{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 1.ERNIE-Layout Introduction\n",
"With the digital transformation of many industries, the structural analysis and content extraction of electronic documents have become a hot research topic. Electronic documents include scanned image documents and computer-generated digital documents, involving documents, industry reports, contracts, employment agreements, invoices, resumes and other types. The intelligent document understanding task aims to understand documents with various formats, layouts and contents, including document classification, document information extraction, document question answering and other tasks. Different from plain text documents, documents contain tables, pictures and other contents, and contain rich visual information. Because the document is rich in content, complex in layout, diverse in font style, and noisy in data, the task of document understanding is extremely challenging. With the great success of pre training language models such as ERNIE in the NLP field, people began to focus on large-scale pre training in the field of document understanding. Baidu put forward the cross modal document understanding model ERNIE-Layout, which is the first time to integrate the layout knowledge enhancement technology into the cross modal document pre training, refreshing the world's best results in four document understanding tasks, and topping the DocVQA list. At the same time, ERNIE Layout has been integrated into Baidu's intelligent document analysis platform TextMind to help enterprises upgrade digitally.\n",
"\n",
"\n",
"ERNIE-Layout takes the Wenxin text big model ERNIE as the base, integrates text, image, layout and other information for cross modal joint modeling, innovatively introduces layout knowledge enhancement, proposes self-monitoring pre training tasks such as reading order prediction, fine grain image text matching, upgrades spatial decoupling attention mechanism, and greatly improves the effect on each data set. Related work [ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding](https://arxiv.org/abs/2210.06155) has been included in the EMNLP 2022 Findings Conference. Considering that document intelligence is widely commercially available in multiple languages, it relies on PaddleNLP to open source the strongest multilingual cross modal document pre training model ERNIE Layout in the industry.\n",
"ERNIE-Layout is a large cross modal model officially produced by the Flying Slurry. For more details about PaddleNLP, please visit for details. \n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2.Model Effect and Application Scenario\n",
"ERNIE-Layout can be used to process but not limited to tasks such as document classification, information extraction, document Q&A with layout data (documents, pictures, etc.). Application scenarios include but not limited to invoice extraction Q&A, poster extraction Q&A, web page extraction Q&A, table extraction Q&A, test paper extraction Q&A, English bill multilingual (Chinese, English, Japanese, Thai, Spanish, Russian) extraction Q&A Chinese bills in multiple languages (simplified, traditional, English, Japanese, French). Taking document information extraction and document visual Q&A as examples, the effect of using ERNIE-Layout model is shown below.\n",
"## 2.1Document Information Extraction Task:\n",
"### 2.1.1Dataset:\n",
"Data sets include FUNSD, XFUND-ZH, etc. FUNSD is an English data set for form understanding on noisy scanned documents. The data set contains 199 real, fully annotated and scanned forms. Documents are noisy, and the appearance of various forms varies greatly, so understanding forms is a challenging task. The dataset can be used for a variety of tasks, including text detection, optical character recognition, spatial layout analysis, and entity tagging/linking. XFUND is a multilingual form understanding benchmark dataset, including manually labeled key value pair forms in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese). XFUND-ZH is the Chinese version of XFUND.\n",
"### 2.1.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on FUNSD is:\n",
"\n",
"\n",
"\n",
"## 2.2Document Visual Question And Answer Task:\n",
"### 2.2.1Dataset:\n",
"The data set is DocVQA-ZH, and DocVQA-ZH has stopped submitting the list. Therefore, we will re divide the original training set to evaluate the model effect. After division, the training set contains 4187 pictures, the verification set contains 500 pictures, and the test set contains 500 pictures.\n",
"### 2.2.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on DocVQA-ZH is:\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3.How To Use The Model\n",
