Human-machine conversation is one of the most important topics in artificial intelligence (AI) and has received much attention across academia and industry in recent years. Currently dialogue system is still in its infancy, which usually converses passively and utters their words more as a matter of response rather than on their own initiatives, which is different from human-human conversation. Therefore, we set up this competition on a new conversation task, named knowledge driven dialogue, where machines converse with humans based on a built knowledge graph. It aims at testing machines’ ability to conduct human-like conversations.<br>
Human-machine conversation is one of the most important topics in artificial intelligence (AI) and has received much attention across academia and industry in recent years. Currently dialogue system is still in its infancy, which usually converses passively and utters their words more as a matter of response rather than on their own initiatives, which is different from human-human conversation. We believe that the ability of proactive conversation of machine is the breakthrough of human-like conversation.
Please refer to [competition website](http://lic2019.ccf.org.cn/talk) for details of the competition.
# about the task
# What we do ?
Given a dialogue goal g and a set of topic-related background knowledge M = f<sub>1</sub> ,f<sub>2</sub> ,..., f<sub>n</sub> , a participating system is expected to output an utterance "u<sub>t</sub>" for the current conversation H = u<sub>1</sub>, u<sub>2</sub>, ..., u<sub>t-1</sub>, which keeps the conversation coherent and informative under the guidance of the given goal. During the dialogue, a participating system is required to proactively lead the conversation from one topic to another. The dialog goal g is given like this: "Start->Topic_A->TOPIC_B", which means the machine should lead the conversation from any start state to topic A and then to topic B. The given background knowledge includes knowledge related to topic A and topic B, and the relations between these two topics.<br>
* We set up a new conversation task, named ___Proactive Converstion___, where machine proactively leads the conversation following a given goal.
Please refer to [task description](https://github.com/baidu/knowledge-driven-dialogue/blob/master/task_description.pdf) for details of the task.
* We also created a new conversation dataset named [DuConv](https://ai.baidu.com/broad/subordinate?dataset=duconv) , and made it publicly available to facilitate the development of proactive conversation systems.
# about the baseline
* We established retrival-based and generation-based ___baseline systems___ for DuConv, which are available in this repo.
We provide retrieval-based and generation-based baseline systems. Both systems were implemented by [PaddlePaddle](http://paddlepaddle.org/)(the Baidu deeplearning framework) and [Pytorch](https://pytorch.org/)(the Facebook deeplearning framework). The performance of the two systems is as follows:
* In addition, we hold ___competitions___ to encourage more researchers to work in this direction.
# Paper
*[Proactive Human-Machine Conversation with Explicit Conversation Goals](https://arxiv.org/abs/1906.05572), accepted by ACL 2019
# Task Description
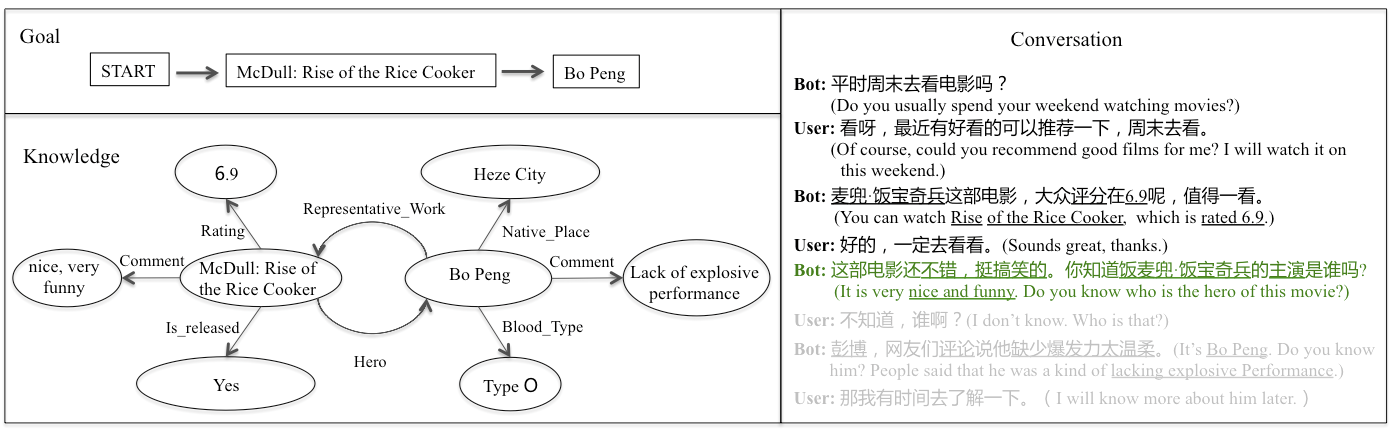
Given a dialogue goal g and a set of topic-related background knowledge M = f<sub>1</sub> ,f<sub>2</sub> ,..., f<sub>n</sub> , the system is expected to output an utterance "u<sub>t</sub>" for the current conversation H = u<sub>1</sub>, u<sub>2</sub>, ..., u<sub>t-1</sub>, which keeps the conversation coherent and informative under the guidance of the given goal. During the dialogue, the system is required to proactively lead the conversation from one topic to another. The dialog goal g is given like this: "Start->Topic_A->TOPIC_B", which means the machine should lead the conversation from any start state to topic A and then to topic B. The given background knowledge includes knowledge related to topic A and topic B, and the relations between these two topics.<br>
*Figure1.Proactive Conversation Case. Each utterance of "BOT" could be predicted by system, e.g., utterances with black words represent history H,and utterance with green words represent the response u<sub>t</sub> predicted by system.*
