diff --git a/tutorials/README.md b/tutorials/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3917b438f9ec43e2a1efe5f42ac4cd791de484f3
--- /dev/null
+++ b/tutorials/README.md
@@ -0,0 +1,13 @@
+# 产业级模型开发教程
+
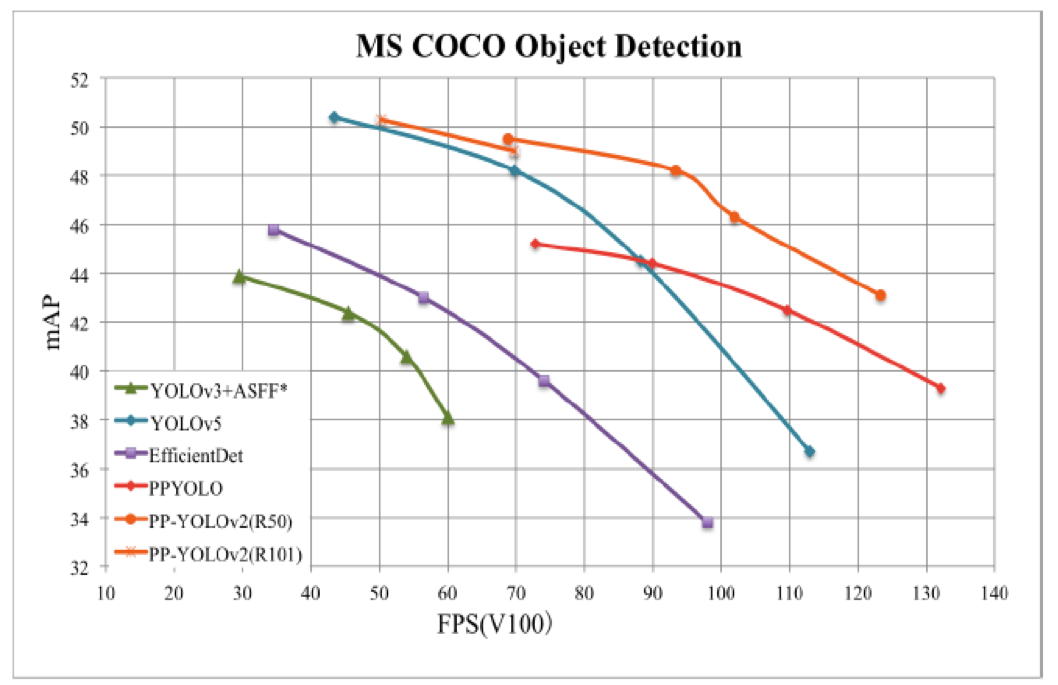
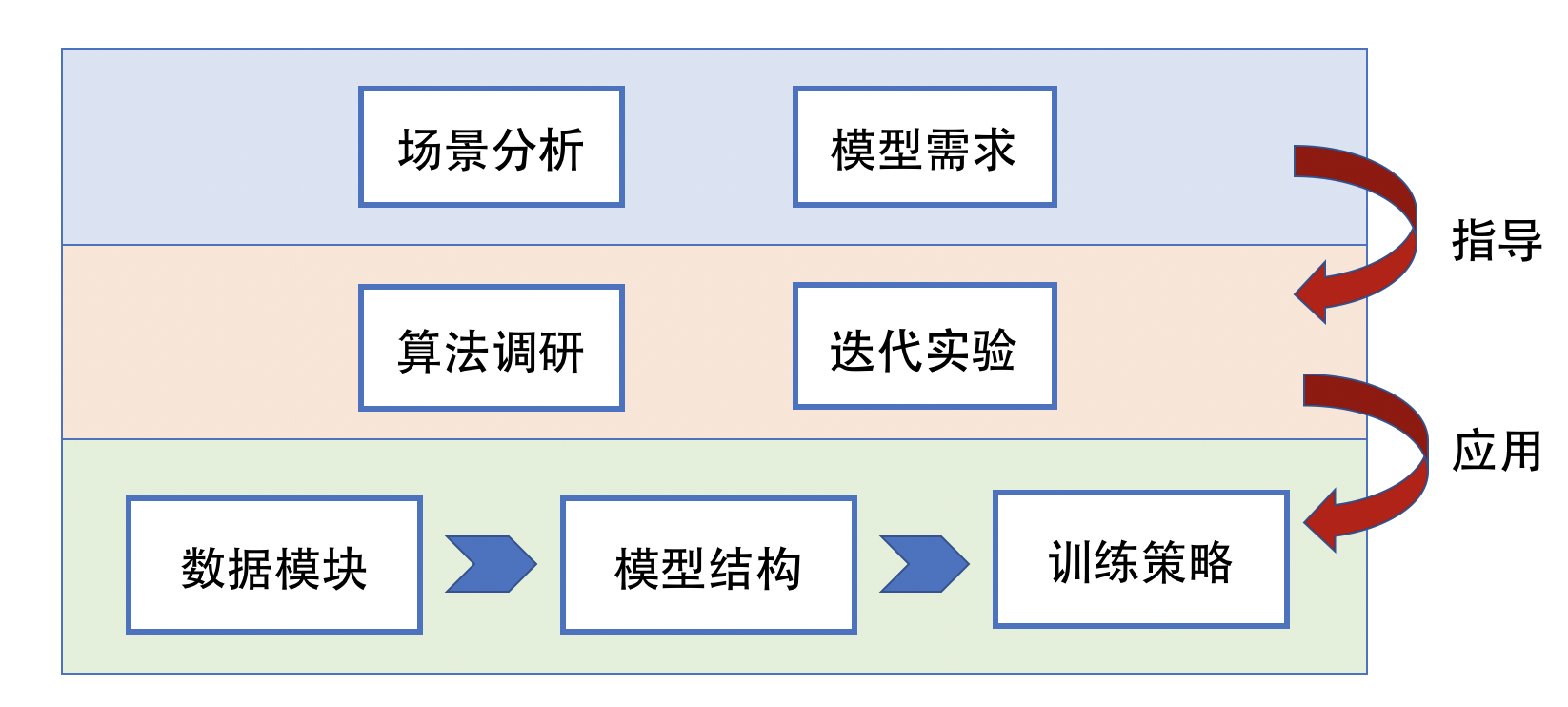
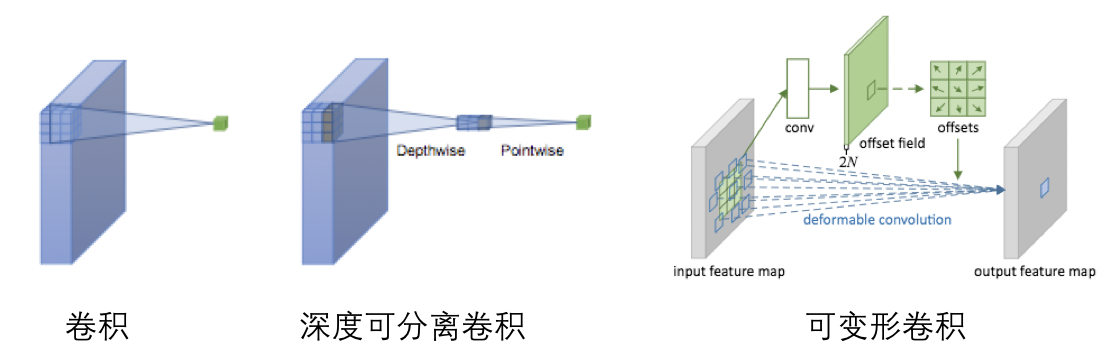
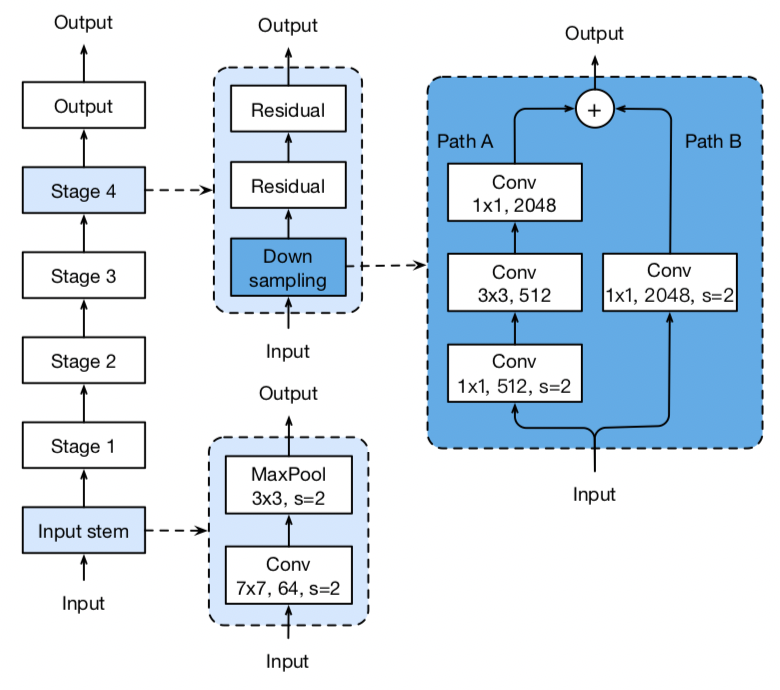
