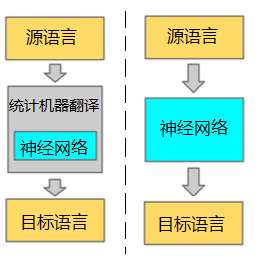
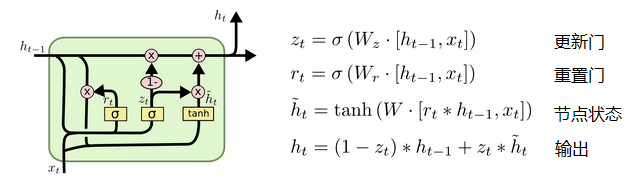本教程主要介绍NMT模型,以及如何用PaddlePaddle来训练一个法英翻译(从法语翻译到英语)的模型。
## 效果展示
当法英翻译的模型训练完毕后,以下面的两句法语为例:
```text
Les avionneurs se querellent au sujet de la largeur des sièges alors que de grosses commandes sont en jeu Jet makers feud over seat width with big orders at stake
La dispute fait rage entre les grands constructeurs aéronautiques à propos de la largeur des sièges de la classe touriste sur les vols long-courriers , ouvrant la voie à une confrontation amère lors du salon aéronautique de Dubaï qui a lieu de mois-ci . A row has flared up between leading plane makers over the width of tourist-class seats on long-distance flights , setting the tone for a bitter confrontation at this month 's Dubai Airshow .
```
如果设定显示的条数(即[集束搜索算法](### 集束搜索算法)的宽度)为3,生成的英语句子如下:
```text
0
0 -19.0179 The will be rotated about the width of the seats , while large orders are at stake .
1 -19.1114 The will be rotated about the width of the seats , while large commands are at stake .
2 -19.5112 The will be rotated about the width of the seats , while large commands are at play .
1
0 -28.1139 The dispute is between the large aviation manufacturers about the width of the tourist seats on the flights , paving the way for a confrontation at the Dubai aviation fair , which is a month .
1 -28.7138 The dispute is between the large aviation manufacturers about the width of the tourist seats on the flights , paving the way for a confrontation at the Dubai aviation fair , which takes place months .
2 -29.3381 The dispute is between the large aviation manufacturers about the width of the tourist seats on the flights , paving the way for a confrontation at the Dubai aviation fair , which takes place in month .
```
- 第一行的“0”和第6行的“1”表示翻译第几条法语句子。
- 其他六行列出了翻译结果,其中右起第一列是生成的英语句子,右起第二列是该条英语句子的得分(从大到小),右起第三列是序号。
- 另外有两个特殊表示:``表示句子的结尾,`unk`表示无法识别(即不在训练字典中)的单词。
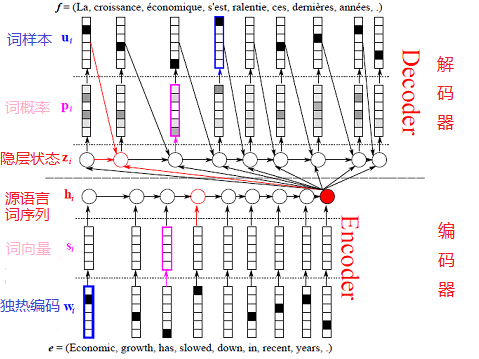
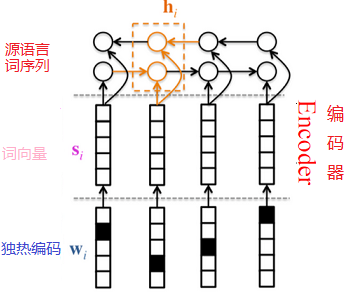
## 模型概览
本节依次介绍GRU模型,NMT中典型的“编码器-解码器”(Encoder-Decoder)框架和“注意力”(Attention)机制,以及集束搜索(Beam Search)算法。
### GRU模型
GRU(Gated Recurrent Unit,门控循环单元)是Cho等人在LSTM上提出的简化版本,如下图所示。GRU单元只有两个门,分别是重置门(Reset Gate)和更新门(Update Gate),用于控制记忆内容是否能继续保存下去。