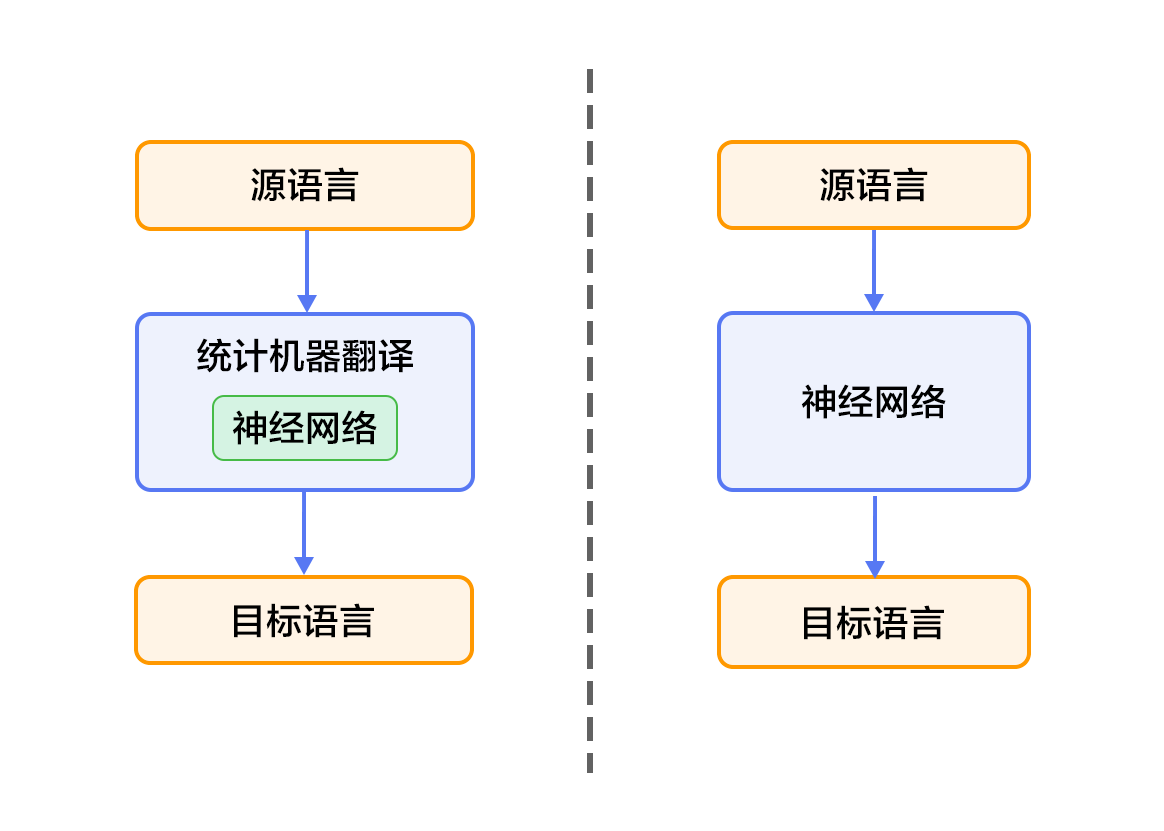
图1. 基于神经网络的机器翻译系统
图1. 基于神经网络的机器翻译系统
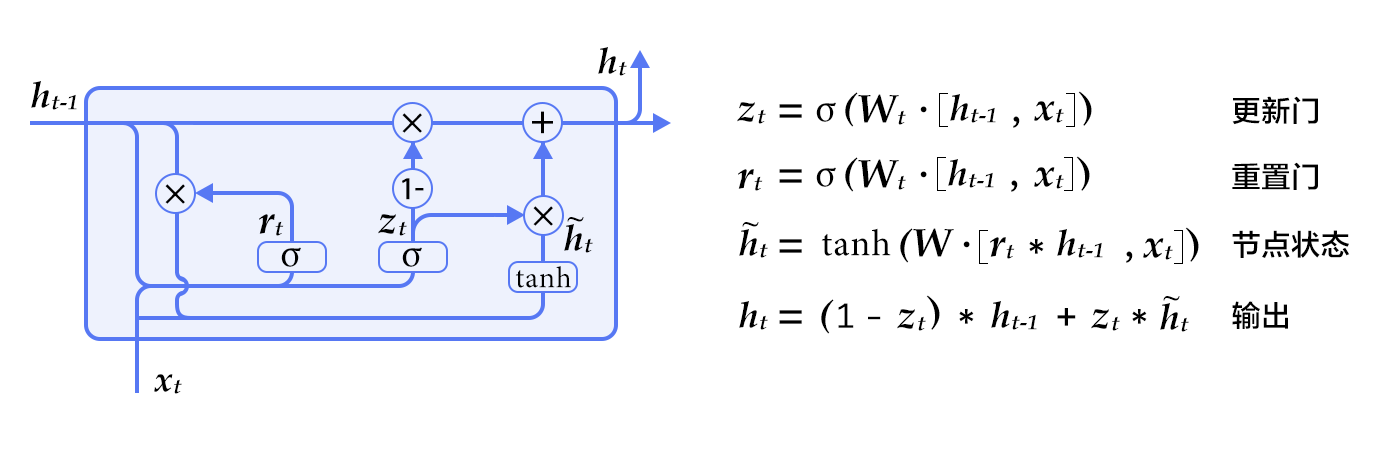
图2. GRU(门控循环单元)
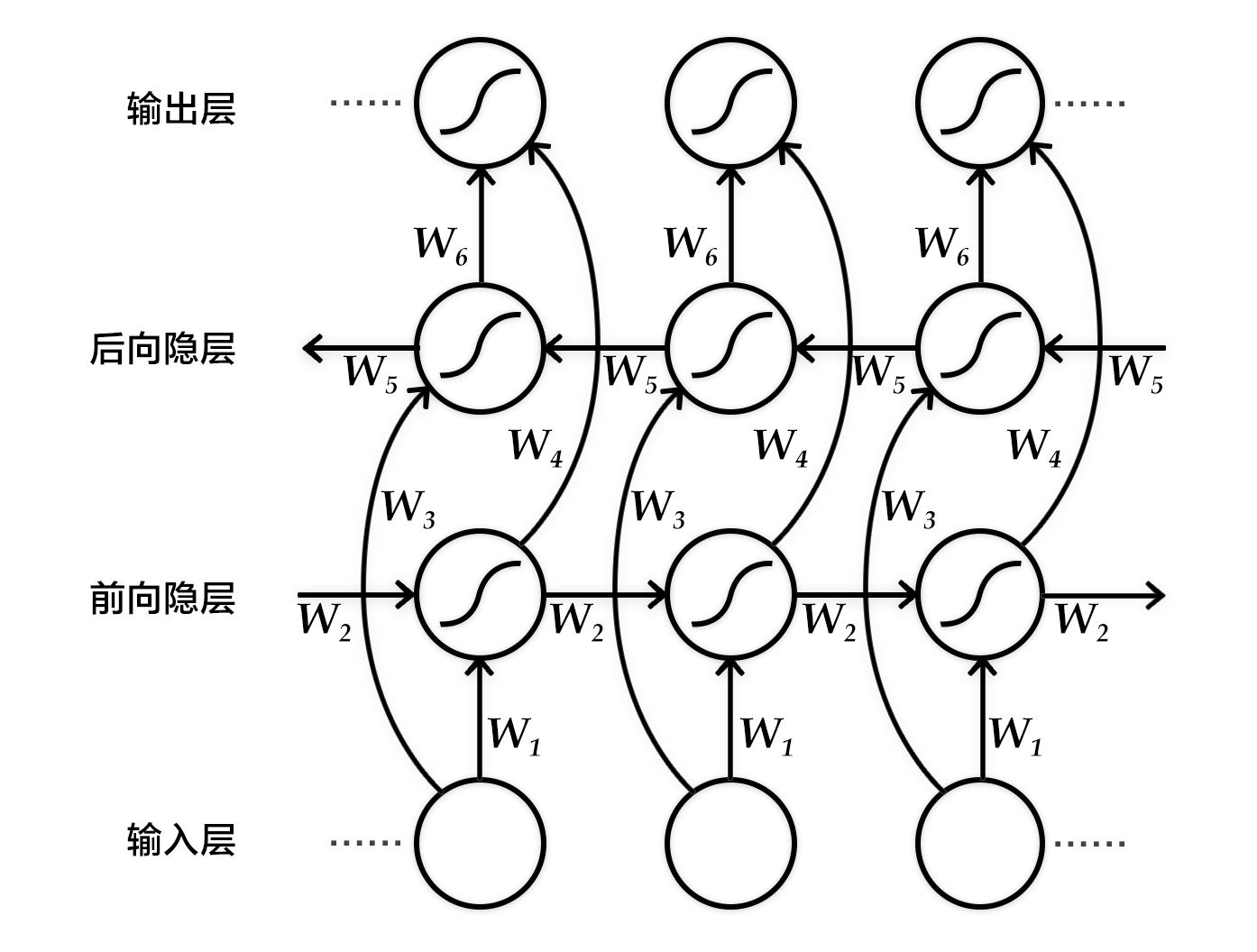
图3. 按时间步展开的双向循环神经网络
