\n",
- "\n",
- "\n",
- "对文档理解来说,文档中的文字阅读顺序至关重要,目前主流的基于 OCR(Optical Character Recognition,文字识别)技术的模型大多遵循「从左到右、从上到下」的原则,然而对于文档中分栏、文本图片表格混杂的复杂布局,根据 OCR 结果获取的阅读顺序多数情况下都是错误的,从而导致模型无法准确地进行文档内容的理解。\n",
"\n",
- "而人类通常会根据文档结构和布局进行层次化分块阅读,受此启发,百度研究者提出在文档预训模型中对阅读顺序进行校正的布局知识增强创新思路。TextMind 平台上业界领先的文档解析工具(Document Parser)能够准确识别文档中的分块信息,产出正确的文档阅读顺序,将阅读顺序信号融合到模型的训练中,从而增强对布局信息的有效利用,提升模型对于复杂文档的理解能力。\n",
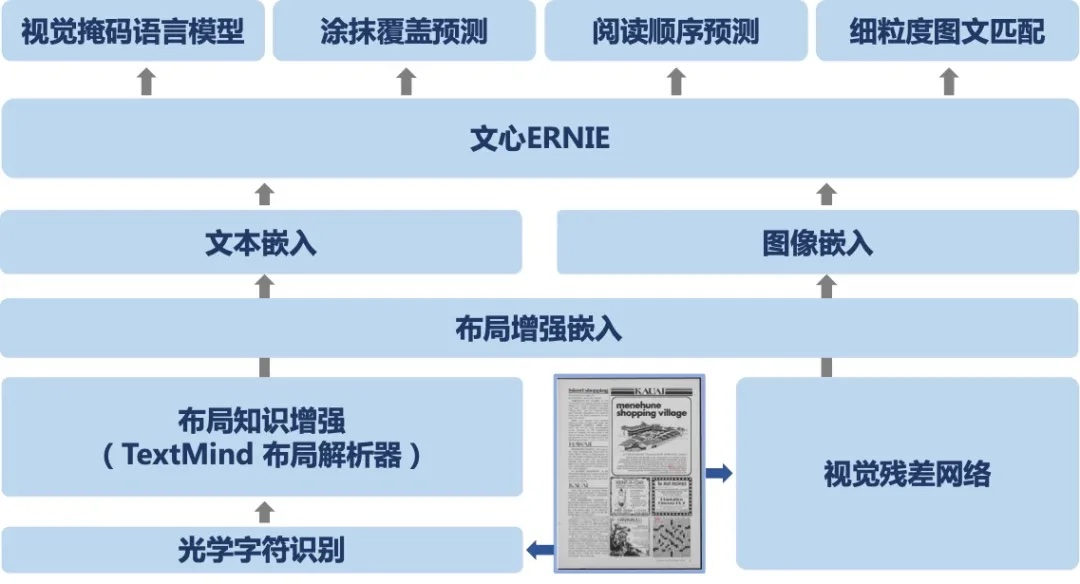
+ "文心 ERNIE-Layout 以文心 ERNIE 为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解耦注意力机制。输入基于 VIMER-StrucTexT 大模型提供的 OCR 结果,在各数据集上效果取得大幅度提升。\n",
"\n",
- "基于布局知识增强技术,同时依托文心 ERNIE,百度研究者提出了融合文本、图像、布局等信息进行联合建模的跨模态通用文档预训练模型 ERNIE-Layout。如下图所示,ERNIE-Layout 创新性地提出了阅读顺序预测和细粒度图文匹配两个自监督预训练任务,有效提升模型在文档任务上跨模态语义对齐能力和布局理解能力。\n",
+ "文心 ERNIE-mmLayout 为进一步探索不同粒度元素关系对文档理解的价值,在文心 ERNIE-Layout 的基础上引入基于 GNN 的多粒度、多模态 Transformer 层,实现文档图聚合(Document Graph Aggregation)表示。最终,在多个信息抽取任务上以更少的模型参数量超过 SOTA 成绩,\n",
"\n",
- "\n",
- "\n",
- ""
+ "附:文档智能(DI,Document Intelligence)主要指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。百度文档智能技术体系立足于强大的 NLP 与 OCR 技术积累,以多语言跨模态布局增强文档智能大模型文心 ERNIE-Layout 为核心底座,结合图神经网络技术,支撑文档布局分析、抽取问答、表格理解、语义表示多个核心模块,满足上层应用各类文档智能分析功能需求。"
]
},
{
@@ -142,13 +164,8 @@
"metadata": {},
"source": [
"# 5.注意事项\n",
- "## 5.1参数配置\n",
- "* batch_size:批处理大小,请结合机器情况进行调整,默认为1。\n",
- "\n",
- "* lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。\n",
"\n",
- "* topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。\n",
- "## 5.2使用技巧\n",
+ "### DocPrompt 使用技巧\n",
"\n",
"* Prompt设计:在DocPrompt中,Prompt可以是陈述句(例如,文档键值对中的Key),也可以是疑问句。因为是开放域的抽取问答,DocPrompt对Prompt的设计没有特殊限制,只要符合自然语言语义即可。如果对当前的抽取结果不满意,可以多尝试一些不同的Prompt。 \n",
"\n",
@@ -205,15 +222,22 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3.8.5 ('base')",
+ "display_name": "Python 3",
"language": "python",
- "name": "python3"
+ "name": "py35-paddle1.2.0"
},
"language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
"name": "python",
- "version": "3.8.5"
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.4"
},
- "orig_nbformat": 4,
"vscode": {
"interpreter": {
"hash": "a5f44439766e47113308a61c45e3ba0ce79cefad900abb614d22e5ec5db7fbe0"
@@ -221,5 +245,5 @@
}
},
"nbformat": 4,
- "nbformat_minor": 2
+ "nbformat_minor": 4
}
diff --git a/modelcenter/ERNIE-Layout/introduction_en.ipynb b/modelcenter/ERNIE-Layout/introduction_en.ipynb
index 4a474d8d08fdae28f12a3845ed7a25223ebc15c7..a296ea4f95203f2589f99e856ad9ce32929a7efa 100644
--- a/modelcenter/ERNIE-Layout/introduction_en.ipynb
+++ b/modelcenter/ERNIE-Layout/introduction_en.ipynb
@@ -5,36 +5,66 @@
"metadata": {},
"source": [
"# 1.ERNIE-Layout Introduction\n",
- "With the digital transformation of many industries, the structural analysis and content extraction of electronic documents have become a hot research topic. Electronic documents include scanned image documents and computer-generated digital documents, involving documents, industry reports, contracts, employment agreements, invoices, resumes and other types. The intelligent document understanding task aims to understand documents with various formats, layouts and contents, including document classification, document information extraction, document question answering and other tasks. Different from plain text documents, documents contain tables, pictures and other contents, and contain rich visual information. Because the document is rich in content, complex in layout, diverse in font style, and noisy in data, the task of document understanding is extremely challenging. With the great success of pre training language models such as ERNIE in the NLP field, people began to focus on large-scale pre training in the field of document understanding. Baidu put forward the cross modal document understanding model ERNIE-Layout, which is the first time to integrate the layout knowledge enhancement technology into the cross modal document pre training, refreshing the world's best results in four document understanding tasks, and topping the DocVQA list. At the same time, ERNIE Layout has been integrated into Baidu's intelligent document analysis platform TextMind to help enterprises upgrade digitally.\n",
