diff --git a/PaddleNLP/README_en.md b/PaddleNLP/README_en.md
index 5575d59691086e5594da7d8f824bf2db068c6b29..15a9d3343d10763390a38716a111c5125bb537fc 100644
--- a/PaddleNLP/README_en.md
+++ b/PaddleNLP/README_en.md
@@ -95,13 +95,16 @@ For more pretrained model selection, please refer to [PretrainedModels](./paddle
- [Models API](./docs/models.md)
+
+
+
## Tutorials
Please refer to our official AI Studio account for more interactive tutorials: [PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)
-* [What's Seq2Vec?](https://aistudio.baidu.com/aistudio/projectdetail/1294333) shows how to use LSTM to do sentiment analysis.
+* [What's Seq2Vec?](https://aistudio.baidu.com/aistudio/projectdetail/1283423) shows how to use LSTM to do sentiment analysis.
-* [Sentiment Analysis with ERNIE](https://aistudio.baidu.com/aistudio/projectdetail/1283423) shows how to exploit the pretrained ERNIE to make sentiment analysis better.
+* [Sentiment Analysis with ERNIE](https://aistudio.baidu.com/aistudio/projectdetail/1294333) shows how to exploit the pretrained ERNIE to make sentiment analysis better.
* [Waybill Information Extraction with BiGRU-CRF Model](https://aistudio.baidu.com/aistudio/projectdetail/1317771) shows how to make use of bigru and crf to do information extraction.
diff --git a/PaddleNLP/examples/text_classification/README.md b/PaddleNLP/examples/text_classification/README.md
index 0eb6c93d4ed829e2525a64ccb51a0e5c25649e9e..f52a6a2bec4454fbb5aa2f159359ffbbe8ba5d94 100644
--- a/PaddleNLP/examples/text_classification/README.md
+++ b/PaddleNLP/examples/text_classification/README.md
@@ -4,7 +4,7 @@
## Conventional RNNs Models
-[Recurrent Neural Networks](./rnn) 展示了如何使用RNN、LSTM、GRU等网络完成文本分类任务。
+[Recurrent Neural Networks](./rnn) 展示了如何使用传统序列模型RNN、LSTM、GRU等网络完成文本分类任务。
## Pretrained Model (PTMs)
@@ -12,10 +12,18 @@
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_classification/pretrained_models/README.md b/PaddleNLP/examples/text_classification/pretrained_models/README.md
index 658112cbc927cb5aa2ddddd12a201c3915304ad1..47efa9ce19d28b436a22b422dfb2602917c8ef66 100644
--- a/PaddleNLP/examples/text_classification/pretrained_models/README.md
+++ b/PaddleNLP/examples/text_classification/pretrained_models/README.md
@@ -1,17 +1,34 @@
# 使用预训练模型Fine-tune完成中文文本分类任务
-随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
+
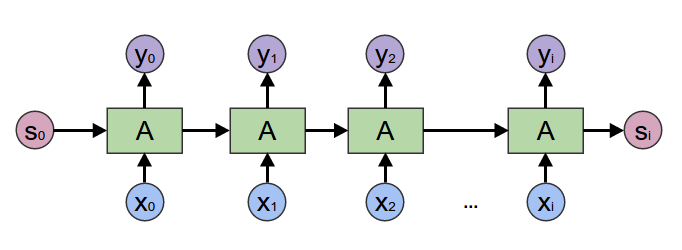
+在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](../rnn).