"## 3.1Model Reasoning\n",
"We have integrated the ERNIE-Layout DocPrompt Engine on the [huggingface page](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout), which can be experienced with one click.\n",
"\n",
"**Taskflow**\n",
"\n",
"Of course, you can also use Taskflow for reasoning. Through `paddlenlp.Taskflow` calls DocPrompt with three lines of code, and has the ability to extract questions and answers from multilingual documents. Some application scenarios are shown below:\n",
"\n",
"* Input Format\n",
"\n",
"```python\n",
"[\n",
" {\"doc\": \"./invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]},\n",
" {\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}\n",
"]\n",
"```\n",
"\n",
"By default, PaddleOCR is used for OCR identification, and users can use the `word_ boxes` Pass in your own OCR results in the format `List[str, List[float, float, float, float]]`.\n",
"\n",
"```python \n",
"[\n",
" {\"doc\": doc_path, \"prompt\": prompt, \"word_boxes\": word_boxes}\n",
"]\n",
"```\n",
"\n",
"* Support single and batch forecasting\n",
"\n",
" * Support local image path input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}]))\n",
" [{'prompt': '五百丁本次想要担任的是什么职位?',\n",
" 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},\n",
" {'prompt': '五百丁是在哪里上的大学?',\n",
" 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},\n",
" {'prompt': '大学学的是什么专业?',\n",
" 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]\n",
" ```\n",
"\n",
" * http image link input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
"\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))\n",
" [{'prompt': '发票号码是多少?',\n",
" 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},\n",
" {'prompt': '校验码是多少?',\n",
" 'result': [{'end': 233,\n",
" 'prob': 1.0,\n",
" 'start': 231,\n",
" 'value': '01107 555427109891646'}]}]\n",
" ```\n",
"\n",
"* Description of configurable parameters\n",
" * `batch_size`:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
" * `lang`:Select the language of PaddleOCR. `ch` can be used in Chinese English mixed pictures. `en` is better in English pictures. The default is `ch`.\n",
" * `topn`: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
"\n",
"## 3.2Model Fine-tuning And Deployment\n",
"ERNIE-Layout is a cross modal general document pre training model that relies on Wenxin ERNIE, based on layout knowledge enhancement technology, and integrates text, image, layout and other information for joint modeling. It can show excellent cross modal semantic alignment and layout understanding ability on tasks including but not limited to document information extraction, document visual question answering, document image classification and so on.\n",
"\n",
"For details about the fine-tuning and deployment of the above tasks using ERNIE-Layout, please refer to: [ERNIE-Layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
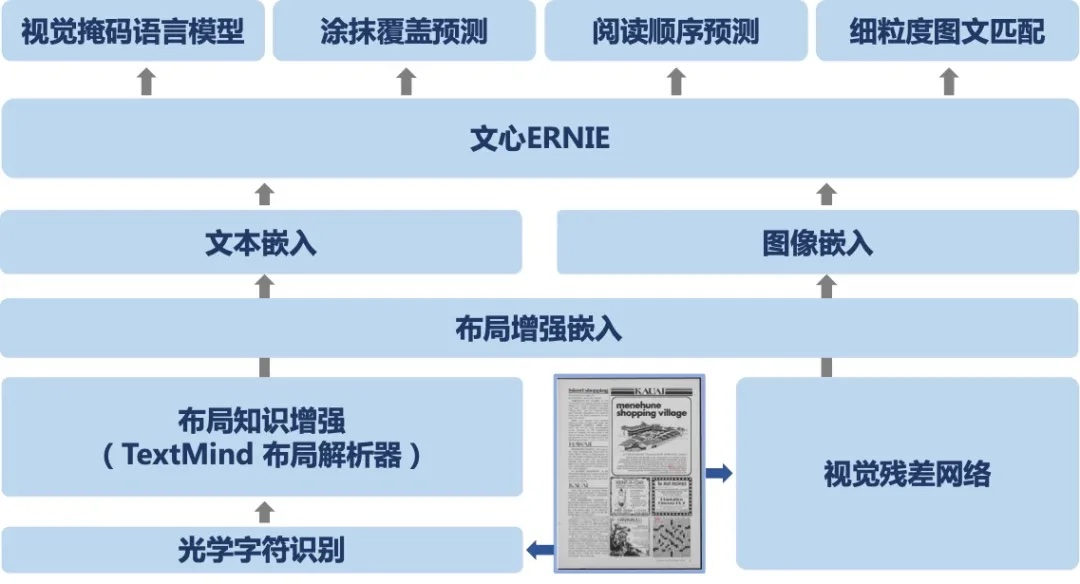
"# 4.Model Principle\n",
"* Layout knowledge enhancement technology\n",
"\n",
"* Fusion of text, image, layout and other information for joint modeling\n",
"\n",
"* Reading order prediction+fine-grained image text matching: two self-monitoring pre training tasks\n",
"\n",
"\n",
"For document understanding, the text reading order in the document is very important. At present, most mainstream models based on OCR (Optical Character Recognition) technology follow the principle of \"from left to right, from top to bottom\". However, for the complex layout of the document with a mixture of columns, text, graphics and tables, the reading order obtained according to the OCR results is wrong in most cases, As a result, the model cannot accurately understand the content of the document.\n",
"\n",
"Humans usually read in hierarchies and blocks according to the document structure and layout. Inspired by this, Baidu researchers proposed an innovative idea of layout knowledge enhancement to correct the reading order in the document pre training model. The industry-leading document parsing tool (Document Parser) on the TextMind platform can accurately identify the block information in the document, produce the correct document reading order, and integrate the reading order signal into the model training, thus enhancing the effective use of layout information and improving the model's understanding of complex documents.\n",
"\n",
