运行本目录下的程序示例需要使用PaddlePaddle v0.10.0 版本。如果您的PaddlePaddle安装版本低于此要求,请按照[安装文档](http://www.paddlepaddle.org/docs/develop/documentation/zh/build_and_install/pip_install_cn.html)中的说明更新PaddlePaddle安装版本。
---
# 排序学习(Learning To Rank)
排序学习技术\[[1](#参考文献1)\]是构建排序模型的机器学习方法,在信息检索、自然语言处理,数据挖掘等机器学场景中具有重要作用。排序学习的主要目的是对给定一组文档,对任意查询请求给出反映相关性的文档排序。在本例子中,利用标注过的语料库训练两种经典排序模型RankNet[[4](#参考文献4)\]和LamdaRank[[6](#参考文献6)\],分别可以生成对应的排序模型,能够对任意查询请求,给出相关性文档排序。
## 背景介绍
排序学习技术随着互联网的快速增长而受到越来越多关注,是机器学习中的常见任务之一。一方面人工排序规则不能处理海量规模的候选数据,另一方面无法为不同渠道的候选数据给于合适的权重,因此排序学习在日常生活中应用非常广泛。排序学习起源于信息检索领域,目前仍然是许多信息检索场景中的核心模块,例如搜索引擎搜索结果排序,推荐系统候选集排序,在线广告排序等等。本例以文档检索任务阐述排序学习模型。
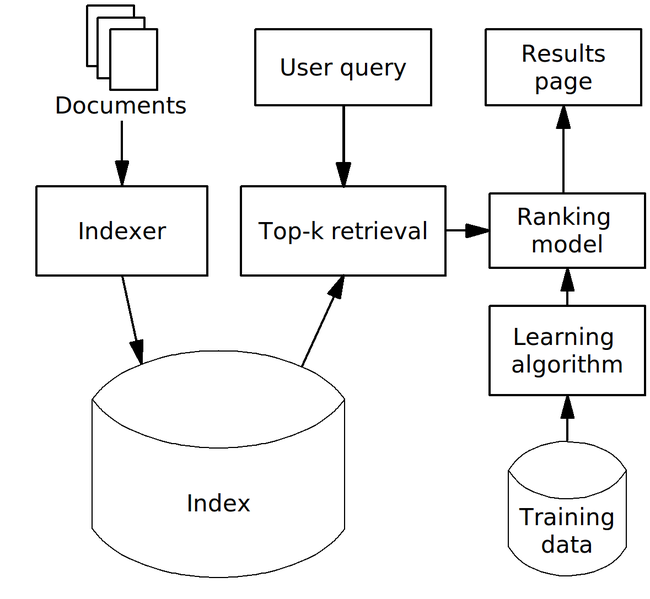
图1. 排序模型在文档检索的典型应用搜索引擎中的作用
假定有一组文档$S$,文档检索任务是依据和请求的相关性,给出文档排列顺序。查询引擎根据查询请求,排序模型会给每个文档打出分数,依据打分情况倒序排列文档,得到查询结果。在训练模型时,给定一条查询,并给出对应的文档最佳排序和得分。在预测时候,给出查询请求,排序模型生成文档排序。常见的排序学习方法划分为以下三类:
- Pointwise 方法
Pointwise方法是通过近似为回归问题解决排序问题,输入的单条样本为**得分-文档**,将每个查询-文档对的相关性得分作为实数分数或者序数分数,使得单个查询-文档对作为样本点(Pointwise的由来),训练排序模型。预测时候对于指定输入,给出查询-文档对的相关性得分。
- Pairwise方法
Pairwise方法是通过近似为分类问题解决排序问题,输入的单条样本为**标签-文档对**。对于一次查询的多个结果文档,组合任意两个文档形成文档对作为输入样本。即学习一个二分类器,对输入的一对文档对AB(Pairwise的由来),根据A相关性是否比B好,二分类器给出分类标签1或0。对所有文档对进行分类,就可以得到一组偏序关系,从而构造文档全集的排序关系。该类方法的原理是对给定的文档全集$S$,降低排序中的逆序文档对的个数来降低排序错误,从而达到优化排序结果的目的。
- Listwise方法
Listwise方法是直接优化排序列表,输入为单条样本为一个**文档排列**。通过构造合适的度量函数衡量当前文档排序和最优排序差值,优化度量函数得到排序模型。由于度量函数很多具有非连续性的性质,优化困难。
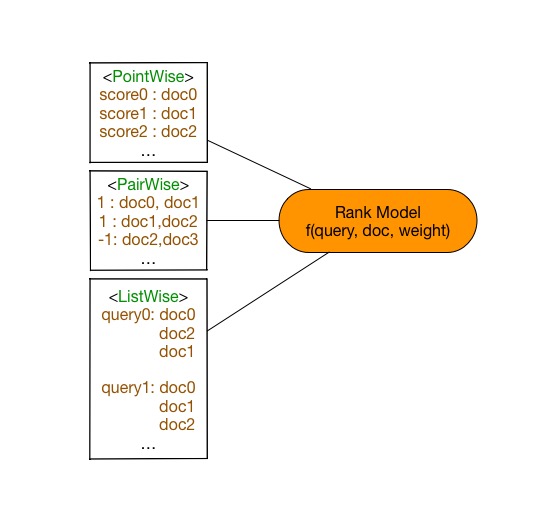
图2. 排序模型三类方法
## 实验数据
本例中的实验数据采用了排序学习中的基准数据[LETOR]([http://research.microsoft.com/en-us/um/beijing/projects/letor/LETOR4.0/Data/MQ2007.rar](http://research.microsoft.com/en-us/um/beijing/projects/letor/LETOR4.0/Data/MQ2007.rar))语料库,部分来自于Gov2网站的查询请求结果,包含了约1700条查询请求结果文档列表,并对文档相关性做出了人工标注。其中,一条查询含有唯一的查询id,对应于多个具有相关性的文档,构成了一次查询请求结果文档列表。每个文档由一个一维数组的特征向量表示,并对应一个人工标注与查询的相关性分数。
本例在第一次运行的时会自动下载LETOR MQ2007数据集并缓存,无需手动下载。
`mq2007`数据集分别提供了三种类型排序模型的生成格式,需要指定生成格式`format`
例如调用接口
```python
pairwise_train_dataset = functools.partial(paddle.dataset.mq2007.train, format="pairwise")
for label, left_doc, right_doc in pairwise_train_dataset():
...
