diff --git a/PaddleCV/image_classification/build_model.py b/PaddleCV/image_classification/build_model.py
index 003111ab86206729ae20d56fca304943f16038da..6b374b17a5a66c3da766fa35f725ee187aaae541 100644
--- a/PaddleCV/image_classification/build_model.py
+++ b/PaddleCV/image_classification/build_model.py
@@ -15,7 +15,7 @@ import paddle
import paddle.fluid as fluid
import utils.utility as utility
-AMP_MODEL_LIST = ["ResNet50", "SE_ResNet50_vd"]
+AMP_MODEL_LIST = ["ResNet50", "SE_ResNet50_vd", "ResNet200_vd"]
def _calc_label_smoothing_loss(softmax_out, label, class_dim, epsilon):
diff --git a/PaddleCV/image_classification/models/resnet_vd.py b/PaddleCV/image_classification/models/resnet_vd.py
index bb04e2f6e73d8f67fae42d6e6666044db4cf3c34..97544931ad6f2c8d901ef5a0fa35fe5dc763bdc7 100644
--- a/PaddleCV/image_classification/models/resnet_vd.py
+++ b/PaddleCV/image_classification/models/resnet_vd.py
@@ -23,7 +23,8 @@ import paddle.fluid as fluid
from paddle.fluid.param_attr import ParamAttr
__all__ = [
- "ResNet", "ResNet18_vd", "ResNet34_vd", "ResNet50_vd", "ResNet101_vd", "ResNet152_vd", "ResNet200_vd"
+ "ResNet", "ResNet18_vd", "ResNet34_vd", "ResNet50_vd", "ResNet101_vd",
+ "ResNet152_vd", "ResNet200_vd"
]
@@ -32,7 +33,7 @@ class ResNet():
self.layers = layers
self.is_3x3 = is_3x3
- def net(self, input, class_dim=1000):
+ def net(self, input, class_dim=1000, data_format="NCHW"):
is_3x3 = self.is_3x3
layers = self.layers
supported_layers = [18, 34, 50, 101, 152, 200]
@@ -40,7 +41,7 @@ class ResNet():
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 18:
- depth = [2, 2, 2, 2]
+ depth = [2, 2, 2, 2]
elif layers == 34 or layers == 50:
depth = [3, 4, 6, 3]
elif layers == 101:
@@ -56,7 +57,8 @@ class ResNet():
num_filters=64,
filter_size=7,
stride=2,
- act='relu')
+ act='relu',
+ data_format=data_format)
else:
conv = self.conv_bn_layer(
input=input,
@@ -64,29 +66,33 @@ class ResNet():
filter_size=3,
stride=2,
act='relu',
- name='conv1_1')
+ name='conv1_1',
+ data_format=data_format)
conv = self.conv_bn_layer(
input=conv,
num_filters=32,
filter_size=3,
stride=1,
act='relu',
- name='conv1_2')
+ name='conv1_2',
+ data_format=data_format)
conv = self.conv_bn_layer(
input=conv,
num_filters=64,
filter_size=3,
stride=1,
act='relu',
- name='conv1_3')
+ name='conv1_3',
+ data_format=data_format)
conv = fluid.layers.pool2d(
input=conv,
pool_size=3,
pool_stride=2,
pool_padding=1,
- pool_type='max')
-
+ pool_type='max',
+ data_format=data_format)
+
if layers >= 50:
for block in range(len(depth)):
for i in range(depth[block]):
@@ -101,22 +107,29 @@ class ResNet():
input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
- if_first=block==i==0,
- name=conv_name)
+ if_first=block == i == 0,
+ name=conv_name,
+ data_format=data_format)
else:
for block in range(len(depth)):
for i in range(depth[block]):
- conv_name="res"+str(block+2)+chr(97+i)
+ conv_name = "res" + str(block + 2) + chr(97 + i)
conv = self.basic_block(
input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
- if_first=block==i==0,
- name=conv_name)
+ if_first=block == i == 0,
+ name=conv_name,
+ data_format=data_format)
pool = fluid.layers.pool2d(
- input=conv, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
+ input=conv,
+ pool_type='avg',
+ global_pooling=True,
+ data_format=data_format)
+ pool_channel = pool.shape[1] if data_format == "NCHW" else pool.shape[
+ -1]
+ stdv = 1.0 / math.sqrt(pool_channel * 1.0)
out = fluid.layers.fc(
input=pool,
@@ -133,7 +146,8 @@ class ResNet():
stride=1,
groups=1,
act=None,
- name=None):
+ name=None,
+ data_format="NCHW"):
conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
@@ -143,7 +157,8 @@ class ResNet():
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_weights"),
- bias_attr=False)
+ bias_attr=False,
+ data_format=data_format)
if name == "conv1":
bn_name = "bn_" + name
else:
@@ -154,7 +169,8 @@ class ResNet():
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance')
+ moving_variance_name=bn_name + '_variance',
+ data_layout=data_format)
def conv_bn_layer_new(self,
input,
@@ -163,14 +179,16 @@ class ResNet():
stride=1,
groups=1,
act=None,
- name=None):
+ name=None,
+ data_format="NCHW"):
pool = fluid.layers.pool2d(
input=input,
pool_size=2,
pool_stride=2,
pool_padding=0,
pool_type='avg',
- ceil_mode=True)
+ ceil_mode=True,
+ data_format=data_format)
conv = fluid.layers.conv2d(
input=pool,
@@ -181,7 +199,8 @@ class ResNet():
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_weights"),
- bias_attr=False)
+ bias_attr=False,
+ data_format=data_format)
if name == "conv1":
bn_name = "bn_" + name
else:
@@ -192,81 +211,114 @@ class ResNet():
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance')
+ moving_variance_name=bn_name + '_variance',
+ data_layout=data_format)
- def shortcut(self, input, ch_out, stride, name, if_first=False):
- ch_in = input.shape[1]
+ def shortcut(self,
+ input,
+ ch_out,
+ stride,
+ name,
+ if_first=False,
+ data_format="NCHW"):
+ ch_in = input.shape[1] if data_format == "NCHW" else input.shape[-1]
if ch_in != ch_out or stride != 1:
if if_first:
- return self.conv_bn_layer(input, ch_out, 1, stride, name=name)
+ return self.conv_bn_layer(
+ input,
+ ch_out,
+ 1,
+ stride,
+ name=name,
+ data_format=data_format)
else:
- return self.conv_bn_layer_new(input, ch_out, 1, stride, name=name)
+ return self.conv_bn_layer_new(
+ input,
+ ch_out,
+ 1,
+ stride,
+ name=name,
+ data_format=data_format)
elif if_first:
- return self.conv_bn_layer(input, ch_out, 1, stride, name=name)
+ return self.conv_bn_layer(
+ input, ch_out, 1, stride, name=name, data_format=data_format)
else:
return input
-
- def bottleneck_block(self, input, num_filters, stride, name, if_first):
+ def bottleneck_block(self,
+ input,
+ num_filters,
+ stride,
+ name,
+ if_first,
+ data_format="NCHW"):
conv0 = self.conv_bn_layer(
input=input,
num_filters=num_filters,
filter_size=1,
act='relu',
- name=name + "_branch2a")
+ name=name + "_branch2a",
+ data_format=data_format)
conv1 = self.conv_bn_layer(
input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu',
- name=name + "_branch2b")
+ name=name + "_branch2b",
+ data_format=data_format)
conv2 = self.conv_bn_layer(
input=conv1,
num_filters=num_filters * 4,
filter_size=1,
act=None,
- name=name + "_branch2c")
+ name=name + "_branch2c",
+ data_format=data_format)
short = self.shortcut(
input,
num_filters * 4,
stride,
if_first=if_first,
- name=name + "_branch1")
+ name=name + "_branch1",
+ data_format=data_format)
return fluid.layers.elementwise_add(x=short, y=conv2, act='relu')
-
-
- def basic_block(self, input, num_filters, stride, name, if_first):
+
+ def basic_block(self, input, num_filters, stride, name, if_first,
+ data_format):
conv0 = self.conv_bn_layer(
- input=input,
- num_filters=num_filters,
- filter_size=3,
- act='relu',
+ input=input,
+ num_filters=num_filters,
+ filter_size=3,
+ act='relu',
stride=stride,
- name=name+"_branch2a")
+ name=name + "_branch2a",
+ data_format=data_format)
conv1 = self.conv_bn_layer(
- input=conv0,
- num_filters=num_filters,
- filter_size=3,
- act=None,
- name=name+"_branch2b")
+ input=conv0,
+ num_filters=num_filters,
+ filter_size=3,
+ act=None,
+ name=name + "_branch2b",
+ data_format=data_format)
short = self.shortcut(
- input,
- num_filters,
- stride,
- if_first=if_first,
- name=name + "_branch1")
+ input,
+ num_filters,
+ stride,
+ if_first=if_first,
+ name=name + "_branch1",
+ data_format=data_format)
return fluid.layers.elementwise_add(x=short, y=conv1, act='relu')
+
def ResNet18_vd():
- model=ResNet(layers=18, is_3x3=True)
+ model = ResNet(layers=18, is_3x3=True)
return model
def ResNet34_vd():
- model=ResNet(layers=34, is_3x3=True)
+ model = ResNet(layers=34, is_3x3=True)
return model
diff --git a/PaddleCV/image_classification/scripts/train/ResNet200_vd_fp16.sh b/PaddleCV/image_classification/scripts/train/ResNet200_vd_fp16.sh
new file mode 100755
index 0000000000000000000000000000000000000000..4631cb357c8a35850d62629288cbdc2746883b7f
--- /dev/null
+++ b/PaddleCV/image_classification/scripts/train/ResNet200_vd_fp16.sh
@@ -0,0 +1,49 @@
+#!/bin/bash -ex
+
+#Training details
+export FLAGS_conv_workspace_size_limit=4000 #MB
+export FLAGS_cudnn_exhaustive_search=1
+export FLAGS_cudnn_batchnorm_spatial_persistent=1
+
+DATA_DIR="Your image dataset path, e.g. ./data/ILSVRC2012/"
+DATA_FORMAT="NHWC"
+USE_AMP=true #whether to use amp
+USE_DALI=true
+USE_ADDTO=true
+
+if ${USE_ADDTO} ;then
+ export FLAGS_max_inplace_grad_add=8
+fi
+if ${USE_DALI}; then
+ export FLAGS_fraction_of_gpu_memory_to_use=0.8
+fi
+
+python train.py \
+ --model=ResNet200_vd \
+ --data_dir=${DATA_DIR} \
+ --batch_size=64 \
+ --num_epochs=200 \
+ --total_images=1281167 \
+ --image_shape 4 224 224 \
+ --class_dim=1000 \
+ --print_step=10 \
+ --model_save_dir=output/ \
+ --lr_strategy=cosine_decay \
+ --use_amp=${USE_AMP} \
+ --scale_loss=128.0 \
+ --use_dynamic_loss_scaling=true \
+ --data_format=${DATA_FORMAT} \
+ --fuse_elewise_add_act_ops=true \
+ --fuse_bn_act_ops=true \
+ --fuse_bn_add_act_ops=true \
+ --enable_addto=${USE_ADDTO} \
+ --validate=true \
+ --is_profiler=false \
+ --profiler_path=profile/ \
+ --reader_thread=10 \
+ --reader_buf_size=4000 \
+ --use_dali=${USE_DALI} \
+ --lr=0.1 \
+ --l2_decay=1e-4 \
+ --use_label_smoothing=True \
+ --label_smoothing_epsilon=0.1
diff --git a/PaddleNLP/README_en.md b/PaddleNLP/README_en.md
index 5575d59691086e5594da7d8f824bf2db068c6b29..15a9d3343d10763390a38716a111c5125bb537fc 100644
--- a/PaddleNLP/README_en.md
+++ b/PaddleNLP/README_en.md
@@ -95,13 +95,16 @@ For more pretrained model selection, please refer to [PretrainedModels](./paddle
- [Models API](./docs/models.md)
+
+
+
## Tutorials
Please refer to our official AI Studio account for more interactive tutorials: [PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)
-* [What's Seq2Vec?](https://aistudio.baidu.com/aistudio/projectdetail/1294333) shows how to use LSTM to do sentiment analysis.
