Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
609dc345
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
609dc345
编写于
4月 13, 2018
作者:
W
whs
提交者:
GitHub
4月 13, 2018
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #798 from wanghaoshuang/ctc_doc
Refine document and scripts of CTC model.
上级
0d489003
bd97b39c
变更
10
显示空白变更内容
内联
并排
Showing
10 changed file
with
397 addition
and
196 deletion
+397
-196
fluid/ocr_recognition/README.md
fluid/ocr_recognition/README.md
+178
-3
fluid/ocr_recognition/crnn_ctc_model.py
fluid/ocr_recognition/crnn_ctc_model.py
+1
-1
fluid/ocr_recognition/ctc_reader.py
fluid/ocr_recognition/ctc_reader.py
+60
-14
fluid/ocr_recognition/ctc_train.py
fluid/ocr_recognition/ctc_train.py
+82
-49
fluid/ocr_recognition/dummy_reader.py
fluid/ocr_recognition/dummy_reader.py
+0
-52
fluid/ocr_recognition/eval.py
fluid/ocr_recognition/eval.py
+38
-23
fluid/ocr_recognition/images/demo.jpg
fluid/ocr_recognition/images/demo.jpg
+0
-0
fluid/ocr_recognition/images/train.jpg
fluid/ocr_recognition/images/train.jpg
+0
-0
fluid/ocr_recognition/inference.py
fluid/ocr_recognition/inference.py
+38
-21
fluid/ocr_recognition/load_model.py
fluid/ocr_recognition/load_model.py
+0
-33
未找到文件。
fluid/ocr_recognition/README.md
浏览文件 @
609dc345
# OCR Model
[toc]
This model built with paddle fluid is still under active development and is not
运行本目录下的程序示例需要使用PaddlePaddle develop最新版本。如果您的PaddlePaddle安装版本低于此要求,请按照安装文档中的说明更新PaddlePaddle安装版本。
the final version. We welcome feedbacks.
# Optical Character Recognition
这里将介绍如何在PaddlePaddle fluid下使用CRNN-CTC 和 CRNN-Attention模型对图片中的文字内容进行识别。
## 1. CRNN-CTC
本章的任务是识别含有单行汉语字符图片,首先采用卷积将图片转为
`features map`
, 然后使用
`im2sequence op`
将
`features map`
转为
`sequence`
,经过
`双向GRU RNN`
得到每个step的汉语字符的概率分布。训练过程选用的损失函数为CTC loss,最终的评估指标为
`instance error rate`
。
本路径下各个文件的作用如下:
-
**ctc_reader.py :**
下载、读取、处理数据。提供方法
`train()`
和
`test()`
分别产生训练集和测试集的数据迭代器。
-
**crnn_ctc_model.py :**
在该脚本中定义了训练网络、预测网络和evaluate网络。
-
**ctc_train.py :**
用于模型的训练,可通过命令
`python train.py --help`
获得使用方法。
-
**inference.py :**
加载训练好的模型文件,对新数据进行预测。可通过命令
`python inference.py --help`
获得使用方法。
-
**eval.py :**
评估模型在指定数据集上的效果。可通过命令
`python inference.py --help`
获得使用方法。
-
**utility.py :**
实现的一些通用方法,包括参数配置、tensor的构造等。
### 1.1 数据
数据的下载和简单预处理都在
`ctc_reader.py`
中实现。
#### 1.1.1 数据格式
我们使用的训练和测试数据如
`图1`
所示,每张图片包含单行不定长的中文字符串,这些图片都是经过检测算法进行预框选处理的。
<p
align=
"center"
>
<img
src=
"images/demo.jpg"
width=
"620"
hspace=
'10'
/>
<br/>
<strong>
图 1
</strong>
</p>
在训练集中,每张图片对应的label是由若干数字组成的sequence。 Sequence中的每个数字表示一个字符在字典中的index。
`图1`
对应的label如下所示:
```
3835,8371,7191,2369,6876,4162,1938,168,1517,4590,3793
```
在上边这个label中,
`3835`
表示字符‘两’的index,
`4590`
表示中文字符逗号的index。
#### 1.1.2 数据准备
**A. 训练集**
我们需要把所有参与训练的图片放入同一个文件夹,暂且记为
`train_images`
。然后用一个list文件存放每张图片的信息,包括图片大小、图片名称和对应的label,这里暂记该list文件为
`train_list`
,其格式如下所示:
```
185 48 00508_0215.jpg 7740,5332,2369,3201,4162
48 48 00197_1893.jpg 6569
338 48 00007_0219.jpg 4590,4788,3015,1994,3402,999,4553
150 48 00107_4517.jpg 5936,3382,1437,3382
...
