# 对抗式生成网络
## 背景介绍
本章我们介绍对抗式生成网络,也称为Generative Adversarial Network(GAN)。对抗式生成网络是生成模型的一种,可以用非监督学习的办法来学习输入数据的分布,从而能达到产生和输入数据拥有同样概率分布的人造数据。
在本章里,我们展对抗式生产网络的细节,以及如何用PaddlePaddle训练一个GAN模型。
## 效果展示
一个简单的例子是向对抗式生成网络输入MNIST手写数字的图片,然后让模型自己产生类似的手写数字图片。由训练好的GAN模型产生的手写数字图片的例子画在图1中。
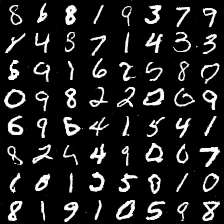
图1. GAN生成的MNIST例图
## 模型概览
对抗式生成网络的大致结构在图2中画出,它由两部分组成:一个生成器(G)和一个分别器(D),两者都是有多层神经网络构成的。生成器的输入是一个多维的已知概率分布的噪音(z),通过神经网络变换,输出伪样本。分别器输的输入是真样本和伪样本,输出为判断样本为真样本的概率。训练时生成器和分别器处于相互竞争对抗状态,生成器会尽量生成和真样本相近的伪样本让分别器无法分辨真伪,而分别器则会尽力去分辨伪样本。具体的损失函数如下:
$$\min_G\max_D \text{Loss} = \min_G\max_D \frac{1}{m}\sum_{i=1}^m[\log D(x^i) + log(1-D(G(z^i)))]$$
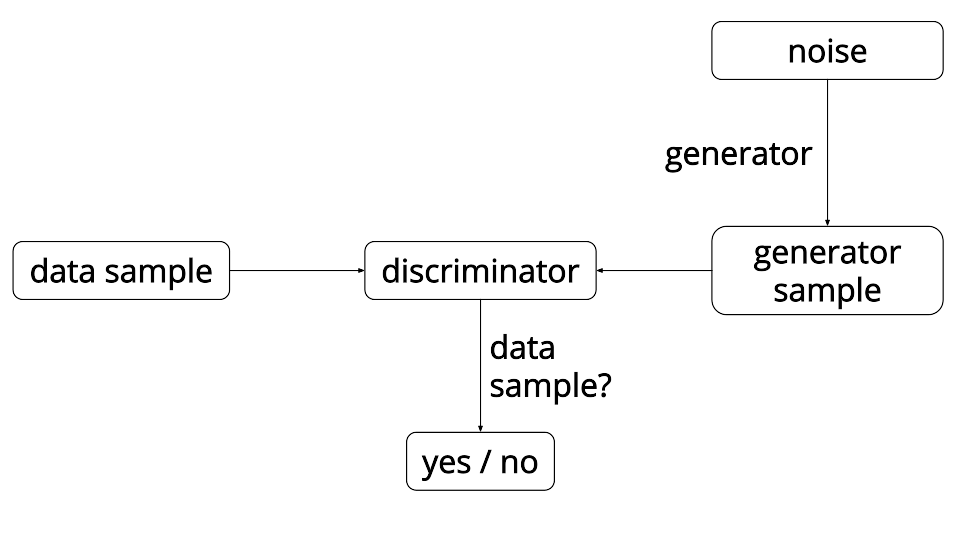
图2. GAN模型结构
figure credit
训练时,生成器和分别器会轮流通过随机梯度下降算法更新参数。生成器的目标函数是让自己产生的样本被分别器分类为真,而分别器的目标函数则是正确的区分真伪样本。当对抗式生成模型训练收敛到平衡态的时候,生成器会把输入的噪音分布转化成真的样本数据分布,而分别器则完全无法分辨真伪图片。
## 数据准备
### 数据介绍与下载
这章会用到两种数据,一种是简单的人造数据,一种是图片。
人造数据是二维均匀分布,由下面的代码生成:
```python
# synthesize 2-D uniform data in gan_trainer.py:114
def load_uniform_data():
data = numpy.random.rand(1000000, 2).astype('float32')
return data
```
图片数据是MNIST手写数字,可由下面的代码下载:
```bash
$cd data/
$./get_mnist_data.sh
```
## 模型配置说明
由于对抗式生产网络涉及到多个神经网络,所以必须用paddle Python API来训练。下面的介绍也可以部分的拿来当作paddle Python API的使用说明。
### 模型结构
在文件gan_conf.py当中我们定义了三个网络, **generator_training**, **discriminator_training** and **generator**. 和前文提到的模型结构的关系是:**discriminator_training** 是分别器,**generator** 是生成器,**generator_training** 是生成器加分别器因为训练生成器时需要用到分别器提供目标函数。这个对应关系在下面这段代码中定义:
```python
if is_generator_training:
noise = data_layer(name="noise", size=noise_dim)
sample = generator(noise)
if is_discriminator_training:
sample = data_layer(name="sample", size=sample_dim)
if is_generator_training or is_discriminator_training:
label = data_layer(name="label", size=1)
prob = discriminator(sample)
cost = cross_entropy(input=prob, label=label)
classification_error_evaluator(
input=prob, label=label, name=mode + '_error')
outputs(cost)
if is_generator:
noise = data_layer(name="noise", size=noise_dim)
outputs(generator(noise))
```
为了能够训练在gan_conf.py中定义的网络,我们需要如下几个步骤:初始化Paddle环境,解析设置,由设置创造GradientMachine以及由GradientMachine创造trainer。这几步分别由下面几段代码实现:
```python
import py_paddle.swig_paddle as api
# init paddle environment
api.initPaddle('--use_gpu=' + use_gpu, '--dot_period=10',
'--log_period=100', '--gpu_id=' + args.gpu_id,
'--save_dir=' + "./%s_params/" % data_source)
# Parse config
gen_conf = parse_config(conf, "mode=generator_training,data=" + data_source)
