Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
c50969ff
M
models
项目概览
PaddlePaddle
/
models
大约 1 年 前同步成功
通知
222
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
c50969ff
编写于
2月 22, 2019
作者:
D
dengkaipeng
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add video doc.
上级
cf4bafc7
变更
9
显示空白变更内容
内联
并排
Showing
9 changed file
with
666 addition
and
6 deletion
+666
-6
fluid/PaddleCV/video/README.md
fluid/PaddleCV/video/README.md
+144
-6
fluid/PaddleCV/video/dataset/README.md
fluid/PaddleCV/video/dataset/README.md
+99
-0
fluid/PaddleCV/video/images/StNet.png
fluid/PaddleCV/video/images/StNet.png
+0
-0
fluid/PaddleCV/video/images/attention_cluster.png
fluid/PaddleCV/video/images/attention_cluster.png
+0
-0
fluid/PaddleCV/video/models/attention_cluster/README.md
fluid/PaddleCV/video/models/attention_cluster/README.md
+98
-0
fluid/PaddleCV/video/models/attention_lstm/README.md
fluid/PaddleCV/video/models/attention_lstm/README.md
+90
-0
fluid/PaddleCV/video/models/nextvlad/README.md
fluid/PaddleCV/video/models/nextvlad/README.md
+66
-0
fluid/PaddleCV/video/models/stnet/README.md
fluid/PaddleCV/video/models/stnet/README.md
+91
-0
fluid/PaddleCV/video/models/tsn/README.md
fluid/PaddleCV/video/models/tsn/README.md
+78
-0
未找到文件。
fluid/PaddleCV/video/README.md
浏览文件 @
c50969ff
# VideoClassification
Video Classification
# Paddle视频模型库
---
## 内容
-
[
安装
](
#安装
)
-
[
简介
](
#简介
)
-
[
数据准备
](
#数据准备
)
-
[
模型库使用
](
#模型库使用
)
-
[
模型简介
](
#模型简介
)
## 安装
在当前模型库运行样例代码需要PadddlePaddle Fluid的v.1.2.0或以上的版本。如果你的运行环境中的PaddlePaddle低于此版本,请根据
[
安装文档
](
http://www.paddlepaddle.org/documentation/docs/zh/1.2/beginners_guide/install/index_cn.html
)
中的说明来更新PaddlePaddle。
## 简介
本次发布的是Paddle视频模型库第一期,包括五个视频分类模型。后续我们将会扩展到视频理解方向的更多应用场景以及视频编辑和生成等方向,以便为开发者提供简单、便捷的使用深度学习算法处理视频的途径。
Paddle视频模型库第一期主要包含如下模型。
| 模型 | 类别 | 描述 |
| :---------------: | :--------: | :------------: |
| Attention Cluster | 视频分类| 百度自研模型,Kinetics600第一名最佳序列模型 |
| Attention LSTM | 视频分类| 常用模型,速度快精度高 |
| NeXtVLAD| 视频分类| 2nd-Youtube-8M最优单模型 |
| StNet| 视频分类| 百度自研模型,Kinetics600第一名模型之一 |
| TSN | 视频分类| 基于2D-CNN经典解决方案 |
## 数据准备
视频模型库使用Youtube-8M和Kinetics数据集, 具体使用方法请参考请参考
[
数据说明
](
./dataset/README.md
)
## 模型库使用
视频模型库提供通用的train/test/infer框架,通过
`train.py/test.py/infer.py`
指定模型名、模型配置参数等可一键式进行训练和预测。
视频库目前支持的模型名如下:
1.
AttentionCluster
2.
AttentionLSTM
3.
NEXTVLAD
4.
STNET
5.
TSN
Paddle提供默认配置文件位于
`./configs`
文件夹下,五种模型对应配置文件如下:
1.
attention
\_
cluster.txt
2.
attention
\_
lstm.txt
3.
nextvlad.txt
4.
stnet.txt
5.