157 48 00387_0622.jpg 2397,1707,5919,1278
```
<center>
文件train_list
</center>
上述文件中的每一行表示一张图片,每行被空格分为四列,前两列分别表示图片的宽和高,第三列表示图片的名称,第四列表示该图片对应的sequence label。
最终我们应有以下类似文件结构:
```
|-train_data
|- train_list
|- train_imags
|- 00508_0215.jpg
|- 00197_1893.jpg
|- 00007_0219.jpg
| ...
```
在训练时,我们通过选项
`--train_images`
和
`--train_list`
分别设置准备好的
`train_images`
和
`train_list`
。
>**注:** 如果`--train_images` 和 `--train_list`都未设置或设置为None, ctc_reader.py会自动下载使用[示例数据](http://cloud.dlnel.org/filepub/?uuid=df937251-3c0b-480d-9a7b-0080dfeee65c),并将其缓存到`$HOME/.cache/paddle/dataset/ctc_data/data/` 路径下。
**B. 测试集和评估集**
测试集、评估集的准备方式与训练集相同。
在训练阶段,测试集的路径通过train.py的选项
`--test_images`
和
`--test_list`
来设置。
在评估时,评估集的路径通过eval.py的选项
`--input_images_dir`
和
`--input_images_list`
来设置。
**C. 待预测数据集**
预测支持三种形式的输入:
第一种:设置
`--input_images_dir`
和
`--input_images_list`
, 与训练集类似, 只不过list文件中的最后一列可以放任意占位字符或字符串,如下所示:
```
185 48 00508_0215.jpg s
48 48 00197_1893.jpg s
338 48 00007_0219.jpg s
...
```
第二种:仅设置
`--input_images_list`
, 其中list文件中只需放图片的完整路径,如下所示:
```
data/test_images/00000.jpg
data/test_images/00001.jpg
data/test_images/00003.jpg
```
第三种:从stdin读入一张图片的path,然后进行一次inference.
#### 1.2 训练
使用默认数据在GPU单卡上训练:
```
env CUDA_VISIABLE_DEVICES=0 python ctc_train.py
```
使用默认数据在GPU多卡上训练:
```
env CUDA_VISIABLE_DEVICES=0,1,2,3 python ctc_train.py --parallel=True
```
执行
`python ctc_train.py --help`
可查看更多使用方式和参数详细说明。
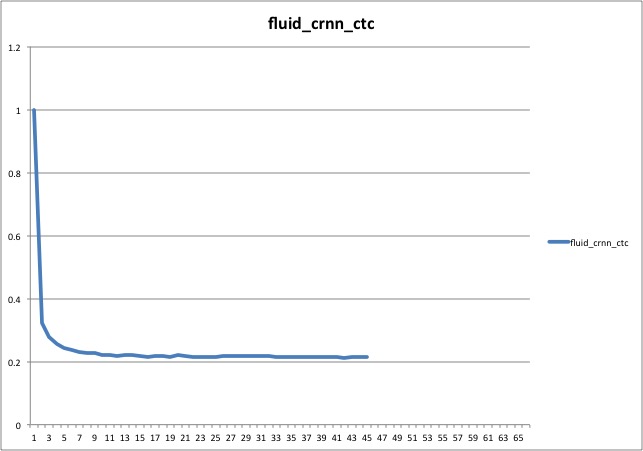
图2为使用默认参数和默认数据集训练的收敛曲线,其中横坐标轴为训练pass数,纵轴为在测试集上的sequence_error.
<p
align=
"center"
>
<img
src=
"images/train.jpg"
width=
"620"
hspace=
'10'
/>
<br/>
<strong>
图 2
</strong>
</p>
### 1.3 评估
通过以下命令调用评估脚本用指定数据集对模型进行评估:
```
env CUDA_VISIBLE_DEVICE=0 python eval.py \
--model_path="./models/model_0" \
--input_images_dir="./eval_data/images/" \
--input_images_list="./eval_data/eval_list\" \
```
执行
`python ctc_train.py --help`
可查看参数详细说明。
### 1.4 预测
从标准输入读取一张图片的路径,并对齐进行预测:
```
env CUDA_VISIBLE_DEVICE=0 python inference.py \
--model_path="models/model_00044_15000"
```
执行上述命令进行预测的效果如下:
```
----------- Configuration Arguments -----------
use_gpu: True
input_images_dir: None
input_images_list: None
model_path: /home/work/models/fluid/ocr_recognition/models/model_00052_15000
------------------------------------------------
Init model from: /home/work/models/fluid/ocr_recognition/models/model_00052_15000.
Please input the path of image: /home/work/models/fluid/ocr_recognition/data/test_images/00001_0060.jpg
result: [3298 2371 4233 6514 2378 3298 2363]
Please input the path of image: /home/work/models/fluid/ocr_recognition/data/test_images/00001_0429.jpg
result: [2067 2067 8187 8477 5027 7191 2431 1462]
```
从文件中批量读取图片路径,并对其进行预测:
```
env CUDA_VISIBLE_DEVICE=0 python inference.py \
--model_path="models/model_00044_15000" \
--input_images_list="data/test.list"
```
fluid/ocr_recognition/crnn_ctc_model.py
浏览文件 @
609dc345
...