+
+
+
+
+
+
+[paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析](https://aistudio.baidu.com/aistudio/projectdetail/1283423)教程介绍了如何使用`paddlenlp.seq2vec`表征文本语义。
+
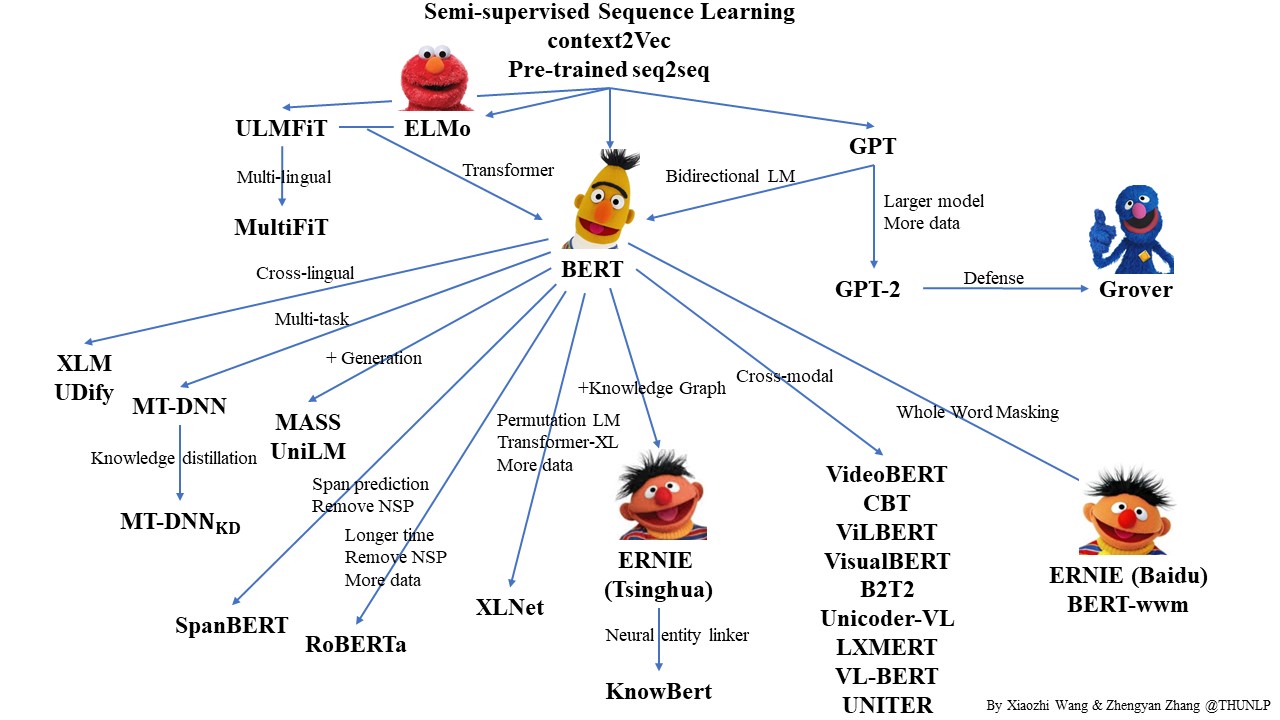
+近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
-本示例展示了以BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))代表的预训练模型如何Finetune完成中文文本分类任务。
+
+
+
+
+
+本图片来自于:https://github.com/thunlp/PLMpapers
+
+本示例展示了以ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223))代表的预训练模型如何Finetune完成中文文本分类任务。
## 模型简介
本项目针对中文文本分类问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
-+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
++ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持24层Transformer网络的`roberta-wwm-ext-large`和12层Transformer网络的`roberta-wwm-ext`。
@@ -29,21 +46,14 @@
## 快速开始
-### 安装说明
-
-* PaddlePaddle 安装
+### 环境依赖
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+- python >= 3.6
+- paddlepaddle >= 2.0.0-rc1
-* PaddleNLP 安装
-
- ```shell
- pip install paddlenlp
- ```
-
-* 环境依赖
-
- Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/1.5/beginners_guide/install/index_cn.html) 部分的内容
+```
+pip install paddlenlp==2.0.0b
+```
### 代码结构说明
@@ -128,10 +138,18 @@ Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_classification/rnn/README.md b/PaddleNLP/examples/text_classification/rnn/README.md
index d41980d6d804219c5b2a5f4c2a89b25afbd64549..32e2a4707e0ef784b432115878c3ce0908a86e20 100644
--- a/PaddleNLP/examples/text_classification/rnn/README.md
+++ b/PaddleNLP/examples/text_classification/rnn/README.md
@@ -2,19 +2,73 @@
文本分类是NLP应用最广的任务之一,可以被应用到多个领域中,包括但不仅限于:情感分析、垃圾邮件识别、商品评价分类...
