Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
942a2de4
M
models
项目概览
PaddlePaddle
/
models
1 年多 前同步成功
通知
222
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
942a2de4
编写于
7月 10, 2019
作者:
W
wanghaoshuang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add notebook demo for quantization strategy on MobileNetV1-SSD.
上级
4fa3046a
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
1386 addition
and
0 deletion
+1386
-0
PaddleSlim/notebook/Mobile-SSD-Quantization.ipynb
PaddleSlim/notebook/Mobile-SSD-Quantization.ipynb
+1386
-0
未找到文件。
PaddleSlim/notebook/Mobile-SSD-Quantization.ipynb
0 → 100644
浏览文件 @
942a2de4
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"该示例内容为对[MobileNet-SSD](https://github.com/PaddlePaddle/models/tree/v1.4/PaddleCV/object_detection)的主干网络进行int8量化训练。\n",
"\n",
"## 0. 目录\n",
"\n",
"[1. 定义工具函数](http://10.255.142.41:8888/notebooks/slim/Mobile-SSD-Quantization.ipynb#1.-%E5%AE%9A%E4%B9%89%E5%B7%A5%E5%85%B7%E5%87%BD%E6%95%B0)\n",
"\n",
"[2. 数据准备](http://10.255.142.41:8888/notebooks/slim/Mobile-SSD-Quantization.ipynb#2.-%E6%95%B0%E6%8D%AE%E5%87%86%E5%A4%87)\n",
"\n",
"[3. 定义网络](http://10.255.142.41:8888/notebooks/slim/Mobile-SSD-Quantization.ipynb#3.-%E5%AE%9A%E4%B9%89%E7%BD%91%E7%BB%9C)\n",
"\n",
"[4. 配置压缩任务](http://10.255.142.41:8888/notebooks/slim/Mobile-SSD-Quantization.ipynb#4.-%E9%85%8D%E7%BD%AE%E5%8E%8B%E7%BC%A9%E4%BB%BB%E5%8A%A1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. 定义工具函数\n",
"\n",
"在[image_util.py](https://github.com/PaddlePaddle/models/blob/v1.4/PaddleCV/object_detection/image_util.py)中定义了图像数据预处理处理使用到的工具函数。"
]
},
{
"cell_type": "code",
"execution_count": 67,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"from PIL import Image, ImageEnhance, ImageDraw\n",
"from PIL import ImageFile\n",
"import numpy as np\n",
"import random\n",
"import math\n",
"\n",
"ImageFile.LOAD_TRUNCATED_IMAGES = True #otherwise IOError raised image file is truncated\n",
"\n",
"\n",
"class sampler():\n",
" def __init__(self, max_sample, max_trial, min_scale, max_scale,\n",
" min_aspect_ratio, max_aspect_ratio, min_jaccard_overlap,\n",
" max_jaccard_overlap):\n",
" self.max_sample = max_sample\n",
" self.max_trial = max_trial\n",
" self.min_scale = min_scale\n",
" self.max_scale = max_scale\n",
" self.min_aspect_ratio = min_aspect_ratio\n",
" self.max_aspect_ratio = max_aspect_ratio\n",
" self.min_jaccard_overlap = min_jaccard_overlap\n",
" self.max_jaccard_overlap = max_jaccard_overlap\n",
"\n",
"\n",
"class bbox():\n",
" def __init__(self, xmin, ymin, xmax, ymax):\n",
" self.xmin = xmin\n",
" self.ymin = ymin\n",
" self.xmax = xmax\n",
" self.ymax = ymax\n",
"\n",
"\n",
"def bbox_area(src_bbox):\n",
" width = src_bbox.xmax - src_bbox.xmin\n",
" height = src_bbox.ymax - src_bbox.ymin\n",
" return width * height\n",
"\n",
"\n",
"def generate_sample(sampler):\n",
" scale = np.random.uniform(sampler.min_scale, sampler.max_scale)\n",
" aspect_ratio = np.random.uniform(sampler.min_aspect_ratio,\n",
" sampler.max_aspect_ratio)\n",
" aspect_ratio = max(aspect_ratio, (scale**2.0))\n",
" aspect_ratio = min(aspect_ratio, 1 / (scale**2.0))\n",
"\n",
" bbox_width = scale * (aspect_ratio**0.5)\n",
" bbox_height = scale / (aspect_ratio**0.5)\n",
" xmin_bound = 1 - bbox_width\n",
" ymin_bound = 1 - bbox_height\n",
" xmin = np.random.uniform(0, xmin_bound)\n",
" ymin = np.random.uniform(0, ymin_bound)\n",
" xmax = xmin + bbox_width\n",
" ymax = ymin + bbox_height\n",
" sampled_bbox = bbox(xmin, ymin, xmax, ymax)\n",
" return sampled_bbox\n",
"\n",
"\n",
"def jaccard_overlap(sample_bbox, object_bbox):\n",
" if sample_bbox.xmin >= object_bbox.xmax or \\\n",
" sample_bbox.xmax <= object_bbox.xmin or \\\n",
" sample_bbox.ymin >= object_bbox.ymax or \\\n",
" sample_bbox.ymax <= object_bbox.ymin:\n",
" return 0\n",
" intersect_xmin = max(sample_bbox.xmin, object_bbox.xmin)\n",
" intersect_ymin = max(sample_bbox.ymin, object_bbox.ymin)\n",
" intersect_xmax = min(sample_bbox.xmax, object_bbox.xmax)\n",
" intersect_ymax = min(sample_bbox.ymax, object_bbox.ymax)\n",
" intersect_size = (intersect_xmax - intersect_xmin) * (\n",
" intersect_ymax - intersect_ymin)\n",
" sample_bbox_size = bbox_area(sample_bbox)\n",
" object_bbox_size = bbox_area(object_bbox)\n",
" overlap = intersect_size / (\n",
" sample_bbox_size + object_bbox_size - intersect_size)\n",
" return overlap\n",
"\n",
"\n",
"def satisfy_sample_constraint(sampler, sample_bbox, bbox_labels):\n",
" if sampler.min_jaccard_overlap == 0 and sampler.max_jaccard_overlap == 0:\n",
" return True\n",
" for i in range(len(bbox_labels)):\n",
" object_bbox = bbox(bbox_labels[i][1], bbox_labels[i][2],\n",
" bbox_labels[i][3], bbox_labels[i][4])\n",
" overlap = jaccard_overlap(sample_bbox, object_bbox)\n",
" if sampler.min_jaccard_overlap != 0 and \\\n",
" overlap < sampler.min_jaccard_overlap:\n",
" continue\n",
" if sampler.max_jaccard_overlap != 0 and \\\n",
" overlap > sampler.max_jaccard_overlap:\n",
" continue\n",
" return True\n",
" return False\n",
"\n",
"\n",
"def generate_batch_samples(batch_sampler, bbox_labels):\n",
" sampled_bbox = []\n",
" index = []\n",
" c = 0\n",
" for sampler in batch_sampler:\n",
" found = 0\n",
" for i in range(sampler.max_trial):\n",
" if found >= sampler.max_sample:\n",
" break\n",
