# Linux GPU/CPU PYTHON 服务化部署功能开发文档
# 目录
- [1. 简介](#1)
- [2. Paddle Serving服务化部署](#2)
- [2.1 准备测试数据](#2.1)
- [2.2 准备环境](#2.2)
- [2.3 准备服务化部署模型](#2.3)
- [2.4 复制部署样例程序](#2.4)
- [2.5 服务端修改](#2.5)
- [2.6 客户端修改](#2.6)
- [2.7 启动服务端模型预测服务](#2.7)
- [2.8 启动客服端](#2.7)
- [3. FAQ](#3)
## 1. 简介
Paddle Serving是飞桨开源的**服务化部署**框架,提供了C++ Serving和Python Pipeline两套框架,C++ Serving框架更倾向于追求极致性能,Python Pipeline框架倾向于二次开发的便捷性。旨在帮助深度学习开发者和企业提供高性能、灵活易用的工业级在线推理服务,助力人工智能落地应用。
更多关于Paddle Serving的介绍,可以参考[Paddle Serving官网repo](https://github.com/PaddlePaddle/Serving)。
本文档主要介绍利用Paddle Serving Pipeline框架实现飞桨模型(以MobilenetV3为例)的服务化部署。
**【注意】**:本项目仅支持Python3.6/3.7/3.8,接下来所有的与Python/Pip相关的操作都需要选择正确的Python版本。
## 2. Paddle Serving服务化部署
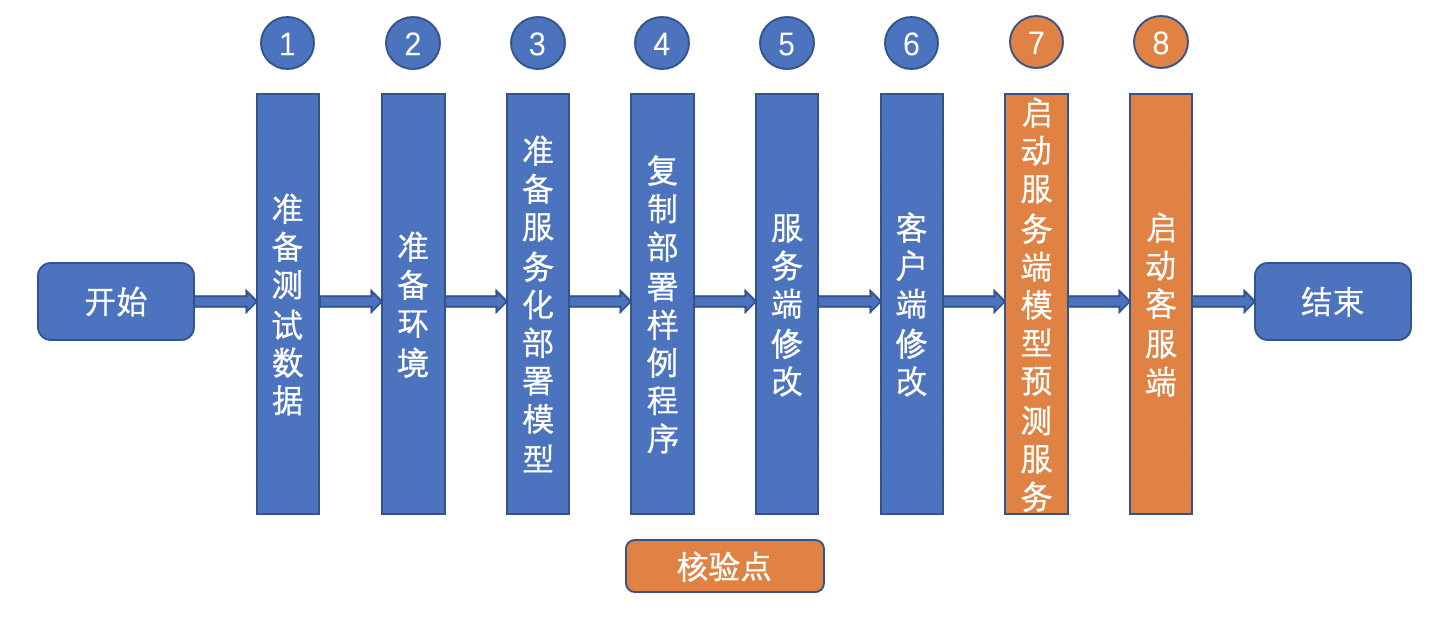
Paddle Serving服务化部署主要包括以下步骤:
其中设置了2个核验点,分别为:
* 启动服务端
* 启动客户端
### 2.1 准备测试数据
为方便快速验证推理预测过程,需要准备一个小数据集(训练集和验证集各8~16张图像即可,压缩后数据大小建议在`20M`以内,确保基础训练推理总时间不超过十分钟),放在`lite_data`文件夹下。
相关文档可以参考[论文复现赛指南3.2章节](../../../docs/lwfx/ArticleReproduction_CV.md),代码可以参考`基于ImageNet准备小数据集的脚本`:[prepare.py](https://github.com/littletomatodonkey/AlexNet-Prod/blob/tipc/pipeline/Step2/prepare.py)。
本教程以`./images/demo.jpg`作为测试用例。
### 2.2 准备环境
**docker**是一个开源的应用容器引擎,可以让应用程序更加方便地被打包和移植。Paddle Serving容器化部署建议在docker中进行Serving服务化部署。本教程在docker环境运行。
**【注意】**:推荐使用docker进行Serving部署。如果您已经准备好了docker环境,那么可以跳过此步骤。
(1)以下安装docker的Paddle Serving环境,CPU/GPU版本二选一即可。
1)docker环境安装(CPU版本)
```bash
# 拉取并进入 Paddle Serving的 CPU Docker
docker pull paddlepaddle/serving:0.7.0-devel
docker run -p 9292:9292 --name test -dit paddlepaddle/serving:0.7.0-devel bash
docker exec -it test bash
````
2)docker环境安装(GPU版本)
```bash
# 拉取并进入 Paddle Serving的GPU Docker
docker pull paddlepaddle/serving:0.7.0-cuda10.2-cudnn7-devel
nvidia-docker run -p 9292:9292 --name test -dit paddlepaddle/serving:0.7.0-cuda10.2-cudnn7-devel bash
nvidia-docker exec -it test bash
```
(2)安装Paddle Serving四个安装包,分别是:paddle-serving-server(CPU/GPU版本二选一), paddle-serving-client, paddle-serving-app和paddlepaddle(CPU/GPU版本二选一)。
```bash
pip3 install paddle-serving-client==0.7.0
#pip3 install paddle-serving-server==0.7.0 # CPU
pip3 install paddle-serving-server-gpu==0.7.0.post102 # GPU with CUDA10.2 + TensorRT6