+* [What's Seq2Vec?](https://aistudio.baidu.com/aistudio/projectdetail/1283423) shows how to use LSTM to do sentiment analysis.
-* [Sentiment Analysis with ERNIE](https://aistudio.baidu.com/aistudio/projectdetail/1283423) shows how to exploit the pretrained ERNIE to make sentiment analysis better.
+* [Sentiment Analysis with ERNIE](https://aistudio.baidu.com/aistudio/projectdetail/1294333) shows how to exploit the pretrained ERNIE to make sentiment analysis better.
* [Waybill Information Extraction with BiGRU-CRF Model](https://aistudio.baidu.com/aistudio/projectdetail/1317771) shows how to make use of bigru and crf to do information extraction.
diff --git a/PaddleNLP/benchmark/bert/README.md b/PaddleNLP/benchmark/bert/README.md
index b5e92687163c14a2ff40c8584143c0809a448cab..0948c3e677fa4c2c64572b2d6e22a922a508556c 100644
--- a/PaddleNLP/benchmark/bert/README.md
+++ b/PaddleNLP/benchmark/bert/README.md
@@ -1,6 +1,6 @@
# BERT Benchmark with Fleet API
BERT - Bidirectional Encoder Representations from Transformers [论文链接](https://arxiv.org/abs/1810.04805)
-PaddlePaddle实现了BERT的预训练模型(Pre-training)和下游任务(Fine-tunning)。在预训练任务上提供单机版本和多机版本,同时提供混合精度接口来进行加速,可以任务需要进行选择。
+PaddlePaddle实现了BERT的预训练模型(Pre-training)和下游任务(Fine-tunning)。
## 数据集
### Pre-training数据集
@@ -10,7 +10,8 @@ PaddlePaddle实现了BERT的预训练模型(Pre-training)和下游任务(Fin
## Pre-training任务训练
### 环境变量设置
1. paddlenlp的安装
-pip install paddlenlp==2.0.0a2 -i https://pypi.org/simple
+pip install paddlenlp==2.0.0b0 -i https://pypi.org/simple
+
2. 设置预训练的数据地址环境变量
```shell
export DATA_DIR=${HOME}/bert_data/wikicorpus_en
@@ -54,26 +55,6 @@ python ./run_pretrain_single.py \
--max_steps 1000000
```
-### 训练速度对比
-进行速度对比的模型是bert-based模型,主要对比的方式是单机单机和多机多卡(4机32卡)下面进行速度对比,所有的GPU测试配置都是基于 Tesla V100-SXM2-16GB,下面的配置如下:
-- InfiniBand 100 Gb/sec (4X EDR), Mellanox Technologies MT27700 Family
-- 48 CPU(s), Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz
-- Memory 500G
-- Ubuntu 16.04.4 LTS (GNU/Linux 4.4.0-116-generic x86_64)
-- CUDA Version: 10.2, Driver API Version: 10.2, Driver Version: 440.33.01
-- cuDNN Version: 7.6
-- PaddlePaddle version: paddlepadle-gpu >= 2.0.0rc1
-- PaddleNLP version: paddlenlp >= 2.0.0a2
-
-速度统计方式是统计每秒预训练模型能处理的样本数量,其中
-- batch_size=64
-- max_seq_length=128
-
-下面是具体速度对比情况:
-| node num | node num | gpu num/node | gpu num | batch_size/gpu |Throughput | Speedup |
-|----------| -------- | -------------| ------- | -------- | ----------| ------- |
-
-
## Fine-tuning任务训练
在完成 BERT 模型的预训练后,即可利用预训练参数在特定的 NLP 任务上做 Fine-tuning。以下利用开源的预训练模型,示例如何进行分类任务的 Fine-tuning。
diff --git a/PaddleNLP/examples/README.md b/PaddleNLP/examples/README.md
index 6f3be9805cd5db26d5b5cb14460e95163fe7ed41..af8d47ee88c006cf88cca4fa0b57b554b5d0e9be 100644
--- a/PaddleNLP/examples/README.md
+++ b/PaddleNLP/examples/README.md
@@ -7,16 +7,16 @@
| 任务类型 | 目录 | 简介 |
| ----------------------------------| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| 中文词法分析 | [LAC(Lexical Analysis of Chinese)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/lexical_analysis) | 百度自主研发中文特色模型词法分析任务,集成了中文分词、词性标注和命名实体识别任务。输入是一个字符串,而输出是句子中的词边界和词性、实体类别。 |
+| 中文词法分析 | [LAC(Lexical Analysis of Chinese)](./lexical_analysis) | 百度自主研发中文特色模型词法分析任务,集成了中文分词、词性标注和命名实体识别任务。输入是一个字符串,而输出是句子中的词边界和词性、实体类别。 |
| 预训练词向量 | [WordEmbedding](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/word_embedding) | 提供了丰富的中文预训练词向量,通过简单配置即可使用词向量来进行热启训练,能支持较多的中文场景下的训练任务的热启训练,加快训练收敛速度。|
### 核心技术模型
| 任务类型 | 目录 | 简介 |
| -------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
-| ERNIE-GEN文本生成 | [ERNIE-GEN(An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_generation/ernie-gen) |ERNIE-GEN是百度发布的生成式预训练模型,是一种Multi-Flow结构的预训练和微调框架。ERNIE-GEN利用更少的参数量和数据,在摘要生成、问题生成、对话和生成式问答4个任务共5个数据集上取得了SOTA效果 |
-| BERT 预训练&GLUE下游任务 | [BERT(Bidirectional Encoder Representation from Transformers)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/bert) | BERT模型作为目前最为火热语义表示预训练模型,PaddleNLP提供了简洁功效的实现方式,同时易用性方面通过简单参数切换即可实现不同的BERT模型。 |
-| Electra 预训练&GLUE下游任务 | [Electra(Pre-training Text Encoders as Discriminators Rather Than Generator)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/electra) |ELECTRA模型新一种模型预训练的框架,采用generator和discriminator的结合方式,相对于BERT来说能提升计算效率,同时缓解BERT训练和预测不一致的问题。|
+| ERNIE-GEN文本生成 | [ERNIE-GEN(An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation)](./text_generation/ernie-gen) |ERNIE-GEN是百度发布的生成式预训练模型,是一种Multi-Flow结构的预训练和微调框架。ERNIE-GEN利用更少的参数量和数据,在摘要生成、问题生成、对话和生成式问答4个任务共5个数据集上取得了SOTA效果 |
+| BERT 预训练&GLUE下游任务 | [BERT(Bidirectional Encoder Representation from Transformers)](./language_model/bert) | BERT模型作为目前最为火热语义表示预训练模型,PaddleNLP提供了简洁功效的实现方式,同时易用性方面通过简单参数切换即可实现不同的BERT模型。 |
+| Electra 预训练&GLUE下游任务 | [Electra(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)](./language_model/electra) |ELECTRA 创新性地引入GAN的思想对BERT预训练过程进行了改进,在和BERT具有相同的模型参数、预训练计算量一样的情况下,ELECTRA GLUE得分明显好。同时相比GPT、ELMo,在GLUE得分略好时,ELECTRA预训练模型只需要很少的参数和计算量。|
### 核心应用模型
@@ -25,20 +25,20 @@
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [Seq2Seq](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/machine_translation/seq2seq) | 使用编码器-解码器(Encoder-Decoder)结构, 同时使用了Attention机制来加强Decoder和Encoder之间的信息交互,Seq2Seq 广泛应用于机器翻译,自动对话机器人,文档摘要自动生成,图片描述自动生成等任务中。|
-| [Transformer](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/machine_translation/transformer) |基于PaddlePaddle框架的Transformer结构搭建的机器翻译模型,Transformer 计算并行度高,能解决学习长程依赖问题。并且模型框架集成了训练,验证,预测任务,功能完备,效果突出。|
+| [Seq2Seq](./machine_translation/seq2seq) | 使用编码器-解码器(Encoder-Decoder)结构, 同时使用了Attention机制来加强Decoder和Encoder之间的信息交互,Seq2Seq 广泛应用于机器翻译,自动对话机器人,文档摘要自动生成,图片描述自动生成等任务中。|
+| [Transformer](./machine_translation/transformer) |基于PaddlePaddle框架的Transformer结构搭建的机器翻译模型,Transformer 计算并行度高,能解决学习长程依赖问题。并且模型框架集成了训练,验证,预测任务,功能完备,效果突出。|
#### 命名实体识别 (Named Entity Recognition)
命名实体识别(Named Entity Recognition,NER)是NLP中一项非常基础的任务。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的准确度,决定了下游任务的效果,是NLP中非常重要的一个基础问题。
在NER任务提供了两种解决方案,一类LSTM/GRU + CRF(Conditional Random Field),RNN类的模型来抽取底层文本的信息,而CRF(条件随机场)模型来学习底层Token之间的联系;另外一类是通过预训练模型,例如ERNIE,BERT模型,直接来预测Token的标签信息。
-因为该类模型较为抽象,提供了一份快递单信息抽取的训练脚本给大家使用,具体的任务是通过两类的模型来抽取快递单的核心信息,例如地址,姓名,手机号码,具体的[快递单任务链接](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/named_entity_recognition/express_ner)。
