Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
0d8986ca
M
models
项目概览
PaddlePaddle
/
models
大约 1 年 前同步成功
通知
222
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
0d8986ca
编写于
3月 22, 2020
作者:
C
chulutao
浏览文件
操作
浏览文件
下载
差异文件
add LaneNet
上级
90d05dbc
eb9994f8
变更
8
隐藏空白更改
内联
并排
Showing
8 changed file
with
130 addition
and
58 deletion
+130
-58
.gitmodules
.gitmodules
+3
-0
PaddleCV/3d_vision/PointNet++/ext_op/src/gather_point_op.cc
PaddleCV/3d_vision/PointNet++/ext_op/src/gather_point_op.cc
+1
-3
PaddleCV/3d_vision/PointNet++/ext_op/src/group_points_op.cc
PaddleCV/3d_vision/PointNet++/ext_op/src/group_points_op.cc
+1
-3
PaddleCV/3d_vision/PointNet++/ext_op/src/three_interp_op.cc
PaddleCV/3d_vision/PointNet++/ext_op/src/three_interp_op.cc
+1
-3
PaddleCV/PaddleDetection
PaddleCV/PaddleDetection
+1
-0
PaddleCV/README.md
PaddleCV/README.md
+90
-34
PaddleCV/imgs/paddlecv.png
PaddleCV/imgs/paddlecv.png
+0
-0
README.md
README.md
+33
-15
未找到文件。
.gitmodules
浏览文件 @
0d8986ca
...
...
@@ -16,3 +16,6 @@
[submodule "PaddleSpeech/Parakeet"]
path = PaddleSpeech/Parakeet
url = https://github.com/PaddlePaddle/Parakeet
[submodule "PaddleCV/PaddleDetection"]
path = PaddleCV/PaddleDetection
url = https://github.com/PaddlePaddle/PaddleDetection.git
PaddleCV/3d_vision/PointNet++/ext_op/src/gather_point_op.cc
浏览文件 @
0d8986ca
...
...
@@ -94,15 +94,13 @@ public:
using
framework
::
SingleGradOpMaker
<
T
>::
SingleGradOpMaker
;
protected:
std
::
unique_ptr
<
T
>
Apply
()
const
override
{
auto
*
op
=
new
T
();
void
Apply
(
GradOpPtr
<
T
>
op
)
const
override
{
op
->
SetType
(
"gather_point_grad"
);
op
->
SetInput
(
"X"
,
this
->
Input
(
"X"
));
op
->
SetInput
(
"Index"
,
this
->
Input
(
"Index"
));
op
->
SetInput
(
framework
::
GradVarName
(
"Output"
),
this
->
OutputGrad
(
"Output"
));
op
->
SetOutput
(
framework
::
GradVarName
(
"X"
),
this
->
InputGrad
(
"X"
));
op
->
SetAttrMap
(
this
->
Attrs
());
return
std
::
unique_ptr
<
T
>
(
op
);
}
};
...
...
PaddleCV/3d_vision/PointNet++/ext_op/src/group_points_op.cc
浏览文件 @
0d8986ca
...
...
@@ -102,15 +102,13 @@ class GroupPointsGradDescMaker : public framework::SingleGradOpMaker<T> {
using
framework
::
SingleGradOpMaker
<
T
>::
SingleGradOpMaker
;
protected:
std
::
unique_ptr
<
T
>
Apply
()
const
override
{
auto
*
op
=
new
T
();
void
Apply
(
GradOpPtr
<
T
>
op
)
const
override
{
op
->
SetType
(
"group_points_grad"
);
op
->
SetInput
(
"X"
,
this
->
Input
(
"X"
));
op
->
SetInput
(
"Idx"
,
this
->
Input
(
"Idx"
));
op
->
SetInput
(
framework
::
GradVarName
(
"Out"
),
this
->
OutputGrad
(
"Out"
));
op
->
SetOutput
(
framework
::
GradVarName
(
"X"
),
this
->
InputGrad
(
"X"
));
op
->
SetAttrMap
(
this
->
Attrs
());
return
std
::
unique_ptr
<
T
>
(
op
);
}
};
...
...
PaddleCV/3d_vision/PointNet++/ext_op/src/three_interp_op.cc
浏览文件 @
0d8986ca
...
...