tsn.txt
### 一、模型训练
**预训练模型下载:**
视频模型库中StNet和TSN模型需要下载Resnet-50预训练模型,运行训练脚本会自动从
[
Resnet-50_pretrained
](
https://paddlemodels.bj.bcebos.com/video_classification/ResNet50_pretrained.tar.gz
)
下载预训练模型,存储于 ~/.paddle/weights/ 目录下,若该目录下已有已下载好的预训练模型,模型库会直接加载该预训练模型权重。
数据准备完毕后,可通过两种方式启动模型训练:
python train.py --model-name=$MODEL_NAME --config=$CONFIG
--save-dir=checkpoints --epoch=10 --log-interval=10 --valid-interval=1
bash scripts/train/train_${MODEL_NAME}.sh
-
通过设置export CUDA
\_
VISIBLE
\_
DEVICES=0,1,2,3,4,5,6,7指定GPU卡训练。
-
可选参数见:
```
python train.py --help
```
-
指定预训练模型可通过如下命令实现:
```
python train.py --model-name=<$MODEL_NAME> --config=<$CONFIG>
--pretrain=$PATH_TO_PRETRAIN
```
-
恢复训练模型可通过如下命令实现:
```
python train.py --model-name=<$MODEL_NAME> --config=<$CONFIG>
--resume=$PATH_TO_RESUME_WEIGHTS
```
### 二、模型评估
数据准备完毕后,可通过两种方式启动模型评估:
python test.py --model-name=$MODEL_NAME --config=$CONFIG
--log-interval=1 --weights=$PATH_TO_WEIGHTS
bash scripts/test/test_${MODEL_NAME}.sh
-
通过设置export CUDA
\_
VISIBLE
\_
DEVICES=0使用GPU单卡评估。
-
可选参数见:
```
python test.py --help
```
-
若模型评估未指定
`--weights`
参数,模型库会自动从
[
PaddleModels
](
https://paddlemodels.bj.bcebos.com
)
下载各模型已训练的Paddle release权重并完成模型评估,权重存储于
`~/.paddle/weights/`
目录下,若该目录下已有已下载好的预训练模型,模型库会直接加载该模型权重。
模型库各模型评估精度如下:
| 模型 | 数据集 | 精度类别 | 精度 |
| :---------------: | :-----------: | :-------: | :------: |
| AttentionCluster | Youtube-8M | GAP | 0.84 |
| AttentionLSTM | Youtube-8M | GAP | 0.86 |
| NeXtVLAD | Youtube=8M | GAP | 0.87 |
| stNet | Kinetics | Hit@1 | 0.69 |
| TSN | Kinetics | Hit@1 | 0.66 |
### 三、模型推断
模型推断可以通过各模型预测指定filelist中视频文件的类别,通过
`infer.py`
进行推断,可通过如下命令运行:
python infer.py --model-name=$MODEL_NAME --config=$CONFIG
--log-interval=1 --weights=$PATH_TO_WEIGHTS --filelist=$FILELIST
模型推断结果存储于
`${MODEL_NAME}_infer_result`
中,通过
`pickle`
格式存储。
-
通过设置export CUDA
\_
VISIBLE
\_
DEVICES=0使用GPU单卡推断。
-
可选参数见:
```
python infer.py --help
```
-
若模型推断未使用
`--weights`
参数,模型库会自动下载Paddle release训练权重,参考
[
模型评估
](
#二、模型评估
)
-
若模型推断未使用
`--filelist`
参数,则使用指定配置文件中配置的
`filelist`
。
## 模型简介
模型库各模型简介请参考:
1.
[
AttentionCluster
](
./models/attention_cluster/README.md
)
2.
[
AttentionLSTM
](
./models/attention_lstm/README.md
)
3.
[
NeXtVLAD
](
./models/nextvlad/README.md
)
4.
[
StNet
](
./models/stnet/README.md
)
5.
[
TSN
](
./models/tsn/README.md
)
To run train:
bash ./scripts/train/train_${model_name}.sh
