update d-net (#3591)
* Remove KD scripts * Add ERNIE2.0 service * Update server * Update MTL * Update README.md * Update README.md for MTL * Update README.md
Showing
{kind=link}
{kind=link}
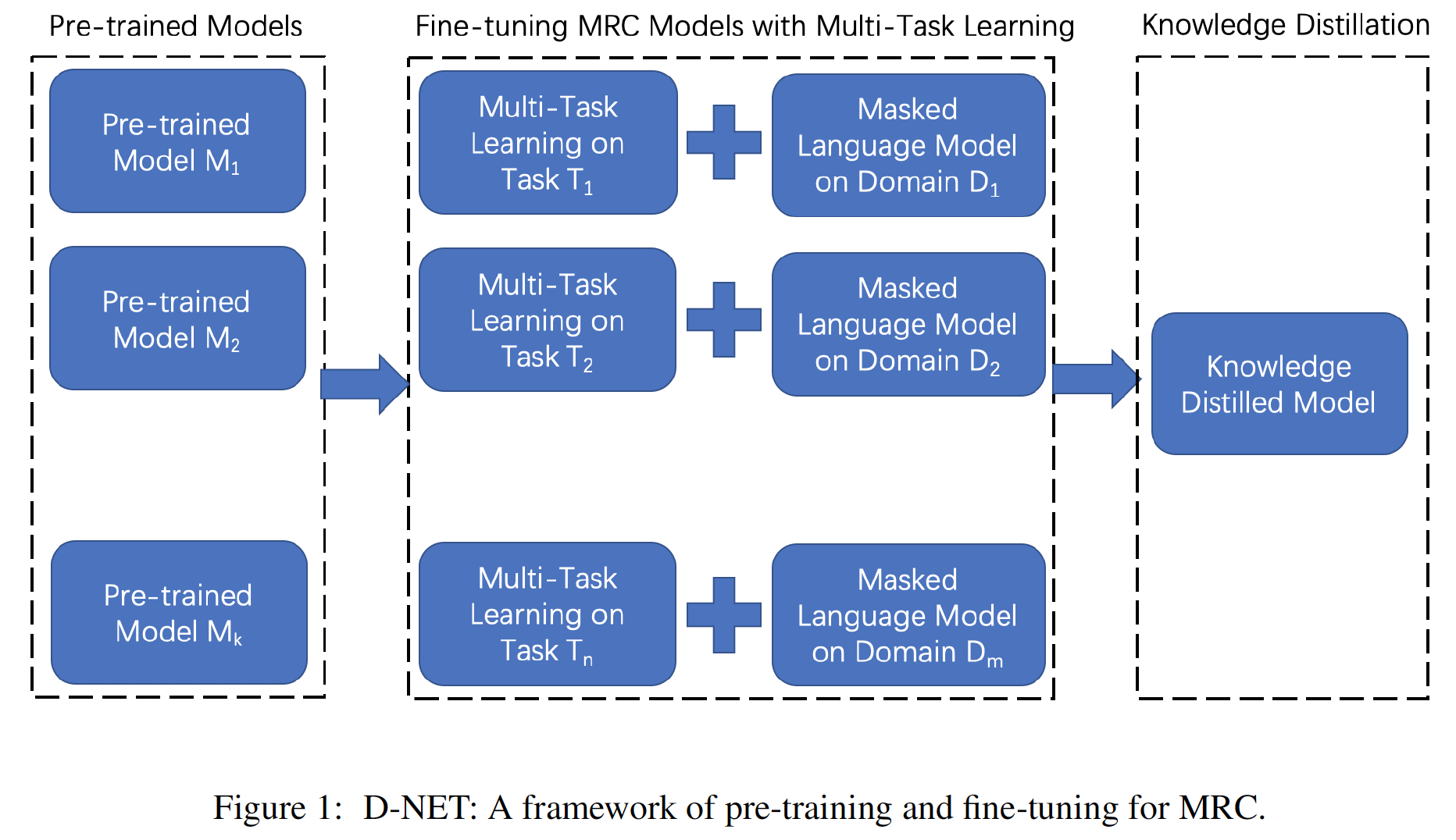
| W: | H:
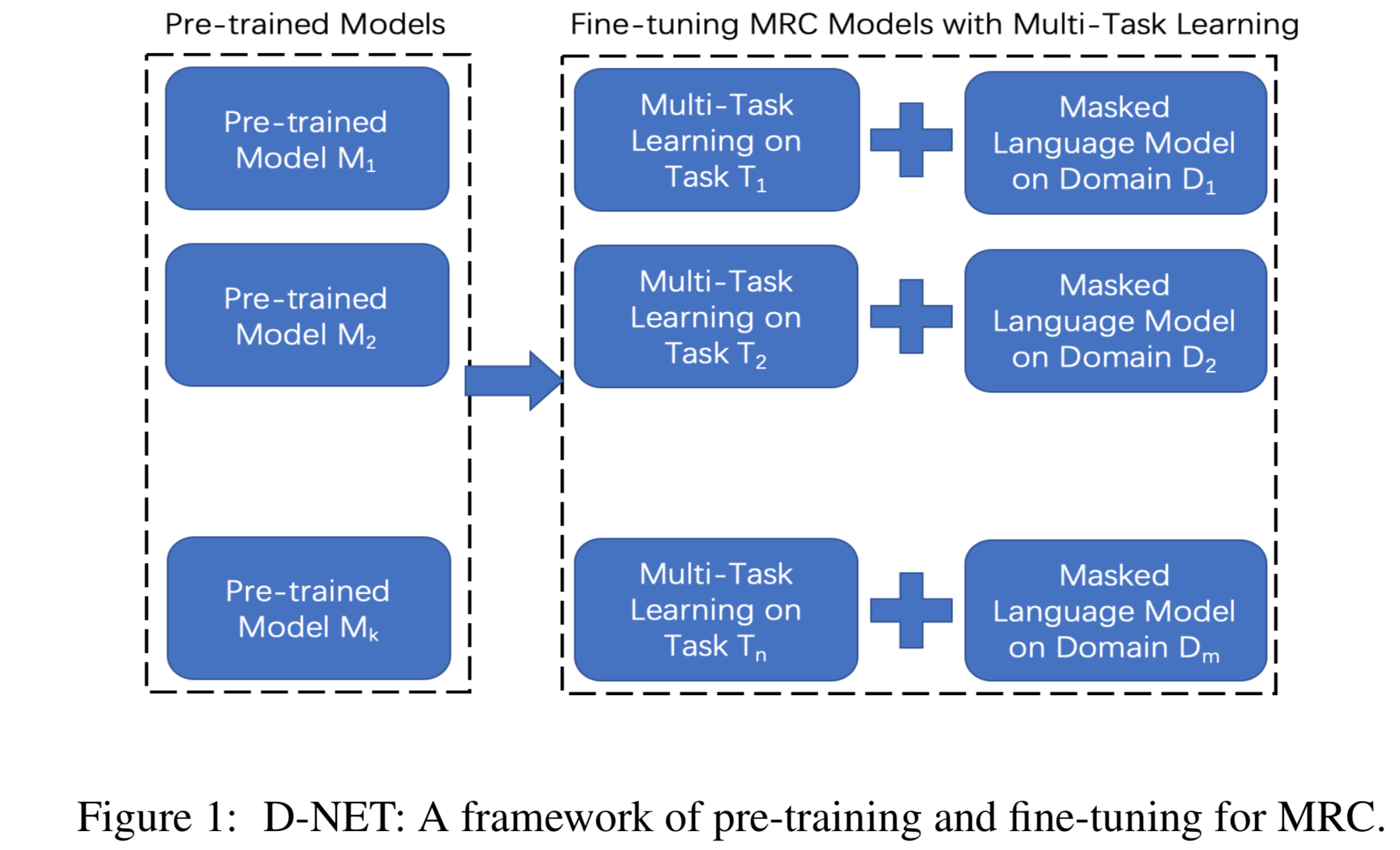
