# 线性回归
让我们从经典的线性回归(Linear Regression \[[1](#参考文献)\])模型开始这份教程。在这一章里,你将使用真实的数据集建立起一个房价预测模型,并且了解到机器学习中的若干重要概念。
本教程源代码目录在[book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line), 初次使用请您参考[Book文档使用说明](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
### 说明:
1.硬件环境要求:
本文可支持在CPU、GPU下运行
2. Docker镜像支持的CUDA/cuDNN版本:
如果使用了Docker运行Book,请注意:这里所提供的默认镜像的GPU环境为 CUDA 8/cuDNN 5,对于NVIDIA Tesla V100等要求CUDA 9的 GPU,使用该镜像可能会运行失败。
3. 文档和脚本中代码的一致性问题:
请注意:为使本文更加易读易用,我们拆分、调整了train.py的代码并放入本文。本文中代码与train.py的运行结果一致,可直接运行[train.py](https://github.com/PaddlePaddle/book/blob/develop/01.fit_a_line/train.py)进行验证。
## 背景介绍
给定一个大小为$n$的数据集 ${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$,其中$x_{i1}, \ldots, x_{id}$是第$i$个样本$d$个属性上的取值,$y_i$是该样本待预测的目标。线性回归模型假设目标$y_i$可以被属性间的线性组合描述,即

例如,在我们将要建模的房价预测问题里,$x_{ij}$是描述房子$i$的各种属性(比如房间的个数、周围学校和医院的个数、交通状况等),而 $y_i$是房屋的价格。
初看起来,这个假设实在过于简单了,变量间的真实关系很难是线性的。但由于线性回归模型有形式简单和易于建模分析的优点,它在实际问题中得到了大量的应用。很多经典的统计学习、机器学习书籍\[[2,3,4](#参考文献)\]也选择对线性模型独立成章重点讲解。
## 效果展示
我们使用从[UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。

图1. 预测值 V.S. 真实值
## 模型概览
### 模型定义
在波士顿房价数据集中,和房屋相关的值共有14个:前13个用来描述房屋相关的各种信息,即模型中的 $x_i$;最后一个值为我们要预测的该类房屋价格的中位数,即模型中的 $y_i$。因此,我们的模型就可以表示成:

$\hat{Y}$ 表示模型的预测结果,用来和真实值$Y$区分。模型要学习的参数即:$\omega_1, \ldots, \omega_{13}, b$。
建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值$\hat{Y}$尽可能地接近真实值$Y$。这里我们引入损失函数([Loss Function](https://en.wikipedia.org/wiki/Loss_function),或Cost Function)这个概念。 输入任意一个数据样本的目标值$y_{i}$和模型给出的预测值$\hat{y_{i}}$,损失函数输出一个非负的实值。这个实值通常用来反映模型误差的大小。
对于线性回归模型来讲,最常见的损失函数就是均方误差(Mean Squared Error, [MSE](https://en.wikipedia.org/wiki/Mean_squared_error))了,它的形式是:
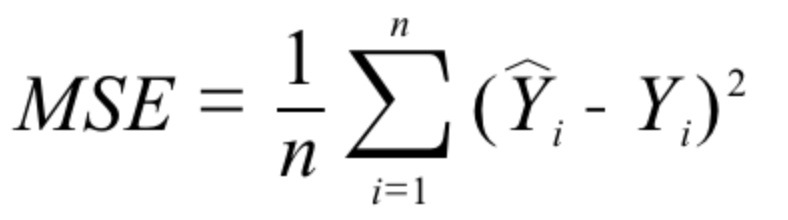
即对于一个大小为$n$的测试集,$MSE$是$n$个数据预测结果误差平方的均值。
对损失函数进行优化所采用的方法一般为梯度下降法。梯度下降法是一种一阶最优化算法。如果$f(x)$在点$x_n$有定义且可微,则认为$f(x)$在点$x_n$沿着梯度的负方向$-▽f(x_n)$下降的是最快的。反复调节$x$,使得$f(x)$接近最小值或者极小值,调节的方式为:

其中λ代表学习率。这种调节的方法称为梯度下降法。
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
1. 初始化参数,其中包括权重$\omega_i$和偏置$b$,对其进行初始化(如0均值,1方差)。
2. 网络正向传播计算网络输出和损失函数。
3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
## 数据集
### 数据集介绍
这份数据集共506行,每行包含了波士顿郊区的一类房屋的相关信息及该类房屋价格的中位数。其各维属性的意义如下:
| 属性名 | 解释 | 类型 |
| ------| ------ | ------ |
| CRIM | 该镇的人均犯罪率 | 连续值 |
| ZN | 占地面积超过25,000平方呎的住宅用地比例 | 连续值 |
| INDUS | 非零售商业用地比例 | 连续值 |
| CHAS | 是否邻近 Charles River | 离散值,1=邻近;0=不邻近 |
| NOX | 一氧化氮浓度 | 连续值 |
| RM | 每栋房屋的平均客房数 | 连续值 |
| AGE | 1940年之前建成的自用单位比例 | 连续值 |
| DIS | 到波士顿5个就业中心的加权距离 | 连续值 |
| RAD | 到径向公路的可达性指数 | 连续值 |
| TAX | 全值财产税率 | 连续值 |
| PTRATIO | 学生与教师的比例 | 连续值 |
| B | 1000(BK - 0.63)^2,其中BK为黑人占比 | 连续值 |
| LSTAT | 低收入人群占比 | 连续值 |
| MEDV | 同类房屋价格的中位数 | 连续值 |
### 数据预处理
#### 连续值与离散值
观察一下数据,我们的第一个发现是:所有的13维属性中,有12维的连续值和1维的离散值(CHAS)。离散值虽然也常使用类似0、1、2这样的数字表示,但是其含义与连续值是不同的,因为这里的差值没有实际意义。例如,我们用0、1、2来分别表示红色、绿色和蓝色的话,我们并不能因此说“蓝色和红色”比“绿色和红色”的距离更远。所以通常对一个有$d$个可能取值的离散属性,我们会将它们转为$d$个取值为0或1的二值属性或者将每个可能取值映射为一个多维向量。不过就这里而言,因为CHAS本身就是一个二值属性,就省去了这个麻烦。