@@ -117,8 +117,7 @@ public:
using
framework
::
SingleGradOpMaker
<
T
>::
SingleGradOpMaker
;
protected:
std
::
unique_ptr
<
T
>
Apply
()
const
override
{
auto
*
op
=
new
T
();
void
Apply
(
GradOpPtr
<
T
>
op
)
const
override
{
op
->
SetType
(
"three_interp_grad"
);
op
->
SetInput
(
"X"
,
this
->
Input
(
"X"
));
op
->
SetInput
(
"Weight"
,
this
->
Input
(
"Weight"
));
...
...
@@ -126,7 +125,6 @@ protected:
op
->
SetInput
(
framework
::
GradVarName
(
"Out"
),
this
->
OutputGrad
(
"Out"
));
op
->
SetOutput
(
framework
::
GradVarName
(
"X"
),
this
->
InputGrad
(
"X"
));
op
->
SetAttrMap
(
this
->
Attrs
());
return
std
::
unique_ptr
<
T
>
(
op
);
}
};
...
...
PaddleDetection
@
f24275a4
Subproject commit f24275a46f225e6111e8650d70baece90a37f324
PaddleCV/README.md
浏览文件 @
0d8986ca
PaddleCV
========
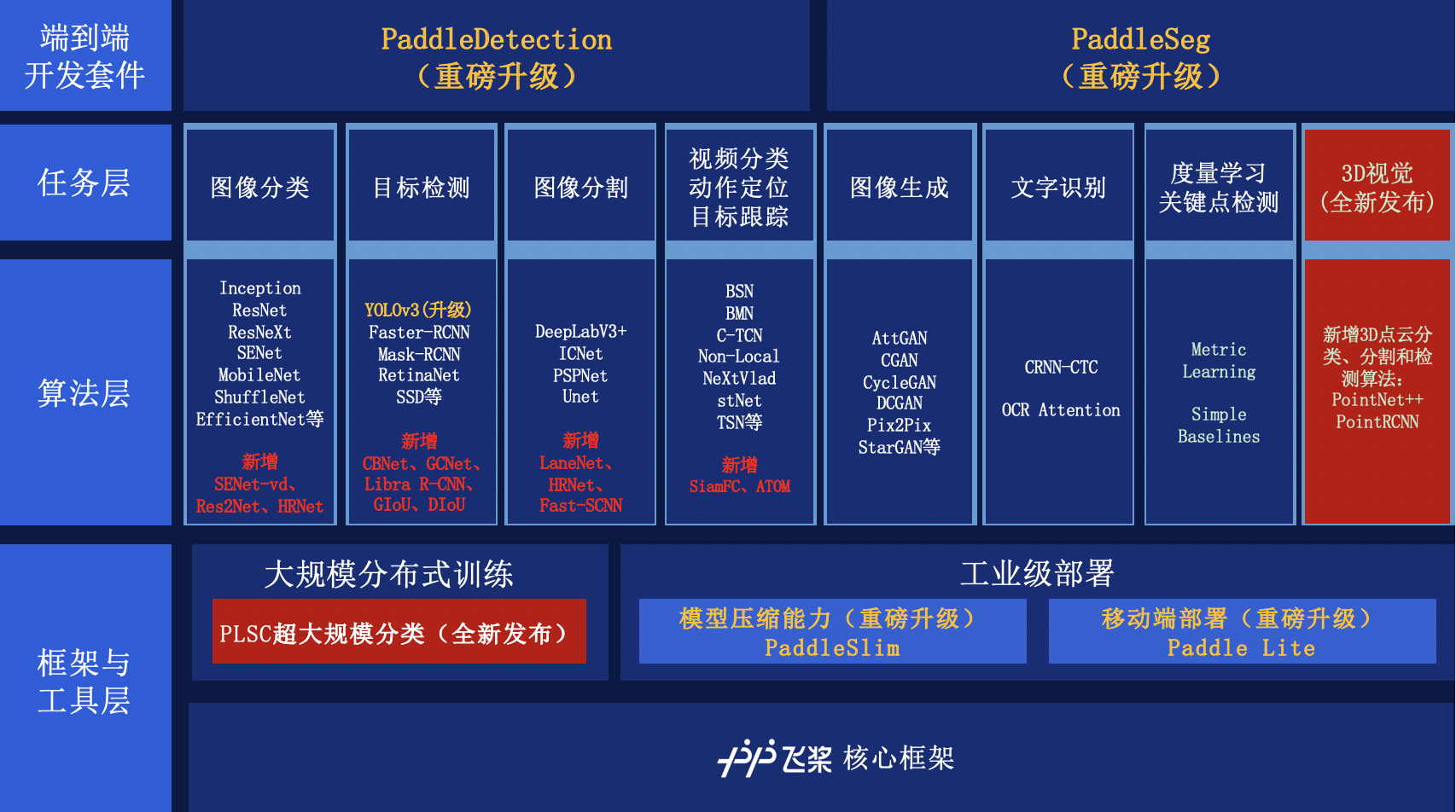
PaddleCV 是基于 PaddlePaddle 深度学习框架开发的智能视觉工具,算法,模型和数据的开源项目。百度在 CV 领域多年的深厚积淀为 PaddleCV 提供了强大的核心动力。PaddleCV集成了丰富的CV模型,涵盖图像分类,目标检测,图像分割,视频分类,动作定位,目标跟踪,图像生成,文字识别,度量学习,关键点检测,3D视觉等 CV 技术。同时,PaddleCV 还提供了实用的工具,PLSC支持超大规模分类,PaddleSlim和PaddleLite支持工业级部署,以及 PaddleDetection、PaddleSeg面向产业的端到端开发套件,打通了模型开发、压缩、部署全流程。
PaddleCV全景图:

图像分类
--------
图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉中重要的基础问题,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层视觉任务的基础,在许多领域都有着广泛的应用。如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
在深度学习时代,图像分类的准确率大幅度提升,在图像分类任务中,我们向大家介绍了如何在经典的数据集ImageNet上,训练常用的模型,包括AlexNet、VGG系列、ResNet系列、ResNeXt系列、Inception系列、MobileNet系列、SENet系列、DarkNet、SqueezeNet、ShuffleNet系列等模型,也开源了
[
训练的模型
](
https://github.com/PaddlePaddle/models/blob/release/1.7/PaddleCV/image_classification/README.md#已有模型及其性能
)
方便用户下载使用。同时提供了能够将Caffe模型转换为PaddlePaddle
Fluid模型配置和参数文件的工具。
-
[
AlexNet
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
SqueezeNet
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
VGG Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
GoogleNet
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
ResNet Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
ResNeXt Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
ShuffleNet Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
DenseNet Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
Inception Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
MobileNet Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
SENet Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
DarkNet
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
ResNeXt101_wsl Series