" sample_bbox = generate_sample(sampler)\n",
" if satisfy_sample_constraint(sampler, sample_bbox, bbox_labels):\n",
" sampled_bbox.append(sample_bbox)\n",
" found = found + 1\n",
" index.append(c)\n",
" c = c + 1\n",
" return sampled_bbox\n",
"\n",
"\n",
"def clip_bbox(src_bbox):\n",
" src_bbox.xmin = max(min(src_bbox.xmin, 1.0), 0.0)\n",
" src_bbox.ymin = max(min(src_bbox.ymin, 1.0), 0.0)\n",
" src_bbox.xmax = max(min(src_bbox.xmax, 1.0), 0.0)\n",
" src_bbox.ymax = max(min(src_bbox.ymax, 1.0), 0.0)\n",
" return src_bbox\n",
"\n",
"\n",
"def meet_emit_constraint(src_bbox, sample_bbox):\n",
" center_x = (src_bbox.xmax + src_bbox.xmin) / 2\n",
" center_y = (src_bbox.ymax + src_bbox.ymin) / 2\n",
" if center_x >= sample_bbox.xmin and \\\n",
" center_x <= sample_bbox.xmax and \\\n",
" center_y >= sample_bbox.ymin and \\\n",
" center_y <= sample_bbox.ymax:\n",
" return True\n",
" return False\n",
"\n",
"\n",
"def transform_labels(bbox_labels, sample_bbox):\n",
" proj_bbox = bbox(0, 0, 0, 0)\n",
" sample_labels = []\n",
" for i in range(len(bbox_labels)):\n",
" sample_label = []\n",
" object_bbox = bbox(bbox_labels[i][1], bbox_labels[i][2],\n",
" bbox_labels[i][3], bbox_labels[i][4])\n",
" if not meet_emit_constraint(object_bbox, sample_bbox):\n",
" continue\n",
" sample_width = sample_bbox.xmax - sample_bbox.xmin\n",
" sample_height = sample_bbox.ymax - sample_bbox.ymin\n",
" proj_bbox.xmin = (object_bbox.xmin - sample_bbox.xmin) / sample_width\n",
" proj_bbox.ymin = (object_bbox.ymin - sample_bbox.ymin) / sample_height\n",
" proj_bbox.xmax = (object_bbox.xmax - sample_bbox.xmin) / sample_width\n",
" proj_bbox.ymax = (object_bbox.ymax - sample_bbox.ymin) / sample_height\n",
" proj_bbox = clip_bbox(proj_bbox)\n",
" if bbox_area(proj_bbox) > 0:\n",
" sample_label.append(bbox_labels[i][0])\n",
" sample_label.append(float(proj_bbox.xmin))\n",
" sample_label.append(float(proj_bbox.ymin))\n",
" sample_label.append(float(proj_bbox.xmax))\n",
" sample_label.append(float(proj_bbox.ymax))\n",
" #sample_label.append(bbox_labels[i][5])\n",
" sample_label = sample_label + bbox_labels[i][5:]\n",
" sample_labels.append(sample_label)\n",
" return sample_labels\n",
"\n",
"\n",
"def crop_image(img, bbox_labels, sample_bbox, image_width, image_height):\n",
" sample_bbox = clip_bbox(sample_bbox)\n",
" xmin = int(sample_bbox.xmin * image_width)\n",
" xmax = int(sample_bbox.xmax * image_width)\n",
" ymin = int(sample_bbox.ymin * image_height)\n",
" ymax = int(sample_bbox.ymax * image_height)\n",
" sample_img = img[ymin:ymax, xmin:xmax]\n",
" sample_labels = transform_labels(bbox_labels, sample_bbox)\n",
" return sample_img, sample_labels\n",
"\n",
"\n",
"def random_brightness(img, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" if prob < settings._brightness_prob:\n",
" delta = np.random.uniform(-settings._brightness_delta,\n",
" settings._brightness_delta) + 1\n",
" img = ImageEnhance.Brightness(img).enhance(delta)\n",
" return img\n",
"\n",
"\n",
"def random_contrast(img, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" if prob < settings._contrast_prob:\n",
" delta = np.random.uniform(-settings._contrast_delta,\n",
" settings._contrast_delta) + 1\n",
" img = ImageEnhance.Contrast(img).enhance(delta)\n",
" return img\n",
"\n",
"\n",
"def random_saturation(img, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" if prob < settings._saturation_prob:\n",
" delta = np.random.uniform(-settings._saturation_delta,\n",
" settings._saturation_delta) + 1\n",
" img = ImageEnhance.Color(img).enhance(delta)\n",
" return img\n",
"\n",
"\n",
"def random_hue(img, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" if prob < settings._hue_prob:\n",
" delta = np.random.uniform(-settings._hue_delta, settings._hue_delta)\n",
" img_hsv = np.array(img.convert('HSV'))\n",
" img_hsv[:, :, 0] = img_hsv[:, :, 0] + delta\n",
" img = Image.fromarray(img_hsv, mode='HSV').convert('RGB')\n",
" return img\n",
"\n",
"\n",
"def distort_image(img, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" # Apply different distort order\n",
" if prob > 0.5:\n",
" img = random_brightness(img, settings)\n",
" img = random_contrast(img, settings)\n",
" img = random_saturation(img, settings)\n",
" img = random_hue(img, settings)\n",
" else:\n",
" img = random_brightness(img, settings)\n",
" img = random_saturation(img, settings)\n",
" img = random_hue(img, settings)\n",
" img = random_contrast(img, settings)\n",
" return img\n",
"\n",
"\n",
"def expand_image(img, bbox_labels, img_width, img_height, settings):\n",
" prob = np.random.uniform(0, 1)\n",
" if prob < settings._expand_prob:\n",
" if settings._expand_max_ratio - 1 >= 0.01:\n",
" expand_ratio = np.random.uniform(1, settings._expand_max_ratio)\n",
" height = int(img_height * expand_ratio)\n",
" width = int(img_width * expand_ratio)\n",
" h_off = math.floor(np.random.uniform(0, height - img_height))\n",
" w_off = math.floor(np.random.uniform(0, width - img_width))\n",
" expand_bbox = bbox(-w_off / img_width, -h_off / img_height,\n",
" (width - w_off) / img_width,\n",
" (height - h_off) / img_height)\n",
" expand_img = np.ones((height, width, 3))\n",
" expand_img = np.uint8(expand_img * np.squeeze(settings._img_mean))\n",
" expand_img = Image.fromarray(expand_img)\n",
