clean v2
Showing
v2/README.cn.md
已删除
100644 → 0
v2/README.md
已删除
100644 → 0
v2/conv_seq2seq/README.md
已删除
100644 → 0
v2/conv_seq2seq/beamsearch.py
已删除
100644 → 0
v2/conv_seq2seq/download.sh
已删除
100644 → 0
v2/conv_seq2seq/infer.py
已删除
100644 → 0
v2/conv_seq2seq/model.py
已删除
100644 → 0
v2/conv_seq2seq/preprocess.py
已删除
100644 → 0
v2/conv_seq2seq/reader.py
已删除
100644 → 0
v2/conv_seq2seq/train.py
已删除
100644 → 0
v2/ctr/README.cn.md
已删除
100644 → 0
v2/ctr/README.md
已删除
100644 → 0
v2/ctr/dataset.md
已删除
100644 → 0
v2/ctr/images/lr_vs_dnn.jpg
已删除
100644 → 0
{kind=link}
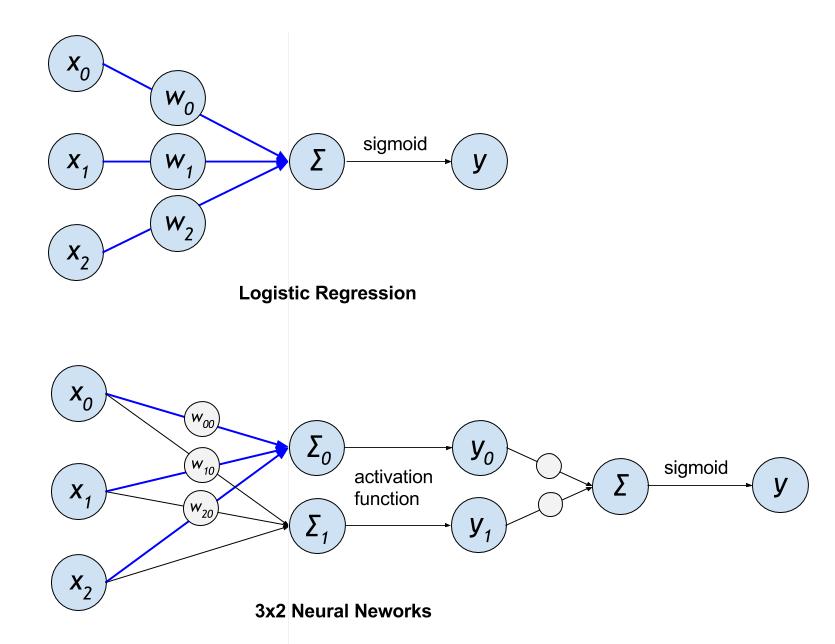
43.1 KB
v2/ctr/images/wide_deep.png
已删除
100644 → 0
{kind=link}
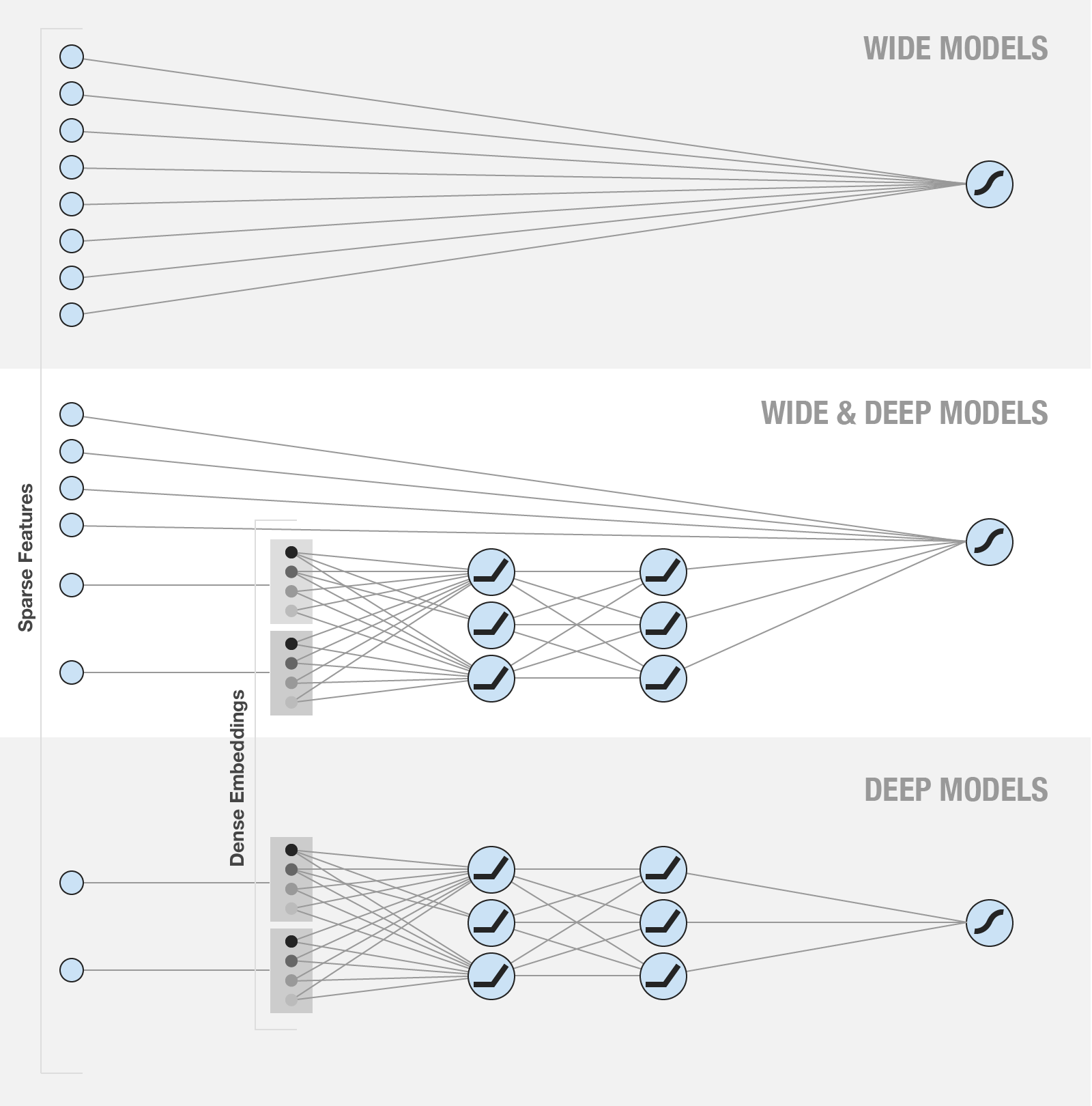
150.6 KB
v2/ctr/infer.py
已删除
100644 → 0
v2/ctr/network_conf.py
已删除
100644 → 0