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification/models
)
-
[
Caffe模型转换为Paddle Fluid配置和模型文件工具
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/caffe2fluid
)
在深度学习时代,图像分类的准确率大幅度提升,在图像分类任务中,我们向大家介绍了如何在经典的数据集ImageNet上,训练常用的模型,包括AlexNet、VGG、ResNet、ResNeXt、Inception、MobileNet、SENet、DarkNet、SqueezeNet、ShuffleNet、Res2Net、DenseNet、DPN、EfficientNet、HRNet、AutoDL、ResNet-ACNet等系列模型,也开源了共105个
[
预训练模型
](
./image_classification/README.md#已发布模型及其性能
)
方便用户下载使用。
-
[
AlexNet
](
./image_classification/models
)
-
[
SqueezeNet
](
./image_classification/models
)
-
[
VGG Series
](
./image_classification/models
)
-
[
GoogleNet
](
./image_classification/models
)
-
[
ResNet Series
](
./image_classification/models
)
-
[
ResNeXt Series
](
./image_classification/models
)
-
[
ShuffleNet Series
](
./image_classification/models
)
-
[
DenseNet Series
](
./image_classification/models
)
-
[
Inception Series
](
./image_classification/models
)
-
[
MobileNet Series
](
./image_classification/models
)
-
[
SENet Series
](
./image_classification/models
)
-
[
DarkNet
](
./image_classification/models
)
-
[
ResNeXt101_wsl Series
](
./image_classification/models
)
-
[
Res2Net Series
](
./image_classification/models
)
-
[
DenseNet Series
](
./image_classification/models
)
-
[
DPN Series
](
./image_classification/models
)
-
[
EfficientNet Series
](
./image_classification/models
)
-
[
HRNet Series
](
./image_classification/models
)
-
[
AutoDL Series
](
./image_classification/models
)
-
[
ResNet-ACNet Series
](
./image_classification/models
)
目标检测
--------
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。对于人类来说,目标检测是一个非常简单的任务。然而,计算机能够“看到”的是图像被编码之后的数字,很难解图像或是视频帧中出现了人或是物体这样的高层语义概念,也就更加难以定位目标出现在图像中哪个区域。与此同时,由于目标会出现在图像或是视频帧中的任何位置,目标的形态千变万化,图像或是视频帧的背景千差万别,诸多因素都使得目标检测对计算机来说是一个具有挑战性的问题。
在目标检测任务中,我们介绍了如何基于
[
PASCAL VOC
](
http://host.robots.ox.ac.uk/pascal/VOC/
)
、
[
MS COCO
](
http://cocodataset.org/#home
)
数据训练通用物体检测模型,当前介绍了SSD算法,SSD全称Single Shot MultiBox Detector,是目标检测领域较新且效果较好的检测算法之一,具有检测速度快且检测精度高的特点。
开放环境中的检测人脸,尤其是小的、模糊的和部分遮挡的人脸也是一个具有挑战的任务。我们也介绍了如何基于
[
WIDER FACE
](
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace
)
数据训练百度自研的人脸检测PyramidBox模型,该算法于2018年3月份在WIDER FACE的多项评测中均获得
[
第一名
](
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/WiderFace_Results.html
)
。
在目标检测任务中,我们介绍了如何基于
[
PASCAL VOC
](
http://host.robots.ox.ac.uk/pascal/VOC/
)
、
[
MS COCO
](
http://cocodataset.org/#home
)
、
[
Objects365
](
http://www.objects365.org/overview.html
)
、
[
Open Images
](
https://storage.googleapis.com/openimages/web/index.html
)