"\n",
+ "Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets.\n",
"\n",
- "ERNIE-Layout takes the Wenxin text big model ERNIE as the base, integrates text, image, layout and other information for cross modal joint modeling, innovatively introduces layout knowledge enhancement, proposes self-monitoring pre training tasks such as reading order prediction, fine grain image text matching, upgrades spatial decoupling attention mechanism, and greatly improves the effect on each data set. Related work [ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding](https://arxiv.org/abs/2210.06155) has been included in the EMNLP 2022 Findings Conference. Considering that document intelligence is widely commercially available in multiple languages, it relies on PaddleNLP to open source the strongest multilingual cross modal document pre training model ERNIE Layout in the industry.\n",
- "ERNIE-Layout is a large cross modal model officially produced by the Flying Slurry. For more details about PaddleNLP, please visit for details. \n",
+ "The work is accepted by EMNLP 2022 (Findings). To expand the scope of commercial applications for document intelligence, we release the multilingual model of ERNIE-Layout in PaddleNLP. You can visit [https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout) for more details. \n",
"\n",
- ""
+ " "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "# 2.Model Effect and Application Scenario\n",
- "ERNIE-Layout can be used to process but not limited to tasks such as document classification, information extraction, document Q&A with layout data (documents, pictures, etc.). Application scenarios include but not limited to invoice extraction Q&A, poster extraction Q&A, web page extraction Q&A, table extraction Q&A, test paper extraction Q&A, English bill multilingual (Chinese, English, Japanese, Thai, Spanish, Russian) extraction Q&A Chinese bills in multiple languages (simplified, traditional, English, Japanese, French). Taking document information extraction and document visual Q&A as examples, the effect of using ERNIE-Layout model is shown below.\n",
- "## 2.1Document Information Extraction Task:\n",
- "### 2.1.1Dataset:\n",
- "Data sets include FUNSD, XFUND-ZH, etc. FUNSD is an English data set for form understanding on noisy scanned documents. The data set contains 199 real, fully annotated and scanned forms. Documents are noisy, and the appearance of various forms varies greatly, so understanding forms is a challenging task. The dataset can be used for a variety of tasks, including text detection, optical character recognition, spatial layout analysis, and entity tagging/linking. XFUND is a multilingual form understanding benchmark dataset, including manually labeled key value pair forms in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese). XFUND-ZH is the Chinese version of XFUND.\n",
- "### 2.1.2Quick View Of Model Effect:\n",
- "The model effect of ERNIE-Layout on FUNSD is:\n",
- "\n",
- "\n",
- "\n",
- "## 2.2Document Visual Question And Answer Task:\n",
- "### 2.2.1Dataset:\n",
- "The data set is DocVQA-ZH, and DocVQA-ZH has stopped submitting the list. Therefore, we will re divide the original training set to evaluate the model effect. After division, the training set contains 4187 pictures, the verification set contains 500 pictures, and the test set contains 500 pictures.\n",
- "### 2.2.2Quick View Of Model Effect:\n",