+因为该类模型较为抽象,提供了一份快递单信息抽取的训练脚本给大家使用,具体的任务是通过两类的模型来抽取快递单的核心信息,例如地址,姓名,手机号码,具体的[快递单任务链接](./named_entity_recognition/express_ner)。
下面是具体的模型信息。
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [BiGRU+CRF](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/named_entity_recognition/express_ner) |传统的序列标注模型,通过双向GRU模型能抽取文本序列的信息和联系,通过CRF模型来学习文本Token之间的联系,本模型集成PaddleNLP自己开发的CRF模型,模型结构清晰易懂。 |
-| [ERNIE/BERT Fine-tuning](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/named_entity_recognition) |通过预训练模型提供的强大的语义信息和ERNIE/BERT类模型的Self-Attention机制来覆盖Token之间的联系,直接通过BERT/ERNIE的序列分类模型来预测文本每个token的标签信息,模型结构简单,效果优异。|
+| [BiGRU-CRF](./named_entity_recognition/express_ner) |传统的序列标注模型,通过双向GRU模型能抽取文本序列的信息和联系,通过CRF模型来学习文本Token之间的联系,本模型集成PaddleNLP自己开发的CRF模型,模型结构清晰易懂。 |
+| [ERNIE/BERT Fine-tuning](./named_entity_recognition) |通过预训练模型提供的强大的语义信息和ERNIE/BERT类模型的Self-Attention机制来覆盖Token之间的联系,直接通过BERT/ERNIE的序列分类模型来预测文本每个token的标签信息,模型结构简单,效果优异。|
#### 文本分类 (Text Classification)
@@ -46,8 +46,8 @@
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [RNN/GRU/LSTM](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_classification/rnn) | 面向通用场景的文本分类模型,网络结构接入常见的RNN类模型,例如LSTM,GRU,RNN。整体模型结构集成在百度的自研的Senta文本情感分类模型上,效果突出,用法简易。|
-| [ERNIE/BERT Fine-tuning](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_classification/pretrained_models) |基于预训练后模型的文本分类的模型,多达11种的预训练模型可供使用,其中有较多中文预训练模型,预训练模型切换简单,情感分析任务上效果突出。|
+| [RNN/GRU/LSTM](./text_classification/rnn) | 面向通用场景的文本分类模型,网络结构接入常见的RNN类模型,例如LSTM,GRU,RNN。整体模型结构集成在百度的自研的Senta文本情感分类模型上,效果突出,用法简易。|
+| [ERNIE/BERT Fine-tuning](./text_classification/pretrained_models) |基于预训练后模型的文本分类的模型,多达11种的预训练模型可供使用,其中有较多中文预训练模型,预训练模型切换简单,情感分析任务上效果突出。|
#### 文本生成 (Text Generation)
@@ -55,7 +55,7 @@
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [ERNIE-GEN(An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_generation/ernie-gen) |ERNIE-GEN是百度发布的生成式预训练模型,通过Global-Attention的方式解决训练和预测曝光偏差的问题,同时使用Multi-Flow Attention机制来分别进行Global和Context信息的交互,同时通过片段生成的方式来增加语义相关性。|
+| [ERNIE-GEN(An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation)](./text_generation/ernie-gen) |ERNIE-GEN是百度发布的生成式预训练模型,通过Global-Attention的方式解决训练和预测曝光偏差的问题,同时使用Multi-Flow Attention机制来分别进行Global和Context信息的交互,同时通过片段生成的方式来增加语义相关性。|
@@ -65,8 +65,8 @@
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [SimNet](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_matching/simnet)|PaddleNLP提供的SimNet模型已经纳入了PaddleNLP的官方API中,用户直接调用API即完成一个SimNet模型的组网,在模型层面提供了Bow/CNN/LSTM/GRU常用信息抽取方式, 灵活高,使用方便。|
-| [SentenceTransformer](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_matching/sentence_transformers)|直接调用简易的预训练模型接口接口完成对Sentence的语义表示,同时提供了较多的中文预训练模型,可以根据任务的来选择相关参数。|
+| [SimNet](./text_matching/simnet)|PaddleNLP提供的SimNet模型已经纳入了PaddleNLP的官方API中,用户直接调用API即完成一个SimNet模型的组网,在模型层面提供了Bow/CNN/LSTM/GRU常用信息抽取方式, 灵活高,使用方便。|
+| [SentenceTransformer](./text_matching/sentence_transformers)|直接调用简易的预训练模型接口接口完成对Sentence的语义表示,同时提供了较多的中文预训练模型,可以根据任务的来选择相关参数。|
#### 语言模型 (Language Model)
@@ -74,8 +74,8 @@
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [RNNLM](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/language_model/rnnlm) |序列任务常用的rnn网络,实现了一个两层的LSTM网络,然后LSTM的结果去预测下一个词出现的概率。是基于RNN的常规的语言模型。|
-| [ELMo](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/language_model/elmo) |ElMo是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。ELMo主要是解决了传统的WordEmbedding的向量表示单一的问题,ELMo通过结合上下文来增强语义表示。|
+| [RNNLM](./language_model/rnnlm) |序列任务常用的rnn网络,实现了一个两层的LSTM网络,然后LSTM的结果去预测下一个词出现的概率。是基于RNN的常规的语言模型。|
+| [ELMo](./language_model/elmo) |ElMo是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。ELMo主要是解决了传统的WordEmbedding的向量表示单一的问题,ELMo通过结合上下文来增强语义表示。|
#### 文本图学习 (Text Graph)
在很多工业应用中,往往出现一种特殊的图:Text Graph。顾名思义,图的节点属性由文本构成,而边的构建提供了结构信息。如搜索场景下的Text Graph,节点可由搜索词、网页标题、网页正文来表达,用户反馈和超链信息则可构成边关系。百度图学习PGL((Paddle Graph Learning)团队提出ERNIESage(ERNIE SAmple aggreGatE)模型同时建模文本语义与图结构信息,有效提升Text Graph的应用效果。图学习是深度学习领域目前的研究热点,如果想对图学习有更多的了解,可以访问[PGL Github链接](https://github.com/PaddlePaddle/PGL/)。
@@ -83,14 +83,14 @@ ERNIESage模型的具体信息如下。
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [ERNIESage(ERNIE SAmple aggreGatE)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/text_graph/erniesage)|通过Graph(图)来来构建自身节点和邻居节点的连接关系,将自身节点和邻居节点的关系构建成一个关联样本输入到ERNIE中,ERNIE作为聚合函数(Aggregators)来表征自身节点和邻居节点的语义关系,最终强化图中节点的语义表示。在TextGraph的任务上ERNIESage的效果非常优秀。|
+| [ERNIESage(ERNIE SAmple aggreGatE)](./text_graph/erniesage)|通过Graph(图)来来构建自身节点和邻居节点的连接关系,将自身节点和邻居节点的关系构建成一个关联样本输入到ERNIE中,ERNIE作为聚合函数(Aggregators)来表征自身节点和邻居节点的语义关系,最终强化图中节点的语义表示。在TextGraph的任务上ERNIESage的效果非常优秀。|
#### 阅读理解(Machine Reading Comprehension)
机器阅读理解是近期自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。得益于深度学习技术和大规模标注数据集的发展,用端到端的神经网络来解决阅读理解任务取得了长足的进步。下面是具体的模型信息。
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [BERT Fine-tuning](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/machine_reading_comprehension/) |通过ERNIE/BERT等预训练模型的强大的语义表示能力,设置在阅读理解上面的下游任务,该模块主要是提供了多个数据集来验证BERT模型在阅读理解上的效果,数据集主要是包括了SQuAD,DuReader,DuReader-robust,DuReader-yesno。同时提供了和相关阅读理解相关的Metric(指标),用户可以简易的调用这些API,快速验证模型效果。|
+| [BERT Fine-tuning](./machine_reading_comprehension/) |通过ERNIE/BERT等预训练模型的强大的语义表示能力,设置在阅读理解上面的下游任务,该模块主要是提供了多个数据集来验证BERT模型在阅读理解上的效果,数据集主要是包括了SQuAD,DuReader,DuReader-robust,DuReader-yesno。同时提供了和相关阅读理解相关的Metric(指标),用户可以简易的调用这些API,快速验证模型效果。|
#### 对话系统(Dialogue System)
@@ -98,7 +98,8 @@ ERNIESage模型的具体信息如下。
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [BERT-DGU](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/dialogue/dgu) |通过ERNIE/BERT等预训练模型的强大的语义表示能力,抽取对话中的文本语义信息,通过对文本分类等操作就可以完成对话中的诸多任务,例如意图识别,行文识别,状态跟踪等。|
+| [DGU](./dialogue/dgu) |通过ERNIE/BERT等预训练模型的强大的语义表示能力,抽取对话中的文本语义信息,通过对文本分类等操作就可以完成对话中的诸多任务,例如意图识别,行文识别,状态跟踪等。|
+| [PLATO-2](./dialogue/plato-2) | 百度自研领先的开放域对话预训练模型。[PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning](https://arxiv.org/abs/2006.16779) |
#### 时间序列预测(Time Series)
时间序列是指按照时间先后顺序排列而成的序列,例如每日发电量、每小时营业额等组成的序列。通过分析时间序列中的发展过程、方向和趋势,我们可以预测下一段时间可能出现的情况。为了更好让大家了解时间序列预测任务,提供了基于19年新冠疫情预测的任务示例,有兴趣的话可以进行研究学习。
@@ -107,4 +108,4 @@ ERNIESage模型的具体信息如下。
