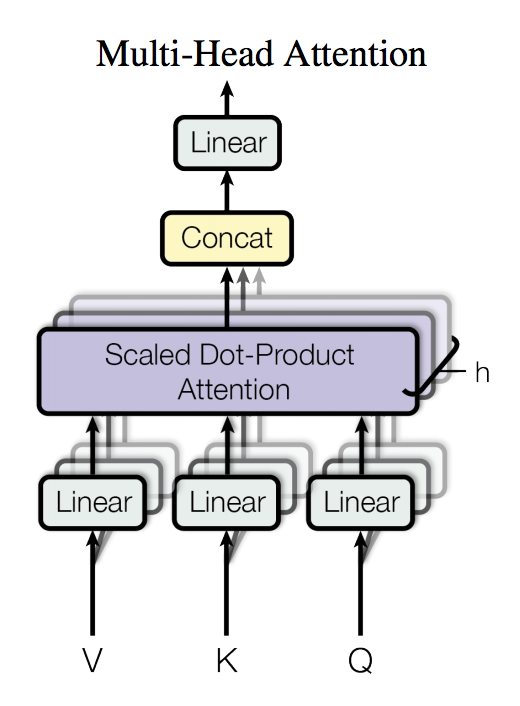
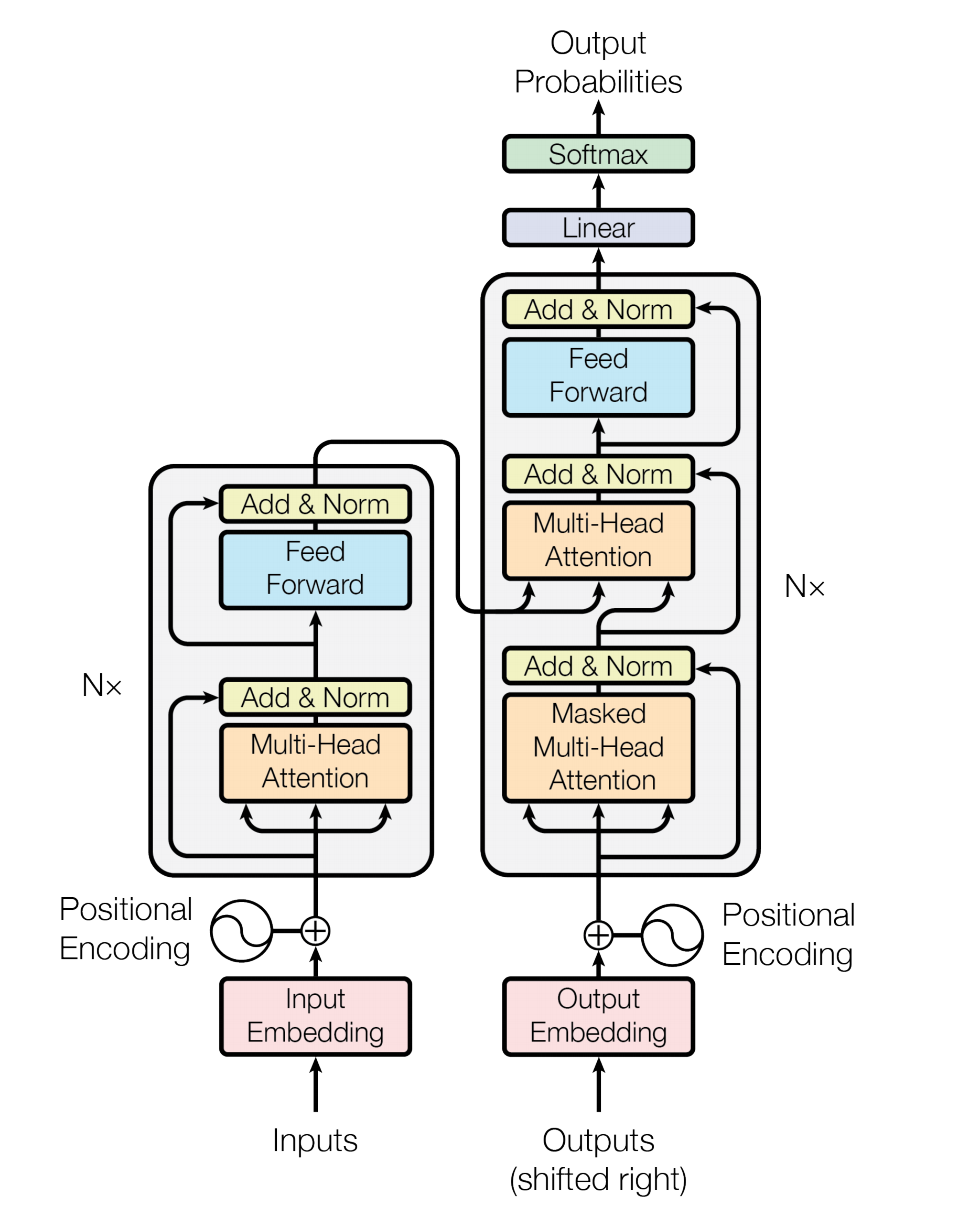
Transformer 是论文 [Attention Is All You Need](https://arxiv.org/abs/1706.03762) 中提出的用以完成机器翻译(machine translation, MT)等序列到序列(sequence to sequence, Seq2Seq)学习任务的一种全新网络结构,其完全使用注意力(Attention)机制来实现序列到序列的建模[1]。
- 特征维度为 d 、长度为 n 的序列,在 RNN 中计算复杂度为 `O(n * d * d)` (n 个时间步,每个时间步计算 d 维的矩阵向量乘法),在 Self-Attention 中计算复杂度为 `O(n * n * d)` (n 个时间步两两计算 d 维的向量点积或其他相关度函数),n 通常要小于 d 。
1. Vaswani A, Shazeer N, Parmar N, et al. [Attention is all you need](http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)[C]//Advances in Neural Information Processing Systems. 2017: 6000-6010.
2. He K, Zhang X, Ren S, et al. [Deep residual learning for image recognition](http://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf)[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
3. Ba J L, Kiros J R, Hinton G E. [Layer normalization](https://arxiv.org/pdf/1607.06450.pdf)[J]. arXiv preprint arXiv:1607.06450, 2016.
4. Sennrich R, Haddow B, Birch A. [Neural machine translation of rare words with subword units](https://arxiv.org/pdf/1508.07909)[J]. arXiv preprint arXiv:1508.07909, 2015.
{kind=link}
{kind=link}