Merge pull request #22 from qingqing01/cyclegan
Add CycleGAN.
Showing
cyclegan/README.md
0 → 100644
cyclegan/__init__.py
0 → 100644
cyclegan/check.py
0 → 100644
cyclegan/cyclegan.py
0 → 100644
cyclegan/data.py
0 → 100644
cyclegan/image/A2B.png
0 → 100644
{kind=link}

154.5 KB
cyclegan/image/B2A.png
0 → 100644
{kind=link}

143.2 KB
cyclegan/image/net.png
0 → 100644
{kind=link}
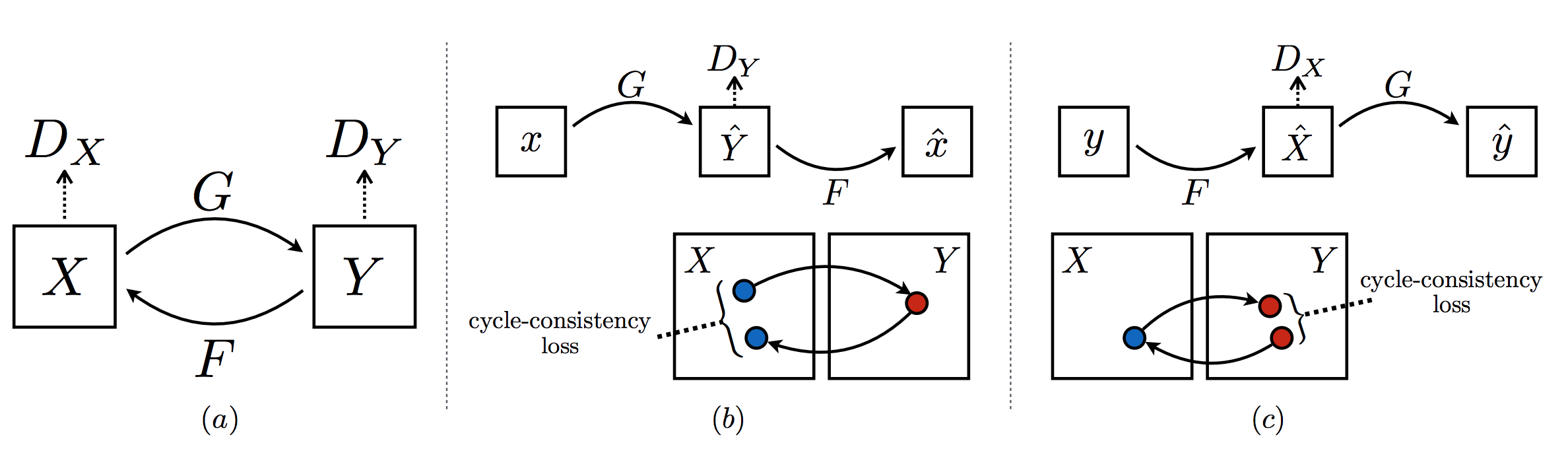
152.5 KB
cyclegan/image/testA/123_A.jpg
0 → 100644
{kind=link}

33.4 KB
cyclegan/image/testB/78_B.jpg
0 → 100644
{kind=link}

24.8 KB
cyclegan/infer.py
0 → 100644
cyclegan/layers.py
0 → 100644
cyclegan/test.py
0 → 100644
cyclegan/train.py
0 → 100644