并发编程第二弹
Showing
{kind=link}
{kind=link}
{kind=link}
{kind=link}

9.7 KB
{kind=link}
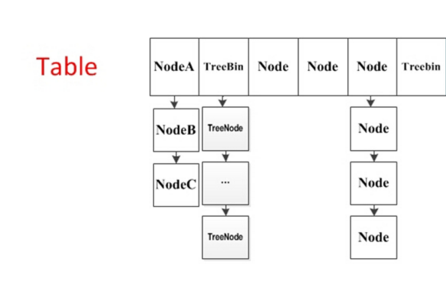
32.2 KB
{kind=link}
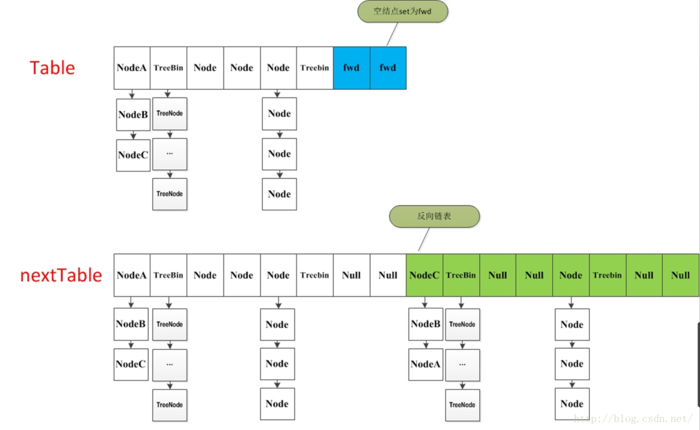
73.5 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
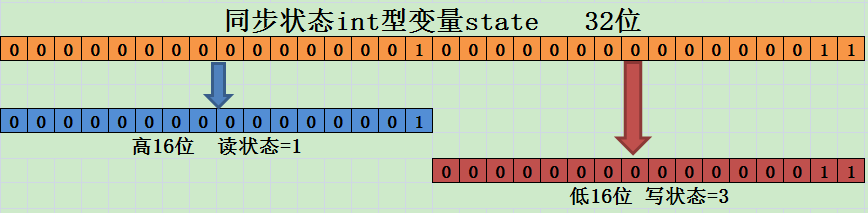
17.7 KB
{kind=link}
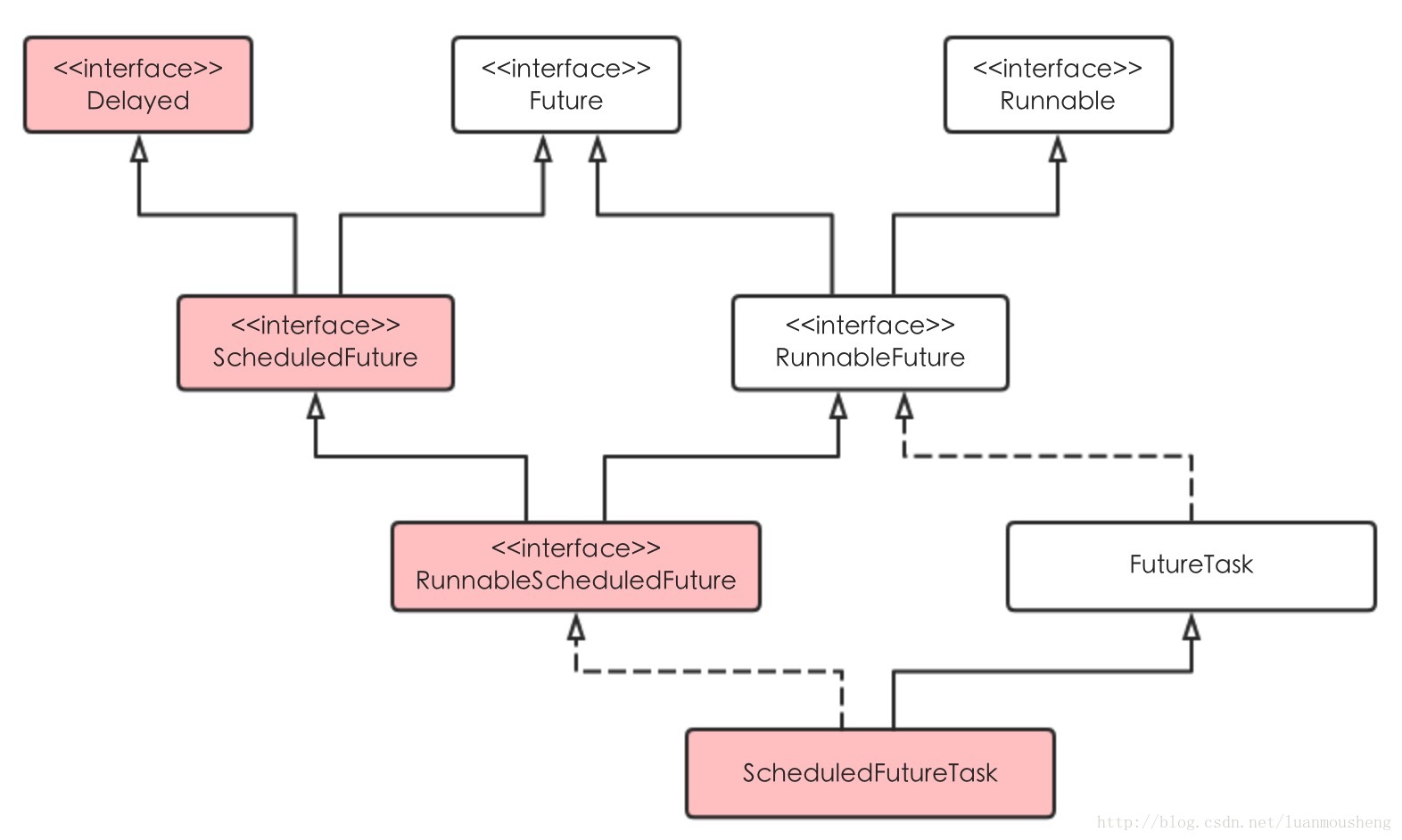
