# 噪声对比估计加速词向量训练
## 背景介绍
在自然语言处理领域中,通常使用特征向量来表示一个单词,但是如何使用准确的词向量来表示语义却是一个难点,详细内容可以在[词向量章节](https://github.com/PaddlePaddle/book/blob/develop/04.word2vec/README.cn.md)中查阅到,原作者使用神经概率语言模型(Neural Probabilistic Language Model, NPLM)来训练词向量,尽管 NPLM 有优异的精度表现,但是相对于传统的 N-gram 统计模型,训练时间还是太漫长了\[[3](#参考文献)\]。常用的优化这个问题算法主要有两个:一个是 hierarchical-sigmoid \[[2](#参考文献)\] 另一个 噪声对比估计(Noise-contrastive estimation, NCE)\[[1](#参考文献)\]。为了克服这个问题本文引入了 NCE 方法。本文将以训练 NPLM 作为例子来讲述如何使用 NCE。
## NCE 概览
NCE 是一种快速对离散分布进行估计的方法,应用到本文中的问题:训练 NPLM 计算开销很大,原因是 softmax 函数计算时需要考虑每个类别的指数项,必须计算字典中的所有单词,而在一般语料集上面字典往往非常大\[[3](#参考文献)\],从而导致整个训练过程十分耗时。与常用的 hierarchical-sigmoid \[[2](#参考文献)\] 方法相比,NCE 不再使用复杂的二叉树来构造目标函数,而是采用相对简单的随机负采样,以大幅提升计算效率。
假设已知具体的上下文 $h$,并且知道这个分布为 $P^h(w)$ ,并将从中抽样出来的数据作为正样例,而从一个噪音分布 $P_n(w)$ 抽样的数据作为负样例。我们可以任意选择合适的噪音分布,默认为无偏的均匀分布。这里我们同时假设噪音样例 k 倍于数据样例,则训练数据被抽中的概率为\[[1](#参考文献)\]:
$$P^h(D=1|w,\theta)=\frac { P_\theta^h(w) }{ P^h_\theta(w)+kP_n(w) } =\sigma (\Delta s_\theta(w,h))$$
其中 $\Delta s_\theta(w,h)=s_\theta(w,h)-\log (kP_n(w))$ ,$s_\theta(w,h)$ 表示选择在生成 $w$ 字并处于上下文 $h$ 时的特征向量,整体目标函数的目的就是增大正样本的概率同时降低负样本的概率。目标函数如下[[1](#参考文献)]:
$$
J^h(\theta )=E_{ P_d^h }\left[ \log { P^h(D=1|w,\theta ) } \right] +kE_{ P_n }\left[ \log P^h (D=0|w,\theta ) \right]$$
$$
\\\\\qquad =E_{ P_d^h }\left[ \log { \sigma (\Delta s_\theta(w,h)) } \right] +kE_{ P_n }\left[ \log (1-\sigma (\Delta s_\theta(w,h))) \right]$$
总体上来说,NCE 是通过构造逻辑回归(logistic regression),对正样例和负样例做二分类,对于每一个样本,将自身的预测词 label 作为正样例,同时采样出 $k$ 个其他词 label 作为负样例,从而只需要计算样本在这 $k+1$ 个 label 上的概率。相比原始的 softmax 分类需要计算每个类别的分数,然后归一化得到概率,节约了大量的时间消耗。