"Based on the layout knowledge enhancement technology, and relying on Wenxin ERNIE, Baidu researchers proposed a cross modal general document pre training model ERNIE-Layout, which integrates text, image, layout and other information for joint modeling. As shown in the figure below, ERNIE-Layout innovatively proposed two self-monitoring pre training tasks: reading order prediction and fine-grained image text matching, which effectively improved the model's cross modal semantic alignment ability and layout understanding ability in document tasks.\n",
"\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 5.Matters Needing Attention\n",
"## 5.1Parameter Configuration\n",
"* batch_size:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
"\n",
"* lang:Choose the language of PaddleOCR. ch can be used in Chinese English mixed pictures. en has better effect on English pictures. The default is ch.\n",
"\n",
"* topn: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
"\n",
"## 5.2Tips\n",
"\n",
"* Prompt design: In DocPrompt, Prompt can be a statement (for example, the Key in the document key value pair) or a question. Because it is an open domain extracted question and answer, DocPrompt has no special restrictions on the design of Prompt, as long as it conforms to natural language semantics. If you are not satisfied with the current extraction results, you can try some different Prompts.\n",
"\n",
"* Languages supported:Support Chinese and English image input of local path or HTTP link. Prompt supports multiple languages. Refer to the examples of different scenarios above."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 6.Relevant Papers And Citations\n",
"#### ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding\n",
"```\n",
"@misc{https://doi.org/10.48550/arxiv.2210.06155,\n",
" doi = {10.48550/ARXIV.2210.06155},\n",
" \n",
" url = {https://arxiv.org/abs/2210.06155},\n",
" \n",
" author = {Peng, Qiming and Pan, Yinxu and Wang, Wenjin and Luo, Bin and Zhang, Zhenyu and Huang, Zhengjie and Hu, Teng and Yin, Weichong and Chen, Yongfeng and Zhang, Yin and Feng, Shikun and Sun, Yu and Tian, Hao and Wu, Hua and Wang, Haifeng},\n",
" \n",
" keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},\n",
" \n",
" title = {ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding},\n",
" \n",
" publisher = {arXiv},\n",
" \n",
" year = {2022},\n",
" \n",
" copyright = {arXiv.org perpetual, non-exclusive license}\n",
"}\n",
"```\n",
"#### ICDAR 2019 Competition on Scene Text Visual Question Answering\n",
"```\n",
"@misc{https://doi.org/10.48550/arxiv.1907.00490,\n",
" doi = {10.48550/ARXIV.1907.00490},\n",
" \n",
" url = {https://arxiv.org/abs/1907.00490},\n",
" \n",
" author = {Biten, Ali Furkan and Tito, Rubèn and Mafla, Andres and Gomez, Lluis and Rusiñol, Marçal and Mathew, Minesh and Jawahar, C. V. and Valveny, Ernest and Karatzas, Dimosthenis},\n",
" \n",
" keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},\n",
" \n",
" title = {ICDAR 2019 Competition on Scene Text Visual Question Answering},\n",
" \n",
" publisher = {arXiv},\n",
" \n",
" year = {2019},\n",
" \n",
" copyright = {arXiv.org perpetual, non-exclusive license}\n",
"}\n",
"```"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.8.5 ('base')",
"language": "python",
"name": "python3"
},
"language_info": {
"name": "python",
"version": "3.8.5"
},
"orig_nbformat": 4,
"vscode": {
"interpreter": {
"hash": "a5f44439766e47113308a61c45e3ba0ce79cefad900abb614d22e5ec5db7fbe0"
}
}
},
"nbformat": 4,
"nbformat_minor": 2
}
 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2.Model Effect and Application Scenario\n",
"ERNIE-Layout can be used to process but not limited to tasks such as document classification, information extraction, document Q&A with layout data (documents, pictures, etc.). Application scenarios include but not limited to invoice extraction Q&A, poster extraction Q&A, web page extraction Q&A, table extraction Q&A, test paper extraction Q&A, English bill multilingual (Chinese, English, Japanese, Thai, Spanish, Russian) extraction Q&A Chinese bills in multiple languages (simplified, traditional, English, Japanese, French). Taking document information extraction and document visual Q&A as examples, the effect of using ERNIE-Layout model is shown below.\n",
"## 2.1Document Information Extraction Task:\n",
"### 2.1.1Dataset:\n",
"Data sets include FUNSD, XFUND-ZH, etc. FUNSD is an English data set for form understanding on noisy scanned documents. The data set contains 199 real, fully annotated and scanned forms. Documents are noisy, and the appearance of various forms varies greatly, so understanding forms is a challenging task. The dataset can be used for a variety of tasks, including text detection, optical character recognition, spatial layout analysis, and entity tagging/linking. XFUND is a multilingual form understanding benchmark dataset, including manually labeled key value pair forms in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese). XFUND-ZH is the Chinese version of XFUND.\n",