数据训练通用物体检测模型。包含的算法有SSD (Single Shot MultiBox Detector)、YOLOv3、RetinaNet、Faster-RCNN、Mask-RCNN、CascadeRCNN、Libra-RCNN、CBNet、GCNet、Open Image V5比赛的最佳单模型CascadeClsAware RCNN等。以及基于G-IoU、D-IoU、C-IoU损失函数的模型。
Faster RCNN模型是典型的两阶段目标检测器,相较于传统提取区域的方法,通过RPN网络共享卷积层参数大幅提高提取区域的效率,并提出高质量的候选区域。
Mask RCNN模型是基于Faster RCNN模型的经典实例分割模型,在原有Faster RCNN模型基础上添加分割分支,得到掩码结果,实现了掩码和类别预测关系的解藕。
除了通用物体检测,还包括人脸检测。开放环境中的检测人脸,尤其是小的、模糊的和部分遮挡的人脸也是一个具有挑战的任务。我们也介绍了如何基于
[
WIDER FACE
](
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace
)
数据训练百度自研的人脸检测PyramidBox模型,该算法于2018年3月份在WIDER FACE的多项评测中均获得
[
第一名
](
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/WiderFace_Results.html
)
。同时还包括,轻量级的人脸检测模型Faceboxes和BlazeFace。
#### 通用目标检测
-
[
Single Shot MultiBox Detector
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Face Detector: PyramidBox
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/face_detection/README_cn.md
)
-
[
YOLOv3
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
RetinaNet
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Faster RCNN
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Mask RCNN
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Two-stage FPN
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Cascade-RCNN
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
Libra-RCNN
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
CascadeClsAware RCNN
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/docs/featured_model/OIDV5_BASELINE_MODEL.md
)
#### 人脸检测
-
[
Face Detector: PyramidBox
](
./face_detection/README_cn.md
)
-
[
Faceboxes
](
https://github.com/PaddlePaddle/PaddleDetection
)
-
[
BalzeFace
](
https://github.com/PaddlePaddle/PaddleDetection
)
在目标检测中,除了模型训练外,还增加目标检测的模型压缩、C++预测部署环节,更全详细的可以参考
[
PaddleDetection
](
https://github.com/PaddlePaddle/PaddleDetection
)
。
图像语义分割
------------
图像语义分割顾名思义是将图像像素按照表达的语义含义的不同进行分组/分割,图像语义是指对图像内容的理解,例如,能够描绘出什么物体在哪里做了什么事情等,分割是指对图片中的每个像素点进行标注,标注属于哪一类别。近年来用在无人车驾驶技术中分割街景来避让行人和车辆、医疗影像分析中辅助诊断等。
在图像语义分割任务中,我们以眼底医疗分割任务为例,介绍了如何应用DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割模型,
我们也
使用LaneNet模型进行车道线检测,演示语义分割在无人驾驶中的应用。我们通过统一的配置,帮助大家更便捷地完成从训练到部署的全流程图像分割应用。
在图像语义分割任务中,我们以眼底医疗分割任务为例,介绍了如何应用DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割模型,
并
使用LaneNet模型进行车道线检测,演示语义分割在无人驾驶中的应用。我们通过统一的配置,帮助大家更便捷地完成从训练到部署的全流程图像分割应用。
-
[
U-Net
](
https://github.com/PaddlePaddle/PaddleSeg/blob/release/v0.4.0/turtorial/finetune_unet.md
)
-
[
ICNet
](
https://github.com/PaddlePaddle/PaddleSeg/blob/release/v0.4.0/turtorial/finetune_icnet.md
)
...
