diff --git a/PaddleNLP/examples/text_classification/pretrained_models/README.md b/PaddleNLP/examples/text_classification/pretrained_models/README.md
index fe98917252615b6fb76ad597a2a7ef895c7813a8..0c69c91ba691c3d2a46efd2b8a8e97c482fbee61 100644
--- a/PaddleNLP/examples/text_classification/pretrained_models/README.md
+++ b/PaddleNLP/examples/text_classification/pretrained_models/README.md
@@ -14,8 +14,6 @@
+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
-+ Electra([ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://arxiv.org/abs/2003.10555)), 支持hidden_size=256的`chinese-electra-discriminator-small`和
- hidden_size=768的`chinese-electra-discriminator-base`
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
@@ -28,8 +26,6 @@
| roberta-wwm-ext-large | 0.95250 | 0.95333 |
| rbt3 | 0.92583 | 0.93250 |
| rbtl3 | 0.9341 | 0.93583 |
-| chinese-electra-base | 0.94500 | 0.94500 |
-| chinese-electra-small | 0.92417 | 0.93417 |
## 快速开始
diff --git a/PaddleNLP/examples/text_classification/pretrained_models/train.py b/PaddleNLP/examples/text_classification/pretrained_models/train.py
index 45308b5d430a744e11b5aa3c2603720dc0a7a947..d9585d2b83e5d08ac0ec714b87e322d137a69649 100644
--- a/PaddleNLP/examples/text_classification/pretrained_models/train.py
+++ b/PaddleNLP/examples/text_classification/pretrained_models/train.py
@@ -32,8 +32,6 @@ MODEL_CLASSES = {
ppnlp.transformers.ErnieTokenizer),
'roberta': (ppnlp.transformers.RobertaForSequenceClassification,
ppnlp.transformers.RobertaTokenizer),
- 'electra': (ppnlp.transformers.ElectraForSequenceClassification,
- ppnlp.transformers.ElectraTokenizer)
}
diff --git a/PaddleNLP/examples/text_classification/rnn/predict.py b/PaddleNLP/examples/text_classification/rnn/predict.py
index 312c3f8d846c5dc56c50497ebb16cee22da93a11..e8bfaa57beea04ac8b3a7bedcfd7e719c25b6f3d 100644
--- a/PaddleNLP/examples/text_classification/rnn/predict.py
+++ b/PaddleNLP/examples/text_classification/rnn/predict.py
@@ -23,7 +23,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--use_gpu", type=eval, default=False, help="Whether use GPU for training, input should be True or False")
parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number of a batch for training.")
parser.add_argument("--vocab_path", type=str, default="./word_dict.txt", help="The path to vocabulary.")
-parser.add_argument('--network_name', type=str, default="bilstm", help="Which network you would like to choose bow, lstm, bilstm, gru, bigru, rnn, birnn, bilstm_attn, cnn and textcnn?")
+parser.add_argument('--network', type=str, default="bilstm_attn", help="Which network you would like to choose bow, lstm, bilstm, gru, bigru, rnn, birnn, bilstm_attn, cnn and textcnn?")
parser.add_argument("--params_path", type=str, default='./chekpoints/final.pdparams', help="The path of model parameter to be loaded.")
args = parser.parse_args()
# yapf: enable
@@ -82,9 +82,7 @@ if __name__ == "__main__":
# Constructs the newtork.
model = ppnlp.models.Senta(
- network_name=args.network_name,
- vocab_size=len(vocab),
- num_classes=len(label_map))
+ network=args.network, vocab_size=len(vocab), num_classes=len(label_map))
# Loads model parameters.
state_dict = paddle.load(args.params_path)
diff --git a/PaddleNLP/examples/text_classification/rnn/train.py b/PaddleNLP/examples/text_classification/rnn/train.py
index cb811770456e98aec4eb8f2a5c3a98fc667be24b..4a3bb3cdcc3f942638a9509f4c7c127dc990d866 100644
--- a/PaddleNLP/examples/text_classification/rnn/train.py
+++ b/PaddleNLP/examples/text_classification/rnn/train.py
@@ -29,7 +29,7 @@ parser.add_argument("--lr", type=float, default=5e-4, help="Learning rate used t
parser.add_argument("--save_dir", type=str, default='chekpoints/', help="Directory to save model checkpoint")
parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number of a batch for training.")
parser.add_argument("--vocab_path", type=str, default="./word_dict.txt", help="The directory to dataset.")
-parser.add_argument('--network_name', type=str, default="bilstm", help="Which network you would like to choose bow, lstm, bilstm, gru, bigru, rnn, birnn, bilstm_attn and textcnn?")