" expand_img.paste(img, (int(w_off), int(h_off)))\n",
" bbox_labels = transform_labels(bbox_labels, expand_bbox)\n",
" return expand_img, bbox_labels, width, height\n",
" return img, bbox_labels, img_width, img_height\n",
"\n",
"class Settings(object):\n",
" def __init__(self,\n",
" dataset=None,\n",
" data_dir=None,\n",
" label_file=None,\n",
" resize_h=300,\n",
" resize_w=300,\n",
" mean_value=[127.5, 127.5, 127.5],\n",
" apply_distort=True,\n",
" apply_expand=True,\n",
" ap_version='11point'):\n",
" self._dataset = dataset\n",
" self._ap_version = ap_version\n",
" self._data_dir = data_dir\n",
" if 'pascalvoc' in dataset:\n",
" self._label_list = []\n",
" label_fpath = os.path.join(data_dir, label_file)\n",
" for line in open(label_fpath):\n",
" self._label_list.append(line.strip())\n",
"\n",
" self._apply_distort = apply_distort\n",
" self._apply_expand = apply_expand\n",
" self._resize_height = resize_h\n",
" self._resize_width = resize_w\n",
" self._img_mean = np.array(mean_value)[:, np.newaxis, np.newaxis].astype(\n",
" 'float32')\n",
" self._expand_prob = 0.5\n",
" self._expand_max_ratio = 4\n",
" self._hue_prob = 0.5\n",
" self._hue_delta = 18\n",
" self._contrast_prob = 0.5\n",
" self._contrast_delta = 0.5\n",
" self._saturation_prob = 0.5\n",
" self._saturation_delta = 0.5\n",
" self._brightness_prob = 0.5\n",
" self._brightness_delta = 0.125\n",
"\n",
" @property\n",
" def dataset(self):\n",
" return self._dataset\n",
"\n",
" @property\n",
" def ap_version(self):\n",
" return self._ap_version\n",
"\n",
" @property\n",
" def apply_distort(self):\n",
" return self._apply_expand\n",
"\n",
" @property\n",
" def apply_distort(self):\n",
" return self._apply_distort\n",
"\n",
" @property\n",
" def data_dir(self):\n",
" return self._data_dir\n",
"\n",
" @data_dir.setter\n",
" def data_dir(self, data_dir):\n",
" self._data_dir = data_dir\n",
"\n",
" @property\n",
" def label_list(self):\n",
" return self._label_list\n",
"\n",
" @property\n",
" def resize_h(self):\n",
" return self._resize_height\n",
"\n",
" @property\n",
" def resize_w(self):\n",
" return self._resize_width\n",
"\n",
" @property\n",
" def img_mean(self):\n",
" return self._img_mean\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. 数据准备\n",
"\n",
"### 2.1 下载数据\n",
"使用PaddlePaddle/models repo下提供的[数据下载脚本](https://github.com/PaddlePaddle/models/blob/release/1.4/PaddleCV/object_detection/data/coco/download.sh)下载数据。\n",
"或通过其它更便捷的方式准备数据\n",
"\n",
"### 2.2 下载pretrained model\n",
"\n",
"使用PaddlePaddle/models repo下提供的[下载脚本](https://github.com/PaddlePaddle/models/blob/release/1.4/PaddleCV/object_detection/pretrained/download_coco.sh)下载pretrained model.\n",
"\n",
"### 2.3 设置数据变量\n",
"\n",
"- args_image_shape:训练数据的shape, 格式为‘channel, height, width’\n",
"- args_mean_BGR: BGR三通道的均值\n",
"- args_data_dir: 数据存放的地址\n",
"- coco2014:使用的数据集名称,该变量主要影响了下文中data reader的表现。\n",
"- args_pretrained_model:pretrained model存放的地址。\n",
"\n",
"代码如下:"
]
},
{
"cell_type": "code",
"execution_count": 68,
"metadata": {},
"outputs": [],
"source": [
"args_image_shape = '3,300,300'\n",
"args_mean_BGR = '127.5,127.5,127.5'\n",
"args_data_dir = '/root/data/coco'\n",
"args_dataset = 'coco2014'\n",
"args_pretrained_model = 'pretrained/ssd_mobilenet_v1_coco/'\n",
"args_ap_version = '11point'\n",
"\n",
"\n",
"data_dir = args_data_dir\n",
"dataset = args_dataset\n",
"assert dataset in ['pascalvoc', 'coco2014', 'coco2017']\n",
"\n",
"# for pascalvoc\n",
"label_file = 'label_list'\n",
"train_file_list = 'trainval.txt'\n",
"val_file_list = 'test.txt'\n",
"\n",
"if dataset == 'coco2014':\n",
" train_file_list = 'annotations/instances_train2014.json'\n",
" val_file_list = 'annotations/instances_val2014.json'\n",
"elif dataset == 'coco2017':\n",
" train_file_list = 'annotations/instances_train2017.json'\n",
" val_file_list = 'annotations/instances_val2017.json'\n",
"\n",
"mean_BGR = [float(m) for m in args_mean_BGR.split(\",\")]\n",
"image_shape = [int(m) for m in args_image_shape.split(\",\")]\n",
"\n",
"data_args = Settings(\n",
"dataset=args_dataset,\n",
"data_dir=data_dir,\n",
"label_file=label_file,\n",
"resize_h=image_shape[1],\n",
"resize_w=image_shape[2],\n",
"mean_value=mean_BGR,\n",
"apply_distort=True,\n",
"apply_expand=True,\n",
"ap_version = args_ap_version)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.4 准备data reader\n",
"\n",
"在paddle中通过data reader为训练网络或测试网络提供数据,reader就是一个数据迭代产生器。\n",
"\n",
"参考[reader.py](https://github.com/PaddlePaddle/models/blob/v1.4/PaddleCV/object_detection/reader.py)实现代码如下:"
]
},
{
"cell_type": "code",
"execution_count": 69,
"metadata": {},
"outputs": [],
"source": [
"import xml.etree.ElementTree\n",
"import os\n",
"import time\n",
"import copy\n",
"import six\n",
"import math\n",
"import numpy as np\n",
"from PIL import Image\n",
"from PIL import ImageDraw\n",
"import paddle\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"def preprocess(img, bbox_labels, mode, settings):\n",
" img_width, img_height = img.size\n",
" sampled_labels = bbox_labels\n",
" if mode == 'train':\n",
" if settings._apply_distort:\n",
" img = distort_image(img, settings)\n",
" if settings._apply_expand:\n",
" img, bbox_labels, img_width, img_height = expand_image(\n",
" img, bbox_labels, img_width, img_height, settings)\n",
" # sampling\n",