"### 2.1.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on FUNSD is:\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2.Model Effect and Application Scenario\n",
"ERNIE-Layout can be used to process but not limited to tasks such as document classification, information extraction, document Q&A with layout data (documents, pictures, etc.). Application scenarios include but not limited to invoice extraction Q&A, poster extraction Q&A, web page extraction Q&A, table extraction Q&A, test paper extraction Q&A, English bill multilingual (Chinese, English, Japanese, Thai, Spanish, Russian) extraction Q&A Chinese bills in multiple languages (simplified, traditional, English, Japanese, French). Taking document information extraction and document visual Q&A as examples, the effect of using ERNIE-Layout model is shown below.\n",
"## 2.1Document Information Extraction Task:\n",
"### 2.1.1Dataset:\n",
"Data sets include FUNSD, XFUND-ZH, etc. FUNSD is an English data set for form understanding on noisy scanned documents. The data set contains 199 real, fully annotated and scanned forms. Documents are noisy, and the appearance of various forms varies greatly, so understanding forms is a challenging task. The dataset can be used for a variety of tasks, including text detection, optical character recognition, spatial layout analysis, and entity tagging/linking. XFUND is a multilingual form understanding benchmark dataset, including manually labeled key value pair forms in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese). XFUND-ZH is the Chinese version of XFUND.\n",
"### 2.1.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on FUNSD is:\n",
"\n",
" \n",
"\n",
"## 2.2Document Visual Question And Answer Task:\n",
"### 2.2.1Dataset:\n",
"The data set is DocVQA-ZH, and DocVQA-ZH has stopped submitting the list. Therefore, we will re divide the original training set to evaluate the model effect. After division, the training set contains 4187 pictures, the verification set contains 500 pictures, and the test set contains 500 pictures.\n",
"### 2.2.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on DocVQA-ZH is:\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3.How To Use The Model\n",
"## 3.1Model Reasoning\n",
"We have integrated the ERNIE-Layout DocPrompt Engine on the [huggingface page](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout), which can be experienced with one click.\n",
"\n",
"**Taskflow**\n",
"\n",
"Of course, you can also use Taskflow for reasoning. Through `paddlenlp.Taskflow` calls DocPrompt with three lines of code, and has the ability to extract questions and answers from multilingual documents. Some application scenarios are shown below:\n",
"\n",
"* Input Format\n",
"\n",
"```python\n",
"[\n",
" {\"doc\": \"./invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]},\n",
" {\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}\n",
"]\n",
"```\n",
"\n",
"By default, PaddleOCR is used for OCR identification, and users can use the `word_ boxes` Pass in your own OCR results in the format `List[str, List[float, float, float, float]]`.\n",
"\n",
"```python \n",
"[\n",
" {\"doc\": doc_path, \"prompt\": prompt, \"word_boxes\": word_boxes}\n",
"]\n",
"```\n",
"\n",
"* Support single and batch forecasting\n",
"\n",
" * Support local image path input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}]))\n",
" [{'prompt': '五百丁本次想要担任的是什么职位?',\n",
" 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},\n",
" {'prompt': '五百丁是在哪里上的大学?',\n",
" 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},\n",
" {'prompt': '大学学的是什么专业?',\n",
" 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]\n",
" ```\n",
"\n",
" * http image link input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
"\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))\n",
" [{'prompt': '发票号码是多少?',\n",
" 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},\n",
" {'prompt': '校验码是多少?',\n",
" 'result': [{'end': 233,\n",
" 'prob': 1.0,\n",
" 'start': 231,\n",
" 'value': '01107 555427109891646'}]}]\n",
" ```\n",
"\n",
"* Description of configurable parameters\n",
" * `batch_size`:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
" * `lang`:Select the language of PaddleOCR. `ch` can be used in Chinese English mixed pictures. `en` is better in English pictures. The default is `ch`.\n",
" * `topn`: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
"\n",
