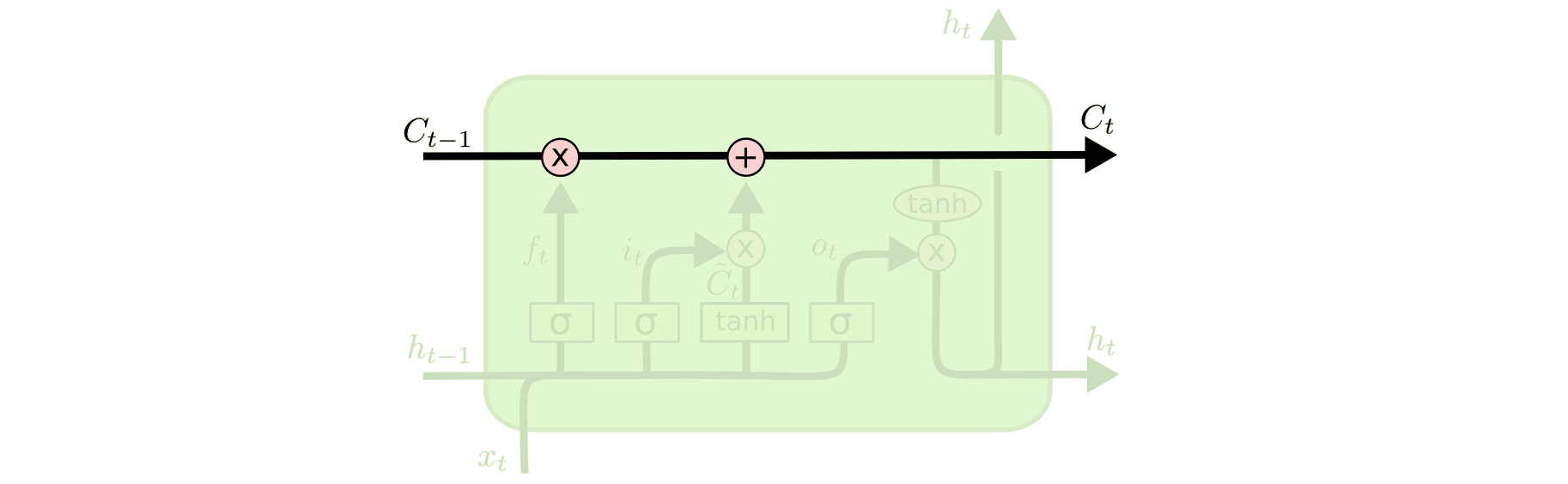
图1. LSTM 中的细胞状态向量作为 “记忆通道” 示意图
#### 动态记忆 2 --- Seq2Seq 中的注意力机制
然而上节所属的单个向量 $h$ 或 $c$ 的信息带宽有限。在序列到序列生成模型中,这样的带宽瓶颈更表现在信息从编码器(Encoder)转移至解码器(Decoder)的过程中:仅仅依赖一个有限长度的状态向量来编码整个变长的源语句,有着较大的潜在信息丢失。
\[[3](#参考文献)\] 提出了注意力机制(Attention Mechanism),以克服上述困难。在解码时,解码器不再仅仅依赖来自编码器的唯一的句级编码向量的信息,而是依赖一个向量组的记忆信息:向量组中的每个向量为编码器的各字符(Token)的编码向量(例如 $h_t$)。通过一组可学习的注意强度(Attention Weights) 来动态分配注意力资源,以线性加权方式读取信息,用于序列的不同时间步的符号生成(可参考 PaddlePaddle Book [机器翻译](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation)一章)。这种注意强度的分布,可看成基于内容的寻址(请参考神经图灵机 \[[1](#参考文献)\] 中的寻址描述),即在源语句的不同位置根据其内容决定不同的读取强度,起到一种和源语句 “软对齐(Soft Alignment)” 的作用。
相比上节的单个状态向量,这里的 “向量组” 蕴含着更多更精准的信息,例如它可以被认为是一个无界的外部记忆模块(Unbounded External Memory),有效拓宽记忆信息带宽。“无界” 指的是向量组的向量个数非固定,而是随着源语句的字符数的变化而变化,数量不受限。在源语句的编码完成时,该外部存储即被初始化为各字符的状态向量,而在其后的整个解码过程中被读取使用。
#### 动态记忆 3 --- 神经图灵机
图灵机(Turing Machines)或冯诺依曼体系(Von Neumann Architecture),是计算机体系结构的雏形。运算器(如代数计算)、控制器(如逻辑分支控制)和存储器三者一体,共同构成了当代计算机的核心运行机制。神经图灵机(Neural Turing Machines)\[[1](#参考文献)\] 试图利用神经网络模拟可微分(即可通过梯度下降来学习)的图灵机,以实现更复杂的智能。而一般的机器学习模型,大部分忽略了显式的动态存储。神经图灵机正是要弥补这样的潜在缺陷。