@@ -143,7 +143,7 @@ def ctc_train_net(images, label, args, num_classes):
...
@@ -143,7 +143,7 @@ def ctc_train_net(images, label, args, num_classes):
gradient_clip
=
None
gradient_clip
=
None
if
args
.
parallel
:
if
args
.
parallel
:
places
=
fluid
.
layers
.
get_places
()
places
=
fluid
.
layers
.
get_places
()
pd
=
fluid
.
layers
.
ParallelDo
(
places
)
pd
=
fluid
.
layers
.
ParallelDo
(
places
,
use_nccl
=
True
)
with
pd
.
do
():
with
pd
.
do
():
images_
=
pd
.
read_input
(
images
)
images_
=
pd
.
read_input
(
images
)
label_
=
pd
.
read_input
(
label
)
label_
=
pd
.
read_input
(
label
)
...
...
fluid/ocr_recognition/ctc_reader.py
浏览文件 @
609dc345
...
@@ -30,10 +30,10 @@ class DataGenerator(object):
...
@@ -30,10 +30,10 @@ class DataGenerator(object):
Reader interface for training.
Reader interface for training.
:param img_root_dir: The root path of the image for training.
:param img_root_dir: The root path of the image for training.
:type
file_list
: str
:type
img_root_dir
: str
:param img_label_list: The path of the <image_name, label> file for training.
:param img_label_list: The path of the <image_name, label> file for training.
:type
file
_list: str
:type
img_label
_list: str
'''
'''
...
@@ -91,10 +91,10 @@ class DataGenerator(object):
...
@@ -91,10 +91,10 @@ class DataGenerator(object):
Reader interface for inference.
Reader interface for inference.
:param img_root_dir: The root path of the images for training.
:param img_root_dir: The root path of the images for training.
:type
file_list
: str
:type
img_root_dir
: str
:param img_label_list: The path of the <image_name, label> file for testing.
:param img_label_list: The path of the <image_name, label> file for testing.
:type
file_list: list
:type
img_label_list: str
'''
'''
def
reader
():
def
reader
():
...
@@ -111,6 +111,42 @@ class DataGenerator(object):
...
@@ -111,6 +111,42 @@ class DataGenerator(object):
return
reader
return
reader
def
infer_reader
(
self
,
img_root_dir
=
None
,
img_label_list
=
None
):
'''A reader interface for inference.
:param img_root_dir: The root path of the images for training.
:type img_root_dir: str
:param img_label_list: The path of the <image_name, label> file for
inference. It should be the path of <image_path> file if img_root_dir
was None. If img_label_list was set to None, it will read image path
from stdin.
:type img_root_dir: str
'''
def
reader
():
if
img_label_list
is
not
None
:
for
line
in
open
(
img_label_list
):
if
img_root_dir
is
not
None
:
# h, w, img_name, labels
img_name
=
line
.
split
(
' '
)[
2
]
img_path
=
os
.
path
.
join
(
img_root_dir
,
img_name
)
else
:
img_path
=
line
.
strip
(
"
\t\n\r
"
)
img
=
Image
.
open
(
img_path
).
convert
(
'L'
)
img
=
np
.
array
(
img
)
-
127.5
img
=
img
[
np
.
newaxis
,
...]
yield
img
,
label
else
:
while
True
:
img_path
=
raw_input
(
"Please input the path of image: "
)
img
=
Image
.
open
(
img_path
).
convert
(
'L'
)
img
=
np
.
array
(
img
)
-
127.5
img
=
img
[
np
.
newaxis
,
...]
yield
img
,
[[
0
]]
return
reader
def
num_classes
():
def
num_classes
():
'''Get classes number of this dataset.
'''Get classes number of this dataset.
...
@@ -124,21 +160,31 @@ def data_shape():
...
@@ -124,21 +160,31 @@ def data_shape():
return
DATA_SHAPE
return
DATA_SHAPE
def
train
(
batch_size
):
def
train
(
batch_size
,
train_images_dir
=
None
,
train_list_file
=
None
):
generator
=
DataGenerator
()
generator
=
DataGenerator
()
if
train_images_dir
is
None
:
data_dir
=
download_data
()
data_dir
=
download_data
()
return
generator
.
train_reader
(
train_images_dir
=
path
.
join
(
data_dir
,
TRAIN_DATA_DIR_NAME
)
path
.
join
(
data_dir
,
TRAIN_DATA_DIR_NAME
),
if
train_list_file
is
None
:
path
.
join
(
data_dir
,
TRAIN_LIST_FILE_NAME
),
batch_size
)
train_list_file
=
path
.
join
(
data_dir
,
TRAIN_LIST_FILE_NAME
)
return
generator
.
