add an article for text generation.
Showing
text_generation/README_cn.md
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
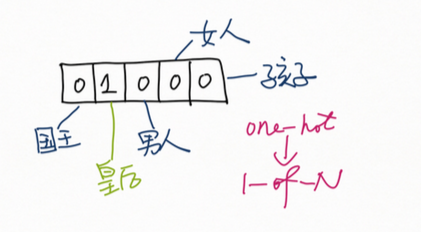
110.3 KB
{kind=link}
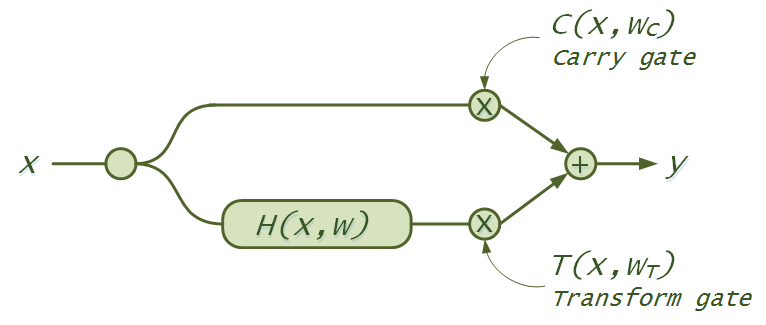
24.1 KB
{kind=link}
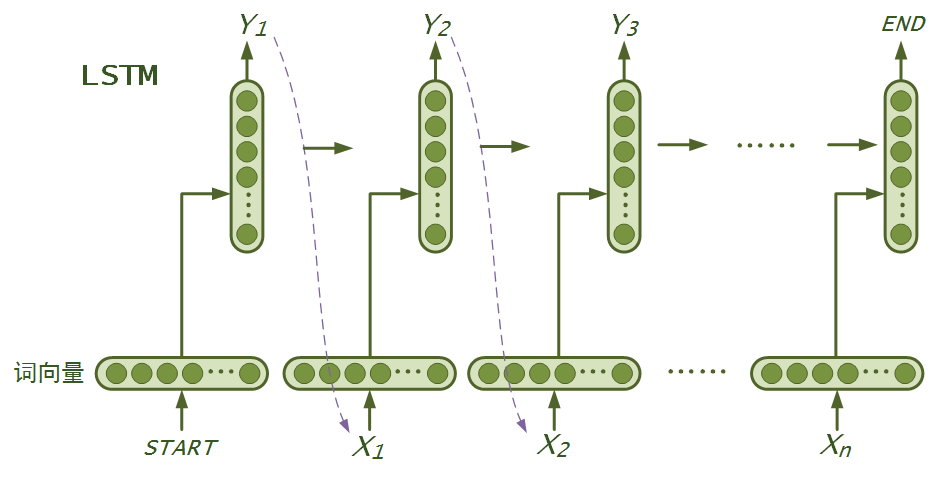
45.8 KB
{kind=link}
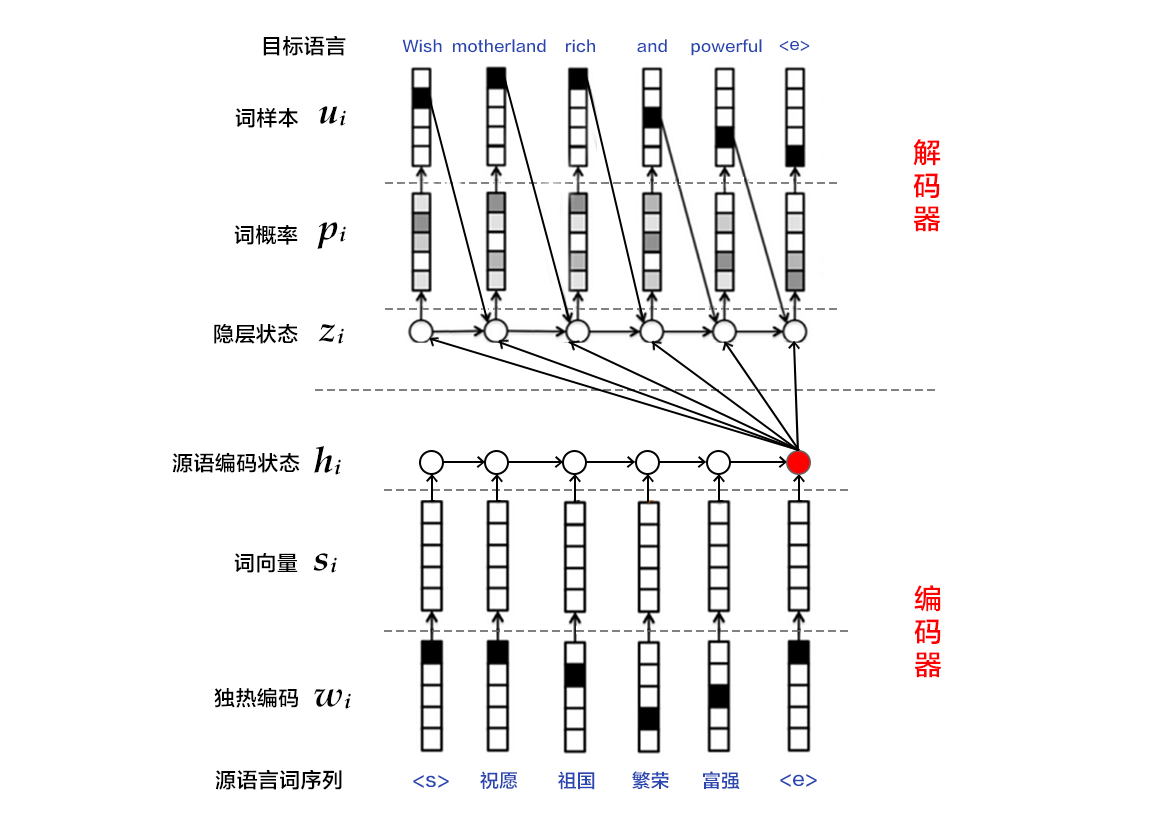
125.0 KB
{kind=link}
90.1 KB
{kind=link}
99.3 KB
{kind=link}
10.3 KB
{kind=link}

11.2 KB
{kind=link}
28.9 KB
{kind=link}
21.1 KB
{kind=link}
18.2 KB
{kind=link}
19.2 KB
{kind=link}

13.6 KB
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动