## 实验数据
本文采用 Penn Treebank (PTB) 数据集([Tomas Mikolov预处理版本](http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz))来训练语言模型。PaddlePaddle 提供 [paddle.dataset.imikolov](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/dataset/imikolov.py) 接口来方便调用这些数据,如果当前目录没有找到数据它会自动下载并验证文件的完整性。并提供大小为5的滑动窗口对数据做预处理工作,方便后期处理。语料语种为英文,共有42068句训练数据,3761句测试数据。
## 网络结构
N-gram 神经概率语言模型详细网络结构见图1:
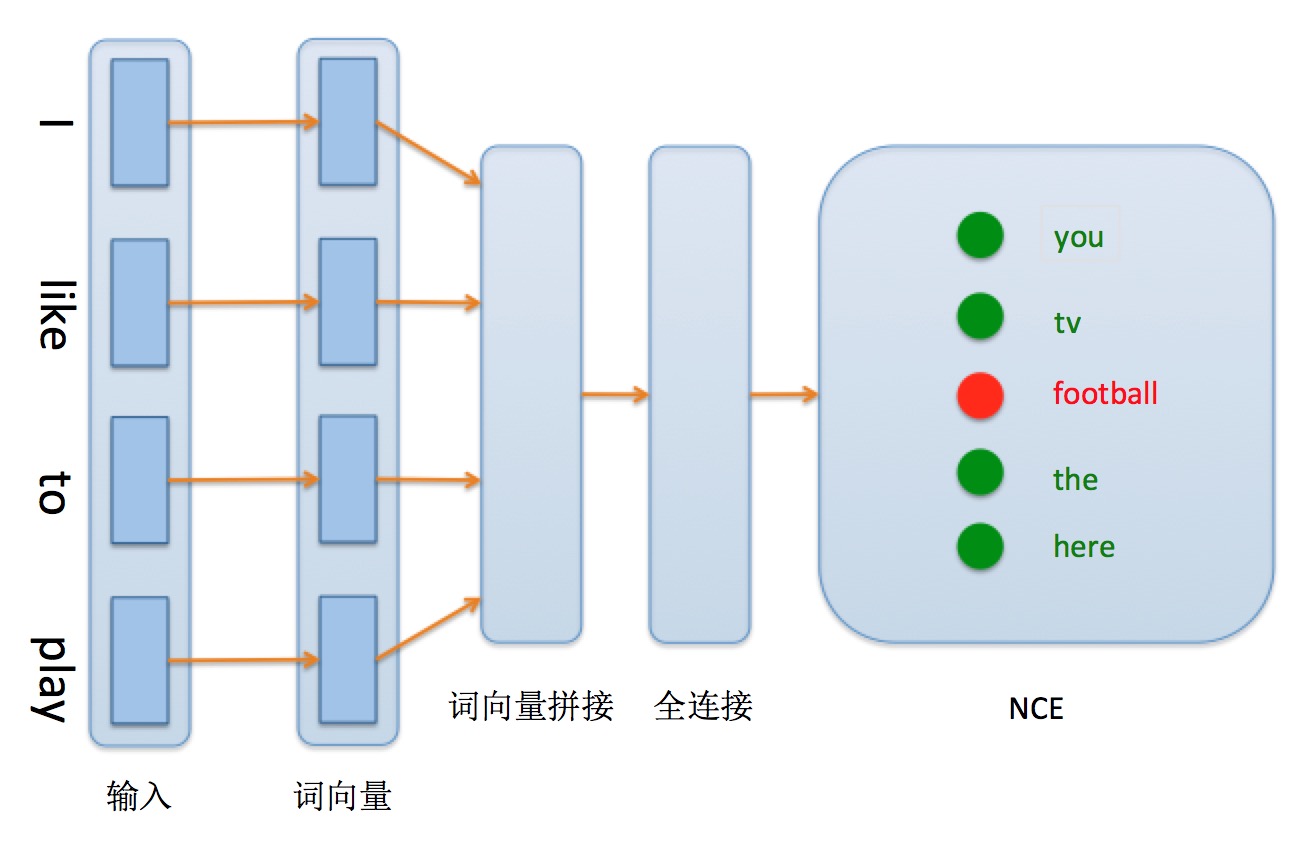
图1. 网络配置结构
可以看到,模型主要分为如下几个部分构成:
1. **输入层**:输入的 ptb 样本由原始的英文单词组成,将每个英文单词转换为字典中的 id 表示,使用唯一的 id 表示可以区分每个单词。
2. **词向量层**:比起原先的 id 表示,词向量表示更能体现词与词之间的语义关系。这里使用可更新的 embedding 矩阵,将原先的 id 表示转换为固定维度的词向量表示。训练完成之后,词语之间的语义相似度可以使用词向量之间的距离来表示,语义越相似,距离越近。
3. **词向量拼接层**:将词向量进行串联,并将词向量首尾相接形成一个长向量。这样可以方便后面全连接层的处理。
4. **全连接隐层**:将上一层获得的长向量输入到一层隐层的神经网络,输出特征向量。全连接的隐层可以增强网络的学习能力。
5. **NCE层**:训练时可以直接实用 PaddlePaddle 提供的 NCE Layer。
## 训练阶段
训练直接运行``` python train.py ```。程序第一次运行会检测用户缓存文件夹中是否包含 ptb 数据集,如果未包含,则自动下载。运行过程中,每1000个 iteration 会打印模型训练信息,主要包含训练损失,每个 pass 会计算测试数据集上的损失,并同时会保存最新的模型快照。在 PaddlePaddle 中有已经实现好的 NCE Layer,一些参数需要自行根据实际场景进行设计,可参考的调参方案如下:
| 参数名 | 参数作用 | 介绍 |
|:------ |:-------| :--------|
| param\_attr / bias\_attr | 用来设置参数名字 | 可以方便后面预测阶段好来实现网络的参数共享,具体内容在下一个章节里会陈述。|
| num\_neg\_samples | 参数负责控制对负样例的采样个数。 | 可以控制正负样本比例,这个值取值区间为 [1, 字典大小-1],负样本个数越多则整个模型的训练速度越慢,模型精度也会越高 |
| neg\_distribution | 控制生成负样例标签的分布,默认是一个均匀分布。 | 可以自行控制负样本采样时各个类别的采样权重,比如希望正样例为“晴天”时,负样例“洪水”在训练时更被着重区分,则可以将“洪水”这个类别的采样权重增加。 |
| act | 表示使用何种激活函数。 | 根据 NCE 的原理,这里应该使用 sigmoid 函数。 |
具体代码实现如下:
```python
cost = paddle.layer.nce(
input=hidden_layer,
label=next_word,
num_classes=dict_size,
param_attr=paddle.attr.Param(name='nce_w'),
bias_attr=paddle.attr.Param(name='nce_b'),
act=paddle.activation.Sigmoid(),
num_neg_samples=25,
neg_distribution=None)
```
## 预测阶段
预测直接运行` python infer.py `,程序首先会加载最新模型,然后按照 batch 大小依次进行预测,并打印预测结果。因为训练和预测计算逻辑不一样,预测阶段需要共享 NCE Layer 中的逻辑回归训练时得到的参数,所以要写一个推断层,推断层的参数为预先训练好的参数。