...
@@ -63,10 +85,15 @@ Mask RCNN模型是基于Faster RCNN模型的经典实例分割模型,在原有
图像生成是指根据输入向量,生成目标图像。这里的输入向量可以是随机的噪声或用户指定的条件向量。具体的应用场景有:手写体生成、人脸合成、风格迁移、图像修复等。当前的图像生成任务主要是借助生成对抗网络(GAN)来实现。
生成对抗网络(GAN)由两种子网络组成:生成器和识别器。生成器的输入是随机噪声或条件向量,输出是目标图像。识别器是一个分类器,输入是一张图像,输出是该图像是否是真实的图像。在训练过程中,生成器和识别器通过不断的相互博弈提升自己的能力。
在图像生成任务中,我们介绍了如何使用DCGAN和ConditioanlGAN来进行手写数字的生成,另外还介绍了用于风格迁移的CycleGAN.
在图像生成任务中,我们介绍了如何使用DCGAN和ConditioanlGAN来进行手写数字的生成,用于风格迁移的CycleGAN、Pix2Pix,用于属性变化的StarGAN、AttGAN、STGAN,以及图像翻译的SPADE。
-
[
DCGAN & ConditionalGAN
](
./gan/c_gan
)
-
[
CycleGAN
](
./gan
)
-
[
Pix2Pix
](
./gan
)
-
[
StarGAN
](
./gan
)
-
[
AttGAN
](
./gan
)
-
[
STGAN
](
./gan
)
-
[
DCGAN & ConditionalGAN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/gan/c_gan
)
-
[
CycleGAN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/gan/cycle_gan
)
场景文字识别
------------
...
...
@@ -75,8 +102,8 @@ Mask RCNN模型是基于Faster RCNN模型的经典实例分割模型,在原有
在场景文字识别任务中,我们介绍如何将基于CNN的图像特征提取和基于RNN的序列翻译技术结合,免除人工定义特征,避免字符分割,使用自动学习到的图像特征,完成字符识别。当前,介绍了CRNN-CTC模型和基于注意力机制的序列到序列模型。
-
[
CRNN-CTC模型
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV
/ocr_recognition
)
-
[
Attention模型
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV
/ocr_recognition
)
-
[
CRNN-CTC模型
](
.
/ocr_recognition
)
-
[
Attention模型
](
.
/ocr_recognition
)
度量学习
...
...
