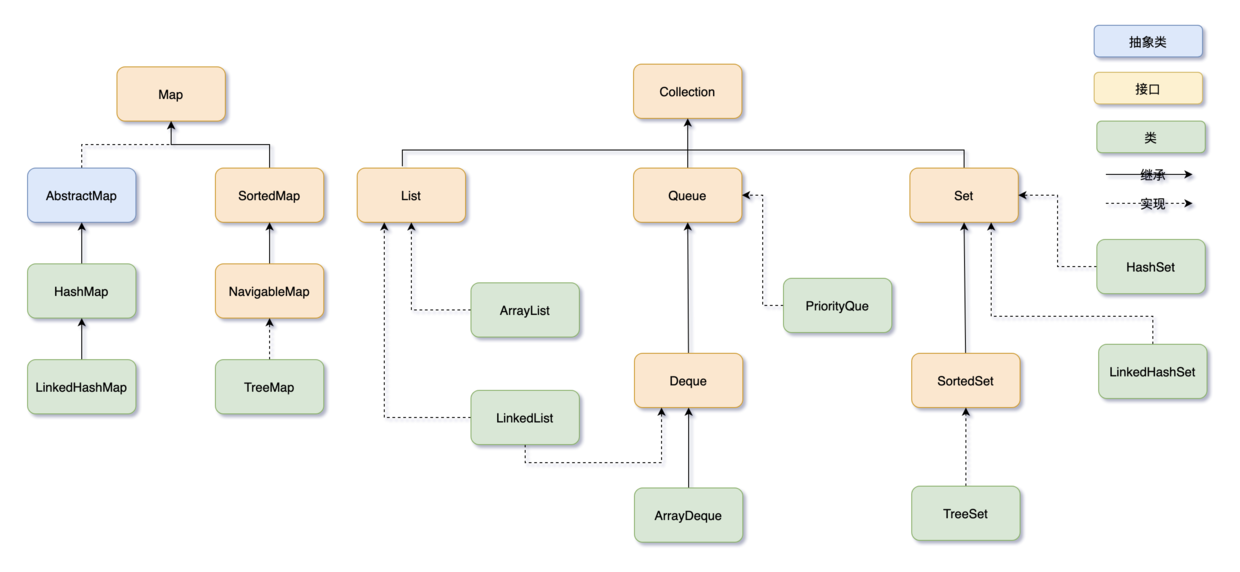
-
-
-“完了没?三妹。”
-
-“完了好一会儿了,二哥,你图画得真慢,让我瞧瞧怎么样?”
-
-“害,图要画得清晰明了,不容易的。三妹,你瞧,不错吧。”
-
-“哇,果然很棒,哥,你可真认真!”
-
-“我来简单介绍一下吧,Java 集合框架可以分为两条大的支线:”
-
-- Collection,主要由 List、Set、Queue 组成,List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQueue。
-- Map,代表键值对的集合,典型代表就是 HashMap。
-
-### 01、List
-
-List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作。
-
-#### **1)ArrayList**
-
-先来一段 ArrayList 的增删改查,学会用。
-
-```java
-// 创建一个集合
-ArrayList list = new ArrayList();
-// 添加元素
-list.add("王二");
-list.add("沉默");
-list.add("陈清扬");
-
-// 遍历集合 for 循环
-for (int i = 0; i < list.size(); i++) {
- String s = list.get(i);
- System.out.println(s);
-}
-// 遍历集合 for each
-for (String s : list) {
- System.out.println(s);
-}
-
-// 删除元素
-list.remove(1);
-// 遍历集合
-for (String s : list) {
- System.out.println(s);
-}
-
-// 修改元素
-list.set(1, "王二狗");
-// 遍历集合
-for (String s : list) {
- System.out.println(s);
-}
-```
-
-简单介绍一下 ArrayList 的特征,[后面还会详细讲](https://tobebetterjavaer.com/collection/arraylist.html)。
-
-- ArrayList 是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素;
-- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动;
-- 如果内部数组的容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低。
-
-#### **2)LinkedList**
-
-同样先来一段 LinkedList 的增删改查,和 ArrayList 几乎没什么差别。
-
-```java
-// 创建一个集合
-LinkedList list = new LinkedList();
-// 添加元素
-list.add("王二");
-list.add("沉默");
-list.add("陈清扬");
-
-// 遍历集合 for 循环
-for (int i = 0; i < list.size(); i++) {
- String s = list.get(i);
- System.out.println(s);
-}
-// 遍历集合 for each
-for (String s : list) {
- System.out.println(s);
-}
-
-// 删除元素
-list.remove(1);
-// 遍历集合
-for (String s : list) {
- System.out.println(s);
-}
-
-// 修改元素
-list.set(1, "王二狗");
-// 遍历集合
-for (String s : list) {
- System.out.println(s);
-}
-```
-
-不过,LinkedList 和 ArrayList 仍然有较大的不同,[后面也会详细地讲](https://tobebetterjavaer.com/collection/linkedlist.html)。
-
-- LinkedList 是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回;
-- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可,不像 ArrayList 那样需要复制和移动数组元素;
-- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些。
-
-#### **3)Vector 和 Stack**
-
-List 的实现类还有一个 Vector,是一个元老级的类,比 ArrayList 出现得更早。ArrayList 和 Vector 非常相似,只不过 Vector 是线程安全的,像 get、set、add 这些方法都加了 `synchronized` 关键字,就导致执行执行效率会比较低,所以现在已经很少用了。
-
-我就不写太多代码了,只看一下 add 方法的源码就明白了。
-
-```java
-public synchronized boolean add(E e) {
- elementData[elementCount++] = e;
- return true;
-}
-```
-
-这种加了同步方法的类,注定会被淘汰掉,就像[StringBuilder取代StringBuffer](https://tobebetterjavaer.com/string/builder-buffer.html)那样。JDK 源码也说了:
-
->如果不需要线程安全,建议使用ArrayList代替Vector。
-
-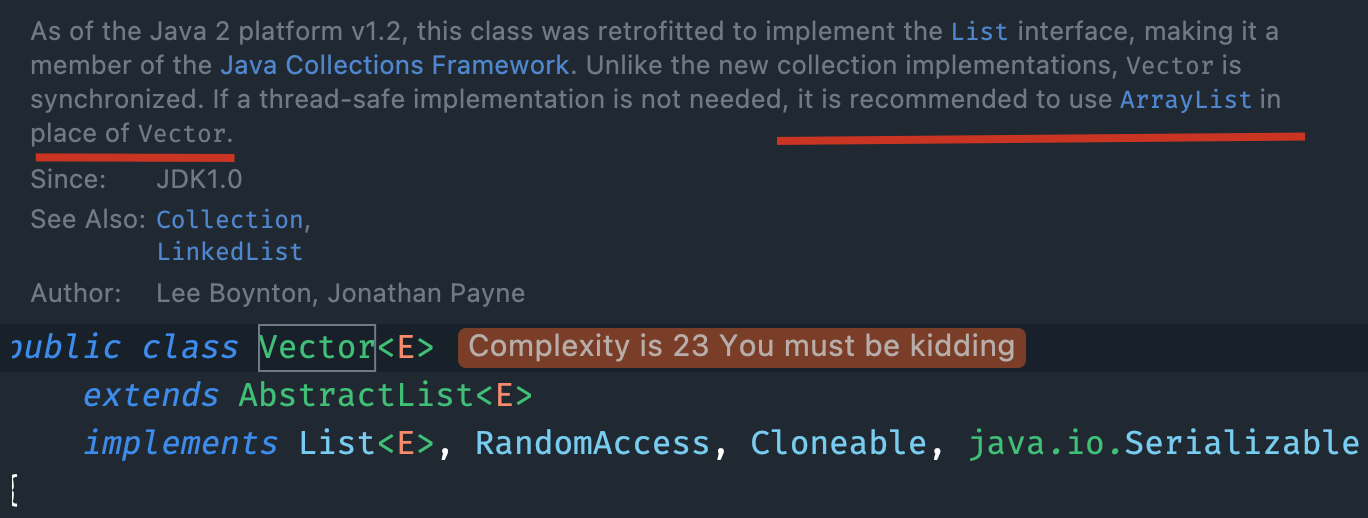
-
-Stack 是 Vector 的一个子类,本质上也是由动态数组实现的,只不过还实现了先进后出的功能(在 get、set、add 方法的基础上追加了 pop「返回并移除栈顶的元素」、peek「只返回栈顶元素」等方法),所以叫栈。
-
-下面是这两个方法的源码,增删改查我就不写了,和 ArrayList 和 LinkedList 几乎一样。
-
-```java
-public synchronized E pop() {
- E obj;
- int len = size();
-
- obj = peek();
- removeElementAt(len - 1);
-
- return obj;
-}
-
-public synchronized E peek() {
- int len = size();
-
- if (len == 0)
- throw new EmptyStackException();
- return elementAt(len - 1);
-}
-```
-
-不过,由于 Stack 执行效率比较低(方法上同样加了 synchronized 关键字),就被双端队列 ArrayDeque 取代了(下面会介绍)。
-
-### 02、Set
-
-Set 的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作,和 List 有很多不同。
-
-#### **1)HashSet**
-
-HashSet 其实是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。来简单看一下它的源码。
-
-```java
-public class HashSet
- extends AbstractSet
- implements Set, Cloneable, java.io.Serializable
-{
- private transient HashMap map;
-
- // Dummy value to associate with an Object in the backing Map
- private static final Object PRESENT = new Object();
-
- public HashSet() {
- map = new HashMap<>();
- }
-
- public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }
-
- public boolean remove(Object o) {
- return map.remove(o)==PRESENT;
- }
-}
-```
-
-实际开发中,HashSet 并不常用,比如,如果我们需要按照顺序存储一组元素,那么ArrayList和LinkedList可能更适合;如果我们需要存储键值对并根据键进行查找,那么HashMap可能更适合。
-
-当然,在某些情况下,HashSet仍然是最好的选择。例如,当我们需要快速查找一个元素是否存在于某个集合中,并且我们不需要对元素进行排序时,HashSet可以提供高效的性能。
-
-来一段增删改查体验一下:
-
-```java
-// 创建一个新的HashSet
-HashSet set = new HashSet<>();
-
-// 添加元素
-set.add("沉默");
-set.add("王二");
-set.add("陈清扬");
-
-// 输出HashSet的元素个数
-System.out.println("HashSet size: " + set.size()); // output: 3
-
-// 判断元素是否存在于HashSet中
-boolean containsWanger = set.contains("王二");
-System.out.println("Does set contain '王二'? " + containsWanger); // output: true
-
-// 删除元素
-boolean removeWanger = set.remove("王二");
-System.out.println("Removed '王二'? " + removeWanger); // output: true
-
-// 修改元素,需要先删除后添加
-boolean removeChenmo = set.remove("沉默");
-boolean addBuChenmo = set.add("不沉默");
-System.out.println("Modified set? " + (removeChenmo && addBuChenmo)); // output: true
-
-// 输出修改后的HashSet
-System.out.println("HashSet after modification: " + set); // output: [陈清扬, 不沉默]
-```
-
-
-#### **2)LinkedHashSet**
-
-LinkedHashSet 虽然继承自 HashSet,其实是由 [LinkedHashMap](https://tobebetterjavaer.com/collection/linkedhashmap.html) 实现的。
-
-这是 LinkedHashSet 的无参构造方法:
-
-```java
-public LinkedHashSet() {
- super(16, .75f, true);
-}
-```
-
-[super](https://tobebetterjavaer.com/oo/this-super.html) 的意思是它将调用父类的 HashSet 的一个有参构造方法:
-
-```java
-HashSet(int initialCapacity, float loadFactor, boolean dummy) {
- map = new LinkedHashMap<>(initialCapacity, loadFactor);
-}
-```
-
-看到 [LinkedHashMap](https://tobebetterjavaer.com/collection/linkedhashmap.html) 了吧,这个我们后面会去讲。
-
-好吧,来看一段 LinkedHashSet 的增删改查吧。
-
-```java
-LinkedHashSet set = new LinkedHashSet<>();
-
-// 添加元素
-set.add("沉默");
-set.add("王二");
-set.add("陈清扬");
-
-// 删除元素
-set.remove("王二");
-
-// 修改元素
-set.remove("沉默");
-set.add("沉默的力量");
-
-// 查找元素
-boolean hasChenQingYang = set.contains("陈清扬");
-System.out.println("set包含陈清扬吗?" + hasChenQingYang);
-```
-
-在以上代码中,我们首先创建了一个LinkedHashSet对象,然后使用add方法依次添加了三个元素:沉默、王二和陈清扬。接着,我们使用remove方法删除了王二这个元素,并使用remove和add方法修改了沉默这个元素。最后,我们使用contains方法查找了陈清扬这个元素是否存在于set中,并打印了结果。
-
-LinkedHashSet是一种基于哈希表实现的Set接口,它继承自HashSet,并且使用链表维护了元素的插入顺序。因此,它既具有HashSet的快速查找、插入和删除操作的优点,又可以维护元素的插入顺序。
-
-#### **3)TreeSet**
-
-“二哥,不用你讲了,我能猜到,TreeSet 是由 [TreeMap(后面会讲)](https://tobebetterjavaer.com/collection/treemap.html) 实现的,只不过同样操作的键位,值由一个固定的 Object 对象填充。”
-
-哇,三妹都学会了推理。
-
-是的,与 TreeMap 相似,TreeSet 是一种基于红黑树实现的有序集合,它实现了 SortedSet 接口,可以自动对集合中的元素进行排序。按照键的自然顺序或指定的比较器顺序进行排序。
-
-```java
-// 创建一个 TreeSet 对象
-TreeSet set = new TreeSet<>();
-
-// 添加元素
-set.add("沉默");
-set.add("王二");
-set.add("陈清扬");
-System.out.println(set); // 输出 [沉默, 王二, 陈清扬]
-
-// 删除元素
-set.remove("王二");
-System.out.println(set); // 输出 [沉默, 陈清扬]
-
-// 修改元素:TreeSet 中的元素不支持直接修改,需要先删除再添加
-set.remove("陈清扬");
-set.add("陈青阳");
-System.out.println(set); // 输出 [沉默, 陈青阳]
-
-// 查找元素
-System.out.println(set.contains("沉默")); // 输出 true
-System.out.println(set.contains("王二")); // 输出 false
-```
-
-需要注意的是,TreeSet 不允许插入 null 元素,否则会抛出 NullPointerException 异常。
-
-“总体上来说,Set 集合不是关注的重点,因为底层都是由 Map 实现的,为什么要用 Map 实现呢?三妹你能猜到原因吗?”