train_reader
(
train_images_dir
,
train_list_file
,
batch_size
)
def
test
(
batch_size
=
1
):
def
test
(
batch_size
=
1
,
test_images_dir
=
None
,
test_list_file
=
None
):
generator
=
DataGenerator
()
generator
=
DataGenerator
()
if
test_images_dir
is
None
:
data_dir
=
download_data
()
data_dir
=
download_data
()
test_images_dir
=
path
.
join
(
data_dir
,
TEST_DATA_DIR_NAME
)
if
test_list_file
is
None
:
test_list_file
=
path
.
join
(
data_dir
,
TEST_LIST_FILE_NAME
)
return
paddle
.
batch
(
generator
.
test_reader
(
test_images_dir
,
test_list_file
),
batch_size
)
def
inference
(
infer_images_dir
=
None
,
infer_list_file
=
None
):
generator
=
DataGenerator
()
return
paddle
.
batch
(
return
paddle
.
batch
(
generator
.
test_reader
(
generator
.
infer_reader
(
infer_images_dir
,
infer_list_file
),
1
)
path
.
join
(
data_dir
,
TRAIN_DATA_DIR_NAME
),
path
.
join
(
data_dir
,
TRAIN_LIST_FILE_NAME
)),
batch_size
)
def
download_data
():
def
download_data
():
...
...
fluid/ocr_recognition/ctc_train.py
浏览文件 @
609dc345
"""Trainer for OCR CTC model."""
"""Trainer for OCR CTC model."""
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
import
dummy_reader
from
utility
import
add_arguments
,
print_arguments
,
to_lodtensor
,
get_feeder_data
from
crnn_ctc_model
import
ctc_train_net
import
ctc_reader
import
ctc_reader
import
argparse
import
argparse
from
load_model
import
load_param
import
functools
import
functools
import
sys
import
sys
from
utility
import
add_arguments
,
print_arguments
,
to_lodtensor
,
get_feeder_data
from
crnn_ctc_model
import
ctc_train_net
import
time
import
time
import
os
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
# yapf: disable
add_arg
(
'batch_size'
,
int
,
32
,
"Minibatch size."
)
add_arg
(
'batch_size'
,
int
,
32
,
"Minibatch size."
)
add_arg
(
'pass_num'
,
int
,
100
,
"#
of training epochs."
)
add_arg
(
'pass_num'
,
int
,
100
,
"Number
of training epochs."
)
add_arg
(
'log_period'
,
int
,
1000
,
"Log period."
)
add_arg
(
'log_period'
,
int
,
1000
,
"Log period."
)
add_arg
(
'save_model_period'
,
int
,
15000
,
"Save model period. '-1' means never saving the model."
)
add_arg
(
'eval_period'
,
int
,
15000
,
"Evaluate period. '-1' means never evaluating the model."
)
add_arg
(
'save_model_dir'
,
str
,
"./models"
,
"The directory the model to be saved to."
)
add_arg
(
'init_model'
,
str
,
None
,
"The init model file of directory."
)
add_arg
(
'learning_rate'
,
float
,
1.0e-3
,
"Learning rate."
)
add_arg
(
'learning_rate'
,
float
,
1.0e-3
,
"Learning rate."
)
add_arg
(
'l2'
,
float
,
0.0004
,
"L2 regularizer."
)
add_arg
(
'l2'
,
float
,
0.0004
,
"L2 regularizer."
)
add_arg
(
'max_clip'
,
float
,
10.0
,
"Max clip threshold."
)
add_arg
(
'min_clip'
,
float
,
-
10.0
,
"Min clip threshold."
)
add_arg
(
'momentum'
,
float
,
0.9
,
"Momentum."
)
add_arg
(
'momentum'
,
float
,
0.9
,
"Momentum."
)
add_arg
(
'rnn_hidden_size'
,
int
,
200
,
"Hidden size of rnn layers."
)
add_arg
(
'rnn_hidden_size'
,
int
,
200
,
"Hidden size of rnn layers."
)
add_arg
(
'device'
,
int
,
0
,
"Device id.'-1' means running on CPU"
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether use GPU to train."
)
"while '0' means GPU-0."
)
add_arg
(
'min_average_window'
,
int
,
10000
,
"Min average window."
)
add_arg
(
'min_average_window'
,
int
,
10000
,
"Min average window."
)
add_arg
(
'max_average_window'
,
int
,
15625
,
"Max average window. It is proposed to be set as the number of minibatch in a pass."
)
add_arg
(
'max_average_window'
,
int
,
15625
,
"Max average window."
)
add_arg
(
'average_window'
,
float
,
0.15
,
"Average window."
)
add_arg
(
'average_window'
,
float
,
0.15
,
"Average window."
)
add_arg
(
'parallel'
,
bool
,
False
,
"Whether use parallel training."
)
add_arg
(
'parallel'
,
bool
,
False
,
"Whether use parallel training."
)
# yapf: disable
add_arg
(
'train_images'
,
str
,
None
,
"The directory of training images."