#### 属性的归一化
另外一个稍加观察即可发现的事实是,各维属性的取值范围差别很大(如图2所示)。例如,属性B的取值范围是[0.32, 396.90],而属性NOX的取值范围是[0.3850, 0.8170]。这里就要用到一个常见的操作-归一化(normalization)了。归一化的目标是把各位属性的取值范围放缩到差不多的区间,例如[-0.5,0.5]。这里我们使用一种很常见的操作方法:减掉均值,然后除以原取值范围。
做归一化(或 [Feature scaling](https://en.wikipedia.org/wiki/Feature_scaling))至少有以下3个理由:
- 过大或过小的数值范围会导致计算时的浮点上溢或下溢。
- 不同的数值范围会导致不同属性对模型的重要性不同(至少在训练的初始阶段如此),而这个隐含的假设常常是不合理的。这会对优化的过程造成困难,使训练时间大大的加长。
- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。

图2. 各维属性的取值范围
#### 整理训练集与测试集
我们将数据集分割为两份:一份用于调整模型的参数,即进行模型的训练,模型在这份数据集上的误差被称为**训练误差**;另外一份被用来测试,模型在这份数据集上的误差被称为**测试误差**。我们训练模型的目的是为了通过从训练数据中找到规律来预测未知的新数据,所以测试误差是更能反映模型表现的指标。分割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为$8:2$
在更复杂的模型训练过程中,我们往往还会多使用一种数据集:验证集。因为复杂的模型中常常还有一些超参数([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization))需要调节,所以我们会尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现选择相对最好的一组超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。由于本章训练的模型比较简单,我们暂且忽略掉这个过程。
## 训练
`fit_a_line/train.py`演示了训练的整体过程。
### 配置数据提供器(Datafeeder)
首先我们引入必要的库:
```python
from __future__ import print_function
import paddle
import paddle.fluid as fluid
import numpy
import math
import sys
```
我们通过uci_housing模块引入了数据集合[UCI Housing Data Set](http://paddlemodels.bj.bcebos.com/uci_housing/housing.data)
其中,在uci_housing模块中封装了:
1. 数据下载的过程。下载数据保存在~/.cache/paddle/dataset/uci_housing/housing.data。
2. 数据预处理的过程。
接下来我们定义了用于训练的数据提供器。提供器每次读入一个大小为`BATCH_SIZE`的数据批次。如果用户希望加一些随机性,它可以同时定义一个批次大小和一个缓存大小。这样的话,每次数据提供器会从缓存中随机读取批次大小那么多的数据。
```python
BATCH_SIZE = 20
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
batch_size=BATCH_SIZE)
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.test(), buf_size=500),
batch_size=BATCH_SIZE)
```
如果想直接从txt文件中读取数据的话,可以参考以下方式。
feature_names = [
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'convert'
]
feature_num = len(feature_names)
data = numpy.fromfile(filename, sep=' ') # 从文件中读取原始数据
data = data.reshape(data.shape[0] // feature_num, feature_num)
maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0)/data.shape[0]
for i in six.moves.range(feature_num-1):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) # six.moves可以兼容python2和python3
ratio = 0.8 # 训练集和验证集的划分比例
offset = int(data.shape[0]*ratio)
train_data = data[:offset]
test_data = data[offset:]
def reader(data):
for d in train_data:
yield d[:1], d[-1:]
train_reader = paddle.batch(
paddle.reader.shuffle(
reader(train_data), buf_size=500),
batch_size=BATCH_SIZE)
test_reader = paddle.batch(
paddle.reader.shuffle(
reader(test_data), buf_size=500),
batch_size=BATCH_SIZE)
### 配置训练程序
训练程序的目的是定义一个训练模型的网络结构。对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。更加复杂的结果,比如卷积神经网络,递归神经网络等会在随后的章节中介绍。训练程序必须返回`平均损失`作为第一个返回值,因为它会被后面反向传播算法所用到。
