# YOLOv3 目标检测模型
---
## 内容
- [模型简介](#模型简介)
- [快速开始](#快速开始)
- [参考论文](#参考论文)
## 模型简介
[YOLOv3](https://arxiv.org/abs/1804.02767) 是由 [Joseph Redmon](https://arxiv.org/search/cs?searchtype=author&query=Redmon%2C+J) 和 [Ali Farhadi](https://arxiv.org/search/cs?searchtype=author&query=Farhadi%2C+A) 提出的单阶段检测器, 该检测器与达到同样精度的传统目标检测方法相比,推断速度能达到接近两倍.
传统目标检测方法通过两阶段检测,第一阶段生成预选框,第二阶段对预选框进行分类和位置坐标的调整,而YOLO将目标检测看做是对框位置和类别概率的一个单阶段回归问题,使得YOLO能达到近两倍的检测速度。而YOLOv3在YOLO的基础上引入的多尺度预测,使得YOLOv3网络对于小物体的检测精度大幅提高。
[YOLOv3](https://arxiv.org/abs/1804.02767) 是一阶段End2End的目标检测器。其目标检测原理如下图所示:

YOLOv3检测原理
YOLOv3将输入图像分成S\*S个格子,每个格子预测B个bounding box,每个bounding box预测内容包括: Location(x, y, w, h)、Confidence Score和C个类别的概率,因此YOLOv3输出层的channel数为B\*(5 + C)。YOLOv3的loss函数也有三部分组成:Location误差,Confidence误差和分类误差。
YOLOv3的网络结构如下图所示:
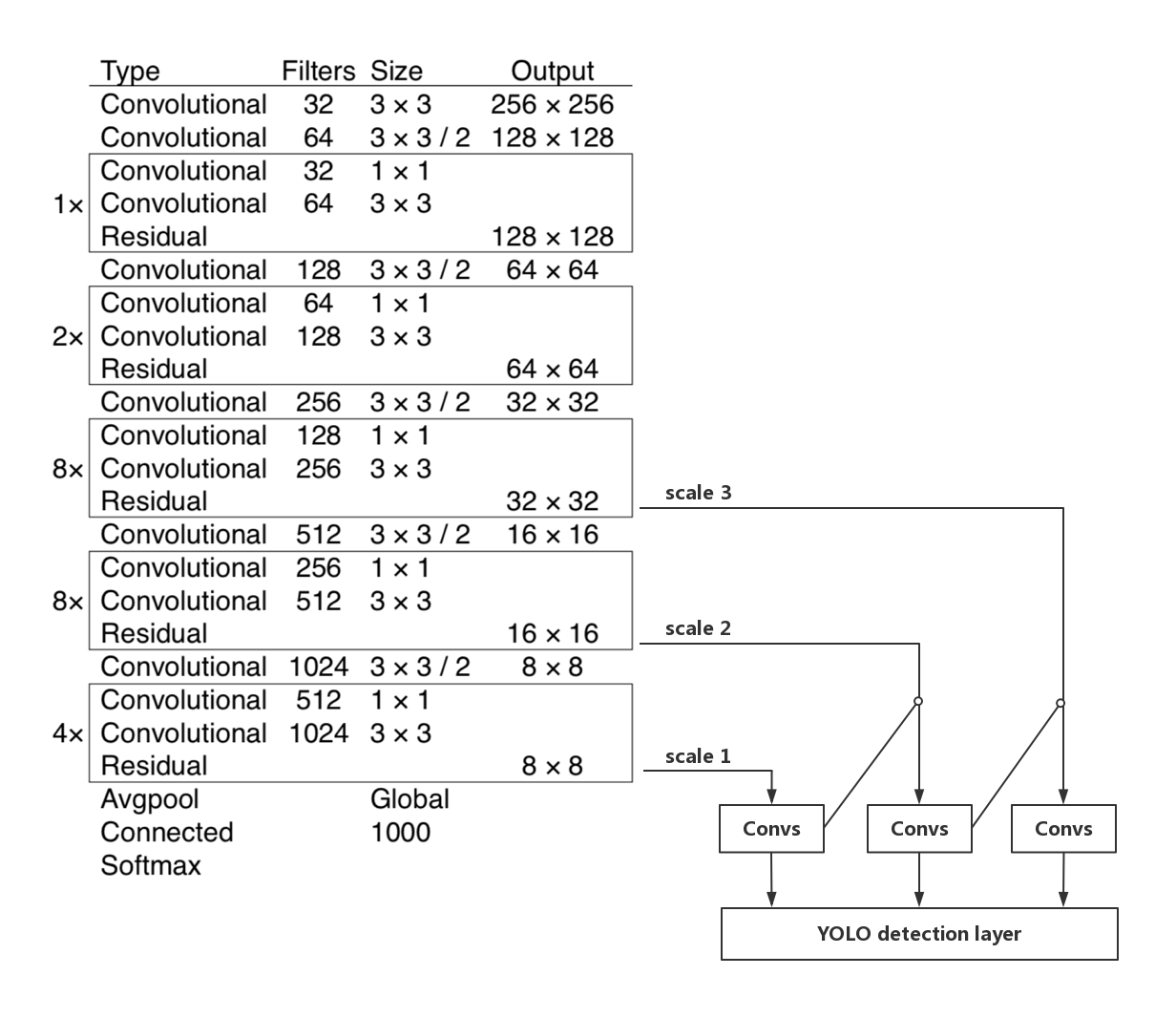
YOLOv3网络结构
YOLOv3 的网络结构由基础特征提取网络、multi-scale特征融合层和输出层组成。
1. 特征提取网络。YOLOv3使用 [DarkNet53](https://arxiv.org/abs/1612.08242)作为特征提取网络:DarkNet53 基本采用了全卷积网络,用步长为2的卷积操作替代了池化层,同时添加了 Residual 单元,避免在网络层数过深时发生梯度弥散。
2. 特征融合层。为了解决之前YOLO版本对小目标不敏感的问题,YOLOv3采用了3个不同尺度的特征图来进行目标检测,分别为13\*13,26\*26,52\*52,用来检测大、中、小三种目标。特征融合层选取 DarkNet 产出的三种尺度特征图作为输入,借鉴了FPN(feature pyramid networks)的思想,通过一系列的卷积层和上采样对各尺度的特征图进行融合。
3. 输出层。同样使用了全卷积结构,其中最后一个卷积层的卷积核个数是255:3\*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示Confidence Score,80表示COCO数据集中80个类别的概率。
## 快速开始
### 安装说明
#### paddle安装
本项目依赖于 PaddlePaddle 1.7及以上版本或适当的develop版本,请参考 [安装指南](http://www.paddlepaddle.org/#quick-start) 进行安装
#### 代码下载及环境变量设置
克隆代码库到本地,并设置`PYTHONPATH`环境变量
```bash
git clone https://github.com/PaddlePaddle/hapi
cd hapi
export PYTHONPATH=$PYTHONPATH:`pwd`
cd tsm
```
#### 安装COCO-API
训练前需要首先下载[COCO-API](https://github.com/cocodataset/cocoapi):
```bash
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
# if cython is not installed
pip install Cython
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python setup.py install --user
```
### 数据准备
模型目前支持COCO数据集格式的数据读入和精度评估,我们同时提供了将转换为COCO数据集的格式的Pascal VOC数据集下载,可通过如下命令下载。
```bash
python dataset/download_voc.py
```
数据目录结构如下:
```
dataset/voc/
├── annotations
│ ├── instances_train2017.json
│ ├── instances_val2017.json
| ...
├── train2017
│ ├── 1013.jpg
│ ├── 1014.jpg
| ...
├── val2017
│ ├── 2551.jpg
│ ├── 2552.jpg
| ...
```
### 模型训练
数据准备完成后,可使用`main.py`脚本启动训练和评估,如下脚本会自动每epoch交替进行训练和模型评估,并将checkpoint默认保存在`yolo_checkpoint`目录下。
YOLOv3模型训练总batch_size为64训练,以下以使用4卡Tesla P40每卡batch_size为16训练介绍训练方式。对于静态图和动态图,多卡训练中`--batch_size`为每卡上的batch_size,即总batch_size为`--batch_size`乘以卡数。
`main.py`脚本参数可通过如下命令查询
```bash
python main.py --help
```
#### 静态图训练
使用如下方式进行多卡训练:
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m paddle.distributed.launch main.py --data= --batch_size=16