v2/ctr/reader.py
已删除
100644 → 0
v2/ctr/train.py
已删除
100644 → 0
v2/ctr/utils.py
已删除
100644 → 0
v2/deep_fm/README.cn.md
已删除
100644 → 0
v2/deep_fm/README.md
已删除
100644 → 0
v2/deep_fm/data/download.sh
已删除
100755 → 0
v2/deep_fm/infer.py
已删除
100755 → 0
v2/deep_fm/network_conf.py
已删除
100644 → 0
v2/deep_fm/preprocess.py
已删除
100755 → 0
v2/deep_fm/reader.py
已删除
100644 → 0
v2/deep_fm/train.py
已删除
100755 → 0
v2/dssm/README.cn.md
已删除
100644 → 0
v2/dssm/README.md
已删除
100644 → 0
v2/dssm/data/rank/test.txt
已删除
100644 → 0
v2/dssm/data/rank/train.txt
已删除
100644 → 0
v2/dssm/data/vocab.txt
已删除
100644 → 0
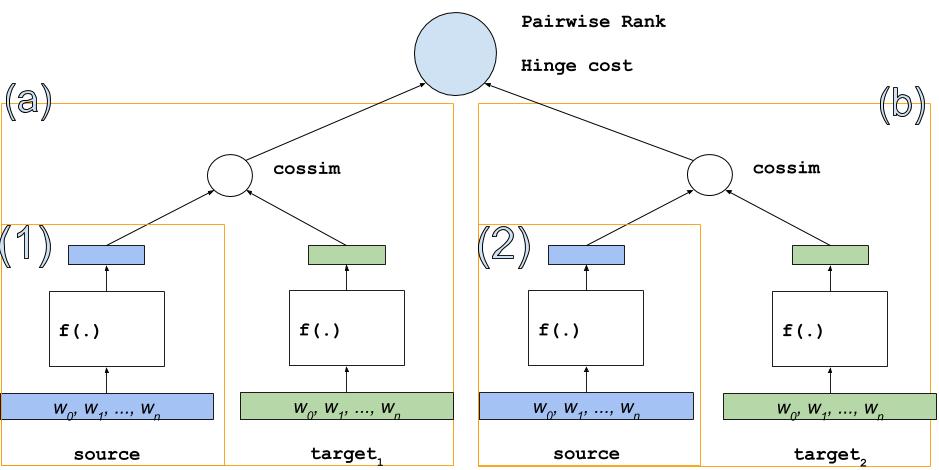
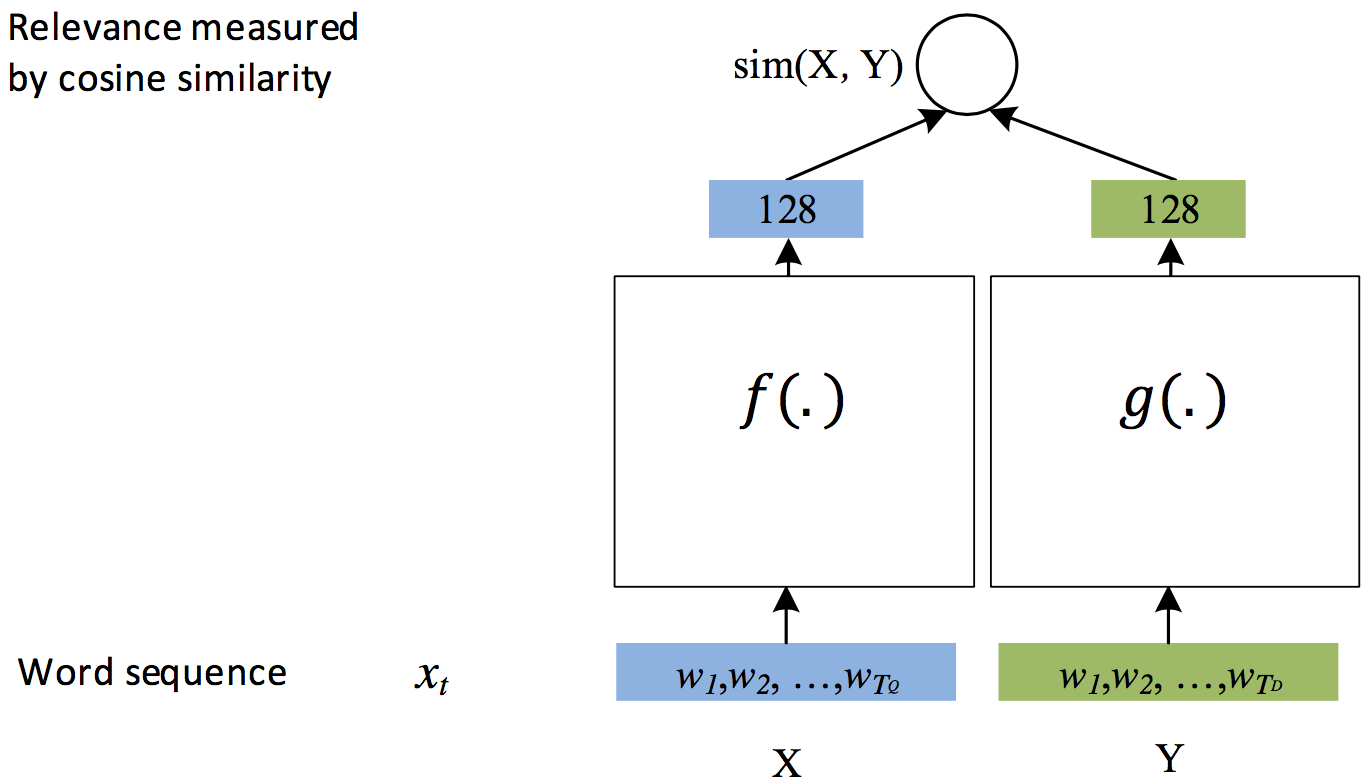
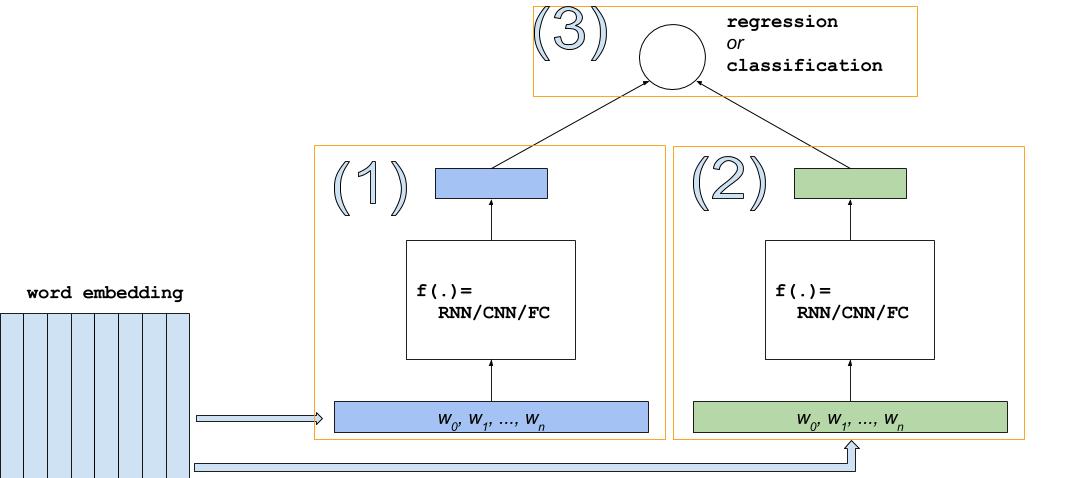
v2/dssm/images/dssm.jpg
已删除
100644 → 0
{kind=link}
