# DeepSpeech2 on PaddlePaddle
*DeepSpeech2 on PaddlePaddle* is an open-source implementation of end-to-end Automatic Speech Recognition (ASR) engine, based on [Baidu's Deep Speech 2 paper](http://proceedings.mlr.press/v48/amodei16.pdf), with [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) platform. Our vision is to empower both industrial application and academic research on speech recognition, via an easy-to-use, efficient and scalable implementation, including training, inference & testing module, distributed [PaddleCloud](https://github.com/PaddlePaddle/cloud) training, and demo deployment. Besides, several pre-trained models for both English and Mandarin are also released.
## Table of Contents
- [Prerequisites](#prerequisites)
- [Installation](#installation)
- [Getting Started](#getting-started)
- [Data Preparation](#data-preparation)
- [Training a Model](#training-a-model)
- [Data Augmentation Pipeline](#data-augmentation-pipeline)
- [Inference and Evaluation](#inference-and-evaluation)
- [Distributed Cloud Training](#distributed-cloud-training)
- [Hyper-parameters Tuning](#hyper-parameters-tuning)
- [Training for Mandarin Language](#training-for-mandarin-language)
- [Trying Live Demo with Your Own Voice](#trying-live-demo-with-your-own-voice)
- [Released Models](#released-models)
- [Experiments and Benchmarks](#experiments-and-benchmarks)
- [Questions and Help](#questions-and-help)
## Prerequisites
- Python 2.7 only supported
- PaddlePaddle the latest version (please refer to the [Installation Guide](https://github.com/PaddlePaddle/Paddle#installation))
## Installation
Please make sure the above [prerequisites](#prerequisites) have been satisfied before moving on.
```bash
git clone https://github.com/PaddlePaddle/models.git
cd models/deep_speech_2
sh setup.sh
```
## Getting Started
Several shell scripts provided in `./examples` will help us to quickly give it a try, for most major modules, including data preparation, model training, case inference and model evaluation, with a few public dataset (e.g. [LibriSpeech](http://www.openslr.org/12/), [Aishell](http://www.openslr.org/33)). Reading these examples will also help you to understand how to make it work with your own data.
Some of the scripts in `./examples` are configured with 8 GPUs. If you don't have 8 GPUs available, please modify `CUDA_VISIBLE_DEVICES` and `--trainer_count`. If you don't have any GPU available, please set `--use_gpu` to False to use CPUs instead. Besides, if out-of-memory problem occurs, just reduce `--batch_size` to fit.
Let's take a tiny sampled subset of [LibriSpeech dataset](http://www.openslr.org/12/) for instance.
- Go to directory
```bash
cd examples/tiny
```
Notice that this is only a toy example with a tiny sampled subset of LibriSpeech. If you would like to try with the complete dataset (would take several days for training), please go to `examples/librispeech` instead.
- Prepare the data
```bash
sh run_data.sh
```
`run_data.sh` will download dataset, generate manifests, collect normalizer's statistics and build vocabulary. Once the data preparation is done, you will find the data (only part of LibriSpeech) downloaded in `~/.cache/paddle/dataset/speech/libri` and the corresponding manifest files generated in `./data/tiny` as well as a mean stddev file and a vocabulary file. It has to be run for the very first time you run this dataset and is reusable for all further experiments.
- Train your own ASR model
```bash
sh run_train.sh
```
`run_train.sh` will start a training job, with training logs printed to stdout and model checkpoint of every pass/epoch saved to `./checkpoints/tiny`. These checkpoints could be used for training resuming, inference, evaluation and deployment.
- Case inference with an existing model
```bash
sh run_infer.sh
```
`run_infer.sh` will show us some speech-to-text decoding results for several (default: 10) samples with the trained model. The performance might not be good now as the current model is only trained with a toy subset of LibriSpeech. To see the results with a better model, you can download a well-trained (trained for several days, with the complete LibriSpeech) model and do the inference:
```bash
sh run_infer_golden.sh
```
- Evaluate an existing model
```bash
sh run_test.sh
```
`run_test.sh` will evaluate the model with Word Error Rate (or Character Error Rate) measurement. Similarly, you can also download a well-trained model and test its performance:
```bash
sh run_test_golden.sh
```
More detailed information are provided in the following sections. Wish you a happy journey with the *DeepSpeech2 on PaddlePaddle* ASR engine!
