# 使用预训练模型Fine-tune完成中文文本分类任务
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](../rnn).
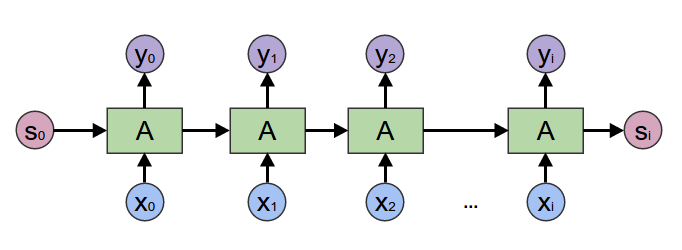
[paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析](https://aistudio.baidu.com/aistudio/projectdetail/1283423)教程介绍了如何使用`paddlenlp.seq2vec`表征文本语义。
近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
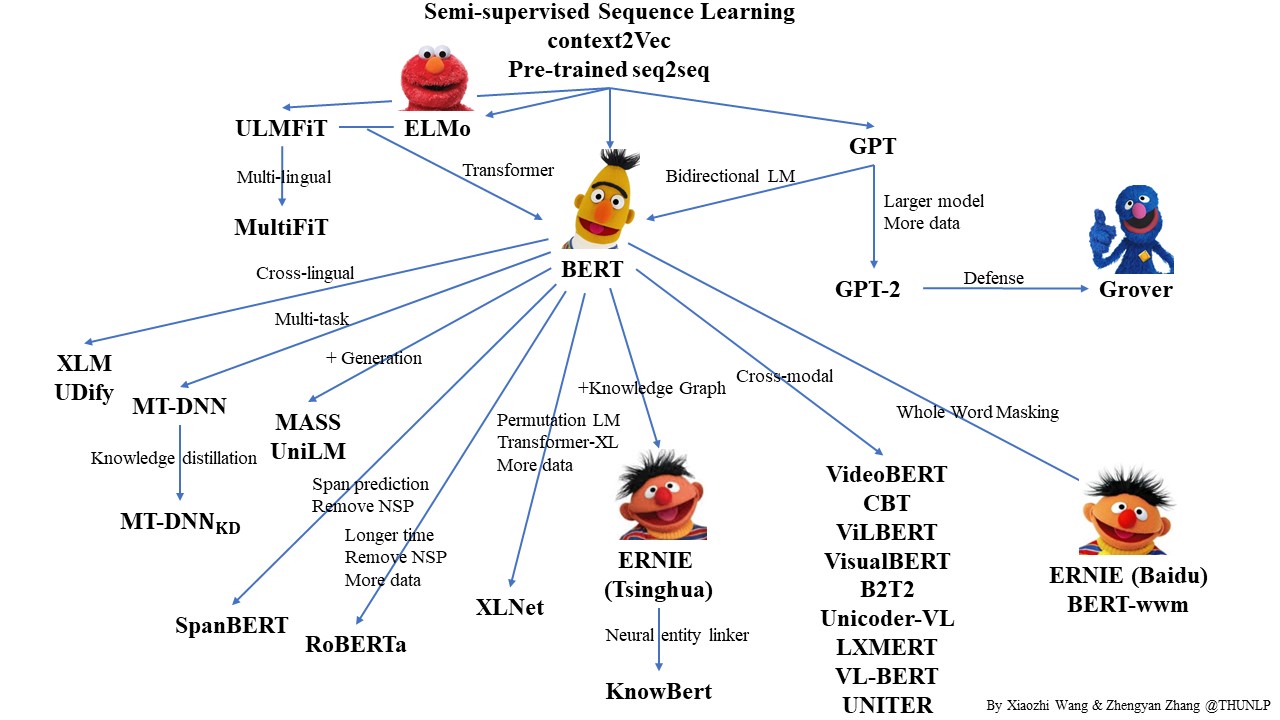
本图片来自于:https://github.com/thunlp/PLMpapers
本示例展示了以ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223))代表的预训练模型如何Finetune完成中文文本分类任务。
## 模型简介
本项目针对中文文本分类问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
| bert-base-chinese | 0.93833 | 0.94750 |
| bert-wwm-chinese | 0.94583 | 0.94917 |
| bert-wwm-ext-chinese | 0.94667 | 0.95500 |
| ernie-1.0 | 0.94667 | 0.95333 |
| ernie-tiny | 0.93917 | 0.94833 |
| roberta-wwm-ext | 0.94750 | 0.95250 |
| roberta-wwm-ext-large | 0.95250 | 0.95333 |
| rbt3 | 0.92583 | 0.93250 |
| rbtl3 | 0.9341 | 0.93583 |
## 快速开始
### 环境依赖
- python >= 3.6
- paddlepaddle >= 2.0.0-rc1
```
pip install paddlenlp>=2.0.0rc
```
### 代码结构说明
以下是本项目主要代码结构及说明:
```text
pretrained_models/
├── export_model.py # 动态图参数导出静态图参数脚本
├── predict.py # 预测脚本
├── README.md # 使用说明
└── train.py # 训练评估脚本
```
### 模型训练
我们以中文情感分类公开数据集ChnSentiCorp为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
```shell
# 设置使用的GPU卡号
CUDA_VISIBLE_DEVICES=0
python train.py --n_gpu 1 --save_dir ./checkpoints
```
可支持配置的参数:
* `save_dir`:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。
* `max_seq_length`:可选,ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。
* `batch_size`:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
* `learning_rate`:可选,Fine-tune的最大学习率;默认为5e-5。
* `weight_decay`:可选,控制正则项力度的参数,用于防止过拟合,默认为0.00。
* `epochs`: 训练轮次,默认为3。
* `warmup_proption`:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.1。
* `init_from_ckpt`:可选,模型参数路径,热启动模型训练;默认为None。
* `seed`:可选,随机种子,默认为1000.
* `n_gpu`:可选,训练过程中使用GPU卡数量,默认为1。若n_gpu=0,则使用CPU训练。
代码示例中使用的预训练模型是ERNIE,如果想要使用其他预训练模型如BERT,RoBERTa,Electra等,只需更换`model` 和 `tokenizer`即可。
```python
# 使用ernie预训练模型
# ernie
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained('ernie',num_classes=2))
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained('ernie')
# ernie-tiny
# model = ppnlp.transformers.ErnieForSequenceClassification.rom_pretrained('ernie-tiny',num_classes=2))
# tokenizer = ppnlp.transformers.ErnieTinyTokenizer.from_pretrained('ernie-tiny')
# 使用bert预训练模型
# bert-base-chinese
model = ppnlp.transformers.BertForSequenceClassification.from_pretrained('bert-base-chinese', num_class=2)