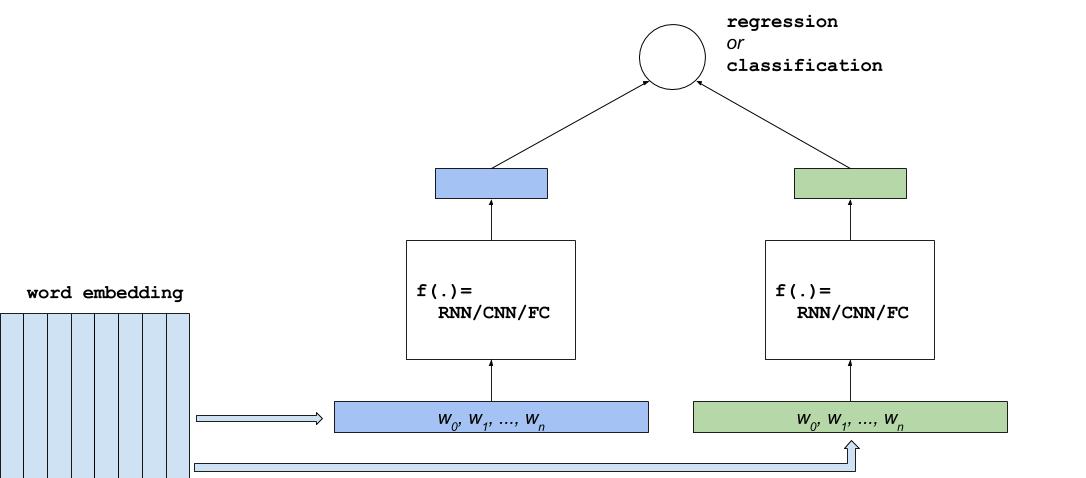
33.0 KB
v2/dssm/images/dssm.png
已删除
100644 → 0
{kind=link}
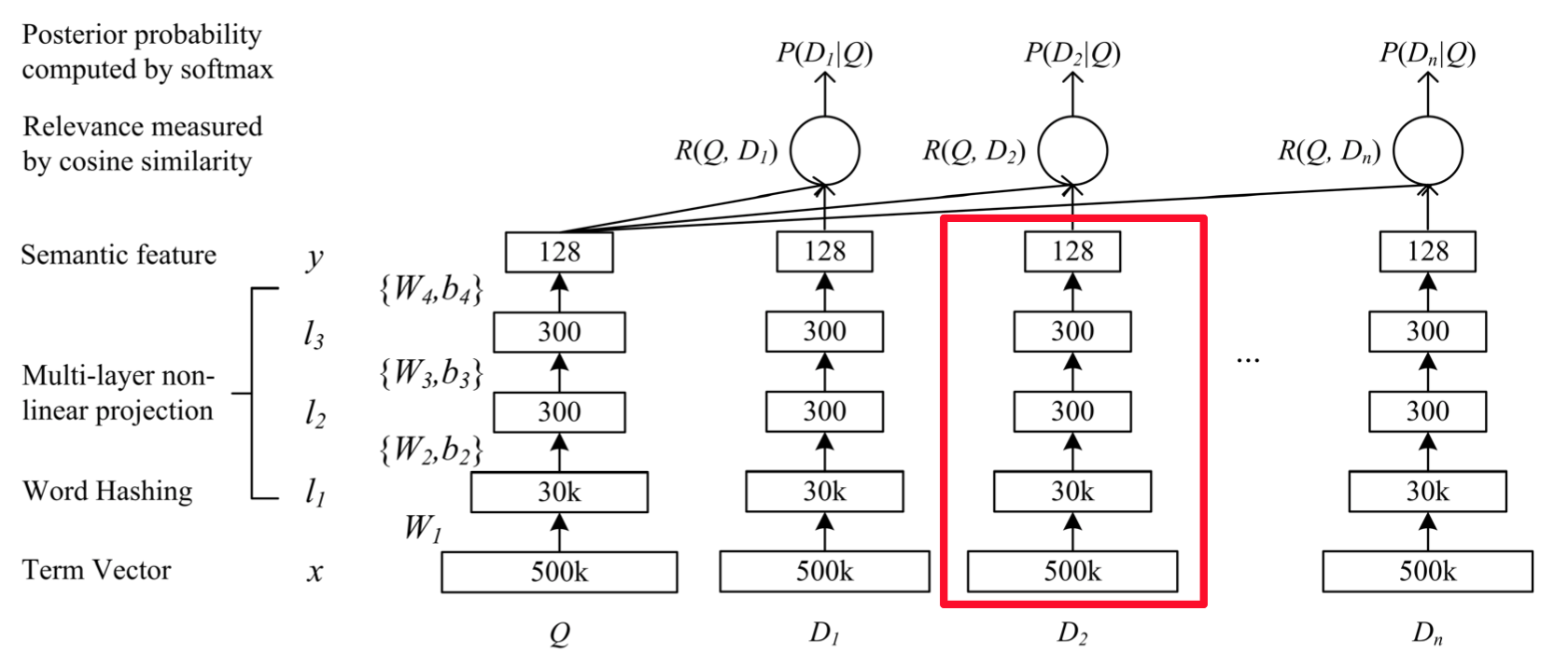
210.2 KB
v2/dssm/images/dssm2.jpg
已删除
100644 → 0
{kind=link}
45.2 KB
v2/dssm/images/dssm2.png
已删除
100644 → 0
{kind=link}
80.9 KB
v2/dssm/images/dssm3.jpg
已删除
100644 → 0
{kind=link}
43.6 KB
v2/dssm/infer.py
已删除
100644 → 0
v2/dssm/network_conf.py
已删除
100644 → 0
此差异已折叠。
v2/dssm/reader.py
已删除
100644 → 0
v2/dssm/train.py
已删除
100644 → 0
此差异已折叠。
v2/dssm/utils.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
67.1 KB
{kind=link}
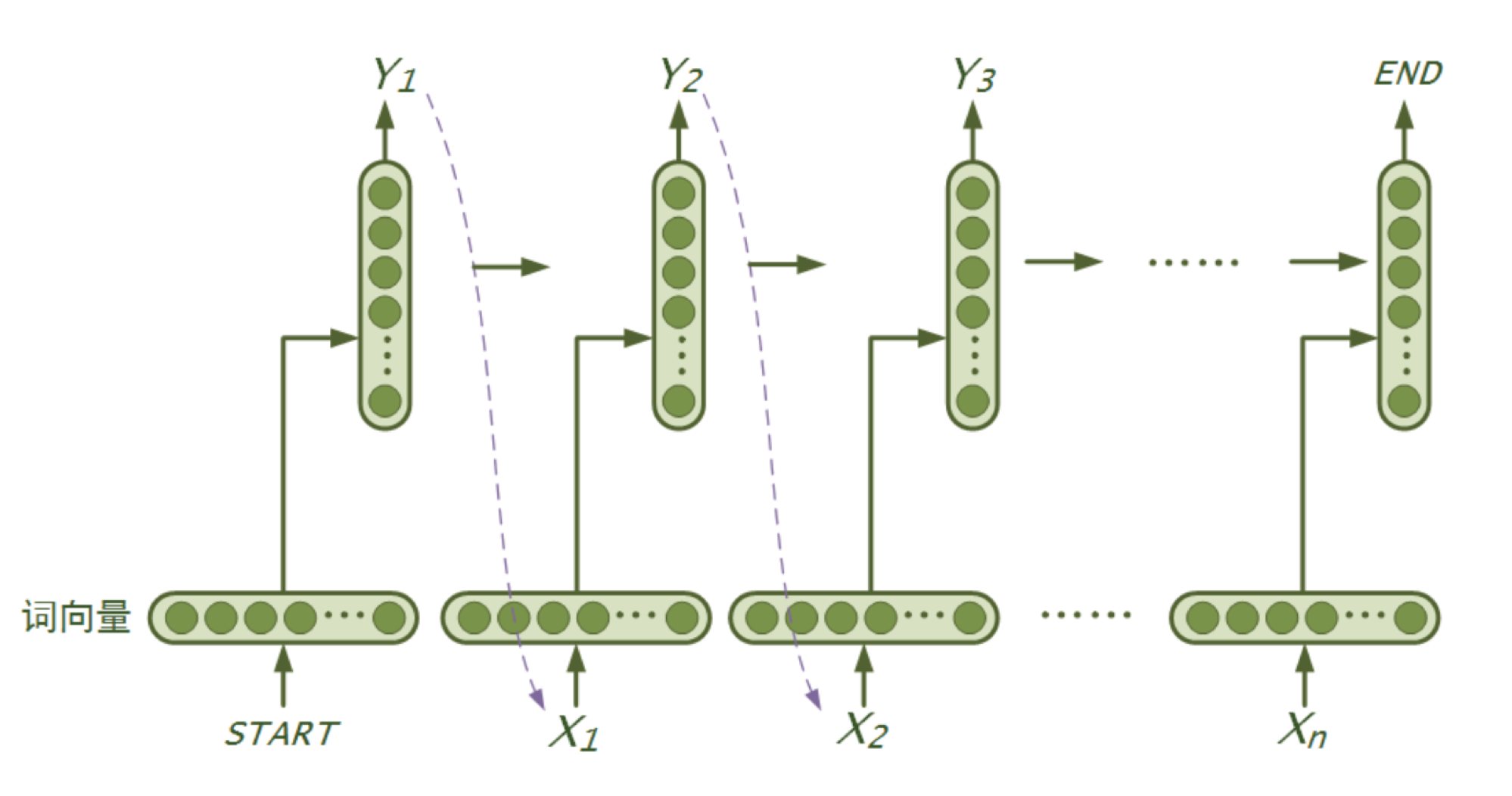
335.3 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/hsigmoid/.gitignore
已删除
100644 → 0
此差异已折叠。
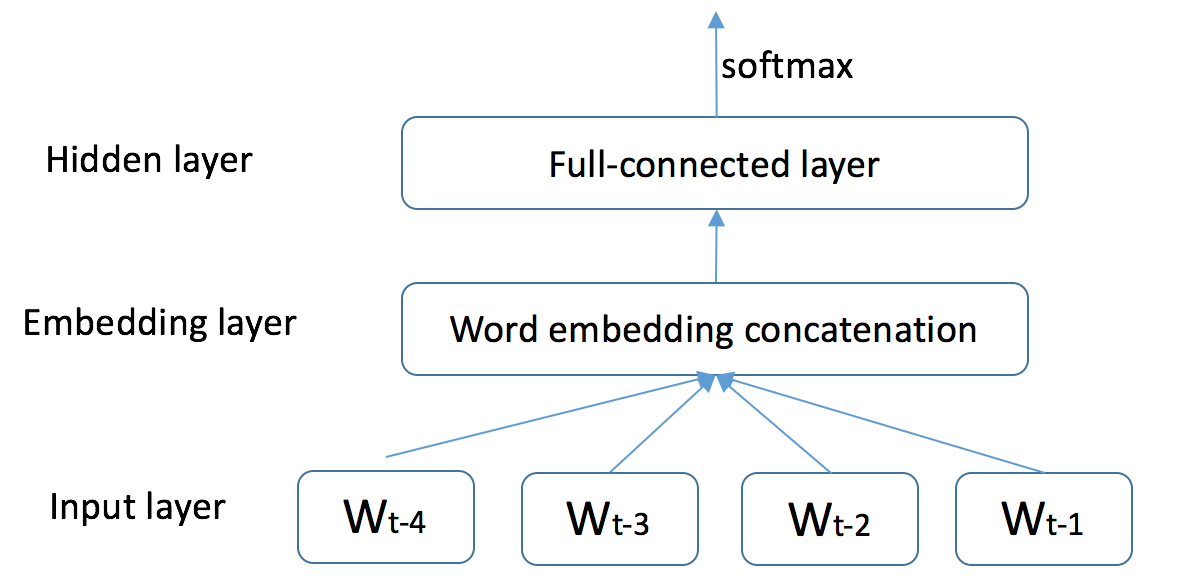
v2/hsigmoid/README.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