pip3 install paddle-serving-app==0.7.0
#pip3 install paddlepaddle==2.2.1 # CPU
pip3 install paddlepaddle-gpu==2.2.1
```
您可能需要使用国内镜像源(例如百度源, 在pip命令中添加`-i https://mirror.baidu.com/pypi/simple`)来加速下载。
Paddle Serving Server更多不同运行环境的whl包下载地址,请参考:[下载页面](https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Latest_Packages_CN.md)
PaddlePaddle更多版本请参考[官网](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html)
(3)在docker中下载工程
```bash
git clone https://github.com/PaddlePaddle/models.git
cd models/tutorials/tipc/serving_python
```
### 2.3 准备服务化部署模型
#### 2.3.1 准备MobilenetV3 inference模型
参考[MobilenetV3](../../mobilenetv3_prod/Step6/README.md#2),确保 inference 模型在当前目录下。
#### 2.3.2 准备服务化部署模型
【基本流程】
为了便于模型服务化部署,需要将静态图模型(模型结构文件:\*.pdmodel和模型参数文件:\*.pdiparams)使用paddle_serving_client.convert按如下命令转换为服务化部署模型:
```bash
python -m paddle_serving_client.convert --dirname {静态图模型路径} --model_filename {模型结构文件} --params_filename {模型参数文件} --serving_server {转换后的服务器端模型和配置文件存储路径} --serving_client {转换后的客户端模型和配置文件存储路径}
```
上面命令中 "转换后的服务器端模型和配置文件" 将用于后续服务化部署。其中`paddle_serving_client.convert`命令是`paddle_serving_client` whl包内置的转换函数,无需修改。
【实战】
针对MobileNetV3网络,将inference模型转换为服务化部署模型的示例命令如下,转换完后在本地生成**serving_server**和**serving_client**两个文件夹。本教程后续主要使用serving_server文件夹中的模型。
```bash
python -m paddle_serving_client.convert \
--dirname ./mobilenet_v3_small_infer/ \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--serving_server serving_server \
--serving_client serving_client
```
**【注意】**:0.7.0版本的 PaddleServing 需要和PaddlePaddle 2.2之后的版本搭配进行模型转换。
### 2.4 复制部署样例程序
**【基本流程】**
服务化部署的样例程序的目录地址为:`./template/code`
该目录下面包含3个文件,具体如下:
- web_service.py:用于开发**服务端模型预测**相关程序。由于使用多卡或者多机部署预测服务,设计高效的服务调度策略比较复杂,Paddle Serving将网络预测进行了封装,在这个程序里面开发者只需要关心部署服务引擎的初始化,模型预测的前处理和后处理开发,不用关心模型预测调度问题。
- config.yml:服务端模型预测相关**配置文件**,里面有各参数的详细说明。开发者只需要关注如下配置:http_port(服务的http端口),model_config(服务化部署模型的路径),device_type(计算硬件类型),devices(计算硬件ID)。
- pipeline_http_client.py:用于**客户端**访问服务的程序,开发者需要设置url(服务地址)、logid(日志ID)和测试图像。
- preprocess_ops.py:用户图片前项处理的一些工具类
**【实战】**
如果服务化部署MobileNetV3网络,拷贝上述三个文件到当前目录,以便做进一步修改。
```bash
cp -r ./template/code/* ./
```
### 2.5 服务端修改
服务端修改包括服务端代码修改(即对web_service.py代码进行修改)和服务端配置文件(即对config.yml代码进行修改)修改。