96.3 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
images/thread/condition-01.png
0 → 100644
{kind=link}
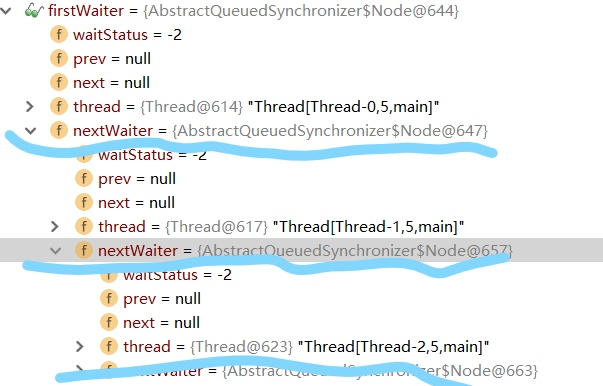
190.3 KB
images/thread/condition-02.png
0 → 100644
{kind=link}
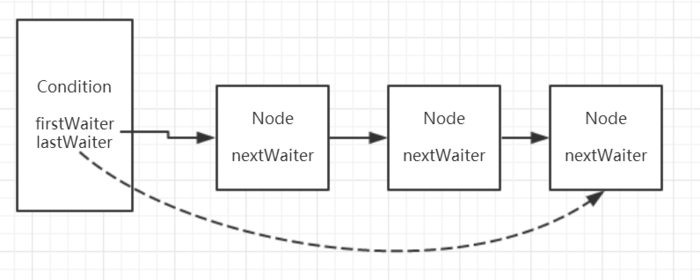
23.5 KB
images/thread/condition-03.png
0 → 100644
{kind=link}
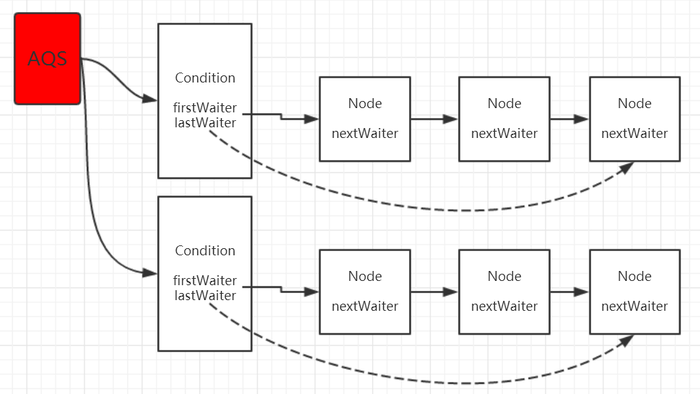
81.8 KB