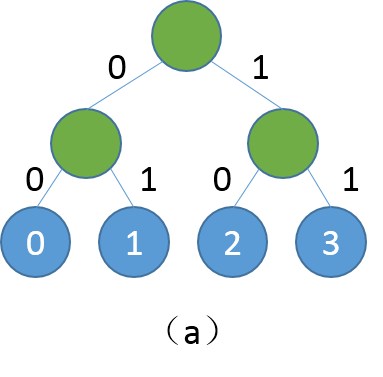
22.9 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
v2/hsigmoid/infer.py
已删除
100644 → 0
此差异已折叠。
v2/hsigmoid/network_conf.py
已删除
100644 → 0
此差异已折叠。
v2/hsigmoid/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/ltr/README.md
已删除
100644 → 0
此差异已折叠。
v2/ltr/README_en.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
v2/ltr/images/lambdarank.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
v2/ltr/images/ranknet.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ltr/images/ranknet_en.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
v2/ltr/infer.py
已删除
100644 → 0
此差异已折叠。
v2/ltr/lambda_rank.py
已删除
100644 → 0
此差异已折叠。
v2/ltr/ranknet.py
已删除
100644 → 0
此差异已折叠。
v2/ltr/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/nce_cost/.gitignore
已删除
100644 → 0
此差异已折叠。
v2/nce_cost/README.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
v2/nce_cost/infer.py
已删除
100644 → 0
此差异已折叠。
v2/nce_cost/network_conf.py
已删除
100644 → 0
此差异已折叠。
v2/nce_cost/train.py
已删除
100644 → 0
此差异已折叠。
v2/nested_sequence/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/neural_qa/.gitignore
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/README.md
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/config.py
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/infer.py
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/network.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/neural_qa/reader.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
v2/neural_qa/test/trn_data.gz