-一般通过将文本表示成向量后接入分类器,完成文本分类。
+情感分析是一个自然语言处理中老生常谈的任务。情感分析的目的是为了找出说话者/作者在某些话题上,或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。其可以用于数据挖掘、Web 挖掘、文本挖掘和信息检索方面得到了广泛的研究。可通过 [AI开放平台-情感倾向分析](http://ai.baidu.com/tech/nlp_apply/sentiment_classify) 线上体验。
-如何用向量表征文本,使得向量携带语义信息,是我们关心的重点。
+
+
+
本项目开源了一系列模型用于进行文本建模,用户可通过参数配置灵活使用。效果上,我们基于开源情感倾向分类数据集ChnSentiCorp对多个模型进行评测。
-情感倾向分析(Sentiment Classification)是一类常见的文本分类任务。其针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度。情感类型分为积极、消极。情感倾向分析能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。可通过 [AI开放平台-情感倾向分析](http://ai.baidu.com/tech/nlp_apply/sentiment_classify) 线上体验。
+## paddlenlp.seq2vec
+
+情感分析任务中关键技术是如何将文本表示成一个**携带语义的文本向量**。随着深度学习技术的快速发展,目前常用的文本表示技术有LSTM,GRU,RNN等方法。
+PaddleNLP提供了一系列的文本表示技术,如`seq2vec`模块。
+
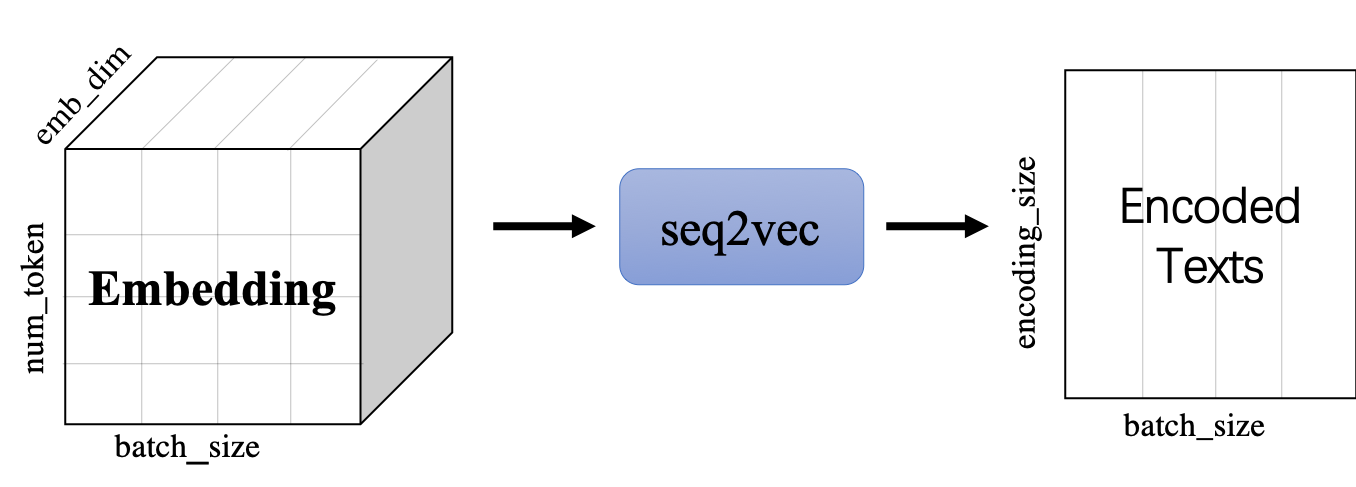
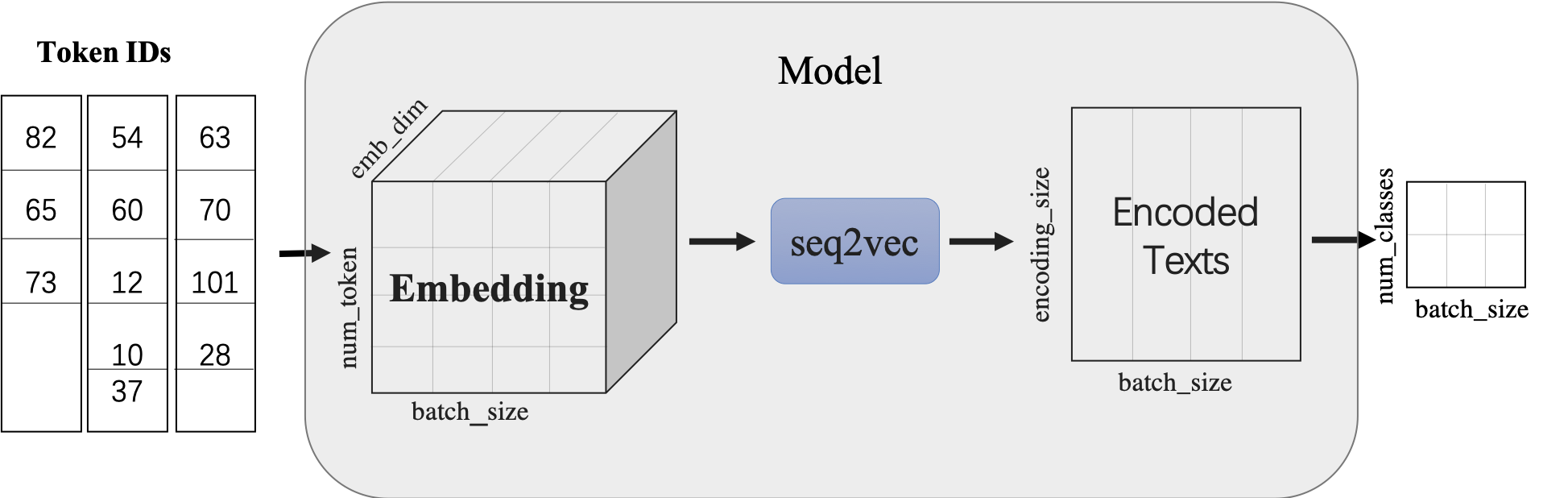
+[`paddlenlp.seq2vec`](../../../paddlenlp/seq2vec) 模块作用为将输入的序列文本表征成一个语义向量。
+
+
+
+
+
## 模型简介
-本项目通过调用[Seq2Vec](../../../paddlenlp/seq2vec/)中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
+本项目通过调用[seq2vec](../../../paddlenlp/seq2vec/)中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
+
+`seq2vec`模块
+
+* 功能是将序列Embedding Tensor(shape是(batch_size, num_token, emb_dim) )转化成文本语义表征Enocded Texts Tensor(shape 是(batch_sie,encoding_size))
+* 提供了`BoWEncoder`,`CNNEncoder`,`GRUEncoder`,`LSTMEncoder`,`RNNEncoder`等模型
+ - `BoWEncoder` 是将输入序列Embedding Tensor在num_token维度上叠加,得到文本语义表征Enocded Texts Tensor。
+ - `CNNEncoder` 是将输入序列Embedding Tensor进行卷积操作,在对卷积结果进行max_pooling,得到文本语义表征Enocded Texts Tensor。
+ - `GRUEncoder` 是对输入序列Embedding Tensor进行GRU运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+ - `LSTMEncoder` 是对输入序列Embedding Tensor进行LSTM运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+ - `RNNEncoder` 是对输入序列Embedding Tensor进行RNN运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
+
+
+`seq2vec`提供了许多语义表征方法,那么这些方法在什么时候更加适合呢?