"None means using the default training images of reader."
)
def
load_parameter
(
place
):
add_arg
(
'train_list'
,
str
,
None
,
"The list file of training images."
params
=
load_param
(
'./name.map'
,
'./data/model/results_without_avg_window/pass-00000/'
)
"None means using the default train_list file of reader."
)
for
name
in
params
:
add_arg
(
'test_images'
,
str
,
None
,
"The directory of training images."
t
=
fluid
.
global_scope
().
find_var
(
name
).
get_tensor
()
"None means using the default test images of reader."
)
t
.
set
(
params
[
name
],
place
)
add_arg
(
'test_list'
,
str
,
None
,
"The list file of training images."
"None means using the default test_list file of reader."
)
add_arg
(
'num_classes'
,
int
,
None
,
"The number of classes."
"None means using the default num_classes from reader."
)
# yapf: enable
def
train
(
args
,
data_reader
=
dummy
_reader
):
def
train
(
args
,
data_reader
=
ctc
_reader
):
"""OCR CTC training"""
"""OCR CTC training"""
num_classes
=
data_reader
.
num_classes
()
num_classes
=
data_reader
.
num_classes
(
)
if
args
.
num_classes
is
None
else
args
.
num_classes
data_shape
=
data_reader
.
data_shape
()
data_shape
=
data_reader
.
data_shape
()
# define network
# define network
images
=
fluid
.
layers
.
data
(
name
=
'pixel'
,
shape
=
data_shape
,
dtype
=
'float32'
)
images
=
fluid
.
layers
.
data
(
name
=
'pixel'
,
shape
=
data_shape
,
dtype
=
'float32'
)
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int32'
,
lod_level
=
1
)
label
=
fluid
.
layers
.
data
(
sum_cost
,
error_evaluator
,
inference_program
,
model_average
=
ctc_train_net
(
images
,
label
,
args
,
num_classes
)
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int32'
,
lod_level
=
1
)
sum_cost
,
error_evaluator
,
inference_program
,
model_average
=
ctc_train_net
(
images
,
label
,
args
,
num_classes
)
# data reader
# data reader
train_reader
=
data_reader
.
train
(
args
.
batch_size
)
train_reader
=
data_reader
.
train
(
test_reader
=
data_reader
.
test
()
args
.
batch_size
,
train_images_dir
=
args
.
train_images
,
train_list_file
=
args
.
train_list
)
test_reader
=
data_reader
.
test
(
test_images_dir
=
args
.
test_images
,
test_list_file
=
args
.
test_list
)
# prepare environment
# prepare environment
place
=
fluid
.
CPUPlace
()
place
=
fluid
.
CPUPlace
()
if
args
.
device
>=
0
:
if
args
.
use_gpu
:
place
=
fluid
.
CUDAPlace
(
args
.
device
)
place
=
fluid
.
CUDAPlace
(
0
)
exe
=
fluid
.
Executor
(
place
)
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
exe
.
run
(
fluid
.
default_startup_program
())
#load_parameter(place)
# load init model
if
args
.
init_model
is
not
None
:
model_dir
=
args
.
init_model
model_file_name
=
None
if
not
os
.
path
.
isdir
(
args
.
init_model
):
model_dir
=
os
.
path
.
dirname
(
args
.
init_model
)
model_file_name
=
os
.
path
.
basename
(
args
.
init_model
)
fluid
.
io
.
load_params
(
exe
,
dirname
=
model_dir
,
filename
=
model_file_name
)
print
"Init model from: %s."
%
args
.
init_model
for
pass_id
in
range
(
args
.
pass_num
):
for
pass_id
in
range
(
args
.
pass_num
):
error_evaluator
.
reset
(
exe
)
error_evaluator
.
reset
(
exe
)
...
@@ -70,29 +91,41 @@ def train(args, data_reader=dummy_reader):
...
@@ -70,29 +91,41 @@ def train(args, data_reader=dummy_reader):
fetch_list
=
[
sum_cost
]
+
error_evaluator
.
metrics
)
fetch_list
=
[
sum_cost
]
+
error_evaluator
.
metrics
)
total_loss
+=
batch_loss
[
0
]
total_loss
+=
batch_loss
[
0
]
total_seq_error
+=
batch_seq_error
[
0
]
total_seq_error
+=
batch_seq_error
[
0
]
if
batch_id
%
100
==
1
:
# training log
print
'.'
,
if
batch_id
%
args
.
log_period
==
0
:
sys
.
stdout
.
flush
()
if
batch_id
%
args
.
log_period
==
1
:
print
"
\n
Time: %s; Pass[%d]-batch[%d]; Avg Warp-CTC loss: %s; Avg seq error: %s."
%
(
print
"
\n
Time: %s; Pass[%d]-batch[%d]; Avg Warp-CTC loss: %s; Avg seq error: %s."
