[TSN](./fluid/PaddleCV/video_classification)|视频分类模型|基于长范围时间结构建模,结合了稀疏时间采样策略和视频级监督来保证使用整段视频时学习得有效和高效|[Temporal Segment Networks: Towards Good Practices for Deep Action Recognition](https://arxiv.org/abs/1608.00859)
[TSN](./fluid/PaddleCV/video_classification)|视频分类模型|基于长范围时间结构建模,结合了稀疏时间采样策略和视频级监督来保证使用整段视频时学习得有效和高效|[Temporal Segment Networks: Towards Good Practices for Deep Action Recognition](https://arxiv.org/abs/1608.00859)
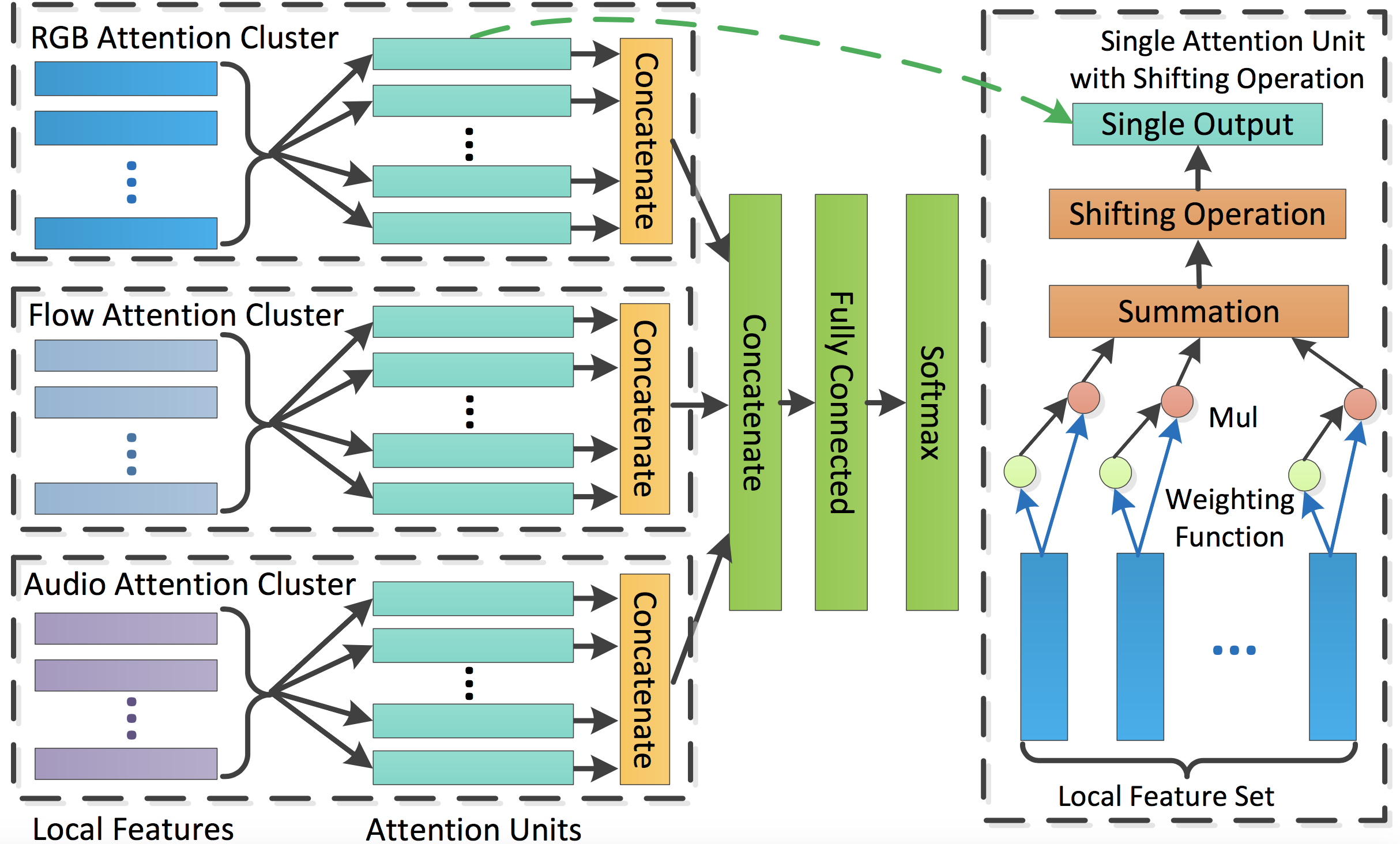
-[Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification](https://arxiv.org/abs/1711.09550), Xiang Long, Chuang Gan, Gerard de Melo, Jiajun Wu, Xiao Liu, Shilei Wen
-[Beyond Short Snippets: Deep Networks for Video Classification](https://arxiv.org/abs/1503.08909) Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, George Toderici
-[Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification](https://arxiv.org/abs/1711.09550), Xiang Long, Chuang Gan, Gerard de Melo, Jiajun Wu, Xiao Liu, Shilei Wen