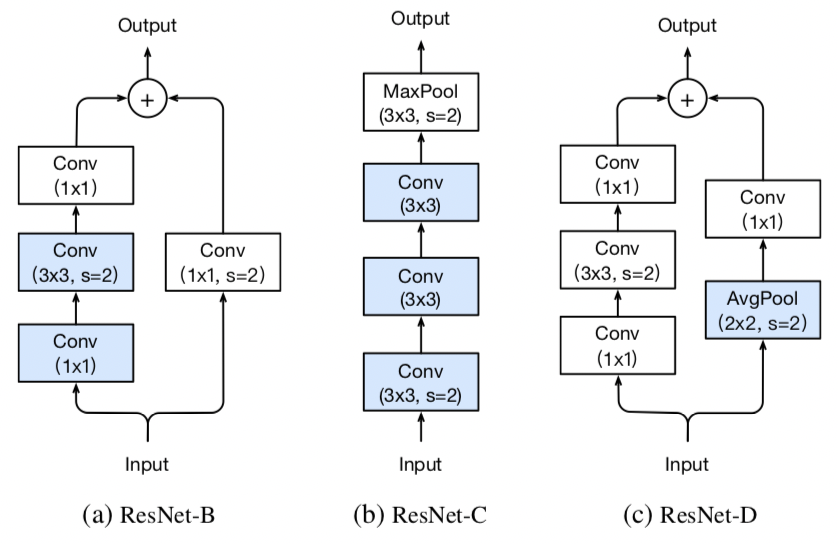
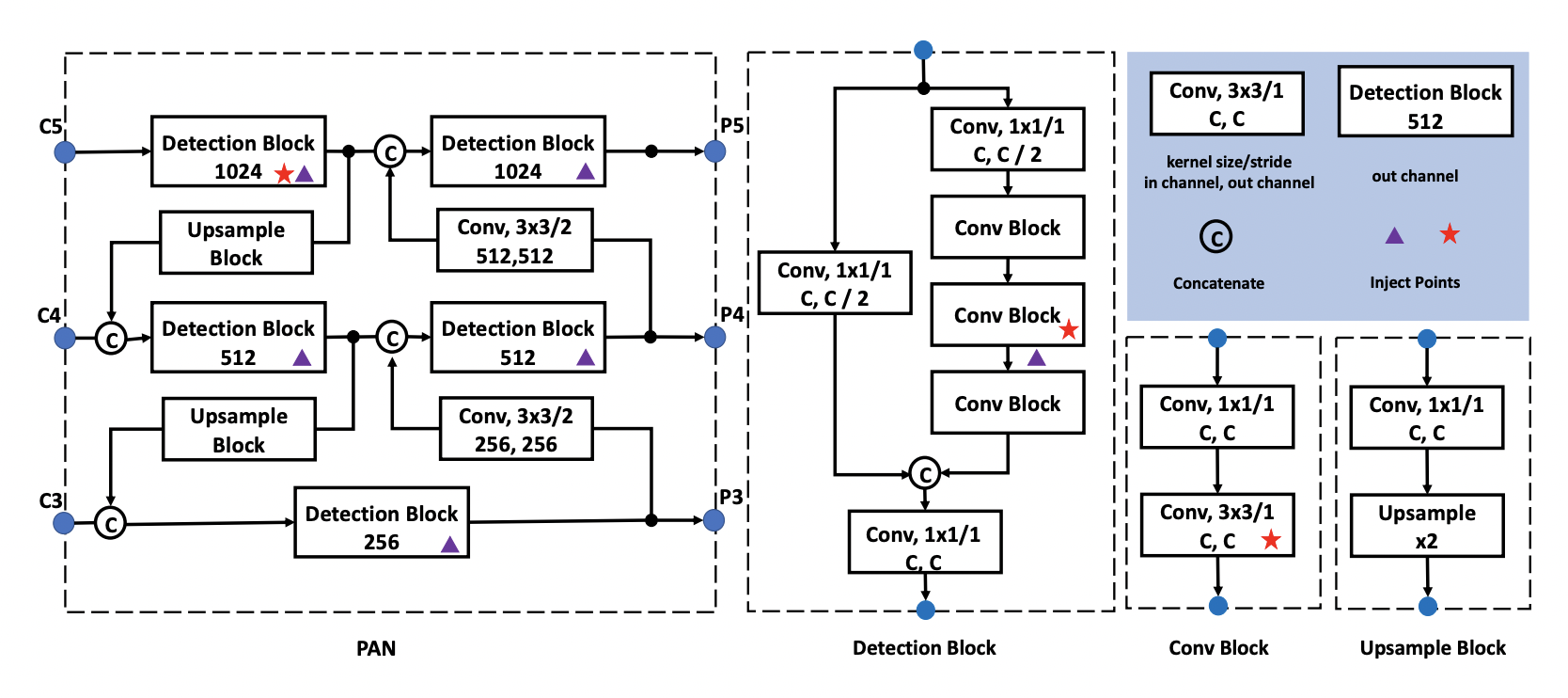
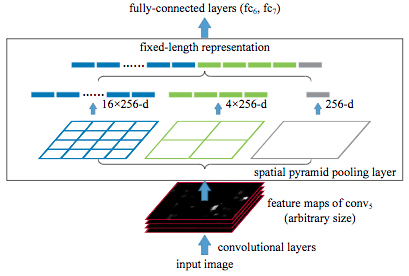
+飞桨是源于产业实践的开源深度学习平台,致力于让深度学习技术的创新与应用更简单。产业级模型的开发过程主要包含下面三个步骤。
+
+
+

+
-

+

+

+
+
+
+
+