%
(
time
.
time
(),
time
.
time
(),
pass_id
,
batch_id
,
pass_id
,
batch_id
,
total_loss
/
(
batch_id
*
args
.
batch_size
),
total_seq_error
/
(
batch_id
*
args
.
batch_size
))
total_loss
/
(
batch_id
*
args
.
batch_size
),
total_seq_error
/
(
batch_id
*
args
.
batch_size
))
sys
.
stdout
.
flush
()
sys
.
stdout
.
flush
()
batch_id
+=
1
# evaluate
if
batch_id
%
args
.
eval_period
==
0
:
with
model_average
.
apply
(
exe
):
with
model_average
.
apply
(
exe
):
error_evaluator
.
reset
(
exe
)
error_evaluator
.
reset
(
exe
)
for
data
in
test_reader
():
for
data
in
test_reader
():
exe
.
run
(
inference_program
,
feed
=
get_feeder_data
(
data
,
place
))
exe
.
run
(
inference_program
,
feed
=
get_feeder_data
(
data
,
place
))
_
,
test_seq_error
=
error_evaluator
.
eval
(
exe
)
_
,
test_seq_error
=
error_evaluator
.
eval
(
exe
)
print
"
\n
End pass[%d]; Test seq error: %s.
\n
"
%
(
print
"
\n
Time: %s; Pass[%d]-batch[%d]; Test seq error: %s.
\n
"
%
(
pass_id
,
str
(
test_seq_error
[
0
]))
time
.
time
(),
pass_id
,
batch_id
,
str
(
test_seq_error
[
0
]))
# save model
if
batch_id
%
args
.
save_model_period
==
0
:
with
model_average
.
apply
(
exe
):
filename
=
"model_%05d_%d"
%
(
pass_id
,
batch_id
)
fluid
.
io
.
save_params
(
exe
,
dirname
=
args
.
save_model_dir
,
filename
=
filename
)
print
"Saved model to: %s/%s."
%
(
args
.
save_model_dir
,
filename
)
batch_id
+=
1
def
main
():
def
main
():
args
=
parser
.
parse_args
()
args
=
parser
.
parse_args
()
print_arguments
(
args
)
print_arguments
(
args
)
train
(
args
,
data_reader
=
ctc_reader
)
train
(
args
,
data_reader
=
ctc_reader
)
if
__name__
==
"__main__"
:
if
__name__
==
"__main__"
:
main
()
main
()
fluid/ocr_recognition/dummy_reader.py
已删除
100644 → 0
浏览文件 @
0d489003
"""A dummy reader for test."""
# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserve.
#
#Licensed under the Apache License, Version 2.0 (the "License");
#you may not use this file except in compliance with the License.
#You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#Unless required by applicable law or agreed to in writing, software
#distributed under the License is distributed on an "AS IS" BASIS,
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
import
numpy
as
np
import
paddle.v2
as
paddle
DATA_SHAPE
=
[
1
,
512
,
512
]
NUM_CLASSES
=
20
def
_read_creater
(
num_sample
=
1024
,
min_seq_len
=
1
,
max_seq_len
=
10
):
def
reader
():
for
i
in
range
(
num_sample
):
sequence_len
=
np
.
random
.
randint
(
min_seq_len
,
max_seq_len
)
x
=
np
.
random
.
uniform
(
0.1
,
1
,
DATA_SHAPE
).
astype
(
"float32"
)
y
=
np
.
random
.
randint
(
0
,
NUM_CLASSES
+
1
,
[
sequence_len
]).
astype
(
"int32"
)
yield
x
,
y
return
reader
def
train
(
batch_size
,
num_sample
=
128
):
"""Get train dataset reader."""
return
paddle
.
batch
(
_read_creater
(
num_sample
=
num_sample
),
batch_size
)
def
test
(
batch_size
=
1
,
num_sample
=
16
):
"""Get test dataset reader."""
return
paddle
.
batch
(
_read_creater
(
num_sample
=
num_sample
),
batch_size
)
def
data_shape
():
"""Get image shape in CHW order."""
return
DATA_SHAPE
def
num_classes
():
"""Get number of total classes."""
return
NUM_CLASSES
fluid/ocr_recognition/eval.py
浏览文件 @
609dc345
import
paddle.v2
as
paddle
import
paddle.v2
as
paddle
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
from
load_model
import
load_param
from
utility
import
add_arguments
,
print_arguments
,
to_lodtensor
,
get_feeder_data
from
utility
import
get_feeder_data
from
crnn_ctc_model
import
ctc_infer
from
crnn_ctc_model
import
ctc_eval
from
crnn_ctc_model
import
ctc_eval
import
ctc_reader
import
ctc_reader
import
dummy_reader
import
argparse
import
functools
import
os
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
add_arg
(
'model_path'
,
str
,
None
,
"The model path to be used for inference."
)
add_arg
(
'input_images_dir'
,
str
,
None
,
"The directory of images."