images/thread/condition-04.png
0 → 100644
{kind=link}
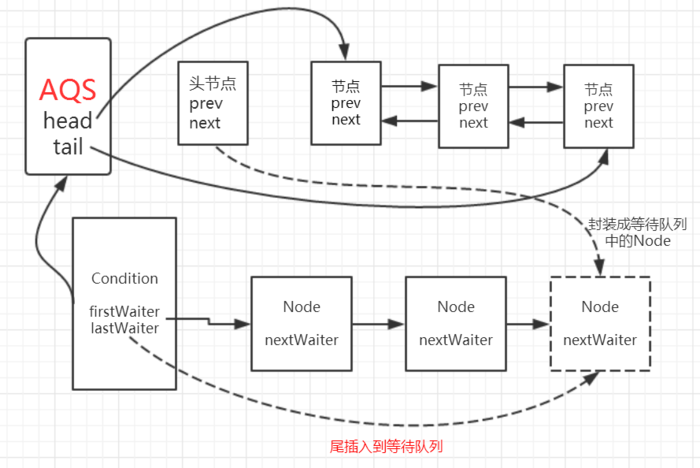
99.8 KB
images/thread/condition-05.png
0 → 100644
{kind=link}
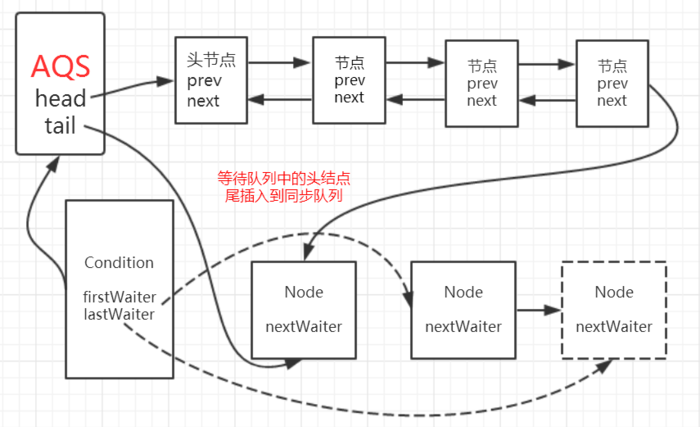
98.3 KB
images/thread/condition-06.png
0 → 100644
{kind=link}
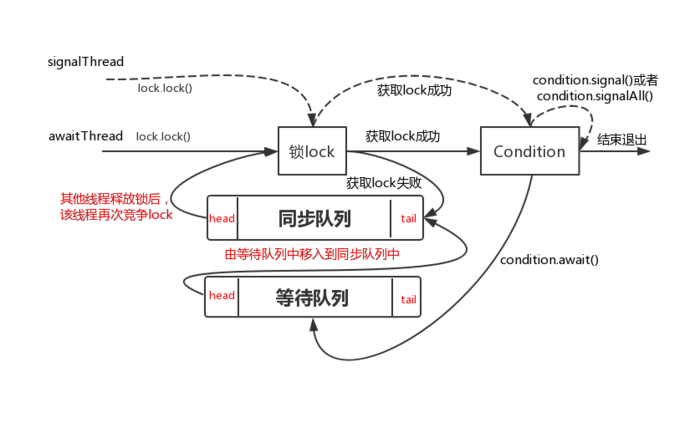
70.9 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}