To run test:
bash ./scripts/test/test_${model_name}.sh
fluid/PaddleCV/video/dataset/README.md
0 → 100644
浏览文件 @
c50969ff
# 数据使用说明
Paddle视频模型库同时涵盖了youtube8m和kinetics两种数据集。其中Attention Cluster、LSTM和NeXtVLAD使用2nd-Youtube-8M数据集,stNet和TSN使用kinetics400数据集。
## Youtube-8M数据集
这里我们用到的是YouTube-8M 2018年更新之后的数据集。使用官方数据集,并将tfrecord文件转化为pickle文件以便paddle使用。Youtube-8M数据集官方提供了frame-level和video-level的特征,我们这里只需使用到frame-level的特征。
### 数据下载
请使用Youtube-8M官方链接分别下载
[
训练集
](
http://us.data.yt8m.org/2/frame/train/index.html
)
和
[
验证集
](
http://us.data.yt8m.org/2/frame/validate/index.html
)
。每个链接里各提供了3844个文件的下载地址,用户也可以使用官方提供的
[
下载脚本
](
https://research.google.com/youtube8m/download.html
)
下载数据。数据下载完成后,将会得到3844个训练数据文件和3844个验证数据文件(tfrecord格式)。
假设存放当前代码库的主目录为: Code_Base_Root,进入dataset/youtube8m目录
cd dataset/youtube8m
在youtube8m下新建目录tf/train和tf/val
mkdir tf && cd tf
mkdir train && mkdir val
并分别将下载的train和validate数据存放在其中。
### 数据格式转化
为了适用于Fluid训练,我们离线将下载好的tfrecord文件格式转成了pickle格式,转换脚本请使用
[
dataset/youtube8m/tf2pkl.py
](
./dataset/youtube8m/tf2pkl.py
)
。
在dataset/youtube8m 目录下新建目录pkl/train和pkl/val
cd dataset/youtube8m
mkdir pkl && cd pkl
mkdir train && mkdir val
转化文件格式(tfrecord -> pkl),进入dataset/youtube8m目录,运行脚本
python tf2pkl.py ./tf/train ./pkl/train
和
python tf2pkl.py ./tf/val ./pkl/val
分别将train和validate数据集转化为pkl文件。tf2pkl.py文件运行时需要两个参数,分别是数据源tf文件存放路径和转化后的pkl文件存放路径。
备注:由于tfrecord文件的读取需要用到tensorflow,用户要先安装tensorflow,或者在安装有tensorflow的环境中转化完数据,再拷贝到dataset/youtube8m/pkl目录下。为了避免和paddle环境冲突,我们建议先在其他地方转化完成再将数据拷贝过来。
### 生成文件列表
进入dataset/youtube8m目录
ls ${Code_Base_Root}/dataset/youtube8m/pkl/train/* > train.list
ls ${Code_Base_Root}/dataset/youtube8m/pkl/val/* > val.list
在dataset/youtube8m目录下将生成两个文件,train.list和val.list,每一行分别保存了一个pkl文件的绝对路径。
## Kinetics数据集
Kinetics数据集是DeepMind公开的大规模视频动作识别数据集,有Kinetics400与Kinetics600两个版本。这里我们使用Kinetics400数据集,具体的数据预处理过程如下。
### mp4视频下载
在Code_Base_Root目录下创建文件夹
cd ${Code_Base_Root}/dataset && mkdir kinetics
cd kinetics && mkdir data_k400 && cd data_k400
mkdir train_mp4 && mkdir val_mp4
ActivityNet官方提供了Kinetics的下载工具,具体参考其
[
官方repo
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics
)
即可下载Kinetics400的mp4视频集合。将kinetics400的训练与验证集合分别下载到dataset/kinetics/data_k400/train_mp4与dataset/kinetics/data_k400/val_mp4。
### mp4文件预处理
为提高数据读取速度,我们提前将mp4文件解帧并打pickle包,dataloader从视频的pkl文件中读取数据(该方法耗费更多存储空间)。pkl文件里打包的内容为(video-id,[frame1, frame2,...,frameN],label)。
