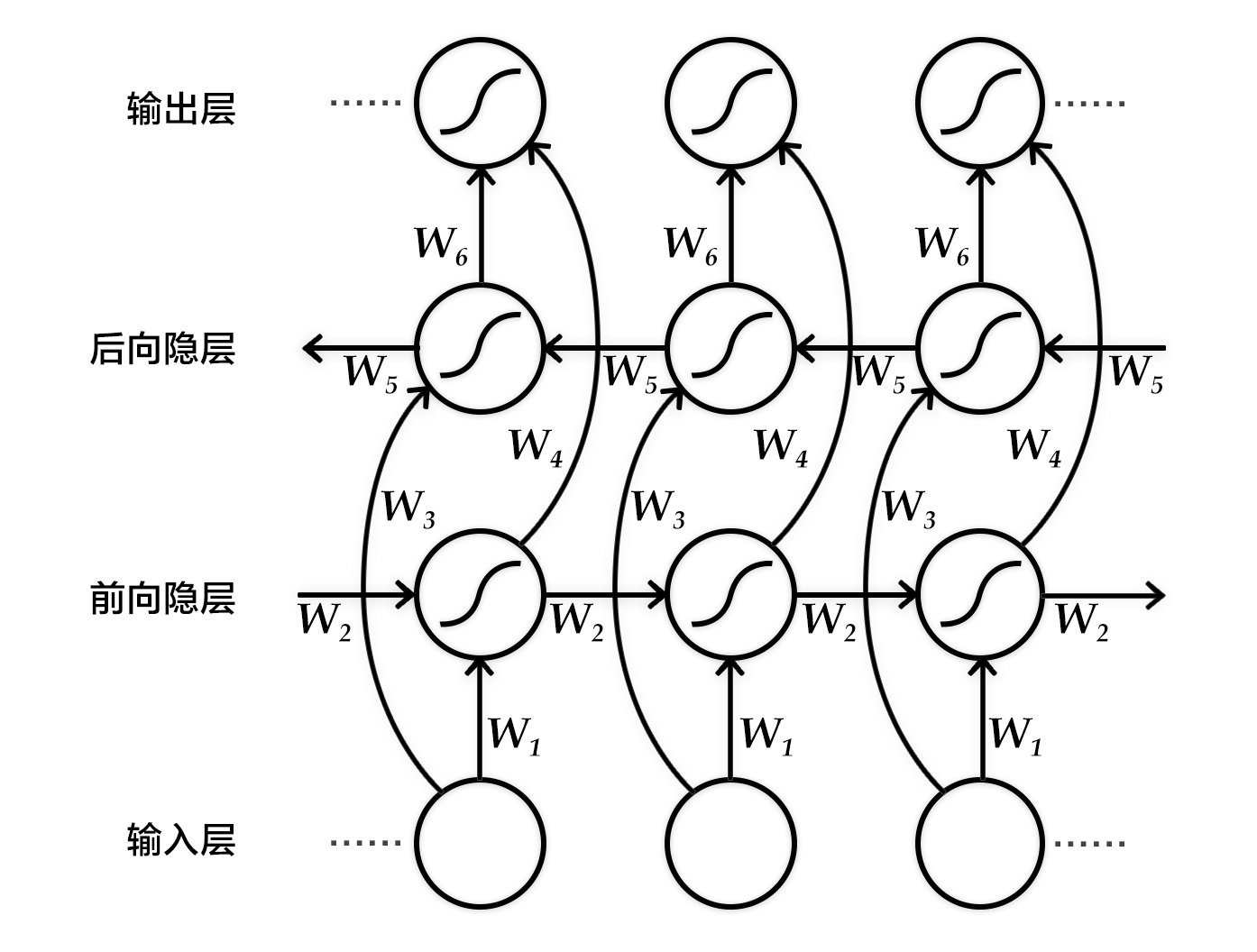
Figure 2. Bi-directional Recurrent Neural Network expanded by time step.
### Encoder-Decoder Structure
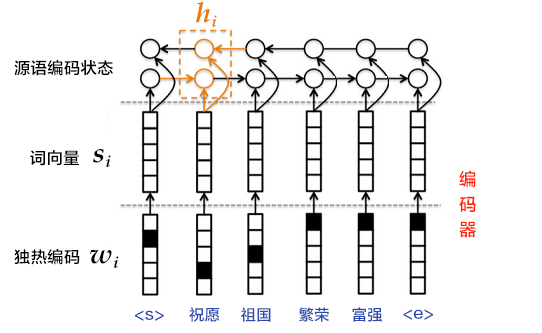
The Encoder-Decoder\[[2](#References)\] structure helps transform a source sequence with arbitrary length to another target sequence with arbitrary length. In the encoding phase, it encodes the entire source sequence into a vector. And in the decoding phase, it decodes the entire target sequence by maximizing the predicted sequence probability. The encoding and decoding process is usually implemented by RNN.