# DuConv
We collected around 30k conversations containing 270k utterances named DuConv. Each conversation was created by two random selected crowdsourced workers. One worker was provided with dialogue goal and the associated knowledge to play the role of leader who proactively leads the conversation by sequentially change the discussion topics following the given goal, meanwhile keeping the conversation as natural and engaging as possible. Another worker was provided with nothing but conversation history and only has to respond to the leader. <br>
We devide the collected conversations into training, development, test1 and test2 splits. The test1 part with reference response is used for local testing such as the automatic evaluation of our paper. The test2 part without reference response is used for online testing such as the [competition](http://lic2019.ccf.org.cn/talk) we had held and the ___Leader Board___ which is opened forever in https://ai.baidu.com/broad/leaderboard?dataset=duconv. The dataset is available at https://ai.baidu.com/broad/subordinate?dataset=duconv.
# Baseline Performance
We provide retrieval-based and generation-based baseline systems. Both systems were implemented by [PaddlePaddle](http://paddlepaddle.org/)(the Baidu deeplearning framework). The performance of the two systems is as follows:
| baseline system | F1/BLEU1/BLEU2 | DISTINCT1/DISTINCT2 |
| baseline system | F1/BLEU1/BLEU2 | DISTINCT1/DISTINCT2 |
*[Knowledge-driven Dialogue task](http://lic2019.ccf.org.cn/talk) in [2019 Language and Intelligence Challenge](http://lic2019.ccf.org.cn/), has been closed.
* Teams number of registration:1536
* Teams number of submission result: 178
* The Top 3 results:
| Rank | F1/BLEU1/BLEU2 | DISTINCT1/DISTINCT2 |
| ------------- | ------------ | ------------ |
| 1 | 49.22/0.449/0.318 | 0.118/0.299 |
| 2 | 47.76/0.430/0.296 | 0.110/0.275 |
| 3 | 46.40/0.422/0.289 | 0.118/0.303 |
*[Leader Board](https://ai.baidu.com/broad/leaderboard?dataset=duconv), is opened forever <br>
We maintain a leader board which provides the official automatic evaluation. You can submit your result to https://ai.baidu.com/broad/submission?dataset=duconv to get the official result. Please make sure submit the result of test2 part.
This is a paddlepaddle implementation of generative-based model for knowledge-driven dialogue
## Requirements
* cuda=9.0
* cudnn=7.0
* python=2.7
* numpy
* paddlepaddle>=1.3.2
## Quickstart
### Step 1: Preprocess the data
Put the data of [DuConv](https://ai.baidu.com/broad/subordinate?dataset=duconv) under the data folder and rename them train/dev/test.txt:
```
./data/resource/train.txt
./data/resource/dev.txt
./data/resource/test.txt
```
### Step 2: Train the model
Train model with the following commands.
```bash
sh run_train.sh
```
### Step 3: Test the Model
Test model with the following commands.
```bash
sh run_test.sh
```
### Note !!!
* The script run_train.sh/run_test.sh shows all the processes including data processing and model training/testing. Be sure to read it carefully and follow it.
* The files in ./data and ./model is just empty file to show the structure of the document.
This is a paddlepaddle implementation of retrieval-based model for knowledge-driven dialogue
## Requirements
* cuda=9.0
* cudnn=7.0
* python=2.7
* numpy
* paddlepaddle>=1.3
## Quickstart
### Step 1: Preprocess the data
Put the data of [DuConv](https://ai.baidu.com/broad/subordinate?dataset=duconv) under the data folder and rename them train/dev/test.txt:
```
./data/resource/train.txt
./data/resource/dev.txt
./data/resource/test.txt
```
### Step 2: Train the model
Train model with the following commands.
```bash
sh run_train.sh model_name
```
3 models were supported:
- match: match, input is history and response
- match_kn: match_kn, input is history, response, chat_path, knowledge
- match_kn_gene: match_kn, input is history, response, chat_path, knowledge and generalizes target_a/target_b of goal for all inputs, replaces them with slot mark
### Step 3: Test the Model
Test model with the following commands.
```bash
sh run_test.sh model_name
```
## Note !!!
* The script run_train.sh/run_test.sh shows all the processes including data processing and model training/testing. Be sure to read it carefully and follow it.
* The files in ./data and ./model is just empty file to show the structure of the document.
{kind=link}