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/train.py
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/utils.py
已删除
100644 → 0
此差异已折叠。
v2/neural_qa/val_and_test.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/ssd/README.cn.md
已删除
100644 → 0
此差异已折叠。
v2/ssd/README.md
已删除
100644 → 0
此差异已折叠。
v2/ssd/config/__init__.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
v2/ssd/data/label_list
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
v2/ssd/data_provider.py
已删除
100644 → 0
此差异已折叠。
v2/ssd/eval.py
已删除
100644 → 0
此差异已折叠。
v2/ssd/image_util.py
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
v2/ssd/images/ssd_network.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ssd/images/vis_1.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ssd/images/vis_2.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ssd/images/vis_3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ssd/images/vis_4.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
v2/ssd/infer.py
已删除
100644 → 0
此差异已折叠。
v2/ssd/train.py
已删除
100644 → 0
此差异已折叠。
v2/ssd/vgg_ssd_net.py
已删除
100644 → 0
此差异已折叠。
v2/ssd/visual.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/text_classification/run.sh
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/youtube_recall/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
v2/youtube_recall/infer.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v2/youtube_recall/reader.py
已删除
100644 → 0
此差异已折叠。
v2/youtube_recall/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
v2/youtube_recall/utils.py
已删除
100644 → 0
此差异已折叠。