{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 1.ERNIE-Layout模型简介\n",
"随着众多行业的数字化转型,电子文档的结构化分析和内容提取成为一项热门的研究课题。电子文档包括扫描图像文件和计算机生成的数字文档两大类,涉及单据、行业报告、合同、雇佣协议、发票、简历等多种类型。智能文档理解任务以理解格式、布局、内容多种多样的文档为目标,包括了文档分类、文档信息抽取、文档问答等任务。与纯文本文档不同的是,文档包含表格、图片等多种内容,包含丰富的视觉信息。因为文档内容丰富、布局复杂、字体样式多样、数据存在噪声,文档理解任务极具挑战性。随着ERNIE等预训练语言模型在NLP领域取得了巨大的成功,人们开始关注在文档理解领域进行大规模预训练。百度提出跨模态文档理解模型 ERNIE-Layout,首次将布局知识增强技术融入跨模态文档预训练,在4项文档理解任务上刷新世界最好效果,登顶 DocVQA 榜首。同时,ERNIE-Layout已集成至百度智能文档分析平台 TextMind,助力企业数字化升级。\n",
"\n",
"\n",
"ERNIE-Layout以文心文本大模型ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解偶注意力机制,在各数据集上效果取得大幅度提升,相关工作[ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding](https://arxiv.org/abs/2210.06155)已被EMNLP 2022 Findings会议收录。考虑到文档智能在多语种上商用广泛,依托PaddleNLP对外开源业界最强的多语言跨模态文档预训练模型ERNIE-Layout。\n",
"ERNIE-Layout是由飞浆官方出品的跨模态大模型,更多有关PaddleNLP的详情请访问了解详情。
\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2.模型效果及应用场景\n",
"ERNIE-Layout可以用于处理但不限于带布局数据(文档、图片等)的文档分类、信息抽取、文档问答等任务,应用场景包括但不限于发票抽取问答、海报抽取问答、网页抽取问答、表格抽取问答、试卷抽取问答、英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答、中文票据多语种(中简、中繁、英、日、法语)抽取问答等。以文档信息抽取和文档视觉问答为例,使用ERNIE-Layout模型效果速览如下。\n",
"## 2.1文档信息抽取任务:\n",
"### 2.1.1数据集:\n",
"数据集有FUNSD、XFUND-ZH等。其中FUNSD是在噪声很多的扫描文档上进行表单理解的英文数据集,数据集包含199个真实的、完全注释的、扫描的表单。文档有很多噪声,而且各种表单的外观差异很大,因此理解表单是一项很有挑战性的任务。该数据集可用于各种任务,包括文本检测、光学字符识别、空间布局分析和实体标记/链接。XFUND是一个多语言表单理解基准数据集,包括7种语言(汉语、日语、西班牙语、法语、意大利语、德语、葡萄牙语)的人为标注键值对表单,XFUND-ZH为中文版本XFUND。\n",
"### 2.1.2模型效果速览:\n",
"ERNIE-Layout在FUNSD上的模型效果为:\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2.模型效果及应用场景\n",
"ERNIE-Layout可以用于处理但不限于带布局数据(文档、图片等)的文档分类、信息抽取、文档问答等任务,应用场景包括但不限于发票抽取问答、海报抽取问答、网页抽取问答、表格抽取问答、试卷抽取问答、英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答、中文票据多语种(中简、中繁、英、日、法语)抽取问答等。以文档信息抽取和文档视觉问答为例,使用ERNIE-Layout模型效果速览如下。\n",
"## 2.1文档信息抽取任务:\n",
"### 2.1.1数据集:\n",
"数据集有FUNSD、XFUND-ZH等。其中FUNSD是在噪声很多的扫描文档上进行表单理解的英文数据集,数据集包含199个真实的、完全注释的、扫描的表单。文档有很多噪声,而且各种表单的外观差异很大,因此理解表单是一项很有挑战性的任务。该数据集可用于各种任务,包括文本检测、光学字符识别、空间布局分析和实体标记/链接。XFUND是一个多语言表单理解基准数据集,包括7种语言(汉语、日语、西班牙语、法语、意大利语、德语、葡萄牙语)的人为标注键值对表单,XFUND-ZH为中文版本XFUND。\n",
"### 2.1.2模型效果速览:\n",
"ERNIE-Layout在FUNSD上的模型效果为:\n",
"\n",
" \n",
"\n",
"## 2.2文档视觉问答任务:\n",
"### 2.2.1数据集:\n",
"数据集为DocVQA-ZH,DocVQA-ZH已停止榜单提交,因此我们将原始训练集进行重新划分以评估模型效果,划分后训练集包含4,187张图片,验证集包含500张图片,测试集包含500张图片。\n",
"### 2.2.2模型效果速览:\n",
"ERNIE-Layout在DocVQA-ZH上的模型效果为:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3.模型如何使用\n",
"## 3.1模型推理\n",
"我们已经在[huggingface网页](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout)集成了ERNIE-Layout DocPrompt Engine,可一键进行体验。 \n",
"
\n",
"\n",
"## 2.2文档视觉问答任务:\n",
"### 2.2.1数据集:\n",
"数据集为DocVQA-ZH,DocVQA-ZH已停止榜单提交,因此我们将原始训练集进行重新划分以评估模型效果,划分后训练集包含4,187张图片,验证集包含500张图片,测试集包含500张图片。\n",