" batch_sampler = []\n",
" # hard-code here\n",
" batch_sampler.append(\n",
" sampler(1, 1, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.1, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.3, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.5, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.7, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.9, 0.0))\n",
" batch_sampler.append(\n",
" sampler(1, 50, 0.3, 1.0, 0.5, 2.0, 0.0, 1.0))\n",
" sampled_bbox = generate_batch_samples(batch_sampler,\n",
" bbox_labels)\n",
"\n",
" img = np.array(img)\n",
" if len(sampled_bbox) > 0:\n",
" idx = int(np.random.uniform(0, len(sampled_bbox)))\n",
" img, sampled_labels = crop_image(\n",
" img, bbox_labels, sampled_bbox[idx], img_width, img_height)\n",
"\n",
" img = Image.fromarray(img)\n",
" img = img.resize((settings.resize_w, settings.resize_h), Image.ANTIALIAS)\n",
" img = np.array(img)\n",
"\n",
" if mode == 'train':\n",
" mirror = int(np.random.uniform(0, 2))\n",
" if mirror == 1:\n",
" img = img[:, ::-1, :]\n",
" for i in six.moves.xrange(len(sampled_labels)):\n",
" tmp = sampled_labels[i][1]\n",
" sampled_labels[i][1] = 1 - sampled_labels[i][3]\n",
" sampled_labels[i][3] = 1 - tmp\n",
" # HWC to CHW\n",
" if len(img.shape) == 3:\n",
" img = np.swapaxes(img, 1, 2)\n",
" img = np.swapaxes(img, 1, 0)\n",
" # RBG to BGR\n",
" img = img[[2, 1, 0], :, :]\n",
" img = img.astype('float32')\n",
" img -= settings.img_mean\n",
" img = img * 0.007843\n",
" return img, sampled_labels\n",
"\n",
"\n",
"def coco(settings, coco_api, file_list, mode, batch_size, shuffle, data_dir):\n",
" from pycocotools.coco import COCO\n",
"\n",
" def reader():\n",
" if mode == 'train' and shuffle:\n",
" np.random.shuffle(file_list)\n",
" batch_out = []\n",
" for image in file_list:\n",
" image_name = image['file_name']\n",
" image_path = os.path.join(data_dir, image_name)\n",
" if not os.path.exists(image_path):\n",
" raise ValueError(\"%s is not exist, you should specify \"\n",
" \"data path correctly.\" % image_path)\n",
" im = Image.open(image_path)\n",
" if im.mode == 'L':\n",
" im = im.convert('RGB')\n",
" im_width, im_height = im.size\n",
" im_id = image['id']\n",
"\n",
" # layout: category_id | xmin | ymin | xmax | ymax | iscrowd\n",
" bbox_labels = []\n",
" annIds = coco_api.getAnnIds(imgIds=image['id'])\n",
" anns = coco_api.loadAnns(annIds)\n",
" for ann in anns:\n",
" bbox_sample = []\n",
" # start from 1, leave 0 to background\n",
" bbox_sample.append(float(ann['category_id']))\n",
" bbox = ann['bbox']\n",
" xmin, ymin, w, h = bbox\n",
" xmax = xmin + w\n",
" ymax = ymin + h\n",
" bbox_sample.append(float(xmin) / im_width)\n",
" bbox_sample.append(float(ymin) / im_height)\n",
" bbox_sample.append(float(xmax) / im_width)\n",
" bbox_sample.append(float(ymax) / im_height)\n",
" bbox_sample.append(float(ann['iscrowd']))\n",
" bbox_labels.append(bbox_sample)\n",
" im, sample_labels = preprocess(im, bbox_labels, mode, settings)\n",
" sample_labels = np.array(sample_labels)\n",
" if len(sample_labels) == 0: continue\n",
" im = im.astype('float32')\n",
" boxes = sample_labels[:, 1:5]\n",
" lbls = sample_labels[:, 0].astype('int32')\n",
" iscrowd = sample_labels[:, -1].astype('int32')\n",
" if 'cocoMAP' in settings.ap_version:\n",
" batch_out.append((im, boxes, lbls, iscrowd,\n",
" [im_id, im_width, im_height]))\n",
" else:\n",
" batch_out.append((im, boxes, lbls, iscrowd))\n",
"\n",
" if len(batch_out) == batch_size:\n",
" yield batch_out\n",
" batch_out = []\n",
"\n",
" if mode == 'test' and len(batch_out) > 1:\n",
" yield batch_out\n",
" batch_out = []\n",
"\n",
" return reader\n",
"\n",
"\n",
"def pascalvoc(settings, file_list, mode, batch_size, shuffle):\n",
" def reader():\n",
" if mode == 'train' and shuffle:\n",
" np.random.shuffle(file_list)\n",
" batch_out = []\n",
" cnt = 0\n",
" for image in file_list:\n",
" image_path, label_path = image.split()\n",
" image_path = os.path.join(settings.data_dir, image_path)\n",
" label_path = os.path.join(settings.data_dir, label_path)\n",
" if not os.path.exists(image_path):\n",
" raise ValueError(\"%s is not exist, you should specify \"\n",
" \"data path correctly.\" % image_path)\n",
" im = Image.open(image_path)\n",
" if im.mode == 'L':\n",
" im = im.convert('RGB')\n",
" im_width, im_height = im.size\n",
"\n",
" # layout: label | xmin | ymin | xmax | ymax | difficult\n",
" bbox_labels = []\n",
" root = xml.etree.ElementTree.parse(label_path).getroot()\n",
" for object in root.findall('object'):\n",
" bbox_sample = []\n",
" # start from 1\n",
" bbox_sample.append(\n",
" float(settings.label_list.index(object.find('name').text)))\n",
" bbox = object.find('bndbox')\n",
" difficult = float(object.find('difficult').text)\n",
" bbox_sample.append(float(bbox.find('xmin').text) / im_width)\n",
" bbox_sample.append(float(bbox.find('ymin').text) / im_height)\n",
" bbox_sample.append(float(bbox.find('xmax').text) / im_width)\n",
" bbox_sample.append(float(bbox.find('ymax').text) / im_height)\n",
" bbox_sample.append(difficult)\n",
" bbox_labels.append(bbox_sample)\n",
" im, sample_labels = preprocess(im, bbox_labels, mode, settings)\n",
" sample_labels = np.array(sample_labels)\n",
" if len(sample_labels) == 0: continue\n",
" im = im.astype('float32')\n",