```python
x = fluid.layers.data(name='x', shape=[13], dtype='float32') # 定义输入的形状和数据类型
y = fluid.layers.data(name='y', shape=[1], dtype='float32') # 定义输出的形状和数据类型
y_predict = fluid.layers.fc(input=x, size=1, act=None) # 连接输入和输出的全连接层
main_program = fluid.default_main_program() # 获取默认/全局主函数
startup_program = fluid.default_startup_program() # 获取默认/全局启动程序
cost = fluid.layers.square_error_cost(input=y_predict, label=y) # 利用标签数据和输出的预测数据估计方差
avg_loss = fluid.layers.mean(cost) # 对方差求均值,得到平均损失
```
详细资料请参考:
[fluid.default_main_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-main-program)
[fluid.default_startup_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-startup-program)
### Optimizer Function 配置
在下面的 `SGD optimizer`,`learning_rate` 是学习率,与网络的训练收敛速度有关系。
```python
#克隆main_program得到test_program
#有些operator在训练和测试之间的操作是不同的,例如batch_norm,使用参数for_test来区分该程序是用来训练还是用来测试
#该api不会删除任何操作符,请在backward和optimization之前使用
test_program = main_program.clone(for_test=True)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_loss)
```
### 定义运算场所
我们可以定义运算是发生在CPU还是GPU
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() # 指明executor的执行场所
###executor可以接受传入的program,并根据feed map(输入映射表)和fetch list(结果获取表)向program中添加数据输入算子和结果获取算子。使用close()关闭该executor,调用run(...)执行program。
exe = fluid.Executor(place)
```
详细资料请参考:
[fluid.executor](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#permalink-15-executor)
### 创建训练过程
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。必要参数有executor,program,reader,feeder,fetch_list,executor表示之前创建的执行器,program表示执行器所执行的program,是之前创建的program,如果该项参数没有给定的话则默认使用default_main_program,reader表示读取到的数据,feeder表示前向输入的变量,fetch_list表示用户想得到的变量或者命名的结果。
```python
num_epochs = 100
def train_test(executor, program, reader, feeder, fetch_list):
accumulated = 1 * [0]
count = 0
for data_test in reader():
outs = executor.run(program=program,
feed=feeder.feed(data_test),
fetch_list=fetch_list)
accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)] # 累加测试过程中的损失值
count += 1 # 累加测试集中的样本数量
return [x_d / count for x_d in accumulated] # 计算平均损失
```
### 训练主循环
给出需要存储的目录名,并初始化一个执行器。
```python
%matplotlib inline
params_dirname = "fit_a_line.inference.model"
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
exe.run(startup_program)
train_prompt = "train cost"
test_prompt = "test cost"
from paddle.utils.plot import Ploter
plot_prompt = Ploter(train_prompt, test_prompt)
step = 0
exe_test = fluid.Executor(place)
```
paddlepaddle提供了reader机制来读取训练数据。reader会一次提供多列数据,因此我们需要一个python的列表来定义读取顺序。我们构建一个循环来进行训练,直到训练结果足够好或者循环次数足够多。
如果训练迭代次数满足参数保存的迭代次数,可以把训练参数保存到`params_dirname`。
设置训练主循环
```python
for pass_id in range(num_epochs):
for data_train in train_reader():
avg_loss_value, = exe.run(main_program,
feed=feeder.feed(data_train),
