# 使用预训练模型Fine-tune完成pointwise中文文本匹配任务
随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
百度的预训练模型ERNIE经过海量的数据训练后,其特征抽取的工作已经做的非常好。借鉴迁移学习的思想,我们可以利用其在海量数据中学习的语义信息辅助小数据集(如本示例中的医疗文本数据集)上的任务。
 使用预训练模型ERNIE完成pointwise文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
使用预训练模型ERNIE完成pointwise文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
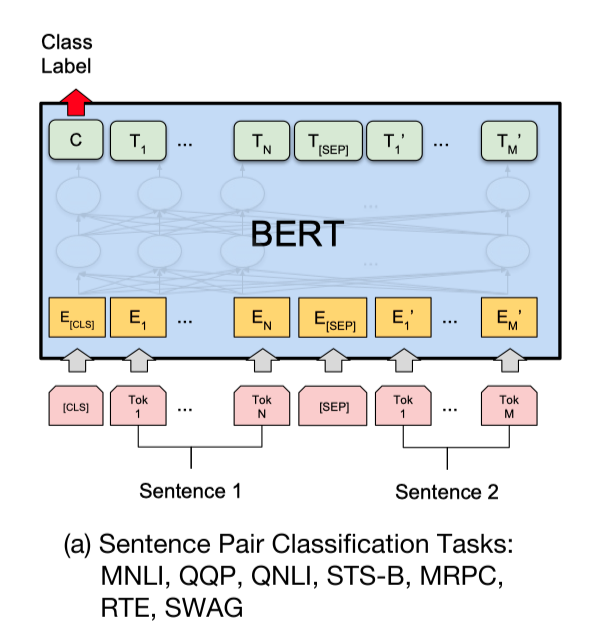
然而,以上用法的问题在于,**ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想**。从而达不到线上业务的要求。针对该问题,可以使用PaddleNLP工具搭建Sentence Transformer网络。
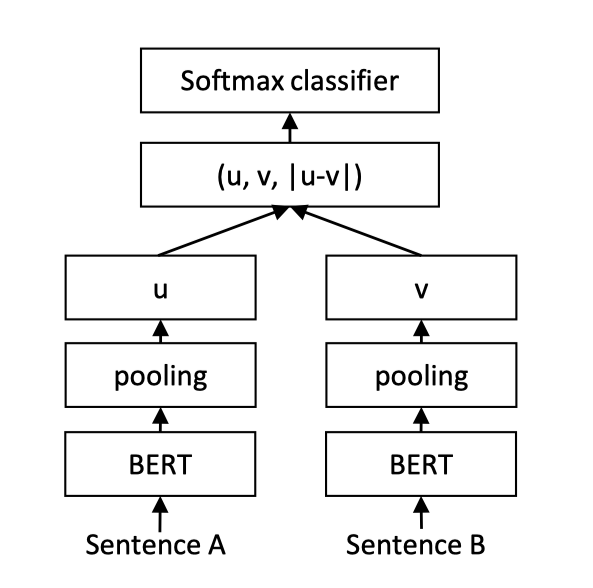
Sentence Transformer采用了双塔(Siamese)的网络结构。Query和Title分别输入ERNIE,共享一个ERNIE参数,得到各自的token embedding特征。之后对token embedding进行pooling(此处教程使用mean pooling操作),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如上图所示。
更多关于Sentence Transformer的信息可以参考论文:https://arxiv.org/abs/1908.10084
**同时,不仅可以使用ERNIR作为文本语义特征提取器,可以利用BERT/RoBerta/Electra等模型作为文本语义特征提取器**
**那么Sentence Transformer采用Siamese的网路结构,是如何提升预测速度呢?**
**Siamese的网络结构好处在于query和title分别输入同一套网络。如在信息搜索任务中,此时就可以将数据库中的title文本提前计算好对应sequence_output特征,保存在数据库中。当用户搜索query时,只需计算query的sequence_output特征与保存在数据库中的title sequence_output特征,通过一个简单的mean_pooling和全连接层进行二分类即可。从而大幅提升预测效率,同时也保障了模型性能。**
关于匹配任务常用的Siamese网络结构可以参考:https://blog.csdn.net/thriving_fcl/article/details/73730552
PaddleNLP提供了丰富的预训练模型,并且可以便捷地获取PaddlePaddle生态下的所有预训练模型。下面展示如何使用PaddleNLP一键加载ERNIE,优化文本匹配任务。
## 模型简介
本项目针对中文文本匹配问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie_tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie_tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
+ Electra([ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://arxiv.org/abs/2003.10555)), 支持hidden_size=256的`chinese-electra-discriminator-small`和
hidden_size=768的`chinese-electra-discriminator-base`
## TODO 增加模型效果
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
| bert-base-chinese | | |
| bert-wwm-chinese | | |
| bert-wwm-ext-chinese | | |
| ernie | | |
| ernie-tiny | | |
| roberta-wwm-ext | | |
| roberta-wwm-ext-large | | |
| rbt3 | | |
| rbtl3 | | |
| chinese-electra-discriminator-base | | |
| chinese-electra-discriminator-small | | |
## 快速开始
### 安装说明
* PaddlePaddle 安装
本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
* PaddleNLP 安装
```shell
pip install paddlenlp
```
* 环境依赖
Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/beginners_guide/install/index_cn.html) 部分的内容
### 代码结构说明
以下是本项目主要代码结构及说明:
```text
sentence_transformers/
├── checkpoint
│ ├── model_100
│ │ ├── model_state.pdparams
│ │ ├── tokenizer_config.json
│ │ └── vocab.txt
│ ├── ...