-
-“让我想想。”
-
-“嗯?难道是因为 Map 的键不允许重复、无序吗?”
-
-老天,竟然被三妹猜到了。
-
-“是的,你这水平长进了呀,三妹。”
-
-### 03、Queue
-
-Queue,也就是队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部。
-
-#### **1)ArrayDeque**
-
-从名字上可以看得出,ArrayDeque 是一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点。
-
-这是一个包含了 4 个元素的双端队列,和一个包含了 5 个元素的双端队列。
-
-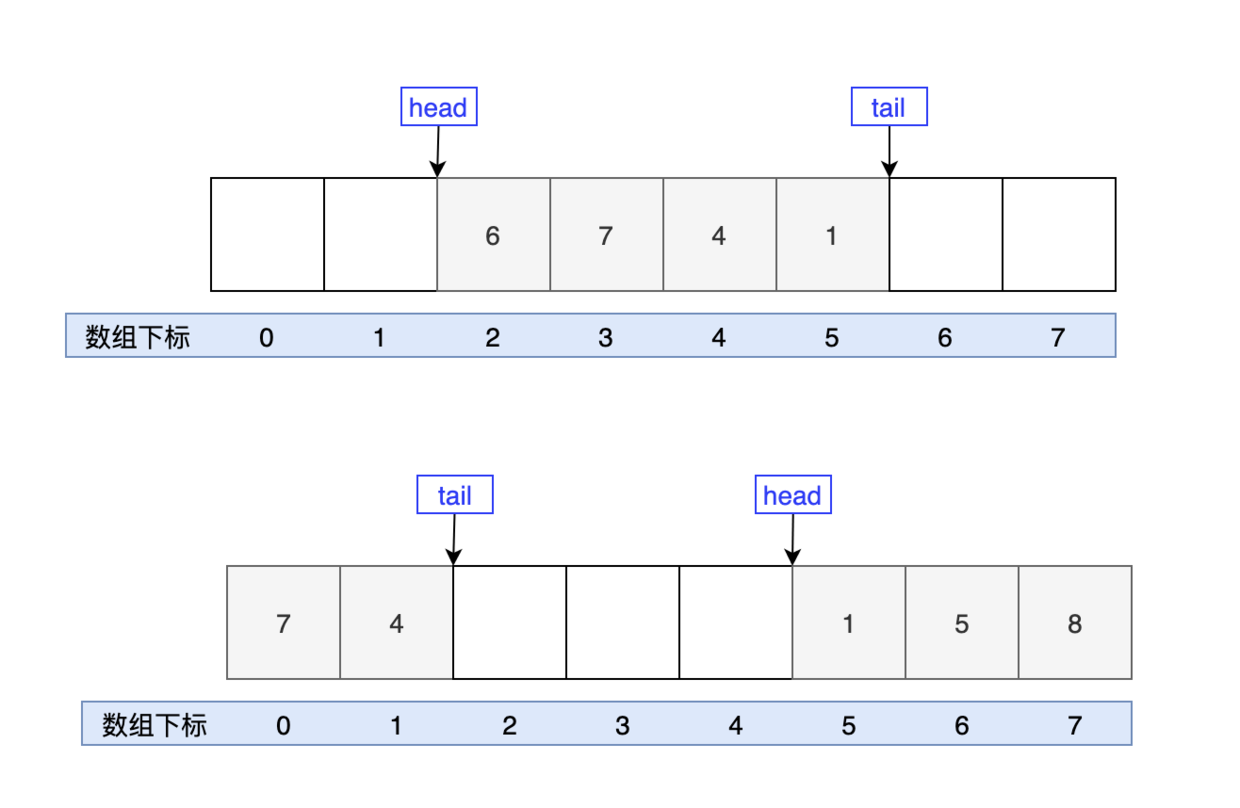
-
-head 指向队首的第一个有效的元素,tail 指向队尾第一个可以插入元素的空位,因为是循环数组,所以 head 不一定从是从 0 开始,tail 也不一定总是比 head 大。
-
-来一段ArrayDeque的增删改查吧。
-
-```java
-// 创建一个ArrayDeque
-ArrayDeque deque = new ArrayDeque<>();
-
-// 添加元素
-deque.add("沉默");
-deque.add("王二");
-deque.add("陈清扬");
-
-// 删除元素
-deque.remove("王二");
-
-// 修改元素
-deque.remove("沉默");
-deque.add("沉默的力量");
-
-// 查找元素
-boolean hasChenQingYang = deque.contains("陈清扬");
-System.out.println("deque包含陈清扬吗?" + hasChenQingYang);
-```
-
-#### **2)LinkedList**
-
-LinkedList 一般应该归在 List 下,只不过,它也实现了 Deque 接口,可以作为队列来使用。等于说,LinkedList 同时实现了 Stack、Queue、PriorityQueue 的所有功能。
-
-```java
-public class LinkedList
- extends AbstractSequentialList
- implements List, Deque, Cloneable, java.io.Serializable
-{}
-```
-
-换句话说,LinkedList 和 ArrayDeque 都是 Java 集合框架中的双向队列(deque),它们都支持在队列的两端进行元素的插入和删除操作。不过,LinkedList 和 ArrayDeque 在实现上有一些不同:
-
-- 底层实现方式不同:LinkedList 是基于链表实现的,而 ArrayDeque 是基于数组实现的。
-- 随机访问的效率不同:由于底层实现方式的不同,LinkedList 对于随机访问的效率较低,时间复杂度为 O(n),而 ArrayDeque 可以通过下标随机访问元素,时间复杂度为 O(1)。
-- 迭代器的效率不同:LinkedList 对于迭代器的效率比较低,因为需要通过链表进行遍历,时间复杂度为 O(n),而 ArrayDeque 的迭代器效率比较高,因为可以直接访问数组中的元素,时间复杂度为 O(1)。
-- 内存占用不同:由于 LinkedList 是基于链表实现的,它在存储元素时需要额外的空间来存储链表节点,因此内存占用相对较高,而 ArrayDeque 是基于数组实现的,内存占用相对较低。
-
-因此,在选择使用 LinkedList 还是 ArrayDeque 时,需要根据具体的业务场景和需求来选择。如果需要在双向队列的两端进行频繁的插入和删除操作,并且需要随机访问元素,可以考虑使用 ArrayDeque;如果需要在队列中间进行频繁的插入和删除操作,可以考虑使用 LinkedList。
-
-来一段 LinkedList 作为队列时候的增删改查吧,注意和它作为 List 的时候有很大的不同。
-
-```java
-// 创建一个 LinkedList 对象
-LinkedList queue = new LinkedList<>();
-
-// 添加元素
-queue.offer("沉默");
-queue.offer("王二");
-queue.offer("陈清扬");
-System.out.println(queue); // 输出 [沉默, 王二, 陈清扬]
-
-// 删除元素
-queue.poll();
-System.out.println(queue); // 输出 [王二, 陈清扬]
-
-// 修改元素:LinkedList 中的元素不支持直接修改,需要先删除再添加
-String first = queue.poll();
-queue.offer("王大二");
-System.out.println(queue); // 输出 [陈清扬, 王大二]
-
-// 查找元素:LinkedList 中的元素可以使用 get() 方法进行查找
-System.out.println(queue.get(0)); // 输出 陈清扬
-System.out.println(queue.contains("沉默")); // 输出 false
-
-// 查找元素:使用迭代器的方式查找陈清扬
-// 使用迭代器依次遍历元素并查找
-Iterator iterator = queue.iterator();
-while (iterator.hasNext()) {
- String element = iterator.next();
- if (element.equals("陈清扬")) {
- System.out.println("找到了:" + element);
- break;
- }
-}
-```
-
-在使用 LinkedList 作为队列时,可以使用 offer() 方法将元素添加到队列的末尾,使用 poll() 方法从队列的头部删除元素。另外,由于 LinkedList 是链表结构,不支持随机访问元素,因此不能使用下标访问元素,需要使用迭代器或者 poll() 方法依次遍历元素。
-
-
-#### **3)PriorityQueue**
-
-PriorityQueue 是一种优先级队列,它的出队顺序与元素的优先级有关,执行 remove 或者 poll 方法,返回的总是优先级最高的元素。
-
-```java
-// 创建一个 PriorityQueue 对象
-PriorityQueue queue = new PriorityQueue<>();
-
-// 添加元素
-queue.offer("沉默");
-queue.offer("王二");
-queue.offer("陈清扬");
-System.out.println(queue); // 输出 [沉默, 王二, 陈清扬]
-
-// 删除元素
-queue.poll();
-System.out.println(queue); // 输出 [王二, 陈清扬]
-
-// 修改元素:PriorityQueue 不支持直接修改元素,需要先删除再添加
-String first = queue.poll();
-queue.offer("张三");
-System.out.println(queue); // 输出 [张三, 陈清扬]
-
-// 查找元素:PriorityQueue 不支持随机访问元素,只能访问队首元素
-System.out.println(queue.peek()); // 输出 张三
-System.out.println(queue.contains("陈清扬")); // 输出 true
-
-// 通过 for 循环的方式查找陈清扬
-for (String element : queue) {
- if (element.equals("陈清扬")) {
- System.out.println("找到了:" + element);
- break;
- }
-}
-```
-
-要想有优先级,元素就需要实现 [Comparable 接口或者 Comparator 接口](https://tobebetterjavaer.com/basic-extra-meal/comparable-omparator.html)(我们后面会讲)。
-
-这里先来一段通过实现 Comparator 接口按照年龄姓名排序的优先级队列吧。
-
-```java
-import java.util.Comparator;
-import java.util.PriorityQueue;
-
-class Student {
- private String name;
- private int chineseScore;
- private int mathScore;
-
- public Student(String name, int chineseScore, int mathScore) {
- this.name = name;
- this.chineseScore = chineseScore;
- this.mathScore = mathScore;
- }
-
- public String getName() {
- return name;
- }
-
- public int getChineseScore() {
- return chineseScore;
- }
-
- public int getMathScore() {
- return mathScore;
- }
-
- @Override
- public String toString() {
- return "Student{" +
- "name='" + name + '\'' +
- ", 总成绩=" + (chineseScore + mathScore) +
- '}';
- }
-}
-
-class StudentComparator implements Comparator {
- @Override
- public int compare(Student s1, Student s2) {
- // 比较总成绩
- return Integer.compare(s2.getChineseScore() + s2.getMathScore(),
- s1.getChineseScore() + s1.getMathScore());
- }
-}
-
-public class PriorityQueueComparatorExample {
-
- public static void main(String[] args) {
- // 创建一个按照总成绩排序的优先级队列
- PriorityQueue queue = new PriorityQueue<>(new StudentComparator());
-
- // 添加元素
- queue.offer(new Student("王二", 80, 90));
- System.out.println(queue);
- queue.offer(new Student("陈清扬", 95, 95));
- System.out.println(queue);
- queue.offer(new Student("小驼铃", 90, 95));
- System.out.println(queue);
- queue.offer(new Student("沉默", 90, 80));
- while (!queue.isEmpty()) {
- System.out.print(queue.poll() + " ");
- }
- }
-}
-```
-
-Student 是一个学生对象,包含姓名、语文成绩和数学成绩。
-
-StudentComparator 实现了 Comparator 接口,对总成绩做了一个排序。
-
-PriorityQueue 是一个优先级队列,参数为 StudentComparator,然后我们添加了 4 个学生对象进去。
-
-来看一下输出结果:
-
-```
-[Student{name='王二', 总成绩=170}]
-[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}]
-[Student{name='陈清扬', 总成绩=190}, Student{name='王二', 总成绩=170}, Student{name='小驼铃', 总成绩=185}]
-Student{name='陈清扬', 总成绩=190} Student{name='小驼铃', 总成绩=185} Student{name='沉默', 总成绩=170} Student{name='王二', 总成绩=170}
-```
-
-我们使用 offer 方法添加元素,最后用 while 循环遍历元素(通过 poll 方法取出元素),从结果可以看得出,[PriorityQueue](https://tobebetterjavaer.com/collection/PriorityQueue.html)按照学生的总成绩由高到低进行了排序。
-
-
-### 04、Map
-
-Map 保存的是键值对,键要求保持唯一性,值可以重复。
-
-#### **1)HashMap**
-
-HashMap 实现了 Map 接口,可以根据键快速地查找对应的值——通过哈希函数将键映射到哈希表中的一个索引位置,从而实现快速访问。[后面会详细聊到](https://tobebetterjavaer.com/collection/hashmap.html)。
-
-这里先大致了解一下 HashMap 的特点:
-
-- HashMap 中的键和值都可以为 null。如果键为 null,则将该键映射到哈希表的第一个位置。
-- 可以使用迭代器或者 forEach 方法遍历 HashMap 中的键值对。
-- HashMap 有一个初始容量和一个负载因子。初始容量是指哈希表的初始大小,负载因子是指哈希表在扩容之前可以存储的键值对数量与哈希表大小的比率。默认的初始容量是 16,负载因子是 0.75。
-
-来个简单的增删改查吧。
-
-```java
-// 创建一个 HashMap 对象
-HashMap hashMap = new HashMap<>();
-
-// 添加键值对
-hashMap.put("沉默", "cenzhong");
-hashMap.put("王二", "wanger");
-hashMap.put("陈清扬", "chenqingyang");
-
-// 获取指定键的值
-String value1 = hashMap.get("沉默");
-System.out.println("沉默对应的值为:" + value1);
-
-// 修改键对应的值
-hashMap.put("沉默", "chenmo");
-String value2 = hashMap.get("沉默");
-System.out.println("修改后沉默对应的值为:" + value2);
-
-// 删除指定键的键值对
-hashMap.remove("王二");
-
-// 遍历 HashMap
-for (String key : hashMap.keySet()) {
- String value = hashMap.get(key);
- System.out.println(key + " 对应的值为:" + value);
-}
-```
-
-#### **2)LinkedHashMap**
-
-HashMap 已经非常强大了,但它是无序的。如果我们需要一个有序的Map,就要用到 [LinkedHashMap](https://tobebetterjavaer.com/collection/linkedhashmap.html)。LinkedHashMap 是 HashMap 的子类,它使用链表来记录插入/访问元素的顺序。
-
-LinkedHashMap 可以看作是 HashMap + LinkedList 的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序。
-
-来一个简单的例子。
-
-```java
-// 创建一个 LinkedHashMap,插入的键值对为 沉默 王二 陈清扬
-LinkedHashMap linkedHashMap = new LinkedHashMap<>();
-linkedHashMap.put("沉默", "cenzhong");
-linkedHashMap.put("王二", "wanger");
