运行本目录下的程序示例需要使用 PaddlePaddle 最新的 develop branch 版本。如果您的 PaddlePaddle 安装版本低于此要求,请按照[安装文档](http://www.paddlepaddle.org/docs/develop/documentation/zh/build_and_install/pip_install_cn.html)中的说明更新 PaddlePaddle 安装版本。
---
## Transformer
以下是本例的简要目录结构及说明:
```text
.
├── images # README 文档中的图片
├── optim.py # learning rate scheduling 计算程序
├── infer.py # 预测脚本
├── model.py # 模型定义
├── reader.py # 数据读取接口
├── README.md # 文档
├── train.py # 训练脚本
└── config.py # 训练、预测以及模型参数配置
```
### 简介
Transformer 是论文 [Attention Is All You Need](https://arxiv.org/abs/1706.03762) 中提出的用以完成机器翻译(Machine Translation, MT)等序列到序列(Sequence to Sequence, Seq2Seq)学习任务的一种全新网络结构。正如论文标题所示,Transformer 完全使用注意力机制(Attention Mechanisms)来获取序列中各位置的上下文信息,这种序列建模的方法摒弃了此前 Seq2Seq 模型中广泛使用的循环神经网络(Recurrent Neural Network, RNN),这使得计算并行度显著提高,训练时间大幅减少;同时在机器翻译任务上的实验结果也表明,这种网络结构能够取得现今最佳的翻译效果;而且作为一种通用的网络结构,它易于迁移到其他任务当中;因而 Transformer 正在被越来越多的使用。
### 模型概览
Transformer 同样使用了 Seq2Seq 模型中典型的编码器-解码器(Encoder-Decoder)的框架结构,整体网络结构如图1所示。Encoder 和 Decoder 由若干相同的 layer 堆叠组成,主要包括 Multi-Head Attention 和 Position-wise Feed-Forward Networks 两种模块,
- Encoder 和 Decoder 由若干相同的 layer 堆叠组成
- 每个 layer 主要包括 Multi-Head Attention 和 Position-wise Feed-Forward Networks 两种 �sub-layer
- 每个 sub-layer 后辅以 Residual Connection 和 �Layer Normalization
- Decoder 比 Encoder 所使用的 layer 额外多 Multi-Head Attention
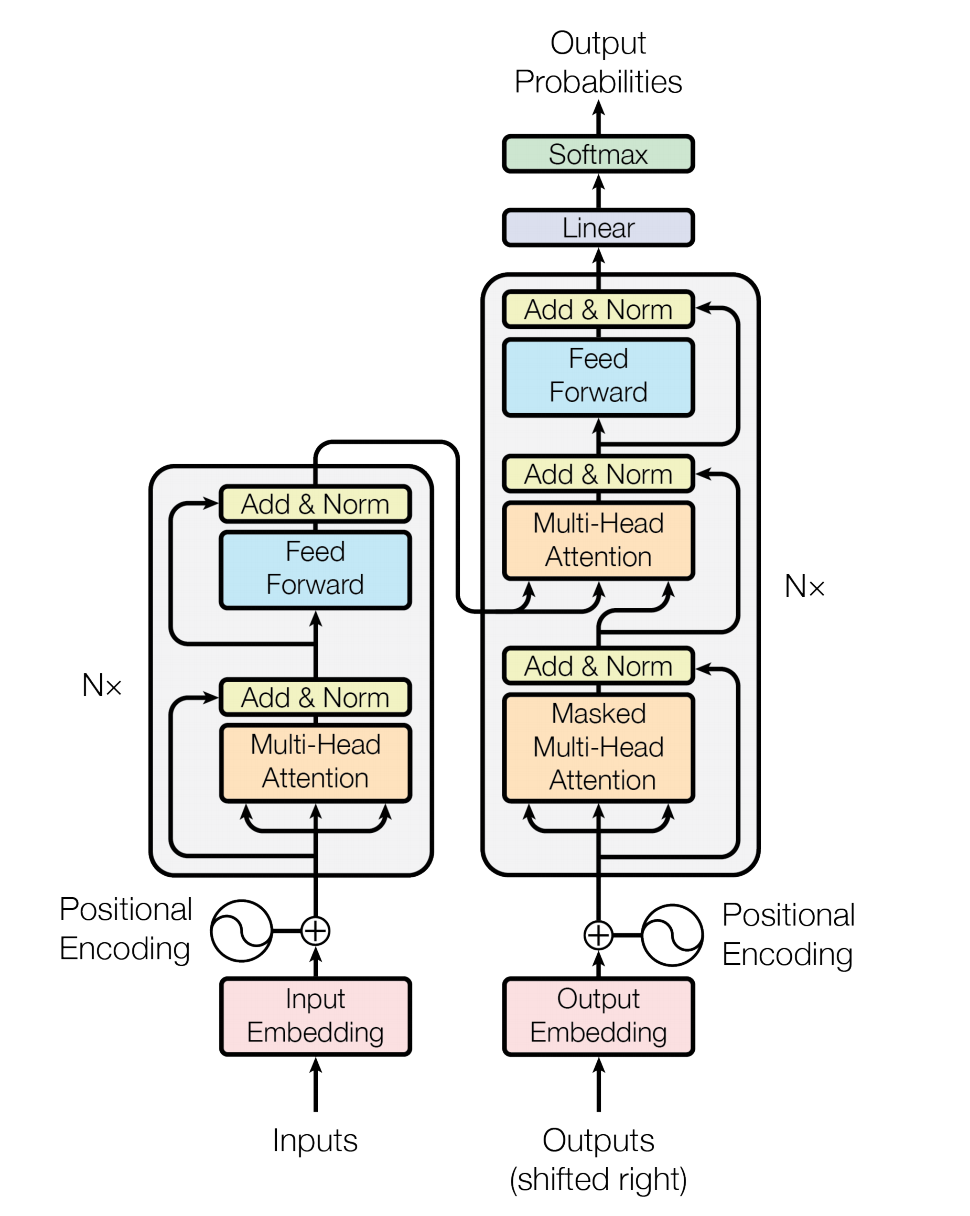
图1. Transformer 网络结构图
### 数据准备
我们这里使用 [WMT'16 EN-DE 数据集](http://www.statmt.org/wmt16/translation-task.html),同时参照论文中的设置使用 [BPE(byte-pair encoding)]()编码的数据,使用这种方式表示的数据能够更好的解决开放词汇(out-of-vocabulary,OOV)的问题。用到的 BPE 数据可以参照[这里](https://github.com/google/seq2seq/blob/master/docs/data.md)进行下载,下载后解压,其中 `train.tok.clean.bpe.32000.en` 和 `train.tok.clean.bpe.32000.de` 为使用 BPE 的训练数据(平行语料,分别对应了英语和德语),`newstest2013.tok.bpe.32000.en` 和 `newstest2013.tok.bpe.32000.de` 等为测试数据,`vocab.bpe.32000` 为相应的词典文件(源语言和目标语言共享该词典文件)。