| 模型 | 简介 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [TCN(Temporal convolutional network)](https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/examples/time_series)|TCN模型基于卷积的时间序列模型,通过因果卷积(Causal Convolution)和空洞卷积(Dilated Convolution) 特定的组合方式解决卷积不适合时间序列任务的问题,TCN具备并行度高,内存低等诸多优点,在某些时间序列任务上效果已经超过传统的RNN模型。|
+| [TCN(Temporal convolutional network)](./time_series)|TCN模型基于卷积的时间序列模型,通过因果卷积(Causal Convolution)和空洞卷积(Dilated Convolution) 特定的组合方式解决卷积不适合时间序列任务的问题,TCN具备并行度高,内存低等诸多优点,在某些时间序列任务上效果已经超过传统的RNN模型。|
diff --git a/PaddleNLP/examples/dialogue/dgu/README.md b/PaddleNLP/examples/dialogue/dgu/README.md
index 8f7d1f0c3f5910e12dc3547381cdadc702884138..6f52035e327dda42db426e993501510bb46fd6e7 100644
--- a/PaddleNLP/examples/dialogue/dgu/README.md
+++ b/PaddleNLP/examples/dialogue/dgu/README.md
@@ -39,17 +39,17 @@ DGU模型中的6个任务,分别采用不同的评估指标在test集上进行
* PaddlePaddle 安装
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+ 本项目依赖于 PaddlePaddle 2.0rc1 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
* PaddleNLP 安装
```shell
- pip install paddlenlp
+ pip install paddlenlp>=2.0.0b
```
* 环境依赖
- Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/install/quick/zh/2.0rc-linux-docker) 部分的内容
+ Python的版本要求 3.6+
### 代码结构说明
diff --git a/PaddleNLP/examples/dialogue/plato-2/README.md b/PaddleNLP/examples/dialogue/plato-2/README.md
index a7b0f68a0cae399045a1f9dc21bc46cf982d16b7..132f00e609ed7d37cfb87ef1bbd2e03b6f772c8b 100644
--- a/PaddleNLP/examples/dialogue/plato-2/README.md
+++ b/PaddleNLP/examples/dialogue/plato-2/README.md
@@ -18,7 +18,7 @@ PLATO-2的训练过程及其他细节详见 [Knover](https://github.com/PaddlePa
* PaddlePaddle 安装
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+ 本项目依赖于 PaddlePaddle 2.0rc1 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
* PaddleNLP 安装
@@ -28,13 +28,13 @@ PLATO-2的训练过程及其他细节详见 [Knover](https://github.com/PaddlePa
* 环境依赖
- Python的版本要求 3.6+
+ Python的版本要求 3.6+
- 本项目依赖sentencepiece和termcolor,请在运行本项目之前进行安装
+ 本项目依赖sentencepiece和termcolor,请在运行本项目之前进行安装
- ```shell
- pip install sentencepiece termcolor
- ```
+ ```shell
+ pip install sentencepiece termcolor
+ ```
### 代码结构说明
diff --git a/PaddleNLP/examples/electra/README.md b/PaddleNLP/examples/language_model/electra/README.md
similarity index 100%
rename from PaddleNLP/examples/electra/README.md
rename to PaddleNLP/examples/language_model/electra/README.md
diff --git a/PaddleNLP/examples/electra/run_glue.py b/PaddleNLP/examples/language_model/electra/run_glue.py
similarity index 100%
rename from PaddleNLP/examples/electra/run_glue.py
rename to PaddleNLP/examples/language_model/electra/run_glue.py
diff --git a/PaddleNLP/examples/electra/run_pretrain.py b/PaddleNLP/examples/language_model/electra/run_pretrain.py
similarity index 100%
rename from PaddleNLP/examples/electra/run_pretrain.py
rename to PaddleNLP/examples/language_model/electra/run_pretrain.py
diff --git a/PaddleNLP/examples/language_model/elmo/README.md b/PaddleNLP/examples/language_model/elmo/README.md
index 4e9b81fbf5d5f49160904b489b04d6cdcd10ea63..d126ea2a4e5d28d75be6d8ff7d84bc92a20b145c 100644
--- a/PaddleNLP/examples/language_model/elmo/README.md
+++ b/PaddleNLP/examples/language_model/elmo/README.md
@@ -18,15 +18,17 @@ ELMo(Embeddings from Language Models)是重要的通用语义表示模型之一
* PaddlePaddle 安装
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+ 本项目依赖于 PaddlePaddle 2.0rc1 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
* 环境依赖
- Python的版本要求 3.6+,并安装sklearn和gensim。其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/beginners_guide/install/index_cn.html) 部分的内容
+ Python的版本要求 3.6+
-```shell
-pip install sklearn gensim
-```
+ 本项目依赖sklearn和gensim,请在运行本项目之前进行安装
+
+ ```shell
+ pip install sklearn gensim
+ ```
### 代码结构说明
diff --git a/PaddleNLP/examples/named_entity_recognition/README.md b/PaddleNLP/examples/named_entity_recognition/README.md
index 537d9ba93e7ac6fcfc721089c573c20f96043e89..923c9d35889e2e951d9d6bc25a0fa4c16ee4f4b9 100644
--- a/PaddleNLP/examples/named_entity_recognition/README.md
+++ b/PaddleNLP/examples/named_entity_recognition/README.md
@@ -1,66 +1,7 @@
-# Name Entity Recognition
+# 命名实体识别
-## 快递单信息抽取
+命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,它是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。在本例中,我们将介绍使用PaddleNLP运行开源数据集MSRA_NER,同时我们还将介绍一个有趣的应用例子——快递单信息抽取。
-## Part1. Bi-LSTM+CRF NER
+* [MSRA_NER](msra_ner/)
-## Part2. BERT NER
-
-### 序列标注任务
-
-以 MSRA 任务为例,启动 Fine-tuning 的方式如下(`paddlenlp` 要已经安装或能在 `PYTHONPATH` 中找到):
-
-```shell
-export CUDA_VISIBLE_DEVICES=0
-
-python -u ./run_msra_ner.py \
- --model_name_or_path bert-base-multilingual-uncased \
- --max_seq_length 128 \
- --batch_size 32 \
- --learning_rate 2e-5 \
- --num_train_epochs 3 \
- --logging_steps 1 \
- --save_steps 500 \
- --output_dir ./tmp/msra_ner/ \
- --n_gpu 1
-```
-
-其中参数释义如下:
-- `model_name_or_path` 指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer。若模型相关内容保存在本地,这里也可以提供相应目录地址。
-- `max_seq_length` 表示最大句子长度,超过该长度将被截断。
-- `batch_size` 表示每次迭代**每张卡**上的样本数目。
-- `learning_rate` 表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。
-- `num_train_epochs` 表示训练轮数。
-- `logging_steps` 表示日志打印间隔。
-- `save_steps` 表示模型保存及评估间隔。
-- `output_dir` 表示模型保存路径。
-- `n_gpu` 表示使用的 GPU 卡数。若希望使用多卡训练,将其设置为指定数目即可;若为0,则使用CPU。
-
-训练过程将按照 `logging_steps` 和 `save_steps` 的设置打印如下日志:
-
-```
-global step 996, epoch: 1, batch: 344, loss: 0.038471, speed: 4.72 step/s
-global step 997, epoch: 1, batch: 345, loss: 0.032820, speed: 4.82 step/s
-global step 998, epoch: 1, batch: 346, loss: 0.008144, speed: 4.69 step/s
-global step 999, epoch: 1, batch: 347, loss: 0.031425, speed: 4.36 step/s
-global step 1000, epoch: 1, batch: 348, loss: 0.073151, speed: 4.59 step/s
-eval loss: 0.019874, precision: 0.991670, recall: 0.991930, f1: 0.991800
-```
-
-使用以上命令进行单卡 Fine-tuning ,在验证集上有如下结果:
- Metric | Result |
-------------------------------|-------------|
-precision | 0.992903 |
-recall | 0.991823 |
-f1 | 0.992363 |
-
-# TODO: 写成教程
-参考run_bert_crf.py,进一步使用CRF
- Metric | Result |
-------------------------------|-------------|
-precision | 0.992266 |
-recall | 0.993056 |
-f1 | 0.992661 |
-
-
-## Part3. BERT+LSTM-CRF NER
+* [快递单信息抽取](express_ner/)
diff --git a/PaddleNLP/examples/named_entity_recognition/express_ner/README.md b/PaddleNLP/examples/named_entity_recognition/express_ner/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f0b61033e3f4028296ffad067fca5257e5a657fd
