# 飞桨训推一体全流程(TIPC)模型开发文档
## 1. TIPC简介
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。飞桨训推一体全流程(Training and Inference Pipeline Criterion(TIPC))旨在建立模型从学术研究到产业落地的桥梁,方便模型更广泛的使用。
## 2. 论文复现流程与规范
### 2.1 复现流程
如果您对于论文复现过程已经非常熟悉,在复现过程中可以按照自己的复现方法进行复现。但是需要注意训练日志与文档内容符合规范。可以参考`2.2章节`。
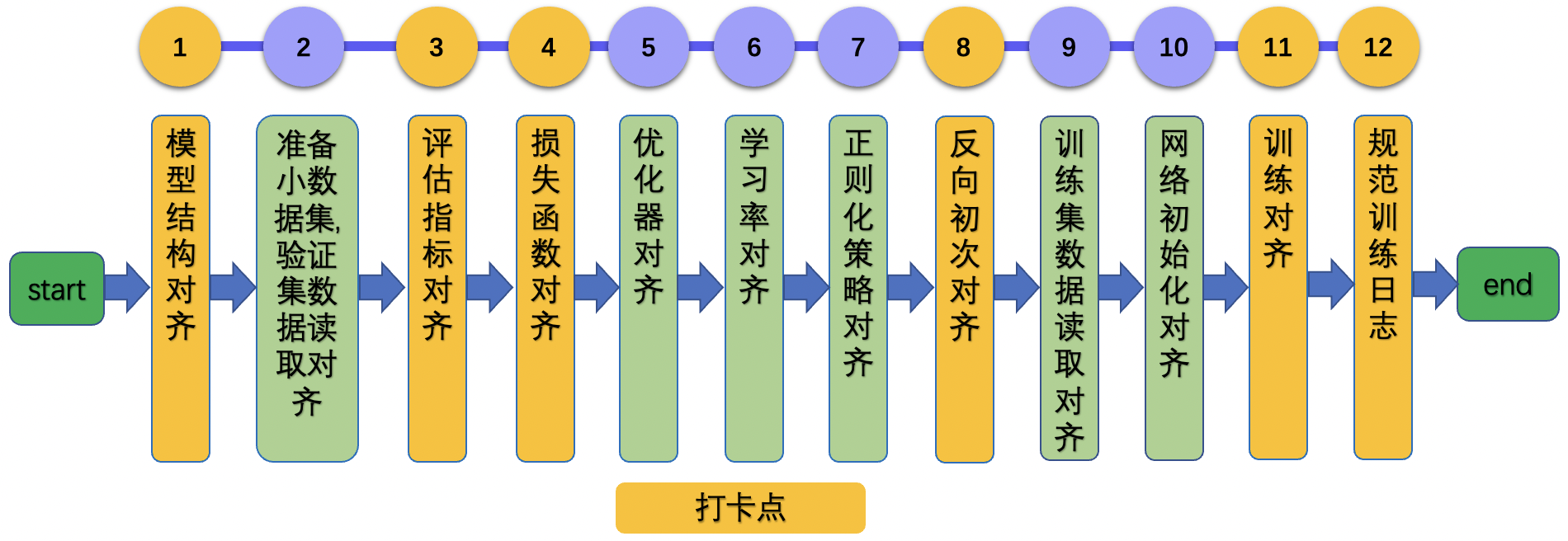
如果您在论文复现方面经验较少或者复现过程中遇到问题,希望定位问题,强烈建议您按照论文复现指南进行操作。以CV任务为例,复现指南将论文复现分为12个步骤,如下所示。
更多内容请参考:[CV方向论文复现指南](../lwfx/ArticleReproduction_CV.md)。
### 2.2 规范验收点
#### 2.2.1 小数据集
repo中包含`lite_data`小数据集压缩包,解压之后可以获取`lite_data`小数据集文件夹。
需要准备好小数据集。方便快速验证。
#### 2.2.2 代码与精度
* 代码中包含训练(`train.py`)、评估(`eval.py`)、预测(`predict.py`)的脚本,分别作为模型训练、评估、预测的入口。
* 模型结构、数据预处理/后处理、优化器、预训练模型与参考代码保持一致。
#### 2.2.3 训练日志
* 输出目录中包含`train.log`文件,每个迭代过程中,至少包含`epoch`, `iter`, `loss`, `avg_reader_cost`, `avg_batch_cost`, `avg_ips`关键字段。含义如下所示。
* `epoch`: 当前训练所处的epoch数
* `iter`: 该epoch中,当前训练的具体迭代轮数
* `loss`: 过去若干个iter的loss值
* `avg_reader_cost`: 过去若干个iter的平均reader耗时 (单位: sec)
* `avg_batch_cost`: 过去若干个iter的平均训练耗时 (单位: sec)
* `avg_ips`: 过段若干个iter个训练速度(单位: images/sec)
#### 2.2.3 文档
* 说明文档中需要有数据准备以及模型训练、评估、预测的命令。
* 介绍预测命令(predict.py)时,需要提供示例图片,并根据示例图片,可视化出使用提供的预测命令运行得到的结果。
## 3. 模型推理开发规范
### 3.1 开发流程
基于Paddle Inference的预测过程分为下面4个步骤。
更多的介绍可以参考:[模型推理开发规范](./inference.md)。
### 3.2 规范验收点
#### 3.1.1 代码与预测结果
* 项目中需要包含`模型动转静`脚本(`export_model.py`)以及`模型基于预测引擎的`预测脚本(`infer.py`)。
#### 3.1.2 文档
* 说明文档中,需要包含`模型动转静`和`模型基于预测引擎`的说明。
## 4. TIPC测试开发规范
### 4.1 开发流程
TIPC测试开发流程与规范可以参考:[Linux GPU/CPU 基础训练推理测试开发规范](./train_infer_python.md)。
### 4.2 规范验收点
验收点包含`目录结构、配置文件、说明文档`,具体内容可以参考[Linux GPU/CPU 基础训练推理测试开发规范](./train_infer_python.md)的`3.3章节`。