"### 2.2.2模型效果速览:\n",
"ERNIE-Layout在DocVQA-ZH上的模型效果为:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3.模型如何使用\n",
"## 3.1模型推理\n",
"我们已经在[huggingface网页](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout)集成了ERNIE-Layout DocPrompt Engine,可一键进行体验。 \n",
"
\n",
"**Taskflow**\n",
"
\n",
"当然,也可以使用Taskflow进行推理。通过`paddlenlp.Taskflow`三行代码调用DocPrompt功能,具备多语言文档抽取问答能力,部分应用场景展示如下:\n",
"\n",
"* 输入格式\n",
"\n",
"```python\n",
"[\n",
" {\"doc\": \"./invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]},\n",
" {\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}\n",
"]\n",
"```\n",
"\n",
"默认使用PaddleOCR进行OCR识别,同时支持用户通过`word_boxes`传入自己的OCR结果,格式为`List[str, List[float, float, float, float]]`。\n",
"\n",
"```python \n",
"[\n",
" {\"doc\": doc_path, \"prompt\": prompt, \"word_boxes\": word_boxes}\n",
"]\n",
"```\n",
"\n",
"* 支持单条、批量预测\n",
"\n",
" * 支持本地图片路径输入\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}]))\n",
" [{'prompt': '五百丁本次想要担任的是什么职位?',\n",
" 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},\n",
" {'prompt': '五百丁是在哪里上的大学?',\n",
" 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},\n",
" {'prompt': '大学学的是什么专业?',\n",
" 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]\n",
" ```\n",
"\n",
" * http图片链接输入\n",
"\n",
" \n",
"\n",
" ```python \n",
" from pprint import pprint\n",
" from paddlenlp import Taskflow\n",
"\n",
" docprompt = Taskflow(\"document_intelligence\")\n",
" pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))\n",
" [{'prompt': '发票号码是多少?',\n",
" 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},\n",
" {'prompt': '校验码是多少?',\n",
" 'result': [{'end': 233,\n",
" 'prob': 1.0,\n",
" 'start': 231,\n",
" 'value': '01107 555427109891646'}]}]\n",
" ```\n",
"\n",
"* 可配置参数说明\n",
" * `batch_size`:批处理大小,请结合机器情况进行调整,默认为1。\n",
" * `lang`:选择PaddleOCR的语言,`ch`可在中英混合的图片中使用,`en`在英文图片上的效果更好,默认为`ch`。\n",
" * `topn`: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。\n",
"\n",
"## 3.2模型微调与部署\n",
"ERNIE-Layout是依托文心ERNIE,基于布局知识增强技术,融合文本、图像、布局等信息进行联合建模的跨模态通用文档预训练模型,能够在包括但不限于文档信息抽取、文档视觉问答、文档图像分类等任务上表现出优秀的跨模态语义对齐能力和布局理解能力。\n",
"\n",
"有关使用ERNIE-Layout进行上述任务的微调与部署详情请参考:[ERNIE-Layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 4.模型原理\n",
"* 布局知识增强技术
\n",
"* 融合文本、图像、布局等信息进行联合建模
\n",
"* 阅读顺序预测 + 细粒度图文匹配两个自监督预训练任务
\n",
"\n",
"\n",
"对文档理解来说,文档中的文字阅读顺序至关重要,目前主流的基于 OCR(Optical Character Recognition,文字识别)技术的模型大多遵循「从左到右、从上到下」的原则,然而对于文档中分栏、文本图片表格混杂的复杂布局,根据 OCR 结果获取的阅读顺序多数情况下都是错误的,从而导致模型无法准确地进行文档内容的理解。\n",
"\n",
"而人类通常会根据文档结构和布局进行层次化分块阅读,受此启发,百度研究者提出在文档预训模型中对阅读顺序进行校正的布局知识增强创新思路。TextMind 平台上业界领先的文档解析工具(Document Parser)能够准确识别文档中的分块信息,产出正确的文档阅读顺序,将阅读顺序信号融合到模型的训练中,从而增强对布局信息的有效利用,提升模型对于复杂文档的理解能力。\n",