--- /dev/null
+++ b/PaddleNLP/examples/named_entity_recognition/express_ner/README.md
@@ -0,0 +1,60 @@
+# 快递单信息抽取
+
+## 1. 简介
+
+本项目将演示如何从用户提供的快递单中,抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
+
+## 2. 快速开始
+
+### 2.1 环境配置
+
+- Python >= 3.6
+
+- paddlepaddle >= 2.0.0rc1,安装方式请参考 [快速安装](https://www.paddlepaddle.org.cn/install/quick)。
+
+- paddlenlp >= 2.0.0b, 安装方式:`pip install paddlenlp>=2.0.0b`
+
+
+### 2.2 数据准备
+
+数据集已经保存在data目录中,示例如下
+
+```
+1�6�6�2�0�2�0�0�0�7�7�宣�荣�嗣�甘�肃�省�白�银�市�会�宁�县�河�畔�镇�十�字�街�金�海�超�市�西�行�5�0�米 T-B�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�P-B�P-I�P-I�A1-B�A1-I�A1-I�A2-B�A2-I�A2-I�A3-B�A3-I�A3-I�A4-B�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I
+1�3�5�5�2�6�6�4�3�0�7�姜�骏�炜�云�南�省�德�宏�傣�族�景�颇�族�自�治�州�盈�江�县�平�原�镇�蜜�回�路�下�段 T-B�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�T-I�P-B�P-I�P-I�A1-B�A1-I�A1-I�A2-B�A2-I�A2-I�A2-I�A2-I�A2-I�A2-I�A2-I�A2-I�A2-I�A3-B�A3-I�A3-I�A4-B�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I�A4-I
+```
+数据集中以特殊字符"\t"分隔文本、标签,以特殊字符"\002"分隔每个字。标签的定义如下:
+
+| 标签 | 定义 | 标签 | 定义 |
+| -------- | -------- |-------- | -------- |
+| P-B | 姓名起始位置 | P-I | 姓名中间位置或结束位置 |
+| T-B | 电话起始位置 | T-I | 电话中间位置或结束位置 |
+| A1-B | 省份起始位置 | A1-I | 省份中间位置或结束位置 |
+| A2-B | 城市起始位置 | A2-I | 城市中间位置或结束位置 |
+| A3-B | 县区起始位置 | A3-I | 县区中间位置或结束位置 |
+| A4-B | 详细地址起始位置 | A4-I | 详细地址中间位置或结束位置 |
+| O | 无关字符 | | |
+
+注意每个标签的结果只有 B、I、O 三种,这种标签的定义方式叫做 BIO 体系。其中 B 表示一个标签类别的开头,比如 P-B 指的是姓名的开头;相应的,I 表示一个标签的延续。
+
+### 2.3 启动训练
+
+本项目提供了两种模型结构,一种是BiGRU + CRF结构,另一种是ERNIE + FC结构,前者显存占用小,后者能够在较小的迭代次数中收敛。
+
+#### 2.3.1 启动BiGRU + CRF训练
+
+```bash
+export CUDA_VISIBLE_DEVICES=0 # 只支持单卡训练
+python run_bigru_crf.py
+```
+
+详细介绍请参考教程:[基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+#### 2.3.2 启动ERNIE + FC训练
+
+```bash
+export CUDA_VISIBLE_DEVICES=0 # 只支持单卡训练
+python run_ernie.py
+```
+
+详细介绍请参考教程:[使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
diff --git a/PaddleNLP/examples/named_entity_recognition/msra_ner/README.md b/PaddleNLP/examples/named_entity_recognition/msra_ner/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8a3e3ee6628c83c7252ed1af8ee2e71314499fff
--- /dev/null
+++ b/PaddleNLP/examples/named_entity_recognition/msra_ner/README.md
@@ -0,0 +1,73 @@
+# 使用PaddleNLP运行MSRA-NER
+
+## 1. 简介
+
+MSRA-NER 数据集由微软亚研院发布,其目标是识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。示例如下:
+
+```
+海�钓�比�赛�地�点�在�厦�门�与�金�门�之�间�的�海�域�。 O�O�O�O�O�O�O�B-LOC�I-LOC�O�B-LOC�I-LOC�O�O�O�O�O�O
+这�座�依�山�傍�水�的�博�物�馆�由�国�内�一�流�的�设�计�师�主�持�设�计�,�整�个�建�筑�群�精�美�而�恢�宏�。 O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O�O
+```
+
+数据集中以特殊字符"\t"分隔文本、标签,以特殊字符"\002"分隔每个字。
+
+## 2. 快速开始
+
+### 2.1 环境配置
+
+- Python >= 3.6
+
+- paddlepaddle >= 2.0.0rc1,安装方式请参考 [快速安装](https://www.paddlepaddle.org.cn/install/quick)。
+
+- paddlenlp >= 2.0.0b, 安装方式:`pip install paddlenlp>=2.0.0b`
+
+### 2.2 启动MSRA-NER任务
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+
+python -u ./run_msra_ner.py \
+ --model_name_or_path bert-base-multilingual-uncased \
+ --max_seq_length 128 \
+ --batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --logging_steps 1 \
+ --save_steps 500 \
+ --output_dir ./tmp/msra_ner/ \
+ --n_gpu 1
+```
+
+其中参数释义如下:
+- `model_name_or_path` 指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer。若模型相关内容保存在本地,这里也可以提供相应目录地址。
+- `max_seq_length` 表示最大句子长度,超过该长度将被截断。
+- `batch_size` 表示每次迭代**每张卡**上的样本数目。
+- `learning_rate` 表示基础学习率大小,将于learning rate scheduler产生的值相乘作为当前学习率。
+- `num_train_epochs` 表示训练轮数。
+- `logging_steps` 表示日志打印间隔。
+- `save_steps` 表示模型保存及评估间隔。
+- `output_dir` 表示模型保存路径。
+- `n_gpu` 表示使用的 GPU 卡数。若希望使用多卡训练,将其设置为指定数目即可;若为0,则使用CPU。
+
+训练过程将按照 `logging_steps` 和 `save_steps` 的设置打印如下日志:
+
+```
+global step 996, epoch: 1, batch: 344, loss: 0.038471, speed: 4.72 step/s
+global step 997, epoch: 1, batch: 345, loss: 0.032820, speed: 4.82 step/s
+global step 998, epoch: 1, batch: 346, loss: 0.008144, speed: 4.69 step/s
+global step 999, epoch: 1, batch: 347, loss: 0.031425, speed: 4.36 step/s
+global step 1000, epoch: 1, batch: 348, loss: 0.073151, speed: 4.59 step/s
+eval loss: 0.019874, precision: 0.991670, recall: 0.991930, f1: 0.991800
+```
+
+使用以上命令进行单卡 Fine-tuning ,在验证集上有如下结果:
+ Metric | Result |
+------------------------------|-------------|
+precision | 0.992903 |
+recall | 0.991823 |
+f1 | 0.992363 |
+
+## 参考
+
+[Microsoft Research Asia Chinese Word-Segmentation Data Set](https://www.microsoft.com/en-us/download/details.aspx?id=52531)
+[The third international Chinese language processing bakeoff: Word segmentation and named entity recognition](https://faculty.washington.edu/levow/papers/sighan06.pdf)
diff --git a/PaddleNLP/examples/named_entity_recognition/run_msra_ner.py b/PaddleNLP/examples/named_entity_recognition/msra_ner/run_msra_ner.py
similarity index 100%
rename from PaddleNLP/examples/named_entity_recognition/run_msra_ner.py
rename to PaddleNLP/examples/named_entity_recognition/msra_ner/run_msra_ner.py
diff --git a/PaddleNLP/examples/text_classification/README.md b/PaddleNLP/examples/text_classification/README.md
index 0eb6c93d4ed829e2525a64ccb51a0e5c25649e9e..f52a6a2bec4454fbb5aa2f159359ffbbe8ba5d94 100644
--- a/PaddleNLP/examples/text_classification/README.md
+++ b/PaddleNLP/examples/text_classification/README.md
@@ -4,7 +4,7 @@
## Conventional RNNs Models
-[Recurrent Neural Networks](./rnn) 展示了如何使用RNN、LSTM、GRU等网络完成文本分类任务。
+[Recurrent Neural Networks](./rnn) 展示了如何使用传统序列模型RNN、LSTM、GRU等网络完成文本分类任务。
## Pretrained Model (PTMs)
@@ -12,10 +12,18 @@
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_classification/pretrained_models/README.md b/PaddleNLP/examples/text_classification/pretrained_models/README.md
index 658112cbc927cb5aa2ddddd12a201c3915304ad1..47efa9ce19d28b436a22b422dfb2602917c8ef66 100644
--- a/PaddleNLP/examples/text_classification/pretrained_models/README.md
+++ b/PaddleNLP/examples/text_classification/pretrained_models/README.md
@@ -1,17 +1,34 @@
# 使用预训练模型Fine-tune完成中文文本分类任务
-随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
+
+在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](../rnn).