"## 3.2Model Fine-tuning And Deployment\n",
"ERNIE-Layout is a cross modal general document pre training model that relies on Wenxin ERNIE, based on layout knowledge enhancement technology, and integrates text, image, layout and other information for joint modeling. It can show excellent cross modal semantic alignment and layout understanding ability on tasks including but not limited to document information extraction, document visual question answering, document image classification and so on.\n",
"\n",
"For details about the fine-tuning and deployment of the above tasks using ERNIE-Layout, please refer to: [ERNIE-Layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4.Model Principle\n",
"* Layout knowledge enhancement technology\n",
"\n",
"* Fusion of text, image, layout and other information for joint modeling\n",
"\n",
"* Reading order prediction+fine-grained image text matching: two self-monitoring pre training tasks\n",
"\n",
"
\n",
"\n",
"## 2.2Document Visual Question And Answer Task:\n",
"### 2.2.1Dataset:\n",
"The data set is DocVQA-ZH, and DocVQA-ZH has stopped submitting the list. Therefore, we will re divide the original training set to evaluate the model effect. After division, the training set contains 4187 pictures, the verification set contains 500 pictures, and the test set contains 500 pictures.\n",
"### 2.2.2Quick View Of Model Effect:\n",
"The model effect of ERNIE-Layout on DocVQA-ZH is:\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3.How To Use The Model\n",
"## 3.1Model Reasoning\n",
"We have integrated the ERNIE-Layout DocPrompt Engine on the [huggingface page](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout), which can be experienced with one click.\n",
"\n",
"**Taskflow**\n",
"\n",
"Of course, you can also use Taskflow for reasoning. Through `paddlenlp.Taskflow` calls DocPrompt with three lines of code, and has the ability to extract questions and answers from multilingual documents. Some application scenarios are shown below:\n",
"\n",
"* Input Format\n",
"\n",
"```python\n",
"[\n",
" {\"doc\": \"./invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]},\n",
" {\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}\n",
"]\n",
"```\n",
"\n",
"By default, PaddleOCR is used for OCR identification, and users can use the `word_ boxes` Pass in your own OCR results in the format `List[str, List[float, float, float, float]]`.\n",
"\n",
"```python \n",
"[\n",
" {\"doc\": doc_path, \"prompt\": prompt, \"word_boxes\": word_boxes}\n",
"]\n",
"```\n",
"\n",
"* Support single and batch forecasting\n",
"\n",
" * Support local image path input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}]))\n",
" [{'prompt': '五百丁本次想要担任的是什么职位?',\n",
" 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},\n",
" {'prompt': '五百丁是在哪里上的大学?',\n",
" 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},\n",
" {'prompt': '大学学的是什么专业?',\n",
" 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]\n",
" ```\n",
"\n",
" * http image link input\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
"\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))\n",
" [{'prompt': '发票号码是多少?',\n",
" 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},\n",
" {'prompt': '校验码是多少?',\n",
" 'result': [{'end': 233,\n",
" 'prob': 1.0,\n",
" 'start': 231,\n",
" 'value': '01107 555427109891646'}]}]\n",
" ```\n",
"\n",
"* Description of configurable parameters\n",
" * `batch_size`:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
" * `lang`:Select the language of PaddleOCR. `ch` can be used in Chinese English mixed pictures. `en` is better in English pictures. The default is `ch`.\n",
" * `topn`: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
"\n",
"## 3.2Model Fine-tuning And Deployment\n",
"ERNIE-Layout is a cross modal general document pre training model that relies on Wenxin ERNIE, based on layout knowledge enhancement technology, and integrates text, image, layout and other information for joint modeling. It can show excellent cross modal semantic alignment and layout understanding ability on tasks including but not limited to document information extraction, document visual question answering, document image classification and so on.\n",
"\n",
"For details about the fine-tuning and deployment of the above tasks using ERNIE-Layout, please refer to: [ERNIE-Layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4.Model Principle\n",
"* Layout knowledge enhancement technology\n",
"\n",
"* Fusion of text, image, layout and other information for joint modeling\n",
"\n",
"* Reading order prediction+fine-grained image text matching: two self-monitoring pre training tasks\n",
"\n",
"