-linkedHashMap.put("陈清扬", "chenqingyang");
-
-// 遍历 LinkedHashMap
-for (String key : linkedHashMap.keySet()) {
- String value = linkedHashMap.get(key);
- System.out.println(key + " 对应的值为:" + value);
-}
-```
-
-来看输出结果:
-
-```
-沉默 对应的值为:cenzhong
-王二 对应的值为:wanger
-陈清扬 对应的值为:chenqingyang
-```
-
-从结果中可以看得出来,LinkedHashMap 维持了键值对的插入顺序,对吧?为了和 LinkedHashMap 做对比,我们用同样的数据试验一下 HashMap。
-
-```java
-// 创建一个HashMap,插入的键值对为 沉默 王二 陈清扬
-HashMap hashMap = new HashMap<>();
-hashMap.put("沉默", "cenzhong");
-hashMap.put("王二", "wanger");
-hashMap.put("陈清扬", "chenqingyang");
-
-// 遍历 HashMap
-for (String key : hashMap.keySet()) {
- String value = hashMap.get(key);
- System.out.println(key + " 对应的值为:" + value);
-}
-```
-
-来看输出结果:
-
-```
-沉默 对应的值为:cenzhong
-陈清扬 对应的值为:chenqingyang
-王二 对应的值为:wanger
-```
-
-HashMap 没有维持键值对的插入顺序,对吧?
-
-#### **3)TreeMap**
-
-[TreeMap](https://tobebetterjavaer.com/collection/treemap.html) 实现了 SortedMap 接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。内部使用红黑树来实现键的排序和查找。
-
-同样来一个增删改查的 demo:
-
-```java
-// 创建一个 TreeMap 对象
-Map treeMap = new TreeMap<>();
-
-// 向 TreeMap 中添加键值对
-treeMap.put("沉默", "cenzhong");
-treeMap.put("王二", "wanger");
-treeMap.put("陈清扬", "chenqingyang");
-
-// 查找键值对
-String name = "沉默";
-if (treeMap.containsKey(name)) {
- System.out.println("找到了 " + name + ": " + treeMap.get(name));
-} else {
- System.out.println("没有找到 " + name);
-}
-
-// 修改键值对
-name = "王二";
-if (treeMap.containsKey(name)) {
- System.out.println("修改前的 " + name + ": " + treeMap.get(name));
- treeMap.put(name, "newWanger");
- System.out.println("修改后的 " + name + ": " + treeMap.get(name));
-} else {
- System.out.println("没有找到 " + name);
-}
-
-// 删除键值对
-name = "陈清扬";
-if (treeMap.containsKey(name)) {
- System.out.println("删除前的 " + name + ": " + treeMap.get(name));
- treeMap.remove(name);
- System.out.println("删除后的 " + name + ": " + treeMap.get(name));
-} else {
- System.out.println("没有找到 " + name);
-}
-
-// 遍历 TreeMap
-for (Map.Entry entry : treeMap.entrySet()) {
- System.out.println(entry.getKey() + ": " + entry.getValue());
-}
-```
-
-与 HashMap 不同的是,TreeMap 会按照键的顺序来进行排序。
-
-```java
-// 创建一个 TreeMap 对象
-Map treeMap = new TreeMap<>();
-
-// 向 TreeMap 中添加键值对
-treeMap.put("c", "cat");
-treeMap.put("a", "apple");
-treeMap.put("b", "banana");
-
-// 遍历 TreeMap
-for (Map.Entry entry : treeMap.entrySet()) {
- System.out.println(entry.getKey() + ": " + entry.getValue());
-}
-```
-
-来看输出结果:
-
-```
-a: apple
-b: banana
-c: cat
-```
-
-默认情况下,已经按照键的自然顺序排过了。
-
-“好了,三妹,关于集合框架,我们就先聊到这,随后我们会针对常用的容器进行详细地讲解,比如说 ArrayList、LinkedList、HashMap 等。”
-
-“哇,二哥,这篇讲的东西可真不少,虽然都是比较基础的,但对于我一个小白来说,还是需要花点时间去消化的。”三妹嘟嘟嘴说到。
-
-
-
-## 6.2 时间复杂度,了解下
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[6.2 时间复杂度,了解下](https://tobebetterjavaer.com/collection/time-complexity.html)
-
-
-
-## 6.3 ArrayList详解(附源码)
-
-“二哥,听说今天我们开讲 ArrayList 了?好期待哦!”三妹明知故问,这个托配合得依然天衣无缝。
-
-“是的呀,三妹。”我肯定地点了点头,继续说道,“ArrayList 可以称得上是集合框架方面最常用的类了,可以和 HashMap 一较高下。”
-
-从名字就可以看得出来,ArrayList 实现了 List 接口,并且是基于数组实现的。
-
-数组的大小是固定的,一旦创建的时候指定了大小,就不能再调整了。也就是说,如果数组满了,就不能再添加任何元素了。ArrayList 在数组的基础上实现了自动扩容,并且提供了比数组更丰富的预定义方法(各种增删改查),非常灵活。
-
-Java 这门编程语言和别的编程语言,比如说 C语言的不同之处就在这里,如果是 C语言的话,你就必须得动手实现自己的 ArrayList,原生的库函数里面是没有的。
-
-### 01、创建 ArrayList
-
-“二哥,**如何创建一个 ArrayList 啊**?”三妹问。
-
-```java
-ArrayList alist = new ArrayList();
-```
-
-可以通过上面的语句来创建一个字符串类型的 ArrayList(通过尖括号来限定 ArrayList 中元素的类型,如果尝试添加其他类型的元素,将会产生编译错误),更简化的写法如下:
-
-```java
-List alist = new ArrayList<>();
-```
-
-由于 ArrayList 实现了 List 接口,所以 alist 变量的类型可以是 List 类型;new 关键字声明后的尖括号中可以不再指定元素的类型,因为编译器可以通过前面尖括号中的类型进行智能推断。
-
-此时会调用无参构造方法(见下面的代码)创建一个空的数组,常量DEFAULTCAPACITY_EMPTY_ELEMENTDATA的值为 `{}`。
-
-```java
-public ArrayList() {
- this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
-}
-```
-
-如果非常确定 ArrayList 中元素的个数,在创建的时候还可以指定初始大小。
-
-```java
-List alist = new ArrayList<>(20);
-```
-
-这样做的好处是,可以有效地避免在添加新的元素时进行不必要的扩容。
-
-### 02、向 ArrayList 中添加元素
-
-“二哥,**那怎么向 ArrayList 中添加一个元素呢**?”三妹继续问。
-
-可以通过 `add()` 方法向 ArrayList 中添加一个元素。
-
-```java
-alist.add("沉默王二");
-```
-
-我们来跟一下源码,看看 add 方法到底执行了哪些操作。跟的过程中,我们也可以偷师到 Java 源码的作者(大师级程序员)是如何优雅地写代码的。
-
-我先给个结论,全当抛砖引玉。
-
-```
-堆栈过程图示:
-add(element)
-└── if (size == elementData.length) // 判断是否需要扩容
- ├── grow(minCapacity) // 扩容
- │ └── newCapacity = oldCapacity + (oldCapacity >> 1) // 计算新的数组容量
- │ └── Arrays.copyOf(elementData, newCapacity) // 创建新的数组
- ├── elementData[size++] = element; // 添加新元素
- └── return true; // 添加成功
-```
-
-来具体看一下,先是 `add()` 方法的源码(已添加好详细地注释)
-
-```java
-/**
- * 将指定元素添加到 ArrayList 的末尾
- * @param e 要添加的元素
- * @return 添加成功返回 true
- */
-public boolean add(E e) {
- ensureCapacityInternal(size + 1); // 确保 ArrayList 能够容纳新的元素
- elementData[size++] = e; // 在 ArrayList 的末尾添加指定元素
- return true;
-}
-```
-
-参数 e 为要添加的元素,此时的值为“沉默王二”,size 为 ArrayList 的长度,此时为 0。
-
-继续跟下去,来看看 `ensureCapacityInternal()`方法:
-
-```java
-/**
- * 确保 ArrayList 能够容纳指定容量的元素
- * @param minCapacity 指定容量的最小值
- */
-private void ensureCapacityInternal(int minCapacity) {
- if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 如果 elementData 还是默认的空数组
- minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); // 使用 DEFAULT_CAPACITY 和指定容量的最小值中的较大值
- }
-
- ensureExplicitCapacity(minCapacity); // 确保容量能够容纳指定容量的元素
-}
-```
-
-此时:
-
-- 参数 minCapacity 为 1(size+1 传过来的)
-- elementData 为存放 ArrayList 元素的底层数组,前面声明 ArrayList 的时候讲过了,此时为空 `{}`
-- DEFAULTCAPACITY_EMPTY_ELEMENTDATA 前面也讲过了,为 `{}`
-
-所以,if 条件此时为 true,if 语句`minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity)`要执行。
-
-DEFAULT_CAPACITY 为 10(见下面的代码),所以执行完这行代码后,minCapacity 为 10,`Math.max()` 方法的作用是取两个当中最大的那个。
-
-```java
-private static final int DEFAULT_CAPACITY = 10;
-```
-
-接下来执行 `ensureExplicitCapacity()` 方法,来看一下源码:
-
-```java
-/**
- * 检查并确保集合容量足够,如果需要则增加集合容量。
- *
- * @param minCapacity 所需最小容量
- */
-private void ensureExplicitCapacity(int minCapacity) {
- // 检查是否超出了数组范围,确保不会溢出
- if (minCapacity - elementData.length > 0)
- // 如果需要增加容量,则调用 grow 方法
- grow(minCapacity);
-}
-```
-
-此时:
-
-- 参数 minCapacity 为 10
-- elementData.length 为 0(数组为空)
-
-所以 10-0>0,if 条件为 true,进入 if 语句执行 `grow()` 方法,来看源码:
-
-```java
-/**
- * 扩容 ArrayList 的方法,确保能够容纳指定容量的元素
- * @param minCapacity 指定容量的最小值
- */
-private void grow(int minCapacity) {
- // 检查是否会导致溢出,oldCapacity 为当前数组长度
- int oldCapacity = elementData.length;
- int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容至原来的1.5倍
- if (newCapacity - minCapacity < 0) // 如果还是小于指定容量的最小值
- newCapacity = minCapacity; // 直接扩容至指定容量的最小值
- if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果超出了数组的最大长度
- newCapacity = hugeCapacity(minCapacity); // 扩容至数组的最大长度
- // 将当前数组复制到一个新数组中,长度为 newCapacity
- elementData = Arrays.copyOf(elementData, newCapacity);
-}
-```
-
-此时:
-
-- 参数 minCapacity 为 10
-- 变量 oldCapacity 为 0
-
-所以 newCapacity 也为 0,于是 `newCapacity - minCapacity` 等于 -10 小于 0,于是第一个 if 条件为 true,执行第一个 if 语句 `newCapacity = minCapacity`,然后 newCapacity 为 10。
-
-紧接着执行 `elementData = Arrays.copyOf(elementData, newCapacity);`,也就是进行数组的第一次扩容,长度为 10。
-
-回到 `add()` 方法:
-
-```java
-public boolean add(E e) {
- ensureCapacityInternal(size + 1);
- elementData[size++] = e;
- return true;
-}
-```
-
-执行 `elementData[size++] = e`。
-
-此时:
-
-- size 为 0
-- e 为 “沉默王二”
-
-所以数组的第一个元素(下标为 0) 被赋值为“沉默王二”,接着返回 true,第一次 add 方法执行完毕。
-
-PS:add 过程中会遇到一个令新手感到困惑的右移操作符 `>>`,借这个机会来解释一下。
-
-ArrayList 在第一次执行 add 后会扩容为 10,那 ArrayList 第二次扩容发生在什么时候呢?