由于本示例中的数据读取脚本 `reader.py` 使用的样本数据的格式为 `\t` 分隔的的源语言和目标语言句子对, 因此需要将源语言到目标语言的平行语料库文件合并为一个文件,可以执行以下命令进行合并:
```sh
paste -d '\t' train.tok.clean.bpe.32000.en train.tok.clean.bpe.32000.de > train.tok.clean.bpe.32000.en-de
```
此外还需要在词典文件中加上表示序列的开始、序列的结束和未登录词的3个特殊符号 `` 、`` 和 `` 。
对于其他自定义数据,遵循或转换为上述的数据格式即可。如果希望在自定义数据中使用 BPE 编码,可以参照[这里](https://github.com/rsennrich/subword-nmt)进行预处理。
### 模型训练
`train.py` 是模型训练脚本,可以执行以下命令进行模型训练:
```sh
python -u train.py \
--src_vocab_fpath data/vocab.bpe.32000 \
--trg_vocab_fpath data/vocab.bpe.32000 \
--train_file_pattern data/train.tok.clean.bpe.32000.en-de \
--use_token_batch True \
--batch_size 3200 \
--pool_size 200000 \
--sort_type pool \
--special_token '' '' ''
```
上述命令中需要设置源语言词典文件路径(`src_vocab_fpath`)、目标语言词典文件路径(`trg_vocab_fpath`)、训练数据文件(`train_file_pattern`)和 batch (`use_token_batch` 指出数据按照 token 数目或者 sequence 数目组成 batch)等数据相关的参数。有关这些参数更详细的信息可以通过执行以下命令查看:
```sh
python train.py --help
```
更多模型训练相关的参数则在 `config.py` 中的 `ModelHyperParams` 和 `TrainTaskConfig` 内定义,其中默认使用了 Transformer 论文中 base model 的配置,如需调整可以在该脚本中进行修改。另外这些参数同样可在执行训练脚本的命令行中设置,传入的配置会合并并覆盖`config.py`中的配置,如可以通过以下命令来训练 Transformer 论文中的 big model :
```sh
python -u train.py \
--src_vocab_fpath data/vocab.bpe.32000 \
--trg_vocab_fpath data/vocab.bpe.32000 \
--train_file_pattern data/train.tok.clean.bpe.32000.en-de \
--use_token_batch True \
--batch_size 3200 \
--pool_size 200000 \
--sort_type pool \
--special_token '' '' '' \
n_layer 8 \
n_head 16 \
d_model 1024 \
d_inner_hid 4096 \
dropout 0.3
```
有关这些参数更详细信息的还请参考 `config.py` 中的注释说明。
### 模型预测
```sh
sed 's/@@ //g' predict.txt > predict_tok.txt
perl multi_bleu.perl data/newstest2013.tok.de < prdict_tok.txt
```