add paddlecv (#5604)
Showing
paddlecv/LICENSE
0 → 100644
paddlecv/MANIFEST.in
0 → 100644
paddlecv/README.md
0 → 100644
paddlecv/__init__.py
0 → 100644
paddlecv/custom_op/inference.py
0 → 100644
paddlecv/custom_op/postprocess.py
0 → 100644
paddlecv/custom_op/preprocess.py
0 → 100644
paddlecv/demo/000000014439.jpg
0 → 100644
{kind=link}

190.7 KB
{kind=link}

201.6 KB
paddlecv/demo/00056221.jpg
0 → 100755
{kind=link}

100.1 KB
{kind=link}

92.7 KB
paddlecv/demo/hrnet_demo.jpg
0 → 100644
{kind=link}

42.1 KB
paddlecv/demo/kie_demo.jpg
0 → 100644
{kind=link}
1.8 MB
paddlecv/demo/pikachu.mp4
0 → 100644
文件已添加
{kind=link}

368.9 KB
{kind=link}

124.9 KB
{kind=link}

757.9 KB
{kind=link}

2.6 MB
paddlecv/demo/table.jpg
0 → 100644
{kind=link}
58.0 KB
paddlecv/demo/table_demo.npy
0 → 100644
文件已添加
paddlecv/demo/word_1.jpg
0 → 100644
{kind=link}

12.2 KB
paddlecv/docs/GETTING_STARTED.md
0 → 100644
paddlecv/docs/INSTALL.md
0 → 100644
paddlecv/docs/config_anno.md
0 → 100644
paddlecv/docs/custom_ops.md
0 → 100644
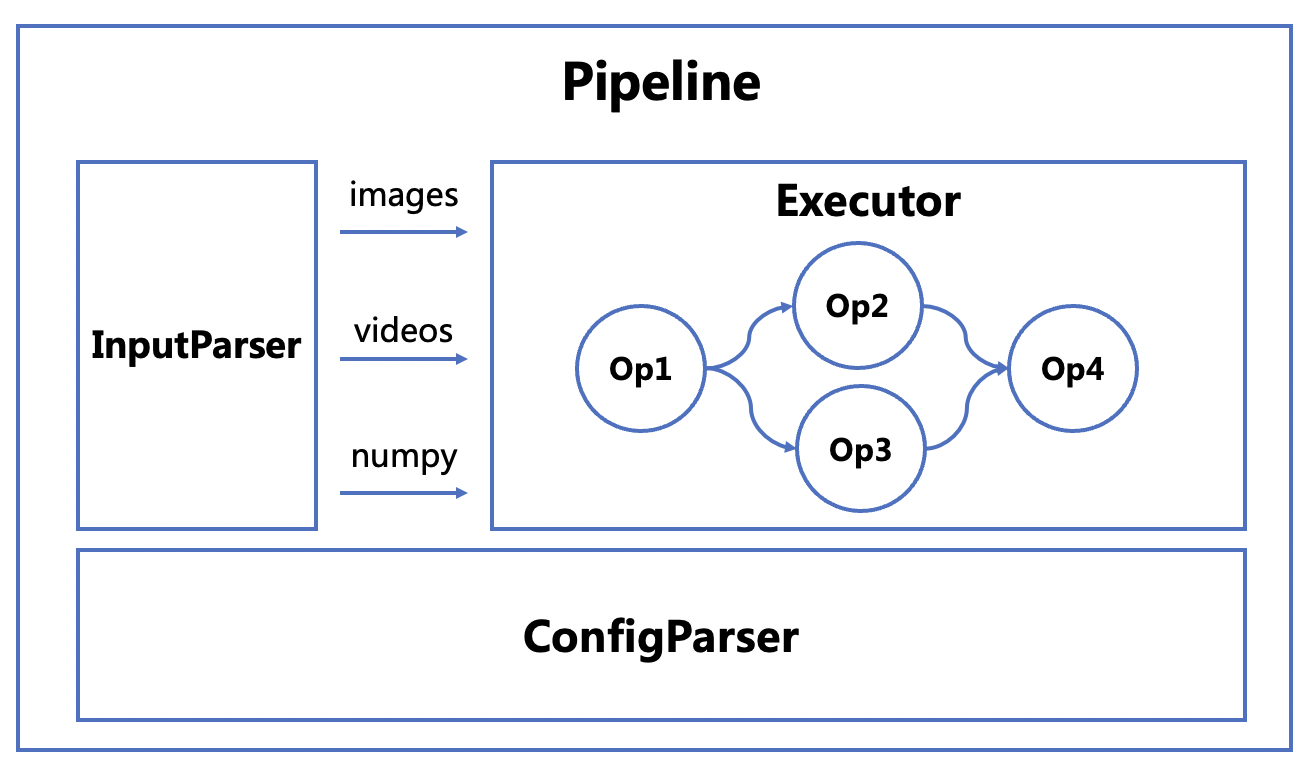
paddlecv/docs/images/pipeline.png
0 → 100644
{kind=link}
259.5 KB
paddlecv/docs/system_design.md
0 → 100644
paddlecv/docs/whl.md
0 → 100644
paddlecv/paddlecv.py
0 → 100644
paddlecv/ppcv/__init__.py
0 → 100644
paddlecv/ppcv/core/__init__.py
0 → 100644
paddlecv/ppcv/core/config.py
0 → 100644
paddlecv/ppcv/core/framework.py
0 → 100644
paddlecv/ppcv/core/workspace.py
0 → 100644
paddlecv/ppcv/engine/__init__.py
0 → 100644
paddlecv/ppcv/engine/pipeline.py
0 → 100644
paddlecv/ppcv/model_zoo/MODEL_ZOO
0 → 100644
paddlecv/ppcv/ops/__init__.py
0 → 100644
paddlecv/ppcv/ops/base.py
0 → 100644
paddlecv/ppcv/ops/models/base.py
0 → 100644
paddlecv/ppcv/ops/output/base.py
0 → 100644
paddlecv/ppcv/ops/output/ocr.py
0 → 100644
paddlecv/ppcv/ops/predictor.py
0 → 100644
paddlecv/ppcv/utils/__init__.py
0 → 100644
paddlecv/ppcv/utils/download.py
0 → 100644
paddlecv/ppcv/utils/helper.py
0 → 100644
paddlecv/ppcv/utils/logger.py
0 → 100644
paddlecv/ppcv/utils/timer.py
0 → 100644
paddlecv/requirements.txt
0 → 100644
paddlecv/scripts/build_wheel.sh
0 → 100644
paddlecv/setup.py
0 → 100644
paddlecv/tests/__init__.py
0 → 100644
paddlecv/tests/test_connector.py
0 → 100644
paddlecv/tests/test_custom_op.py
0 → 100644
paddlecv/tests/test_detection.py
0 → 100644
paddlecv/tests/test_get_model.py
0 → 100644
paddlecv/tests/test_keypoint.py
0 → 100644
paddlecv/tests/test_list_model.py
0 → 100644
paddlecv/tests/test_ocr.py
0 → 100644
paddlecv/tests/test_pipeline.py
0 → 100644
paddlecv/tools/check_name.py
0 → 100644
paddlecv/tools/predict.py
0 → 100644