>运行该示例前请安装Paddle1.6或更高版本。 本示例中的run.sh脚本仅适用于linux系统,在windows环境下,请参考run.sh内容编写适合windows环境的脚本。
# 分类模型量化压缩示例
## 概述
该示例使用PaddleSlim提供的[量化压缩策略](https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/tutorial.md#1-quantization-aware-training%E9%87%8F%E5%8C%96%E4%BB%8B%E7%BB%8D)对分类模型进行压缩。
>本文默认使用ILSVRC2012数据集,数据集存放在`models/PaddleSlim/data/`路径下, 可以参考[数据准备](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#数据准备)在执行训练脚本run.sh前配置好您的数据集
在阅读该示例前,建议您先了解以下内容:
- [分类模型的常规训练方法](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification)
- [PaddleSlim使用文档](https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md)
## 配置文件说明
关于配置文件如何编写您可以参考:
- [PaddleSlim配置文件编写说明](https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md#122-%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E7%9A%84%E4%BD%BF%E7%94%A8)
- [量化策略配置文件编写说明](https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md#21-%E9%87%8F%E5%8C%96%E8%AE%AD%E7%BB%83)
其中save_out_nodes需要传入分类概率结果的Variable的名称,下面介绍如何确定save_out_nodes的参数
以MobileNet V1为例,可在compress.py中构建好网络之后,直接打印Variable得到Variable的名称信息。
代码示例:
```
#model definition, args.model=MobileNet
model = models.__dict__[args.model]()
out = model.net(input=image, class_dim=1000)
print(out)
cost = fluid.layers.cross_entropy(input=out, label=label)
```
根据运行结果可看到Variable的名字为:`fc_0.tmp_2`。
## 训练
根据 [PaddleCV/image_classification/train.py](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/train.py) 编写压缩脚本compress.py。
在该脚本中定义了Compressor对象,用于执行压缩任务。
可以通过命令`python compress.py`用默认参数执行压缩任务,通过`python compress.py --help`查看可配置参数,简述如下:
- use_gpu: 是否使用gpu。如果选择使用GPU,请确保当前环境和Paddle版本支持GPU。默认为True。
- batch_size: 在量化之后,对模型进行fine-tune训练时用的batch size。