在 dataset/kinetics/data_k400目录下创建目录train_pkl和val_pkl
cd ${Code_Base_Root}/dataset/kinetics/data_k400
mkdir train_pkl && mkdir val_pkl
进入${Code_Base_Root}/dataset/kinetics目录,使用video2pkl.py脚本进行数据转化。首先需要下载
[
train
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics/data/kinetics-400_train.csv
)
和
[
validation
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics/data/kinetics-400_val.csv
)
数据集的文件列表。
执行如下程序:
python video2pkl.py kinetics-400_train.csv $Source_dir $Target_dir 8 #以8个进程为例
对于train数据,
Source_dir = ${Code_Base_Root}/dataset/kinetics/data_k400/train_mp4
Target_dir = ${Code_Base_Root}/dataset/kinetics/data_k400/train_pkl
对于val数据,
Source_dir = ${Code_Base_Root}/dataset/kinetics/data_k400/val_mp4
Target_dir = ${Code_Base_Root}/dataset/kinetics/data_k400/val_pkl
这样即可将mp4文件解码并保存为pkl文件。
### 生成训练和验证集合list
cd ${Code_Base_Root}/dataset/kinetics
ls ${Code_Base_Root}/dataset/kinetics/data_k400/train_pkl /
*
> train.list
ls ${Code_Base_Root}/dataset/kinetics/data_k400/val_pkl /
*
> val.list
即可生成相应的文件列表,train.list和val.list的每一行表示一个pkl文件的绝对路径。
fluid/PaddleCV/video/images/StNet.png
0 → 100644
浏览文件 @
c50969ff
195.9 KB
fluid/PaddleCV/video/images/attention_cluster.png
0 → 100644
浏览文件 @
c50969ff
598.0 KB
fluid/PaddleCV/video/models/attention_cluster/README.md
0 → 100644
浏览文件 @
c50969ff
# Attention Cluster 视频分类模型
---
## 内容
-
[
模型简介
](
#简介
)
-
[
数据准备
](
#数据准备
)
-
[
模型训练
](
#模型训练
)
-
[
模型评估
](
#模型评估
)
-
[
模型推断
](
#模型推断
)
## 简介
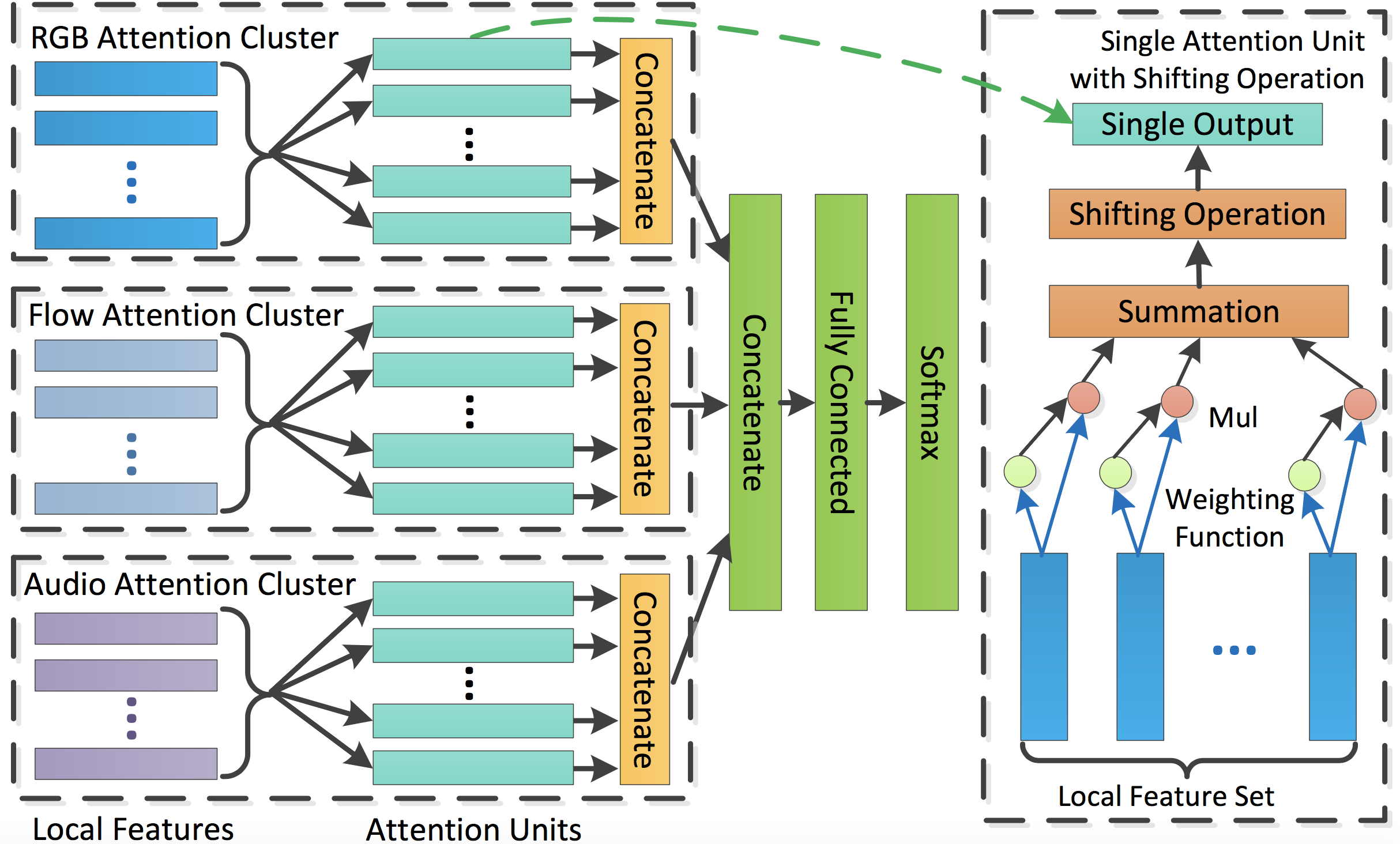
Attention Cluster为百度自研模型,该模型是ActivityNet Kinetics Challenge 2017中最佳序列模型。该模型通过带Shifting Opeation的Attention Clusters处理已抽取好的RGB、Flow、Audio数据,Attention Cluster结构如下图所示。
<p
align=
"center"
>
<img
src=
"../../images/attention_cluster.png"
height=
300
width=
400
hspace=
'10'
/>
<br
/>
Multimodal Attention Cluster with Shifting Operation
</p>
详细内容请参考
[
Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification
](
https://arxiv.org/abs/1711.09550
)
## 数据准备
Attention Cluster模型使用2nd-Youtube-8M数据集, 数据下载及准备请参考
[
数据说明
](
../../dataset/README.md
)
## 模型训练
数据准备完毕后,可以通过如下两种方式启动训练:
python train.py --model-name=AttentionCluster
--config=./configs/attention_cluster.txt
--save-dir=checkpoints
--epoch=8
--log-interval=10
--valid-interval=1
bash scripts/train/train_attention_cluster.sh
-
可下载Paddle release权重
[
PaddleAttentionCluster