│
├── model.py # Sentence Transfomer 组网文件
├── README.md # 文本说明
└── train.py # 模型训练评估
```
### 模型训练
我们以中文文本匹配公开数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
```shell
# 设置使用的GPU卡号
CUDA_VISIBLE_DEVICES=0
python train.py --model_type ernie --model_name ernie-1.0 --n_gpu 1 --save_dir ./checkpoints
```
可支持配置的参数:
* `model_type`:必选,模型类型,可以选择bert,ernie,roberta。
* `model_name`: 必选,具体的模型简称。如`model_type=ernie`,则model_name可以选择`ernie`和`ernie_tiny`。`model_type=bert`,则model_name可以选择`bert-base-chinese`。
`model_type=roberta`,则model_name可以选择`roberta-wwm-ext-large`和`roberta-wwm-ext`。
* `save_dir`:必选,保存训练模型的目录。
* `max_seq_length`:可选,ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。
* `batch_size`:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
* `learning_rate`:可选,Fine-tune的最大学习率;默认为5e-5。
* `weight_decay`:可选,控制正则项力度的参数,用于防止过拟合,默认为0.00。
* `warmup_proption`:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.1。
* `init_from_ckpt`:可选,模型参数路径,热启动模型训练;默认为None。
* `seed`:可选,随机种子,默认为1000.
* `n_gpu`:可选,训练过程中使用GPU卡数量,默认为1。若n_gpu=0,则使用CPU训练。
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的`save_dir`中。
如:
```text
checkpoints/
├── model_100
│ ├── model_config.json
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...
```
**NOTE:**
* 如需恢复模型训练,则可以设置`init_from_ckpt`, 如`init_from_ckpt=checkpoints/model_100/model_state.pdparams`。
* 如需使用ernie_tiny模型,则需要提前先安装sentencepiece依赖,如`pip install sentencepiece`
### 模型预测
启动预测:
```shell
CUDA_VISIBLE_DEVICES=0
python predict.py --model_type ernie --model_name ernie_tiny --params_path checkpoints/model_400/model_state.pdparams
```
将待预测数据如以下示例:
```text
世界上什么东西最小 世界上什么东西最小?
光眼睛大就好看吗 眼睛好看吗?
小蝌蚪找妈妈怎么样 小蝌蚪找妈妈是谁画的
```
可以直接调用`predict`函数即可输出预测结果。
如
```text
Data: ['世界上什么东西最小', '世界上什么东西最小?'] Label: similar
Data: ['光眼睛大就好看吗', '眼睛好看吗?'] Label: dissimilar
Data: ['小蝌蚪找妈妈怎么样', '小蝌蚪找妈妈是谁画的'] Label: dissimilar
```
## 引用
关于Sentence Transformer更多信息参考[www.SBERT.net](https://www.sbert.net)以及论文:
- [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084) (EMNLP 2019)
- [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://arxiv.org/abs/2004.09813) (EMNLP 2020)
- [Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks](https://arxiv.org/abs/2010.08240) (arXiv 2020)
```
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
```
@inproceedings{reimers-2020-multilingual-sentence-bert,
title = "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.09813",
}
```
```
@article{thakur-2020-AugSBERT,
title = "Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks",
author = "Thakur, Nandan and Reimers, Nils and Daxenberger, Johannes and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2010.08240",
month = "10",
year = "2020",
url = "https://arxiv.org/abs/2010.08240",
}
```