- model: 要压缩的目标模型,该示例支持'MobileNet', 'MobileNetV2'和'ResNet50'。
- pretrained_model: 预训练模型的路径,可以从[这里](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#%E5%B7%B2%E5%8F%91%E5%B8%83%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E6%80%A7%E8%83%BD)下载。
- config_file: 压缩策略的配置文件。
您可以通过运行脚本`run.sh`运行该示例,请确保已正确下载[pretrained model](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#%E5%B7%B2%E5%8F%91%E5%B8%83%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E6%80%A7%E8%83%BD)。
### 训练时的模型结构
这部分介绍来源于[量化low-level API介绍](https://github.com/PaddlePaddle/models/tree/develop/PaddleSlim/quant_low_level_api#1-%E9%87%8F%E5%8C%96%E8%AE%AD%E7%BB%83low-level-apis%E4%BB%8B%E7%BB%8D)。
PaddlePaddle框架中和量化相关的IrPass有QuantizationTransformPass、QuantizationFreezePass、ConvertToInt8Pass。在训练时,对网络应用了QuantizationTransformPass,作用是在网络中的conv2d、depthwise_conv2d、mul等算子的各个输入前插入连续的量化op和反量化op,并改变相应反向算子的某些输入。示例图如下:
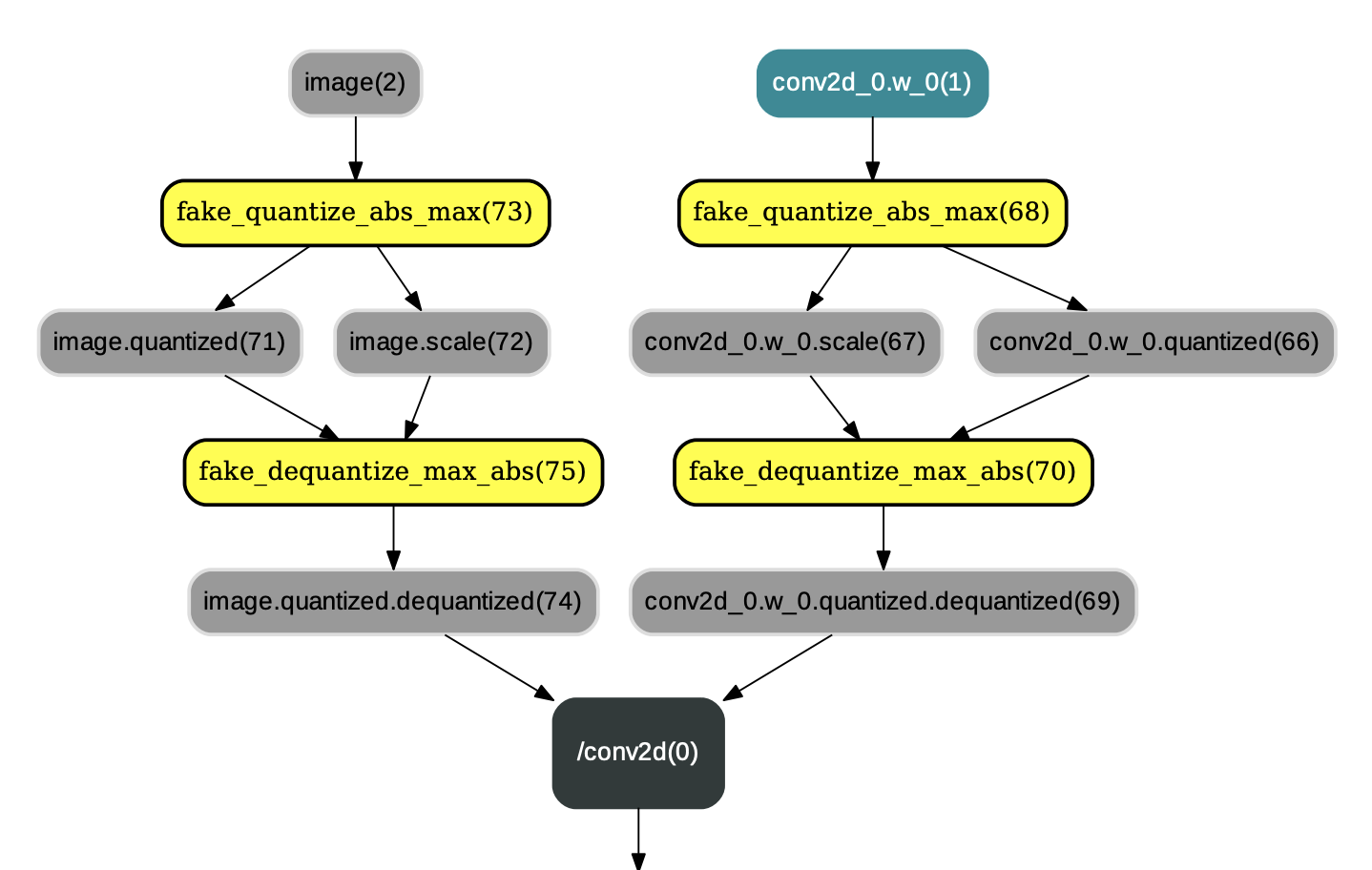
图1:应用QuantizationTransformPass后的结果
### 保存断点(checkpoint)
如果在配置文件中设置了`checkpoint_path`, 则在压缩任务执行过程中会自动保存断点,当任务异常中断时,
重启任务会自动从`checkpoint_path`路径下按数字顺序加载最新的checkpoint文件。如果不想让重启的任务从断点恢复,
需要修改配置文件中的`checkpoint_path`,或者将`checkpoint_path`路径下文件清空。
>注意:配置文件中的信息不会保存在断点中,重启前对配置文件的修改将会生效。
### 保存评估和预测模型
如果在配置文件的量化策略中设置了`float_model_save_path`, `int8_model_save_path`,在训练结束后,会保存模型量化压缩之后用于评估和预测的模型。接下来介绍这2种模型的区别。
#### FP32模型
在介绍量化训练时的模型结构时介绍了PaddlePaddle框架中和量化相关的IrPass, 有QuantizationTransformPass、QuantizationFreezePass、ConvertToInt8Pass。FP32预测模型是在应用QuantizationFreezePass并删除eval_program中多余的operators之后,保存的模型。