+parser.add_argument('--network', type=str, default="bilstm_attn", help="Which network you would like to choose bow, lstm, bilstm, gru, bigru, rnn, birnn, bilstm_attn and textcnn?")
parser.add_argument("--init_from_ckpt", type=str, default=None, help="The path of checkpoint to be loaded.")
args = parser.parse_args()
# yapf: enable
@@ -88,7 +88,7 @@ if __name__ == "__main__":
# Constructs the newtork.
label_list = train_ds.get_labels()
model = ppnlp.models.Senta(
- network_name=args.network_name,
+ network=args.network,
vocab_size=len(vocab),
num_classes=len(label_list))
model = paddle.Model(model)
diff --git a/PaddleNLP/examples/text_matching/README.md b/PaddleNLP/examples/text_matching/README.md
index a875dcbc7cecf5ab210191a3796d2ae66380dea0..7b84d6b1959949e9214dc156de5b27384f22496c 100644
--- a/PaddleNLP/examples/text_matching/README.md
+++ b/PaddleNLP/examples/text_matching/README.md
@@ -1,4 +1,4 @@
-# Pointwise文本匹配
+# 文本匹配
**文本匹配一直是自然语言处理(NLP)领域一个基础且重要的方向,一般研究两段文本之间的关系。文本相似度计算、自然语言推理、问答系统、信息检索等,都可以看作针对不同数据和场景的文本匹配应用。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配,对话系统可以归结为前一句对话和回复的匹配,机器翻译则可以归结为两种语言的匹配。**
@@ -12,18 +12,15 @@
-文本匹配任务可以分为pointwise和pairwise类型。
+文本匹配任务数据每一个样本通常由两个文本组成(query,title)。类别形式为0或1,0表示query与title不匹配; 1表示匹配。
-pointwise,每一个样本通常由两个文本组成(query,title)。类别形式为0或1,0表示query与title不匹配; 1表示匹配。
-pairwise,每一个样本通常由三个文本组成(query,positive_title, negative_title)。positive_title比negative_title更加匹配query。
-根据本数据集示例,该匹配任务为pointwise类型。
-该项目展示了使用传统的[SimNet](./simnet) 和 [SentenceBert](./sentence_bert)两种方法完成pointwise本匹配任务。
+该项目展示了使用传统的[SimNet](./simnet) 和 [SentenceBert](./sentence_bert)两种方法完成本匹配任务。
-## Conventional Models
+## SimNet
-[SimNet](./simnet) 展示了如何使用CNN、LSTM、GRU等网络完成pointwise文本匹配任务。
+[SimNet](./simnet) 展示了如何使用CNN、LSTM、GRU等网络完成文本匹配任务。
-## Pretrained Model (PTMs)
+## Sentence Transformers
-[Sentence Transformers](./sentence_transformers) 展示了如何使用以ERNIE为代表的模型Fine-tune完成pointwise文本匹配任务。
+[Sentence Transformers](./sentence_transformers) 展示了如何使用以ERNIE为代表的模型Fine-tune完成文本匹配任务。
diff --git a/PaddleNLP/examples/text_matching/sentence_transformers/README.md b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
index 83871a18a22e529f82fe14d5bdb05eacd0981aaa..12b022e00b6e08110c4d5895bcab515a884c758e 100644
--- a/PaddleNLP/examples/text_matching/sentence_transformers/README.md
+++ b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
@@ -1,4 +1,4 @@
-# 使用预训练模型Fine-tune完成pointwise中文文本匹配任务
+# 使用预训练模型Fine-tune完成中文文本匹配任务
随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
@@ -8,7 +8,7 @@
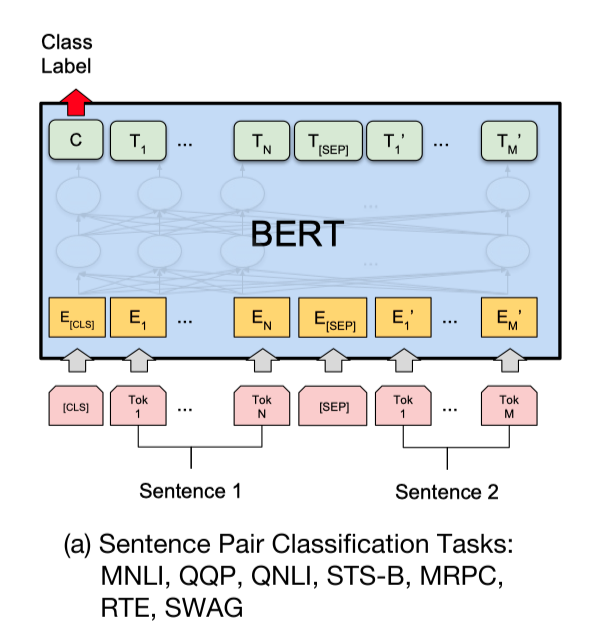
 -使用预训练模型ERNIE完成pointwise文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
+使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
-使用预训练模型ERNIE完成pointwise文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
+使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
@@ -42,23 +42,18 @@ PaddleNLP提供了丰富的预训练模型,并且可以便捷地获取PaddlePa
+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
-+ Electra([ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://arxiv.org/abs/2003.10555)), 支持hidden_size=256的`chinese-electra-discriminator-small`和
- hidden_size=768的`chinese-electra-discriminator-base`
## TODO 增加模型效果
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
| bert-base-chinese | 0.86537 | 0.84440 |
| bert-wwm-chinese | 0.86333 | 0.84128 |
-| bert-wwm-ext-chinese | | |
+| bert-wwm-ext-chinese | 0.86049 | 0.83848 |
| ernie | 0.87480 | 0.84760 |
| ernie-tiny | 0.86071 | 0.83352 |