@@ -85,13 +112,42 @@ Mask RCNN模型是基于Faster RCNN模型的经典实例分割模型,在原有
度量学习也称作距离度量学习、相似度学习,通过学习对象之间的距离,度量学习能够用于分析对象时间的关联、比较关系,在实际问题中应用较为广泛,可应用于辅助分类、聚类问题,也广泛用于图像检索、人脸识别等领域。以往,针对不同的任务,需要选择合适的特征并手动构建距离函数,而度量学习可根据不同的任务来自主学习出针对特定任务的度量距离函数。度量学习和深度学习的结合,在人脸识别/验证、行人再识别(human Re-ID)、图像检索等领域均取得较好的性能,在这个任务中我们主要介绍了基于Fluid的深度度量学习模型,包含了三元组、四元组等损失函数。
-
[
Metric Learning
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/metric_learning
)
-
[
Metric Learning
](
./metric_learning
)
视频
分类
视频
-------
视频分类是视频理解任务的基础,与图像分类不同的是,分类的对象不再是静止的图像,而是一个由多帧图像构成的、包含语音数据、包含运动信息等的视频对象,因此理解视频需要获得更多的上下文信息,不仅要理解每帧图像是什么、包含什么,还需要结合不同帧,知道上下文的关联信息。视频分类方法主要包含基于卷积神经网络、基于循环神经网络、或将这两者结合的方法。该任务中我们介绍基于Fluid的视频分类模型,目前包含Temporal Segment Network(TSN)模型,后续会持续增加更多模型。
PaddleCV全面开源了视频分类、动作定位 和 目标跟踪等视频任务的领先实用算法。视频数据包含语音、图像等多种信息,因此理解视频任务不仅需要处理语音和图像,还需要提取视频帧时间序列中的上下文信息。
视频分类模型提供了提取全局时序特征的方法,主要方式有卷积神经网络 (C3D, I3D, C2D等),神经网络和传统图像算法结合 (VLAD 等),循环神经网络等建模方法。
视频动作定位模型需要同时识别视频动作的类别和起止时间点,通常采用类似于图像目标检测中的算法在时间维度上进行建模。
视频摘要生成模型是对视频画面信息进行提取,并产生一段文字描述。视频查找模型则是基于一段文字描述,查找到视频中对应场景片段的起止时间点。这两类模型需要同时对视频图像和文本信息进行建模。
目标跟踪任务是在给定某视频序列中找到目标物体,并将不同帧中的物体一一对应,然后给出不同物体的运动轨迹,目标跟踪的主要应用在视频监控、人机交互等系统中。跟踪又分为单目标跟踪和多目标跟踪,当前在飞桨模型库中增加了单目标跟踪的算法。主要包括Siam系列算法和ATOM算法。
| 模型名称 | 模型简介 | 数据集 | 评估指标 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | -------------------------- | ----------- |
|
[
TSN
](
./video
)
| ECCV'16 提出的基于 2D-CNN 经典解决方案 | Kinetics-400 | Top-1 = 67% |
|
[
Non-Local
](
./video
)
| 视频非局部关联建模模型 | Kinetics-400 | Top-1 = 74% |
|
[
StNet
](
./video
)
| AAAI'19 提出的视频联合时空建模方法 | Kinetics-400 | Top-1 = 69% |
|
[
TSM
](
./video
)
| 基于时序移位的简单高效视频时空建模方法 | Kinetics-400 | Top-1 = 70% |
|
[
Attention LSTM
](
./video
)
| 常用模型,速度快精度高 | Youtube-8M | GAP = 86% |
|
[
Attention Cluster
](
./video
)
| CVPR'18 提出的视频多模态特征注意力聚簇融合方法 | Youtube-8M | GAP = 84% |
|
[
NeXtVlad
](
./video
)
| 2nd-Youtube-8M 比赛第 3 名的模型 | Youtube-8M | GAP = 87% |
|
[
C-TCN
](
./video
)
| 2018 年 ActivityNet 夺冠方案 | ActivityNet1.3 | MAP=31% |
|
[
BSN
](
./video
)
| 为视频动作定位问题提供高效的 proposal 生成方法 | ActivityNet1.3 | AUC=66.64% |
|
[
BMN
](
./video
)
| 2019 年 ActivityNet 夺冠方案 | ActivityNet1.3 | AUC=67.19% |
|
[
ETS
](
./video
)
| 视频摘要生成领域的基准模型 | ActivityNet Captions | METEOR:10.0 |
|
[
TALL
](
./video
)
| 视频Grounding方向的BaseLine模型 | TACoS | R1@IOU5=0.13 |
|
[
SiamFC
](
./tracking
)
| ECCV’16提出的全卷积神经网络视频跟踪模型 | VOT2018 | EAO = 0.211 |
|
[
ATOM
](
./tracking
)
| CVPR’19提出的两阶段目标跟踪模型 | VOT2018 | EAO = 0.399 |
3D视觉
-------
计算机3D视觉技术是解决包含高度、宽度、深度信息的三维立体图像的分类、分割、检测、识别等任务的计算机技术,广泛地应用于如机器人、无人车、AR等领域。3D点云是3D图像数据的主要表达形式之一,基于3D点云的形状分类、语义分割、目标检测模型是3D视觉方向的基础任务。当前飞桨模型库开源了基于3D点云数据的用于分类、分割的PointNet++模型和用于检测的PointRCNN模型。
-
[
TSN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
[
PointNet++
](
./3d_vision/PointNet++
)
[
PointRCNN
](
./3d_vision/PointRCNN
)
PaddleCV/imgs/paddlecv.png
0 → 100644
浏览文件 @
0d8986ca
529.2 KB
README.md
浏览文件 @
0d8986ca
...