```
#### 动态图训练
动态图训练只需要在运行脚本时添加`-d`参数即可。
使用如下方式进行多卡训练:
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m paddle.distributed.launch --data= --batch_size=16 -d
```
### 模型评估
YOLOv3模型输出为LoDTensor,只支持使用batch_size为1进行评估,可通过如下两种方式进行模型评估。
1. 自动下载Paddle发布的[YOLOv3-DarkNet53](https://paddlemodels.bj.bcebos.com/hapi/yolov3_darknet53.pdparams)权重评估
```bash
python main.py --data=dataset/voc --eval_only
```
2. 加载checkpoint进行精度评估
```bash
python main.py --data=dataset/voc --eval_only --weights=yolo_checkpoint/no_mixup/final
```
同样可以通过指定`-d`参数进行动态图模式的评估。
#### 评估精度
在10类小数据集下训练模型权重见[YOLOv3-DarkNet53](https://paddlemodels.bj.bcebos.com/hapi/yolov3_darknet53.pdparams),评估精度如下:
```bash
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.503
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.779
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.562
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.190
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.390
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.578
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.405
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.591
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.599
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.294
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.506
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.670
```
### 模型推断及可视化
可通过如下两种方式进行模型推断。
1. 自动下载Paddle发布的[YOLOv3-DarkNet53](https://paddlemodels.bj.bcebos.com/hapi/yolov3_darknet53.pdparams)权重评估
```bash
python infer.py --label_list=dataset/voc/label_list.txt --infer_image=image/dog.jpg
```
2. 加载checkpoint进行精度评估
```bash
python infer.py --label_list=dataset/voc/label_list.txt --infer_image=image/dog.jpg --weights=yolo_checkpoint/mo_mixup/final
```
推断结果可视化图像会保存于`--output`指定的文件夹下,默认保存于`./output`目录。
模型推断会输出如下检测结果日志:
```text
2020-04-02 08:26:47,268-INFO: detect bicycle at [116.14993, 127.278336, 579.7716, 438.44214] score: 0.97
2020-04-02 08:26:47,273-INFO: detect dog at [127.44086, 215.71997, 316.04276, 539.7584] score: 0.99
2020-04-02 08:26:47,274-INFO: detect car at [475.42343, 80.007484, 687.16095, 171.27374] score: 0.98
2020-04-02 08:26:47,274-INFO: Detection bbox results save in output/dog.jpg
```
## 参考论文
- [You Only Look Once: Unified, Real-Time Object Detection](https://arxiv.org/abs/1506.02640v5), Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi.
- [YOLOv3: An Incremental Improvement](https://arxiv.org/abs/1804.02767v1), Joseph Redmon, Ali Farhadi.
- [Bag of Freebies for Training Object Detection Neural Networks](https://arxiv.org/abs/1902.04103v3), Zhi Zhang, Tong He, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li.