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained('bert-base-chinese')
# bert-wwm-chinese
# model = ppnlp.transformers.BertForSequenceClassification.from_pretrained('bert-wwm-chinese', num_class=2)
# tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained('bert-wwm-chinese')
# bert-wwm-ext-chinese
# model = ppnlp.transformers.BertForSequenceClassification.from_pretrained('bert-wwm-ext-chinese', num_class=2)
# tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained('bert-wwm-ext-chinese')
# 使用roberta预训练模型
# roberta-wwm-ext
# model = ppnlp.transformers.RobertaForSequenceClassification.from_pretrained('roberta-wwm-ext', num_class=2)
# tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained('roberta-wwm-ext')
# roberta-wwm-ext
# model = ppnlp.transformers.RobertaForSequenceClassification.from_pretrained('roberta-wwm-ext-large', num_class=2)
# tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained('roberta-wwm-ext-large')
```
更多预训练模型,参考[transformers](../../../docs/transformers.md)
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的`save_dir`中。
如:
```text
checkpoints/
├── model_100
│ ├── model_config.json
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...
```
**NOTE:**
* 如需恢复模型训练,则可以设置`init_from_ckpt`, 如`init_from_ckpt=checkpoints/model_100/model_state.pdparams`。
* 如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如`pip install sentencepiece`
* 使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在`output_path`指定路径中。
运行方式:
```shell
python export_model.py --params_path=./checkpoint/model_900/model_state.pdparams --output_path=./static_graph_params
```
其中`params_path`是指动态图训练保存的参数路径,`output_path`是指静态图参数导出路径。
### 模型预测
启动预测:
```shell
export CUDA_VISIBLE_DEVICES=0
python predict.py --params_path checkpoints/model_900/model_state.pdparams
```
将待预测数据如以下示例:
```text
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。
```
可以直接调用`predict`函数即可输出预测结果。
如
```text
Data: 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 Label: negative
Data: 怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片 Label: negative
Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。 Label: positive
```
## 线上体验教程
- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。