## Data Preparation
### Generate Manifest
*DeepSpeech2 on PaddlePaddle* accepts a textual **manifest** file as its data set interface. A manifest file summarizes a set of speech data, with each line containing some meta data (e.g. filepath, transcription, duration) of one audio clip, in [JSON](http://www.json.org/) format, such as:
```
{"audio_filepath": "/home/work/.cache/paddle/Libri/134686/1089-134686-0001.flac", "duration": 3.275, "text": "stuff it into you his belly counselled him"}
{"audio_filepath": "/home/work/.cache/paddle/Libri/134686/1089-134686-0007.flac", "duration": 4.275, "text": "a cold lucid indifference reigned in his soul"}
```
To use your custom data, you only need to generate such manifest files to summarize the dataset. Given such summarized manifests, training, inference and all other modules can be aware of where to access the audio files, as well as their meta data including the transcription labels.
For how to generate such manifest files, please refer to `data/librispeech/librispeech.py`, which will download data and generate manifest files for LibriSpeech dataset.
### Compute Mean & Stddev for Normalizer
To perform z-score normalization (zero-mean, unit stddev) upon audio features, we have to estimate in advance the mean and standard deviation of the features, with some training samples:
```bash
python tools/compute_mean_std.py \
--num_samples 2000 \
--specgram_type linear \
--manifest_paths data/librispeech/manifest.train \
--output_path data/librispeech/mean_std.npz
```
It will compute the mean and standard deviation of power spectrum feature with 2000 random sampled audio clips listed in `data/librispeech/manifest.train` and save the results to `data/librispeech/mean_std.npz` for further usage.
### Build Vocabulary
A vocabulary of possible characters is required to convert the transcription into a list of token indices for training, and in decoding, to convert from a list of indices back to text again. Such a character-based vocabulary can be built with `tools/build_vocab.py`.
```bash
python tools/build_vocab.py \
--count_threshold 0 \
--vocab_path data/librispeech/eng_vocab.txt \
--manifest_paths data/librispeech/manifest.train
```
It will write a vocabuary file `data/librispeeech/eng_vocab.txt` with all transcription text in `data/librispeech/manifest.train`, without vocabulary truncation (`--count_threshold 0`).
### More Help
For more help on arguments:
```bash
python data/librispeech/librispeech.py --help
python tools/compute_mean_std.py --help
python tools/build_vocab.py --help
```
## Training a model
`train.py` is the main caller of the training module. Examples of usage are shown below.
- Start training from scratch with 8 GPUs:
```
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python train.py --trainer_count 8
```
- Start training from scratch with 16 CPUs:
```
python train.py --use_gpu False --trainer_count 16
```
- Resume training from a checkpoint:
```
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
python train.py \
--init_model_path CHECKPOINT_PATH_TO_RESUME_FROM
```
For more help on arguments:
```bash
python train.py --help
```
or refer to `example/librispeech/run_train.sh`.
## Data Augmentation Pipeline
Data augmentation has often been a highly effective technique to boost the deep learning performance. We augment our speech data by synthesizing new audios with small random perturbation (label-invariant transformation) added upon raw audios. You don't have to do the syntheses on your own, as it is already embedded into the data provider and is done on the fly, randomly for each epoch during training.
Six optional augmentation components are provided to be selected, configured and inserted into the processing pipeline.
- Volume Perturbation
- Speed Perturbation
- Shifting Perturbation
- Online Bayesian normalization
- Noise Perturbation (need background noise audio files)
- Impulse Response (need impulse audio files)
In order to inform the trainer of what augmentation components are needed and what their processing orders are, it is required to prepare in advance a *augmentation configuration file* in [JSON](http://www.json.org/) format. For example:
```
[{
"type": "speed",
"params": {"min_speed_rate": 0.95,
"max_speed_rate": 1.05},
"prob": 0.6
},
{
"type": "shift",
"params": {"min_shift_ms": -5,
"max_shift_ms": 5},
"prob": 0.8
}]
```
When the `--augment_conf_file` argument of `trainer.py` is set to the path of the above example configuration file, every audio clip in every epoch will be processed: with 60% of chance, it will first be speed perturbed with a uniformly random sampled speed-rate between 0.95 and 1.05, and then with 80% of chance it will be shifted in time with a random sampled offset between -5 ms and 5 ms. Finally this newly synthesized audio clip will be feed into the feature extractor for further training.