-
-答案是添加第 11 个元素时,大家可以尝试分析一下这个过程。
-
-### 03、右移操作符
-
-“oldCapacity 等于 10,`oldCapacity >> 1` 这个表达式等于多少呢?三妹你知道吗?”我问三妹。
-
-“不知道啊,`>>` 是什么意思呢?”三妹很疑惑。
-
-“`>>` 是右移运算符,`oldCapacity >> 1` 相当于 oldCapacity 除以 2。”我给三妹解释道,“在计算机内部,都是按照二进制存储的,10 的二进制就是 1010,也就是 `0*2^0 + 1*2^1 + 0*2^2 + 1*2^3`=0+2+0+8=10 。。。。。。”
-
-还没等我解释完,三妹就打断了我,“二哥,能再详细解释一下到底为什么吗?”
-
-“当然可以啊。”我拍着胸脯对三妹说。
-
-先从位权的含义说起吧。
-
-平常我们使用的是十进制数,比如说 39,并不是简单的 3 和 9,3 表示的是 `3*10 = 30`,9 表示的是 `9*1 = 9`,和 3 相乘的 10,和 9 相乘的 1,就是**位权**。位数不同,位权就不同,第 1 位是 10 的 0 次方(也就是 `10^0=1`),第 2 位是 10 的 1 次方(`10^1=10`),第 3 位是 10 的 2 次方(`10^2=100`),最右边的是第一位,依次类推。
-
-位权这个概念同样适用于二进制,第 1 位是 2 的 0 次方(也就是 `2^0=1`),第 2 位是 2 的 1 次方(`2^1=2`),第 3 位是 2 的 2 次方(`2^2=4`),第 34 位是 2 的 3 次方(`2^3=8`)。
-
-十进制的情况下,10 是基数,二进制的情况下,2 是基数。
-
-10 在十进制的表示法是 `0*10^0+1*10^1`=0+10=10。
-
-10 的二进制数是 1010,也就是 `0*2^0 + 1*2^1 + 0*2^2 + 1*2^3`=0+2+0+8=10。
-
-然后是**移位运算**,移位分为左移和右移,在 Java 中,左移的运算符是 `<<`,右移的运算符 `>>`。
-
-拿 `oldCapacity >> 1` 来说吧,`>>` 左边的是被移位的值,此时是 10,也就是二进制 `1010`;`>>` 右边的是要移位的位数,此时是 1。
-
-1010 向右移一位就是 101,空出来的最高位此时要补 0,也就是 0101。
-
-“那为什么不补 1 呢?”三妹这个问题很尖锐。
-
-“因为是算术右移,并且是正数,所以最高位补 0;如果表示的是负数,就需要补 1。”我慢吞吞地回答道,“0101 的十进制就刚好是 `1*2^0 + 0*2^1 + 1*2^2 + 0*2^3`=1+0+4+0=5,如果多移几个数来找规律的话,就会发现,右移 1 位是原来的 1/2,右移 2 位是原来的 1/4,诸如此类。”
-
-也就是说,ArrayList 的大小会扩容为原来的大小+原来大小/2,也就是 1.5 倍。
-
-这下明白了吧?
-
-你可以通过在 ArrayList 中添加第 11 个元素来 debug 验证一下。
-
-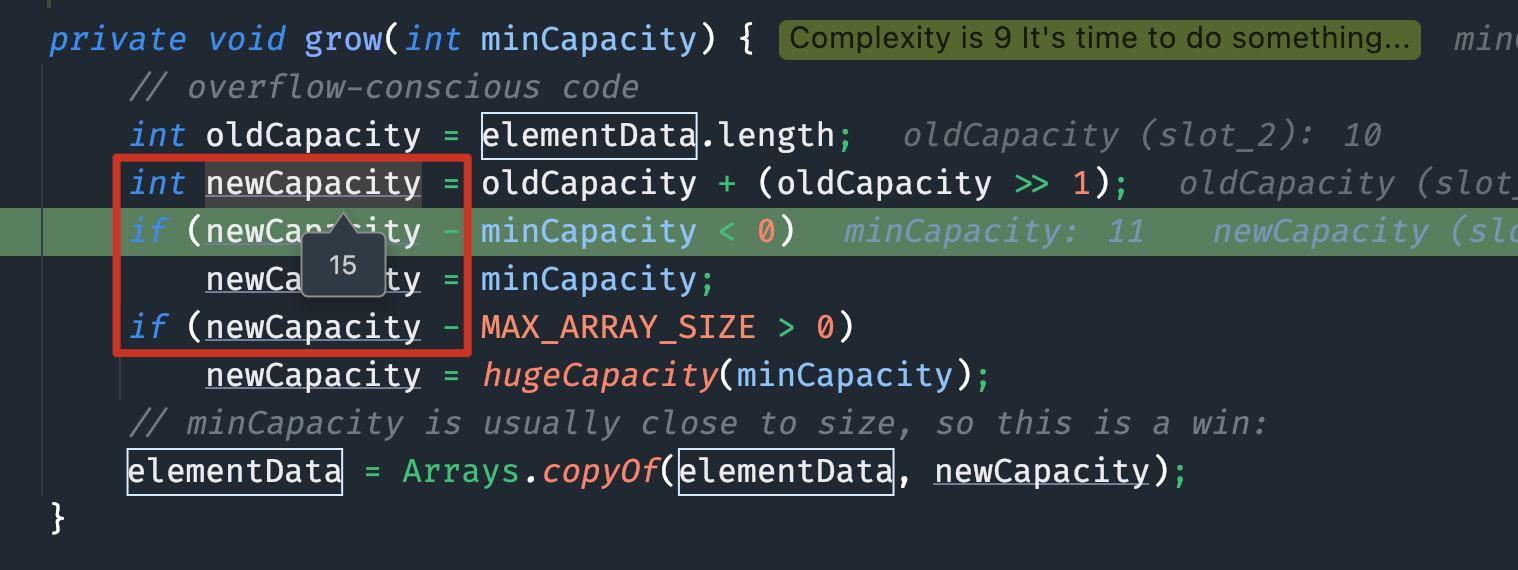
-
-### 04、向 ArrayList 的指定位置添加元素
-
-除了 `add(E e)` 方法,还可以通过 `add(int index, E element)` 方法把元素添加到 ArrayList 的指定位置:
-
-```java
-alist.add(0, "沉默王三");
-```
-
-`add(int index, E element)` 方法的源码如下:
-
-```java
-/**
- * 在指定位置插入一个元素。
- *
- * @param index 要插入元素的位置
- * @param element 要插入的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
- */
-public void add(int index, E element) {
- rangeCheckForAdd(index); // 检查索引是否越界
-
- ensureCapacityInternal(size + 1); // 确保容量足够,如果需要扩容就扩容
- System.arraycopy(elementData, index, elementData, index + 1,
- size - index); // 将 index 及其后面的元素向后移动一位
- elementData[index] = element; // 将元素插入到指定位置
- size++; // 元素个数加一
-}
-```
-
-`add(int index, E element)`方法会调用到一个非常重要的[本地方法](https://tobebetterjavaer.com/oo/native-method.html) `System.arraycopy()`,它会对数组进行复制(要插入位置上的元素往后复制)。
-
-来细品一下。
-
-这是 arraycopy() 的语法:
-
-```java
-System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
-```
-
-在 `ArrayList.add(int index, E element)` 方法中,具体用法如下:
-
-```java
-System.arraycopy(elementData, index, elementData, index + 1, size - index);
-```
-
-- elementData:表示要复制的源数组,即 ArrayList 中的元素数组。
-- index:表示源数组中要复制的起始位置,即需要将 index 及其后面的元素向后移动一位。
-- elementData:表示要复制到的目标数组,即 ArrayList 中的元素数组。
-- index + 1:表示目标数组中复制的起始位置,即将 index 及其后面的元素向后移动一位后,应该插入到的位置。
-- size - index:表示要复制的元素个数,即需要将 index 及其后面的元素向后移动一位,需要移动的元素个数为 size - index。
-
-
-“三妹,注意看,我画幅图来表示下。”我认真地做起了图。
-
-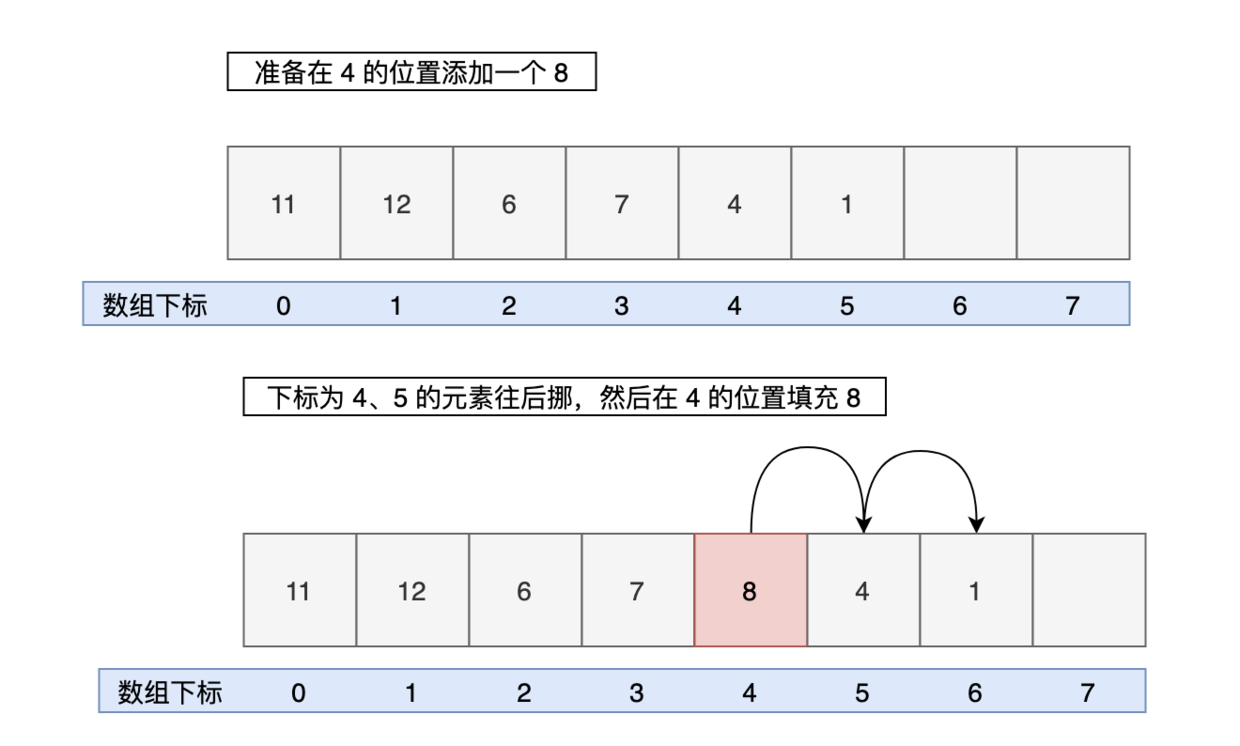
-
-### 05、更新 ArrayList 中的元素
-
-“二哥,那怎么**更新 ArrayList 中的元素**呢?”三妹继续问。
-
-可以使用 `set()` 方法来更改 ArrayList 中的元素,需要提供下标和新元素。
-
-```java
-alist.set(0, "沉默王四");
-```
-
-假设原来 0 位置上的元素为“沉默王三”,现在可以将其更新为“沉默王四”。
-
-来看一下 `set()` 方法的源码:
-
-```java
-/**
- * 用指定元素替换指定位置的元素。
- *
- * @param index 要替换的元素的索引
- * @param element 要存储在指定位置的元素
- * @return 先前在指定位置的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
- */
-public E set(int index, E element) {
- rangeCheck(index); // 检查索引是否越界
-
- E oldValue = elementData(index); // 获取原来在指定位置上的元素
- elementData[index] = element; // 将新元素替换到指定位置上
- return oldValue; // 返回原来在指定位置上的元素
-}
-```
-
-该方法会先对指定的下标进行检查,看是否越界,然后替换新值并返回旧值。
-
-### 06、删除 ArrayList 中的元素
-
-“二哥,那怎么**删除 ArrayList 中的元素**呢?”三妹继续问。
-
-`remove(int index)` 方法用于删除指定下标位置上的元素,`remove(Object o)` 方法用于删除指定值的元素。
-
-```java
-alist.remove(1);
-alist.remove("沉默王四");
-```
-
-先来看 `remove(int index)` 方法的源码:
-
-```java
-/**
- * 删除指定位置的元素。
- *
- * @param index 要删除的元素的索引
- * @return 先前在指定位置的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
- */
-public E remove(int index) {
- rangeCheck(index); // 检查索引是否越界
-
- E oldValue = elementData(index); // 获取要删除的元素
-
- int numMoved = size - index - 1; // 计算需要移动的元素个数
- if (numMoved > 0) // 如果需要移动元素,就用 System.arraycopy 方法实现
- System.arraycopy(elementData, index+1, elementData, index,
- numMoved);
- elementData[--size] = null; // 将数组末尾的元素置为 null,让 GC 回收该元素占用的空间
-
- return oldValue; // 返回被删除的元素
-}
-```
-
-需要注意的是,在 ArrayList 中,删除元素时,需要将删除位置后面的元素向前移动一位,以填补删除位置留下的空缺。如果需要移动元素,则需要使用 System.arraycopy 方法将删除位置后面的元素向前移动一位。最后,将数组末尾的元素置为 null,以便让垃圾回收机制回收该元素占用的空间。
-
-再来看 `remove(Object o)` 方法的源码:
-
-```java
-/**
- * 删除列表中第一次出现的指定元素(如果存在)。
- *
- * @param o 要删除的元素
- * @return 如果列表包含指定元素,则返回 true;否则返回 false
- */
-public boolean remove(Object o) {
- if (o == null) { // 如果要删除的元素是 null
- for (int index = 0; index < size; index++) // 遍历列表
- if (elementData[index] == null) { // 如果找到了 null 元素
- fastRemove(index); // 调用 fastRemove 方法快速删除元素
- return true; // 返回 true,表示成功删除元素
- }
- } else { // 如果要删除的元素不是 null