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_cluster_youtube8m.tar.gz
)
通过
`--pretrain`
指定权重存放路径进行finetune等开发
**数据读取器说明:**
模型读取Youtube-8M数据集中已抽取好的
`rgb`
和
`audio`
数据,对于每个视频的数据,均匀采样100帧,该值由配置文件中的
`seg_num`
参数指定。
**模型设置:**
模型主要可配置参数为
`cluster_nums`
和
`seg_num`
参数,当配置
`cluster_nums`
为32,
`seg_num`
为100时,在Nvidia Tesla P40上单卡可跑
`batch_size=256`
。
**训练策略:**
*
采用Adam优化器,初始learning
\_
rate=0.001。
*
训练过程中不使用权重衰减。
*
参数主要使用MSRA初始化
## 模型评估
可通过如下两种方式进行模型评估:
python test.py --model-name=AttentionCluster
--config=configs/attention_cluster.txt
--log-interval=1 --weights=$PATH_TO_WEIGHTS
bash scripts/test/test_attention_cluster.sh
-
使用
`scripts/test/test_attention_cluster.sh`
进行评估时,需要修改脚本中的
`--weights`
参数指定需要评估的权重。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleAttentionCluster
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_cluster_youtube8m.tar.gz
)
进行评估
当取如下参数时:
| 参数 | 取值 |
| :---------: | :----: |
| cluster
\_
nums | 32 |
| seg
\_
num | 100 |
| batch
\_
size | 2048 |
| nums
\_
gpu | 7 |
在2nd-YouTube-8M数据集下评估精度如下:
| 精度指标 | 模型精度 |
| :---------: | :----: |
| Hit@1 | 0.87 |
| PERR | 0.78 |
| GAP | 0.84 |
## 模型推断
可通过如下命令进行模型推断:
python infer.py --model-name=attention_cluster
--config=configs/attention_cluster.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
-
模型推断结果存储于
`AttentionCluster_infer_result`
中,通过
`pickle`
格式存储。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleAttentionCluster
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_cluster_youtube8m.tar.gz
)
进行推断
fluid/PaddleCV/video/models/attention_lstm/README.md
0 → 100644
浏览文件 @
c50969ff
# AttentionLSTM视频分类模型
--
## 内容
-
[
模型简介
](
#简介
)
-
[
数据准备
](
#数据准备
)
-
[
模型训练
](
#模型训练
)
-
[
模型评估
](
#模型评估
)
-
[
模型推断
](
#模型推断
)
## 模型简介
递归神经网络(RNN)常用于序列数据的处理,可建模视频连续多帧的时序信息,在视频分类领域为基础常用方法。该模型采用了双向长短记忆网络(LSTM),将视频的所有帧特征依次编码。与传统方法直接采用LSTM最后一个时刻的输出不同,该模型增加了一个Attention层,每个时刻的隐状态输出都有一个自适应权重,然后线性加权得到最终特征向量。论文中实现的是两层LSTM结构,而本代码实现的是带Attention的双向LSTM,Attention层可参考论文
[
AttentionCluster
](
https://arxiv.org/abs/1711.09550
)
。
详细内容请参考
[
Beyond Short Snippets: Deep Networks for Video Classification
](
https://arxiv.org/abs/1503.08909
)
。
## 数据准备
AttentionLSTM模型使用2nd-Youtube-8M数据集,关于数据本分请参考
[
数据说明
](
../../dataset/README.md
)
## 模型训练
### 随机初始化开始训练
数据准备完毕后,可以通过如下两种方式启动训练:
python train.py --model-name=AttentionLSTM
--config=./configs/attention_lstm.txt
--save-dir=checkpoints
--epoch=10
--log-interval=10