For other configuration examples, please refer to `conf/augmenatation.config.example`.
Be careful when utilizing the data augmentation technique, as improper augmentation will do harm to the training, due to the enlarged train-test gap.
## Inference and Evaluation
### Prepare Language Model
A language model is required to improve the decoder's performance. We have prepared two language models (with lossy compression) for users to download and try. One is for English and the other is for Mandarin. Users can simply run this to download the preprared language models:
```bash
cd models/lm
sh download_lm_en.sh
sh download_lm_ch.sh
```
If you wish to train your own better language model, please refer to [KenLM](https://github.com/kpu/kenlm) for tutorials.
TODO: any other requirements or tips to add?
### Speech-to-text Inference
An inference module caller `infer.py` is provided to infer, decode and visualize speech-to-text results for several given audio clips. It might help to have an intuitive and qualitative evaluation of the ASR model's performance.
- Inference with GPU:
```bash
CUDA_VISIBLE_DEVICES=0 python infer.py --trainer_count 1
```
- Inference with CPUs:
```bash
python infer.py --use_gpu False --trainer_count 12
```
We provide two types of CTC decoders: *CTC greedy decoder* and *CTC beam search decoder*. The *CTC greedy decoder* is an implementation of the simple best-path decoding algorithm, selecting at each timestep the most likely token, thus being greedy and locally optimal. The [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) otherwise utilizes a heuristic breadth-first graph search for reaching a near global optimality; it also requires a pre-trained KenLM language model for better scoring and ranking. The decoder type can be set with argument `--decoding_method`.
For more help on arguments:
```
python infer.py --help
```
or refer to `example/librispeech/run_infer.sh`.
### Evaluate a Model
To evaluate a model's performance quantitatively, please run:
- Evaluation with GPUs:
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python test.py --trainer_count 8
```
- Evaluation with CPUs:
```bash
python test.py --use_gpu False --trainer_count 12
```
The error rate (default: word error rate; can be set with `--error_rate_type`) will be printed.
For more help on arguments:
```bash
python test.py --help
```
or refer to `example/librispeech/run_test.sh`.
## Hyper-parameters Tuning
The hyper-parameters $\alpha$ (coefficient for language model scorer) and $\beta$ (coefficient for word count scorer) for the [*CTC beam search decoder*](https://arxiv.org/abs/1408.2873) often have a significant impact on the decoder's performance. It would be better to re-tune them on a validation set when the acoustic model is renewed.
`tools/tune.py` performs a 2-D grid search over the hyper-parameter $\alpha$ and $\beta$. You must provide the range of $\alpha$ and $\beta$, as well as the number of their attempts.
- Tuning with GPU:
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
python tools/tune.py \
--trainer_count 8 \
--alpha_from 0.1 \
--alpha_to 0.36 \
--num_alphas 14 \
--beta_from 0.05 \
--beta_to 1.0 \
--num_betas 20
```
- Tuning with CPU:
```bash
python tools/tune.py --use_gpu False
```
After tuning, you can reset $\alpha$ and $\beta$ in the inference and evaluation modules to see if they really help improve the ASR performance.
```bash
python tune.py --help
```
or refer to `example/librispeech/run_tune.sh`.
TODO: add figure.
## Distributed Cloud Training
We also provide a cloud training module for users to do the distributed cluster training on [PaddleCloud](https://github.com/PaddlePaddle/cloud), to achieve a much faster training speed with multiple machines. To start with this, please first install PaddleCloud client and register a PaddleCloud account, as described in [PaddleCloud Usage](https://github.com/PaddlePaddle/cloud/blob/develop/doc/usage_cn.md#%E4%B8%8B%E8%BD%BD%E5%B9%B6%E9%85%8D%E7%BD%AEpaddlecloud).
Please take the following steps to submit a training job:
- Go to directory:
```bash
cd cloud
```
- Upload data:
Data must be uploaded to PaddleCloud filesystem to be accessed within a cloud job. `pcloud_upload_data.sh` helps do the data packing and uploading:
```bash
sh pcloud_upload_data.sh
```
Given input manifests, `pcloud_upload_data.sh` will:
- Extract the audio files listed in the input manifests.