- for (int index = 0; index < size; index++) // 遍历列表
- if (o.equals(elementData[index])) { // 如果找到了要删除的元素
- fastRemove(index); // 调用 fastRemove 方法快速删除元素
- return true; // 返回 true,表示成功删除元素
- }
- }
- return false; // 如果找不到要删除的元素,则返回 false
-}
-```
-
-该方法通过遍历的方式找到要删除的元素,null 的时候使用 == 操作符判断,非 null 的时候使用 `equals()` 方法,然后调用 `fastRemove()` 方法。
-
-注意:
-
-- 有相同元素时,只会删除第一个。
-- 判断两个元素是否相等,可以参考[Java如何判断两个字符串是否相等](https://tobebetterjavaer.com/string/equals.html)
-
-继续往后面跟,来看一下 `fastRemove()` 方法:
-
-```java
-/**
- * 快速删除指定位置的元素。
- *
- * @param index 要删除的元素的索引
- */
-private void fastRemove(int index) {
- int numMoved = size - index - 1; // 计算需要移动的元素个数
- if (numMoved > 0) // 如果需要移动元素,就用 System.arraycopy 方法实现
- System.arraycopy(elementData, index+1, elementData, index,
- numMoved);
- elementData[--size] = null; // 将数组末尾的元素置为 null,让 GC 回收该元素占用的空间
-}
-```
-
-同样是调用 `System.arraycopy()` 方法对数组进行复制和移动。
-
-“三妹,注意看,我画幅图来表示下。”我认真地做起了图。
-
-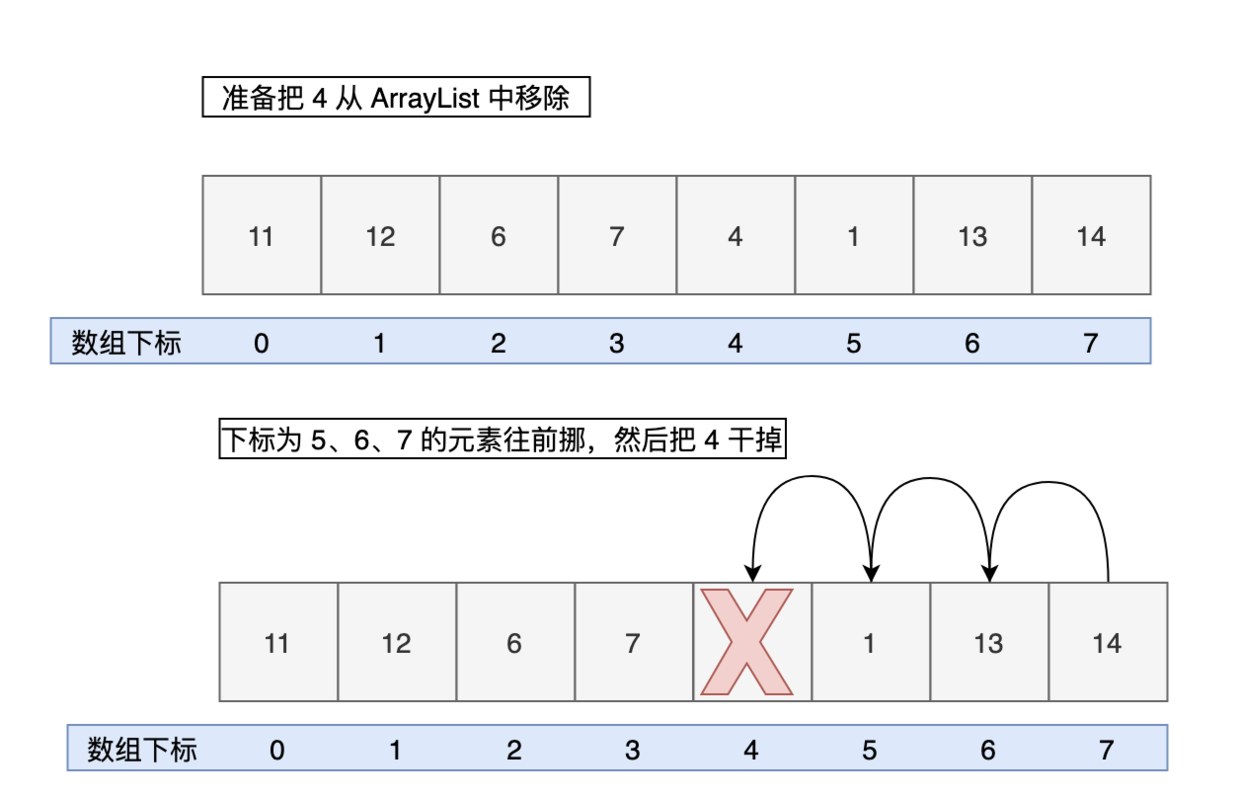
-
-### 07、查找 ArrayList 中的元素
-
-“二哥,那怎么**查找 ArrayList 中的元素**呢?”三妹继续问。
-
-如果要正序查找一个元素,可以使用 `indexOf()` 方法;如果要倒序查找一个元素,可以使用 `lastIndexOf()` 方法。
-
-```java
-alist.indexOf("沉默王二");
-alist.lastIndexOf("沉默王二");
-```
-
-来看一下 `indexOf()` 方法的源码:
-
-```java
-/**
- * 返回指定元素在列表中第一次出现的位置。
- * 如果列表不包含该元素,则返回 -1。
- *
- * @param o 要查找的元素
- * @return 指定元素在列表中第一次出现的位置;如果列表不包含该元素,则返回 -1
- */
-public int indexOf(Object o) {
- if (o == null) { // 如果要查找的元素是 null
- for (int i = 0; i < size; i++) // 遍历列表
- if (elementData[i]==null) // 如果找到了 null 元素
- return i; // 返回元素的索引
- } else { // 如果要查找的元素不是 null
- for (int i = 0; i < size; i++) // 遍历列表
- if (o.equals(elementData[i])) // 如果找到了要查找的元素
- return i; // 返回元素的索引
- }
- return -1; // 如果找不到要查找的元素,则返回 -1
-}
-```
-
-如果元素为 null 的时候使用“==”操作符,否则使用 `equals()` 方法。
-
-`lastIndexOf()` 方法和 `indexOf()` 方法类似,不过遍历的时候从最后开始。
-
-```java
-/**
- * 返回指定元素在列表中最后一次出现的位置。
- * 如果列表不包含该元素,则返回 -1。
- *
- * @param o 要查找的元素
- * @return 指定元素在列表中最后一次出现的位置;如果列表不包含该元素,则返回 -1
- */
-public int lastIndexOf(Object o) {
- if (o == null) { // 如果要查找的元素是 null
- for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
- if (elementData[i]==null) // 如果找到了 null 元素
- return i; // 返回元素的索引
- } else { // 如果要查找的元素不是 null
- for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
- if (o.equals(elementData[i])) // 如果找到了要查找的元素
- return i; // 返回元素的索引
- }
- return -1; // 如果找不到要查找的元素,则返回 -1
-}
-```
-
-`contains()` 方法可以判断 ArrayList 中是否包含某个元素,其内部就是通过 `indexOf()` 方法实现的:
-
-```java
-public boolean contains(Object o) {
- return indexOf(o) >= 0;
-}
-```
-
-### 08、二分查找法
-
-如果 ArrayList 中的元素是经过排序的,就可以使用二分查找法,效率更快。
-
-[`Collections`](https://tobebetterjavaer.com/common-tool/collections.html) 类的 `sort()` 方法可以对 ArrayList 进行排序,该方法会按照字母顺序对 String 类型的列表进行排序。如果是自定义类型的列表,还可以指定 Comparator 进行排序。
-
-这里先简单地了解一下,后面会详细地讲。
-
-```java
-List copy = new ArrayList<>(alist);
-copy.add("a");
-copy.add("c");
-copy.add("b");
-copy.add("d");
-
-Collections.sort(copy);
-System.out.println(copy);
-```
-
-输出结果如下所示:
-
-```
-[a, b, c, d]
-```
-
-排序后就可以使用二分查找法了:
-
-```java
-int index = Collections.binarySearch(copy, "b");
-```
-
-### 09、ArrayList增删改查时的时间复杂度
-
-“最后,三妹,我们来简单总结一下 ArrayList 的时间复杂度吧,方便后面学习 LinkedList 时对比。”我喝了一口水后补充道。
-
-#### 1)查询
-
-时间复杂度为 O(1),因为 ArrayList 内部使用数组来存储元素,所以可以直接根据索引来访问元素。
-
-```java
-/**
- * 返回列表中指定位置的元素。
- *
- * @param index 要返回的元素的索引
- * @return 列表中指定位置的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
- */
-public E get(int index) {
- rangeCheck(index); // 检查索引是否合法
- return elementData(index); // 调用 elementData 方法获取元素
-}
-
-/**
- * 返回列表中指定位置的元素。
- * 此方法不进行边界检查,因此只应由内部方法和迭代器调用。
- *
- * @param index 要返回的元素的索引
- * @return 列表中指定位置的元素
- */
-E elementData(int index) {
- return (E) elementData[index]; // 返回指定索引位置上的元素
-}
-```
-
-#### 2)插入
-
-添加一个元素(调用 `add()` 方法时)的时间复杂度最好情况为 O(1),最坏情况为 O(n)。
-
-- 如果在列表末尾添加元素,时间复杂度为 O(1)。
-- 如果要在列表的中间或开头插入元素,则需要将插入位置之后的元素全部向后移动一位,时间复杂度为 O(n)。
-
-#### 3)删除
-
-删除一个元素(调用 `remove(Object)` 方法时)的时间复杂度最好情况 O(1),最坏情况 O(n)。
-
-- 如果要删除列表末尾的元素,时间复杂度为 O(1)。
-- 如果要删除列表中间或开头的元素,则需要将删除位置之后的元素全部向前移动一位,时间复杂度为 O(n)。
-
-
-#### 4)修改
-
-修改一个元素(调用 `set()`方法时)与查询操作类似,可以直接根据索引来访问元素,时间复杂度为 O(1)。
-
-```java
-/**
- * 用指定元素替换列表中指定位置的元素。
- *
- * @param index 要替换元素的索引
- * @param element 要放入列表中的元素
- * @return 原来在指定位置上的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
- */
-public E set(int index, E element) {
- rangeCheck(index); // 检查索引是否合法
-
- E oldValue = elementData(index); // 获取原来在指定位置上的元素
- elementData[index] = element; // 将指定位置上的元素替换为新元素
- return oldValue; // 返回原来在指定位置上的元素
-}
-```
-
-### 10、总结
-
-ArrayList,如果有个中文名的话,应该叫动态数组,也就是可增长的数组,可调整大小的数组。动态数组克服了静态数组的限制,静态数组的容量是固定的,只能在首次创建的时候指定。而动态数组会随着元素的增加自动调整大小,更符合实际的开发需求。
-
-学习集合框架,ArrayList 是第一课,也是新手进阶的重要一课。要想完全掌握 ArrayList,扩容这个机制是必须得掌握,也是面试中经常考察的一个点。
-
-要想掌握扩容机制,就必须得读源码,也就肯定会遇到 `oldCapacity >> 1`,有些初学者会选择跳过,虽然不影响整体上的学习,但也错过了一个精进的机会。
-
-计算机内部是如何表示十进制数的,右移时又发生了什么,静下心来去研究一下,你就会发现,哦,原来这么有趣呢?