+
+* `BoWEncoder`采用Bag of Word Embedding方法,其特点是简单。但其缺点是没有考虑文本的语境,所以对文本语义的表征不足以表意。
+
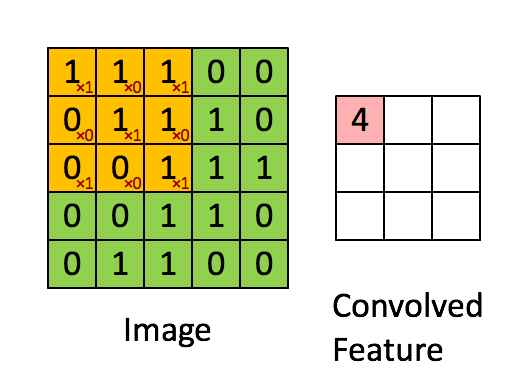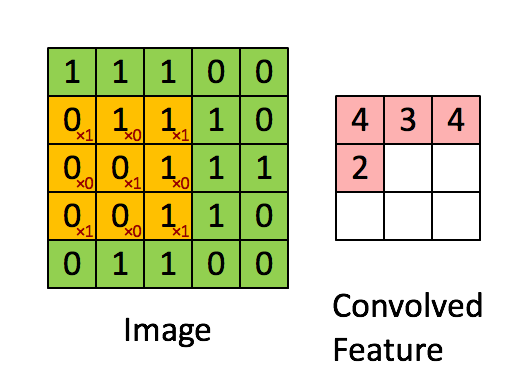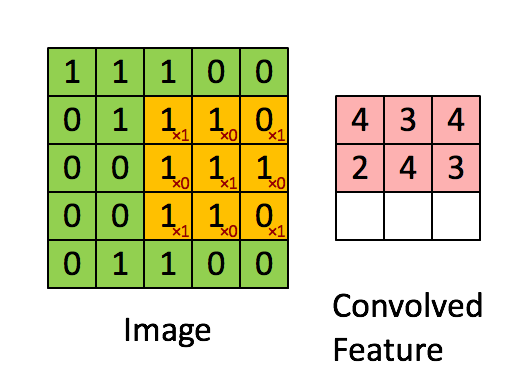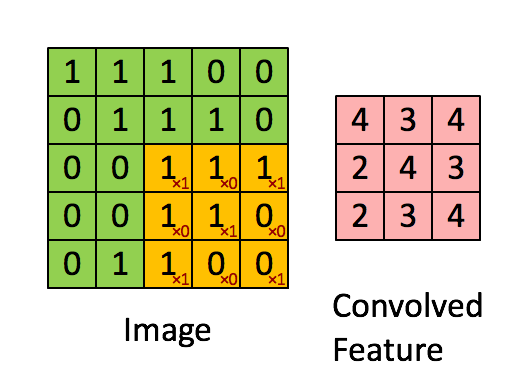
+* `CNNEncoder`采用卷积操作,提取局部特征,其特点是可以共享权重。但其缺点同样只考虑了局部语义,上下文信息没有充分利用。
+
+
+
+
+
+* `RNNEnocder`采用RNN方法,在计算下一个token语义信息时,利用上一个token语义信息作为其输入。但其缺点容易产生梯度消失和梯度爆炸。
+
+
+
+
+
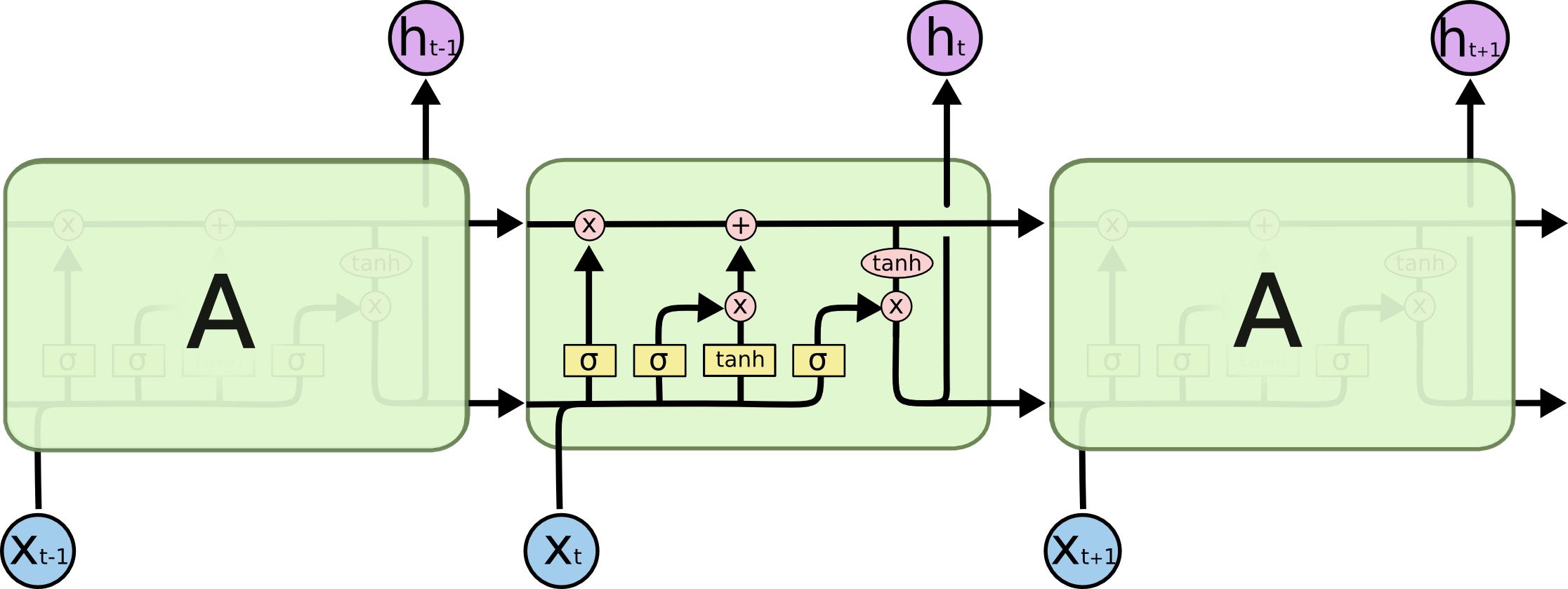
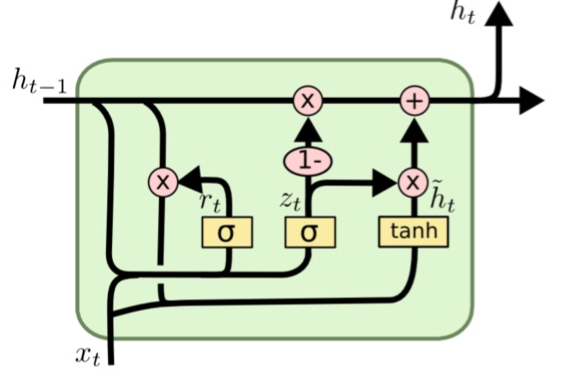
+* `LSTMEnocder`采用LSTM方法,LSTM是RNN的一种变种。为了学到长期依赖关系,LSTM 中引入了门控机制来控制信息的累计速度,
+ 包括有选择地加入新的信息,并有选择地遗忘之前累计的信息。
+
+
+
+
+
+* `GRUEncoder`采用GRU方法,GRU也是RNN的一种变种。一个LSTM单元有四个输入 ,因而参数是RNN的四倍,带来的结果是训练速度慢。
+ GRU对LSTM进行了简化,在不影响效果的前提下加快了训练速度。
+
+
+
+
+
| 模型 | 模型介绍 |
| ------------------------------------------------ | ------------------------------------------------------------ |
@@ -38,25 +92,31 @@
| Bi-LSTM Attention | 0.8992 | 0.8856 |
| TextCNN | 0.9102 | 0.9107 |
-## 快速开始
-### 安装说明
+
+
+
-* PaddlePaddle 安装
- 本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
+关于CNN、LSTM、GRU、RNN等更多信息参考:
-* PaddleNLP 安装
+* https://canvas.stanford.edu/files/1090785/download
+* https://colah.github.io/posts/2015-08-Understanding-LSTMs/
+* https://arxiv.org/abs/1412.3555
+* https://arxiv.org/pdf/1506.00019
+* https://arxiv.org/abs/1404.2188
- ```shell
- pip install paddlenlp
- ```
-* 环境依赖
+## 快速开始
- 本项目依赖于jieba分词,请在运行本项目之前,安装jieba,如`pip install -U jieba`
+### 环境依赖
- Python的版本要求 3.6+,其它环境请参考 PaddlePaddle [安装说明](https://www.paddlepaddle.org.cn/install/quick/zh/2.0rc-linux-docker) 部分的内容
+- python >= 3.6
+- paddlepaddle >= 2.0.0-rc1
+
+```
+pip install paddlenlp==2.0.0b
+```
### 代码结构说明
@@ -164,10 +224,18 @@ Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场
