Merge pull request #1243 from guochaorong/remove_unrelease_models
reomve unrelease models
Showing
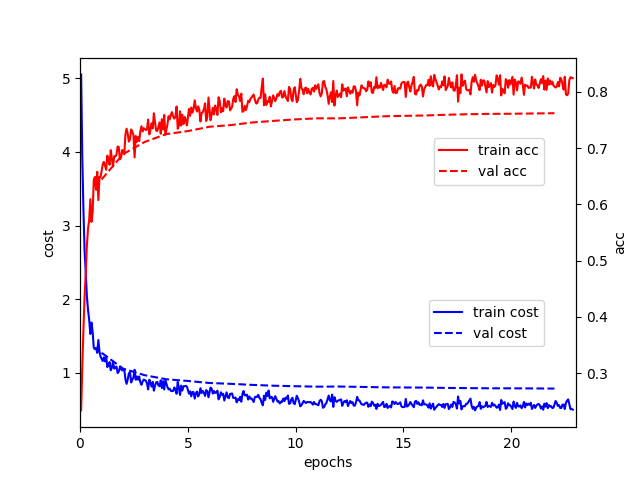
fluid/DeepASR/README.md
已删除
100644 → 0
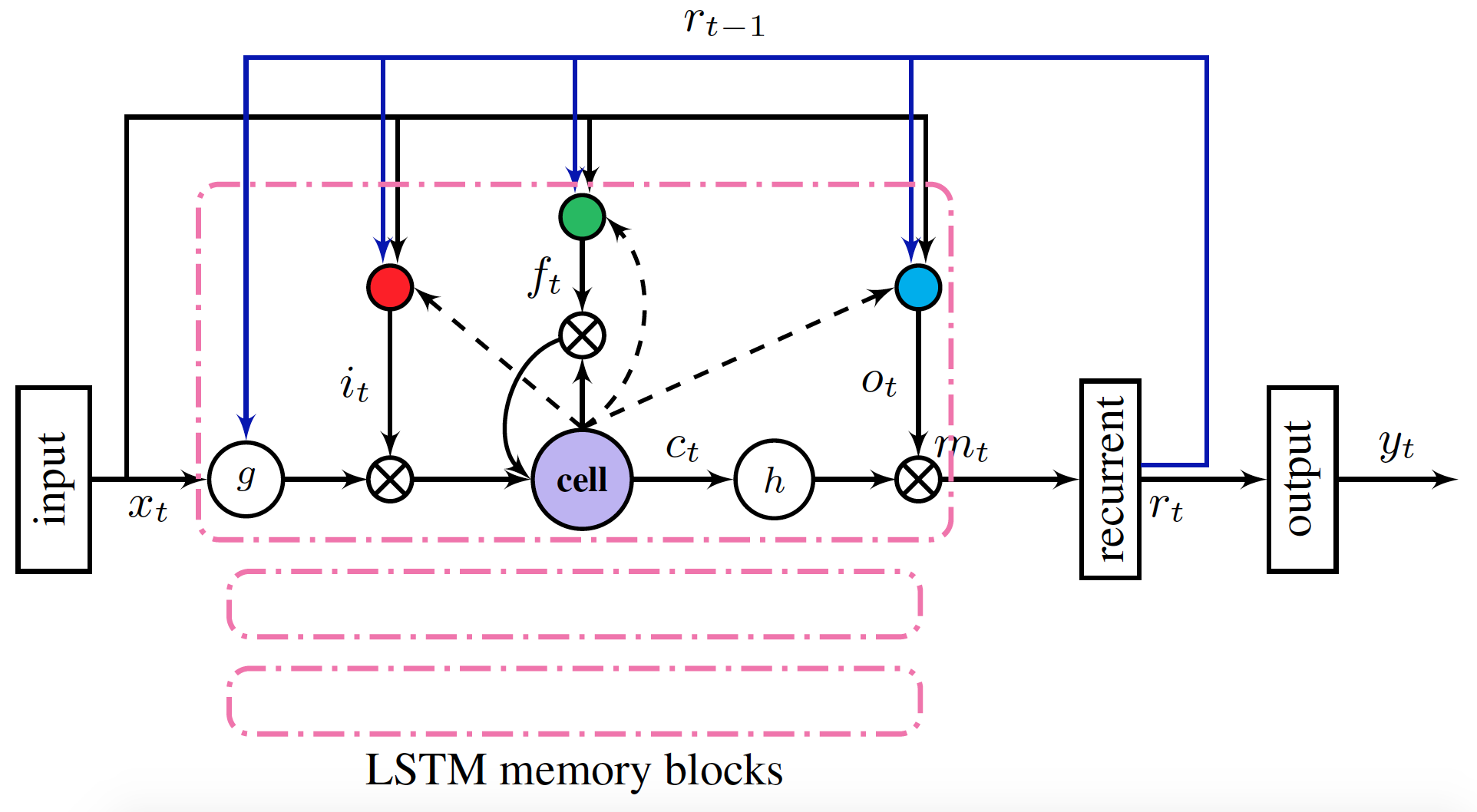
fluid/DeepASR/README_cn.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
41.7 KB
{kind=link}
173.7 KB
fluid/DeepASR/infer.py
已删除
100644 → 0
fluid/DeepASR/train.py
已删除
100644 → 0
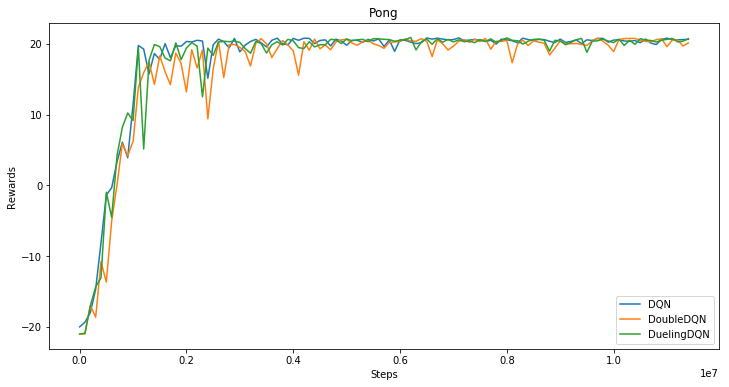
fluid/DeepQNetwork/README.md
已删除
100644 → 0
{kind=link}