QuantizationFreezePass主要用于改变IrGraph中量化op和反量化op的顺序,即将类似图1中的量化op和反量化op顺序改变为图2中的布局。除此之外,QuantizationFreezePass还会将`conv2d`、`depthwise_conv2d`、`mul`等算子的权重离线量化为int8_t范围内的值(但数据类型仍为float32),以减少预测过程中对权重的量化操作,示例如图2:
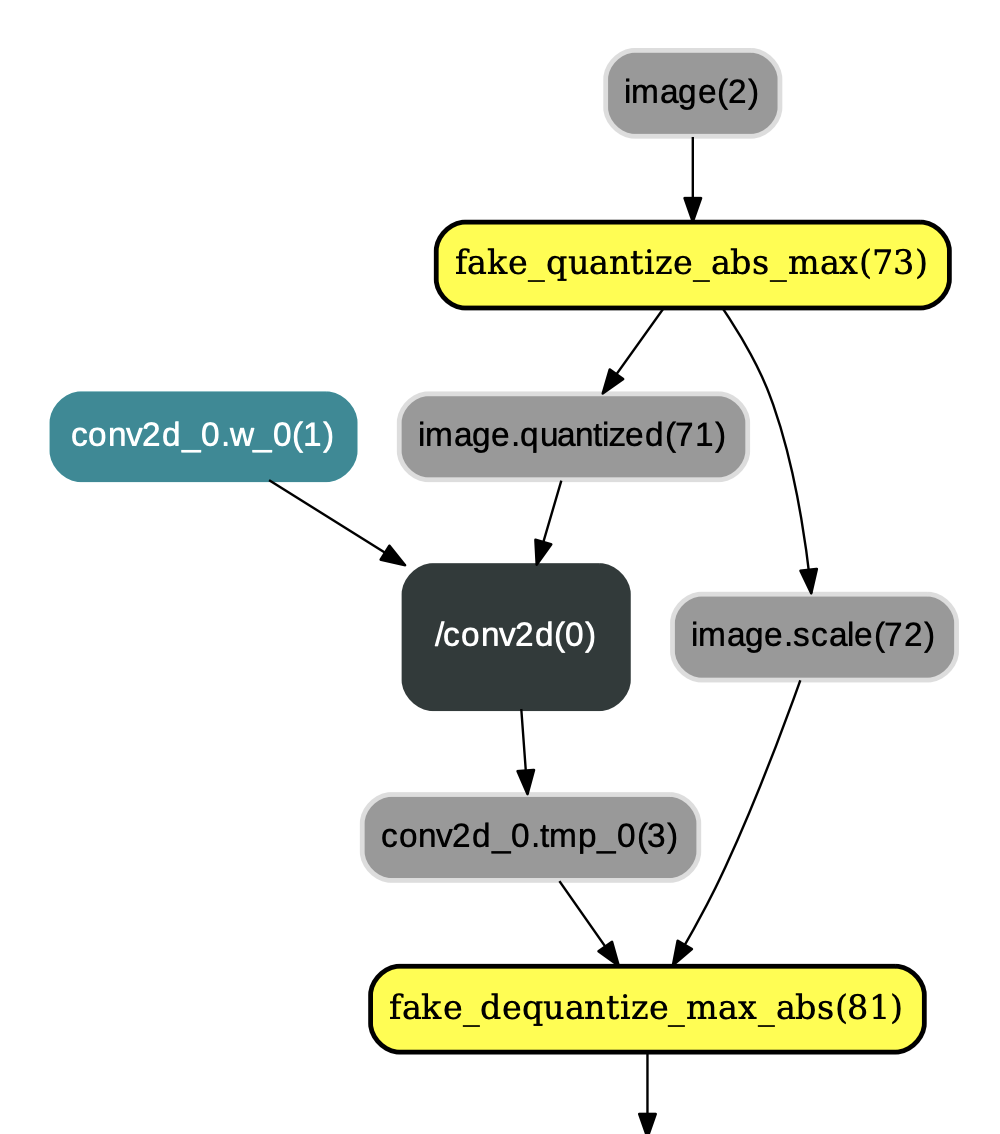
图2:应用QuantizationFreezePass后的结果
#### 8-bit模型
在对训练网络进行QuantizationFreezePass之后,执行ConvertToInt8Pass,
其主要目的是将执行完QuantizationFreezePass后输出的权重类型由`FP32`更改为`INT8`。换言之,用户可以选择将量化后的权重保存为float32类型(不执行ConvertToInt8Pass)或者int8_t类型(执行ConvertToInt8Pass),示例如图3:
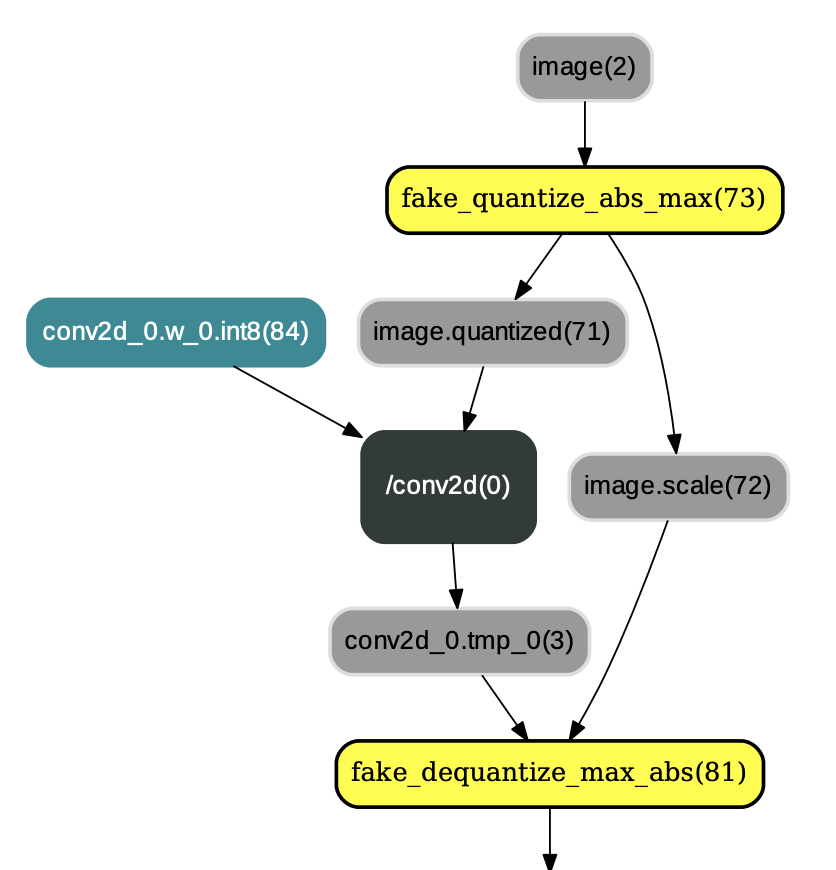
图3:应用ConvertToInt8Pass后的结果
> 综上,可得在量化过程中有以下几种模型结构:
1. 原始模型
2. 经QuantizationTransformPass之后得到的适用于训练的量化模型结构,在${checkpoint_path}下保存的`eval_model`是这种结构,在训练过程中每个epoch结束时也使用这个网络结构进行评估,虽然这个模型结构不是最终想要的模型结构,但是每个epoch的评估结果可用来挑选模型。
3. 经QuantizationFreezePass之后得到的FP32模型结构,具体结构已在上面进行介绍。本文档中列出的数据集的评估结果是对FP32模型结构进行评估得到的结果。这种模型结构在训练过程中只会保存一次,也就是在量化配置文件中设置的`end_epoch`结束时进行保存,如果想将其他epoch的训练结果转化成FP32模型,可使用脚本 PaddleSlim/classification/quantization/freeze.py进行转化,具体使用方法在[评估](#评估)中介绍。
4. 经ConvertToInt8Pass之后得到的8-bit模型结构,具体结构已在上面进行介绍。这种模型结构在训练过程中只会保存一次,也就是在量化配置文件中设置的`end_epoch`结束时进行保存,如果想将其他epoch的训练结果转化成8-bit模型,可使用脚本 PaddleSlim/classification/quantization/freeze.py进行转化,具体使用方法在[评估](#评估)中介绍。
## 评估
### 每个epoch保存的评估模型
因为量化的最终模型只有在end_epoch时保存一次,不能保证保存的模型是最好的,因此
如果在配置文件中设置了`checkpoint_path`,则每个epoch会保存一个量化后的用于评估的模型,
该模型会保存在`${checkpoint_path}/${epoch_id}/eval_model/`路径下,包含`__model__`和`__params__`两个文件。
其中,`__model__`用于保存模型结构信息,`__params__`用于保存参数(parameters)信息。模型结构和训练时一样。
如果不需要保存评估模型,可以在定义Compressor对象时,将`save_eval_model`选项设置为False(默认为True)。
脚本PaddleSlim/classification/eval.py中为使用该模型在评估数据集上做评估的示例。
运行命令示例:
```
python eval.py \
--use_gpu 1 \
--model_path ${checkpoint_path}/${epoch_id}/eval_model
```