- Pack them into a specified number of tar files.
- Upload these tar files to PaddleCloud filesystem.
- Create cloud manifests by replacing local filesystem paths with PaddleCloud filesystem paths. New manifests will be used to inform the cloud jobs of audio files' location and their meta information.
It should be done only once for the very first time to do the cloud training. Later, the data is kept persisitent on the cloud filesystem and reusable for further job submissions.
For argument details please refer to [Train DeepSpeech2 on PaddleCloud](https://github.com/PaddlePaddle/models/tree/develop/deep_speech_2/cloud).
- Configure training arguments:
Configure the cloud job parameters in `pcloud_submit.sh` (e.g. `NUM_NODES`, `NUM_GPUS`, `CLOUD_TRAIN_DIR`, `JOB_NAME` etc.) and then configure other hyper-parameters for training in `pcloud_train.sh` (just as what you do for local training).
For argument details please refer to [Train DeepSpeech2 on PaddleCloud](https://github.com/PaddlePaddle/models/tree/develop/deep_speech_2/cloud).
- Submit the job:
By running:
```bash
sh pcloud_submit.sh
```
a training job has been submitted to PaddleCloud, with the job name printed to the console.
- Get training logs
Run this to list all the jobs you have submitted, as well as their running status:
```bash
paddlecloud get jobs
```
Run this, the corresponding job's logs will be printed.
```bash
paddlecloud logs -n 10000 $REPLACED_WITH_YOUR_ACTUAL_JOB_NAME
```
For more information about the usage of PaddleCloud, please refer to [PaddleCloud Usage](https://github.com/PaddlePaddle/cloud/blob/develop/doc/usage_cn.md#提交任务).
For more information about the DeepSpeech2 training on PaddleCloud, please refer to
[Train DeepSpeech2 on PaddleCloud](https://github.com/PaddlePaddle/models/tree/develop/deep_speech_2/cloud).
## Training for Mandarin Language
TODO: to be added
## Trying Live Demo with Your Own Voice
Until now, an ASR model is trained and tested qualitatively (`infer.py`) and quantitatively (`test.py`) with existing audio files. But it is not yet tested with your own speech. `deploy/demo_server.py` and `deploy/demo_client.py` helps quickly build up a real-time demo ASR engine with the trained model, enabling you to test and play around with the demo, with your own voice.
To start the demo's server, please run this in one console:
```bash
CUDA_VISIBLE_DEVICES=0 \
python deploy/demo_server.py \
--trainer_count 1 \
--host_ip localhost \
--host_port 8086
```
For the machine (might not be the same machine) to run the demo's client, please do the following installation before moving on.
For example, on MAC OS X:
```bash
brew install portaudio
pip install pyaudio
pip install pynput
```
Then to start the client, please run this in another console:
```bash
CUDA_VISIBLE_DEVICES=0 \
python -u deploy/demo_client.py \
--host_ip 'localhost' \
--host_port 8086
```
Now, in the client console, press the `whitespace` key, hold, and start speaking. Until finishing your utterance, release the key to let the speech-to-text results shown in the console. To quit the client, just press `ESC` key.
Notice that `deploy/demo_client.py` must be run on a machine with a microphone device, while `deploy/demo_server.py` could be run on one without any audio recording hardware, e.g. any remote server machine. Just be careful to set the `host_ip` and `host_port` argument with the actual accessible IP address and port, if the server and client are running with two separate machines. Nothing should be done if they are running on one single machine.
Please also refer to `examples/mandarin/run_demo_server.sh`, which will first download a pre-trained Mandarin model (trained with 3000 hours of internal speech data) and then start the demo server with the model. With running `examples/mandarin/run_demo_client.sh`, you can speak Mandarin to test it. If you would like to try some other models, just update `--model_path` argument in the script.