## 线上体验教程
-* [paddlenlp.seq2vec是什么? 瞧瞧它怎么完成情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1294333)展示了使用序列模型LSTM完成情感分析任务。
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
-* [使用PaddleNLP语义预训练模型ERNIE优化情感分析教程](https://aistudio.baidu.com/aistudio/projectdetail/1283423)展示了使用ERNIE优化情感分析任务。
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
-* [基于Bi-GRU+CRF的快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
-* [使用PaddleNLP预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_matching/README.md b/PaddleNLP/examples/text_matching/README.md
index 7b84d6b1959949e9214dc156de5b27384f22496c..f51e74afdf43ddcebc0831daff08f89876369786 100644
--- a/PaddleNLP/examples/text_matching/README.md
+++ b/PaddleNLP/examples/text_matching/README.md
@@ -24,3 +24,21 @@
## Sentence Transformers
[Sentence Transformers](./sentence_transformers) 展示了如何使用以ERNIE为代表的模型Fine-tune完成文本匹配任务。
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_matching/sentence_transformers/README.md b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
index ad4547a9fa684e3563f188f2c096c2cd51dce107..f35931c7bf44884613c30a1b72c13862111f9617 100644
--- a/PaddleNLP/examples/text_matching/sentence_transformers/README.md
+++ b/PaddleNLP/examples/text_matching/sentence_transformers/README.md
@@ -39,7 +39,7 @@ PaddleNLP提供了丰富的预训练模型,并且可以便捷地获取PaddlePa
本项目针对中文文本匹配问题,开源了一系列模型,供用户可配置地使用:
+ BERT([Bidirectional Encoder Representations from Transformers](https://arxiv.org/abs/1810.04805))中文模型,简写`bert-base-chinese`, 其由12层Transformer网络组成。
-+ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/pdf/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
++ ERNIE([Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)),支持ERNIE 1.0中文模型(简写`ernie-1.0`)和ERNIE Tiny中文模型(简写`ernie-tiny`)。
其中`ernie`由12层Transformer网络组成,`ernie-tiny`由3层Transformer网络组成。