" boxes = sample_labels[:, 1:5]\n",
" lbls = sample_labels[:, 0].astype('int32')\n",
" difficults = sample_labels[:, -1].astype('int32')\n",
"\n",
" batch_out.append((im, boxes, lbls, difficults))\n",
" if len(batch_out) == batch_size:\n",
" yield batch_out\n",
" cnt += len(batch_out)\n",
" batch_out = []\n",
"\n",
" if mode == 'test' and len(batch_out) > 1:\n",
" yield batch_out\n",
" cnt += len(batch_out)\n",
" batch_out = []\n",
"\n",
" return reader\n",
"\n",
"\n",
"def train_data_reader(settings,\n",
" file_list,\n",
" batch_size,\n",
" shuffle=True,\n",
" num_workers=8,\n",
" enable_ce=False):\n",
" file_path = os.path.join(settings.data_dir, file_list)\n",
" readers = []\n",
" if 'coco' in settings.dataset:\n",
" # cocoapi\n",
" from pycocotools.coco import COCO\n",
" coco_api = COCO(file_path)\n",
" image_ids = coco_api.getImgIds()\n",
" images = coco_api.loadImgs(image_ids)\n",
" n = int(math.ceil(len(images) // num_workers))\n",
" image_lists = [images[i:i + n] for i in range(0, len(images), n)]\n",
"\n",
" if '2014' in file_list:\n",
" sub_dir = \"train2014\"\n",
" elif '2017' in file_list:\n",
" sub_dir = \"train2017\"\n",
" data_dir = os.path.join(settings.data_dir, sub_dir)\n",
" for l in image_lists:\n",
" readers.append(\n",
" coco(settings, coco_api, l, 'train', batch_size, shuffle,\n",
" data_dir))\n",
" else:\n",
" images = [line.strip() for line in open(file_path)]\n",
" n = int(math.ceil(len(images) // num_workers))\n",
" image_lists = [images[i:i + n] for i in range(0, len(images), n)]\n",
" for l in image_lists:\n",
" readers.append(pascalvoc(settings, l, 'train', batch_size, shuffle))\n",
"\n",
" return paddle.reader.multiprocess_reader(readers, False)\n",
"\n",
"\n",
"def test_data_reader(settings, file_list, batch_size):\n",
" file_list = os.path.join(settings.data_dir, file_list)\n",
" if 'coco' in settings.dataset:\n",
" from pycocotools.coco import COCO\n",
" coco_api = COCO(file_list)\n",
" image_ids = coco_api.getImgIds()\n",
" images = coco_api.loadImgs(image_ids)\n",
" if '2014' in file_list:\n",
" sub_dir = \"val2014\"\n",
" elif '2017' in file_list:\n",
" sub_dir = \"val2017\"\n",
" data_dir = os.path.join(settings.data_dir, sub_dir)\n",
" return coco(settings, coco_api, images, 'test', batch_size, False,\n",
" data_dir)\n",
" else:\n",
" image_list = [line.strip() for line in open(file_list)]\n",
" return pascalvoc(settings, image_list, 'test', batch_size, False)\n",
"\n",
"\n",
"def infer(settings, image_path):\n",
" def reader():\n",
" if not os.path.exists(image_path):\n",
" raise ValueError(\"%s is not exist, you should specify \"\n",
" \"data path correctly.\" % image_path)\n",
" img = Image.open(image_path)\n",
" if img.mode == 'L':\n",
" img = im.convert('RGB')\n",
" im_width, im_height = img.size\n",
" img = img.resize((settings.resize_w, settings.resize_h),\n",
" Image.ANTIALIAS)\n",
" img = np.array(img)\n",
" # HWC to CHW\n",
" if len(img.shape) == 3:\n",
" img = np.swapaxes(img, 1, 2)\n",
" img = np.swapaxes(img, 1, 0)\n",
" # RBG to BGR\n",
" img = img[[2, 1, 0], :, :]\n",
" img = img.astype('float32')\n",
" img -= settings.img_mean\n",
" img = img * 0.007843\n",
" return img\n",
"\n",
" return reader"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"在以上实现的reader中,通过调用`train_data_reader`函数返回一个数据迭代器, 以下代码示例简单展示了该迭代器如何使用:"
]
},
{
"cell_type": "code",
"execution_count": 70,
"metadata": {},
"outputs": [],
"source": [
"#train_reader = train_data_reader(data_args,\n",
"# train_file_list,\n",
"# 2,\n",
"# shuffle=False,\n",
"# num_workers=1)\n",
"\n",
"#for i, data in enumerate(train_reader()):\n",
"# print(\"len: {}\".format(len(data)))\n",
"# if i > 1:\n",
"# break"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3. 定义网络\n",
"\n",
"MobileNet-V1-SSD网络结构如下:\n",
"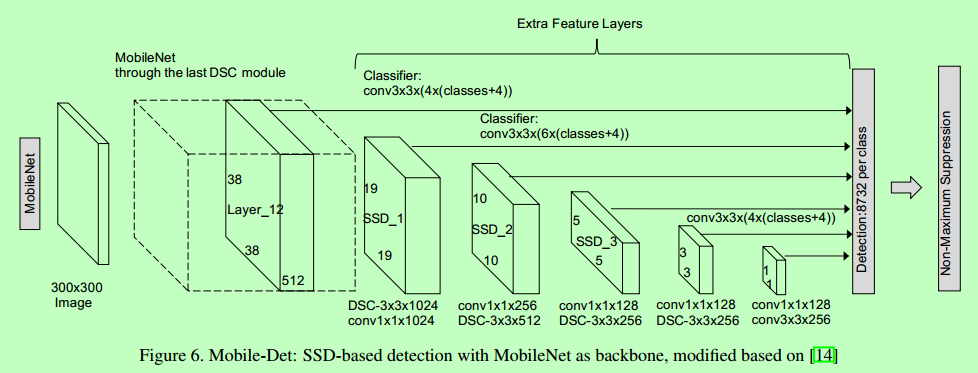\n",
"\n",
"在文件[mobilenet_ssd.py](https://github.com/PaddlePaddle/models/blob/v1.4/PaddleCV/object_detection/mobilenet_ssd.py)中定义了MobileNet-V1-SSD网络结构。"
]
},
{
"cell_type": "code",
"execution_count": 71,
"metadata": {},
"outputs": [],
"source": [
"import paddle.fluid as fluid\n",
"from paddle.fluid.initializer import MSRA\n",
"from paddle.fluid.param_attr import ParamAttr\n",
"\n",
"\n",
"def conv_bn(input,\n",
" filter_size,\n",
" num_filters,\n",
" stride,\n",
" padding,\n",
" channels=None,\n",
" num_groups=1,\n",
" act='relu',\n",
" use_cudnn=True,\n",
" name=None):\n",
" parameter_attr = ParamAttr(learning_rate=0.1, initializer=MSRA())\n",
" conv = fluid.layers.conv2d(\n",
" input=input,\n",
" num_filters=num_filters,\n",
" filter_size=filter_size,\n",
" stride=stride,\n",
" padding=padding,\n",
" groups=num_groups,\n",
" act=None,\n",
" use_cudnn=use_cudnn,\n",
" param_attr=parameter_attr,\n",
" bias_attr=False)\n",
" return fluid.layers.batch_norm(input=conv, act=act)\n",
"\n",
"\n",
"def depthwise_separable(input, num_filters1, num_filters2, num_groups, stride,\n",
" scale):\n",
" depthwise_conv = conv_bn(\n",
" input=input,\n",
" filter_size=3,\n",
" num_filters=int(num_filters1 * scale),\n",
" stride=stride,\n",
" padding=1,\n",
" num_groups=int(num_groups * scale),\n",
" use_cudnn=False)\n",
"\n",
" pointwise_conv = conv_bn(\n",
" input=depthwise_conv,\n",
" filter_size=1,\n",
" num_filters=int(num_filters2 * scale),\n",