-
-“好了,三妹,这一节我们就学到这里,收工!”
-
-
-
-## 6.4 LinkedList详解(附源码)
-
->这篇换个表达方式,一起来欣赏。
-
-大家好,我是 LinkedList,和 ArrayList 是同门师兄弟,但我俩练的内功却完全不同。师兄练的是动态数组,我练的是链表。
-
-问大家一个问题,知道我为什么要练链表这门内功吗?
-
-举个例子来讲吧,假如你们手头要管理一推票据,可能有一张,也可能有一亿张。
-
-该怎么办呢?
-
-申请一个 10G 的大数组等着?那万一票据只有 100 张呢?
-
-申请一个默认大小的数组,随着数据量的增大扩容?要知道扩容是需要重新复制数组的,很耗时间。
-
-关键是,数组还有一个弊端就是,假如现在有 500 万张票据,现在要从中间删除一个票据,就需要把 250 万张票据往前移动一格。
-
-遇到这种情况的时候,我师兄几乎情绪崩溃,难受的要命。师父不忍心看到师兄这样痛苦,于是打我进入师门那一天,就强迫我练链表这门内功,一开始我很不理解,害怕师父偏心,不把师门最厉害的内功教我。
-
-直到有一天,我亲眼目睹师兄差点因为移动数据而走火入魔,我才明白师父的良苦用心。从此以后,我苦练“链表”这门内功,取得了显著的进步,师父和师兄都夸我有天赋。
-
-链表这门内功大致分为三个层次:
-
-- 第一层叫做“单向链表”,我只有一个后指针,指向下一个数据;
-- 第二层叫做“双向链表”,我有两个指针,后指针指向下一个数据,前指针指向上一个数据。
-- 第三层叫做“二叉树”,把后指针去掉,换成左右指针。
-
-但我现在的功力还达不到第三层,不过师父说我有这个潜力,练成神功是早晚的事。
-
-### 01、LinkedList的内功心法
-
-好了,经过我这么样的一个剖白后,大家对我应该已经不陌生了。那么接下来,我给大家展示一下我的内功心法。
-
-我的内功心法主要是一个私有的静态内部类,叫 Node,也就是节点。
-
-```java
-/**
- * 链表中的节点类。
- */
-private static class Node {
- E item; // 节点中存储的元素
- Node next; // 指向下一个节点的指针
- Node prev; // 指向上一个节点的指针
-
- /**
- * 构造一个新的节点。
- *
- * @param prev 前一个节点
- * @param element 节点中要存储的元素
- * @param next 后一个节点
- */
- Node(Node prev, E element, Node next) {
- this.item = element; // 存储元素
- this.next = next; // 设置下一个节点
- this.prev = prev; // 设置上一个节点
- }
-}
-```
-
-它由三部分组成:
-
-- 节点上的元素
-- 下一个节点
-- 上一个节点
-
-我画幅图给你们展示下吧。
-
-
-
-- 对于第一个节点来说,prev 为 null;
-- 对于最后一个节点来说,next 为 null;
-- 其余的节点呢,prev 指向前一个,next 指向后一个。
-
-我的内功心法就这么简单,其实我早已经牢记在心了。但师父叮嘱我,每天早上醒来的时候,每天晚上睡觉的时候,一定要默默地背诵一遍。虽然我有些厌烦,但我对师父的教诲从来都是言听计从。
-
-### 02、LinkedList的招式
-
-和师兄 ArrayList 一样,我的招式也无外乎“增删改查”这 4 种。在此之前,我们都必须得初始化。
-
-```java
-LinkedList list = new LinkedList();
-```
-
-师兄在初始化的时候可以指定大小,也可以不指定,等到添加第一个元素的时候进行第一次扩容。而我,没有大小,只要内存够大,我就可以无穷大。
-
-#### **1)招式一:增**
-
-可以调用 add 方法添加元素:
-
-```java
-list.add("沉默王二");
-list.add("沉默王三");
-list.add("沉默王四");
-```
-
-add 方法内部其实调用的是 linkLast 方法:
-
-```java
-/**
- * 将指定的元素添加到列表的尾部。
- *
- * @param e 要添加到列表的元素
- * @return 始终为 true(根据 Java 集合框架规范)
- */
-public boolean add(E e) {
- linkLast(e); // 在列表的尾部添加元素
- return true; // 添加元素成功,返回 true
-}
-```
-
-linkLast,顾名思义,就是在链表的尾部添加元素:
-
-```java
-/**
- * 在列表的尾部添加指定的元素。
- *
- * @param e 要添加到列表的元素
- */
-void linkLast(E e) {
- final Node l = last; // 获取链表的最后一个节点
- final Node newNode = new Node<>(l, e, null); // 创建一个新的节点,并将其设置为链表的最后一个节点
- last = newNode; // 将新的节点设置为链表的最后一个节点
- if (l == null) // 如果链表为空,则将新节点设置为头节点
- first = newNode;
- else
- l.next = newNode; // 否则将新节点链接到链表的尾部
- size++; // 增加链表的元素个数
-}
-```
-
-- 添加第一个元素的时候,first 和 last 都为 null。
-- 然后新建一个节点 newNode,它的 prev 和 next 也为 null。
-- 然后把 last 和 first 都赋值为 newNode。
-
-此时还不能称之为链表,因为前后节点都是断裂的。
-
-
-
-- 添加第二个元素的时候,first 和 last 都指向的是第一个节点。
-- 然后新建一个节点 newNode,它的 prev 指向的是第一个节点,next 为 null。
-- 然后把第一个节点的 next 赋值为 newNode。
-
-此时的链表还不完整。
-
-
-
-- 添加第三个元素的时候,first 指向的是第一个节点,last 指向的是最后一个节点。
-- 然后新建一个节点 newNode,它的 prev 指向的是第二个节点,next 为 null。
-- 然后把第二个节点的 next 赋值为 newNode。
-
-此时的链表已经完整了。
-
-
-
-我这个增的招式,还可以演化成另外两个版本:
-
-- `addFirst()` 方法将元素添加到第一位;
-- `addLast()` 方法将元素添加到末尾。
-
-addFirst 内部其实调用的是 linkFirst:
-
-```java
-/**
- * 在列表的开头添加指定的元素。
- *
- * @param e 要添加到列表的元素
- */
-public void addFirst(E e) {
- linkFirst(e); // 在列表的开头添加元素
-}
-```
-
-linkFirst 负责把新的节点设为 first,并将新的 first 的 next 更新为之前的 first。
-
-```java
-/**
- * 在列表的开头添加指定的元素。
- *
- * @param e 要添加到列表的元素
- */
-private void linkFirst(E e) {
- final Node f = first; // 获取链表的第一个节点
- final Node newNode = new Node<>(null, e, f); // 创建一个新的节点,并将其设置为链表的第一个节点
- first = newNode; // 将新的节点设置为链表的第一个节点
- if (f == null) // 如果链表为空,则将新节点设置为尾节点
- last = newNode;
- else
- f.prev = newNode; // 否则将新节点链接到链表的头部
- size++; // 增加链表的元素个数
-}
-```
-
-addLast 的内核其实和 addFirst 差不多,内部调用的是 linkLast 方法,前面分析过了。
-
-```java
-/**
- * 在列表的尾部添加指定的元素。
- *
- * @param e 要添加到列表的元素
- * @return 始终为 true(根据 Java 集合框架规范)
- */
-public boolean addLast(E e) {
- linkLast(e); // 在列表的尾部添加元素
- return true; // 添加元素成功,返回 true
-}
-```
-
-
-#### **2)招式二:删**
-
-我这个删的招式还挺多的:
-
-- `remove()`:删除第一个节点
-- `remove(int)`:删除指定位置的节点
-- `remove(Object)`:删除指定元素的节点
-- `removeFirst()`:删除第一个节点
-- `removeLast()`:删除最后一个节点
-
-`remove()` 内部调用的是 `removeFirst()`,所以这两个招式的功效一样。
-
-`remove(int)` 内部其实调用的是 unlink 方法。
-
-```java
-/**
- * 删除指定位置上的元素。
- *
- * @param index 要删除的元素的索引
- * @return 从列表中删除的元素
- * @throws IndexOutOfBoundsException 如果索引越界(index < 0 || index >= size())
- */
-public E remove(int index) {
- checkElementIndex(index); // 检查索引是否越界
- return unlink(node(index)); // 删除指定位置的节点,并返回节点的元素
-}
-
-```
-
-unlink 方法其实很好理解,就是更新当前节点的 next 和 prev,然后把当前节点上的元素设为 null。
-
-```java
-/**
- * 从链表中删除指定节点。
- *
- * @param x 要删除的节点
- * @return 从链表中删除的节点的元素
- */
-E unlink(Node x) {
- final E element = x.item; // 获取要删除节点的元素
- final Node next = x.next; // 获取要删除节点的下一个节点
- final Node prev = x.prev; // 获取要删除节点的上一个节点
-
- if (prev == null) { // 如果要删除节点是第一个节点
- first = next; // 将链表的头节点设置为要删除节点的下一个节点
- } else {
- prev.next = next; // 将要删除节点的上一个节点指向要删除节点的下一个节点
- x.prev = null; // 将要删除节点的上一个节点设置为空
- }
-
- if (next == null) { // 如果要删除节点是最后一个节点
- last = prev; // 将链表的尾节点设置为要删除节点的上一个节点
- } else {
- next.prev = prev; // 将要删除节点的下一个节点指向要删除节点的上一个节点
- x.next = null; // 将要删除节点的下一个节点设置为空
- }
-
- x.item = null; // 将要删除节点的元素设置为空
- size--; // 减少链表的元素个数
- return element; // 返回被删除节点的元素
-}
-```
-
-remove(Object) 内部也调用了 unlink 方法,只不过在此之前要先找到元素所在的节点:
-
-```java
-/**
- * 从链表中删除指定元素。
- *
- * @param o 要从链表中删除的元素
- * @return 如果链表包含指定元素,则返回 true;否则返回 false
- */
-public boolean remove(Object o) {
- if (o == null) { // 如果要删除的元素为 null
- for (Node x = first; x != null; x = x.next) { // 遍历链表
- if (x.item == null) { // 如果节点的元素为 null
- unlink(x); // 删除节点
- return true; // 返回 true 表示删除成功
- }
- }
- } else { // 如果要删除的元素不为 null
- for (Node x = first; x != null; x = x.next) { // 遍历链表