--valid-interval=1
bash scripts/train/train_attention_lstm.sh
-
AttentionLSTM模型使用8卡Nvidia Tesla P40来训练的,总的batch size数是1024。
### 使用我们提供的预训练模型做finetune
请先将我们提供的
[
PaddleAttentionLSTM
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_lstm_youtube8m.tar.gz
)
下载到本地,并在上述脚本文件中添加
`--resume`
为所保存的预模型存放路径。
## 模型评估
可通过如下两种方式进行模型评估:
python test.py --model-name=AttentionLSTM
--config=configs/attention_lstm.txt
--log-interval=1 --weights=$PATH_TO_WEIGHTS
bash scripts/test/test_attention_lstm.sh
-
使用
`scripts/test/test_attention_LSTM.sh`
进行评估时,需要修改脚本中的
`--weights`
参数指定需要评估的权重。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleAttentionCluster
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_lstm_youtube8m.tar.gz
)
进行评估
使用Paddle Fluid实现了论文中的单模型结构,使用2nd-Youtube-8M的train数据集作为训练集,在val数据集上做测试。
模型参数列表如下:
| 参数 | 取值 |
| :---------: | :----: |
| embedding
\_
size | 512 |
| lstm
\_
size | 1024 |
| drop
\_
rate | 0.5 |
计算指标列表如下:
| 精度指标 | 模型精度 |
| :---------: | :----: |
| Hit@1 | 0.8885 |
| PERR | 0.8012 |
| GAP | 0.8594 |
## 模型推断
可通过如下命令进行模型推断:
python infer.py --model-name=attention_lstm
--config=configs/attention_lstm.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
-
模型推断结果存储于
`AttentionLSTM_infer_result`
中,通过
`pickle`
格式存储。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleAttentionLSTM
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_lstm_youtube8m.tar.gz
)
进行推断
fluid/PaddleCV/video/models/nextvlad/README.md
0 → 100644
浏览文件 @
c50969ff
# NeXtVLAD视频分类模型
## 1 模型简介
NeXtVLAD模型是第二届Youtube-8M视频理解竞赛中效果最好的单模型,在参数量小于80M的情况下,能得到高于0.87的GAP指标。该模型提供了一种将桢级别的视频特征转化并压缩成特征向量,以适用于大尺寸视频文件的分类的方法。其基本出发点是在NetVLAD模型的基础上,将高维度的特征先进行分组,通过引入attention机制聚合提取时间维度的信息,这样既可以获得较高的准确率,又可以使用更少的参数量。详细内容请参考原
[
论文
](
https://arxiv.org/abs/1811.05014
)
。
## 2 参数及计算指标
这里使用Paddle Fluid实现了论文中的单模型结构,使用2nd-Youtube-8M的train数据集作为训练集,在val数据集上做测试。
模型参数列表如下:
| 参数 | 取值 |
| :---------: | :----: |
| cluster
\_
size | 128 |
| hidden
\_
size | 2048 |
| groups | 8 |
| expansion | 2 |
| drop
\_
rate | 0.5 |
| gating
\_
reduction | 8 |
计算指标列表如下:
| 精度指标 | 模型精度 |
| :---------: | :----: |
| Hit@1 | 0.8960 |
| PERR | 0.8132 |
| GAP | 0.8709 |
## 3 数据准备
NeXtVLAD模型使用2nd-Youtube-8M数据集,关于数据本分请参考
[
数据说明
](
../../dataset/README.md
)
## 4 模型训练
### 随机初始化开始训练
在video目录下运行如下脚本即可
bash ./scripts/train/train_nextvlad.sh
### 使用我们提供的预训练模型做finetune
请先将我们提供的
[
预训练模型
](
model