具体实现推断层的方法:先是通过 `paddle.attr.Param` 方法获取参数值,然后使用 `paddle.layer.trans_full_matrix_projection` 对隐层输出向量 `hidden_layer` 做一个矩阵右乘,PaddlePaddle 会自行在模型中寻找相同参数名的参数并获取。右乘求和后得到类别向量,将类别向量输入 softmax 做一个归一操作,和为1,从而得到最后的类别概率分布。
代码实现如下:
```python
with paddle.layer.mixed(
size=dict_size,
act=paddle.activation.Softmax(),
bias_attr=paddle.attr.Param(name='nce_b')) as prediction:
prediction += paddle.layer.trans_full_matrix_projection(
input=hidden_layer, param_attr=paddle.attr.Param(name='nce_w'))
```
预测的输出形式为:
```
--------------------------
No.68 Input: ' for possible
Ground Truth Output:
Predict Output:
--------------------------
No.69 Input: for possible
Ground Truth Output: on
Predict Output:
--------------------------
No.70 Input: for possible on
Ground Truth Output: the
Predict Output: the
```
每一个短线表示一次的预测,第二行显示第几条测试样例,并给出输入的4个单词,第三行为真实的标签,第四行为预测的标签。
## 参考文献
1. Mnih A, Kavukcuoglu K. [Learning word embeddings efficiently with noise-contrastive estimation](https://papers.nips.cc/paper/5165-learning-word-embeddings-efficiently-with-noise-contrastive-estimation.pdf)[C]//Advances in neural information processing systems. 2013: 2265-2273.
2. Morin, F., & Bengio, Y. (2005, January). [Hierarchical Probabilistic Neural Network Language Model](http://www.iro.umontreal.ca/~lisa/pointeurs/hierarchical-nnlm-aistats05.pdf). In Aistats (Vol. 5, pp. 246-252).
3. Mnih A, Teh Y W. [A Fast and Simple Algorithm for Training Neural Probabilistic Language Models](http://xueshu.baidu.com/s?wd=paperuri%3A%280735b97df93976efb333ac8c266a1eb2%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fabs%2F1206.6426&ie=utf-8&sc_us=5770715420073315630)[J]. Computer Science, 2012:1751-1758.