" stride=1,\n",
" padding=0)\n",
" return pointwise_conv\n",
"\n",
"\n",
"def extra_block(input, num_filters1, num_filters2, num_groups, stride, scale):\n",
" # 1x1 conv\n",
" pointwise_conv = conv_bn(\n",
" input=input,\n",
" filter_size=1,\n",
" num_filters=int(num_filters1 * scale),\n",
" stride=1,\n",
" num_groups=int(num_groups * scale),\n",
" padding=0)\n",
"\n",
" # 3x3 conv\n",
" normal_conv = conv_bn(\n",
" input=pointwise_conv,\n",
" filter_size=3,\n",
" num_filters=int(num_filters2 * scale),\n",
" stride=2,\n",
" num_groups=int(num_groups * scale),\n",
" padding=1)\n",
" return normal_conv\n",
"\n",
"\n",
"def mobile_net(num_classes, img, img_shape, scale=1.0):\n",
" # 300x300\n",
" tmp = conv_bn(img, 3, int(32 * scale), 2, 1, 3)\n",
" # 150x150\n",
" tmp = depthwise_separable(tmp, 32, 64, 32, 1, scale)\n",
" tmp = depthwise_separable(tmp, 64, 128, 64, 2, scale)\n",
" # 75x75\n",
" tmp = depthwise_separable(tmp, 128, 128, 128, 1, scale)\n",
" tmp = depthwise_separable(tmp, 128, 256, 128, 2, scale)\n",
" # 38x38\n",
" tmp = depthwise_separable(tmp, 256, 256, 256, 1, scale)\n",
" tmp = depthwise_separable(tmp, 256, 512, 256, 2, scale)\n",
"\n",
" # 19x19\n",
" for i in range(5):\n",
" tmp = depthwise_separable(tmp, 512, 512, 512, 1, scale)\n",
" module11 = tmp\n",
" tmp = depthwise_separable(tmp, 512, 1024, 512, 2, scale)\n",
"\n",
" # 10x10\n",
" module13 = depthwise_separable(tmp, 1024, 1024, 1024, 1, scale)\n",
" module14 = extra_block(module13, 256, 512, 1, 2, scale)\n",
" # 5x5\n",
" module15 = extra_block(module14, 128, 256, 1, 2, scale)\n",
" # 3x3\n",
" module16 = extra_block(module15, 128, 256, 1, 2, scale)\n",
" # 2x2\n",
" module17 = extra_block(module16, 64, 128, 1, 2, scale)\n",
"\n",
" mbox_locs, mbox_confs, box, box_var = fluid.layers.multi_box_head(\n",
" inputs=[module11, module13, module14, module15, module16, module17],\n",
" image=img,\n",
" num_classes=num_classes,\n",
" min_ratio=20,\n",
" max_ratio=90,\n",
" min_sizes=[60.0, 105.0, 150.0, 195.0, 240.0, 285.0],\n",
" max_sizes=[[], 150.0, 195.0, 240.0, 285.0, 300.0],\n",
" aspect_ratios=[[2.], [2., 3.], [2., 3.], [2., 3.], [2., 3.], [2., 3.]],\n",
" base_size=img_shape[2],\n",
" offset=0.5,\n",
" flip=True)\n",
"\n",
" return mbox_locs, mbox_confs, box, box_var"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4. 配置压缩任务\n",
"\n",
"### 4.1 配置int8量化压缩策略\n",
"\n",
"现阶段的量化训练主要针对卷积层(包括二维卷积和Depthwise卷积)以及全连接层进行量化。卷积层和全连接层在PaddlePaddle框架中对应算子包括conv2d、depthwise_conv2d和mul等。量化训练会对所有的conv2d、depthwise_conv2d和mul进行量化操作,且要求它们的输入中必须包括激活和参数两部分。\n",
"int8量化训练策略目前可配置的参数如下:\n",
"\n",
"- **class:** 量化策略的类名称,目前仅支持QuantizationStrategy\n",
"\n",
"- **start_epoch:** 在start_epoch开始之前,量化训练策略会往train_program和eval_program插入量化operators和反量化operators. 从start_epoch开始,进入量化训练阶段。\n",
"\n",
"- **end_epoch:** 在end_epoch结束之后,会保存用户指定格式的模型。注意:end_epoch之后并不会停止量化训练,而是继续训练到compressor.epoch为止。\n",
"\n",
"- **float_model_save_path:** 保存float数据格式模型的路径。模型weight的实际大小在int8可表示范围内,但是是以float格式存储的。如果设置为None, 则不存储float格式的模型。默认为None.\n",
"\n",
"- **int8_model_save_path:** 保存int8数据格式模型的路径。如果设置为None, 则不存储int8格式的模型。默认为None.\n",
"\n",
"- **mobile_model_save_path:** 保存兼容paddle-mobile框架的模型的路径。如果设置为None, 则不存储mobile格式的模型。默认为None.\n",
"\n",
"- **weight_bits:** 量化weight的bit数,bias不会被量化。\n",
"\n",
"- **activation_bits:** 量化activation的bit数。\n",
"\n",
"- **weight_quantize_type:** 对于weight的量化方式,目前支持'abs_max', 'channel_wise_abs_max'.\n",
"\n",
"- **activation_quantize_type:** 对activation的量化方法,目前可选abs_max或range_abs_max。abs_max意为在训练的每个step和inference阶段动态的计算量化范围。range_abs_max意为在训练阶段计算出一个静态的范围,并将其用于inference阶段。\n",
"\n",
"- **save_in_nodes:** variable名称列表。在保存量化后模型的时候,需要根据save_in_nodes对eval programg 网络进行前向遍历剪枝。默认为eval_feed_list内指定的variable的名称列表。\n",
"\n",
"- **save_out_nodes:** varibale名称列表。在保存量化后模型的时候,需要根据save_out_nodes对eval programg 网络进行回溯剪枝。默认为eval_fetch_list内指定的variable的名称列表。\n",
"\n",
"其中`save_in_nodes`和`save_out_nodes`中的variable名称,可以在构建网络时,通过`print`打印。例如:\n",
"\n",
"\n",
"```\n",
"\n",
"nmsed_out = fluid.layers.detection_output(\n",
" locs, confs, box, box_var, nms_threshold=0.45)\n",
"print(nms_out.name)\n",
"\n",
"```\n",
"\n",
"以下代码将配置文件写到当前工作路径下:"
]
},
{
"cell_type": "code",
"execution_count": 72,
"metadata": {},
"outputs": [],
"source": [
"config=\"\"\"\n",
"version: 1.0\n",
"strategies:\n",
" quantization_strategy:\n",
" class: 'QuantizationStrategy'\n",
" start_epoch: 0\n",
" end_epoch: 20\n",
" float_model_save_path: './output/float'\n",
" mobile_model_save_path: './output/mobile'\n",
" int8_model_save_path: './output/int8'\n",
" weight_bits: 8\n",
" activation_bits: 8\n",
" weight_quantize_type: 'abs_max'\n",
" activation_quantize_type: 'abs_max'\n",
" save_in_nodes: ['image']\n",
" save_out_nodes: ['inferenceinferencedetection_output_0.tmp_0']\n",
"compressor:\n",
" epoch: 2\n",
" checkpoint_path: './checkpoints/'\n",
" strategies:\n",
" - quantization_strategy\n",
"\"\"\"\n",
"\n",
"f = open(\"./compress.yaml\", 'w')\n",
"f.write(config)\n",
"f.close()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.2 配置Compressor\n",
"\n",
"压缩目标即我们要压缩的网络,我们需要为其准一下内容:\n",
"#### 4.2.1 准备工作\n",
"##### step1: import"
]
},
{
"cell_type": "code",
"execution_count": 73,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import time\n",
"import numpy as np\n",