- if (o.equals(x.item)) { // 如果节点的元素等于要删除的元素
- unlink(x); // 删除节点
- return true; // 返回 true 表示删除成功
- }
- }
- }
- return false; // 如果链表中不包含要删除的元素,则返回 false 表示删除失败
-}
-```
-
-元素为 null 的时候,必须使用 == 来判断;元素为非 null 的时候,要使用 equals 来判断。
-
-removeFirst 内部调用的是 unlinkFirst 方法:
-
-```java
-/**
- * 从链表中删除第一个元素并返回它。
- * 如果链表为空,则抛出 NoSuchElementException 异常。
- *
- * @return 从链表中删除的第一个元素
- * @throws NoSuchElementException 如果链表为空
- */
-public E removeFirst() {
- final Node f = first; // 获取链表的第一个节点
- if (f == null) // 如果链表为空
- throw new NoSuchElementException(); // 抛出 NoSuchElementException 异常
- return unlinkFirst(f); // 调用 unlinkFirst 方法删除第一个节点并返回它的元素
-}
-```
-
-unlinkFirst 负责的就是把第一个节点毁尸灭迹,并且捎带把后一个节点的 prev 设为 null。
-
-```java
-/**
- * 删除链表中的第一个节点并返回它的元素。
- *
- * @param f 要删除的第一个节点
- * @return 被删除节点的元素
- */
-private E unlinkFirst(Node f) {
- final E element = f.item; // 获取要删除的节点的元素
- final Node next = f.next; // 获取要删除的节点的下一个节点
- f.item = null; // 将要删除的节点的元素设置为 null
- f.next = null; // 将要删除的节点的下一个节点设置为 null
- first = next; // 将链表的头节点设置为要删除的节点的下一个节点
- if (next == null) // 如果链表只有一个节点
- last = null; // 将链表的尾节点设置为 null
- else
- next.prev = null; // 将要删除节点的下一个节点的前驱设置为 null
- size--; // 减少链表的大小
- return element; // 返回被删除节点的元素
-}
-```
-
-#### **3)招式三:改**
-
-可以调用 `set()` 方法来更新元素:
-
-```java
-list.set(0, "沉默王五");
-```
-
-来看一下 `set()` 方法:
-
-```java
-/**
- * 将链表中指定位置的元素替换为指定元素,并返回原来的元素。
- *
- * @param index 要替换元素的位置(从 0 开始)
- * @param element 要插入的元素
- * @return 替换前的元素
- * @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
- */
-public E set(int index, E element) {
- checkElementIndex(index); // 检查索引是否超出范围
- Node x = node(index); // 获取要替换的节点
- E oldVal = x.item; // 获取要替换节点的元素
- x.item = element; // 将要替换的节点的元素设置为指定元素
- return oldVal; // 返回替换前的元素
-}
-```
-
-来看一下node方法:
-
-```java
-/**
- * 获取链表中指定位置的节点。
- *
- * @param index 节点的位置(从 0 开始)
- * @return 指定位置的节点
- * @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
- */
-Node node(int index) {
- if (index < (size >> 1)) { // 如果索引在链表的前半部分
- Node x = first;
- for (int i = 0; i < index; i++) // 从头节点开始向后遍历链表,直到找到指定位置的节点
- x = x.next;
- return x; // 返回指定位置的节点
- } else { // 如果索引在链表的后半部分
- Node x = last;
- for (int i = size - 1; i > index; i--) // 从尾节点开始向前遍历链表,直到找到指定位置的节点
- x = x.prev;
- return x; // 返回指定位置的节点
- }
-}
-```
-
-`size >> 1`:也就是右移一位,相当于除以 2。对于计算机来说,移位比除法运算效率更高,因为数据在计算机内部都是以二进制存储的。
-
-换句话说,node 方法会对下标进行一个初步判断,如果靠近前半截,就从下标 0 开始遍历;如果靠近后半截,就从末尾开始遍历,这样可以提高效率,最大能提高一半的效率。
-
-找到指定下标的节点就简单了,直接把原有节点的元素替换成新的节点就 OK 了,prev 和 next 都不用改动。
-
-#### **4)招式四:查**
-
-我这个查的招式可以分为两种:
-
-- indexOf(Object):查找某个元素所在的位置
-- get(int):查找某个位置上的元素
-
-来看一下 indexOf 方法的源码。
-
-```java
-/**
- * 返回链表中首次出现指定元素的位置,如果不存在该元素则返回 -1。
- *
- * @param o 要查找的元素
- * @return 首次出现指定元素的位置,如果不存在该元素则返回 -1
- */
-public int indexOf(Object o) {
- int index = 0; // 初始化索引为 0
- if (o == null) { // 如果要查找的元素为 null
- for (Node x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
- if (x.item == null) // 如果找到了要查找的元素
- return index; // 返回该元素的索引
- index++; // 索引加 1
- }
- } else { // 如果要查找的元素不为 null
- for (Node x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
- if (o.equals(x.item)) // 如果找到了要查找的元素
- return index; // 返回该元素的索引
- index++; // 索引加 1
- }
- }
- return -1; // 如果没有找到要查找的元素,则返回 -1
-}
-```
-
-get 方法的内核其实还是 node 方法,node 方法之前已经说明过了,这里略过。
-
-```java
-public E get(int index) {
- checkElementIndex(index);
- return node(index).item;
-}
-```
-
-其实,查这个招式还可以演化为其他的一些,比如说:
-
-- `getFirst()` 方法用于获取第一个元素;
-- `getLast()` 方法用于获取最后一个元素;
-- `poll()` 和 `pollFirst()` 方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的);
-- `pollLast()` 方法用于删除并返回最后一个元素;
-- `peekFirst()` 方法用于返回但不删除第一个元素。
-
-### 03、LinkedList 的挑战
-
-说句实在话,我不是很喜欢和师兄 ArrayList 拿来比较,因为我们各自修炼的内功不同,没有孰高孰低。
-
-虽然师兄经常喊我一声师弟,但我们之间其实挺和谐的。但我知道,在外人眼里,同门师兄弟,总要一较高下的。
-
-比如说,我们俩在增删改查时候的时间复杂度。
-
-也许这就是命运吧,从我进入师门的那天起,这种争论就一直没有停息过。
-
-无论外人怎么看待我们,在我眼里,师兄永远都是一哥,我敬重他,他也愿意保护我。
-
-[好戏在后头](https://tobebetterjavaer.com/collection/list-war-2.html),等着瞧吧。
-
-我这里先简单聊一下,权当抛砖引玉。
-
-想象一下,你在玩一款游戏,游戏中有一个道具栏,你需要不断地往里面添加、删除道具。如果你使用的是我的师兄 ArrayList,那么每次添加、删除道具时都需要将后面的道具向后移动或向前移动,这样就会非常耗费时间。但是如果你使用的是我 LinkedList,那么只需要将新道具插入到链表中的指定位置,或者将要删除的道具从链表中删除即可,这样就可以快速地完成道具栏的更新。
-
-除了游戏中的道具栏,我 LinkedList 还可以用于实现 LRU(Least Recently Used)缓存淘汰算法。LRU 缓存淘汰算法是一种常用的缓存淘汰策略,它的基本思想是,当缓存空间不够时,优先淘汰最近最少使用的缓存数据。在实现 LRU 缓存淘汰算法时,你可以使用我 LinkedList 来存储缓存数据,每次访问缓存数据时,将该数据从链表中删除并移动到链表的头部,这样链表的尾部就是最近最少使用的缓存数据,当缓存空间不够时,只需要将链表尾部的缓存数据淘汰即可。
-
-总之,各有各的好,且行且珍惜。
-
-
-
-## 6.5 ArrayList和LinkedList的区别
-
-完整版的 PDF 足足 83M,有些软件最大只支持 50M,所以忍痛精简了部分内容。你可以到百度网盘或者阿里云盘上下载完整版 PDF 阅读,也可以通过以下链接访问在线版。
-
-[6.5 ArrayList和LinkedList的区别](https://tobebetterjavaer.com/collection/list-war-2.html)
-
-## 6.6 Java泛型,深入解析
-
-“二哥,为什么要设计泛型啊?”三妹开门见山地问。
-
-“三妹啊,听哥慢慢给你讲啊。”我说。
-
-Java 在 1.5 时增加了泛型机制,据说专家们为此花费了 5 年左右的时间(听起来是相当不容易)。有了泛型之后,尤其是对集合类的使用,就变得更规范了。
-
-看下面这段简单的代码。
-
-```java
-ArrayList list = new ArrayList();
-list.add("沉默王二");
-String str = list.get(0);
-```
-
-“三妹,你能想象到在没有泛型之前该怎么办吗?”
-
-“嗯,想不到,还是二哥你说吧。”
-
-嗯,我们可以使用 Object 数组来设计 `Arraylist` 类。
-
-```java
-class Arraylist {
- private Object[] objs;
- private int i = 0;
- public void add(Object obj) {
- objs[i++] = obj;
- }
-
- public Object get(int i) {
- return objs[i];
- }
-}
-```
-
-然后,我们向 `Arraylist` 中存取数据。
-
-```java
-Arraylist list = new Arraylist();
-list.add("沉默王二");
-list.add(new Date());
-String str = (String)list.get(0);
-```
-
-“三妹,你有没有发现这两个问题?”
-
-- Arraylist 可以存放任何类型的数据(既可以存字符串,也可以混入日期),因为所有类都继承自 Object 类。
-- 从 Arraylist 取出数据的时候需要强制类型转换,因为编译器并不能确定你取的是字符串还是日期。
-
-“嗯嗯,是的呢。”三妹说。
-
-对比一下,你就能明显地感受到泛型的优秀之处:使用**类型参数**解决了元素的不确定性——参数类型为 String 的集合中是不允许存放其他类型元素的,取出数据的时候也不需要强制类型转换了。
-
-### 动手设计一个泛型
-
-“二哥,那怎么才能设计一个泛型呢?”