+

+
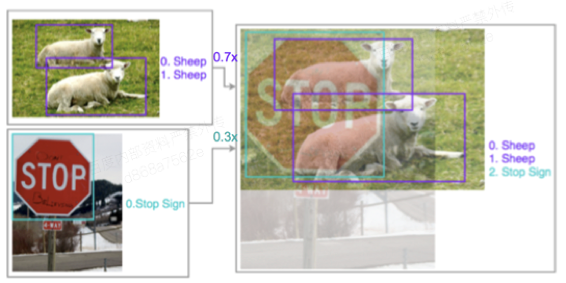
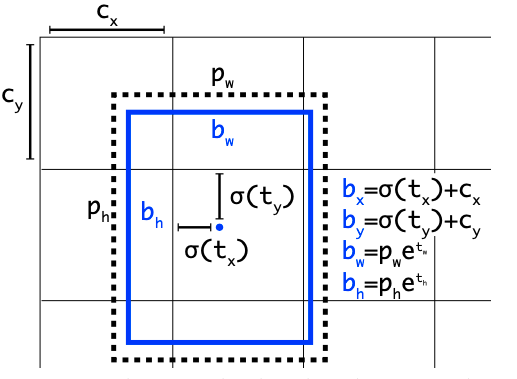
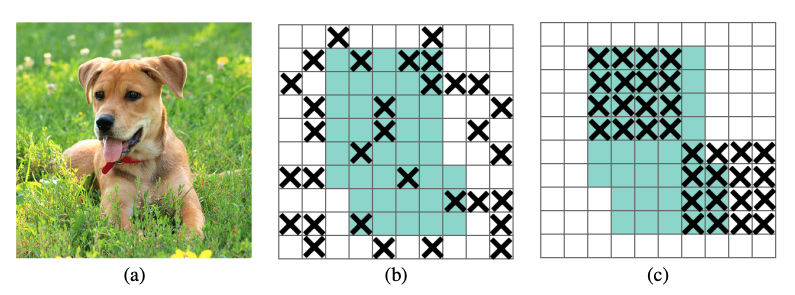
AutoAugment数据增广
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+