# 使用传统Recurrent Neural Networks完成中文文本分类任务
文本分类是NLP应用最广的任务之一,可以被应用到多个领域中,包括但不仅限于:情感分析、垃圾邮件识别、商品评价分类...
情感分析是一个自然语言处理中老生常谈的任务。情感分析的目的是为了找出说话者/作者在某些话题上,或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。其可以用于数据挖掘、Web 挖掘、文本挖掘和信息检索方面得到了广泛的研究。可通过 [AI开放平台-情感倾向分析](http://ai.baidu.com/tech/nlp_apply/sentiment_classify) 线上体验。

本项目开源了一系列模型用于进行文本建模,用户可通过参数配置灵活使用。效果上,我们基于开源情感倾向分类数据集ChnSentiCorp对多个模型进行评测。
## paddlenlp.seq2vec
情感分析任务中关键技术是如何将文本表示成一个**携带语义的文本向量**。随着深度学习技术的快速发展,目前常用的文本表示技术有LSTM,GRU,RNN等方法。
PaddleNLP提供了一系列的文本表示技术,如`seq2vec`模块。
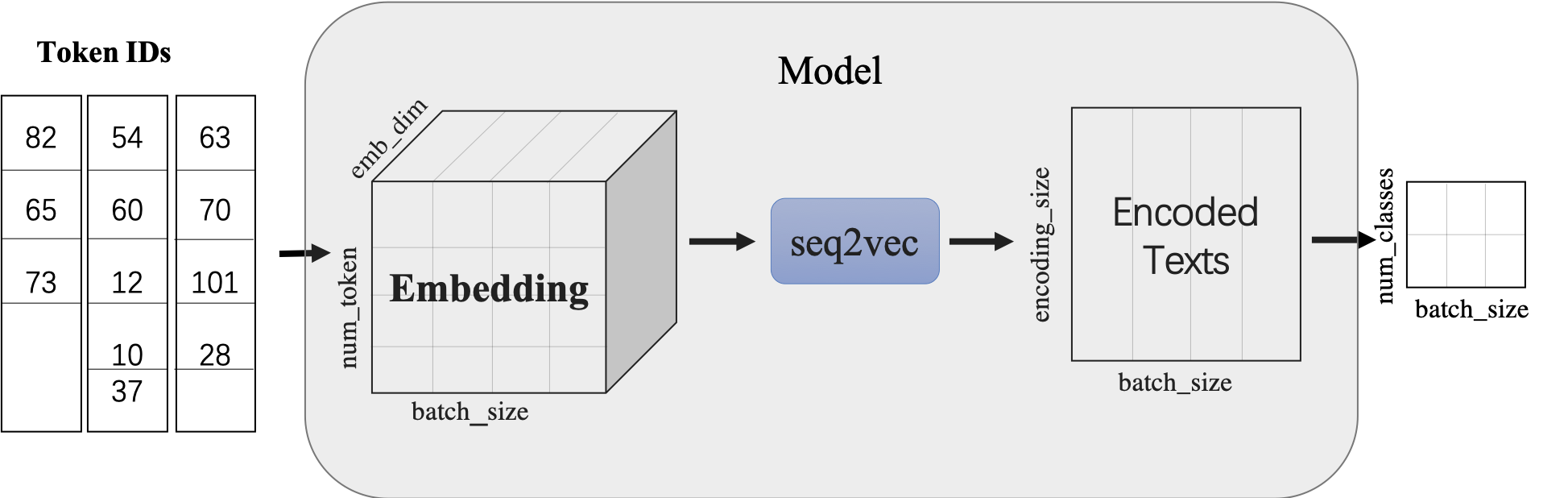
[`paddlenlp.seq2vec`](../../../paddlenlp/seq2vec) 模块作用为将输入的序列文本表征成一个语义向量。
## 模型简介
本项目通过调用[seq2vec](../../../paddlenlp/seq2vec/)中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