在评估之后,选取效果最好的epoch的模型,可使用脚本 PaddleSlim/classification/quantization/freeze.py将该模型转化为以上介绍的2种模型:FP32模型,8-bit模型,需要配置的参数为:
- model_path, 加载的模型路径,`为${checkpoint_path}/${epoch_id}/eval_model/`
- weight_quant_type 模型参数的量化方式,和配置文件中的类型保持一致
- save_path `FP32`, `8-bit`模型的保存路径,分别为 `${save_path}/float/`, `${save_path}/int8/`
运行命令示例:
```
python freeze.py \
--model_path ${checkpoint_path}/${epoch_id}/eval_model/ \
--weight_quant_type ${weight_quant_type} \
--save_path ${any path you want}
```
### 最终评估模型
最终使用的评估模型是FP32模型,使用脚本PaddleSlim/classification/eval.py该模型在评估数据集上做评估。
运行命令示例:
```
python eval.py \
--use_gpu 1 \
--model_path ${save_path}/float \
--model_name model \
--params_name weights
```
## 预测
### python预测
FP32模型可直接使用原生PaddlePaddle Fluid预测方法进行预测。
在脚本PaddleSlim/classification/infer.py中展示了如何使用fluid python API加载使用预测模型进行预测。
运行命令示例:
```
python infer.py \
--model_path ${save_path}/float \
--use_gpu 1 \
--model_name model \
--params_name weights
```
### PaddleLite预测
FP32模型可使用Paddle-Lite进行加载预测,可参见教程[Paddle-Lite如何加载运行量化模型](https://github.com/PaddlePaddle/Paddle-Lite/wiki/model_quantization)。
## 示例结果
### MobileNetV1
| weight量化方式 | activation量化方式| top1_acc/top5_acc |Paddle Fluid inference time(ms)| Paddle Lite inference time(ms)| 模型下载|
|---|---|---|---|---| ---|
|baseline|- |70.99%/89.68%|- |-| [下载模型](http://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV1_pretrained.tar)|
|abs_max|abs_max|70.74%/89.55% |- |-| [下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fmobilenetv1_w_abs_a_abs_7074_8955.tar.gz)|
|abs_max|moving_average_abs_max|70.89%/89.67% |- |-| [下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fmobilenetv1_w_abs_a_move_7089_8967.tar.gz)|