"import argparse\n",
"import functools\n",
"import shutil\n",
"import math\n",
"import multiprocessing\n",
"\n",
"import paddle\n",
"import paddle.fluid as fluid\n",
"from paddle.fluid.contrib.slim import Compressor"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### step2: 设置训练相关参数"
]
},
{
"cell_type": "code",
"execution_count": 74,
"metadata": {},
"outputs": [],
"source": [
"args_learning_rate= 0.001\n",
"args_batch_size = 32\n",
"args_epoc_num = 120\n",
"args_use_gpu = False\n",
"args_parallel = True\n",
"\n",
"args_model_save_dir = 'model'\n",
"\n",
"\n",
"train_parameters = {\n",
" \"pascalvoc\": {\n",
" \"train_images\": 16551,\n",
" \"image_shape\": [3, 300, 300],\n",
" \"class_num\": 21,\n",
" \"batch_size\": 64,\n",
" \"lr\": 0.001,\n",
" \"lr_epochs\": [40, 60, 80, 100],\n",
" \"lr_decay\": [1, 0.5, 0.25, 0.1, 0.01],\n",
" \"ap_version\": '11point',\n",
" },\n",
" \"coco2014\": {\n",
" \"train_images\": 82783,\n",
" \"image_shape\": [3, 300, 300],\n",
" \"class_num\": 91,\n",
" \"batch_size\": 64,\n",
" \"lr\": 0.001,\n",
" \"lr_epochs\": [12, 19],\n",
" \"lr_decay\": [1, 0.5, 0.25],\n",
" \"ap_version\": 'integral', # should use eval_coco_map.py to test model\n",
" },\n",
" \"coco2017\": {\n",
" \"train_images\": 118287,\n",
" \"image_shape\": [3, 300, 300],\n",
" \"class_num\": 91,\n",
" \"batch_size\": 64,\n",
" \"lr\": 0.001,\n",
" \"lr_epochs\": [12, 19],\n",
" \"lr_decay\": [1, 0.5, 0.25],\n",
" \"ap_version\": 'integral', # should use eval_coco_map.py to test model\n",
" }\n",
"}\n",
"\n",
"train_parameters[dataset]['image_shape'] = image_shape\n",
"train_parameters[dataset]['batch_size'] = args_batch_size\n",
"train_parameters[dataset]['lr'] = args_learning_rate\n",
"train_parameters[dataset]['epoc_num'] = args_epoc_num\n",
"train_parameters[dataset]['ap_version'] = args_ap_version"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### step3: 定义优化器生成函数"
]
},
{
"cell_type": "code",
"execution_count": 75,
"metadata": {},
"outputs": [],
"source": [
"def optimizer_setting(train_params):\n",
" batch_size = train_params[\"batch_size\"]\n",
" iters = train_params[\"train_images\"] // batch_size\n",
" lr = train_params[\"lr\"]\n",
" boundaries = [i * iters for i in train_params[\"lr_epochs\"]]\n",
" values = [ i * lr for i in train_params[\"lr_decay\"]]\n",
"\n",
" optimizer = fluid.optimizer.RMSProp(\n",
" # learning_rate=fluid.layers.piecewise_decay(boundaries, values),\n",
" learning_rate=0.1,\n",
" regularization=fluid.regularizer.L2Decay(0.00005), )\n",
"\n",
" return optimizer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### step4: 定义构建网络函数\n",
"\n",
">注意:Paddle1.5版本的压缩库才开始支持py_reader. 本步骤的示例代码用的是普通reader,而不是py_reader.\n",
"如果需要py_reader, 需要修改build_program函数。"
]
},
{
"cell_type": "code",
"execution_count": 76,
"metadata": {},
"outputs": [],
"source": [
"def build_program(main_prog, startup_prog, train_params, is_train):\n",
" image_shape = train_params['image_shape']\n",
" class_num = train_params['class_num']\n",
" ap_version = train_params['ap_version']\n",
" outs = []\n",
" with fluid.program_guard(main_prog, startup_prog):\n",
" #py_reader = fluid.layers.py_reader(\n",
" # capacity=64,\n",
" # shapes=[[-1] + image_shape, [-1, 4], [-1, 1], [-1, 1]],\n",
" # lod_levels=[0, 1, 1, 1],\n",
" # dtypes=[\"float32\", \"float32\", \"int32\", \"int32\"],\n",
" # use_double_buffer=True)\n",
" with fluid.unique_name.guard():\n",
" \n",
" image = fluid.layers.data(name=\"image\", shape=[-1]+image_shape, dtype=\"float32\", lod_level=0)\n",
" gt_box = fluid.layers.data(name=\"gt_box\", shape=[-1, 4], dtype=\"float32\", lod_level=1)\n",
" gt_label = fluid.layers.data(name=\"gt_label\", shape=[-1, 1], dtype=\"float32\", lod_level=1)\n",
" difficult = fluid.layers.data(name=\"difficult\", shape=[-1, 1], dtype=\"float32\", lod_level=1)\n",
" fluid.layers.Print(image, message=\"image\", summarize=10)\n",
" fluid.layers.Print(gt_box, message=\"gt_box\", summarize=10)\n",
" fluid.layers.Print(gt_label, message=\"gt_label\", summarize=10)\n",
" fluid.layers.Print(difficult, message=\"difficult\", summarize=10)\n",
" #image, gt_box, gt_label, difficult = fluid.layers.read_file(py_reader)\n",
" locs, confs, box, box_var = mobile_net(class_num, image, image_shape)\n",
" gt_label.stop_gradient=True\n",
" difficult.stop_gradient=True\n",
" gt_box.stop_gradient=True\n",
" if is_train:\n",
" with fluid.unique_name.guard(\"train\"):\n",
" \n",
" loss = fluid.layers.ssd_loss(locs, confs, gt_box, gt_label, box,\n",
" box_var)\n",
" loss = fluid.layers.reduce_sum(loss)\n",
" optimizer = optimizer_setting(train_parameters[dataset])\n",
" optimizer.minimize(loss)\n",
" outs = ((image, gt_box, gt_label, difficult), loss, optimizer)\n",
" else:\n",
" with fluid.unique_name.guard(\"inference\"):\n",
" nmsed_out = fluid.layers.detection_output(\n",
" locs, confs, box, box_var, nms_threshold=0.45)\n",
" \n",
" print(\"nmsed_out: {}\".format(nmsed_out))\n",
" gt_label = fluid.layers.cast(x=gt_label, dtype=gt_box.dtype)\n",
" if difficult:\n",
" difficult = fluid.layers.cast(x=difficult, dtype=gt_box.dtype)\n",
" gt_label = fluid.layers.reshape(gt_label, [-1, 1])\n",
" difficult = fluid.layers.reshape(difficult, [-1, 1])\n",
" label = fluid.layers.concat([gt_label, difficult, gt_box], axis=1)\n",