NeXtVLAD模型是第二届Youtube-8M视频理解竞赛中效果最好的单模型,在参数量小于80M的情况下,能得到高于0.87的GAP指标。该模型提供了一种将桢级别的视频特征转化并压缩成特征向量,以适用于大尺寸视频文件的分类的方法。其基本出发点是在NetVLAD模型的基础上,将高维度的特征先进行分组,通过引入attention机制聚合提取时间维度的信息,这样既可以获得较高的准确率,又可以使用更少的参数量。详细内容请参考[NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification](https://arxiv.org/abs/1811.05014)。
-[NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification](https://arxiv.org/abs/1811.05014), Rongcheng Lin, Jing Xiao, Jianping Fan
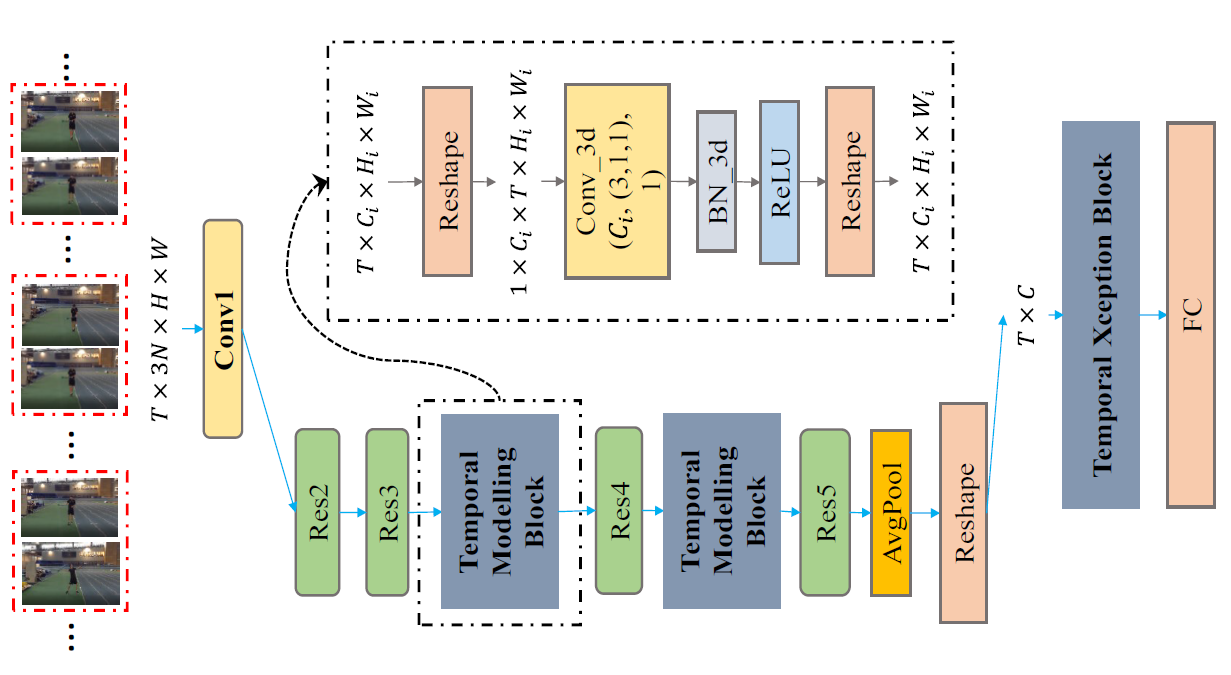
[StNet:Local and Global Spatial-Temporal Modeling for Human Action Recognition](https://arxiv.org/abs/1811.01549), Dongliang He, Zhichao Zhou, Chuang Gan, Fu Li, Xiao Liu, Yandong Li, Limin Wang, Shilei Wen
-[StNet:Local and Global Spatial-Temporal Modeling for Human Action Recognition](https://arxiv.org/abs/1608.00859), Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, Luc Van Gool
{kind=link}
{kind=link}