服务端代码修改主要修改:初始化部署引擎、开发数据预处理程序、开发预测结果后处理程序三个模块。
服务端配置文件主要修改:
**【注意】**:后续代码修改,主要修改包含`TIPC`字段的代码模块。
#### 2.5.1 初始化服务端部署配置引擎
**【基本流程】**
针对模型名称,修改web_service.py中类TIPCExampleService、TIPCExampleOp的名称,以及这些类初始化中任务名称name。
**【实战】**
针对MobileNetV3网络
(1)修改web_service.py文件后的代码如下:
```python
from paddle_serving_server.web_service import WebService, Op
class MobileNetV3Op(Op):
def init_op(self):
pass
def preprocess(self, input_dicts, data_id, log_id):
pass
def postprocess(self, input_dicts, fetch_dict, data_id, log_id):
pass
class MobileNetV3Service(WebService):
def get_pipeline_response(self, read_op):
mobilenetv3_op = MobileNetV3Op(name="imagenet", input_ops=[read_op])
return mobilenetv3_op
uci_service = MobileNetV3Service(name="imagenet")
uci_service.prepare_pipeline_config("config.yml")
uci_service.run_service()
```
#### 2.5.2 开发数据预处理程序
**【基本流程】**
web_service.py文件中的TIPCExampleOp类的preprocess函数用于开发数据预处理程序,包含输入、处理流程和输出三部分。
**(1)输入:** 一般开发者使用时,只需要关心input_dicts和log_id两个输入参数。这两个参数与客户端访问服务程序tipc_pipeline_http_client.py中的请求参数相对应,即:
```
data = {"key": ["image"], "value": [image], "logid":logid}
```
其中key和value的数据类型都是列表,并且一一对应。input_dicts是一个字典,它的key和value和data中的key和value是一致的。log_id和data中的logid一致。
**(2)处理流程:** 数据预处理流程和基于Paddle Inference的模型预处理流程相同。
**(3)输出:** 需要返回四个参数,一般开发者使用时只关心第一个返回值,网络输入字典,其余返回值使用默认的即可。
```
{"input": input_imgs}, False, None, ""
```
上述网络输入字典的key可以通过服务化模型配置文件serving_server/serving_server_conf.prototxt中的feed_var字典的name字段获取。
**【实战】**
针对MobileNetV3网络的数据预处理开发,修改web_service.py文件中代码如下:
添加头文件:
```py
import sys
import numpy as np
import base64
from PIL import Image
import io
from preprocess_ops import ResizeImage, CenterCropImage, NormalizeImage, ToCHW, Compose
```
修改MobileNetV3Op中的init_op和preprocess函数相关代码:
```py
class MobileNetV3Op(Op):
def init_op(self):
self.seq = Compose([
ResizeImage(256), CenterCropImage(224), NormalizeImage(), ToCHW()
])
def preprocess(self, input_dicts, data_id, log_id):
(_, input_dict), = input_dicts.items()
batch_size = len(input_dict.keys())
imgs = []
for key in input_dict.keys():
data = base64.b64decode(input_dict[key].encode('utf8'))
byte_stream = io.BytesIO(data)
img = Image.open(byte_stream)
img = img.convert("RGB")
img = self.seq(img)