+
+
+
+
+
+
+[paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析](https://aistudio.baidu.com/aistudio/projectdetail/1283423)教程介绍了如何使用`paddlenlp.seq2vec`表征文本语义。
+
+近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
-本示例展示了以BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))代表的预训练模型如何Finetune完成中文文本分类任务。
+
+
+
+
+
+本图片来自于:https://github.com/thunlp/PLMpapers
+
+本示例展示了以ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223))代表的预训练模型如何Finetune完成中文文本分类任务。
## 模型简介
本项目针对中文文本分类问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
-+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
++ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
@@ -29,21 +46,14 @@
## 快速开始
-### 安装说明
-
-* PaddlePaddle 安装
+### 环境依赖
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+- python >= 3.6
+- paddlepaddle >= 2.0.0-rc1
-* PaddleNLP 安装
-
- ```shell
- pip install paddlenlp
- ```
-
-* 环境依赖
-
- Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/beginners_guide/install/index_cn.html) 部分的内容
+```
+pip install paddlenlp==2.0.0b
+```
### 代码结构说明
@@ -128,10 +138,18 @@ Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_classification/rnn/README.md b/PaddleNLP/examples/text_classification/rnn/README.md
index d41980d6d804219c5b2a5f4c2a89b25afbd64549..32e2a4707e0ef784b432115878c3ce0908a86e20 100644
--- a/PaddleNLP/examples/text_classification/rnn/README.md
+++ b/PaddleNLP/examples/text_classification/rnn/README.md
@@ -2,19 +2,73 @@
文本分类是NLP应用最广的任务之一,可以被应用到多个领域中,包括但不仅限于:情感分析、垃圾邮件识别、商品评价分类...
-一般通过将文本表示成向量后接入分类器,完成文本分类。
+情感分析是一个自然语言处理中老生常谈的任务。情感分析的目的是为了找出说话者/作者在某些话题上,或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。其可以用于数据挖掘、Web 挖掘、文本挖掘和信息检索方面得到了广泛的研究。可通过 [AI开放平台-情感倾向分析](http://ai.baidu.com/tech/nlp_apply/sentiment_classify) 线上体验。
-如何用向量表征文本,使得向量携带语义信息,是我们关心的重点。
+
+
+
本项目开源了一系列模型用于进行文本建模,用户可通过参数配置灵活使用。效果上,我们基于开源情感倾向分类数据集ChnSentiCorp对多个模型进行评测。
-情感倾向分析(Sentiment Classification)是一类常见的文本分类任务。其针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度。情感类型分为积极、消极。情感倾向分析能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。可通过 [AI开放平台-情感倾向分析](http://ai.baidu.com/tech/nlp_apply/sentiment_classify) 线上体验。
+## paddlenlp.seq2vec
+
+情感分析任务中关键技术是如何将文本表示成一个**携带语义的文本向量**。随着深度学习技术的快速发展,目前常用的文本表示技术有LSTM,GRU,RNN等方法。
+PaddleNLP提供了一系列的文本表示技术,如`seq2vec`模块。
+
+[`paddlenlp.seq2vec`](../../../paddlenlp/seq2vec) 模块作用为将输入的序列文本表征成一个语义向量。
+
+
+
+
+
## 模型简介
-本项目通过调用[Seq2Vec](../../../paddlenlp/seq2vec/)中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
+本项目通过调用[seq2vec](../../../paddlenlp/seq2vec/)中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
+
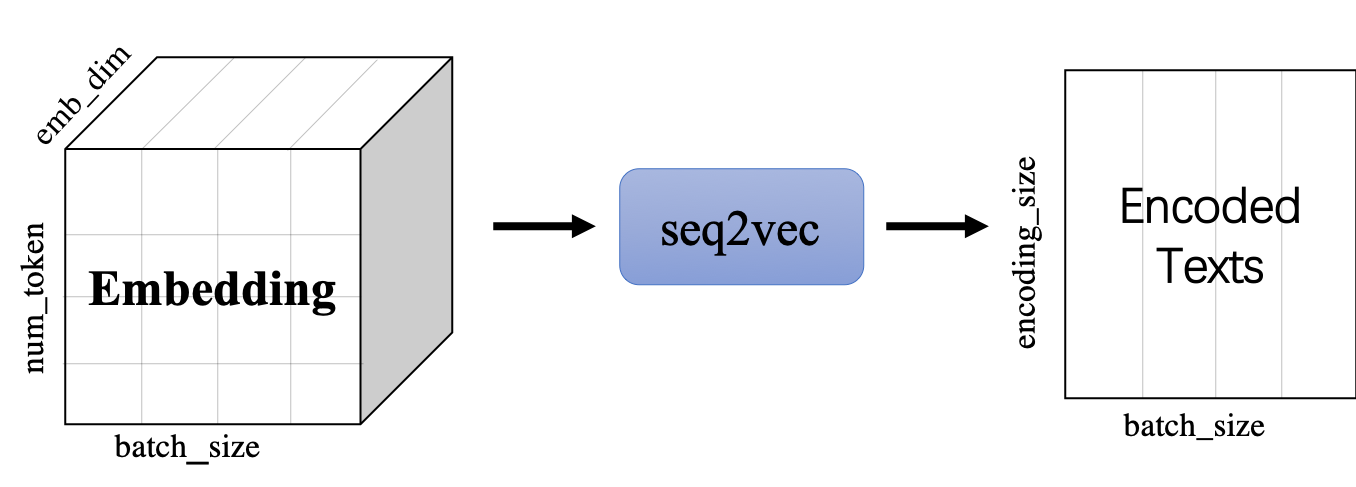
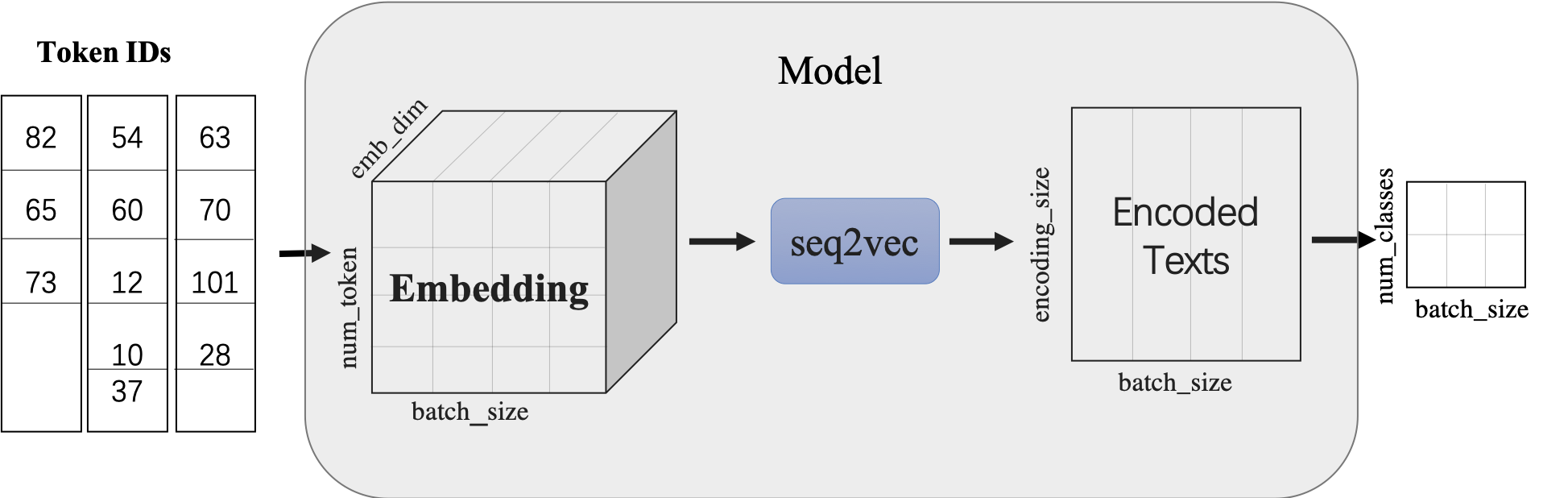
+`seq2vec`模块
+
+* 功能是将序列Embedding Tensor(shape是(batch_size, num_token, emb_dim) )转化成文本语义表征Enocded Texts Tensor(shape 是(batch_sie,encoding_size))
+* 提供了`BoWEncoder`,`CNNEncoder`,`GRUEncoder`,`LSTMEncoder`,`RNNEncoder`等模型
+ - `BoWEncoder` 是将输入序列Embedding Tensor在num_token维度上叠加,得到文本语义表征Enocded Texts Tensor。
+ - `CNNEncoder` 是将输入序列Embedding Tensor进行卷积操作,在对卷积结果进行max_pooling,得到文本语义表征Enocded Texts Tensor。
+ - `GRUEncoder` 是对输入序列Embedding Tensor进行GRU运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+ - `LSTMEncoder` 是对输入序列Embedding Tensor进行LSTM运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+ - `RNNEncoder` 是对输入序列Embedding Tensor进行RNN运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+
+
+`seq2vec`提供了许多语义表征方法,那么这些方法在什么时候更加适合呢?