-| roberta-wwm-ext | | |
-| roberta-wwm-ext-large | | |
-| rbt3 | | |
-| rbtl3 | | |
-| chinese-electra-discriminator-base | | |
-| chinese-electra-discriminator-small | | |
+| roberta-wwm-ext | 0.87526 | 0.84904 |
+| rbt3 | 0.85367 | 0.83464 |
+| rbtl3 | 0.85174 | 0.83744 |
## 快速开始
diff --git a/PaddleNLP/examples/text_matching/sentence_transformers/train.py b/PaddleNLP/examples/text_matching/sentence_transformers/train.py
index c9a1d46b968ebef981fae5b8cffc45f1d240fac3..f67ed78e727952c52c7f3c194b0ecec97d0f4d4b 100644
--- a/PaddleNLP/examples/text_matching/sentence_transformers/train.py
+++ b/PaddleNLP/examples/text_matching/sentence_transformers/train.py
@@ -32,7 +32,6 @@ MODEL_CLASSES = {
'ernie': (ppnlp.transformers.ErnieModel, ppnlp.transformers.ErnieTokenizer),
'roberta': (ppnlp.transformers.RobertaModel,
ppnlp.transformers.RobertaTokenizer),
- 'electra': (ppnlp.transformers.Electra, ppnlp.transformers.ElectraTokenizer)
}
diff --git a/PaddleNLP/examples/text_matching/simnet/README.md b/PaddleNLP/examples/text_matching/simnet/README.md
index 111f836e21601303de6bf588f176206756f4668b..ac3aa710c26ccc891156afc514b988393a975f27 100644
--- a/PaddleNLP/examples/text_matching/simnet/README.md
+++ b/PaddleNLP/examples/text_matching/simnet/README.md
@@ -1,4 +1,4 @@
-# 使用SimNet完成pointwise文本匹配任务
+# 使用SimNet完成文本匹配任务
短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。
SimNet框架在百度各产品上广泛应用,主要包括BOW、CNN、RNN、MMDNN等核心网络结构形式,提供语义相似度计算训练和预测框架,
@@ -21,10 +21,10 @@ SimNet框架在百度各产品上广泛应用,主要包括BOW、CNN、RNN、MM
## TBD 增加模型效果
| 模型 | dev acc | test acc |
| ---- | ------- | -------- |
-| BoW | | |
-| CNN | | |
-| GRU | | |
-| LSTM | | |
+| BoW | 0.7290 | 0.75232 |
+| CNN | 0.7042 | 0.73760 |
+| GRU | 0.7781 | 0.77808 |
+| LSTM | 0.73760 | 0.77320 |
@@ -91,7 +91,7 @@ query title label
wget https://paddlenlp.bj.bcebos.com/data/simnet_word_dict.txt
```
-我们以中文pointwise文本匹配数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
+我们以中文文本匹配数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
CPU启动:
diff --git a/PaddleNLP/examples/text_matching/simnet/predict.py b/PaddleNLP/examples/text_matching/simnet/predict.py
index 07e252aa4c4297585c914f1a5f0fd8ff86a7f0f1..73393d31d421f7a2a09e32d1ec789991b5e0e814 100644
--- a/PaddleNLP/examples/text_matching/simnet/predict.py
+++ b/PaddleNLP/examples/text_matching/simnet/predict.py
@@ -25,7 +25,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--use_gpu", type=eval, default=False, help="Whether use GPU for training, input should be True or False")
parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number of a batch for training.")
parser.add_argument("--vocab_path", type=str, default="./data/term2id.dict", help="The path to vocabulary.")
-parser.add_argument('--network_name', type=str, default="lstm", help="Which network you would like to choose bow, cnn, lstm or gru ?")
+parser.add_argument('--network', type=str, default="lstm", help="Which network you would like to choose bow, cnn, lstm or gru ?")
parser.add_argument("--params_path", type=str, default='./chekpoints/final.pdparams', help="The path of model parameter to be loaded.")
args = parser.parse_args()
# yapf: enable
@@ -86,9 +86,7 @@ if __name__ == "__main__":
# Constructs the newtork.
model = ppnlp.models.SimNet(
- network_name=args.network_name,
- vocab_size=len(vocab),
- num_classes=len(label_map))
+ network=args.network, vocab_size=len(vocab), num_classes=len(label_map))
# Loads model parameters.
state_dict = paddle.load(args.params_path)