url)下载到本地,并在上述脚本文件中添加--resume为所保存的预模型存放路径。
这里我们是使用4卡Nvidia Tesla P40来训练的,总的batch size数是160。
## 5 模型测试
用户可以下载我们的预训练模型参数,或者使用自己训练好的模型参数,请在
./scripts/test/test_nextvald.sh
文件中修改--weights参数为保存模型参数的目录。运行
bash ./scripts/test/test_nextvlad.sh
由于youtube-8m提供的数据中test数据集是没有ground truth标签的,所以这里我们使用validation数据集来做测试。
## 6 预测输出
用户可以下载我们的预训练模型参数,或者使用自己训练好的模型参数,请在
./scripts/infer/infer_nextvald.sh
文件中修改--weights参数为保存模型参数的目录,运行
bash ./scripts/infer/infer_nextvald.sh
fluid/PaddleCV/video/models/stnet/README.md
0 → 100644
浏览文件 @
c50969ff
# StNet 视频分类模型
---
## 内容
-
[
简介
](
#简介
)
-
[
数据准备
](
#数据准备
)
-
[
模型训练
](
#模型训练
)
-
[
模型评估
](
#模型评估
)
-
[
模型推断
](
#模型推断
)
## 简介
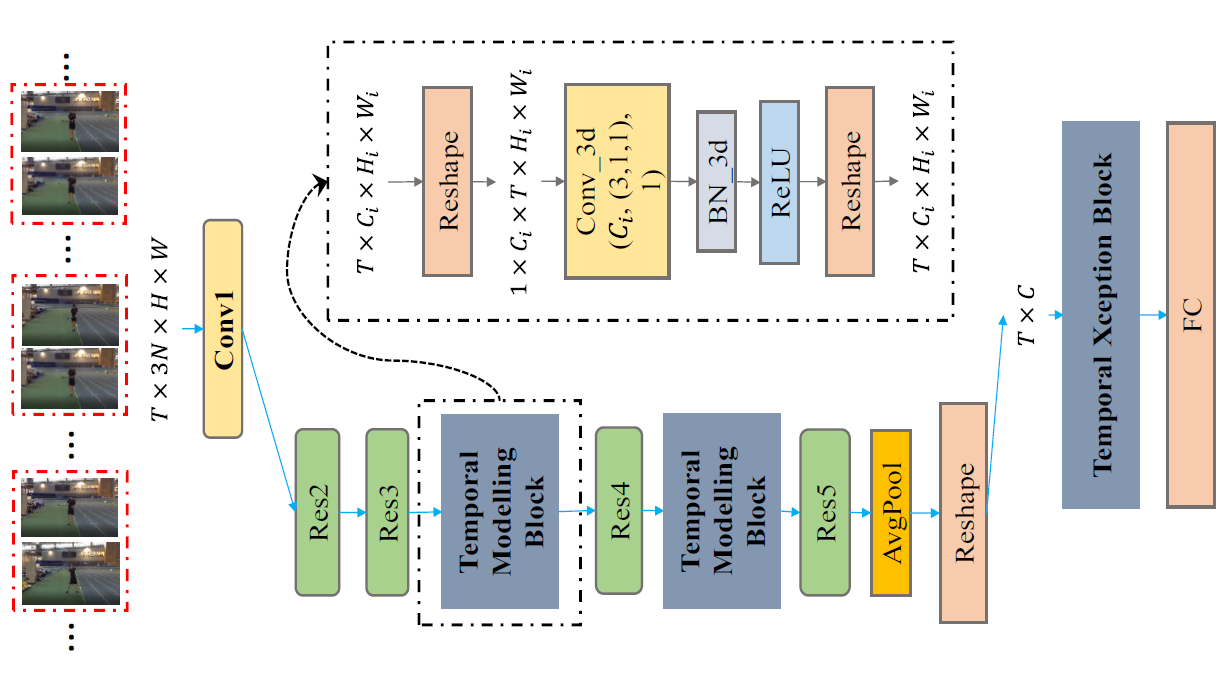
StNet为百度自研模型,该框架为百度在ActivityNet Kinetics Challenge 2018中夺冠的基础网络框架,本次开源的是基于ResNet50实现的StNet模型,基于其他backbone网络的框架用户可以依样配置。该模型提出“super-image"的概念,在super-image上进行2D卷积,建模视频中局部时空相关性。另外通过temporal modeling block建模视频的全局时空依赖,最后用一个temporal Xception block对抽取的特征序列进行长时序建模。StNet主体网络结构如下图所示:
<p
align=
"center"
>
<img
src=
"../../images/StNet.png"
height=
300
width=
500
hspace=
'10'
/>
<br
/>
StNet Framework Overview
</p>
详细内容请参考AAAI'2019年论文
[
StNet:Local and Global Spatial-Temporal Modeling for Human Action Recognition
](
https://arxiv.org/abs/1811.01549
)
## 数据准备
StNet的训练数据采用由DeepMind公布的Kinetics-400动作识别数据集。数据下载及准备请参考
[
数据说明
](
../../dataset/README.md
)
## 模型训练
数据准备完毕后,可以通过如下两种方式启动训练:
python train.py --model-name=STNET
--config=./configs/attention_stnet.txt
--save-dir=checkpoints
--epoch=20
--log-interval=10
--valid-interval=1
bash scripts/train/train_attention_stnet.sh
**数据读取器说明:**
模型读取Kinetics-400数据集中的
`mp4`
数据,每条数据抽取
`seg_num`
段,每段抽取
`seg_len`
帧图像,对每帧图像做随机增强后,缩放至
`target_size`
。
**训练策略:**
*
采用Momentum优化算法训练,momentum=0.9
*
权重衰减系数为1e-4
*
学习率在训练的总epoch数的1/3和2/3时分别做0.1的衰减
## 模型评估
可通过如下两种方式进行模型评估:
python test.py --model-name=STNET
--config=configs/attention_stnet.txt
--log-interval=1 --weights=$PATH_TO_WEIGHTS
bash scripts/test/test_attention_stnet.sh
-
使用
`scripts/test/test_attention_stnet.sh`
进行评估时,需要修改脚本中的
`--weights`
参数指定需要评估的权重。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleStNet
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_stnet_kinetics.tar.gz
)
进行评估
当取如下参数时:
| 参数 | 取值 |
| :---------: | :----: |
| seg
\_
num | 25 |
| seglen | 5 |
| target
\_
size | 256 |
在Kinetics400的validation数据集下评估精度如下:
| 精度指标 | 模型精度 |
| :---------: | :----: |
| Prec@1 | 0.69 |