+
+* `BoWEncoder`采用Bag of Word Embedding方法,其特点是简单。但其缺点是没有考虑文本的语境,所以对文本语义的表征不足以表意。
+
+* `CNNEncoder`采用卷积操作,提取局部特征,其特点是可以共享权重。但其缺点同样只考虑了局部语义,上下文信息没有充分利用。
+
+
+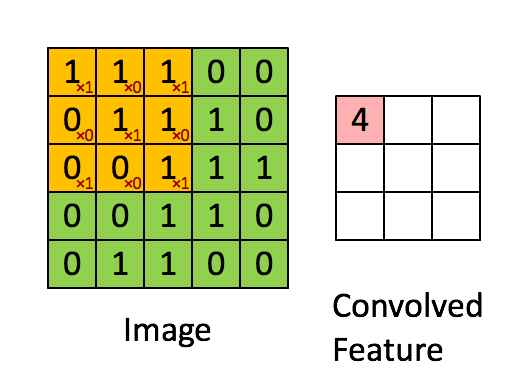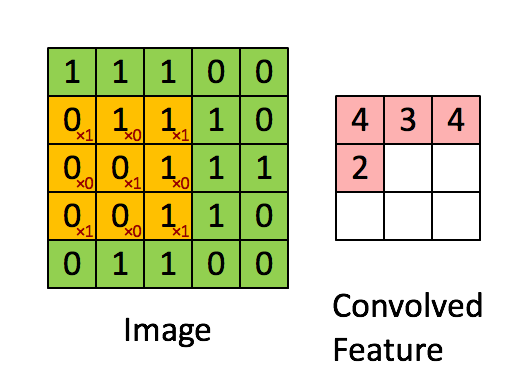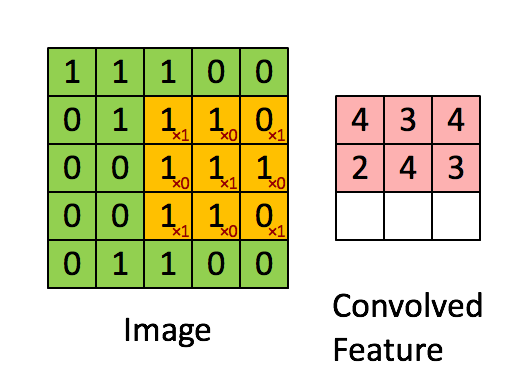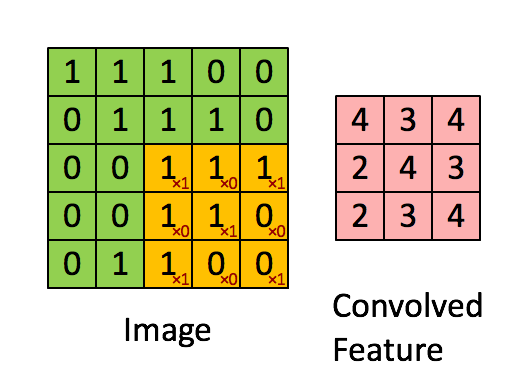
+
+
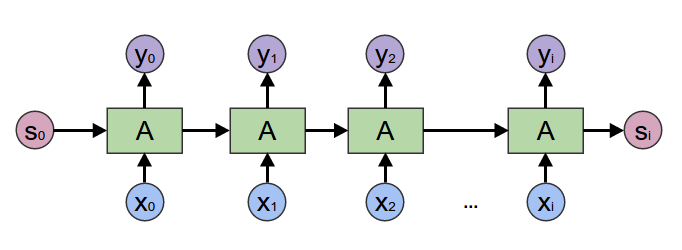
+* `RNNEnocder`采用RNN方法,在计算下一个token语义信息时,利用上一个token语义信息作为其输入。但其缺点容易产生梯度消失和梯度爆炸。
+
+
+
+
+
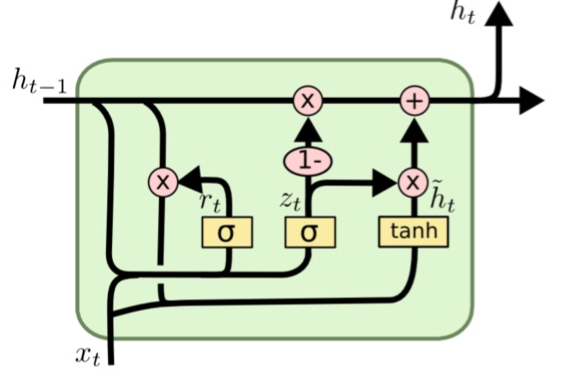
+* `LSTMEnocder`采用LSTM方法,LSTM是RNN的一种变种。为了学到长期依赖关系,LSTM 中引入了门控机制来控制信息的累计速度,
+ 包括有选择地加入新的信息,并有选择地遗忘之前累计的信息。
+
+
+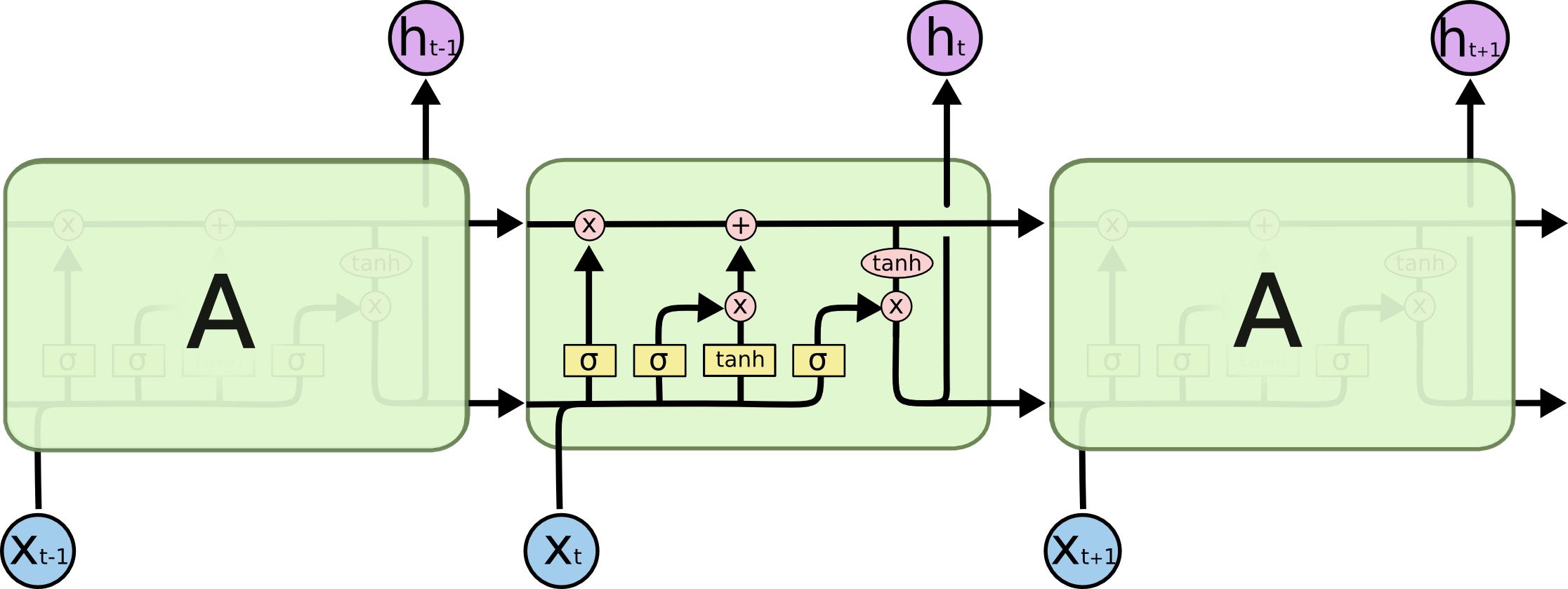
+
+
+* `GRUEncoder`采用GRU方法,GRU也是RNN的一种变种。一个LSTM单元有四个输入 ,因而参数是RNN的四倍,带来的结果是训练速度慢。
+ GRU对LSTM进行了简化,在不影响效果的前提下加快了训练速度。
+
+
+
+
+
| 模型 | 模型介绍 |
| ------------------------------------------------ | ------------------------------------------------------------ |
@@ -38,25 +92,31 @@
| Bi-LSTM Attention | 0.8992 | 0.8856 |
| TextCNN | 0.9102 | 0.9107 |
-## 快速开始
-### 安装说明
+
+
+
-* PaddlePaddle 安装
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+关于CNN、LSTM、GRU、RNN等更多信息参考:
-* PaddleNLP 安装
+* https://canvas.stanford.edu/files/1090785/download
+* https://colah.github.io/posts/2015-08-Understanding-LSTMs/
+* https://arxiv.org/abs/1412.3555
+* https://arxiv.org/pdf/1506.00019
+* https://arxiv.org/abs/1404.2188
- ```shell
- pip install paddlenlp
- ```
-* 环境依赖
+## 快速开始
- 本项目依赖于jieba分词,请在运行本项目之前,安装jieba,如`pip install -U jieba`
+### 环境依赖
- Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/install/quick/zh/2.0rc-linux-docker) 部分的内容
+- python >= 3.6
+- paddlepaddle >= 2.0.0-rc1
+
+```
+pip install paddlenlp==2.0.0b
+```
### 代码结构说明
@@ -164,10 +224,18 @@ Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_generation/ernie-gen/README.md b/PaddleNLP/examples/text_generation/ernie-gen/README.md
index 861ca92163d4f05ab9150145b77d00aabf2d87c3..f95c487b528ba5c5a0f2d3f51894f3d3642389c3 100644
--- a/PaddleNLP/examples/text_generation/ernie-gen/README.md
+++ b/PaddleNLP/examples/text_generation/ernie-gen/README.md
@@ -124,3 +124,9 @@ python -u ./predict.py \
year={2020}
}
```
+
+## 线上教程体验
+
+我们为诗歌文本生成提供了线上教程,欢迎体验:
+
+* [使用PaddleNLP预训练模型ERNIE-GEN生成诗歌](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
diff --git a/PaddleNLP/examples/text_matching/README.md b/PaddleNLP/examples/text_matching/README.md
index 7b84d6b1959949e9214dc156de5b27384f22496c..f51e74afdf43ddcebc0831daff08f89876369786 100644
--- a/PaddleNLP/examples/text_matching/README.md
+++ b/PaddleNLP/examples/text_matching/README.md
@@ -24,3 +24,21 @@
## Sentence Transformers
[Sentence Transformers](./sentence_transformers) 展示了如何使用以ERNIE为代表的模型Fine-tune完成文本匹配任务。
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_matching/sentence_transformers/README.md b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
index ad4547a9fa684e3563f188f2c096c2cd51dce107..f35931c7bf44884613c30a1b72c13862111f9617 100644
--- a/PaddleNLP/examples/text_matching/sentence_transformers/README.md
+++ b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
@@ -39,7 +39,7 @@ PaddleNLP提供了丰富的预训练模型,并且可以便捷地获取PaddlePa
本项目针对中文文本匹配问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
-+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
++ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持12层Transformer网络的`roberta-wwm-ext`。
@@ -195,3 +195,22 @@ Data: ['小蝌蚪找妈妈怎么样', '小蝌蚪找妈妈是谁画的'] Lab
url = "https://arxiv.org/abs/2010.08240",
}
```
+
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_matching/simnet/README.md b/PaddleNLP/examples/text_matching/simnet/README.md
index 26ccbbe0a1bf15dd0ad58d0e602d043a555423be..91c66b00626282a67e72d816f753d1e586ab5d73 100644
--- a/PaddleNLP/examples/text_matching/simnet/README.md
+++ b/PaddleNLP/examples/text_matching/simnet/README.md
@@ -164,3 +164,22 @@ Data: ['世界上什么东西最小', '世界上什么东西最小?'] Lab
Data: ['光眼睛大就好看吗', '眼睛好看吗?'] Label: dissimilar
Data: ['小蝌蚪找妈妈怎么样', '小蝌蚪找妈妈是谁画的'] Label: dissimilar
```
+
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/time_series/README.md b/PaddleNLP/examples/time_series/README.md
index 1f615fd9ac8b1ea35b0fa5f5147c0084ba3b0be2..651875911fc8e810ab3f20f60eb3581d640084c0 100644
--- a/PaddleNLP/examples/time_series/README.md
+++ b/PaddleNLP/examples/time_series/README.md
@@ -53,6 +53,8 @@ python predict.py --data_path time_series_covid19_confirmed_global.csv \
```
-## 如何贡献代码
+## 线上教程体验
-如果你可以修复某个 issue 或者增加一个新功能,欢迎给我们提交 PR。如果对应的 PR 被接受了,我们将根据贡献的质量和难度 进行打分(0-5 分,越高越好)。如果你累计获得了 10 分,可以联系我们获得面试机会或为你写推荐信。
+我们为时间序列预测任务提供了线上教程,欢迎体验:
+
+* [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
diff --git a/PaddleNLP/examples/time_series/covid-19_forecasting.ipynb b/PaddleNLP/examples/time_series/covid-19_forecasting.ipynb
deleted file mode 100644
index 35a29a72155ccbd7c79b9c3526e4af05148286c0..0000000000000000000000000000000000000000
--- a/PaddleNLP/examples/time_series/covid-19_forecasting.ipynb
+++ /dev/null
@@ -1,589 +0,0 @@
-{
- "nbformat": 4,
- "nbformat_minor": 2,
- "metadata": {
- "language_info": {
- "name": "python",
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "version": "3.6.10-final"
- },
- "orig_nbformat": 2,
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "npconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": 3,