```
## 模型概览
对于排序模型,本例中提供了Pairwise方法的模型RankNet和Listwise方法的模型LambdaRank,分别代表了两类学习方法。Pointwise方法的排序模型退化为回归问题,请参考PaddleBook中[推荐系统](https://github.com/PaddlePaddle/book/blob/develop/05.recommender_system/README.cn.md)一课。
## RankNet排序模型
[RankNet](http://icml.cc/2015/wp-content/uploads/2015/06/icml_ranking.pdf)是一种经典的Pairwise的排序学习方法,是典型的前向神经网络排序模型。在文档集合$S$中的第$i$个文档记做$U_i$,它的文档特征向量记做$x_i$,对于给定的一个文档对$U_i$, $U_j$,RankNet将输入的单个文档特征向量$x$映射到$f(x)$,得到$s_i=f(x_i)$, $s_j=f(x_j)$。将$U_i$相关性比$U_j$好的概率记做$P_{i,j}$,则
$$P_{i,j}=P(U_{i}>U_{j})=\frac{1}{1+e^{-\sigma (s_{i}-s_{j}))}}$$
由于排序度量函数大多数非连续,非光滑,因此RankNet需要一个可以优化的度量函数$C$。首先使用交叉熵作为度量函数衡量预测代价,将损失函数$C$记做
$$C_{i,j}=-\bar{P_{i,j}}logP_{i,j}-(1-\bar{P_{i,j}})log(1-P_{i,j})$$
其中$\bar{P_{i,j}}$代表真实概率,记做
$$\bar{P_{i,j}}=\frac{1}{2}(1+S_{i,j})$$
而$S_{i,j}$ = {+1,0},表示$U_i$和$U_j$组成的Pair的标签,即Ui相关性是否好于$U_j$。
最终得到了可求导的度量损失函数
$$C=\frac{1}{2}(1-S_{i,j})\sigma (s_{i}-s{j})+log(1+e^{-\sigma (s_{i}-s_{j})})$$
可以使用常规的梯度下降方法进行优化。细节见[RankNet](http://icml.cc/2015/wp-content/uploads/2015/06/icml_ranking.pdf)
同时,得到文档$U_i$在排序优化过程的梯度信息为
$$\lambda _{i,j}=\frac{\partial C}{\partial s_{i}} = \frac{1}{2}(1-S_{i,j})-\frac{1}{1+e^{\sigma (s_{i}-s_{j})}}$$
表示的含义是本轮排序优化过程中文档$U_i$的上升或者下降量。
根据以上推论构造RankNet网络结构,由若干层隐藏层和全连接层构成,如图所示,将文档特征使用隐藏层,全连接层逐层变换,完成了底层特征空间到高层特征空间的变换。其中docA和docB结构对称,分别输入到最终的RankCost层中。
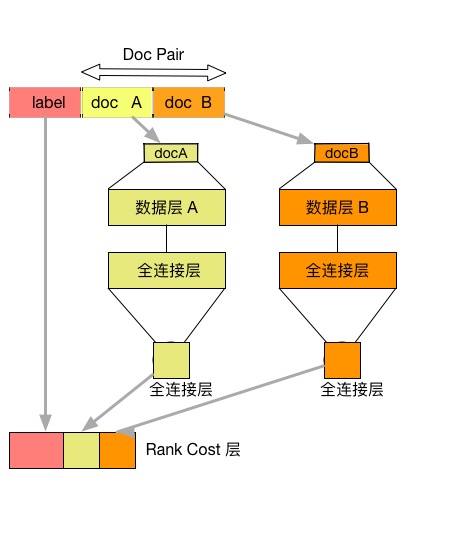
图3. RankNet网络结构示意图
- 全连接层(fully connected layer) : 指上一层中的每个节点都连接到下层网络。本例子中同样使用`paddle.layer.fc`实现,注意输入到RankCost层的全连接层维度为1。
- RankCost层: RankCost层是排序网络RankNet的核心,度量docA相关性是否比docB好,给出预测值并和label比较。使用了交叉熵(cross enctropy)作为度量损失函数,使用梯度下降方法进行优化。细节可见[RankNet](http://icml.cc/2015/wp-content/uploads/2015/06/icml_ranking.pdf)[4]。
由于Pairwise中的网络结构是左右对称,可定义一半网络结构,另一半共享网络参数。在PaddlePaddle中允许网络结构中共享连接,具有相同名字的参数将会共享参数。使用PaddlePaddle实现RankNet排序模型,定义网络结构的示例代码见 [ranknet.py](ranknet.py) 中的 `half_ranknet` 函数。
`half_ranknet` 函数中定义的结构使用了和图3相同的模型结构:两层隐藏层,分别是`hidden_size=10`的全连接层和`hidden_size=1`的全连接层。本例中的`input_dim`指输入**单个文档**的特征的维度,label取值为1,0。每条输入样本为`