...
@@ -13,7 +13,7 @@ PaddlePaddle 提供了丰富的计算单元,使得用户可以采用模块化
*
[
图像生成
](
#图像生成
)
*
[
场景文字识别
](
#场景文字识别
)
*
[
度量学习
](
#度量学习
)
*
[
视频
分类和动作定位
](
#视频分类和动作定位
)
*
[
视频
](
#视频
)
*
[
智能文本处理(PaddleNLP)
](
#PaddleNLP
)
*
[
NLP 基础技术
](
#NLP-基础技术
)
*
[
NLP 核心技术
](
#NLP-核心技术
)
...
...
@@ -131,24 +131,42 @@ PaddlePaddle 提供了丰富的计算单元,使得用户可以采用模块化
|
[
ResNet50使用eml微调
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/metric_learning
)
| 在 arcmargin loss 基础上,使用 eml loss 微调的特征模型 | Stanford Online Product(SOP) | 80.11% |
|
[
ResNet50使用npairs微调
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/metric_learning
)
| 在 arcmargin loss基础上,使用npairs loss 微调的特征模型 | Stanford Online Product(SOP) | 79.81% |
### 视频分类和动作定位
视频分类和动作定位是视频理解任务的基础。视频数据包含语音、图像等多种信息,因此理解视频任务不仅需要处理语音和图像,还需要提取视频帧时间序列中的上下文信息。视频分类模型提供了提取全局时序特征的方法,主要方式有卷积神经网络 (C3D, I3D, C2D等),神经网络和传统图像算法结合 (VLAD 等),循环神经网络等建模方法。视频动作定位模型需要同时识别视频动作的类别和起止时间点,通常采用类似于图像目标检测中的算法在时间维度上进行建模。
### 视频
PaddleCV全面开源了视频分类、动作定位 和 目标跟踪等视频任务的领先实用算法。视频数据包含语音、图像等多种信息,因此理解视频任务不仅需要处理语音和图像,还需要提取视频帧时间序列中的上下文信息。
视频分类模型提供了提取全局时序特征的方法,主要方式有卷积神经网络 (C3D, I3D, C2D等),神经网络和传统图像算法结合 (VLAD 等),循环神经网络等建模方法。
视频动作定位模型需要同时识别视频动作的类别和起止时间点,通常采用类似于图像目标检测中的算法在时间维度上进行建模。
视频摘要生成模型是对视频画面信息进行提取,并产生一段文字描述。视频查找模型则是基于一段文字描述,查找到视频中对应场景片段的起止时间点。这两类模型需要同时对视频图像和文本信息进行建模。
目标跟踪任务是在给定某视频序列中找到目标物体,并将不同帧中的物体一一对应,然后给出不同物体的运动轨迹,目标跟踪的主要应用在视频监控、人机交互等系统中。跟踪又分为单目标跟踪和多目标跟踪,当前在飞桨模型库中增加了单目标跟踪的算法。主要包括Siam系列算法和ATOM算法。
| 模型名称 | 模型简介 | 数据集 | 评估指标 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | -------------------------- | ----------- |
|
[
TSN
](
./PaddleCV/video
)
| ECCV'16 提出的基于 2D-CNN 经典解决方案 | Kinetics-400 | Top-1 = 67% |
|
[
Non-Local
](
./PaddleCV/video
)
| 视频非局部关联建模模型 | Kinetics-400 | Top-1 = 74% |
|
[
StNet
](
./PaddleCV/video
)
| AAAI'19 提出的视频联合时空建模方法 | Kinetics-400 | Top-1 = 69% |
|
[
TSM
](
./PaddleCV/video
)
| 基于时序移位的简单高效视频时空建模方法 | Kinetics-400 | Top-1 = 70% |
|
[
Attention LSTM
](
./PaddleCV/video
)
| 常用模型,速度快精度高 | Youtube-8M | GAP = 86% |
|
[
Attention Cluster
](
./PaddleCV/video
)
| CVPR'18 提出的视频多模态特征注意力聚簇融合方法 | Youtube-8M | GAP = 84% |
|
[
NeXtVlad
](
./PaddleCV/video
)
| 2nd-Youtube-8M 比赛第 3 名的模型 | Youtube-8M | GAP = 87% |
|
[
C-TCN
](
./PaddleCV/video
)
| 2018 年 ActivityNet 夺冠方案 | ActivityNet1.3 | MAP=31% |
|
[
BSN
](
./PaddleCV/video
)
| 为视频动作定位问题提供高效的 proposal 生成方法 | ActivityNet1.3 | AUC=66.64% |
|
[
BMN
](
./PaddleCV/video
)
| 2019 年 ActivityNet 夺冠方案 | ActivityNet1.3 | AUC=67.19% |
|
[
ETS
](
./PaddleCV/video
)
| 视频摘要生成领域的基准模型 | ActivityNet Captions | METEOR:10.0 |
