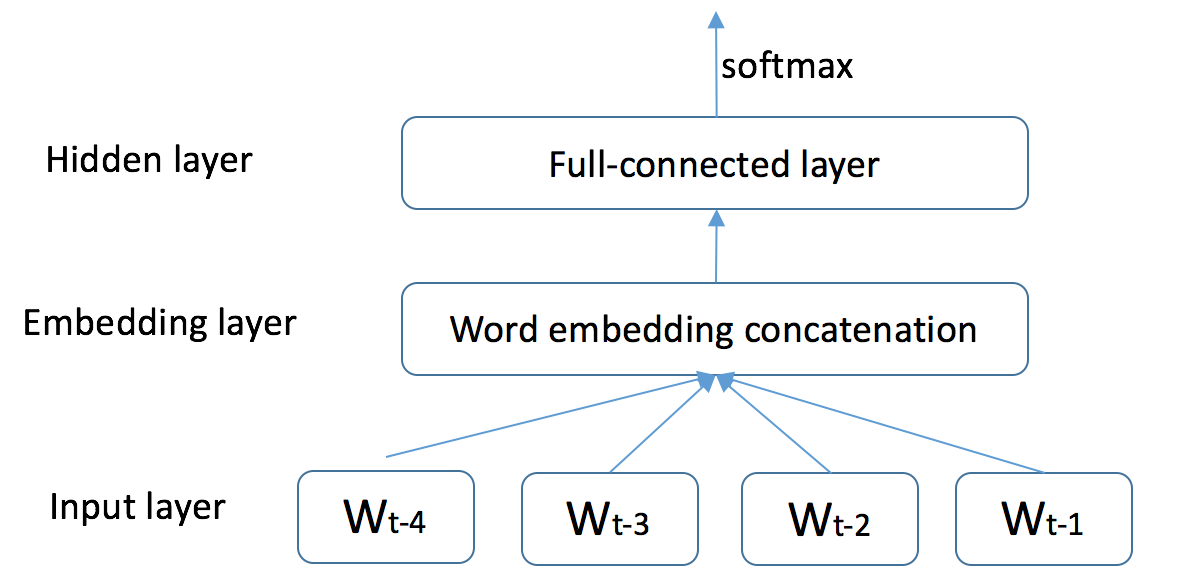
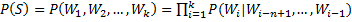# 语言模型
## 简介
语言模型即 Language Model,简称LM,它是一个概率分布模型,简单来说,就是用来计算一个句子的概率的模型。给定句子(词语序列):
它的概率可以表示为:
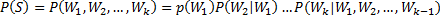
(式1)