+ RoBERTa([A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)),支持12层Transformer网络的`roberta-wwm-ext`。
@@ -195,3 +195,22 @@ Data: ['小蝌蚪找妈妈怎么样', '小蝌蚪找妈妈是谁画的'] Lab
url = "https://arxiv.org/abs/2010.08240",
}
```
+
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/examples/text_matching/simnet/README.md b/PaddleNLP/examples/text_matching/simnet/README.md
index 26ccbbe0a1bf15dd0ad58d0e602d043a555423be..91c66b00626282a67e72d816f753d1e586ab5d73 100644
--- a/PaddleNLP/examples/text_matching/simnet/README.md
+++ b/PaddleNLP/examples/text_matching/simnet/README.md
@@ -164,3 +164,22 @@ Data: ['世界上什么东西最小', '世界上什么东西最小?'] Lab
Data: ['光眼睛大就好看吗', '眼睛好看吗?'] Label: dissimilar
Data: ['小蝌蚪找妈妈怎么样', '小蝌蚪找妈妈是谁画的'] Label: dissimilar
```
+
+
+## 线上体验教程
+
+- [使用seq2vec模块进行句子情感分类](https://aistudio.baidu.com/aistudio/projectdetail/1283423)
+
+- [如何将预训练模型Fine-tune下游任务](https://aistudio.baidu.com/aistudio/projectdetail/1294333)
+
+- [使用Bi-GRU+CRF完成快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1317771)
+
+- [使用预训练模型ERNIE优化快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/1329361)
+
+- [使用Seq2Seq模型完成自动对联模型](https://aistudio.baidu.com/aistudio/projectdetail/1321118)
+
+- [使用预训练模型ERNIE-GEN实现智能写诗](https://aistudio.baidu.com/aistudio/projectdetail/1339888)
+
+- [使用TCN网络完成新冠疫情病例数预测](https://aistudio.baidu.com/aistudio/projectdetail/1290873)
+
+更多教程参见[PaddleNLP on AI Studio](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995)。
diff --git a/PaddleNLP/paddlenlp/__init__.py b/PaddleNLP/paddlenlp/__init__.py
index 98b2546fa63bb05fff519bb81a8bfb4a87b60b09..78baa6f82ae42b77d7bcef62f5dbaf9015d095b4 100644
--- a/PaddleNLP/paddlenlp/__init__.py
+++ b/PaddleNLP/paddlenlp/__init__.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-__version__ = '2.0.0a9'
+__version__ = '2.0.0b0'
from . import data
from . import datasets