| W: | H:
{kind=link}
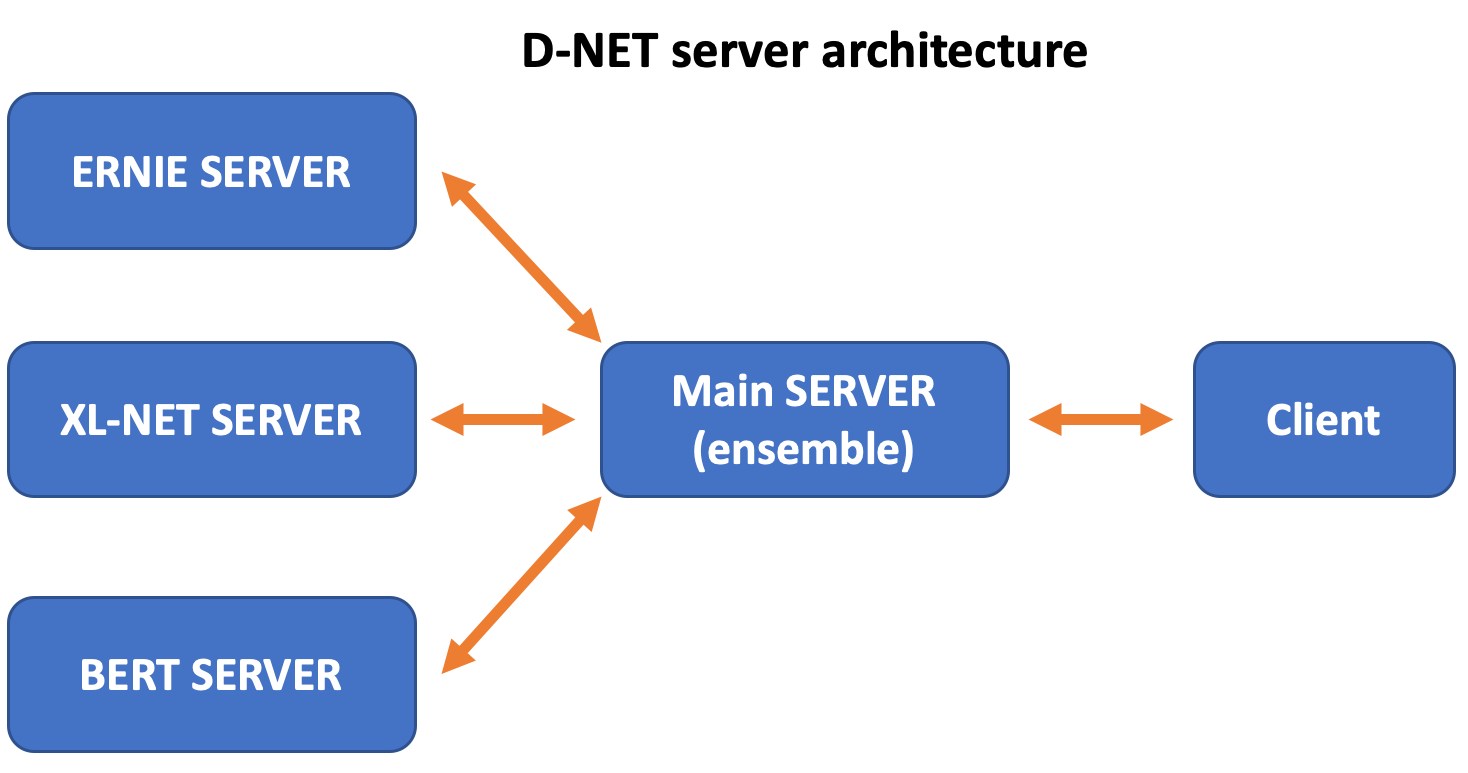
78.4 KB
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动