fetch_list=[avg_loss])
if step % 10 == 0: # 每10个批次记录并输出一下训练损失
plot_prompt.append(train_prompt, step, avg_loss_value[0])
plot_prompt.plot()
print("%s, Step %d, Cost %f" %
(train_prompt, step, avg_loss_value[0]))
if step % 100 == 0: # 每100批次记录并输出一下测试损失
test_metics = train_test(executor=exe_test,
program=test_program,
reader=test_reader,
fetch_list=[avg_loss.name],
feeder=feeder)
plot_prompt.append(test_prompt, step, test_metics[0])
plot_prompt.plot()
print("%s, Step %d, Cost %f" %
(test_prompt, step, test_metics[0]))
if test_metics[0] < 10.0: # 如果准确率达到要求,则停止训练
break
step += 1
if math.isnan(float(avg_loss_value[0])):
sys.exit("got NaN loss, training failed.")
#保存训练参数到之前给定的路径中
if params_dirname is not None:
fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe)
```
## 预测
需要构建一个使用训练好的参数来进行预测的程序,训练好的参数位置在`params_dirname`。
### 准备预测环境
类似于训练过程,预测器需要一个预测程序来做预测。我们可以稍加修改我们的训练程序来把预测值包含进来。
```python
infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
```
### 预测
保存图片
```python
def save_result(points1, points2):
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
x1 = [idx for idx in range(len(points1))]
y1 = points1
y2 = points2
l1 = plt.plot(x1, y1, 'r--', label='predictions')
l2 = plt.plot(x1, y2, 'g--', label='GT')
plt.plot(x1, y1, 'ro-', x1, y2, 'g+-')
plt.title('predictions VS GT')
plt.legend()
plt.savefig('./image/prediction_gt.png')
```
通过fluid.io.load_inference_model,预测器会从`params_dirname`中读取已经训练好的模型,来对从未遇见过的数据进行预测。
```python
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe) # 载入预训练模型
batch_size = 10
infer_reader = paddle.batch(
paddle.dataset.uci_housing.test(), batch_size=batch_size) # 准备测试集
infer_data = next(infer_reader())
infer_feat = numpy.array(
[data[0] for data in infer_data]).astype("float32") # 提取测试集中的数据
infer_label = numpy.array(
[data[1] for data in infer_data]).astype("float32") # 提取测试集中的标签
assert feed_target_names[0] == 'x'
results = infer_exe.run(inference_program,
feed={feed_target_names[0]: numpy.array(infer_feat)},
fetch_list=fetch_targets) # 进行预测
#打印预测结果和标签并可视化结果
print("infer results: (House Price)")
for idx, val in enumerate(results[0]):
print("%d: %.2f" % (idx, val)) # 打印预测结果
print("\nground truth:")
for idx, val in enumerate(infer_label):
print("%d: %.2f" % (idx, val)) # 打印标签值
save_result(results[0], infer_label) # 保存图片
```
由于每次都是随机选择一个minibatch的数据作为当前迭代的训练数据,所以每次得到的预测结果会有所不同。
## 总结
在这章里,我们借助波士顿房价这一数据集,介绍了线性回归模型的基本概念,以及如何使用PaddlePaddle实现训练和测试的过程。很多的模型和技巧都是从简单的线性回归模型演化而来,因此弄清楚线性模型的原理和局限非常重要。
## 参考文献
1. https://en.wikipedia.org/wiki/Linear_regression
2. Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
3. Murphy K P. Machine learning: a probabilistic perspective[M]. MIT press, 2012.
4. Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.

本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。