- "kernelspec": {
- "name": "python3",
- "display_name": "Python 3"
- }
- },
- "cells": [
- {
- "source": [
- "# 使用PaddlePaddle完成新冠疫情病例数预测\n",
- "\n",
- "2019年12月以来,新冠疫情在全球肆虐,呈现大流行的特征。新型冠状病毒肺炎以发热、干咳、乏力等为主要表现,重症病例多在1周后出现呼吸困难,严重者快速进展为急性呼吸窘迫综合征、脓毒症休克、难以纠正的代谢性酸中毒和出凝血功能障碍及多器官功能衰竭等,对人们的健康造成了极其严重的威胁。同时,为抵御新冠病毒的扩散,不少国家和地区采取了封锁性防疫举措,全球经济复苏的进程因此受阻,政府债务不断上升。\n",
- "\n",
- "在这种背景下,各国人民都期盼着疫情的结束,早日恢复往常的生产、生活方式。本文关注到这一问题,结合约翰斯·霍普金斯大学发布的全球新冠肺炎实时统计数据,通过时间卷积神经网络对时间序列建模,实现预测未来病例数的目的。"
- ],
- "cell_type": "markdown",
- "metadata": {}
- },
- {
- "source": [
- "## 准备环境\n",
- "\n",
- "在开始建模之前,我们需要导入必要的包,同时为了更好地展示数据结果,我们在这里配置画图功能。"
- ],
- "cell_type": "markdown",
- "metadata": {}
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [
- {
- "output_type": "stream",
- "name": "stderr",
- "text": "/mnt/qiujinxuan/PaddleNLP/paddlenlp/seq2vec/encoder.py:683: DeprecationWarning: invalid escape sequence \\s\n \"\"\"\n/mnt/qiujinxuan/PaddleNLP/paddlenlp/seq2vec/encoder.py:740: DeprecationWarning: invalid escape sequence \\s\n \"\"\"\n"
- }
- ],
- "source": [
- "import os\n",
- "import sys\n",
- "\n",
- "import paddle\n",
- "import paddle.nn as nn\n",
- "import numpy as np\n",
- "import pandas as pd\n",
- "import seaborn as sns\n",
- "from pylab import rcParams\n",
- "import matplotlib.pyplot as plt\n",
- "from matplotlib import rc\n",
- "from sklearn.preprocessing import MinMaxScaler\n",
- "from pandas.plotting import register_matplotlib_converters\n",
- "\n",
- "sys.path.append(os.path.abspath(os.path.join(os.getcwd(), \"../..\")))\n",
- "from paddlenlp.seq2vec import TCNEncoder\n",
- "\n",
- "\n",
- "# config matplotlib\n",
- "%matplotlib inline\n",
- "%config InlineBackend.figure_format='retina'\n",
- "sns.set(style='whitegrid', palette='muted', font_scale=1.2)\n",
- "HAPPY_COLORS_PALETTE = [\"#01BEFE\", \"#FFDD00\", \"#FF7D00\", \"#FF006D\", \"#93D30C\", \"#8F00FF\"]\n",
- "sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))\n",
- "rcParams['figure.figsize'] = 14, 10\n",
- "register_matplotlib_converters()"
- ]
- },
- {
- "source": [
- "## 数据下载\n",
- "\n",
- "数据集由约翰·霍普金斯大学系统科学与工程中心提供,每日最新数据可以从https://github.com/CSSEGISandData/COVID-19 仓库中获取,我们在本例中提供了2020年11月24日下载的病例数据。"
- ],
- "cell_type": "markdown",
- "metadata": {}
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [],
- "source": [
- "# !wget https://github.com/CSSEGISandData/COVID-19/blob/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv"
- ]
- },
- {
- "source": [
- "数据集中包含了国家、省份、纬度、经度以及从2020年1月22日至今的病例数等信息。"
- ],
- "cell_type": "markdown",
- "metadata": {}
- },
- {
- "source": [
- "## 数据预览\n",
- "\n",
- "数据集中包含了国家/地区、省份/州、纬度、经度、日期、病例数等信息。"
- ],
- "cell_type": "markdown",
- "metadata": {}
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [
- {
- "output_type": "execute_result",
- "data": {
- "text/plain": " Province/State Country/Region Lat Long 1/22/20 1/23/20 \\\n0 NaN Afghanistan 33.93911 67.709953 0 0 \n1 NaN Albania 41.15330 20.168300 0 0 \n2 NaN Algeria 28.03390 1.659600 0 0 \n3 NaN Andorra 42.50630 1.521800 0 0 \n4 NaN Angola -11.20270 17.873900 0 0 \n\n 1/24/20 1/25/20 1/26/20 1/27/20 ... 11/13/20 11/14/20 11/15/20 \\\n0 0 0 0 0 ... 42969 43035 43240 \n1 0 0 0 0 ... 26701 27233 27830 \n2 0 0 0 0 ... 65975 66819 67679 \n3 0 0 0 0 ... 5725 5725 5872 \n4 0 0 0 0 ... 13228 13374 13451 \n\n 11/16/20 11/17/20 11/18/20 11/19/20 11/20/20 11/21/20 11/22/20 \n0 43403 43628 43851 44228 44443 44503 44706 \n1 28432 29126 29837 30623 31459 32196 32761 \n2 68589 69591 70629 71652 72755 73774 74862 \n3 5914 5951 6018 6066 6142 6207 6256 \n4 13615 13818 13922 14134 14267 14413 14493 \n\n[5 rows x 310 columns]",
- "text/html": "\n\n
\n \n \n | \n Province/State | \n Country/Region | \n Lat | \n Long | \n 1/22/20 | \n 1/23/20 | \n 1/24/20 | \n 1/25/20 | \n 1/26/20 | \n 1/27/20 | \n ... | \n 11/13/20 | \n 11/14/20 | \n 11/15/20 | \n 11/16/20 | \n 11/17/20 | \n 11/18/20 | \n 11/19/20 | \n 11/20/20 | \n 11/21/20 | \n 11/22/20 | \n
\n \n \n \n | 0 | \n NaN | \n Afghanistan | \n 33.93911 | \n 67.709953 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n ... | \n 42969 | \n 43035 | \n 43240 | \n 43403 | \n 43628 | \n 43851 | \n 44228 | \n 44443 | \n 44503 | \n 44706 | \n
\n \n | 1 | \n NaN | \n Albania | \n 41.15330 | \n 20.168300 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n ... | \n 26701 | \n 27233 | \n 27830 | \n 28432 | \n 29126 | \n 29837 | \n 30623 | \n 31459 | \n 32196 | \n 32761 | \n
\n \n | 2 | \n NaN | \n Algeria | \n 28.03390 | \n 1.659600 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n ... | \n 65975 | \n 66819 | \n 67679 | \n 68589 | \n 69591 | \n 70629 | \n 71652 | \n 72755 | \n 73774 | \n 74862 | \n
\n \n | 3 | \n NaN | \n Andorra | \n 42.50630 | \n 1.521800 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n ... | \n 5725 | \n 5725 | \n 5872 | \n 5914 | \n 5951 | \n 6018 | \n 6066 | \n 6142 | \n 6207 | \n 6256 | \n
\n \n | 4 | \n NaN | \n Angola | \n -11.20270 | \n 17.873900 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n 0 | \n ... | \n 13228 | \n 13374 | \n 13451 | \n 13615 | \n 13818 | \n 13922 | \n 14134 | \n 14267 | \n 14413 | \n 14493 | \n
\n \n
\n
5 rows × 310 columns
\n