|channel_wise_abs_max|abs_max|70.93%/89.65% |- |-|[下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fmobilenetv1_w_chan_a_abs_7093_8965.tar.gz)|
>训练超参:
优化器
```
fluid.optimizer.Momentum(momentum=0.9,
learning_rate=fluid.layers.piecewise_decay(
boundaries=[5000 * 12],
values=[0.0001, 0.00001]),
regularization=fluid.regularizer.L2Decay(1e-4))
```
8卡,batch size 1024,epoch 30, 挑选好的结果
### MobileNetV2
| weight量化方式 | activation量化方式| top1_acc/top5_acc |Paddle Fluid inference time(ms)| Paddle Lite inference time(ms)|
|---|---|---|---|---|
|baseline|- |72.15%/90.65%|- |-|
|abs_max|abs_max|- |- |-|
|abs_max|moving_average_abs_max|- |- |-|
|channel_wise_abs_max|abs_max|- |- |-|
>训练超参:
### ResNet50
| weight量化方式 | activation量化方式| top1_acc/top5_acc |Paddle Fluid inference time(ms)| Paddle Lite inference time(ms)|模型下载|
|---|---|---|---|---|---|
|baseline|- |76.50%/93.00%|- |-|[下载模型](http://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_pretrained.tar)|
|abs_max|abs_max|76.71%/93.10% |- |-|[下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fresnet50_w_abs_a_abs_7670_9310.tar.gz)|
|abs_max|moving_average_abs_max|76.65%/93.12% |- |-|[下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fresnet50_w_abs_a_move_7665_9312.tar.gz) |
|channel_wise_abs_max|abs_max|76.56%/93.05% |- |-| [下载模型](https://paddle-slim-models.bj.bcebos.com/quantization%2Fresnet50_w_chan_a_abs_7656_9304.tar.gz)|
>训练超参:
优化器
```
fluid.optimizer.Momentum(momentum=0.9,
learning_rate=fluid.layers.piecewise_decay(
boundaries=[5000 * 12],
values=[0.0001, 0.00001]),
regularization=fluid.regularizer.L2Decay(1e-4))
```
8卡,batch size 1024,epoch 30, 挑选好的结果
## FAQ