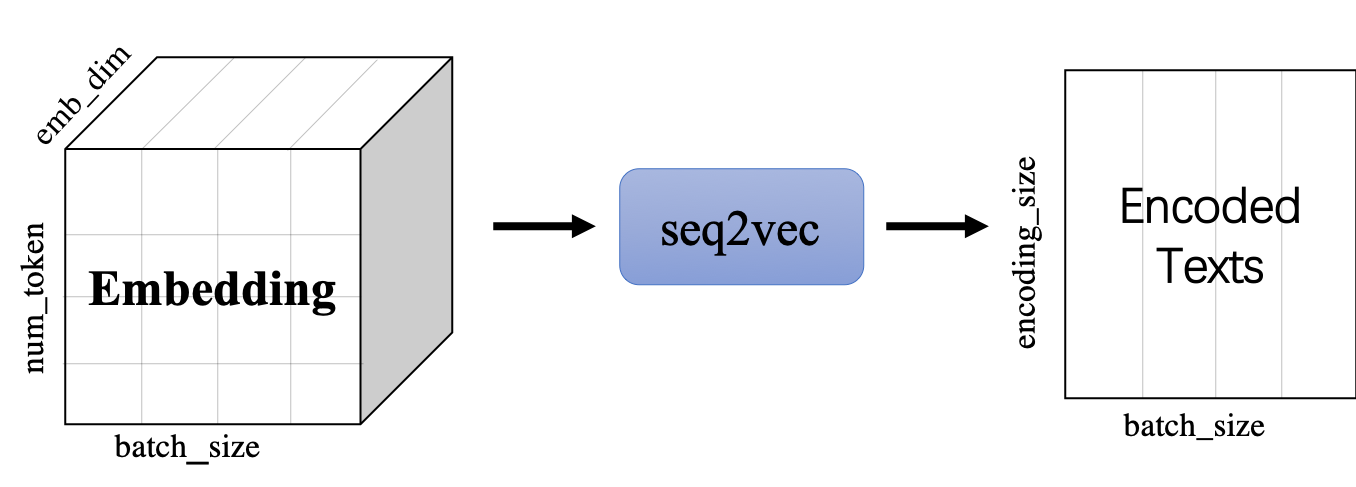
`seq2vec`模块
* 功能是将序列Embedding Tensor(shape是(batch_size, num_token, emb_dim) )转化成文本语义表征Enocded Texts Tensor(shape 是(batch_sie,encoding_size))
* 提供了`BoWEncoder`,`CNNEncoder`,`GRUEncoder`,`LSTMEncoder`,`RNNEncoder`等模型
- `BoWEncoder` 是将输入序列Embedding Tensor在num_token维度上叠加,得到文本语义表征Enocded Texts Tensor。
- `CNNEncoder` 是将输入序列Embedding Tensor进行卷积操作,在对卷积结果进行max_pooling,得到文本语义表征Enocded Texts Tensor。
- `GRUEncoder` 是对输入序列Embedding Tensor进行GRU运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
- `LSTMEncoder` 是对输入序列Embedding Tensor进行LSTM运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
- `RNNEncoder` 是对输入序列Embedding Tensor进行RNN运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
`seq2vec`提供了许多语义表征方法,那么这些方法在什么时候更加适合呢?