-
-“三妹啊,你一个小白只要会用泛型就行了,还想设计泛型啊?!不过,既然你想了解,哥义不容辞。”
-
-首先,我们来按照泛型的标准重新设计一下 `Arraylist` 类。
-
-```java
-class Arraylist {
- private Object[] elementData;
- private int size = 0;
-
- public Arraylist(int initialCapacity) {
- this.elementData = new Object[initialCapacity];
- }
-
- public boolean add(E e) {
- elementData[size++] = e;
- return true;
- }
-
- E elementData(int index) {
- return (E) elementData[index];
- }
-}
-```
-
-一个泛型类就是具有一个或多个类型变量的类。Arraylist 类引入的类型变量为 E(Element,元素的首字母),使用尖括号 `<>` 括起来,放在类名的后面。
-
-然后,我们可以用具体的类型(比如字符串)替换类型变量来实例化泛型类。
-
-```java
-Arraylist list = new Arraylist();
-list.add("沉默王三");
-String str = list.get(0);
-```
-
-Date 类型也可以的。
-
-```java
-Arraylist list = new Arraylist();
-list.add(new Date());
-Date date = list.get(0);
-```
-
-其次,我们还可以在一个非泛型的类(或者泛型类)中定义泛型方法。
-
-```java
-class Arraylist {
- public T[] toArray(T[] a) {
- return (T[]) Arrays.copyOf(elementData, size, a.getClass());
- }
-}
-```
-
-不过,说实话,泛型方法的定义看起来略显晦涩。来一副图吧(注意:方法返回类型和方法参数类型至少需要一个)。
-
-
-
-现在,我们来调用一下泛型方法。
-
-```java
-Arraylist list = new Arraylist<>(4);
-list.add("沉");
-list.add("默");
-list.add("王");
-list.add("二");
-
-String [] strs = new String [4];
-strs = list.toArray(strs);
-
-for (String str : strs) {
- System.out.println(str);
-}
-```
-
-### 泛型限定符
-
-然后,我们再来说说泛型变量的限定符 `extends`。
-
-在解释这个限定符之前,我们假设有三个类,它们之间的定义是这样的。
-
-```java
-class Wanglaoer {
- public String toString() {
- return "王老二";
- }
-}
-
-class Wanger extends Wanglaoer{
- public String toString() {
- return "王二";
- }
-}
-
-class Wangxiaoer extends Wanger{
- public String toString() {
- return "王小二";
- }
-}
-```
-
-我们使用限定符 `extends` 来重新设计一下 `Arraylist` 类。
-
-```java
-class Arraylist {
-}
-```
-
-当我们向 `Arraylist` 中添加 `Wanglaoer` 元素的时候,编译器会提示错误:`Arraylist` 只允许添加 `Wanger` 及其子类 `Wangxiaoer` 对象,不允许添加其父类 `Wanglaoer`。
-
-```java
-Arraylist list = new Arraylist<>(3);
-list.add(new Wanger());
-list.add(new Wanglaoer());
-// The method add(Wanger) in the type Arraylist is not applicable for the arguments
-// (Wanglaoer)
-list.add(new Wangxiaoer());
-```
-
-也就是说,限定符 `extends` 可以缩小泛型的类型范围。
-
-### 类型擦除
-
-“哦,明白了。”三妹若有所思的点点头,“二哥,听说虚拟机没有泛型?”
-
-“三妹,你功课做得可以啊。哥可以肯定地回答你,虚拟机是没有泛型的。”
-
-“怎么确定虚拟机有没有泛型呢?”三妹问。
-
-“只要我们把泛型类的字节码进行反编译就看到了!”用反编译工具(我写这篇文章的时候用的是 jad,你也可以用其他的工具)将 class 文件反编译后,我说,“三妹,你看。”
-
-```java
-// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
-// Jad home page: http://www.kpdus.com/jad.html
-// Decompiler options: packimports(3)
-// Source File Name: Arraylist.java
-
-package com.cmower.java_demo.fanxing;
-
-import java.util.Arrays;
-
-class Arraylist
-{
-
- public Arraylist(int initialCapacity)
- {
- size = 0;
- elementData = new Object[initialCapacity];
- }
-
- public boolean add(Object e)
- {
- elementData[size++] = e;
- return true;
- }
-
- Object elementData(int index)
- {
- return elementData[index];
- }
-
- private Object elementData[];
- private int size;
-}
-```
-
-类型变量 `` 消失了,取而代之的是 Object !
-
-“既然如此,那如果泛型类使用了限定符 `extends`,结果会怎么样呢?”三妹这个问题问的很巧妙。
-
-来看这段代码。
-
-```java
-class Arraylist2 {
- private Object[] elementData;
- private int size = 0;
-
- public Arraylist2(int initialCapacity) {
- this.elementData = new Object[initialCapacity];
- }
-
- public boolean add(E e) {
- elementData[size++] = e;
- return true;
- }
-
- E elementData(int index) {
- return (E) elementData[index];
- }
-}
-```
-
-反编译后的结果如下。
-
-```java
-// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
-// Jad home page: http://www.kpdus.com/jad.html
-// Decompiler options: packimports(3)
-// Source File Name: Arraylist2.java
-
-package com.cmower.java_demo.fanxing;
-
-
-// Referenced classes of package com.cmower.java_demo.fanxing:
-// Wanger
-
-class Arraylist2
-{
-
- public Arraylist2(int initialCapacity)
- {
- size = 0;
- elementData = new Object[initialCapacity];
- }
-
- public boolean add(Wanger e)
- {
- elementData[size++] = e;
- return true;
- }
-
- Wanger elementData(int index)
- {
- return (Wanger)elementData[index];
- }
-
- private Object elementData[];
- private int size;
-}
-```
-
-“你看,类型变量 `` 不见了,E 被替换成了 `Wanger`”,我说,“通过以上两个例子说明,Java 虚拟机会将泛型的类型变量擦除,并替换为限定类型(没有限定的话,就用 `Object`)”
-
-“二哥,类型擦除会有什么问题吗?”三妹又问了一个很有水平的问题。
-
-“三妹啊,你还别说,类型擦除真的会有一些问题。”我说,“来看一下这段代码。”
-
-```java
-public class Cmower {
-
- public static void method(Arraylist list) {
- System.out.println("Arraylist list");
- }
-
- public static void method(Arraylist list) {
- System.out.println("Arraylist list");
- }
-
-}
-```
-
-在浅层的意识上,我们会想当然地认为 `Arraylist list` 和 `Arraylist list` 是两种不同的类型,因为 String 和 Date 是不同的类。
-
-但由于类型擦除的原因,以上代码是不会通过编译的——编译器会提示一个错误(这正是类型擦除引发的那些“问题”):
-
-```
->Erasure of method method(Arraylist) is the same as another method in type
- Cmower
->
->Erasure of method method(Arraylist) is the same as another method in type
- Cmower
-```
-
-
-大致的意思就是,这两个方法的参数类型在擦除后是相同的。
-
-也就是说,`method(Arraylist list)` 和 `method(Arraylist list)` 是同一种参数类型的方法,不能同时存在。类型变量 `String` 和 `Date` 在擦除后会自动消失,method 方法的实际参数是 `Arraylist list`。
-
-有句俗话叫做:“百闻不如一见”,但即使见到了也未必为真——泛型的擦除问题就可以很好地佐证这个观点。
-
-### 泛型通配符
-
-“哦,明白了。二哥,听说泛型还有通配符?”
-
-“三妹啊,哥突然觉得你很适合作一枚可爱的程序媛啊!你这预习的功课做得可真到家啊,连通配符都知道!”
-
-通配符使用英文的问号`(?)`来表示。在我们创建一个泛型对象时,可以使用关键字 `extends` 限定子类,也可以使用关键字 `super` 限定父类。
-
-我们来看下面这段代码。
-
-```java
-// 定义一个泛型类 Arraylist,E 表示元素类型
-class Arraylist {
- // 私有成员变量,存储元素数组和元素数量
- private Object[] elementData;
- private int size = 0;
-
- // 构造函数,传入初始容量 initialCapacity,创建一个指定容量的 Object 数组
- public Arraylist(int initialCapacity) {
- this.elementData = new Object[initialCapacity];
- }
-
- // 添加元素到数组末尾,返回添加成功与否
- public boolean add(E e) {
- elementData[size++] = e;
- return true;
- }
-
- // 获取指定下标的元素
- public E get(int index) {
- return (E) elementData[index];
- }
-
- // 查找指定元素第一次出现的下标,如果找不到则返回 -1
- public int indexOf(Object o) {
- if (o == null) {
- for (int i = 0; i < size; i++)
- if (elementData[i]==null)
- return i;
- } else {
- for (int i = 0; i < size; i++)
- if (o.equals(elementData[i]))
- return i;
- }
- return -1;
- }
-
- // 判断指定元素是否在数组中出现
- public boolean contains(Object o) {
- return indexOf(o) >= 0;
- }
-
- // 将数组中的元素转化成字符串输出
- public String toString() {
- StringBuilder sb = new StringBuilder();
-
- for (Object o : elementData) {
- if (o != null) {
- E e = (E)o;
- sb.append(e.toString());
- sb.append(',').append(' ');
- }
- }
- return sb.toString();
- }
-
- // 返回数组中元素的数量
- public int size() {
- return size;
- }
-
- // 修改指定下标的元素,返回修改前的元素
- public E set(int index, E element) {
- E oldValue = (E) elementData[index];
- elementData[index] = element;
- return oldValue;
- }
-}
-```
-
-1)新增 `indexOf(Object o)` 方法,判断元素在 `Arraylist` 中的位置。注意参数为 `Object` 而不是泛型 `E`。
-
-2)新增 `contains(Object o)` 方法,判断元素是否在 `Arraylist` 中。注意参数为 `Object` 而不是泛型 `E`。
-
-3)新增 `toString()` 方法,方便对 `Arraylist` 进行打印。
-
-4)新增 `set(int index, E element)` 方法,方便对 `Arraylist` 元素的更改。
-
-因为泛型擦除的原因,`Arraylist list = new Arraylist();` 这样的语句是无法通过编译的,尽管 Wangxiaoer 是 Wanger 的子类。但如果我们确实需要这种 “向上转型” 的关系,该怎么办呢?这时候就需要通配符来发挥作用了。
-
-利用 `` 形式的通配符,可以实现泛型的向上转型,来看例子。
-
-```java
-Arraylist list2 = new Arraylist<>(4);
-list2.add(null);
-// list2.add(new Wanger());
-// list2.add(new Wangxiaoer());
-
-Wanger w2 = list2.get(0);
-// Wangxiaoer w3 = list2.get(1);
-```
-
-list2 的类型是 `Arraylist`,翻译一下就是,list2 是一个 `Arraylist`,其类型是 `Wanger` 及其子类。
-
-注意,“关键”来了!list2 并不允许通过 `add(E e)` 方法向其添加 `Wanger` 或者 `Wangxiaoer` 的对象,唯一例外的是 `null`。
-
-“那就奇了怪了,既然不让存放元素,那要 `Arraylist` 这样的 list2 有什么用呢?”三妹好奇地问。
-
-虽然不能通过 `add(E e)` 方法往 list2 中添加元素,但可以给它赋值。
-
-```java
-Arraylist list = new Arraylist<>(4);
-
-Wanger wanger = new Wanger();
-list.add(wanger);
-
-Wangxiaoer wangxiaoer = new Wangxiaoer();
-list.add(wangxiaoer);
-
-Arraylist list2 = list;
-
-Wanger w2 = list2.get(1);
-System.out.println(w2);
-
-System.out.println(list2.indexOf(wanger));
-System.out.println(list2.contains(new Wangxiaoer()));
-```
-
-`Arraylist list2 = list;` 语句把 list 的值赋予了 list2,此时 `list2 == list`。由于 list2 不允许往其添加其他元素,所以此时它是安全的——我们可以从容地对 list2 进行 `get()`、`indexOf()` 和 `contains()`。想一想,如果可以向 list2 添加元素的话,这 3 个方法反而变得不太安全,它们的值可能就会变。
-
-利用 `` 形式的通配符,可以向 Arraylist 中存入父类是 `Wanger` 的元素,来看例子。
-
-```java
-Arraylist list3 = new Arraylist<>(4);
-list3.add(new Wanger());
-list3.add(new Wangxiaoer());
-
-// Wanger w3 = list3.get(0);
-```
-
-需要注意的是,无法从 `Arraylist` 这样类型的 list3 中取出数据。
-
-### 小结
-
-好了,三妹,关于泛型,我们再来做一个简单的总结。
-
-在 Java 中,泛型是一种强类型约束机制,可以在编译期间检查类型安全性,并且可以提高代码的复用性和可读性。
-
-#### 1)类型参数化
-
-泛型的本质是参数化类型,也就是说,在定义类、接口或方法时,可以使用一个或多个类型参数来表示参数化类型。
-
-例如这样可以定义一个泛型类。
-
-```java
-public class Box {
- private T value;
-
- public Box(T value) {
- this.value = value;
- }
-
- public T getValue() {
- return value;
- }
-
- public void setValue(T value) {
- this.value = value;
- }
-}
-```
-
-在这个例子中,`` 表示类型参数,可以在类中任何需要使用类型的地方使用 T 代替具体的类型。通过使用泛型,我们可以创建一个可以存储任何类型对象的盒子。
-
-```java
-Box intBox = new Box<>(123);
-Box strBox = new Box<>("Hello, world!");
-```
-
-泛型在实际开发中的应用非常广泛,例如集合框架中的 List、Set、Map 等容器类,以及并发框架中的 Future、Callable 等工具类都使用了泛型。
-
-#### 2)类型擦除
-
-在 Java 的泛型机制中,有两个重要的概念:类型擦除和通配符。
-
-泛型在编译时会将泛型类型擦除,将泛型类型替换成 Object 类型。这是为了向后兼容,避免对原有的 Java 代码造成影响。
-
-例如,对于下面的代码:
-
-```java
-List intList = new ArrayList<>();
-intList.add(123);
-int value = intList.get(0);
-```
-
-在编译时,Java 编译器会将泛型类型 `List` 替换成 `List