For more help on arguments:
```bash
python deploy/demo_server.py --help
python deploy/demo_client.py --help
```
## Released Models
#### Speech Model Released
Language | Model Name | Training Data | Training Hours
:-----------: | :------------: | :----------: | -------:
English | [LibriSpeech Model](http://cloud.dlnel.org/filepub/?uuid=17404caf-cf19-492f-9707-1fad07c19aae) | [LibriSpeech Dataset](http://www.openslr.org/12/) | 960 h
English | [Internal English Model](to-be-added) | Baidu English Dataset | 8000 h
Mandarin | [Aishell Model](http://cloud.dlnel.org/filepub/?uuid=6c83b9d8-3255-4adf-9726-0fe0be3d0274) | [Aishell Dataset](http://www.openslr.org/33/) | 151 h
Mandarin | [Internal Mandarin Model](to-be-added) | Baidu Mandarin Dataset | 2917 h
#### Language Model Released
Language Model | Training Data | Token-based | Size | Filter Configuraiton
:-------------:| :------------:| :-----: | -----: | -----------------:
[English LM (Median)](http://paddlepaddle.bj.bcebos.com/model_zoo/speech/common_crawl_00.prune01111.trie.klm) | To Be Added | Word-based | 8.3 GB | To Be Added
[English LM (Big)](to-be-added) | To Be Added | Word-based | X.X GB | To Be Added
[Mandarin LM (Median)](http://cloud.dlnel.org/filepub/?uuid=d21861e4-4ed6-45bb-ad8e-ae417a43195e) | To Be Added | Character-based | 2.8 GB | To Be Added
[Mandarin LM (Big)](to-be-added) | To Be Added | Character-based | X.X GB | To Be Added
## Experiments and Benchmarks
#### English Model Evaluation (Word Error Rate)
Test Set | LibriSpeech Model | Internal English Model
:---------------------: | :---------------: | :-------------------:
LibriSpeech-Test-Clean | 7.9 | X.X
LibriSpeech-Test-Other | X.X | X.X
VoxForge-Test | X.X | X.X
Baidu-English-Test | X.X | X.X
#### English Model Evaluation (Character Error Rate)
Test Set | LibriSpeech Model | Internal English Model
:---------------------: | :---------------: | :-------------------:
LibriSpeech-Test-Clean | X.X | X.X
LibriSpeech-Test-Other | X.X | X.X
VoxForge-Test | X.X | X.X
Baidu-English-Test | X.X | X.X
#### Mandarin Model Evaluation (Character Error Rate)
Test Set | Aishell Model | Internal Mandarin Model
:---------------------: | :---------------: | :-------------------:
Aishell-Test | X.X | X.X
Baidu-Mandarin-Test | X.X | X.X
#### Acceleration with Multi-GPUs
We compare the training time with 1, 2, 4, 8, 16 Tesla K40m GPUs (with a subset of LibriSpeech samples whose audio durations are between 6.0 and 7.0 seconds). And it shows that a **near-linear** acceleration with multiple GPUs has been achieved. In the following figure, the time (in seconds) used for training is plotted on the blue bars.
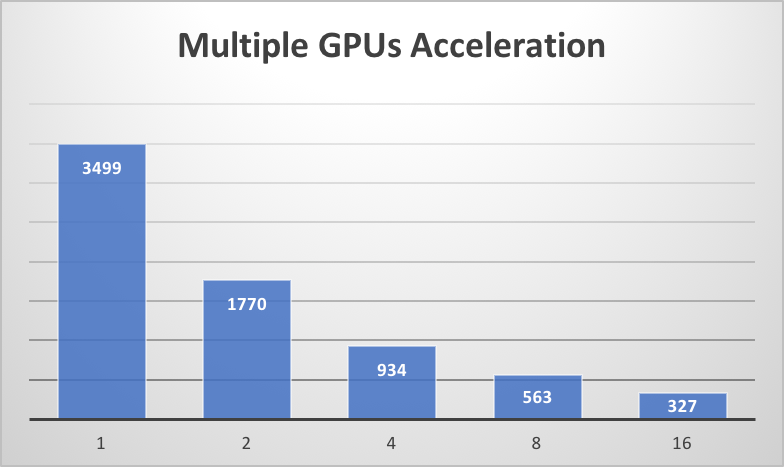
| # of GPU | Acceleration Rate |
| -------- | --------------: |
| 1 | 1.00 X |
| 2 | 1.97 X |
| 4 | 3.74 X |
| 8 | 6.21 X |
|16 | 10.70 X |
`tools/profile.sh` provides such a profiling tool.
## Questions and Help
You are welcome to submit questions and bug reports in [Github Issues](https://github.com/PaddlePaddle/models/issues). You are also welcome to contribute to this project.