|
[
TALL
](
./PaddleCV/video
)
| 视频Grounding方向的BaseLine模型 | TACoS | R1@IOU5=0.13 |
|
[
SiamFC
](
./PaddleCV/tracking
)
| ECCV’16提出的全卷积神经网络视频跟踪模型 | VOT2018 | EAO = 0.211 |
|
[
ATOM
](
./PaddleCV/tracking
)
| CVPR’19提出的两阶段目标跟踪模型 | VOT2018 | EAO = 0.399 |
### 3D视觉
计算机3D视觉技术是解决包含高度、宽度、深度三个方向信息的三维立体图像的分类、分割、检测、识别等任务的计算机技术,广泛地应用于如机器人、无人车、AR等领域。3D点云是3D图像数据的主要表达形式之一,基于3D点云的形状分类、语义分割、目标检测模型是3D视觉方向的基础任务。当前飞桨模型库开源了基于3D点云数据的用于分类、分割的PointNet++模型和用于检测的PointRCNN模型。
| 模型名称 | 模型简介 | 数据集 | 评估指标 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | -------------------------- | ----------- |
|
[
TSN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| ECCV'16 提出的基于 2D-CNN 经典解决方案 | Kinetics-400 | Top-1 = 67% |
|
[
Non-Local
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 视频非局部关联建模模型 | Kinetics-400 | Top-1 = 74% |
|
[
StNet
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| AAAI'19 提出的视频联合时空建模方法 | Kinetics-400 | Top-1 = 69% |
|
[
TSM
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 基于时序移位的简单高效视频时空建模方法 | Kinetics-400 | Top-1 = 70% |
|
[
Attention LSTM
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 常用模型,速度快精度高 | Youtube-8M | GAP = 86% |
|
[
Attention Cluster
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| CVPR'18 提出的视频多模态特征注意力聚簇融合方法 | Youtube-8M | GAP = 84% |
|
[
NeXtVlad
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 2nd-Youtube-8M 比赛第 3 名的模型 | Youtube-8M | GAP = 87% |
|
[
C-TCN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 2018 年 ActivityNet 夺冠方案 | ActivityNet1.3 | MAP=31% |
|
[
BSN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 为视频动作定位问题提供高效的 proposal 生成方法 | ActivityNet1.3 | AUC=66.64% |
|
[
BMN
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video
)
| 2019 年 ActivityNet 夺冠方案 | ActivityNet1.3 | AUC=67.19% |
|
[
ETS
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video/models/ets
)
| 视频摘要生成领域的基准模型 | ActivityNet Captions | METEOR:10.0 |
|
[
TALL
](
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/video/models/tall
)
| 视频Grounding方向的BaseLine模型 | TACoS | R1@IOU5=0.13 |
|
[
PointNet++
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/3d_vision/PointNet++
)
| 改进的PointNet网络,加入局部特征提取提高模型泛化能力 | ModelNet40(分类) / Indoor3D(分割) | 分类:Top-1 = 90% / 分割:Top-1 = 86% |
|
[
PointRCNN
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/3d_vision/PointRCNN
)
| 自下而上的3D检测框生成方法 | KITTI(Car) | 3D AP@70(easy/median/hard) = 86.66/76.65/75.90 |
## PaddleNLP
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}