* `BoWEncoder`采用Bag of Word Embedding方法,其特点是简单。但其缺点是没有考虑文本的语境,所以对文本语义的表征不足以表意。
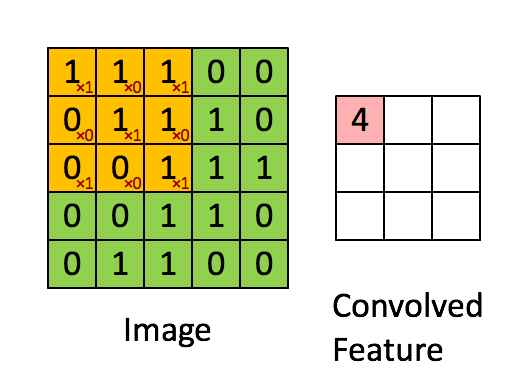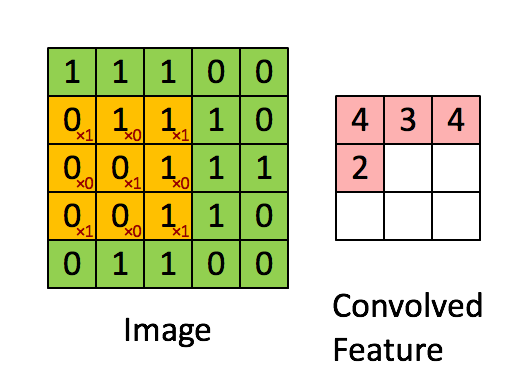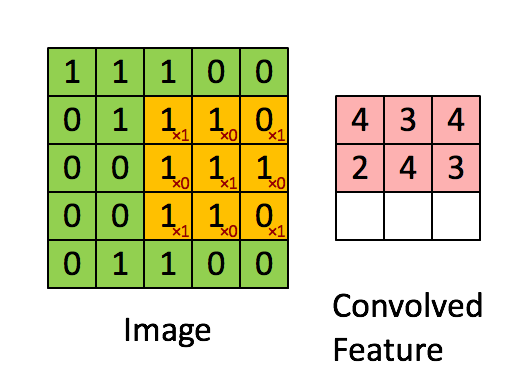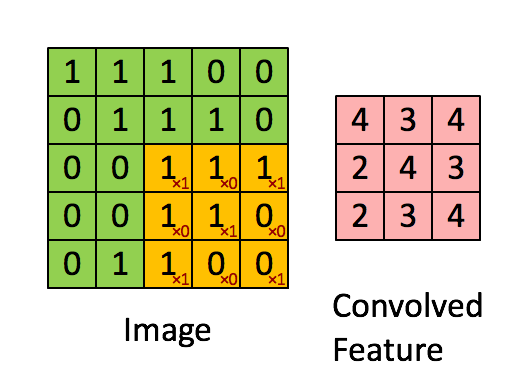
* `CNNEncoder`采用卷积操作,提取局部特征,其特点是可以共享权重。但其缺点同样只考虑了局部语义,上下文信息没有充分利用。
* `RNNEnocder`采用RNN方法,在计算下一个token语义信息时,利用上一个token语义信息作为其输入。但其缺点容易产生梯度消失和梯度爆炸。
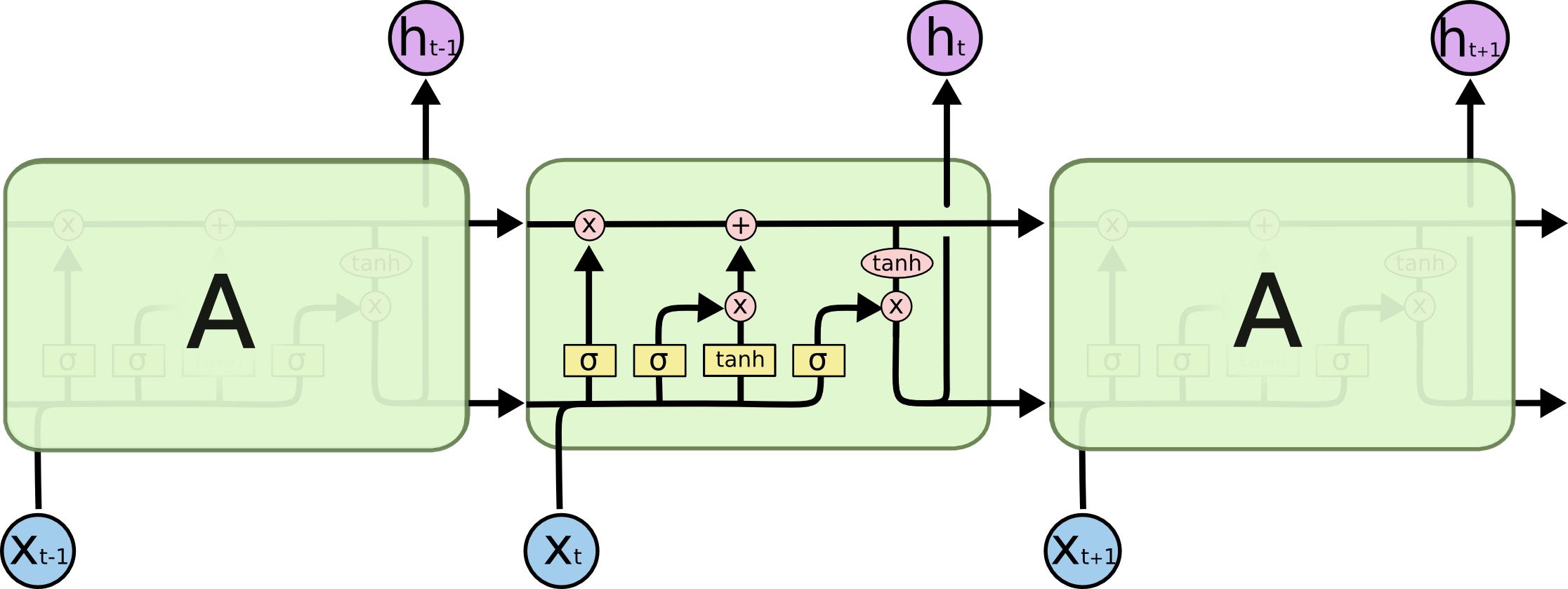
* `LSTMEnocder`采用LSTM方法,LSTM是RNN的一种变种。为了学到长期依赖关系,LSTM 中引入了门控机制来控制信息的累计速度,
包括有选择地加入新的信息,并有选择地遗忘之前累计的信息。
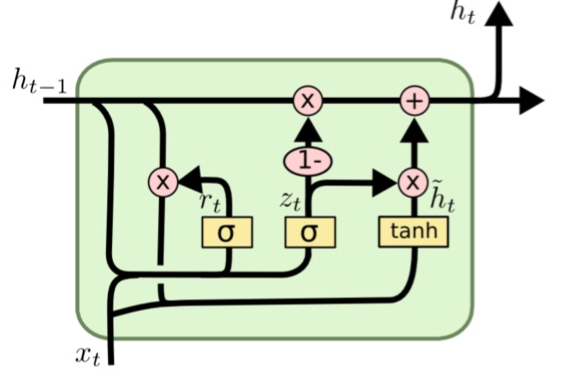
* `GRUEncoder`采用GRU方法,GRU也是RNN的一种变种。一个LSTM单元有四个输入 ,因而参数是RNN的四倍,带来的结果是训练速度慢。
GRU对LSTM进行了简化,在不影响效果的前提下加快了训练速度。
| 模型 | 模型介绍 |
| ------------------------------------------------ | ------------------------------------------------------------ |
| BOW(Bag Of Words) | 非序列模型,将句子表示为其所包含词的向量的加和 |
| RNN (Recurrent Neural Network) | 序列模型,能够有效地处理序列信息 |
| GRU(Gated Recurrent Unit) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| LSTM(Long Short Term Memory) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| Bi-LSTM(Bidirectional Long Short Term Memory) | 序列模型,采用双向LSTM结构,更好地捕获句子中的语义特征 |
| Bi-GRU(Bidirectional Gated Recurrent Unit) | 序列模型,采用双向GRU结构,更好地捕获句子中的语义特征 |
| Bi-RNN(Bidirectional Recurrent Neural Network) | 序列模型,采用双向RNN结构,更好地捕获句子中的语义特征 |
| Bi-LSTM Attention | 序列模型,在双向LSTM结构之上加入Attention机制,结合上下文更好地表征句子语义特征 |
| TextCNN | 序列模型,使用多种卷积核大小,提取局部区域地特征 |
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
| BoW | 0.8970 | 0.8908 |
| Bi-LSTM | 0.9098 | 0.8983 |
| Bi-GRU | 0.9014 | 0.8785 |