" else:\n",
" label = fluid.layers.concat([gt_label, gt_box], axis=1)\n",
" map_var = fluid.layers.detection.detection_map(\n",
" nmsed_out,\n",
" label,\n",
" class_num,\n",
" background_label=0,\n",
" overlap_threshold=0.5,\n",
" evaluate_difficult=False,\n",
" ap_version=ap_version)\n",
" \n",
" # nmsed_out and image is used to save mode for inference\n",
" outs = ((image, gt_box, gt_label, difficult), map_var, nmsed_out, image)\n",
" return outs"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 4.2.2 配置Compressor"
]
},
{
"cell_type": "code",
"execution_count": 77,
"metadata": {},
"outputs": [],
"source": [
"#def compress(args,\n",
"# data_args,\n",
"# train_params,\n",
"# train_file_list,\n",
"# val_file_list):\n",
"\n",
"model_save_dir = args_model_save_dir\n",
"pretrained_model = args_pretrained_model\n",
"use_gpu = args_use_gpu\n",
"parallel = args_parallel\n",
"is_shuffle = True"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 设置device信息,并根据device信息设置batch size"
]
},
{
"cell_type": "code",
"execution_count": 78,
"metadata": {},
"outputs": [],
"source": [
"if not use_gpu:\n",
" devices_num = int(os.environ.get('CPU_NUM',\n",
" multiprocessing.cpu_count()))\n",
" devices_num = 1\n",
"else:\n",
" devices_num = fluid.core.get_cuda_device_count()\n",
"\n",
"batch_size = train_parameters[dataset]['batch_size']\n",
"batch_size_per_device = batch_size // devices_num "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 声明并构造train_program和test_program\n",
"\n",
"- **train_program:** 用于在压缩过程中迭代训练模型,该program必须包含loss。一般改program不要有backward op和weights update op,否则不能使用蒸馏策略。\n",
"\n",
"- **test_program:** 用于在压缩过程中评估模型的精度,一般会包含accuracy、IoU等评估指标的计算layer。"
]
},
{
"cell_type": "code",
"execution_count": 79,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"nmsed_out: name: \"inferenceinferencedetection_output_0.tmp_0\"\n",
"type {\n",
" type: LOD_TENSOR\n",
" lod_tensor {\n",
" tensor {\n",
" data_type: FP32\n",
" dims: 1917\n",
" dims: 6\n",
" }\n",
" }\n",
"}\n",
"persistable: false\n",
"\n"
]
}
],
"source": [
"\n",
"epoc_num = train_parameters[dataset]['epoc_num']\n",
"\n",
"startup_prog = fluid.Program()\n",
"train_prog = fluid.Program()\n",
"test_prog = fluid.Program()\n",
"\n",
"train_inputs, loss, optimizer = build_program(\n",
" main_prog=train_prog,\n",
" startup_prog=startup_prog,\n",
" train_params=train_parameters[dataset],\n",
" is_train=True)\n",
" \n",
"test_inputs, map_var, _, _ = build_program(\n",
" main_prog=test_prog,\n",
" startup_prog=startup_prog,\n",
" train_params=train_parameters[dataset],\n",
" is_train=False)\n",
" \n",
"test_prog = test_prog.clone(for_test=True) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 初始化网络并加载预训练模型"
]
},
{
"cell_type": "code",
"execution_count": 80,
"metadata": {},
"outputs": [],
"source": [
"place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()\n",
"exe = fluid.Executor(place)\n",
"exe.run(startup_prog)\n",
" \n",
"if pretrained_model:\n",
" def if_exist(var):\n",
" return os.path.exists(os.path.join(pretrained_model, var.name))\n",
" fluid.io.load_vars(exe, pretrained_model, main_program=train_prog,\n",
" predicate=if_exist)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 构造data reader\n",
"\n",
"- train_reader: 用于给train_program的执行提供数据\n",
"\n",
"- eval_reader: 用于给eval_program的执行提供数据"
]
},
{
"cell_type": "code",
"execution_count": 105,
"metadata": {},
"outputs": [],
"source": [
"num_workers = 8\n",
"train_reader = train_data_reader(data_args,\n",
" train_file_list,\n",
" batch_size_per_device,\n",
" shuffle=is_shuffle,\n",
" num_workers=num_workers)\n",
"test_reader = test_data_reader(data_args, val_file_list, batch_size)\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 指定训练网络和测试网络的input和output\n",
"\n",
"feed list和fetch list是两个有序的字典, 其中,feed_list中的key为自定义的有一定含义的字符串,value是Variable的名称, feed_list中的顺序需要和DataReader提供的数据的顺序对应。\n",
"\n",
"对于train_program和test_program都需要有与其对应的feed_list和fetch_list。\n",
"\n",
">注意: 在train_program对应的fetch_list中,loss variable(loss layer的输出)对应的key一定要是‘‘loss’’"
]
},
{
"cell_type": "code",
"execution_count": 85,
"metadata": {},
"outputs": [],
"source": [
"image, gt_box, gt_label, difficult = train_inputs\n",
"train_feed_list = [(\"image\", \"image\"), (\"gt_box\", \"gt_box\"), (\"gt_label\", \"gt_label\"), (\"difficult\", \"difficult\")]\n",
"train_fetch_list=[(\"loss\", loss.name)]\n",
"\n",
"image, gt_box, gt_label, difficult = test_inputs\n",
"val_feed_list=[(\"image\", \"image\"), (\"gt_box\", \"gt_box\"), (\"gt_label\", \"gt_label\"), (\"difficult\", \"difficult\")]\n",
"val_fetch_list=[(\"map\", map_var.name)]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.3 构造并执行Compressor"
]
},
{
"cell_type": "code",
"execution_count": 104,
"metadata": {},
"outputs": [],
"source": [
"com_pass = Compressor(\n",
" place,\n",
" fluid.global_scope(),\n",
" train_prog,\n",
" train_reader=train_reader,\n",
" train_feed_list=train_feed_list,\n",
" train_fetch_list=train_fetch_list,\n",
" eval_program=test_prog,\n",
" eval_reader=test_reader,\n",
" eval_feed_list=val_feed_list,\n",
" eval_fetch_list=val_fetch_list,\n",
" train_optimizer=None)\n",
"com_pass.config('./compress.yaml')\n",
"eval_graph = com_pass.run()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录