38.1 KB
fluid/DeepQNetwork/atari.py
已删除
100644 → 0
fluid/DeepQNetwork/play.py
已删除
100644 → 0
文件已删除
文件已删除
fluid/DeepQNetwork/train.py
已删除
100644 → 0
fluid/DeepQNetwork/utils.py
已删除
100644 → 0
fluid/adversarial/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/chinese_ner/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/chinese_ner/infer.py
已删除
100644 → 0
此差异已折叠。
fluid/chinese_ner/reader.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/chinese_ner/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
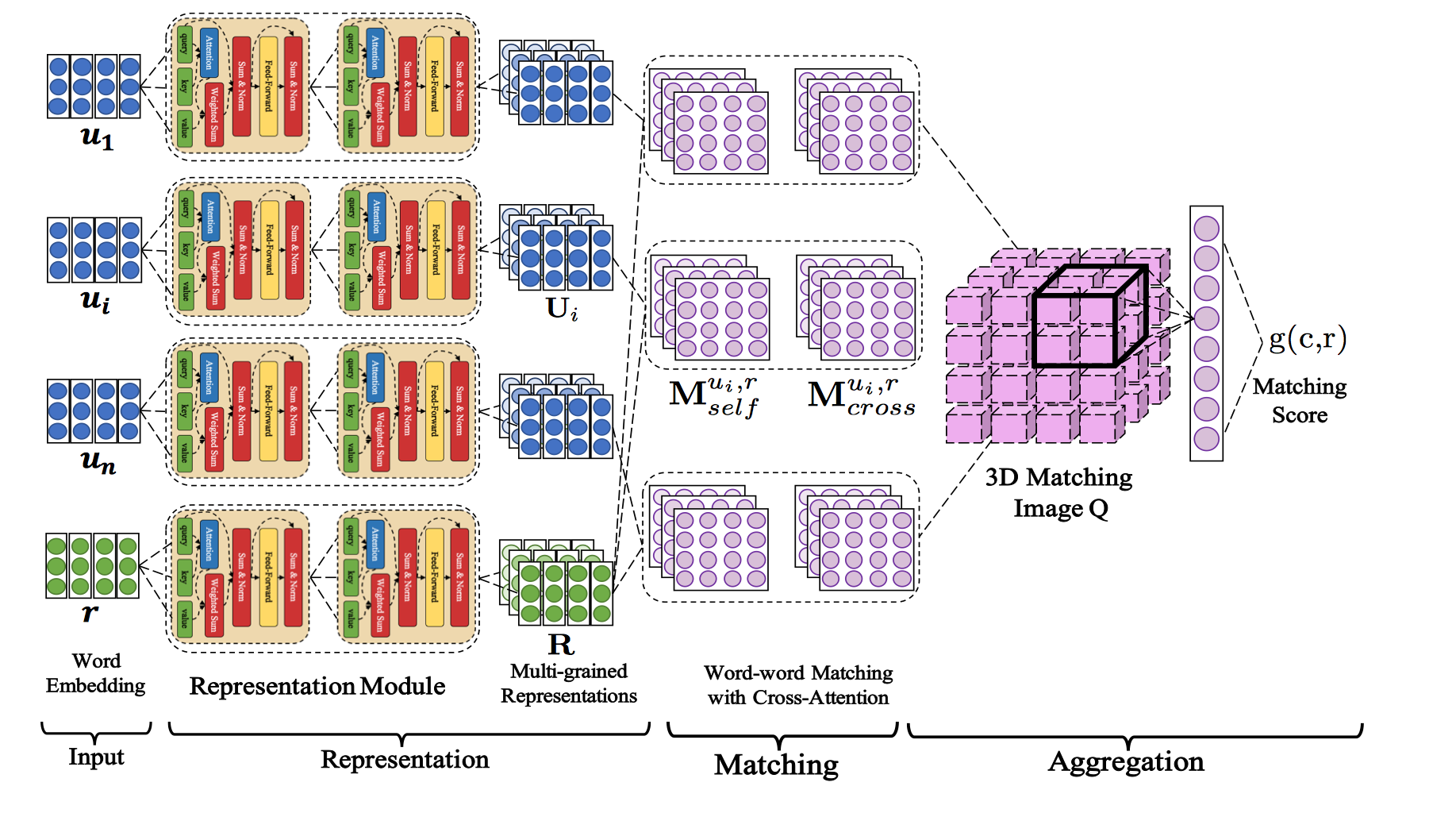
705.0 KB
{kind=link}
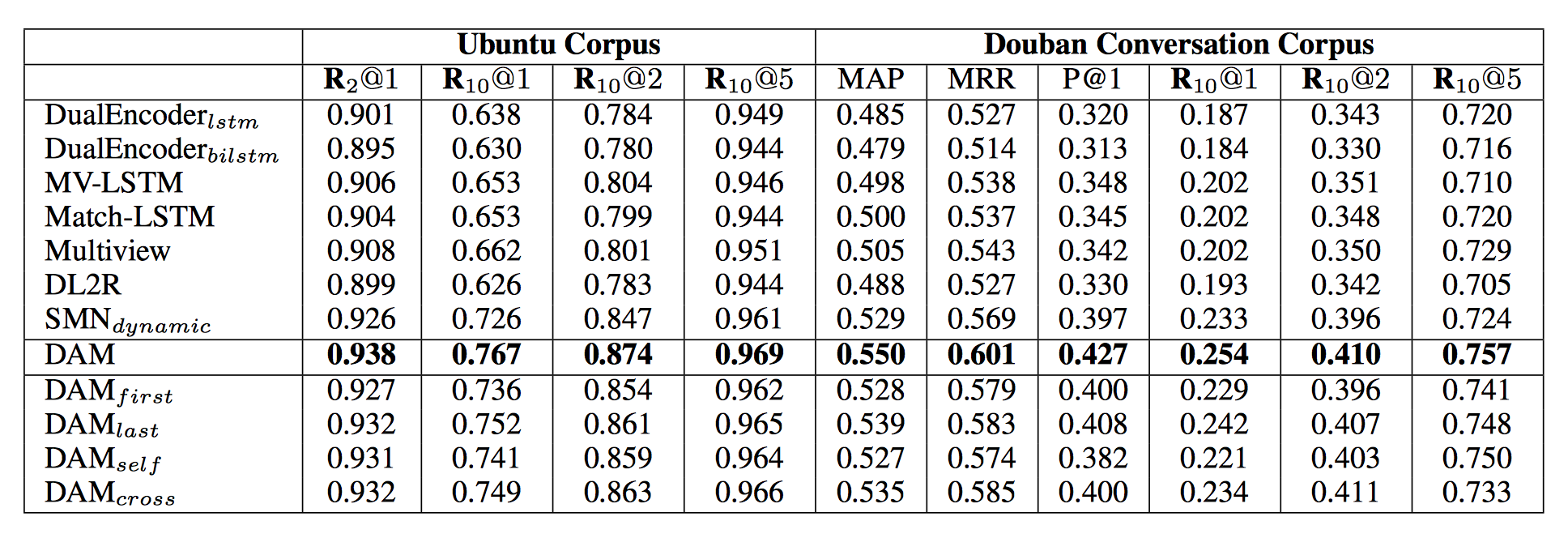
209.1 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/face_detection/train.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/metric_learning/eval.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/policy_gradient/env.py
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
fluid/policy_gradient/run.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。