dis_conf = parse_config(conf, "mode=discriminator_training,data=" + data_source)
generator_conf = parse_config(conf, "mode=generator,data=" + data_source)
# Create GradientMachine
dis_training_machine = api.GradientMachine.createFromConfigProto(
dis_conf.model_config)
gen_training_machine = api.GradientMachine.createFromConfigProto(
gen_conf.model_config)
generator_machine = api.GradientMachine.createFromConfigProto(
generator_conf.model_config)
# Create trainer
dis_trainer = api.Trainer.create(dis_conf, dis_training_machine)
gen_trainer = api.Trainer.create(gen_conf, gen_training_machine)
```
为了能够平衡生成器和分别器之间的能力,我们依据它们各自的损失函数的大小来决定训练对象,即我们选择训练那个损失函数更大的网络。损失函数的值可以通过GradientMachine的forward pass来计算。
```python
def get_training_loss(training_machine, inputs):
outputs = api.Arguments.createArguments(0)
training_machine.forward(inputs, outputs, api.PASS_TEST)
loss = outputs.getSlotValue(0).copyToNumpyMat()
return numpy.mean(loss)
```
每当训练完一个网络,我们需要和其他几个网络同步互相分享的参数值。下面的代码展示了其中一个例子:
```python
# Train the gen_training
gen_trainer.trainOneDataBatch(batch_size, data_batch_gen)
# Copy the parameters from gen_training to dis_training and generator
copy_shared_parameters(gen_training_machine,
dis_training_machine)
copy_shared_parameters(gen_training_machine, generator_machine)
```
### 数据定义
这里数据没有通过dataprovider提供,而是在gan_trainer.py里面直接产生data_batch并提供给trainer。
```python
code to be inserted
```
### 算法配置
在这里,我们指定了模型的训练参数, 选择学习率和batch size。这里的beta1参数比默认值0.9小很多是为了使学习的过程更稳定。
```python
settings(
batch_size=128,
learning_rate=1e-4,
learning_method=AdamOptimizer(beta1=0.5))
```
##训练模型
用MNIST手写数字图片训练对抗式生成网络可以用如下的命令:
```bash
$python gan_trainer.py -d mnist --useGpu 1
```
## 总结
本章中,
## 参考文献
1. Bengio Y, Ducharme R, Vincent P, et al. [A neural probabilistic language model](http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)[J]. journal of machine learning research, 2003, 3(Feb): 1137-1155.
2. Mikolov T, Sutskever I, Chen K, et al. [Distributed representations of words and phrases and their compositionality](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)[C]//Advances in neural information processing systems. 2013: 3111-3119.
3. Mikolov T, Kombrink S, Deoras A, et al. [Rnnlm-recurrent neural network language modeling toolkit](http://www.fit.vutbr.cz/~imikolov/rnnlm/rnnlm-demo.pdf)[C]//Proc. of the 2011 ASRU Workshop. 2011: 196-201.
4. Mikolov T, Chen K, Corrado G, et al. [Efficient estimation of word representations in vector space\[J\]](https://arxiv.org/pdf/1301.3781.pdf). arXiv preprint arXiv:1301.3781, 2013.