)
add_arg
(
'input_images_list'
,
str
,
None
,
"The list file of images."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether use GPU to eval."
)
# yapf: enable
def
load_parameter
(
place
):
params
=
load_param
(
'./name.map'
,
'./data/model/results/pass-00062/'
)
for
name
in
params
:
print
"param: %s"
%
name
t
=
fluid
.
global_scope
().
find_var
(
name
).
get_tensor
()
t
.
set
(
params
[
name
],
place
)
def
evaluate
(
args
,
eval
=
ctc_eval
,
data_reader
=
ctc_reader
):
def
evaluate
(
eval
=
ctc_eval
,
data_reader
=
dummy_reader
):
"""OCR inference"""
"""OCR inference"""
num_classes
=
data_reader
.
num_classes
()
num_classes
=
data_reader
.
num_classes
()
data_shape
=
data_reader
.
data_shape
()
data_shape
=
data_reader
.
data_shape
()
...
@@ -26,29 +29,41 @@ def evaluate(eval=ctc_eval, data_reader=dummy_reader):
...
@@ -26,29 +29,41 @@ def evaluate(eval=ctc_eval, data_reader=dummy_reader):
evaluator
,
cost
=
eval
(
images
,
label
,
num_classes
)
evaluator
,
cost
=
eval
(
images
,
label
,
num_classes
)
# data reader
# data reader
test_reader
=
data_reader
.
test
()
test_reader
=
data_reader
.
test
(
test_images_dir
=
args
.
input_images_dir
,
test_list_file
=
args
.
input_images_list
)
# prepare environment
# prepare environment
place
=
fluid
.
CPUPlace
()
if
use_gpu
:
place
=
fluid
.
CUDAPlace
(
0
)
place
=
fluid
.
CUDAPlace
(
0
)
#place = fluid.CPUPlace()
exe
=
fluid
.
Executor
(
place
)
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
exe
.
run
(
fluid
.
default_startup_program
())
print
fluid
.
default_main_program
()
load_parameter
(
place
)
# load init model
model_dir
=
args
.
model_path
model_file_name
=
None
if
not
os
.
path
.
isdir
(
args
.
model_path
):
model_dir
=
os
.
path
.
dirname
(
args
.
model_path
)
model_file_name
=
os
.
path
.
basename
(
args
.
model_path
)
fluid
.
io
.
load_params
(
exe
,
dirname
=
model_dir
,
filename
=
model_file_name
)
print
"Init model from: %s."
%
args
.
model_path
evaluator
.
reset
(
exe
)
evaluator
.
reset
(
exe
)
count
=
0
count
=
0
for
data
in
test_reader
():
for
data
in
test_reader
():
count
+=
1
count
+=
1
print
'Process samples: %d
\r
'
%
(
count
,
),
exe
.
run
(
fluid
.
default_main_program
(),
feed
=
get_feeder_data
(
data
,
place
))
result
,
avg_distance
,
avg_seq_error
=
exe
.
run
(
fluid
.
default_main_program
(),
feed
=
get_feeder_data
(
data
,
place
),
fetch_list
=
[
cost
]
+
evaluator
.
metrics
)
avg_distance
,
avg_seq_error
=
evaluator
.
eval
(
exe
)
avg_distance
,
avg_seq_error
=
evaluator
.
eval
(
exe
)
print
"avg_distance: %s; avg_seq_error: %s"
%
(
avg_distance
,
avg_seq_error
)
print
"Read %d samples; avg_distance: %s; avg_seq_error: %s"
%
(
count
,
avg_distance
,
avg_seq_error
)
def
main
():
def
main
():
evaluate
(
data_reader
=
ctc_reader
)
args
=
parser
.
parse_args
()
print_arguments
(
args
)
evaluate
(
args
,
data_reader
=
ctc_reader
)
if
__name__
==
"__main__"
:
if
__name__
==
"__main__"
:
...
...
fluid/ocr_recognition/images/demo.jpg
0 → 100644
浏览文件 @
609dc345
3.2 KB
fluid/ocr_recognition/images/train.jpg
0 → 100644
浏览文件 @
609dc345
30.2 KB
fluid/ocr_recognition/inference.py
浏览文件 @
609dc345
import
paddle.v2
as
paddle
import
paddle.v2
as
paddle
import
paddle.v2.fluid
as
fluid
import
paddle.fluid
as
fluid
from
load_model
import
load_param
from
utility
import
add_arguments
,
print_arguments
,
to_lodtensor
,
get_feeder_data
from
utility
import
get_feeder_data
from
crnn_ctc_model
import
ctc_infer
from
crnn_ctc_model
import
ctc_infer
import
numpy
as
np
import
ctc_reader
import
ctc_reader
import
dummy_reader
import
argparse
import
functools
import
os
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
add_arg
(
'model_path'
,
str
,
None
,
"The model path to be used for inference."
)
add_arg
(
'input_images_dir'
,
str
,
None
,
"The directory of images."