"\n",
"基于布局知识增强技术,同时依托文心 ERNIE,百度研究者提出了融合文本、图像、布局等信息进行联合建模的跨模态通用文档预训练模型 ERNIE-Layout。如下图所示,ERNIE-Layout 创新性地提出了阅读顺序预测和细粒度图文匹配两个自监督预训练任务,有效提升模型在文档任务上跨模态语义对齐能力和布局理解能力。\n",
"\n",
"\n",
"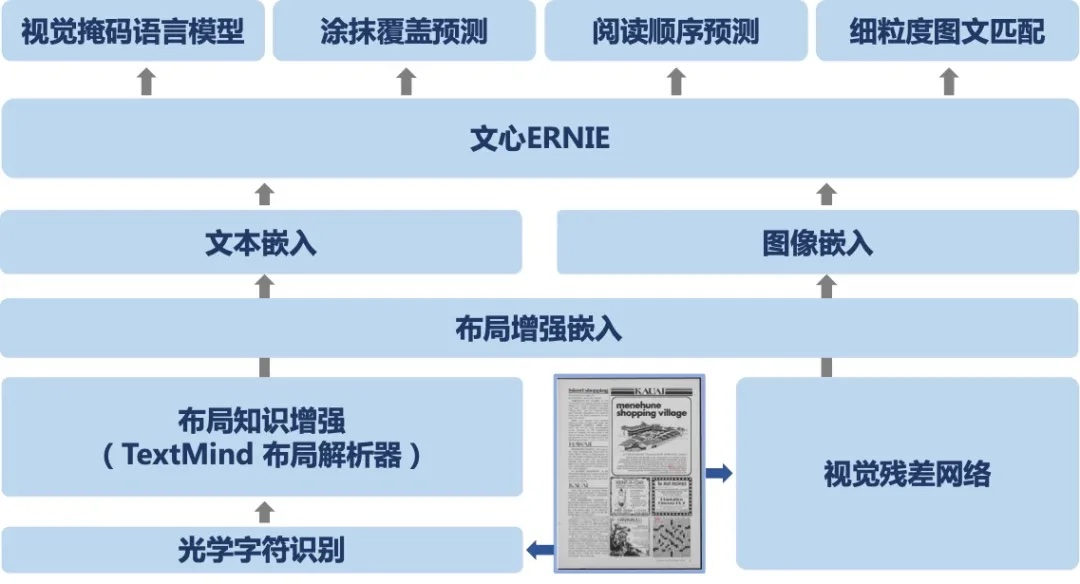\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 5.注意事项\n",
"## 5.1参数配置\n",
"* batch_size:批处理大小,请结合机器情况进行调整,默认为1。\n",
"\n",
"* lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。\n",
"\n",
"* topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。\n",
"## 5.2使用技巧\n",
"\n",
"* Prompt设计:在DocPrompt中,Prompt可以是陈述句(例如,文档键值对中的Key),也可以是疑问句。因为是开放域的抽取问答,DocPrompt对Prompt的设计没有特殊限制,只要符合自然语言语义即可。如果对当前的抽取结果不满意,可以多尝试一些不同的Prompt。 \n",
"\n",
"* 支持的语言:支持本地路径或者HTTP链接的中英文图片输入,Prompt支持多种不同语言,参考以上不同场景的例子。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 6.相关论文以及引用信息\n",
"#### ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding\n",
"```\n",
"@misc{https://doi.org/10.48550/arxiv.2210.06155,\n",
" doi = {10.48550/ARXIV.2210.06155},\n",
" \n",
" url = {https://arxiv.org/abs/2210.06155},\n",
" \n",
" author = {Peng, Qiming and Pan, Yinxu and Wang, Wenjin and Luo, Bin and Zhang, Zhenyu and Huang, Zhengjie and Hu, Teng and Yin, Weichong and Chen, Yongfeng and Zhang, Yin and Feng, Shikun and Sun, Yu and Tian, Hao and Wu, Hua and Wang, Haifeng},\n",
" \n",
" keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},\n",
" \n",
" title = {ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding},\n",
" \n",
" publisher = {arXiv},\n",
" \n",
" year = {2022},\n",
" \n",
" copyright = {arXiv.org perpetual, non-exclusive license}\n",
"}\n",
"```\n",
"#### ICDAR 2019 Competition on Scene Text Visual Question Answering\n",
"```\n",
"@misc{https://doi.org/10.48550/arxiv.1907.00490,\n",
" doi = {10.48550/ARXIV.1907.00490},\n",
" \n",
" url = {https://arxiv.org/abs/1907.00490},\n",
" \n",
" author = {Biten, Ali Furkan and Tito, Rubèn and Mafla, Andres and Gomez, Lluis and Rusiñol, Marçal and Mathew, Minesh and Jawahar, C. V. and Valveny, Ernest and Karatzas, Dimosthenis},\n",
" \n",
" keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},\n",
" \n",
" title = {ICDAR 2019 Competition on Scene Text Visual Question Answering},\n",
" \n",
" publisher = {arXiv},\n",
" \n",
" year = {2019},\n",
" \n",
" copyright = {arXiv.org perpetual, non-exclusive license}\n",
"}\n",
"```"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.8.5 ('base')",
"language": "python",
"name": "python3"
},
"language_info": {
"name": "python",
"version": "3.8.5"
},
"orig_nbformat": 4,
"vscode": {
"interpreter": {
"hash": "a5f44439766e47113308a61c45e3ba0ce79cefad900abb614d22e5ec5db7fbe0"
}
}
},
"nbformat": 4,
"nbformat_minor": 2
}