## 模型推断
可通过如下命令进行模型推断:
python infer.py --model-name=attention_stnet
--config=configs/attention_stnet.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
-
模型推断结果存储于
`STNET_infer_result`
中,通过
`pickle`
格式存储。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleStNet
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_stnet_kinetics.tar.gz
)
进行推断
fluid/PaddleCV/video/models/tsn/README.md
0 → 100644
浏览文件 @
c50969ff
# TSN 视频分类模型
---
## 内容
-
[
简介
](
#简介
)
-
[
数据准备
](
#数据准备
)
-
[
模型训练
](
#模型训练
)
-
[
模型评估
](
#模型评估
)
-
[
模型推断
](
#模型推断
)
## 简介
Temporal Segment Network (TSN) 是视频分类领域经典的基于2D-CNN的解决方案。该方法主要解决视频的长时间行为判断问题,通过稀疏采样视频帧的方式代替稠密采样,既能捕获视频全局信息,也能去除冗余,降低计算量。最终将每帧特征平均融合后得到视频的整体特征,并用于分类。本代码实现的模型为基于单路RGB图像的TSN网络结构,Backbone采用ResNet-50结构。
详细内容请参考ECCV 2016年论文
[
StNet:Local and Global Spatial-Temporal Modeling for Human Action Recognition
](
https://arxiv.org/abs/1608.00859
)
## 数据准备
TSN的训练数据采用由DeepMind公布的Kinetics-400动作识别数据集。数据下载及准备请参考
[
数据说明
](
../../dataset/README.md
)
## 模型训练
数据准备完毕后,可以通过如下两种方式启动训练:
python train.py --model-name=TSNET
--config=./configs/attention_tsn.txt
--save-dir=checkpoints
--epoch=20
--log-interval=10
--valid-interval=1
bash scripts/train/train_attention_tsn.sh
**数据读取器说明:**
模型读取Kinetics-400数据集中的
`mp4`
数据,每条数据抽取
`seg_num`
段,每段抽取1帧图像,对每帧图像做随机增强后,缩放至
`target_size`
。
**训练策略:**
*
采用Momentum优化算法训练,momentum=0.9
*
权重衰减系数为1e-4
*
学习率在训练的总epoch数的1/3和2/3时分别做0.1的衰减
## 模型评估
可通过如下两种方式进行模型评估:
python test.py --model-name=TSN
--config=configs/attention_tsn.txt
--log-interval=1 --weights=$PATH_TO_WEIGHTS
bash scripts/test/test_attention_tsn.sh
-
使用
`scripts/test/test_attention_tnsn.sh`
进行评估时,需要修改脚本中的
`--weights`
参数指定需要评估的权重。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleTSN
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_tsn_kinetics.tar.gz
)
进行评估
当取如下参数时,在Kinetics400的validation数据集下评估精度如下:
| seg
\_
num | target
\_
size | Prec@1 |
| :------: | :----------: | :----: |
| 3 | 224 | 0.66 |
| 7 | 224 | 0.67 |
## 模型推断
可通过如下命令进行模型推断:
python infer.py --model-name=attention_tsn
--config=configs/attention_tsn.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
-
模型推断结果存储于
`TSN_infer_result`
中,通过
`pickle`
格式存储。
-
若未指定
`--weights`
参数,脚本会下载Paddle release权重
[
PaddleTSN
](
https://paddlemodels.bj.bcebos.com/video_classification/attention_tsn_kinetics.tar.gz
)
进行推断
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}