- "The model effect of ERNIE-Layout on DocVQA-ZH is:\n",
- "\n",
- "\n"
+ "# 2.Model Performance\n",
+ "\n",
+ "ERNIE-Layout can be used to process and analyze multimodal documents. ERNIE-Layout is effective in tasks such as document classification, information extraction, document VQA with layout data (documents, pictures, etc). \n",
+ "\n",
+ "- Invoice VQA\n",
+ "\n",
+ "
\n",
+ "\n",
+ "- Chinese invoice VQA by multilingual(CHS, CHT, EN, JP, FR) prompt\n",
+ "\n",
+ "
\n",
+ " \n",
+ "
"
]
},
{
@@ -42,14 +72,15 @@
"metadata": {},
"source": [
"# 3.How To Use The Model\n",
- "## 3.1Model Reasoning\n",
- "We have integrated the ERNIE-Layout DocPrompt Engine on the [huggingface page](https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout), which can be experienced with one click.\n",
"\n",
- "**Taskflow**\n",
+ "## 3.1 Model Inference\n",
"\n",
- "Of course, you can also use Taskflow for reasoning. Through `paddlenlp.Taskflow` calls DocPrompt with three lines of code, and has the ability to extract questions and answers from multilingual documents. Some application scenarios are shown below:\n",
+ "You can use DocPrompt through `paddlenlp.Taskflow` for model inference.\n",
"\n",
"* Input Format\n",
+ " * Support single and batch forecasting\n",
+ " * Support local image path input\n",
+ " * Support http image link input\n",
"\n",
"```python\n",
"[\n",
@@ -66,51 +97,53 @@
"]\n",
"```\n",
"\n",
- "* Support single and batch forecasting\n",
- "\n",
- " * Support local image path input\n",
- "\n",
- " \n",
- "\n",
- " ```python \n",
- " from pprint import pprint\n",
- " from paddlenlp import Taskflow\n",
- " docprompt = Taskflow(\"document_intelligence\")\n",
- " pprint(docprompt([{\"doc\": \"./resume.png\", \"prompt\": [\"五百丁本次想要担任的是什么职位?\", \"五百丁是在哪里上的大学?\", \"大学学的是什么专业?\"]}]))\n",
- " [{'prompt': '五百丁本次想要担任的是什么职位?',\n",
- " 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},\n",
- " {'prompt': '五百丁是在哪里上的大学?',\n",
- " 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},\n",
- " {'prompt': '大学学的是什么专业?',\n",
- " 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]\n",
- " ```\n",
- "\n",
- " * http image link input\n",
- "\n",
- " \n",
"\n",
- " ```python \n",
- " from pprint import pprint\n",
- " from paddlenlp import Taskflow\n",
"\n",
- " docprompt = Taskflow(\"document_intelligence\")\n",
- " pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))\n",
- " [{'prompt': '发票号码是多少?',\n",
- " 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]},\n",
- " {'prompt': '校验码是多少?',\n",
- " 'result': [{'end': 233,\n",
- " 'prob': 1.0,\n",
- " 'start': 231,\n",
- " 'value': '01107 555427109891646'}]}]\n",
- " ```\n",
+ " \n",
"\n",
"* Description of configurable parameters\n",
" * `batch_size`:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
" * `lang`:Select the language of PaddleOCR. `ch` can be used in Chinese English mixed pictures. `en` is better in English pictures. The default is `ch`.\n",
- " * `topn`: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
+ " * `topn`: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true,
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Install PaddleNLP and PaddleOCR\n",
+ "!pip install --upgrade paddlenlp\n",
+ "!pip install --upgrade paddleocr "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true,
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from pprint import pprint\n",
+ "from paddlenlp import Taskflow\n",
+ "\n",
+ "docprompt = Taskflow(\"document_intelligence\")\n",
+ "pprint(docprompt([{\"doc\": \"https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg\", \"prompt\": [\"发票号码是多少?\", \"校验码是多少?\"]}]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3.2 Model Fine-tuning And Deployment\n",
"\n",
- "## 3.2Model Fine-tuning And Deployment\n",