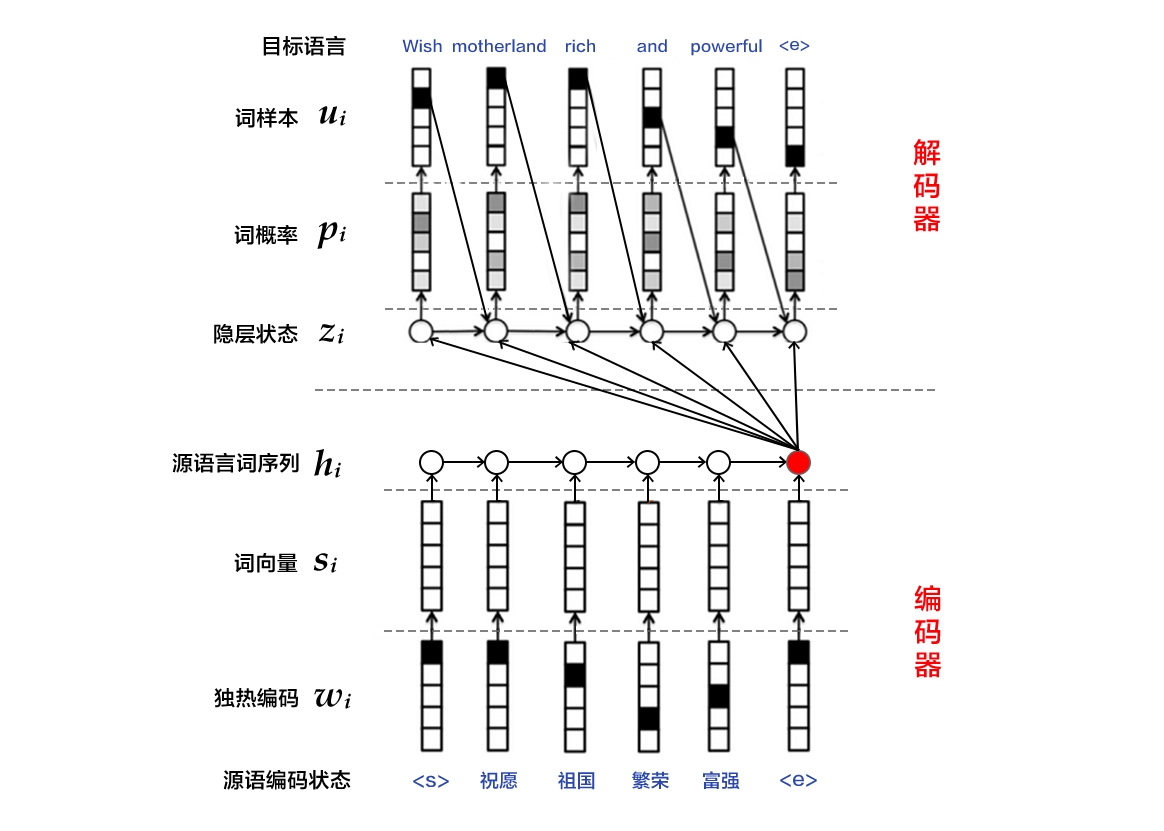
图4. 编码器-解码器框架
**Note: "源语言词序列" 和 "源语编码状态" 位置标反了,需要互换**
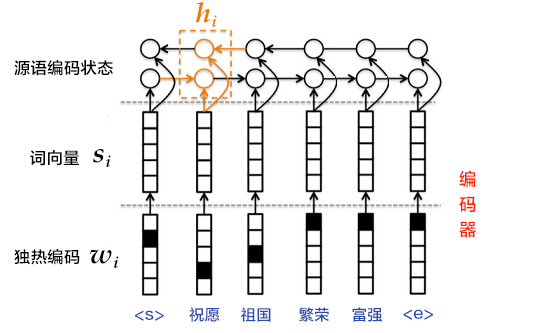
图5. 使用双向GRU的编码器
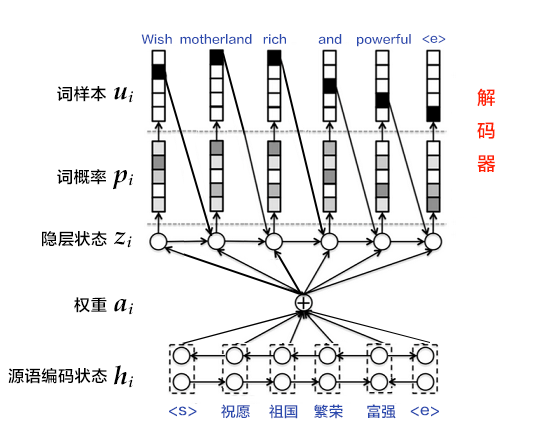
图6. 基于注意力机制的解码器
| 文件夹名 | 法英平行语料文件 | 文件数 | 文件大小 |
| train | ccb2_pc30.src, ccb2_pc30.trg, etc | 12 | 3.55G |
| test | ntst1213.src, ntst1213.trg | 2 | 1636k |
| gen | ntst14.src, ntst14.trg | 2 | 864k |