imgs.append(img[np.newaxis, :].copy())
input_imgs = np.concatenate(imgs, axis=0)
return {"input": input_imgs}, False, None, ""
```
#### 2.5.3 开发预测结果后处理程序
【基本流程】
web_service.py文件中的TIPCExampleOp类的 postprocess 函数用于开发预测结果后处理程序,包含输入、处理流程和输出三部分。
**(1)输入:** 包含四个参数,其中参数input_dicts、log_id和数据预处理函数preprocess中一样,data_id可忽略,fetch_dict 是网络预测输出字典,其中输出的key可以通过服务化模型配置文件serving_server/serving_server_conf.prototxt中的fetch_var字典的name字段获取。
**(2)处理流程:** 数据预处理流程和基于Paddle Inference的预测结果后处理一致。
**(3)输出:** 需要返回三个参数,一般开发者使用时只关心第一个返回值,预测结果字典,其余返回值使用默认的即可。
```
result, None, ""
```
【实战】
针对MobileNet网络的预测结果后处理开发,修改web_service.py文件中MobileNetOp中的postprocess函数相关代码如下:
```py
def postprocess(self, input_dicts, fetch_dict, data_id, log_id):
score_list = fetch_dict["softmax_1.tmp_0"]
result = {"class_id": [], "prob": []}
for score in score_list:
score = score.tolist()
max_score = max(score)
result["class_id"].append(score.index(max_score))
result["prob"].append(max_score)
result["class_id"] = str(result["class_id"])
result["prob"] = str(result["prob"])
return result, None, ""
```
#### 2.5.4 修改服务配置文件config.yml
- http_port:使用默认的端口号18080
- OP名称:第14行修改成imagenet
- model_config:与2.4转换后服务化部署模型文件夹路径一致,这里使用默认配置 "./serving_server"
- device_type:使用默认配置1,基于GPU预测;使用参数0,基于CPU预测。
- devices:使用默认配置"0",0号卡预测
### 2.6 客户端修改
修改pipeline_http_client.py程序,用于访问2.6中的服务端服务。
**【基本流程】**
主要设置客户端代码中的url(服务地址)、logid(日志ID)和测试图像。其中服务地址的url的样式为 "http://127.0.0.1:18080/tipc_example/prediction" ,url的设置需要将url中的tipc_example更新为TIPCExampleService类初始化的name。
**【实战】**
针对MobileNet网络, 修改pipeline_http_client.py程序中的url(服务地址)、logid(日志ID)和测试图像地址,其中url改为:
```
url = "http://127.0.0.1:18080/imagenet/prediction"
img_path = "./images/demo.jpg"
```
### 2.7 启动服务端模型预测服务
**【基本流程】**
当完成服务化部署引擎初始化、数据预处理和预测结果后处理开发,则可以按如下命令启动模型预测服务:
```bash
python web_service.py &
```
**【实战】**
针对MobileNet网络, 启动成功的界面如下:

#### 2.8 启动客户端
**【基本流程】**
当成功启动了模型预测服务,可以启动客户端代码,访问服务。
**【实战】**
客户端访问服务的命令如下:
```bash
python pipeline_http_client.py
```
访问成功的界面如下图:

与基于Paddle Inference的推理结果一致,结果正确。
【注意事项】
如果访问不成功,可能设置了代理影响的,可以用下面命令取消代理设置。
```
unset http_proxy
unset https_proxy
```
## 3. FAQ
如果您在使用该文档完成Paddle Serving服务化部署的过程中遇到问题,可以给在[这里](https://github.com/PaddlePaddle/Serving/issues)提一个ISSUE,我们会高优跟进。