- "ERNIE-Layout is a cross modal general document pre training model that relies on Wenxin ERNIE, based on layout knowledge enhancement technology, and integrates text, image, layout and other information for joint modeling. It can show excellent cross modal semantic alignment and layout understanding ability on tasks including but not limited to document information extraction, document visual question answering, document image classification and so on.\n",
+ "ERNIE-Layout is a multimodal pretrained model based on layout knowledge enhancement technology, and it integrates text, image, layout and other information for joint modeling. It can show excellent cross modal semantic alignment and layout understanding ability on tasks including but not limited to document information extraction, document visual question answering, document image classification and so on.\n",
"\n",
"For details about the fine-tuning and deployment of the above tasks using ERNIE-Layout, please refer to: [ERNIE-Layout](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout\n",
")"
@@ -120,23 +153,13 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# 4.Model Principle\n",
- "* Layout knowledge enhancement technology\n",
- "\n",
- "* Fusion of text, image, layout and other information for joint modeling\n",
+ "# 4. Model Principle\n",
"\n",
- "* Reading order prediction+fine-grained image text matching: two self-monitoring pre training tasks\n",
- "\n",
- "\n",
"For document understanding, the text reading order in the document is very important. At present, most mainstream models based on OCR (Optical Character Recognition) technology follow the principle of \"from left to right, from top to bottom\". However, for the complex layout of the document with a mixture of columns, text, graphics and tables, the reading order obtained according to the OCR results is wrong in most cases, As a result, the model cannot accurately understand the content of the document.\n",
"\n",
"Humans usually read in hierarchies and blocks according to the document structure and layout. Inspired by this, Baidu researchers proposed an innovative idea of layout knowledge enhancement to correct the reading order in the document pre training model. The industry-leading document parsing tool (Document Parser) on the TextMind platform can accurately identify the block information in the document, produce the correct document reading order, and integrate the reading order signal into the model training, thus enhancing the effective use of layout information and improving the model's understanding of complex documents.\n",
"\n",
- "Based on the layout knowledge enhancement technology, and relying on Wenxin ERNIE, Baidu researchers proposed a cross modal general document pre training model ERNIE-Layout, which integrates text, image, layout and other information for joint modeling. As shown in the figure below, ERNIE-Layout innovatively proposed two self-monitoring pre training tasks: reading order prediction and fine-grained image text matching, which effectively improved the model's cross modal semantic alignment ability and layout understanding ability in document tasks.\n",
- "\n",
- "\n",
- "\n",
- ""
+ "Based on the layout knowledge enhancement technology, and relying on Wenxin ERNIE, Baidu researchers proposed a cross modal general document pre training model ERNIE-Layout, which integrates text, image, layout and other information for joint modeling. As shown in the figure below, ERNIE-Layout innovatively proposed two self-monitoring pre training tasks: reading order prediction and fine-grained image text matching, which effectively improved the model's cross modal semantic alignment ability and layout understanding ability in document tasks."