)
add_arg
(
'input_images_list'
,
str
,
None
,
"The list file of images."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether use GPU to infer."
)
# yapf: enable
def
load_parameter
(
place
):
params
=
load_param
(
'./name.map'
,
'./data/model/results/pass-00062/'
)
for
name
in
params
:
print
"param: %s"
%
name
t
=
fluid
.
global_scope
().
find_var
(
name
).
get_tensor
()
t
.
set
(
params
[
name
],
place
)
def
inference
(
args
,
infer
=
ctc_infer
,
data_reader
=
ctc_reader
):
def
inference
(
infer
=
ctc_infer
,
data_reader
=
dummy_reader
):
"""OCR inference"""
"""OCR inference"""
num_classes
=
data_reader
.
num_classes
()
num_classes
=
data_reader
.
num_classes
()
data_shape
=
data_reader
.
data_shape
()
data_shape
=
data_reader
.
data_shape
()
# define network
# define network
images
=
fluid
.
layers
.
data
(
name
=
'pixel'
,
shape
=
data_shape
,
dtype
=
'float32'
)
images
=
fluid
.
layers
.
data
(
name
=
'pixel'
,
shape
=
data_shape
,
dtype
=
'float32'
)
sequence
,
tmp
=
infer
(
images
,
num_classes
)
sequence
=
infer
(
images
,
num_classes
)
fluid
.
layers
.
Print
(
tmp
)
# data reader
# data reader
test_reader
=
data_reader
.
test
()
infer_reader
=
data_reader
.
inference
(
infer_images_dir
=
args
.
input_images_dir
,
infer_list_file
=
args
.
input_images_list
)
# prepare environment
# prepare environment
place
=
fluid
.
CPUPlace
()
if
use_gpu
:
place
=
fluid
.
CUDAPlace
(
0
)
place
=
fluid
.
CUDAPlace
(
0
)
exe
=
fluid
.
Executor
(
place
)
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
exe
.
run
(
fluid
.
default_startup_program
())
load_parameter
(
place
)
# load init model
model_dir
=
args
.
model_path
model_file_name
=
None
if
not
os
.
path
.
isdir
(
args
.
model_path
):
model_dir
=
os
.
path
.
dirname
(
args
.
model_path
)
model_file_name
=
os
.
path
.
basename
(
args
.
model_path
)
fluid
.
io
.
load_params
(
exe
,
dirname
=
model_dir
,
filename
=
model_file_name
)
print
"Init model from: %s."
%
args
.
model_path
for
data
in
test
_reader
():
for
data
in
infer
_reader
():
result
=
exe
.
run
(
fluid
.
default_main_program
(),
result
=
exe
.
run
(
fluid
.
default_main_program
(),
feed
=
get_feeder_data
(
feed
=
get_feeder_data
(
data
,
place
,
need_label
=
False
),
data
,
place
,
need_label
=
False
),
fetch_list
=
[
tmp
])
fetch_list
=
[
sequence
],
print
"result: %s"
%
(
list
(
result
[
0
].
flatten
()),
)
return_numpy
=
False
)
print
"result: %s"
%
(
np
.
array
(
result
[
0
]).
flatten
(),
)
def
main
():
def
main
():
inference
(
data_reader
=
ctc_reader
)
args
=
parser
.
parse_args
()
print_arguments
(
args
)
inference
(
args
,
data_reader
=
ctc_reader
)
if
__name__
==
"__main__"
:
if
__name__
==
"__main__"
:
...
...
fluid/ocr_recognition/load_model.py
已删除
100644 → 0
浏览文件 @
0d489003
import
sys
import
numpy
as
np
import
ast
def
load_parameter
(
file_name
):
with
open
(
file_name
,
'rb'
)
as
f
:
f
.
read
(
16
)
# skip header.
return
np
.
fromfile
(
f
,
dtype
=
np
.
float32
)
def
load_param
(
name_map_file
,
old_param_dir
):
result
=
{}
name_map
=
{}
shape_map
=
{}
with
open
(
name_map_file
,
'r'
)
as
map_file
:
for
param
in
map_file
:
old_name
,
new_name
,
shape
=
param
.
strip
().
split
(
'='
)
name_map
[
new_name
]
=
old_name
shape_map
[
new_name
]
=
ast
.
literal_eval
(
shape
)
for
new_name
in
name_map
:
result
[
new_name
]
=
load_parameter
(
"/"
.
join
(
[
old_param_dir
,
name_map
[
new_name
]])).
reshape
(
shape_map
[
new_name
])
return
result
if
__name__
==
"__main__"
:
name_map_file
=
"./name.map"
old_param_dir
=
"./data/model/results/pass-00062/"
result
=
load_param
(
name_map_file
,
old_param_dir
)
for
p
in
result
:
print
"name: %s; param.shape: %s"
%
(
p
,
result
[
p
].
shape
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}