| Bi-RNN | 0.8649 | 0.8504 |
| Bi-LSTM Attention | 0.8992 | 0.8856 |
| TextCNN | 0.9102 | 0.9107 |
关于CNN、LSTM、GRU、RNN等更多信息参考:
* https://canvas.stanford.edu/files/1090785/download
* https://colah.github.io/posts/2015-08-Understanding-LSTMs/
* https://arxiv.org/abs/1412.3555
* https://arxiv.org/pdf/1506.00019
* https://arxiv.org/abs/1404.2188
## 快速开始
### 环境依赖
- python >= 3.6
- paddlepaddle >= 2.0.0-rc1
```
pip install paddlenlp>=2.0.0rc
```
### 代码结构说明
以下是本项目主要代码结构及说明:
```text
rnn/
├── export_model.py # 动态图参数导出静态图参数脚本
├── predict.py # 模型预测
├── utils.py # 数据处理工具
├── train.py # 训练模型主程序入口,包括训练、评估
└── README.md # 文档说明
```
### 数据准备
#### 使用PaddleNLP内置数据集
```python
from paddlenlp.datasets import ChnSentiCorp
train_ds, dev_ds, test_ds = ChnSentiCorp.get_datasets(['train', 'dev', 'test'])
```
### 模型训练
在模型训练之前,需要先下载词汇表文件word_dict.txt,用于构造词-id映射关系。
```shell
wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
```
我们以中文情感分类公开数据集ChnSentiCorp为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
CPU 启动:
```shell
python train.py --vocab_path='./senta_word_dict.txt' --use_gpu=False --network=bilstm --lr=5e-4 --batch_size=64 --epochs=10 --save_dir='./checkpoints'
```
GPU 启动:
```shell
CUDA_VISIBLE_DEVICES=0 python train.py --vocab_path='./senta_word_dict.txt' --use_gpu=True --network=bilstm --lr=5e-4 --batch_size=64 --epochs=10 --save_dir='./checkpoints'
```
以上参数表示:
* `vocab_path`: 词汇表文件路径。
* `use_gpu`: 是否使用GPU进行训练, 默认为`False`。
* `network`: 模型网络名称,默认为`bilstm_attn`, 可更换为bilstm, bigru, birnn,bow,lstm,rnn,gru,bilstm_attn,textcnn等。
* `lr`: 学习率, 默认为5e-5。
* `batch_size`: 运行一个batch大小,默认为64。
* `epochs`: 训练轮次,默认为10。
* `save_dir`: 训练保存模型的文件路径。
* `init_from_ckpt`: 恢复模型训练的断点路径。
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的`save_dir`中。
如:
```text
checkpoints/
├── 0.pdopt
├── 0.pdparams
├── 1.pdopt
├── 1.pdparams
├── ...
└── final.pdparams
```
**NOTE:**
* 如需恢复模型训练,则init_from_ckpt只需指定到文件名即可,不需要添加文件尾缀。如`--init_from_ckpt=checkpoints/0`即可,程序会自动加载模型参数`checkpoints/0.pdparams`,也会自动加载优化器状态`checkpoints/0.pdopt`。
* 使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在`output_path`指定路径中。
运行方式:
```shell
python export_model.py --vocab_path=./senta_word_dict.txt --network=bilstm --params_path=./checkpoints/final.pdparam --output_path=./static_graph_params
```
其中`params_path`是指动态图训练保存的参数路径,`output_path`是指静态图参数导出路径。
### 模型预测
启动预测:
CPU启动:
```shell
python predict.py --vocab_path='./senta_word_dict.txt' --use_gpu=False --network=bilstm --params_path=checkpoints/final.pdparams
```
GPU启动:
```shell
CUDA_VISIBLE_DEVICES=0 python predict.py --vocab_path='./senta_word_dict.txt' --use_gpu=True --network=bilstm --params_path='./checkpoints/final.pdparams'
```
将待预测数据分词完毕后,如以下示例:
```text
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。
```
处理成模型所需的`Tensor`,如可以直接调用`preprocess_prediction_data`函数既可处理完毕。之后传入`predict`函数即可输出预测结果。
如
```text
Data: 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 Lable: negative
Data: 怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片 Lable: negative
Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。 Lable: positive
```
## 线上体验教程
- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。