]
},
{
@@ -144,14 +167,8 @@
"metadata": {},
"source": [
"# 5.Matters Needing Attention\n",
- "## 5.1Parameter Configuration\n",
- "* batch_size:Please adjust the batch size according to the machine conditions. The default value is 1.\n",
- "\n",
- "* lang:Choose the language of PaddleOCR. ch can be used in Chinese English mixed pictures. en has better effect on English pictures. The default is ch.\n",
- "\n",
- "* topn: If the model identifies multiple results, it will return the first n results with the highest probability value, which is 1 by default.\n",
"\n",
- "## 5.2Tips\n",
+ "## DocPrompt Tips\n",
"\n",
"* Prompt design: In DocPrompt, Prompt can be a statement (for example, the Key in the document key value pair) or a question. Because it is an open domain extracted question and answer, DocPrompt has no special restrictions on the design of Prompt, as long as it conforms to natural language semantics. If you are not satisfied with the current extraction results, you can try some different Prompts.\n",
"\n",
@@ -208,15 +225,22 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3.8.5 ('base')",
+ "display_name": "Python 3",
"language": "python",
- "name": "python3"
+ "name": "py35-paddle1.2.0"
},
"language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
"name": "python",
- "version": "3.8.5"
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.4"
},
- "orig_nbformat": 4,
"vscode": {
"interpreter": {
"hash": "a5f44439766e47113308a61c45e3ba0ce79cefad900abb614d22e5ec5db7fbe0"
@@ -224,5 +248,5 @@
}
},
"nbformat": 4,
- "nbformat_minor": 2
+ "nbformat_minor": 4
}
diff --git a/modelcenter/ERNIE-M/info.yaml b/modelcenter/ERNIE-M/info.yaml
index 1f32b2c9f0fa8327f96dcc1a7ba75845b66f935f..fa4a5dba85f51954b5b89c084afca06cccf4e4cc 100644
--- a/modelcenter/ERNIE-M/info.yaml
+++ b/modelcenter/ERNIE-M/info.yaml
@@ -10,7 +10,10 @@ Task:
tag: "自然语言处理"
sub_tag_en: "Pretrained Model"
sub_tag: "预训练模型"
-
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Pretrained Model"
+ sub_tag: "预训练模型"
Example:
Datasets: ""
Publisher: "Baidu"
diff --git a/modelcenter/ERNIE-UIE/APP/app.py b/modelcenter/ERNIE-UIE/APP/app.py
index f09cc4a98ac3390c3cdc41ce7b85389a1d8f86d6..acc9dd4debaa4d0dc34dd91397af81b6440056a2 100644
--- a/modelcenter/ERNIE-UIE/APP/app.py
+++ b/modelcenter/ERNIE-UIE/APP/app.py
@@ -24,11 +24,11 @@ with gr.Blocks() as demo:
with gr.Column(scale=1, min_width=100):
schema = gr.Textbox(
placeholder="ex. ['时间', '选手', '赛事名称']",
- label="Schema (You can type any schema.)",
+ label="Type any schema you want:",
lines=2)
text = gr.Textbox(
placeholder="ex. 2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!",
- label="Text (You can type any input sequence.)",
+ label="Input Sequence:",
lines=2)
with gr.Row():
diff --git a/modelcenter/ERNIE-UIE/info.yaml b/modelcenter/ERNIE-UIE/info.yaml
index 92765718e3dc67a1edba318aa51e3521b1597298..529d0054922ad814a84cfae7593f2b1ca7677484 100644
--- a/modelcenter/ERNIE-UIE/info.yaml
+++ b/modelcenter/ERNIE-UIE/info.yaml
@@ -6,28 +6,52 @@ Model_Info:
icon: "https://user-images.githubusercontent.com/11793384/203492521-8d09d089-5576-41d3-8bc7-eec7a5385c35.png"
from_repo: "PaddleNLP"
Task:
+- tag_en: "Natural Language Processing"
+ tag: "自然语言处理"
+ sub_tag_en: "Named Entity Recognition"
+ sub_tag: "命名实体识别"
- tag_en: "Natural Language Processing"
tag: "自然语言处理"
sub_tag_en: "Relationship Extraction"
sub_tag: "关系抽取"
- tag_en: "Natural Language Processing"
tag: "自然语言处理"
- sub_tag_en: "Named Entity Recognition"
- sub_tag: "命名实体识别"
+ sub_tag_en: "Event Extraction"
+ sub_tag: "事件抽取"
- tag_en: "Natural Language Processing"
tag: "自然语言处理"
- sub_tag_en: "Emotional Classification"
- sub_tag: "情感分类"
+ sub_tag_en: "Opinion Extraction"
+ sub_tag: "评论观点抽取"
- tag_en: "Natural Language Processing"
tag: "自然语言处理"
- sub_tag_en: "Pos labeling"
- sub_tag: "词性标注"
+ sub_tag_en: "Emotional Classification"
+ sub_tag: "情感分类"
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Named Entity Recognition"
+ sub_tag: "命名实体识别"
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Relationship Extraction"
+ sub_tag: "关系抽取"
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Event Extraction"
+ sub_tag: "事件抽取"
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Opinion Extraction"
+ sub_tag: "评论观点抽取"
+- tag_en: "Wenxin Big Models"
+ tag: "文心大模型"
+ sub_tag_en: "Emotional Classification"
+ sub_tag: "情感分类"
Example:
- tag_en: "Intelligent Finance"
tag: "智慧金融"
sub_tag_en: "Key Word Extraction"
title: "使用PaddleNLP UIE模型抽取PDF版上市公司公告"
- sub_tag: "关键字段抽取"
+ sub_tag: "上市公司公告信息抽取"
url: "https://aistudio.baidu.com/aistudio/projectdetail/4497591"
- tag_en: "Intelligent Retail"
tag: "智慧零售"
 \n",
+ "
\n",
+ " "
+ "
"
+ " \n",
- "\n",
- "## 2.2文档视觉问答任务:\n",
- "### 2.2.1数据集:\n",
- "数据集为DocVQA-ZH,DocVQA-ZH已停止榜单提交,因此我们将原始训练集进行重新划分以评估模型效果,划分后训练集包含4,187张图片,验证集包含500张图片,测试集包含500张图片。\n",
- "### 2.2.2模型效果速览:\n",
- "ERNIE-Layout在DocVQA-ZH上的模型效果为:\n",
- "\n",
- ""
+ "ERNIE-Layout 可以用于多模态文档的分类、信息抽取、文档问答等各个任务,应用场景包括但不限于发票抽取问答、海报抽取问答、网页抽取问答、表格抽取问答、试卷抽取问答、英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答、中文票据多语种(中简、中繁、英、日、法语)抽取问答等。\n",
+ "\n",
+ "DocPrompt 以 ERNIE-Layout 为底座,在开放域文档抽取问答任务中效果强悍,例如:\n",
+ "\n",
+ "- 发票抽取问答\n",
+ "\n",
+ "
\n",
- "\n",
- "## 2.2文档视觉问答任务:\n",
- "### 2.2.1数据集:\n",
- "数据集为DocVQA-ZH,DocVQA-ZH已停止榜单提交,因此我们将原始训练集进行重新划分以评估模型效果,划分后训练集包含4,187张图片,验证集包含500张图片,测试集包含500张图片。\n",
- "### 2.2.2模型效果速览:\n",
- "ERNIE-Layout在DocVQA-ZH上的模型效果为:\n",
- "\n",
- ""
+ "ERNIE-Layout 可以用于多模态文档的分类、信息抽取、文档问答等各个任务,应用场景包括但不限于发票抽取问答、海报抽取问答、网页抽取问答、表格抽取问答、试卷抽取问答、英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答、中文票据多语种(中简、中繁、英、日、法语)抽取问答等。\n",
+ "\n",
+ "DocPrompt 以 ERNIE-Layout 为底座,在开放域文档抽取问答任务中效果强悍,例如:\n",
+ "\n",
+ "- 发票抽取问答\n",
+ "\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ "